20 張手繪圖講透 AI 核心概念,從神經網絡到 Agent 一次看懂
整理版優先睇
20 張手繪圖覆蓋 AI 核心技術棧,由神經網絡到 Agent 一次搞掂
呢篇文章係翻譯整理自 X 用戶 @sairahul1 嘅 20 張手繪 AI 科普圖,作者將每個核心概念畫成一張插圖,配上簡潔英文解釋。中文版加入咗作者自己嘅理解,目的係幫讀者用一張圖就睇明由神經網絡到 Agent 嘅 AI 核心技術棧。成個系列分四大部分:基礎概念、大語言模型運作、模型訓練技術、真實系統搭建。
第一部分由神經網絡、分詞、詞嵌入、注意力機制到 Transformer 架構,解釋 AI 點樣處理語言。第二部分深入 LLM 內部,包括上下文窗口、温度參數、幻覺問題同提示工程。第三部分講模型點樣變強:遷移學習、微調、RLHF、LoRA 同量化,展示點樣用低成本得到高性能模型。第四部分係實際應用架構:RAG、向量數據庫、AI Agent、思維鏈同擴散模型。整體結論係呢 20 個概念構成完整嘅 AI 知識地圖,由底層到上層,由訓練到推理,全部喺真實產品中發揮作用。
- 呢 20 個概念覆蓋 AI 技術棧全貌,由底層神經網絡到上層 Agent,係理解現代 AI 嘅必備知識框架。
- Transformer 架構係所有大模型嘅基礎,注意力機制讓模型動態關註上下文,令到並行處理成為可能。
- LLM 核心只係預測下一個 token,但透過 RLHF 對齊人類偏好,透過 RAG 減低幻覺,先至變得實用可靠。
- LoRA 同量化技術分別降低微調同部署成本 100 倍,令到開源模型可以喺筆記本甚至手機運行。
- 日常使用 AI 時,用提示工程(角色+任務+格式)可以大幅提升輸出質量;用思維鏈讓模型分步推理可以提高準確率。
從神經網絡到 Transformer 基礎
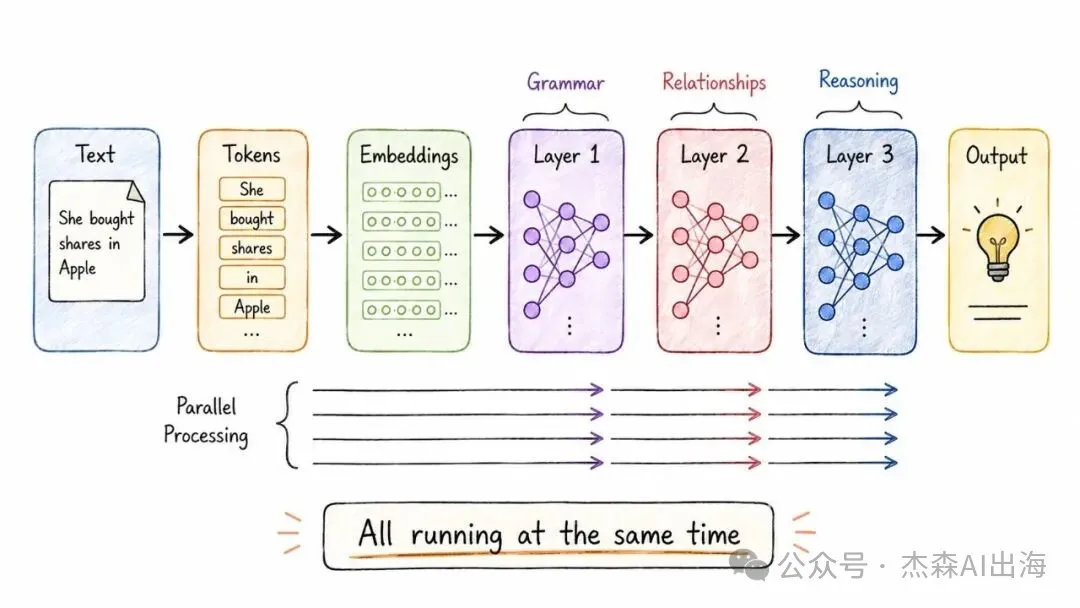
神經網絡模仿大腦結構,有輸入層、隱藏層同輸出層,學習過程就係調整層與層之間嘅權重。分詞(Tokenization)將文字切分成token,每個 token 對應一個數字 ID,例如「She is playing football」會切成 She / is / play / ##ing / foot / ##ball。
詞嵌入(Embeddings)將每個 token 映射到高維空間,語義相近嘅詞距離近,例如 Doctor 同 Nurse 黐埋一齊。注意力機制(Attention)讓模型根據上下文動態分配關注度,例如喺「She bought shares in Apple」入面,bought 同 shares 令 Apple 被理解為公司。
相比傳統 RNN 逐個詞讀取,Transformer 一次讀完整句話,大幅提升效率。
大語言模型係點樣運作
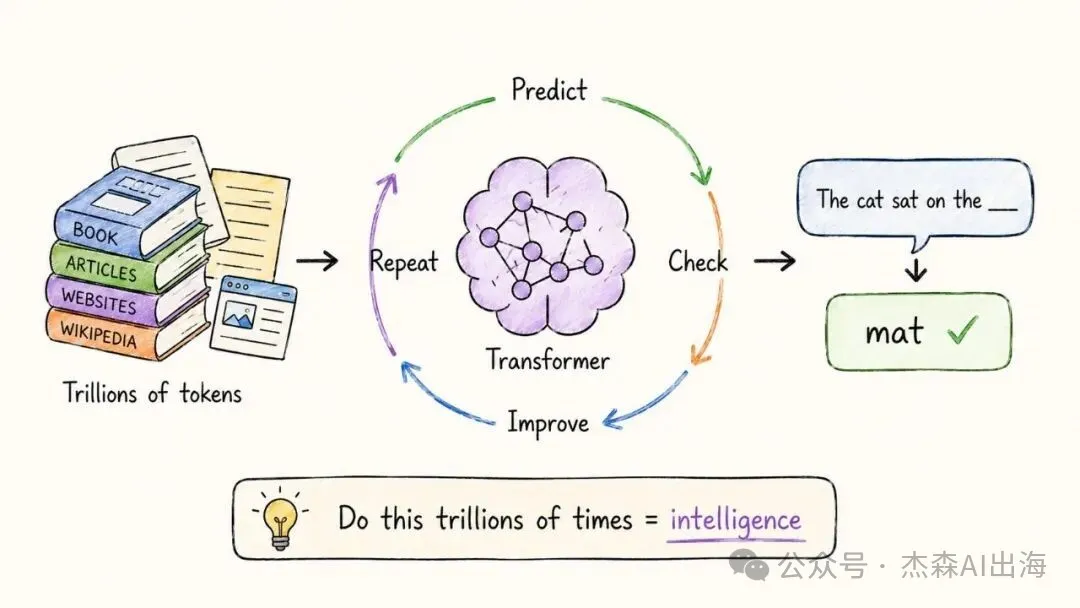
大語言模型(LLM)本質上係一個超大型 Transformer,核心動作始終係預測下一個 token。GPT-4 有超過一萬億參數,但工作循環好簡單:預測、檢查、調整、重複。
上下文窗口(Context Window)決定模型一次能睇幾多內容,由早期 4K token 到而家 Gemini 百萬級別;温度參數(Temperature)控制輸出隨機性,寫代碼用低温,寫小說用高温,日常 0.7 至 1 就夠。
幻覺(Hallucination)係模型一本正經編造事實,佢嘅自信唔等於正確。緩解方法包括 RAG、多路驗證、讓模型講「我不確定」。
模型係點樣變強
遷移學習(Transfer Learning)利用預訓練模型,用少量新數據微調即可適應新任務,成本由幾百萬降到幾千蚊。微調(Fine-Tuning)喺基礎模型上用特定領域數據繼續訓練,同一個底座可以變成醫療助手、法律顧問。
RLHF(人類反饋強化學習)透過人類標註員選出最佳回答,模型重複調整而對齊人類偏好;ChatGPT 好用全靠佢。LoRA(低秩適配)凍結原始參數,只加小組可訓練「適配器」,效果相近但成本降低 100 倍。
真實 AI 系統係點樣搭建
RAG(檢索增強生成)先檢索相關資料再生成答案,大幅降低幻覺率,而且知識可以實時更新。向量數據庫(Vector Databases)按語義搜索,例如搜「如何提高效率」都匹配到「提升生產力的方法」,係 RAG 嘅核心組件。
AI Agent(智能體)超越對話,有思考-行動-觀察-重複循環,可以自主拆解任務、調用工具、觀察結果。2025 年 Agent 爆發,Manus、Claude Code、Cursor、Devin 等正重塑工作流。
擴散模型(Diffusion Models)用於 Midjourney、DALL-E、Stable Diffusion:訓練時逐步加噪變純噪點,推理時反過來,用文字引導去噪方向,生成圖片。
20 張手繪圖講曬 AI 核心概念,由神經網絡到 Agent 一次過睇明
最近 X 上面有一組手繪 AI 科普圖洗版,作者 @sairahul1 將由神經網絡到擴散模型嘅 20 個核心概念,每個都畫成一張一目瞭然嘅插圖,配合簡單嘅英文解釋。我將呢 20 個概念翻譯整理成中文版,再加自己嘅理解,方便大家收藏參考
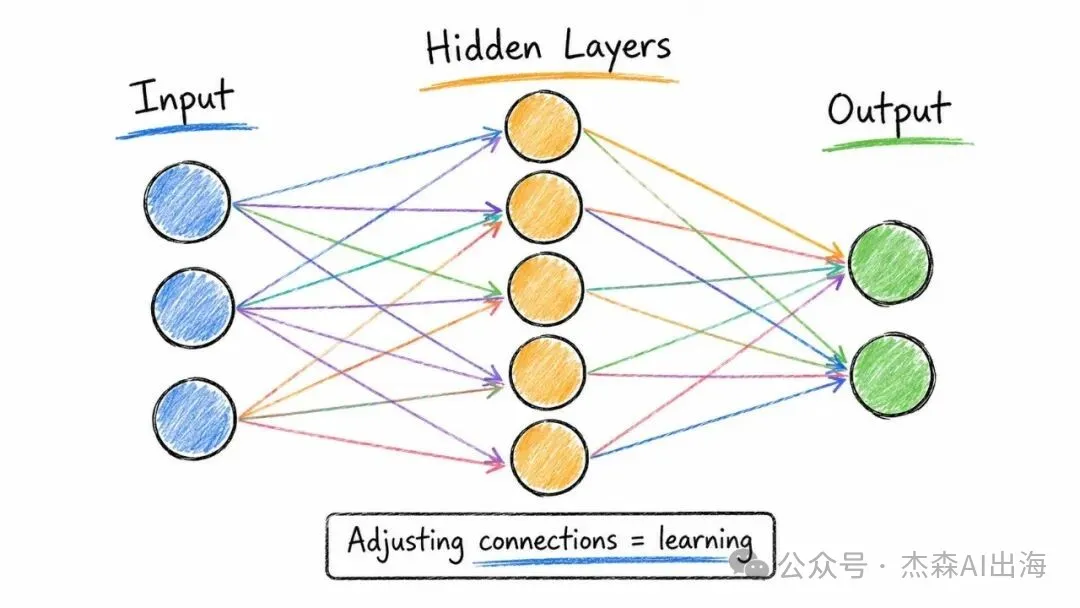
1. 神經網絡 Neural Networks
大腦有神經元,AI 都有。輸入層接收數據,經過幾個隱藏層嘅運算,最後輸出結果。學習嘅過程就係不斷調整呢啲連接嘅權重
成個結構其實好簡單,輸入入嚟,逐層傳遞,輸出出去。關鍵係中間嗰啲隱藏層,每一層都喺提取唔同層次嘅特徵
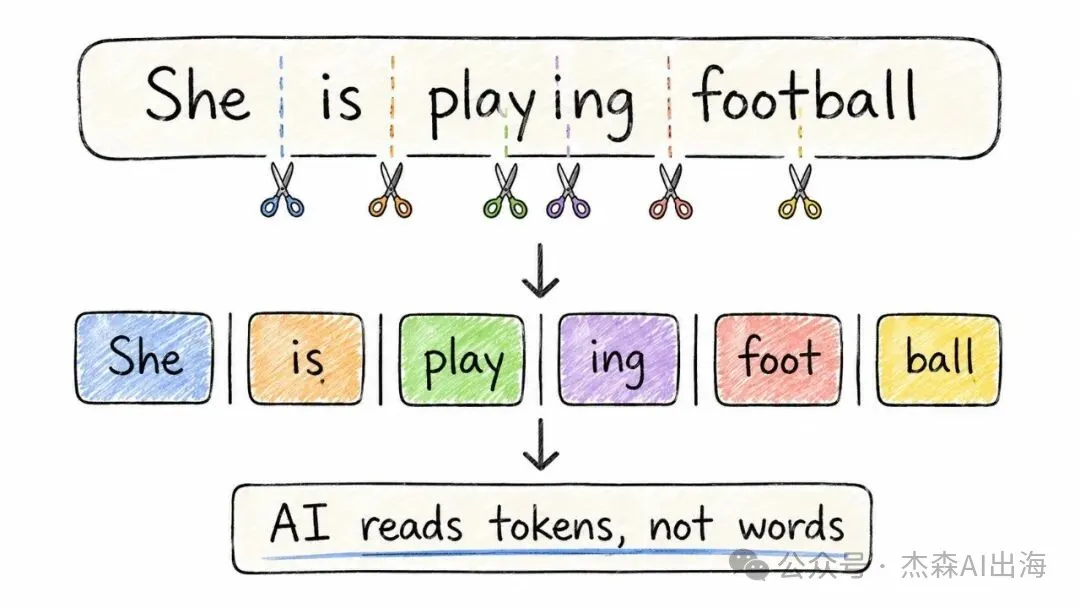
2. 分詞 Tokenization
模型唔識「文字」,佢只識數字。所以第一步就係將一句話切開做細塊,每塊對應一個數字編號
「She is playing football」會切成 She / is / play / ##ing / foot / ##ball 呢啲 token。中文都差唔多,「人工智能」可能會切成「人工」同「智能」兩個 token
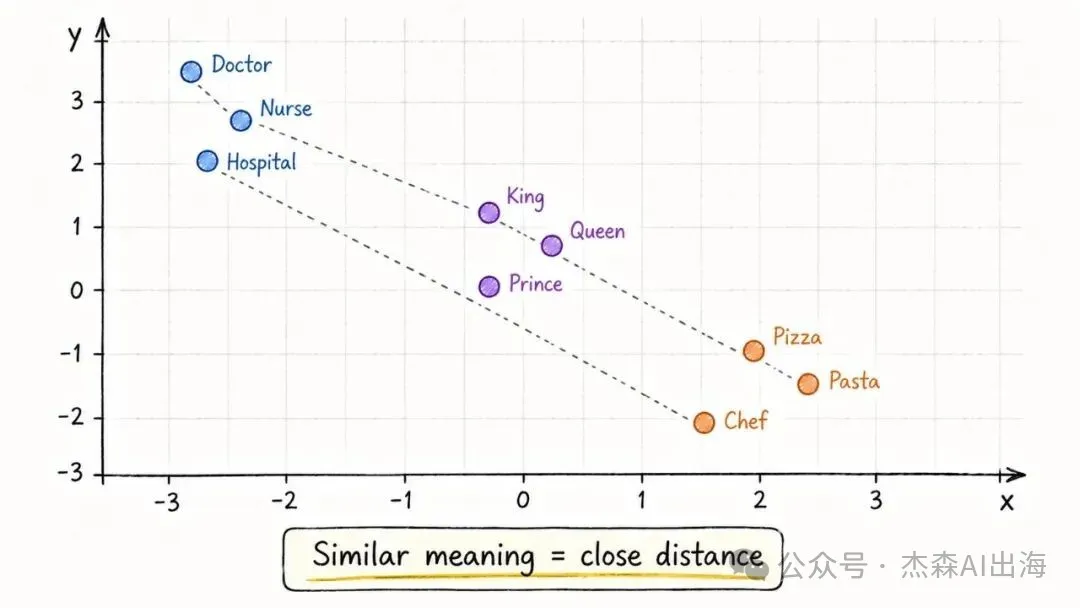
3. 詞嵌入 Embeddings
將每個 token 映射到一個高維空間嘅座標點。語義相近嘅詞,座標距離就近。Doctor 同 Nurse 黐埋,King 同 Queen 黐埋
呢個就係點解大模型可以理解同義詞同類比關係。佢唔係靠字面匹配,而係靠空間距離
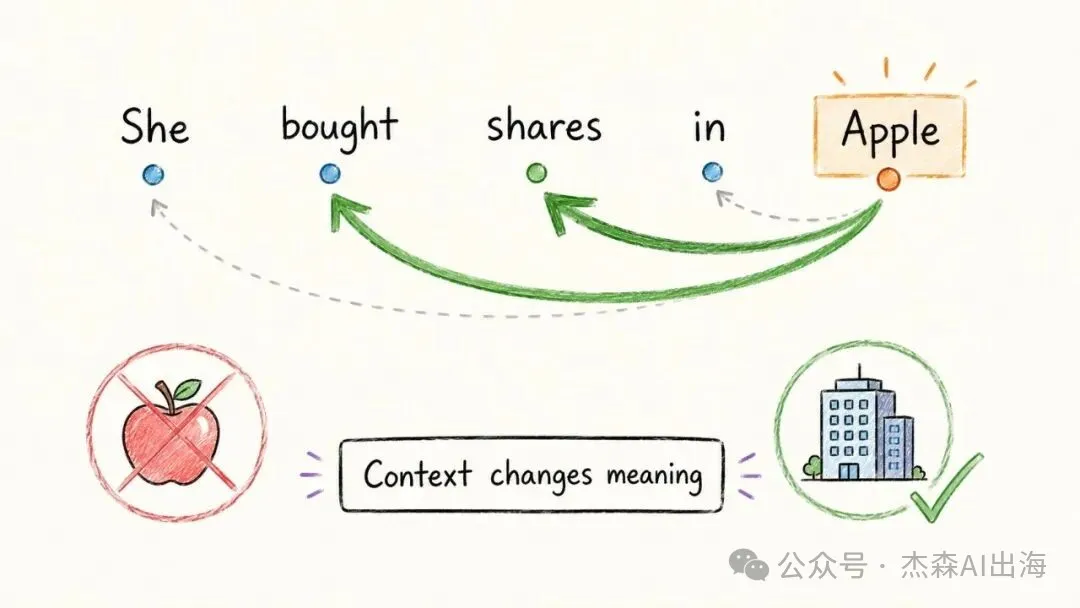
4. 注意力機制 Attention
「She bought shares in Apple」呢句入面,Apple 係生果定係公司?模型透過注意力機制睇曬成句嘅上文下理嚟判斷。bought 同 shares 呢兩個詞嘅權重好高,所以 Apple 被理解為公司
一個詞嘅意思取決於佢周圍嘅詞。注意力機制令模型可以動態咁分配關注度
5. Transformer 架構
2017 年 Google 提出嘅架構,將上面嘅分詞、嵌入、注意力全部串埋一齊,而且所有 token 可以並行處理。傳統 RNN 一個詞一個詞咁讀,Transformer 一次過讀曬成句
呢個架構係現時所有大模型嘅基礎,GPT、Claude、Gemini、Llama 全部都係靠佢
Part 2: 大語言模型係點樣運作
6. 大語言模型 LLMs
本質上就係一個超大號嘅 Transformer,用海量文本訓練出嚟。佢嘅工作循環好簡單:預測下一個詞,檢查啱唔啱,調整參數,重複
GPT-4 有超過一萬億個參數,訓練數據覆蓋互聯網上大部分公開文本。但佢嘅核心動作始終係「預測下一個 token」
7. 上下文窗口 Context Window
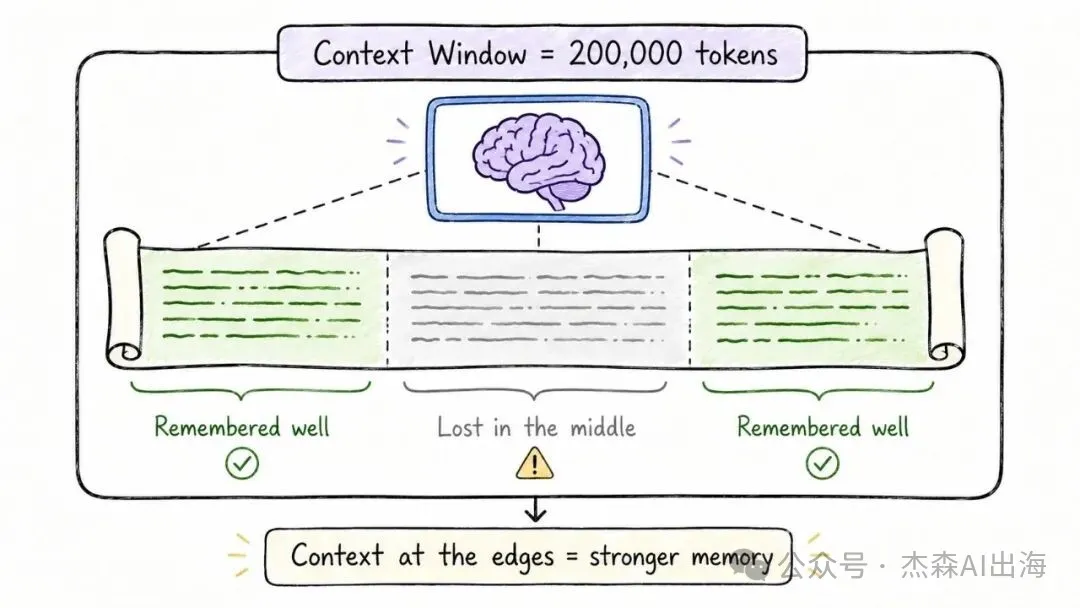
模型一次過可以睇到幾多內容係有上限嘅。呢個上限就係上下文窗口。早期嘅 GPT-3 得 4K token,而家 Claude 3 已經去到 200K token,Gemini 更加做到百萬級別
窗口愈大,模型可以處理嘅資訊愈多,但計算成本都會跟住升。對於長文檔分析、代碼庫理解呢類任務,大窗口係基本要求
8. 温度 Temperature
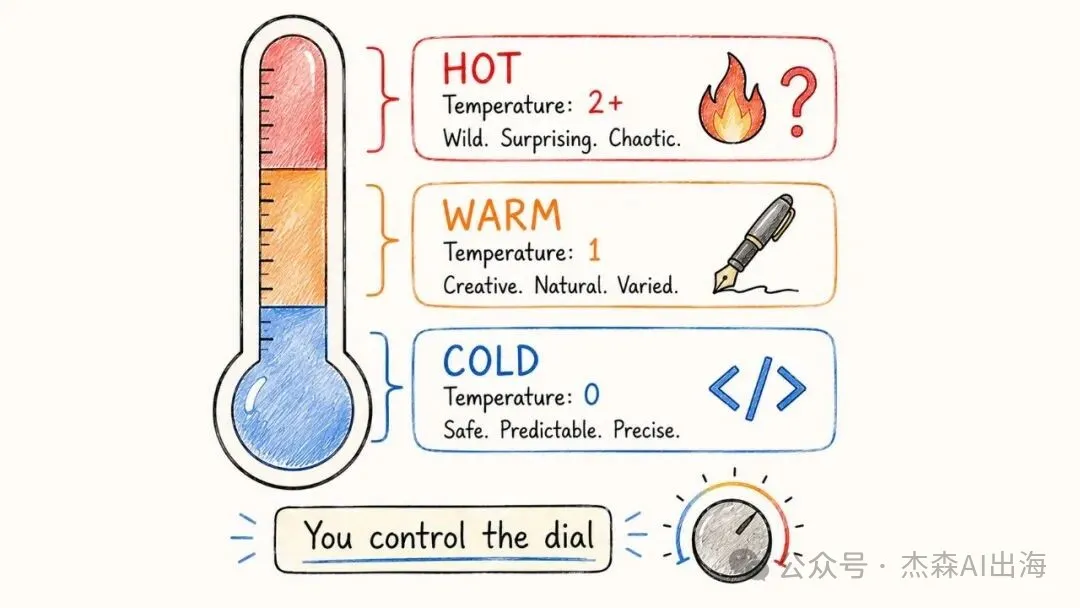
温度參數控制模型輸出嘅隨機性。Temperature = 0 嘅時候,模型每次都揀概率最高嘅詞,輸出穩定可預測。Temperature 調高到 2,輸出就會天馬行空
寫代碼用低温度,寫小說用高温度。大多數日常場景 0.7 到 1 之間就夠
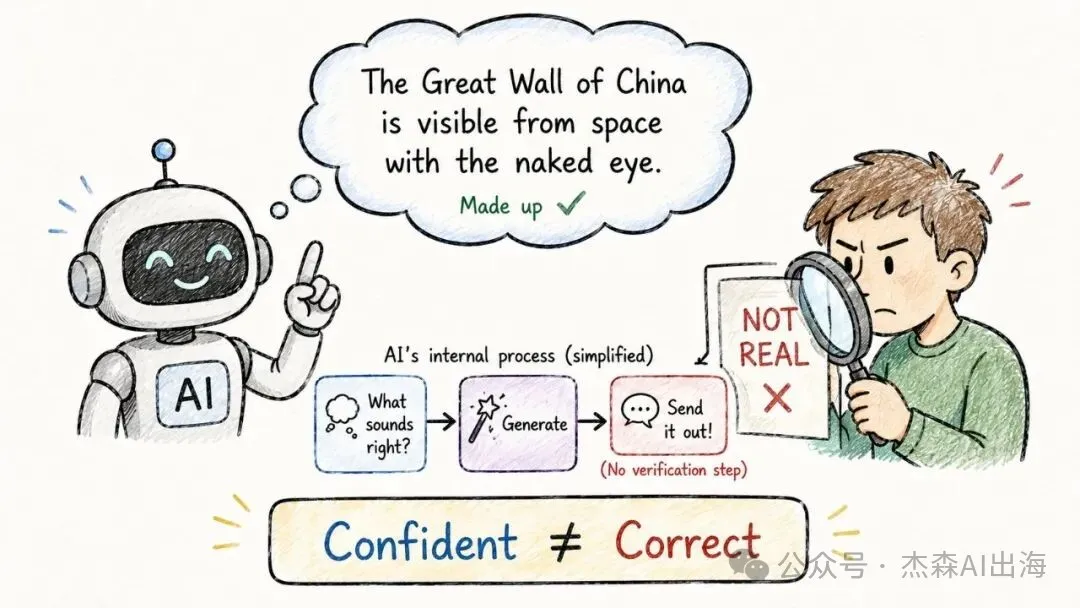
9. 幻覺 Hallucination
模型會一本正經咁老作事實。佢嘅「自信」唔等於「正確」。問佢一個唔存在嘅論文題目,佢可能會作曬完整嘅作者、期刊同摘要出嚟
呢個係現時大模型最大嘅可靠性問題。緩解方法包括 RAG(之後會講)、多重驗證、叫模型講「我唔肯定」
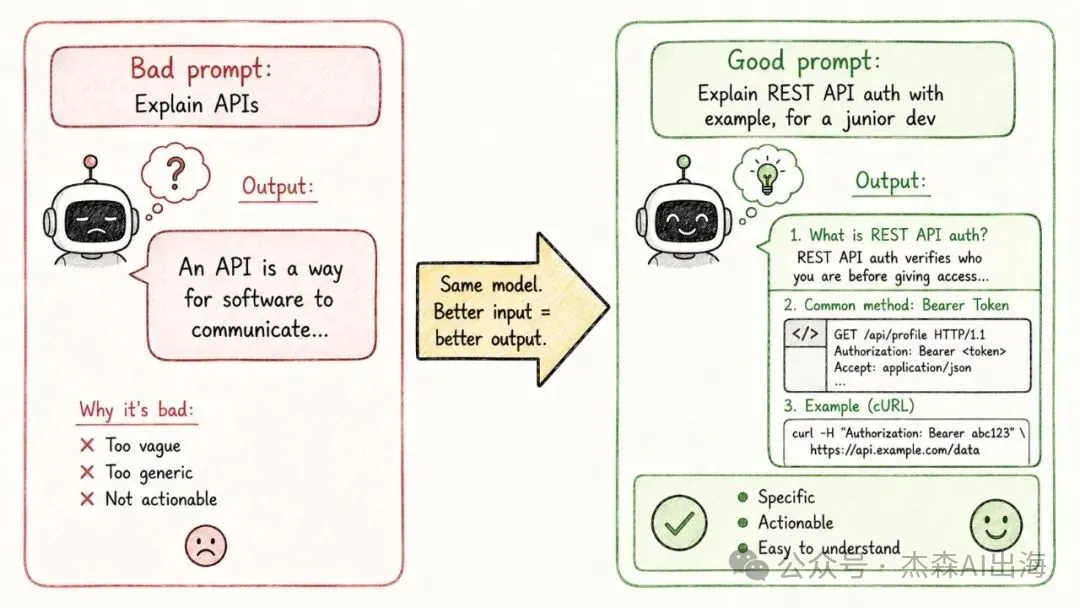
10. 提示工程 Prompt Engineering
同一個模型,俾唔同嘅提示詞,輸出質量可以差好遠。一個含糊嘅提示同一個結構清晰、有示例嘅提示,結果可能天同地
好嘅提示包含三個元素:角色設定、具體任務描述、輸出格式要求。呢個就係點解「提示工程師」變咗一個新職位
Part 3: AI 模型係點樣變強
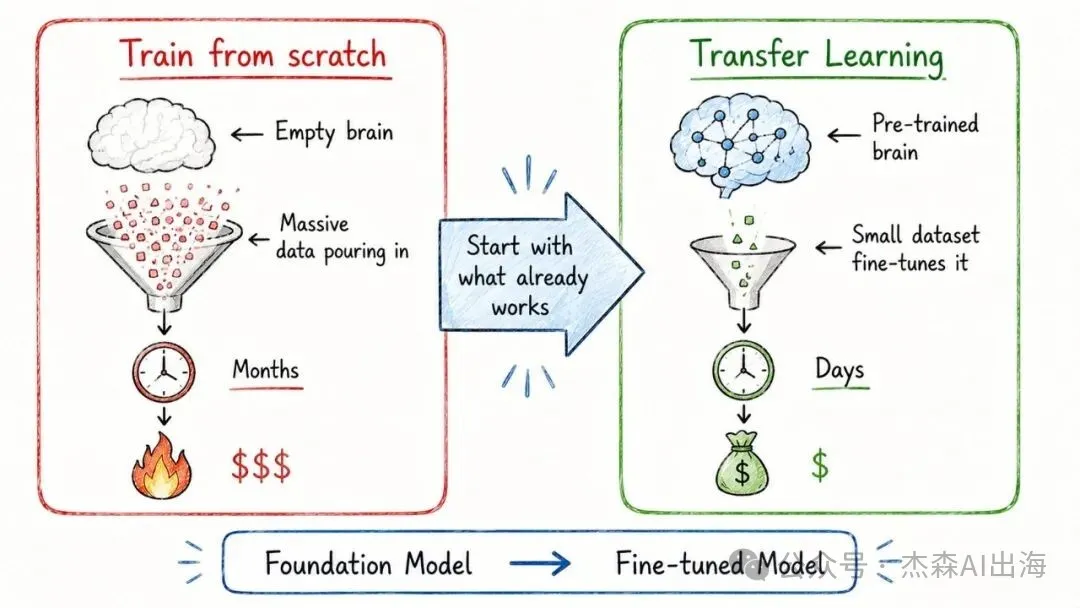
11. 遷移學習 Transfer Learning
由零開始訓練一個模型要花幾個月同幾百萬美元。遷移學習嘅諗法係:攞一個已經訓練好嘅基礎模型,用少量新數據微調一下,就可以適應新任務
訓練成本由幾百萬降到幾千蚊,時間由幾個月縮短到幾日。呢個就係點解開源基礎模型(Llama、Mistral)對行業咁重要
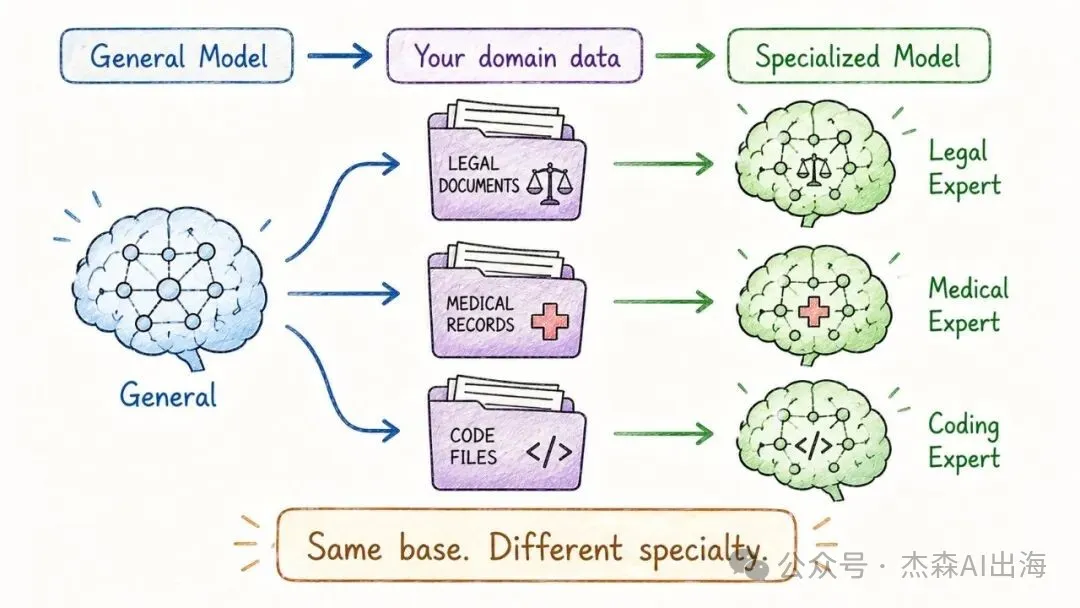
12. 微調 Fine-Tuning
喺基礎模型上用特定領域嘅數據繼續訓練。同一個底座模型,微調出嚟可以變成醫療助手、法律顧問、代碼生成器
微調唔會改變模型嘅核心架構,只係調整參數權重。類似於一個全科醫生去進修某個專科
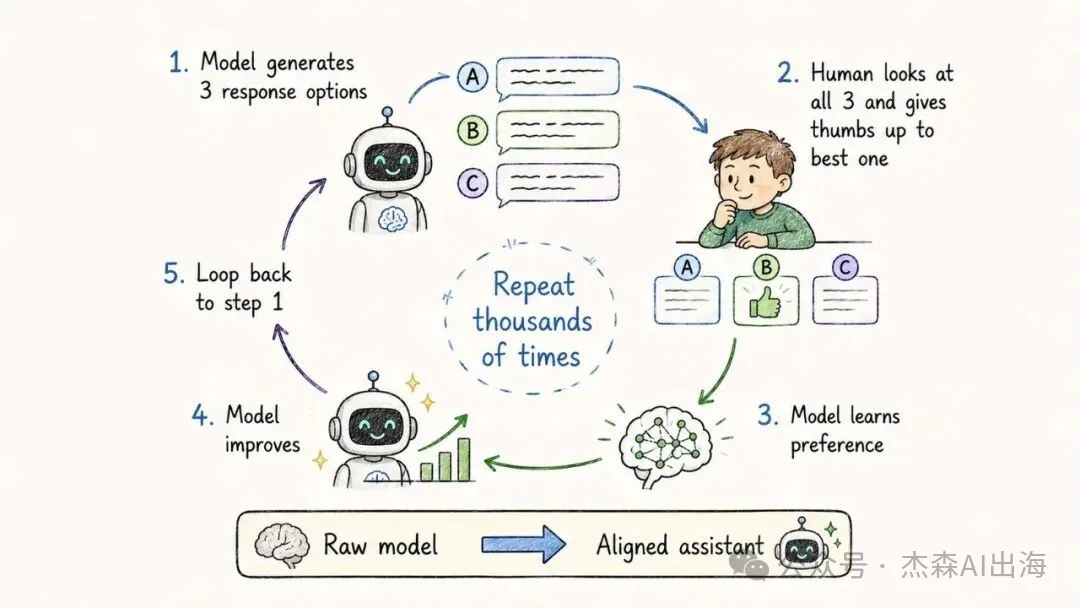
13. RLHF 人類反饋強化學習
訓練出嚟嘅原始模型可能會講有毒嘅嘢或者俾錯資訊。RLHF 嘅做法係:叫模型生成多個回答,人類標註員揀最好嗰個,模型根據呢啲偏好反饋嚟調整自己
呢個過程重複成千上萬次,原始模型慢慢變成一個對齊人類偏好嘅助手。ChatGPT 好用,RLHF 功不可沒
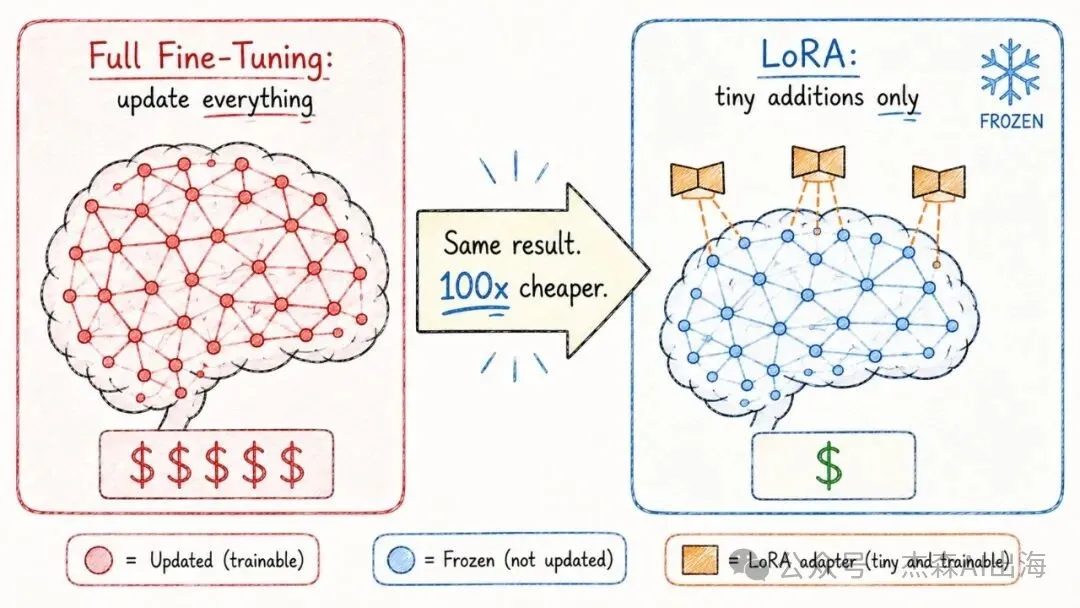
14. LoRA 低秩適配
全面微調一個大模型需要更新曬所有參數,成本太高。LoRA 嘅諗法係鎖死原始模型嘅所有參數,只喺旁邊加一小組可以訓練嘅「適配器」
效果幾乎一樣,成本降低 100 倍。而家社區入面大量嘅開源微調模型都係用 LoRA 做的
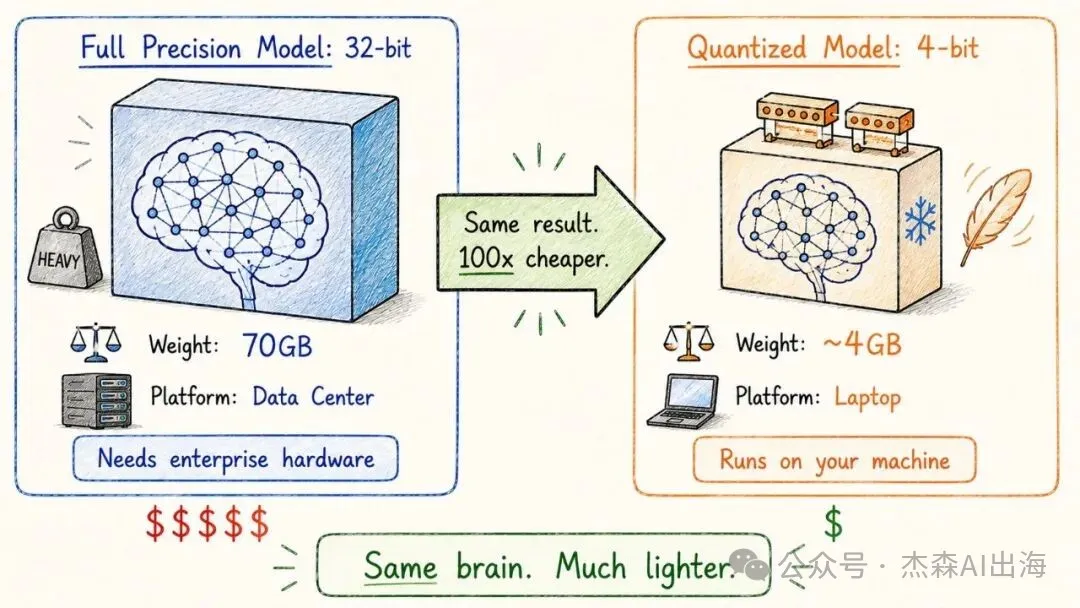
15. 量化 Quantization
將模型參數由 32 位浮點數壓縮到 8 位甚至 4 位整數。一個 70GB 嘅模型可以壓縮到 4GB 左右,喺 Notebook 上面就可以行
精度會有一啲損失,但對大部分應用場景嚟講幾乎感覺唔到。呢個就係點解而家手機上面都可以行到大模型
Part 4: 真正嘅 AI 系統係點樣搭建
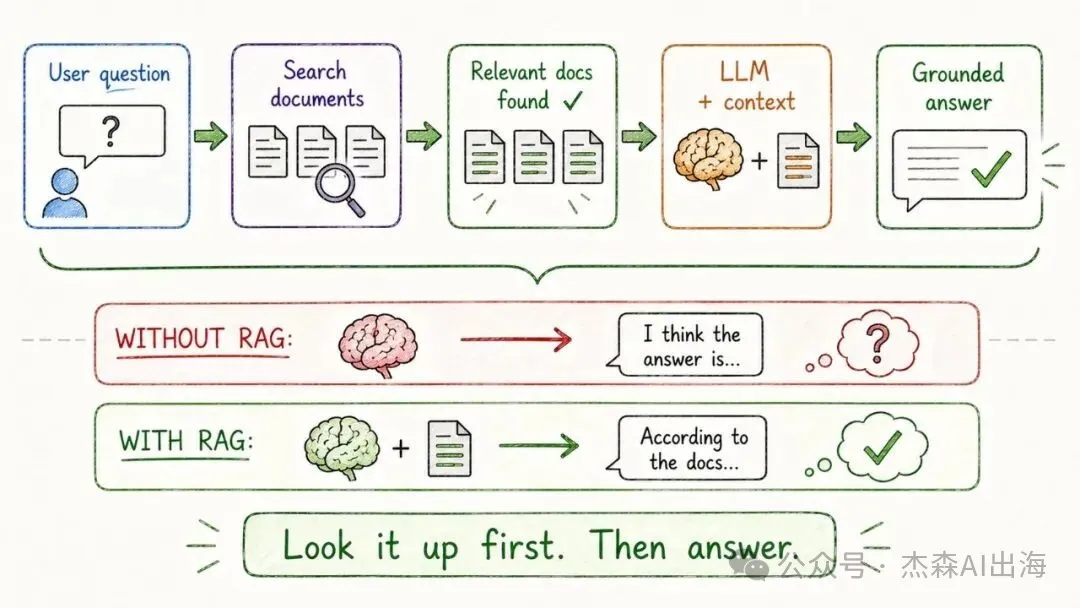
16. RAG 檢索增強生成
叫模型喺回答之前先去檢索相關資料,然後根據檢索結果生成答案。先查再答,唔係靠記憶老作
RAG 大幅降低咗幻覺率,而且知識可以即時更新,唔需要重新訓練模型。企業級 AI 應用幾乎全部用緊呢個架構
17. 向量數據庫 Vector Databases
傳統數據庫按關鍵詞搜索,向量數據庫按語義搜索。搜「點樣提高效率」都可以匹配到「提升生產力嘅方法」
呢個係 RAG 架構嘅核心組件。將文檔切開做細塊,每塊轉成向量存入數據庫,查詢時用語義相似度嚟召回最相關嘅內容
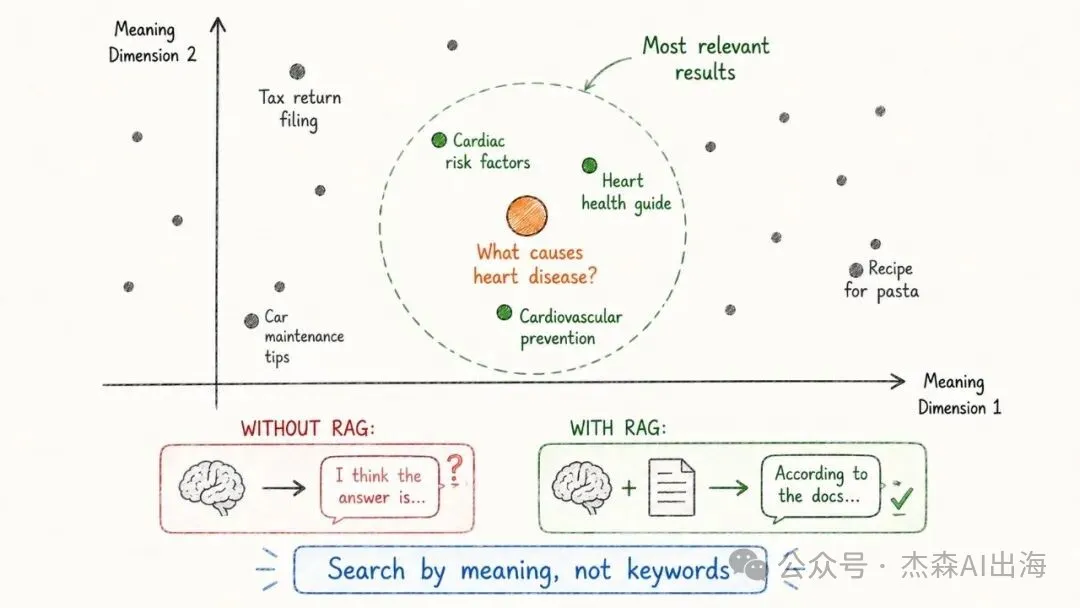
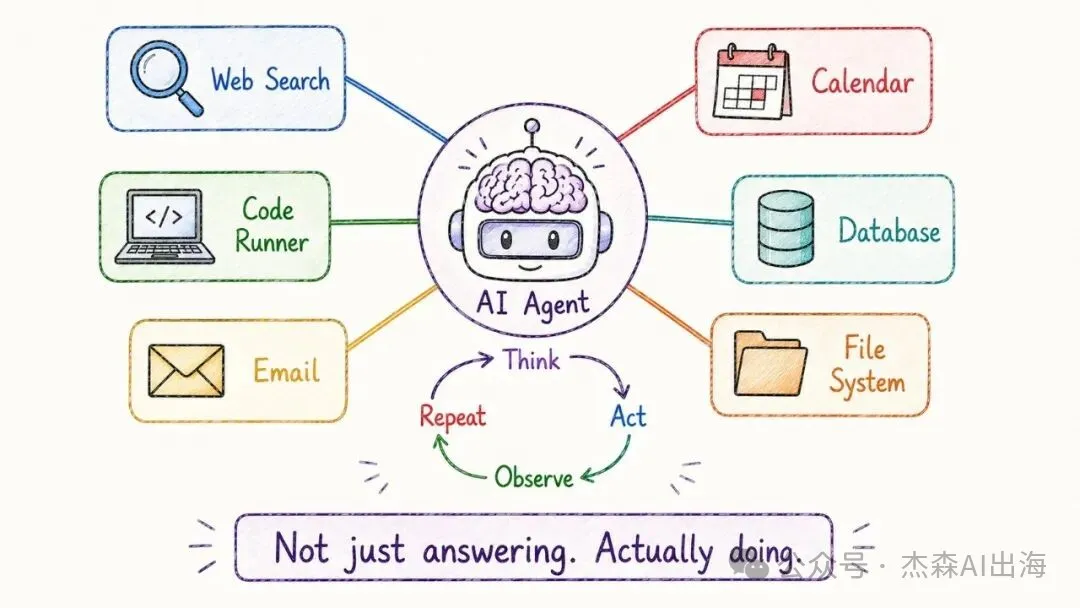
18. AI Agent 智能體
傳統嘅 LLM 只能對話,Agent 可以行動。佢有一個思考-行動-觀察-重複嘅循環:接到任務之後自己拆解步驟,調用工具執行,觀察結果,再決定下一步
2025 年係 Agent 爆發嘅一年,由 Manus 到 Claude Code,由 Cursor 到 Devin,能夠自主完成複雜任務嘅 AI Agent 正在重塑工作流程
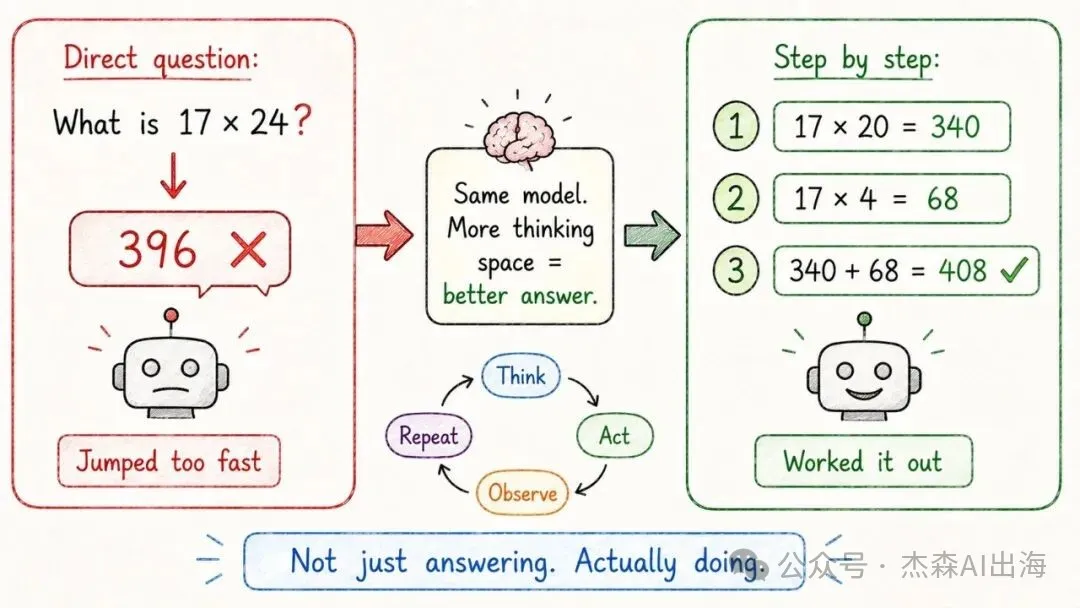
19. 思維鏈 Chain of Thought
直接問 AI「17 x 24 = ?」佢可能會計錯。但如果叫佢逐步思考(17x20=340,17x4=68,340+68=408),正確率大幅提升
同一個模型,俾更多「思考空間」就可以俾出更好嘅答案。呢個亦係 o1、o3、Claude 3.5 Sonnet 等推理模型嘅核心原理
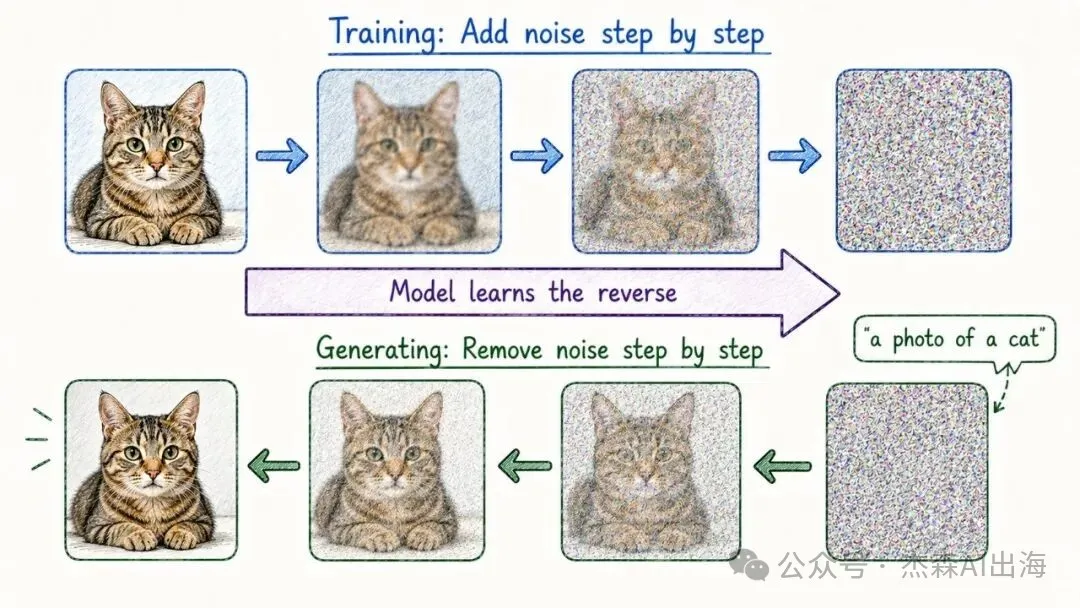
20. 擴散模型 Diffusion Models
Midjourney、DALL-E、Stable Diffusion 背後嘅技術。訓練時將圖片逐步加噪聲直到變成純粹嘅噪點,推理時反轉,由噪點一步步還原出圖片
文字生成圖片嘅關鍵在於:用文字描述嚟引導去噪嘅方向。同樣嘅噪點,唔同嘅文字提示,會生成完全唔同嘅圖片
以上 20 個概念覆蓋咗現時 AI 領域最核心嘅技術棧。由底層嘅神經網絡到上層嘅 Agent 應用,由訓練方面嘅 RLHF 到推理方面嘅思維鏈,每一個概念都喺真實嘅產品同系統入面發揮作用
所有插圖來自 X 用戶 @sairahul1 嘅原創手繪系列,原文連結:https://x.com/sairahul1/status/2057740928908161461
20 張手繪圖講透 AI 核心概念,從神經網絡到 Agent 一次看懂
最近 X 上有一組手繪 AI 科普圖刷屏了,作者 @sairahul1 把從神經網絡到擴散模型的 20 個核心概念,每個都畫成一張一目瞭然的插圖,配上簡潔的英文解釋。我把這 20 個概念翻譯整理成中文版,加上自己的理解,方便大家收藏查閲
1. 神經網絡 Neural Networks
大腦有神經元,AI 也有。輸入層接收數據,經過若干隱藏層的運算,最終輸出結果。學習的過程就是不斷調整這些連接的權重
整個結構其實很樸素,輸入進來,層層傳遞,輸出出去。關鍵在於中間那些隱藏層,每一層都在提取不同層級的特徵
2. 分詞 Tokenization
模型不認識"文字",它只認識數字。所以第一步是把一句話切成小塊,每塊對應一個數字編號
"She is playing football" 會被切成 She / is / play / ##ing / foot / ##ball 這樣的 token。中文也類似,"人工智能"可能被切成"人工"和"智能"兩個 token
3. 詞嵌入 Embeddings
把每個 token 映射到一個高維空間裏的座標點。語義相近的詞,座標距離就近。Doctor 和 Nurse 挨着,King 和 Queen 挨着
這也是為什麼大模型能理解同義詞和類比關係。它不是靠字面匹配,是靠空間距離
4. 注意力機制 Attention
"She bought shares in Apple" 這句話裏,Apple 是水果還是公司?模型通過注意力機制看整句話的上下文來判斷。bought 和 shares 這兩個詞的權重很高,所以 Apple 被理解為公司
一個詞的含義取決於它周圍的詞。注意力機制讓模型能夠動態地分配關注度
5. Transformer 架構
2017 年 Google 提出的架構,把上面的分詞、嵌入、注意力全串起來,而且所有 token 可以並行處理。傳統 RNN 一個詞一個詞地讀,Transformer 一次讀完整句話
這個架構是當前所有大模型的基礎,GPT、Claude、Gemini、Llama 全都基於它
Part 2: 大語言模型是怎麼工作的
6. 大語言模型 LLMs
本質上就是一個超大號的 Transformer,用海量文本訓練出來。它的工作循環很簡單:預測下一個詞,檢查對不對,調整參數,重複
GPT-4 有超過一萬億參數,訓練數據覆蓋互聯網上大部分公開文本。但它的核心動作始終是"預測下一個 token"
7. 上下文窗口 Context Window
模型一次能看多少內容是有上限的。這個上限就是上下文窗口。早期的 GPT-3 只有 4K token,現在 Claude 3 已經到了 200K token,Gemini 更是做到了百萬級別
窗口越大,模型能處理的信息越多,但計算成本也跟着漲。對於長文檔分析、代碼庫理解這類任務,大窗口是剛需
8. 温度 Temperature
温度參數控制模型輸出的隨機性。Temperature = 0 時,模型每次都選概率最高的詞,輸出穩定可預測。Temperature 調高到 2,輸出變得天馬行空
寫代碼用低温度,寫小說用高温度。大多數日常場景 0.7 到 1 之間就夠了
9. 幻覺 Hallucination
模型會一本正經地編造事實。它的"自信"不等於"正確"。問它一個不存在的論文標題,它可能會編出完整的作者、期刊和摘要
這是當前大模型最大的可靠性問題。緩解方法包括 RAG(後面會講)、多路驗證、讓模型說"我不確定"
10. 提示工程 Prompt Engineering
同一個模型,給它不同的提示詞,輸出質量差異巨大。一個含糊的提示和一個結構清晰、包含示例的提示,結果可能天差地別
好的提示包含三個要素:角色設定、具體任務描述、輸出格式要求。這也是為什麼"提示工程師"成了一個新職位
Part 3: AI 模型是怎麼變強的
11. 遷移學習 Transfer Learning
從零訓練一個模型要花幾個月和幾百萬美元。遷移學習的思路是:拿一個已經訓練好的基礎模型,用少量新數據微調一下,就能適應新任務
訓練成本從幾百萬降到幾千塊,時間從幾個月縮短到幾天。這也是為什麼開源基礎模型(Llama、Mistral)對行業這麼重要
12. 微調 Fine-Tuning
在基礎模型上用特定領域的數據繼續訓練。同一個底座模型,微調出來可以變成醫療助手、法律顧問、代碼生成器
微調不改變模型的核心架構,只是調整參數權重。類似於一個全科醫生去進修某個專科
13. RLHF 人類反饋強化學習
訓練出來的原始模型可能會說有毒的話或者給出錯誤的信息。RLHF 的做法是:讓模型生成多個回答,人類標註員選出最好的那個,模型根據這些偏好反饋來調整自己
這個過程重複成千上萬次,原始模型逐漸變成一個對齊人類偏好的助手。ChatGPT 能好用,RLHF 功不可沒
14. LoRA 低秩適配
全量微調一個大模型需要更新所有參數,代價太高。LoRA 的思路是凍結原始模型的所有參數,只在旁邊加一小組可訓練的"適配器"
效果幾乎一樣,成本降低 100 倍。現在社區裏大量的開源微調模型都是用 LoRA 做的
15. 量化 Quantization
把模型參數從 32 位浮點數壓縮到 8 位甚至 4 位整數。一個 70GB 的模型可以壓縮到 4GB 左右,在筆記本上就能跑
精度會有一點損失,但對大多數應用場景來說幾乎感覺不到。這也是為什麼現在手機上也能跑大模型了
Part 4: 真實 AI 系統是怎麼搭建的
16. RAG 檢索增強生成
讓模型在回答前先去檢索相關資料,然後基於檢索結果生成答案。先查再答,不是憑記憶編
RAG 大幅降低了幻覺率,而且知識可以實時更新,不需要重新訓練模型。企業級 AI 應用幾乎都在用這個架構
17. 向量數據庫 Vector Databases
傳統數據庫按關鍵詞搜索,向量數據庫按語義搜索。搜"如何提高效率"也能匹配到"提升生產力的方法"
這是 RAG 架構的核心組件。把文檔切塊,每塊轉成向量存進數據庫,查詢時用語義相似度來召回最相關的內容
18. AI Agent 智能體
傳統的 LLM 只能對話,Agent 能行動。它有一個思考-行動-觀察-重複的循環:接到任務後自己拆解步驟,調用工具執行,觀察結果,再決定下一步
2025 年是 Agent 爆發的一年,從 Manus 到 Claude Code,從 Cursor 到 Devin,能自主完成複雜任務的 AI Agent 正在重塑工作流
19. 思維鏈 Chain of Thought
直接問 AI "17 x 24 = ?" 它可能算錯。但如果讓它分步思考(17x20=340,17x4=68,340+68=408),正確率大幅提升
同一個模型,給更多"思考空間"就能給出更好的答案。這也是 o1、o3、Claude 3.5 Sonnet 等推理模型的核心原理
20. 擴散模型 Diffusion Models
Midjourney、DALL-E、Stable Diffusion 背後的技術。訓練時把圖片逐步加噪聲直到變成純噪點,推理時反過來,從噪點一步步還原出圖片
文本生成圖片的關鍵在於:用文字描述來引導去噪的方向。同樣的噪點,不同的文字提示,生成完全不同的圖片
以上 20 個概念覆蓋了當前 AI 領域最核心的技術棧。從底層的神經網絡到上層的 Agent 應用,從訓練側的 RLHF 到推理側的思維鏈,每一個概念都在真實的產品和系統中發揮着作用
所有插圖來自 X 用戶 @sairahul1 的原創手繪系列,原文連結:https://x.com/sairahul1/status/2057740928908161461