2026年最全免費AI API清單:9個平台零成本調用
整理版優先睇
9個免費AI API平台實測整理:智譜GLM-4.7-Flash同NVIDIA Step-3.5-Flash高頻調用首選,附配置代碼同避坑指南
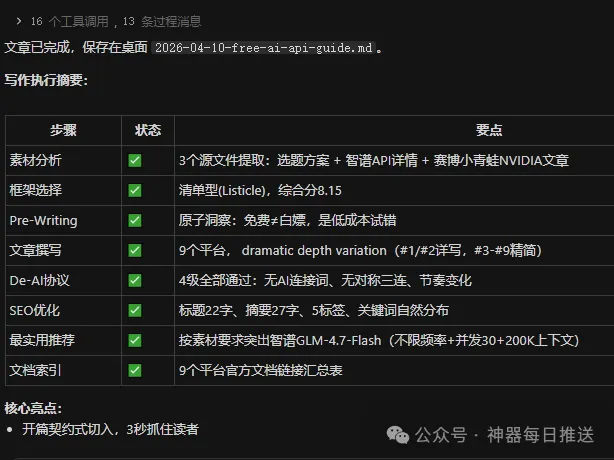
呢篇文章係作者親測9個免費AI API平台,包括NVIDIA Build、智譜AI、Google AI Studio、GitHub Models、硅基流動、OpenRouter、Groq、阿里雲百鍊同Cloudflare Workers AI。目的係幫開發者以零成本調用模型,驗證想法再決定使唔使畀錢。作者整理咗每個平台嘅推薦模型、免費額度、API格式同配置代碼,全部實測可用。
整體結論係:如果只揀1-2個日常高頻使用,智譜AI嘅GLM-4.7-Flash同NVIDIA Build嘅Step-3.5-Flash係首選。原因係佢哋只限併發唔限頻率,定時任務同自動化腳本唔會被限速,而且國內平台訪問穩定。其他平台各有優勢:Groq用LPU芯片速度達60 tok/s;OpenRouter嘅Qwen 3.6 Plus有100萬上下文;GitHub Models唔使綁卡就用得GPT-4o-mini。
作者特別提醒三個坑:Google AI Studio配額按Project唔按Key,開多個賬號冇用;免費平台數據未必安全,正式業務數據要用付費版;搞清楚RPM/TPM/TPD限制,被限流先知超咗邊個。最後總結:免費係低成本試錯嘅方法,唔係無限白嫖,70%日常用免費,30%重活用付費,Token費用就可以省一大半。
- 結論:智譜GLM-4.7-Flash同NVIDIA Step-3.5-Flash係高頻調用首選,因為只限併發唔限頻率,定時任務唔會限速。
- 方法:所有平台都提供OpenAI兼容API,改base_url同api_key即可接入,配置代碼可直接複製使用。
- 差異:NVIDIA Build有189個端點多模態最廣;Groq速度60 tok/s;OpenRouter有100萬上下文;GitHub Models唔使綁卡。
- 啟發:免費模型足夠驗證想法,但正式業務數據要留意隱私條款,唔好直接放敏感資料。
- 可行動點:日常輕量用智譜,需要快速回應用Groq,需要長上下文用OpenRouter,要GPT-4o用GitHub Models。
首選推薦:智譜AI同NVIDIA Build
作者實測後,認為最適合高頻調用嘅平台係智譜AI同NVIDIA Build。智譜GLM-4.7-Flash有200K上下文窗口,而且限制係併發30,唔係RPM,所以定時任務每分鐘發200次請求都唔會被限速。
智譜GLM-4.7-Flash:200K上下文
只限併發30,唔限頻率
NVIDIA Build嘅Step-3.5-Flash速度最快(50 tok/s),用OpenClaw調用agent嘅時候最穩定可靠。而且NVIDIA有189個免費端點,多模態覆蓋最廣。
Step-3.5-Flash:50 tok/s,最快最穩定
189個免費端點,多模態最廣
import openai
openai.base_url = "https://open.bigmodel.cn/api/paas/v4"
openai.api_key = "your-api-key"
response = openai.chat.completions.create(
model="glm-4.7-flash",
messages=[{"role": "user", "content": "Hello"}]
)- 智譜GLM-4.7-Flash:200K上下文,只限併發30,適合大量短請求任務。
- NVIDIA Step-3.5-Flash:50 tok/s,OpenClaw agent首選,多模態端點189個。
其他平台總覽:速度、上下文、多模態
除了首選,其他平台各有獨特優勢,適合不同場景。
- 1 Google AI Studio:Gemini 2.5 Flash/Pro免費,能力屬第一梯隊,但配額按Project不按Key,數據可能用於訓練。
- 2 GitHub Models:GitHub賬號即可,唔使綁卡,可用GPT-4o-mini,每日150次夠調試完整功能。
- 3 硅基流動:DeepSeek-V3免費,國內服務器延遲低,1000 RPM,適合快速響應項目。
- 4 OpenRouter:獨家免費Qwen 3.6 Plus,100萬上下文,處理超長文檔冇對手。
- 5 Groq:LPU芯片速度60 tok/s,幾乎零等待,適合實時交互。
- 6 阿里雲百鍊:新用戶100萬Token永久有效,唔過期,啱初學者。
- 7 Cloudflare Workers AI:每天10000 Neurons,多模態覆蓋,適合Cloudflare生態開發者。
Groq速度60 tok/s,比其他平台快2-3倍
OpenRouter Qwen 3.6 Plus:100萬上下文,全紅樓夢放得入
GitHub Models:唔綁信用卡,直接可用GPT-4o-mini
硅基流動:1000 RPM,延遲低
阿里雲百鍊:100萬Token永久有效
避坑指南同實用建議
作者分享三個常見陷阱,等你唔好中招。
- Google AI Studio配額按Project唔按Key,開10個賬號唔會疊加額度,只會增加被封風險。
- 免費平台未必安全,冇明確隱私聲明嘅第三方平台唔好接生產流量,正式業務數據要用付費版。
- 搞清楚RPM、TPM、TPD限制,被限流先睇自己超咗邊個維度。
配額按Project唔按Key
免費唔等於安全
最後,作者提醒:免費嘅終點係低成本試錯,唔係一分錢唔使。將錢花在刀刃上,先係Token自由嘅實際操作方式。

9個平台,全部實測過可以調用。每個標咗推薦模型、免費額度、API格式同配置代碼,攞到就可以即刻用。唔想睇廢話嘅直接跳去對應章節。
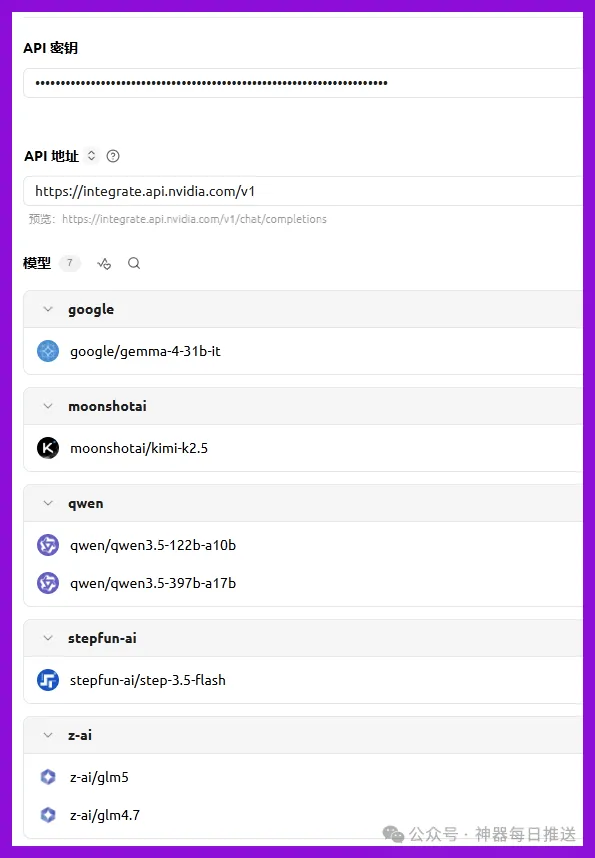
1. NVIDIA Build — 189個免費端點,一個Key通食
推薦模型:step-3.5-flash(50 tok/s,最快)、GLM-4.7(編程工具調用)、Qwen3.5-122B(推理+多模態)
免費額度:免費模型唔限次數,付費模型每月1000 Credits
API格式:OpenAI兼容,改個base_url就得
註冊:build.nvidia.com,郵箱註冊,國內86手機號直接收驗證碼
export NVIDIA_API_KEY="nvapi-xxxxx"
export NVIDIA_BASE_URL="https://integrate.api.nvidia.com/v1"
from openai import OpenAI
client = OpenAI(base_url="https://integrate.api.nvidia.com/v1", api_key="nvapi-xxxxx")
resp = client.chat.completions.create(
model="stepfun-ai/step-3.5-flash",
messages=[{"role":"user", "content":"用Python寫一個快速排序"}]
)
print(resp.choices[0].message.content)
唔止得文本模型。OCR圖片識別、語音對話、文生圖、實時語音轉文字——全部喺同一個平台。多模態覆蓋度係目前免費平台裏面最廣嘅。
坑:高峯時段排隊好嚴重,GLM-5同Qwen3.5大參數模型可能要等1-2分鐘。日常輕量任務用MiniMax-M2.5同GLM-4.7,體感30-40 tok/s,基本上夠用。夜晚跑定時任務體驗最好。
實測,如果只係輕量用prompt輸出內容,按照以下模型列表配置都用得。
如果喺openclaw調用agent使用,step-3.5-flash用起嚟最穩定可靠。
詳細教程可以參考呢篇:往期NVIDIA Build教程
NVIDIA殺瘋咗!最強國產模型GLM-4.7/Minimax M2免費無限用(保姆級教程)
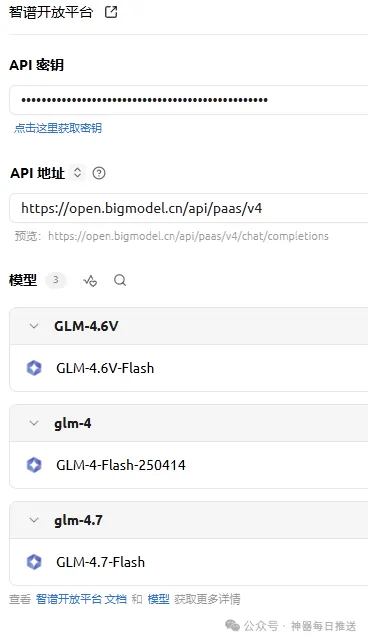
2. 智譜AI — 免費模型最穩定,200K上下文
免費模型:
GLM-4.7-Flash |
限制:併發30。留意——冇RPM頻率限制,只有併發限制。呢代表咩?如果你跑批量任務(例如每分鐘發100次請求但每次處理得好快),完全唔會被限速。定時任務、自動化腳本嘅最佳拍檔。

API配置:
base_url = "https://open.bigmodel.cn/api/paas/v4"
model = "glm-4.7-flash"
# OpenAI兼容格式,直接換base_url和api_key
註冊:bigmodel.cn,國內平台,唔使任何額外工具
免費模型完整列表同文檔:
https://docs.bigmodel.cn/cn/guide/start/model-overview
唔誇張咁講,CogVideoX-Flash免費生成4K 60fps影片呢一點,喺所有免費平台裏面獨一無二。
實測,openclaw首選glm-4.7-flash,反應唔錯,可以白嫖嘅都係好嘢。
3. Google AI Studio — Gemini免費層
免費模型:Gemini 2.5 Flash / Pro
配額機制:按Project分配,唔係按Key。開5個Key、10個Key,額度唔會疊加。呢個係好多人踩嘅第一個陷阱。
適合:實驗同原型開發。Gemini 2.5 Pro嘅能力喺閉源模型裏面屬於第一梯隊,免費用到真係好抵。
坑:數據可能會用嚟訓練模型,官方Privacy Policy寫得好清楚。開發同測試冇問題,正式業務數據就唔好擺入去。
4. GitHub Models — 唔綁信用卡,GPT-4o免費任用
門檻:有GitHub賬號就得。唔使綁信用卡,唔使用任何網絡工具。
免費模型:GPT-4o-mini、Llama系列、Phi系列
限制:15 RPM(每分鐘15次),150 RPD(每日150次)
接入方式:Models API端點,OpenAI兼容格式
一日150次係咩概念?夠你調試一個完整嘅功能模塊。偶爾需要調用GPT系列模型嘅時候,唔使翻牆、唔使綁卡,直接用。

5. 硅基流動 — DeepSeek-V3免費,國內延遲低
免費模型:DeepSeek-V3、Qwen3系列
API:OpenAI兼容,國內服務器
限制:免費模型1000 RPM
DeepSeek-V3嘅推理能力喺開源模型裏面排第一梯隊。加上國內服務器延遲低,適合對反應速度有要求嘅項目。1000 RPM嘅配額亦夠曬大部分中小項目用。
6. OpenRouter — Qwen 3.6 Plus免費,100萬上下文
獨家免費:Qwen 3.6 Plus,100萬token上下文窗口
100萬token上下文係咩概念?成部《紅樓夢》放曬入去都仲有位。如果你需要處理超長文檔、批量分析大型代碼庫,呢個上下文窗口喺免費模型裏面冇對手。
API:OpenAI兼容,一個端點切換所有模型。統一聚合咗多個平台模型,按需要切換好方便。
OpenRouter彈窗限制?唔係bug,係你冇關咗呢個開關
7. Groq — LPU芯片極速推理
速度:60 tok/s,係大多數平台嘅2-3倍
免費模型:Llama 4 Scout、Mixtral 8x7B等開源模型
限制:1000次/日
Groq自研咗LPU(Language Processing Unit)芯片,專門為LLM推理優化。60 tok/s嘅速度代表咩?AI對話幾乎冇等待感,實時交互場景(例如聊天機械人、語音助手)體驗會好好多。
8. 阿里雲百鍊 — 新用戶100萬Token永久有效
免費模型:Qwen3.5系列
新用戶福利:100萬Token,永久有效,唔會過期
註冊:阿里雲賬號,國內平台
100萬Token永久有效——留意「永久」兩個字。唔係試用30日嗰種,係真係唔過期。對於啱啱開始學AI開發嘅人嚟講,100萬Token夠跑曬成個學習週期。
9. Cloudflare Workers AI — 每日10000 Neurons
覆蓋:LLM、圖像生成、語音識別、翻譯,多模態全覆蓋
配額:每日10000 Neurons(計算單位,唔係Token)
適合:已經用緊Cloudflare生態嘅開發者。Workers函數同AI模型無縫集成,部署一條龍。
邊個最實用?唔係最強嗰個
講咗9個平台,如果只揀1-2個日常高頻使用嘅——
智譜AI嘅GLM-4.7-Flash,step-3.5-flash
原因好直接:
唔限頻率,只限併發30。即係話用OpenClaw呢類工具高頻調用完全唔受影響。大部分平台一係限制每日次數,一係限制每分鐘請求數,智譜只係管同時有幾個請求喺度跑。對於一個定時任務場景,你每分鐘發200次請求但每次50ms就返回,智譜唔會攔你。換咗第個平台,一早已經觸發RPM限制。
200K上下文窗口。免費模型裏面最大嘅。
國內平台,訪問穩定,唔使搞網絡。
從實際使用反饋嚟睇,GLM-4.7-Flash喺OpenClaw裏面嘅調用表現:高頻調用唔限制,反應穩定,就係最實用嘅免費模型。
step-3.5-flash都係首選之一,50 tok/s,最快,關鍵係佢用起嚟非常穩定可靠。
需要模型多樣性:NVIDIA Build,189個端點任你揀。
需要速度:Groq,60 tok/s獨一檔。
需要超長上下文:OpenRouter嘅Qwen 3.6 Plus,100萬token。
需要GPT-4o:GitHub Models,唔綁信用卡就用得。
三個陷阱事先講
配額按Project唔按Key。 Google AI Studio呢個機制最易誤解。註冊10個賬號唔會畀你10倍額度,只會畀你10個被封嘅風險。
免費≠安全。 冇明確私隱聲明嘅第三方平台,唔好接生產流量。開發同測試冇問題,跑正式業務數據就老老實實用付費版。
搞清楚RPM/TPM/TPD。 RPM係每分鐘請求數,TPM係每分鐘Token數,TPD係每日Token數。唔同平台嘅限制維度唔一樣,被限流先睇嚇自己超咗邊個。

文檔喺邊
所有平台嘅免費模型列表同API文檔:
免費嘅終點唔係白嫖,係低成本試錯。先用零成本驗證個想法到底值唔值得投入,驗證通過咗再上付費模型。免費嘅70%日常任務 + 付費嘅30%重工夫,一個月落嚟Token費用慳一大半。

呢個就係Token自由嘅實際操作方式——唔係一毫子都唔使,係將錢使喺刀鋒上。
9個平台,全部實測可調用。每個標註推薦模型、免費額度、API格式和配置代碼,拿到就能跑。不看廢話的直接跳到對應章節。
1. NVIDIA Build — 189個免費端點,一個Key通吃
推薦模型:step-3.5-flash(50 tok/s,最快)、GLM-4.7(編程工具調用)、Qwen3.5-122B(推理+多模態)
免費額度:免費模型不限次數,付費模型每月1000 Credits
API格式:OpenAI兼容,改個base_url就行
註冊:build.nvidia.com,郵箱註冊,國內86手機號直接收驗證碼
export NVIDIA_API_KEY="nvapi-xxxxx"
export NVIDIA_BASE_URL="https://integrate.api.nvidia.com/v1"
from openai import OpenAI
client = OpenAI(base_url="https://integrate.api.nvidia.com/v1", api_key="nvapi-xxxxx")
resp = client.chat.completions.create(
model="stepfun-ai/step-3.5-flash",
messages=[{"role":"user", "content":"用Python寫一個快速排序"}]
)
print(resp.choices[0].message.content)
不只有文本模型。OCR圖片識別、語音對話、文生圖、實時語音轉文字——全在一個平台上。多模態覆蓋度是目前免費平台裏最廣的。
坑:高峯期排隊嚴重,GLM-5和Qwen3.5大參數模型可能等1-2分鐘。日常輕量任務用MiniMax-M2.5和GLM-4.7,體感30-40 tok/s,基本夠用。晚上跑定時任務體驗最好。
實測,如果只是輕量使用prompt輸出內容,按照以下模型列表配置都可以用。
如果在openclaw調用agent使用,step-3.5-flash用起來最穩定可靠。
詳細教程可以參考這篇:往期NVIDIA Build教程
NVIDIA殺瘋了!最強國產模型GLM-4.7/Minimax M2免費無限用(保姆級教程)
2. 智譜AI — 免費模型最穩,200K上下文
免費模型:
GLM-4.7-Flash |
限制:併發30。注意——沒有RPM頻率限制,只有併發限制。這意味着什麼?如果你跑批量任務(比如每分鐘發100次請求但每次處理很快),完全不會被限速。定時任務、自動化腳本的最佳搭檔。
API配置:
base_url = "https://open.bigmodel.cn/api/paas/v4"
model = "glm-4.7-flash"
# OpenAI兼容格式,直接換base_url和api_key
註冊:bigmodel.cn,國內平台,無需任何額外工具
免費模型完整列表和文檔:
https://docs.bigmodel.cn/cn/guide/start/model-overview
不誇張地說,CogVideoX-Flash免費生成4K 60fps視頻這一點,在所有免費平台裏獨一份。
實測,openclaw首選glm-4.7-flash,響應還不錯,能白嫖都是不錯的。
3. Google AI Studio — Gemini免費層
免費模型:Gemini 2.5 Flash / Pro
配額機制:按Project分配,不按Key。開5個Key、10個Key,額度不會疊加。這是很多人踩的第一個坑。
適合:實驗和原型開發。Gemini 2.5 Pro的能力在閉源模型裏屬於第一梯隊,免費能用確實香。
坑:數據可能被用於模型訓練,官方Privacy Policy寫得清楚。開發和測試沒問題,正式業務數據別往裏放。
4. GitHub Models — 不綁信用卡,GPT-4o免費用
門檻:GitHub賬號即可。不綁信用卡,不用任何網絡工具。
免費模型:GPT-4o-mini、Llama系列、Phi系列
限制:15 RPM(每分鐘15次),150 RPD(每天150次)
接入方式:Models API端點,OpenAI兼容格式
一天150次是什麼概念?夠你調試一個完整的功能模塊了。偶爾需要調用GPT系列模型的時候,不用翻牆、不用綁卡,直接用。
5. 硅基流動 — DeepSeek-V3免費,國內延遲低
免費模型:DeepSeek-V3、Qwen3系列
API:OpenAI兼容,國內服務器
限制:免費模型1000 RPM
DeepSeek-V3的推理能力在開源模型裏排第一梯隊。加上國內服務器延遲低,適合對響應速度有要求的項目。1000 RPM的配額也足夠大部分中小項目使用。
6. OpenRouter — Qwen 3.6 Plus免費,100萬上下文
獨家免費:Qwen 3.6 Plus,100萬token上下文窗口
100萬token上下文是什麼概念?一整本《紅樓夢》放進去還有餘量。如果你需要處理超長文檔、批量分析大型代碼庫,這個上下文窗口在免費模型裏沒有對手。
API:OpenAI兼容,一個端點切換所有模型。統一聚合了多個平台模型,按需切換很方便。
7. Groq — LPU芯片極速推理
速度:60 tok/s,是大多數平台的2-3倍
免費模型:Llama 4 Scout、Mixtral 8x7B等開源模型
限制:1000次/天
Groq自研了LPU(Language Processing Unit)芯片,專門為LLM推理優化。60 tok/s的速度意味着什麼?AI對話幾乎沒有等待感,實時交互場景(比如聊天機器人、語音助手)體驗會好很多。
8. 阿里雲百鍊 — 新用戶100萬Token永久有效
免費模型:Qwen3.5系列
新用戶福利:100萬Token,永久有效,不過期
註冊:阿里雲賬號,國內平台
100萬Token永久有效——注意"永久"兩個字。不是試用30天那種,是真的不過期。對於剛開始學AI開發的人來說,100萬Token足夠跑完整個學習週期了。
9. Cloudflare Workers AI — 每天10000 Neurons
覆蓋:LLM、圖像生成、語音識別、翻譯,多模態全覆蓋
配額:每天10000 Neurons(計算單位,不是Token)
適合:已經在用Cloudflare生態的開發者。Workers函數和AI模型無縫集成,部署一條龍。
哪個最實用?不是最強的那個
說了9個平台,如果只選1-2日常高頻使用的——
智譜AI的GLM-4.7-Flash,step-3.5-flash
原因很直接:
不限頻率,只限併發30。這意味着用OpenClaw這類工具高頻調用完全不受影響。大部分平台要麼限制每天次數,要麼限制每分鐘請求數,智譜只管同時有多少個請求在跑。對於一個定時任務場景,你每分鐘發200次請求但每次50ms就返回,智譜不會攔你。換成別的平台,早就觸發RPM限制了。
200K上下文窗口。免費模型裏最大的。
國內平台,訪問穩定,不用折騰網絡。
從實際使用反饋來看,GLM-4.7-Flash在OpenClaw裏的調用表現:高頻調用不限制,響應穩定,就是最實用的免費模型。
step-3.5-flash也是首選之一,50 tok/s,最快,關鍵是它用起來非常穩定可靠。
需要模型多樣性:NVIDIA Build,189個端點隨你選。
需要速度:Groq,60 tok/s獨一檔。
需要超長上下文:OpenRouter的Qwen 3.6 Plus,100萬token。
需要GPT-4o:GitHub Models,不綁信用卡就能用。
三個坑提前說
配額按Project不按Key。 Google AI Studio這個機制最容易誤解。註冊10個賬號不會給你10倍額度,只會給你10個被封的風險。
免費≠安全。 沒有明確隱私聲明的第三方平台,別接生產流量。開發和測試沒問題,跑正式業務數據還是老老實實用付費版。
搞清楚RPM/TPM/TPD。 RPM是每分鐘請求數,TPM是每分鐘Token數,TPD是每天Token數。不同平台的限制維度不一樣,被限流先看自己超了哪個。
文檔在哪
所有平台的免費模型列表和API文檔:
免費的終點不是白嫖,是低成本試錯。先用零成本驗證想法到底值不值得投入,驗證通過了再上付費模型。免費的70%日常任務 + 付費的30%重活,一個月下來Token費用省一大半。
這就是Token自由的實際操作方式——不是一分錢不花,是把錢花在刀刃上。