44K人收藏!Karpathy 公開 AI 知識庫搭建全流程,3 個文件夾就夠了
整理版優先睇
Karpathy 公開用三個文件夾加一份 Schema 搭建 AI 知識庫嘅方法,強調工具簡單、Schema 比工具更重要,形成素材越多越聰明嘅正循環。
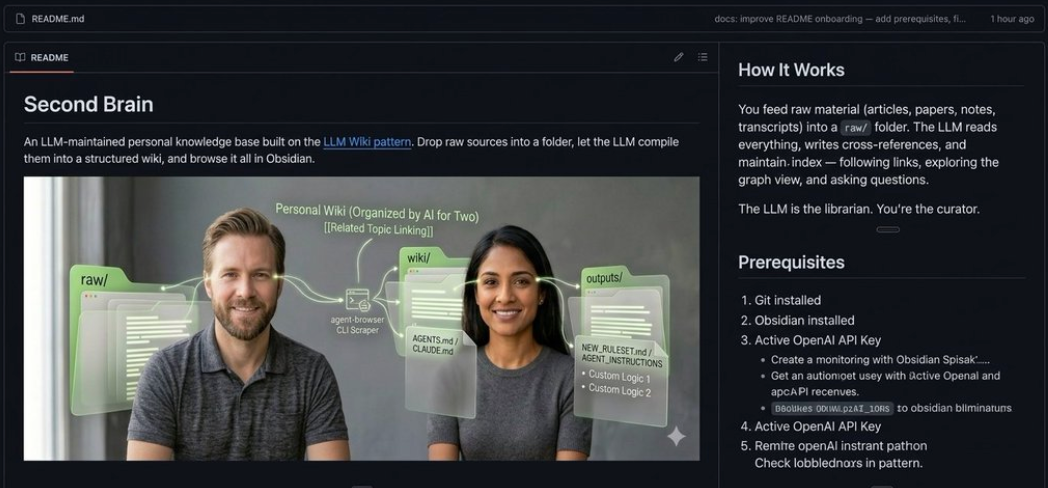
呢篇文章係由專注 AI 工具嘅作者小智整理,佢跟住 Karpathy 嘅思路同博主 Nick Spisak 嘅實操指南,由頭到尾試咗一次,再分享出嚟。Karpathy 係 Tesla 前 AI 總監、OpenAI 創始團隊成員,佢最近喺 X 上話自己將大量 token 用喺「處理內容」而唔係寫 code,仲公開咗佢嘅個人知識管理系統——核心就係一個檔案夾統一存放,再由 AI 幫手歸類、串聯、生成摘要。成個系統嘅骨架得三個目錄:raw(放原始素材)、wiki(AI 整理後嘅產出)、outputs(分析報告),完全扁平,冇複雜嵌套。
Karpathy 強調「Schema 比工具重要」,即係寫一份純文字檔案(例如 CLAUDE.md)話畀 AI 知知識庫嘅結構同規則,唔好喺工具配置上浪費時間。作者實測後發現,只要目錄、Schema、AI 工具三樣到位,就可以形成正循環:素材越多 → wiki 越全 → 提問質量越高 → 產出越有價值。佢亦提醒要留意 AI 錯誤累積嘅風險,建議定期做知識庫體檢。
文章最後呼籲讀者唔好收藏完就算,要真正動手做——將散落各處嘅筆記集中,用 AI 幫手梳理,好過沉迷工具配置。
- 用三個目錄(raw、wiki、outputs)就夠,毋須複雜嘅標籤或嵌套結構,目錄越扁平越好。
- 素材收集唔使分類,乜嘢格式都可以直接掉入 raw,AI 會負責整理。
- 寫一份 Schema 檔案(如 CLAUDE.md)係成個系統嘅關鍵,佢話畀 AI 知點樣整理,比揀邊款工具更重要。
- Agent-browser 呢類工具可以大幅提升素材收集效率,直接由 AI 抓取動態網頁內容,省 token 又方便。
- 定期檢查 wiki 有冇矛盾內容,避免 AI 錯誤隨引用不斷放大——呢個係最易忽視嘅隱患。
agent-browser
Vercel Labs 開源嘅命令行工具,可以等 AI 直接控制 Chrome 實例抓取動態網頁內容,提取正文後輸出純文字,比起 Playwright MCP 更省 token。
骨架就三個檔案夾,唔使諗太複雜
成個系統嘅基礎係三個目錄,喺終端敲一句 `mkdir -p my-knowledge-base/{raw,wiki,outputs}` 就搞掂。raw 放所有原始素材,乜嘢格式都得;wiki 係 AI 整理後嘅產區,你唔好自己鬱手改;outputs 用嚟存 AI 根據你提問生成嘅分析報告。
Karpathy 自己都係咁分,冇嵌套,冇標籤,扁平到冇得再扁。
好多人都卡喺呢一步:整完目錄之後唔知放乜嘢入去,驚格式唔統一、文件名唔靚。其實完全多餘,你手上有乜嘢就掟乜嘢入 raw,分類呢啲嘢全部交畀 AI 搞掂。
收集素材:見一個撈一個,再加個自動加速器
平時刷到好文章,成日因為要手動複製貼上而放棄?作者推薦用 agent-browser 呢個開源工具,佢可以畀 AI 直接控制一個 Chrome 實例,自動打開網頁、提取正文、輸出成純文字。
- 1 安裝 agent-browser 後,指令就兩步:`agent-browser open https://目標網址` 同 `agent-browser gettext "article"`。
- 2 AI 會自動打開頁面、抽走內文,你再將結果存返入 raw 就搞掂。
- 3 比起 Playwright MCP 佢慳 token 好多,同一輪對話可以抓多幾倍嘅內容。
而家作者見到長文或者競品分析,直接掉條 link 畀 AI 去抓,連瀏覽器都唔使開。
最易 skip 嘅一步:寫 Schema,等 AI 識做你個腦
好多人 skip 咗呢步,但佢直接決定 AI 整理出嚟嘅質素。喺項目根目錄整一個純文字檔案,叫 CLAUDE.md 或者 AGENTS.md 都得,當係畀 AI 嘅工作手冊。
Karpathy 對佢自己個 Schema 嘅評價得四個字:「超級簡單」。
下面係作者用緊嘅精簡模板,你可以直接改:
# My Knowledge Base
## 用途
[填你嘅主題,例如「AI 應用開發」]
## 目錄約定
raw 目錄存原始素材,任何情況下都唔好改動入面嘅檔案
wiki 目錄由你全權維護,我只負責閲讀同提問
outputs 目錄存放你生成嘅報告同分析結果
## 整理規範
一個話題對應 wiki 裏嘅一個獨立 md 檔案
檔案開頭寫一段 100 字以內嘅核心摘要
用 [[文件名]] 格式喺唔同話題之間建立關聯
維護一份 INDEX.md 作為全域目錄
每次 raw 新增素材後同步更新對應嘅 wiki 檔案
## 我重點關注嘅方向
1. [方向一]
2. [方向二]
3. [方向三]Schema 寫得好唔好,比你揀邊款工具重要十倍。
一句指令等 AI 開工,之後你只係讀者同提問者
素材同規矩準備好之後,打開你用開嘅 AI 編碼工具(Claude Code、Cursor、Windsurf 都得),入去項目目錄,下一條指令:
「掃描 raw 嘅全部檔案,根據 CLAUDE.md 定義嘅規範生成 wiki。每個核心話題獨立一個 md 檔案,檔案之間用雙鏈關聯,最後生成一份 INDEX.md 做導航。」
然後就唔使理,等佢跑完。wiki 會多咗一批按話題分類好嘅檔案,每篇有摘要,仲有 cross-reference。你自己冇為意嘅跨主題關聯,AI 會幫你挖出嚟。
越用越聰明嘅正循環,同埋一個你唔會想中嘅伏
當 wiki 累積到十幾篇之後,你可以開始向自己嘅知識庫提問。例如:
- 「將 wiki 關於 Agent 架構同 RAG 嘅內容擺埋一齊睇,揾出交叉領域同盲區。」
- 「對比 A 同 B 兩篇素材喺同一個話題上嘅唔同觀點,畀我 300 字差異分析。」
- 「淨係根據我知識庫現有內容,幫我起草一份某領域嘅技術調研摘要。」
AI 畀嘅答案全部來自你自己積累嘅素材,唔係互聯網搜返嚟。
呢啲答案可以存入 outputs,或者將新 insight 反饋返入 wiki。每一次提問同反饋都會令知識庫更完善,形成正飛輪。
不過要留心一個坑:如果 AI 寫咗一條唔準確嘅總結,你存咗,下次 AI 引用佢就會放大錯誤。解決方法係定期做知識庫體檢,叫 AI check wiki 有冇前後矛盾、冇展開嘅概念、或者喺 raw 揾唔到出處嘅結論。
一個月養成呢個習慣,慳返嘅 token 遠比花嘅多。
大家好,我係小智,專注 AI 工具、AI 智能體同編程提效
Karpathy 到底講咗啲乜
Tesla 前 AI 總監、OpenAI 創始團隊成員 Karpathy,前排喺 X 隨手發咗條動態。佢提到自己最近將大量 token 用咗喺「處理內容」上面,而唔係寫 code。具體做法係用大模型幫自己整咗套個人知識管理系統。
呢條動態兩日內俾上百萬人睇到。
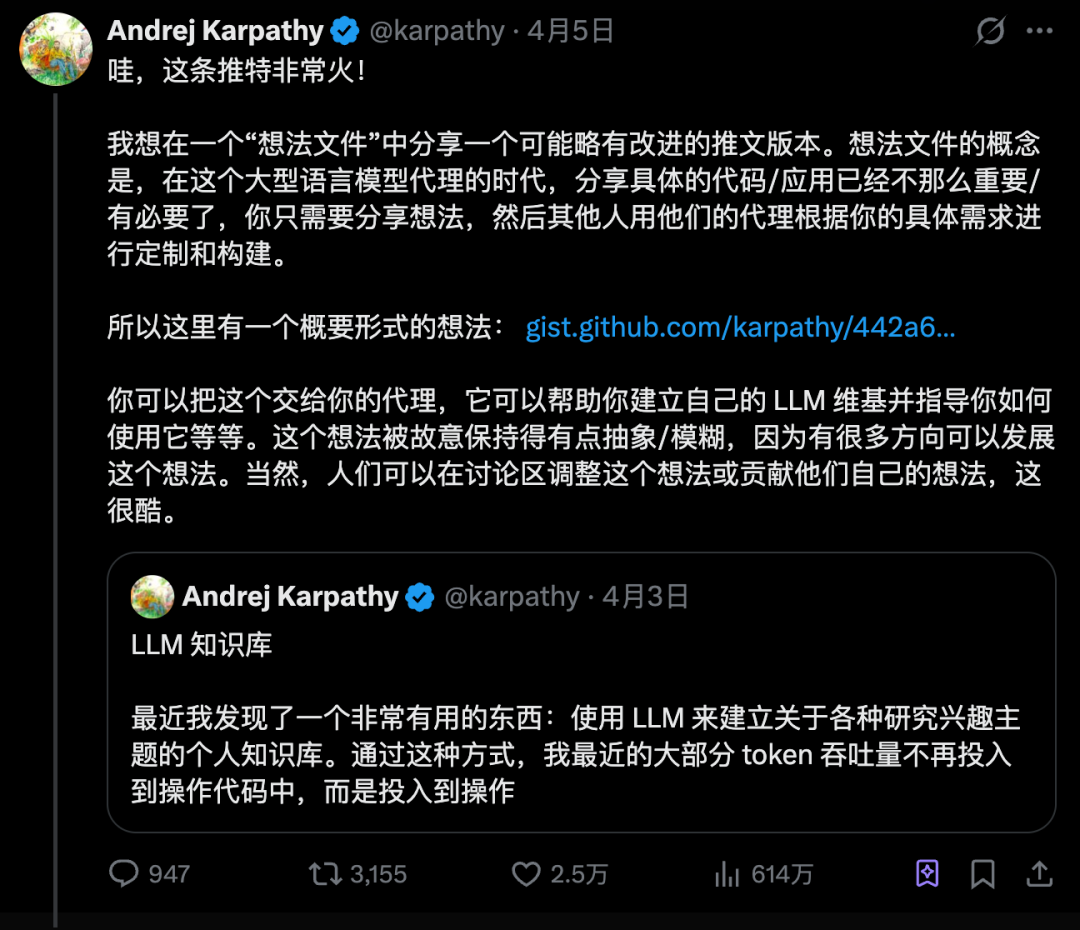
佢嘅核心主張就一句話:唔好再將筆記散落喺十幾個 App 裏面喇,揾一個資料夾統一存放,然後交俾 AI 幫你歸類、串聯、生成摘要。
隨後有個博主叫 Nick Spisak,將 Karpathy 嘅思路整成咗一份手把手嘅實操指南。我拎住呢份指南由頭行咗一次,中間確實遇到唔少細節問題(問就係經驗教訓),今日將我整理完嘅版本分享出嚟。
我哋言歸正傳。
首先打好地基:目錄結構
成個系統嘅骨架得三個目錄,打開終端機打一行指令就起好。
mkdir -p my-knowledge-base/{raw,wiki,outputs}raw 放你收集嘅所有原始素材,咩格式都得,唔使理亂唔亂。
wiki 係 AI 幫你整理完之後嘅產出區,你自己唔好搞呢度嘅檔案。
outputs 存 AI 按你嘅問題生成嘅分析報告、簡報、對比總結。
Karpathy 自己都係咁分。冇嵌套五六層嘅複雜目錄,冇標籤系統,扁平到冇得再扁平。
素材收集:唔好猶豫,掉入去先講
我觀察咗一下,大部份人卡咗喺呢一步。創完目錄之後望住空盪盪嘅 raw 資料夾唔知放咩好,開始糾結要唔要先分類、要唔要統一改名。
呢個想法完全多餘。
你手邊而家有咩就掉咩入去。瀏覽器囤咗半年嘅書籤,直接匯出。微信收藏嘅文章,複製出嚟存做 txt。開會時隨手記嘅筆記、下載過嘅 PDF 研究報告、截圖、思維導圖,全部塞入 raw 資料夾。
格式混亂冇問題,文件名隨意都冇問題,歸類整理呢件事由頭到尾都係 AI 負責。
我自己第一次掉入去嘅時候,17 個檔案裏面有 markdown、有純文字、有截圖,亂成一鍋粥。完全唔影響之後 AI 嘅處理。
素材收集加速器:agent-browser
手動將嘢存入 raw 效率有限。遇到啲需要滾動加載、JavaScript 動態渲染、甚至要登入先睇到嘅網頁,複製貼上根本拎唔到完整內容。
Vercel Labs 開源咗一個叫 agent-browser 嘅指令工具(GitHub 兩萬幾粒星),可以令 AI 直接控制一個獨立嘅 Chrome 實例去抓取網頁。裝好之後操作得兩步:
agent-browser open https://目標文章地址
agent-browser gettext "article"AI 自動打開頁面、提取正文、輸出做純文字。你再將結果存落 raw 就搞掂。
唔好睇呢樣嘢唔起眼,用起上嚟比 Playwright MCP 慳咗大量 token。我實測同一輪對話入面可以多抓好幾倍嘅頁面內容。而家我遇到想睇嘅長文或者競品分析,直接掟個連結俾 AI 去抓,自己連瀏覽器都唔使打開。
日常積累素材嘅節奏就變成:刷到好文章,話俾 AI 知將呢個連結嘅內容存到 raw 目錄。raw 資料夾會好似滾雪球咁越來越充實。
最易被忽略嘅一步:寫一份 Schema
到呢一步你已經有咗目錄結構同一堆原始素材。跟住呢件事好多人會直接 skip 咗,但佢直接決定咗 AI 整理出嚟嘅質素好唔好。
喺項目根目錄新建一個純文字檔案,我習慣叫 CLAUDE.md,你叫 AGENTS.md 或者 README.md 都得。呢個檔案相當於俾 AI 寫嘅一份工作手冊,話俾佢知你個知識庫係咩樣、應該按咩規矩整理。
下面係我自己用緊嘅一份精簡模版,你可以直接拎去改:
# My Knowledge Base
## 用途
[填你的主題,比如"AI 應用開發"或"產品設計方法論"]
## 目錄約定
raw 目錄存原始素材,任何情況下都不要改動裏面的文件
wiki 目錄由你全權維護,我只負責閲讀和提問
outputs 目錄存放你生成的報告和分析結果
## 整理規範
一個話題對應 wiki 裏的一個獨立 md 文件
文件開頭寫一段 100 字以內的核心摘要
用 [[文件名]] 格式在不同話題之間建立關聯
維護一份 INDEX.md 作為全局目錄
每次 raw 裏新增素材後同步更新對應的 wiki 文件
## 我重點關注的方向
1. [方向一]
2. [方向二]
3. [方向三]Karpathy 講起自己嘅 schema 時講咗四個字:「超級簡單」。冇數據庫、冇插件、冇任何第三方依賴。一個純文字檔案加幾條清晰嘅規則,夠曬。
講句直白嘅話,schema 寫得好唔好,比你揀咩工具重要十倍。
讓 AI 開始做嘢
素材有咗,規矩都定好咗,而家打開你用開嘅 AI 編碼工具。Claude Code、Cursor、Windsurf 都得,只要可以訪問本地檔案系統。
入咗項目目錄,俾 AI 下一條指令。我通常咁講:
「掃描 raw 裏面全部檔案,根據 CLAUDE.md 定義嘅規範生成 wiki。每個核心話題單獨開一個 md 檔案,檔案之間用雙鏈關聯,最後生成一份 INDEX.md 做導航入口。」
跟住就唔使理,等佢行完。
結果會令你有啲驚喜。wiki 目錄入面會出現一批按話題拆分好嘅檔案,每篇開頭有精煉嘅摘要,文章之間透過雙鏈串埋一齊。有啲你自己都冇留意到嘅跨主題關聯,AI 幫你挖咗出嚟。
順便提嚇,wiki 裏面嘅內容從今以後全部由 AI 維護。你嘅角色係讀者同提問者,唔係編輯者。手動改 wiki 檔案反而會打亂 AI 嘅整理邏輯。
越用越聰明嘅正循環
當 wiki 裏面積累到十幾篇文章之後,真正好玩嘅部分就嚟喇。你可以開始向自己嘅知識庫提問。
例如我成日會問呢幾類問題:
「將 wiki 裏面關於 Agent 架構嘅內容同 RAG 相關嘅內容擺埋一齊睇,揾出佢哋嘅交叉領域同我仲未覆蓋到嘅盲區。」
「對比 A 呢篇素材同 B 呢篇素材喺同一個話題上嘅唔同觀點,俾我一份 300 字嘅差異分析。」
「淨係基於我知識庫現有嘅內容,幫我起草一份某領域嘅技術調研摘要。」
AI 畀出嘅答案全部嚟自你自己儲嘅素材,唔係上網即時搜嘅。呢啲答案你可以直接存到 outputs 目錄,又可以叫 AI 將新洞察反饋到 wiki 嘅對應文章入面。
每一次提問同反饋都會令知識庫變得更完善。呢個就係一個正向飛輪:素材越多,wiki 越全,提問質素越高,產出越有價值。
有一個坑必須提前防範
呢套系統有一個隱性風險。有人喺 Karpathy 嘅帖子下面講咗一句特別到位嘅話:當 AI 嘅輸出被存返落知識庫之後,如果入面有錯誤,呢個錯誤會隨住後續引用不斷放大。
確實係咁。AI 寫咗一條唔係咁準確嘅總結,你存咗。下一次提問時 AI 將呢條錯誤總結當成事實嚟引用,錯誤就會好似滾雪球咁(血淚教訓)。
應對方法係定期幫知識庫做一次體檢。叫 AI 檢查 wiki 有冇前後矛盾嘅內容,邊啲概念被提到但冇展開解釋,邊啲結論喺 raw 目錄揾唔到原始出處。
呢個習慣一個月養成,後面慳到嘅 token 遠比花嘅多。
關於工具選擇,我真實嘅想法
Karpathy 嗰條帖子下面有唔少人喺推薦各種 Obsidian 插件同 Notion 模版。
但 Karpathy 本人被問到嘅時候,回答係佢只用一個扁平嘅 md 檔案目錄,冇任何花巧嘢。
我自己嘅體驗都一樣。用 Claude Code 喺終端機操作成個知識系統,VS Code 間中打開嚟睇嚇檔案內容,夠曬。
講句真心話,我見過太多人喺工具配置上使嘅時間遠遠超過咗真正使用知識庫嘅時間。裝幾十個插件、調各種主題配色、研究雙鏈語法,搞咗半日知識庫入面仲係空嘅。
呢個同當年嘅 Notion 陷阱一模一樣。工具本身變成咗目的,而唔係手段。
一個資料夾加一份寫清楚嘅 schema,實際效果比大部份重度配置嘅方案都要好(踩過坑嘅人都明)。
寫喺最後
回顧嚇成個流程:起好三個目錄,將手頭嘅素材掉入去,裝個自動抓取工具提高收集效率,寫一份 schema 令 AI 知道點樣整理,然後一條指令叫 AI 行起嚟。
Karpathy 嗰條帖子俾四萬幾人收藏咗。收藏係最易嘅一步,真正去做先至係有用嘅一步。
呢個週末揀一個你最近在研究嘅話題,將散落喺各處嘅筆記同文章集中埋一齊,叫 AI 幫你捋一次。你會發現好多之前冇留意到嘅知識關聯。
工欲善其事,必先利其器。成套工具已經擺喺面前,動手試嚇啦。
如果本文對你有幫助,都請幫手點個 讚👍 + 在看 呀!❤️關注小智AI指南公眾號,AI 路上唔迷路
大家好,我是小智,專注 AI 工具,AI 智能體和編程提效
Karpathy 到底說了什麼
特斯拉前 AI 總監、OpenAI 創始團隊成員 Karpathy,前陣子在 X 上隨手發了條動態。他提到自己最近把大量 token 花在了"處理內容"上,而不是寫代碼。具體做法是拿大模型給自己搭了一套個人知識管理系統。
這條動態兩天內被上百萬人看到。
他的核心主張就一句話:別再把筆記散落在十幾個 App 裏了,找一個文件夾統一存放,然後交給 AI 幫你歸類、串聯、生成摘要。
隨後有個博主叫 Nick Spisak,把 Karpathy 的思路做成了一份手把手的實操指南。我拿着這份指南從頭走了一遍,中間確實遇到不少細節問題(問就是經驗教訓),今天把我整理後的版本分享出來。
咱們言歸正傳。
先把地基打好:目錄結構
整套系統的骨架就三個目錄,打開終端敲一行命令就建好了。
mkdir -p my-knowledge-base/{raw,wiki,outputs}raw 放你收集的所有原始素材,什麼格式都行,不用管亂不亂。
wiki 是 AI 幫你整理之後的產出區,你自己別動這裏面的文件。
outputs 存 AI 根據你的提問生成的分析報告、簡報、對比總結。
Karpathy 自己也是這麼分的。沒有嵌套五六層的複雜目錄,沒有標籤系統,扁平到不能再扁平。
素材收集:別猶豫,先扔進去再說
我觀察了一下,大部分人卡在這一步。創完目錄之後盯着空蕩蕩的 raw 文件夾不知道該放什麼,開始糾結要不要先分類、要不要統一命名。
這個想法完全多餘。
你手邊現在有什麼就往裏丟什麼。瀏覽器裏囤了半年的書籤,直接導出。微信收藏的文章,複製出來存成 txt。開會時隨手記的筆記、下載過的 PDF 研究報告、截圖、思維導圖,全部塞進 raw 文件夾。
格式混亂沒關係,文件名隨意也沒關係,歸類整理這件事從頭到尾都是 AI 負責。
我自己第一次往裏扔的時候,17 個文件裏有 markdown、有純文本、有截圖,亂成一鍋粥。完全不影響後面 AI 的處理。
素材收集加速器:agent-browser
手動往 raw 裏存東西效率有限。碰到那種需要滾動加載、JavaScript 動態渲染、甚至要登錄才能看的網頁,複製粘貼根本拿不到完整內容。
Vercel Labs 開源了一個叫 agent-browser 的命令行工具(GitHub 兩萬多星),能讓 AI 直接控制一個獨立的 Chrome 實例去抓取網頁。裝好之後操作就兩步:
agent-browser open https://目標文章地址
agent-browser gettext "article"AI 自動打開頁面、提取正文、輸出成純文本。你再把結果存進 raw 就完事了。
別看這玩意兒不起眼,用起來比 Playwright MCP 省了大量 token。我實測同一輪對話裏能多抓好幾倍的頁面內容。現在我碰到想看的長文或者競品分析,直接甩個連結讓 AI 去抓,自己連瀏覽器都不用打開。
日常積累素材的節奏就變成了:刷到好文章,告訴 AI 把這個連結的內容存到 raw 目錄。raw 文件夾會像滾雪球一樣越來越充實。
最容易被忽略的一步:寫一份 Schema
到這一步你已經有了目錄結構和一堆原始素材。接下來這件事很多人會直接跳過,但它直接決定了 AI 整理出來的質量好不好。
在項目根目錄新建一個純文本文件,我習慣叫 CLAUDE.md,你叫 AGENTS.md 或者 README.md 都行。這個文件相當於給 AI 寫的一份工作手冊,告訴它你的知識庫長什麼樣、該按什麼規矩來整理。
下面是我自己在用的一份精簡模板,你可以直接拿去改:
# My Knowledge Base
## 用途
[填你的主題,比如"AI 應用開發"或"產品設計方法論"]
## 目錄約定
raw 目錄存原始素材,任何情況下都不要改動裏面的文件
wiki 目錄由你全權維護,我只負責閲讀和提問
outputs 目錄存放你生成的報告和分析結果
## 整理規範
一個話題對應 wiki 裏的一個獨立 md 文件
文件開頭寫一段 100 字以內的核心摘要
用 [[文件名]] 格式在不同話題之間建立關聯
維護一份 INDEX.md 作為全局目錄
每次 raw 裏新增素材後同步更新對應的 wiki 文件
## 我重點關注的方向
1. [方向一]
2. [方向二]
3. [方向三]Karpathy 聊到他自己的 schema 時說了四個字:"超級簡單"。沒有數據庫、沒有插件、沒有任何第三方依賴。一個純文本文件加上幾條清晰的規則,夠了。
說句直白的話,schema 寫得好不好,比你選什麼工具重要十倍。
讓 AI 開始幹活
素材有了,規矩也定好了,現在打開你用的 AI 編碼工具。Claude Code、Cursor、Windsurf 都行,只要能訪問本地文件系統。
進入項目目錄,給 AI 下一條指令。我一般這樣說:
"掃描 raw 裏的全部文件,根據 CLAUDE.md 定義的規範生成 wiki。每個核心話題單獨建一個 md 文件,文件之間用雙鏈關聯,最後生成一份 INDEX.md 作為導航入口。"
然後就不用管了,讓它跑完。
結果會讓你有點驚喜。wiki 目錄裏會出現一批按話題拆分好的文件,每篇開頭有精煉的摘要,文章之間通過雙鏈串在一起。有些你自己都沒注意到的跨主題關聯,AI 給你挖了出來。
順便提一下,wiki 裏的內容從此以後全部由 AI 維護。你的角色是讀者和提問者,不是編輯者。手動改 wiki 文件反而會打亂 AI 的整理邏輯。
越用越聰明的正循環
當 wiki 裏積累到十幾篇文章之後,真正好玩的部分來了。你可以開始向自己的知識庫提問。
比如我經常會問這幾類問題:
"把 wiki 裏關於 Agent 架構的內容和 RAG 相關的內容放在一起看,找出它們的交叉領域和我還沒覆蓋到的盲區。"
"對比 A 這篇素材和 B 這篇素材在同一個話題上的不同觀點,給我一份 300 字的差異分析。"
"只基於我知識庫裏現有的內容,幫我起草一份某領域的技術調研摘要。"
AI 給出的答案全部來自你自己攢的素材,不是從互聯網現搜的。這些答案你可以直接存到 outputs 目錄,也可以讓 AI 把新的洞察反哺到 wiki 的對應文章裏去。
每一次提問和反饋都會讓知識庫變得更完善。這就是一個正向飛輪:素材越多,wiki 越全,提問質量越高,產出越有價值。
有一個坑必須提前防
這套系統有一個隱性風險。有人在 Karpathy 的帖子下面提了一句特別到位的話:當 AI 的輸出被存回知識庫之後,如果裏面有錯誤,這個錯誤會隨着後續引用不斷放大。
確實如此。AI 寫了一條不太準確的總結,你存了。下一次提問的時候 AI 把這條錯誤總結當成事實來引用,錯誤就滾雪球了(血淚教訓)。
應對方法是定期給知識庫做一次體檢。讓 AI 檢查 wiki 裏有沒有前後矛盾的內容,哪些概念被提到了但沒有展開解釋,哪些結論在 raw 目錄裏找不到原始出處。
這個習慣一個月養成,後面省的 token 遠比花的多。
關於工具選擇,我的真實想法
Karpathy 那條帖子下面有不少人在推薦各種 Obsidian 插件和 Notion 模板。
但 Karpathy 本人被問到的時候,回答是他只用一個扁平的 md 文件目錄,沒有任何花哨的東西。
我自己的體驗也是一樣。用 Claude Code 在終端裏操作整個知識系統,VS Code 偶爾打開看看文件內容,夠了。
說句掏心窩子的話,我見過太多人在工具配置上花的時間遠遠超過了真正使用知識庫的時間。裝幾十個插件、調各種主題配色、研究雙鏈語法,折騰半天知識庫裏還是空的。
這跟當年的 Notion 陷阱一模一樣。工具本身變成了目的,而不是手段。
一個文件夾加一份寫清楚的 schema,實際效果比大多數重度配置的方案都好(踩過坑的人都懂)。
寫在最後
回顧一下整套流程:搭好三個目錄,把手頭的素材扔進去,裝個自動抓取工具提高收集效率,寫一份 schema 讓 AI 知道該怎麼整理,然後一條指令讓 AI 跑起來。
Karpathy 那條帖子被四萬多人收藏了。收藏是最容易的一步,做起來才是真正有用的一步。
這個週末挑一個你最近在研究的話題,把散落在各處的筆記和文章集中到一起,讓 AI 幫你理一遍。你會發現很多之前沒注意到的知識關聯。
工欲善其事必先利其器。整套工具已經擺在面前了,動手試試。
如果本文對您有幫助,也請幫忙點個 贊👍 + 在看 哈!❤️關注小智AI指南公眾號,AI 路上不迷路