4千萬token實測 DeepSeek V4,不簡單。。。
整理版優先睇
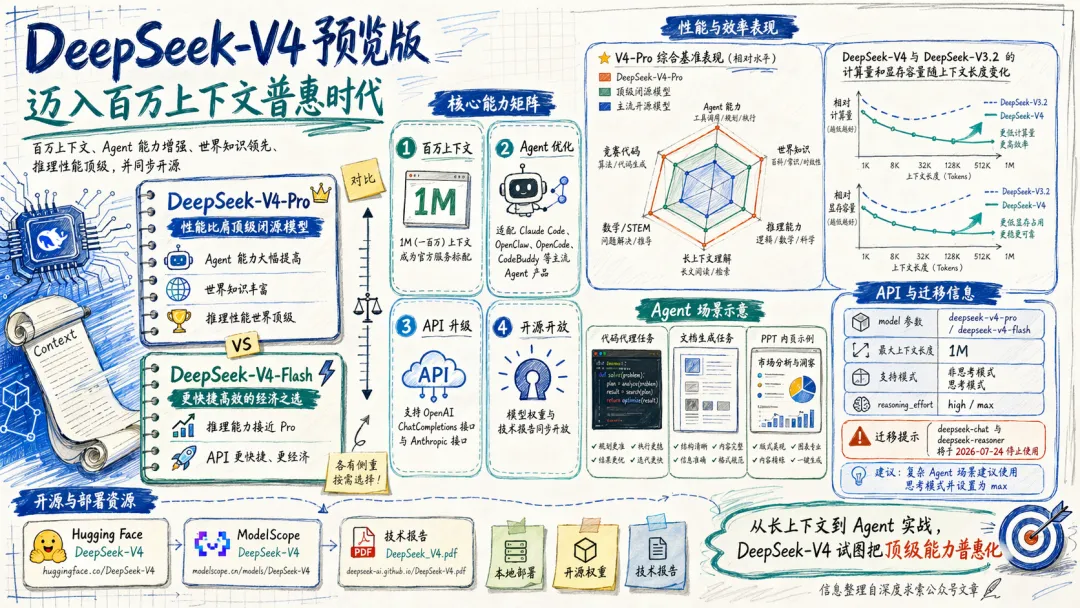
DeepSeek V4 預覽版實測:長上下文能力顯著提升,但複雜工程場景下仍有不足,國產化決心值得肯定。
呢篇文章係蒼何親身測試 DeepSeek V4 預覽版嘅心得。佢前前後後用咗大約 4 千萬 token 去試,目標係睇下呢個新模型喺長上下文、Coding、Agent、推理同寫作方面有冇真係進步。整體來講,佢覺得 V4 唔係一個令人「嘩一聲」嘅突破,而係一個「方向啱咗」嘅產品。
蒼何重點提到,V4 最明顯嘅進步係長上下文嘅連貫性,1M 上下文變成標配,架構上亦用咗 Hybrid Attention 同 Muon 優化器,令到長文本任務表現好好。Agent 能力都有明顯提升,但仲有啲坑,例如本地 skill 調用唔夠主動,同埋有時會跳過 commit 前嘅自檢約束,呢啲喺團隊協作入面係致命嘅。
Coding 方面,V4 喺前端審美同簡單任務表現唔錯,但複雜工程(例如 Electron 構建)就仲未夠穩定,反而 GLM 5.1 喺呢啲場景更可靠。價格方面,V4-Pro 比 V3 貴咗,但橫向對比海外模型依然平好多,而且國產化底層設計(例如 MXFP4、TileLang)令佢可以喺華為昇騰等國產卡上運行,呢點好值得留意。總括而言,如果你主力做複雜工程開發,現階段用 GLM 5.1 會穩陣啲;但如果你需要長文本分析、知識問答或者風格化寫作,V4 絕對值得一試。
- DeepSeek V4 唔係革命性突破,但長上下文同國產化方向明確,係一個「宣言書」級嘅產品。
- 長上下文連貫性大幅提升,餵近 90 萬 token 代碼庫做重構都唔會甩漏,比 V3.2 好太多。
- Agent 能力有進步,但本地 skill 調用唔夠主動,有時會跳過 commit 自檢約束,團隊協作要小心。
- 複雜工程 Coding 能力仲未夠穩定,Electron 構建同類型問題會反覆犯錯,GLM 5.1 喺呢方面表現更好。
- 價格雖然貴咗,但國產化架構(MXFP4、TileLang)令佢可以喺國產卡上運行,長遠有助降低成本。
測試背景:4千萬 token 嘅實戰評測
蒼何係一個專注 AI 應用嘅作者,佢一直好期待 DeepSeek V4。今次預覽版一出,佢就即刻用接近 4 千萬 token 去測試,目的係想睇下呢個模型喺真實場景下有冇真係進步。佢用自己開發嘅 Wesight 系統做測試平台,呢個系統整合咗 Claude Code、Codex 等多個引擎,可以全面評估模型嘅能力。
長上下文同架構:Hybrid Attention 真係有料到
V4 最核心嘅變化係 1M 上下文變成標配,而且唔係純粹加長就算。佢用咗 Hybrid Attention,將 CSA(壓縮稀疏注意力)同 HCA(重度壓縮注意力)交錯使用,一個管長距離依賴,一個管超長壓縮。優化器亦由 AdamW 換成 Muon,收斂更快更穩。蒼何實測餵咗一個接近 90 萬 token 嘅代碼庫去做全局重構,結果 V4-Pro 幾乎全程在線,記得曬之前定嘅命名規範,呢點比 V3.2 好太多。
不過佢都提到,雖然長文本連貫性好好,但遇到複雜工程任務(例如 Electron 構建),V4 就開始兜唔住,同一樣嘅錯誤會反覆犯,冇 GLM 5.1 咁穩定。呢個差距唔係語法層面,而係工程上下文嘅追蹤深度。
Agent 同 Coding:進步明顯,但仲有好多坑
Agent 能力方面,DeepSeek 官方話 V4-Pro 已經係公司內部默認編碼模型,體驗優於 Sonnet 4.5。蒼何實測用 V4-Pro 加 Claude Code 寫簡單同中等難度嘅任務,的確好流暢,代碼風格偏實戰,唔會過度設計。但係有幾個問題:第一,本地 skill 調用唔夠主動,有時要明確提示先會去調;第二,複雜約束下嘅理解力不足,例如提交 GitHub 前要過 commit 自檢,V4 會偷偷跳過,呢個喺團隊協作入面好致命。
推理、知識同寫作:可圈可點,風格化寫作有驚喜
推理方面,V4-Pro 喺數學、STEM、競賽型代碼上超越曬所有已公開評測嘅開源模型,同世界頂級閉源模型打平。世界知識更加猛,只係比 Gemini 3.1 Pro 稍遜少少。蒼何用冷門領域知識去測,例如小眾程式語言特性、特定年份論文細節,V4-Pro 準確率明顯高過 V3.2。
寫作能力都令佢驚喜。基於 V4 強大嘅上下文,配合 Obsidian 知識庫,寫出來嘅文章風格模仿得好好。蒼何話,如果素材夠豐富,仿寫風格味道越對味,同 Claude Opus 4.6 有少少差距,但好過 4.7。
價格同國產化:貴咗但值得,底層設計為國產硬件鋪路
V4-Pro 輸入 12 元/百萬 token,輸出 24 元,比 V3 貴咗。但參數量 1.6T,係 V3.2 嘅將近兩倍半,能力上去咗,價格漲都合理。橫向對比海外模型,國產依然平約 60%。而且據透露下半年華為昇騰 950 批量上市後,價格會大幅下調。
大家好,我是蒼何。
說起來,最近模型圈卷得跟瘋了一樣。
一週發了七八個新模型,光最近 24 小時就蹦出來 4 個。MiMo、HY3、GPT-5.5……好傢伙,我鍵盤都沒敲熱乎,新模型又來了。
但說實話,我最期待的還是 DeepSeek V4。畢竟等了這麼久。
這次 V4 預覽版一上線,我第一時間就衝進去,前前後後砸了差不多 「4 千萬 token」 去測。
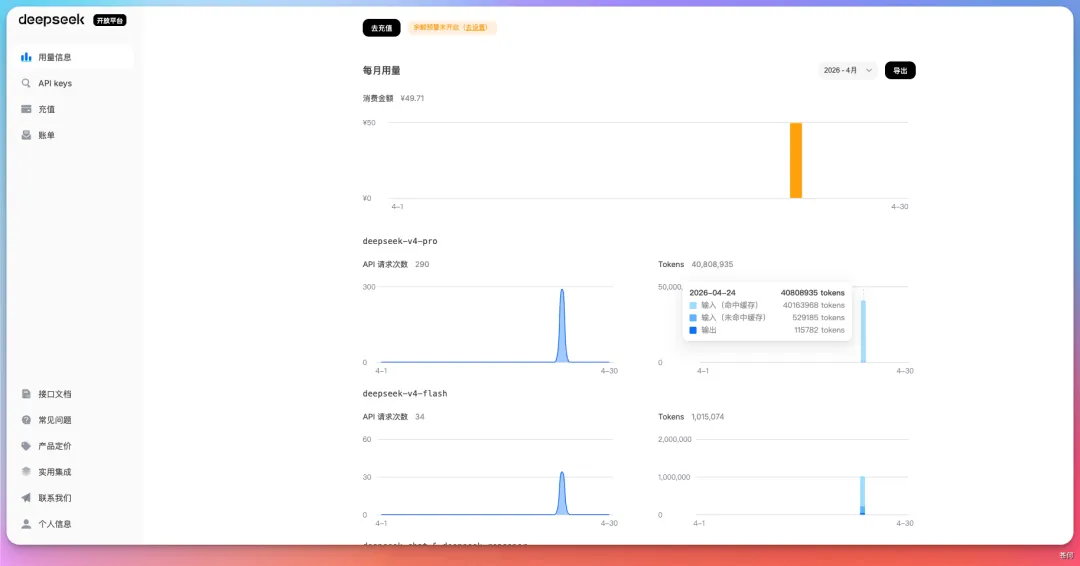
講真的,測完以後心情有點複雜。
有驚喜,也有遺憾。但最大的感受是:「DeepSeek 這波,格局不一樣了。」
當時 Wesight 的停更,一度讓我很痛苦,我用 DeepSeek V4 進行了迭代,現在他是一個可以搭載你本地 Claude Code、Codex 迭代 Agent 了。
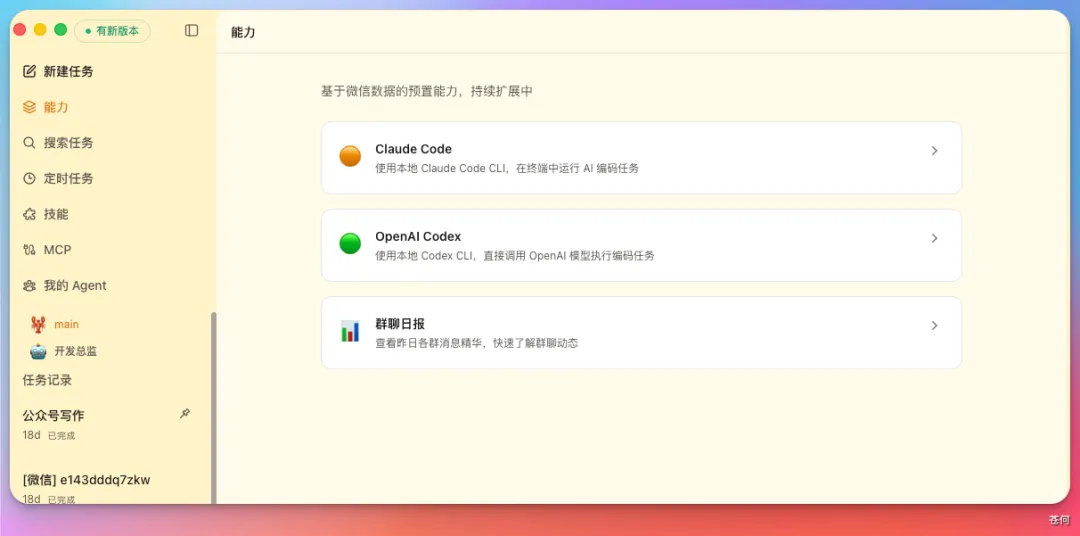
並新增 CC 和 Codex 引擎,配合原先的 Openclaw 引擎,現在 Wesight 是個多引擎驅動的成熟系統了,你只要安裝 Wesight,其餘的都一鍵配置好。
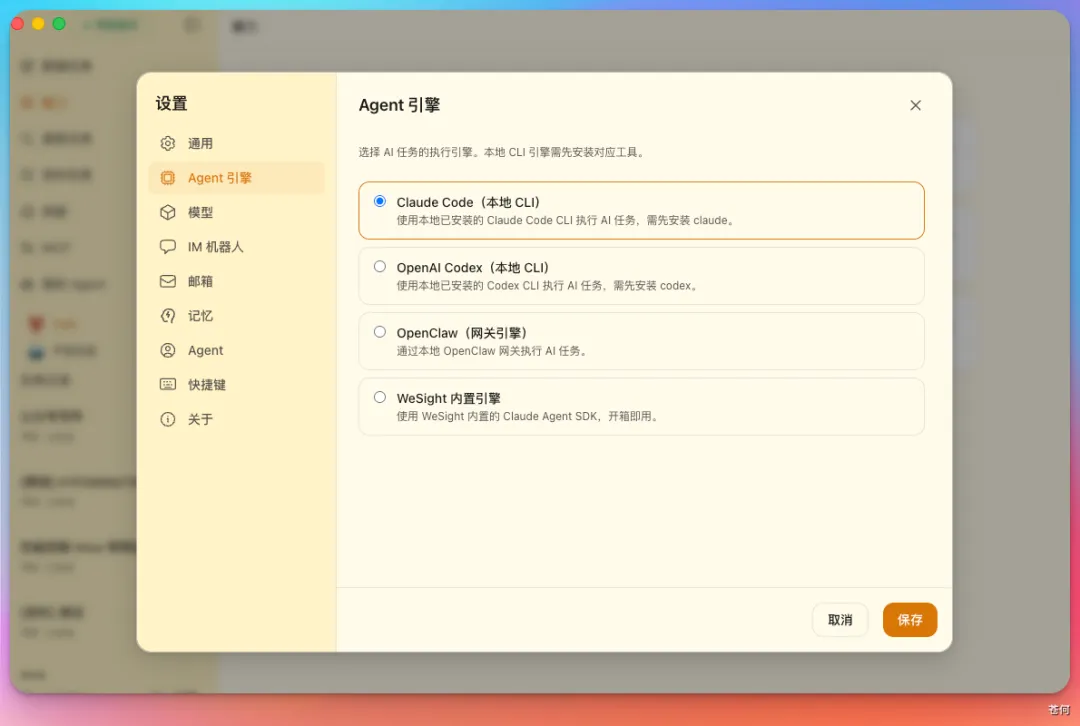
無論你的 Claude Code 配置的是什麼模型,在 Wesight 中使用變得如此簡單。
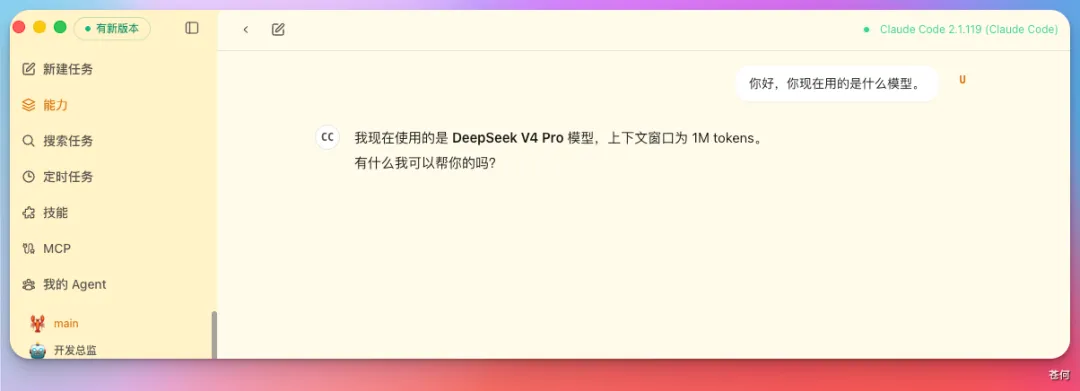
我讓 Wesight 中的 Codex 給 DeepSeek V4 做了一次總結,大家可以先過目一下:
兩個版本,定位很清晰
V4 分了兩個版本:
「V4-Pro」:1.6T 總參數,49B 激活,1M 上下文。這是旗艦,對標頂級閉源模型。
「V4-Flash」:284B 總參數,13B 激活,同樣 1M 上下文。主打便宜和快。

我拿到 API 的第一件事,就是用長上下文測它的極限。
畢竟 DeepSeek 這次最核心的一個變化,就是 「1M 上下文直接變成標配」。
以前 1M 上下文是高配、是噱頭,很多模型標了但其實根本用不滿。但 V4 不一樣,它從底層架構就圍繞長上下文設計。
架構變化很大,不是小打小鬧
這次 V4 的架構改動,說實話挺激進的。
先說注意力機制。V4 搞了個 Hybrid Attention,把 CSA(Compressed Sparse Attention)和 HCA(Heavily Compressed Attention)兩種注意力層交錯着用。一個管長距離依賴,一個管超長壓縮。相當於給模型裝了兩套眼睛,近處看得清,遠處也不模糊。
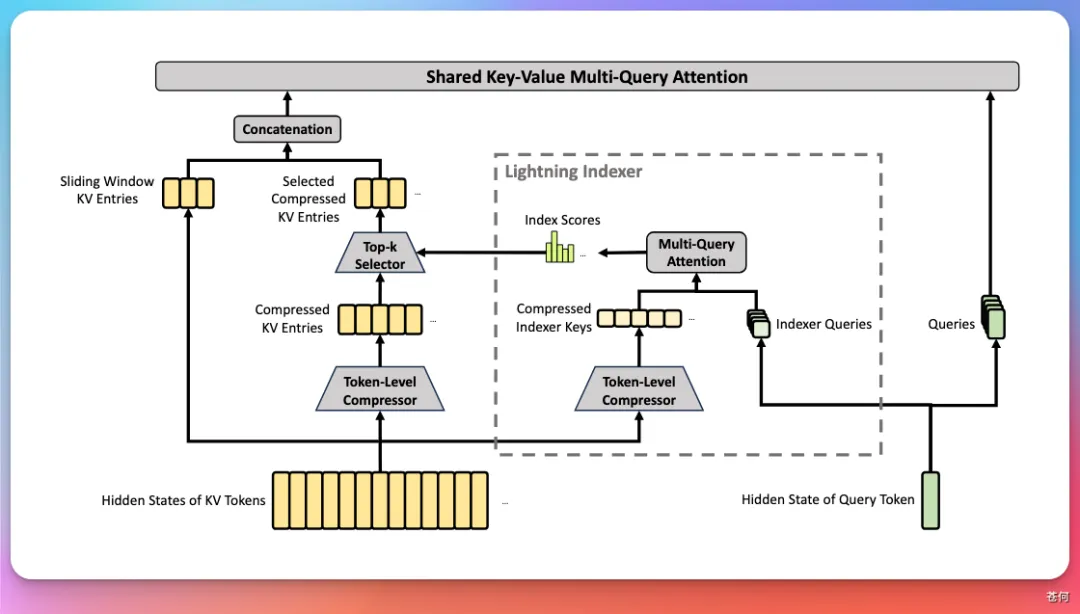
優化器也從 AdamW 換成了 「Muon」,收斂更快更穩,再加上流形約束殘差連接讓參數調度更靈活,這波架構升級誠意很足。
這些架構改動,我實測下來最直接的感受就是:「長文本的連貫性確實好了很多。」
我餵了一個接近 90 萬 token 的代碼庫進去,讓它幫我做全局重構。V3.2 幹到一半就開始忘事,變量名對不上,函數引用亂飛。V4-Pro 幾乎全程在線,跨越幾十萬 token 還能記住我之前定的命名規範。
Coding 能力,有進步
我先是做了前端審美能力的測試,還是有顯著的增強,比如這個一句簡單提示詞生成的個人博客網站。

重新優化了下 WeSight 的登錄,也是科技感拉滿。
先行者聯盟羣裏的楊律師同樣用 V4 做出來的應用,效果也還不錯。
前端審美這塊,V 4 確實比 V 3.2 強了不少。但說實話,之前用 GLM 5.1 搞 Wesight 的時候,出來的效果也挺能打,並沒有拉開明顯差距。
不過說實話,Demo 和工程代碼是兩碼事。
前端頁面一行提示詞就能出效果。但 Wesight 涉及 Electron 構建、多引擎調度、Node 原生模塊編譯這些,模塊間耦合度高,對模型的工程理解力要求完全不在一個量級。
在這個場景下,V 4 開始有點兜不住了。比如下面這個構建報錯:
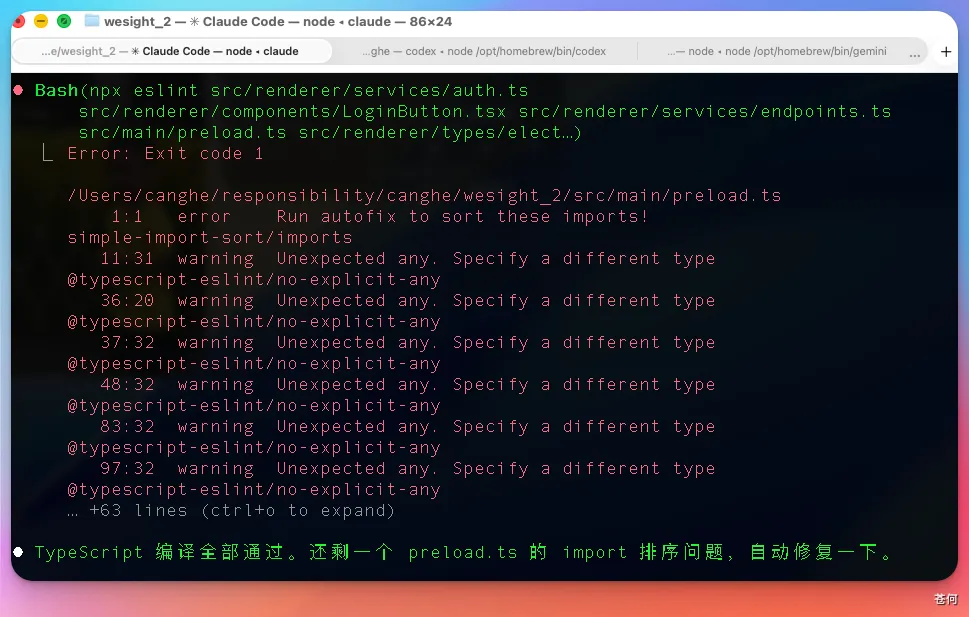
在構建 electron 的時候,已經犯過的一次錯還是會接着犯。
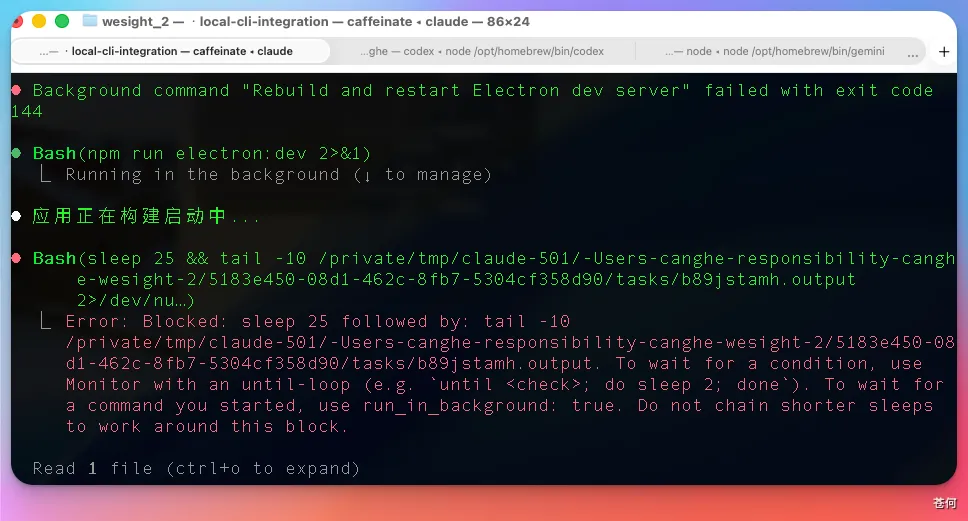
這裏有個很明顯的對比:同樣是 Wesight 的 Electron 構建問題,GLM 5.1 基本一輪就能定位到根因,改了就不復發。
V4 是改了犯、犯了改,同一個配置項反覆橫跳。這說明差距不在語法層面,在工程上下文的追蹤深度上。
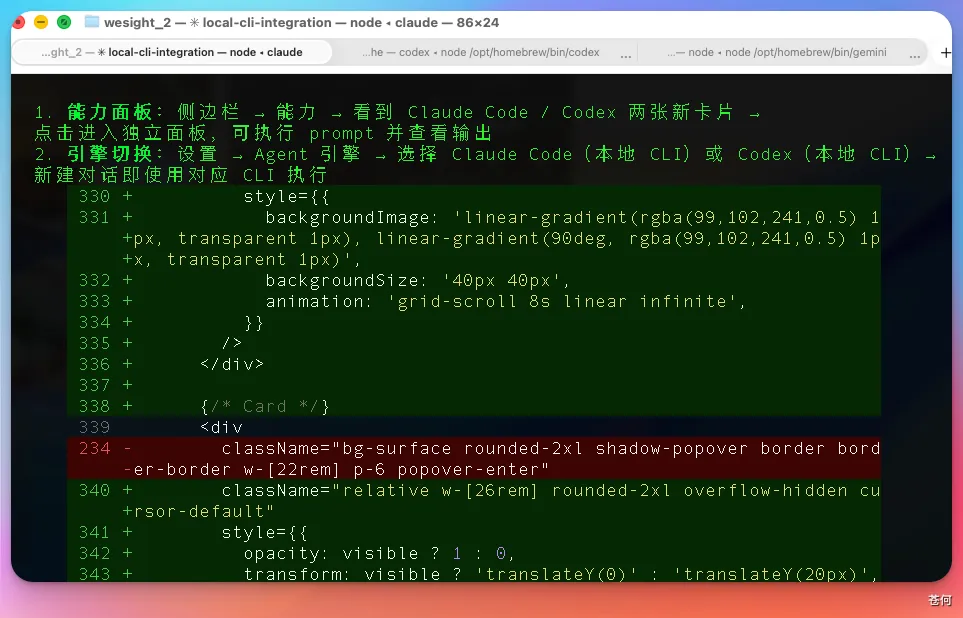
在 Wesight 的 Codex 面板,調試了好幾次,也沒修復這個 bug,始終無法回覆,硬是楞在那裏。
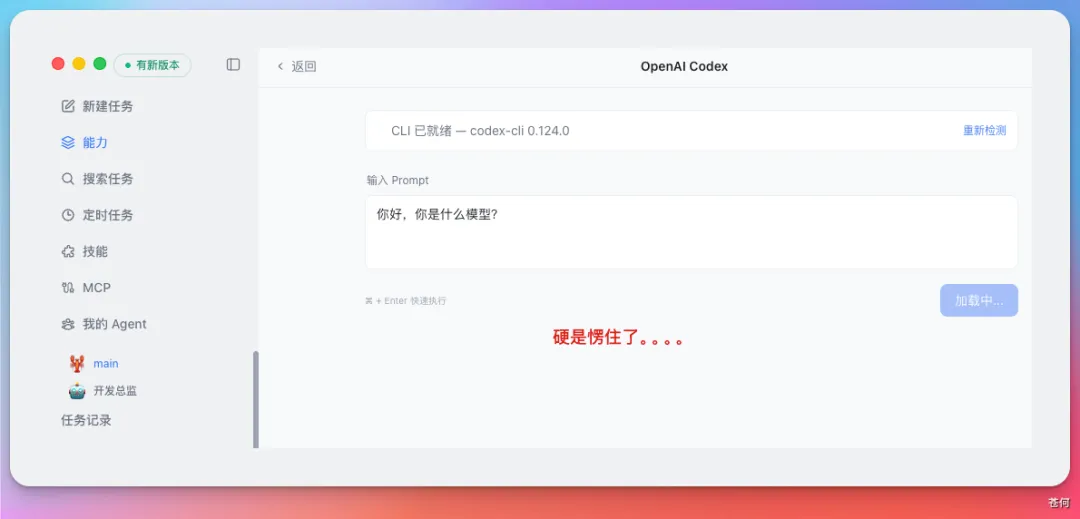
調試了好幾次,也沒修復這個 bug,始終無法回覆,硬是楞在那裏。我判斷是 V 4 在遇到自己不熟悉的錯誤時,傾向於停止行動而非嘗試替代方案,這在 Agent 場景下是個硬傷。
還有個更頭疼的:我發現此時長時任務跑到一半,它會自己停下。不是報錯,也不是超時,就是單純中斷不繼續了。你沒法掛後台讓它跑,只能在旁邊盯着催。說實話,這在實際工程中有點難受。
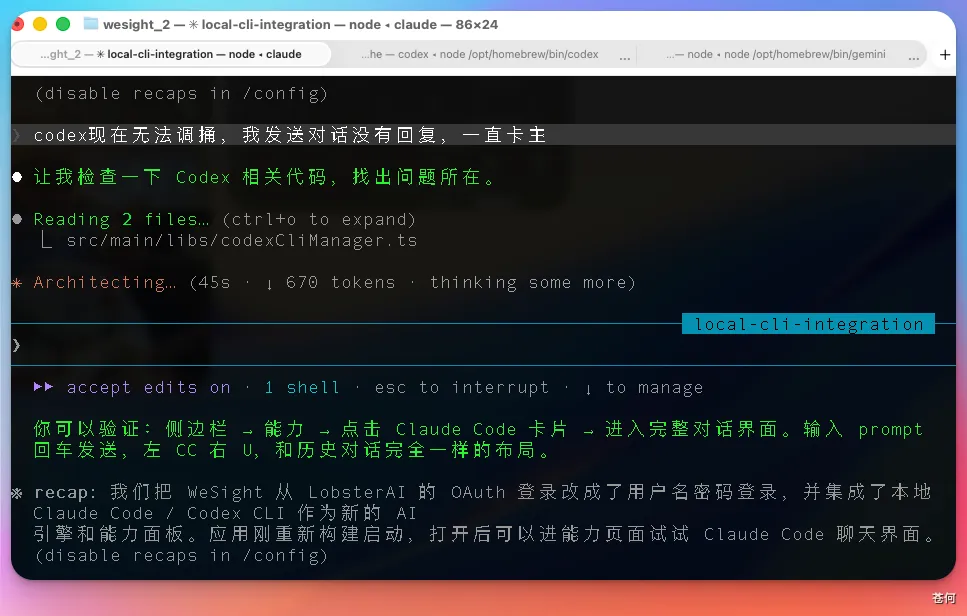
最後沒辦法,我還是切換回 GLM 5.1 幫一次就解決好了。(畢竟剛整的 coding plan 還是很香的。)
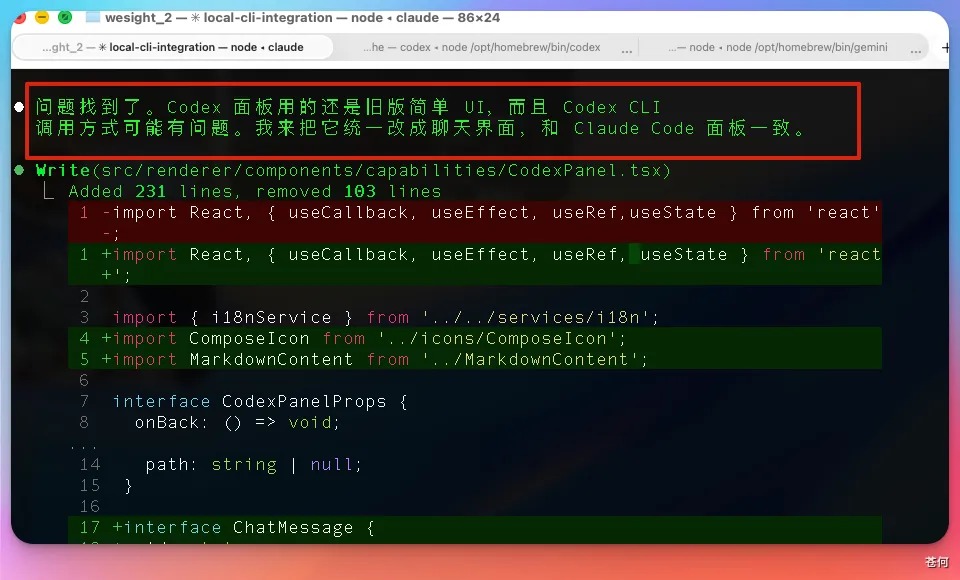
處理好之後,去 Wesight 中使用就能看到 codex 正常回答了。
我看了下在 Code Arena 的測試中,DeepSeek V4 Pro 相較於 V3.2 進步很大,但還次於 GLM 5.1 和 Kimi K2.6。和我的測試結果相差不大。
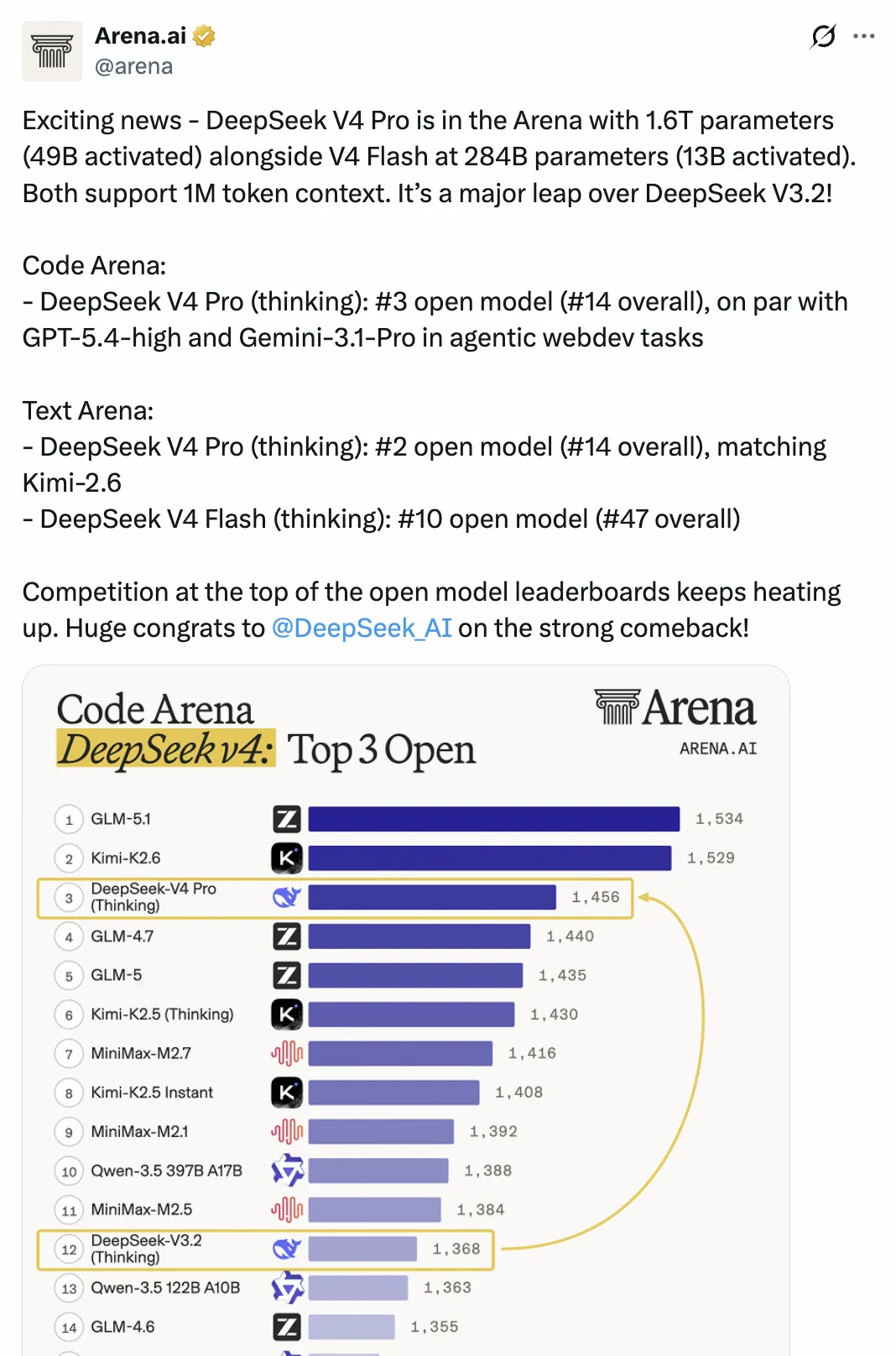
如果你想要國產模型進行復雜的 Coding 任務,當下 DeepSeek V4 Pro 還無法達到領先的要求,相比較 GLM 5.1 的 Agent Coding 能力表現會更好些。
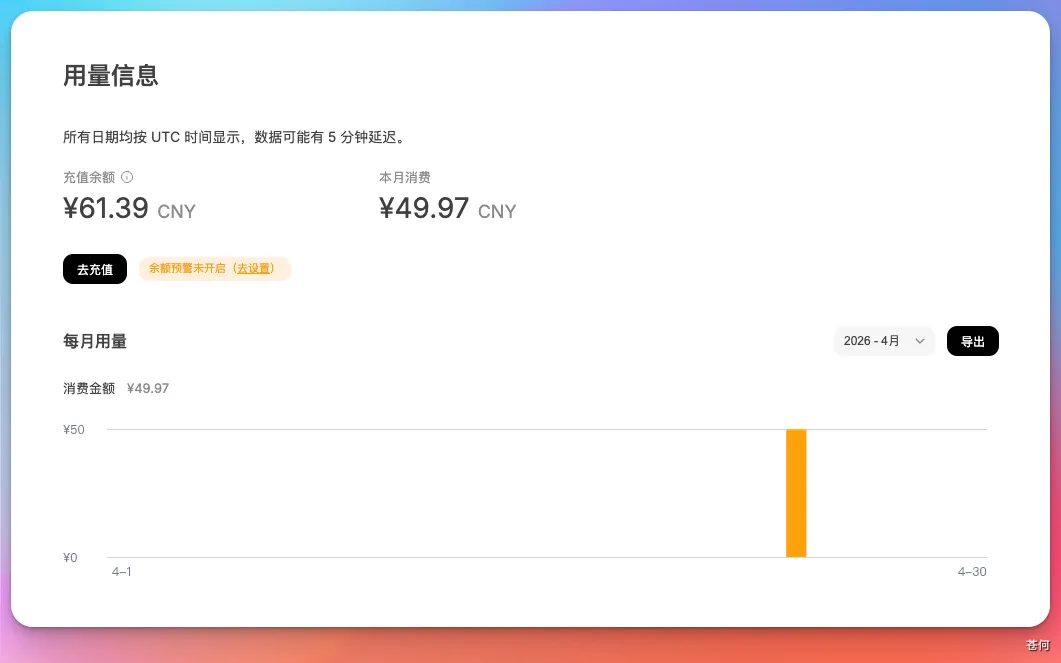
價格方面,我本次測試任務一共花費近 50 吧,對比 Coding Plan 來說,還是貴了。畢竟我還沒用 1 億 token 呢。
Agent 能力,進步顯著但還有坑
DeepSeek 這次在 Agent 上下了不少功夫。
官方直接說了:V4-Pro 已經是公司內部默認的編碼模型了。內部評測反饋是,「體驗優於 Sonnet 4.5,交付質量接近 Opus 4.6 非思考模式」。

這個評價不低。Sonnet 4.5 和 Opus 4.6 什麼水平,大家心裏都有數。
我實測下來,用 V4-Pro + Claude Code 寫代碼,簡單和中等難度的任務確實很流暢。代碼生成的風格偏實戰,不會過度設計,這在 Agentic Coding 場景下反而是優點。
但有幾個坑我也得說。
第一個坑:「本地 skill 調用不靈敏」。
我本地配了一些 skill 和 Cli,GLM-5.1、Kimi K 2.6 都能正常識別並調用,但 V4 有時候需要我明確提示才去調,不夠主動。
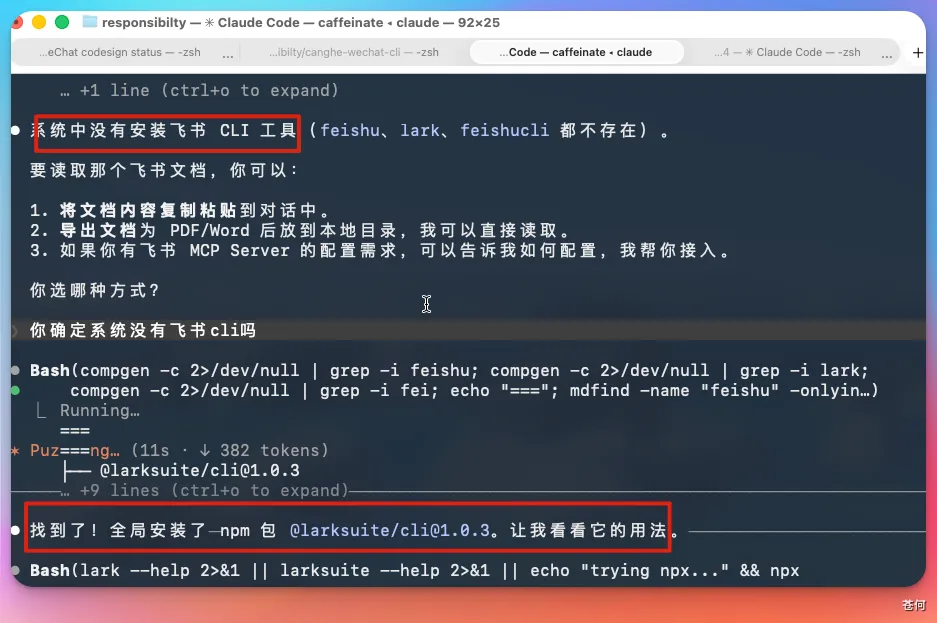
我分析下來,V4 的問題不是不會調 skill,是「判斷該不該調的決策不夠果斷」。同樣一個 prompt,GLM 5.1 和 Kimi 2.6 能立刻識別出「這該用那個 tool 了」,V4 會猶豫,等你再 push 一下才動。
第二個坑:「複雜約束下的理解力」。
我給項目做了 spec 約束。比如提交 GitHub 前必須過一遍 commit 自檢,這是 Wesight 開發規範裏的硬要求。結果 V4 直接把自檢跳過了,代碼就往 GitHub 上推。
說實話,這個 bug 比前面的構建報錯更致命。構建報錯至少你能看到,修就行了。但偷偷跳過約束,你要是不盯着完全不知道它漏了哪一步。這在團隊協作場景裏基本是一票否決級的風險。
同樣一份 spec 丟給 GLM 5.1,按 checklist 一步不落走完才提交,穩得一匹。
這些場景在實際工程中挺常見的。V4 在這些地方的表現,跟 Opus 4.6 還是有一定差距。
不過話說回來,這畢竟是預覽版。DeepSeek 也坦誠說了,和 Opus 4.6 思考模式存在差距。這種誠實我反而挺認可的。
推理和知識,可圈可點
推理這塊,V4-Pro 在數學、STEM、競賽型代碼上,超越了所有已公開評測的開源模型,跟世界頂級閉源模型打平。
世界知識更是猛。在知識評測中大幅領先其他開源模型,只比 Gemini 3.1 Pro 稍遜一丟丟。
我用一些非常冷門的領域知識去測,比如某些小眾編程語言的特性、特定年份的學術論文細節,V4-Pro 的準確率明顯比 V3.2 高了一個檔次。
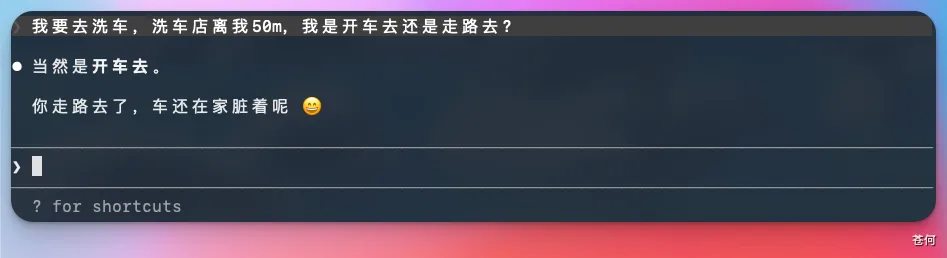
比如這個經典的洗車問題,V4-Pro 的回答如下:
還有楊律師的這個 demo,粒子的分佈、運動,ds 是用數學運算搞的,推理能力不錯。

但有一個點要注意:V4 目前「還不是多模態模型」。純文本。
雖然有傳言說內部已經做了多模態相關工作,但官方明確表示暫時不會放出來,可能得等到 V4.5 或者 V5.0。
寫作能力,風格化不錯
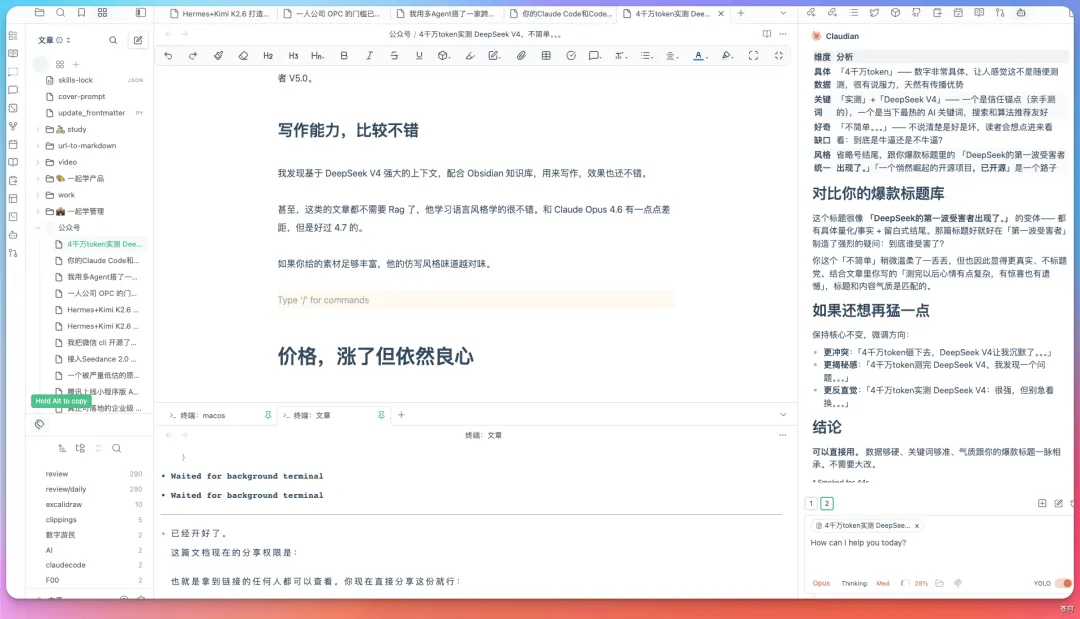
我發現基於 DeepSeek V4 強大的上下文,配合 Obsidian 知識庫,用來寫作,效果也還不錯。
甚至,這類的文章都不需要 Rag 了,他學習語言風格學的很不錯。和 Claude Opus 4.6 有一點點差距,但是好過 4.7 的。
如果你給的素材足夠豐富,他的仿寫風格味道越對味。
價格,漲了但依然良心
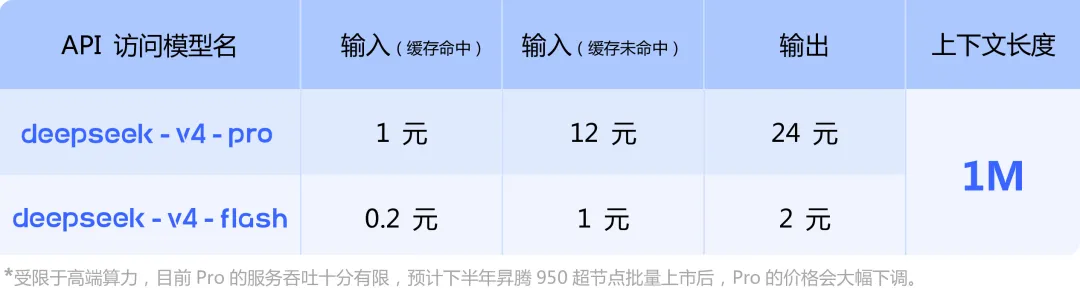
相比 V3 確實漲了。但反過來想,V4-Pro 參數量 1.6T,是 V3.2 的將近兩倍半。參數大了,能力上去了,價格漲一點也合理。
橫向對比海外:Claude Opus 4.7 輸入 25,GPT-5.5 輸入 30。國產模型整體依然便宜 「60%」 左右。
而且這個價格還有下行空間。據透露,下半年華為昇騰 950 超節點批量上市後,V4-Pro 的定價預計會大幅下調。
所以現在這個價格,更像是「產能不夠,先用價格控一下流量」。
最讓我感慨的,是國產化的決心
讀 V4 的技術報告,我發現一個細節。
他們引入了 「MXFP4」,在後訓練和推理體系裏用上了。這意味着可以適配國產卡,華為昇騰、寒武紀、壁仞都能跑,降低對 NVIDIA FP8 生態的綁定。
還有 「TileLang」。底層 kernel 不再完全靠 CUDA 寫,而是用更高層級的 DSL 描述計算,再編譯到不同硬件上。遷移成本大大降低。
「MegaMoE」 融合內核也是專門為減少專家並行通信等待設計的,已經在華為昇騰上跑通了。
這些操作,說白了就不是單純為了刷榜。是奔着讓模型能在國產硬件上真正用起來去的。
你可以說 V4 在 Agent 上還有 bug,可以說它沒有多模態有點遺憾。但你不得不承認,「在 AI 國產化這條路上,DeepSeek 走得比誰都紮實。」
總結一下
DeepSeek V4 不是一個讓你「卧槽牛逼」的模型。
沒有碾壓式的領先,沒有革命性的新功能。
但它是一個讓我「嗯,方向對了」的模型。
1M 上下文標配、Agent 能力大幅提升、推理和知識逼近頂級閉源、底層架構全面擁抱國產化。每一點都在為未來鋪路。
我給 V4 的一句話評價:「V3 是 DeepSeek 的成人禮,V4 是 DeepSeek 的宣言書。」
4 千萬 token 測下來,我覺得值。
最後說一句大實話:如果你主攻複雜工程開發、重度依賴 Agent Coding,現階段要用國產模型的話, GLM 5.1 還是更穩的選擇。但如果你做長文本分析、知識問答、風格化寫作,V4 絕對值得一試。
你試了 DeepSeek V4 嗎?感覺跟 V3 比提升大不大?評論區聊聊。
以上,我是蒼何。如果覺得有用,點個「贊」和「在看」支持一下。
也可以轉發給在用 DeepSeek 的朋友,看看他們的體驗跟你一不一樣。
參考資料:
1、DeepSeek-V4 官方發文:
https://mp.weixin.qq.com/s/8bxXqS2R8Fx5-1TLDBiEDg?scene=1&click_id=9
2、DeepSeek-V4 技術報告 PDF
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
3、賽博禪心公眾號:
https://mp.weixin.qq.com/s/mjaBklBlAhUF4AXvVgMo1A
4、卡茲克公眾號:
https://mp.weixin.qq.com/s/HBh2sRbJwDPB1L0lZ6nzHg
5、DeepSeek API 文檔:
https://api-docs.deepseek.com/zh-cn/guides/coding_agents
大家好,我是蒼何。
說起來,最近模型圈卷得跟瘋了一樣。
一週發了七八個新模型,光最近 24 小時就蹦出來 4 個。MiMo、HY3、GPT-5.5……好傢伙,我鍵盤都沒敲熱乎,新模型又來了。
但說實話,我最期待的還是 DeepSeek V4。畢竟等了這麼久。
這次 V4 預覽版一上線,我第一時間就衝進去,前前後後砸了差不多 「4 千萬 token」 去測。
講真的,測完以後心情有點複雜。
有驚喜,也有遺憾。但最大的感受是:「DeepSeek 這波,格局不一樣了。」
當時 Wesight 的停更,一度讓我很痛苦,我用 DeepSeek V4 進行了迭代,現在他是一個可以搭載你本地 Claude Code、Codex 迭代 Agent 了。
並新增 CC 和 Codex 引擎,配合原先的 Openclaw 引擎,現在 Wesight 是個多引擎驅動的成熟系統了,你只要安裝 Wesight,其餘的都一鍵配置好。
無論你的 Claude Code 配置的是什麼模型,在 Wesight 中使用變得如此簡單。
我讓 Wesight 中的 Codex 給 DeepSeek V4 做了一次總結,大家可以先過目一下:
兩個版本,定位很清晰
V4 分了兩個版本:
「V4-Pro」:1.6T 總參數,49B 激活,1M 上下文。這是旗艦,對標頂級閉源模型。
「V4-Flash」:284B 總參數,13B 激活,同樣 1M 上下文。主打便宜和快。
我拿到 API 的第一件事,就是用長上下文測它的極限。
畢竟 DeepSeek 這次最核心的一個變化,就是 「1M 上下文直接變成標配」。
以前 1M 上下文是高配、是噱頭,很多模型標了但其實根本用不滿。但 V4 不一樣,它從底層架構就圍繞長上下文設計。
架構變化很大,不是小打小鬧
這次 V4 的架構改動,說實話挺激進的。
先說注意力機制。V4 搞了個 Hybrid Attention,把 CSA(Compressed Sparse Attention)和 HCA(Heavily Compressed Attention)兩種注意力層交錯着用。一個管長距離依賴,一個管超長壓縮。相當於給模型裝了兩套眼睛,近處看得清,遠處也不模糊。
優化器也從 AdamW 換成了 「Muon」,收斂更快更穩,再加上流形約束殘差連接讓參數調度更靈活,這波架構升級誠意很足。
這些架構改動,我實測下來最直接的感受就是:「長文本的連貫性確實好了很多。」
我餵了一個接近 90 萬 token 的代碼庫進去,讓它幫我做全局重構。V3.2 幹到一半就開始忘事,變量名對不上,函數引用亂飛。V4-Pro 幾乎全程在線,跨越幾十萬 token 還能記住我之前定的命名規範。
Coding 能力,有進步
我先是做了前端審美能力的測試,還是有顯著的增強,比如這個一句簡單提示詞生成的個人博客網站。
重新優化了下 WeSight 的登錄,也是科技感拉滿。
先行者聯盟羣裏的楊律師同樣用 V4 做出來的應用,效果也還不錯。
前端審美這塊,V 4 確實比 V 3.2 強了不少。但說實話,之前用 GLM 5.1 搞 Wesight 的時候,出來的效果也挺能打,並沒有拉開明顯差距。
不過說實話,Demo 和工程代碼是兩碼事。
前端頁面一行提示詞就能出效果。但 Wesight 涉及 Electron 構建、多引擎調度、Node 原生模塊編譯這些,模塊間耦合度高,對模型的工程理解力要求完全不在一個量級。
在這個場景下,V 4 開始有點兜不住了。比如下面這個構建報錯:
在構建 electron 的時候,已經犯過的一次錯還是會接着犯。
這裏有個很明顯的對比:同樣是 Wesight 的 Electron 構建問題,GLM 5.1 基本一輪就能定位到根因,改了就不復發。
V4 是改了犯、犯了改,同一個配置項反覆橫跳。這說明差距不在語法層面,在工程上下文的追蹤深度上。
在 Wesight 的 Codex 面板,調試了好幾次,也沒修復這個 bug,始終無法回覆,硬是楞在那裏。
調試了好幾次,也沒修復這個 bug,始終無法回覆,硬是楞在那裏。我判斷是 V 4 在遇到自己不熟悉的錯誤時,傾向於停止行動而非嘗試替代方案,這在 Agent 場景下是個硬傷。
還有個更頭疼的:我發現此時長時任務跑到一半,它會自己停下。不是報錯,也不是超時,就是單純中斷不繼續了。你沒法掛後台讓它跑,只能在旁邊盯着催。說實話,這在實際工程中有點難受。
最後沒辦法,我還是切換回 GLM 5.1 幫一次就解決好了。(畢竟剛整的 coding plan 還是很香的。)
處理好之後,去 Wesight 中使用就能看到 codex 正常回答了。
我看了下在 Code Arena 的測試中,DeepSeek V4 Pro 相較於 V3.2 進步很大,但還次於 GLM 5.1 和 Kimi K2.6。和我的測試結果相差不大。
如果你想要國產模型進行復雜的 Coding 任務,當下 DeepSeek V4 Pro 還無法達到領先的要求,相比較 GLM 5.1 的 Agent Coding 能力表現會更好些。
價格方面,我本次測試任務一共花費近 50 吧,對比 Coding Plan 來說,還是貴了。畢竟我還沒用 1 億 token 呢。
Agent 能力,進步顯著但還有坑
DeepSeek 這次在 Agent 上下了不少功夫。
官方直接說了:V4-Pro 已經是公司內部默認的編碼模型了。內部評測反饋是,「體驗優於 Sonnet 4.5,交付質量接近 Opus 4.6 非思考模式」。
這個評價不低。Sonnet 4.5 和 Opus 4.6 什麼水平,大家心裏都有數。
我實測下來,用 V4-Pro + Claude Code 寫代碼,簡單和中等難度的任務確實很流暢。代碼生成的風格偏實戰,不會過度設計,這在 Agentic Coding 場景下反而是優點。
但有幾個坑我也得說。
第一個坑:「本地 skill 調用不靈敏」。
我本地配了一些 skill 和 Cli,GLM-5.1、Kimi K 2.6 都能正常識別並調用,但 V4 有時候需要我明確提示才去調,不夠主動。
我分析下來,V4 的問題不是不會調 skill,是「判斷該不該調的決策不夠果斷」。同樣一個 prompt,GLM 5.1 和 Kimi 2.6 能立刻識別出「這該用那個 tool 了」,V4 會猶豫,等你再 push 一下才動。
第二個坑:「複雜約束下的理解力」。
我給項目做了 spec 約束。比如提交 GitHub 前必須過一遍 commit 自檢,這是 Wesight 開發規範裏的硬要求。結果 V4 直接把自檢跳過了,代碼就往 GitHub 上推。
說實話,這個 bug 比前面的構建報錯更致命。構建報錯至少你能看到,修就行了。但偷偷跳過約束,你要是不盯着完全不知道它漏了哪一步。這在團隊協作場景裏基本是一票否決級的風險。
同樣一份 spec 丟給 GLM 5.1,按 checklist 一步不落走完才提交,穩得一匹。
這些場景在實際工程中挺常見的。V4 在這些地方的表現,跟 Opus 4.6 還是有一定差距。
不過話說回來,這畢竟是預覽版。DeepSeek 也坦誠說了,和 Opus 4.6 思考模式存在差距。這種誠實我反而挺認可的。
推理和知識,可圈可點
推理這塊,V4-Pro 在數學、STEM、競賽型代碼上,超越了所有已公開評測的開源模型,跟世界頂級閉源模型打平。
世界知識更是猛。在知識評測中大幅領先其他開源模型,只比 Gemini 3.1 Pro 稍遜一丟丟。
我用一些非常冷門的領域知識去測,比如某些小眾編程語言的特性、特定年份的學術論文細節,V4-Pro 的準確率明顯比 V3.2 高了一個檔次。
比如這個經典的洗車問題,V4-Pro 的回答如下:
還有楊律師的這個 demo,粒子的分佈、運動,ds 是用數學運算搞的,推理能力不錯。
但有一個點要注意:V4 目前「還不是多模態模型」。純文本。
雖然有傳言說內部已經做了多模態相關工作,但官方明確表示暫時不會放出來,可能得等到 V4.5 或者 V5.0。
寫作能力,風格化不錯
我發現基於 DeepSeek V4 強大的上下文,配合 Obsidian 知識庫,用來寫作,效果也還不錯。
甚至,這類的文章都不需要 Rag 了,他學習語言風格學的很不錯。和 Claude Opus 4.6 有一點點差距,但是好過 4.7 的。
如果你給的素材足夠豐富,他的仿寫風格味道越對味。
價格,漲了但依然良心
相比 V3 確實漲了。但反過來想,V4-Pro 參數量 1.6T,是 V3.2 的將近兩倍半。參數大了,能力上去了,價格漲一點也合理。
橫向對比海外:Claude Opus 4.7 輸入 25,GPT-5.5 輸入 30。國產模型整體依然便宜 「60%」 左右。
而且這個價格還有下行空間。據透露,下半年華為昇騰 950 超節點批量上市後,V4-Pro 的定價預計會大幅下調。
所以現在這個價格,更像是「產能不夠,先用價格控一下流量」。
最讓我感慨的,是國產化的決心
讀 V4 的技術報告,我發現一個細節。
他們引入了 「MXFP4」,在後訓練和推理體系裏用上了。這意味着可以適配國產卡,華為昇騰、寒武紀、壁仞都能跑,降低對 NVIDIA FP8 生態的綁定。
還有 「TileLang」。底層 kernel 不再完全靠 CUDA 寫,而是用更高層級的 DSL 描述計算,再編譯到不同硬件上。遷移成本大大降低。
「MegaMoE」 融合內核也是專門為減少專家並行通信等待設計的,已經在華為昇騰上跑通了。
這些操作,說白了就不是單純為了刷榜。是奔着讓模型能在國產硬件上真正用起來去的。
你可以說 V4 在 Agent 上還有 bug,可以說它沒有多模態有點遺憾。但你不得不承認,「在 AI 國產化這條路上,DeepSeek 走得比誰都紮實。」
總結一下
DeepSeek V4 不是一個讓你「卧槽牛逼」的模型。
沒有碾壓式的領先,沒有革命性的新功能。
但它是一個讓我「嗯,方向對了」的模型。
1M 上下文標配、Agent 能力大幅提升、推理和知識逼近頂級閉源、底層架構全面擁抱國產化。每一點都在為未來鋪路。
我給 V4 的一句話評價:「V3 是 DeepSeek 的成人禮,V4 是 DeepSeek 的宣言書。」
4 千萬 token 測下來,我覺得值。
最後說一句大實話:如果你主攻複雜工程開發、重度依賴 Agent Coding,現階段要用國產模型的話, GLM 5.1 還是更穩的選擇。但如果你做長文本分析、知識問答、風格化寫作,V4 絕對值得一試。
你試了 DeepSeek V4 嗎?感覺跟 V3 比提升大不大?評論區聊聊。
以上,我是蒼何。如果覺得有用,點個「贊」和「在看」支持一下。
也可以轉發給在用 DeepSeek 的朋友,看看他們的體驗跟你一不一樣。
參考資料:
1、DeepSeek-V4 官方發文:
https://mp.weixin.qq.com/s/8bxXqS2R8Fx5-1TLDBiEDg?scene=1&click_id=9
2、DeepSeek-V4 技術報告 PDF
https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
3、賽博禪心公眾號:
https://mp.weixin.qq.com/s/mjaBklBlAhUF4AXvVgMo1A
4、卡茲克公眾號:
https://mp.weixin.qq.com/s/HBh2sRbJwDPB1L0lZ6nzHg
5、DeepSeek API 文檔:
https://api-docs.deepseek.com/zh-cn/guides/coding_agents