80 個 canary 測 6 個 vibe coding 平台:UI 漂亮後端沒一個能跑
整理版優先睇
vibe coding六大平台UI漂亮但後端全軍覆沒,80條canary測出規格壓縮、前後脱鈎、生產懸崖、安全失守四大共性短板
呢篇文拆解咗一篇叫SWE-WebDev Bench嘅論文,佢將市面上6個主流vibe coding平台——Lovable、Replit Agent3、Vercel v0-Max、Base44、Emergent E1-OPUS、QwikBuild——拉出嚟正面PK。作者係研究人員,其中有兩位來自QwikBuild團隊,佢哋想解決嘅問題係:呢啲平台標榜「一句話變上線產品」,實際上有冇真係做到?整體結論係所有平台嘅Engineering綜合分都冇超過60%,前端UI大家都做得靚,但後端、安全同生產就緒度集體翻車,冇一個可以直接交付一個能跑嘅系統。
論文嘅評測方法好紮實:3個維度(ACR創建/AMR修改、PM/Engineering/Ops角色、T4傳統SaaS/T5 AI原生)乘68個指標(分7大組,25主+43診斷),判分用4層金字塔(40%全自動、35% LLM、15% LLM+人工、10%專家組)。核心係睇平台可唔可以將模糊需求變成能上線嘅系統,而唔係寫出啱嘅函數。最精彩嘅設計係80條「canary requirements」——文化特定要求,例如日期格式、貨幣符號,睇模型係真懂業務定只係拼模板。結果CRR(Canary留存率)極差達5.5倍,最差嘅平台留住得17.7%,意思係用戶花一小時寫嘅需求,有八成被靜靜刪走。
呢篇文對選平台嘅PM、CTO、獨立開發者好有用,因為佢提供嘅唔係「買邊家」嘅答案,而係「評估任何vi…
- 結論:所有vibe coding平台目前都係「Demo階段」,UI靚但後端、安全同生產就緒度全部不過關,要拎去生產至少需要12至60小時人工修復。
- 方法:論文用3維度×68指標×80條canary要求嘅框架評測,canary係文化特定細節(如日期格式、貨幣符號),用來檢測平台係真懂業務定係拼模板,結果CRR極差5.5倍。
- 差異:六大平台分成三條路線——基建一體化(QwikBuild後端強但規格理解弱)、生態借力(Replit Agent3泛化唔夠)、前端優先(Vercel v0-Max同Lovable後台跑批得分0-2%),短板分佈唔同但全員有共通問題。
- 啟發:評測框架(3維度、4層判分金字塔、canary方法)比具體排名更有價值,可以用來評估任何AI編程平台;而80條canary嘅方法論值得做LLM評測嘅研究者參考。
- 可行動點:產品經理或CTO可自行復現論文嘅canary測試,專注睇規格壓縮、前後脱鈎、生產就緒度同安全分數;獨立開發者用vibe coding時要預留大量時間修復後端同安全漏洞,唔好畀靚UI呃到。
完整論文(arxiv)
SWE-WebDev Bench 論文原文,包含完整評測框架、指標定義同平台排名。
GitHub 倉庫
GitHub 上嘅 benchmark 倉庫,可以睇到 prompt、canary 設計同重現方法。
評測框架:3維度×68指標×80條canary
論文直接用真實業務場景(教育、現場服務、金融科技+AI)測試,而唔係用LeetCode呢類小函數題。佢哋將平台當成完整嘅「虛擬軟件工作室」,從三個維度切開:Mode(ACR創建新應用同AMR修改已有應用)、Angle(PM需求理解、Engineering代碼質量、Ops部署運維)、Tier(T4傳統SaaS同T5 AI原生應用)。
68個指標分7大組(G1規格保真到G7生產就緒),25個主指標加43個診斷指標。判分用4層金字塔:Tier 0全自動(Lighthouse、k6、npm audit)佔40%,Tier 1 LLM評分佔35%,Tier 2 LLM+人工佔15%,Tier 3專家組佔10%。核心係睇平台可唔可以將模糊需求變成能上線嘅系統。
四大共性短板:全部平台都跌入同一批坑
呢啲平台喺某個維度都有明顯短板,但短板分佈唔一樣,例如QwikBuild後端強但規格理解弱,Vercel v0-Max同Lovable後台跑批得0-2%。
簡單講,所有平台都逃唔甩呢四條坑,而家冇一個平台可以聲稱自己「生產就緒」。
三條路線:架構選擇決定你嘅短板喺邊
論文將6家平台歸成三條架構路線,每條路線嘅強項同短板都好唔同。
Base44同Emergent E1-OPUS亦參評,得分介乎呢三檔之間。如果你用過其中一個平台,值得對照論文完整指標表睇清楚。
唔好畀UI呃到——後端跑批分先反映真實生產力,前端得分靚只係基本盤。
利益衝突要先知:點樣用呢份評測先穩陣?
呢篇論文最關鍵嘅事係利益衝突:3個作者有2個來自QwikBuild,而QwikBuild係被評平台之一。AMR(修改場景)嘅跨平台測試未做完,目前得QwikBuild跑曬完整AMR評估,CAR 100%、迴歸率0%呢啲靚數字都係單平台數據。
論文自己披露咗COI,但完全雙盲冇做到。第三作者Saxena獨立設計咗prompt同canary,係降低COI影響嘅機制。建議你:80條canary方法、3維度評測框架、4個共性短板可以放心抄;具體平台排名就最好自己復現一次先下結論。
最近 arxiv 有篇幾紮心嘅論文叫 SWE-WebDev Bench,將市面上 6 個主流 vibe coding 平台拉出嚟正面 PK:Lovable、Replit Agent3、Vercel v0-Max、Base44、Emergent E1-OPUS、QwikBuild。一句話總結:所有平台 Engineering 綜合分冇一個超過 60%,前端 UI 大家都整得靚,但後端、安全、生產就緒度全部炒車,冇一個可以直接交貨行得嘅系統。下面講佢點樣測、測咗啲乜、點解要睇點用。先講一個利益衝突重點:論文 2 個作者嚟自 QwikBuild,AMR 修改場景嘅測試亦只係跑咗 QwikBuild 一間,呢件事論文自己披露咗,下面會專門講。

評測點樣做:3 個維度 × 68 個指標 × 6 個平台
直接用 LeetCode 嗰啲小函數題去考 vibe coding 平台冇意思,因為呢啲平台標榜嘅係「一句話變上線產品」。SWE-WebDev Bench 嘅設計思路係將呢啲平台當成完整嘅「虛擬軟件工作室」嚟評。

3 個維度切出成套評測。Mode 維度分 ACR(創建新應用)同 AMR(修改已有應用),AMR 係呢篇論文新引入嘅。Angle 維度分 PM、Engineering、Ops 三個角色,分別睇需求理解、代碼質量、部署運維。Tier 維度分 T4 傳統 SaaS 同 T5 AI 原生應用。
業務場景揀咗 3 個真實領域:教育(ExamEdge 類考試系統)、現場服務(FieldOps 類巡檢系統)、金融科技 + AI(VettAI 類風險評估系統)。68 個指標分 7 大組(G1 規格保真到 G7 生產就緒),25 個主指標加 43 個診斷指標。判分係 4 層金字塔,Tier 0 全自動(Lighthouse、k6、npm audit)佔 40%,Tier 1 LLM 評分佔 35%,Tier 2 LLM + 人工佔 15%,Tier 3 專家組佔 10%。
成套設計嘅核心係睇「平台可唔可以將模糊需求變成上到線嘅系統」,而唔係睇「可唔可以寫出啱嘅函數」。
4 個共通短板:所有平台都走唔甩
測完 6 間發現所有平台都跌入同一批坑。

第一個坑係規格壓縮。同一個 prompt 畀唔同平台,PM 角色問得出嘅澄清問題數量由 0 到 15 不等,規格推斷質量分 3.5 倍極差。最差嘅平台直接沉默咗壓縮需求就開始寫 code,用戶根本唔知邊啲細節被砍咗。
第二個坑係前後端脱鈎。前端工程分大家都做到 68-74%,UI 睇落都幾似樣。但後台跑批同定時任務(CBS)嘅得分由 0 到 49.3%,50 個百分點嘅極差。即係話幾個平台嘅 UI 完全係「一個靚殼」,㩒掣落去後面冇任何真實工作流喺度行。
第三個坑係生產就緒懸崖。論文用 ETF(人工修復工時)同 CDI(聲稱功能 vs 真實功能差距)量化,ETF 由 12 工時到 60 工時,5 倍極差。CDI 高嘅平台會令你以為系統行咗,結果用戶先過你發現 bug。
第四個坑係安全全員炒車。Security Score 全員 38-65%,目標線係 90%。常見問題包括硬編碼 API key、冇 CSRF 保護、冇限流。並發負載分(CLS)只得 6-42%,目標線 70%。
所有 6 間喺某個維度都有明顯短板,但短板分佈唔同。
Canary 設計:80 條文化特定需求睇真係明定係拼湊
呢篇論文最巧妙嘅設計係 canary requirements 呢套方法。

Canary 就係埋喺 prompt 裏面嘅特定要求,例如「日期格式一定要係 DD/MM/YYYY」「金額要帶泰銖符號 ฿」「一定要支援泰文輸入」。呢類文化特定嘅、域內嵌入嘅細節,個 model 如果真係明業務就會保留,如果只係用訓練數據裏面嘅模板拼砌,就會靜靜雞丟咗。
80 條 canary 分 4 種。Original 21 條係初始 prompt 裏面明確寫嘅。New 37 條係 AMR 修改階段新加嘅。Surviving 18 條係修改之後一定要保留嘅。Contradiction 4 條係邏輯互相衝突嘅,睇個 model 敢唔敢質疑用戶而唔係悶聲實現。
CRR(Canary 留存率)嘅 5.5 倍極差係呢套方法測出嚟最有信息量嘅指標。最高嘅平台留住 97.7%,最低嘅只留住 17.7%,即係話用戶花一個鐘寫嘅需求描述,最差情況下有成 80% 被靜雞雞刪咗。
6 平台 3 條路線:架構選擇決定短板喺邊度
雖然所有平台都炒車,但炒車嘅姿勢唔同。論文將 6 間歸類成 3 條架構路線。
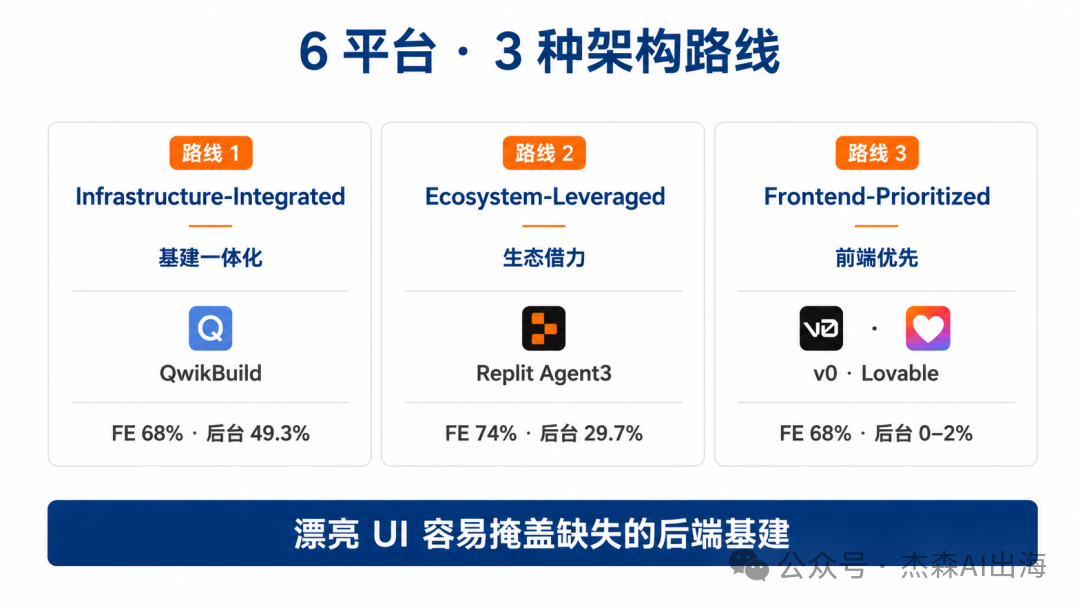
路線一係基建一體化,代表係 QwikBuild。前端工程分 68%,後台跑批 49.3%,強項係真係有完整後端基建喺度行。短板仲係規格理解唔夠細。
路線二係生態借力,代表係 Replit Agent3。前端 74.3%、後台 29.7%。靠 Replit 自己嘅開發環境生態,可以拉外部服務,但跨域穩定性有限。Replit 喺唔同業務域嘅得分極差 13 個百分點,即係話對特定領域嘅泛化能力仲未夠。
路線三係前端優先,代表係 Vercel v0-Max 同 Lovable。前端工程都做到 68%,但後台跑批 0-2%。呢兩個平台最大嘅問題係「靚 UI 畀你信心,令你以為系統行咗」,等到你攞到生產環境先發現㩒掣落去後面乜都冇。
Base44 同 Emergent E1-OPUS 都有參評,得分介乎上面三檔之間。論文裏面完整嘅指標對照表值得對照自己用過嘅平台睇一次。
利益衝突一定要先睇
呢篇論文最關鍵嘅事係利益衝突。

論文 3 個作者裏面有 2 個嚟自 QwikBuild,而 QwikBuild 又係 6 個被評測平台之一。AMR(修改場景)嘅跨平台測試仲未做完,目前只係喺 QwikBuild 一間上面跑過完整嘅 AMR 評估,CAR 100%、迴歸率 0% 呢啲好睇嘅數字都係單平台數據。
論文自己披露咗呢個 COI,做咗 G1 指標嘅盲評(評分人唔知係邊個平台嘅 code),亦專門列出 QwikBuild 嘅失敗點。但完全嘅雙盲冇做到。第三作者 Saxena 獨立設計咗 prompt 同 canary,呢個係降低 COI 影響嘅另一個機制。
讀呢篇點用:80 個 canary 嘅方法論、3 個維度嘅評測框架、4 個共通短板嘅發現可以放心抄。具體平台排名建議自己復現一次先下結論。論文承諾會做成 living benchmark,每季重測,未來版本要換獨立評測員。
一句話捉重點
vibe coding 呢一波平台目前都仲喺「Demo 階段」,UI 可以畀老細演示,但攞到生產環境都需要 12-60 小時嘅人工修復。SWE-WebDev Bench 提供嘅唔係「應該買邊間」嘅答案,而係「評估任何 vibe coding 平台時應該睇邊啲指標」嘅腳手架。
適合邊個睇:喺度揀 vibe coding 平台嘅產品經理、CTO、獨立開發者;想做 AI 編程產品嘅創業者,睇完知道邊啲短板可以做差異化;做 LLM 評測嘅研究員,可以參考 canary 方法論。
唔適合邊個:純發燒友隨便玩 demo 嘅話唔使睇咁仔細,睇完反而會焦慮。
完整論文:arxiv.org/abs/2605.04637 倉庫 github.com/snowmountainAi/webdevbench。論文叫 Evaluating Coding Agent Application Platforms as Virtual Software Agencies,作者 3 人,2 人嚟自 QwikBuild 團隊,第三作者 Saxena 負責 prompt 同 canary 設計。
最近 arxiv 上有篇挺扎心的論文叫 SWE-WebDev Bench,把市面上 6 個主流 vibe coding 平台拉出來正面 PK:Lovable、Replit Agent3、Vercel v0-Max、Base44、Emergent E1-OPUS、QwikBuild。一句話結論:所有平台 Engineering 綜合分都沒超過 60%,前端 UI 大家都做得漂亮,但後端、安全、生產就緒度集體翻車,沒有一個能直接交付能跑的系統。下面把它怎麼測的、測出了什麼、為什麼得看怎麼用拆給你。先說一個利益衝突要點:論文 2 個作者來自 QwikBuild,AMR 修改場景的測試也只跑了 QwikBuild 一家,這個事論文自己披露了,下面會專門講。
評測怎麼做:3 維度 × 68 指標 × 6 平台
直接拿 LeetCode 那種小函數題考 vibe coding 平台沒意義,因為這些平台標榜的是「一句話變上線產品」。SWE-WebDev Bench 的設計思路是把這些平台當成完整的「虛擬軟件工作室」來評。
3 個維度切出整套評測。Mode 維度分 ACR(創建新應用)和 AMR(修改已有應用),AMR 是這篇論文新引入的。Angle 維度分 PM、Engineering、Ops 三個角色,分別看需求理解、代碼質量、部署運維。Tier 維度分 T4 傳統 SaaS 和 T5 AI 原生應用。
業務場景挑了 3 個真實領域:教育(ExamEdge 類考試系統)、現場服務(FieldOps 類巡檢系統)、金融科技 + AI(VettAI 類風險評估系統)。68 個指標分 7 大組(G1 規格保真到 G7 生產就緒),25 個主指標加 43 個診斷指標。判分是 4 層金字塔,Tier 0 全自動(Lighthouse、k6、npm audit)佔 40%,Tier 1 LLM 評分佔 35%,Tier 2 LLM + 人工佔 15%,Tier 3 專家組佔 10%。
整套設計核心是看「平台能不能把模糊需求變成能上線的系統」,而不是看「能不能寫出對的函數」。
4 個共性短板:所有平台都沒逃掉
測完 6 家發現所有平台都掉同一批坑。
第一坑是規格壓縮。同一個 prompt 給不同平台,PM 角色能問的澄清問題數從 0 到 15 不等,規格推斷質量分 3.5 倍極差。最差的平台直接默默壓縮需求開始寫代碼,用戶根本不知道哪些細節被砍了。
第二坑是前後端脱鈎。前端工程分大家都能做到 68-74%,UI 看起來都挺像那麼回事。但後台跑批和定時任務(CBS)的得分從 0 到 49.3%,50 個百分點的極差。意思是幾個平台的 UI 完全是「一張漂亮的殼」,按鈕點下去後面沒有任何真實工作流在跑。
第三坑是生產就緒懸崖。論文用 ETF(人工修復工時)和 CDI(聲稱功能 vs 真實功能差距)量化,ETF 從 12 工時到 60 工時,5 倍極差。CDI 高的平台會讓你以為系統跑起來了,結果用戶先於你發現 bug。
第四坑是安全全員翻車。Security Score 全員 38-65%,目標線是 90%。常見問題包括硬編碼 API key、缺 CSRF 保護、沒限流。併發負載分(CLS)只有 6-42%,目標線 70%。
所有 6 家在某個維度都有明顯短板,但短板分佈不一樣。
Canary 設計:80 條文化特定需求看真懂還是拼湊
這篇論文最巧的設計是 canary requirements 這套方法。
Canary 就是埋在 prompt 裏的特定要求,比如「日期格式必須是 DD/MM/YYYY」「金額要帶泰銖符號 ฿」「必須支持泰文輸入」。這種文化特定的、域內嵌入的細節,模型如果是真懂業務就會保留,如果只是拿訓練數據裏的模板拼,就會默默丟掉。
80 條 canary 分 4 種。Original 21 條是初始 prompt 裏明確寫的。New 37 條是 AMR 修改階段新加的。Surviving 18 條是修改之後必須保留的。Contradiction 4 條是邏輯互相沖突的,看模型敢不敢質疑用戶而不是悶頭實現。
CRR(Canary 留存率)的 5.5 倍極差是這套方法測出來的最有信息量的指標。最高的平台留住 97.7%,最低的只留 17.7%,意味着用戶花一小時寫的需求描述,最差情況下有 80% 被默默刪掉了。
6 平台 3 路線:架構選擇決定短板長在哪
雖然所有平台都翻車,但翻車的姿勢不一樣。論文把 6 家歸成 3 條架構路線。
路線一是基建一體化,代表是 QwikBuild。前端工程分 68%,後台跑批 49.3%,強項是真有完整後端基建在跑。短板還是規格理解不夠細。
路線二是生態借力,代表是 Replit Agent3。前端 74.3%、後台 29.7%。靠 Replit 自己的開發環境生態,能拉外部服務,但跨域穩定性有限。Replit 在不同業務域上的得分極差 13 個百分點,說明對特定領域的泛化能力還不夠。
路線三是前端優先,代表是 Vercel v0-Max 和 Lovable。前端工程也能做到 68%,但後台跑批 0-2%。這倆平台最大的問題是「漂亮 UI 給你信心,讓你以為系統跑了」,等你拿到生產環境才發現按鈕點下去後面什麼都沒有。
Base44 和 Emergent E1-OPUS 也參評,得分介於上述三檔之間。論文裏完整的指標對照表值得對照自己用過的平台看一遍。
利益衝突必須先看
這篇論文最關鍵的事是利益衝突。
論文 3 個作者裏有 2 個來自 QwikBuild,QwikBuild 又是 6 個被評測平台之一。AMR(修改場景)的跨平台測試還沒做完,目前只在 QwikBuild 一家上跑過完整的 AMR 評估,CAR 100%、迴歸率 0% 這些好看的數字都是單平台數據。
論文自己披露了這個 COI,做了 G1 指標的盲評(評分人不知道是哪個平台的代碼),也專門列出了 QwikBuild 的失敗點。但完全的雙盲沒做到。第三作者 Saxena 獨立設計了 prompt 和 canary,這是降低 COI 影響的另一個機制。
讀這篇怎麼用:80 個 canary 的方法論、3 維度的評測框架、4 個共性短板的發現可以放心抄。具體平台排名建議自己復現一次再下結論。論文承諾會做成 living benchmark,每季度重測,未來版本要換獨立評測員。
一句話抓重點
vibe coding 這一波平台目前都還在「Demo 階段」,UI 能給老闆演示,但拿到生產環境都需要 12-60 小時的人工修復。SWE-WebDev Bench 提供的不是「該買哪家」的答案,是「評估任何 vibe coding 平台時該看哪些指標」的腳手架。
適合誰看:在選 vibe coding 平台的產品經理、CTO、獨立開發者;想做 AI 編程產品的創業者,看完知道哪些短板可以做差異化;做 LLM 評測的研究者,可以參考 canary 方法論。
不適合誰:純愛好者隨便玩 demo 的話不用看這麼細,看完反而焦慮。
完整論文:arxiv.org/abs/2605.04637 倉庫 github.com/snowmountainAi/webdevbench。論文叫 Evaluating Coding Agent Application Platforms as Virtual Software Agencies,作者 3 人,2 人來自 QwikBuild 團隊,第三作者 Saxena 負責 prompt 和 canary 設計。