9項benchmark第一、35小時不停手,Qwen3.7-Max有點東西
整理版優先睇
Qwen3.7-Max喺Agent能力上突破,9項benchmark第一、35小時長程任務表現驚人
呢篇文章係由女媧公眾號嘅主理人寫嘅,佢一直關注AI大模型嘅發展。佢喺X上見到Artificial Analysis嘅評測,Qwen3.7-Max嘅Intelligence Index有56.6分,比上一代高咗近5分。重要嘅係,第三方話呢個模型係阿里離前沿最近嘅一次。另外Text Arena盲測榜單顯示,Qwen3.7-Max排第六,同第一名Claude Opus 4.6只差27分。作者就想深入分析呢個模型喺Agent能力上嘅真實表現。
阿里呢個月20號準時發佈咗Qwen3.7-Max,距離上個版本只係一個月。官方放出12項Agent評測,其中9項第一,包括Terminal-Bench、SWE-bench Pro呢啲。特別係IFBench指令遵循攞咗79.1分,全場第一,即係模型好少會漏咗你畀嘅約束。仲有一個35小時長程任務實驗:模型喺平頭哥芯片上自主優化SGLang嘅推理kernel,總共432次評估、1158次工具調用,達到10倍加速比。其他模型中途自己停咗,但Qwen3.7冇停,仲識得自己發現新優化點。
作者自己都實測咗。佢用claude-code-router將Qwen3.7-Max接入Claude Code,依次跑咗三個複雜任務:女媧skill蒸餾蒙台梭利專家、用huashu-design整官宣動畫、結合兩個skill分析十年讀書數據整DNA圖譜。三個任務都全程順暢,冇需要人工介入。作者認為,Qwen3.7-…
- Qwen3.7-Max喺9項Agent benchmark攞第一,整體接近Anthropic等前沿模型,係國產模型最新突破。
- 阿里採取穩定按月迭代節奏,每次更新都推前Agent能力,今次重點係指令遵循同長程任務。
- 同上一代Qwen3.6-Max相比,Intelligence Index高咗近5分;同Claude Opus 4.6相比,Text Arena盲測只差27分。
- 長程任務35小時不中斷,仲可以自主發現新優化點,呢種能力超越咗其他模型自己停頓嘅情況。
- 開發者可以將Qwen3.7-Max接入Claude Code等框架,嘗試多skill協作任務,例如自動調優或數據分析。
評測掛帥:9項第一的Agent能力
Artificial Analysis 係國外公認嘅第三方評測機構,佢哋嘅 Intelligence Index 畀 Qwen3.7-Max 評咗 56.6 分,比 Qwen3.6-Max 高咗近 5 分。原文仲話:「阿里仍然落後於 OpenAI、Anthropic 同 Google,但 Qwen3.7-Max 係佢哋離前沿最近嘅一次。」
另一個重要榜單係 Text Arena 盲測,超過 600 萬人投票,Qwen3.7-Max 排第六,離第一名 Claude Opus 4.6 只差 27 分。國產模型喺呢個榜單上算係比較前嘅站位。
其中 IFBench 指令遵循 79.1 分全場第一,意思係你畀 prompt 入面嘅多個約束,模型基本唔會丟。呢個能力喺Agent時代好重要。
35小時不間斷:長程任務的天花板
千問團隊設計咗一個真實 AI Infra 工程師嘅任務:喺平頭哥真武 M890 芯片上自主優化 SGLang 推理 kernel。模型只有任務描述、參考實現同評估腳本,然後自己開工。
結果係:連續自主執行 35 小時,432 次 kernel 評估,1158 次工具調用,幾何平均加速比 10.0 倍。其他模型喺連續5輪冇發出工具調用後自己停咗,但 Qwen3.7-Max 冇停,仲發現咗關鍵嘅架構重設計。
呢個實驗說明 長程任務執行 唔單止係耐力,仲係決策質量。Qwen3.7-Max 喺呢方面交出咗好靚嘅數據。
跨框架泛化:模型不挑工具棧
官方強調 Qwen3.7-Max 並非針對某一特定框架優化,而係喺 Claude Code、OpenClaw、Qwen Code 同各類自定義框架下都穩定發揮。呢個工程意義比單一 benchmark 大好多。
過去國產模型嘅痛點係「benchmark 仲得,換個 harness 就拉胯」。Qwen3.7-Max 嘅12項評測都係多框架下完成,意味住 tool use 能力冇綁死任何模式。
作者之前寫過嘅 Claude Code、Hermes Agent 等橙皮書,本來預設係「Claude 模型 + harness」,而家可以換成 Qwen3.7-Max + 同一個 harness,多咗一個選擇。
真實任務實測:女媧、動畫、讀書DNA
作者用 claude-code-router 將 Qwen3.7-Max 接入 Claude Code,跑咗三個複雜任務。第一個係女媧 skill 蒸餾蒙台梭利專家,模型需要並行調用 6 個 subagent 做調研,再經過質量自檢同雙 Agent 精煉,最終輸出角色一致嘅回答。
第二個任務係用 huashu-design 整一段 30 秒官宣動畫,模型自己搜索資料、寫腳本、構建 HTML、Playwright 截圖自檢、ffmpeg 合成,9分49秒一氣呵成。
- 1 調用 search 蒐集模型資訊
- 2 寫腳本同 HTML 動畫
- 3 Playwright 多幀截圖驗證
- 4 ffmpeg 合 BGM 導出 MP4
第三個任務最難:結合 huashu-weread 同 huashu-design,分析十年讀書數據畫成 DNA 雙螺旋。模型自己寫 4 個 Python 腳本,定義 6 個維度,處理 5318 條筆記,最後輸出排版精緻嘅可視化。
觀察:穩定迭代的價值
呢次體驗令作者體會到唔係單一分數,而係阿里喺Agent路線嘅具體推進:長程任務穩定性、跨框適應、指令遵循——呢三樣嘢加埋,先形成真正嘅產品力。
阿里已經連續幾個月每月20號準時發新版本,每個版本都將 Agent 能力推前少少。呢種節奏喺國內廠商入面唔多見。
Qwen3.7-Max 已經喺 阿里雲百鍊 正式上線,模型 Code 係 qwen3.7-max,function calling、cache、結構化輸出等能力都齊。開發者可以即刻接落去試。
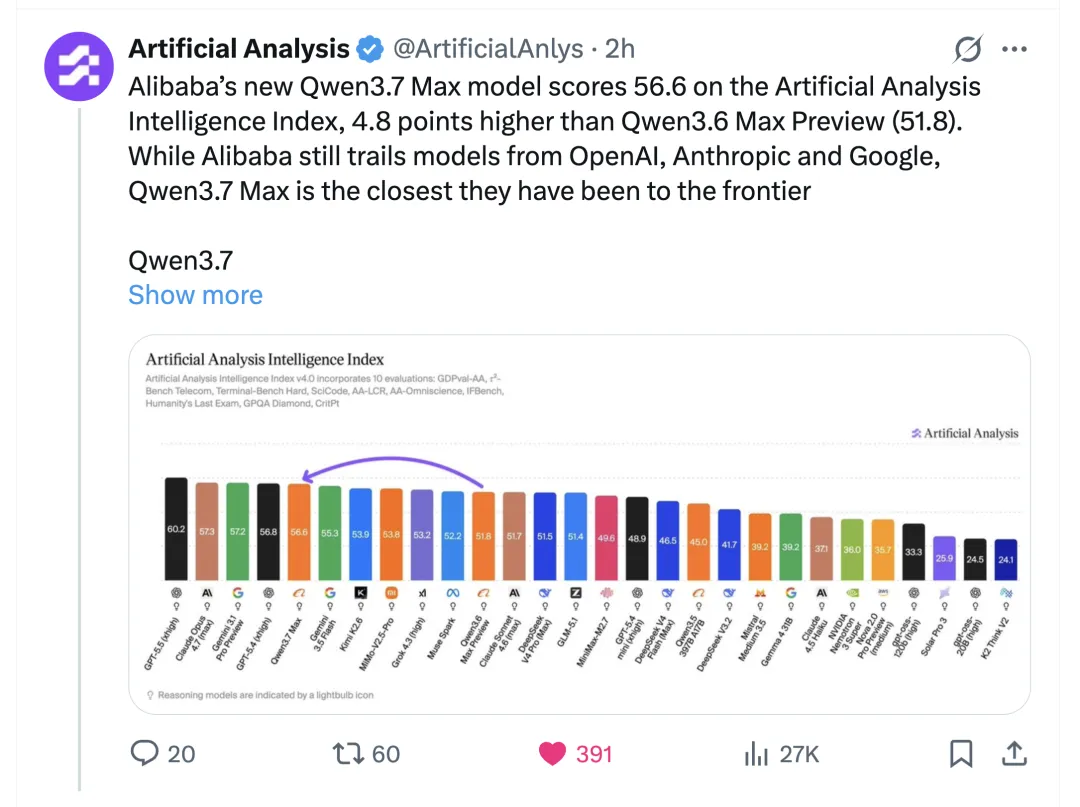
Qwen3.7-Max 的 Intelligence Index 評了 56.6 分,比上一代 Qwen3.6-Max 高了將近 5 分。讓我停下來看了兩眼的是他們的原話:「阿里仍然落後於 OpenAI、Anthropic 和 Google,但 Qwen3.7-Max 是他們離前沿最近的一次」。
往下翻評論區,又看到有人貼了 Text Arena 的盲測榜單。Text Arena 是全球用戶匿名盲測投票產生的大模型排行榜,已經有 600 萬人參與投票,被視為最接近真實使用體驗的口碑指標。
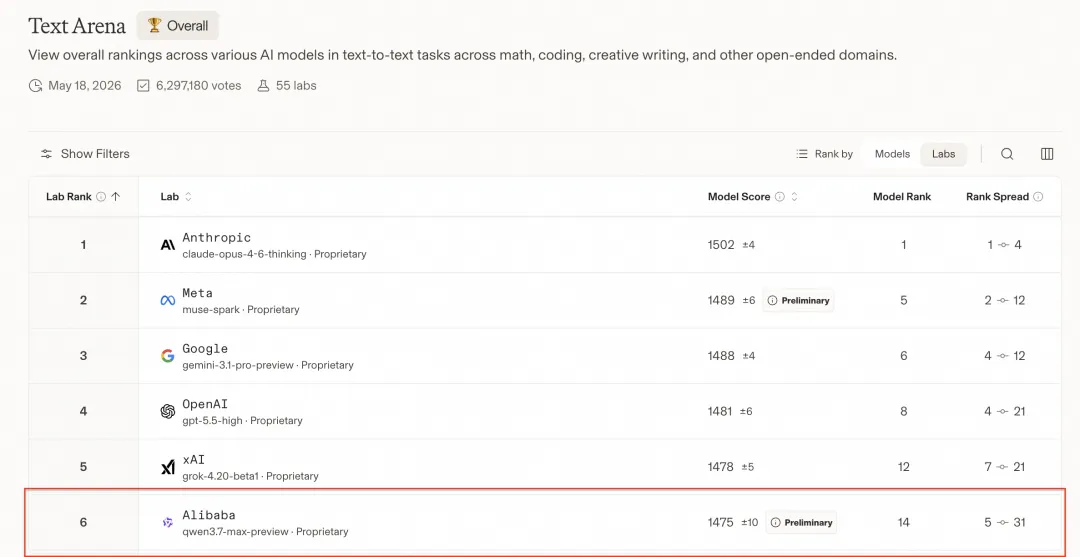
前五名清一色是 Anthropic、Meta、Google、OpenAI、xAI 的旗艦模型。第六名是阿里的 qwen3-7-max-preview,離第一名 Claude Opus 4.6 thinking 只差 27 分。國產模型這段時間相對靠前的一次站位。
回頭查了下,阿里幾天前剛發了 Qwen3.7-Max。再看官方放出來的 12 項 agent 評測,9 項第一。
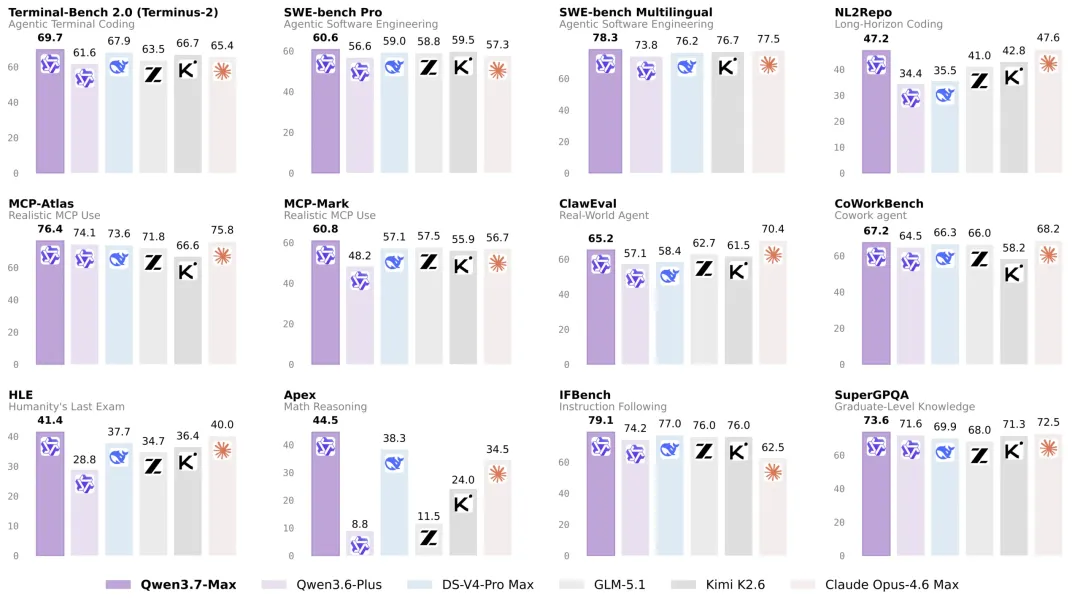
看來人員的一些變化是一點沒影響阿里在大模型上的投入和卷。我印象中離 Qwen3.6 發佈也還沒過去幾天,往回翻了下,3 月 Qwen3.5、4 月 Qwen3.6、5 月 Qwen3.7,每個月 20 號準時發新版本,節奏挺穩。
以及,我從阿里的模型發佈文章裏看到了一些很有趣的現象,他們特意強調了Qwen3.7-Max很適合接入Claude Code、OpenClaw、Hermes Agent、Qwen Coder這些agent harness。看起來大模型的Agentic Coding的能力已經成了各個模型廠商最關注的方向了。
我跑了幾個真實任務。這篇想聊清楚這事。
先說說這12項benchmark
那張表裏有幾個細節挺值得說。
9 項第一的項目幾乎都是 agent 類:Terminal-Bench、SWE-bench Pro、SWE-bench Multilingual、MCP-Atlas、MCP-Mark、HLE、Apex 數學、IFBench 指令遵循、SuperGPQA。Opus 4.6 反超的 3 項(NL2Repo、ClawEval、CoWorkBench)都是真實 agent 協作場景,差距分別是 0.4、5.2、1.0。Anthropic 在這塊還是有積累。
裏面最值得拎出來說的是 IFBench 指令遵循 79.1 分,全場第一。指令遵循這件事翻譯成用戶視角就是:你給的 prompt 裏有 5 個約束,它基本不會丟任何一個。這正是 agent 時代用戶最在乎的能力之一。
最近幾個月整個行業最關注的方向就兩條:大模型編程能力(LM coding)和長程任務執行(Long Horizon)。Opus 4.7、GPT 5.5、DeepSeek V4,都在拼這兩條線。
Qwen3.7-Max 這次拿出來的核心指標,命中的正是這兩條線。前面 12 項裏有一大半就是這兩類。35 小時 1158 次工具調用的長程任務實驗,更是直接蹦着Long Horizon的天花板取得。
我仔細理解了下他們的測試,千問團隊找了一個真實 AI Infra 工程師的日常任務給模型做:在平頭哥真武 M890 芯片上自主優化 SGLang 的推理 kernel。kernel 簡單理解就是 GPU 上跑模型推理的那段核心計算代碼,AI Infra 工程師的日常工作之一就是給它做調優。
這個芯片千問之前沒見過。給模型的只有:一個任務描述、一份 SGLang Triton 參考實現、一個評估腳本。剩下的事情,模型自己幹。
然後它真的自己幹了 35 小時。
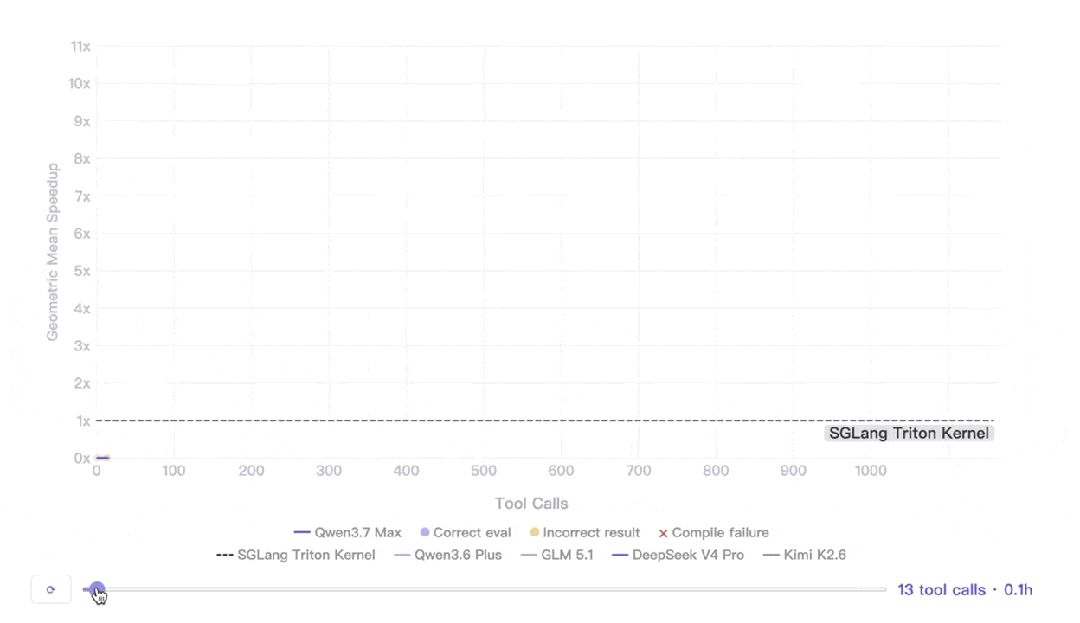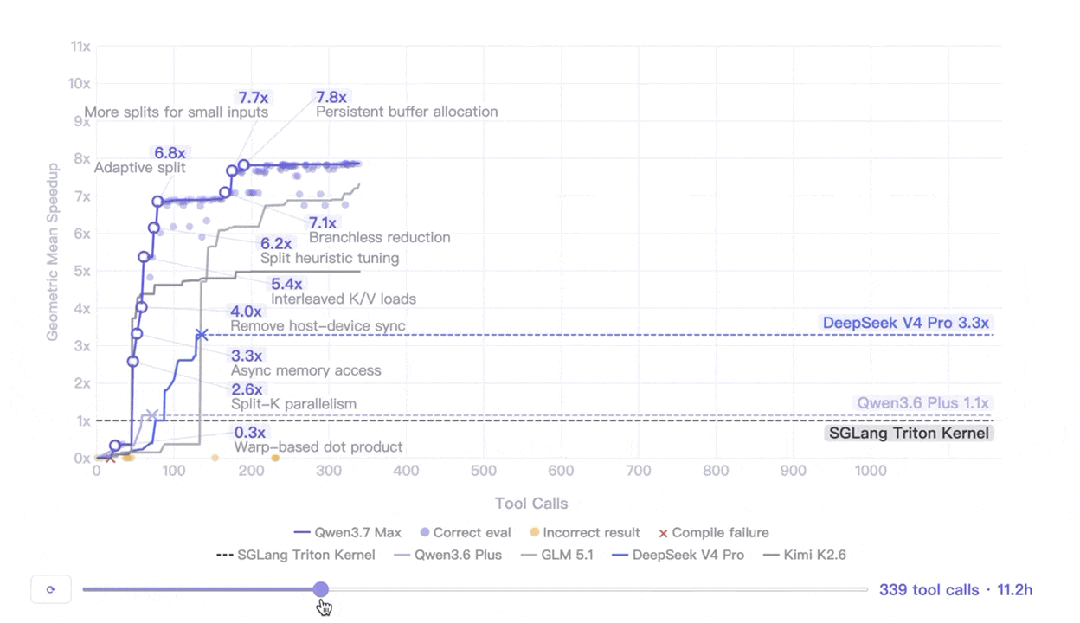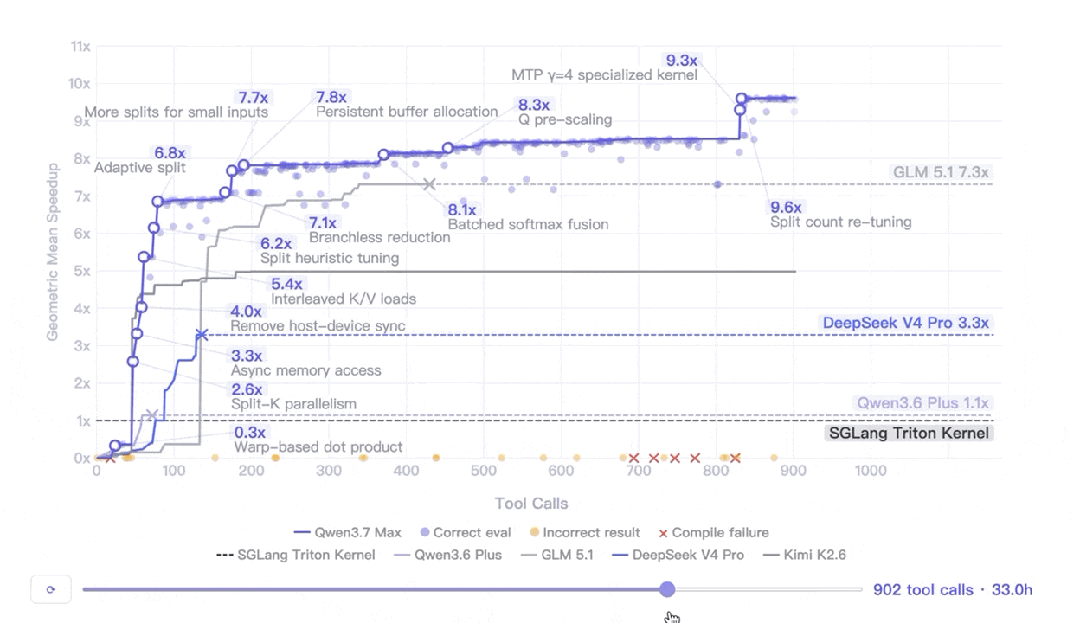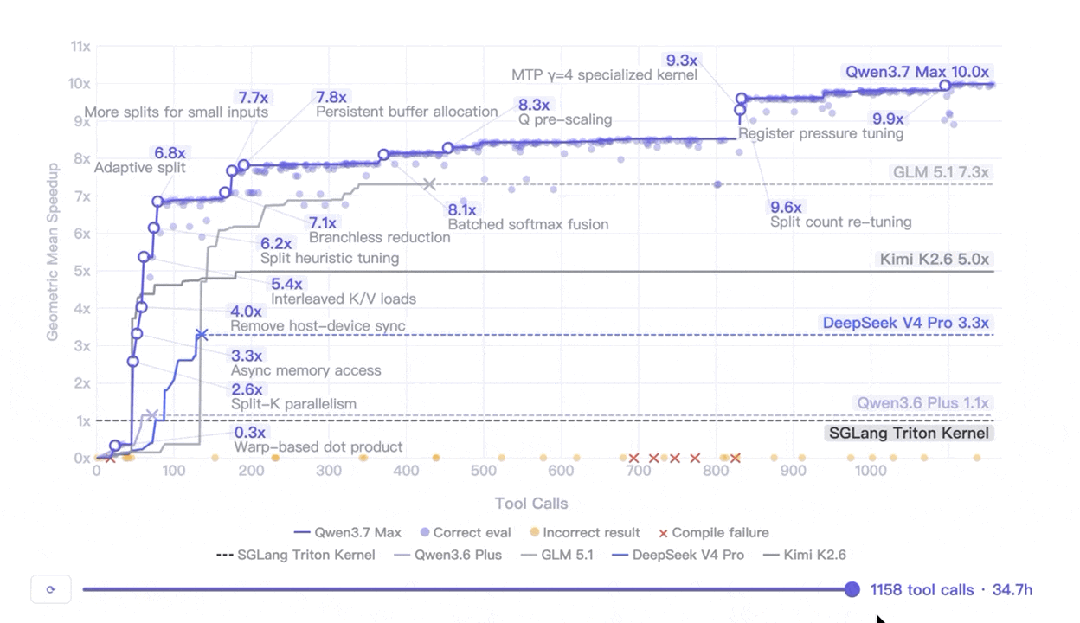
完整數據:
35 小時連續自主執行 432 次 kernel 評估 1158 次 工具調用 10.0 倍 幾何平均加速比(vs SGLang Triton 參考實現)
更有意思的細節是其他幾個模型「停下來的原因」。它們不是被人打斷的,是連續 5 輪沒發出任何工具調用,模型自己判斷幹不動了主動停了。Qwen3.7 沒停。30+ 小時之後還在發現新的優化點,其中一次是關鍵的架構重設計。
具體技術上,模型自主完成了兩次結構性躍遷。這些原本都是真人 AI Infra 工程師的活兒。我猜業內做這塊的同行看到這組數據,應該會想一會兒。
能在標準答案題上拿滿分,和能 35 小時不停摸索 kernel 設計,是兩種很不一樣的能力。前者靠 benchmark 這種考試式的分數衡量。後者要靠 trajectory 沉澱,也就是模型在長程任務裏一步步走過的決策軌跡。Qwen3.7 這次在兩邊都拿出了能看的數據。
跨框架泛化:我覺得這次最重要的事
回頭看官方博客裏有句話,乍讀會被忽略:「上述評測分數來自多種不同的智能體框架。Qwen3.7-Max 並非針對某一特定框架優化,而是在 Claude Code、OpenClaw、Qwen Code 和各類自定義框架下都能穩定發揮。」

留意下官方這張頭圖。長桌上那排吉祥物,除了官方點名的三家,Hermes Agent 也畫在裏面。
這事的工程含義比一個 benchmark 分數大很多。
過去半年我寫過 4 篇 Claude Code 的文章,也專門做過 Hermes Agent 和 OpenClaw 的橙皮書。這幾家 agent harness 各有各的設計哲學:Claude Code 是 tool use 緊耦合,OpenClaw 偏個人助手型,Hermes Agent 是消息驅動,Qwen Code 自家的更輕量。要讓一個模型在差異這麼大的幾家框架下都跑出體面分數,意味着它的 tool use 能力沒綁死任何特定模式。
之前國產模型最大的痛點之一就是「benchmark 還行,換個 harness 就拉胯」。Qwen3.7 這次的 12 項評測都是在多框架下完成的,模型不挑工具棧。
我自己之前出的 4 本相關橙皮書,剛好可以對照看看:
這 4 本之前的預設都是「Claude 模型 + 某個 harness」的組合。現在多了一種可能:國產模型 + 同一個 harness,也能跑。
下面就實測一下這事。
我把 Qwen3.7-Max 接進了 Claude Code
具體做法是通過 claude-code-router(CCR)這個開源工具把 Qwen3.7-Max 接到 Claude Code 後端。日常的 claude 命令保留訂閲模式不動,另起一個 claude-qwen 命令啓動 CCR,把 banner 顯示名設成 Qwen3.7-Max。
接下來跑兩個有點意思的任務。
讓它跑一次女媧
公眾號老粉應該都知道我上個月開源的女媧(nuwa.skill)。前幾天 GitHub stars 剛過 2 萬,已經被好幾個大廠的 agent 產品納進給用戶預裝的默認 skill,也有不少團隊在研究它的 harness 架構設計。
社區裏更多的驚喜來自延伸用法。這個 skill 我做的時候默認場景是蒸餾 PG、芒格、費曼這種思想家,但社區拿它玩出了各種我意想不到的花樣。昨天就有個朋友告訴我,她用女媧蒸餾了一波育兒專家,給自己和她的用戶用。
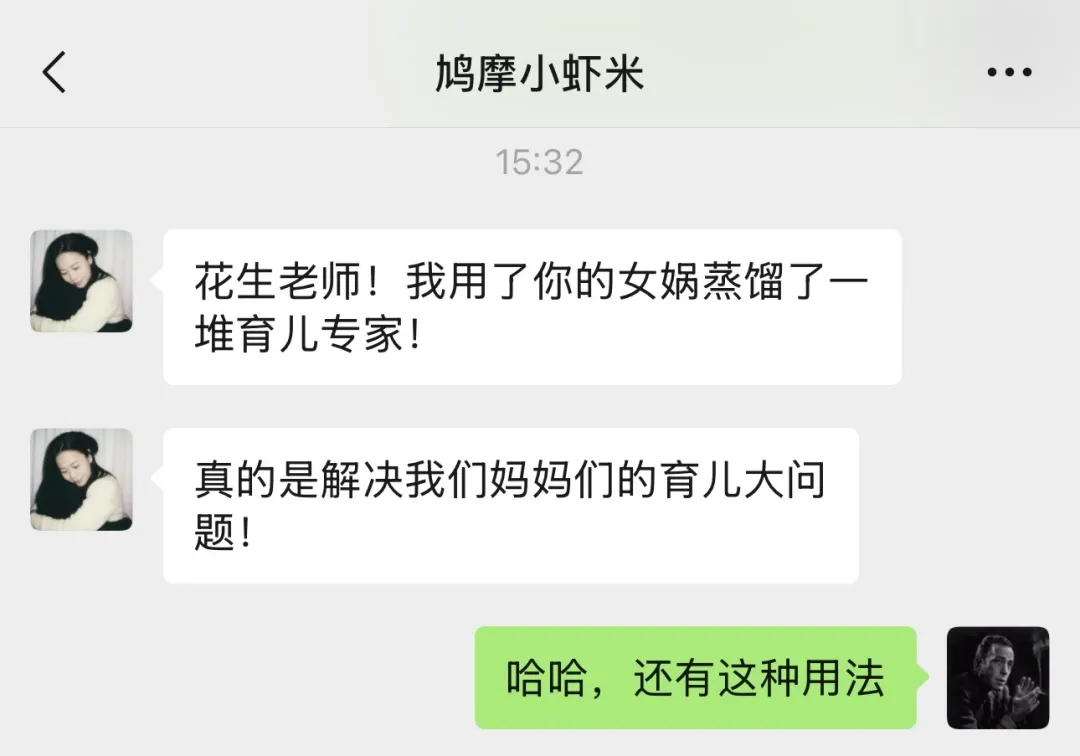
這種用法我自己也沒想到。
女媧這工具對模型很挑。調研階段就要並行啓動 6 個 subagent,分別去查著作、對話、表達 DNA、外部評價、決策記錄、時間線。調研出來之後還要做質量自檢、3 個驗證 agent、2 個精煉 agent 的雙 Agent 評審。整套流程跑下來,子 agent 調用數量輕鬆上百,單次執行半小時起步。
這種任務對指令遵循和長程任務執行兩個維度都是硬考驗。在某一步跑偏,後面就連環錯。
我用 claude-qwen 把女媧跑了一遍,主題選的是蒙台梭利教育學專家。Qwen3.7-Max 跑下來全流程順:6 個調研 agent 全部完成(其中 1 個文件路徑寫錯,自己偵測到並 fallback 找到了文件)、Voice Check 5/5 PASS、Sanity Check 3/3 PASS、Edge Case 通過、雙 Agent 精煉綜合應用了 11 項改進建議。
蒸餾出來的蒙台梭利專家 skill 測試結果挺有意思。我問她:「在智能被無限供給的時代,怎麼看蒙台梭利教育?」
她回答的片段:
1907 年沒有 AI,沒有計算機,甚至沒有收音機。但那些聖洛倫佐貧民區的孩子,面對的挑戰和今天的孩子本質上是一樣的——成人世界總是急於把他們塑造成某種標準產品,而不是尊重他們內在的發展藍圖。
AI 是什麼?在我的框架裏,它是一種極其強大的環境要素。僅此而已。
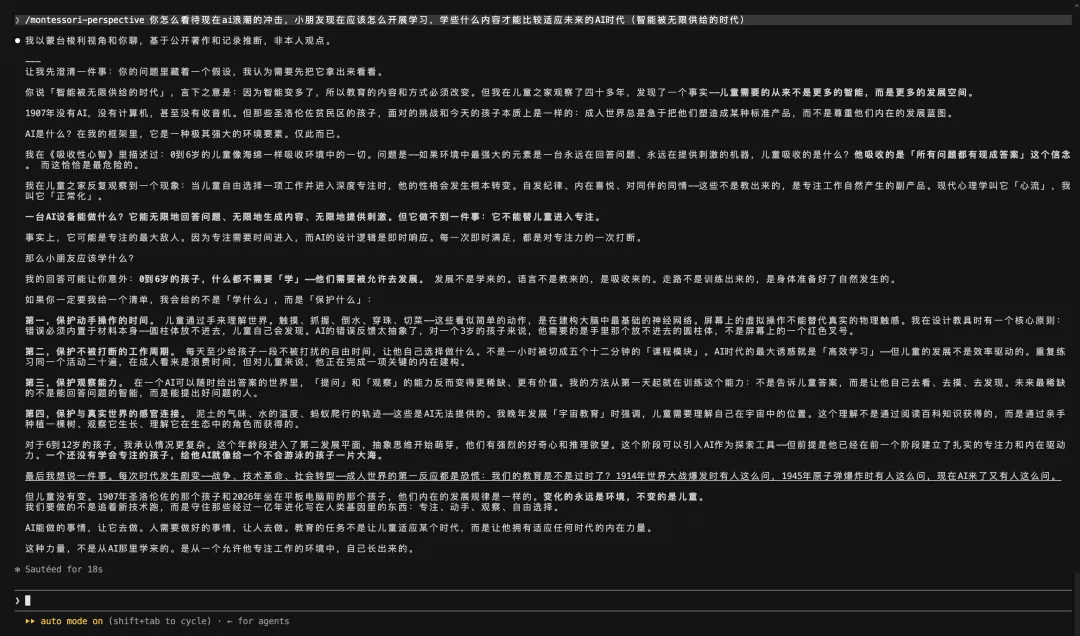
這種回答的角色一致性,是評判蒸餾質量的核心指標。模型不僅要知道蒙台梭利說過什麼,還要能在新問題上保持她的論證方式。Qwen3.7-Max 在我這個測試裏做到了。
完整跑女媧的過程錄了視頻,可以感受一下 subagent 一個接一個起來的節奏:
順手讓它給自己做了一段宣傳動畫
跑完女媧又起了個念頭:讓 Qwen3.7 用我另一個 skill(huashu-design)給自己做一段官宣動畫。
huashu-design 是端到端的:主題調研、腳本拆解、HTML 動畫構建、Playwright 多幀截圖驗證、MP4 導出,最後用 ffmpeg 合 BGM。整條鏈路下來涉及一二十種工具調用,對模型在長鏈路裏既穩又有審美都有要求。
我給的 prompt 很簡單:「阿里最近剛發佈了 Qwen3.7-Max 模型,請幫我收集這個模型的信息,然後用 /huashu-design 給它做一個 30 秒左右的信息和數據豐富的宣傳動畫」。
Qwen3.7 一氣呵成跑了 9 分 49 秒,中間穿插多次搜索、文件寫入、HTML 構建、Playwright 截圖自檢、ffmpeg 合成。最後產物是一段 24.5 秒的 1920x1080 動畫。
這段流程裏最值得說的是它的執行穩定性。從調研到寫腳本、HTML 構建、Playwright 自檢、ffmpeg 合成,9 分多鐘裏一二十種工具混着用,模型沒有卡在任何一步。長鏈路任務能這樣跑下來的國產模型不多。

短期看,這就是一個 demo。但能把這種調研 + 工程 + 審美串在一起的複合任務一氣呵成跑完,對模型本身的執行穩定性是個不小的考驗。
再讓它做了一次「讀書 DNA」
最後一個我想試的,比前兩個都複雜。
我前幾天寫過一篇微信讀書 skill 的文章,反響挺好。裏面提過我自己另做了個增強版叫 huashu-weread,能在底層 weread API 之上做交叉分析。這次想讓 Qwen3.7 同時調用 huashu-weread 和 huashu-design 兩個 skill,把我十年的讀書數據畫成一張可視化。
我給的 prompt 也很簡單:讓它把書架和筆記本里的數據都拉出來,自己定 6-8 個能區分「讀者」的維度,給筆記多的書逐本打分,最後畫成 DNA 雙螺旋。
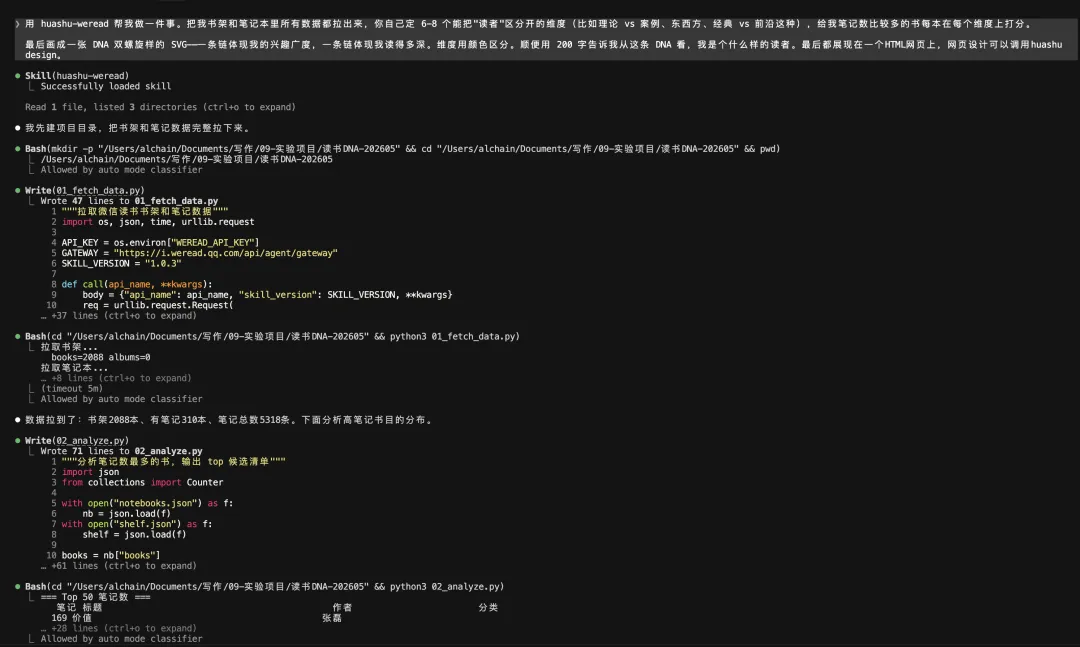
整個過程它做了挺多事。先調 huashu-weread 拉書架——返回 2088 本;再拉筆記本——310 本筆記書、5318 條筆記。然後自己寫了 4 個 Python 腳本:第一個 fetch 數據、第二個 analyze 筆記分佈、第三個定義 6 個維度(思想↔故事 / 科學↔人文 / 行動↔反思 / 東方↔西方 / 古典↔當代 / 個人↔系統)+ 給筆記數最多的 24 本逐本打分、第四個用 huashu-design 的設計規範構建 HTML。中間還自己跑 Playwright 截圖自校驗,發現一處不滿意就重截。
最後產物是這樣:

排版是編輯式磁書風格:cream 底色、襯線 display + 無襯線 body、中央一條豎向雙螺旋(左鏈興趣廣度、右鏈閲讀深度),橫檔顏色標這本書最強烈的維度。完全符合我 huashu-design skill 裏寫的反 AI slop 規範,沒有那種「賽博霓虹 + 紫色光圈」的俗氣審美。
讀者畫像那段我覺得寫得還蠻有洞察的。三個並存的人格:「要麼讀純思想(芒格、波茲曼、Ridley),要麼讀純故事(傅高義、Instagram、Simons),中間地帶的"半思半敍"基本不碰」「西方學方法,東方讀系統,西方書挑《掌控習慣》《卡片筆記》《俞軍方法論》,中文幾乎全在"系統級"(《美團》《置身事內》《沸騰新十年》)」。我很建議大家都用我的skill去診斷下自己的閲讀品味,可能會讓你發現些不一樣的自己。
這個測試比前兩個都難。兩個 skill 並用、自己寫 4 個 Python 腳本、幾次外部 API 調用、幾千條數據處理、最後還要按設計規範輸出可發佈的 HTML。整套鏈路跑下來,Qwen3.7 沒有需要我中途介入。
一些觀察
跑完這兩個真實任務,再回頭看那些 benchmark 數字,感受會平實一些。
讓我有體感的不是某項分數,是阿里在 agent 這條線上的幾個具體推進。
長程任務的穩定性是其中比較直接的一個。35 小時連着 1158 次工具調用還能產生新發現,這種能力是過去 trajectory RL 一直在打磨的事。我自己跑女媧那個半小時上百次 subagent 調用,跑宣傳動畫那個十分鐘串起搜索、HTML、Playwright、ffmpeg 一整條鏈路,中間可能跑偏的地方都沒跑偏。
跨 harness 這件事的意義在另一層。它意味着你手裏之前那套 agent 工具棧不用換,模型這一層多了一種選擇。
指令遵循也算順帶的進步。IFBench 79.1 這個數字翻譯成日常使用,就是你 prompt 裏寫的約束模型基本不會丟,尤其是給它一長串要求時。大部分 agent workflow 是被約束撐起來的,不是被代碼撐起來的,這一點對體驗影響其實挺大。
我不太想用千問殺回來了這種話。國內幾家模型這兩年本來就是 GLM、DeepSeek、Kimi、千問輪流刷榜的格局,誰也沒真正"殺回來"。能穩定按月迭代的廠商不多,阿里這幾個月幾乎每個月20號都準時發新版本,每一代都把 agent 這條線往前推一點。Qwen3.7-Max 是這條節奏裏最新的一站。
Anthropic 這幾個月也在使勁做同一件事,Opus 從 4.6 升到 4.7 的 system card 裏花了大量篇幅寫長程任務和評估意識。前面我寫 Opus 4.7 那篇裏也聊過這事。兩邊在同一個方向上推,方向多半是對的。
Qwen3.7-Max 已經在阿里雲百鍊正式上線,模型 Code 就是 qwen3.7-max。function calling、cache 緩存、結構化輸出、聯網搜索、模型微調這些能力都給齊了。
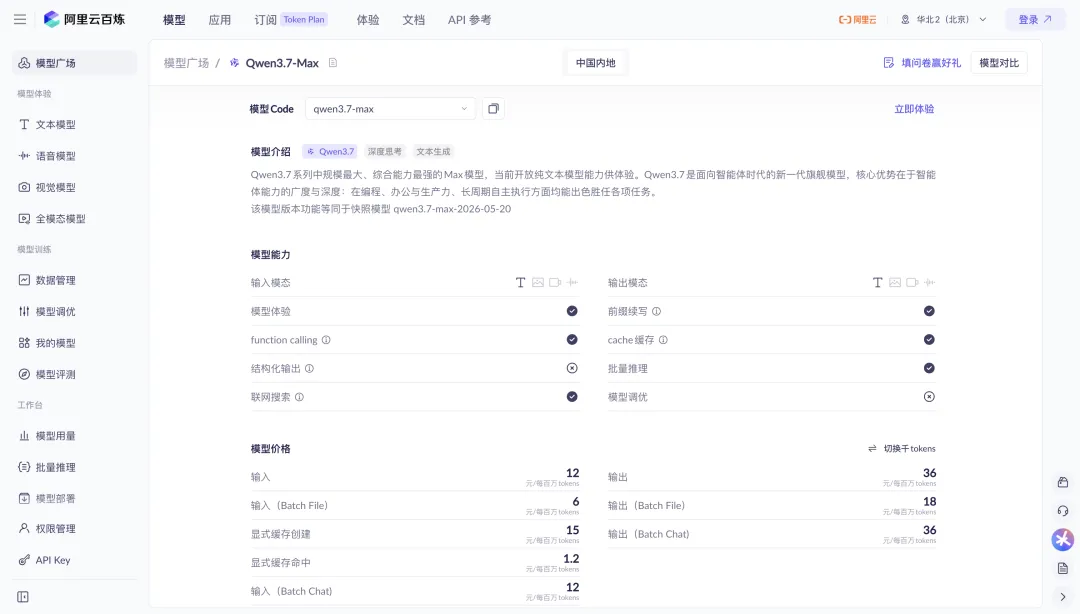
不管你手裏的 agent 客戶端是 Claude Code、OpenClaw 還是 Qwen Code,現在都多了一個能直接調的後端。親自上手跑一遍,比看我的文章介紹獲得的體感會實在得多。