Agent Skills 完全指南:從原理到實戰徹底搞懂!
整理版優先睇
Agent Skills 係一種模塊化能力插件,透過漸進式披露機制按需加載,比 MCP 更慳 Token 同提升 AI 注意力,成為教 AI 做嘢嘅標準實踐。
呢篇文章出自技術作者 ConardLi 嘅《code秘密花園》,目標係幫讀者徹底搞懂 Agent Skills 呢個新標準。作者先講到 Skills 嘅背景:由 Anthropic 推出後,Cusor、OpenCode 等客戶端相繼支援,社區湧現大量開源 Skills,已經成為擴展 Agent 能力嘅主流方式。作者想解決嘅問題係:MCP 雖然標準化,但每次對話都要將所有工具定義塞入 Context Window,導致 Token 消耗大、AI 注意力下降。
整體結論係:Skills 透過「文件系統基礎」同「漸進式披露」機制,只係喺需要嗰陣先加載相關說明同腳本,大幅減少成本同提升準確率。未來格局會係:Agent 內置核心能力、少數通用 MCP Server 負責遠程連接、大量 Skills 封裝標準工作流。Skills 唔會完全取代 MCP,但會承擔大部分「教 AI 點樣做嘢」嘅工作。
文章詳細講解咗 Skills 嘅結構(SKILL.md、參考、腳本、資源)、核心機制(元數據→指令→運行時資源),同 MCP 嘅對比,同埋點樣揾 Skills、點樣用、點樣自己創建。最後預告下一期會用 Skills 實現知識庫檢索,比較同傳統 RAG 嘅效果。
- Skills 係文件系統基礎嘅模塊化能力插件,包含 SKILL.md、參考、腳本同資源,放喺指定目錄即可自動生效。
- 核心機制「漸進式披露」分三層:先睇元數據(名同描述),確認任務後再讀指令(SKILL.md),執行時先加載運行時資源(參考、腳本),有效慳 Token 同提升注意力。
- 同 MCP 比較:MCP 每次對話要注入所有工具定義(數萬 Token),仲會降低模型調用準確率;Skills 只加載需要部分,成本更低、準確率更高。
- 編寫門檻極低:只要識寫提示詞就能整 Skills,社區 Skills 數量爆發式增長,比 MCP 更容易普及。
- 使用簡單:將 Skills 文件夾放到 .agentName/skills 目錄,Agent 會自動根據用戶需求匹配並調用,唔使手動安裝或設定。
AI 教程完整匯總(飛書文檔)
作者整理嘅 AI 相關教程合集,包含本文同其他資源。
學習資源匯總(GitHub)
作者開源嘅 easy-learn-ai 倉庫,收錄各種學習材料。
Skills 係咩?點樣組成?
傳統 AI 對話模式係靠訓練數據同即時提示詞,就好似請個實習生每次都要重新教。Agent Skills 就係一種「模塊化能力插件」,你可以將 Claude 想像成一個超級大腦,Skills 就係外接工具箱,入面唔只有工具,仲有詳細嘅「官方使用說明書」。大腦唔需要記住全部,需要嗰陣先攞出嚟睇。
SKILL.md 嘅內容好簡單,上面有三條橫線嘅 metadata,包括 name 同 description,描述決定咗幾時會觸發呢個 Skill。下面係目標、使用步驟、注意事項,就好似一個詳細嘅工作流程說明。
呢個設計嘅關鍵係:你只需要將 Skills 文件放啱位置,Agent 就會自動根據需求匹配,唔使手動啟用或設定。
漸進式披露:按需加載嘅聰明機制
如果一個 Agents 有 50 個 Skills,每個都有幾千字說明書,一次過塞曬入 Context Window 會令成本爆炸、AI 注意力分散。Skills 嘅「漸進式披露」機制就係為咗解決呢個問題,好似喺圖書館查資料咁:先睇目錄,再翻開手冊,最後先動手幹活。
呢個機制令 Skills 可以打包大量說明同執行腳本,但只要任務唔需要,就永遠唔會佔用上下文。相比 MCP 一次過注入所有工具定義,Skills 明顯更慳 Token,仲可以保持 AI 嘅專注度。
Skills vs MCP:點解 Skills 更適合教 AI 做嘢?
MCP 嘅本質係標準化接口,等 AI 可以統一連接外部工具。但佢有個死穴:每個 MCP Server 必須喺對話開始前將所有工具嘅完整定義(名稱、描述、參數 Schema、使用示例)一次過注入 LLM 上下文。例如 GitHub MCP 自己有 30 幾個工具,每個消耗 500 Token,淨係連一個 Server 就用咗近 20000 Token。
更嚴重嘅問題係:連結過多 MCP Server 會降低 LLM 嘅工具調用準確率。根據 MCP Atlas 基準,即使係最強嘅 Claude Opus 4.5,喺 40 幾個 Server、300 個工具嘅環境下準確率得 62%,而且工具越多就越差。
Skills 透過漸進式披露解決咗呢兩個問題:一係節省 Token,二係透過「漏斗式」引導提升注意力。未來格局係:Agent 內置核心能力(bash、read 等)、少數通用 MCP(數據庫、雲 API)、大量 Skills 封裝工作流。MCP 唔會完全淘汰,但需求會大幅減少,因為 Skills 承擔咗大部分「教 AI 點樣做嘢」嘅工作。
點樣揾 Skills、用 Skills、創建 Skills?
同 MCP 一樣,Skills 成為開放標準後社區爆發增長,好多 MCP Market 都加咗 Skills 分類。例如 skillsmp.com 上面嘅 Skills 數量正以驚人速度增加,仲快過當年 MCP 爆火嘅時候。呢啲得益於 Skills 嘅編寫門檻極低——只要你識寫提示詞,就識整 Skills。
使用 Skills 好簡單:將下載落嚟嘅 Skills 文件夾放喺 .agentName/skills 目錄(例如 .opencode/skills),然後直接同 AI 講你想做乜,佢就會自動調用對應嘅 Skills。
wget skill.zip
unzip skill.zip -d .opencode/skills/創建 Skills 仲可以藉助 Anthropic 官方提供嘅「Skill Creator」Skills:你只需要用自然語言話畀佢知你想做咩,佢就會自動生成一個完整嘅 Skills 包,包括 SKILL.md 同所需腳本。例如叫佢「創建一個可以準確獲取當前系統時間嘅 Skill,用 Node.js 腳本」,佢就會幫你搞掂。
呢個低門檻意味住大量固定工作流好快會被編寫成 Skills,Agent 嘅應用會變得更加普及同強大。
Agent Skills 最近好 hit,係繼 MCP 之後 Anthropic 推出嘅另一個 Agent 領域嘅行業標準。
佢嘅發展路線同 MCP 都好相似,25 年 10 月發佈嗰陣時得 Anthropic 自己嘅產品支援,後來 Cursor、Codex、Opencode、Gemini CLI 呢啲產品見到 Skills 嘅優勢就開始陸續支援。
再之後社區開始湧現大量開源 Skills 同 Skills 開放市場,而家大家已經默認 Skills 成為另一個擴展 Agent 能力嘅標準做法。
簡單嚟講,Skills 嘅作用就係將啲重複性、專業嘅流程打包封裝。當你需要用某種能力嘅時候,唔再需要好似以前咁每次都去查手冊或者重新輸入長篇提示詞,而係好似叫工具咁直接用。
喺呢篇文章入面,我哋會由淺入深,同大家一齊學以下嘅知識:
Skills 入門理解:Skills 究竟係咩?係點樣嘅?點樣運作? Skills VS MCP:Skills 同 MCP 有咩分別,MCP 會唔會被淘汰? Skills 初步嘗試:去邊度揾 Skill?點樣用 Skill?點樣自己整一個 Skill? Skills 實戰使用:點樣用 Skills 實現外部知識檢索?比起傳統 RAG 嘅優勢喺邊? Skills 安全分析:Skills 嘅安全性點樣?用佢有咩風險?
一、 Skills 入門理解
1.1 Skills 究竟係咩?
喺傳統嘅 AI 傾偈模式入面,AI 嘅能力取決於:
佢本身學過啲咩(訓練數據) 你臨時喺對話框入面話畀佢知啲咩(提示詞、工具、記憶)
呢個就好似你請咗個樣樣都識少少嘅實習生,每次做嘢你都要重新教一次。
而 Agent Skills 帶嚟咗一種全新嘅玩法:模塊化能力插件。
你可以將 Claude(支援 Skills 嘅客戶端)想像成一個超級大腦,而 Agent Skills 就係畀呢個大腦裝嘅外接工具箱。
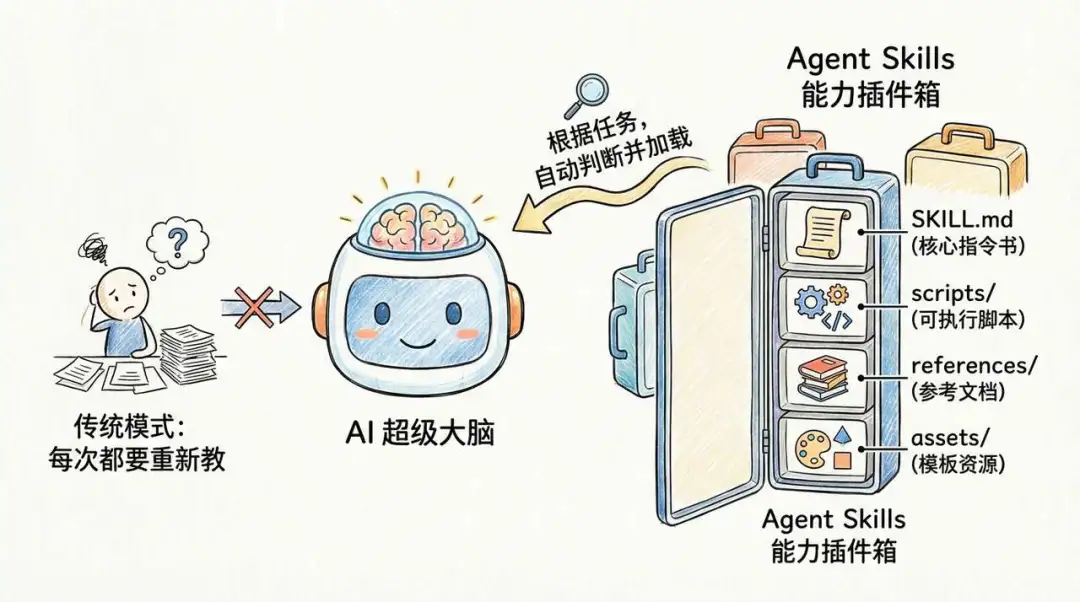
呢個工具箱入面唔止有工具本身,仲包含咗詳細嘅「官方使用說明書」,大腦唔需要理解具體有啲咩工具同工具嘅用法係點,只需要喺需要用某個工具嘅時候睇嚇工具說明書,再攞個工具出嚟用。
1.2 Skills 係點樣嘅?
Agent Skills 嘅官方文檔入面強調咗一個核心關鍵詞:File-system based(基於文件系統)。
如果你寫過 code,可能好易理解。
要寫一個程式,並唔一定所有 code 都係我哋自己寫嘅。
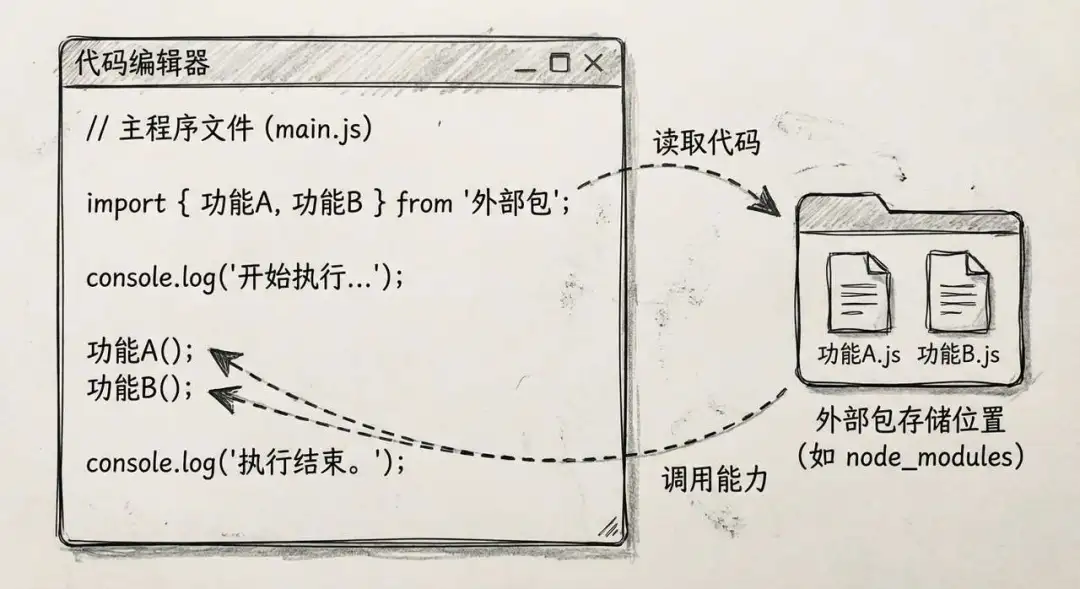
我哋可能會通過 import xxx 嚟引入一啲外部 package,呢啲 package 放喺固定嘅位置(例如 node_modules)。
當程式需要調用呢啲 package 嘅能力嘅時候,就會從指定嘅 folder 攞出對應嘅 code 然後執行。
Agent Skills 都係類似嘅邏輯,每個 Skill 都係一個實實在在存在嘅 folder,佢放喺一個固定嘅位置(例如 .claude/skills)。呢個 folder 入面裝住下面幾樣嘢:
指令(SKILL.md):話畀 AI 點樣做嘢嘅 SOP。 參考(reference):更詳細嘅參考文檔(可選)。 腳本(scripts):例如 Python code,令 Skill 都可以調用外部能力(可選)。 資源(assets):圖片、template 等可能會用到嘅資源(可選)。

如果你喺你嘅 Agent(例如 Claude Code)執行目錄(例如你嘅 project code 目錄)下面放咗呢個 folder,
咁下次同 Agent 傾偈嘅時候就會自動根據你嘅需求匹配到呢個 Skill,唔需要再做任何額外設定。
例如,你想 Agent 幫你潤飾文章,就可以寫一個好似下面咁嘅 Skill:
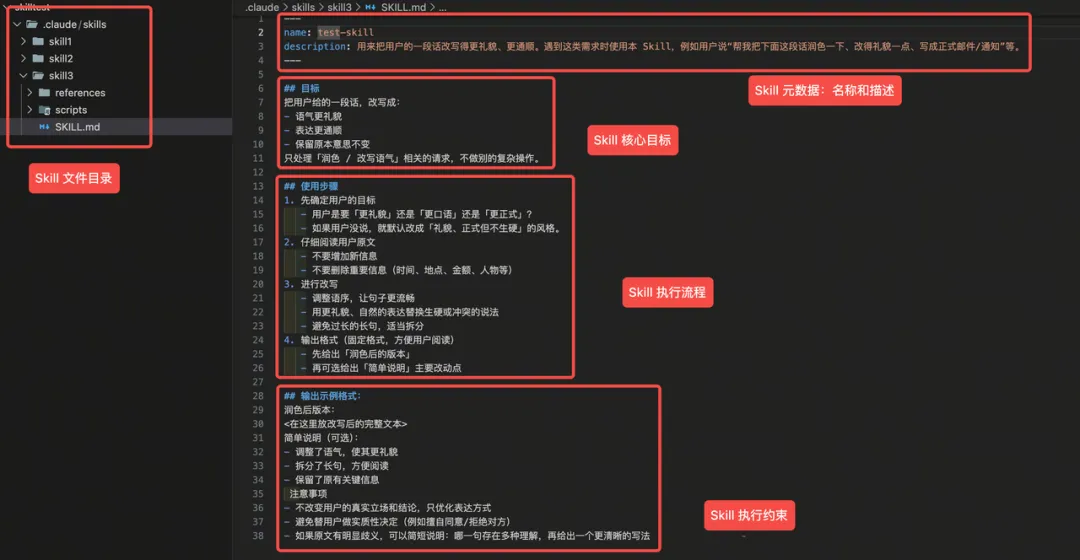
上面嘅三條短橫線部分相當於 Skill 嘅「身份證」:
name 係佢嘅唯一標識,改個簡單易記嘅英文名就得 description 就決定咗幾時會觸發呢個 Skill,描述呢個 Skills 係做咩嘅、遇到咩用戶請求應該用佢、提醒讀者:描述越具體,越容易喺正確場景被調用
下面就係 Skill 嘅正文部分:
目標:簡單描述清楚呢個 Skill 要做嘅嘢 使用步驟:列出 Skill 嘅操作流程(先搞清楚想要咩風格、再讀原文、再改寫、最後規定輸出格式) 注意事項:話畀模型「咩唔好做」(唔好亂加內容、唔好幫用戶做決定、有歧義要提醒)
睇落好似好普通?似乎好多能力都可以做到呢件事?
可以將呢段文字同要潤飾嘅文章直接 send 畀大模型? 可以將呢段文字放入系統提示詞? 可以將呢段固定嘅流程封裝成一個 Workflow? 可以將呢段文字寫成一個 Agent.md 或者 project 級嘅 Rules?
呢啲方式睇落唔同,但本質上都係將提示詞放喺唔同位置,你同 AI 每次傾偈都會帶住呢啲提示詞。
喺真實嘅業務場景入面,一個 Agent 唔可能只係做一件咁簡單嘅事。大家試諗嚇,如果你要畀 AI 裝 50 個技能,每個技能都有幾千字嘅說明書,如果系統一啟動就將呢啲全部塞入 AI 個腦(Context Window)度,咁就會:
成本爆炸,每次對話可能都會消耗幾萬 Token。 AI 嘅注意力都會被分散,變成「呢樣又想搞,嗰樣又想搞」。
Skill 嘅出現就係為咗解決呢種問題,佢有一個非常核心嘅機制,叫做漸進式披露(Progressive Disclosure)。講人話就係:按需加載,用幾多拎幾多。
1.3 Skills 嘅核心機制
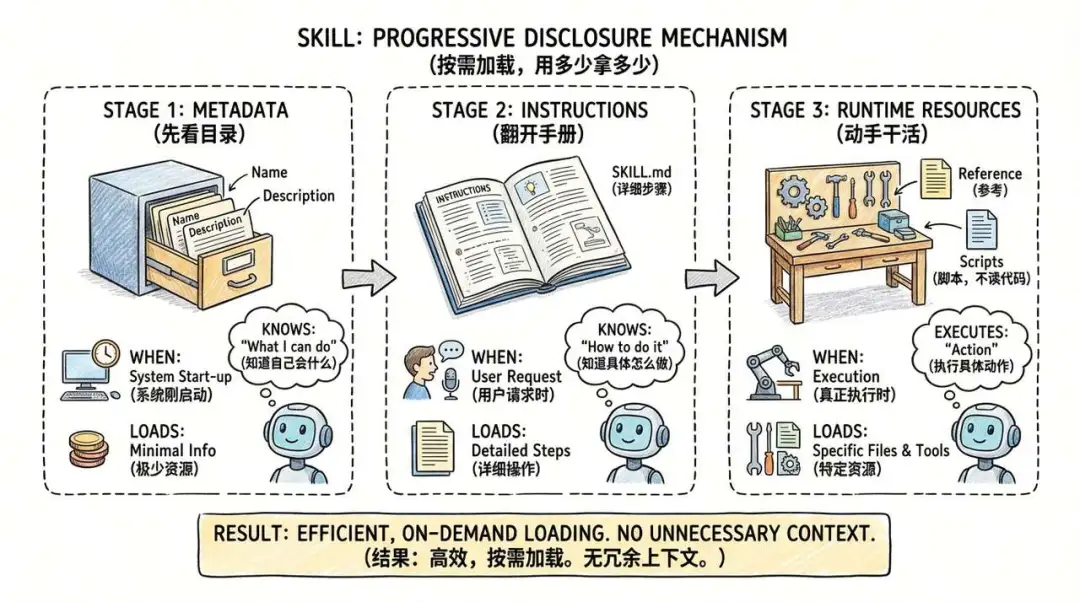
呢個係我覺得 Agent Skills 設計得最聰明嘅地方。你可以將佢想像成我哋喺圖書館查資料嘅三個步驟,非常直觀:
第一層:先睇目錄(元數據 Metadata)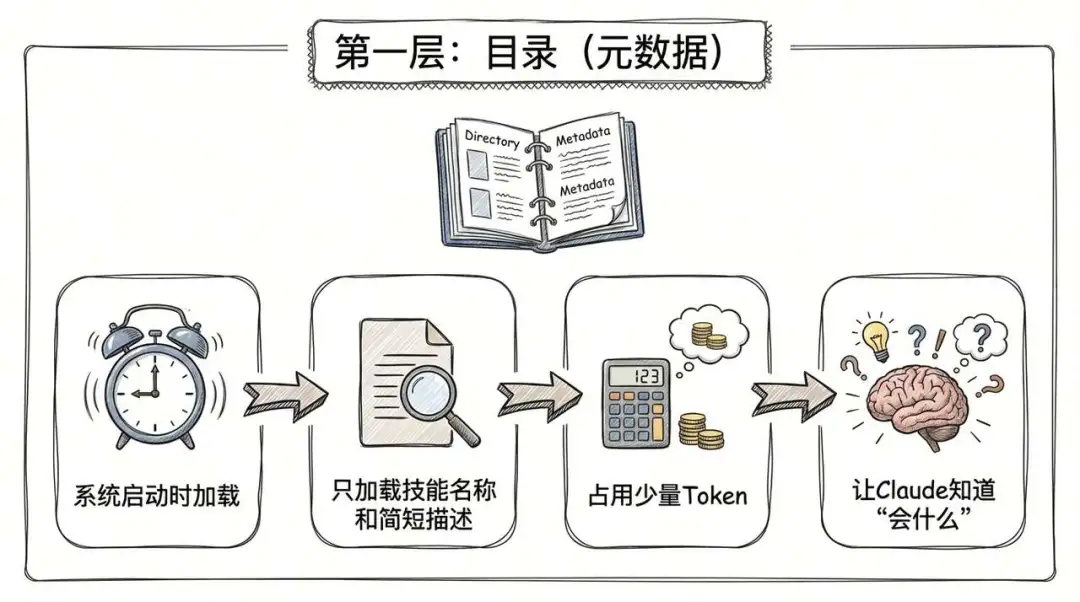
幾時加載?系統啱啱啟動嘅時候。 加載咩?只係加載每個技能嘅名同一段簡短嘅描述。 有咩用?呢一層佔用嘅資源好少,可能得幾百個 Token。佢嘅作用就係話畀 Claude 聽:「喂,你個工具箱入面有『查週報』、『處理 Excel』呢幾個工具㗎。」 結果:Claude 知道自己「識啲咩」,但仲未知道「具體點做」。
第二層:揭開手冊(指令 Instructions)
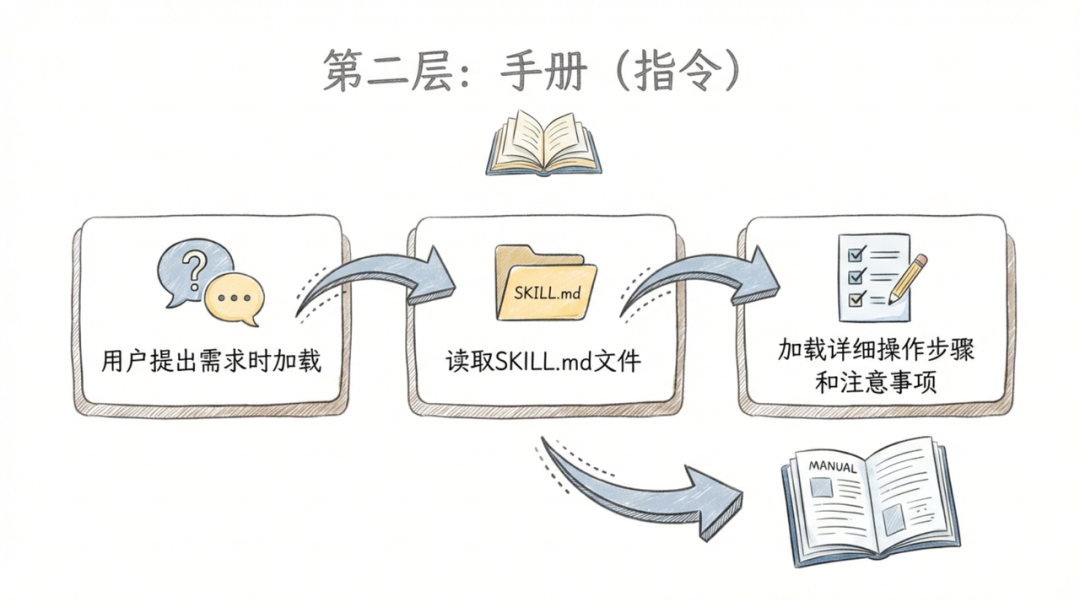
幾時加載?當你話「幫我處理嚇呢個 Excel」嘅時候。 加載咩?Claude 發現呢件事係關「Excel 處理」呢個技能事,於是佢先會透過後台命令,去讀嗰個 folder 入面嘅 SKILL.md 檔案。 有咩用?只有喺呢個時候,啲詳細嘅操作步驟、注意事項先會入到 AI 個腦。
第三層:動手做嘢(運行時資源 Runtime Resources)
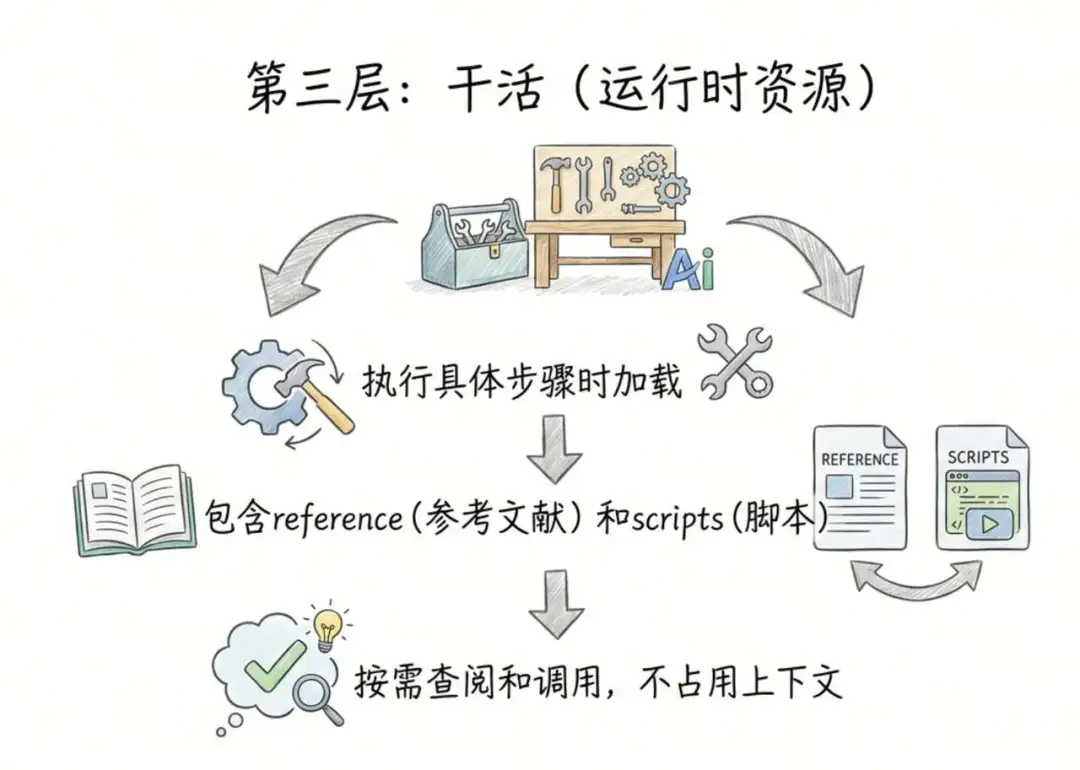
幾時加載?真正執行具體步驟嘅時候。加載咩? 參考(reference):用戶落嘅任務可能係分析 Excel,都可能係創建 Excel,呢兩個操作可能有好唔同嘅處理步驟,詳細步驟唔一定全部喺 SKILL.md 入面,可以分開放喺唔同嘅參考文獻(reference)下面,當 Claude 識別到你係要做分析 Excel 嘅時候,先會去查閲分析 Excel 嘅 reference。 腳本(scripts):Skill 可以內置一啲可執行嘅 Excel 處理腳本,喺 SKILL.md 或者具體嘅參考文獻(reference)下面會話畀你知應該點樣調用同點樣用呢啲腳本。仲有最重要嘅一點,Claude 只需要跟住指引執行腳本,而腳本本身嘅 code 係唔會塞畀 AI 去讀嘅,你完全唔使擔心一個超大 code 檔案會消耗 Token。
呢個意味住:一個 Skill 可以打包成套說明文檔、大量嘅執行腳本,但只要任務唔需要,呢啲內容就永遠唔會佔用上下文。
二、Skills VS MCP
睇到呢度,你可能會覺得 Skills 同 MCP 有啲似?
佢哋似乎都可以做到按需加載、畀 AI 擴展外部能力?
呢個都係好多同學可能會搞亂嘅問題。
2.1 MCP 有咩問題
在 全網最細,一文帶你搞明 MCP 嘅核心原理! 中,我哋介紹咗 MCP 出現嘅意義同執行原理:
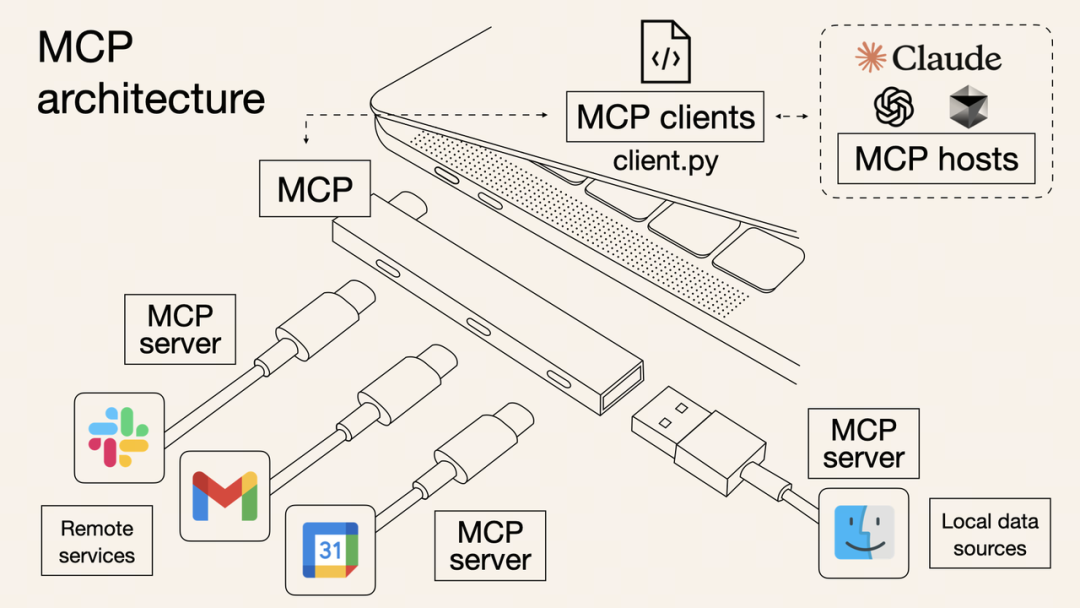
MCP(Model Context Protocol,模型上下文協議)係由 Anthropic 公司推出嘅一個開放標準協議,佢就好似一個「通用插頭」或者「USB 接口」,制定咗統一嘅規範,無論係連接數據庫、第三方 API,定係本地檔案等各種外部資源,都可以透過呢個「通用接口」嚟完成,令 AI 模型同外部工具或數據源之間嘅互動更加標準化、可重用。
所以 MCP 嘅本質,都係喺度做「標準化」,佢令到畀 AI 擴展外部能力呢件事更加「標準化」。
假如你嘅 Agent 連接咗多個 MCP,佢似乎都可以做到「按需加載」(根據用戶嘅意圖決定調用邊個工具)。
但係呢個「按需加載」背後嘅代價係非常之大,喺 MCP 嘅架構下,淨係「連接」呢個動作,已經喺度透支你嘅額度喇。
呢個係由 LLM 嘅工具調用機制決定嘅。為咗令 AI 知道佢有咩能力可以用,每一個連接嘅 MCP Server 必須喺對話開始前,將佢所有工具嘅完整定義(名稱、詳細描述、參數 Schema、使用範例)一次性注入 LLM 嘅上下文中。
每個 MCP Server 通常都會包含大量嘅工具,例如 Github MCP,佢自己就包含咗 30 幾個工具:
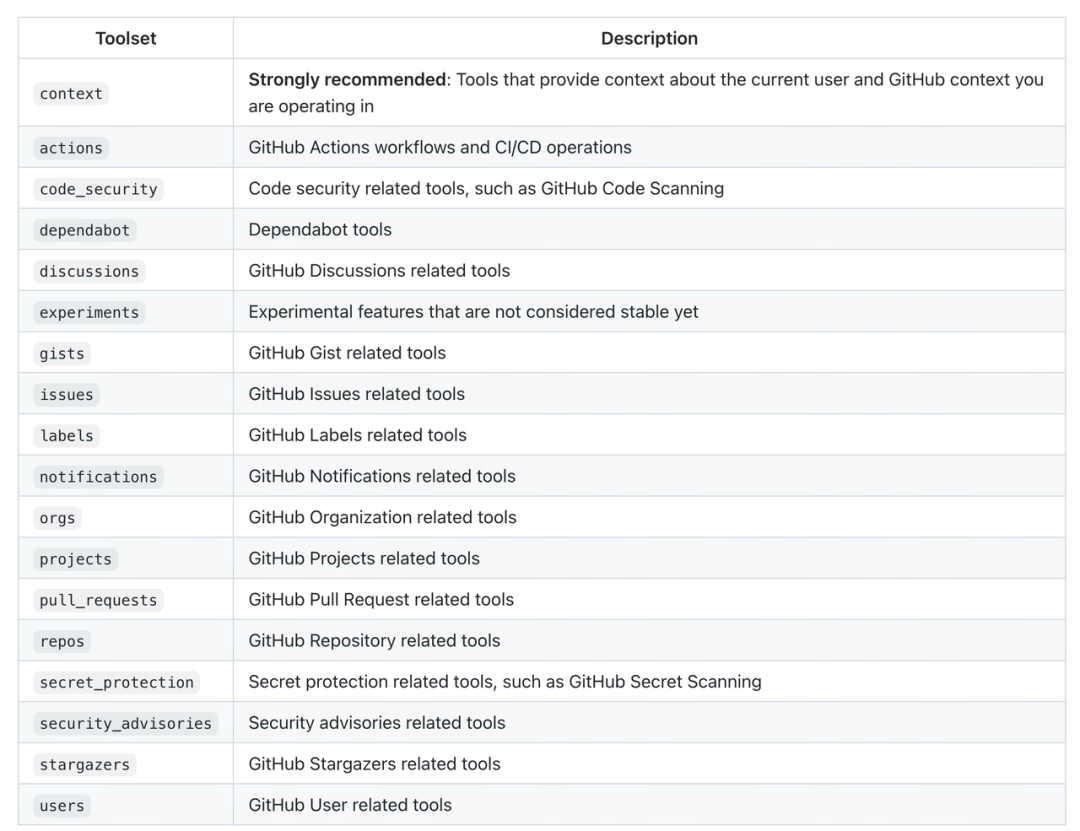
假如每個工具消耗 500 個 Token,咁淨係連接呢一個工具就需要消耗差唔多 20000 Token。
喺真實環境下,一個 Agent 唔會淨係連接一個 MCP Server。
假如你只係問咗 AI 一個非常簡單嘅問題(1+1=?),Agent 已經燒咗大幾萬 Token,呢個成本係非常恐怖。
更深層嘅問題在於連接太多 MCP Server 可能會導致 LLM 嘅「注意力」下降,從而降低工具調用嘅準確性。
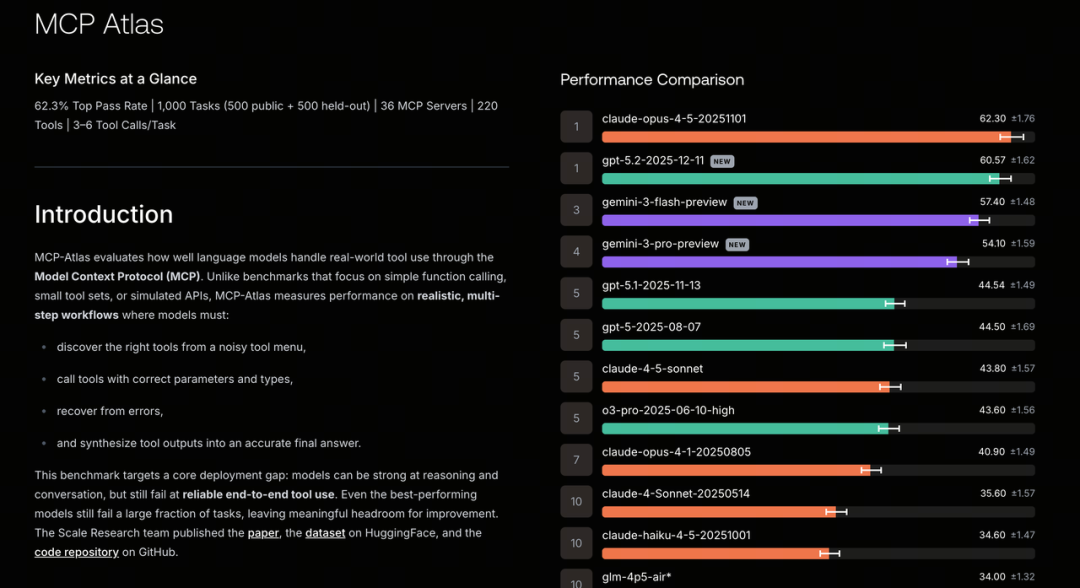
我之前嘅文章入面有講過一個專門測試 MCP Server 調用準確度嘅基準:MCP Atlas(世界最頂級嘅大模型,喺度 PK 啲咩?(大模型評估完全指南)),呢個基準入麪包含咗 40 幾個唔同 server、300 幾個工具嘅複雜環境。
模型必須自己發現合適嘅工具、正確調用,並將多步結果整合成最終答案。目前最強嘅 Claude Opus 4.5 都只能拎到 62% 嘅準確率,呢個值仲會隨住工具增多而進一步下降。
而我哋上面講到嘅 Skills 核心機制:漸進式披露,啱啱好可以解決呢兩個問題:
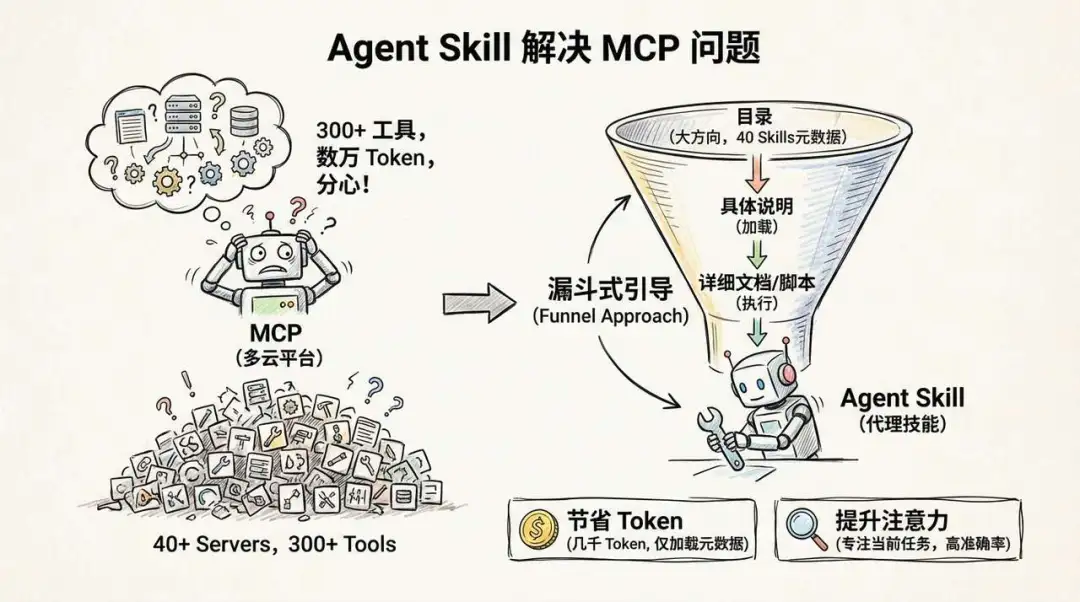
節省 Token:首次連接時,相比 MCP 要將 40 幾個 MCP Server 下面 300 個工具全部塞入模型上下文(消耗幾萬 Token),模型只需要加載 40 個 Skills 嘅元數據(幾千 Token)。
提升注意力:面對幾百個工具,AI 好容易分心。Skills 採用嘅係「漏斗式」引導:先透過目錄判斷大方向,確認要做嘢,再加載具體說明,最後透過說明揾到詳細文檔同腳本然後執行。令 AI 每次只專注於當前任務。即使係能力稍弱嘅模型,喺呢種機制下都能保持極高嘅調用準確率。
2.2 MCP 會唔會被淘汰?
睇到呢度你可能會問,Skills 睇落更智能、更慳資源,咁 MCP 會唔會被淘汰?
結論係:MCP 唔會完全被淘汰,但對佢嘅需求會大幅減少!
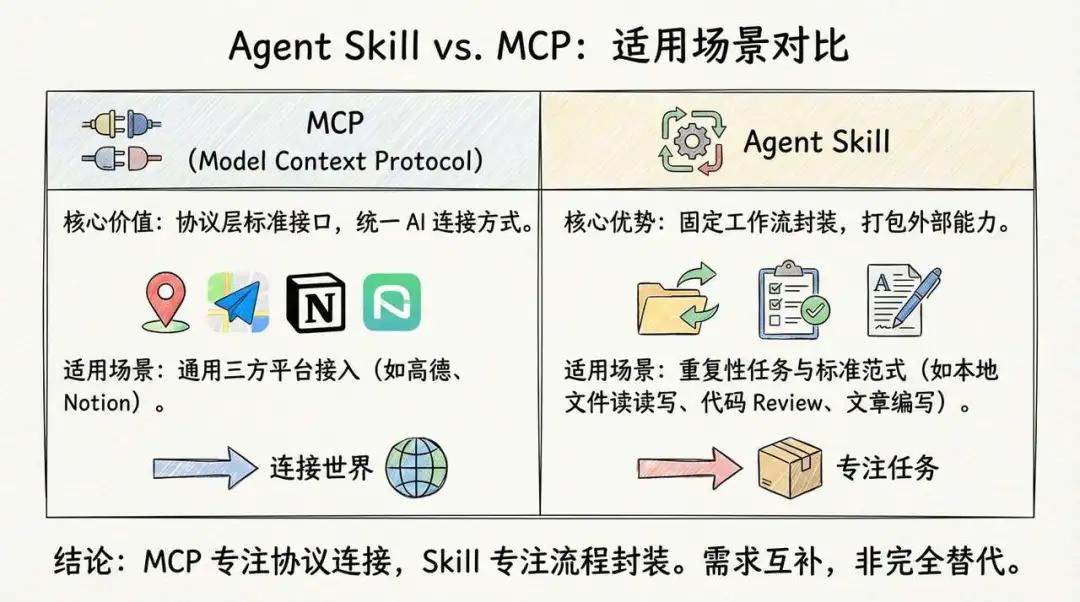
首先,MCP 協議層嘅價值不可替代:MCP 嘅真正價值唔在於佢點樣將文本塞入 Prompt,而在於佢制定咗一套標準接口。
佢統一咗 AI 連接世界嘅方式。如果你係一個通用嘅第三方平台(高德地圖、Notion 等),想發佈一個工具令其他 Agent 都用到你嘅能力,咁首先選擇嘅都係 MCP。
但係,如果你有一啲重複性嘅 workflow,例如要用固定流程讀寫本地檔案、要用一個標準範式嚟 Review code、有一套固定風格嚟寫文章,呢啲場景都推薦用 Skill 嚟實現。
喺過去呢幾個需求入面嘅本地檔案讀寫、連接 Github、俾文章生成圖片呢啲需要連接外部世界嘅能力都要透過 MCP 嚟實現,但而家你可以將佢哋全部打包入 Skill 入面。
未來嘅格局可能會係咁嘅(出自寶玉老師):
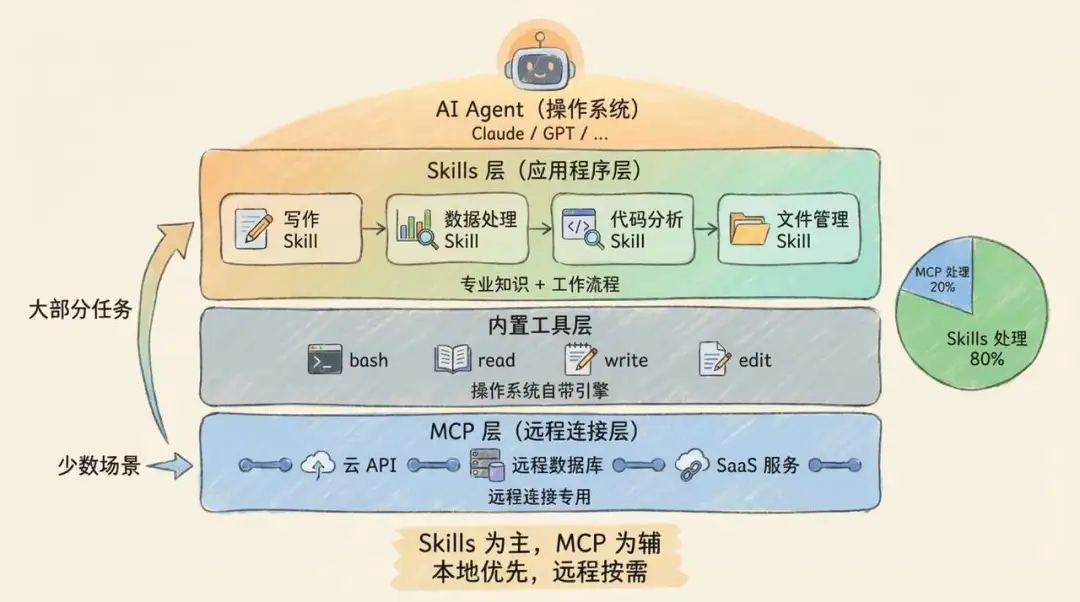
Agent 本身內置部分核心能力(bash、read、edit、write)
少數通用 MCP Server 負責遠程連接(數據庫、雲 API、SaaS 集成)
大量 Skills 負責封裝標準 workflow、連接本地知識庫
兩者喺必要時協作,但 Skills 會承擔絕大部分「教 AI 點樣做嘢」嘅工作(呢個入面都包括教 AI 點樣用 McpServer、點樣用其他 Skills、點樣更好咁調用核心能力)
三、Skills 嘅初步嘗試
3.1 去邊度揾 Skills?
同 MCP 一樣,Skills 成為開放標準後開始爆發式增長,社區出現咗大量開源 Skills,好多 Skills 開放市場都應運而生,之前大部分 MCP Market 都加咗 Skills 嘅分類:
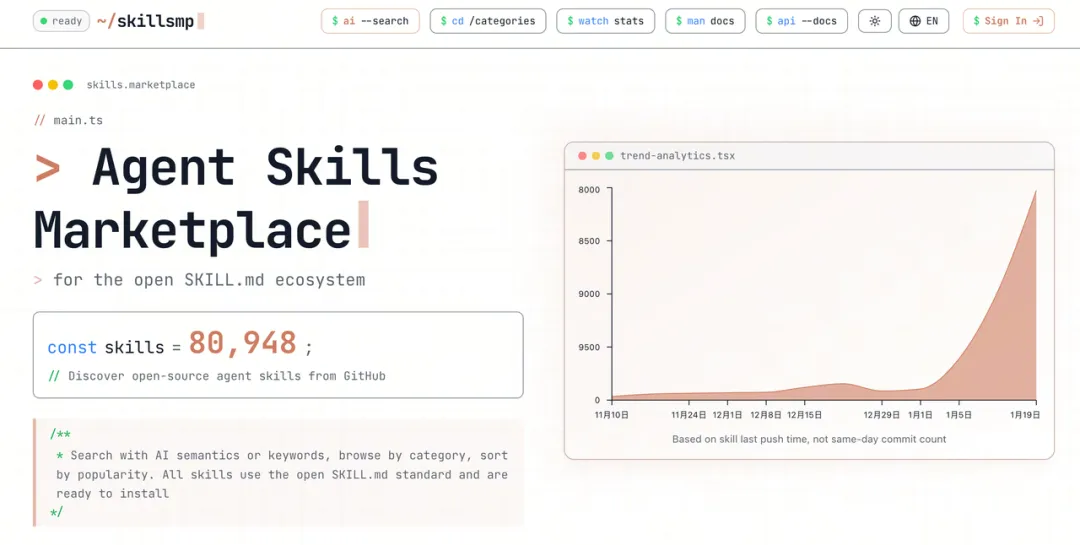
我哋可以見到 skillsmp 入面嘅 Skills 數量最近經歷緊爆發式增長,呢個增長速度仲快過之前 MCP 爆紅嗰陣時。咁就不得不提 Skills 嘅另一個大優點:編寫門檻低!
MCP 雖然有一套標準規範,但始終都要靠 code 編寫,就算有 AI 輔助,對於新手嚟講都仲有一定門檻。
而 Skills 就唔同,只要你識寫提示詞,就可以寫 Skill,可以預見嘅係,之前嗰啲大量嘅固定 workflow 喺未來可能都會被寫成 Skill,呢個都意味住 Agent 嘅編寫門檻再次大幅降低!
3.2 點樣用 Skills?
我哋隨便入一個 MCP 市場,然後搜尋我哋要用嘅 Skills,例如呢度我哋仲以繪圖軟件 Excalidraw 做例子:
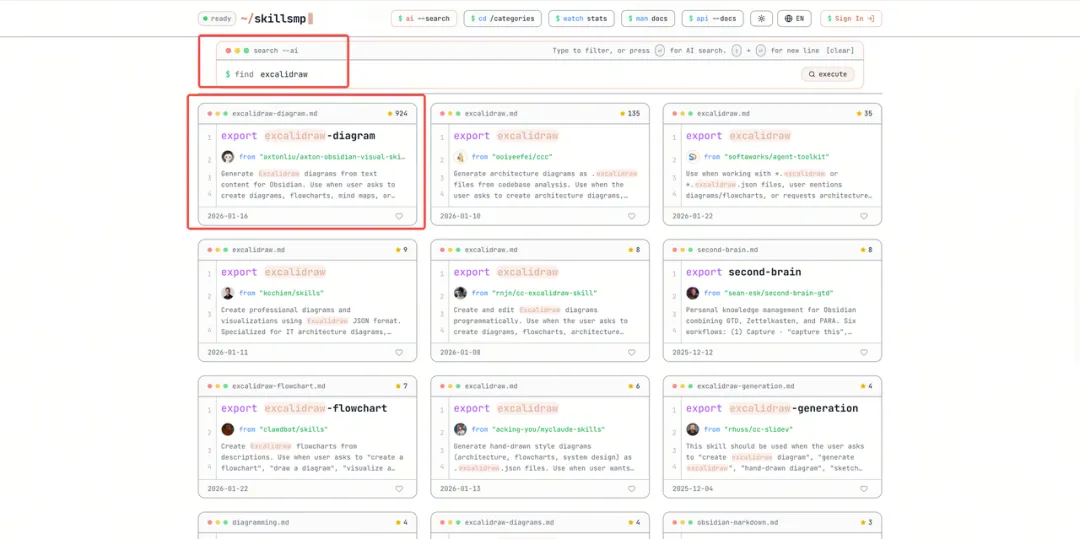
可以見到社區已經有大量 Excalidraw 嘅 Skill,我哋呢度揀最多 Star 嗰款:
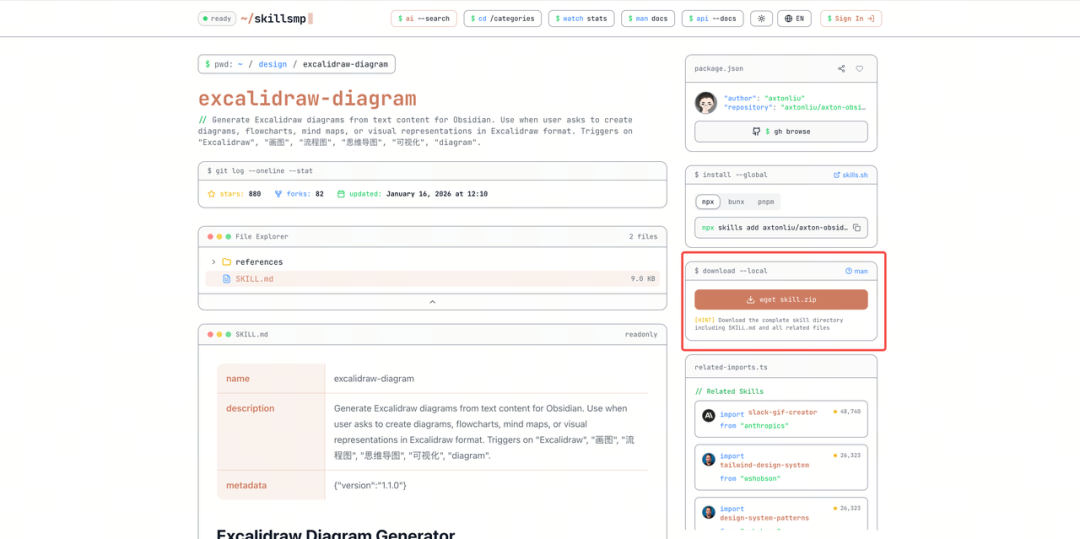
入咗詳情之後,我哋揀一個最簡單嘅安裝方式,直接將呢個 Skill 下載到本地,點擊 wget skill.zip:
然後我哋將呢個壓縮檔解壓,你就會見到熟悉嘅目錄。接下來,你只需要將呢個目錄下載到指定位置:

唔同客戶端嘅目錄大同小異,基本上都係 .agentName/skills 目錄,呢度我哋用最近比較 hit 嘅 OpenCode 做示範(大家可以自行選擇 Cursor、Codex 等支援 skills 嘅客戶端),所以我哋開一個新 folder,然後將啱啱下載嘅 folder 放喺 .opencode/skills 目錄下面:
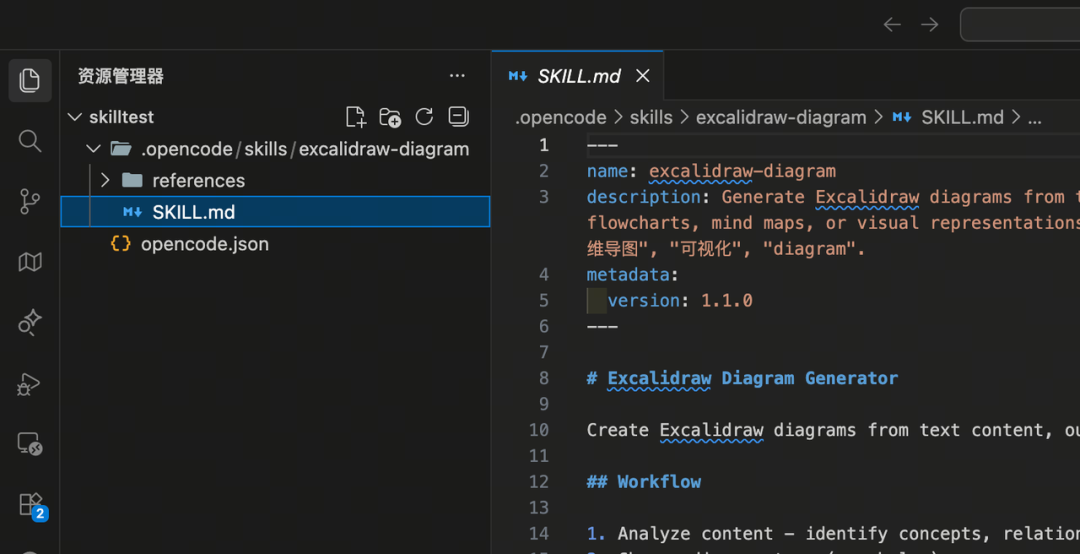
接下來,我哋喺呢個目錄下面打開 opencode 客戶端,輸入下面嘅提示詞:
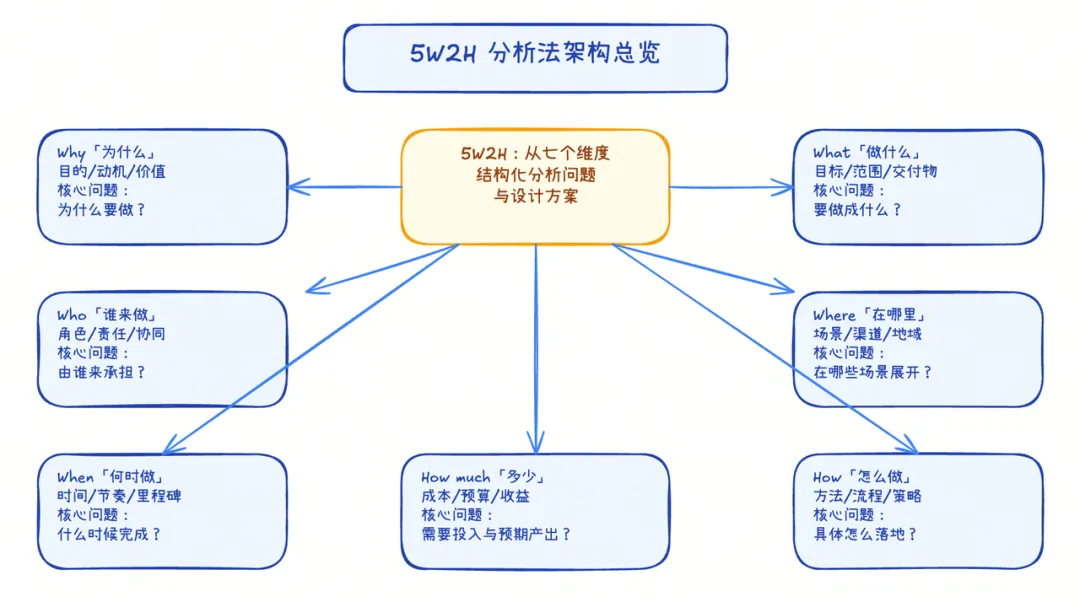
幫我畫一個架構圖,講解咩係 5W2H 分析法,直接喺當前目錄下面幫我 generate 一個 excalidraw 檔案。
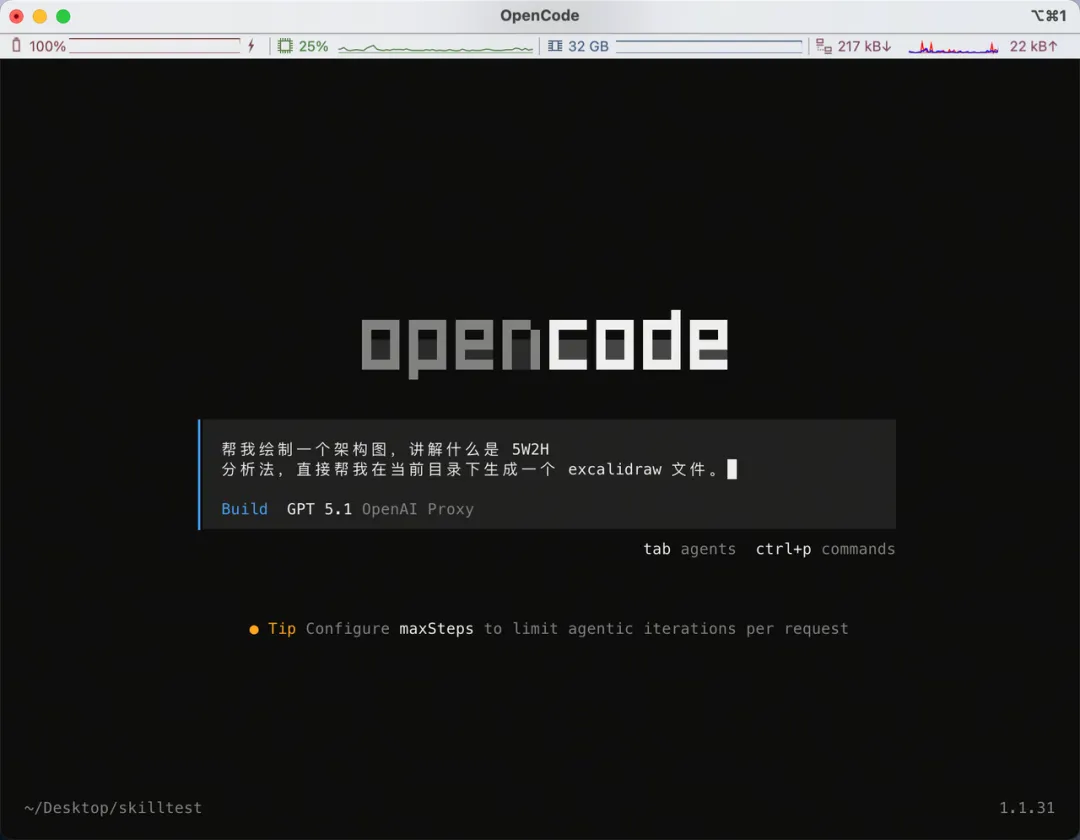
你唔需要手動去「安裝」或者「運行」Skill,只要檔案放啱位置,OpenCode 嘅 AI 就會自動根據用戶嘅需求判斷要調用呢個 Skill,然後幫我 generate 咗 code:
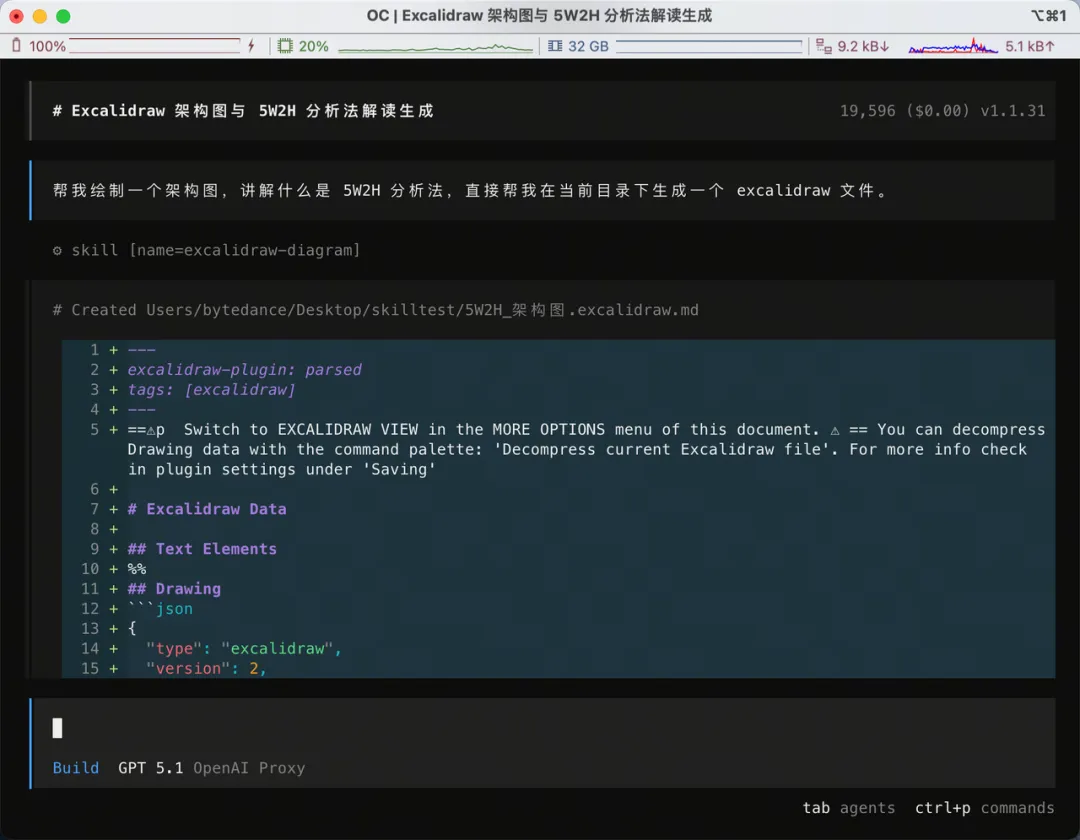
我哋將 generate 嘅 code 貼上 https://excalidraw.com/,就可以見到已經生成好嘅架構圖:
3.3 創建你嘅第一個 Skill
下面,我哋一齊嘗試做第一個 Skill,雖然 Skill 嘅開發門檻低,但呢個唔代表我哋就要自己寫!
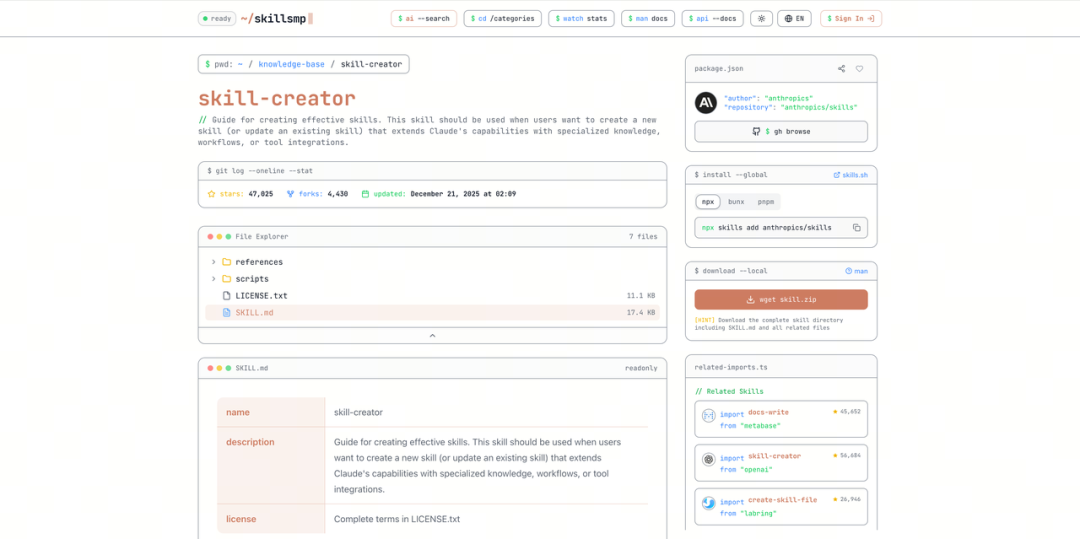
Anthropic 官方直接畀咗我哋一個生產 Skills 嘅 Skill:Skill Creator。你唔需要寫一行 code 或配置文件,只需要用自然語言話畀佢知你想做咩,佢就會自動幫你生成一個符合標準嘅 Skill 包。
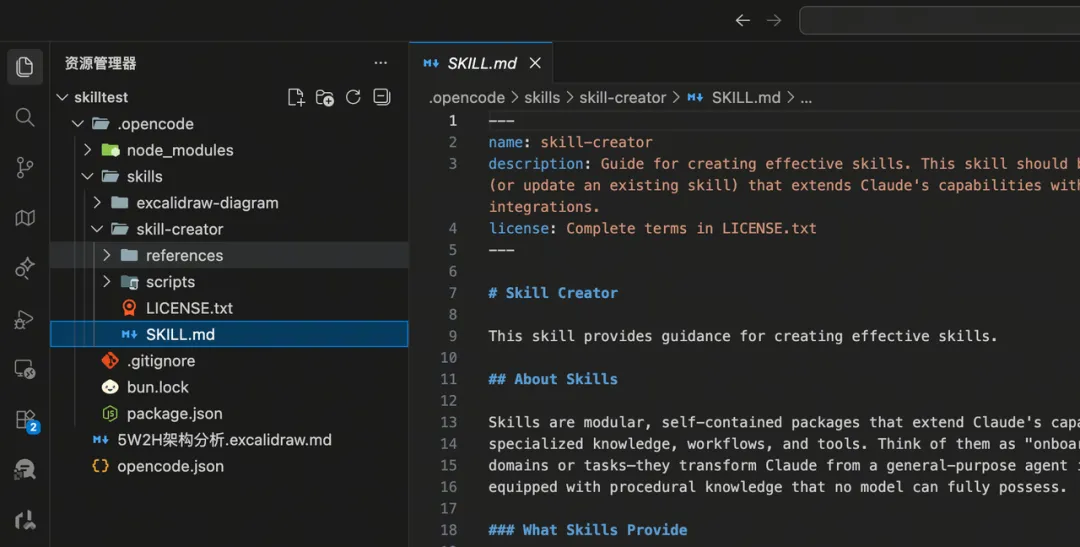
接下來,跟住啱啱嘅流程,我哋將呢個 Skill 下載落嚟,放喺 .opencode/skills 目錄下面:
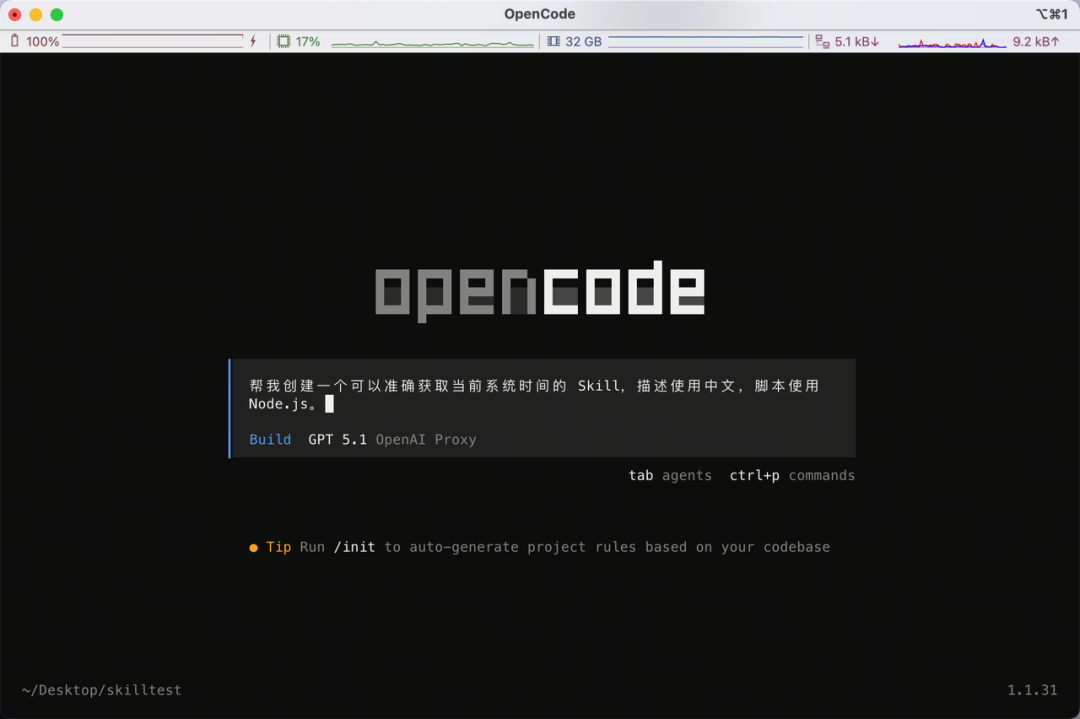
然後我哋俾出下面嘅提示詞:
幫我創建一個可以準確獲取當前系統時間嘅 Skill,描述用中文,腳本用 Node.js。
然後,opencode 識別到我哋嘅需求,開始調用 skill-creator:
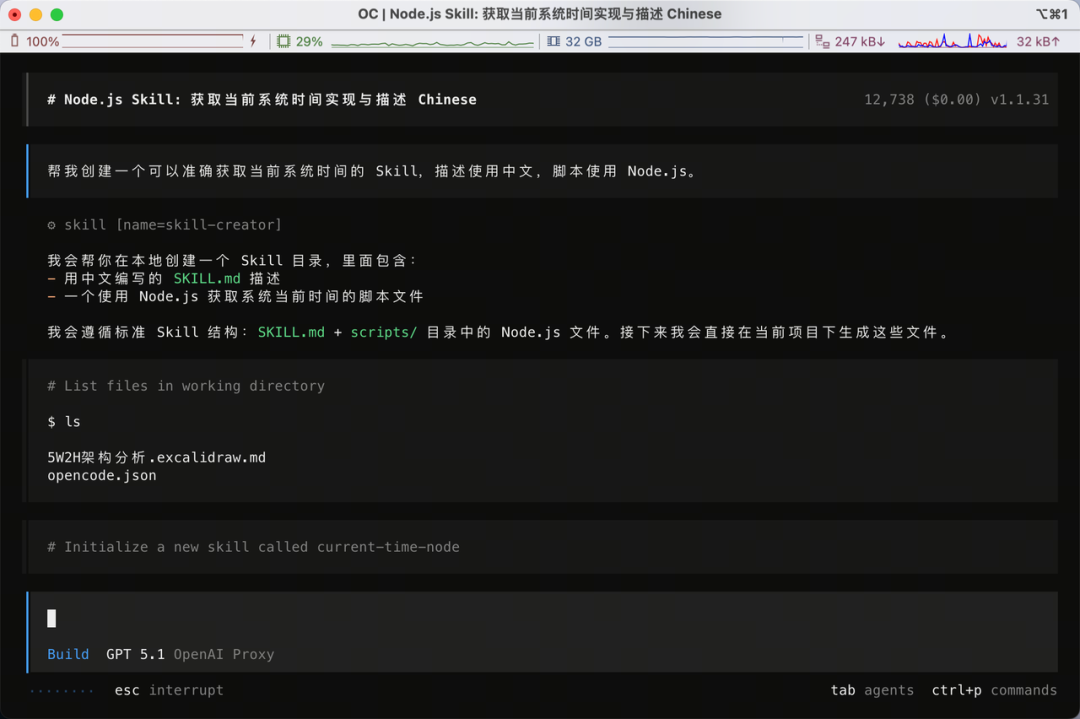
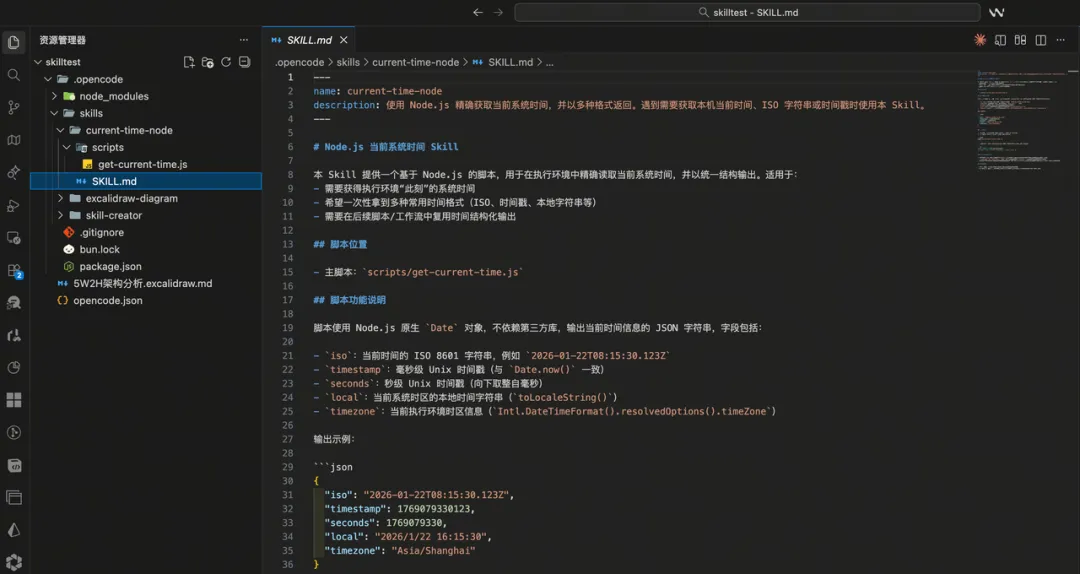
然後我哋打開本地嘅 .opencode/skills 目錄,發現多咗一個 current-time-node skill,包含一個 SKILL.md 加一個獲取準確時間嘅 Node.js 腳本:
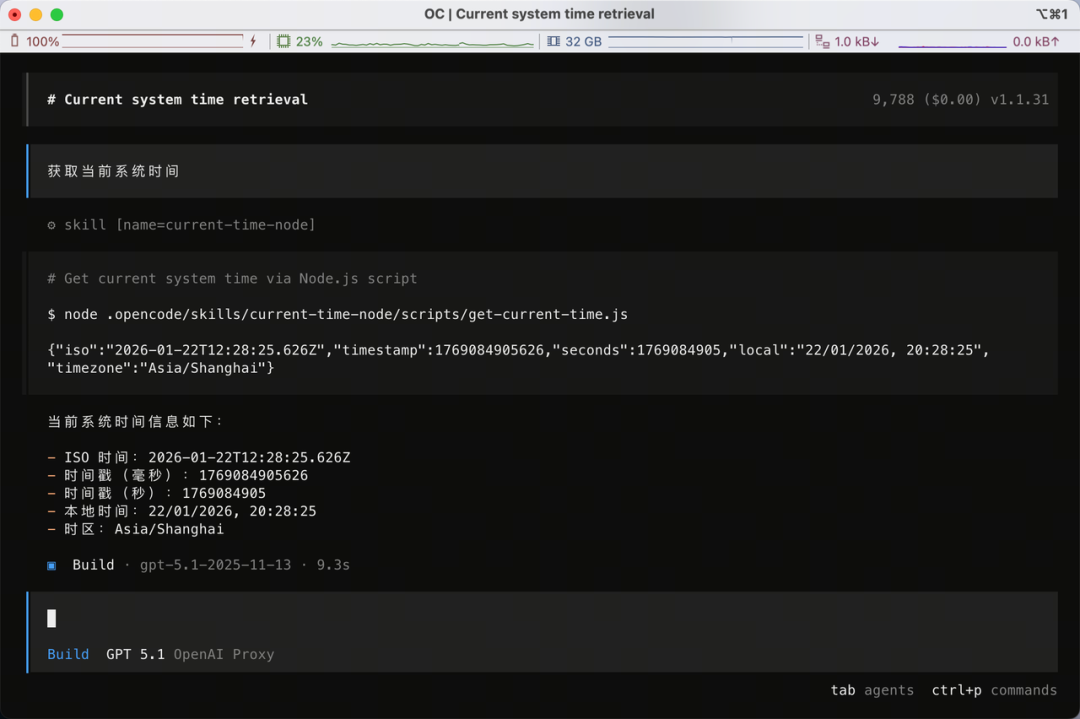
接下來,我哋問 opencode:「獲取當前系統時間」,然後佢就會自動揾到啱啱生成嘅 Skill 並調用入面嘅腳本:
最後
今期教程我哋就先講到呢度。
大家已經瞭解咗 Agent Skill 嘅基本原理,同埋點樣用同創建一個 Skill。
如果今期教程對你有幫助,希望得到一個免費嘅三連同關注。
下一期,我哋會進入實戰章節,一齊用 Agent Skill 實現一個知識庫檢索功能,相比傳統嘅 RAG,佢嘅效果究竟點樣呢?我哋下期見。
關注《code秘密花園》從此學習 AI 唔迷路,相關連結:
AI 教程完整彙總:https://rncg5jvpme.feishu.cn/wiki/U9rYwRHQoil6vBkitY8cbh5tnL9 相關學習資源彙總在:https://github.com/ConardLi/easy-learn-ai
如果今期對你有幫助,希望得到一個免費嘅三連,多謝大家支持!
Agent Skills 最近非常的火,它是既 MCP 後 Anthropic 推出的又一個 Agent 領域的行業標準。
它的成長路線和 MCP 也非常像,25 年 10 月份發佈時只有 Anthropic 自家產品支持,後來 Cursor、Codex、Opencode、Gemini CLI 等產品看到了 Skills 的優勢於是紛紛開始支持。
再後來社區開始湧現大量的開源 Skills 以及 Skills 開放市場,當下大家已經默認 Skills 成為了又一個擴展 Agent 能力的標準實踐。
簡單來說,Skills 的作用就是將那些重複性的、專業的流程進行打包封裝。當你需要使用某種能力時,不再需要像過去那樣每次都去查閲手冊或重新輸入冗長的提示詞,而是像調用工具一樣直接使用。
在本篇文章中,我們將從淺入深,和大家一起學習以下知識:
Skills 入門理解:Skills 到底是什麼?長什麼樣?怎麼工作的? Skills VS MCP:Skills 和 MCP 的區別是什麼,MCP 會被淘汰嗎? Skills 初步嘗試:去哪裏找 Skill?怎麼使用 Skill?怎麼自己創建一個 Skill? Skills 實戰使用:如何用 Skills 實現外部知識檢索?比傳統 RAG 的優勢在哪? Skills 安全分析:Skills 的安全性如何?使用它有哪些風險?
一、 Skills 入門理解
1.1 Skills 到底是什麼?
在傳統的 AI 聊天模式中,AI 的能力取決於:
它原本學過什麼(訓練數據) 你臨時在對話框裏告訴它什麼(提示詞、工具、記憶)
這就像你招了個什麼都懂一點的實習生,每次幹活你都得重新教一遍。
而 Agent Skills 帶來了一種全新的玩法:模塊化能力插件。
你可以把 Claude(支持 Skills 的客戶端)想象成一個超級大腦,而 Agent Skills 就是給這個大腦安裝的外接工具箱。
這個工具箱裏不僅有工具本身,還包含了詳細的 “官方使用說明書”,大腦不需要理解具體有哪些工具以及工具的用法是什麼,只需要在需要使用某個工具時查看工具說明書,再把工具拿出來用。
1.2 Skills 長什麼樣?
Agent Skills 的官方文檔中強調了一個核心關鍵詞:File-system based(基於文件系統)。
如果你寫過代碼,可能很容易理解。
要編寫一個程序,並不一定所有代碼都是我們自己寫的。
我們可能會通過 import xxx 來引入一些外部包,這些包存放在固定的位置(如 node_modules)。
當程序需要調用這些包的能力時,就會從指定文件夾取出對應的代碼然後執行。
Agent Skills 也是類似的邏輯,每個 Skill 都是一個實實在在存在的文件夾,它存放在一個固定的位置(如 .claude/skills)這個文件夾裏裝着下面幾樣東西:
指令(SKILL.md): 告訴 AI 怎麼幹活的 SOP。 參考(reference): 更詳細的參考文檔(可選)。 腳本(scripts): 比如 Python 代碼,讓 Skill 也能調用外部能力(可選)。 資源(assets):圖片、模版等可能使用到的資源(可選)。
如果你在你的 Agent(如 Claude Code)執行目錄(如你的項目代碼目錄)下放了這個文件夾,
那下次和 Agent 對話的時候就能自動根據你的需求匹配到這個 Skill,不需要再進行任何額外的配置。
比如,你希望 Agent 幫你潤色文章,就可以編寫一個下面這樣的 Skill:
上面的三根短橫線部分相當於 Skill 的「身份證」:
name 是它的唯一標識,起個簡單好記的英文名字就行 description 則決定什麼時候會觸發這個 Skill,描述這個 Skills 是做什麼的、遇到什麼樣的用戶請求應該用它、提醒讀者:描述越具體,越容易在正確場景被調用
下面就是 Skill 的正文部分:
目標:簡單描述清楚這個 Skill 要做的事情 使用步驟:列出 Skill 的操作流程(先搞清楚想要什麼風格、再讀原文、再改寫、最後規定輸出格式) 注意事項:告訴模型「什麼不要做」(不要亂加內容、不要替用戶做決定、有歧義要提醒)
看起來挺普通的?似乎很多能力都可以做這件事?
可以把這段文字和要潤色的文章直接發給大模型? 可以把這段文字放到系統提示詞? 可以把這段固定的流程封裝為一個 Workflow? 可以把這段文字編寫為一個 Agent.md 或者項目級的 Rules?
這些方式看似不同,但本質上只是把提示詞放在了不同的位置,你給 AI 的每次對話都會帶上這些提示詞。
在真實的業務場景中,一個 Agent 不可能只幹一件這麼簡單的事。大家試想一下,如果你要給 AI 裝 50 個技能,每個技能都有幾千字的說明書,要是系統一啓動就把這些全塞進 AI 的腦子(Context Window)裏,那麼就會:
成本爆炸,每次對話可能都會消耗幾萬 Token。 AI 的注意力也會被分散,變得“這也想幹,那也想幹”。
Skill 的出現就是為了解決這種問題,它有一個非常核心的機制,叫漸進式披露(Progressive Disclosure)。說人話就是:按需加載,用多少拿多少。
1.3 Skills 的核心機制
這是我覺得 Agent Skills 設計得最聰明的地方。你可以把它想象成我們在圖書館查資料的三個步驟,非常直觀:
第一層:先看目錄(元數據 Metadata)
什麼時候加載? 系統剛啓動的時候。 加載什麼? 只加載每個技能的名字和一段簡短的描述。 有什麼用? 這一層佔用的資源極少,可能就幾百個 Token。它的作用就是告訴 Claude:“嘿,你的工具箱裏有‘查週報’、‘處理 Excel’ 這幾個工具哦。” 結果: Claude 知道自己 “會什麼”,但還不知道 “具體怎麼做”。
第二層:翻開手冊(指令 Instructions)
什麼時候加載? 當你說 “幫我把這個 Excel 處理一下” 的時候。 加載什麼? Claude 發現這事兒歸 “Excel 處理” 這個技能管,於是它才會通過後台命令,去讀取那個文件夾裏的 SKILL.md 文件。 有什麼用? 只有在這個時候,那些詳細的操作步驟、注意事項才會進入 AI 的腦子。
第三層:動手幹活(運行時資源 Runtime Resources)
什麼時候加載? 真正執行具體步驟的時候。加載什麼? 參考(reference): 用戶下達的任務可能是分析 Excel,也可能是創建 Excel,這兩個操作可能有完全不同的處理步驟,詳細的步驟不一定都在 SKILL.md 中,可以分開放在不同的參考文獻(reference)下,當 Claude 識別到你要做的是分析 Excel 時,才會去查閲分析 Excel 的 reference。 腳本(scripts):Skill 中可以內置一些可執行的 Excel 處理腳本,在 SKILL.md 或者具體的參考文獻(reference)下會告訴你應該調用以及如何調用這些腳本。還有最重要的一點,Claude 只需要按照指引執行腳本,而腳本本身的代碼是不會塞給 AI 去讀的,你完全不用擔心一個超大代碼文件會消耗 Token。
這意味着:一個 Skill 可以打包整套說明文檔、大量的執行腳本,但只要任務不需要,這些內容就永遠不會佔用上下文。
二、Skills VS MCP
看到這,你可能會覺得 Skills 和 MCP 有點像?
它們似乎都可以做到按需加載、給 AI 擴展外部能力?
這也是很多同學可能會弄混的問題。
2.1 MCP 有什麼問題
在 全網最細,一文帶你弄懂 MCP 的核心原理! 中,我們介紹了 MCP 出現的意義和執行原理:
MCP(Model Context Protocol,模型上下文協議)是由 Anthropic 公司推出的一個開放標準協議,它就像是一個 “通用插頭” 或者 “USB 接口”,制定了統一的規範,不管是連接數據庫、第三方 API,還是本地文件等各種外部資源,都可以通過這個 “通用接口” 來完成,讓 AI 模型與外部工具或數據源之間的交互更加標準化、可複用。
所以 MCP 的本質,還是在做 “標準化”,它讓給 AI 擴展外部能力這件事更 “標準化”。
假如你的 Agent 連接了多個 MCP,它似乎也能實現 “按需加載”(根據用戶的意圖決定調用哪個工具)。
但這個 “按需加載” 背後的代價是非常巨大的,在 MCP 的架構下,僅僅是“連接”這個動作,就已經在透支你的額度了。
這是由 LLM 的工具調用機制決定的。為了讓 AI 知道它有哪些能力可用,每一個連接的 MCP Server 必須在對話開始前,將其所有工具的完整定義(名稱、詳細描述、參數 Schema、使用示例)一次性注入 LLM 的上下文中。
每個 MCP Server 一般都會包含大量的工具,比如 Github MCP ,它自己就包含了 30 多個工具:
假如每個工具消耗 500 個 Token,那隻連結這一個工具就需要消耗將近 20000 Token。
在真實環境下,一個 Agent 不會僅連結一個 MCP Server。
假如你只問了 AI 一個非常簡單的問題(1+1=?),Agent 已經燒掉了大幾萬的 Token,這個成本是非常恐怖的。
更深層的問題在於連結過多的 MCP Server 可能導致 LLM 的 “注意力” 下降,從而降低工具調用的準確性。
我在之前的文章中有講過一個專門測試 MCP Server 調用準確度的基準:MCP Atlas(世界最頂級的大模型,都在 PK 些啥? (大模型評估完全指南)),在這個基準中包含了 40 多個不同服務器、300 多個工具的複雜環境。
模型必須自己發現合適的工具、正確調用,並把多步結果彙總成最終答案。目前最強的 Claude Opus 4.5 也只能拿到 62% 的準確率,這個值還會隨着工具的增多而進一步下降。
而我們上面講到的 Skills 的核心機制:漸進式披露 ,恰好可以解決這兩個問題:
節省 Token:首次連結時,相比 MCP 需要將 40 多個 MCP Server 下 300 個工具全部塞進模型上下文(消耗數萬 Token),模型只需要加載 40 個 Skills 的元數據(幾千 Token)。
提升注意力: 面對幾百個工具,AI 很容易分心。Skills 採用的是“漏斗式”引導:先通過目錄判斷大方向,確認要幹活了,再加載具體的說明,最後通過說明找到詳細的文檔和腳本最後再執行。讓 AI 每次只專注於當前任務。即使是能力稍弱的模型,在這種機制下也能保持極高的調用準確率。
2.2 MCP 會被淘汰嗎?
看到這你可能會問了,Skills 看起來更智能、更節省資源,那 MCP 會被淘汰嗎?
結論是:MCP 不會被完全淘汰,但對它的需求會大幅減少!
首先,MCP 協議層的價值不可替代: MCP 的真正價值不在於它如何把文本塞進 Prompt,而在於它制定了一套標準接口。
它統一了 AI 連接世界的方式。如果你是一個通用的三方平台(高德地圖、Notion 等),想發佈一個工具讓其他 Agent 都能用上你的能力,那首先選擇的還是 MCP。
但是,如果你有一些重複性的工作流,比如要以固定的流程讀寫本地文件、要用一個標準的範式來 Review 代碼、有一套固定的風格來編寫文章,這些場景都推薦使用 Skill 來實現。
在過去這幾個需求中的本地文件讀寫、連結 Github、給文章生成圖片這些需要連結外部世界的能力都得通過 MCP 去實現,但現在你可以都把它們打包到 Skill 裏。
未來的格局可能是這樣的(來自寶玉老師):
Agent 本身內置部分核心能力(bash、read、edit、write)
少數通用 MCP Server 負責遠程連接(數據庫、雲 API、SaaS 集成)
大量 Skills 負責封裝標準工作流、連接本地知識庫
兩者在必要時協作,但 Skills 會承擔絕大部分 “教 AI 怎麼做事” 的工作(這其中也包含教 AI 怎麼用 McpServer、怎麼用其他 Skills、怎麼更好的調用核心能力)
三、Skills 的初步嘗試
3.1 去哪找 Skills?
和 MCP 一樣,Skills 成了開放標準後開始爆發式增長,社區出現了大量的開源 Skills,很多 Skills 開放市場也應運而生,之前大部分 MCP Market 也都增加了 Skills 的分類:
我們可以看到 skillsmp 中的 Skills 數量在最近經歷着爆發式增長,這個增長速度要比之前的 MCP 爆火的時候還要快。這就不得不提 Skills 的另一大優點:編寫門檻低!
MCP 雖然有一套標準的規範,但終究還是要靠代碼編寫的,即便有了 AI 輔助,對於小白來講還是有一定的門檻的。
而 Skills 就不一樣了,只要你會寫提示詞,就能寫 Skill,可以預見的是,之前那些大量的固定工作流在未來可能都會被編寫為 Skill,這也意味着 Agent 的編寫門檻被再一次大幅降低了!
3.2 怎麼使用 Skills?
我們隨便進入一個 MCP 市場,然後搜索我們要使用的 Skills,比如這裏我們還以繪圖軟件 Excalidraw 為例:
可以看到社區已經有大量 Excalidraw 的 Skill 了,我們這裏選擇 Star 最多的一款:
進入詳情後,我們選擇一個最簡單的安裝方式,直接把這個 Skill 下載到本地,點擊 wget skill.zip:
然後我們把這個壓縮包解壓,你就會看到熟悉的目錄。接下來,你只需要把這個目錄下載到指定的位置:
不同客戶端的目錄大同小異,基本上都是 .agentName/skills 目錄,這裏我們使用最近比較火的 OpenCode 進行演示(大家看可以自行選擇 Cusor、Codex 等支持 skills 的客戶端),所以我們創建一個新的文件夾,然後把剛剛下載的文件夾放到 .opencode/skills 目錄下:
接下來,我們在這個目錄下打開 opencode 客戶端,輸入下面的提示詞:
幫我繪製一個架構圖,講解什麼是 5W2H 分析法,直接幫我在當前目錄下生成一個 excalidraw 文件。
你不需要手動去 “安裝” 或 “運行” Skill,只要文件放對位置了,OpenCode 的 AI 就會自動根據用戶的需求判斷要調用這個 Skill,然後幫我生成了代碼:
我們將生成的代碼粘貼到 https://excalidraw.com/,就可以看到已經生成好的架構圖:
3.3 創建你的第一個 Skill
下面,我們一起來嘗試做第一個 Skill,雖然 Skill 的開發門檻低,但這不意味着我們就要自己寫!
Anthropic 官方直接給我們提供了一個 生產 Skills 的 Skill:Skill Creator。你不需要寫一行代碼或配置文件,只需要用自然語言告訴它你想做什麼,它就會自動為你生成一個符合標準的 Skill 包。
接下來,按照剛才的流程,我們把這個 Skill 下載下來,放到 .opencode/skills 目錄下:
然後我們給出下面的提示詞:
幫我創建一個可以準確獲取當前系統時間的 Skill,描述使用中文,腳本使用 Node.js。
然後,opencode 識別到我們的需求,開始調用 skill-creator:
然後我們打開本地的 .opencode/skills 目錄,發現多了一個 current-time-node skill,包含一個 SKILL.md 加一個獲取準確時間的 Node.js 腳本:
接下來,我們詢問 opencode:“獲取當前系統時間”,然後它就會自動找到剛剛生成的 Skill 並調用裏面的腳本:
最後
本期教程我們就先講到這。
大家已經瞭解了 Agent Skill 的基本原理,以及如何使用和創建一個 Skill。
如果本期教程對你有所幫助,希望得到一個免費的三連和關注。
下一期,我們會進入實戰章節,一期來使用 Agent Skill 實現一個知識庫檢索的功能,相比傳統的 RAG ,它的效果究竟怎麼樣呢,我們下期見。
關注《code秘密花園》從此學習 AI 不迷路,相關連結:
AI 教程完整彙總:https://rncg5jvpme.feishu.cn/wiki/U9rYwRHQoil6vBkitY8cbh5tnL9 相關學習資源彙總在:https://github.com/ConardLi/easy-learn-ai
如果本期對你有所幫助,希望得到一個免費的三連,感謝大家支持!