Agent Skills 完全科普指南
整理版優先睇
Agent Skills 係一個開放標準,可以俾 AI Agent 裝技能包,令佢變成特定領域專家,唔使每次重複俾相同上下文。
呢篇文章係一篇科普指南,由技術作者整理,全面介紹 Agent Skills 呢個開放標準。作者想解決嘅問題係:點樣可以令 AI Agent 更容易掌握特定領域嘅知識同工作流程,而唔係每次都要由頭講起。整體結論係:Agent Skills 透過可移植、受版本控制嘅技能包,配合漸進式披露機制,可以大幅減少重複上下文,提高效率。
文章首先解釋咗咩係 Agent Skill,佢似係俾 Agent 嘅「插件」或者「技能包」,將領域知識、工作流程、腳本同最佳實踐封裝埋一齊。核心設計理念係漸進式披露,即係 Agent 只會喺需要嘅時候先加載必要資訊,分三級:元數據(~100 tokens)、指令(<5000 tokens)同資源(按需)。呢個機制令到安裝幾十個 Skill 都唔會造成上下文壓力。
然後文章詳細講解咗 Agent 消費 Skill 嘅流程:Agent 啟動時掃描檔案系統,將每個 Skill 嘅 name 同 description 注入 System Prompt,形成技能目錄;LLM 根據語義決定係咪要讀取對應 SKILL.md,透過 Read 工具調用;之後仲可以讀取參考文件或者執行腳本。文章仲將 Skill 同 MCP Tool 做對比:MCP Tool 提供能力(做嘢),Skill 提供指令(教點做),兩者互補。最後文章提供咗寫高質 Skill 嘅最佳實踐,例如 description 要包含觸發關鍵詞、命名…
- Agent Skill 係可移植、受版本控制嘅技能包,將領域知識同工作流程封裝,令通用 Agent 變成領域專家,減少重複上下文。
- 漸進式披露係核心設計:三級加載(元數據、指令、資源),確保只在必要時消耗 token,可安裝幾十個 Skill 而無壓力。
- Skill 同 MCP Tool 本質唔同:前者係指令(手冊),後者係能力(工具);組合使用可以同時獲得操作能力同行為指南。
- 腳本型 Skill 將確定性代碼與靈活決策結合,腳本唔會佔用上下文 token,只有輸出結果進入對話,更可靠高效。
- 寫高質 Skill 嘅關鍵:description 要具體兼包含觸發詞,命名用動名詞,主檔案控制喺 500 行內,避免嵌套引用同不一致術語。
內容結構
<available_skills><skill><name>pdf-processing</name><description>Extract PDF text, fill forms, merge files. Use when handling PDFs.</description><location>~/.agents/skills/pdf-processing/SKILL.md</location></skill><skill><name>data-analysis</name><description>Analyze datasets, generate charts, and create summary reports.</description><location>~/project/.agents/skills/data-analysis/SKILL.md</location></skill></available_skills>咩係 Agent Skill?點解需要佢?
Agent Skill 係一個開放標準,將特定領域嘅知識、工作流程、腳本同最佳實踐打包成可移植、受版本控制嘅「技能包」,俾 AI Agent 喺合適嘅時機自動調用。你可以理解為俾 Agent 裝插件,令佢由通才變成領域專家。
四大特性:可移植、受版本控制、可操作、漸進式
如果 AI Agent 係一位通才型新員工,Skill 就係佢嘅入職培訓手冊——唔會改變智力水平,但會令佢即刻掌握公司特定流程。需要 Skill 嘅原因好直接:每次對話都要重複講同一套上下文(代碼規範、部署流程等),浪費時間之餘又容易漏嘢。Skill 嘅解決方案係專業化、減少重複、能力組合同知識沉澱。
漸進式披露:唔曬 token 嘅秘密
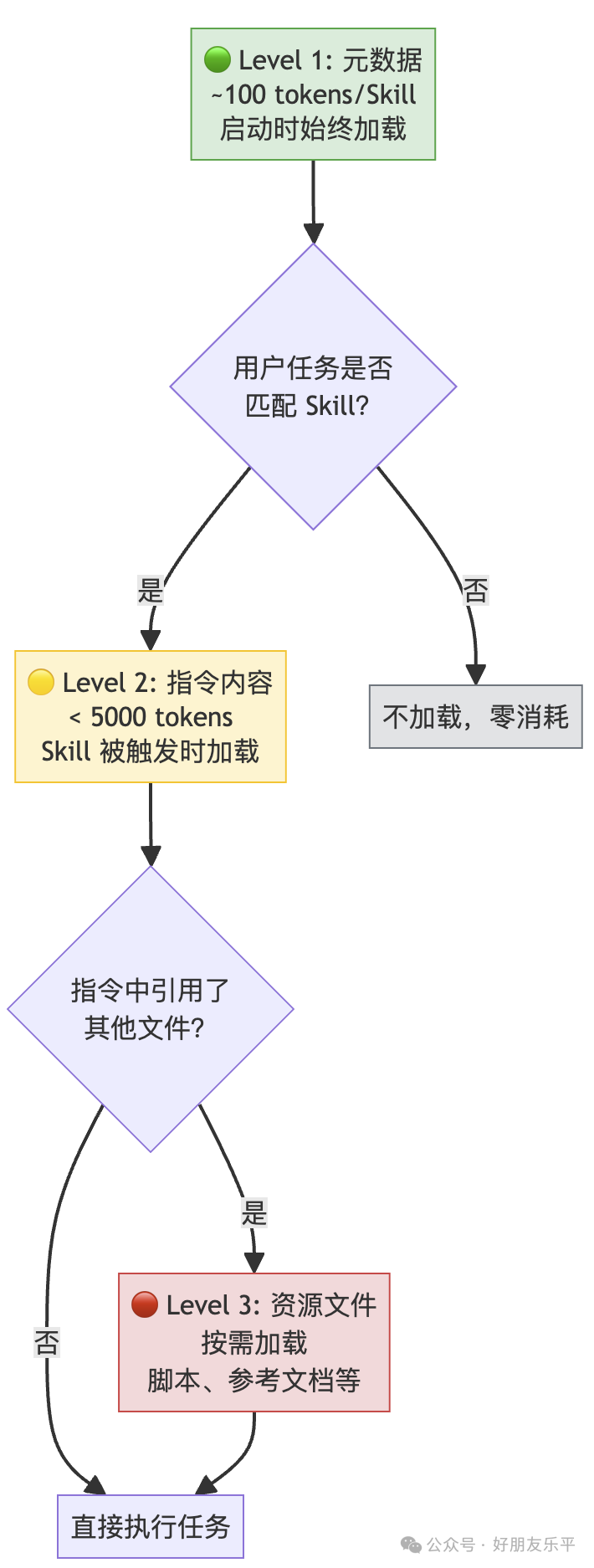
漸進式披露係 Agent Skills 最核心嘅設計理念,確保 Agent 只喺需要嘅時候先加載必要資訊,而唔係一開始就塞爆上下文。
- 1 Level 1 元數據:啟動時始終加載,約 100 tokens/Skill,包含 name 同 description。
- 2 Level 2 指令:Skill 被觸發時加載,少過 5000 tokens,即 SKILL.md 主體。
- 3 Level 3 資源:按需加載,理論上無限,包括腳本、參考文檔等。
Agent 點樣用 Skill?同 MCP Tool 有咩分別?
Agent 消費 Skill 嘅流程好關鍵:啟動時掃描檔案系統,將每個 Skill 嘅 name 同 description 注入 System Prompt,形成技能目錄。LLM 根據語義決定係咪要讀取 SKILL.md,透過 Read 工具調用。之後仲可以讀參考文件或執行腳本,全部都係 LLM 驅動。
Skill 目錄同 MCP 工具定義同時存在 prompt 入面
同 MCP Tool 嘅本質分別:MCP Tool 提供能力(做某件事),Skill 提供指令(教點做)。一個常見嘅組合係 MCP 俾 Agent 調用 BigQuery 嘅能力,而 Skill 教佢公司嘅表結構同查詢規範。
腳本型 Skill:確定性加靈活性
支援腳本係 Agent Skill 最強大嘅能力之一。腳本本身唔會消耗上下文 token,淨係輸出結果會進入 Agent 嘅上下文,比臨時生成代碼更可靠高效。
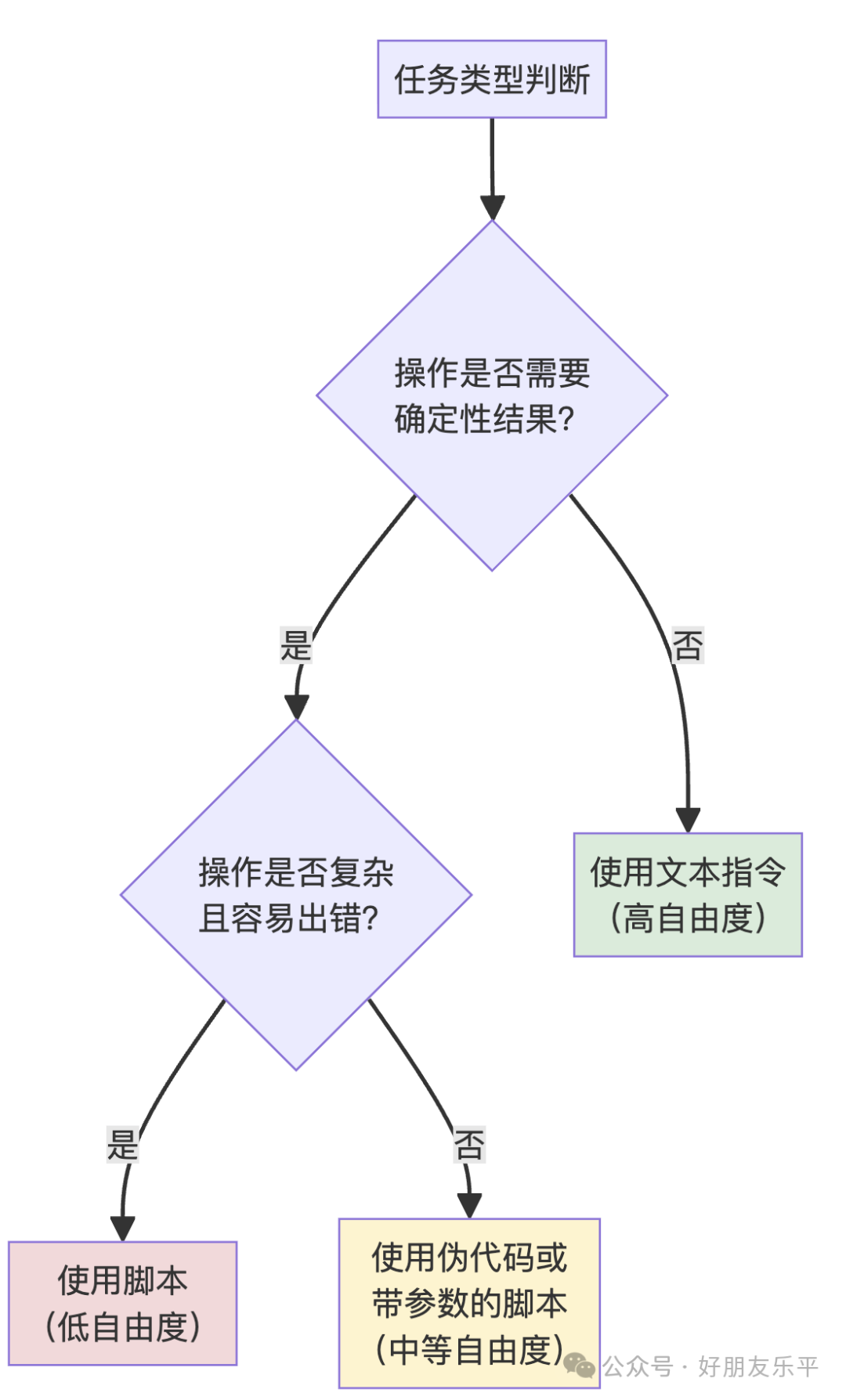
- 高自由度:靠自然語言指令,適合代碼審查、寫作風格等。
- 中自由度:用偽代碼或帶參數腳本,有推薦模式但容許變通,如報告生成。
- 低自由度:固定腳本操作,適合數據庫遷移、部署等一致性關鍵嘅任務。
腳本設計原則:禁止交互式提示、提供 --help、輸出結構化 JSON、冪等性
文章提供咗一個完整嘅天氣查詢 Skill 做 Demo,展示腳本點樣透過 wttr.in API 攞天氣數據,然後由 LLM 根據指令格式化輸出。呢個示範體現咗「腳本提供確定性、指令提供靈活性」嘅核心價值。
寫高質 Skill 嘅要訣
最後文章總結咗好多實用建議,幫你寫出唔曬 token 又易用嘅 Skill。
description 係決定能否正確觸發嘅關鍵
- 用第三人稱同埋觸發關鍵詞,例如 'Processes CSV files' 而唔係 'I can help you'。
- 命名用動名詞形式,例如 'processing-pdfs' 好過 'pdf-processing'。
- SKILL.md 主體控制喺 500 行以內,詳細內容拆到獨立文件,引用保持一層深度。
- 避免反模式:用正斜槓路徑、唔好用魔法數字、保持術語一致。

Agent Skills 係一個開放標準,用嚟幫 AI Agent 擴展專用能力。呢篇文章會從概念、工作原理、規範、分類、腳本支援、最佳實踐等多個角度,帶你全面瞭解 Agent Skills。
一、咩嘢係 Agent Skill?
1.1 基本概念
Agent Skill(技能) 係一種可移植、受版本控制嘅包,用嚟教 AI Agent 執行特定領域嘅任務。你可以當佢係畀 AI Agent 安裝嘅「插件」或「技能包」——佢將特定領域嘅知識、工作流程、腳本同埋最佳實踐打包封裝,等 Agent 喺合適嘅時候自動調用。
用一個更直接嘅比喻:如果 AI Agent 係一個全能型新員工,咁 Skill 就係你幫佢準備嘅入職培訓手冊——佢唔會改變員工嘅智力水平,但會令佢即刻掌握公司特定嘅工作流程同領域知識。
1.2 四大特性
| 可移植 | |
| 受版本控制 | |
| 可操作 | |
| 漸進式 |
1.3 點解需要 Skill?
問題場景:你每次同 AI Agent 對話嘅時候,都要重複提供相同嘅上下文——好似公司嘅代碼規範、部署流程、數據庫表結構等。呢樣嘢好浪費時間,亦容易漏嘢。
Skill 嘅解決方案:
- 專業化
:令通用 Agent 變成特定領域嘅專家 - 減少重複
:一次建立,自動使用 - 能力組合
:多個 Skill 可以組合使用,建立複雜工作流 - 知識沉澱
:將團隊嘅工作流程、最佳實踐同機構知識固化落嚟
二、核心設計理念:漸進式披露
漸進式披露(Progressive Disclosure)係 Agent Skills 最核心嘅設計理念。佢確保 Agent 淨係喺需要嘅時候加載必要資訊,而唔係一開始就塞曬所有內容入上下文視窗。
2.1 三級加載機制
name 和 description | |||
2.2 點解咁重要?
上下文視窗係一種公共資源,你嘅 Skill 同以下內容共享呢個空間:
系統提示詞(System Prompt) 對話歷史 其他 Skill 嘅元數據 用戶嘅實際請求
漸進式披露令你可以安裝幾十個 Skill 都唔會有上下文壓力——Agent 淨係知道每個 Skill 嘅存在同用途,等到真係需要嗰陣先加載完整內容。
三、Agent 點樣消費 Skill?
理解 Skill 嘅消費機制係理解成個體系嘅關鍵。呢度需要分清三個角色:Agent(程式)、LLM(大模型) 和 Skill 檔案(檔案系統)。Agent 係 LLM 嘅「外殼程式」,負責管理對話、調用工具、組裝 prompt;LLM 係做決策嘅大腦;Skill 檔案係靜態嘅知識包。
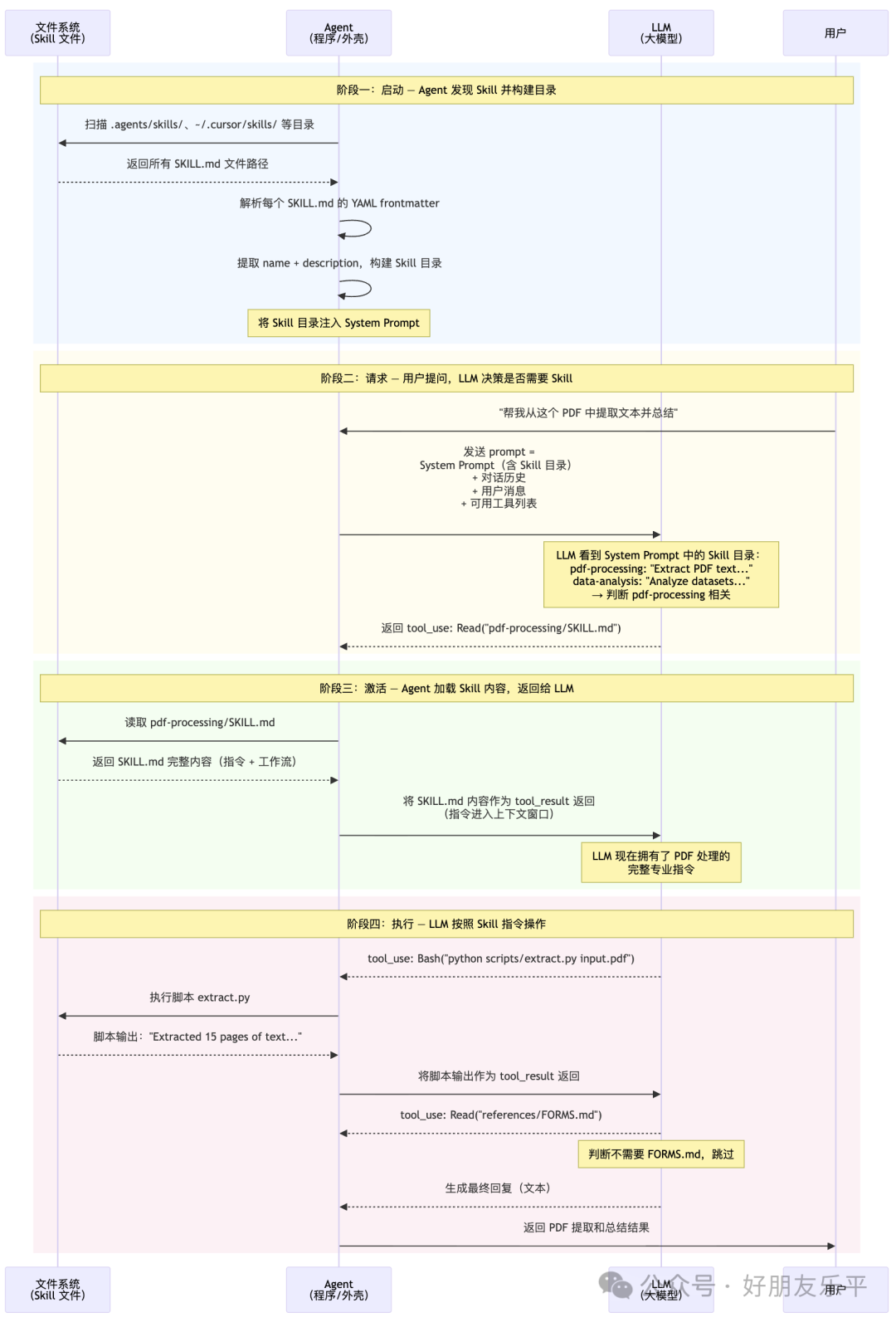
3.1 Agent、LLM 同 Skill 嘅完整互動流程
下面呢張圖完整展示咗由 Agent 啟動到 Skill 被使用嘅全過程。留意關鍵點:Skill 嘅篩選同激活係由 LLM 決定,Agent 淨係負責執行 LLM 嘅指令(讀檔案、行腳本)。
關鍵要點
上面呢張圖有幾個位值得特別留意:
1. Skill 目錄喺啟動時就注入 System Prompt
Agent 啟動時掃描檔案系統,提取每個 Skill 嘅 name 和 description(每個約 100 tokens),拼成一個「技能目錄」塊,注入到 System Prompt 入面。呢個目錄類似咁樣:
<available_skills>
<skill>
<name>pdf-processing</name>
<description>Extract PDF text, fill forms, merge files. Use when handling PDFs.</description>
<location>~/.agents/skills/pdf-processing/SKILL.md</location>
</skill>
<skill>
<name>data-analysis</name>
<description>Analyze datasets, generate charts, and create summary reports.</description>
<location>~/project/.agents/skills/data-analysis/SKILL.md</location>
</skill>
</available_skills>
2. Skill 篩選由 LLM 完成,唔係 Agent 硬編碼匹配
Agent 唔會自己做關鍵詞匹配嚟決定用邊個 Skill。而係將「技能目錄」同用戶訊息一齊發畀 LLM,由 LLM 根據語義理解決定係咪要加載某個 Skill。LLM 嘅決策體現為一次工具調用——調用 Read 工具讀取對應嘅 SKILL.md 文件。
3. Skill 內容透過「工具調用-工具結果」機制進入上下文
SKILL.md 嘅內容唔係直接塞入 prompt,而係透過 LLM 主動發起一次 Read 工具調用,Agent 執行讀取後將內容作為 tool_result 返回。呢個意味住 Skill 嘅加載係用同其他工具調用完全一樣嘅通訊機制。
4. 後續操作(讀引用檔案、執行腳本)都係由 LLM 驅動
加載 SKILL.md 之後,LLM 可能會繼續發起工具調用嚟讀取參考文檔或執行腳本。每次都係 LLM 做決策、Agent 執行、結果返回,循環進行。
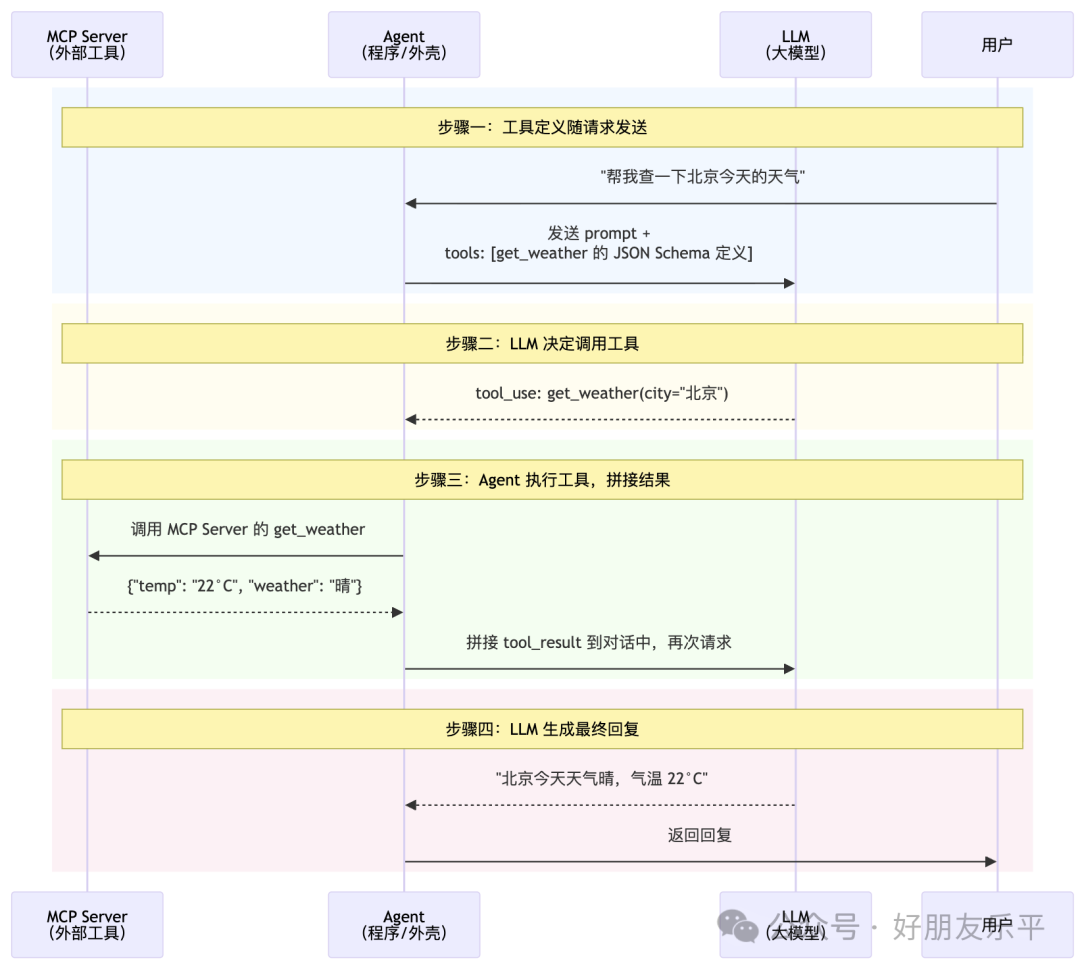
3.2 同 MCP Tool 互動流程嘅對比
Skills 同 MCP Tools 都係擴展 Agent 能力嘅方式,但互動模式有本質分別。下面用兩張並排嘅時序圖嚟對比:
MCP Tool 嘅互動流程
Skill 同 MCP Tool 嘅本質分別
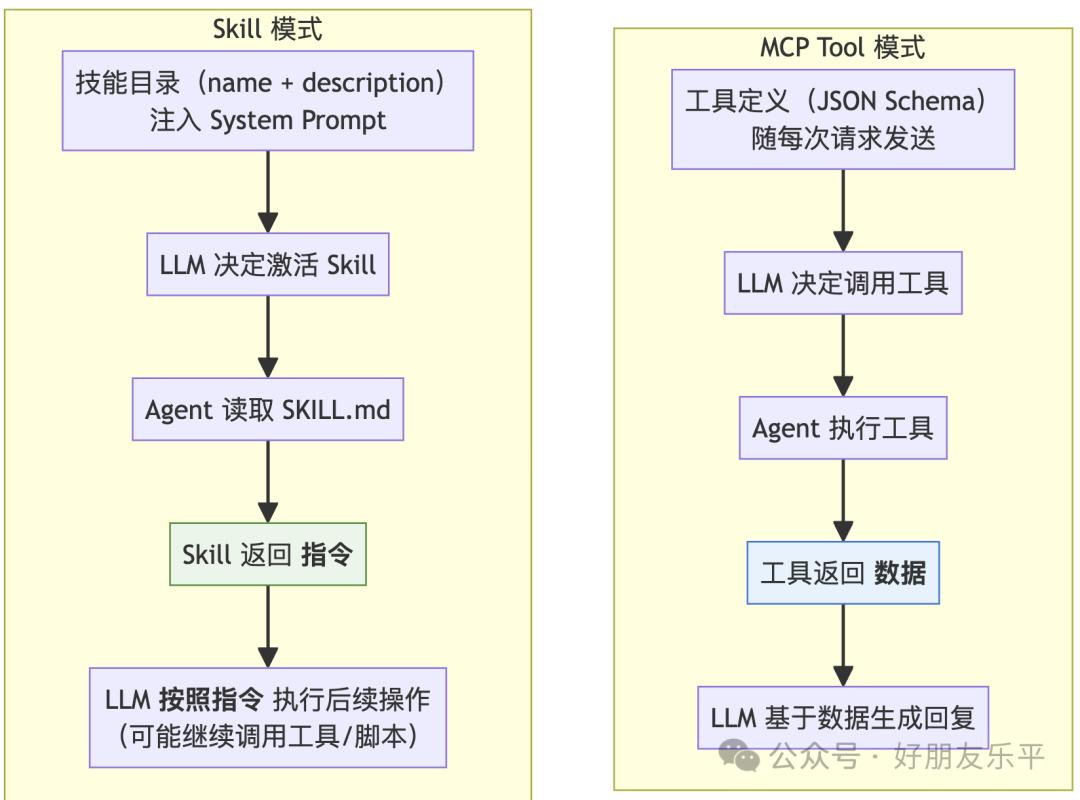
總結兩者嘅核心差異:
| 本質 | ||
| 資訊注入位置 | tools 參數發送 | |
| 觸發結果 | ||
| LLM 行為變化 | ||
| 類比 | ||
| 組合使用 |
一個常見嘅強力組合場景:MCP 畀 Agent 提供咗調用 BigQuery 嘅能力(工具),Skill 教識 Agent 你哋公司嘅表結構、查詢規範同注意事項(指令)。兩者互補,缺一不可。
3.3 完整嘅 Prompt 拼接示意
為咗更直觀噉理解 Skill 點樣融入 Agent 同 LLM 嘅對話流程,下面展示一次完整互動中 Agent 發畀 LLM 嘅 prompt 結構:
┌──────────────────────────────────────────────────────────┐
│ SystemPrompt │
│ ┌────────────────────────────────────────────────────┐ │
│ │ 基礎指令(你是一個 AI 助手...) │ │
│ ├────────────────────────────────────────────────────┤ │
│ │ 📦 可用技能目錄(~100tokens × N 個 Skill) │ │
│ │ • pdf-processing:ExtractPDFtext,fillforms... │ │
│ │ • data-analysis:Analyzedatasets,generate... │ │
│ │ • deploy-app:Deploytheapplicationto... │ │
│ │ 當任務匹配技能描述時,使用 Read 工具加載 SKILL.md │ │
│ ├────────────────────────────────────────────────────┤ │
│ │ 🔧 可用工具列表 │ │
│ │ • Read(讀取文件) │ │
│ │ • Bash(執行命令) │ │
│ │ • get_weather(MCP 工具) │ │
│ │ • ... │ │
│ └────────────────────────────────────────────────────┘ │
├──────────────────────────────────────────────────────────┤
│ 對話歷史 │
│ [user]: 幫我從這個 PDF 中提取文本 │
│ [assistant]:tool_use → Read("pdf-processing/SKILL.md") │
│ [tool_result]:#PDFProcessing...(SKILL.md 內容) │
│ [assistant]:tool_use → Bash("python scripts/extract.py")│
│ [tool_result]:Extracted15pagesoftext... │
│ [assistant]: 已從 PDF 中提取文本,以下是總結... │
├──────────────────────────────────────────────────────────┤
│ 當前用戶消息 │
│ [user]: 再幫我把提取的內容生成一份 Word 文檔 │
└──────────────────────────────────────────────────────────┘
可以見到:
- Skill 目錄
和 MCP 工具定義同時存在喺 prompt 入面 Skill 嘅激活(讀取 SKILL.md)喺對話歷史中表現為一次普通嘅工具調用 SKILL.md 嘅內容作為 tool_result留喺對話歷史入面,持續影響之後 LLM 嘅行為
3.4 發現階段詳解
Agent 啟動時,會從以下目錄自動發現技能:
.agents/skills/ | ||
.cursor/skills/ | ||
~/.cursor/skills/ | ||
.claude/skills/ | ||
~/.claude/skills/ |
掃描規則:
跳過 .git/、node_modules/等無關目錄設定合理嘅掃描深度(一般 4-6 層)同目錄數上限(~2000 個) 項目級 Skill 優先級高過用戶級 Skill(同名時覆蓋)
3.5 觸發激活方式
Skill 有兩種激活方式:
自動觸發(Model-driven):LLM 見到 System Prompt 入面嘅技能目錄後,根據用戶請求嘅語義自動判斷係咪需要加載某個 Skill。呢個係最常見嘅方式——LLM 嘅決策體現為一次讀取 SKILL.md 嘅工具調用。
手動調用(User-explicit):用戶喺對話中輸入 /skill-name(斜槓命令)嚟顯式調用特定 Skill。呢個時候 Agent(程式側)直接將 SKILL.md 內容注入上下文,唔需要 LLM 做判斷。適用於設定咗 disable-model-invocation: true 嘅 Skill。
3.6 腳本執行嘅高效性
當 Skill 入面嘅指令引用咗腳本檔案時,Agent 透過 bash 直接執行腳本,而唔係將腳本代碼讀入上下文:
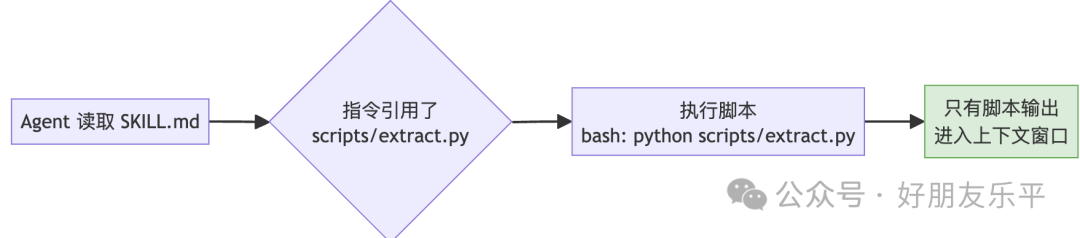
呢個意味住:
腳本代碼本身不會消耗上下文 token 得腳本嘅輸出結果會進入 Agent 嘅上下文 比起等 Agent 臨時生成代碼更可靠、更高效
四、Skill 嘅規範同結構
4.1 目錄結構
每個 Skill 係一個包含 SKILL.md 檔案嘅資料夾:
my-skill/
├── SKILL.md # 必需:元數據 + 指令
├── scripts/ # 可選:可執行代碼
│ ├── deploy.sh
│ └── validate.py
├── references/ # 可選:補充文檔
│ ├── REFERENCE.md
│ └── FORMS.md
├── assets/ # 可選:模板、圖片等靜態資源
│ └── config-template.json
└── ...# 任何其他文件或目錄
各目錄嘅職責:
SKILL.md | ||
scripts/ | ||
references/ | ||
assets/ |
4.2 SKILL.md 檔案格式
每個 Skill 喺帶有 YAML frontmatter 嘅 SKILL.md 檔案中定義:
---
name: pdf-processing
description: Extract PDF text, fill forms, merge files. Use when handling PDFs.
license: Apache-2.0
metadata:
author: example-org
version: "1.0"
---
# PDF Processing
## Quick start
Use pdfplumber to extract text from PDFs:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
Advanced features
Form filling: See FORMS.md for complete guide
API reference: See REFERENCE.md for all methods
### 4.3 Frontmatter 字段詳解
#### 必填字段
| 字段 | 約束 | 說明 |
|------|------|------|
| `name` | 最多 64 字符,僅允許小寫字母、數字和連字符,不能以連字符開頭或結尾,不能包含連續連字符,必須與父文件夾名一致 | 技能標識符 |
| `description` | 最多 1024 字符,不能為空 | 描述技能功能和使用場景,Agent 用它來判斷相關性 |
#### 可選字段
| 字段 | 約束 | 說明 |
|------|------|------|
| `license` | 無 | 許可證名稱或對隨附許可證文件的引用 |
| `compatibility` | 最多 500 字符 | 環境要求(目標產品、系統軟件包、網絡訪問等) |
| `metadata` | 鍵值對映射 | 用於附加元數據(如 author、version) |
| `disable-model-invocation` | 布爾值 | 為 `true` 時僅在通過 `/skill-name` 顯式調用時才使用 |
| `allowed-tools` | 空格分隔的工具列表 | 預批准該 Skill 可使用的工具(實驗性功能) |
#### name 字段示例
```yaml
# ✅ 合法
name: pdf-processing
name: data-analysis
name: code-review
# ❌ 非法
name: PDF-Processing # 不允許大寫
name: -pdf # 不能以連字符開頭
name: pdf--processing # 不能有連續連字符
description 字段示例
# ✅ 好的描述:具體且包含觸發關鍵詞
description:>
Extract text and tables from PDF files, fill forms, merge documents.
Use when working with PDF files or when the user mentions PDFs,
forms, or document extraction.
# ❌ 差的描述:太模糊
description:HelpswithPDFs.
4.4 檔案引用規範
喺 Skill 入面引用其他檔案時,用相對於 Skill 根目錄嘅路徑:
See [the reference guide](references/REFERENCE.md) for details.
Run the extraction script:
scripts/extract.py
關鍵規則:
永遠用正斜槓 references/guide.md,而唔係反斜槓檔案引用保持一層深度,避免嵌套引用鏈 檔案名應該有描述性:用 form_validation_rules.md而不是doc2.md
五、Skill 嘅分類

5.1 預構建 Skill(Anthropic Skills)
由 Anthropic 官方建立同維護嘅 Skill,開箱即用:
pptx | ||
xlsx | ||
docx | ||
pdf |
呢啲 Skill 喺 claude.ai 同 Claude API 上對所有用戶可用,Agent 會喺相關任務中自動調用。
5.2 自定義 Skill(Custom Skills)
用戶或組織自己建立嘅 Skill,用喺特定領域嘅工作流。按內容構成可以分為:
純指令型 Skill
只包含 SKILL.md,透過自然語言指令指導 Agent:
code-review/
└── SKILL.md
適用場景:代碼審查流程、寫作風格指南、會議記錄模板等唔需要執行代碼嘅任務。
包含參考文檔嘅 Skill
除咗主指令之外,附帶額外嘅參考文檔,Agent 按需要讀取:
bigquery-skill/
├── SKILL.md
└── reference/
├── finance.md
├── sales.md
└── product.md
適用場景:需要大量領域知識嘅任務,例如數據庫分析、API 對接等。
包含腳本嘅 Skill
附帶可執行腳本,Agent 喺執行任務時調用:
deploy-app/
├── SKILL.md
└── scripts/
├── deploy.sh
└── validate.py
適用場景:部署、數據處理、表格填充等需要確定性操作嘅任務。
複合型 Skill
同時包含指令、參考文檔、腳本同資源:
pdf-processing/
├── SKILL.md
├── FORMS.md
├── REFERENCE.md
├── examples.md
├── scripts/
│ ├── analyze_form.py
│ ├── fill_form.py
│ └── validate.py
└── assets/
└── template.json
5.3 組織級 Skill(Organization Provisioned)
針對 Team 同 Enterprise 計劃,組織嘅管理員可以為所有用戶統一配置 Skill:
分發經過審批嘅工作流,確保全員一致 確保團隊用標準化嘅流程同最佳實踐 部署新能力唔需要每個用戶單獨上傳 Skill 可以設為預設啟用或停用
5.4 合作伙伴 Skill(Partner Skills)
由合作伙伴(例如 Notion、Figma、Atlassian 等)專業構建嘅 Skill,設計成同對應嘅 MCP 連接器無縫配合使用,實現強大嘅集成工作流。
六、支援腳本嘅 Skill
支援腳本係 Agent Skill 最強大嘅能力之一。佢將確定性嘅代碼執行同 Agent 嘅靈活決策結合埋一齊。
6.1 腳本 vs 指令嘅選擇
6.2 一次性命令
當現有工具包已經可以滿足需求嗰陣,可以直接喺 SKILL.md 中引用,而唔需要 scripts/ 目錄:
uvx | uvx ruff@0.8.0 check . | |
pipx | pipx run 'black==24.10.0' . | |
npx | npx eslint@9 --fix . | |
bunx | bunx eslint@9 --fix . | |
deno run | deno run npm:create-vite@6 my-app | |
go run | go run golang.org/x/tools/cmd/goimports@v0.28.0 . |
關鍵原則:鎖定版本號,確保行為一致。
6.3 自包含腳本
當需要自定義邏輯嗰陣,將腳本放入 scripts/ 目錄並聲明內聯依賴:
Python 示例(PEP 723):
# /// script
# dependencies = [
# "beautifulsoup4",
# ]
# ///
from bs4 import BeautifulSoup
html = '<html><body><h1>Welcome</h1><p class="info">Test.</p></body></html>'
print(BeautifulSoup(html, "html.parser").select_one("p.info").get_text())
使用 uv run scripts/extract.py 運行,uv 會自動建立隔離環境並安裝依賴。
Deno 示例:
#!/usr/bin/env -S deno run
import * as cheerio from"npm:cheerio@1.0.0";
const html = `<html><body><p class="info">Test.</p></body></html>`;
const $ = cheerio.load(html);
console.log($("p.info").text());
6.4 腳本設計原則
為 Agent 設計腳本嗰陣,要跟以下原則:
禁止互動式提示
Agent 喺非互動式 shell 中運行,冇辦法回應 TTY 提示。所有輸入透過命令列參數、環境變量或 stdin 接收:
# ❌ 錯誤:會掛起等待輸入
$ python scripts/deploy.py
Target environment: _
# ✅ 正確:清晰的錯誤提示
$ python scripts/deploy.py
Error: --env is required. Options: development, staging, production.
Usage: python scripts/deploy.py --env staging --tag v1.2.3
提供 --help 文檔
--help 輸出係 Agent 瞭解腳本介面嘅主要方式:
Usage: scripts/process.py [OPTIONS] INPUT_FILE
Process input data and produce a summary report.
Options:
--formatFORMATOutputformat: json, csv, table (default: json)
--outputFILE Write output to FILE instead of stdout
--verbose Print progress to stderr
提供有意義嘅錯誤資訊
# ❌ 不好:模糊
Error: invalid input
# ✅ 好:具體且有指導性
Error: --format must be one of: json, csv, table.
Received: "xml"
使用結構化輸出
優先使用 JSON、CSV 等結構化格式,而唔係自由文字。將數據輸出到 stdout,診斷資訊輸出到 stderr。
其他原則
- 冪等性
:Agent 可能會重試命令,「唔存在就創建」比「創建然後重複時失敗」更安全 - 幹運行支援
:對於破壞性操作,提供 --dry-run標誌 - 有意義嘅退出碼
:唔同失敗類型用唔同退出碼 - 可預測嘅輸出大小
:Agent 嘅工具輸出通常有截斷閾值,支援 --offset等分頁參數
6.5 工作流同反饋循環
支援腳本嘅 Skill 特別適合構建驗證反饋循環:

呢種「計劃-驗證-執行」模式透過喺每個關鍵步驟後加入機器可驗證嘅檢查,大幅提高輸出質量:
- 早期捕獲錯誤
:驗證喺變更應用之前發現問題 - 機器可驗證
:腳本提供客觀驗證 - 可逆規劃
:Agent 可以喺唔掂原始檔案嘅情況下迭代計劃
6.6 實戰 Demo:天氣查詢 Skill
下面透過一個完整、可運行嘅天氣查詢 Skill,嚟展示腳本型 Skill 嘅完整結構同工作方式。
目錄結構
check-weather/
├── SKILL.md
└── scripts/
└── get-weather.mjs
SKILL.md 檔案
---
name: check-weather
description: >
Query current weather conditions for any city worldwide.
Use when the user asks about weather, temperature, wind,
humidity, or atmospheric conditions for a specific location.
compatibility: Requires Node.js 18+ (uses native fetch API)
metadata:
author: demo
version: "1.0"
---
# Check Weather
Query real-time weather data for any city using the wttr.in API.
## Usage
Run the weather script with the city name:
```bash
node scripts/get-weather.mjs <city>
Examples:
node scripts/get-weather.mjs Beijing
node scripts/get-weather.mjs "New York"
node scripts/get-weather.mjs Tokyo
Output Format
The script outputs JSON with the following fields:
{
"city":"Beijing",
"country":"China",
"temperature":"22°C",
"feels_like":"20°C",
"weather":"Partly cloudy",
"humidity":"45%",
"wind_speed":"15 km/h",
"wind_direction":"NE",
"visibility":"10 km",
"pressure":"1015 mb",
"uv_index":"5",
"observation_time":"02:30 PM"
}
Guidelines
If the user provides a Chinese city name, translate it to English
before calling the script (e.g. 北京 → Beijing)If the script fails due to network issues, inform the user and
suggest trying again laterPresent the weather data in a readable, conversational format
rather than dumping raw JSON
#### scripts/get-weather.mjs 腳本
```javascript
#!/usr/bin/env node
const city = process.argv[2];
if (!city) {
console.error(JSON.stringify({
error: "City name is required",
usage: "node scripts/get-weather.mjs <city>",
examples: [
'node scripts/get-weather.mjs Beijing',
'node scripts/get-weather.mjs "New York"'
]
}, null, 2));
process.exit(1);
}
try {
const url = `https://wttr.in/${encodeURIComponent(city)}?format=j1`;
const response = await fetch(url);
if (!response.ok) {
console.error(JSON.stringify({
error: `HTTP ${response.status}: Failed to fetch weather for"${city}"`,
suggestion: "Check the city name and try again"
}));
process.exit(1);
}
const data = await response.json();
const current = data.current_condition?.[0];
const area = data.nearest_area?.[0];
if (!current) {
console.error(JSON.stringify({
error: `No weather data available for"${city}"`
}));
process.exit(1);
}
const result = {
city: area?.areaName?.[0]?.value ?? city,
country: area?.country?.[0]?.value ?? "Unknown",
temperature: `${current.temp_C}°C`,
feels_like: `${current.FeelsLikeC}°C`,
weather: current.weatherDesc?.[0]?.value ?? "Unknown",
humidity: `${current.humidity}%`,
wind_speed: `${current.windspeedKmph} km/h`,
wind_direction: current.winddir16Point,
visibility: `${current.visibility} km`,
pressure: `${current.pressure} mb`,
uv_index: current.uvIndex,
observation_time: current.observation_time
};
console.log(JSON.stringify(result, null, 2));
} catch (err) {
console.error(JSON.stringify({
error: `Network error: ${err.message}`,
suggestion: "Check your internet connection and try again"
}));
process.exit(1);
}
實際互動過程
當用戶講「北京今日天氣點樣」,Agent 同 LLM 嘅互動過程如下:
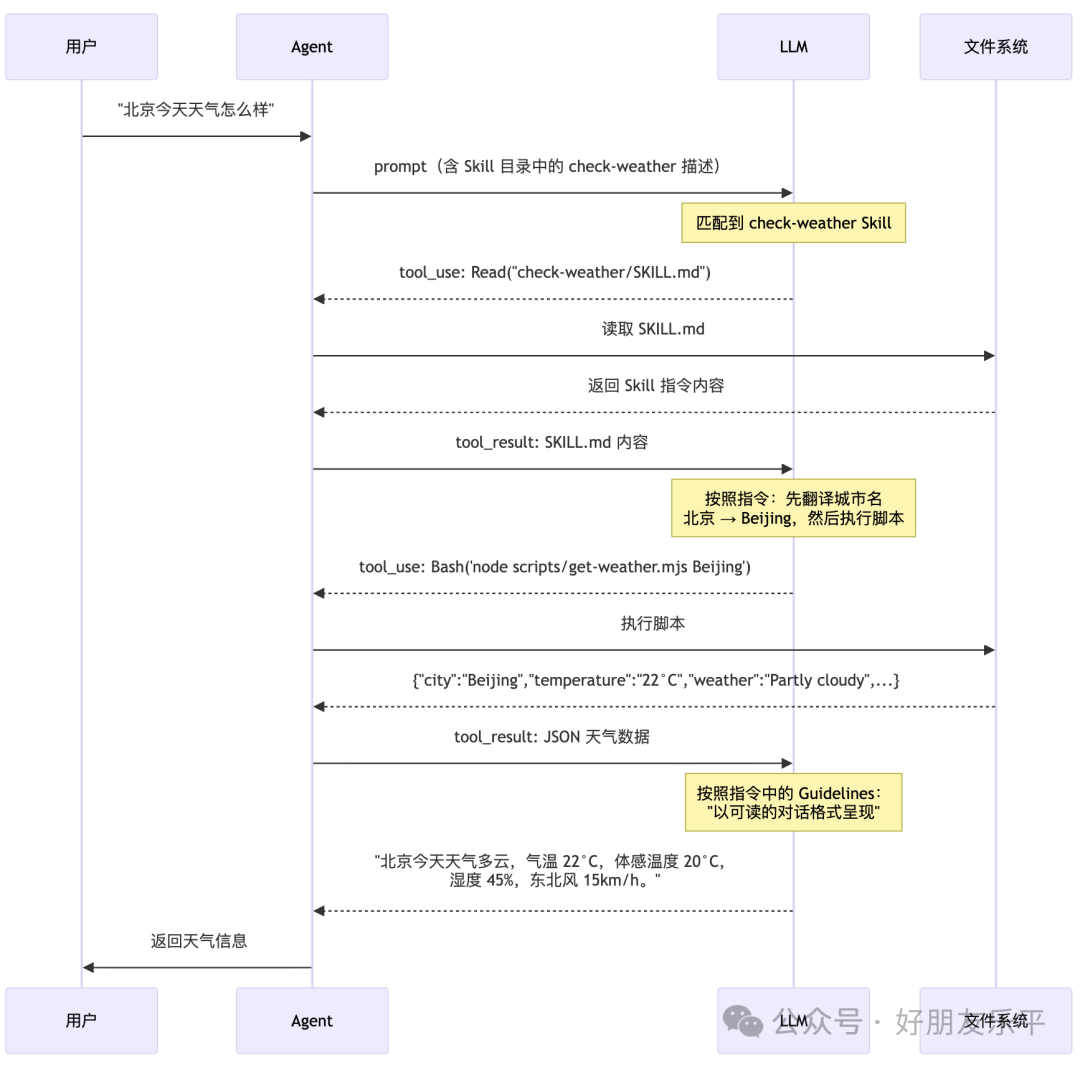
呢個 Demo 體現咗腳本型 Skill 嘅幾個核心價值:
- 腳本提供確定性能力
:API 調用同數據解析由腳本保證,唔依賴 LLM 生成代碼 - 指令提供靈活指導
:翻譯城市名、格式化輸出等由 LLM 根據指令靈活完成 - 錯誤處理自包含
:腳本自己處理各種異常,提供結構化嘅錯誤資訊 - 零 token 浪費
:腳本代碼唔進入上下文,得 JSON 輸出進入
七、Skill 喺唔同平台嘅使用
Agent Skills 可以喺多個平台上使用,但各平台嘅支援程度同限制有啲唔同:
7.1 平台支援矩陣
7.2 跨平台限制
自定義 Skill 唔會喺唔同平台之間自動同步:
上傳到 claude.ai 嘅 Skill 要另外上傳到 API 透過 API 上傳嘅 Skill 喺 claude.ai 上唔可用 Claude Code 嘅 Skill 係基於檔案系統,同 claude.ai 同 API 都獨立
7.3 喺 Claude API 中使用
使用 Claude API 嗰陣,透過 container 參數指定 Skill:
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=4096,
betas=["code-execution-2025-08-25", "skills-2025-10-02"],
container={
"skills": [
{"type": "anthropic", "skill_id": "pptx", "version": "latest"}
]
},
messages=[
{"role": "user", "content": "Create a presentation about AI"}
],
tools=[{"type": "code_execution_20250825", "name": "code_execution"}],
)
需要三個 beta 頭:
code-execution-2025-08-25:Skill 喺代碼執行容器中運行 skills-2025-10-02:啟用 Skills 功能 files-api-2025-04-14:用嚟上傳/下載檔案到容器
7.4 喺 Cursor 中使用
Cursor 支援自定義 Skill,從以下目錄自動發現:
.agents/skills/ | |
.cursor/skills/ | |
~/.cursor/skills/ |
亦可以喺 Cursor Settings → Rules 嘅「Agent Decides」區域睇已發現嘅 Skill。
手動調用方式:喺 Agent 對話中輸入 / 並搜尋技能名稱。
八、Skill 嘅安裝同管理
8.1 本地建立
最簡單嘅方式,直接喺項目或全局目錄中建立 Skill 資料夾:
# 項目級
mkdir -p .agents/skills/my-skill
touch .agents/skills/my-skill/SKILL.md
# 全局級
mkdir -p ~/.agents/skills/my-skill
touch ~/.agents/skills/my-skill/SKILL.md
8.2 從 GitHub 安裝
喺 Cursor 中:
打開 Cursor Settings → Rules 喺 Project Rules 部分,撳 Add Rule 揀 Remote Rule (Github) 輸入 GitHub 倉庫地址
8.3 透過 API 上傳
使用 Skills API (/v1/skills 端點) 上傳自定義 Skill,上傳後喺成個工作區範圍內共享。
8.4 喺 claude.ai 上傳
透過 Settings > Features 上傳 Skill 嘅 zip 檔案。需要 Pro、Max、Team 或 Enterprise 計劃,同埋啟用代碼執行。
8.5 規則同命令遷移
Cursor 2.4 版本內置咗 /migrate-to-skills 技能,可以將現有嘅動態規則同斜槓命令轉換為 Skill:
- 動態規則
( alwaysApply: false)→ 轉換為標準 Skill - 斜槓命令
→ 轉換為設定咗 disable-model-invocation: true嘅 Skill
8.6 使用驗證工具
使用 skills-ref 參考庫驗證 Skill:
skills-ref validate ./my-skill
九、編寫高質量 Skill 嘅最佳實踐
9.1 簡潔係關鍵
Agent 已經好聰明,淨係加佢真正唔知嘅資訊:
# ✅ 好的:簡潔(~50 tokens)
## Extract PDF text
Use pdfplumber for text extraction:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
❌ 差嘅:囉嗦(~150 tokens)
Extract PDF text
PDF (Portable Document Format) files are a common file format
that contains text, images, and other content. To extract text
from a PDF, you'll need to use a library...
對每條信息的價值進行挑戰:
- "Agent 真的需要這個解釋嗎?"
- "我能假設 Agent 已經知道這個嗎?"
- "這段內容值得它佔用的 token 嗎?"
### 9.2 編寫有效的 description
`description` 字段是 Skill 能否被正確觸發的**決定性因素**:
-**使用第三人稱**:`"Processes Excel files"` 而非 `"I can help you process"`
-**包含觸發關鍵詞**:既描述做什麼,也描述何時使用
-**具體而不模糊**:列出具體的操作和文件類型
-**適度寬泛**:包含用戶可能不會直接點名但仍然相關的場景
```yaml
# ✅ 優秀的 description
description: >
Analyze CSV and tabular data files — compute summary statistics,
add derived columns, generate charts, and clean messy data. Use
when the user has a CSV, TSV, or Excel file and wants to explore,
transform, or visualize the data, even if they don't explicitly
mention "CSV" or "analysis."
# ❌ 糟糕的 description
description: Process CSV files.
9.3 命名規範
推薦使用動名詞形式(gerund),清晰描述 Skill 提供嘅能力:
processing-pdfs | pdf-processing | helper |
analyzing-spreadsheets | spreadsheet-analysis | utils |
managing-databases | process-pdfs | tools |
testing-code | analyze-spreadsheets | documents |
9.4 漸進式披露嘅檔案組織
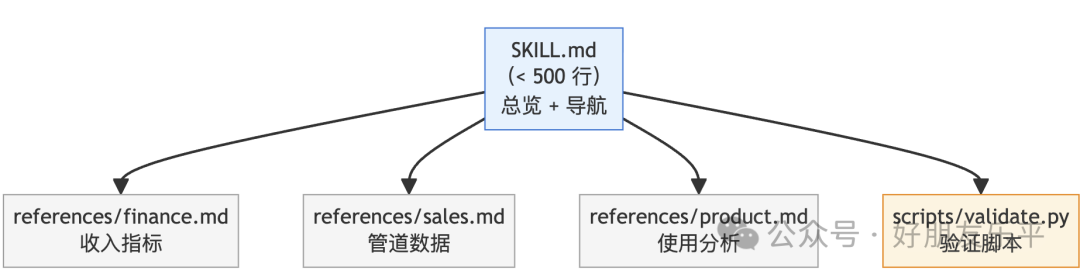
核心原則:
SKILL.md 主體控制在 500 行以內 詳細內容拆分到獨立檔案 檔案引用保持一層深度(唔嵌套引用) 超過 100 行嘅參考檔案加上目錄索引
9.5 避免常見反模式
scripts\helper.py | scripts/helper.py |
A → B → C → 實際內容 | |
9.6 使用一致嘅術語
# ✅ 一致
Always "API endpoint"
Always "field"
Always "extract"
# ❌ 不一致
Mix "API endpoint", "URL", "API route", "path"
Mix "field", "box", "element", "control"
Mix "extract", "pull", "get", "retrieve"
十、Skill 嘅評估同迭代
10.1 評估驅動嘅開發
喺寫大量文檔之前,先建立評估用例。咁確保你嘅 Skill 解決嘅係真實問題:

10.2 測試用例結構
{
"skill_name":"csv-analyzer",
"evals":[
{
"id":1,
"prompt":"我有一個月度銷售數據的 CSV 文件,能找出收入最高的 3 個月並做一個柱狀圖嗎?",
"expected_output":"柱狀圖顯示收入最高的 3 個月,有標註的座標軸和數值。",
"files":["evals/files/sales_2025.csv"],
"assertions":[
"輸出包含柱狀圖文件",
"圖表恰好顯示 3 個月",
"兩個座標軸都有標籤",
"圖表標題或說明提到了收入"
]
}
]
}
10.3 雙實例迭代法
最有效嘅 Skill 開發過程涉及兩個 Agent 實例協作:
| Claude A | |
| Claude B |
迭代步驟:
用 Claude A 完成一個冇 Skill 嘅任務,記錄你提供嘅上下文 叫 Claude A 將呢啲上下文轉化為 Skill 用 Claude B 測試 Skill 喺相似任務上嘅表現 將觀察結果反饋畀 Claude A 進行改進 循環往復
10.4 觸發描述優化
透過設計觸發評估查詢嚟測試同優化 description 嘅準確性:
準備大約 20 個查詢:8-10 個應該觸發、8-10 個唔應該觸發 每個查詢運行多次(至少 3 次),計算觸發率 使用訓練集/驗證集分拆(60%/40%)避免過度擬合 迭代 5 次通常已經夠
10.5 觀察 Agent 點樣用 Skill
喺迭代過程中留意觀察:
- 意外嘅瀏覽路徑
:Agent 係咪跟你預期嘅順序讀檔案? - 遺漏嘅連接
:Agent 係咪冇跟蹤到重要檔案嘅引用? - 過度依賴某啲部分
:Agent 重複讀同一個檔案,可能嗰啲內容應該放入主 SKILL.md - 被忽略嘅內容
:Agent 從未訪問嘅檔案,可能係唔必要嘅
十一、安全考量
11.1 信任模型
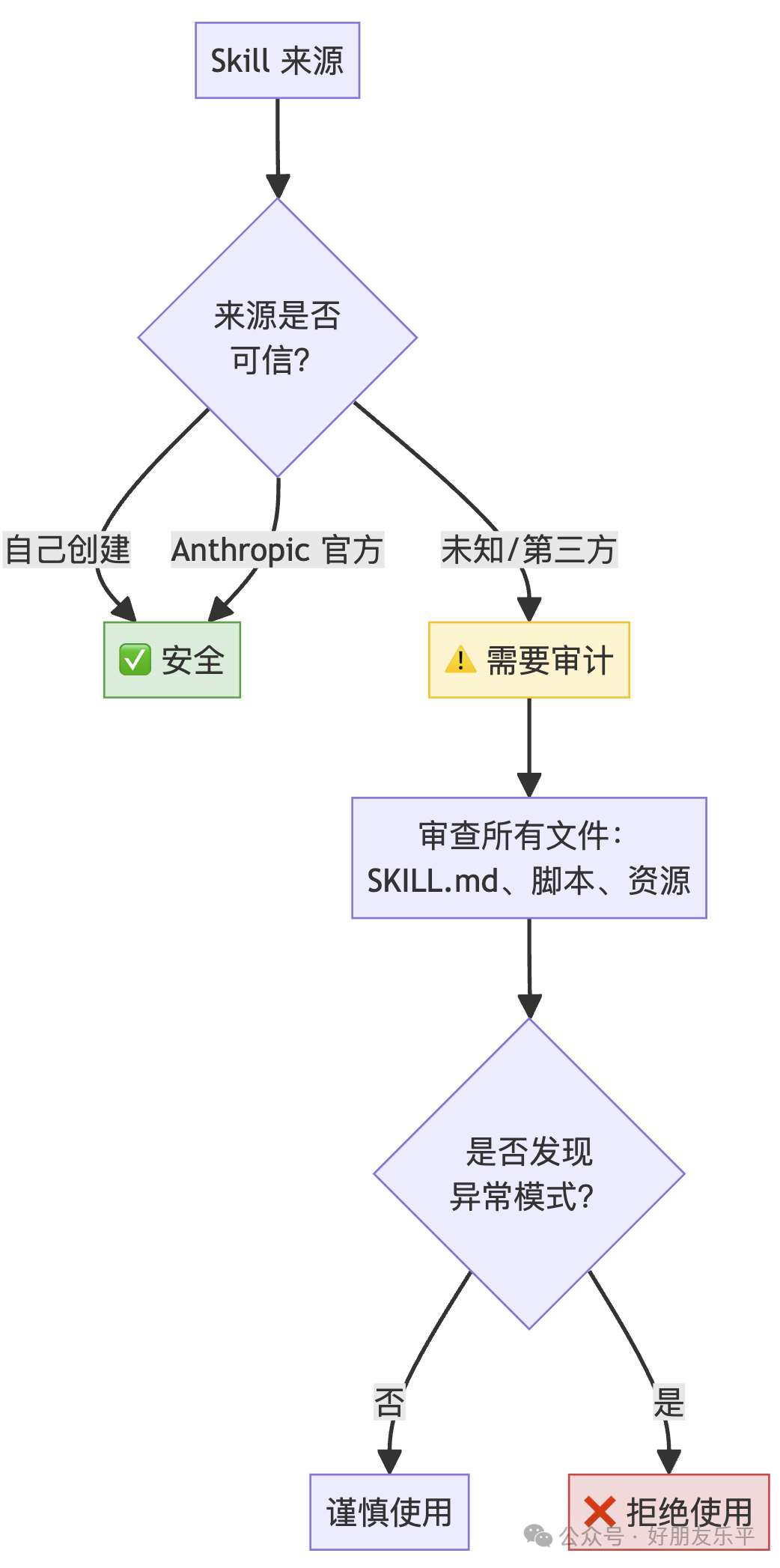
11.2 關鍵安全原則
| 工具濫用 | ||
| 數據泄露 | ||
| 外部源風險 | ||
| 項目級注入 |
11.3 審計清單
審查 SKILL.md 入面所有指令 審查 scripts/ 入面所有腳本檔案 檢查係咪有意外嘅網絡請求 檢查檔案存取模式係咪同 Skill 聲明嘅用途一致 檢查係咪有操作唔匹配 Skill 聲明用途嘅行為
十二、同其他能力嘅對比
Agent Skills 唔係 Agent 擴展能力嘅唯一方式,理解佢同其他方式嘅分別有助於喺正確嘅場景揀正確嘅工具:
| 定位 | ||||
| 加載方式 | ||||
| 適用範圍 | ||||
| 典型內容 | ||||
| 組合使用 |
一個常見嘅強力組合:MCP 提供工具存取,Skill 教 Agent 點樣有效使用呢啲工具。
例如,MCP 連接令 Agent 可以調用 BigQuery API,而 Skill 話畀 Agent 知你哋公司嘅表結構、命名規範同常見查詢模式。
十三、開放標準同生態
13.1 開放標準
Agent Skills 規範作為開放標準發佈喺 agentskills.io。呢個意味住:
你建立嘅 Skill 唔會鎖死到特定平台 同一套 Skill 格式可以用喺所有採用該標準嘅 AI 平台同工具中 提供 Python 參考 SDK 畀開發者喺自己嘅平台中實現 Skills 支援
13.2 幫你嘅 Agent 加 Skills 支援
如果你喺開發自己嘅 AI Agent 或開發工具,可以跟以下步驟加 Skills 支援:

核心實現要點:
- 發現
:掃描約定目錄,揾出包含 SKILL.md嘅子目錄 - 解析
:提取 YAML frontmatter 同 markdown 主體 - 披露
:喺系統提示詞中注入技能目錄(淨係 name + description) - 激活
:透過檔案讀取或專用工具將完整指令加載到上下文 - 上下文管理
:保護 Skill 內容唔畀上下文壓縮算法移除,去重複激活
13.3 生態現狀
目前支援 Agent Skills 標準嘅平台包括:
- Cursor
:透過檔案系統自動發現同使用 - Claude Code
:原生支援,檔案系統集成 - Claude API
:透過 Skills API 上傳同使用 - Claude.ai
:透過設定上傳同使用 - Agent SDK
:TypeScript 同 Python SDK 支援
附錄:Skill 效果檢查清單
喺分享你嘅 Skill 之前,逐一確認以下項目:
核心質量
description具體而且包含關鍵詞description同時說明做啲乜同幾時用SKILL.md 主體喺 500 行以內 額外細節放喺獨立檔案 冇時效性資訊(或放喺「舊模式」區域) 全程術語一致 示例具體,唔抽象 檔案引用得一層深度 合理使用漸進式披露 工作流有清晰嘅步驟
代碼同腳本
腳本主動處理錯誤,而唔係將問題拋畀 Agent 錯誤處理明確而且有幫助 冇「魔法常數」(所有值都有註釋解釋) 所需軟件包喺指令中列出並驗證可用 腳本有清晰嘅 --help文檔唔用 Windows 風格路徑 關鍵操作有驗證/確認步驟 質量關鍵任務包含反饋循環
測試
至少建立 3 個評估用例 喺計劃使用嘅所有模型上測試 使用真實使用場景測試 納入團隊反饋(如適用)
Agent Skills 是一個開放標準,用於為 AI Agent 擴展專用能力。本文將從概念、工作原理、規範、分類、腳本支持、最佳實踐等多個維度,帶你全面瞭解 Agent Skills。
一、什麼是 Agent Skill?
1.1 基本概念
Agent Skill(技能) 是一種可移植、受版本控制的包,用來教會 AI Agent 執行特定領域的任務。你可以把它理解為給 AI Agent 安裝的「插件」或「技能包」——它把特定領域的知識、工作流程、腳本和最佳實踐打包封裝,供 Agent 在合適的時機自動調用。
用一個更直觀的比喻:如果 AI Agent 是一位通才型的新員工,那麼 Skill 就是你為他準備的入職培訓手冊——它不會改變員工的智力水平,但會讓他立刻掌握公司特定的工作流程和領域知識。
1.2 四大特性
| 可移植 | |
| 受版本控制 | |
| 可操作 | |
| 漸進式 |
1.3 為什麼需要 Skill?
問題場景:你每次和 AI Agent 對話時,都需要反覆提供相同的上下文——比如公司的代碼規範、部署流程、數據庫表結構等。這既浪費時間,也容易遺漏。
Skill 的解決方案:
- 專業化
:讓通用 Agent 變成特定領域的專家 - 減少重複
:一次創建,自動使用 - 能力組合
:多個 Skill 可以組合使用,構建複雜工作流 - 知識沉澱
:將團隊的工作流程、最佳實踐和機構知識固化下來
二、核心設計理念:漸進式披露
漸進式披露(Progressive Disclosure)是 Agent Skills 最核心的設計理念。它確保 Agent 只在需要時加載必要的信息,而非一開始就把所有內容塞進上下文窗口。
2.1 三級加載機制
name 和 description | |||
2.2 為什麼這很重要?
上下文窗口是一種公共資源,你的 Skill 和以下內容共享這個空間:
系統提示詞(System Prompt) 對話歷史 其他 Skill 的元數據 用戶的實際請求
漸進式披露讓你可以安裝幾十個 Skill 而不會產生上下文壓力——Agent 只知道每個 Skill 的存在和用途,只有在真正需要時才加載完整內容。
三、Agent 如何消費 Skill?
理解 Skill 的消費機制是理解整個體系的關鍵。這裏需要區分三個角色:Agent(程序)、LLM(大模型) 和 Skill 文件(文件系統)。Agent 是 LLM 的"外殼程序",負責管理對話、調用工具、組裝 prompt;LLM 是做決策的大腦;Skill 文件是靜態的知識包。
3.1 Agent、LLM 與 Skill 的完整交互流程
下面這張圖完整展示了從 Agent 啓動到 Skill 被使用的全過程。注意關鍵點:Skill 的篩選和激活是由 LLM 決策的,Agent 只負責執行 LLM 的指令(讀文件、跑腳本)。
關鍵要點
上面這張圖有幾個值得特別注意的地方:
1. Skill 目錄在啓動時就注入 System Prompt
Agent 啓動時掃描文件系統,提取每個 Skill 的 name 和 description(每個約 100 tokens),拼接成一個"技能目錄"塊,注入到 System Prompt 中。這個目錄類似這樣:
<available_skills>
<skill>
<name>pdf-processing</name>
<description>Extract PDF text, fill forms, merge files. Use when handling PDFs.</description>
<location>~/.agents/skills/pdf-processing/SKILL.md</location>
</skill>
<skill>
<name>data-analysis</name>
<description>Analyze datasets, generate charts, and create summary reports.</description>
<location>~/project/.agents/skills/data-analysis/SKILL.md</location>
</skill>
</available_skills>
2. Skill 篩選由 LLM 完成,不是 Agent 硬編碼匹配
Agent 不會自己做關鍵詞匹配來決定用哪個 Skill。而是將"技能目錄"和用戶消息一起發給 LLM,由 LLM 根據語義理解決定是否加載某個 Skill。LLM 的決策體現為一次工具調用——調用 Read 工具讀取對應的 SKILL.md 文件。
3. Skill 內容通過"工具調用-工具結果"機制進入上下文
SKILL.md 的內容不是直接塞進 prompt 的,而是通過 LLM 主動發起一次 Read 工具調用,Agent 執行讀取後將內容作為 tool_result 返回。這意味着 Skill 的加載使用的是和其他工具調用完全相同的通信機制。
4. 後續操作(讀引用文件、執行腳本)也都是 LLM 驅動的
加載 SKILL.md 後,LLM 可能繼續發起工具調用來讀取參考文檔或執行腳本。每次都是 LLM 做決策、Agent 執行、結果返回,循環進行。
3.2 與 MCP Tool 交互流程的對比
Skills 和 MCP Tools 都是擴展 Agent 能力的方式,但交互模式有本質區別。下面用兩張並排的時序圖來對比:
MCP Tool 的交互流程
Skill 與 MCP Tool 的本質區別
總結兩者的核心差異:
| 本質 | ||
| 信息注入位置 | tools 參數發送 | |
| 觸發結果 | ||
| LLM 行為變化 | ||
| 類比 | ||
| 組合使用 |
一個常見的強力組合場景:MCP 給 Agent 提供了調用 BigQuery 的能力(工具),Skill 教會 Agent 你們公司的表結構、查詢規範和注意事項(指令)。兩者互補,缺一不可。
3.3 完整的 Prompt 拼接示意
為了更直觀地理解 Skill 是如何融入 Agent 與 LLM 的對話流程中的,下面展示一次完整交互中 Agent 發給 LLM 的 prompt 結構:
┌──────────────────────────────────────────────────────────┐
│ SystemPrompt │
│ ┌────────────────────────────────────────────────────┐ │
│ │ 基礎指令(你是一個 AI 助手...) │ │
│ ├────────────────────────────────────────────────────┤ │
│ │ 📦 可用技能目錄(~100tokens × N 個 Skill) │ │
│ │ • pdf-processing:ExtractPDFtext,fillforms... │ │
│ │ • data-analysis:Analyzedatasets,generate... │ │
│ │ • deploy-app:Deploytheapplicationto... │ │
│ │ 當任務匹配技能描述時,使用 Read 工具加載 SKILL.md │ │
│ ├────────────────────────────────────────────────────┤ │
│ │ 🔧 可用工具列表 │ │
│ │ • Read(讀取文件) │ │
│ │ • Bash(執行命令) │ │
│ │ • get_weather(MCP 工具) │ │
│ │ • ... │ │
│ └────────────────────────────────────────────────────┘ │
├──────────────────────────────────────────────────────────┤
│ 對話歷史 │
│ [user]: 幫我從這個 PDF 中提取文本 │
│ [assistant]:tool_use → Read("pdf-processing/SKILL.md") │
│ [tool_result]:#PDFProcessing...(SKILL.md 內容) │
│ [assistant]:tool_use → Bash("python scripts/extract.py")│
│ [tool_result]:Extracted15pagesoftext... │
│ [assistant]: 已從 PDF 中提取文本,以下是總結... │
├──────────────────────────────────────────────────────────┤
│ 當前用戶消息 │
│ [user]: 再幫我把提取的內容生成一份 Word 文檔 │
└──────────────────────────────────────────────────────────┘
可以看到:
- Skill 目錄
和 MCP 工具定義同時存在於 prompt 中 Skill 的激活(讀取 SKILL.md)在對話歷史中表現為一次普通的工具調用 SKILL.md 的內容作為 tool_result留在對話歷史中,持續影響後續 LLM 的行為
3.4 發現階段詳解
Agent 啓動時,會從以下目錄自動發現技能:
.agents/skills/ | ||
.cursor/skills/ | ||
~/.cursor/skills/ | ||
.claude/skills/ | ||
~/.claude/skills/ |
掃描規則:
跳過 .git/、node_modules/等無關目錄設置合理的掃描深度(一般 4-6 層)和目錄數上限(~2000 個) 項目級 Skill 優先級高於用戶級 Skill(同名時覆蓋)
3.5 觸發激活方式
Skill 有兩種激活方式:
自動觸發(Model-driven):LLM 看到 System Prompt 中的技能目錄後,根據用戶請求的語義自動判斷是否需要加載某個 Skill。這是最常見的方式——LLM 的決策體現為一次讀取 SKILL.md 的工具調用。
手動調用(User-explicit):用戶在對話中輸入 /skill-name(斜槓命令)來顯式調用特定 Skill。此時 Agent(程序側)直接將 SKILL.md 內容注入上下文,不需要 LLM 做判斷。適用於設置了 disable-model-invocation: true 的 Skill。
3.6 腳本執行的高效性
當 Skill 中的指令引用了腳本文件時,Agent 通過 bash 直接執行腳本,而不是將腳本代碼讀入上下文:
這意味着:
腳本代碼本身不會消耗上下文 token 只有腳本的輸出結果會進入 Agent 的上下文 比讓 Agent 臨時生成代碼更可靠、更高效
四、Skill 的規範與結構
4.1 目錄結構
每個 Skill 是一個包含 SKILL.md 文件的文件夾:
my-skill/
├── SKILL.md # 必需:元數據 + 指令
├── scripts/ # 可選:可執行代碼
│ ├── deploy.sh
│ └── validate.py
├── references/ # 可選:補充文檔
│ ├── REFERENCE.md
│ └── FORMS.md
├── assets/ # 可選:模板、圖片等靜態資源
│ └── config-template.json
└── ...# 任何其他文件或目錄
各目錄的職責:
SKILL.md | ||
scripts/ | ||
references/ | ||
assets/ |
4.2 SKILL.md 文件格式
每個 Skill 在帶有 YAML frontmatter 的 SKILL.md 文件中定義:
---
name: pdf-processing
description: Extract PDF text, fill forms, merge files. Use when handling PDFs.
license: Apache-2.0
metadata:
author: example-org
version: "1.0"
---
# PDF Processing
## Quick start
Use pdfplumber to extract text from PDFs:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
Advanced features
Form filling: See FORMS.md for complete guide
API reference: See REFERENCE.md for all methods
### 4.3 Frontmatter 字段詳解
#### 必填字段
| 字段 | 約束 | 說明 |
|------|------|------|
| `name` | 最多 64 字符,僅允許小寫字母、數字和連字符,不能以連字符開頭或結尾,不能包含連續連字符,必須與父文件夾名一致 | 技能標識符 |
| `description` | 最多 1024 字符,不能為空 | 描述技能功能和使用場景,Agent 用它來判斷相關性 |
#### 可選字段
| 字段 | 約束 | 說明 |
|------|------|------|
| `license` | 無 | 許可證名稱或對隨附許可證文件的引用 |
| `compatibility` | 最多 500 字符 | 環境要求(目標產品、系統軟件包、網絡訪問等) |
| `metadata` | 鍵值對映射 | 用於附加元數據(如 author、version) |
| `disable-model-invocation` | 布爾值 | 為 `true` 時僅在通過 `/skill-name` 顯式調用時才使用 |
| `allowed-tools` | 空格分隔的工具列表 | 預批准該 Skill 可使用的工具(實驗性功能) |
#### name 字段示例
```yaml
# ✅ 合法
name: pdf-processing
name: data-analysis
name: code-review
# ❌ 非法
name: PDF-Processing # 不允許大寫
name: -pdf # 不能以連字符開頭
name: pdf--processing # 不能有連續連字符
description 字段示例
# ✅ 好的描述:具體且包含觸發關鍵詞
description:>
Extract text and tables from PDF files, fill forms, merge documents.
Use when working with PDF files or when the user mentions PDFs,
forms, or document extraction.
# ❌ 差的描述:太模糊
description:HelpswithPDFs.
4.4 文件引用規範
在 Skill 中引用其他文件時,使用相對於 Skill 根目錄的路徑:
See [the reference guide](references/REFERENCE.md) for details.
Run the extraction script:
scripts/extract.py
關鍵規則:
始終使用正斜槓 references/guide.md,而非反斜槓文件引用保持一層深度,避免嵌套引用鏈 文件名應當有描述性:用 form_validation_rules.md而不是doc2.md
五、Skill 的分類
5.1 預構建 Skill(Anthropic Skills)
由 Anthropic 官方創建和維護的 Skill,開箱即用:
pptx | ||
xlsx | ||
docx | ||
pdf |
這些 Skill 在 claude.ai 和 Claude API 上對所有用戶可用,Agent 會在相關任務中自動調用。
5.2 自定義 Skill(Custom Skills)
用戶或組織自行創建的 Skill,用於特定領域的工作流。按內容構成可分為:
純指令型 Skill
只包含 SKILL.md,通過自然語言指令指導 Agent:
code-review/
└── SKILL.md
適用場景:代碼審查流程、寫作風格指南、會議紀要模板等不需要執行代碼的任務。
包含參考文檔的 Skill
除主指令外,附帶額外的參考文檔,Agent 按需讀取:
bigquery-skill/
├── SKILL.md
└── reference/
├── finance.md
├── sales.md
└── product.md
適用場景:需要大量領域知識的任務,如數據庫分析、API 對接等。
包含腳本的 Skill
附帶可執行腳本,Agent 在執行任務時調用:
deploy-app/
├── SKILL.md
└── scripts/
├── deploy.sh
└── validate.py
適用場景:部署、數據處理、表單填充等需要確定性操作的任務。
複合型 Skill
同時包含指令、參考文檔、腳本和資源:
pdf-processing/
├── SKILL.md
├── FORMS.md
├── REFERENCE.md
├── examples.md
├── scripts/
│ ├── analyze_form.py
│ ├── fill_form.py
│ └── validate.py
└── assets/
└── template.json
5.3 組織級 Skill(Organization Provisioned)
針對 Team 和 Enterprise 計劃,組織的管理員可以為所有用戶統一配置 Skill:
分發經過審批的工作流,確保全員一致 確保團隊使用標準化的流程和最佳實踐 部署新能力無需每個用戶單獨上傳 Skill 可設為默認啓用或禁用
5.4 合作伙伴 Skill(Partner Skills)
由合作伙伴(如 Notion、Figma、Atlassian 等)專業構建的 Skill,設計為與對應的 MCP 連接器無縫配合使用,實現強大的集成工作流。
六、支持腳本的 Skill
支持腳本是 Agent Skill 最強大的能力之一。它將確定性的代碼執行與 Agent 的靈活決策結合起來。
6.1 腳本 vs 指令的選擇
6.2 一次性命令
當現有工具包已經能滿足需求時,可以直接在 SKILL.md 中引用,而不需要 scripts/ 目錄:
uvx | uvx ruff@0.8.0 check . | |
pipx | pipx run 'black==24.10.0' . | |
npx | npx eslint@9 --fix . | |
bunx | bunx eslint@9 --fix . | |
deno run | deno run npm:create-vite@6 my-app | |
go run | go run golang.org/x/tools/cmd/goimports@v0.28.0 . |
關鍵原則:鎖定版本號,確保行為一致。
6.3 自包含腳本
當需要自定義邏輯時,將腳本放入 scripts/ 目錄並聲明內聯依賴:
Python 示例(PEP 723):
# /// script
# dependencies = [
# "beautifulsoup4",
# ]
# ///
from bs4 import BeautifulSoup
html = '<html><body><h1>Welcome</h1><p class="info">Test.</p></body></html>'
print(BeautifulSoup(html, "html.parser").select_one("p.info").get_text())
使用 uv run scripts/extract.py 運行,uv 會自動創建隔離環境並安裝依賴。
Deno 示例:
#!/usr/bin/env -S deno run
import * as cheerio from"npm:cheerio@1.0.0";
const html = `<html><body><p class="info">Test.</p></body></html>`;
const $ = cheerio.load(html);
console.log($("p.info").text());
6.4 腳本設計原則
為 Agent 設計腳本時,需要遵循以下原則:
禁止交互式提示
Agent 在非交互式 shell 中運行,無法響應 TTY 提示。所有輸入通過命令行參數、環境變量或 stdin 接收:
# ❌ 錯誤:會掛起等待輸入
$ python scripts/deploy.py
Target environment: _
# ✅ 正確:清晰的錯誤提示
$ python scripts/deploy.py
Error: --env is required. Options: development, staging, production.
Usage: python scripts/deploy.py --env staging --tag v1.2.3
提供 --help 文檔
--help 輸出是 Agent 瞭解腳本接口的主要方式:
Usage: scripts/process.py [OPTIONS] INPUT_FILE
Process input data and produce a summary report.
Options:
--formatFORMATOutputformat: json, csv, table (default: json)
--outputFILE Write output to FILE instead of stdout
--verbose Print progress to stderr
提供有意義的錯誤信息
# ❌ 不好:模糊
Error: invalid input
# ✅ 好:具體且有指導性
Error: --format must be one of: json, csv, table.
Received: "xml"
使用結構化輸出
優先使用 JSON、CSV 等結構化格式,而非自由文本。將數據輸出到 stdout,診斷信息輸出到 stderr。
其他原則
- 冪等性
:Agent 可能重試命令,「不存在則創建」比「創建然後在重複時失敗」更安全 - 幹運行支持
:對於破壞性操作,提供 --dry-run標誌 - 有意義的退出碼
:不同失敗類型使用不同退出碼 - 可預測的輸出大小
:Agent 的工具輸出通常有截斷閾值,支持 --offset等分頁參數
6.5 工作流與反饋循環
支持腳本的 Skill 特別適合構建驗證反饋循環:
這種「計劃-驗證-執行」模式通過在每個關鍵步驟後加入機器可驗證的檢查,大幅提高輸出質量:
- 早期捕獲錯誤
:驗證在變更應用之前發現問題 - 機器可驗證
:腳本提供客觀驗證 - 可逆規劃
:Agent 可以在不觸碰原始文件的情況下迭代計劃
6.6 實戰 Demo:天氣查詢 Skill
下面通過一個完整的、可運行的天氣查詢 Skill,來展示腳本型 Skill 的完整結構和工作方式。
目錄結構
check-weather/
├── SKILL.md
└── scripts/
└── get-weather.mjs
SKILL.md 文件
---
name: check-weather
description: >
Query current weather conditions for any city worldwide.
Use when the user asks about weather, temperature, wind,
humidity, or atmospheric conditions for a specific location.
compatibility: Requires Node.js 18+ (uses native fetch API)
metadata:
author: demo
version: "1.0"
---
# Check Weather
Query real-time weather data for any city using the wttr.in API.
## Usage
Run the weather script with the city name:
```bash
node scripts/get-weather.mjs <city>
Examples:
node scripts/get-weather.mjs Beijing
node scripts/get-weather.mjs "New York"
node scripts/get-weather.mjs Tokyo
Output Format
The script outputs JSON with the following fields:
{
"city":"Beijing",
"country":"China",
"temperature":"22°C",
"feels_like":"20°C",
"weather":"Partly cloudy",
"humidity":"45%",
"wind_speed":"15 km/h",
"wind_direction":"NE",
"visibility":"10 km",
"pressure":"1015 mb",
"uv_index":"5",
"observation_time":"02:30 PM"
}
Guidelines
If the user provides a Chinese city name, translate it to English
before calling the script (e.g. 北京 → Beijing)If the script fails due to network issues, inform the user and
suggest trying again laterPresent the weather data in a readable, conversational format
rather than dumping raw JSON
#### scripts/get-weather.mjs 腳本
```javascript
#!/usr/bin/env node
const city = process.argv[2];
if (!city) {
console.error(JSON.stringify({
error: "City name is required",
usage: "node scripts/get-weather.mjs <city>",
examples: [
'node scripts/get-weather.mjs Beijing',
'node scripts/get-weather.mjs "New York"'
]
}, null, 2));
process.exit(1);
}
try {
const url = `https://wttr.in/${encodeURIComponent(city)}?format=j1`;
const response = await fetch(url);
if (!response.ok) {
console.error(JSON.stringify({
error: `HTTP ${response.status}: Failed to fetch weather for"${city}"`,
suggestion: "Check the city name and try again"
}));
process.exit(1);
}
const data = await response.json();
const current = data.current_condition?.[0];
const area = data.nearest_area?.[0];
if (!current) {
console.error(JSON.stringify({
error: `No weather data available for"${city}"`
}));
process.exit(1);
}
const result = {
city: area?.areaName?.[0]?.value ?? city,
country: area?.country?.[0]?.value ?? "Unknown",
temperature: `${current.temp_C}°C`,
feels_like: `${current.FeelsLikeC}°C`,
weather: current.weatherDesc?.[0]?.value ?? "Unknown",
humidity: `${current.humidity}%`,
wind_speed: `${current.windspeedKmph} km/h`,
wind_direction: current.winddir16Point,
visibility: `${current.visibility} km`,
pressure: `${current.pressure} mb`,
uv_index: current.uvIndex,
observation_time: current.observation_time
};
console.log(JSON.stringify(result, null, 2));
} catch (err) {
console.error(JSON.stringify({
error: `Network error: ${err.message}`,
suggestion: "Check your internet connection and try again"
}));
process.exit(1);
}
實際交互過程
當用戶說 "北京今天天氣怎麼樣",Agent 和 LLM 的交互過程如下:
這個 Demo 體現了腳本型 Skill 的幾個核心價值:
- 腳本提供確定性能力
:API 調用和數據解析由腳本保證,不依賴 LLM 生成代碼 - 指令提供靈活指導
:翻譯城市名、格式化輸出等由 LLM 根據指令靈活完成 - 錯誤處理自包含
:腳本自己處理各種異常,提供結構化的錯誤信息 - 零 token 浪費
:腳本代碼不進入上下文,只有 JSON 輸出進入
七、Skill 在不同平台的使用
Agent Skills 可以在多個平台上使用,但各平台的支持程度和限制有所不同:
7.1 平台支持矩陣
7.2 跨平台限制
自定義 Skill 不會在不同平台之間自動同步:
上傳到 claude.ai 的 Skill 需要單獨上傳到 API 通過 API 上傳的 Skill 在 claude.ai 上不可用 Claude Code 的 Skill 是基於文件系統的,與 claude.ai 和 API 均獨立
7.3 在 Claude API 中使用
使用 Claude API 時,通過 container 參數指定 Skill:
response = client.beta.messages.create(
model="claude-opus-4-6",
max_tokens=4096,
betas=["code-execution-2025-08-25", "skills-2025-10-02"],
container={
"skills": [
{"type": "anthropic", "skill_id": "pptx", "version": "latest"}
]
},
messages=[
{"role": "user", "content": "Create a presentation about AI"}
],
tools=[{"type": "code_execution_20250825", "name": "code_execution"}],
)
需要三個 beta 頭:
code-execution-2025-08-25:Skill 在代碼執行容器中運行 skills-2025-10-02:啓用 Skills 功能 files-api-2025-04-14:用於上傳/下載文件到容器
7.4 在 Cursor 中使用
Cursor 支持自定義 Skill,從以下目錄自動發現:
.agents/skills/ | |
.cursor/skills/ | |
~/.cursor/skills/ |
也可以在 Cursor Settings → Rules 的「Agent Decides」區域查看已發現的 Skill。
手動調用方式:在 Agent 對話中輸入 / 並搜索技能名稱。
八、Skill 的安裝與管理
8.1 本地創建
最簡單的方式,直接在項目或全局目錄中創建 Skill 文件夾:
# 項目級
mkdir -p .agents/skills/my-skill
touch .agents/skills/my-skill/SKILL.md
# 全局級
mkdir -p ~/.agents/skills/my-skill
touch ~/.agents/skills/my-skill/SKILL.md
8.2 從 GitHub 安裝
在 Cursor 中:
打開 Cursor Settings → Rules 在 Project Rules 部分,點擊 Add Rule 選擇 Remote Rule (Github) 輸入 GitHub 倉庫地址
8.3 通過 API 上傳
使用 Skills API (/v1/skills 端點) 上傳自定義 Skill,上傳後在整個工作區範圍內共享。
8.4 在 claude.ai 上傳
通過 Settings > Features 上傳 Skill 的 zip 文件。需要 Pro、Max、Team 或 Enterprise 計劃,且啓用代碼執行。
8.5 規則和命令遷移
Cursor 2.4 版本內置了 /migrate-to-skills 技能,可以將現有的動態規則和斜槓命令轉換為 Skill:
- 動態規則
( alwaysApply: false)→ 轉換為標準 Skill - 斜槓命令
→ 轉換為設置了 disable-model-invocation: true的 Skill
8.6 使用驗證工具
使用 skills-ref 參考庫驗證 Skill:
skills-ref validate ./my-skill
九、編寫高質量 Skill 的最佳實踐
9.1 簡潔是關鍵
Agent 已經非常聰明,只添加它真正不知道的信息:
# ✅ 好的:簡潔(~50 tokens)
## Extract PDF text
Use pdfplumber for text extraction:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
❌ 差的:囉嗦(~150 tokens)
Extract PDF text
PDF (Portable Document Format) files are a common file format
that contains text, images, and other content. To extract text
from a PDF, you'll need to use a library...
對每條信息的價值進行挑戰:
- "Agent 真的需要這個解釋嗎?"
- "我能假設 Agent 已經知道這個嗎?"
- "這段內容值得它佔用的 token 嗎?"
### 9.2 編寫有效的 description
`description` 字段是 Skill 能否被正確觸發的**決定性因素**:
-**使用第三人稱**:`"Processes Excel files"` 而非 `"I can help you process"`
-**包含觸發關鍵詞**:既描述做什麼,也描述何時使用
-**具體而不模糊**:列出具體的操作和文件類型
-**適度寬泛**:包含用戶可能不會直接點名但仍然相關的場景
```yaml
# ✅ 優秀的 description
description: >
Analyze CSV and tabular data files — compute summary statistics,
add derived columns, generate charts, and clean messy data. Use
when the user has a CSV, TSV, or Excel file and wants to explore,
transform, or visualize the data, even if they don't explicitly
mention "CSV" or "analysis."
# ❌ 糟糕的 description
description: Process CSV files.
9.3 命名規範
推薦使用動名詞形式(gerund),清晰描述 Skill 提供的能力:
processing-pdfs | pdf-processing | helper |
analyzing-spreadsheets | spreadsheet-analysis | utils |
managing-databases | process-pdfs | tools |
testing-code | analyze-spreadsheets | documents |
9.4 漸進式披露的文件組織
核心原則:
SKILL.md 主體控制在 500 行以內 詳細內容拆分到獨立文件 文件引用保持一層深度(不嵌套引用) 超過 100 行的參考文件加上目錄索引
9.5 避免常見反模式
scripts\helper.py | scripts/helper.py |
A → B → C → 實際內容 | |
9.6 使用一致的術語
# ✅ 一致
Always "API endpoint"
Always "field"
Always "extract"
# ❌ 不一致
Mix "API endpoint", "URL", "API route", "path"
Mix "field", "box", "element", "control"
Mix "extract", "pull", "get", "retrieve"
十、Skill 的評估與迭代
10.1 評估驅動的開發
在編寫大量文檔之前,先創建評估用例。這確保你的 Skill 解決的是真實問題:
10.2 測試用例結構
{
"skill_name":"csv-analyzer",
"evals":[
{
"id":1,
"prompt":"我有一個月度銷售數據的 CSV 文件,能找出收入最高的 3 個月並做一個柱狀圖嗎?",
"expected_output":"柱狀圖顯示收入最高的 3 個月,有標註的座標軸和數值。",
"files":["evals/files/sales_2025.csv"],
"assertions":[
"輸出包含柱狀圖文件",
"圖表恰好顯示 3 個月",
"兩個座標軸都有標籤",
"圖表標題或說明提到了收入"
]
}
]
}
10.3 雙實例迭代法
最有效的 Skill 開發過程涉及兩個 Agent 實例協作:
| Claude A | |
| Claude B |
迭代步驟:
用 Claude A 完成一個沒有 Skill 的任務,記錄你提供的上下文 讓 Claude A 將這些上下文轉化為 Skill 用 Claude B 測試 Skill 在相似任務上的表現 將觀察結果反饋給 Claude A 進行改進 循環往復
10.4 觸發描述優化
通過設計觸發評估查詢來測試和優化 description 的準確性:
準備約 20 個查詢:8-10 個應當觸發、8-10 個不應觸發 每個查詢運行多次(至少 3 次),計算觸發率 使用訓練集/驗證集拆分(60%/40%)避免過擬合 迭代 5 次通常足夠
10.5 觀察 Agent 如何使用 Skill
在迭代過程中注意觀察:
- 意外的瀏覽路徑
:Agent 是否按你預期的順序讀取文件? - 遺漏的連接
:Agent 是否未能跟蹤到重要文件的引用? - 過度依賴某些部分
:Agent 反覆讀取同一個文件,可能該內容應放入主 SKILL.md - 被忽略的內容
:Agent 從未訪問的文件,可能是不必要的
十一、安全考量
11.1 信任模型
11.2 關鍵安全原則
| 工具濫用 | ||
| 數據泄露 | ||
| 外部源風險 | ||
| 項目級注入 |
11.3 審計清單
審查 SKILL.md 中的所有指令 審查 scripts/ 中的所有腳本文件 檢查是否有意外的網絡請求 檢查文件訪問模式是否與 Skill 聲明的用途一致 檢查是否有操作不匹配 Skill 聲明用途的行為
十二、與其他能力的對比
Agent Skills 並不是 Agent 擴展能力的唯一方式,理解它與其他方式的區別有助於在正確的場景選擇正確的工具:
| 定位 | ||||
| 加載方式 | ||||
| 適用範圍 | ||||
| 典型內容 | ||||
| 組合使用 |
一個常見的強力組合:MCP 提供工具訪問,Skill 教會 Agent 如何有效使用這些工具。
例如,MCP 連接讓 Agent 可以調用 BigQuery API,而 Skill 告訴 Agent 你們公司的表結構、命名規範和常見查詢模式。
十三、開放標準與生態
13.1 開放標準
Agent Skills 規範作為開放標準發佈在 agentskills.io。這意味着:
你創建的 Skill 不會被鎖定到特定平台 同一套 Skill 格式可以在所有采用該標準的 AI 平台和工具中使用 提供 Python 參考 SDK 供開發者在自己的平台中實現 Skills 支持
13.2 為你的 Agent 添加 Skills 支持
如果你在開發自己的 AI Agent 或開發工具,可以按照以下步驟添加 Skills 支持:
核心實現要點:
- 發現
:掃描約定目錄,查找包含 SKILL.md的子目錄 - 解析
:提取 YAML frontmatter 和 markdown 主體 - 披露
:在系統提示詞中注入技能目錄(僅 name + description) - 激活
:通過文件讀取或專用工具將完整指令加載到上下文 - 上下文管理
:保護 Skill 內容不被上下文壓縮算法移除,去重重複激活
13.3 生態現狀
目前支持 Agent Skills 標準的平台包括:
- Cursor
:通過文件系統自動發現和使用 - Claude Code
:原生支持,文件系統集成 - Claude API
:通過 Skills API 上傳和使用 - Claude.ai
:通過設置上傳和使用 - Agent SDK
:TypeScript 和 Python SDK 支持
附錄:Skill 效果檢查清單
在分享你的 Skill 之前,逐一確認以下項目:
核心質量
description具體且包含關鍵詞description同時說明做什麼和何時使用SKILL.md 主體在 500 行以內 額外細節放在獨立文件中 沒有時效性信息(或放在「舊模式」區域) 全程術語一致 示例具體,非抽象 文件引用只有一層深度 合理使用漸進式披露 工作流有清晰的步驟
代碼和腳本
腳本主動處理錯誤,而非把問題拋給 Agent 錯誤處理明確且有幫助 沒有「魔法常數」(所有值都有註釋說明) 所需軟件包在指令中列出並驗證可用 腳本有清晰的 --help文檔不使用 Windows 風格路徑 關鍵操作有驗證/確認步驟 質量關鍵任務包含反饋循環
測試
至少創建 3 個評估用例 在計劃使用的所有模型上測試 使用真實使用場景測試 納入團隊反饋(如適用)