Agent Skills:我們的專業,正在被封裝
整理版優先睇
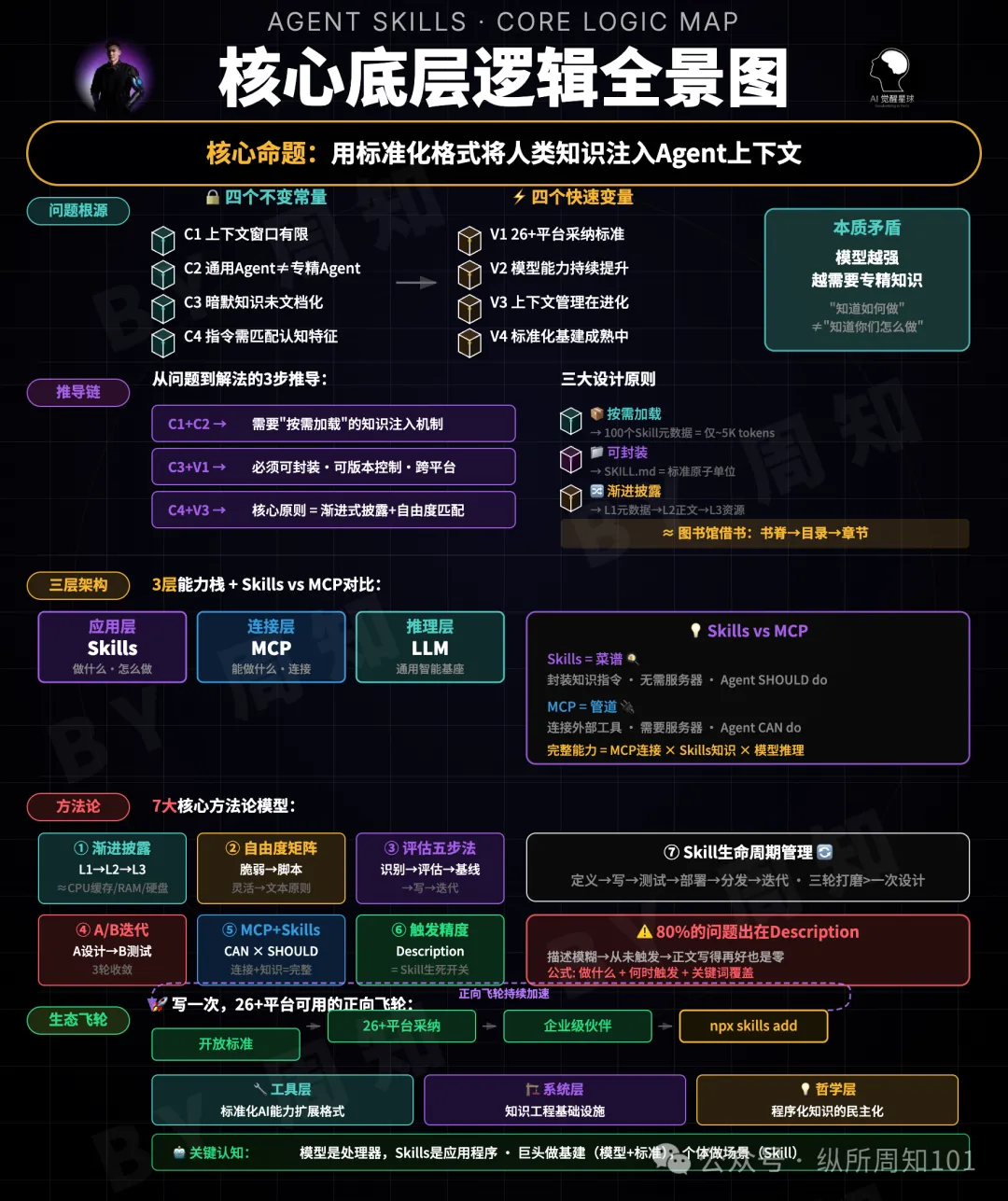
Agent Skills唔係提示詞,而係可跨平台封裝專家知識嘅標準化文件夾,關鍵在於漸進式披露同精準描述。
呢篇文章係由超級個體實踐者周知撰寫,佢想探討Agent Skills呢個概念背後嘅真正意義。作者指出,好多人以為Skills只係長啲嘅提示詞,但其實完全唔一樣——提示詞冇文件系統、冇版本控制、冇跨平台移植性,每次新對話都要重新貼一次,造成知識不斷重複流失。
作者對Agent Skills嘅定義係「一個標準化文件夾,用Markdown文件將專家知識封裝成可複用、可發現、可跨平台部署嘅能力插件」。呢個標準已經被多個平台採納,包括Claude、Cursor、Copilot等。整體結論係:Agent Skills係同時滿足按需加載、標準化封裝、漸進式披露三重約束嘅唯一解,而且係程序化知識民主化嘅體現。
文章仲深入解釋咗兩個決定Skills成敗嘅機制:漸進式披露(三級信息加載,避開上下文窗口限制)同description字段(決定Agent會唔會觸發呢個Skill)。最後作者提供咗實踐三步:識別知識漏點、從最小版本起步、封裝領域深度。佢強調領域深度比技術能力更重要,任何人都可以寫出高質Skill。
- Agent Skills係一個標準化文件夾,用Markdown封裝專家知識,可以跨平台重用,唔係普通提示詞。
- 漸進式披露機制(元數據、正文、資源三級)令Skills唔受上下文窗口限制,係架構級解藥。
- Description字段決定Agent會唔會揀中呢個Skill,所以應該先花八成精力打磨描述,確保觸發場景明確。
- 實踐三步:記錄重複解釋嘅知識漏點、寫一個少於200行嘅最小版本、用真實任務迭代,封裝領域深度而非AI技巧。
- 最好嘅Skill作者係最懂自己行當嘅人,領域深度比技術能力更重要,任何人都可以參與。
格物:Agent Skills唔係提示詞
好多人以為Agent Skills只係長啲嘅提示詞,但呢個理解完全錯曬。提示詞冇文件系統、冇版本控制、冇跨平台移植性,每次新對話都要重新貼一次——寫作風格解釋上百次,代碼審查標準複製幾十遍,品牌色值每開一次對話重新喂一遍。呢啲重複,就係知識在漏。
Agent Skills嘅準確定義:一個標準化文件夾,用Markdown文件把專家知識封裝為可複用、可發現、可跨平台部署嘅能力插件。
寫一次,二十六個平台通用。Claude、Cursor、Copilot、Codex、Gemini CLI、Kiro——全部採納同一套標準。Anthropic開放標準後四十八小時,微軟同OpenAI同時採納。
致知:穿透兩個決定成敗嘅機制
第一個機制係漸進式披露——Skills最核心嘅架構原理。三級信息加載金字塔:
- 1 元數據始終在線,佔約五千個token,成本極低。
- 2 正文按需激活,只有觸發咗先會加載完整指令。
- 3 資源僅在必要時讀取,例如樣板文件或參考資料。
呢個機制令Skills容量唔受上下文窗口制約,仲避開咗Context Distraction同lost-in-the-middle效應。窗口越大,漸進式披露越重要——係架構級解藥,唔係權宜之計。另外要分清Skills同MCP:MCP係管道,Skills係菜譜;沒有Skill嘅MCP等於畀廚師一堆食材但冇菜譜。
第二個機制:Description字段決定生死。Agent喺一百個Skill裏面揀邊個嚟執行,全靠description字段嘅語義匹配。大多數人花八成精力打磨正文,兩成寫描述——因果鏈方向完全相反。
- 先花八成精力打磨description:用明確觸發場景、關鍵詞同反面排除條件確保匹配率。
- 再迭代正文內容,因為描述模糊導致Skill從未被觸發,正文寫得再好都係零。
力行:從認知到動作嘅三步
四個常量支撐住Skills存在嘅必然性:上下文窗口係有限公共資源;通用Agent缺乏領域程序化知識;人類最有價值嘅專業知識以暗默知識形態存在;好指令必須匹配模型認知特徵。呢啲常量推導出同一個結論:Agent Skills係同時滿足按需加載、標準化封裝、漸進式披露三重約束嘅唯一解。
- 1 第一步:識別知識漏點。記錄呢一週向AI重複解釋咗幾多次同樣嘅嘢——寫作風格、代碼規範、審核流程、行業判斷邏輯,每一次重複就係一個等待封裝嘅Skill。按頻率排序,最高頻嘅就係第一個目標。
- 2 第二步:從最小版本起步。一個SKILL.md唔超過兩百行。寫完每一行問自己:如果唔寫呢行,模型會做錯嗎?答案係唔會嘅就刪掉。精簡後嘅Skill表現更好——少即是多喺呢度有精確嘅量化含義。三輪真實任務迭代後嘅版本質量遠超一次性設計。
- 3 第三步:封裝領域深度,而非AI技巧。最好嘅Skill作者永遠係最懂自己行當嘅人。一個精通合規審計但唔寫代碼嘅法務專家,寫出嘅合規Skill比提示詞工程師強。Vercel封裝十年前端經驗,Pulumi封裝基礎設施最佳實踐。價值來自領域深度。
標準已經開放,二十六個平台已經採納,飛輪已經轉起。但要保持清醒——觸發機制仍係黑箱,標準仲喺快速演化,生態尚未成熟。清醒地擁抱,比盲目衝入去更有競爭力。
hi,我係超級個體實踐者周知,文章底部配底層邏輯視圖
一、格物:睇清呢件事嘅真實座標
對Agent Skills嘅理解係:一段更長嘅提示詞。肯定唔啱!
提示詞冇檔案系統,冇版本控制,冇跨平台可攜性,冇按需載入機制。每次新對話,我哋將同樣嘅指令重新貼一次。寫作風格解釋咗上百次,程式碼審查標準複製咗幾十遍,品牌色值每次開新對話重新餵一次,行業裏面只有老手先至識嘅判斷邏輯每次從頭講起。模型換咗四代,我哋重複解釋嘅嘢一個字都冇變。
呢啲重複,係知識喺度漏。
Agent Skills嘅準確定義:一個標準化文件夾,用Markdown檔案將專家知識封裝成可重用、可發現、可跨平台部署嘅能力插件。 寫一次,二十六個平台通用。Claude、Cursor、Copilot、Codex、Gemini CLI、Kiro——全部採用同一套標準。Anthropic開放標準後四十八個鐘,微軟同OpenAI同時採用。成個行業都好渴望呢件事發生。
Karpathy嘅比喻講得最清楚:大模型係CPU,Agent運行時係操作系統,MCP協議係硬件接口。Agent Skills就係應用程式。 模型決定算力上限,Skills決定能力邊界。我哋寫嘅每一個Skill,都喺度定義AI嘅生態邊界。
理解到呢一層,已經超過八成嘅人。但係淨係知道「係咩」遠遠唔夠。決定Skills好唔好用嘅,係兩個我哋必須睇透嘅底層機制。
二、致知:睇穿兩個決定成敗嘅機制
第一個機制:漸進式披露。
呢個係Skills最核心嘅架構原理。三級資訊載入金字塔——元數據永遠在線,正文按需激活,資源只係必要時先讀取。 一百個Skill同時裝喺Agent身上,只係佔大約五千個token嘅元數據成本。實際觸發邊個,先載入邊個嘅完整指令。
比喻電腦記憶體:元數據等於CPU快取,正文等於記憶體,資源檔案等於硬碟。Skills嘅容量從根本上唔受上下文窗口制約。
好多人以為上下文窗口夠大就萬事大吉。啱啱相反。學術界發現嘅Context Distraction現象表明,無關資訊太多嘅時候模型注意力會被嚴重稀釋,執行精度反而下降。研究者仲發現咗lost-in-the-middle效應——擺喺上下文中間位置嘅資訊,被遺忘嘅概率最高。一百萬token嘅窗口塞滿內容,模型並冇變強。窗口越大,漸進式披露越重要。 呢個係架構級解藥,而唔係權宜之計。
有人將Skills同MCP搞亂。兩者完全係唔同層面。MCP係管道,負責連接外部工具同數據源。Skills係菜譜,話畀Agent知道拎到數據之後應該點做。 冇Skill嘅MCP等於畀廚師一堆食材但冇菜譜——做得,但係唔穩定。Simon Willison嘅判斷係Skills可能比MCP更重要。原因在於門檻差異:MCP需要伺服器同程式碼,Skills只需要一個Markdown檔案。
第二個機制:Description字段決定生死。
Agent喺一百個Skill裏面揀邊個嚟做任務,全靠description字段嘅語義匹配。大多數人用八成精力打磨正文,兩成寫描述。因果鏈嘅方向啱啱相反。 描述模糊導致Skill從未被觸發,正文寫得再完美都係零。
正確嘅做法:先用八成精力打磨description,用明確觸發場景、關鍵詞同反面排除條件確保匹配率,再迭代正文內容。 方向啱咗,努力先有意義。
三、力行:從認知到動作嘅三步
致知之後,力行。
四個常量支撐住Skills存在嘅必然性:上下文窗口係有限嘅公共資源,所有消息共享同一空間;通用Agent缺乏領域程序化知識;人類最有價值嘅專業知識以暗默知識形態存在,從未被系統文件化;好指令必須匹配模型認知特徵,過詳會稀釋注意力,過簡會導致歧義。
四條常量推導出同一個結論:Agent Skills係同時滿足按需載入、標準化封裝、漸進式披露三重約束嘅唯一解。
呢個結論嘅深層含義值得停低諗清楚。工業革命將手藝人腦裏面嘅隱性經驗編碼成標準操作手冊。今日同樣嘅事正喺度對知識工作者發生。本質係程序化知識嘅民主化——令AI變專業嘅權力,從擁有算力嘅巨頭手中,交到擁有領域知識嘅個體手中。
認知到位,行動三步走。
第一步:識別知識漏點。 記錄呢個星期我哋向AI重複解釋咗幾多次同樣嘅嘢。寫作風格、程式碼規範、審核流程、行業判斷邏輯——每一次重複就係一個等緊封裝嘅Skill。列曬出嚟,按照頻率排序,最高頻嘅就係我哋嘅第一個目標。
第二步:從最小版本起步。 一個SKILL.md,唔超過兩百行。我哋寫完每一行問自己:如果唔寫呢行,模型會做錯嗎?答案係唔會嘅話,刪咗佢。精簡後嘅Skill表現更好——少即是多喺呢度有精確嘅量化含義。三輪真實任務迭代後嘅版本質量遠超一次性設計。
第三步:封裝領域深度,而唔係AI技巧。 最好嘅Skill作者從來都係最瞭解自己行業嘅人。一個精通合規審計但唔識寫程式碼嘅法務專家,寫出嚟嘅合規Skill比提示詞工程師仲要勁。Vercel封裝咗十年前端經驗,Pulumi封裝基礎設施最佳實踐。價值嚟自領域深度。Skill嘅格式係Markdown,門檻係零。瓶頸從來都係領域深度,而唔係技術能力。
標準已經開放,二十六個平台已經採用,飛輪已經轉起咗。但我哋都需要保持清醒——觸發機制仍然係黑箱,標準仲喺度快速演化,生態尚未成熟。清醒咁擁抱,比起盲目衝入去更有競爭力。
「我係用AI開一人公司嘅周知,下回再傾。心裏有念,亦能執劍。」
想同我一齊探索AI×一人公司嘅可能性,連結我,暗號「AI覺醒星球小程序」
hi,我是超級個體實踐者周知,文章底部配底層邏輯視圖
一、格物:看清這件事的真實座標
對Agent Skills的理解是:一段更長的提示詞。肯定不對!
提示詞沒有文件系統,沒有版本控制,沒有跨平台可移植性,沒有按需加載機制。每次新對話,我們把同樣的指令重新粘貼一遍。寫作風格解釋了上百次,代碼審查標準複製了幾十遍,品牌色值每開一次對話重新喂一遍,行業裏只有老手才知道的判斷邏輯每次從頭講起。模型換了四代,我們重複解釋的東西一個字沒變。
這些重複,是知識在漏。
Agent Skills的準確定義:一個標準化文件夾,用Markdown文件把專家知識封裝為可複用、可發現、可跨平台部署的能力插件。 寫一次,二十六個平台通用。Claude、Cursor、Copilot、Codex、Gemini CLI、Kiro——全部採納同一套標準。Anthropic開放標準後四十八小時,微軟和OpenAI同時採納。整個行業都在渴望這件事發生。
Karpathy的類比說得最清楚:大模型是CPU,Agent運行時是操作系統,MCP協議是硬件接口。Agent Skills就是應用程序。 模型決定算力上限,Skills決定能力邊界。我們寫的每一個Skill,都在定義AI的生態邊界。
理解到這一層,已經超過八成人。但僅僅知道"是什麼"遠遠不夠。決定Skills好不好用的,是兩個我們必須穿透的底層機制。
二、致知:穿透兩個決定成敗的機制
第一個機制:漸進式披露。
這是Skills最核心的架構原理。三級信息加載金字塔——元數據始終在線,正文按需激活,資源僅在必要時讀取。 一百個Skill同時裝在Agent身上,只佔約五千個token的元數據成本。實際觸發哪個,才加載哪個的完整指令。
類比計算機內存:元數據等於CPU緩存,正文等於內存,資源文件等於硬盤。Skills的容量從根本上不受上下文窗口制約。
很多人以為上下文窗口夠大就萬事大吉。恰恰相反。學術界發現的Context Distraction現象表明,無關信息過多時模型注意力被嚴重稀釋,執行精度反而下降。研究者還發現了lost-in-the-middle效應——放在上下文中間位置的信息,被遺忘的概率最高。一百萬token的窗口塞滿內容,模型並沒有變強。窗口越大,漸進式披露越重要。 這是架構級解藥,而非權宜之計。
有人把Skills和MCP搞混。兩者完全是不同層面。MCP是管道,負責連接外部工具和數據源。Skills是菜譜,告訴Agent拿到數據後該怎麼做。 沒有Skill的MCP等於給廚師一堆食材但沒菜譜——能做,但不穩定。Simon Willison的判斷是Skills可能比MCP更重要。原因在於門檻差異:MCP需要服務器和代碼,Skills只需要一個Markdown文件。
第二個機制:Description字段決定生死。
Agent在一百個Skill裏選誰來執行任務,全靠description字段的語義匹配。大多數人花八成精力打磨正文,兩成寫描述。因果鏈的方向恰好相反。 描述模糊導致Skill從未被觸發,正文寫得再完美也是零。
正確的做法:先花八成精力打磨description,用明確觸發場景、關鍵詞和反面排除條件確保匹配率,再迭代正文內容。 方向對了,努力才有意義。
三、力行:從認知到動作的三步
致知之後,力行。
四個常量支撐着Skills存在的必然性:上下文窗口是有限的公共資源,所有消息共享同一空間;通用Agent缺乏領域程序化知識;人類最有價值的專業知識以暗默知識形態存在,從未被系統文檔化;好指令必須匹配模型認知特徵,過詳稀釋注意力,過簡導致歧義。
四條常量推導出同一個結論:Agent Skills是同時滿足按需加載、標準化封裝、漸進式披露三重約束的唯一解。
這個結論的深層含義值得停下來想清楚。工業革命將手藝人腦子裏的隱性經驗編碼為標準操作手冊。今天同樣的事情正在對知識工作者發生。本質是程序化知識的民主化——讓AI變專業的權力,從擁有算力的巨頭手中,交到了擁有領域知識的個體手中。
認知到位,行動三步走。
第一步:識別知識漏點。 記錄這一週我們向AI重複解釋了多少次同樣的東西。寫作風格、代碼規範、審核流程、行業判斷邏輯——每一次重複就是一個等待封裝的Skill。列出來,按照頻率排序,最高頻的就是我們的第一個目標。
第二步:從最小版本起步。 一個SKILL.md,不超過兩百行。我們寫完每一行問自己:如果不寫這行,模型會做錯嗎?答案是不會的,刪掉。精簡後的Skill表現更好——少即是多在這裏有精確的量化含義。三輪真實任務迭代後的版本質量遠超一次性設計。
第三步:封裝領域深度,而非AI技巧。 最好的Skill作者從來都是最懂自己行當的人。一個精通合規審計但不寫代碼的法務專家,寫出的合規Skill比提示詞工程師強。Vercel封裝十年前端經驗,Pulumi封裝基礎設施最佳實踐。價值來自領域深度。Skill的格式是Markdown,門檻為零。瓶頸從來都是領域深度,而非技術能力。
標準已經開放,二十六個平台已經採納,飛輪已經轉起來。但我們也需要保持清醒——觸發機制仍是黑箱,標準還在快速演化,生態尚未成熟。清醒地擁抱,比盲目衝進去更有競爭力。
「我是用AI開一人公司的周知,下回聊。心裏有念,亦能執劍。」
想和我一起探索AI×一人公司的可能性,連結我,暗號「AI覺醒星球小程序」