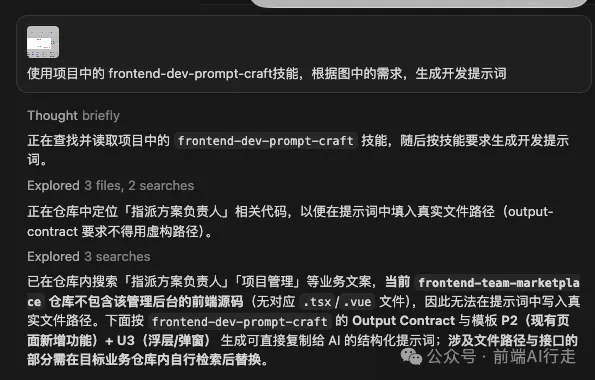
AI Agent Skill 工程化(實戰):我如何把一年 AI 編程經驗"數字化"
整理版優先睇
從100+次真實請求中提煉,將個人AI編程經驗數碼化為結構化Skill嘅完整流程
呢篇文章係作者分享佢點樣將自己一年幾嘅AI編程經驗,通過工程化方法轉化為一個可重用嘅Skill。作者用咗Cursor、Claude Code等工具,記錄咗大量提示詞,發現每次寫提示詞格式唔一致,導致AI理解有偏差。為瞭解決呢個問題,佢設計咗一個名為frontend-dev-prompt-craft嘅Skill,目標係將模糊嘅前端需求轉化為結構化嘅AI編碼提示詞。
佢首先回顧咗過去100+次請求,將任務分類為8種類型,每種類型定義咗必填字段。然後設計咗追問機制,確保信息充足。再通過編寫SKILL.md、測試用例、建立Baseline同問題池,形成咗一個完整嘅閉環。整個過程強調「任務分類係起點」、「必填字段係核心」、「追問係交互設計嘅靈魂」、「Baseline係迭代嘅錨點」、「問題池係持續進化嘅基礎」。
最終,呢個Skill本質上係作者兩年AI編程經驗嘅「數碼化身」。佢唔係憑空設計,而係從真實需求中提煉、從踩坑中總結、從Eval驗證中打磨出來。文章強調:好嘅Skill唔係寫出來,而係「養」出來嘅,需要持續迭代,每次發現問題 -> 記錄到issues -> 轉化為Eval -> 修改SKILL.md -> 驗證唔退化。
- 前端開發任務分為8種類型(PAGE、UI、API、ARCH、REFACTOR、DEBUG、PRD、MIGRATE),每種需要唔同嘅輸入信息。
- Input Contract設計關鍵:必填字段係「信息不足就無法生成有效輸出」嘅字段,唔係「可能有用」嘅想象。
- 追問機制係交互設計嘅核心:AI唔應該猜測,缺失信息必須追問,呢個係Skill同用戶之間嘅契約。
- Baseline(第一次Eval 14/14通過)作為迭代嘅退化檢測線,確保每次修改唔會破壞已有能力。
- 問題池(skill-issues.jsonl)記錄每次發現嘅問題,轉化為Eval測試用例,形成持續進化嘅閉環。
frontend-dev-prompt-craft SKILL.md
完整技能定義,包含description、trigger、Input Contract、workflow、output_contract等
skill-issues.jsonl 模板
問題記錄JSONL格式模板,用於收集迭代中發現的問題
案例倉庫
frontend-team-marketplace 倉庫,包含完整 Skill 結構
內容結構
frontend-dev-prompt-craft/├──
SKILL.md # 技能定義(核心)├── skill-meta.json # 元數據 + Baseline├── test-prompts.json # 測試用例├── skill-issues.jsonl # 問題記錄├── CHANGELOG.md # 變更日誌├── LEARNINGS.md # 學習沉澱└──
README.md # 使用指南背景與問題
作者用咗一年幾嘅AI編程工具,累積咗大量提示詞數據。佢發現每次寫提示詞格式唔一致,令到AI理解有偏差,效率時高時低。為咗統一團隊嘅提示詞質量,佢決定創建一個 Skill,將模糊需求轉化為結構化提示詞。
一年幾嘅AI編程經驗
提示詞格式唔一致
需求分析與任務分類
團隊回顧咗過去100+次AI編碼請求,歸納出8種前端開發任務類型,每種都有對應嘅適用場景同頻率。呢個分類係後續設計嘅基礎。
- PAGE(35%):新增頁面、按鈕、列表、表單
- UI(15%):設計稿還原、動畫效果
- API(20%):Yapi文檔、多接口聯動
- ARCH(5%):架構重構、維護性問題
- REFACTOR(10%):域名替換、批量配置修改
- DEBUG(10%):排查問題、修復Bug
- PRD(3%):生成開發文檔、增量開發
- MIGRATE(2%):跨項目遷移、替換依賴
8種前端開發任務類型
任務分類係起點
Input Contract 與追問機制
每種任務類型定義咗必填字段,核心原則係:信息不足就無法生成有效輸出。同時設計咗追問規則,當用戶描述需求後,Skill會從關鍵詞推斷類型,檢查缺失字段並追問。
信息不足就無法生成有效輸出
追問規則
例如用戶話「幫我寫個用戶列表頁嘅提示詞」,Skill會識別為PAGE類型,然後追問頁面位置、數據來源、功能描述。
測試、Baseline 與迭代
作者寫咗8個測試用例,每個類型至少一個,覆蓋追問行為。第一次跑Eval結果14/14全部通過,呢個就係Baseline。
8個測試用例
14/14 passing (100%)
另外仲建立咗問題池 skill-issues.jsonl,記錄每個發現嘅問題,標記係咪轉化為Eval測試用例,status追蹤狀態。
問題池係持續進化嘅基礎
converted_to_eval
實戰回顧與核心結論
作者用一個真實需求示範:唔用Skill時,AI理解有偏差;用咗Skill之後,AI生成嘅提示詞幾乎可以直接做開發文檔,只需要補少少接口數據。真正做到一句話就完成需求開發。
一句話就完成需求開發
- 1 任務分類係起點:唔清楚任務類型,就無法設計Input Contract。
- 2 必填字段係核心:每個字段背後都應該係「缺失就無法工作」嘅真實場景。
- 3 追問係交互設計嘅靈魂:AI唔應該猜測,缺失信息必須追問。
- 4 Baseline係迭代嘅錨點:第一次跑Eval嘅100%唔係終點,而係退化檢測線。
- 5 問題池係持續進化嘅基礎:每個open問題都應該轉化為Eval或修復。
前言
導讀:我之前對於設計 Skill 傾向於靠數據去支撐,而家理論講完,就嚟睇真實案例。
呢篇文章用
frontend-dev-prompt-craftSkill 做完整案例,帶你行一次由需求分析到 Eval 驗證嘅 Skill 創建全流程。
📖 本文屬於《AI Agent Skill 工程化》系列實戰篇
案例倉庫:
https://github.com/yangmeishux/frontend-team-marketplace/tree/main/plugins/frontend-team-toolkit/skills/frontend-dev-prompt-craft
呢個技能係基於我嘅真實項目業務存在嘅,所有數據同信息,都係建基於我之前做過嘅所有業務嘅基礎之上。
可以話呢個技能喺某個層面上,就係複製咗我個人嘅開發經驗同個人開發經驗。
數據同信息嘅來源,大約一年前我開始用 Cursor,到而家我基本上主力係 Cursor,其次係 Claude Code + 阿里百鍊 同 Qoder。
我由用 AI 工具編程開始,就用 markdown 記低咗我大部分需求開發時,同 AI 對話 Chat 嘅時候,我記錄咗一系列相關嘅提示詞。
有一日我突然發現呢啲數據信息,可以俾 AI 幫我分析總結歸類。
呢個其實就係我嘅經驗同開發風格具體化嘅呈現。
提示詞就係需求開發文檔
需求開發嗰陣,我哋冇辦法直接俾份文檔 AI 就可以搞掂曬,每個人唔同,寫嘅提示詞都唔一樣,我哋發現一個問題:
每次俾 AI 編碼工具寫提示詞,格式五花八門。
有人寫一段話,有人寫列表,有人寫需求文檔截圖。
結果呢?AI 理解不一致,效率時高時低。
所以我覺得,我可以將之前記錄嘅數據轉化,我哋團隊需要:
需要一個 Skill 去統一轉化模糊需求 → 結構化提示詞。
這就是 frontend-dev-prompt-craft Skill 嘅誕生背景。
而且呢個技能仲可以不斷迭代,集合曬大家嘅提示詞,從而打造成團隊一個重要嘅工具。
一套集合咗成個團隊開發人員嘅提示詞 Skill,佢根據真實嘅項目場景而誕生,意味住佢集合咗我哋而家用緊嘅所有項目基礎知識,咁佢就可以對我哋每個項目好熟悉,提示詞就會根據項目好精準。
完整嘅提示詞就係需求描述 亦都係需求開發文檔。
一、需求分析:識別任務類型
第一步:回顧歷史請求
團隊回顧過去 100+ 次 AI 編碼請求,分類歸納。
結果:8 種前端開發任務
關鍵洞察:前端開發唔係「一個任務」,而係「8 種任務類型」。每種需要唔同嘅信息。
二、定義觸發邊界
觸發條件
## trigger
用戶需要將模糊的前端需求轉化為結構化AI編碼提示詞時激活。包括:
- 用戶說「幫我寫個提示詞」「幫我寫個AI能懂的描述」
- 拆解PRD為編碼任務
- 不知道如何向AI描述開發任務
唔觸發場景
## trigger_negation
- 用戶直接要求寫代碼(不是要提示詞)
- 非前端任務(後端、運維、測試等)
- 用戶已有完善提示詞,只想微調一句話
設計要點:
•觸發要具體(可識別嘅用戶語言)
•唔觸發要明確(邊界清晰,避免誤觸發)
三、設計 Input Contract
每種類型需要唔同嘅信息。我哋定義 必填字段:
核心原則:必填字段 = 信息不足就無法生成有效提示詞嘅字段。
四、追問機制設計
追問規則
## followup_rules
當用戶描述需求後:
1. 從關鍵詞推斷任務類型
2. 檢查 Input Contract 必填字段
3. 缺失字段必須追問
4. 追問格式:「關於【字段名】,請補充:...」
追問示例
用戶輸入:
幫我寫個用戶列表頁的提示詞
Skill 行為:
•識別:PAGE 類型(關鍵詞「列表頁」)
•檢查必填:頁面位置?數據來源?功能描述?
•追問:
檢測到【PAGE】類型任務。請補充以下信息:
1. 關於【頁面位置】:這個列表頁放在哪個路由下?
2. 關於【數據來源】:用戶數據從哪個接口獲取?(Yapi連結或接口地址)
3. 關於【功能描述】:列表需要哪些字段?是否需要篩選/排序/分頁?
五、暫停檢查點設計
三個必須暫停嘅場景:
六、編寫 SKILL.md(關鍵片段)
文件結構
frontend-dev-prompt-craft/
├── SKILL.md # 技能定義(核心)
├── skill-meta.json # 元數據 + Baseline
├── test-prompts.json # 測試用例
├── skill-issues.jsonl # 問題記錄
├── CHANGELOG.md # 變更日誌
├── LEARNINGS.md # 學習沉澱
└── README.md # 使用指南
SKILL.md 核心內容(關鍵片段)
# frontend-dev-prompt-craft
## description
將模糊的前端需求轉化為結構化的AI編碼提示詞。支持 8 種任務類型:PAGE/UI/API/ARCH/REFACTOR/DEBUG/PRD/MIGRATE。
## trigger
用戶需要將模糊的前端需求轉化為結構化AI編碼提示詞時激活。
## Input Contract
| 類型 | 必填字段 |
|------|----------|
| PAGE | 頁面位置、功能描述、數據來源、參考頁面 |
| UI | 設計稿連結、目標位置、交互要求 |
| API | 接口地址、調用場景、字段映射 |
| ARCH | 現狀問題、目標架構、約束條件 |
| REFACTOR | 修改範圍、修改規則、影響評估 |
| DEBUG | 預期行為、實際行為、復現信息、相關代碼 |
| PRD | PRD連結、開發階段、相關代碼位置 |
| MIGRATE | 源組件位置、目標項目、遷移策略 |
## workflow
1. 識別任務類型(從關鍵詞推斷)
2. 檢查 Input Contract 必填字段
3. 追問缺失信息
4. 加載對應模板
5. 填充生成提示詞
6. 自檢輸出
7. 交付
## output_contract
每條提示詞必須包含:
- 任務類型標籤(如 [PAGE])
- 結構化需求描述
- 驗收標準
- 可直接複製使用
七、編寫 test-prompts.json(關鍵片段)
測試用例結構
[
{
"id":1,
"prompt":"幫我寫個用戶列表頁的提示詞",
"expected":{
"task_type":"PAGE",
"behavior":"追問頁面位置、數據來源、功能描述"
}
},
{
"id":2,
"prompt":"這個Figma設計稿幫我還原成Vue組件",
"expected":{
"task_type":"UI",
"behavior":"追問設計稿連結、目標位置、交互要求"
}
},
{
"id":4,
"prompt":"接口返回500錯誤,幫我排查一下",
"expected":{
"task_type":"DEBUG",
"behavior":"追問預期行為、實際行為、復現信息、相關代碼"
}
}
// ...共 8 個用例
]
設計要點:每個類型至少 1 個測試用例,覆蓋追問行為。
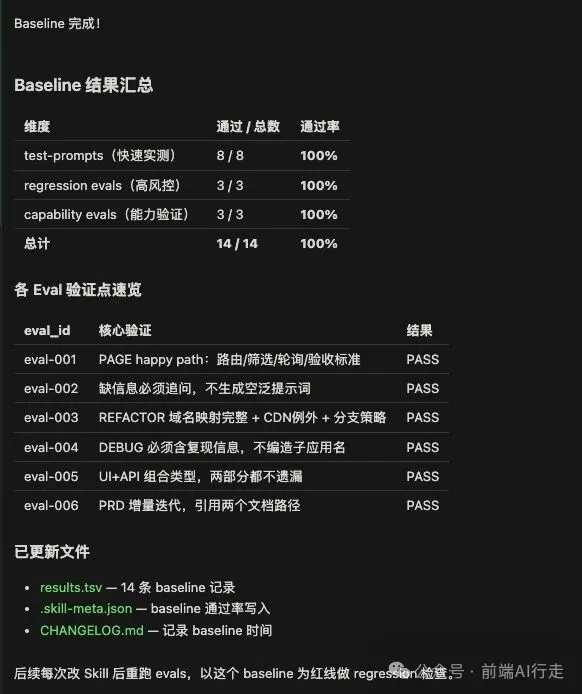
八、建立 Baseline
第一次跑 Eval
Skill: frontend-dev-prompt-craft
Test Prompts: 8 個
Eval Result:
- Test Prompts: 8/8 passing (100%)
- Regression: 3/3 (100%)
- Capability: 3/3 (100%)
Total: 14/14 passing (100%)✅
Baseline 記錄(skill-meta.json 關鍵片段)
{
"skill_name":"frontend-dev-prompt-craft",
"version":"0.1.0",
"maturity":"draft",
"baseline":{
"regression_pass_rate":"3/3 (100%)",
"capability_pass_rate":"3/3 (100%)",
"test_prompts_pass_rate":"8/8 (100%)",
"total":"14/14 (100%)"
}
}
九、設置 skill-issues.jsonl
問題記錄格式
{
"date":"2026-06-09",
"skill":"frontend-dev-prompt-craft",
"task_type":"PAGE",
"symptom":"追問了不必要的字段(參考頁面非必填)",
"expected":"只追問必填字段",
"severity":"medium",
"source":"首次使用",
"converted_to_eval":false,
"status":"open"
}
設計要點:
•每個 issue 記錄一個問題
•converted_to_eval 標記係咪轉化為測試用例
•status 跟蹤問題狀態
十、使用 skill-engineering 腳手架驗證
# 驗證 Skill 結構
python validate-skill.py frontend-dev-prompt-craft
# 輸出
✅ SKILL.md 存在
✅ skill-meta.json 存在
✅ test-prompts.json 存在
✅ skill-issues.jsonl 存在
✅ 目錄結構完整
PASS: Skill 結構驗證通過
十、實戰回顧
從真實嘅提示詞文件數據出發,讓 AI 對所有四個提示詞文檔進行分析提煉。
創建提煉過程,截圖如下:




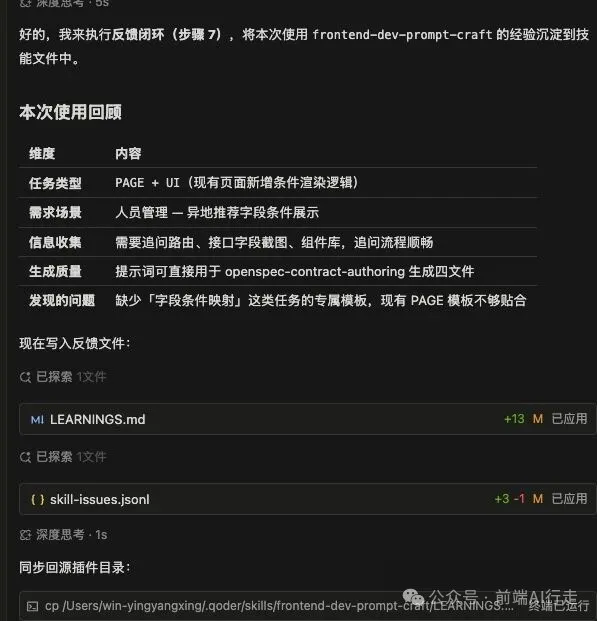

真實需求演示:
我揾咗個需求,如下圖:
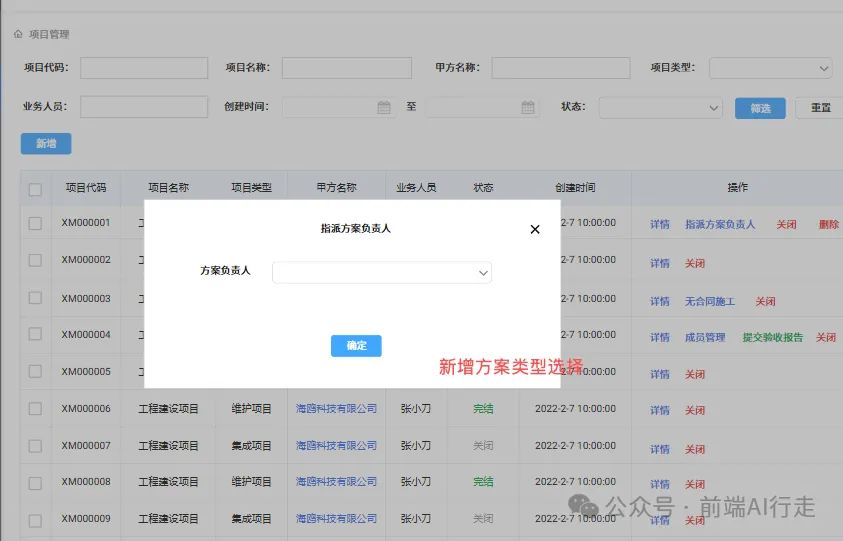
唔用技能,AI 理解嘅需求:
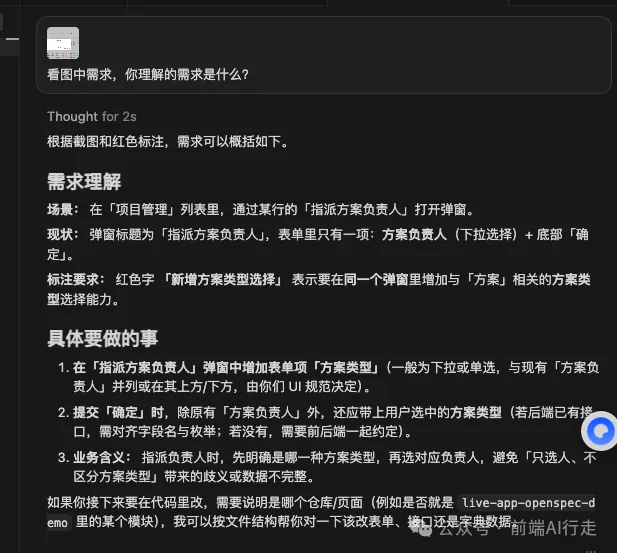
用技能,AI 理解嘅需求,並生成嘅提示詞:
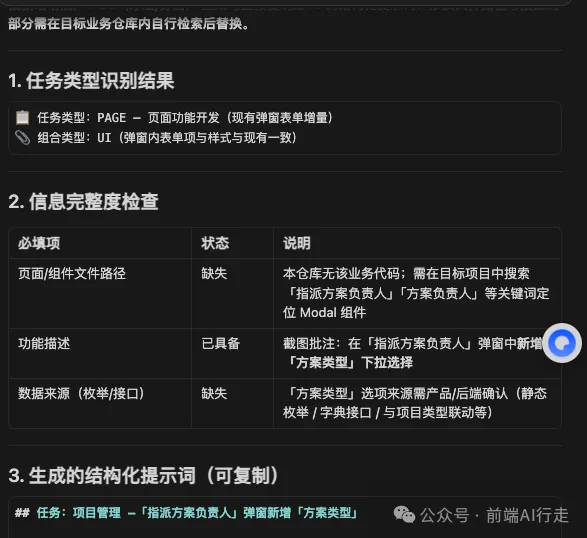
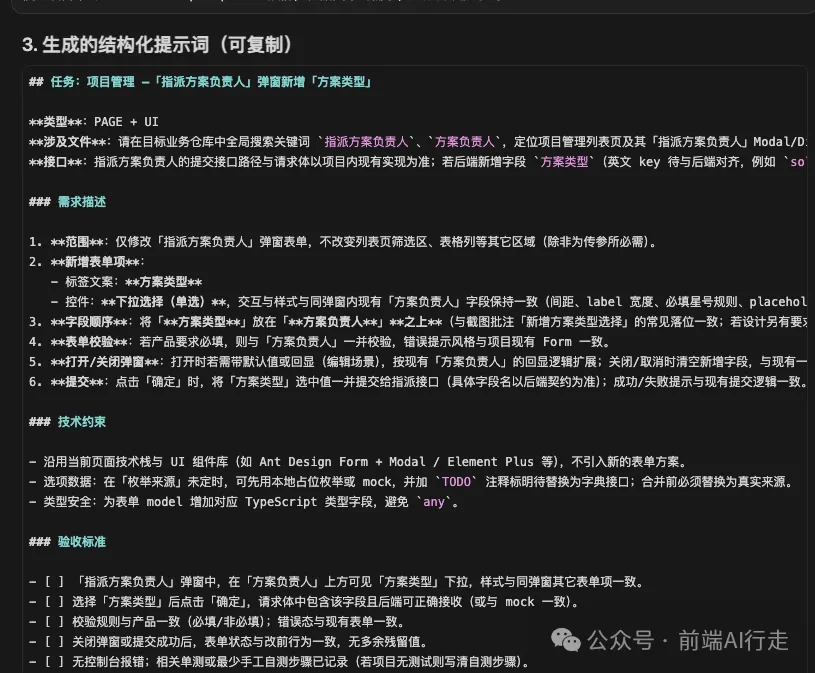
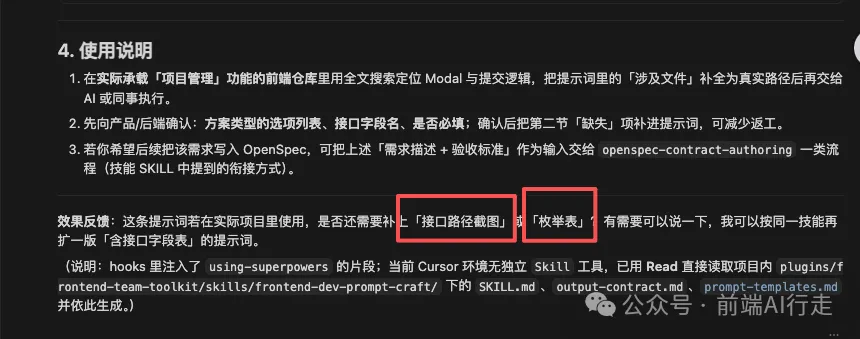
由上面嘅提示詞可以睇到,只要你補充返接口同相關嘅數據枚舉值,咁呢個生成嘅提示詞就係你今次需求開發嘅開發文檔。
你唔需要寫太多嘅需求描述。只要補充返少少,呢啲提示詞就係真實需求嘅開發文檔。
我呢個係網上揾嘅截圖,如果係真實嘅項目入面,提示詞仲會俾出符合你當前項目嘅需求功能描述。
所以後續開發就直接讓 AI 根據你嘅提示詞進行開發就得。
真正做到一句說話就可以完成成個需求開發。
案例展示嘅功能,比較適合二次迭代項目。當然新嘅需求都得嘅。
創建過程回顧
關鍵要點
1.任務分類係起點:唔清楚任務類型,就設計唔到 Input Contract
2.必填字段係核心:信息不足就無法生成有效輸出
3.追問係交互設計:缺失信息一定要追問,唔可以靠估
4.Baseline 係錨點:第一次跑 Eval 嘅結果,係後續迭代嘅基線
5.問題池係迭代基礎:skill-issues.jsonl 記錄發現嘅問題,後續轉化為 Eval
附贈資產
| 完整 SKILL.md | ||
| 完整 test-prompts.json | ||
| skill-issues 模板 |
skill-issues.jsonl 模板
{"date":"YYYY-MM-DD","skill":"SKILL_NAME","task_type":"TYPE","symptom":"問題描述","expected":"期望行為","severity":"high/medium/low","source":"首次使用/迭代發現/用戶反饋","converted_to_eval":false,"eval_id":null,"status":"open/resolved/converted"}
核心結論:由「憑感覺」到「有章法」
呢篇文章行完咗一個 Skill 由 0 到 1 嘅完整生命週期。
返轉頭睇,Skill 工程化嘅核心唔在於工具或格式,而在於思維方式嘅轉變:
五個關鍵認知:
1.任務分類係起點——唔清楚 AI 要處理咩類型嘅請求,就設計唔到有效嘅 Input Contract
2.必填字段係核心——每個字段背後都應該係「缺咗就做唔到」嘅真實場景,而唔係「可能有啲用」嘅想像
3.追問係交互設計嘅靈魂——AI 唔應該估,缺失信息一定要問,呢個係 Skill 同用戶之間嘅契約
4.Baseline 係迭代嘅錨點——第一次跑 Eval 嘅 100% 唔係終點,而係後續所有修改嘅「退化檢測線」
5.問題池係持續進化嘅基礎——skill-issues.jsonl 唔係擺設,每個 open 嘅問題都應該喺下一次迭代入面轉化為 Eval 或者修復
最後嘅話:
這個 frontend-dev-prompt-craft Skill 本質上係我差唔多兩年時間嘅 AI 編程經驗嘅「數字化身」。
佢唔係憑空設計出嚟嘅,而係由 100+ 次真實請求中提煉、由反覆踩坑中總結、由 Eval 驗證中打磨出嚟嘅。
Skill 工程化唔係「寫完就完」,而係「發佈先開始」。
真正嘅價值在於後續嘅持續迭代:
每次發現問題 → 記錄到 issues → 轉化為 Eval → 修改 SKILL.md → 驗證唔退化。
呢個閉環跑起之後,你嘅 Skill 先會真正成為團隊嘅「集體智慧沉澱」。
好嘅 Skill 唔係寫出嚟嘅,係「養」出嚟嘅。
前言
導讀: 我之前對於設計 Skill 傾向於就是依據數據來支撐,現在理論講完了,那麼就來看真實案例。
這篇文章以
frontend-dev-prompt-craftSkill 為完整案例,帶你走一遍從需求分析到 Eval 驗證的 Skill 創建全流程。
📖 本文屬於《AI Agent Skill 工程化》系列實戰篇
案例倉庫:
https://github.com/yangmeishux/frontend-team-marketplace/tree/main/plugins/frontend-team-toolkit/skills/frontend-dev-prompt-craft
這個技能是基於我的真實項目業務存在的,所有的數據與信息,都是基於之前我做過的所有業務的基礎上做的。
可以說這個技能從某種層面上,就是複製了我個人的開發經驗與個人開發經驗。
數據與信息的來源,大概從一年前,我使Cursor開始,到現在我基本上是Cursor為主要,Claude Code + 阿里百鍊 和 Qoder 為次要。
我從使用AI工具進行編程的時候,就使用 markdown 記錄下了我大部分需求開發的時候,與AI 進行對話 Chat 的時候,我記錄下了一系列的相關提示詞。
我某一天突然發現這些數據信息,還是可以讓AI 幫我進行分析總結歸類的。
這個其實就是我自己的經驗與開發風格具體化的呈現。
提示詞既是需求開發文檔
需求開發的時候,我們沒有辦法直接對給AI一份文檔就可以搞定所有,我們每個人不一樣,寫的提示詞也是不一樣的,我們發現一個問題:
每次給 AI 編碼工具寫提示詞,格式五花八門。
有人寫一段話,有人寫列表,有人寫需求文檔截圖。
結果呢?AI 理解不一致,效率忽高忽低。
為此我覺得,我可以將我之前記錄的數據進行轉換, 我們團隊需要:
需要一個 Skill 來統一轉化模糊需求 →結構化提示詞。
這就是 frontend-dev-prompt-craft Skill 的誕生背景。
而且這個技能還可以不斷迭代,集大家的所有提示詞,從而打造成團隊的一個重要的工具。
一套集合了全部團隊開發人員的提示詞 Skill ,它依據真實的項目場景而誕生,意味了它集合了我們先用的所有的項目基礎知識,那麼它就可以對我們每個項目很熟悉,那麼提示詞就好根據項目非常的精準。
完整的提示詞就是需求描述 也是需求開發文檔。
一、需求分析:識別任務類型
第一步:回顧歷史請求
團隊回顧過去 100+ 次 AI 編碼請求,分類歸納。
結果:8 種前端開發任務
關鍵洞察:前端開發不是"一個任務",而是"8 種任務類型"。每種類型需要不同的信息。
二、定義觸發邊界
觸發條件
## trigger
用戶需要將模糊的前端需求轉化為結構化AI編碼提示詞時激活。包括:
- 用戶說「幫我寫個提示詞」「幫我寫個AI能懂的描述」
- 拆解PRD為編碼任務
- 不知道如何向AI描述開發任務
不觸發場景
## trigger_negation
- 用戶直接要求寫代碼(不是要提示詞)
- 非前端任務(後端、運維、測試等)
- 用戶已有完善提示詞,只想微調一句話
設計要點:
•觸發要具體(可識別的用戶語言)
•不觸發要明確(邊界清晰,避免誤觸發)
三、設計 Input Contract
每種類型需要不同的信息。我們定義 必填字段:
核心原則:必填字段 =信息不足就無法生成有效提示詞的字段。
四、追問機制設計
追問規則
## followup_rules
當用戶描述需求後:
1. 從關鍵詞推斷任務類型
2. 檢查 Input Contract 必填字段
3. 缺失字段必須追問
4. 追問格式:「關於【字段名】,請補充:...」
追問示例
用戶輸入:
幫我寫個用戶列表頁的提示詞
Skill 行為:
•識別:PAGE 類型(關鍵詞"列表頁")
•檢查必填:頁面位置?數據來源?功能描述?
•追問:
檢測到【PAGE】類型任務。請補充以下信息:
1. 關於【頁面位置】:這個列表頁放在哪個路由下?
2. 關於【數據來源】:用戶數據從哪個接口獲取?(Yapi連結或接口地址)
3. 關於【功能描述】:列表需要哪些字段?是否需要篩選/排序/分頁?
五、暫停檢查點設計
三個必須暫停的場景:
六、編寫 SKILL.md(關鍵片段)
文件結構
frontend-dev-prompt-craft/
├── SKILL.md # 技能定義(核心)
├── skill-meta.json # 元數據 + Baseline
├── test-prompts.json # 測試用例
├── skill-issues.jsonl # 問題記錄
├── CHANGELOG.md # 變更日誌
├── LEARNINGS.md # 學習沉澱
└── README.md # 使用指南
SKILL.md 核心內容(關鍵片段)
# frontend-dev-prompt-craft
## description
將模糊的前端需求轉化為結構化的AI編碼提示詞。支持 8 種任務類型:PAGE/UI/API/ARCH/REFACTOR/DEBUG/PRD/MIGRATE。
## trigger
用戶需要將模糊的前端需求轉化為結構化AI編碼提示詞時激活。
## Input Contract
| 類型 | 必填字段 |
|------|----------|
| PAGE | 頁面位置、功能描述、數據來源、參考頁面 |
| UI | 設計稿連結、目標位置、交互要求 |
| API | 接口地址、調用場景、字段映射 |
| ARCH | 現狀問題、目標架構、約束條件 |
| REFACTOR | 修改範圍、修改規則、影響評估 |
| DEBUG | 預期行為、實際行為、復現信息、相關代碼 |
| PRD | PRD連結、開發階段、相關代碼位置 |
| MIGRATE | 源組件位置、目標項目、遷移策略 |
## workflow
1. 識別任務類型(從關鍵詞推斷)
2. 檢查 Input Contract 必填字段
3. 追問缺失信息
4. 加載對應模板
5. 填充生成提示詞
6. 自檢輸出
7. 交付
## output_contract
每條提示詞必須包含:
- 任務類型標籤(如 [PAGE])
- 結構化需求描述
- 驗收標準
- 可直接複製使用
七、編寫 test-prompts.json(關鍵片段)
測試用例結構
[
{
"id":1,
"prompt":"幫我寫個用戶列表頁的提示詞",
"expected":{
"task_type":"PAGE",
"behavior":"追問頁面位置、數據來源、功能描述"
}
},
{
"id":2,
"prompt":"這個Figma設計稿幫我還原成Vue組件",
"expected":{
"task_type":"UI",
"behavior":"追問設計稿連結、目標位置、交互要求"
}
},
{
"id":4,
"prompt":"接口返回500錯誤,幫我排查一下",
"expected":{
"task_type":"DEBUG",
"behavior":"追問預期行為、實際行為、復現信息、相關代碼"
}
}
// ...共 8 個用例
]
設計要點:每個類型至少 1 個測試用例,覆蓋追問行為。
八、建立 Baseline
第一次跑 Eval
Skill: frontend-dev-prompt-craft
Test Prompts: 8 個
Eval Result:
- Test Prompts: 8/8 passing (100%)
- Regression: 3/3 (100%)
- Capability: 3/3 (100%)
Total: 14/14 passing (100%)✅
Baseline 記錄(skill-meta.json 關鍵片段)
{
"skill_name":"frontend-dev-prompt-craft",
"version":"0.1.0",
"maturity":"draft",
"baseline":{
"regression_pass_rate":"3/3 (100%)",
"capability_pass_rate":"3/3 (100%)",
"test_prompts_pass_rate":"8/8 (100%)",
"total":"14/14 (100%)"
}
}
九、設置 skill-issues.jsonl
問題記錄格式
{
"date":"2026-06-09",
"skill":"frontend-dev-prompt-craft",
"task_type":"PAGE",
"symptom":"追問了不必要的字段(參考頁面非必填)",
"expected":"只追問必填字段",
"severity":"medium",
"source":"首次使用",
"converted_to_eval":false,
"status":"open"
}
設計要點:
•每個 issue 記錄一個問題
•converted_to_eval 標記是否轉化為測試用例
•status 跟蹤問題狀態
十、使用 skill-engineering 腳手架驗證
# 驗證 Skill 結構
python validate-skill.py frontend-dev-prompt-craft
# 輸出
✅ SKILL.md 存在
✅ skill-meta.json 存在
✅ test-prompts.json 存在
✅ skill-issues.jsonl 存在
✅ 目錄結構完整
PASS: Skill 結構驗證通過
十、實戰回顧
從真實的提示詞文件數據出發,讓AI對所有的四個提示詞文檔進行分析提煉。
創建提煉過程,截圖如下:
真實需求演示:
我找了個需求,如下圖:
不使用技能,AI理解的需求:
使用技能,AI理解的需求,並生成的提示詞:
從上述的提示詞可以看出來,只有你補充一下接口和相關的數據枚舉值,那麼這個生成的提示詞就是你本次需求開發的開發文檔。
你不需要寫太多的需求描述。只需要補充一下,這樣的提示詞就是真實需求的開發文檔。
我的這個是網上找的截圖,如果是真實的項目中,提示詞還是會給出符合你當前項目的需求功能描述。
所以後續開發就直接讓AI根據你的提示詞進行開發就可以了。
真正做到了一句話就可以完成整個需求開發。
案例展示的功能,比較適合二次迭代項目。當然新的需求也是可以的。
創建過程回顧
關鍵要點
1.任務分類是起點:不清楚任務類型,就無法設計 Input Contract
2.必填字段是核心:信息不足就無法生成有效輸出
3.追問是交互設計:缺失信息必須追問,不能假設
4.Baseline 是錨點:第一次跑 Eval 的結果,是後續迭代的基線
5.問題池是迭代基礎:skill-issues.jsonl 記錄發現的問題,後續轉化為 Eval
附贈資產
| 完整 SKILL.md | ||
| 完整 test-prompts.json | ||
| skill-issues 模板 |
skill-issues.jsonl 模板
{"date":"YYYY-MM-DD","skill":"SKILL_NAME","task_type":"TYPE","symptom":"問題描述","expected":"期望行為","severity":"high/medium/low","source":"首次使用/迭代發現/用戶反饋","converted_to_eval":false,"eval_id":null,"status":"open/resolved/converted"}
核心結論:從"憑感覺"到"有章法"
這篇文章走完了一個 Skill 從 0 到 1 的完整生命週期。
回頭來看,Skill 工程化的核心不在於工具或格式,而在於思維方式的轉變:
五個關鍵認知:
1.任務分類是起點——不清楚 AI 要處理什麼類型的請求,就無法設計有效的 Input Contract
2.必填字段是核心——每個字段背後都應該是"缺失就無法工作"的真實場景,而不是"可能有用"的想象
3.追問是交互設計的靈魂——AI 不應該猜測,缺失信息必須追問,這是 Skill 與用戶之間的契約
4.Baseline 是迭代的錨點——第一次跑 Eval 的 100% 不是終點,而是後續所有修改的"退化檢測線"
5.問題池是持續進化的基礎——skill-issues.jsonl 不是擺設,每個 open 的問題都應該在下一次迭代中轉化為 Eval 或修復
最後的話:
這個 frontend-dev-prompt-craft Skill 本質上是我差不多兩年時間的 AI 編程經驗的"數字化身"。
它不是憑空設計出來的,而是從 100+ 次真實請求中提煉、從反覆踩坑中總結、從 Eval 驗證中打磨出來的。
Skill 工程化不是"寫完就結束",而是"發佈才開始"。
真正的價值在於後續的持續迭代:
每次發現問題 → 記錄到 issues → 轉化為 Eval → 修改 SKILL.md → 驗證不退化。
這個閉環跑起來之後,你的 Skill 才會真正成為團隊的"集體智慧沉澱"。
好的 Skill 不是寫出來的,是"養"出來的。