AI + Skill,能夠讓生成的文章去除 AI 味嗎?
整理版優先睇
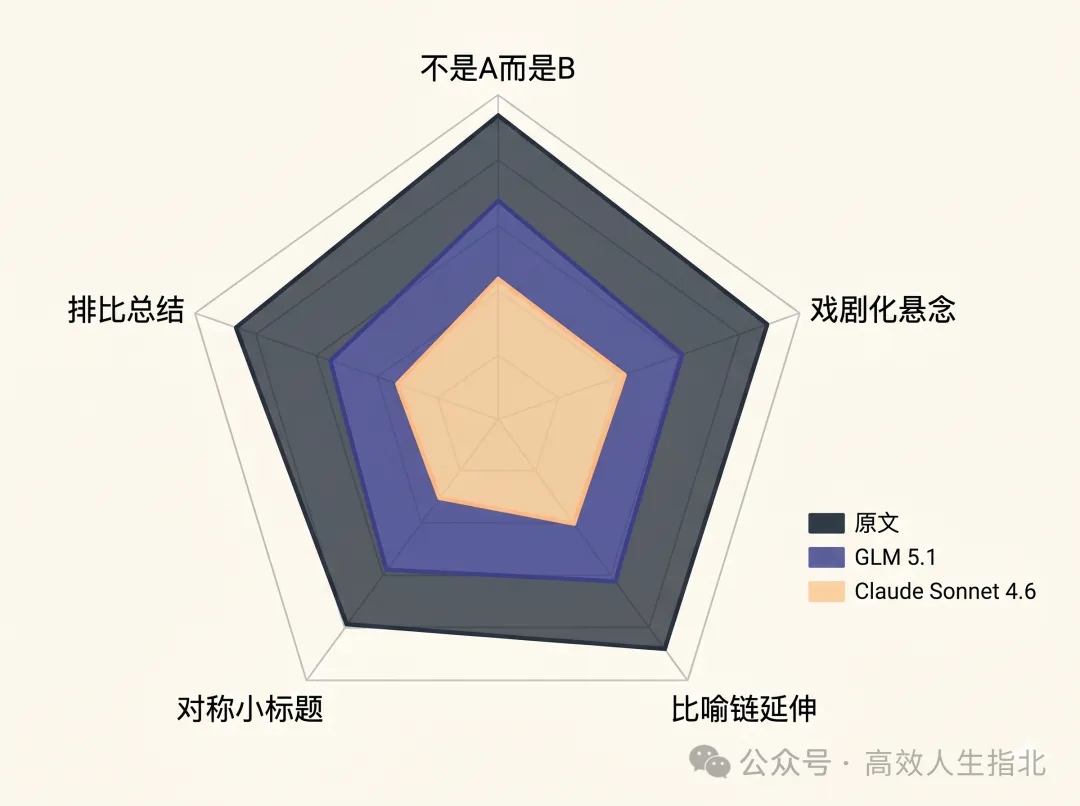
AI + Skill 可去除四至五成 AI 味,但美感仍需人類把關
呢篇文章出自一位自媒體創作者兼 AI 實踐者,佢之前用 Claude Opus 寫嘅文章攞咗獎,但被讀者話 AI 味好重。佢想知如果配合自己整嘅 mp-article-writor Skill,AI 重新生成嘅文章會唔會好啲。
佢將同一批素材同 prompt 分別交畀 GLM 5.1 同 Claude Sonnet 4.6,再用 Skill 引導寫作。Skill 嘅設計係先理解作者意圖、校準語感、確認大綱,再用三個 subagent 獨立審讀、核查事實同終審自檢。結果發現兩篇新稿都去除咗 4 到 5 成典型 AI 味,例如「不是 A 而是 B」句式減少、比喻鏈收斂、標題口語化等。
整體結論係:AI + Skill 喺去除結構性 AI 味上有效,但排比對仗、過渡機械化呢類慣性好難完全根除。作者認為文章嘅靈魂同美感,始終要靠人類作者親自介入同潤色。
- 結論:AI + Skill 組合能有效去除 4 至 5 成 AI 味,但無法完全取代人類寫作嘅美學判斷。
- 方法:透過理解意圖、校準語感、確認大綱三步前置,加上三個 subagent 獨立審讀,系統化減低 AI 味。
- 差異:Claude Sonnet 4.6 喺句式自然度、比喻收斂同過渡口語化上比 GLM 5.1 表現更好。
- 啟發:去除 AI 味唔係一味禁止,而係從句式結構、標點使用、比喻延伸入手,且過度規則可能產生新嘅 AI 味。
- 可行動點:作者已經將 mp-article-writor Skill 開源,其他人可以直接下載使用或參考改進。
mp-article-writor GitHub
作者開源嘅 AI 文章寫作 Skill,包含前置三步同 subagent 審讀流程
流量日記 Mac App
作者開發嘅自媒體數據分析工具,可永久保存分析各平台數據
點解要研究 AI + Skill 去 AI 味?
作者之前投稿少數派徵文比賽嘅文章「你是專家這句話,到底係幫 AI 定係害你?」攞咗獎,但收到讀者留言話佢篇文 AI 味好重。佢承認原文係 Claude Opus 一次性生成,自己冇改過,的確有明顯問題。
於是我決定用自建嘅 mp-article-writor Skill,喺完全一樣嘅上下文入面,叫 AI 重寫同一篇文,睇嚇 AI 結合 Skill 會唔會令文章質素有提升。呢個實驗本身就係一個方法論測試。
原文嘅 AI 味有咩特徵?
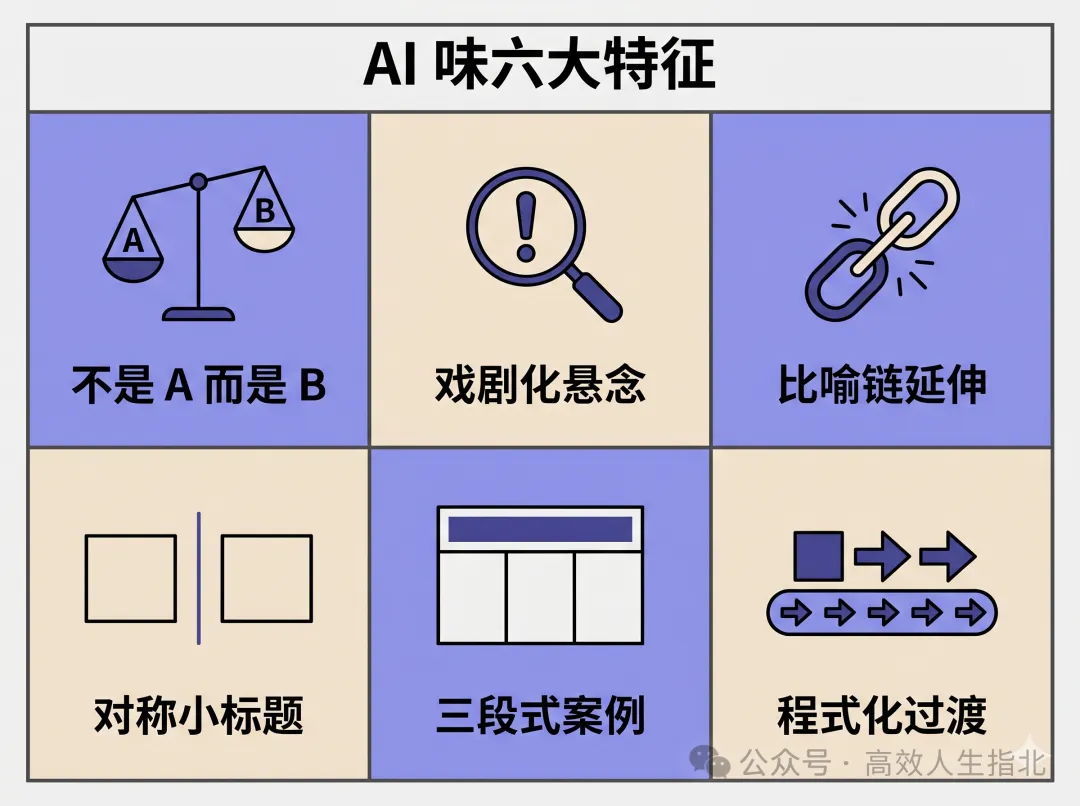
作者細拆原文,發現幾種典型 AI 味:「不是 A,而是 B」句式氾濫、身份設定用「編」字而非「寫」、過度戲劇化嘅 懸念製造(例如「出了一身冷汗」)、比喻鏈過度延伸(遙控器比喻拆成頻道、音量、天線三層),仲有過度對稱同公式化嘅小標題。
「不是因為它知道更多,而是因為它會在回答前先想一想」呢類句式全篇反複出現
- 否定式定義 + 對稱結構嘅小標題,例如「你……,AI 就……」
- 過渡句程式化,例如「一個自然的追問」、「如果說……則是」
- 結尾用 ✅ ❌ 場景分類,似說明手冊多過文章
mp-article-writor Skill 點樣運作?
Skill 嘅設計係先做好 理解意圖、校準語感、確認大綱 呢三步前置。AI 會從「切入角度」「深度偏好」「核心主旨」「素材補充」四方面向作者確認信息,再讀取「範文風格分析」同「行文風格指南」嚟模仿作者風格。
AI 完成大綱後會停落嚟問作者意見,先正式開始初稿
完成初稿後,系統會啟動三個 subagent 分別做「獨立審讀」「事實核查」同「終審自檢」。獨立審讀專注 AI 味同邏輯,事實核查防止幻覺,終審自檢核對自檢清單。好處係隔離上下文,唔畀主 Agent 盲目自信。
另外,Skill 中要求禁用冒號同破折號,呢個間接令 AI 減少用「不是 A 而是 B」句式,因為呢類句式成日依賴嗰兩個標點。
同一批素材,兩次改寫嘅結果
作者用同一 prompt 同一素材,分別叫 GLM 5.1 同 Claude Sonnet 4.6 配合 Skill 重寫。結果兩篇都比原文好,但 Claude Sonnet 4.6 喺多數維度上更遠離 AI 味。
「不是 A 而是 B」句式:Claude 只出現 2-3 次,GLM 仍有 5 次以上
比喻鏈:Claude 點到為止,冇拆子比喻;GLM 收斂但仍有「頻道 vs 錯覺」
小標題:Claude 用口語「第一個係樸素嘅疑問句」;GLM 似大綱「穿上白大褂就會看病了?」
總體嚟講,Skill 幫手去除咗 4 到 5 成 AI 味,但剩低嘅部分(例如過渡句微妙的機械感、排比慣性)好難靠規則完全消除。作者認為 過度規則可能產生新嘅 AI 味,最終文章嘅美感同靈魂仍需要人類作者親自潤色。
如果你對呢個 Skill 有興趣,佢已經 開源喺 GitHub,歡迎交流。佢亦介紹咗自己開發嘅 Mac App「流量日記」,專為自媒體創作者設計。
之前投稿去少數派年度徵文比賽嘅文章,「你係專家」呢句話,到底係幫緊 AI 定係害緊你?,好彩得到咗「Team Silicon」賽道嘅第一名,不過佢近期收到咗咁樣一條評論:
多謝作者嘅分享,不過我自己就覺得呢篇文章嘅 AI 味真係幾重嚇,有啲措辭我睇咗兩次都理解唔到 AI 想表達嘅意思 hhh
係呀,呢篇文章當時係由 Claude Opus 4.6 一次性生成嘅,我冇做任何調整。佢可以贏可能係因為命題巧妙同實踐內容紮實,但係由文章結構同語言表達嘅角度嚟睇,存在好多缺陷。
於是我就決定用自己整嘅 mp-article-writor Skill,喺完全一樣嘅上下文環境入面,叫 AI 重寫呢篇文章,觀察 AI 結合 Skill 嘅組合,寫出嚟嘅文章係咪可以有質嘅提升。
原文嘅 AI 味
雖然原文係由 Claude Opus 4.6 呢啲頂級模型生成嘅,但係全文仍然出現咗大量 AI 味嘅典型特徵。
「唔係 A,而係 B」句式泛濫。
身份設定唔係喺度同模型講「點樣寫」,而係同佢講「你係邊個」
呢個唔係簡單嘅「作」,而係一種更高級、更具欺騙性嘅幻覺
唔係因為佢「知得更多」,而係因為佢會喺回答之前先「諗一諗」
過度戲劇化嘅懸念製造。
用「成身冷汗」嚟形容實驗結果,誇大咗實際嘅情緒。
有啲結果喺意料之中,有啲就令我成身冷汗
專登標明實驗結果嘅排序,太過刻意。
我將最令人不安嘅結果放喺最前面
比喻鏈過度延伸。
結尾嘅「遙控器」比喻係典型問題:
佢做嘅嘢更加似一個遙控器——調嘅係頻道,唔係信號強度
情感措辭就似係音量旋鈕
而真正決定「信號強度」嘅,係模型底層嘅推理能力——係天線嘅事,唔係遙控器管得到嘅
一個比喻拆出三個子比喻(頻道、音量、天線),每個啱啱好對應一個實驗結論,工整到失真。真實寫作入面,比喻通常係點到即止;AI 嘅傾向係將佢當框架,一路鋪滿。
過度對稱同公式化嘅小標題 。
呢啲標題嘅共同特徵:否定式定義 + 對稱結構。讀起嚟似係同一個標題生成器出嚟嘅。尤其係「你……,AI 就……」呢種對稱,真實作者好少會咁寫。
AI 冇咁易被「道德綁架」
呢個唔係「模型好壞」嘅問題
白袍≠醫術
你認真對待呢個請求,AI 就認真對待呢個輸出
每個案例都係同一套三段式。
四個案例嘅結構完全一致:實驗設計 → 結果 → 小結,而且每個小結全部係 " 短句 + 破折號或冒號 + 解釋 " 嘅統一格式,節奏完全重複。
真實長文通常會喺唔同章節變換收束方式,唔會每個結尾都好似教案嘅 " 本節要點 "。
過渡句嘅程式化。
「一個自然嘅追問」係 AI 標準過渡語。
睇完專家幻覺嘅結果之後,一個自然嘅追問係
轉折太過刻意,好似 PPT 切頁咁。
前面兩個案例講嘅都係「唔好咁用」。而家我哋嚟睇,身份設定真正擅長啲乜
「如果話……則係」都係 AI 高頻過渡模版。
如果話案例 1 驗證咗……案例 2 要驗證嘅則係另一個更微妙嘅變量
mp-article-skill
喺叫 AI 重新生成文章之前,先等我解釋下 mp-article-skill 嘅設計原理。
呢個係我自己建立嘅 Skill,喺我每次完成實踐探索或者問題調研之後,會叫 AI 利用探索或者調研嘅完整過程做上下文,結合 Skill 幫我完成文章嘅初稿。
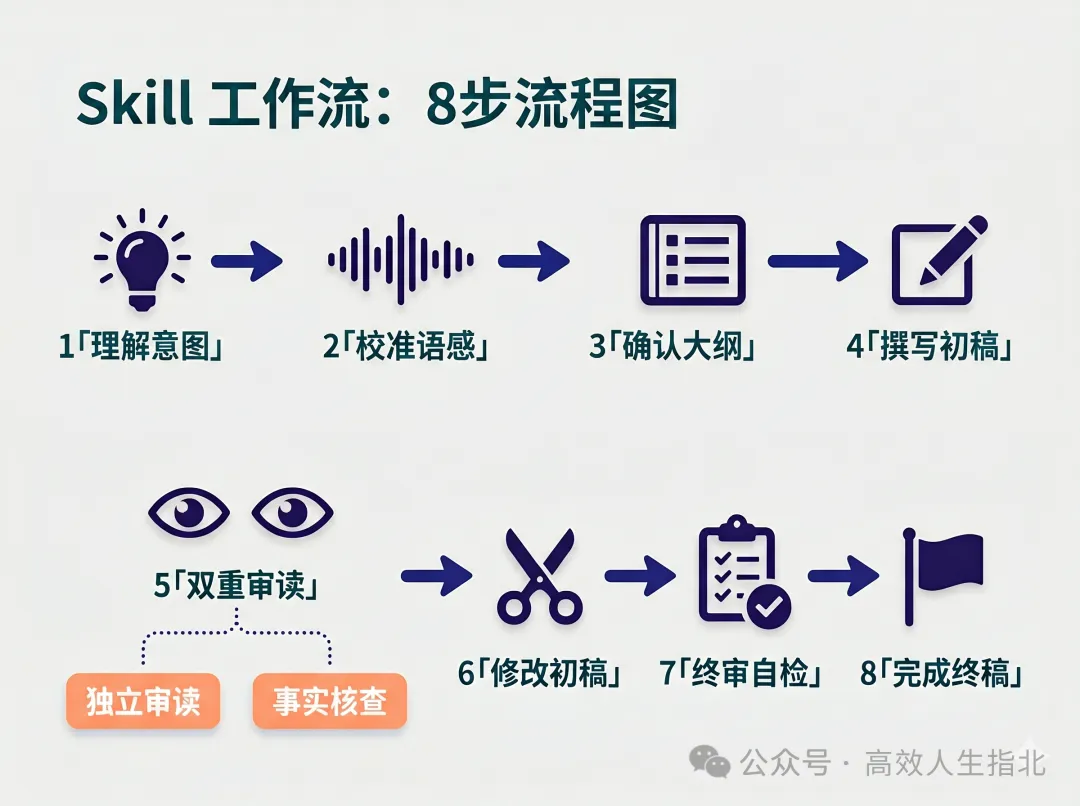
理解意圖、校準語感同確認大綱,呢個係我喺 Skill 入面要求 AI 喺開始寫作之前優先做嘅三件事,確保最後生成嘅文章唔會出現結構性嘅問題。
AI 會由「切入角度」「深度偏好」「核心主旨」「素材補充」呢四個方面向我確認資訊,理解我嘅寫作意圖:
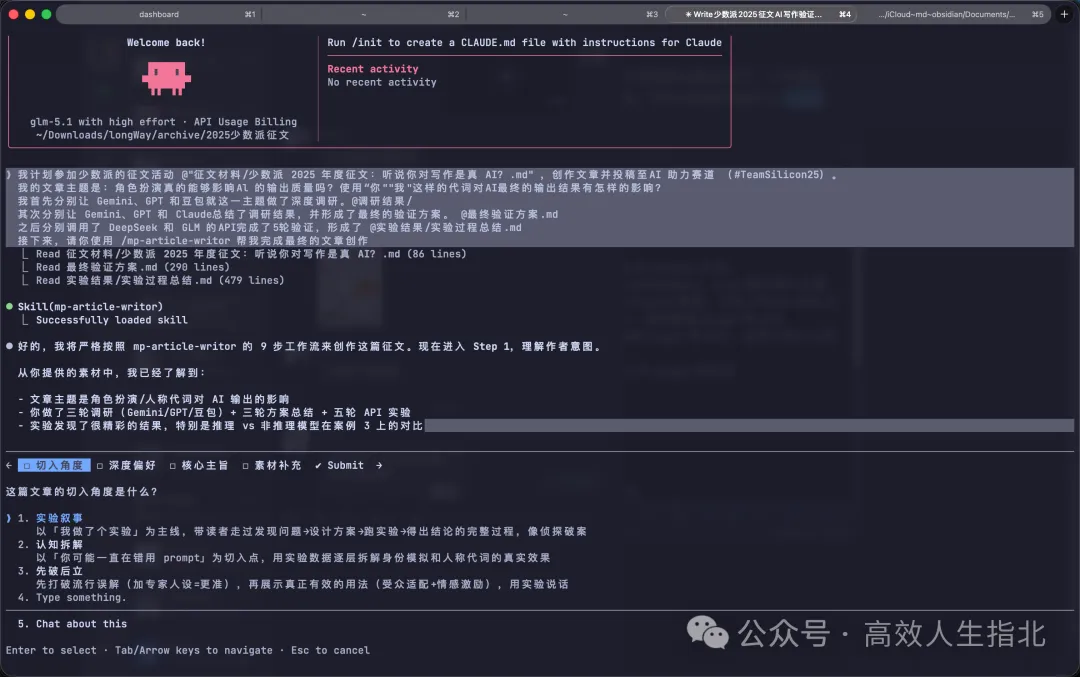
之後讀取「範文風格分析」文檔模擬我嘅寫作風格,讀取「行文風格指南」確保語句入面唔會出現 AI 濫用嘅加粗、破折號等習慣。
「範文風格分析」文檔入面我總結咗自己比較滿意嘅文章,以及我希望可以寫出嚟嘅文章風格,「行文風格指南」就主要參考少數派嘅「風格指南」。
當 AI 完成文章大綱之後,會展示大綱內容,然後停低問我意見。
完成以上三步之後,AI 先開始寫初稿。
初稿完成之後,我設立咗三個 subagent 分別完成「獨立審讀」「事實核查」同「終審自檢」。用 subagent 嘅好處在於隔離上下文,只俾文章本身,唔俾背景,防止主 Agent 受會話上下文嘅影響而「盲目自信」,成日覺得自己「好出色咁完成咗任務」。
「獨立審讀 subagent」重點審查 AI 味太重、邏輯唔連貫、結構生硬等語言表達類問題,「事實核查 subagent」重點核查事實性內容,防止 AI 出現幻覺,老作事實。

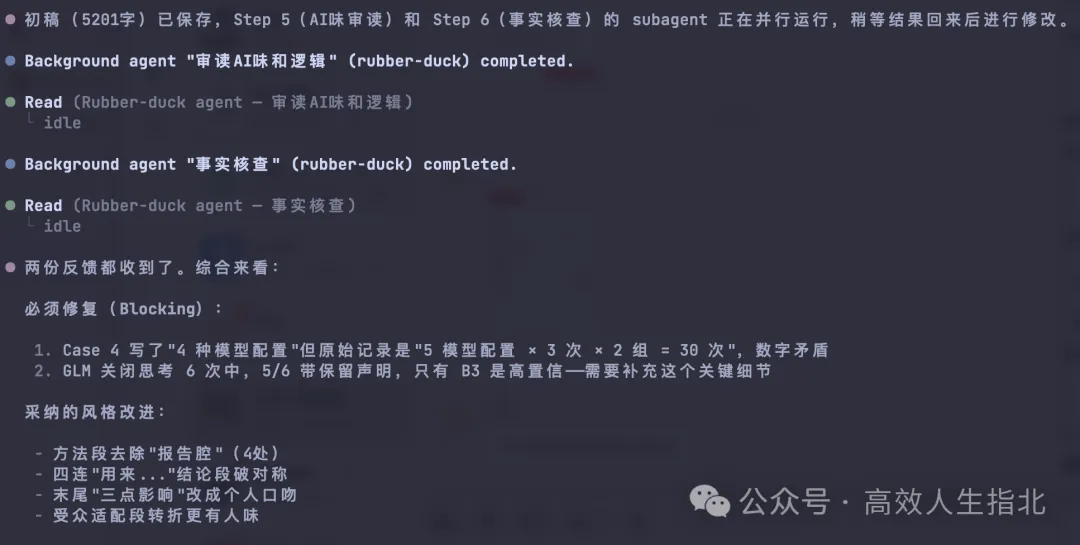
當主 Agent 收到呢兩個 subagent 返嚟嘅資訊並修改初稿之後,「終審自檢」subagent 就會啟動,針對修改咗嘅稿,核對 SKILL.md 文檔入面提供嘅「自檢清單」,並提供自檢報告。
去除 AI 味嘅技巧同「自檢清單」嘅內容部分係參考自卡茲克嘅 khazix-writer Skill,多謝佢嘅開源項目。
同一批素材,兩次改寫
為咗確保上下文一致,我引用咗相同嘅文檔,並提供同第一次生成文章完全一樣嘅 prompt(prompt 入面 file: 代表引用咗本地文檔):
我計劃參加少數派嘅徵文活動,創作文章並投稿到 AI 助力賽道 (TeamSilicon25)。file:少數派 2025 年度徵文:聽講你對寫作係真 Al?.md
我嘅文章主題係:角色扮演真係可以影響 Al 嘅輸出質量咩?用“你 "" 我 " 呢類代詞對 AI 最終嘅輸出結果有咩影響?
我首先分別叫 Gemini、GPT 同豆包就呢個主題做咗深度調研。file:調研結果
其次分別叫 Gemini、GPT 同 Claude 總結咗調研結果,並形成咗最終嘅驗證方案。 file:最終驗證方案.md
之後分別叫咗 DeepSeek 同 GLM 嘅 API 完成咗 5 輪驗證,形成咗 file:實驗過程總結.md
請你幫我生成最後嘅文章。
因為 Copilot Pro 套餐唔再支援調用 Claude Opus 4.6 模型,所以我只能分別叫 GLM 5.1 同 Claude Sonnet 4.6 重寫,呢個係比較可惜嘅地方。
新生成嘅兩篇文章共用同一批素材、同一個核心比喻,比起原文都有好轉,但 Claude Sonnet 4.6 係多數維度上比 GLM 5.1 更加遠離 AI 味。
唔係 A 而係 B 句式
兩篇都有用,但 GLM 5.1 用得更加密、更加規整。
Claude Sonnet 4.6 只出現咗 2-3 次:
唔止換咗詞彙,仲換咗邏輯順序
唔係因為佢太蠢,而係因為佢冇內省嘅機會
GLM 5.1 仍然有 5 次以上,同原文差唔多:
唔係「角色扮演有冇用」,而係「佢到底擅長做啲乜」
分別唔在於 prompt 寫得好唔好,分別在於模型生成之前有冇「停低諗一諗」
身份設定調嘅係風格,唔係準確度
權威感唔等於準確性
準確性比起「好睇」重要得多
我喺 Skill 入面冇明確禁止用「唔係...而係...」嘅句式,而係要求 AI 唔可以用冒號同破折號。咁樣喺一定程度上帶嚟咗間接效果,因為 AI 最鍾意用嘅幾種句式都依賴呢兩個標點:
「唔係 A,而係 B」成日寫成「A——唔係 B」 定義式總結成日寫成「關鍵在於:A 係 B」 解釋性展開成日寫成「原因在於:……」
禁咗呢兩個標點之後,模型焗住要換句式,而呢啲替代句式往往更加口語化。兩篇新稿入面「唔係 A 而係 B」嘅減少,有一部分就係標點禁令嘅間接功勞。
戲劇化懸念
原文嘅情緒詞明顯過度,兩個版本嘅新稿都有收斂,但收斂方式同程度唔同。
原文用嘅「成身冷汗」「觸目驚心」「令人警覺」「完美」呢啲詞,遠超一個對照實驗結果需要嘅強度。
Claude Sonnet 4.6 用限定詞嚟降温:
呢個結論令我覺得有啲細思極恐
意外,又有啲放心
GLM 5.1 幾乎冇用幾多情緒詞。
呢個應該係 Skill 入面我要求用「冷靜平和中藴含力量,唔用誇張嘅口語或語氣詞」風格嚟寫作起到咗作用。
同時我用咗 subagent 獨立審讀全篇嘅 AI 味,GLM 5.1 嘅審讀反饋入面明確要求「將『背脊發涼』改為『呆咗一下』,降低情緒詞」。
比喻鏈延伸
原文入面遙控器比喻被拆成咗頻道、音量、天線三層,呢個係最典型嘅 AI 過度延伸。兩篇新稿都收斂咗,但程度唔同。
Claude Sonnet 4.6 只用咗一個延伸:
遙控器可以令你收到更加清晰、更加適合當前場景嘅內容,但信號本身嘅質量,係由模型嘅推理能力決定嘅
點到即止,冇拆出子比喻。
GLM 5.1 同樣收斂咗,用「正確用法 vs 錯覺」收尾,比起原文嘅頻道、音量、天線乾淨:
下次打開 ChatGPT 之前,先諗清楚你係喺度調頻道,定係指望加外掛。前者係工具嘅正確用法,後者係錯覺。
呢度嘅 AI 味改善同下一節加粗總結句嘅特徵改善,應該都係透過獨立審查 AI 味嘅環節修正,例如喺獨立審查環節之後,subagent 要求明確修正嘅內容包括:
三段加粗結論嘅第二段由同構模版改為唔同句式 四連「用嚟...」結論段打破對稱 尾段「三點影響」改成個人語氣
加粗總結句嘅密度同模式
三個版本嘅結尾都用咗「遙控器」呢個比喻,但落腳點唔同。
舊文嘅結尾係一份使用指南,帶 ✅ 同 ❌ 嘅符號,按場景話畀讀者知幾時應該用角色扮演,幾時唔應該用。
✅ 應該用身份設定嘅場景
……
❌ 唔應該用身份設定嘅場景
……
GLM 5.1 嘅結尾係三條加粗判斷句:
身份設定調嘅係風格,唔係準確度。
情感激勵的確可以令 AI 更加賣力,但賣力嘅方向你話唔到事。
推理能力係比任何 prompt 技巧更加根本嘅分界線。
Claude Sonnet 4.6 嘅結尾係三條第一人稱實踐,
要改輸出風格,我會直接描述係對邊個講嘢。……
要寫帶數字嘅材料,數字由我嚟提供,唔畀模型自由發揮。……
要核查任何可能超出模型知識邊界嘅事實,換推理模型,唔好押注喺專家人設度。
相比之下,兩個新版確實好咗啲,冇用到原文嗰種「參考手冊」嘅建議風格,改為正常嘅語句,但係仍然保持咗排比句式,放喺總結段落入面又唔算生硬。
雖然我已經喺獨立審讀環節要求 AI 明確審查太過整齊、對仗嘅結構,都係冇辦法完全避免,只能夠話喺「提供建議」呢個場景上面,排比句式係 AI 繞唔過嘅難關。
小標題風格
Claude Sonnet 4.6 嘅標題更加似人話:
實驗係點樣設計嘅
情感激勵有用,但佢「努力」嘅方式有啲野
第一個係樸素嘅疑問句,第二個用咗有啲野呢種口語化表達,帶個人語氣。
GLM 5.1 嘅標題更加似大綱:
着咗白袍就會睇病咩?
咁佢到底擅長啲乜?
甚至唔需要角色扮演
標題風格部分喺 Skill 入面冇明確約束。不過「好似一個有見識嘅朋友喺度認真同你傾一件打動佢嘅事(參考自卡茲克嘅 khazix-writer Skill)」呢個要求喺一定程度上對呢度有影響。
過渡句
原文嘅過渡係程式化嘅,相比之下,Claude Sonnet 4.6 嘅過渡更加口語化:
測完幻覺,我順便測咗另一件事
測完呢兩個,我開始諗,問題可能由一開始就問錯咗
四個案例測完,可以返返去開頭嗰個問題喇
GLM 5.1 嘅過渡更加似論文:
驗證完 system 層嘅身份設定,我接下來想睇 user 層嘅措辭會點
身份設定可以調頻道,咁如果唔加身份,只改措辭呢?
返返去開頭嘅問題
我喺 Skill 入面要求禁用「首先…其次…最後」「綜上所述」「值得注意的是」呢啲套話,但好難話兩個新版喺過渡句上面有幾多 AI 味嘅改善,至少我讀起嚟總有種微妙嘅感覺,唔似係真人寫嘅,至少我唔會咁寫。
仲可以做多啲咩?
總體嚟講,喺 Skill 嘅作用之下,兩篇新稿都去除咗 4 到 5 成嘅 AI 味,但仲有剩餘。例如「唔係 A 而係 B」句式嘅殘餘、小標題或過渡句嘅過度範式、提供建議時用排比對仗嘅慣性等等。
理論上呢啲剩餘嘅 AI 味都可以透過加強規則約束嚟去除,但係太多、太過嘅規則限制會唔會又導致最終生成嘅內容支離破碎,變得牛頭唔搭馬嘴。
強硬規則約束之下嘅公式化表達,就算去除咗而家嘅 AI 味,會唔會產生新嘅 AI 味呢?
我更傾向於 AI 結合 Skill 嘅組合只用嚟去除重度 AI 味,而文章嘅美感同靈魂,喺而家甚至未來好長一段時間之內,依然需要人類作者嘅親自介入同潤色。
如果你對 mp-article-writor Skill 有興趣嘅話,我已經將佢開源咗喺 GitHub 上面,balabalabalading/mp-article-writor[2],歡迎交流討論。
我獨立開發嘅 Mac 版 App「流量日記[3]」已經上線 Mac App Store,專為自媒體創作者打造,可以永久保存、分析各平台匯出嘅賬號數據。如果你係用 Mac 嘅內容創作者,歡迎下載體驗,半年內免費使用。
「你係專家」呢句話,到底係幫緊%20AI%20定係害緊你?.md ↩ https://github.com/balabalabalading/mp-article-writor ↩ https://apps.apple.com/cn/app/%E6%B5%81%E9%87%8F%E6%97%A5%E8%AE%B0/id6753135743?mt=12 ↩
之前投稿至少數派年度徵文大賽的文章,「你是專家」這句話,到底是在幫 AI 還是在害你?,有幸獲得了「Team Silicon」賽道的第一名,然而它在近期收穫了這樣一條評論:
謝謝作者的分享,不過我個人覺得這篇文章的 AI 味真的還蠻重的,有些措辭我看了兩遍都沒能理解 AI 想表達的含義 hhh
確實,這篇文章當時是由 Claude Opus 4.6 一次性生成的,我沒有作任何調整。它能勝出可能勝在命題巧妙和實踐內容紮實,然而從文章結構和語言表達的角度來說,存在許多缺陷。
於是我決定使用自建的 mp-article-writor Skill,在完全相同的上下文環境中,讓 AI 重寫這篇文章,觀察 AI 結合 Skill 的組合,寫出的文章是否能有質的提升。
原文的 AI 味
雖然原文是由 Claude Opus 4.6 這樣頂級的模型生成的,但是全文仍然出現了大量 AI 味的典型特徵。
「不是 A,而是 B」句式氾濫。
身份設定不是在告訴模型「怎麼寫」,而是在告訴它「你是誰」
這不是簡單的「編」,而是一種更高級、更具欺騙性的幻覺
不是因為它「知道更多」,而是因為它會在回答前先「想一想」
過度戲劇化的懸念製造。
使用「出了一身冷汗」來描述實驗結果,誇大實際的情緒。
有些結果在意料之中,有些則讓我出了一身冷汗
專門點明實驗結果排序,過於刻意。
我把最令人不安的結果放在最前面
比喻鏈過度延伸。
結尾的「遙控器」比喻是典型問題:
它做的事情更像是一個遙控器——調的是頻道,不是信號強度
情感措辭則像是音量旋鈕
而真正決定「信號強度」的,是模型底層的推理能力——那是天線的事,不是遙控器能管的
一個比喻拆出三個子比喻(頻道、音量、天線),每個都恰好對應一個實驗結論,工整到失真。真實寫作中,比喻通常是點到即止的;AI 的傾向是把它當框架,一路鋪滿。
過度對稱和公式化的小標題 。
這些標題的共同特徵:否定式定義 + 對稱結構。讀起來像是從同一個標題生成器裏出來的。尤其是「你……,AI 就……」這種對稱,真實作者很少會這麼寫。
AI 沒那麼容易被「道德綁架」
這不是「模型好壞」的問題
白大褂≠醫術
你認真對待這個請求,AI 就認真對待這個輸出
每個案例都是同一套三段式。
四個案例的結構完全一致:實驗設計 → 結果 → 小結,且每個小結全部是 " 短句 + 破折號或冒號 + 解釋 " 的統一格式,節奏完全重複。
真實長文通常會在不同章節變換收束方式,不會每個結尾都像教案的 " 本節要點 "。
過渡句的程式化。
「一個自然的追問」是 AI 標準過渡語。
看完專家幻覺的結果後,一個自然的追問是
轉折過於刻意,像 PPT 切頁。
前面兩個案例講的都是「別這麼用」。現在我們來看,身份設定真正擅長什麼
「如果說……則是」也是 AI 高頻過渡模板。
如果說案例 1 驗證了……案例 2 要驗證的則是另一個更微妙的變量
mp-article-skill
在讓 AI 重新生成文章之前,先讓我解釋下 mp-article-skill 的設計原理。
這是我自己創建的 Skill,在我每次完成實踐探索或是問題調研後,會讓 AI 利用探索或調研的完整過程作為上下文,結合 Skill 幫我完成文章的初稿。
理解意圖、校準語感和確認大綱,這是我在 Skill 中要求 AI 在開始寫作前優先執行的三件事,保證最後生成的文章不出現結構性的問題。
AI 會從「切入角度」「深度偏好」「核心主旨」「素材補充」四個方面向我確認信息,理解我的寫作意圖:
之後讀取「範文風格分析」文檔模擬我的寫作風格,讀取「行文風格指南」保證語句中不出現 AI 濫用的加粗、破折號等習慣。
「範文風格分析」文檔中我總結了自己比較滿意的文章,以及我希望能寫出來的文章風格,「行文風格指南」則主要參考少數派的「風格指南」。
當 AI 完成文章大綱後,會展示大綱內容,並停下來向我詢問意見。
完成以上三步後,AI 才開始初稿的寫作。
初稿完成後,我設立了三個 subagent 分別完成「獨立審讀」「事實核查」和「終審自檢」。使用 subagent 的好處在於隔離上下文,只給文章本身,不給背景,防止主 Agent 受會話上下文的影響而「盲目自信」,總覺得自己「非常優秀地完成了任務」。
「獨立審讀 subagent」 重點審查 AI 味過重、邏輯不連貫、結構生硬等語言表達類問題,「事實核查 subagent」 重點核查事實性內容,防止 AI 出現幻覺,杜撰事實。
當主 Agent 接收到這兩個 subagent 返回的信息並修改初稿後,「終審自檢」subagent 會啓動,針對修改後的稿子,核對 SKILL.md 文檔中提供的「自檢清單」,並提供自檢報告。
去除 AI 味的技巧和「自檢清單」的內容部分借鑑自卡茲克的 khazix-writer Skill,感謝他的開源項目。
同一批素材,兩次改寫
為了保證上下文一致,我引用了相同的文檔,並提供與第一次生成文章完全相同的 prompt(prompt 中 file: 代表引用了本地文檔):
我計劃參加少數派的徵文活動,創作文章並投稿至 AI 助力賽道 (TeamSilicon25)。file:少數派 2025 年度徵文:聽說你對寫作是真 Al?.md
我的文章主題是:角色扮演真的能夠影響 Al 的輸出質量嗎?使用“你 "" 我 " 這樣的代詞對 AI 最終的輸出結果有怎樣的影響?
我首先分別讓 Gemini、GPT 和豆包就這一主題做了深度調研。file:調研結果
其次分別讓 Gemini、GPT 和 Claude 總結了調研結果,並形成了最終的驗證方案。 file:最終驗證方案.md
之後分別調用了 DeepSeek 和 GLM 的 API 完成了 5 輪驗證,形成了 file:實驗過程總結.md
請你為我生成最終的文章。
由於 Copilot Pro 套餐不再支持調用 Claude Opus 4.6 模型,因此我只能分別讓 GLM 5.1 和 Claude Sonnet 4.6 重寫,這是比較遺憾的地方。
新生成的兩篇文章共用同一批素材、同一個核心比喻,相比原文都有好轉,但 Claude Sonnet 4.6 在多數維度上比 GLM 5.1 更遠離 AI 味。
不是 A 而是 B 句式
兩篇都在用,但 GLM 5.1 用得更密、更規整。
Claude Sonnet 4.6 只出現了 2-3 次:
不只是換了詞彙,還換了邏輯順序
不是因為它太笨,而是因為它沒有內省的機會
GLM 5.1 仍有 5 次以上,與原文相近:
不是「角色扮演有沒有用」,而是「它到底擅長做什麼」
差別不在 prompt 寫得好不好,差別在模型生成前有沒有「停下來想一想」
身份設定調的是風格,不是準確度
權威感不等於準確性
準確性比「好看」重要得多
我在 Skill 中沒有明確禁止使用「不是...而是...」的句式,而是要求 AI 不能使用冒號和破折號。這在一定程度上帶來了間接效果,因為 AI 最愛用的幾種句式都依賴這兩個標點:
「不是 A,而是 B」經常寫成「A——不是 B」 定義式總結經常寫成「關鍵在於:A 是 B」 解釋性展開經常寫成「原因在於:……」
禁掉這兩個標點後,模型不得不換句式,而這些替代句式往往更口語化。兩篇新稿中「不是 A 而是 B」的減少,有一部分就是標點禁令的間接功勞。
戲劇化懸念
原文的情緒詞明顯過載,兩版新稿都有收斂,但收斂方式和程度不同。
原文使用的「出一身冷汗」「觸目驚心」「令人警覺」「完美」這些詞,遠超一個對照實驗結果所需的強度。
Claude Sonnet 4.6 使用限定詞來降温:
這個結論讓我覺得有點細思極恐
意外,也有點放心
GLM 5.1 幾乎沒有使用多少情緒詞。
這應當是 Skill 中我要求使用「冷靜平和中藴含力量,不使用誇張的口語或語氣詞」風格來寫作起了作用。
同時我使用了 subagent 獨立審讀全篇的 AI 味,GLM 5.1 的審讀反饋中明確要求「將『背後發涼』改為『愣了一下』,降級情緒詞」。
比喻鏈延伸
原文裏遙控器比喻被拆成了頻道、音量、天線三層,這是最典型的 AI 過度延伸。兩篇新稿都收斂了,但程度不同。
Claude Sonnet 4.6 只用了一個延伸:
遙控器可以讓你收到更清晰、更適合當前場景的內容,但信號本身的質量,是由模型的推理能力決定的
點到為止,沒有拆出子比喻。
GLM 5.1 同樣收斂了,用「正確用法 vs 錯覺」收束,比原文的頻道、音量、天線乾淨:
下次打開 ChatGPT 之前,先想清楚你是在調頻道,還是在指望加外掛。前者是工具的正確用法,後者是錯覺。
這裏的 AI 味改善與下一節加粗總結句的特徵改善,應當都是通過獨立審查 AI 味的環節修正,比如在獨立審查環節後,subagent 要求明確修正的內容包括:
三段加粗結論的第二段從同構模板改為不同句式 四連「用來...」結論段破對稱 末尾「三點影響」改成個人口吻
加粗總結句的密度和模式
三版的結尾都用了「遙控器」這個比喻,但落腳點不同。
舊文的結尾是一份使用指南,帶 ✅ 和 ❌ 的符號,按場景告訴讀者什麼時候該用角色扮演,什麼時候不該用。
✅ 該用身份設定的場景
……
❌ 不該用身份設定的場景
……
GLM 5.1 的結尾是三條加粗判斷句:
身份設定調的是風格,不是準確度。
情感激勵確實能讓 AI 更賣力,但賣力的方向你說了不算。
推理能力是比任何 prompt 技巧更根本的分界線。
Claude Sonnet 4.6 的結尾是三條第一人稱實踐,
要改輸出風格,我會直接描述在對誰說話。……
要寫帶數字的材料,數字由我來提供,不讓模型自由發揮。……
要核查任何可能超出模型知識邊界的事實,換推理模型,別押注在專家人設上。
相比之下,兩個新版確實好了一些,沒有使用原文那種「參考手冊」的建議風格,改為正常的語句,但仍然保持了排比句式,放在總結段落裏倒也不至於生硬。
雖然我已經在獨立審讀環節要求 AI 明確審查過於整齊、對仗的結構,還是無法完全避免,只能說在「提供建議」這一場景上,排比句式是 AI 繞不過去的坎。
小標題風格
Claude Sonnet 4.6 的標題更像人話:
實驗是怎麼設計的
情感激勵有用,但它「努力」的方式有點野
第一個是樸素的疑問句,第二個用了有點野這種口語化表達,帶個人語氣。
GLM 5.1 的標題更像大綱:
穿上白大褂就會看病了?
那它到底擅長什麼?
甚至不需要角色扮演
標題風格部分在 Skill 中沒有明確約束。不過「像一個有見識的朋友在認真跟你聊一件打動他的事(借鑑自卡茲克的 khazix-writer Skill)」這個要求一定程度上對此處有影響。
過渡句
原文的過渡是程式化的,相比之下,Claude Sonnet 4.6 的過渡更口語化:
測完幻覺,我順手測了另一件事
測完這兩個,我開始想,問題可能從一開始就問偏了
四個案例測完,可以回到開頭那個問題了
GLM 5.1 的過渡更像論文:
驗證完 system 層的身份設定,我接着想看 user 層的措辭會怎樣
身份設定能調頻道,那如果不加身份,只改措辭呢?
回到開頭的問題
我在 Skill 中要求禁用「首先…其次…最後」「綜上所述」「值得注意的是」等套話,但很難說兩個新版在過渡句上有多少 AI 味的改善,至少我讀起來總有種微妙的感覺,不像是活人寫的,至少我不會這麼寫。
還能做得更多嗎?
總體來說,在 Skill 的作用下,兩篇新稿都去除了 4 到 5 成的 AI 味,但仍有剩餘。比如「不是 A 而是 B」句式的殘餘、小標題或過渡句的過度範式、提供建議時使用排比對仗的慣性等等。
理論上這些剩餘的 AI 味也可以通過加強規則約束來去除,但過多、過度的規則限制是否又會導致最終生成的內容支離破碎,變得驢唇不對馬嘴。
強硬規則約束下的公式化表達,即便去除了現在的 AI 味,會不會產生新的 AI 味呢?
我更傾向於 AI 結合 Skill 的組合只用來去除重度 AI 味,而文章的美感與靈魂,在當下甚至未來很長一段時間內,依然需要人類作者的親自介入與潤色。
如果你對 mp-article-writor Skill 感興趣的話,我已經將它開源在 GitHub 上,balabalabalading/mp-article-writor[2],歡迎交流討論。
我獨立開發的 Mac 端 App「流量日記[3]」已上線 Mac App Store,專為自媒體創作者打造,可永久保存、分析各平台導出的賬號數據。如果你是用 Mac 的內容創作者,歡迎下載體驗,半年內免費使用。
「你是專家」這句話,到底是在幫%20AI%20還是在害你?.md ↩ https://github.com/balabalabalading/mp-article-writor ↩ https://apps.apple.com/cn/app/%E6%B5%81%E9%87%8F%E6%97%A5%E8%AE%B0/id6753135743?mt=12 ↩