AI 寫得PRD"還行",那到底是行?還是不行?10 道題讓它現原形
整理版優先睇
用10道題考卷量化AI輸出,告別「還行」嘅模糊驗收
呢篇文章講嘅係產品經理成日遇到嘅問題:用AI寫PRD或者報告,睇完只識講「還行」,但講唔出到底係得定唔得。作者指出,呢種憑手感驗收嘅方式好隱蔽,會導致反覆改、無標準、判斷唔穩定。
為咗解決呢個問題,作者引入一個叫「評估集」(evals)嘅概念。評估集唔係新潮玩具,而係一套標準答案嘅考卷:揀10條真實工作入面嘅題目,每條定義清楚「合格答案要滿足乜嘢條件」,然後每次改提示詞或者模型之前後都跑一次,比分數。作者強調,評估集嘅核心唔係技術,而係定義「好答案」嘅標準——呢個正正係產品經理最擅長嘅部分。
整體結論係:AI時代嘅產品判斷,唔係睇AI寫得似唔似人,而係你有冇一把可以反覆用嘅尺。透過建立考卷,你可以將「手感」變成可交接嘅「資產」,避免每次靠感覺浪費時間。文章仲提供一個具體場景(財務報表分析)作為參考,鼓勵讀者從最高頻嘅AI任務開始,先做10題跑起來。
- 憑手感驗收AI輸出係最隱蔽嘅返工原因,判斷唔穩定、無法標準化。
- 建立評估集(eval):10道真實題目加合格標準,反覆跑分取代主觀感覺。
- 評估集嘅關鍵係定義「好答案」,呢件事產品經理最拿手,唔係工程師。
- 從「呢次睇住OK」變成「反覆用嘅分數」,判斷可以交接俾人。
- 揀最高頻AI任務,先起10題考卷,跑出基準後每次改動前後比分數。
「還行」嘅陷阱
「你睇下呢個,AI寫嘅,還行吧?」呢句話你一定講過,亦聽過。問題係——「還行」到底係得定唔得?你講唔清。於是改一版又一版,每版都「還行」,但冇人證明到邊版更好。
憑手感驗收,係AI時代最隱蔽嘅返工原因
手感呢樣嘢,換個人就飄,換個模型都飄,改一句提示詞又會飄。同一份嘢,今日睇「還行」,聽日睇「唔多掂」,全憑當下注意力。更弊嘅係,「還行」令你唔敢直接用,又講唔清要改邊度——於是隻能「再改改」。
AI一日產出十幾份,你冇可能每份都親自睇一次
就算睇咗,呢次判斷都帶唔到下一次。要破局,就要將「憑手感檢查」變成「可以反覆跑嘅標準」。
評估集係乜?講人話版
成熟團隊一早唔靠「更資深嘅眼光」——一線而家嘅標準動作叫eval,即係評估集。簡單講,就係俾AI出一份有標準答案嘅考卷。
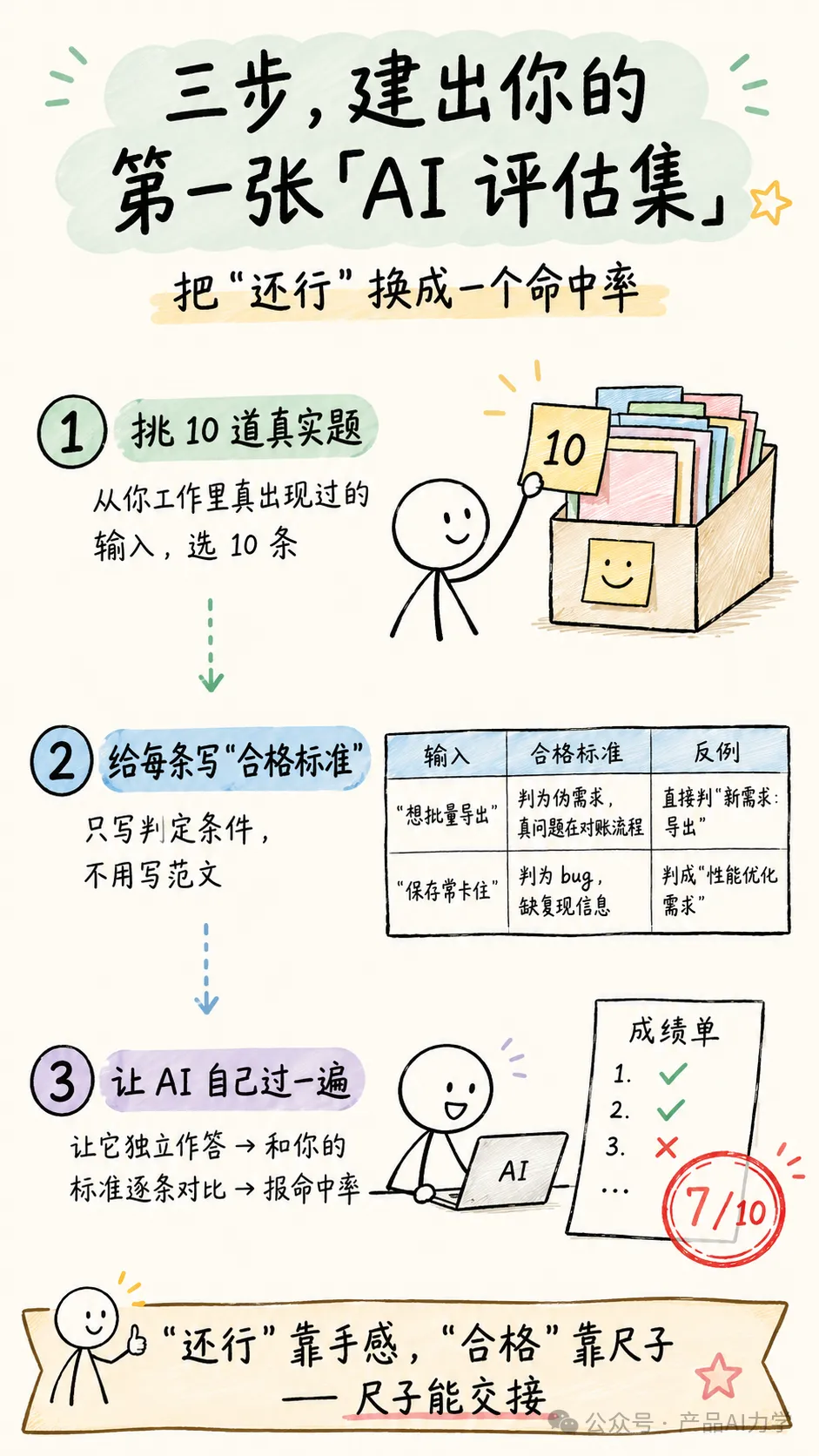
Eval主要得三樣嘢:一組真實輸入 + 你認可嘅合格標準 + 反覆跑
具體操作:揀10條你工作入面真實出現過嘅題目,每條寫清楚「合格答案要滿足咩條件」,然後每次叫AI做呢10條,睇嚇佢啱幾多。
關鍵在於:你唔使每次都重新判斷,你只睇分數
改提示詞、換模型、加新規則之前,先跑一次存低分數;改完再跑一次,跌喺邊條題目上面,即刻見到。
- 1 一組真實輸入:揀你工作入面最常用、最關鍵嘅輸入場景
- 2 你認可嘅合格標準:每條題目寫清楚「點先叫過關」,例如分類正確、覆蓋所有風險項
- 3 反覆跑:每次改動前後跑一次,比分數變化
一個直接抄走嘅動作
揀你最高頻嗰類AI活,先建立第一張考卷。舉個例:叫AI將用戶反饋分類。
用10條真實反饋做考題,定義每條嘅正確分類
跑完你會得到一個具體數字——例如「10題啱7題」。呢個數字就係你以後所有「還行」嘅替身。你手上就多咗一把可以反覆用、仲可以交俾人用嘅尺。
先10題,能跑起嚟比全面更重要
評估集唔係越大越好,一嚟就做100題,多半半途而廢。亦唔係所有事都值得做eval:一次性嘅、用完即棄嘅活,憑手感就夠。值得建考卷嘅,係你會反覆做、而且做錯有代價嘅高頻任務。
AI時代嘅產品判斷,係你有冇一把可以反覆用嘅尺
如果你仲係靠感覺,不如而家就開個試算表,揀10題出來跑一次。
"你睇下呢個,AI寫嘅,叫做得啦?"
呢句話你一定講過,都聽過。問題係
——""叫做得啦",到底係得定係唔得?
你講唔清。於是改咗一版,又一版,每版都話「叫做得啦」,但冇人可以證明邊一版更好。一個禮拜後換咗個更新嘅模型,輸出變咗,你都只能再靠感覺講句「嗯,叫做得啦」。
呢個說明:你驗收佢嘅方式,仲停留喺「靠感覺」。
靠感覺驗收,係AI時代最隱蔽嘅返工
感覺呢樣嘢,換個人就唔同,換個模型都唔同,改一句提示詞仲會唔同。同一份嘢,你今日睇話「叫做得啦」,聽日睇話「唔多得」,全靠當下嘅注意力。
更慘嘅係,「叫做得啦」令你既唔敢直接用,又講唔清要改邊度——於是隻能「再改改」。
AI一日可以產出十幾份,你冇可能每份都親自睇一次;就算睇咗,今次嘅判斷都帶唔到去下一次。
要打破呢個僵局,就要將「靠感覺嘅檢查」,變成「可以重複用嘅標準」。
成熟團隊一早已經唔靠「更加資深嘅眼光」啦
一線而家嘅標準動作,叫做 eval(評估集)。講白啲,就係畀AI出一張有標準答案嘅考卷。
呢個唔係乜嘢新潮玩具,舊年上半年就已經有EDD(評估驅動開發)嘅AI理論同實踐。呢半年不斷被引用之後,基本形成共識:
• Anthropic嘅工程博客講得好直白——先寫評估集,定義你想要嘅能力,再去迭代,而唔係反轉頭先做、做完靠感覺驗收。 • Lenny專登寫咗一篇PM嘅評估指南,標題就叫《Beyond vibe checks》,直譯過嚟就係「唔好再靠感覺檢查啦」。 • 一門叫《AI Evals for Engineers & PMs》嘅課,成為Maven平台銷量第一,兩千幾個PM同工程師喺度學。 • 行業入面而家有句話:識唔識寫eval,正在區分初級同高級嘅AI產品經理。
點解呢件事偏偏要產品經理嚟做?因為評估集嘅核心唔係技術,而係「點先算一個好答案」
——而呢個正正係產品經理最熟悉、工程師最唔熟悉嘅部分。呢張考卷,本來就應該你出。
評估集到底係乜(講人話)
唔好俾術語嚇親,Evals其實主要得三樣嘢:
一組真實輸入 + 你認可嘅合格標準 + 反覆跑。
具體操作就係:揀10題你工作入面真實出現過嘅題目,俾每題寫清楚「合格答案要滿足啲乜」,然後每次叫AI行呢10題,掂咗幾題一目瞭然。
關鍵在於——你唔使每次重新判斷,你只睇分數。 改提示詞、換模型、加新規則之前先行一次留個底,改完再行一次,邊題出錯,即刻見到。
一個可以直接抄走嘅動作
揀你最高頻嘅嗰類AI工作,先整第一張考卷。以「叫AI將用戶反饋分類」為例:
行完你會得到一個具體嘅數字——例如「10題啱7題」。呢個數字,就係你以後所有「叫做得啦」嘅替身。
你手上面有一把可以重複用、仲可以交俾人用嘅尺。
唔好整到佢太複雜
評估集唔係越大越好。一開始就想做100題,多數半途而廢——先10題,可以行得順比起全面更加重要。
亦唔係所有事都值得做eval。一次性、用完即棄嘅工作,靠感覺就夠。值得整考卷嘅,係嗰啲你會重複做、而且做錯有代價嘅高頻任務。
仲有一條底線:合格標準要可以俾另一個人跟住判斷,唔可以只係喺你個腦入面。 判斷一旦可以交接,佢先至從「感覺」變咗做「資產」。
AI時代嘅產品判斷,唔係睇AI寫得似唔似人,而係你有冇一把可以重複用嘅尺。
如果文章仲唔夠直觀嘅話,可以喺評論區舉個手,我發個實例俾你做參考(為咗脱敏做咗微調)。
場景:俾AI一組財務報表數據,寫個SKILL.md,配個reference模板,叫佢輸出分析同預警報告。
你可以按自己嘅產品細節做加工,拎嚟測試唔同模型、唔同提示詞、唔同智能體嘅穩定性。
"你看一下這個,AI 寫的,還行吧?"
這句話你肯定說過,也聽過。問題是
——"還行",到底是行,還是不行?
你說不清。於是改了一版,又一版,每版都"還行",但沒人能證明哪一版更好。一週後換了個更新的模型,輸出變了,你也只能再憑感覺說一句"嗯,還行"。
這說明:你驗收它的方式,還停在"憑手感"。
憑手感驗收,是 AI 時代最隱蔽的返工
手感這東西,換個人就飄,換個模型也飄,改一句提示詞還會飄。同一份東西,你今天看"還行",明天看"不太行",全憑當下的注意力。
更要命的是,"還行"讓你既不敢直接用,也說不清要改哪——於是只能"再改改"。
AI 一天能產出十幾份,你不可能每份都親自瞪一遍;就算瞪了,這次的判斷也帶不到下一次。
要破這個局,得把"憑手感的檢查",變成"能反覆跑的標準"。
成熟團隊早就不靠"更資深的眼光"了
一線現在的標準動作,叫 eval(評估集)。說白了,就是給 AI 出一張有標準答案的考卷。
這不是什麼新潮玩具,去年上半年就已經有EDD(評估驅動開發)的AI理論和實踐。這半年被反覆蓋章以後,基本形成共識:
• Anthropic 的工程博客把它講得很直白——先寫評估集,定義你要的能力,再去迭代,而不是反過來先做、做完憑感覺驗收。 • Lenny 專門寫了一篇 PM 的評估指南,標題就叫《Beyond vibe checks》,直譯過來就是"別再憑感覺檢查了"。 • 一門叫《AI Evals for Engineers & PMs》的課,成了 Maven 平台銷量第一,兩千多個 PM 和工程師在學。 • 行業裏現在有句話:會不會寫 eval,正在區分初級和高級的 AI 產品經理。
為什麼這件事偏偏該產品經理來做?因為評估集的核心不是技術,是"什麼才算一個好答案"
——而這恰恰是產品經理最懂、工程師最不懂的部分。這張考卷,本來就該你出。
評估集到底是什麼(說人話)
別被術語嚇到,Evals其實主要就三樣東西:
一組真實輸入 + 你認可的合格標準 + 反覆跑。
具體到操作,就是:挑 10 道你工作裏真實出現過的題,給每道寫清楚"合格答案該滿足什麼",然後每次讓 AI 跑這 10 道,對了幾道一目瞭然。
關鍵在於——你不用每次重新判斷,你只看分。 改提示詞、換模型、加新規則之前先跑一遍存個底,改完再跑一遍,崩在哪道題上,立刻看見。
一個可以直接抄走的動作
選你最高頻的那類 AI 活兒,先建第一張考卷。以"讓 AI 把用戶反饋分類"為例:
跑完你會得到一個具體的數字——比如"10 題對 7 題"。這個數字,就是你以後所有"還行"的替身。
你手裏有一把能反覆用、還能交給別人用的尺子。
別把它做複雜
評估集不是越大越好。一上來就想做 100 題,多半半途而廢——先 10 題,能跑起來比全面更重要。
也不是所有事都值得做 eval。一次性的、用完即棄的活兒,憑手感就夠了。值得建考卷的,是那些你會反覆做、且做錯有代價的高頻任務。
還有一條底線:合格標準要能讓另一個人照着判,不能只活在你腦子裏。 判斷一旦能交接,它才從"手感"變成了"資產"。
AI 時代的產品判斷,不是看 AI 寫得像不像人,而是你有沒有一把能反覆用的尺子。
如果文章還不夠直觀的話,可以評論區舉個手,我發你個實例做參考(為了脱敏做了微調)。
場景:給 AI 一組財務報表數據,寫個SKILL.md,配個reference模板,讓它輸出分析和預警報告。
你可以按自己的產品細節做加工,拿來測試不同模型、不同提示詞、不同智能體的穩定性。