AI 編程進階:三件套實戰中的10個常見陷阱與避坑指南
整理版優先睇
三件套唔係萬能,10個常見陷阱令AI編程仍然跑偏,附避坑指南
呢篇文章係作者回應用《AI編程進階:三件套》嘅讀者反饋,好多用咗OpenSpec、Superpowers同Agent Skills嘅人仍然遇到流程失控、需求走樣嘅問題。作者深入分析根因:三件套本質係「行為約束」而唔係「系統強制」,分為程序性強制(最強)、AI行為約束(中等)同流程慣例(最弱)三層。跑偏嘅根源在於使用者對工具定位有認知偏差、執行細節唔到位、同埋工具配置缺失或衝突。
文章將10個陷阱分為認知層、操作層同工具層,每個陷阱都有識別標誌、根因分析同避坑指南。作者強調,要令三件套真正生效,需要三層保險:理解工具定位、執行到位同配置CI閘門。整體結論係:skill約束AI行為,CI阻斷不達標,人審關鍵節點,三層疊加先做到可預測嘅工程化交付。
呢篇文唔單止列陷阱,仲提供具體檢查清單,例如spec一定要用RFC 2119關鍵詞、人審至少5分鐘、技能唔好開超過8個、一定要配CI閘門等。適合想真正活用三件套嘅開發者參考。
- 三件套係行為約束唔係系統強制,需要理解分層強度先唔會跑偏
- Spec必須用RFC 2119關鍵詞(MUST/MUST NOT),人審要逐條檢查,唔可以掃一眼就算
- Skill要顯式指定並按階段啓用,避免一次開太多導致AI『失憶』
- 計劃同審查需要精確到文件路徑同驗收標準,唔可以信口頭『睇落似對』
- 一定要配CI閘門(覆蓋率、安全掃描)做程序性強制,雙保險先穩陣
OpenSpec
人機契約工具,用RFC 2119關鍵詞寫spec,確保需求對齊
Superpowers
AI行為流程約束工具,透過skill控制AI步驟
Agent Skills
AI技能庫,提供test-coverage、security-secrets等可組合技能
陷阱分類與分層約束:先搞清三件套嘅真實強度
三件套唔係裝咗就搞掂,佢哋嘅強度分三層:程序性強制(CLI/CI)、AI行為約束(Skill元數據+模型選擇)、流程慣例(文檔+人審)。跑偏嘅根因正正係使用者將AI行為約束當成系統強制,或者以為裝咗就會自動生效。
OpenSpec嘅本質係人機契約,而唔係普通需求文檔
Superpowers嘅skill只係注入上下文,AI可以繞過
- 1 認知層陷阱:源於唔理解工具定位,例如將spec當做普通文檔、規格寫得模糊
- 2 操作層陷阱:執行細節唔到位,例如計劃模糊、忽略審查結果
- 3 工具層陷阱:配置缺失或衝突,例如開太多技能、唔配CI
認知層與操作層嘅關鍵陷阱:逐條審閲、精確計劃、證據驗收
認知層最常見係「spec當普通文檔」同「規格寫得模糊」。作者用live-share案例示範:spec嘅MUST條款要逐條諗點驗證,Open Questions一定要有人拍板先可以開工。
spec.md嘅MUST條款係驗收契約,人審至少花5分鐘
RFC 2119關鍵詞:MUST/MUST NOT/SHOULD/MAY,避免「應該」「盡量」等軟詞
操作層陷阱包括「計劃模糊」同「忽略審查結果」。計劃要精確到文件路徑、接口名、預估時間同驗收口徑,唔可以寫「實現導出CSV功能」就算。
- Task N: 任務名稱(約X分鐘)- 文件: 精確路徑 - 改動: 具體接口/函數 - 驗收: 驗收標準
- 審查結果:CRITICAL必須阻塞,HIGH盡量修,覆蓋率低過80%唔合得
工具層陷阱:skill唔好開太多、必要步驟唔好跳、一定要配CI
工具層陷阱包括技能開太多、跳過必要步驟同只靠AI約束唔配CI。好多用家一次開曬15個skill,搞到AI上下文爆滿、反應變慢、仲會『失憶』。
初期只開5-8個核心skill,按階段啓用/關閉
TDD幾乎唔應該跳過,就算係bug修復都要先寫RED測試
- 跳過OpenSpec直接寫代碼 → 需求漂移
- 跳過Superpowers直接實現 → 流程混亂
- 跳過Agent Skills直接提交 → 質量失控
最關鍵係要配CI閘門:覆蓋率門檻、安全掃描、代碼規範檢查。skill + CI先係真正嘅雙保險,純靠AI約束,AI隨時會漏。
name: QualityGate
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- run: npm install
- run: npm test
- run: npm run coverage-check
security:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: gitleaks/gitleaks-action@v2
- uses: aquasecurity/trivy-action@master防跑偏檢查清單:10個陷阱嘅自查方法
作者整合咗一張速查表,分三層檢查。認知層:係咪逐條審閲MUST條款?有冇用RFC 2119?人審夠唔夠5分鐘?skill有冇觸發到?
操作層檢查:計劃係咪精確到文件路徑同驗收口徑?CRITICAL有冇修?有冇要求證據?
工具層檢查:技能數量<=8?必要步驟有冇跳過?CI閘門配咗未?
- 認知層:人審時間>=5分鐘?spec冇軟詞?skill自動反問需求?
- 操作層:每條task有文件路徑?審查結果有處理?有測試輸出覆蓋率?
- 工具層:技能<=8個?bug修復有測試?有coverage workflow?
一句話總結:skill約束AI行為,CI阻斷不達標合入,人審關鍵節點。三層疊加先係可預測嘅工程化交付。
前言:點解會走偏?
由「睇落似啱」到「證據確鑿」——令三件套真正發揮作用嘅實戰手冊
看完《AI 編程進階:三件套 OpenSpec 定方向,Superpowers 帶節奏,Agent Skills 守紀律,打造可預測嘅工程化工作流程》嗰篇文章,你可能會覺得:裝咗呢三個工具,AI 編程就由「靠運氣」變成「可以複製」喇。
但現實往往更殘酷。
好多讀者反饋:用咗三件套,依然走偏。
•OpenSpec 嘅 spec 寫完就掉埋一邊,AI 照樣自由發揮
•Superpowers 嘅 brainstorming 被跳過,AI 直接動手寫 code
•Agent Skills 嘅約束被當成「建議」,覆蓋率報告話「睇落似啱」
問題出喺邊?
根因:三件套嘅真實強度
三件套唔係「系統層強制」,而係分層約束:
| 程序性強制 | |||
| AI 行為約束 | |||
| 流程慣例 |
走偏嘅根因,就喺呢三層各自嘅漏洞:
1.認知偏差 —— 唔理解工具嘅真實強度,以為「裝咗就搞掂曬」
2.操作失誤 —— 觸發條件冇達成,AI 行為約束層失效
3.工具誤解 —— 將「AI 行為約束」當成「系統強制」,唔配 CI 閘門
10個陷阱嘅分類
本文將10個常見陷阱分為三層:
| 認知層 | ||
| 操作層 | ||
| 工具層 |
每個陷阱都有三個部分:
識別標誌 → 你怎麼知道自己是否掉進這個陷阱?
根因分析 → 為什麼會掉進去?
避坑指南 → 怎麼爬出來並預防再次掉進去?
第一章:認知層陷阱
認知層嘅陷阱,源於唔理解工具嘅真實定位。
陷阱1:將 spec 當成普通文檔
識別標誌
你寫完 /opsx:propose 後,AI 生成了 proposal.md、specs/、design.md、tasks.md。
你睇咗一眼標題,覺得「好似都啱」,就㩒「確認進入實現」。
典型場景:
AI:已生成提案,請審閲確認
你:(看了一眼proposal標題)嗯,看起來對,確認
AI:開始實現...
你:(心裏想)終於可以寫代碼了
根因分析
OpenSpec 嘅本質係人機契約——喺寫 code 之前先喺人同 AI 之間達成共識。
好多人當佢係「需求文檔」,覺得「寫完就等於對齊咗」。
實際上:
誤解導致嘅後果:
•spec 裏面嘅 MUST 條款冇逐條審閲 → AI 理解同人嘅預期有偏差
•design.md 嘅 Open Questions 冇拍板 → 實現時先發現歧義
•tasks.md 嘅任務冇驗證可行性 → 開工後發現做唔到
真實案例
三件套原文入面嘅 feat-live-share-third-party 案例:
需求表裏面寫住:「保持 app 後台運行,直播狀態」。
如果人冇審閲 spec,AI 可能理解為:
•理解A:宿主進程唔被殺(錯誤)
•理解B:唔向直播域發送停止指令(正確)
正確理解係 spec.md 裏面嘅 MUST 條款:
在用戶進入第三方授權、編輯或發佈流程期間,宿主 App MUST NOT 主動向音視頻模塊
發送「停止直播/停止推流」指令;除非操作系統強殺或用戶顯式結束直播,
直播核心狀態 MUST 與進入分享流程前保持一致。
呢一條 MUST 條款,將模糊嘅「保持 app 後台運行」翻譯成可驗證嘅程序性條款。
如果唔審閲呢條,AI 可能喺實現時漏咗「唔調用停止指令」嘅關鍵約束。
仲有其實有些需求裏面有交互設計嘅,你冇仔細睇生成嘅文檔,咁你生成嘅交互就可能係缺失嘅,而後續補充係件痛苦嘅事。
避坑指南
✅ 實操清單:
Step 1: proposal.md —— 讀標題 + Why部分
- Why部分解釋了"為什麼要做",確認AI理解了意圖
Step 2: specs/spec.md —— 逐條審閲 MUST / MUST NOT / MAY
- 每條MUST條款思考:怎麼驗證?(測試?日誌?手工?)
- MUST NOT條款思考:哪些代碼路徑可能違規?
Step 3: design.md —— 檢查 Open Questions
- 每個Open Question必須有人拍板(產品/技術/法務)
- 沒拍板的不能進入實現
Step 4: 確認前問AI一個驗證問題
- "這些MUST條款你怎麼理解?能舉一個違反的例子嗎?"
- 如果AI回答模糊,說明spec本身需要修正
⏱️ 耗時對比:
呢5分鐘,慳咗後面幾個鐘嘅返工。
陷阱2:規格寫得模糊
識別標誌
你打開 spec.md,發現裏面用嘅係呢啲詞:
•“應該顯示進度條」
•“儘量保持直播狀態」
•“最好使用主播頭像」
•“建議加一個取消按鈕」
典型表現:冇 MUST / MUST NOT,全部係軟性描述。需要硬性嘅描述。
根因分析
OpenSpec 嘅 spec 語法基於 RFC 2119 關鍵詞:
軟詞嘅陷阱:
•「應該」 → AI 可以唔做,但做咗都算啱 → 驗收時拗數
•「儘量」 → AI 做到咗80%算唔算盡力? → 標準模糊
•「最好」 → AI 冇做到算唔算錯? → 無法阻斷
真實問題:軟詞寫成嘅 spec,等於冇 spec。
真實案例
對比兩種 spec 寫法:
模糊寫法:
分享面板應該顯示可選渠道。
分享時儘量保持直播狀態。
標題最好使用直播間標題。
精確寫法(RFC 2119):
用戶點擊分享 MUST 展示包含微信、朋友圈、QQ、QQ空間、微博的渠道列表。
宿主App MUST NOT 在分享流程中主動調用「停止直播」指令。
分享文案 MUST 優先使用直播間標題;標題缺失時 MUST 使用系統模板。
區別:
•模糊寫法 → AI 做咗一半算唔算完成?無法判斷
•精確寫法 → MUST 冇達成就係失敗,可以阻斷
避坑指南
✅ 實操清單:
Step 1: 寫spec時,強制用RFC 2119關鍵詞
- 驗收條款 → MUST / MUST NOT
- 推薦做法 → SHOULD / NOT RECOMMENDED
- 可選功能 → MAY
Step 2: 檢查每條MUST條款的可驗證性
- MUST "顯示進度條" → 怎麼驗證?UI截圖?日誌?
- MUST NOT "調用停止指令" → 怎麼檢測?代碼審計?測試斷言?
Step 3: 避免這些軟詞
- ❌ 應該、儘量、最好、建議
- ✅ MUST、MUST NOT、SHOULD、MAY
Step 4: 給AI一個模板提示
"請用 RFC 2119 關鍵詞(MUST/MUST NOT/MAY)重寫以下規格..."
📋 RFC 2119 關鍵詞速查表:
陷阱3:人審環節走過場
識別標誌
AI 生成 spec 後,你見到一長串文件,心諗「AI 寫嘅應該冇問題啩」。
你嘅審閲動作:
1.睇一眼標題 → 「嗯,睇落似啱」
2.碌到最底 → 「好,有 tasks 喇」
3.㩒確認 → 「開始寫 code」
典型表現:審閲時間 < 30秒,冇讀 MUST 條款,冇諗驗證方法。
根因分析
OpenSpec 嘅設計哲學係:人喺關鍵節點拍板,AI 喺邊界內執行。
人審環節走過場,導致:
人嘅惰性來源:
•「AI 寫嘅應該冇問題」 → 過度信任
•「反正有測試會覆蓋」 → 卸膊
•「審閲太花時間」 → 想快啲見到 code
現實:AI 寫 spec 時只係「估你嘅意圖」,人審先係真正嘅「確認意圖」。
真實案例
原文入面嘅 feat-live-share-third-party 案例:
AI 喺 design.md 生成了 Open Questions:
## Open Questions
- 微博最終走「官方SDK」還是「系統分享面板降級」——需產品+法務確認後回填到spec.md
如果人唔審閲,直接進入實現:
•Agent-Weibo 開始寫 code → 寫嘅係 SDK 方案
•法務後來話:SDK 有合規風險,唔用得 → 全部返工
審閲時拍板,慳嘅係成個 Agent 嘅返工成本。
避坑指南
✅ 實操清單:
人審的必做項:
Step 1: 讀 proposal.md 的 Why 部分
- Why解釋"為什麼要做",確認AI理解了業務意圖
- 如果Why偏離你的理解,直接指出修正
Step 2: 讀 specs/spec.md 的 MUST條款
- 每條MUST條款思考:
- 這條真的必要嗎?
- 怎麼驗證?(測試代碼?日誌?手工?)
- 有遺漏場景嗎?
Step 3: 讀 design.md 的 Open Questions
- 每個Open Question必須有人拍板
- 沒拍板的不能開工
Step 4: 讀 tasks.md 的任務列表
- 任務是否覆蓋所有MUST條款?
- 任務粒度是否可獨立驗證?
Step 5: 確認前問AI一個問題
- "如果要驗證第一條MUST條款,測試應該怎麼寫?"
- AI的回答驗證了條款的可驗證性
⏱️ 時間分配建議:
| 總計 | 5分鐘 |
陷阱4:將 skill 當成可選建議
識別標誌
你問 AI:「幫我實現一個導出 CSV 功能」。
AI 嘅回應:
好的,我來實現導出CSV功能。
[開始寫代碼...]
export function exportCSV(data: Data[]) {
...
}
典型表現:AI 冇反問需求細節,冇澄清邊界,直接開始寫 code。
你心諗:「Superpowers 裝咗,但 AI 好似冇觸發 brainstorming?算啦,反正開始寫喇。」
根因分析
Superpowers 嘅 skill 係AI 行為約束——AI 應該跟 skill 嘅流程執行,唔係自由發揮。
但 skill 嘅觸發有兩層依賴:
Superpowers 唔會自動「接管」AI——佢只係將流程注入到 AI 嘅上下文裏面,AI 需要主動選擇遵守。
典型失效場景:
•任務描述太簡單 → AI 覺得「呢個簡單,唔使 brainstorming」
•上下文窗口太雜 → AI 冇注意到 AGENTS.md 裏面嘅 skill 描述
•模型選擇失誤 → AI 優先考慮「快速響應」唔係「嚴格流程」
真實案例
對比兩種交互:
skill 失效嘅交互:
你:幫我加一個導出CSV按鈕
AI:好的,我來寫代碼 [開始寫]
你:(等待)
AI:寫完了,請測試
你:測試發現沒處理空數據情況...
skill 生效嘅交互:
你:幫我加一個導出CSV按鈕,請先用brainstorming澄清需求
AI:進入brainstorming模式...
Q1. CSV文件編碼用什麼?UTF-8還是UTF-8 BOM(Excel兼容)?
Q2. 需要支持自定義導出字段嗎?
Q3. 空數據時導出什麼?
Q4. 超過10000條時需要進度條嗎?
你:回答這些問題
AI:已記錄到design.md,開始寫實現計劃
區別:顯式指定 skill,強制 AI 進入流程。
避坑指南
✅ 實操清單:
Step 1: 觀察AI的行為模式
- AI直接開始寫代碼 → brainstorming沒觸發
- AI沒寫實現計劃 → writing-plans沒觸發
- AI沒跑測試 → test-driven-development沒觸發
Step 2: 顯式指定skill
- 發現AI跳過流程時,主動說:
- "請先按brainstorming技能澄清需求"
- "請按writing-plans寫一個詳細實現計劃"
- "請按test-driven-development先寫RED測試"
Step 3: 確認skill已安裝
- Claude Code: /plugin list 看superpowers是否在
- Cursor: 檢查 .cursorrules 或 AGENTS.md
- Gemini CLI: gemini extensions list
Step 4: 保持上下文清潔
- 清理無關對話,讓AI更容易注意到skill描述
- 開始新任務時,可以新建一個對話窗口
🔧 skill 觸發檢查表:
唔好以為裝咗技能,AI 就會自動跟住行。你太想當然喇。
第二章:操作層陷阱
操作層嘅陷阱,源於執行細節唔到位。
陷阱5:實現計劃寫得模糊
識別標誌
AI 生成嘅實現計劃係咁嘅:
# Tasks
- [ ] 實現導出CSV功能
- [ ] 添加導出按鈕
- [ ] 集成到Dashboard
- [ ] 寫單元測試
典型表現:任務描述唔精確到文件路徑、接口名、驗收口徑。
你心諗:「反正 AI 知道點做,等佢自己發揮啦。」
根因分析
Superpowers 嘅 writing-plans skill 要求:計劃必須精確到「一個冇判斷力嘅初級工程師都執行到」。
模糊計劃導致:
真實問題:模糊計劃 = AI 自由發揮 = 不確定性。
真實案例
對比兩種計劃寫法:
模糊計劃:
- [ ] 實現導出CSV功能
- [ ] 添加導出按鈕
- [ ] 集成到Dashboard
精確計劃(Superpowers 標準):
Task 1: 創建CSV工具函數 (約3分鐘)
- 文件: src/utils/csv.ts
- 導出: escapeCSV(), generateCSV(), downloadCSV()
- 驗收: generateCSV能處理逗號和換行符
Task 2: 添加導出按鈕 (約2分鐘)
- 文件: src/components/DashboardToolbar.tsx
- 位置: Toolbar右側,在Refresh按鈕後
- 接口: onClick觸發handleExport
- 驗收: 未選中數據時按鈕禁用
Task 3: 集成到Dashboard (約3分鐘)
- 文件: src/pages/Dashboard.tsx
- 改動: 添加handleExport方法,獲取selectedRows
- 驗收: 點擊按鈕下載CSV文件,文件名export-YYYY-MM-DD.csv
區別:
•模糊計劃 → AI 可能將 code 寫喺任何位置
•精確計劃 → AI 知道寫邊個文件、邊個接口、點樣驗收,
具體嘅計劃顆粒度需要自己把控。
避坑指南
✅ 實操清單:
精確計劃的必備要素:
每個任務必須包含:
1. 文件路徑 —— 寫在哪裏
2. 接口/函數名 —— 命名是什麼
3. 預估時間 —— 大概多久(防止AI耗時失控)
4. 驗收口徑 —— 怎麼驗證完成
格式模板:
Task N: [任務名稱] (約X分鐘)
- 文件: [精確路徑]
- 改動: [具體接口/函數]
- 驗收: [驗收標準]
📋 Superpowers 計劃標準(原文引用):
「Plans must be clear enough for an enthusiastic junior engineer with poor taste, no judgement, no project context, and an aversion to testing to follow.」
翻譯:計劃必須精確到「一個冇判斷力嘅初級工程師都執行到」。
陷阱6:忽略代碼審查結果
識別標誌
AI 完成實現後,進入代碼審查階段。
審查報告顯示:
🔴 CRITICAL: csv.ts的downloadCSV在IE瀏覽器會報錯
🟡 WARNING: escapeCSV沒有處理null值
🟢 INFO: 建議把導出邏輯抽成獨立模塊
📊 測試覆蓋率: 78% (< 80%門檻)
你嘅反應:
"CRITICAL是IE瀏覽器問題,現在沒人用IE了,先繼續吧"
"WARNING先不管,以後再說"
"覆蓋率78%接近80%了,差不多"
典型表現:繼續推進,唔修復問題。
根因分析
Superpowers 嘅 requesting-code-review skill 要求:CRITICAL 必須阻斷,HIGH 儘量修復。
審查嘅分級含義:
| 必須阻斷 | ||
| 應該修復 | ||
忽略審查嘅後果:
•CRITICAL 冇修 → 上線後可能冧機/洩漏
•HIGH 冇修 → 用戶發現問題後返工
•覆蓋率冇達標 → 合入後發現質量問題
真實案例
原文入面嘅閘門子圖:
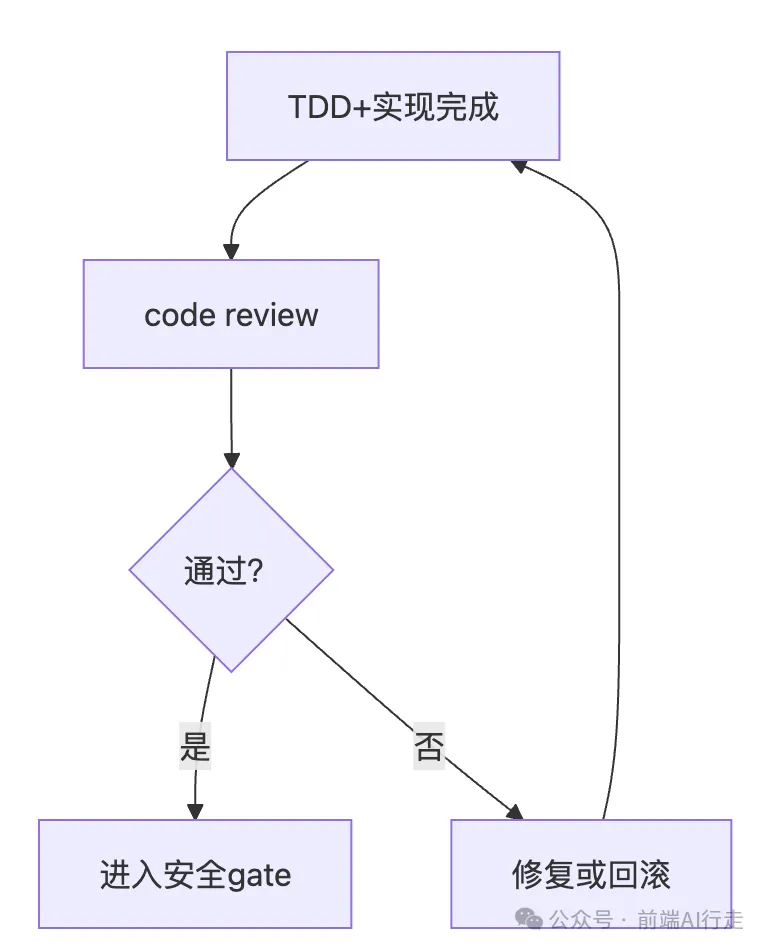
如果唔跟閘門執行:
•CRITICAL 冇修 → 進入安全 gate → 安全檢查發現更多問題 → 全部返工
•更糟嘅情況 → skip 安全 gate → 合入主分支 → 生產事故
避坑指南
✅ 實操清單:
審查結果處理標準:
CRITICAL → 必須立即修復
- 如果不修復,必須有人書面拍板承擔風險
- 通常CRITICAL意味着"不修會出事"
HIGH → 儘量修復
- 如果不修復,在tasks.md記錄"延後理由"
- HIGH問題通常會在後續測試/使用中暴露
MEDIUM/LOW → 可延後
- 記錄到"改進清單",不阻塞當前任務
覆蓋率不達標 → 必須達標才能合入
- test-coverage skill要求80%門檻
- 如果CI配置了覆蓋率閘門,不達標無法合入
⚠️ Superpowers 審查原則:
「Critical issues during code review block progress.」
翻譯:CRITICAL 問題阻斷進度。
陷阱7:相信「睇落似啱」
識別標誌
AI 完成實現後話:
測試已運行,看起來都通過了。
覆蓋率大約80%。
代碼審查沒什麼大問題。
你問:「具體測試報告喺邊?」
AI 話:「我 run 過喇,結果係 OK 嘅。」
典型表現:接受口頭確認,唔要求證據。
根因分析
Agent Skills 嘅核心原則:「Seems right」 is never sufficient.
AI 口頭確認嘅問題:
點解 AI 會話「睇落似啱」:
•AI 可能真係 run 咗測試,但只睇咗「測試結束」冇睇失敗數
•AI 可能生成咗覆蓋率報告,但冇仔細睇數字
•AI 可能做咗部分審查,冇覆蓋所有安全項
真實案例
對比兩種驗收方式:
口頭確認:
AI: 測試已運行,看起來通過了
你: 好,繼續下一步
[合入後發現測試實際有2個失敗]
證據驗收:
AI: 測試已運行
你: 請給出測試報告的完整輸出
AI:
$ npm test
Test Suites: 5 passed, 5 total
Tests: 23 passed, 23 total
Coverage: 85% branches, 92% lines
你: 覆蓋率85% > 80%,可以繼續
區別:證據驗收確保 AI 真係 run 咗測試、真係讀咗覆蓋率、真係確認通過。
避坑指南
✅ 實操清單:
證據驗收的必看項:
Step 1: 測試輸出
- 要求AI給出完整的測試命令輸出
- 檢查:passed / failed 數量
- 檢查:是否有 skipped tests
Step 2: 覆蓋率報告
- 要求AI給出覆蓋率數字
- 檢查:branches / lines / functions
- 對照:團隊門檻(通常是80%分支覆蓋)
Step 3: 安全檢查報告
- 要求AI給出security-* skills的掃描結果
- 檢查:是否有 secrets / vulnerabilities / API issues
Step 4: 手工驗證關鍵場景
- 對spec裏的核心Scenario,要求AI給出測試代碼
- 確保測試真的覆蓋了MUST條款
📋 Agent Skills 驗證原則:
「'Seems right' is never sufficient. Every skill requires evidence requirements - tests passing, build output, runtime data.」
翻譯:「睇落似啱」永遠唔夠。每個 skill 都要求證據——測試通過、構建輸出、運行數據。
第三章:工具層陷阱
工具層嘅陷阱,源於配置缺失或工具衝突。
陷阱8:開咗太多技能
識別標誌
你安裝 Agent Skills 後,將所有技能都開咗:
agent-skills on \
test-coverage test-quality \
code-structure code-documentation \
design-architect design-api design-db design-frontend design-security \
security-dependencies security-secrets security-api \
req-clarify req-breakdown req-review \
production-ready code-incident-review code-refactoring doc-generate
典型表現:同時啟用15+個技能。
然後發現:
•AI 回應變慢
•AI 經常「唔記得」之前嘅對話
•AI 輸出嘅質量反而下降
根因分析
Agent Skills 嘅每個技能都會注入到 AI 嘅上下文窗口。
上下文窗口嘅消耗:
後果:
•上下文窗口爆滿 → AI「唔記得」早期對話
•模型注意力分散 → AI 可能漏選關鍵 skill
•回應變慢 → 每次推理要處理更多上下文
Agent Skills 嘅設計意圖:按階段啟用,按需添加。
真實案例
原文建議嘅啟用策略:
# 初期:只啓用最核心的5-8個技能
agent-skills on \
test-coverage \
code-structure \
code-documentation \
security-secrets \
production-ready
# 需求階段再加
agent-skills on req-clarify req-breakdown
# 需求完成後關閉(釋放上下文)
agent-skills off req-clarify req-breakdown
策略:動態啟用/關閉,保持上下文清潔。按需加載,按需使用。唔好 All in。
避坑指南
✅ 實操清單:
技能啓用策略:
Step 1: 初期只開核心技能(5-8個)
核心技能:
- test-coverage (覆蓋率門檻)
- code-structure (文件/函數行數)
- security-secrets (密鑰檢測)
- production-ready (上線檢查)
Step 2: 按階段添加
- 需求階段:req-clarify, req-breakdown
- 設計階段:design-architect, design-api
- 開發階段:保持核心技能
- 發佈階段:production-ready
Step 3: 階段結束後關閉
- 需求完成後:off req-clarify req-breakdown
- 設計完成後:off design-* (保留security)
Step 4: 監控上下文消耗
- Claude Code: 看token usage
- Cursor: 檢查響應速度
- 如果AI"忘記"對話 → 減少技能數量
📋 技能分類與推薦啟用時機:
陷阱9:跳過必要步驟
識別標誌
你心諗:「呢個係一個小 bug 修復,唔使行完整流程啩。」
於是:
•跳過 /opsx:propose → 直接寫 code
•skip brainstorming → 直接動手
•skip TDD → 直接寫實現
典型表現:將「細改動」當成「可以 skip 全流程」嘅理由。
根因分析
三件套原文有一個表格:跳過某些步驟嘅藝術。
但呢個表格有明確嘅邊界:
| 保留 TDD | |||
| 完整流程 | 完整流程 | 完整紀律 | |
| 完整流程(TDD關鍵) | |||
關鍵發現:
•TDD 幾乎唔應該 skip(即使係 bug 修復)
•安全相關必須行完整流程
•重構必須行 TDD(防止改壞)
真實案例
原文嘅一個警告:
❌ 跳過 OpenSpec 直接寫代碼 → 需求漂移
❌ 跳過 Superpowers 直接實現 → 流程混亂
❌ 跳過 Agent Skills 直接提交 → 質量失控
✅ 三步都做到 → 需求清晰、流程規範、質量可控
「小 bug 修復 skip TDD」嘅陷阱:
•你修咗一個 bug → 冇寫測試 → bug 可能翻發
•你改咗一行 code → 冇驗證影響 → 改壞咗其他功能
•你做咗「快速修復」 → 冇記錄 → 以後冇人知點解咁改
真係要 skip,係你真係知道應該點樣實現,功能涉及邊啲改動先得。
避坑指南
✅ 實操清單:
不可跳過的底線:
1. TDD底線:
- 即使bug修復,也要先寫一個"bug會重現"的測試
- 然後修bug,看測試從RED變GREEN
- 這樣bug不會重現
2. 安全底線:
- 安全相關改動必須走security-* skills
- 不跳過security-secrets、security-dependencies
3. 重構底線:
- 重構必須有測試覆蓋
- 先跑測試確保GREEN
- 重構後再跑測試確保仍GREEN
4. 多文件改動底線:
- 任何改動超過3個文件 → 走完整流程
- worktree隔離防止污染主分支
📋 Superpowers TDD 原則:
「Deletes code written before tests. The TDD skill enforces RED-GREEN-REFACTOR: write failing test, watch it fail, write minimal code, watch it pass, commit.」
翻譯:刪除先寫 code 後寫測試嘅 code。TDD 強制 RED-GREEN-REFACTOR 循環。
陷阱10:只靠 AI 約束唔配 CI
識別標誌
你裝咗三件套,AI 行為約束睇落生效咗:
•test-coverage skill 話要求80%
•security-secrets skill 話要檢測密鑰
•code-structure skill 話文件唔超過500行
但你冇配置 pre-commit 或 CI 檢查。
典型表現:依賴 skill 約束,唔配程序性強制。
根因分析
三件套原文嘅邊界聲明:
只靠 AI 約束嘅風險:
解決方案:關鍵質量門檻同時落兩層——skill + CI。
真實案例
原文嘅實務建議:
關鍵質量門檻同時落兩層:
1. test-coverage: 既寫進skill(讓AI主動達標),也配置到CI(不達標禁止合併)
2. security-*: 既用skill早期發現,也接入gitleaks/trivy等CI掃描
3. code-structure: 既用skill約束,也配置detekt/ktlint等lint
AI行為約束 + CI閘門 = 雙保險
冇 CI 嘅真實風險:
•skill 冇生效 → AI 寫咗唔達標 code → 合入主分支 → CI 發現失敗 → 返工
•更糟情況 → 冇 CI 檢查 → 唔達標 code 合入 → 生產問題
避坑指南
✅ 實操清單:
CI配置必做項:
Step 1: 覆蓋率閘門
- GitHub Actions: 配置coverage-check workflow
- 工具: jest coverage / jacoco / pytest-cov
- 門檻: 分支覆蓋率 >= 80%
Step 2: 安全掃描閘門
- gitleaks: 檢測密鑰泄露
- trivy: 檢測依賴漏洞
- OWASP Dependency-Check: Java項目
Step 3: 代碼規範閘門
- detekt (Kotlin)
- eslint + TypeScript rules
- ktlint / checkstyle
Step 4: 文件行數檢查(可選)
- 自定義腳本檢查文件行數
- 或配置lint規則
Step 5: pre-commit hook(可選)
- 在提交前跑lint/安全掃描
- 阻止不達標代碼提交
🔧 CI 配置示例:
# GitHub Actions example
name:QualityGate
on: [push, pull_request]
jobs:
test:
runs-on:ubuntu-latest
steps:
-uses:actions/checkout@v3
-run:npminstall
-run:npmtest
-run:npmruncoverage-check
# 要求覆蓋率 >= 80%
security:
runs-on:ubuntu-latest
steps:
-uses:actions/checkout@v3
-uses:gitleaks/gitleaks-action@v2
-uses:aquasecurity/trivy-action@master
第四章:防走偏檢查清單
10個陷阱,10條對照清單。
一、認知層檢查清單
✅ 檢查項1:proposal 是否逐條審閲
[ ] 讀proposal.md的Why部分
[ ] 讀specs/spec.md的每條MUST條款
[ ] 每條MUST條款思考:怎麼驗證?
[ ] design.md的Open Questions有人拍板
✅ 檢查項2:spec 是否用 RFC 2119 關鍵詞
[ ] 驗收條款用MUST / MUST NOT
[ ] 推薦做法用SHOULD
[ ] 可選功能用MAY
[ ] 沒有"應該"、"儘量"、"最好"等軟詞
✅ 檢查項3:人審時間是否足夠
[ ] proposal審閲 >= 1分鐘
[ ] spec審閲 >= 3分鐘
[ ] design審閲 >= 1分鐘
[ ] tasks審閲 >= 1分鐘
[ ] 總計 >= 5分鐘
✅ 檢查項4:skill 是否觸發
[ ] AI是否反問需求細節(brainstorming)
[ ] AI是否寫詳細計劃(writing-plans)
[ ] AI是否先寫測試(TDD)
[ ] 發現跳過時是否顯式指定skill
二、操作層檢查清單
✅ 檢查項5:計劃是否精確
[ ] 每條任務有文件路徑
[ ] 每條任務有接口/函數名
[ ] 每條任務有驗收口徑
[ ] 每條任務有預估時間
✅ 檢查項6:審查是否處理
[ ] CRITICAL問題已修復
[ ] HIGH問題已修復或有延後理由
[ ] 覆蓋率 >= 80%
[ ] 沒有口頭"看起來對"
✅ 檢查項7:是否有證據
[ ] 有測試命令的完整輸出
[ ] 有覆蓋率數字
[ ] 有安全掃描結果
[ ] 測試覆蓋spec的核心Scenario
三、工具層檢查清單
✅ 檢查項8:技能是否適量
[ ] 啓用技能 <= 8個
[ ] 按階段啓用/關閉
[ ] AI沒有"忘記"對話
[ ] 響應速度正常
✅ 檢查項9:必要步驟是否跳過
[ ] bug修復有測試覆蓋
[ ] 安全相關走完整流程
[ ] 重構有TDD
[ ] 多文件改動走完整流程
✅ 檢查項10:CI 是否配置
[ ] 有覆蓋率閘門(CI)
[ ] 有安全掃描閘門(CI)
[ ] 有代碼規範閘門(CI)
[ ] skill + CI雙保險
檢查清單速查表
總結:令三件套真正發揮作用
核心結論
三件套係「行為約束」,唔係「系統強制」。
要令三件套真正發揮作用,需要三層保障:
| 認知層 | ||
| 操作層 | ||
| 程序層 |
一句話:
skill 約束 AI 行為,CI 阻斷唔達標合入,人審關鍵節點。三層疊加 = 可預測嘅工程化交付。
三件套唔係必須嘅,點樣用返嚟睇你自己。
如果你係工具控,可以 All In AI Skill;如果你認為工具唔使太多,夠用就得,咁用乜嘢工具,你自己把控,自己編排,自己指揮。
有時真正嘅減法亦係真本事,加法亦未必唔係真能力強者。
參考資源
•OpenSpec: https://github.com/Fission-AI/OpenSpec
•Superpowers: https://github.com/obra/superpowers
•Agent Skills: https://github.com/addyosmani/agent-skills
前言:為什麼會跑偏?
從"看起來對"到"證據確鑿"——讓三件套真正生效的實戰手冊
看完《AI 編程進階:三件套 OpenSpec 定方向,Superpowers 帶節奏,Agent Skills 守紀律,打造可預測的工程化工作流》那篇文章,你可能覺得:裝上這三個工具,AI 編程就從"碰運氣"變成"可複製"了。
但現實往往更殘酷。
很多讀者反饋:用了三件套,依然跑偏。
•OpenSpec 的 spec 寫完就被扔一邊,AI照樣自由發揮
•Superpowers 的 brainstorming 被跳過,AI直接動手寫代碼
•Agent Skills 的約束被當成"建議",覆蓋率報告說"看起來對"
問題出在哪?
根因:三件套的真實強度
三件套不是"系統級強制",而是分層約束:
| 程序性強制 | |||
| AI行為約束 | |||
| 流程慣例 |
跑偏的根因,就在這三層各自的漏洞:
1.認知偏差 —— 不理解工具的真實強度,以為"裝上就萬事大吉"
2.操作失誤 —— 觸發條件沒達成,AI行為約束層失效
3.工具誤解 —— 把"AI行為約束"當成"系統強制",不配CI閘門
10個陷阱的分類
本文將10個常見陷阱分為三層:
| 認知層 | ||
| 操作層 | ||
| 工具層 |
每個陷阱都有三個部分:
識別標誌 → 你怎麼知道自己是否掉進這個陷阱?
根因分析 → 為什麼會掉進去?
避坑指南 → 怎麼爬出來並預防再次掉進去?
第一章:認知層陷阱
認知層的陷阱,源於不理解工具的真實定位。
陷阱1:把 spec 當成普通文檔
識別標誌
你寫完 /opsx:propose 後,AI生成了 proposal.md、specs/、design.md、tasks.md。
你掃了一眼標題,覺得"好像都對",就點"確認進入實現"。
典型場景:
AI:已生成提案,請審閲確認
你:(看了一眼proposal標題)嗯,看起來對,確認
AI:開始實現...
你:(心裏想)終於可以寫代碼了
根因分析
OpenSpec的本質是人機契約——在寫代碼前先在人和AI之間達成共識。
很多人把它當成"需求文檔",覺得"寫完就等於對齊了"。
實際上:
誤解導致的後果:
•spec裏的MUST條款沒被逐條審閲 → AI理解與人的預期有偏差
•design.md的Open Questions沒被拍板 → 實現時才發現歧義
•tasks.md的任務沒被驗證可行性 → 開工後發現做不了
真實案例
三件套原文中的 feat-live-share-third-party 案例:
需求表裏寫着:「保持app後台運行,直播狀態」。
如果人沒審閲 spec,AI可能理解為:
•理解A:宿主進程不被殺(錯誤)
•理解B:不向直播域發送停止指令(正確)
正確理解是 spec.md 裏的MUST條款:
在用戶進入第三方授權、編輯或發佈流程期間,宿主 App MUST NOT 主動向音視頻模塊
發送「停止直播/停止推流」指令;除非操作系統強殺或用戶顯式結束直播,
直播核心狀態 MUST 與進入分享流程前保持一致。
這一條MUST條款,把模糊的「保持app後台運行」翻譯成可驗證的程序性條款。
如果不審閲這條,AI可能在實現時漏掉"不調用停止指令"的關鍵約束。
還有其實有些需求裏面有交互設計的,你沒有仔細看生成的文檔,那麼你生成的交互就可能是缺失的,而後續補是件痛苦的事情。
避坑指南
✅ 實操清單:
Step 1: proposal.md —— 讀標題 + Why部分
- Why部分解釋了"為什麼要做",確認AI理解了意圖
Step 2: specs/spec.md —— 逐條審閲 MUST / MUST NOT / MAY
- 每條MUST條款思考:怎麼驗證?(測試?日誌?手工?)
- MUST NOT條款思考:哪些代碼路徑可能違規?
Step 3: design.md —— 檢查 Open Questions
- 每個Open Question必須有人拍板(產品/技術/法務)
- 沒拍板的不能進入實現
Step 4: 確認前問AI一個驗證問題
- "這些MUST條款你怎麼理解?能舉一個違反的例子嗎?"
- 如果AI回答模糊,說明spec本身需要修正
⏱️ 耗時對比:
這5分鐘,省了後面數小時的返工。
陷阱2:規格寫得模糊
識別標誌
你打開 spec.md,發現裏面用的是這些詞:
•“應該顯示進度條”
•“儘量保持直播狀態”
•“最好使用主播頭像”
•“建議加一個取消按鈕”
典型表現:沒有 MUST / MUST NOT,全是軟性描述。需要硬性的描述。
根因分析
OpenSpec 的 spec 語法基於 RFC 2119 關鍵詞:
軟詞的陷阱:
•“應該” → AI可以不做,但做了也算對 → 驗收時扯皮
•“儘量” → AI做到了80%算不算盡力? → 標準模糊
•“最好” → AI沒做到算不算錯? → 無法阻斷
真實問題:軟詞寫成的spec,等於沒有spec。
真實案例
對比兩種spec寫法:
模糊寫法:
分享面板應該顯示可選渠道。
分享時儘量保持直播狀態。
標題最好使用直播間標題。
精確寫法(RFC 2119):
用戶點擊分享 MUST 展示包含微信、朋友圈、QQ、QQ空間、微博的渠道列表。
宿主App MUST NOT 在分享流程中主動調用「停止直播」指令。
分享文案 MUST 優先使用直播間標題;標題缺失時 MUST 使用系統模板。
區別:
•模糊寫法 → AI做了一半算不算完成?無法判斷
•精確寫法 → MUST沒達成就是失敗,可以阻斷
避坑指南
✅ 實操清單:
Step 1: 寫spec時,強制用RFC 2119關鍵詞
- 驗收條款 → MUST / MUST NOT
- 推薦做法 → SHOULD / NOT RECOMMENDED
- 可選功能 → MAY
Step 2: 檢查每條MUST條款的可驗證性
- MUST "顯示進度條" → 怎麼驗證?UI截圖?日誌?
- MUST NOT "調用停止指令" → 怎麼檢測?代碼審計?測試斷言?
Step 3: 避免這些軟詞
- ❌ 應該、儘量、最好、建議
- ✅ MUST、MUST NOT、SHOULD、MAY
Step 4: 給AI一個模板提示
"請用 RFC 2119 關鍵詞(MUST/MUST NOT/MAY)重寫以下規格..."
📋 RFC 2119關鍵詞速查表:
陷阱3:人審環節走過場
識別標誌
AI生成 spec 後,你看到一長串文件,心想"AI寫的應該沒問題吧"。
你的審閲動作:
1.看一眼標題 → “嗯,看起來對”
2.滾動到底部 → “好,有tasks了”
3.點確認 → “開始寫代碼”
典型表現:審閲時間 < 30秒,沒讀MUST條款,沒思考驗證方法。
根因分析
OpenSpec 的設計哲學是:人在關鍵節點拍板,AI在邊界內執行。
人審環節走過場,導致:
人的惰性來源:
•“AI寫的應該沒問題” → 過度信任
•“反正有測試會覆蓋” → 推卸責任
•“審閲太花時間” → 想快點看到代碼
現實:AI寫spec時只是"猜測你的意圖",人審才是真正的"確認意圖"。
真實案例
原文中的 feat-live-share-third-party 案例:
AI在 design.md 生成了 Open Questions:
## Open Questions
- 微博最終走「官方SDK」還是「系統分享面板降級」——需產品+法務確認後回填到spec.md
如果人不審閲,直接進入實現:
•Agent-Weibo 開始寫代碼 → 寫的是SDK方案
•法務後來說:SDK有合規風險,不能用 → 全部返工
審閲時拍板,省的是整個Agent的返工成本。
避坑指南
✅ 實操清單:
人審的必做項:
Step 1: 讀 proposal.md 的 Why 部分
- Why解釋"為什麼要做",確認AI理解了業務意圖
- 如果Why偏離你的理解,直接指出修正
Step 2: 讀 specs/spec.md 的 MUST條款
- 每條MUST條款思考:
- 這條真的必要嗎?
- 怎麼驗證?(測試代碼?日誌?手工?)
- 有遺漏場景嗎?
Step 3: 讀 design.md 的 Open Questions
- 每個Open Question必須有人拍板
- 沒拍板的不能開工
Step 4: 讀 tasks.md 的任務列表
- 任務是否覆蓋所有MUST條款?
- 任務粒度是否可獨立驗證?
Step 5: 確認前問AI一個問題
- "如果要驗證第一條MUST條款,測試應該怎麼寫?"
- AI的回答驗證了條款的可驗證性
⏱️ 時間分配建議:
| 總計 | 5分鐘 |
陷阱4:把 skill 當成可選建議
識別標誌
你問AI:“幫我實現一個導出CSV功能”。
AI的響應:
好的,我來實現導出CSV功能。
[開始寫代碼...]
export function exportCSV(data: Data[]) {
...
}
典型表現:AI沒反問需求細節,沒澄清邊界,直接開始寫代碼。
你心想:“Superpowers裝了,但AI好像沒觸發brainstorming?算了,反正開始寫了。”
根因分析
Superpowers 的 skill 是AI行為約束——AI應該按skill的流程執行,而不是自由發揮。
但skill的觸發有兩層依賴:
Superpowers不會自動"接管"AI——它只是把流程注入到AI的上下文裏,AI需要主動選擇遵守。
典型失效場景:
•任務描述太簡單 → AI覺得"這個簡單,不用brainstorming"
•上下文窗口太雜 → AI沒注意到AGENTS.md裏的skill描述
•模型選擇失誤 → AI優先考慮"快速響應"而非"嚴格流程"
真實案例
對比兩種交互:
skill失效的交互:
你:幫我加一個導出CSV按鈕
AI:好的,我來寫代碼 [開始寫]
你:(等待)
AI:寫完了,請測試
你:測試發現沒處理空數據情況...
skill生效的交互:
你:幫我加一個導出CSV按鈕,請先用brainstorming澄清需求
AI:進入brainstorming模式...
Q1. CSV文件編碼用什麼?UTF-8還是UTF-8 BOM(Excel兼容)?
Q2. 需要支持自定義導出字段嗎?
Q3. 空數據時導出什麼?
Q4. 超過10000條時需要進度條嗎?
你:回答這些問題
AI:已記錄到design.md,開始寫實現計劃
區別:顯式指定skill,強制AI進入流程。
避坑指南
✅ 實操清單:
Step 1: 觀察AI的行為模式
- AI直接開始寫代碼 → brainstorming沒觸發
- AI沒寫實現計劃 → writing-plans沒觸發
- AI沒跑測試 → test-driven-development沒觸發
Step 2: 顯式指定skill
- 發現AI跳過流程時,主動說:
- "請先按brainstorming技能澄清需求"
- "請按writing-plans寫一個詳細實現計劃"
- "請按test-driven-development先寫RED測試"
Step 3: 確認skill已安裝
- Claude Code: /plugin list 看superpowers是否在
- Cursor: 檢查 .cursorrules 或 AGENTS.md
- Gemini CLI: gemini extensions list
Step 4: 保持上下文清潔
- 清理無關對話,讓AI更容易注意到skill描述
- 開始新任務時,可以新建一個對話窗口
🔧 skill觸發檢查表:
不要認為裝了技能,AI就會,它也應該會找會走這個技能的。你太想當然了。
第二章:操作層陷阱
操作層的陷阱,源於執行細節不到位。
陷阱5:實現計劃寫得模糊
識別標誌
AI生成的實現計劃是這樣的:
# Tasks
- [ ] 實現導出CSV功能
- [ ] 添加導出按鈕
- [ ] 集成到Dashboard
- [ ] 寫單元測試
典型表現:任務描述不精確到文件路徑、接口名、驗收口徑。
你心想:“反正AI知道怎麼做,讓他自己發揮吧。”
根因分析
Superpowers 的 writing-plans skill 要求:計劃必須精確到"一個無判斷力的初級工程師也能執行"。
模糊計劃導致:
真實問題:模糊計劃 = AI自由發揮 = 不確定性。
真實案例
對比兩種計劃寫法:
模糊計劃:
- [ ] 實現導出CSV功能
- [ ] 添加導出按鈕
- [ ] 集成到Dashboard
精確計劃(Superpowers標準):
Task 1: 創建CSV工具函數 (約3分鐘)
- 文件: src/utils/csv.ts
- 導出: escapeCSV(), generateCSV(), downloadCSV()
- 驗收: generateCSV能處理逗號和換行符
Task 2: 添加導出按鈕 (約2分鐘)
- 文件: src/components/DashboardToolbar.tsx
- 位置: Toolbar右側,在Refresh按鈕後
- 接口: onClick觸發handleExport
- 驗收: 未選中數據時按鈕禁用
Task 3: 集成到Dashboard (約3分鐘)
- 文件: src/pages/Dashboard.tsx
- 改動: 添加handleExport方法,獲取selectedRows
- 驗收: 點擊按鈕下載CSV文件,文件名export-YYYY-MM-DD.csv
區別:
•模糊計劃 → AI可能把代碼寫在任何位置
•精確計劃 → AI知道寫哪個文件、哪個接口、怎麼驗收,
具體的計劃顆粒度需要自己把控的。
避坑指南
✅ 實操清單:
精確計劃的必備要素:
每個任務必須包含:
1. 文件路徑 —— 寫在哪裏
2. 接口/函數名 —— 命名是什麼
3. 預估時間 —— 大概多久(防止AI耗時失控)
4. 驗收口徑 —— 怎麼驗證完成
格式模板:
Task N: [任務名稱] (約X分鐘)
- 文件: [精確路徑]
- 改動: [具體接口/函數]
- 驗收: [驗收標準]
📋 Superpowers 計劃標準(原文引用):
“Plans must be clear enough for an enthusiastic junior engineer with poor taste, no judgement, no project context, and an aversion to testing to follow.”
翻譯:計劃必須精確到"一個無判斷力的初級工程師也能執行"。
陷阱6:忽略代碼審查結果
識別標誌
AI完成實現後,進入代碼審查階段。
審查報告顯示:
🔴 CRITICAL: csv.ts的downloadCSV在IE瀏覽器會報錯
🟡 WARNING: escapeCSV沒有處理null值
🟢 INFO: 建議把導出邏輯抽成獨立模塊
📊 測試覆蓋率: 78% (< 80%門檻)
你的反應:
"CRITICAL是IE瀏覽器問題,現在沒人用IE了,先繼續吧"
"WARNING先不管,以後再說"
"覆蓋率78%接近80%了,差不多"
典型表現:繼續推進,不修復問題。
根因分析
Superpowers 的 requesting-code-review skill 要求:CRITICAL必須阻斷,HIGH儘量修復。
審查的分級含義:
| 必須阻斷 | ||
| 應該修復 | ||
忽略審查的後果:
•CRITICAL沒修 → 上線後可能崩潰/泄露
•HIGH沒修 → 用戶發現問題後返工
•覆蓋率沒達標 → 合入後發現質量問題
真實案例
原文中的閘門子圖:
如果不按閘門執行:
•CRITICAL沒修 → 進入安全gate → 安全檢查發現更多問題 → 全部返工
•更糟的情況 → 跳過安全gate → 合入主分支 → 生產事故
避坑指南
✅ 實操清單:
審查結果處理標準:
CRITICAL → 必須立即修復
- 如果不修復,必須有人書面拍板承擔風險
- 通常CRITICAL意味着"不修會出事"
HIGH → 儘量修復
- 如果不修復,在tasks.md記錄"延後理由"
- HIGH問題通常會在後續測試/使用中暴露
MEDIUM/LOW → 可延後
- 記錄到"改進清單",不阻塞當前任務
覆蓋率不達標 → 必須達標才能合入
- test-coverage skill要求80%門檻
- 如果CI配置了覆蓋率閘門,不達標無法合入
⚠️ Superpowers 審查原則:
“Critical issues during code review block progress.”
翻譯:CRITICAL問題阻斷進度。
陷阱7:相信"看起來對"
識別標誌
AI完成實現後說:
測試已運行,看起來都通過了。
覆蓋率大約80%。
代碼審查沒什麼大問題。
你問:“具體測試報告在哪?”
AI說:“我跑過了,結果是OK的。”
典型表現:接受口頭確認,不要求證據。
根因分析
Agent Skills 的核心原則:“Seems right” is never sufficient.
AI口頭確認的問題:
為什麼AI會說"看起來對":
•AI可能真的跑了測試,但只看了"測試結束"沒看失敗數
•AI可能生成了覆蓋率報告,但沒仔細讀數字
•AI可能做了部分審查,沒覆蓋所有安全項
真實案例
對比兩種驗收方式:
口頭確認:
AI: 測試已運行,看起來通過了
你: 好,繼續下一步
[合入後發現測試實際有2個失敗]
證據驗收:
AI: 測試已運行
你: 請給出測試報告的完整輸出
AI:
$ npm test
Test Suites: 5 passed, 5 total
Tests: 23 passed, 23 total
Coverage: 85% branches, 92% lines
你: 覆蓋率85% > 80%,可以繼續
區別:證據驗收確保AI真的跑了測試、真的讀了覆蓋率、真的確認通過。
避坑指南
✅ 實操清單:
證據驗收的必看項:
Step 1: 測試輸出
- 要求AI給出完整的測試命令輸出
- 檢查:passed / failed 數量
- 檢查:是否有 skipped tests
Step 2: 覆蓋率報告
- 要求AI給出覆蓋率數字
- 檢查:branches / lines / functions
- 對照:團隊門檻(通常是80%分支覆蓋)
Step 3: 安全檢查報告
- 要求AI給出security-* skills的掃描結果
- 檢查:是否有 secrets / vulnerabilities / API issues
Step 4: 手工驗證關鍵場景
- 對spec裏的核心Scenario,要求AI給出測試代碼
- 確保測試真的覆蓋了MUST條款
📋 Agent Skills 驗證原則:
“‘Seems right’ is never sufficient. Every skill requires evidence requirements - tests passing, build output, runtime data.”
翻譯:"看起來對"永遠不夠。每個skill都要求證據——測試通過、構建輸出、運行數據。
第三章:工具層陷阱
工具層的陷阱,源於配置缺失或工具衝突。
陷阱8:開啓太多技能
識別標誌
你安裝Agent Skills後,把所有技能都開了:
agent-skills on \
test-coverage test-quality \
code-structure code-documentation \
design-architect design-api design-db design-frontend design-security \
security-dependencies security-secrets security-api \
req-clarify req-breakdown req-review \
production-ready code-incident-review code-refactoring doc-generate
典型表現:同時啓用15+個技能。
然後發現:
•AI響應變慢
•AI經常"忘記"之前的對話
•AI輸出的質量反而下降
根因分析
Agent Skills 的每個技能都會注入到AI的上下文窗口。
上下文窗口的消耗:
後果:
•上下文窗口爆滿 → AI"忘記"早期對話
•模型注意力分散 → AI可能漏選關鍵skill
•響應變慢 → 每次推理要處理更多上下文
Agent Skills的設計意圖:按階段啓用,按需添加。
真實案例
原文建議的啓用策略:
# 初期:只啓用最核心的5-8個技能
agent-skills on \
test-coverage \
code-structure \
code-documentation \
security-secrets \
production-ready
# 需求階段再加
agent-skills on req-clarify req-breakdown
# 需求完成後關閉(釋放上下文)
agent-skills off req-clarify req-breakdown
策略:動態啓用/關閉,保持上下文清潔。按需加載,按需使用。不要All in。
避坑指南
✅ 實操清單:
技能啓用策略:
Step 1: 初期只開核心技能(5-8個)
核心技能:
- test-coverage (覆蓋率門檻)
- code-structure (文件/函數行數)
- security-secrets (密鑰檢測)
- production-ready (上線檢查)
Step 2: 按階段添加
- 需求階段:req-clarify, req-breakdown
- 設計階段:design-architect, design-api
- 開發階段:保持核心技能
- 發佈階段:production-ready
Step 3: 階段結束後關閉
- 需求完成後:off req-clarify req-breakdown
- 設計完成後:off design-* (保留security)
Step 4: 監控上下文消耗
- Claude Code: 看token usage
- Cursor: 檢查響應速度
- 如果AI"忘記"對話 → 減少技能數量
📋 技能分類與推薦啓用時機:
陷阱9:跳過必要步驟
識別標誌
你心想:“這是一個小bug修復,不用走完整流程吧。”
於是:
•跳過 /opsx:propose → 直接寫代碼
•跳過 brainstorming → 直接動手
•跳過 TDD → 直接寫實現
典型表現:把"小改動"當成"可跳過全流程"的理由。
根因分析
三件套原文有一個表格:跳過某些步驟的藝術。
但這個表格有明確的邊界:
| 保留TDD | |||
| 完整流程 | 完整流程 | 完整紀律 | |
| 完整流程(TDD關鍵) | |||
關鍵發現:
•TDD 幾乎不應該跳過(即使是bug修復)
•安全相關必須走完整流程
•重構必須走TDD(防止改壞)
真實案例
原文的一個警告:
❌ 跳過 OpenSpec 直接寫代碼 → 需求漂移
❌ 跳過 Superpowers 直接實現 → 流程混亂
❌ 跳過 Agent Skills 直接提交 → 質量失控
✅ 三步都做到 → 需求清晰、流程規範、質量可控
"小bug修復跳過TDD"的陷阱:
•你修了一個bug → 沒寫測試 → bug可能重現
•你改了一行代碼 → 沒驗證影響 → 改壞了其他功能
•你做了"快速修復" → 沒記錄 → 以後沒人知道為什麼這麼改
真要跳過,是你真的知道應該如何實現,功能涉及哪些改動的。
避坑指南
✅ 實操清單:
不可跳過的底線:
1. TDD底線:
- 即使bug修復,也要先寫一個"bug會重現"的測試
- 然後修bug,看測試從RED變GREEN
- 這樣bug不會重現
2. 安全底線:
- 安全相關改動必須走security-* skills
- 不跳過security-secrets、security-dependencies
3. 重構底線:
- 重構必須有測試覆蓋
- 先跑測試確保GREEN
- 重構後再跑測試確保仍GREEN
4. 多文件改動底線:
- 任何改動超過3個文件 → 走完整流程
- worktree隔離防止污染主分支
📋 Superpowers TDD原則:
“Deletes code written before tests. The TDD skill enforces RED-GREEN-REFACTOR: write failing test, watch it fail, write minimal code, watch it pass, commit.”
翻譯:刪除先寫代碼後寫測試的代碼。TDD強制RED-GREEN-REFACTOR循環。
陷阱10:只靠AI約束不配CI
識別標誌
你裝了三件套,AI行為約束看起來生效了:
•test-coverage skill 說要求80%
•security-secrets skill 說要檢測密鑰
•code-structure skill 說文件不超過500行
但你沒有配置 pre-commit 或 CI 檢查。
典型表現:依賴skill約束,不配程序性強制。
根因分析
三件套原文的邊界聲明:
只靠AI約束的風險:
解決方案:關鍵質量門檻同時落兩層——skill + CI。
真實案例
原文的實務建議:
關鍵質量門檻同時落兩層:
1. test-coverage: 既寫進skill(讓AI主動達標),也配置到CI(不達標禁止合併)
2. security-*: 既用skill早期發現,也接入gitleaks/trivy等CI掃描
3. code-structure: 既用skill約束,也配置detekt/ktlint等lint
AI行為約束 + CI閘門 = 雙保險
沒有CI的真實風險:
•skill沒生效 → AI寫了不達標代碼 → 合入主分支 → CI發現失敗 → 返工
•更糟情況 → 沒CI檢查 → 不達標代碼合入 → 生產問題
避坑指南
✅ 實操清單:
CI配置必做項:
Step 1: 覆蓋率閘門
- GitHub Actions: 配置coverage-check workflow
- 工具: jest coverage / jacoco / pytest-cov
- 門檻: 分支覆蓋率 >= 80%
Step 2: 安全掃描閘門
- gitleaks: 檢測密鑰泄露
- trivy: 檢測依賴漏洞
- OWASP Dependency-Check: Java項目
Step 3: 代碼規範閘門
- detekt (Kotlin)
- eslint + TypeScript rules
- ktlint / checkstyle
Step 4: 文件行數檢查(可選)
- 自定義腳本檢查文件行數
- 或配置lint規則
Step 5: pre-commit hook(可選)
- 在提交前跑lint/安全掃描
- 阻止不達標代碼提交
🔧 CI配置示例:
# GitHub Actions example
name:QualityGate
on: [push, pull_request]
jobs:
test:
runs-on:ubuntu-latest
steps:
-uses:actions/checkout@v3
-run:npminstall
-run:npmtest
-run:npmruncoverage-check
# 要求覆蓋率 >= 80%
security:
runs-on:ubuntu-latest
steps:
-uses:actions/checkout@v3
-uses:gitleaks/gitleaks-action@v2
-uses:aquasecurity/trivy-action@master
第四章:防跑偏檢查清單
10個陷阱,10條對照清單。
一、認知層檢查清單
✅ 檢查項1:proposal是否逐條審閲
[ ] 讀proposal.md的Why部分
[ ] 讀specs/spec.md的每條MUST條款
[ ] 每條MUST條款思考:怎麼驗證?
[ ] design.md的Open Questions有人拍板
✅ 檢查項2:spec是否用RFC 2119關鍵詞
[ ] 驗收條款用MUST / MUST NOT
[ ] 推薦做法用SHOULD
[ ] 可選功能用MAY
[ ] 沒有"應該"、"儘量"、"最好"等軟詞
✅ 檢查項3:人審時間是否足夠
[ ] proposal審閲 >= 1分鐘
[ ] spec審閲 >= 3分鐘
[ ] design審閲 >= 1分鐘
[ ] tasks審閲 >= 1分鐘
[ ] 總計 >= 5分鐘
✅ 檢查項4:skill是否觸發
[ ] AI是否反問需求細節(brainstorming)
[ ] AI是否寫詳細計劃(writing-plans)
[ ] AI是否先寫測試(TDD)
[ ] 發現跳過時是否顯式指定skill
二、操作層檢查清單
✅ 檢查項5:計劃是否精確
[ ] 每條任務有文件路徑
[ ] 每條任務有接口/函數名
[ ] 每條任務有驗收口徑
[ ] 每條任務有預估時間
✅ 檢查項6:審查是否處理
[ ] CRITICAL問題已修復
[ ] HIGH問題已修復或有延後理由
[ ] 覆蓋率 >= 80%
[ ] 沒有口頭"看起來對"
✅ 檢查項7:是否有證據
[ ] 有測試命令的完整輸出
[ ] 有覆蓋率數字
[ ] 有安全掃描結果
[ ] 測試覆蓋spec的核心Scenario
三、工具層檢查清單
✅ 檢查項8:技能是否適量
[ ] 啓用技能 <= 8個
[ ] 按階段啓用/關閉
[ ] AI沒有"忘記"對話
[ ] 響應速度正常
✅ 檢查項9:必要步驟是否跳過
[ ] bug修復有測試覆蓋
[ ] 安全相關走完整流程
[ ] 重構有TDD
[ ] 多文件改動走完整流程
✅ 檢查項10:CI是否配置
[ ] 有覆蓋率閘門(CI)
[ ] 有安全掃描閘門(CI)
[ ] 有代碼規範閘門(CI)
[ ] skill + CI雙保險
檢查清單速查表
總結:讓三件套真正生效
核心結論
三件套是"行為約束",不是"系統強制"。
要讓三件套真正生效,需要三層保險:
| 認知層 | ||
| 操作層 | ||
| 程序層 |
一句話:
skill約束AI行為,CI阻斷不達標合入,人審關鍵節點。 三層疊加 = 可預測的工程化交付。
三件套不是必須的,如何包括還是看你自己的。
如果你是工具控,可以All In AI Skill 如果你認為工具不必太多,夠用就行,那麼使用什麼工具,你自己把控,自己編排,自己指揮。
有時候真正的減法也是真本事,加法也未必不是真能力強者。
參考資源
•OpenSpec: https://github.com/Fission-AI/OpenSpec
•Superpowers: https://github.com/obra/superpowers
•Agent Skills: https://github.com/addyosmani/agent-skills