AI寫代碼不再需要你按回車了:拆解/goal命令的技術內核
整理版優先睇
定義好「完成」,AI自動幫你跑完全程
呢篇文章係作者分享自己用/goal命令嘅親身經驗。佢之前改一個200幾files嘅語音轉錄軟件,要逐下撳回車,改完已經冇曬耐性。今次佢只打咗一行/goal,然後去飲杯嘢,返嚟任務已經自動完成咗37輪循環,完全唔使介入。作者想帶出嘅係,/goal嘅核心唔係新技術,而係將「判斷完成」嘅責任從工作模型分離出來,用一個輕量評估者模型(如Claude Haiku)去檢查目標係咪達成。呢個分離係關鍵,因為做嘢嘅人同判斷完成嘅人唔應該係同一個。
文章進一步解釋/goal嘅技術前身係Ralph Wiggum loop,一種用bash循環加全新agent實例嘅做法,目的係避免對話記憶腐爛。/goal將呢個概念產品化,加入自動評估、狀態管理同安全邊界。但最重要嘅係,/goal嘅成敗取決於你點寫目標:弱目標好似許願,強目標要有可驗證終態、測試命令同邊界約束。
整體結論係,/goal唔單止係一個命令,而係一個新嘅原語,令到AI編程工具之間可以統一溝通。Codex做構建、Claude Code做審查、Hermes做編排,三個工具用同一種格式交接,成條流水線先至work。最終,模糊需求嘅時代結束咗,你要將形容詞變成可檢查嘅輸出。
- /goal 將你從「人肉調度器」變成「驗收員」,AI 自主循環直到滿足你寫嘅條件,唔使逐下撳回車。
- 雙模型架構:工作模型負責編碼,評估者模型(如Haiku)只判斷「完成未」,避免上下文腐爛同幻覺。
- 弱目標係許願(/goal improve onboarding),強目標要有可驗證終態(如「冇 legacyAuth import,npm test exits 0」)同安全閥。
- 實用強目標模板包括:目標描述、來源文件、驗收標準、驗證方式、邊界約束同循環行為,缺一不可。
- 三個工具角色:Codex 構建、Claude Code 審查、Hermes 編排,統一嘅/goal 原語令多 Agent 流水線成為可能。
/goal 強目標模板
目標描述:具體終態,唔係形容詞。來源文件:讀邊個 spec、計劃、狀態檔案。驗收標準:可觀察行為1、2,負面用例,非迴歸條件。驗證方式:測試命令、靜態檢查、必要時瀏覽器驗證。邊界約束:只改邊個路徑、唔碰邊啲系統、保持邊啲API不變。循環行為:每次改動後跑驗證、更新狀態、N輪後仍然阻塞就報告。
從回車操作員到驗收員:一次自動化實戰
上個禮拜我喺終端跑咗一個任務:改一個200幾個files嘅本地語音實時轉錄小軟件。以前做呢啲嘢,我要坐喺屏幕前面,Claude 做一步我就撳一次回車,就算用 bypass 都要介入好多次。改file、跑test、睇結果、繼續,循環往復,好似一個冇感情嘅回車鍵操作員。
今次我只打咗一行命令,然後去咗飲杯老黃同款蜜雪冰城。返嚟嘅時候,任務跑完咗。37輪循環,冇一次需要我介入。呢個就係 Claude Code 同 Codex 最近推出嘅 /goal 命令做到嘅嘢。
/goal 將你從「人肉調度器」變成「驗收員」
普通 prompt 係你推一下,AI 行一步。你問「改完未」,佢話「改咗」,你問「測試呢」,佢話「測咗」,每一步都要你在線。/goal 就完全唔同:你一次性寫清楚「完成」係點樣,AI 就開始自主循環——規劃、改file、跑test、修bug、再跑test,直到滿足你寫嘅條件,或者你手動打斷。
雙模型架構:點解判斷完成嘅人唔可以做返同一份工
Claude Code 嘅實現方式係雙模型架構。工作模型做實際編碼,每完成一輪,一個輕量評估者模型(預設 Claude Haiku)就會讀一次對話記錄,只回答一個問題:目標達成了未?未達成繼續,達成咗就停。Codex 嘅機制類似,但用長時間運行嘅 harness 檢查目標狀態。
呢個做法嘅技術前身係 Ralph Wiggum loop——一個好粗魯但有效嘅 bash 循環方案:每次循環開一個全新嘅 agent 實例,畀佢讀 spec、計劃、任務列表,做完就重新開始。佢解決咗普通 AI 對話嘅致命問題:上下文腐爛。一個對話跑咗20000 token之後,模型會忘記你開頭講嘅關鍵約束。Ralph Wiggum loop 唔信對話記憶,佢信持久化嘅檔案。/goal 將呢個洞察產品化,加咗自動判斷、狀態管理同循環預算。
弱目標 vs 強目標:寫錯目標,AI都幫你唔到
/goal 嘅成敗,八成都取決於你寫咗咩目標。弱目標例如「/goal improve onboarding」,就係一個許願。Claude 可以做好多嘢,但佢永遠唔知自己做完未,可能陷入無限循環,或者評估者模型產生幻覺,宣稱目標已完成。
弱目標係許願,強目標係合同
強目標例如:「/goal migrate all imports from legacyAuth to authClient in app/auth. No legacyAuth imports remain in app/auth. npm test -- auth exits 0. npm run typecheck exits 0. Stop after 15 turns if any usage is ambiguous.」分別在於:有可觀察嘅終態(可以用 grep 驗證)、有驗證手段(測試退出碼)、有邊界(路徑限制同安全閥)。
- 強目標有可觀察終態:唔係形容詞,係具體狀態(如「冇 legacyAuth import」)
- 強目標有驗證手段:每一條完成條件都可以用一條命令檢查,評估者唔使估
- 強目標有邊界:限定改動範圍、限制資源消耗,就算出事都可控
Nuri Jananian 總結咗一個實用模板:目標描述、來源文件、驗收標準、驗證方式、邊界約束、循環行為。每一行都係回答同一個問題:「AI 點樣知道自己做完?」以前呢個問題係工程師喺腦入面補全,而家要寫到一個自主運行嘅模型讀得明。
三個工具角色,同一種原語
/goal 真正有意思嘅地方係,唔同工具開始接受同一種指令格式。Codex 擅長實現,Claude Code 擅長審查,Hermes 係編排器,負責喺構建器同審查器之間調度任務。三個工具,三個角色:構建器、審查器、編排器。
工具可以換,角色不變,原語不變
Saboo Shubham 嘅演示好清楚:佢同 Hermes 講「整一個 CLI 工具監控 X 提到我嘅內容」,Hermes 就拆成六張卡片——第一張寫 SPEC.md,第二張 Codex 用 /goal 實行,第三張 Claude Code 用 /goal 審查,第四、五張修復循環,第六張做總結。一條消息,三個工具,六張卡片,你只同 Hermes 講嘢。如果 Codex 同 Claude Code 各自用唔同格式交接,編排器根本做唔到。
驗證者先係靈魂
Hermes 從來唔信 Codex 嘅自報告。Codex 話「構建通過咗」?Hermes 自己行一次 npm test。Codex 話「測試全綠」?Hermes 自己行 npm run build。模型好自信,佢會話你知「搞掂啦」,就算測試從來冇執行過。冇驗證,/goal 只係一個花巧嘅 prompt;有驗證,先係一個可執行嘅可交付物。
最後回歸原語:HTTP、JSON、TCP之所以成為原語,係因為整個生態自發喺佢哋之上建立協議。/goal 行緊同一條路。一個月前仲冇/goal,一個月後已經成為AI編程工具之間嘅事實標準接口。呢個就係原語嘅速度。
上個週末我喺終端度跑咗個任務。改一個200幾個檔案嘅本地語音實時轉錄小軟件。
以前做呢啲嘢,我要坐喺屏幕前面,Claude 做一步我就㩒一次回車(就算係 bypass 中間都要介入好多次)。改檔案、跑測試、睇結果、繼續。循環往復,好似個冇感情嘅回車鍵操作員。200個檔案改完,我嘅耐心都改冇咗。
今次我只係打咗一行命令,然後去咗飲杯老黃同款蜜雪冰城。

返嚟嘅時候,任務已經跑完咗。37輪循環,冇一次需要我介入。
呢個已經唔係咩新鮮事喇,係 Claude Code 同 Codex 最近推出嘅 /goal 命令做到嘅嘢,尤其係對於之前用過 Ralph Loop 嘅老友應該更熟悉。
用最簡單嘅話講,/goal 將你由「人肉調度器」變咗做「驗收員」。
普通 prompt 嘅工作模式係,你推一下,AI 就行一步。你問「改完未」,佢話「改咗」,你問「測試呢」,佢話「測咗」。每一步都要你喺線。
/goal 嘅工作模式完全唔同。你一次性寫清楚「完成」係點樣,AI 就開始自主循環。規劃、改檔案、跑測試、修 bug、再跑測試。一輪接一輪,直到滿足你寫嘅條件,或者你手動打斷。
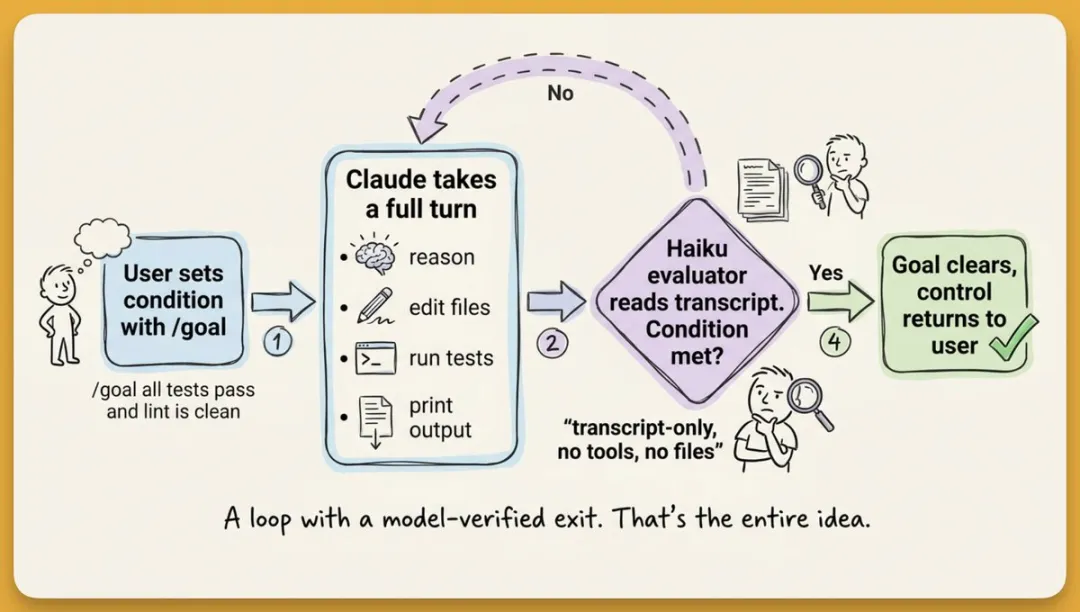
Claude Code 嘅實現方式係雙模型架構。工作模型做實際編碼,每完成一輪,一個輕量評估者模型(預設 Claude Haiku)讀一次對話記錄,只回答一個問題:目標達成未?未達成就繼續,達成咗就停。
Codex 嘅機制類似,但評估方式有少少唔同。佢用長時間運行嘅 harness 嚟檢查目標狀態,而唔係用獨立嘅評估者模型。
兩者殊途同歸。核心思想得一個:將「判斷完成」嘅職責由工作模型度分離出嚟。
呢個分離至關重要。做嘢嘅人同判斷做咗嘅人,唔應該係同一個人。軟件工程裏便呢個叫「build嘅人唔可以judge build」,AI 編程都一樣。
02 從 bash 循環到原生原語
/goal 唔係憑空出嚟嘅。佢有一個技術前身,叫 Ralph Wiggum loop。Ralph Wiggum 係《辛普森一家》嘅角色,以簡單粗暴見稱。社區借呢個名嚟形容一種最樸素嘅多輪 AI 循環方案。

幾個月前有人喺社區度火咗一把,做法非常樸素:將 AI 塞入 bash 循環度,每次循環俾一個全新嘅 agent 實例,叫佢讀 spec、讀計劃、讀任務列表,揀下一個未完成嘅任務,做完,跑測試,通過就標記完成,然後重新開始。
聽落好粗糙,但佢嘅核心洞察比表面睇起嚟深刻得多。
普通嘅 AI 對話有個致命問題:上下文腐爛。一個長對話跑咗2萬 token 之後,模型開始忘記你開頭講嘅關鍵約束。你第3輪強調嘅「唔好改數據庫 schema」,到咗第30輪佢可能就唔記得咗,順手幫你改咗。
Ralph Wiggum loop 嘅解法係:唔信對話記憶。每輪循環開始時,叫 agent 重新加載持久化嘅檔案。spec 檔案、實現計劃、任務列表、測試套件、狀態記錄。對話會腐爛,檔案唔會。
/goal 將呢個洞察做咗做產品級嘅原語。
但 /goal 比原始 bash 循環多咗幾層產品化設計。評估者模型自動判斷完成狀態,唔使你手動檢查。原生嘅狀態管理令你隨時睇到循環跑到邊度。任務邊界同循環預算嘅設置令失控風險可控。
從粗糙嘅 bash 循環到原生原語,呢個進化路徑同好多基礎設施嘅進化一樣。首先係有人喺邊緣地帶用膠紙同鐵絲將啲嘢拼埋一齊,然後有人將拼好嘅嘢標準化、產品化,最後所有人開始講同一種語言。
03 弱目標 vs 強目標
/goal 嘅成敗,80%取決於你寫咗啲咩目標。

弱目標係咁樣:
/goal improve onboarding
呢個就係一個許願。Claude 見到會點做?改名掣、加引導步驟、改文案、簡化頁面、寫測試、提 PR。每一步睇落都合理。但目標本身冇俾佢任何判斷「完成咗未」嘅根據。
兩種死法。
第一種,Claude 陷入無限循環。佢不斷嘗試「改進」引導流程,但永遠冇辦法確定自己改進咗未,因為「improve」唔可以量化。
第二種更危險。評估者模型產生幻覺,喺冇任何可驗證證據嘅情況下宣佈「目標已完成」。Claude 好自信,佢會話你知一切正常,就算測試從來冇行過。
強目標係咁樣:
/goal migrate all imports from legacyAuth to authClient in app/auth. No legacyAuth imports remain in app/auth. npm test -- auth exits 0. npm run typecheck exits 0. Stop after 15 turns if any usage is ambiguous.
分別喺邊?
強目標有可觀察嘅終態。No legacyAuth imports remain 係可以用 grep 驗證嘅。npm test exits 0 係有確定退出碼嘅。Stop after 15 turns 係有安全閥嘅。
強目標有驗證手段。每一條完成條件都可以透過一條命令嚟檢查。評估者模型唔需要估,佢只需要睇對話記錄裏面有冇出現對應嘅輸出。
強目標有邊界。in app/auth 限定咗改動範圍,Stop after 15 turns 限制咗資源消耗。就算出咗問題,損失都係可控嘅。
弱目標同強目標之間嘅差距,唔係措辭嘅問題,係思維方式嘅差距。弱目標係俾人類同事嘅需求,靠對話中嘅默契嚟補全。強目標係俾自主運行嘅 agent 嘅合同,必須自包含、可驗證、有邊界。
04 一個強目標嘅完整模板
Nuri Jananian(AI 編程同 PM 工具領域嘅博主,專注 agentic coding 對產品工作流嘅影響)總結咗一個實用嘅 /goal 模板,我覺得值得完整展開:
目標描述:具體嘅終態,唔係形容詞
來源檔案:
• 讀邊個 spec 檔案 • 跟邊個實現計劃 • 更新邊個狀態檔案
驗收標準:
• 可觀察行為 1 • 可觀察行為 2 • 負面用例(唔應該發生乜嘢) • 非迴歸條件(已有功能唔可以被破壞)
驗證方式:
• 測試命令(npm test、pytest 等) • 靜態檢查(lint、typecheck、build) • 必要時嘅瀏覽器或者視覺驗證
邊界約束:
• 只改邊啲路徑 • 唔掂邊啲系統 • 保持邊啲契約/數據/API 行為不變
循環行為:
• 每次有意義嘅改動後跑相關驗證 • 更新狀態檔案,記錄改咗乜、結果如何、風險喺邊 • N 輪後仍然阻塞就報告,唔好無限循環
呢個模板裏面每一行都喺度回答同一個問題:AI 點樣知道自己做完咗?
以前呢個問題係工程師喺腦入面補全嘅。而家佢必須被寫落嚟,寫到一個自主運行嘅模型可以讀得明嘅程度。
呢個唔係增加工作量。係將一路做緊嘅嘢顯性化。
05 三個角色,三個工具
/goal 真正有意思嘅地方唔係單一工具,而係唔同工具開始接受同一種指令格式。
Codex 擅長實現。俾佢一個清晰嘅 spec,佢可以高效咁將 code 寫出嚟。Claude Code 擅長審查。俾佢一段 code,佢可以揾出 spec 偏離、安全漏洞、邊界錯誤。Hermes 唔係編碼工具,佢係編排器,負責喺構建器同審查器之間調度任務。
三個工具,三個角色。構建器、審查器、編排器。
工具可以換。角色不變。原語不變。
Saboo Shubham(多 Agent 編排工具嘅作者)喺佢嘅 Mac Mini 度跑咗一個端到端嘅演示。佢俾 Hermes 發咗一條訊息:「建一個 CLI 工具,監控 X 上面提到我嘅內容,有大事發生時通知我。」
Hermes 將呢條訊息拆咗做六張卡片。
第一張,Hermes 自己寫 SPEC.md。定義技術棧、倉庫路徑、唯讀約束、mock 模式、測試命令同驗證方式。呢個係 PM 嘅工作。
第二張,Codex 揸住 /goal 對住 SPEC.md 開工。建項目、寫 code、加測試。大約15分鐘,npm test 通過,npm run build 通過,git status 乾乾淨淨。
第三張,Claude Code 揸住 /goal 審查 Codex 嘅產出。檢查 spec 合規、唯讀安全、API key 處理、錯誤狀態、安全漏洞。結果:PASS,冇阻塞問題。
第四張同第五張係修復循環同二次驗證,因為審查通過咗,直接 skip 咗。
第六張,Hermes 做最終總結。驗證本地路徑、UI 同 API 喺 mock 模式下都工作正常。
一條訊息。三個工具。六張卡片。你只係同 Hermes 講嘢。
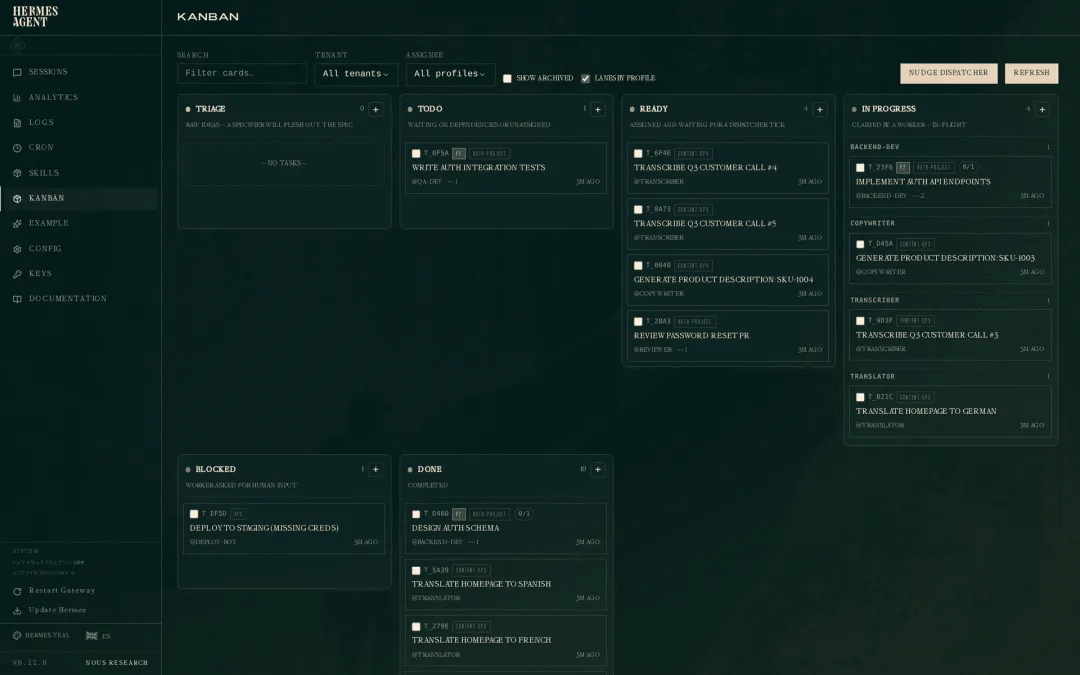
如果 Codex 同 Claude Code 各自發明唔同嘅任務交接格式,編排器根本冇辦法喺佢哋之間路由。係原語嘅統一令呢條流水線變成可能。
06 驗證者先係靈魂
成個流程入面最容易被忽略嘅角色,係驗證者。
Hermes 從來唔信 Codex 嘅自報告。Codex 話「構建通過咗」?Hermes 自己跑一次 npm test。Codex 話「測試全綠」?Hermes 自己跑 npm run build。
呢個同軟件工程嘅基本常識一模一樣。你唔會信開發者嘅口頭彙報「我測過冇問題」。你要睇 CI 綠咗、睇測試覆蓋率、睇 code 審查記錄。
AI 編程都一樣。模型好自信。佢會話你知「構建通過咗」,即使構建從來冇行過。佢會話你知「測試全部通過」,即使佢寫嘅測試從來冇執行過。
冇驗證,/goal 只係一個更花巧嘅 prompt。有驗證,佢先變成一個可執行嘅可交付物。
07 模糊需求嘅時代結束咗
Nuri Jananian(AI 編程同 PM 工具領域博主,專注 agentic coding 對產品工作流嘅影響)寫咗一篇面向產品經理嘅 /goal 指南,裏面有一個特別扎心嘅觀點。
你俾 agent 嘅需求,同你俾人類工程師嘅一樣模糊。
「優化下性能」「令用戶體驗更好」「減少 code 冗餘」。呢啲說話對人類工程師嚟講,佢哋仲可以靠經驗去估你到底想要乜。對 agent 嚟講,呢啲說話等於乜都冇講。
因為 agent 冇經驗。佢唔會估。佢會跟字面意思去理解你嘅需求,然後用一種你自己都諗唔到嘅方式「完成」佢。最後你覺得佢做得唔啱,佢覺得自己做咗,雙方都好沮喪。
/goal 強迫你將需求寫成可驗證嘅終態。唔係「優化性能」,係「p95 延遲降到 200ms 以下」。唔係「令體驗更好」,係「用戶由打開到完成操作嘅路徑由4步減到2步」。
呢個唔係 agent 嘅能力問題。係你嘅需求表達能力問題。

Jananian 總結咗一套寫強需求嘅模板。先定義唯一嘅真實來源檔案,再定義驗證命令,再定義邊界約束。三個部分,缺一不可。冇驗證命令嘅需求唔係需求,係願望。
PM 應該停止俾 agent 嘅嘢
形容詞。所有嘅形容詞。
「快速」「穩定」「美觀」「簡潔」「高效」。呢啲詞喺 PRD 入面可以用嚟定方向,但喺俾 agent 嘅時候,用一個形容詞就係俾一個唔驗收嘅藉口。
換成可觀察嘅狀態。可跑嘅測試。可量嘅指標。可檢查嘅輸出。
Claude Code 嘅官方文檔入面有一句總結得幾好:watch the first few loops。你設咗一個 /goal,唔好走開先,睇佢跑頭幾輪。如果佢跑偏咗,大概率唔係模型嘅問題,係你嘅目標寫得唔清晰。
08 點解話佢係原語
HTTP 係原語。JSON 係原語。TCP 係原語。
佢哋之所以成為原語,唔係因為某個公司發明咗佢哋,而係因為成個生態自發咗喺佢哋之上建立協議同工具。
/goal 正喺度行同一條路。
Claude Code 用佢嚟驅動自主編碼循環。Codex 用佢嚟定義可交付物。Hermes 用佢嚟做多 Agent 編排嘅任務原子單位。三個唔同嘅工具,三種唔同嘅用法,同一個原語。
你可以寫一個 /goal,喺 Codex 度執行,然後交俾 Claude Code 審查,成個過程由 Hermes 編排。工具之間唔需要任何翻譯。
原語嘅威力唔在於佢本身可以做啲乜,而在於有幾多人願意喺佢之上建造。
一個月前,/goal 仲未出現。一個月後,佢已經成為 AI 編程工具之間嘅事實標準接口。
呢個就係原語嘅速度。
Macaron 🧁 | 定義done,先會done
上週末我在終端裏跑了一個任務。改一個200多文件的本地語音實時轉錄小軟件。
以前幹這種活,我得坐在屏幕前面,Claude 做一步我按一次回車(就算是 bypass 中間也得介入N多次)。改文件、跑測試、看結果、繼續。循環往復,像個沒感情的回車鍵操作員。200個文件改完,我的耐心也改沒了。
這次我只打了一行命令,然後去喝了杯老黃同款蜜雪冰城。
回來的時候,任務跑完了。37輪循環,沒有一次需要我介入。
這已經不是什麼新鮮事兒了,這是 Claude Code 和 Codex 最近推出的 /goal 命令能做到的事,尤其是對於此前用過 Ralph Loop 的老鐵來說應該更熟悉了。
用最樸素的話說,/goal 把你從「人肉調度器」變成了「驗收員」。
普通 prompt 的工作模式是,你推一下,AI 走一步。你問「改完了嗎」,它說「改了」,你問「測試呢」,它說「測了」。每一步都需要你在線。
/goal 的工作模式完全不同。你一次性寫清楚「完成」長什麼樣,AI 就開始自主循環。規劃、改文件、跑測試、修 bug、再跑測試。一輪接一輪,直到滿足你寫的條件,或者你手動打斷。
Claude Code 的實現方式是雙模型架構。工作模型做實際編碼,每完成一輪,一個輕量評估者模型(默認 Claude Haiku)讀一遍對話記錄,只回答一個問題:目標達成了嗎?沒達成就繼續,達成了就停。
Codex 的機制類似,但評估方式略有不同。它用長時間運行的 harness 來檢查目標狀態,而不是單獨的評估者模型。
兩者殊途同歸。核心思想只有一個:把「判斷完成」的職責從工作模型裏分離出來。
這個分離至關重要。做工作的人和判斷工作是否完成的人,不應該同一個人。軟件工程裏這叫「build的人不能judge build」,AI 編程也一樣。
02 從 bash 循環到原生原語
/goal 不是憑空冒出來的。它有一個技術前身,叫 Ralph Wiggum loop。Ralph Wiggum 是《辛普森一家》裏的角色,以簡單粗暴著稱。社區借這個名字來形容一種最樸素的多輪 AI 循環方案。
幾個月前有人在社區裏火了一把,做法非常樸素:把 AI 塞進 bash 循環裏,每次循環給一個全新的 agent 實例,讓它讀 spec、讀計劃、讀任務列表,挑下一個沒完成的任務,做完,跑測試,通過就標記完成,然後重新開始。
聽起來很粗糙,但它的核心洞察比表面看起來深刻得多。
普通的 AI 對話有個致命問題:上下文腐爛。一個長對話跑了2萬 token 之後,模型開始忘記你開頭說的關鍵約束。你第3輪強調的「不要改數據庫 schema」,到了第30輪它可能就忘了,順手給你改了。
Ralph Wiggum loop 的解法是:不信任對話記憶。每輪循環開始時,讓 agent 重新加載持久化的文件。spec 文件、實現計劃、任務列表、測試套件、狀態記錄。對話會腐爛,文件不會。
/goal 把這個洞察做成了產品級的原語。
但 /goal 比原始 bash 循環多了幾層產品化設計。評估者模型自動判斷完成狀態,不用你手動檢查。原生的狀態管理讓你隨時能看到循環跑到哪了。任務邊界和循環預算的設置讓失控風險可控。
從粗糙的 bash 循環到原生原語,這個進化路徑和很多基礎設施的進化一樣。先是有人在邊緣地帶用膠帶和鐵絲把東西拼起來,然後有人把拼起來的東西標準化、產品化,最後所有人開始說同一種語言。
03 弱目標 vs 強目標
/goal 的成敗,80%取決於你寫了什麼樣的目標。
弱目標長這樣:
/goal improve onboarding
這就是一個許願。Claude 看到它會怎麼做?改名按鈕、加引導步驟、改文案、簡化頁面、寫測試、提 PR。每一步看起來都合理。但目標本身沒有給它任何判斷「完成了沒有」的依據。
兩種死法。
第一種,Claude 陷入無限循環。它不斷嘗試「改進」引導流程,但永遠無法確定自己改進了沒有,因為「improve」不可量化。
第二種更危險。評估者模型產生幻覺,在沒有任何可驗證證據的情況下宣佈「目標已完成」。Claude 很自信,它會告訴你一切正常,即使測試從來沒有跑過。
強目標長這樣:
/goal migrate all imports from legacyAuth to authClient in app/auth. No legacyAuth imports remain in app/auth. npm test -- auth exits 0. npm run typecheck exits 0. Stop after 15 turns if any usage is ambiguous.
區別在哪?
強目標有可觀察的終態。No legacyAuth imports remain 是可以用 grep 驗證的。npm test exits 0 是有確定退出碼的。Stop after 15 turns 是有安全閥的。
強目標有驗證手段。每一條完成條件都可以通過一條命令來檢查。評估者模型不需要猜測,它只需要看對話記錄裏有沒有出現對應的輸出。
強目標有邊界。in app/auth 限定了改動範圍,Stop after 15 turns 限制了資源消耗。即使出了問題,損失也是可控的。
弱目標和強目標之間的差距,不是措辭的問題,是思維方式的差距。弱目標是給人類同事寫的需求,靠對話中的默契來補全。強目標是給自主運行的 agent 寫的合同,必須自包含、可驗證、有邊界。
04 一個強目標的完整模板
Nuri Jananian(AI 編程和 PM 工具領域的博主,專注 agentic coding 對產品工作流的影響)總結了一個實用的 /goal 模板,我覺得值得完整展開:
目標描述:具體的終態,不是形容詞
來源文件:
• 讀哪個 spec 文件 • 跟哪個實現計劃 • 更新哪個狀態文件
驗收標準:
• 可觀察行為 1 • 可觀察行為 2 • 負面用例(不應該發生什麼) • 非迴歸條件(已有功能不能被破壞)
驗證方式:
• 測試命令(npm test、pytest 等) • 靜態檢查(lint、typecheck、build) • 必要時的瀏覽器或視覺驗證
邊界約束:
• 只改哪些路徑 • 不碰哪些系統 • 保持哪些契約/數據/API 行為不變
循環行為:
• 每次有意義的改動後跑相關驗證 • 更新狀態文件,記錄改了什麼、結果如何、風險在哪 • N 輪後仍阻塞則報告,不要無限循環
這個模板裏每一行都在回答同一個問題:AI 怎麼知道自己做完了?
以前這個問題是工程師在腦子裏補全的。現在它必須被寫下來,寫到一個自主運行的模型能讀懂的程度。
這不是增加工作量。這是把一直在做的事情顯性化了。
05 三個角色,三個工具
/goal 真正有意思的地方不在單個工具,在於不同工具開始接受同一種指令格式。
Codex 擅長實現。給它一個清晰的 spec,它能高效地把代碼寫出來。Claude Code 擅長審查。給它一段代碼,它能找出 spec 偏離、安全漏洞、邊界錯誤。Hermes 不是編碼工具,它是編排器,負責在構建器和審查器之間調度任務。
三個工具,三個角色。構建器、審查器、編排器。
工具可以換。角色不變。原語不變。
Saboo Shubham(多 Agent 編排工具的作者)在他的 Mac Mini 上跑了一個端到端的演示。他給 Hermes 發了一條消息:「建一個 CLI 工具,監控 X 上提到我的內容,有大事發生時通知我。」
Hermes 把這條消息拆成了六張卡片。
第一張,Hermes 自己寫 SPEC.md。定義技術棧、倉庫路徑、只讀約束、mock 模式、測試命令和驗證方式。這是 PM 的工作。
第二張,Codex 拿着 /goal 對着 SPEC.md 開幹。建項目、寫代碼、加測試。大約15分鐘,npm test 通過,npm run build 通過,git status 乾乾淨淨。
第三張,Claude Code 拿着 /goal 審查 Codex 的產出。檢查 spec 合規、只讀安全、API key 處理、錯誤狀態、安全漏洞。結果:PASS,沒有阻塞問題。
第四張和第五張是修復循環和二次驗證,因為審查通過了,直接跳過。
第六張,Hermes 做最終總結。驗證本地路徑、UI 和 API 在 mock 模式下都工作正常。
一條消息。三個工具。六張卡片。你只跟 Hermes 說話。
如果 Codex 和 Claude Code 各自發明不同的任務交接格式,編排器根本無法在它們之間路由。是原語的統一讓這條流水線成為可能。
06 驗證者才是靈魂
整個流程裏最容易被忽視的角色,是驗證者。
Hermes 從來不信任 Codex 的自報告。Codex 說「構建通過了」?Hermes 自己跑一遍 npm test。Codex 說「測試全綠」?Hermes 自己跑 npm run build。
這和軟件工程的基本常識一模一樣。你不會信任開發者的口頭彙報「我測過了沒問題」。你要看 CI 綠了、看測試覆蓋率、看代碼審查記錄。
AI 編程也一樣。模型很自信。它會告訴你「構建通過了」,即使構建從來沒跑過。它會告訴你「測試全部通過」,即使它寫的測試從來沒執行過。
沒有驗證,/goal 只是一個更花哨的 prompt。有驗證,它才變成一個可執行的可交付物。
07 模糊需求的時代結束了
Nuri Jananian(AI 編程和 PM 工具領域博主,專注 agentic coding 對產品工作流的影響)寫了一篇面向產品經理的 /goal 指南,裏面有一個特別扎心的觀點。
你給 agent 下的需求,和你給人類工程師下的一樣模糊。
「優化一下性能」「讓用戶體驗更好」「減少代碼冗餘」。這些話對人類工程師來說,他們還能靠經驗去猜你到底要什麼。對 agent 來說,這些話等於什麼都沒說。
因為 agent 沒有經驗。它不會猜。它會按照字面意思去理解你的需求,然後用一種你自己都想不到的方式「完成」它。最後你覺得它做得不對,它覺得自己做完了,雙方都很沮喪。
/goal 強迫你把需求寫成可驗證的終態。不是「優化性能」,是「p95 延遲降到 200ms 以下」。不是「讓體驗更好」,是「用戶從打開到完成操作的路徑從4步減到2步」。
這不是 agent 的能力問題。這是你的需求表達能力問題。
Jananian 總結了一套寫強需求的模板。先定義唯一的真實來源文件,再定義驗證命令,再定義邊界約束。三個部分,缺一不可。沒有驗證命令的需求不是需求,是願望。
PM 應該停止交給 agent 的東西
形容詞。所有的形容詞。
「快速」「穩定」「美觀」「簡潔」「高效」。這些詞在 PRD 裏可以用來定方向,但在給 agent 的時候,每用一個形容詞就是在給一個不驗收的藉口。
換成可觀察的狀態。可跑的測試。可量的指標。可檢查的輸出。
Claude Code 的官方文檔裏有一句話總結得很好:watch the first few loops。你設了一個 /goal,先別走開,看它跑前幾輪。如果它跑偏了,大概率不是模型的問題,是你的目標寫得不清晰。
08 為什麼說它是原語
HTTP 是原語。JSON 是原語。TCP 是原語。
它們之所以成為原語,不是因為某個公司發明了它們,而是因為整個生態自發地在它們之上建立了協議和工具。
/goal 正在走同樣的路。
Claude Code 用它來驅動自主編碼循環。Codex 用它來定義可交付物。Hermes 用它來做多 Agent 編排的任務原子單位。三個不同的工具,三種不同的用法,同一個原語。
你可以寫一個 /goal,在 Codex 裏執行,然後交給 Claude Code 審查,整個過程由 Hermes 編排。工具之間不需要任何翻譯。
原語的威力不在於它本身能做什麼,而在於有多少人願意在它之上建造。
一個月前,/goal 還不存在。一個月後,它已經成了 AI 編程工具之間的事實標準接口。
這就是原語的速度。
Macaron 🧁 | 定義done,才能done