AI控制瀏覽器的最佳方案:Playwright-cli + AI Coding ——寫不出來的爬蟲、跑不通的腳本,讓 AI 對着瀏覽器幫你調
整理版優先睇
AI控制瀏覽器嘅最佳方案:Playwright-cli幫你寫爬蟲、調腳本,仲可以固化成獨立程式
呢篇文章介紹咗微軟最近開源嘅 playwright-cli 工具,佢嘅核心能力係讓 AI 接管你嘅瀏覽器,邊睇真實頁面邊幫你調代碼,調完直接生成可獨立運行嘅 Python 腳本。作者想解決兩個常見問題:自己寫 Playwright 腳本跑唔通,成日要反覆改;同埋每次靠 AI 完成操作,用完就冇,下次要重新嚟。整體結論係:AI 只負責探索同生產腳本,唔參與後續運行,咁就可以將瀏覽器自動化由「每次靠 AI」變成「一次探索,永久運行」。
同傳統自動化工具(如 Selenium、Playwright)唔同,playwright-cli 唔使你寫代碼,只係用自然語言描述目標,AI 就會透過 CLI 命令操控瀏覽器。佢仲提供咗一條從探索到固化嘅完整路徑:遇到新需求就讓 AI 接管瀏覽器探索;腳本有 bug 就讓 AI 睇住真實瀏覽器幫你調;路徑確認後就讓 AI 生成標準 .py 腳本,之後完全脱離 AI 獨立運行。最終跑喺服務器上嘅係一個普通 Python 腳本,冇大模型依賴,冇網絡要求。
作者特別強調,playwright-cli 係探索工具,唔係運行環境。佢解決咗企業內網、斷網場景嘅自動化問題,而且對非程序員非常友好——以前要學工具,而家工具適應你。如果你日常已經用緊 Claude Code、GitHub Copilot 呢類工具,playwright-cli 係一個值得即刻安裝嘅擴展能力。
- 結論:playwright-cli 讓 AI 探索瀏覽器並生成獨立腳本,之後完全唔需要 AI 環境,實現一次探索、永久運行。
- 方法:用自然語言指揮 AI,透過 CLI 命令操控瀏覽器,唔使自己寫任何代碼;AI 會邊睇邊調,直接生成標準 Python 文件。
- 差異:CLI 比 MCP 更省 Token,適合同時處理大型代碼庫同瀏覽器操作嘅編程代理;MCP 則適合深度分析,兩者互補。
- 啟發:瀏覽器自動化門檻大降,以前要學 Selenium、XPath,而家只要識講嘢就得;企業內網、斷網場景都用到,因為最終腳本完全獨立。
- 可行動點:安裝 playwright-cli、安裝 Skills、啟用瀏覽器調試端口(--remote-debugging-port=9222),然後用自然語言交代任務,例如「幫我將本月銷售報表導出成 Excel」。
playwright-cli GitHub 倉庫
微軟官方開源倉庫,包含安裝指引、文檔同 Skills 安裝命令。
Playwright 官方文檔
Playwright 瀏覽器自動化框架嘅完整文檔,適合深入瞭解底層 API。
呢個工具解決咩問題?
好多人寫 Playwright 腳本跑唔通,要靠反覆 print、猜原因、改代碼,浪費大量時間。另一種情況係每次用 AI 完成一個操作,用完就冇,下次要重頭嚟過。
微軟最近喺 GitHub 低調發布呢個工具,已經有 9000+ stars。核心能力就一句:讓 AI 接管你嘅瀏覽器,邊睇真實頁面邊幫你調代碼,調完直接生成 可獨立運行嘅 Python 腳本。
- 自己寫嘅腳本有 bug → 以前要加 print、猜原因、反覆改;而家 AI 睇住真實瀏覽器幫你實時定位
- 想固化一套操作流程 → 以前要學 Playwright API、自己寫;而家 AI 探索完直接生成 .py 腳本
- 每天手動下載報表 → 以前一步步點;而家腳本跑一下,自動完成
點解 CLI 比 MCP 更受編程代理青睞?
目前 AI 操控瀏覽器有兩種主流方式:MCP(模型上下文協議)同 CLI(命令行)。微軟喺文檔明確解釋咗兩者嘅區別。
MCP 則適合「深度探索」,當 AI 需要持續睇住一個頁面、反覆調整策略、做複雜自主推理時,MCP 嘅持久狀態更有優勢。簡單講:CLI 係高效執行,MCP 係深度分析,兩者唔係替代,而係互補。
五個真實場景,感受下威力
- 1 場景一:每天下載報表太煩人。啟動帶調試端口嘅瀏覽器(一次性配置),告訴 AI:「幫我將 XX 系統本月的銷售報表導出來」,AI 自動完成。
- 2 場景二:按鈕冇反應,排查好耐。AI 可以直接扒出按鈕背後綁定嘅 JavaScript 邏輯,例如發現 導出按鈕只喺工作時間生效,前端寫死時間校驗,從唔話畀用戶知。
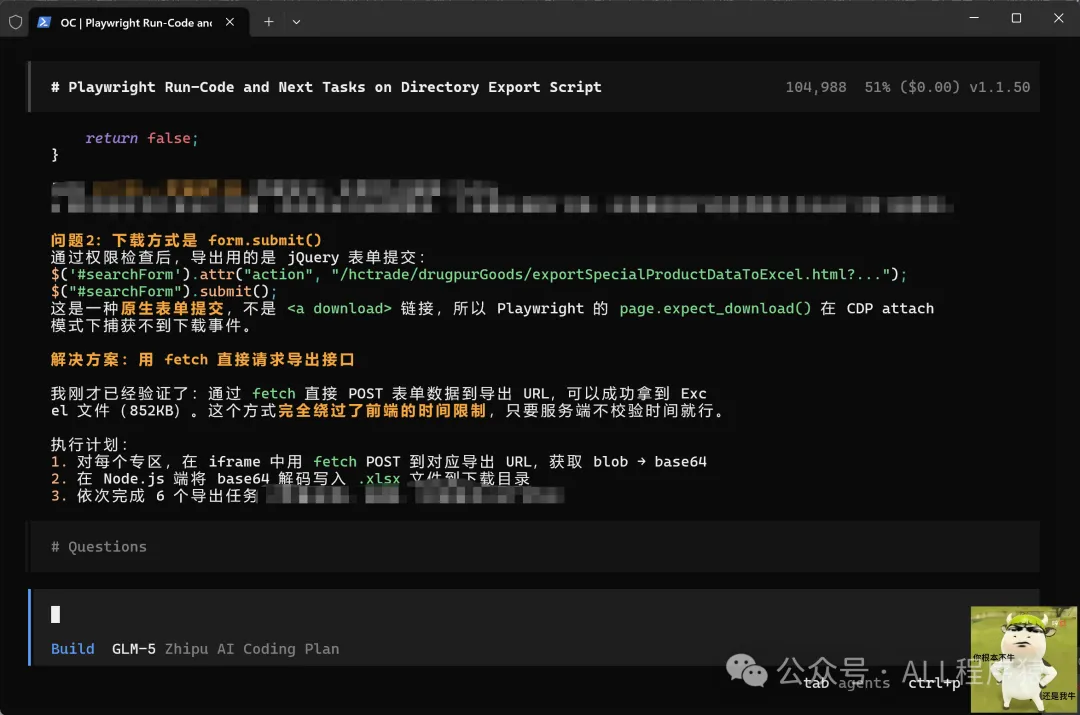
- 3 場景三:下載文件捕獲唔到。用 CDP 協議繞過 expect_download() 嘅限制,AI 幫你改好代碼。
- 4 場景四:政務/企業系統滿係 iframe。AI 會自動識別 iframe 結構,選擇正確嘅進入方式。
- 5 場景五:自己寫嘅 Playwright 代碼跑唔通。AI 讀你嘅代碼、接管瀏覽器、檢查事件綁定同網絡請求,直接定位問題並修改,唔使你打一行調試代碼。
場景六尤其值得講:探索完成後固化成獨立腳本。正確工作流係:第一階段 AI + playwright-cli 探索,確認操作路徑可行;第二階段 AI 生成標準 Python 腳本,保存到項目目錄;第三階段直接運行 .py,完全脱離 AI——定時任務、CI/CD 都支援,唔需要 Claude、網絡或任何大模型環境。場景七仲可以繞過前端權限限制:AI 分析請求後用 fetch 直接調用後端接口拎數據。
點樣開始用?
第一步:安裝 npm install -g @playwright/cli@latest,需要 Node.js 18 或更高版本。第二步:安裝 Skills——playwright-cli install --skills,呢步會將操作指南安裝到本地,Claude Code、GitHub Copilot 等助手會自動讀取。
第三步:啟動瀏覽器時加上調試端口參數 --remote-debugging-port=9222,之後 AI 就可以通過呢個端口接管你個瀏覽器。第四步:直接同 AI 講「我嘅瀏覽器已經喺 localhost:9222 運行,登錄咗 XX 系統,幫我將本月數據導出到 Excel」,剩下嘅交畀 AI。
# 打開網頁
playwright-cli open https://example.com --headed
# 睇頁面結構(AI 最常用)
playwright-cli snapshot
# 點擊元素
playwright-cli click e15
# 填寫表單
playwright-cli fill e5 "要輸入嘅內容"
# 截圖
playwright-cli screenshot --filename=result.png
# 接管已有瀏覽器
playwright-cli attach --cdp=http://localhost:9222
# 保存登錄狀態
playwright-cli state-save my-session
playwright-cli state-load my-session # 下次直接恢復,唔使重新登錄你有冇遇到呢兩種情況?
自己寫嘅 Playwright 腳本跑唔通,唔知邊度出問題,淨係得不停改不停估 每次靠 AI 完成一個操作,用完就冇咗,下次又要重新嚟過一次 呢兩個問題,playwright-cli 都解決曬。
微軟最近喺 GitHub 低調發布咗 playwright-cli,而家已經有 9000+ stars。
核心能力得一句話:俾 AI 接管你嘅瀏覽器,一邊睇真實頁面一邊幫你改 code,改完直接生成可以獨立運行嘅 Python 腳本。
用一次,就有一個腳本,之後定時跑、伺服器跑、斷網跑,完全唔使依賴 AI 環境。
呢個係好多人未諗清楚嘅分別:AI 負責探索同生產腳本,唔參與之後嘅運行。
具體嚟講,佢可以幫你做呢啲嘢:
生成嘅腳本係標準 Python 檔案,唔依賴任何 AI 服務,放喺伺服器定時跑完全冇問題。
呢個同以前嘅瀏覽器自動化有咩唔同?
瀏覽器自動化唔係新鮮事。Selenium、Playwright、RPA 工具……大家可能都聽過。但呢啲工具都有一個共同嘅門檻:你要寫 code。
playwright-cli 嘅思路完全唔同。
佢將 Playwright 嘅能力封裝成一個個簡潔嘅命令列指令,AI 助手可以直接調用呢啲指令嚟操控瀏覽器。你只需要用自然語言話俾 AI 知你嘅目標,剩下嘅交俾佢。
舉個例子,你想測試一個待辦事項網站,只需要話俾 AI:
"用 playwright-cli 測試一下 https://demo.playwright.dev/todomvc/ 呢個網站,截圖保存所有成功同失敗嘅場景。"
AI 會自己執行一系列命令:
playwright-cli open https://demo.playwright.dev/todomvc/
playwright-cli type "Buy groceries"
playwright-cli press Enter
playwright-cli check e21
playwright-cli screenshot
成個過程你唔使寫任何 code。
點解 CLI 比 MCP 更受編程代理青睞?
呢度有個值得留意嘅技術趨勢。
目前 AI 操控瀏覽器有兩種主流方式:MCP(模型上下文協議)同 CLI(命令列)。微軟喺文件入面明確解釋咗兩者嘅分別:
CLI 嘅優勢在於「省 Token」"。
MCP 每次調用工具,都要將大量嘅工具描述、頁面可訪問性樹等資訊塞入模型上下文,消耗大量 Token。而 CLI 命令簡潔,AI 只需要知道命令本身,避免咗冗餘資訊嘅加載。
對於需要同時處理大型代碼庫 + 瀏覽器操作嘅編程代理嚟講,Token 窗口就係生命線,CLI 方式明顯更實用。
MCP 則適合「深度探索」。當你需要 AI 持續睇住一個頁面、反覆調整策略、做複雜嘅自主推理時,MCP 嘅持久狀態更有優勢。
簡單講:CLI 係高效執行,MCP 係深度分析。 兩者唔係取代關係,而係互補。
五個真實場景,感受下
場景一:每日下載報表太煩人
好多企業系統嘅數據導出需要登入、㩒幾個菜單、揀條件、導出……每日重複。
而家你只需要:
啟動帶除錯埠嘅瀏覽器(一次性配置) 話俾 AI:「幫我將 XX 系統入面今個月嘅銷售報表導出嚟」 AI 接管瀏覽器,自動完成所有步驟
場景二:按鈕㩒咗冇反應,排查半日
有冇遇到過㩒「導出」按鈕完全冇反應,都唔報錯?
用 playwright-cli 可以俾 AI 直接挖出按鈕背後綁定咗啲乜 JavaScript 邏輯:
// 檢查按鈕是否有時間限制
jQuery._data(document.getElementById('export'), 'events')
有位用戶就係咁發現咗一個政務系統嘅隱藏限制:導出按鈕只喺工作時間生效,前端直接寫死咗時間校驗,從來唔話俾用戶知原因。
場景三:下載檔案捕獲唔到
Python Playwright 腳本入面用 expect_download() 卻捕獲唔到透過 form.submit() 觸發嘅下載?
AI 可以直接用 CDP 協議繞過:
const cdp = await page.context().newCDPSession(page);
cdp.send('Browser.setDownloadBehavior', {
behavior: 'allow',
downloadPath: 'D:\\Downloads',
});
話俾 AI 你嘅問題,佢會幫你揾到解法並直接改好 code。
場景四:政務/企業系統全部係 iframe
呢類系統幾乎全部係 iframe 嵌套,普通自動化腳本經常定位唔到元素。
AI 會自動識別 iframe 結構,揀啱嘅進入方式:
const frame = page.frames().find(f => f.name() === 'mainframe');
await frame.evaluate(() => { /* 在 iframe 內直接執行操作 */ });
場景五:自己寫嘅 Playwright code 跑唔通
好多人學咗 Playwright 之後自己寫腳本,結果運行起嚟好多問題:元素定位失敗、㩒擊冇效果、下載捕獲唔到……
傳統除錯方式係:加 print、睇報錯、對住文件估、改咗再跑……循環往復。
而家換另一種玩法:俾 AI 一邊睇住真實瀏覽器,一邊幫你改 code。
你只需要:
我有一個 Playwright 腳本 D:\...\export.py,
運行後點擊"導出"按鈕沒有觸發下載,
瀏覽器已經打開在 localhost:9222,幫我排查
AI 會:
讀你嘅 code,理解下載邏輯 接管瀏覽器,即時睇頁面狀態 檢查按鈕嘅事件綁定,睇網絡請求有冇發出去 直接定位問題,修改 code,儲存
全程你唔使自己打一行除錯 code,亦唔使重複「改→跑→報錯→再改」嘅循環。
場景六:探索完成後,固化做獨立腳本
呢個係 playwright-cli 最容易被忽略嘅價值:佢係探索工具,唔係運行環境。
好多人以為用咗 AI + playwright-cli 就永遠要依賴 AI 先可以運行。其實完全唔係咁。
正確嘅工作流程係:
第一階段(一次性):AI + playwright-cli 探索
→ AI 接管瀏覽器,找元素、測操作、排查問題
→ 確認操作路徑完全可行
第二階段(固化):AI 生成 Python 腳本
→ 把剛才的操作流程寫成標準 .py 文件
→ 保存到你的項目目錄
第三階段(後續):直接運行 .py,完全脱離 AI
→ python export.py
→ 定時任務、批處理、CI/CD 全都支持
→ 不需要 Claude,不需要網絡,不需要任何大模型環境
你可以話俾 AI:
剛才的操作流程已經驗證可行了,幫我把它整理成一個標準的
Python Playwright 腳本,保存到 D:\scripts\export.py,
要支持命令行傳參(開始日期、結束日期)
AI 生成嘅腳本可以直接掉去伺服器上面跑定時任務,同普通 Python 腳本完全冇分別——AI 只係參與咗生產呢個腳本嘅過程,唔參與運行。
呢個解決咗好多人對「AI 自動化」嘅顧慮:企業環境、內網伺服器、斷網場景,都冇問題。
場景七:接口有前端限制但後端冇
發現某個導出功能喺前端做咗權限限制,但後端接口其實可以直接調用?AI 可以幫你分析請求,用 fetch 繞過前端直接拎數據(生成好之後同樣可以固化做腳本):
const resp = await fetch('/api/exportData', {
method: 'POST',
credentials: 'include', // 帶上登錄態
body: formData
});
點樣開始用?
第一步:安裝
npm install -g @playwright/cli@latest
需要 Node.js 18 或更高版本。
第二步:安裝 Skills(令 AI 助手學識點用佢)
playwright-cli install --skills
呢一步會將操作指南安裝到本地,Claude Code、GitHub Copilot 等助手會自動讀取並學識點用。
第三步:啟動瀏覽器時加上除錯埠
# Chrome/Edge 啓動時加上這個參數
--remote-debugging-port=9222
之後 AI 就可以透過呢個埠接管你嘅瀏覽器。
第四步:話俾 AI 你想做啲乜
我的瀏覽器已經在 localhost:9222 運行了,已經登錄了 XX 系統,
幫我把本月的數據導出到 Excel
剩下嘅嘢交俾 AI。
一啲實用嘅命令速查
如果你間中想手動操作,呢啲命令夠用㗎喇:
# 打開網頁
playwright-cli open https://example.com --headed
# 看頁面結構(AI 最常用的命令)
playwright-cli snapshot
# 點擊元素
playwright-cli click e15
# 填寫表單
playwright-cli fill e5 "要輸入的內容"
# 截圖
playwright-cli screenshot --filename=result.png
# 接管已有瀏覽器
playwright-cli attach --cdp=http://localhost:9222
# 保存登錄狀態
playwright-cli state-save my-session
playwright-cli state-load my-session # 下次直接恢復,不用重新登錄
關於安全同邊界
有人會問:咁樣俾 AI 操控瀏覽器,安唔安全?
幾個注意點:
AI 唔會主動亂咁操作。設計良好嘅提示詞會令 AI 先話俾你知要做啲乜,確認之後先執行。 除錯埠只喺本地暴露。 localhost:9222只有本機可以訪問,唔會對外開放。敏感操作建議逐步確認。可以話俾 AI:「每一步先講清楚你要做啲乜,我確認之後先執行」。 會話互相隔離。唔同嘅會話( -s=name)使用獨立嘅瀏覽器實例,互不幹擾。
寫喺最後
瀏覽器自動化唔係乜嘢新技術,但 playwright-cli 嘅出現,令佢第一次真正對非程式員變得友好。
核心變化得一個:以前你要學工具,而家工具嚟適應你。
你只需要用自然語言描述目標,AI 負責翻譯成具體操作。嗰啲需要「先學 Selenium」、「先學 XPath」、「先搞懂異步等待」嘅門檻,全部消失曬。
更重要係,佢提供咗一條由探索到固化嘅完整路徑:
遇到新需求?俾 AI 接管瀏覽器探索,一邊試一邊確認 自己嘅腳本有 bug?俾 AI 睇住真實瀏覽器幫你改 路徑確認咗之後?俾 AI 生成標準 .py 腳本,之後完全脱離 AI 獨立運行
最後跑喺伺服器上面嘅,係一個普通嘅 Python 腳本,冇大模型依賴,冇網絡要求,冇額外嘅運行環境。AI 只係出現喺「生產腳本」呢一步,唔參與之後嘅運行。
如果你日常已經在用 Claude Code、GitHub Copilot 呢類工具,playwright-cli 係一個值得即刻安裝嘅擴展能力。
相關資源
playwright-cli GitHub 倉庫:github.com/microsoft/playwright-cli Playwright 官方文檔:playwright.dev 當前版本:v0.1.8(2026年4月)
如果你有具體嘅自動化需求想傾,歡迎留言。
你有沒有遇到這兩種情況:
自己寫的 Playwright 腳本跑不通,不知道哪裏出問題,只能反覆改反覆猜 每次靠 AI 完成一個操作,用完就沒了,下次還得重新來一遍 這兩個問題,playwright-cli 都解決了。
微軟最近在 GitHub 上低調發布了 playwright-cli,目前已有 9000+ stars。
核心能力只有一句話:讓 AI 接管你的瀏覽器,邊看真實頁面邊幫你調代碼,調完直接生成可獨立運行的 Python 腳本。
用一次,沉澱一個腳本,之後定時跑、服務器跑、斷網跑,完全不依賴 AI 環境。
這是很多人沒想清楚的區別:AI 負責探索和生產腳本,不參與後續運行。
具體來說,它能幫你做這些事:
生成的腳本是標準 Python 文件,不依賴任何 AI 服務,放服務器上定時跑沒有任何問題。
這跟以前的瀏覽器自動化有什麼不一樣?
瀏覽器自動化不是新鮮事。Selenium、Playwright、RPA 工具……大家可能都聽說過。但這些工具有一個共同的門檻:你得寫代碼。
playwright-cli 的思路完全不同。
它把 Playwright 的能力封裝成一個個簡潔的命令行指令,AI 助手可以直接調用這些指令來操控瀏覽器。你只需要用自然語言告訴 AI 你的目標,剩下的交給它。
舉個例子,你想測試一個待辦事項網站,只需要告訴 AI:
"用 playwright-cli 測試一下 https://demo.playwright.dev/todomvc/ 這個網站,截圖保存所有成功和失敗的場景。"
AI 會自己執行一系列命令:
playwright-cli open https://demo.playwright.dev/todomvc/
playwright-cli type "Buy groceries"
playwright-cli press Enter
playwright-cli check e21
playwright-cli screenshot
整個過程你不需要寫任何代碼。
為什麼 CLI 比 MCP 更受編程代理青睞?
這裏有個值得關注的技術趨勢。
目前 AI 操控瀏覽器有兩種主流方式:MCP(模型上下文協議)和 CLI(命令行)。微軟在文檔裏明確解釋了兩者的區別:
CLI 的優勢在於"省 Token"。
MCP 每次調用工具,都需要把大量的工具描述、頁面可訪問性樹等信息塞入模型上下文,消耗大量 Token。而 CLI 命令簡潔,AI 只需要知道命令本身,避免了冗餘信息的加載。
對於需要同時處理大型代碼庫 + 瀏覽器操作的編程代理來說,Token 窗口就是生命線,CLI 方式明顯更實用。
MCP 則適合"深度探索"。當你需要 AI 持續盯着一個頁面、反覆調整策略、做複雜的自主推理時,MCP 的持久狀態更有優勢。
簡單說:CLI 是高效執行,MCP 是深度分析。 兩者不是替代關係,而是互補。
五個真實場景,感受一下
場景一:每天下載報表太煩人
很多企業系統的數據導出需要登錄、點幾個菜單、選條件、導出……每天重複。
現在你只需要:
啓動帶調試端口的瀏覽器(一次性配置) 告訴 AI:"幫我把 XX 系統裏本月的銷售報表導出來" AI 接管瀏覽器,自動完成所有步驟
場景二:按鈕點了沒反應,排查半天
有沒有遇到過點擊"導出"按鈕沒有任何反應,也不報錯?
用 playwright-cli 可以讓 AI 直接扒出按鈕背後綁定了什麼 JavaScript 邏輯:
// 檢查按鈕是否有時間限制
jQuery._data(document.getElementById('export'), 'events')
某位用戶就是這樣發現了一個政務系統的隱藏限制:導出按鈕只在工作時間生效,前端直接寫死了時間校驗,從不告訴用戶原因。
場景三:下載文件捕獲不到
Python Playwright 腳本里用 expect_download() 卻捕獲不到通過 form.submit() 觸發的下載?
AI 可以直接用 CDP 協議繞過:
const cdp = await page.context().newCDPSession(page);
cdp.send('Browser.setDownloadBehavior', {
behavior: 'allow',
downloadPath: 'D:\\Downloads',
});
告訴 AI 你的問題,它會幫你找到解法並直接改好代碼。
場景四:政務/企業系統滿是 iframe
這類系統幾乎全是 iframe 嵌套,普通自動化腳本經常定位不到元素。
AI 會自動識別 iframe 結構,選擇正確的進入方式:
const frame = page.frames().find(f => f.name() === 'mainframe');
await frame.evaluate(() => { /* 在 iframe 內直接執行操作 */ });
場景五:自己寫的 Playwright 代碼跑不通
很多人學了 Playwright 之後自己寫腳本,結果運行起來各種問題:元素定位失敗、點擊沒有效果、下載捕獲不到……
傳統調試方式是:加 print、看報錯、對着文檔猜、改了再跑……循環往復。
現在換一種玩法:讓 AI 邊看着真實瀏覽器,邊幫你改代碼。
你只需要:
我有一個 Playwright 腳本 D:\...\export.py,
運行後點擊"導出"按鈕沒有觸發下載,
瀏覽器已經打開在 localhost:9222,幫我排查
AI 會:
讀你的代碼,理解下載邏輯 接管瀏覽器,實時看頁面狀態 檢查按鈕的事件綁定,看網絡請求有沒有發出去 直接定位問題,修改代碼,保存
全程你不需要自己打一行調試代碼,也不需要重複"改→跑→報錯→再改"的循環。
場景六:探索完成後,固化成獨立腳本
這是 playwright-cli 最容易被忽略的價值:它是探索工具,不是運行環境。
很多人以為用了 AI + playwright-cli 就永遠依賴 AI 才能運行。其實完全不是這樣。
正確的工作流是:
第一階段(一次性):AI + playwright-cli 探索
→ AI 接管瀏覽器,找元素、測操作、排查問題
→ 確認操作路徑完全可行
第二階段(固化):AI 生成 Python 腳本
→ 把剛才的操作流程寫成標準 .py 文件
→ 保存到你的項目目錄
第三階段(後續):直接運行 .py,完全脱離 AI
→ python export.py
→ 定時任務、批處理、CI/CD 全都支持
→ 不需要 Claude,不需要網絡,不需要任何大模型環境
你可以告訴 AI:
剛才的操作流程已經驗證可行了,幫我把它整理成一個標準的
Python Playwright 腳本,保存到 D:\scripts\export.py,
要支持命令行傳參(開始日期、結束日期)
AI 生成的腳本可以直接丟到服務器上跑定時任務, 和普通 Python 腳本沒有任何區別——AI 只參與了生產這個腳本的過程,不參與運行。
這解決了很多人對"AI 自動化"的顧慮:企業環境、內網服務器、斷網場景,都沒有問題。
場景七:接口有前端限制但後端沒有
發現某個導出功能在前端做了權限限制,但後端接口其實可以直接調用?AI 可以幫你分析請求,用 fetch 繞過前端直接拿數據(生成好後同樣可以固化成腳本):
const resp = await fetch('/api/exportData', {
method: 'POST',
credentials: 'include', // 帶上登錄態
body: formData
});
怎麼開始用?
第一步:安裝
npm install -g @playwright/cli@latest
需要 Node.js 18 或更高版本。
第二步:安裝 Skills(讓 AI 助手學會使用它)
playwright-cli install --skills
這一步會把操作指南安裝到本地,Claude Code、GitHub Copilot 等助手會自動讀取並學會使用。
第三步:啓動瀏覽器時加上調試端口
# Chrome/Edge 啓動時加上這個參數
--remote-debugging-port=9222
之後 AI 就可以通過這個端口接管你的瀏覽器。
第四步:告訴 AI 你要幹什麼
我的瀏覽器已經在 localhost:9222 運行了,已經登錄了 XX 系統,
幫我把本月的數據導出到 Excel
剩下的事交給 AI。
一些實用的命令速查
如果你偶爾想手動操作,這些命令夠用了:
# 打開網頁
playwright-cli open https://example.com --headed
# 看頁面結構(AI 最常用的命令)
playwright-cli snapshot
# 點擊元素
playwright-cli click e15
# 填寫表單
playwright-cli fill e5 "要輸入的內容"
# 截圖
playwright-cli screenshot --filename=result.png
# 接管已有瀏覽器
playwright-cli attach --cdp=http://localhost:9222
# 保存登錄狀態
playwright-cli state-save my-session
playwright-cli state-load my-session # 下次直接恢復,不用重新登錄
關於安全和邊界
有人會問:這樣讓 AI 操控瀏覽器,安不安全?
幾個注意點:
AI 不會主動亂操作。設計良好的提示詞會讓 AI 先告訴你要做什麼,確認後再執行。 調試端口只在本地暴露。 localhost:9222只有本機能訪問,不會對外開放。敏感操作建議逐步確認。可以告訴 AI:"每一步先說明你要做什麼,我確認後再執行"。 會話相互隔離。不同的會話( -s=name)使用獨立的瀏覽器實例,互不干擾。
寫在最後
瀏覽器自動化並不是什麼新技術,但 playwright-cli 的出現,讓它第一次真正對非程序員變得友好。
核心變化只有一個:以前你要學工具,現在工具來適應你。
你只需要用自然語言描述目標,AI 負責翻譯成具體操作。那些需要"先學 Selenium"、"先學 XPath"、"先搞懂異步等待"的門檻,統統消失了。
更重要的是,它提供了一條從探索到固化的完整路徑:
遇到新需求?讓 AI 接管瀏覽器探索,邊試邊確認 自己的腳本有 bug?讓 AI 盯着真實瀏覽器幫你調 路徑確認後?讓 AI 生成標準 .py 腳本,之後完全脱離 AI 獨立運行
最終跑在服務器上的,是一個普通的 Python 腳本,沒有大模型依賴,沒有網絡要求,沒有額外的運行環境。AI 只出現在"生產腳本"這一步,不參與後續運行。
如果你日常已經在用 Claude Code、GitHub Copilot 這類工具,playwright-cli 是一個值得立刻安裝的擴展能力。
相關資源
playwright-cli GitHub 倉庫:github.com/microsoft/playwright-cli Playwright 官方文檔:playwright.dev 當前版本:v0.1.8(2026年4月)
如果你有具體的自動化需求想聊,歡迎留言。