AI繪畫是下一個十年的船票
整理版優先睇
作者認為AI繪畫係下個十年嘅關鍵,因為人類係多模態生物,而Agent已經夠成熟,瓶頸在於創意同詞彙封裝。
呢篇文章嘅作者係一個AI Agent嘅重度用家,佢最近發現Agent能力已經好足夠,瓶頸反而係自己嘅創意唔夠。所以佢開始由Agent轉向AI繪畫,認為呢個先係未來嘅方向。
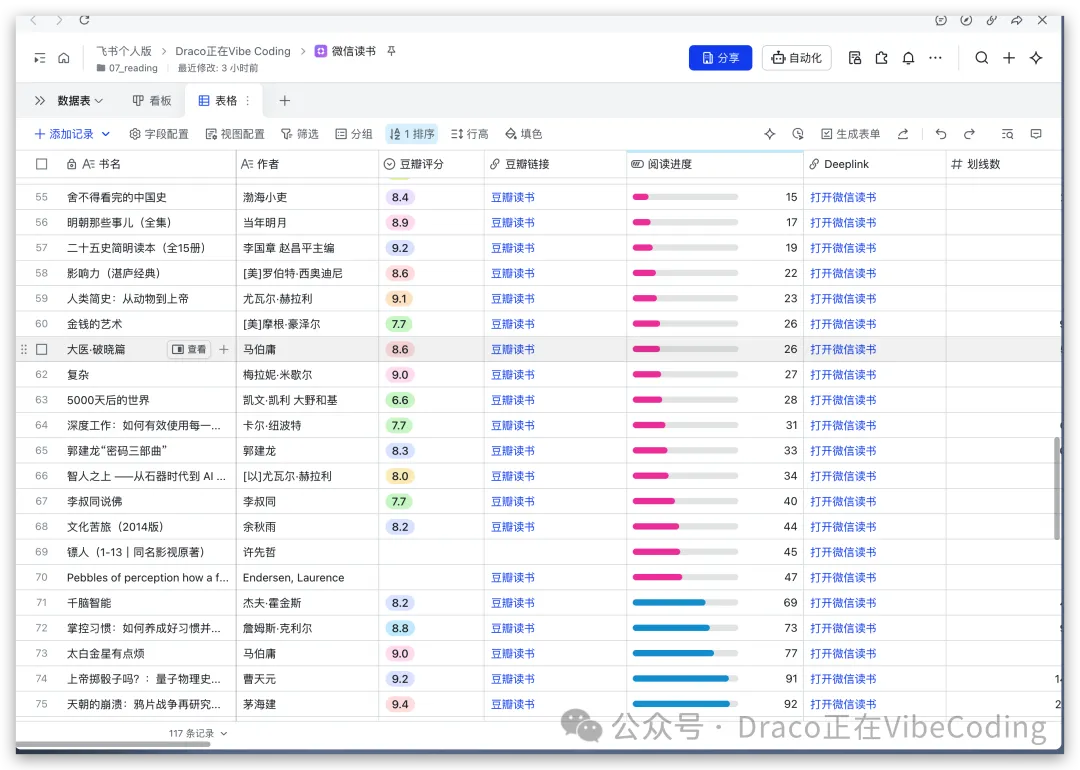
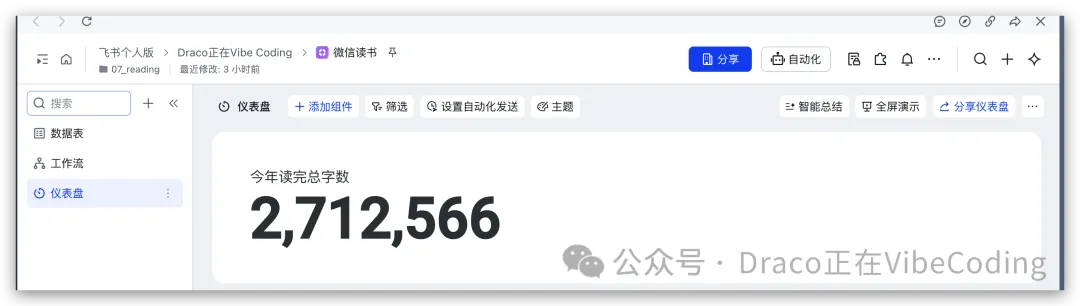
佢回顧咗五月自己build嘅幾個項目,包括一個將書本地名標註喺3D地球儀嘅應用、AI信源集合站、微信讀書個人看板、AI短劇Skill,同埋爆肝咗1112張AI繪圖。佢特別強調AI繪畫嘅難點在於「概念封裝」,即係要用準確詞彙表達腦海入面嘅意象,呢個需要刻意練習。
作者認為人類係多模態生物,圖像嘅信息密度遠高於文字,未來大部分人就業喺服務業甚至娛樂業,學習都應該娛樂化。所以佢建議大家從而家開始積累AI繪畫詞彙,為可視化時代做好準備,呢個就係下一個十年嘅船票。
- Agent能力已足夠強,瓶頸在於人類創意不足,唔好再折騰工具,要專注用Agent嚟build乜嘢。
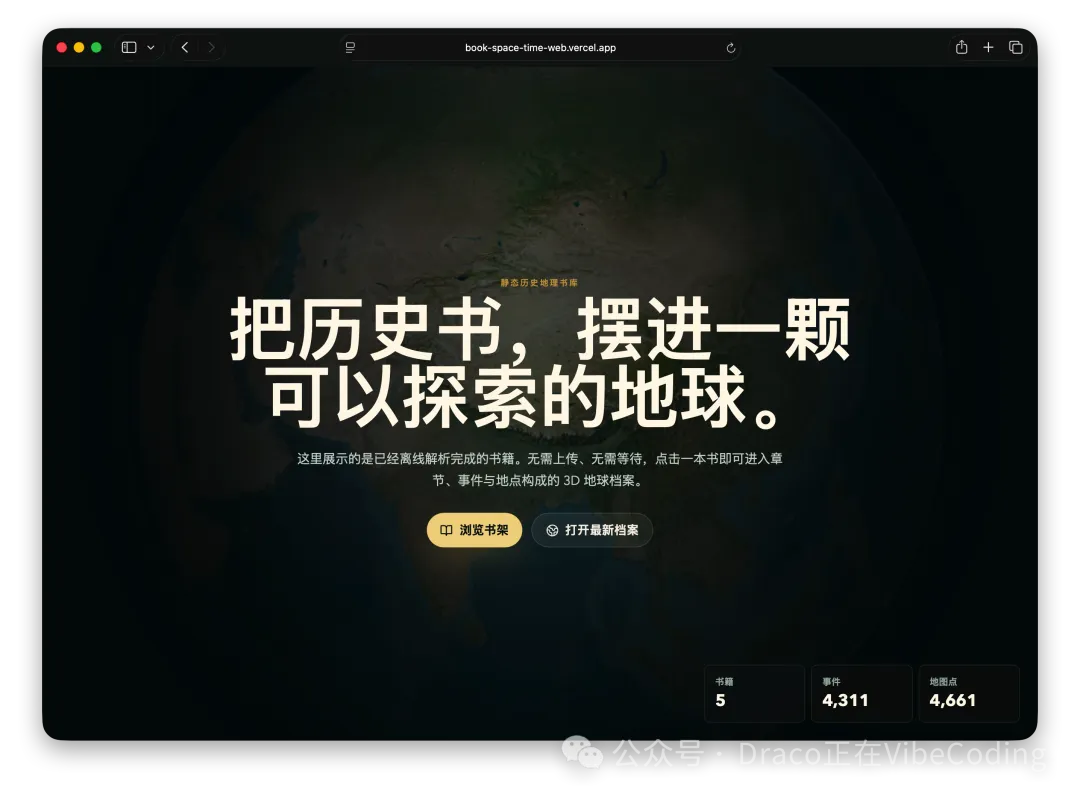
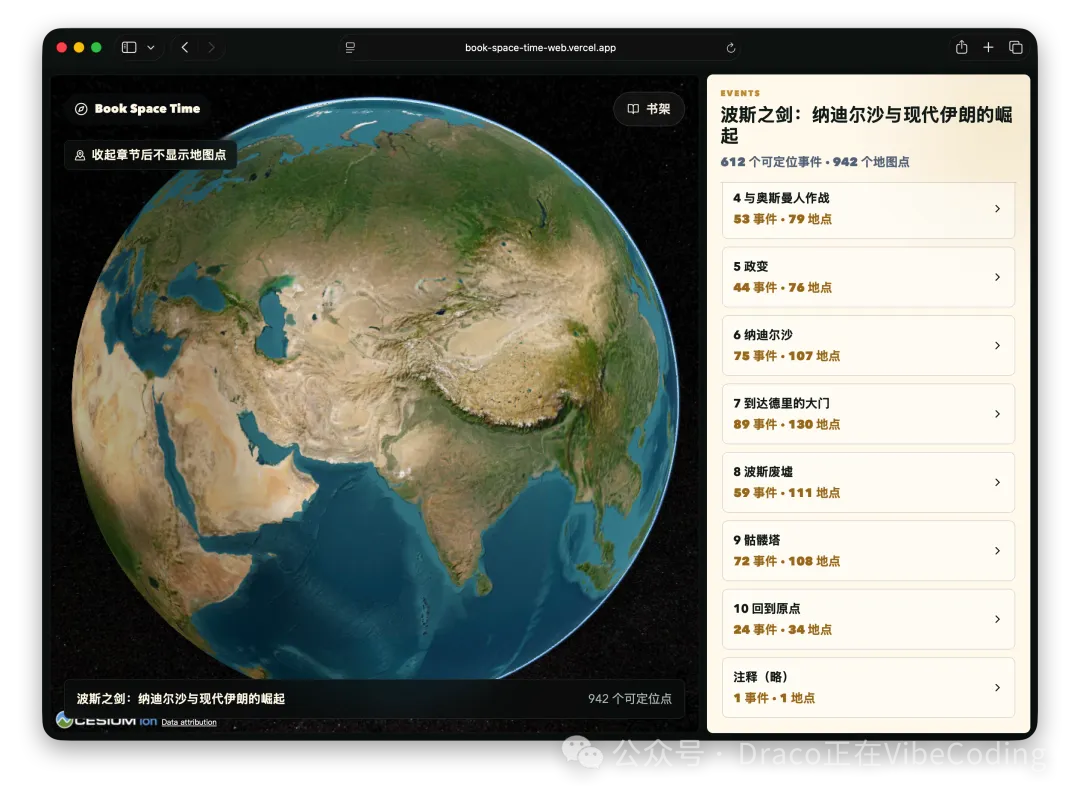
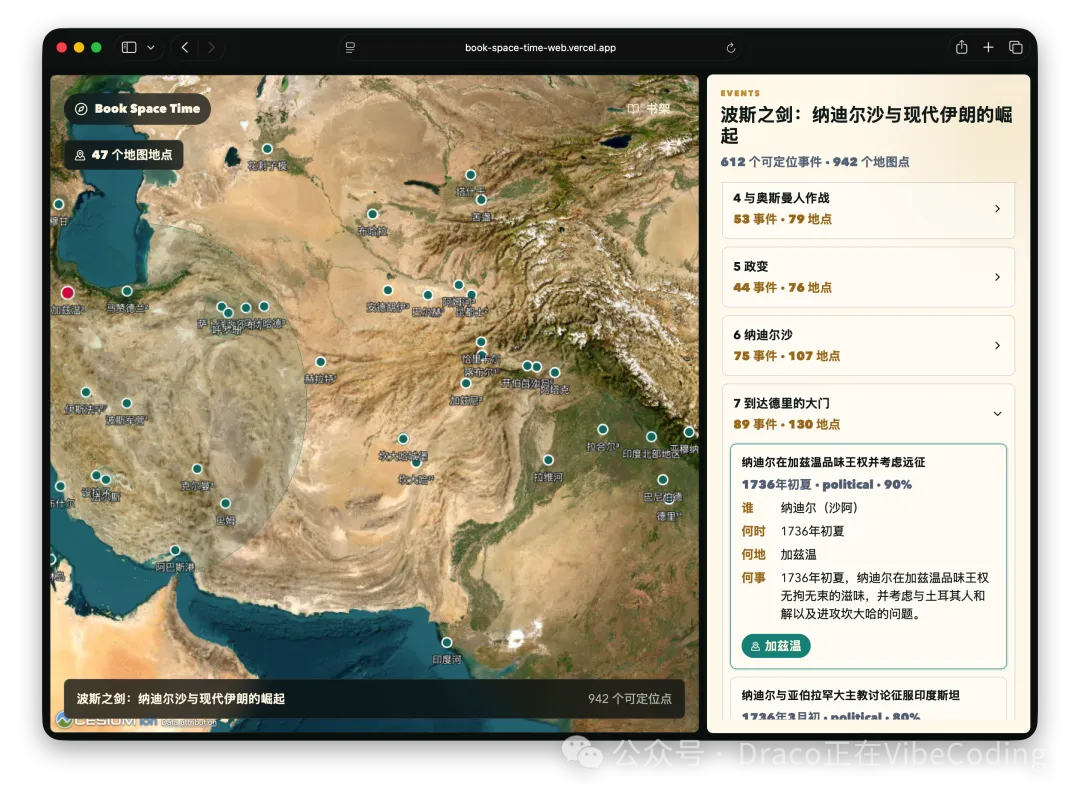
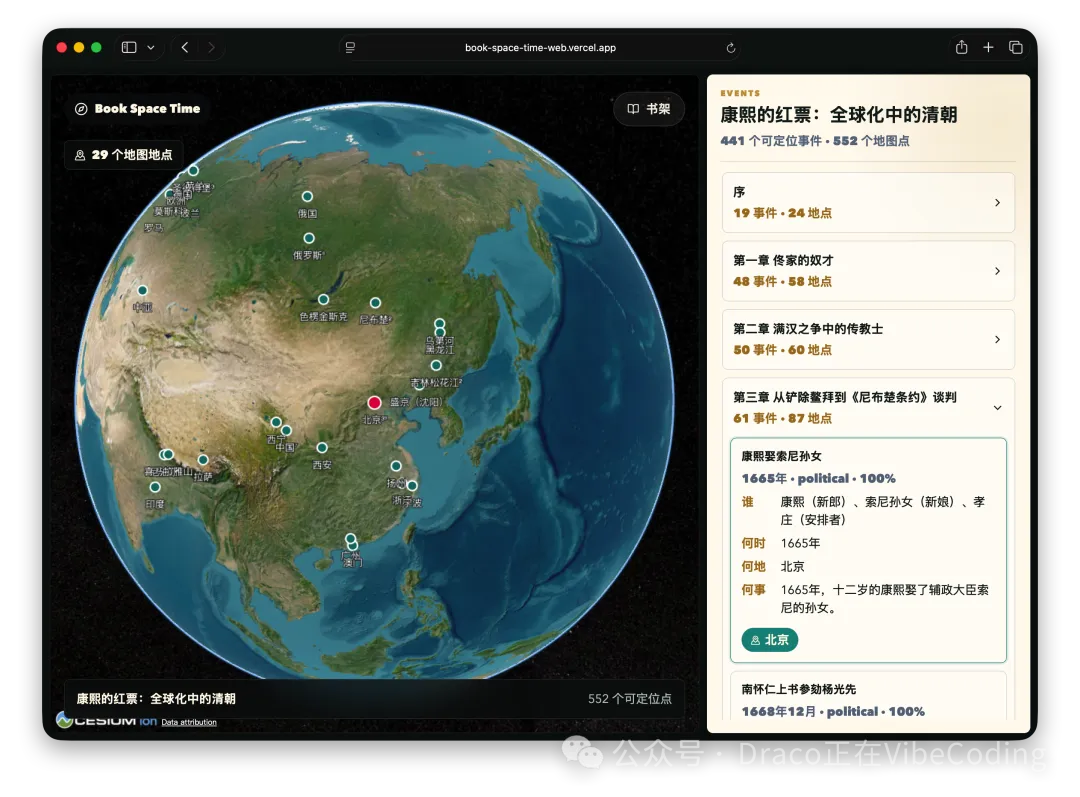
- 作者開發咗Book: Space & Time,將書中地名標註喺3D地球儀,大幅提升歷史閲讀體驗。
- AI繪畫比文字更能高效傳遞信息,因為人腦處理圖像嘅比特率遠高於文字。
- AI繪畫嘅難點係「概念封裝」,要用準確詞彙描述意象,需要刻意練習積累詞彙。
- 建議從而家開始學AI繪畫,為多模態時代攢基本功,呢個係未來十年嘅船票。
Book: Space & Time
將書中地名標註喺Cesium 3D地球儀上嘅應用,適合歷史書籍閲讀。需DeepSeek API KEY。
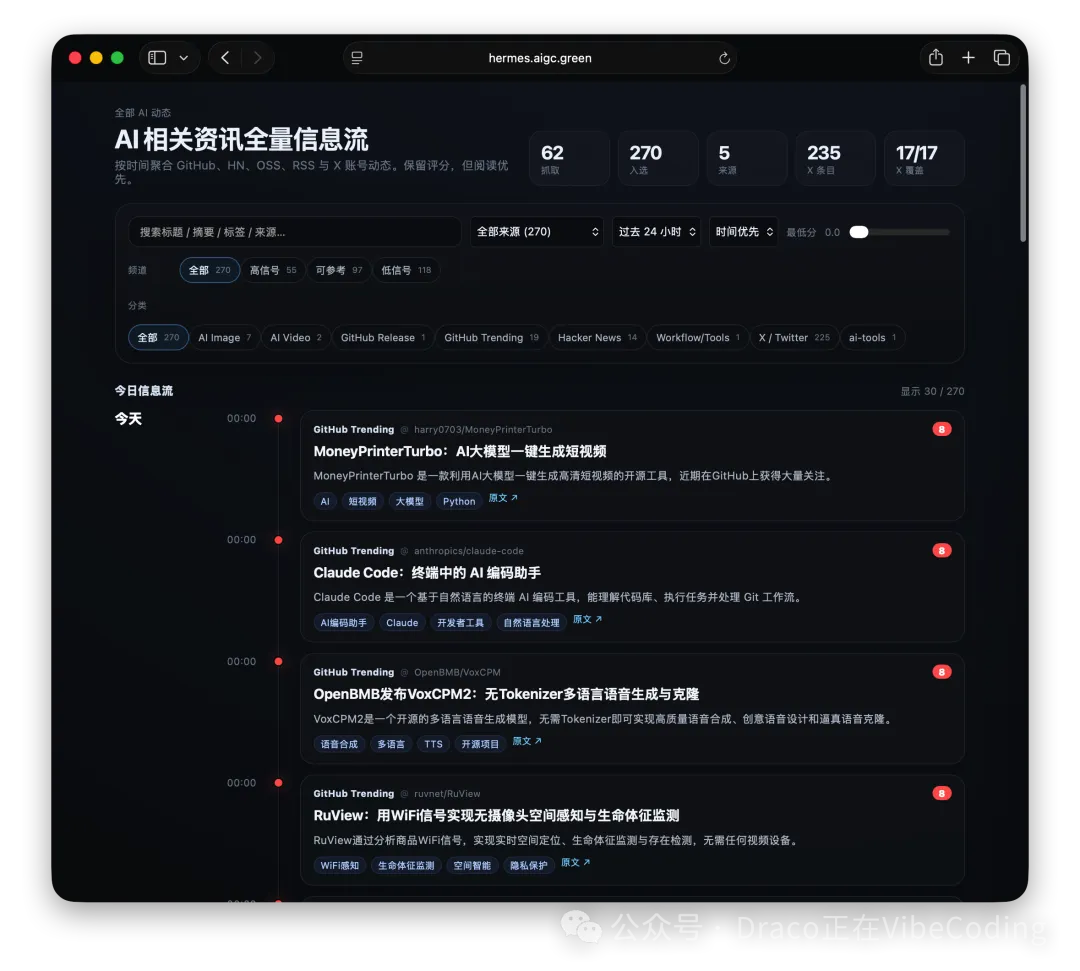
AI信源集合站
基於Horizon開源項目構建嘅AI新聞信息源集合站。
告別Agent,回歸創意
作者成日被問點解最近少咗寫Agent,原因好簡單:Agent能力已經足夠強,已經過咗「人等Agent」嗰條金線,而家係Agent等緊你,瓶頸明顯係你自己。
無論係複雜Coding用Codex,定係遠程嘴控用Hermes,定係本地知識庫用Obsidian,Agent真係夠用。唔好再折騰五花八門嘅Agent,關鍵係你諗住用Agent嚟build啲乜。
五月Build咗嘅項目
呢個月作者爆肝咗幾個項目,最自豪嘅係Book: Space & Time,將書入面嘅地名同事件標註喺Cesium 3D地球儀,睇歷史書嗰時山川河流一目瞭然,真係大殺器。
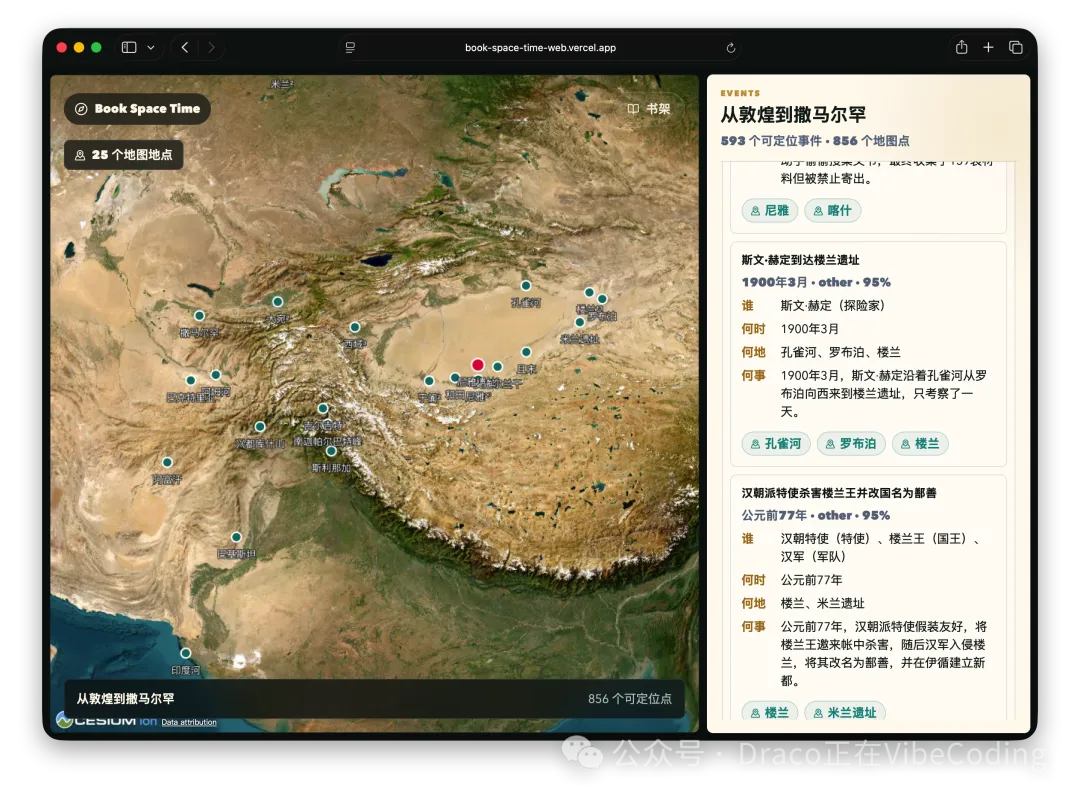
- Book: Space & Time - 將書本內容自動化為3D地圖,仲有《從敦煌到撒馬爾罕》等案例。
- AI信源集合站 - 基於Horizon項目整理AI新聞同Agent資訊。
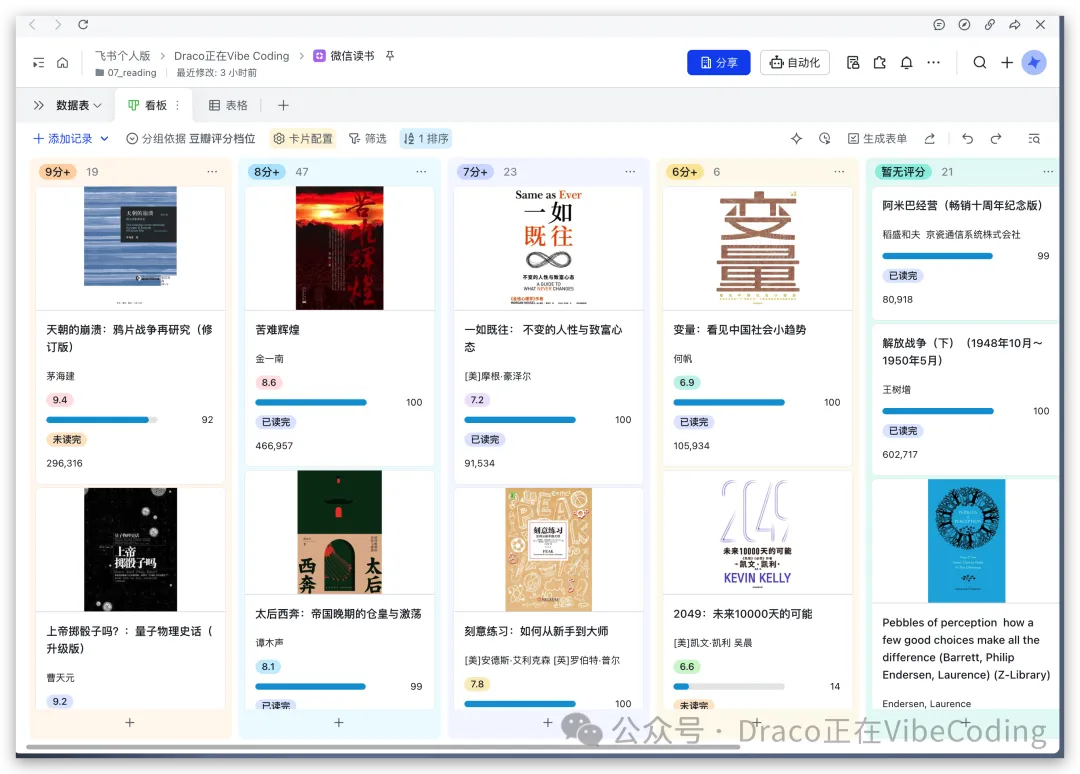
- 微信讀書個人看板 - 整合微信讀書進度同豆瓣評分。
- AI短劇Skill開源 - 用GPT-Image-2 + SeeDance2.0整AI短劇,但成本仍然好高。
- AI繪畫系列 - 爆肝1112張圖,推出咗人物繪畫手冊同動漫風百科。
其中AI繪畫係作者呢個月嘅重心,佢強調使用GPT-Image-2需要思維模式轉變,要構造Meta-Prompt模板,仲整咗Graphics Academy。
點解轉向AI繪畫?
其實唔係「轉向」,而係「回到」。作者2023年已經為Stable Diffusion裝備咗3090,一年畫咗幾萬張圖。最近HTML vs Markdown之爭揭露咗一個本質:人終究係多模態生物,睇得圖就唔想淨係睇字。
人腦處理文字嘅比特率太慢,但圖像一眼掃過去就接收咗上億像素。既然圖片生成嘅速度、質量、成本都夠好,點解唔直接用圖片?作者直覺未來社會可能只需要1%甚至0.1%人處理第一、第二產業,其餘都係服務業同泛娛樂業,學習本身都應該娛樂化。
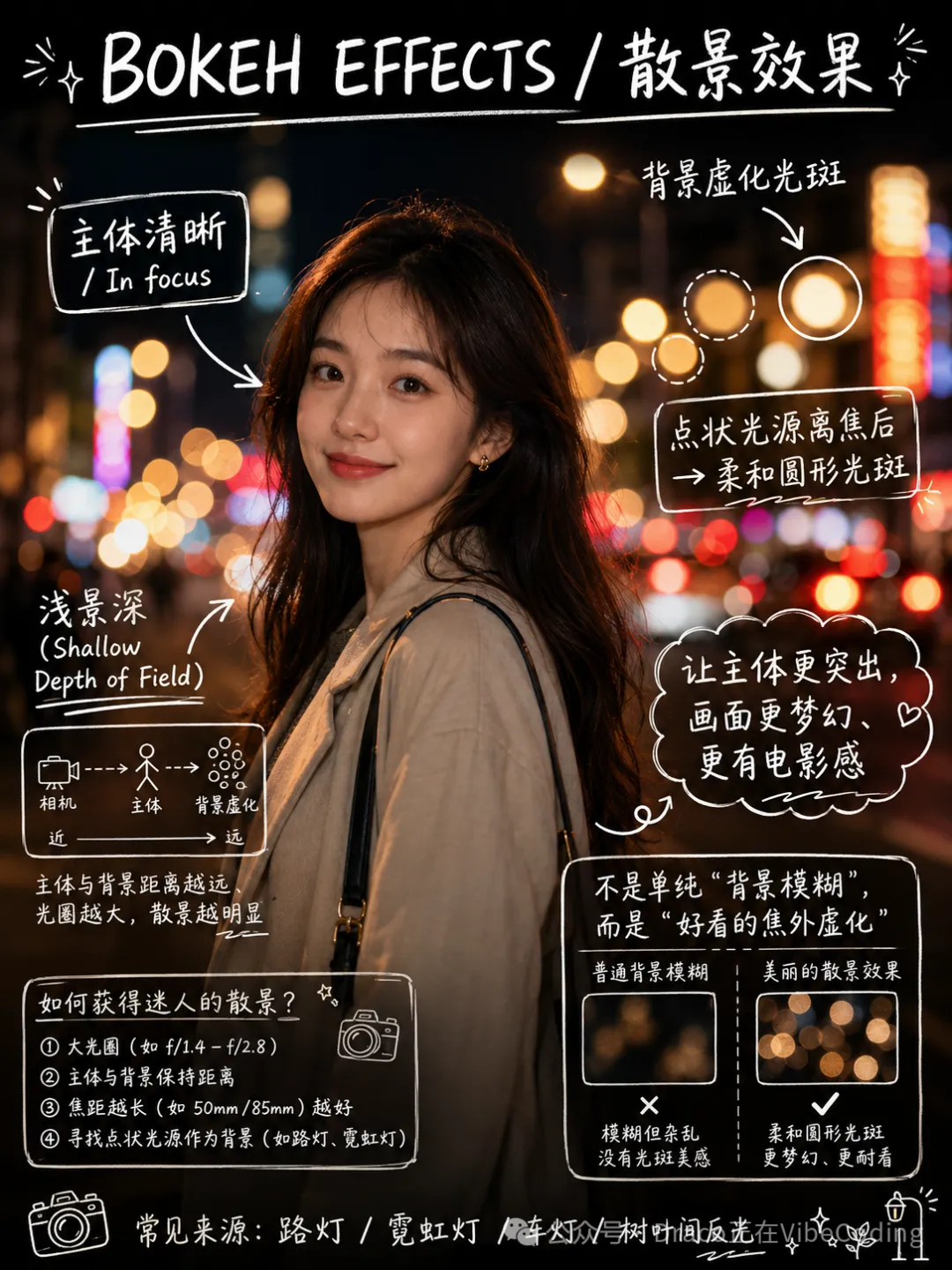
佢舉咗個例:研究AI繪畫關鍵詞時遇到bokeh effects,Agent直接生成圖解,將成個概念拍咗上塊面,呢啲邊係學習定娛樂?總之,能用多模態嘅就唔好用文字,而家視頻成本高,圖片就係最好平衡點。
AI繪畫嘅難點係「概念封裝」。要將腦中意象用準確詞彙表達,否則AI唔明你想畫乜。普通人詞彙貧乏,連風格、構圖、服飾都講唔出。作者爆肝咗關鍵詞百科,經過刻意練習,而家已經可以拆解甚至描述睇到嘅圖片。
呢個年代要點樣分配知識?
作者提出一個重要問題:邊啲know-how可以交畀Agent,邊啲必須留喺自己大腦?佢認為最少AI繪畫能力必須自己掌握,因為你唔可以同Agent講「我要一張好靚嘅圖」,搞笑。
所以佢呼籲大家從而家開始下功夫,積累詞彙,咁樣先可以喺下個多模態十年拎到船票。呢篇文本身冇靚排版,但內容絕對值得你一讀再讀。
呢篇文章冇好似平時咁喺飛書度寫好然後用skill自動渲染推送去公眾號草稿箱,而係直接喺公眾號後台寫同發佈,所以冇乜靚排版。


這篇文章沒有像往常一樣先在飛書上寫好然後用skill自動渲染並推送到公眾號草稿箱,而是直接在公眾號後台撰寫和發佈,因此沒有什麼好看的排版。