AI視頻工具悄悄走到了第三階段
整理版優先睇
AI視頻工具進化到第三階段:畫布原生Agent,由RHTV示範透明協作同生態賦能
呢篇文章係由一位長期關注AI視頻工具嘅創作者所寫。佢觀察到過去兩年AI視頻工具經歷咗三個階段:第一代係文生視頻盲盒,完全不可控;第二代加入咗Agent,但Agent只係懸浮喺畫布外嘅插件,體驗撕裂;而家第三代以RHTV為代表,進入「畫布原生Agent」時代——Agent就係畫布本身嘅大腦,同用家一齊睇住同一張畫布,每一步決策都透明可改。
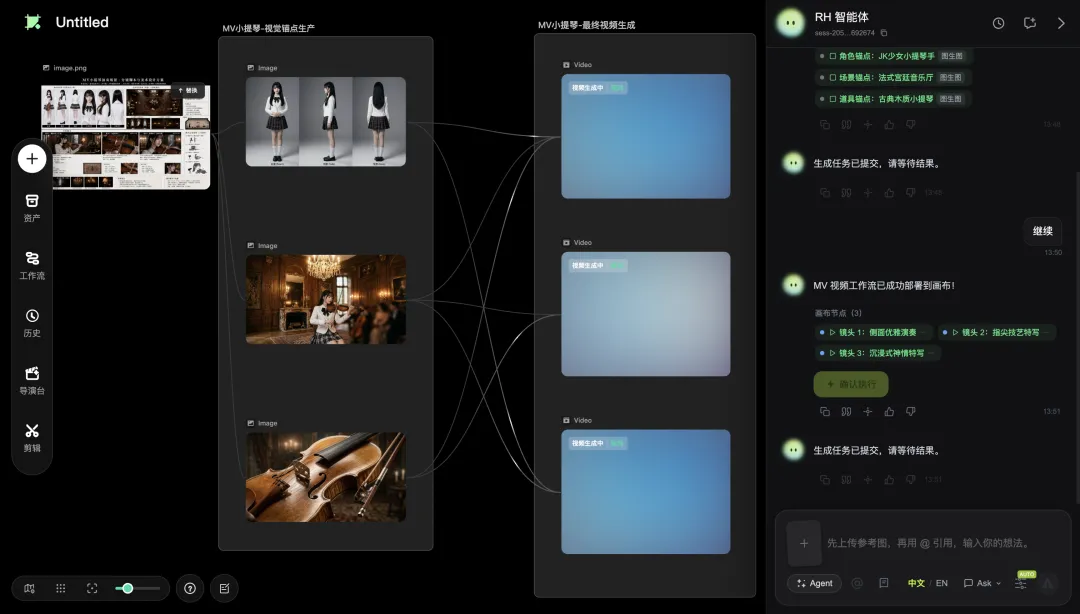
作者用RHTV實際做咗一個MV項目,將一張包含角色、場景、分鏡、燈光嘅高密度參考板直接掟入畫布,講一句「按呢張分鏡板生成MV,3個鏡頭」,Agent就自動識別、拆解、建工作流,仲調用Seedance 2.0生成三個鏡頭。成個過程唔使寫prompt、唔使摳圖、唔使切畫面,最關鍵係Agent嘅思考過程全部攤開畀用家睇,每個節點都可以獨立修改,解決咗AI創作一直以嚟「不可控」嘅痛點。
結論係:畫布原生Agent唔單止係功能升級,更係範式轉變——將人同AI嘅關係從「使喚AI」變成「一齊諗」。而且RHTV嘅能力天花板由RunningHub呢個開源生態決定,全球社區每日貢獻新節點同工作流,封閉系統根本追唔上。作者認為未來一年AI視頻工具嘅競爭會圍繞三條線展開:係咪畫布原生、係咪透明化、係咪站喺開源生態之上。
- AI視頻工具已進入第三階段「畫布原生Agent」,Agent同畫布融為一體,唔再係外掛插件。
- RHTV示範咗點樣由一張高密度參考板一句話生成MV:Agent自動識別、拆解、建工作流、調度模型。
- 呢一代最大差異係透明化——Agent嘅決策過程(理解、規劃、生成提示詞、組裝節點)全部可見可改,解決「不可控」問題。
- 產品能力上限應該由生態(開源社區)決定,而唔係產品團隊;RunningHub嘅10萬+應用同13681個節點令RHTV持續進化。
- 創作者應嘗試「畫布原生」工具,體驗AI做搭檔而唔係黑盒;未來競爭關鍵係透明度同生態整合度。
RHTV
畫布原生AI視頻工具,Agent內建於畫布,支援透明協作同生態擴展。
RunningHub
國內最大AI內容創作者共創平台,沉澱10萬+社區應用、13681個節點、170+標準模型API,為RHTV提供生態能力。
AI視頻工具嘅三階段演化
呢兩年我睇咗一堆號稱要顛覆AI視頻嘅新產品,慢慢睇出一個規律。第一代係文生視頻盲盒:你一句話掟入去,等幾分鐘,開出乜嘢算乜嘢,唔滿意只能重新投幣。呢個階段最大問題係不可控——想換一個鏡頭就要成條片重做,根本冇局部修改嘅概念。
第二代多咗個Agent入口,可以用對話方式調度,但Agent只係懸浮喺畫布外嘅「插件」,對話歸對話,畫布歸畫布。你喺畫布精雕細琢一個分鏡,想揾AI幫手,要切到對話框由頭解釋,因為Agent唔知你畫布嘅上下文,每次都要由頭講起。呢種「雙入口模式」本質上 Agent 係個外接傳話筒,唔係真正嘅搭檔。
第三階段終於出現——畫布原生Agent,以RHTV為代表。Agent就喺畫布裏面,左下角一個掣就喚起。你揀中一個素材或者節點,直接對智能體講「將呢個調暗啲」,佢知道你講嘅「呢個」係乜,因為佢同你睇緊同一張畫布。呢三個階段,本質上係三種「人同AI嘅關係」:第一階段係使喚AI,第二階段係協助AI,第三階段先係同AI一齊諗。
畫布原生嘅力量:由一張參考板到一支MV
我用RHTV跑咗一個真實嘅MV項目,用GPT-Image-2生成咗一張「MV小提琴演奏場景·分鏡腳本與美術設計方案」綜合參考板,一張圖包含角色6視角圖、場景平面立面剖面圖、3個分鏡方案、4種燈光參考同色調推薦。文生圖模型走到今日,一張圖就可以將一支MV嘅前期規劃全部做完,但跟住問題嚟:點樣將呢張高密度板變成可執行嘅視頻?
傳統玩法要手動拆解(角色圖、場景圖、分鏡文字逐個處理)或者成張板直接丟俾模型(結果識別混亂),兩條路都又慢又唔可控。我決定用RHTV嘅方式:將成張參考板掟入畫布,對RH智能體講一句「按呢張分鏡板生成MV,3個鏡頭」。然後我坐喺度,睇住佢點做。
智能體第一件事係識別:佢喺對話面板逐條標記出參考板嘅核心元素——角色(JK制服小提琴少女)、場景(法式宮廷)、道具(小提琴)。關鍵唔係佢「識別啱」,而係佢將識別過程暴露畀我睇,我可以確認冇錯先繼續。確認完之後,佢自動喺畫布拉出兩組節點:一組叫「MV小提琴-視覺資產生產」(3個image節點:拆解、角色生成、場景生成),另一組叫「MV小提琴-最終視頻生成」(3個video節點對應3個鏡頭),仲自動配置好參考關係。
我喺呢個流程入面完全冇掂過prompt、冇自己摳過圖、冇切換過界面。想做調整?換衫只改character節點,換燈光只改lighting節點,調某個鏡頭運鏡只改對應video節點,下游會自動適配,唔使重跑成條鏈路。呢種「可改」嘅能力對專業創作者尤其重要,因為廣告片、品牌片、短劇幾乎唔可能一次成型,每次迭代都要重新跑成條流程嘅話,AI唔係幫你創作,係浪費你時間。
生態賦能同Seedance 2.0嘅特殊化處理
點解係RHTV做出畫布原生Agent而唔係其他家?答案係生態。AI視頻工具嘅核心矛盾係用戶需求邊界不斷擴展,但單個產品團隊開發能力有限。RHTV企喺RunningHub生態之上——呢個平台有國內規模最大嘅ComfyUI創作者,沉澱咗10萬+社區應用、13681個可用節點、170+標準模型API。每日全球開源社區貢獻嘅新節點、工作流、模型,都會自動納入RHTV能力矩陣。
呢種模式令產品能力上限由全球開源社區決定,而唔係產品團隊。短期封閉系統可能靠精打磨嘅官方能力贏用戶,但長期嚟講,五萬+工作流複用、十大萬+應用可調用、五大模態覆蓋,呢種規模單個團隊追唔上。RHTV嘅智能體能力唔會過時,因為能力天花板由社區決定。呢個係一個關於長期主義嘅產品判斷。
具體到Seedance 2.0呢個模型——字節嘅「導演之選」,支援@參考、首尾幀、真人參考視頻驅動動作。喺大多數平台只係「接入」咗,調用基礎、排隊長、畫質有限。但RHTV對佢做咗增強式接入:唔使排隊、速度快、支援4K同真人生成,年度會員折算約六折。更重要係,RHTV將Seedance 2.0嘅全部能力以節點參數形式開放——模型版本、解像度、時長、寬高比、參考模式、Seed細節全部可見可改。優秀嘅AI工具平台唔係做加法(接入更多模型),而係做乘法(令最好嘅模型喺你平台上用得最好)。
收尾:新範式——同AI一齊諗
返到開頭個判斷:AI視頻工具走到第三階段。第一階段解決「AI能唔能夠做出視頻」,第二階段解決「用戶點樣調用AI」,第三階段開始解決「人同AI點樣一齊做事」。畫布原生Agent唔單止係功能升級,更係範式更新:將Agent由「畫布之外嘅服務」變成「畫布之內嘅大腦」,將AI創作由「開盲盒」變成「睇得見嘅協作」,將產品能力天花板由「團隊上限」變成「生態上限」。
我有個直覺:未來一年,AI視頻工具嘅競爭會沿住三條線展開——邊啲產品做畫布原生,邊啲仲停留喺雙入口;邊啲將Agent思考過程暴露喺外,邊啲仲收喺後端;邊啲企喺開源生態上,邊啲仲喺自研封閉體系度。呢三條線決定邊個會沉澱成新一代AI視頻工具嘅基礎設施,邊個只係過渡形態。
返去我支MV:由我將分鏡板掟入畫布、講一句話,到Agent自動拆解、配置參考、調度Seedance 2.0生成——成個過程我冇掂過prompt、冇自己摳過圖、冇切換過界面。我只係做咗兩件事:上傳一張參考板,講一句中文。呢種體驗對我嚟講好新。如果你都係創作者,建議你去自己跑一趟,睇下「Agent住喺畫布裏」係種點樣嘅體驗。
- 1 第一階段:盲盒式文生視頻,不可控,局部修改要全片重做。
- 2 第二階段:雙入口模式,Agent係外掛,唔知畫布上下文,協作撕裂。
- 3 第三階段:畫布原生Agent,Agent係畫布大腦,過程透明可改,由生態決定上限。
呢兩年我睇咗一大堆話要顛覆AI視頻嘅新產品。睇咗一排,我大概睇到一個規律。
第一代AI視頻工具,係文生視頻嘅盲盒。 一句嘢掉入去,等幾分鐘,開出嚟係乜就係乜,唔滿意嘅話唯有重新入錢。
第二代多咗個Agent入口,AI開始可以用對話方式調度。但Agent係浮喺產品外面嘅「插件」,對話還對話,畫布還畫布,AI喺另一個房幫你跑腿。
最近我用咗一個國產嘅畫布型AI視頻工具,叫RHTV。打開第一眼我就覺得,AI視頻工具可能靜靜雞步入第三階段喇。
呢一代嘅關鍵詞係「畫布原生」。Agent唔係浮喺畫布外面嘅服務,而係畫布本身嘅大腦。佢住喺你嘅工作流程入面,睇得到你每一步做緊乜,亦都俾你睇到佢每一步諗緊乜。
聽起身好似只係產品形態嘅少少調整,但用過之後我意識到,佢其實係重新定義「人同AI點樣一齊做嘢」呢件事。
一、AI視頻工具嘅三階段演化
將過去兩年嘅AI視頻工具按使用體驗排一排,可以好清楚見到三個階段。
第一階段,文生視頻盲盒。
你輸入一句嘢,等模型出片。成個過程係黑盒,AI點樣理解你嘅需求、點樣揀模型、點樣處理細節,全部喺後端,用戶睇唔到。結果唔滿意嘅話唯有重新生成,冇局部修改嘅概念。
呢個階段最大嘅問題唔係出唔出到好嘢,係不可控。 一條15秒嘅短片,你想換其中一個鏡頭,一定要將成條15秒重新做過。呢種「一鋪過定生死」嘅體驗,可以用嚟玩,但好難用嚟真正做嘢。
第二階段,雙入口模式。
產品意識到「全自動」嘅問題,於是引入咗Agent。但好多產品只係喺原本嘅畫布旁邊加咗一個「對話面板」:你同Agent傾偈,Agent幫你生成,結果再返去畫布。
睇起身「AI智能體」係有咗,但本質上Agent係個外掛插件。佢唔喺畫布入面,佢喺畫布旁邊。
呢個階段嘅體驗有種微妙嘅撕裂感。你喺畫布入面精雕細琢一個分鏡,想叫AI幫手優化,就要切去對話框,同Agent解釋你喺度做緊乜。AI唔知道你畫布入面嘅上文下理,每次都要由頭講起。Agent變咗個外接嘅傳話筒,唔係真正嘅拍檔。 第三階段,畫布原生Agent。
呢個就係RHTV做緊嘅嘢。Agent就喺畫布入面,左下角一個掣叫出嚟。你揀中一個素材或者節點,直接同RH智能體講「將呢個調暗啲」,佢知道你講嘅「呢個」係乜,因為佢同你睇緊同一張畫布。
更加關鍵嘅係,RH智能體唔係淨係負責執行。佢有自己完整嘅本地決策鏈:理解需求 → 規劃路徑 → 生成提示詞 → 組裝節點。每一步都可見,每一步都可以改。你見到嘅唔止係結果,而係佢點樣得出呢個結果。
呢三個階段,本質上係三種「人同AI嘅關係」。第一階段係「使喚AI」,第二階段係「協助AI」,第三階段先係「同AI一齊諗」 。
二、乜嘢係「畫布原生」
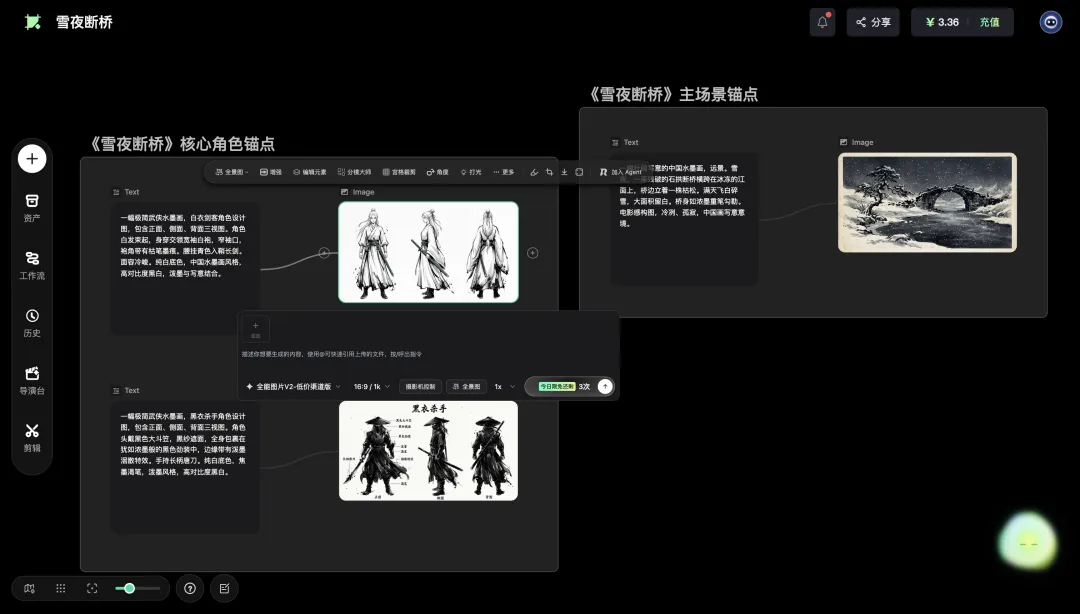
「畫布原生」呢個詞第一次出現嘅時候,我都唔係好明佢同「喺畫布加個AI掣」有咩分別。後尾喺RHTV度行咗一個真實嘅MV項目,我大概理清咗佢嘅樣。
先講背景。我用GPT-Image-2做咗一張「MV小提琴演奏場景·分鏡腳本與美術設計方案」嘅綜合參考板。一張圖入面,將呢支MV嘅前期工作幾乎做曬:角色6視角圖(JK制服小提琴少女)、法式宮廷場景嘅平面圖+立面圖+剖面圖、3個分鏡嘅方案(側面中景、小提琴特寫、斜側情緒特寫)、4種燈光參考、仲有色調推薦。

呢張圖本身都幾值得講嚇。文生圖模型去到今日,一張圖就可以將一支MV嘅前期規劃做曬。 導演腦裏面所有要諗嘅:人物、場景、鏡頭、運鏡、光線、色調,都可以叫AI一次性鋪曬出嚟。
但問題隨之而來:前期規劃完成度高咗,但下一步點行?
按傳統玩法,我有兩個選項。
選項一係手動拆解:將參考板裏面嘅角色圖摳出嚟作為@參考,將場景圖摳出嚟作為另一組@參考,將分鏡文字複製成prompt,再分3次手動調度Seedance 2.0。呢個流程行落嚟,淨係準備工夫就夠你搞大半日,每改一處又要重新嚟過。
選項二係直接將成塊參考板掉俾Seedance 2.0:佢會將呢塊密密麻麻嘅板當成「一張包含人物+場景+小圖+文字框嘅圖」整體識別。結果就係穩定性差、可控性差、可拓展性差,輸出基本上係不可用。
即係話,當文生圖將「諗清楚」呢件事壓縮到幾分鐘,AI視頻領域反而出現咗一個新嘅工具空缺:有冇一個工具,睇得明呢張參考板,可以將佢結構化拆解,可以將每個分鏡變成畫布上可調度嘅節點?
呢個就係我講嘅「畫布原生Agent」要解決嘅問題之一。佢唔止係型,亦真係有能力去適配最新一代具有agent思維嘅圖像生成模型掟出嚟嘅高密度規劃素材。
我決定換個玩法:將整塊參考板掉俾RHTV嘅畫布,對RH智能體講一句嘢:
「按呢張分鏡板生成MV,3個鏡頭」。
然後我就坐喺度唔鬱。
RH智能體接到指令之後,冇好似傳統模型咁直接埋頭開生成。佢先做咗一件事:識別。
佢喺畫布嘅對話面板入面,將呢張參考板嘅核心元素逐條標記出嚟:
角色:JK制服小提琴少女 場景:法式宮廷 道具:小提琴
呢個動作嘅關鍵唔係佢「識別啱咗」,而係佢將識別過程暴露俾我睇。我可以睇到RH智能體對呢張參考板嘅全部解讀,確認冇錯先至等佢繼續。如果佢將JK制服理解成和服,我喺呢一步就可以叫停佢,唔使等10分鐘之後見到一團離譜嘅成品先嚟後悔。
我一直覺得,能夠睇到AI諗緊乜,係判斷一個AI產品係工具定係拍檔嘅分水嶺。 工具只對結果負責,拍檔要對過程透明。
三、透明嘅力量
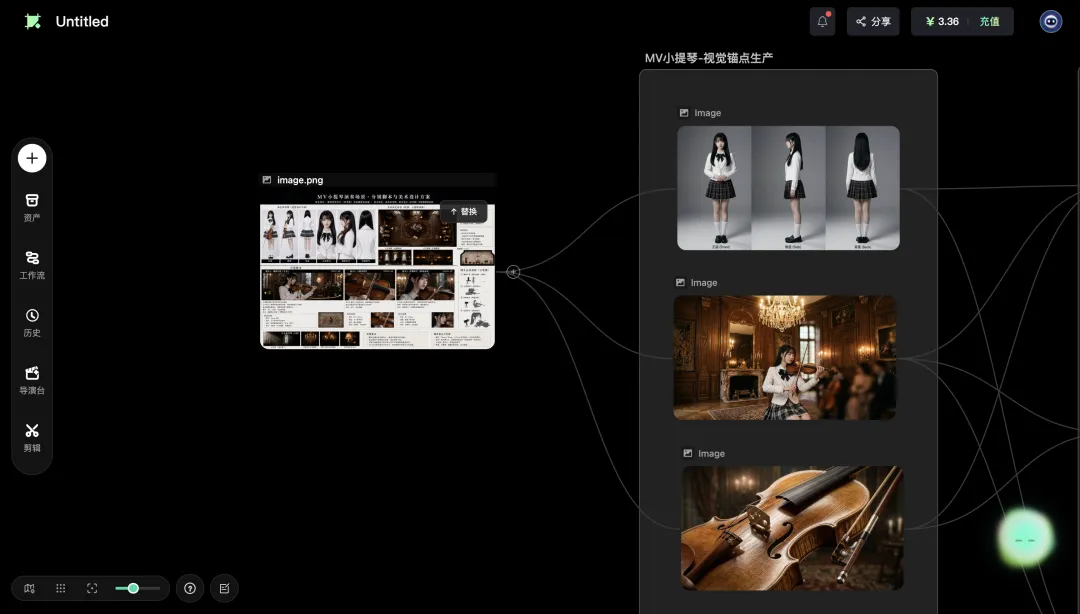
確認完元素,RH智能體開始自己建立工作流。
佢喺畫布上拉出咗兩組節點:
第一組叫「MV小提琴-視覺資產生產」,入面係3個image節點,分別負責參考板拆解、角色生成、場景生成。
第二組叫「MV小提琴-最終視頻生成」,入面係3個video節點,對應分鏡板裏面嘅3個鏡頭:
鏡頭1:側面優雅演奏 鏡頭2:指尖技藝特寫 鏡頭3:沉浸式神情特寫
更加令我意外嘅係,RH智能體仲將節點之間嘅參考關係都自動配置好曬。邊個視頻鏡頭用邊張圖做參考、參考嘅優先級係乜,全部攤開喺對話面板度。
呢個係傳統Agent模式做唔到嘅嘢。佢哋嘅輸出係個「黑盒視頻」,佢知道自己點做,但唔會話你知。RHTV嘅智能體係將佢成個工作思路攤開成畫布上一張可視化嘅圖,邊個節點做乜、連俾邊個,一目瞭然。
AI創作呢兩年最大嘅痛點,其實唔係模型唔夠勁,係不可控。
你可能聽過太多創作者抱怨:「呢個鏡頭明明得一個細節唔滿意,點解要重新做整條片?」呢個痛點嘅根源就係黑盒。第一代同第二代AI視頻工具,將創作過程鎖喺後端。你輸入prompt,等結果,唔滿意再改prompt,再等結果。成個反饋循環入面,你永遠唔知AI到底係點樣處理你嘅話。
畫布原生Agent真正值錢嘅,可能唔係佢會自動搭工作流,而係佢將成個工作流程攤開俾你睇。
每個節點都帶住明確嘅語義角色,每條連線背後都有可解釋嘅參考關係。我想喺邊個環節插手就喺邊個環節插手:換衫只改character節點,換燈光只改lighting節點,調某個鏡頭嘅運鏡只改對應嘅video節點,下游會自動適配,唔使重新行成條鏈路。
呢一點對專業創作者特別重要。輕度玩家要嘅係「一鍵出片」,專業創作者要嘅係「可改」。 一段廣告片、一段品牌視頻、一支短劇,幾乎冇可能一次成型,一定係要來回修改。如果每次修改都要重新行成條流程,咁AI唔係幫你創作,係浪費你時間。
四、能力上限嘅賭注
講到呢度要答一個問題:點解係RHTV做出咗「畫布原生Agent」,而唔係其他公司?
我覺得答案喺生態。
AI視頻工具嘅核心矛盾,係用戶嘅需求邊界永遠喺度擴張,而單一產品團隊嘅開發能力係有限嘅。今日用戶要漫劇,聽日要TVC,後日要MV,再後日要新嘅視覺風格。每一個新需求,封閉系統都要自己開發模型、調試節點、上線功能。
呢種模式有個天然嘅天花板:產品能力嘅上限就係產品團隊嘅上限。
RHTV嘅解法係企喺Runninghub生態之上。RunningHub係而家國內最活躍嘅AI內容創作者共創嘅圖像音視頻內容平台,有國內規模最大嘅ComfyUI創作者,沉澱咗10萬+社區AI應用、13681個可用節點、170+標準模型API。每日全球開源社區貢獻嘅新節點、新工作流、新模型,都會自動納入RHTV嘅能力矩陣。
呢個唔係「接入咗開源」咁簡單,而係「產品嘅能力上限由全球開源社區決定」。每日都有開發者貢獻新嘅節點、新嘅工作流、新嘅插件,呢啲全部會自動出現喺RHTV用戶嘅能力面板度。
封閉系統同全球社區鬥快,結果其實係註定嘅。
短期睇,封閉系統可能可以透過精雕細琢嘅官方能力贏得用戶。但長期睇,5萬+工作流嘅重用、10萬+應用嘅可調用、五大模態全覆蓋(圖像、視頻、音頻、3D、文本),呢種規模一旦展開,單一團隊係追唔上嘅。
RHTV嘅智能體能力唔會過時,因為佢嘅能力天花板由社區決定,唔由產品團隊決定。呢個係一個關於長期主義嘅產品判斷。
五、Seedance 2.0嘅特殊化處理
講完範式同生態,再講一個具體嘅、近半年內創作者最關心嘅話題:Seedance 2.0。
字節呢一代視頻模型,業內已經叫佢做「導演之選」。佢支援@參考、首尾幀、上傳真人參考視頻驅動動作。呢啲能力令佢喺動作戲、複雜運鏡、人物表演等場景成為第一梯隊。
但Seedance 2.0呢種頂級模型,有個普遍問題:喺大多數平台上,佢就係被「接入」咗。你可以調用佢,但調得好基本,等嘅時間長、畫質有限、玩法受限。
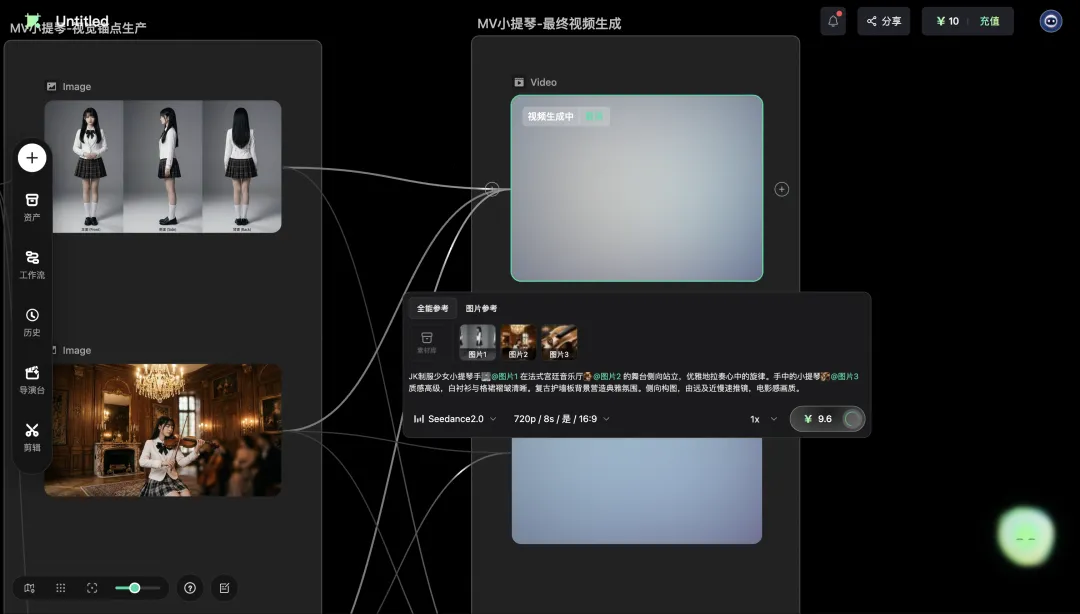
返番去我啱啱嗰支小提琴MV。Agent建立好工作流之後,我㩒咗「確認執行」,Seedance 2.0就接管咗視頻生成。
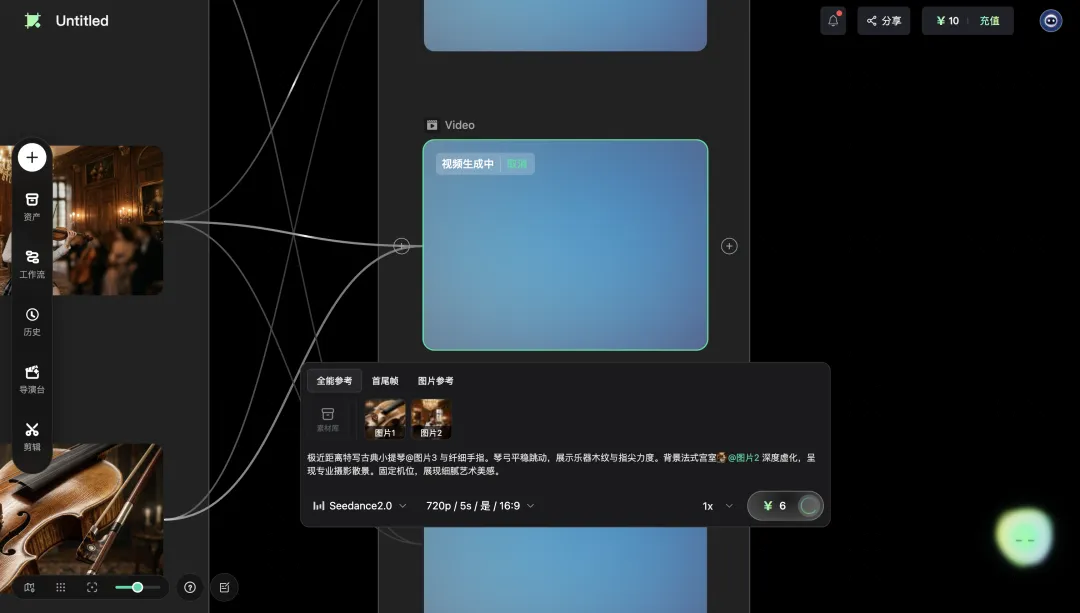
配置面板上可以睇到模型版本(Seedance 2.0)、解像度(720p)、時長(5秒/幀)、闊高比(16:9),仲有「全部參考 / 首尾幀 / 圖片參考」三種參考模式嘅切換,連Seed呢啲細節參數都可以睇。呢啲嘢全部暴露俾用戶,每一個我都可以睇到、可以改、可以針對單個鏡頭微調。
行完之後,第一個鏡頭出咗嚟:一個JK制服嘅少女喺法式宮廷宴會廳度演奏小提琴。水晶吊燈嘅光喺佢身上散開,木地板嘅反光、牆身嘅雕花、遠處濛濛嘅燭台全部都有。少女演奏嘅姿態自然,冇早期AI視頻嗰種「融化感」,運鏡平穩。
呢個係我對Seedance 2.0最新嘅印象更新。RHTV對佢嘅處理方式叫「增強式接入」:唔使排隊、速度快、支援4K同真人生成,年度會員折算落嚟等於六折用。
但我覺得最值得講嘅,仲唔係價錢同速度,而係RHTV將Seedance 2.0嘅全部能力以節點參數嘅形式開放俾用戶。你唔只係用一個模型,你係調度一個模型。
優秀嘅AI工具平台同普通嘅「模型接入商」嘅分別,就係在於對核心模型嘅特殊化處理。 唔係做加法(接入更多模型),而係做乘法(令最好嘅模型喺你嘅平台上用得最好)。
收尾·新範式
返番去開頭嗰個判斷:AI視頻工具行到咗第三階段。
第一階段解決「AI得唔得做出視頻」,第二階段解決「用戶點樣調用AI」,第三階段開始解決「人同AI點樣一齊做嘢」。
畫布原生Agent唔止係功能升級,更加似範式更新。 佢將Agent由「畫布外面嘅服務」變成「畫布入面嘅大腦」,將AI創作由「開盲盒」變成「睇得見嘅協作」,將產品嘅能力天花板由「團隊上限」變成「生態上限」。
我有個直覺:未來一年,AI視頻工具嘅競爭會沿住呢三條線展開。邊啲產品做畫布原生,邊啲仍然停留喺雙入口;邊啲將Agent嘅思考過程暴露出嚟,邊啲仲收埋喺後端;邊啲企喺開源生態之上,邊啲仲喺自研封閉體系入面。
呢三條線決定咗,邊個會沉澱成呢一代AI視頻工具嘅基礎設施,邊個只係過渡形態。
返番去我嗰支MV:由我將分鏡板掉入畫布、講一句嘢,到Agent自動拆解、配置參考、調度Seedance 2.0生成——成個過程我冇掂過prompt,冇自己摳過圖,冇切換過界面。我做嘅嘢得兩樣:上傳一張參考板、講一句中文。
呢種體驗對我嚟講都幾新鮮。佢同我以前用過嘅所有AI視頻工具,的確有啲唔同。
如果你都係創作者,建議你親自去行一次,體驗嚇「Agent住喺畫布入面」係咩感覺。
RHTV.ai
這兩年我看了一堆號稱要顛覆AI視頻的新產品。看了一陣子,我大概看出了一個規律。
第一代AI視頻工具,是文生視頻的盲盒。 一句話扔進去,等幾分鐘,開出來什麼算什麼,不滿意只能重新投幣。
第二代多了個Agent入口,AI開始能用對話方式調度。但Agent是懸浮在產品之外的「插件」,對話歸對話,畫布歸畫布,AI在另一個房間幫你跑腿。
最近我用了一個國產的畫布型AI視頻工具,叫RHTV。打開第一眼我就感覺,AI視頻工具可能在悄悄進第三階段了。
這一代的關鍵詞是「畫布原生」。Agent不是懸浮在畫布之外的服務,而是畫布本身的大腦。它住在你的工作流裏,看得見你每一步在做什麼,也讓你看得見它每一步在想什麼。
聽起來好像只是產品形態的小調整,但用過之後我意識到,它其實在重新定義「人和AI怎麼一起做事」這件事。
一、AI視頻工具的三階段演化
把過去兩年的AI視頻工具按使用體驗排一下,能很清晰地看到三個階段。
第一階段,文生視頻盲盒。
你輸入一句話,等模型出片。整個過程是黑盒,AI怎麼理解你的需求、怎麼選模型、怎麼處理細節,全在後端,用戶看不到。結果不滿意只能重新生成,沒有局部修改的概念。
這個階段最大的問題不是出不出好東西,是不可控。 一支15秒的短片,你想換其中一個鏡頭,必須把整個15秒重做。這種「一擲定乾坤」的體驗,能用來玩,但很難拿來真正幹活。
第二階段,雙入口模式。
產品意識到了「全自動」的問題,於是引入了Agent。但很多產品只是在原有的畫布旁邊加了一個「對話面板」:你跟Agent聊天,Agent幫你生成,結果再回到畫布。
看起來「AI智能體」是有了,但本質上Agent是個外掛插件。它不在畫布裏,它在畫布旁邊。
這個階段的體驗有種微妙的撕裂感。你在畫布裏精雕細琢一個分鏡,想讓AI幫忙優化,得切到對話框,跟Agent解釋你在做什麼。AI不知道你畫布裏的上下文,每次都得從頭說起。Agent成了一個外接的傳話筒,不是真正的搭檔。 第三階段,畫布原生Agent。
這就是RHTV在做的事。Agent就在畫布裏,左下角一個按鈕喚起。你選中一個素材或節點,直接對RH智能體說「把這個調暗一點」,它知道你說的「這個」是什麼,因為它和你看的是同一張畫布。
更關鍵的是,RH智能體不是隻負責執行。它有自己完整的本地決策鏈:理解需求 → 規劃路徑 → 生成提示詞 → 組裝節點。每一步都可見,每一步都可改。你看到的不只是結果,是它怎麼得出這個結果的。
這三個階段,本質上是三種「人和AI的關係」。第一階段是「使喚AI」,第二階段是「協助AI」,第三階段才是「和AI一起想」。
二、什麼是「畫布原生」
「畫布原生」這個詞第一次出現的時候,我也沒太懂它和「在畫布里加個AI按鈕」有什麼區別。後來在RHTV裏跑了一個真實的MV項目,我大概理清了它的樣子。
先說背景。我用GPT-Image-2做了一張「MV小提琴演奏場景·分鏡腳本與美術設計方案」的綜合參考板。一張圖裏,把這支MV的前期工作幾乎全做完了:角色6視角圖(JK制服小提琴少女)、法式宮廷場景的平面圖+立面圖+剖面圖、3個分鏡的方案(側面中景、小提琴特寫、斜側情緒特寫)、4種燈光參考、還有色調推薦。
這張圖本身就挺值得說一下。文生圖模型走到今天,一張圖就能把一支MV的前期規劃全做完。 導演腦子裏所有該想的:人物、場景、鏡頭、運鏡、光線、色調,都可以讓AI一次性鋪出來。
但問題隨之而來:前期規劃完成度變高了,可下一步怎麼走?
按傳統玩法,我有兩個選項。
選項一是手動拆解:把參考板裏的角色圖摳出來作為@參考,把場景圖摳出來作為另一組@參考,把分鏡文字複製成prompt,再分3次手動調度Seedance 2.0。這個流程下來,光準備工作就夠你折騰大半天,每改一處還得重來一遍。
選項二是直接把整張參考板丟給Seedance 2.0:它會把這張密密麻麻的板子當成「一張包含人物+場景+小圖+文字框的圖」整體識別。結果就是穩定性差、可控性差、可拓展性差,輸出基本是不可用的。
也就是說,當文生圖把「想清楚」這件事壓縮到幾分鐘,AI視頻領域反而出現了一個新的工具空缺:能不能有一個工具,看得懂這張參考板,能把它結構化拆解,能把每個分鏡變成畫布上可調度的節點?
這就是我說的「畫布原生Agent」要解決的問題之一。它不止是酷炫,也是真的有能力去適配是最新一代具有agent思維的圖像生成模型甩出來的高密度規劃素材。
我決定換個玩法:把整張參考板丟給RHTV的畫布,對RH智能體說一句話:
「按這張分鏡板生成MV,3個鏡頭」。
然後我就坐着不動了。
RH智能體接到指令之後,沒有像傳統模型那樣直接悶頭開生成。它先做了一件事:識別。
它在畫布的對話面板裏,把這張參考板的核心元素逐條標記出來:
角色:JK制服小提琴少女 場景:法式宮廷 道具:小提琴
這個動作的關鍵不是它「識別對了」,而是它把識別過程暴露給我看了。我能看到RH智能體對這張參考板的全部解讀,確認無誤後才讓它繼續。如果它把JK制服理解成了和服,我可以在這一步就攔住它,不會等10分鐘後看到一團離譜的成片再來反悔。
我一直覺得,能不能看見AI在想什麼,是判斷一個AI產品是工具還是搭檔的分水嶺。 工具只對結果負責,搭檔要對過程透明。
三、透明的力量
確認完元素,RH智能體開始自己建工作流。
它在畫布上拉出了兩組節點:
第一組叫「MV小提琴-視覺資產生產」,裏面是3個image節點,分別承擔參考板拆解、角色生成、場景生成。
第二組叫「MV小提琴-最終視頻生成」,裏面是3個video節點,對應分鏡板裏的3個鏡頭:
鏡頭1:側面優雅演奏 鏡頭2:指尖技藝特寫 鏡頭3:沉浸式神情特寫
更讓我意外的是,RH智能體還把節點之間的參考關係也自動配置好了。哪個視頻鏡頭用哪張圖做參考、參考的優先級是什麼,全部展開在對話面板裏。
這是傳統Agent模式做不到的事情。它們的輸出是個「黑盒視頻」,它知道自己怎麼做的,但不告訴你。RHTV的智能體是把它的整個工作思路展開成畫布上一張可視化的圖,哪個節點幹什麼、連給誰,一目瞭然。
AI創作這兩年最大的痛點,其實不是模型不夠強,是不可控。
你可能聽過太多創作者抱怨:「這個鏡頭明明只有一個細節不滿意,憑什麼要重做整支視頻?」這個痛點的根源就是黑盒。第一代和第二代AI視頻工具,把創作過程鎖在後端。你輸入prompt,等結果,不滿意再調prompt,再等結果。整個反饋循環裏,你永遠不知道AI到底是怎麼處理你的話的。
畫布原生Agent真正值錢的,可能不是它會自動搭工作流,而是它把整個工作流攤開給你看。
每個節點都帶着明確的語義角色,每條連線背後都有可解釋的參考關係。我想在哪個環節插手就在哪個環節插手:換衣服只改character節點,換燈光只改lighting節點,調某個鏡頭的運鏡只改對應的video節點,下游會自動適配,不用重跑整條鏈路。
這一點對專業創作者特別重要。輕度玩家要的是「一鍵出片」,專業創作者要的是「可改」。 一段廣告片、一段品牌視頻、一支短劇,幾乎不可能一次成型,必然要反覆迭代。如果每次迭代都意味着重新跑整條流程,那AI不是在幫你創作,是在浪費你的時間。
四、能力上限的賭注
聊到這裏要回答一個問題:為什麼是RHTV做出了「畫布原生Agent」,而不是其他家?
我覺得答案在生態。
AI視頻工具的核心矛盾,是用戶的需求邊界永遠在擴展,而單個產品團隊的開發能力是有限的。今天用戶要漫劇,明天要TVC,後天要MV,再後天要新的視覺風格。每一個新需求,封閉系統都得自己開發模型、調試節點、上線功能。
這種模式有個天然的天花板:產品能力的上限就是產品團隊的上限。
RHTV的解法是站在Runninghub生態之上。RunningHub是目前國內最活躍的AI內容創作者共創的圖像音視頻內容平台,有國內規模最大的ComfyUI創作者,沉澱了10萬+社區AI應用、13681個可用節點、170+標準模型API。每天全球開源社區貢獻的新節點、新工作流、新模型,都會自動納入RHTV的能力矩陣。
這不是「接入了開源」那麼簡單,是「產品的能力上限由全球開源社區決定」。每天都有開發者在貢獻新的節點、新的工作流、新的插件,這些都會自動出現在RHTV用戶的能力面板裏。
封閉系統在和全球社區賽跑,結果其實是註定的。
短期看,封閉系統可能能通過精打細磨的官方能力贏得用戶。但長期看,5萬+工作流的複用、10萬+應用的可調用、五大模態全覆蓋(圖像、視頻、音頻、3D、文本),這種規模一旦展開,單個團隊是追不上的。
RHTV的智能體能力不會過時,因為它的能力天花板由社區決定,不由產品團隊決定。這是一個關於長期主義的產品判斷。
五、Seedance 2.0的特殊化處理
講完範式和生態,再講一個具體的、最近半年內創作者最關心的話題:Seedance 2.0。
字節這一代視頻模型,業內已經在叫「導演之選」。它支持@參考、首尾幀、上傳真人蔘考視頻驅動動作。這些能力讓它在動作戲、複雜運鏡、人物表演等場景成了第一梯隊。
但Seedance 2.0這種頂級模型,有個普遍問題:在大多數平台上,它就是被「接入」了。你能調用它,但調得很基礎,等待時間長、畫質有限、玩法受限。
回到我剛才那支小提琴MV。Agent建好工作流之後,我點了「確認執行」,Seedance 2.0就接管了視頻生成。
配置面板上能看到模型版本(Seedance 2.0)、分辨率(720p)、時長(5秒/幀)、寬高比(16:9),還有「全部參考 / 首尾幀 / 圖片參考」三種參考模式的切換,連Seed這種細節參數都可以看。這些東西全部暴露給用戶,每一個我都能看到、能改、能針對單個鏡頭微調。
跑完之後,第一個鏡頭出來了:一個JK制服的少女在法式宮廷宴會廳裏演奏小提琴。水晶吊燈的光在她身上散開,木地板的反光、牆面的雕花、遠處虛化的燭台都在。少女演奏的姿態自然,沒有早期AI視頻裏那種「融化感」,運鏡平穩。
這是我對Seedance 2.0的最新印象更新。RHTV對它的處理方式叫「增強式接入」:不排隊、速度快、支持4K和真人生成,年度會員折算下來等於6折用。
但我覺得最值得說的,還不是價格和速度,而是RHTV把Seedance 2.0的全部能力以節點參數的形式開放給用戶。你不只是在用一個模型,你是在調度一個模型。
優秀的AI工具平台和普通的「模型接入商」的差別,就在於對核心模型的特殊化處理。 不是做加法(接入更多模型),而是做乘法(讓最好的模型在你的平台上用得最好)。
收尾·新範式
回到開頭那個判斷:AI視頻工具走到了第三階段。
第一階段解決「AI能不能做出視頻」,第二階段解決「用戶怎麼調用AI」,第三階段開始解決「人和AI怎麼一起做事」。
畫布原生Agent不只是功能升級,更像是範式更新。 它把Agent從「畫布之外的服務」變成「畫布之內的大腦」,把AI創作從「開盲盒」變成「看得見的協作」,把產品的能力天花板從「團隊上限」變成「生態上限」。
我有個直覺:未來一年,AI視頻工具的競爭會沿着這三條線展開。哪些產品在做畫布原生,哪些還停留在雙入口;哪些把Agent的思考過程暴露出來,哪些還藏在後端;哪些站在開源生態上,哪些還在自研封閉體系裏。
這三條線決定了,誰會沉澱成這一代AI視頻工具的基礎設施,誰只是過渡形態。
回到我那支MV:從我把分鏡板丟進畫布、說一句話,到Agent自動拆解、配置參考、調度Seedance 2.0生成——整個過程我沒碰過prompt,沒自己摳過圖,沒切換過界面。我做的事情只有兩件:上傳一張參考板、說一句中文。
這種體驗對我來說挺新的。它和我過去用過的所有AI視頻工具,確實不太一樣。
如果你也是創作者,建議你去自己跑一遍,看看「Agent住在畫布裏」是種什麼樣的體驗。
RHTV.ai