Anthropic 和 Perplexity 公開了內部 Skills 設計方法論:9 類分類、3 層成本、4 層 Eval
整理版優先睇
Anthropic同Perplexity分享Skills設計方法論:Context Engineering取代Prompt Engineering,三層成本模型同四層Eval確保質量
呢篇文章係術哥根據Anthropic同Perplexity嘅官方技術博客整理出嚟,講佢哋喺Agent Skills設計上嘅實戰方法論。作者想糾正一個常見誤解:Skills唔係prompt,亦唔係插件,而係Context Engineering(上下文工程)。整體結論係,要設計高質素Skills,需要掌握三層成本模型、Hub-and-Spoke目錄結構、Gotchas飛輪迭代同四層Eval評估體系。
Anthropic嘅Claude Code團隊工程師Thariq Shihipar同Perplexity Research團隊都指出,Skills係一個包含腳本、資源文件嘅文件夾,智能體可以發現同探索。佢哋嘅設計理念幾乎一致,只係面向場景唔同:一個係開發者工具擴展,一個係終端用戶Agent能力模塊。
兩家公司都強調,寫Skills時要避免一次過將所有信息塞入一個文件,而要用描述性語言寫觸發條件,而唔係功能說明。高質素Skill必須由人類基於實戰經驗編寫,再通過Eval持續驗證。呢套方法論對任何想建設Agent能力模塊嘅團隊都有參考價值。
- 結論:Skills係Context Engineering,核心係點樣組織上下文而唔係優化指令。
- 方法:採用三層成本模型(Index/Load/Runtime)同Hub-and-Spoke目錄結構,按需加載,分級付費。
- 差異:Anthropic提出9類Skills分類,Perplexity提出5步開發流程(Step 0寫Evals),兩者互補。
- 啟發:Gotchas(踩坑點)係核心資產,要透過飛輪機制持續累積;負面示例比正面示例更重要。
- 可行動點:建設Skills團隊應先搭建Eval基礎設施,將評估放喺開發之前,並用PreToolUse鈎子監控使用情況。
內容結構
my-skill/├──
SKILL.md # frontmatter + 指令(hub
- 中樞)├── scripts/ # Agent 運行的代碼,不需要重新發明的├── references/ # 重文檔,條件加載├── assets/ # 模板、schema 和數據└── config.json # 首次用戶設置認知轉變:Skills唔係Prompt,而係Context Engineering
傳統Prompt Engineering核心係優化單次指令,引導模型畀出正確輸出。Context Engineering關注嘅完全係另一個層面:喺模型做決策之前,點樣組織好所有相關信息——包括結構、優先級、加載時機。
Skills係上下文工程,唔係Prompt Engineering
打個比方:Prompt Engineering係向專家提一個精準嘅問題;Context Engineering係喺專家嚟之前,將所有相關報告分好類、標好優先級、整齊咁擺喺枱上。
將Skill當prompt寫,大概率會踩呢啲坑:一次性將所有信息寫喺一個文件裏面;用描述性語言寫功能說明,而唔係觸發條件;等模型自己寫Skills。
LLM自己寫嘅Skills平均冇收益——模型無法可靠編寫程序性知識
咩時候需要Skill?模型冇特殊上下文就會犯錯、需要跨運行保持一致性、知識持久但唔喺訓練數據中、涉及企業特定工作流。唔需要嘅情況:模型本來就做得啱、信息變化太快、同系統prompt重複。
三層成本模型:Token經濟學嘅工程實踐
Perplexity提出嘅三層上下文成本模型,係對Skill架構設計指導性最強嘅框架。佢將Skill嘅上下文成本分成Index、Load、Runtime三層。
- 1 Index層:每個Skill嘅name + description,約100 tokens,每個session每個用戶始終付費。多寫一句廢話,全世界每個用戶每次對話都替你買單。每個Skill都係税。
- 2 Load層:完整SKILL.md body,約5,000 tokens。加載時付費,後續每個對話輪次累積。要跳過顯而易見嘅內容,聚焦gotchas同負面示例。
- 3 Runtime層:scripts/、references/、assets/等內容,無上限。僅當Agent實際讀取時先付費,實現按需加載。
按需加載,分級付費
對應嘅目錄結構叫Hub-and-Spoke:SKILL.md做中樞,scripts/、references/、assets/做分支。Anthropic嘅最佳實踐強調同樣思路:詳細函數簽名拆到references/,輸出模板放assets/,核心指令保持精簡。
實戰方法論:分類體系同開發流程
Anthropic內部活躍使用幾百個Claude Code Skills,梳理後歸為9大類別。以下係各類別嘅核心用途同典型示例。
- 庫與API參考:幫助正確使用某個庫/CLI/SDK,例如billing-lib(計費庫踩坑點)
- 產品驗證:測試/驗證代碼是否正常工作,例如signup-flow-driver(無頭瀏覽器跑註冊全流程)
- 數據獲取與分析:連接數據和監控體系,例如funnel-query(轉化漏斗事件JOIN)
- 業務流程與團隊自動化:將重複性工作流自動化,例如standup-post(自動站會彙報)
- 代碼腳手架與模板:生成框架樣板代碼,例如new-workflow(搭建新服務)
- 代碼質量與審查:執行質量標準並輔助審查,例如adversarial-review(子智能體挑刺)
- CI/CD與部署:拉取、推送和部署代碼,例如babysit-pr(監控PR→重試CI→自動合併)
- 運維手冊:多工具排查流程→結構化報告,例如*-debugging
babysit-pr Skill展示Skills編排複雜多步工作流嘅能力
Perplexity嘅開發流程有一個反直覺特點:第一步唔係寫Skill,而係寫測試。佢哋嘅5步流程如下。
- 1 Step 0:寫Evals——從真實用戶查詢、已知失敗、鄰域混淆中採樣,負面示例比正面示例更重要
- 2 Step 1:寫Description——公認最難,係路由觸發器唔係功能文檔,以Load when...開頭,50字以內
- 3 Step 2:寫Body——跳過顯而易見嘅內容,聚焦gotchas同負面示例,重內容移到spoke文件
- 4 Step 3:搭建層次結構——scripts/(確定性邏輯)、references/(條件加載)、assets/(輸出模板)
- 5 Step 4:迭代與發佈——喺分支上大量迭代,搭建hero query集,運行大量evals
Description係路由觸發器,唔係功能摘要
評估維護同開放標準
兩家公司都有一個反常識共識:Skill中價值最高嘅內容唔係正面教程,而係踩坑點(Gotchas)。Anthropic嘅做法係每次Agent犯錯時,喺Gotchas章節追加一條。Perplexity將呢個機制系統化為Gotchas飛輪。
Perplexity嘅四層Eval套件覆蓋Skills從加載到執行嘅完整鏈路。
- 1 Skill加載Eval:測試精度(該加載嘅有冇加載)同召回(唔該加載嘅有冇避免)
- 2 漸進加載Eval:檢查Agent係咪讀取咗正確嘅spoke文件
- 3 端到端任務Eval:完整Agent循環 + LLM judge評分
- 4 跨模型Eval:喺GPT、Claude Opus、Claude Sonnet三種編排模型上運行,確保行為一致性
跨模型Eval容易被跳過,但Perplexity經驗說明唔該跳過
2025年12月18日,Anthropic將Agent Skills發佈為開放標準,捐贈畀Agentic AI Foundation。標準結構係Hub-and-Spoke目錄,同Perplexity高度一致。合作伙伴包括Atlassian、Figma、Notion、微軟、Cursor等。
Agent Skills開放標準—統一格式,多環境使用
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 137 篇,AI 編程最佳實戰「2026」系列第 41 篇
大家好,歡迎來到 術哥無界 | ShugeX | 運維有術。
我是術哥,一名專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫的技術實踐者與開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
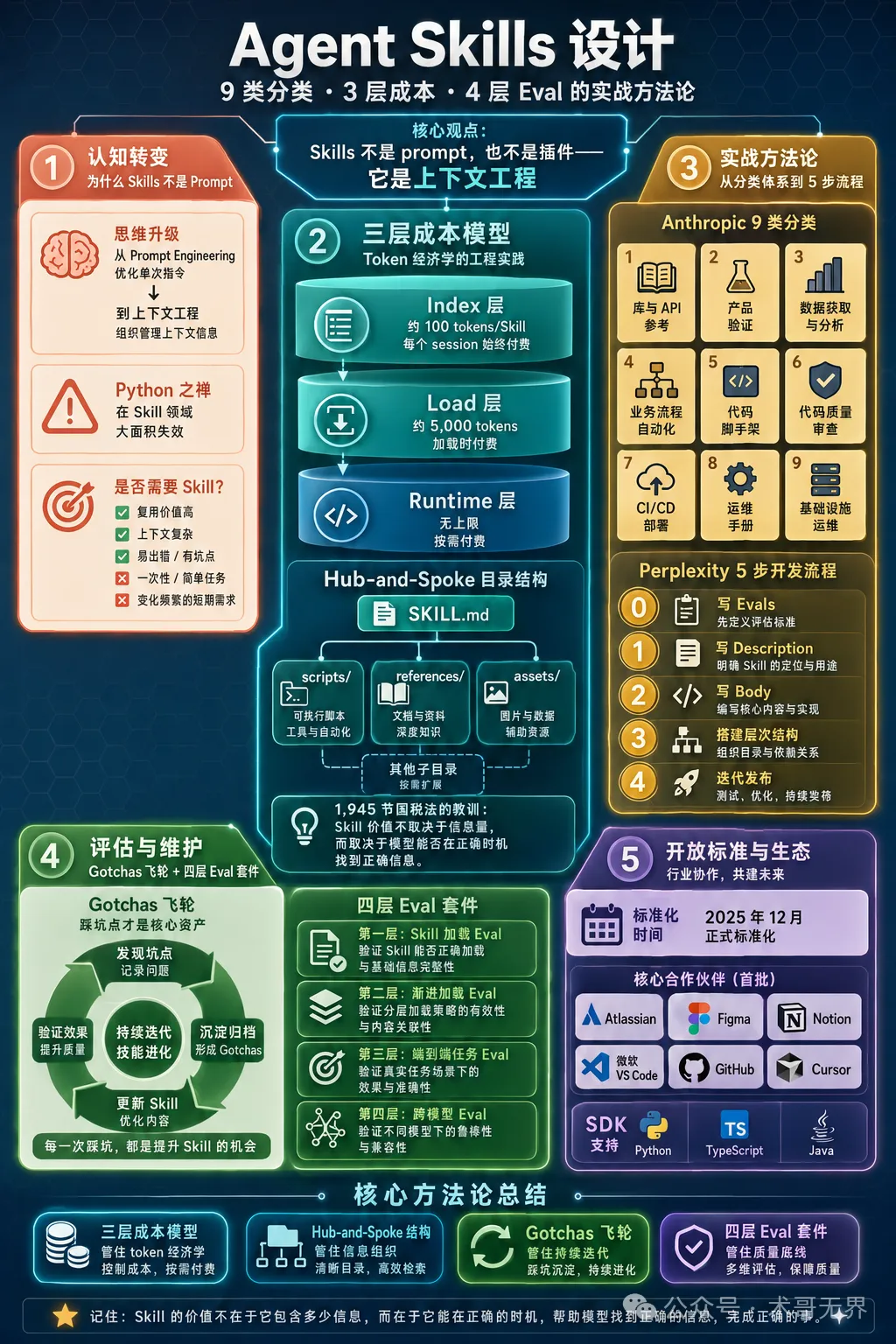
圖 1:Agent Skills 設計方法論全景圖
說明:本文內容基於 Anthropic 官方博客(Thariq Shihipar,Claude Code 團隊)和 Perplexity Research 官方技術文章分析整理而成,源碼級細節來自已公開的設計文檔和工程實踐分享。文中的配置模板和參數建議僅供參考,實際效果請以你的業務數據和環境測試結果為準。如果有實際使用經驗,歡迎在評論區分享交流。
翻了一遍 Anthropic 和 Perplexity 的官方技術博客,有一個共識反覆出現:Skills 不是 prompt,也不是插件——它是上下文工程(Context Engineering)。
這不是文字遊戲。Perplexity 的原話說得很直接:如果你像寫代碼一樣寫 Skill,你會失敗。 Anthropic 的 Claude Code 團隊工程師 Thariq Shihipar 則專門糾正了一個常見誤解——Skills 不是只不過是個 markdown 文件,而是包含腳本、資源文件、數據的文件夾,智能體可以發現、探索和使用這些內容。
兩篇文章發佈時間差兩個月(Anthropic 2026 年 3 月,Perplexity 2026 年 5 月),面向的場景也不同——一個是開發者工具的擴展機制,一個是終端用戶的 Agent 產品能力模塊。但兩邊的設計理念幾乎一模一樣。
下面把兩家的做法掰開揉碎說一遍。
1. 認知轉變:為什麼 Skills 不是 Prompt
從 Prompt Engineering 到 Context Engineering
傳統 Prompt Engineering 的核心是優化單次指令,引導模型給出正確輸出。Context Engineering 關注的完全是另一個層面:在模型做決策之前,如何組織好所有相關信息——包括結構、優先級、加載時機。
打個比方:Prompt Engineering 是向專家提一個精準的問題;Context Engineering 是在專家來之前,把所有相關報告分好類、標好優先級、整齊地擺在桌上。問題問得好當然有用,但如果桌上堆着一堆無關材料、關鍵數據又找不到,再好的問題也白搭。
把 Skill 當 prompt 寫,大概率會踩這些坑:
一次性把所有信息寫在一個文件裏 用描述性語言寫功能說明,而不是觸發條件 讓模型自己寫 Skills

圖 2:Prompt Engineering vs Context Engineering
第四點尤其值得注意。Perplexity 的研究表明,LLM 自己寫的 Skills 平均沒有收益——他們的原話是模型無法可靠地編寫它們受益的程序性知識。高質量的 Skill 必須由人類基於實戰經驗編寫,再通過 Eval 套件持續驗證。
Python 之禪在 Skill 領域大面積失效
Perplexity 團隊做了一個很扎心的對比。他們發現 PEP20 裏至少一半的智慧,在寫 Skill 時是錯誤的或誤導性的:
最後一條切中要害。很多人寫 Skill 的第一反應是寫教程式說明文檔,但模型已經知道的東西寫進去只會浪費上下文窗口。Anthropic 的第一條最佳實踐也是同一個意思:不要說顯而易見的事,把重點放在能打破模型常規思維模式的信息上。
什麼時候需要 Skill?什麼時候不需要
兩家的判斷標準很明確。
需要 Skill 的情況:
模型沒有特殊上下文就會犯錯 需要跨運行保持行為一致性 知識是持久的但不在訓練數據中 涉及企業特定工作流或團隊約定
不需要 Skill 的情況:
模型本來就能做對的事情 信息變化速度超過維護速度 和系統 prompt 重複的指令
Perplexity 的設計 Skills 是個很好的例子。這些 Skills 由設計負責人 Henry Modisett 編寫,指定用哪些字體、不用哪些字體、不同字體的感覺。這些判斷是純主觀的品味問題,模型不可能從訓練數據中學到,但用戶能明顯感受到輸出質量的差異。
Anthropic 的 frontend-design Skill 也是類似思路。它不是教模型怎麼寫 CSS,而是通過與用戶反覆迭代來改進模型的設計品味,專門避免典型套路(比如過度使用 Inter 字體和紫色漸變)。Thariq Shihipar 提到這個 Skill 由一位工程師專門打磨——說明品味類 Skills 需要持續的人類投入。
2. 三層成本模型:Token 經濟學的工程實踐
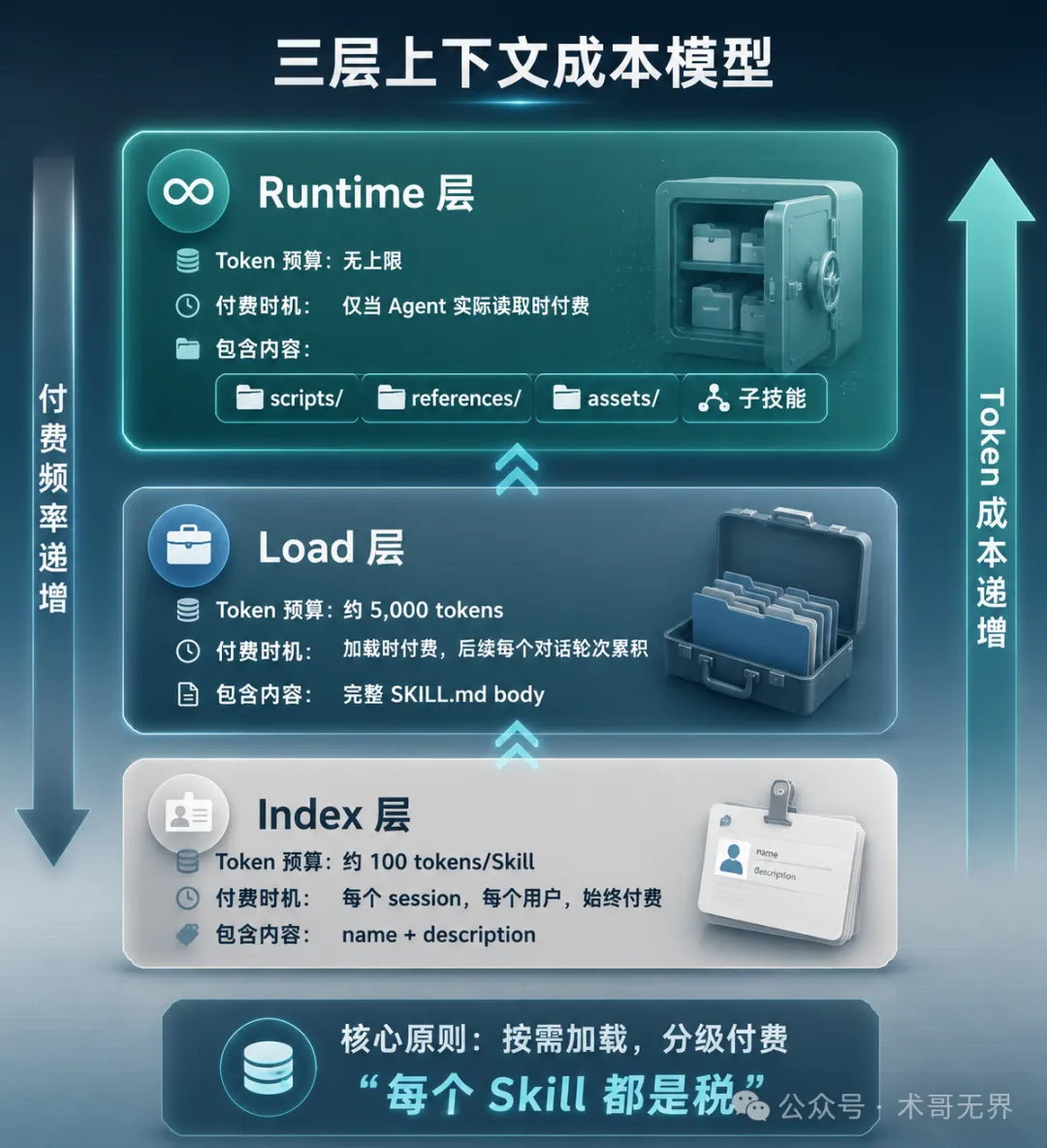
圖 3:三層上下文成本模型
Perplexity 提出的三層上下文成本模型,是我見過的對 Skill 架構設計指導性最強的框架。它把 Skill 的上下文成本分成三層:
| Index | name + description | ||
| Load | SKILL.md body | ||
| Runtime | scripts/references/、assets/、子技能 |
核心理念是六個字:按需加載,分級付費。
Index 層:寸土寸金
每個用戶每次對話,所有 Skills 的 name 和 description 都會被加載。你多寫一句廢話,全世界每個用戶每次對話都在替你買單。Perplexity 給了一個直白的說法:每個 Skill 都是税(Every Skill is a Tax)。
對 Skill 中的每句話,都要問一個問題:沒有這條指令,Agent 會做錯嗎? 如果不會,就不能留在那裏。
Load 層:預算有限,精打細算
Load 層稍微寬鬆,但一次對話可能同時加載 3-5 個 Skill,成本疊加。5,000 tokens 的預算意味着要在信息密度和完整性之間做權衡。跳過顯而易見的內容,聚焦 gotchas 和負面示例,把重內容移到 spoke 文件中。
Runtime 層:按需自由
腳本、詳細文檔、模板這些重內容放在 scripts/、references/、assets/ 目錄中,只有 Agent 實際讀取時才消耗 token。這就是漸進式披露(Progressive Disclosure)的核心思路——也是 Agent Skills 開放標準的三階段加載模型:Discovery → Activation → Execution。
Hub-and-Spoke 目錄結構
三層成本模型對應的標準目錄結構叫 Hub-and-Spoke:
my-skill/
├── SKILL.md # frontmatter + 指令(hub - 中樞)
├── scripts/ # Agent 運行的代碼,不需要重新發明的
├── references/ # 重文檔,條件加載
├── assets/ # 模板、schema 和數據
└── config.json # 首次用戶設置
SKILL.md 是中樞,包含元數據和核心指令。scripts/、references/、assets/ 是分支,Agent 按需讀取。你可以把 token 預算精準分配給不同層級的信息。
Anthropic 的最佳實踐也強調同樣的思路:詳細函數簽名拆到 references/ 目錄,輸出模板放 assets/,核心指令保持精簡。兩家公司的目錄結構雖然表述不同,底層邏輯完全一致。
信息組織的邊界:1,945 節國税法的教訓
Perplexity 用一個具體案例說明了信息組織的極限。他們測試美國所得税 Skill 時,把全部 1,945 節美國國税法放在單個文件夾中。結果性能比不加載 Skill 還糟糕。
解決方案是多級層次結構。當 Skill 需要覆蓋 300 個主題時,讓模型在 300 箇中做可靠選擇,目前還是未解決的挑戰。但分成 20 個主題領域,模型先選領域再在 15 箇中選擇,準確率就上來了。Perplexity 的美國所得税 Skill 使用了三級主題嵌套。
這個案例說明了一個重要原則:Skill 的價值不取決於包含多少信息,而取決於模型能否在正確時機找到正確信息。再好的知識庫,索引做得爛,效果還不如沒有。
你在項目中用過類似的分層信息組織方案嗎?歡迎在評論區聊聊。
3. 實戰方法論:從分類體系到 5 步流程
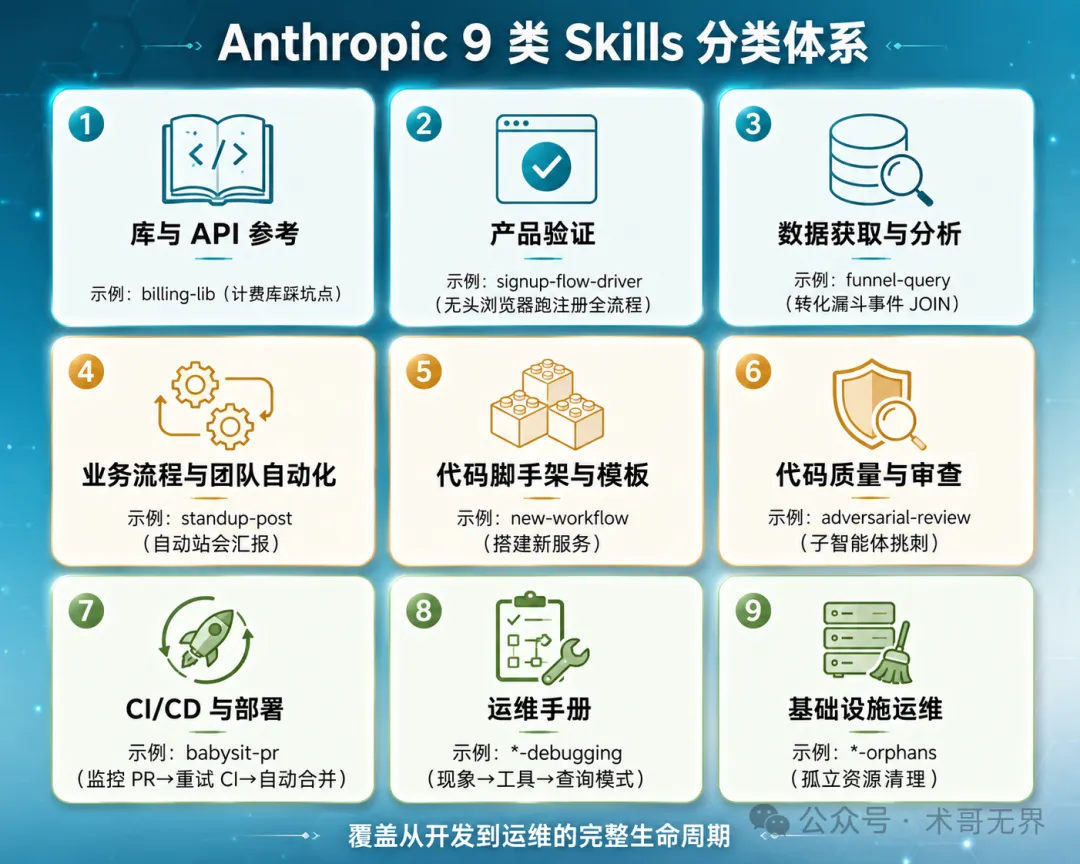
圖 4:Anthropic 9 類 Skills 分類體系
Anthropic 的 9 類分類體系
Anthropic 內部活躍使用的 Claude Code Skills 已有幾百個。梳理後歸為 9 大類別:
9 個類別覆蓋了從開發到運維的完整生命週期。幾個有意思的案例值得單獨說說。
babysit-pr Skill 展示了 Skills 編排複雜多步工作流的能力:監控 PR 狀態、重試不穩定的 CI、解決合併衝突、啓用自動合併,整個過程不需要人工干預。它不是簡單的命令別名,而是一個有狀態的工作流編排。
/careful Skill 通過 PreToolUse 鈎子攔截 rm -rf、DROP TABLE、force-push 等危險操作,只在需要時激活。這是 Skills 與鈎子系統結合的典型用法,也說明 Skills 不只是文本知識——它們可以包含行為邏輯。
adversarial-review Skill 的設計思路很巧妙:用一個全新的子智能體來挑刺,而不是讓同一個模型既寫代碼又審代碼。這避免了自己審自己的盲區。
Perplexity 的 5 步開發流程
Perplexity 的開發流程有一個反直覺的特點:第一步不是寫 Skill,而是寫測試。
| Step 0:寫 Evals | |
| Step 1:寫 Description | |
| Step 2:寫 Body | |
| Step 3:搭建層次結構 | |
| Step 4:迭代與發佈 |
Step 0 把 Evals 放在寫 Skill 之前,這和 TDD 的思路一脈相承。先定義成功標準,再寫實現。Perplexity 專門強調,負面示例可能比正面示例更重要——知道 Skill 在什麼情況下不該觸發,和知道它應該觸發一樣關鍵。
Step 1 是公認最難的一步。Description 不是功能描述,而是路由觸發器。Anthropic 的 Thariq Shihipar 也強調了同樣的觀點:description 字段描述的是何時該觸發這個 Skill,不是功能摘要。好的 description 讀起來更像 if-then 條件。比如 babysit-pr 的 description 可能是 Load when the user asks to monitor, babysit, or manage a pull request ——用的是用戶真實說法,而不是功能定義。
這個區別看着細微,但實際影響很大。如果你的 description 寫的是 This skill helps with PR management,模型很難判斷當前對話是否需要它。但如果寫的是 Load when the user mentions babysitting a PR or monitoring CI status,觸發準確率會高得多。
4. 評估與維護:Gotchas 飛輪與四層 Eval 套件
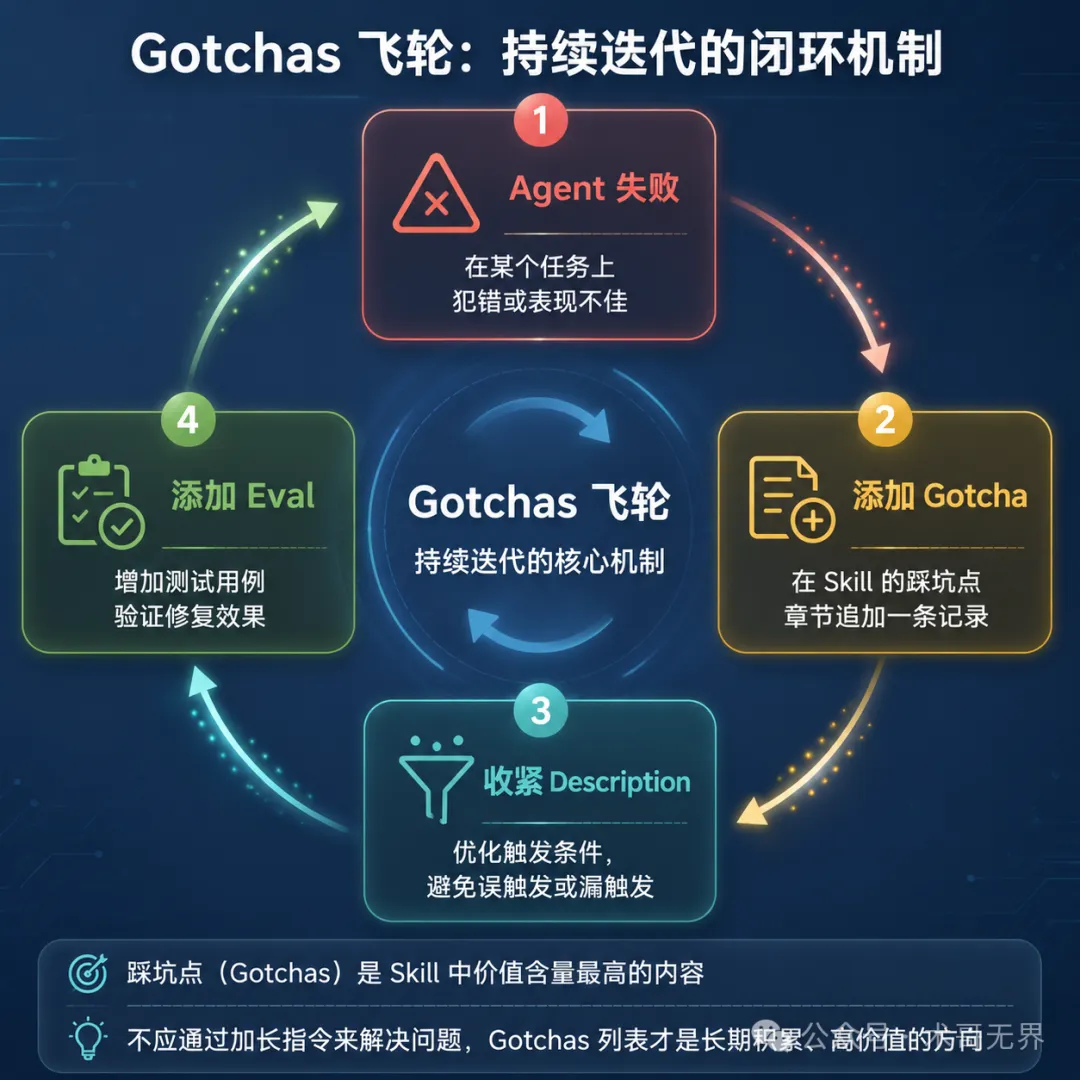
圖 5:Gotchas 飛輪——持續迭代的核心機制
Gotchas 飛輪:踩坑點才是核心資產
兩家公司都有一個反常識的共識:Skill 中價值含量最高的內容不是正面教程,而是踩坑點(Gotchas)。
Anthropic 的做法是:每次 Agent 犯錯時,在 Skill 的 Gotchas 章節追加一條。Thariq Shihipar 把這列為 8 條最佳實踐的第 2 條,並明確說這是高價值內容。
Perplexity 把這個機制系統化為 Gotchas 飛輪:
Agent 在某事上失敗 → 添加 gotcha Agent 不該加載時加載了 → 收緊 description,添加負面 evals Agent 該加載時沒加載 → 添加關鍵詞和正面 evals 系統 prompt 變化 → 檢查競爭或重複
有一說一,這個機制聽着簡單,但 Perplexity 明確指出一個容易做錯的地方:不應該通過添加更長指令或改變 description 來解決問題。Gotchas 列表才是長期積累、高價值的地方。
為什麼?因為加長指令會讓 Load 層的 token 成本上升,影響所有用戶。而 Gotchas 是有針對性的——它只在特定的失敗模式上增加上下文,ROI 高得多。
四層 Eval 套件
Perplexity 的評估體系覆蓋了 Skills 從加載到執行的完整鏈路:
| Skill 加載 Eval | |
| 漸進加載 Eval | |
| 端到端任務 Eval | |
| 跨模型 Eval |
跨模型 Eval 這事容易被跳過,但 Perplexity 的經驗說明它不該被跳過。不同模型在處理 Skills 時行為差異不小。如果你的 Skill 只在 Claude 上測過,換到 GPT 上可能完全不是一回事。
Anthropic 的做法更偏實戰:用 PreToolUse 鈎子記錄 Skill 使用情況,從日誌裏找受歡迎的 Skills 和觸發頻率偏低的 Skills。這和他們的內部管理策略一致——讓好用的 Skills 自己冒出來,用數據說話。
管理上也有分層:小團隊直接提交到代碼倉庫的 ./.claude/skills 目錄就行;人多了,再搭內部插件市場(Plugin Marketplace)。Skills 之間可以直接按名字引用,形成依賴鏈。
5. 開放標準與生態:從內部實踐到行業基礎設施
Agent Skills 開放標準
2025 年 12 月 18 日,Anthropic 將 Agent Skills 發佈為開放標準,並捐贈給 Agentic AI Foundation(AAIF)。標準的核心是前面提到的文件夾結構加上漸進式披露三階段加載。標準結構為:
my-skill/
├── SKILL.md # Required: 元數據 + 指令
├── scripts/ # Optional: 可執行代碼
├── references/ # Optional: 參考文檔
├── assets/ # Optional: 模板和資源
└── ... # 任意額外文件或目錄
這個結構和 Perplexity 的 Hub-and-Spoke 結構高度一致。說明開放標準不是憑空設計的,而是從實踐中抽象出來的。
生態採納情況
合作伙伴名單很有分量:Atlassian(Jira/Confluence)、Figma(設計→代碼)、Notion(規格→任務)、Canva、Sentry、Cloudflare、Ramp、Box。微軟在 VS Code 和 GitHub 中採納了這個標準,Cursor 的 Nightly 版也已經支持。SDK 層面提供 Python、TypeScript 和 Java 三種語言的支持。
從時間線看發展速度不慢:2025 年 10 月 Claude Skills 功能正式上線,12 月開放標準化並引入一批合作伙伴,到 2026 年 3-5 月兩家公司幾乎同時發佈深度技術文章分享內部經驗。
對技術團隊意味着什麼
如果你是技術負責人或架構師,Agent Skills 開放標準意味着幾件事。
統一的能力擴展格式。團隊不再需要為每個 Agent 平台寫不同格式的能力模塊。一個符合標準的 Skill 文件夾,理論上可以在 Claude Code、VS Code、Cursor 等多個環境中使用。
上下文工程將成為必備技能。寫好 Skill 的核心不是編程能力,而是對上下文成本的理解和信息組織的能力。這是一個新的技能維度。
評估體系不可省略。Perplexity 把 Evals 放在 Step 0,Anthropic 用鈎子系統持續監控——兩家都把評估作為 Skill 生命週期的核心環節。準備建設 Skills 的團隊,Eval 基礎設施應該和 Skill 開發同步規劃。
至於 OpenAI 和 Google 是否有類似的 Skill 系統、大規模 Skills 庫的路由準確率閾值在哪、合作伙伴生態中 Skills 如何定價——這些問題當前公開資料中未發現相關依據。但從 Anthropic 和 Perplexity 已公開的方法論來看,Agent Skills 的工程化體系已經有了比較清晰的輪廓:三層成本模型管住 token 經濟學,Hub-and-Spoke 結構管住信息組織,Gotchas 飛輪管住持續迭代,四層 Eval 套件管住質量底線。
如果你也在做 Agent 能力模塊的設計,這四根柱子值得認真參考。
好啦,謝謝你觀看我的文章,如果喜歡可以點贊轉發給需要的朋友,我們下一期再見!敬請期待!