Anthropic重磅更新skill-creator:創建skill全面告別“草台班子”時代
整理版優先睇
Anthropic升級skill-creator,加入測試評估機制,令創建skill更可靠
呢篇文章係Anthropic官方公佈skill-creator升級嘅消息,由作者花不玩整理。Anthropic發現好多skill作者係領域專家而非工程師,佢哋清楚工作流但缺乏工具驗證skill喺新模型下係咪仲有效、會唔會誤觸發或者改完有冇改善。為咗解決呢個問題,Anthropic將軟件開發嘅測試、基準評估和迭代機制引入skill創作過程,而且全程唔使寫code。
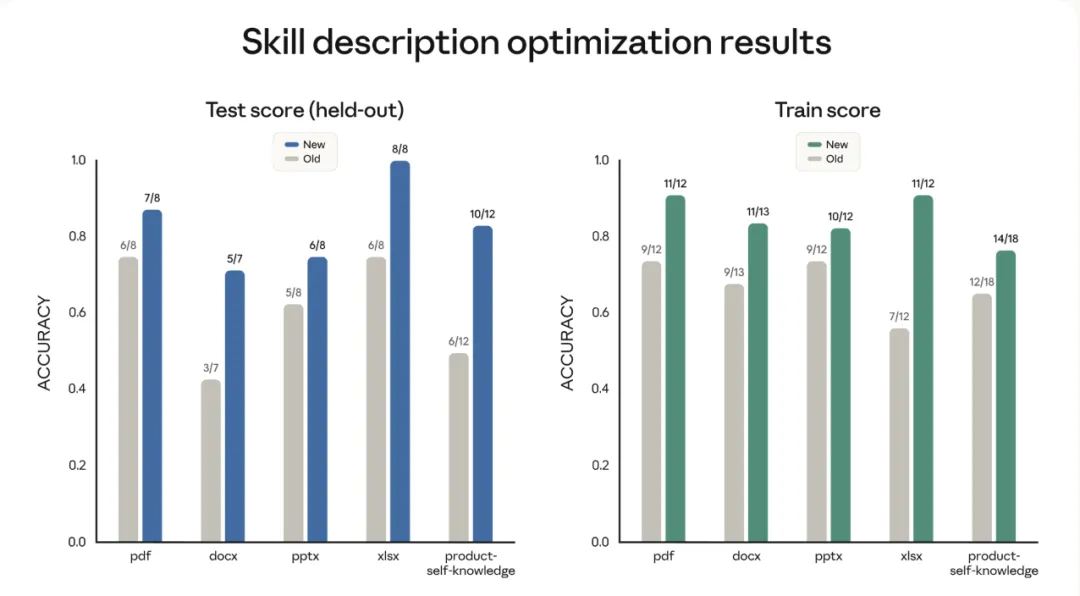
新版skill-creator可以幫用戶建立評估機制(evals),只要設定測試提示詞同預期結果,系統就會自動驗證skill達唔達到標準。呢個機制主要解決兩個問題:第一係捕捉質量衰退,當模型或底層基礎設施改變時,上個月仲掂嘅skill今日可能會出錯;第二係瞭解模型進展,如果基礎模型唔加載skill都通過測試,即係話個skill嘅技術可能已被模型默認吸收咗。另外仲有基準評估模式,可以系統追蹤通過率、耗時同token用量,數據歸用戶所有,支援本地存儲同接入CI系統。
為咗提升效率,skill-creator而家支援多智能體並行運行測試,每個智能體喺乾淨上下文工作,獨立統計token同時間。新增嘅對比智能體可以做A/B測試,盲測唔同版本或者對比有冇skill嘅差異。同時仲優化咗觸發器描述,避免誤觸發或永遠唔觸發。Anthropic內部測試中,呢項功能優化咗6個公開文檔創建skill嘅其中5個。總括嚟講,呢次升級令skill創作由「草台班子」變成有系統驗證嘅專業流程…
- 新版skill-creator引入測試評估機制,驗證skill有效性,唔使靠感覺。
- 方法係設定測試提示詞同預期結果,由系統自動判斷係咪達標。
- 區分能力提升型(可能被模型吸收)同偏好編碼型(需長期維護)skill,測試重點唔同。
- 測試能捕捉質量衰退同判斷模型進展,幫你決定skill係咪仲需要保留。
- 用戶而家即可喺Claude.ai或Cowork使用skill-creator,或透過Claude Code安裝官方插件開始創作。
Anthropic官方blog:Improving skill-creator
原文詳細介紹skill-creator升級內容,包括測試、多智能體同觸發器優化。
背景:點解要升級skill-creator?
Anthropic發現好多skill作者係垂直領域專家,唔係工程師。佢哋清楚自己嘅工作流,但缺乏工具驗證skill喺新模型下係咪仲有效、會唔會誤觸發,或者修改後有冇改善。為咗解決呢個問題,Anthropic宣佈升級skill-creator,將軟件開發嘅嚴謹測試、基準評估同迭代機制引入skill創作,全程唔使寫code。
引入測試能讓看起來有效的skill,變成真正被驗證有效的skill。
兩類skill,測試重點唔同
要設計測試,首先要釐清skill嘅兩種主要類型,因為佢哋需要測試嘅原因唔同。
- 1 能力提升型:幫Claude完成基礎模型做唔到或唔穩定嘅任務,例如特定文檔生成模式。隨住模型進化,呢類skill可能變得唔再需要,測試判斷模型係咪已經掌握咗呢啲能力。
- 2 偏好編碼型:Claude本身有能力完成各環節,但需要skill按團隊特定流程編排,例如審核NDA或結合MCP數據起草週報。呢類skill生命週期較長,測試核心係驗證係咪忠實於實際工作流。
用評估機制測試並改進skill
更新後嘅skill-creator可以幫助用戶建立評估機制(evals)。用戶只需設定測試提示詞,並描述預期嘅理想結果,系統就會驗證該skill係咪達到標準。
建立評估機制主要解決兩個實際問題:首先係捕捉質量衰退,當模型或基礎設施改變時,上個月表現良好嘅skill今日可能出現異常;其次係瞭解模型進展,如果基礎模型唔加載skill都通過測試,即係話個skill嘅技術方法可能已被吸收進模型默認行為。
評估機制可以喺影響實際工作前提供預警信號,亦幫你判斷skill係咪仲有存在價值。
另外仲有基準評估模式,係一種標準化評估流程,適合喺模型更新或skill迭代後運行,系統追蹤測試通過率、運行耗時同token用量。所有數據歸用戶所有,支援本地存儲,亦可接入儀表盤或CI系統。
多智能體支援同觸發器優化
順序運行測試通常較慢,而且上下文積累容易產生幹擾。為提升效率同準確性,skill-creator而家支援多智能體機制,可以啟動獨立嘅智能體並行運行測試,每個智能體喺乾淨上下文工作,有獨立token同時間統計。
新增嘅對比智能體專門用於A/B測試,可以盲測唔同版本嘅skill,或者對比使用同唔使用skill嘅輸出差異,直觀判斷某項修改係咪真係帶嚟提升。
對比智能體可以在不知道對照組信息的情況下盲測不同版本的 skill,避免主觀偏差。
除咗輸出質量,skill係咪喺正確時間觸發都關鍵。skill-creator而家會比對現有描述同示例提示詞,提供修改建議。Anthropic內部測試中,呢項功能優化咗6個公開文檔創建skill嘅其中5個,有效降低誤報同漏報率。
未來展望:從點樣做到做啲乜
隨住模型持續改進,skill同規範說明之間嘅界線將會逐漸模糊。目前SKILL.md本質上係一個執行方案,詳細指示Claude應該點樣做某事。將來用戶可能只需要用自然語言描述skill應該做啲乜,模型自己解決具體實現。

Anthropic官方有個專門用嚟建立skill嘅skill叫skill-creator,今日Anthropic對呢個skill進行咗升級,升級後嘅skill對普通人更加友好,更加重要嘅係個人建立skill嘅有效性會大大提高,我自己覺得普通人與其不斷搞龍蝦,養龍蝦OpenClaw,不如點樣建立skill學好,呢個係一個對日常工作好有用嘅大殺器
所有 skill-creator 嘅更新現已喺 Claude.ai 同 Cowork 上線,用戶只需向 Claude 提出使用 skill-creator 就可以開始。
Claude Code 用戶可以安裝官方插件或者從代碼庫攞相關資源。安裝好簡單
/plugin install {plugin-name}@claude-plugin-directory
或者 /plugin > Discover
安裝好之後就可以開心咁建立skill喇
隨住 Agent 技術嘅深入應用,寫 skill 成為咗而家好流行嘅做法。Anthropic 喺上年嘅實踐中發現,大多數 skill 嘅作者係垂直領域嘅專家,唔係工程師。佢哋清楚自己嘅工作流程,但係就缺乏工程化工具去驗證呢啲 skill 係咪仲適合新模型、可唔可以喺啱嘅時候觸發,或者修改之後係咪真係有改善。
為咗解決呢個問題,Anthropic 宣佈對 skill-creator 進行升級,將軟件開發入面嚴謹嘅測試、基準評估同迭代機制引入 skill 創作過程,而且成個過程都唔需要作者寫任何代碼。
理解兩類唔同嘅 skill
喺討論測試工具之前,需要釐清 skill 嘅兩種主要類型,因為佢哋需要測試嘅原因唔同。
第一類係能力提升型 skill,主要幫助 Claude 完成基礎模型做唔到或者表現唔夠穩定嘅任務,例如特定嘅文檔生成模式。隨住底層模型能力嘅進化,呢類 skill 可能會變得唔再需要,所以就要通過測試去判斷模型係咪已經掌握咗呢啲能力。
第二類係偏好編碼型 skill,呢類任務 Claude 本身有能力完成各個環節,但係需要 skill 將佢按照團隊特定流程進行編排,例如按既定標準審核 NDA,或者結合多個 MCP 嘅數據起草週報。呢類 skill 嘅生命週期較長,測試嘅核心在於驗證佢係咪忠實於你嘅實際工作流程。
無論屬於邊一類,引入測試都可以令到睇落有效嘅 skill,變成真正被驗證有效嘅 skill。
用評估機制測試同改進 skill
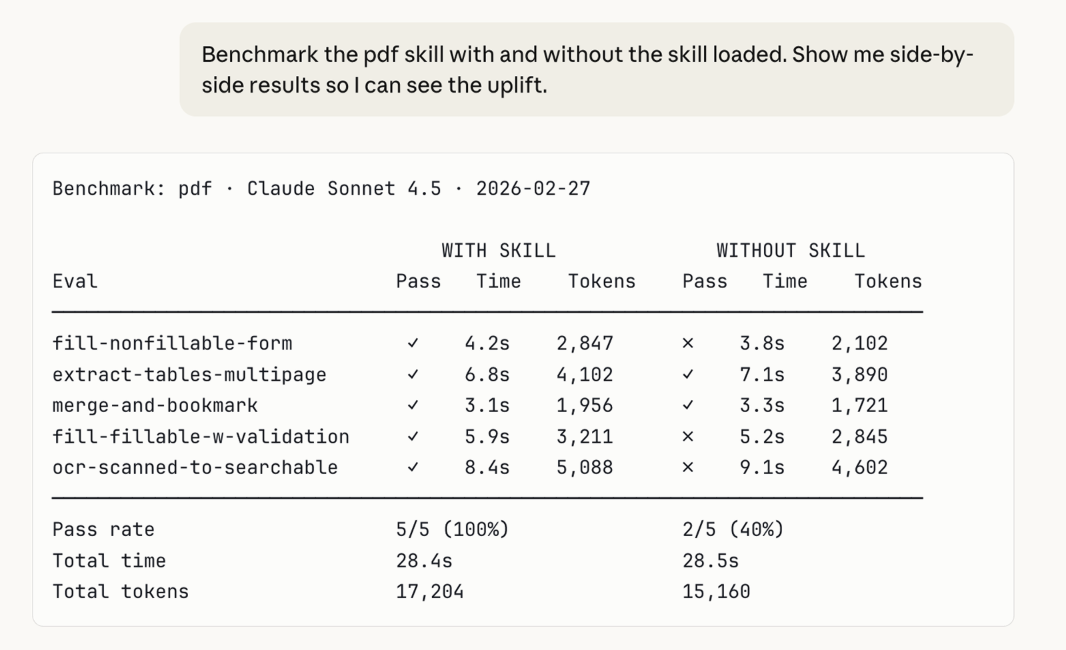
更新後嘅 skill-creator 可以幫助用戶建立評估機制(evals)。用戶只需要設定測試提示詞,並描述預期嘅理想結果,skill-creator 就會驗證個 skill 係咪達到標準。以處理非填表類 PDF 為例,原先 Claude 難以喺冇預設字段嘅情況下精準放文字。Anthropic 團隊正係通過評估機制鎖定咗呢個缺陷,然後發佈咗修復方案,改為通過提取文字座標嚟錨定位置。

建立呢種評估機制主要解決兩個實際問題:
首先係捕捉質量衰退。當模型或者底層基礎設施有變化嗰陣,上個月表現良好嘅 skill 今日可能會出現異常。針對新模型去運行測試,可以喺影響實際工作之前提供預警信號。
其次係瞭解模型進展。呢個主要針對能力提升型 skill,如果基礎模型喺唔加載 skill 嘅情況下都通過到測試,就表示嗰個 skill 嘅技術方法可能已經被吸收咗入模型嘅默認行為入面。呢個唔代表 skill 壞咗,只係唔再需要。
除此之外,Anthropic 仲加咗基準評估模式。呢個係一種標準化評估流程,適合喺模型更新或者 skill 迭代之後運行,佢會系統性追蹤測試通過率、運行耗時同 token 用量。呢啲測試同結果數據歸用戶所有,支援本地儲存,亦都可以接入儀錶板或者持續整合(CI)系統。
多智能體支援同觸發器優化
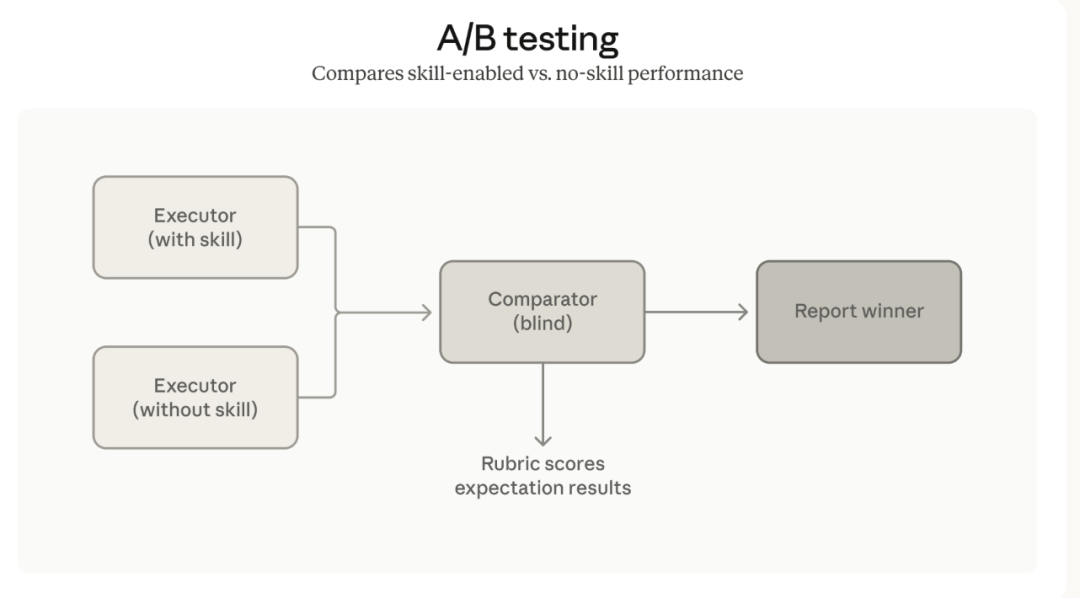
順序執行測試通常比較慢,而且上下文不斷累積容易喺測試用例之間產生幹擾。為咗提升效率同準確性,skill-creator 而家支援多智能體機制,可以啟動獨立嘅智能體並行運行測試。每個智能體都喺一個乾淨嘅上下文入面工作,擁有獨立嘅 token 同時間統計。
同時新增嘅仲有對比智能體,專門用嚟進行 A/B 測試。對比智能體可以喺唔知道對照組信息嘅情況下盲測唔同版本嘅 skill,或者對比使用同唔使用 skill 嘅輸出分別,從而直觀判斷某項修改係咪真係帶嚟咗提升。
除咗輸出質量,skill 係咪喺啱嘅時間觸發同樣關鍵。隨住用戶持有嘅 skill 數量增加,描述嘅精準度變得至關重要:描述太闊會導致誤觸發,太窄又會導致永遠唔觸發。skill-creator 而家會比對現有嘅描述同示例提示詞,並提供修改建議。喺 Anthropic 嘅內部測試中,呢項功能優化咗 6 個公開文檔建立 skill 入面嘅 5 個,有效降低咗誤報同漏報率。
下一步
隨住模型嘅持續改進,skill 同規範說明之間嘅界限會逐漸模糊。目前嘅 SKILL.md 文件本質上仲係一個執行方案,詳細指示 Claude 應該點樣做某件事。喺未來,用戶可能只需要用自然語言描述 skill 應該做啲乜,模型就可以自行解決具體嘅實現過程。今日發佈嘅評估框架,正係向呢個方向過渡嘅步驟之一。#skill
source:
https://claude.com/blog/improving-skill-creator-test-measure-and-refine-agent-skills
--完--
最後記得⭐️我,每日都有更新:如果覺得文章唔錯嘅話可以讚好轉發推薦留言
/...@作者:花不玩
Anthropic官方有個專門創建skill 的skill叫skill-creator,今天Anthropic對這個skill進行了升級,升級後的skill對普通人更友好了,更重要的是個人創建skill的有效性將大大提高,我個人覺得普通人與其不斷折騰龍蝦,養龍蝦OpenClaw,不如把怎麼創建skill學好,這是一個對日常工作非常有用的大殺器
所有 skill-creator 的更新現已在 Claude.ai 和 Cowork 中上線,用戶只需向 Claude 提出使用 skill-creator 即可開始。
Claude Code 用戶可以安裝官方插件或從代碼庫獲取相關資源。安裝很簡單
/plugin install {plugin-name}@claude-plugin-directory
或者 /plugin > Discover
安裝好後就可以愉快的創建skill了
隨着 Agent 技術的深入應用,編寫 skill 成為當下熱門的實踐。Anthropic 在去年的實踐中發現,大多數 skill 的作者是垂直領域的專家,而非工程師。他們清楚自己的工作流,卻缺乏工程化工具來驗證這些 skill 是否依然適配新模型、能否在正確的時機觸發,或者在修改之後是否真有改善。
為了解決這一問題,Anthropic 宣佈對 skill-creator 進行升級,將軟件開發中嚴謹的測試、基準評估和迭代機制引入 skill 創作過程中,且全過程不需要作者編寫任何代碼。
理解兩類不同的 skill
在探討測試工具前,需要釐清 skill 的兩種主要類型,因為它們需要測試的原因各不相同。
第一類是能力提升型 skill,主要幫助 Claude 完成基礎模型做不到或表現不夠穩定的任務,例如特定的文檔生成模式。隨着底層模型能力的進化,這類 skill 可能會變得不再必要,因此需要通過測試來判斷模型是否已經掌握了這些能力。
第二類是偏好編碼型 skill,這類任務 Claude 本身具備完成各環節的能力,但需要 skill 將其按照團隊特定流程進行編排,例如按既定標準審核 NDA,或結合多個 MCP 的數據起草週報。這類 skill 的生命週期較長,測試的核心在於驗證其是否忠實於你的實際工作流。
無論屬於哪一類,引入測試都能讓看起來有效的 skill,變成真正被驗證有效的 skill。
用評估機制測試並改進 skill
更新後的 skill-creator 能夠幫助用戶建立評估機制(evals)。用戶只需設定測試提示詞,並描述預期的理想結果,skill-creator 就會驗證該 skill 是否達到標準。以處理非填表類 PDF 為例,原先 Claude 難以在沒有預設字段的情況下精準放置文本。Anthropic 團隊正是通過評估機制鎖定了這個缺陷,隨後發佈了修復方案,改為通過提取文本座標來錨定位置。
建立這種評估機制主要解決兩個實際問題:
首先是捕捉質量衰退。當模型或底層基礎設施發生變化時,上個月表現良好的 skill 今天可能會出現異常。針對新模型運行測試,可以在影響實際工作前提供預警信號。
其次是瞭解模型進展。這主要針對能力提升型 skill,如果基礎模型在不加載 skill 的情況下也能通過測試,說明該 skill 的技術方法可能已經被吸收進了模型的默認行為中。這不代表 skill 壞了,只是不再被需要。
除此之外,Anthropic 還加入了基準評估模式。這是一種標準化評估流程,適合在模型更新或 skill 迭代後運行,它會系統追蹤測試通過率、運行耗時以及 token 用量。這些測試和結果數據歸用戶所有,支持本地存儲,也可接入儀表盤或持續集成(CI)系統。
多智能體支持與觸發器優化
順序運行測試通常較慢,且上下文的不斷積累容易在測試用例間產生干擾。為提升效率與準確性,skill-creator 現已支持多智能體機制,可以啓動獨立的智能體並行運行測試。每個智能體都在一個乾淨的上下文中工作,擁有獨立的 token 和時間統計。
同時新增的還有對比智能體,專門用於進行 A/B 測試。對比智能體可以在不知道對照組信息的情況下盲測不同版本的 skill,或者對比使用和不使用 skill 的輸出差異,從而直觀判斷某項修改是否真的帶來了提升。
除了輸出質量,skill 是否在正確的時間觸發同樣關鍵。隨着用戶持有的 skill 數量增加,描述的精準度變得至關重要:描述太寬泛會導致誤觸發,太狹窄又會導致永遠不觸發。skill-creator 現在會比對現有的描述和示例提示詞,並提供修改建議。在 Anthropic 的內部測試中,這項功能優化了 6 個公開文檔創建 skill 中的 5 個,有效降低了誤報和漏報率。
下一步
隨着模型的持續改進,skill 和規範說明之間的界限將會逐漸模糊。目前的 SKILL.md 文件本質上還是一個執行方案,詳細指示 Claude 應該如何做某事。在未來,用戶可能只需要用自然語言描述 skill 應該做什麼,模型就能自行解決具體的實現過程。今天發佈的評估框架,正是向這一方向過渡的步驟之一。#skill
source:
https://claude.com/blog/improving-skill-creator-test-measure-and-refine-agent-skills
--end--
最後記得⭐️我,每天都在更新:如果覺得文章還不錯的話可以點贊轉發推薦評論
/...@作者:花不玩