Browser Use:讓 AI 替你點鼠標的開源項目,GitHub 已過 9.6 萬 star
整理版優先睇
Browser Use 係一個開源 Python 庫,透過多模態大模型「睇」頁面截圖同 DOM 元素,令 AI 好似人咁操作瀏覽器,自動完成網頁任務。呢個項目喺 GitHub 已經有 9.6 萬 star,代表 AI 開始直接用人類軟件,而唔係淨係輸出文字。
呢篇文章介紹咗一個 GitHub 上已有 9.6 萬 star 嘅開源項目 Browser Use。佢嘅核心係用多模態大模型(例如 GPT-4o、Claude)去「睇」瀏覽器畫面嘅截圖,再配合 DOM 提取嘅可交互元素列表,嚟決定下一步要點擊邊個掣、輸入咩字。同傳統用 XPath 或 CSS 選擇器嘅自動化方案唔同,佢唔怕網站小改版,因為模型係靠視覺同語義理解,而唔係硬編碼嘅規則。
作者清楚指出,呢個方案唔係萬能——佢破解唔到強反爬機制(例如 Cloudflare、阿里雲盾),而且每一步都要調用一次大模型,所以又慢又貴。佢同 Anthropic 嘅 Computer Use 嘅分別在於:Computer Use 可以操作成個電腦,Browser Use 只侷限喺瀏覽器,但可以揀用邊個模型。作者特別提到三個適合用 Browser Use 嘅場景:每日自動整理行業資訊做日報、盯住商品價格、自動填寫表單。每個場景都有判斷同提醒。
整體結論係:Browser Use 代表咗一種新嘅「AI 用工具嘅方式」——AI 唔再只輸出文字,而係直接用人類用嘅軟件。雖然有限制,但對於網站經常改版、冇 API 嘅內部系統、一次性任務呢啲情況,佢比寫死腳本靈活好多。作者鼓勵讀者早啲親手試玩,體驗呢條路嘅可能性。
- Browser Use 用多模態大模型「睇圖 + 解析 DOM 元素」嚟操控瀏覽器,比傳統自動化更抗網站改版。
- 工作流程係六步循環:截圖 → 解析可交互元素 → 大模型理解 → 決策 → 執行 → 再截圖,直到任務完成。
- 同 Anthropic Computer Use 嘅分別:Browser Use 只侷限喺瀏覽器內,但可以接 GPT、Claude、Gemini 等任意模型;Computer Use 可操作整台電腦,但只能用 Claude。
- 啟發:AI 開始直接使用人類軟件,而唔係淨係輸出文字;Browser Use 係呢個方向嘅第一個代表性工具,改變咗 AI 與軟件互動嘅方式。
- 可行動點:安裝 browser-use 同 playwright,寫幾行 Python 程式碼就可以令 AI 自動搜尋網頁、整理資訊,即時上手體驗。
Browser Use 開源庫
令 AI 自動操作瀏覽器嘅 Python 庫,GitHub 上已有 9.6 萬 star。
呢個項目做咩?同傳統自動化有咩分別?
寫過爬蟲或者 Selenium 腳本嘅人都知,網站改版係最大痛點。Browser Use 嘅解法係:用多模態大模型直接「睇」頁面截圖,同時從 DOM 抽取出所有可點擊同輸入嘅元素,俾模型決定下一步動作。
- requests + BeautifulSoup:靠解析 HTML 同 DOM 選擇器,改版即死。
- Selenium / Playwright:寫死 XPath 或 CSS 選擇器,改版照樣癱。
- Browser Use:多模態大模型「睇」截圖 + 解析可交互元素,改版多數仲行到。
但係要潑一盆冷水:Cloudflare、阿里雲盾、瑞數呢類強反爬照樣會攔,佢唔係繞過風控嘅銀彈。
邊啲場景用得著?有咩限制?
作者提出三個真正適合嘅場景,每個都有具體嘅判斷同提醒。
- 1 每日自動整理行業資訊做日報:定時打開固定資訊源,模型理解「咩內容值得放」,唔係機械堆連結;偶爾被登錄彈窗卡住,加句「遇到彈窗關掉」就解決。
- 2 盯商品價格到位通知:用到專門工具更省錢,但 Browser Use 唔使為每個網站寫代碼,同一段 task 換個網址就搞掂。
- 3 自動填選項好多嘅表單:根據準備好嘅回答說明填寫,但必須人工校驗,尤其係「其他(請說明)」呢類開放題容易出古古怪怪嘅答案。
做唔好嘅嘢:複雜驗證碼(滑塊、點選漢字、reCAPTCHA)、強反爬牆、超過 20–30 步嘅長任務容易走錯路。
上手實戰:由零到第一次跑通
首先,確保 Python 3.11 或以上。然後安裝 browser-use 同瀏覽器內核。配好大模型 API key,就可以寫最細嘅程式碼。
import asyncio
from browser_use import Agent, ChatOpenAI
async def main():
agent = Agent(
task="打開百度,搜索 Browser Use,把第一條結果的標題告訴我",
llm=ChatOpenAI(model="gpt-4o"),
)
await agent.run()
asyncio.run(main())- 第一次跑通標誌:終端打印出任務結果,顯示第一條結果標題。
- 想睇瀏覽器實時操作?確保 headless 係 False(預設就係可見)。
- 想記住登錄態?複用 Chrome 用戶目錄:設定 user_data_dir 參數,第一次手動登錄,之後自動帶 cookie 啟動。
常見報錯:Executable doesn't exist 代表未裝瀏覽器內核,跑 playwright install chromium;Incorrect API key 就檢查環境變數;任務卡喺某個頁面就喺 task 描述加句「遇到彈窗關掉」。
原理:六步循環,同最終啟發
代價係每一步都要等模型推理,一個 30 步嘅任務就係 30 次 API 調用,慢同貴係天生缺點。
模型在變強,但真正改變工作方式的,往往是圍繞模型的工具和流程。
Browser Use 代表咗一類新嘅「AI 用工具的方式」——AI 不再只輸出文字,它能直接去用人類用的軟件。
呢條路先啱開始,瀏覽器只係第一個被接管嘅入口。早啲親手玩過,就早啲知道條路通去邊。
Browser Use 呢個項目喺 GitHub 上已經有 9.6 萬個 star。佢做嘅嘢好直接:你講一段中文,瀏覽器就會幫你完成網頁操作。
項目地址: https://github.com/browser-use/browser-use[1]
先睇一個場景
打開終端,打一行指令:
回車。
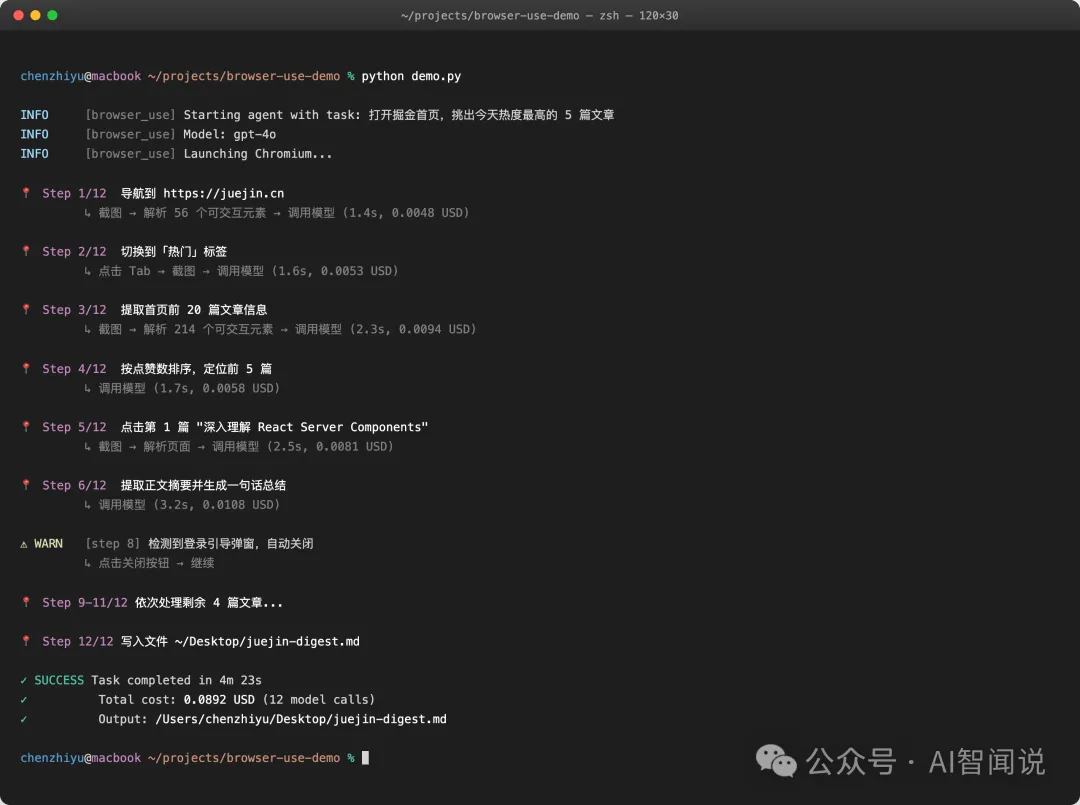
一個 Chromium 視窗彈出嚟,自動打開 juejin.cn,等頁面加載、識別熱門文章列表、按熱度排序、逐一點開前 5 篇提取標題同摘要、關掉中途出現嘅彈窗,最後喺桌面生成一份 juejin-digest.md。
全程冇用鍵盤同滑鼠。
呢個就係 Browser Use——一個開源 Python 庫,令大模型好似人咁用瀏覽器。
下面係一次完整運行嘅終端日誌,可以直觀感受佢點樣一步步完成任務:
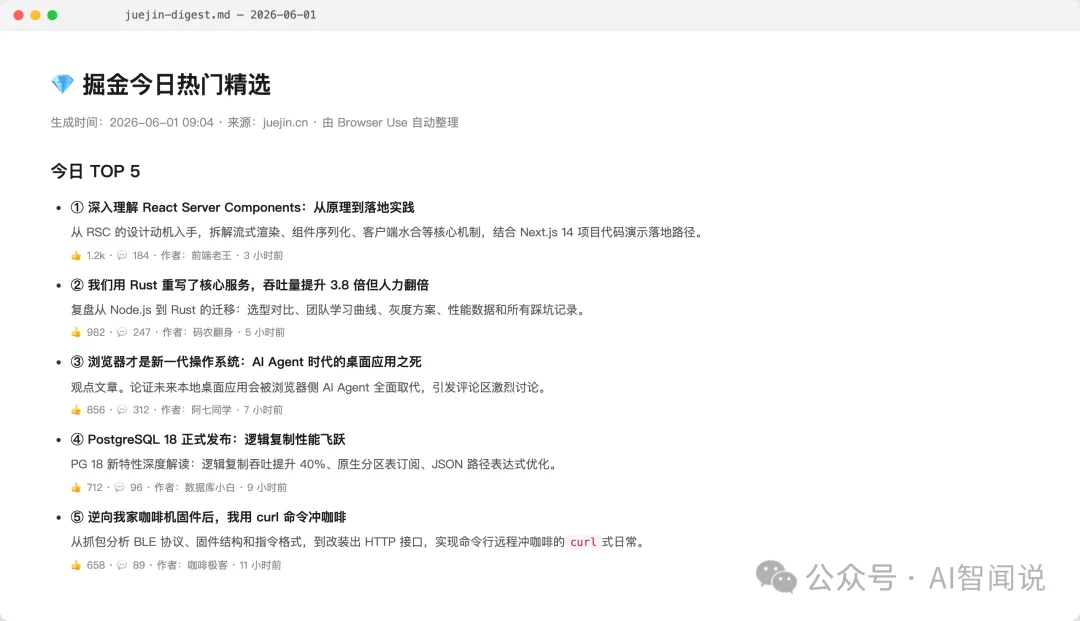
最後生成嘅產物係咁樣:
呢樣嘢同以前嘅「自動化」有咩本質區別
寫過爬蟲、寫過 Selenium 腳本嘅人會問:自動化操作瀏覽器唔係十幾年前就有喇咩?
差別在 「靠咩定位元素」:
多模態大模型 = 可以直接睇圖、唔只係睇文字嘅大模型,例如 GPT-4o、Claude Sonnet、Gemini。
前兩種方案嘅本質係「按規則匹配 DOM」,規則一改就冇用。Browser Use 嘅做法係:將當前瀏覽器畫面截圖 + 抽出頁面上所有可點擊/可輸入嘅元素列表,一齊交俾大模型判斷「而家應該做咩、撳邊個」,然後調用 Playwright 將動作落到頁面上。
同人用瀏覽器好相似——人唔會睇 DOM 選擇器,人就係「見到一個掣,伸手去撳」。
要潑一盆冷水:Browser Use 對小幅改版好穩定,但唔等於無敵。Cloudflare、阿里雲盾、瑞數呢類強反爬一樣會攔。佢解決嘅係「DOM 選擇器維護成本」同「網頁結構複雜冇辦法用腳本」嘅問題,唔係繞過風控嘅銀彈。
順便講清楚:同 Anthropic 嘅 Computer Use 係咩關係
好多人將呢兩個搞亂,簡單區分:
簡單直接咁揀:要操作瀏覽器以外嘅嘢(Excel、本地檔案、桌面軟件)用 Computer Use;淨係喺網頁入面搞嘢用 Browser Use。
兩者邊界正在模糊——Browser Use 都喺度融合「睇像素 + 計座標點擊」嘅 Computer Use 模式,俾 Claude 系列模型默認開啓。
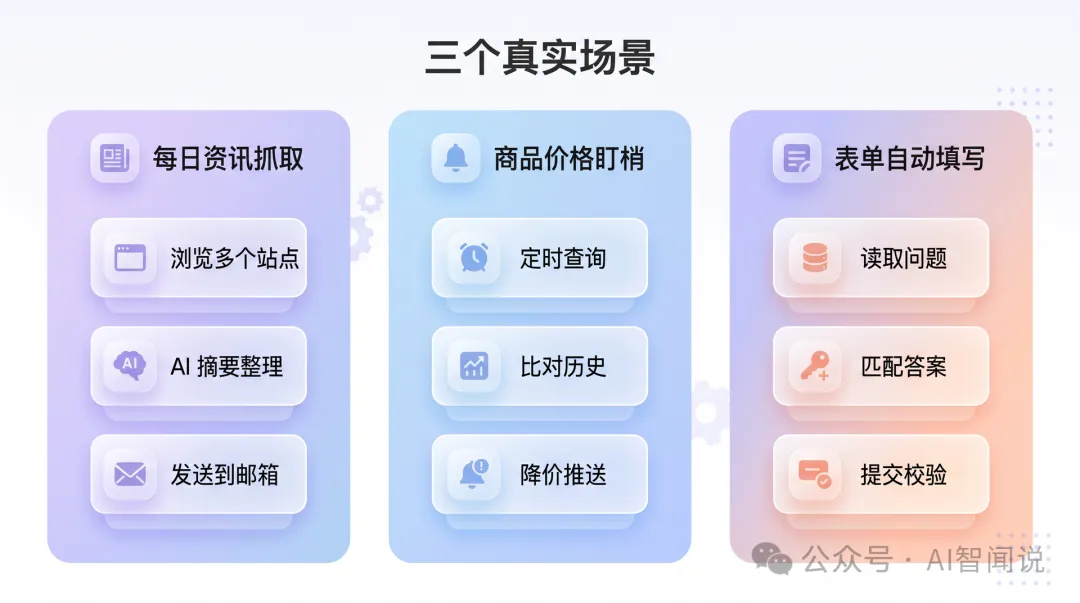
三個適合用 Browser Use 嘅場景
下面三個場景都係佢真正擅長嘅方向。具體效果會隨網絡、模型、網站狀態浮動,冇必要執著絕對數字,關鍵係睇佢嘅能力邊界喺邊。
場景一:每日早上自動執行業資訊做日報
任務描述:定時打開幾個固定資訊源(掘金、InfoQ、若干公眾號網頁版、知乎專欄),揀出最新更新,每條做一句話摘要,整理成 markdown 發去郵箱或存到本地。
判斷:完全可用。比起 RSS 工具嘅好處係模型能理解「咩內容值得放入日報」,唔係機械式堆連結。間中會被某個站點嘅登錄彈窗或權限牆卡住,task 入面加多句「遇到彈窗就關掉」就能解決大半。
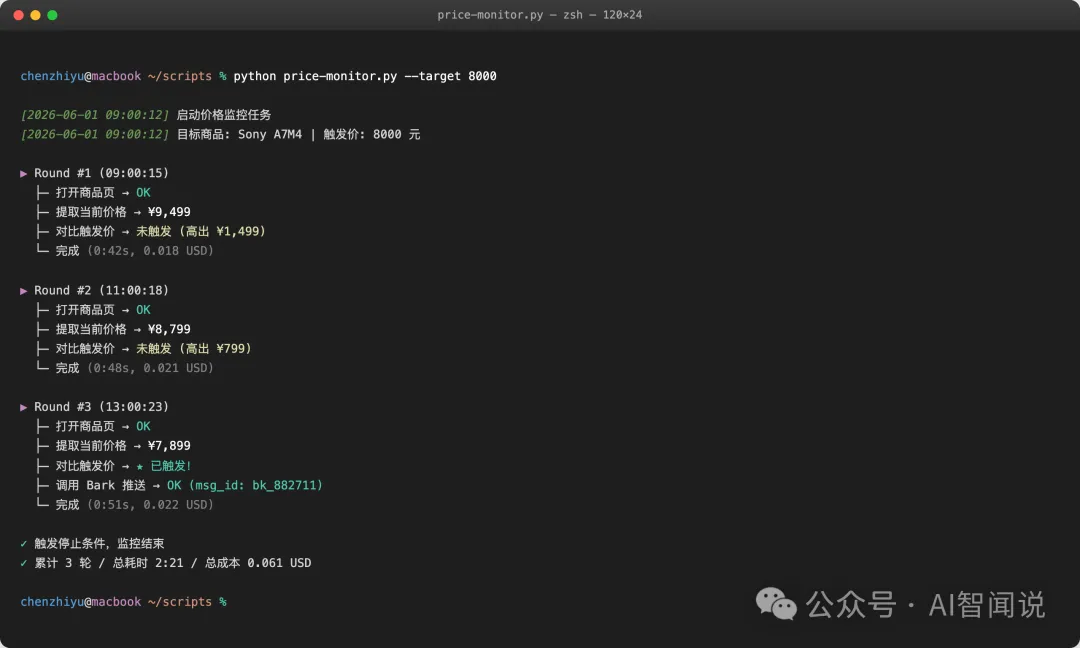
場景二:睇住一個商品價格,到位通知
任務描述:睇住某電商頁面一個商品嘅價格,每隔幾小時檢查一次,達到目標價就透過推送服務(Server 醬、Bark、企微機器人)通知。
判斷:用得,但老實講:呢種任務用專門比價工具或一段 Playwright 腳本更慳錢亦更穩定。AI 方案嘅真正價值係唔使為每個新網站獨立寫代碼——同一段 task 描述換個網址就跑到。
一次實際運行嘅日誌參考:
場景三:自動填一份選項好多嘅表單
任務描述:內部調研問卷或公開表單,根據一份事先準備好嘅回答說明,按要求填寫並提交。
判斷:用得但一定要人工校驗。表單類任務最怕填錯,建議喺 task 入面要求 AI 提交前先產生一份「答案預覽」,人睇一眼先放行。「其他(請說明)」呢種開放題間中會猶豫或填出奇怪答案,對成功率要求高嘅場景要小心用。
上手:由零到第一次成功運行
環境準備:
Playwright = 微軟出品嘅瀏覽器自動化底層工具,Browser Use 用佢嚟執行真實嘅點擊同輸入動作。
最細可以跑嘅代碼:
存成 demo.py,運行 python demo.py,瀏覽器會自動彈出嚟開始操作。
第一次成功運行嘅標誌:終端打印出任務結果,並俾出搜到嘅第一條標題。
想睇瀏覽器實時操作?關閉無頭模式
默認情況下瀏覽器係「可見」嘅,但如果你裝咗某啲雲端版本或者改咗配置,可能跑親都睇唔到嘢。強制令瀏覽器顯示出嚟:
想令佢「記得登錄狀態」?重用 Chrome 用戶目錄
每次都要重新登錄係新手最頭痛嘅問題。解決方法係令 Browser Use 重用一個固定嘅用戶目錄——你手動登錄一次,下次自動帶住 cookie 啓動:
第一次跑會彈出空白瀏覽器,你手動登錄目標網站;之後所有任務都會帶住呢套登錄狀態啓動。注意:呢個目錄入面會存放 cookie 同緩存,等同密碼,唔好提交到 git。
常見錯誤
原理:六步循環
成個工作流程就係一個不斷循環嘅過程:
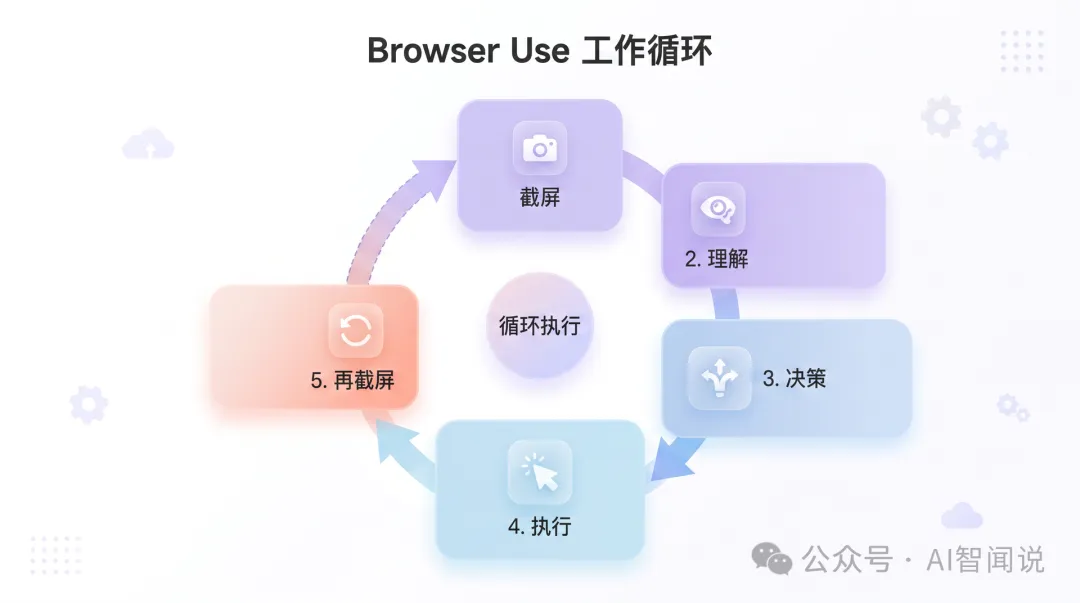
注意第 2 步——Browser Use 唔係淨係「睇圖」。佢同時將頁面入面可以交互嘅元素提取出嚟俾模型一份清單,咁樣模型可以話「撳第 7 號連結」而唔係「撳座標 (480, 320)」。呢個係佢比純 Computer Use 喺網頁場景下更準嘅原因。
但代價係:每一步都要調一次多模態大模型 + 等模型回應 + 執行動作 + 再截圖。一個 30 步嘅任務就係 30 次模型調用,呢個就係佢慢同貴嘅根本原因。
而家嘅邊界:做到咩、做唔到咩
冇吹水。呢樣嘢而家仲有唔少限制,事前講清楚好過事後失望。
做唔好嘅事:
適合嘅場景:
唔適合嘅場景:
寫喺最後
模型變緊強,但真正改變工作方式嘅,往往係圍繞模型嘅工具同流程。Browser Use 唔係又一個新 AI 工具,佢代表咗一類新嘅「AI 用工具嘅方式」——AI 唔再淨係輸出文字,佢可以直接去用人類用嘅軟件。呢條路先啱啱開始,瀏覽器只係第一個俾佢接管嘅入口。
國內中文社羣對佢嘅深度內容仲好少,大部分人只係聽過個名。早啲親手玩過,就早啲知道呢條路可以去到邊。
Browser Use 這個項目在 GitHub 上已經累積了 9.6 萬 star。它做的事很直接:你說一段中文,瀏覽器就開始替你完成網頁操作。
項目地址: https://github.com/browser-use/browser-use[1]
先看一個場景
打開終端,敲一行命令:
回車。
一個 Chromium 窗口彈出來,自動打開 juejin.cn,等頁面加載、識別熱門文章列表、按熱度排序、依次點開前 5 篇提取標題和摘要、關掉中途出現的彈窗,最後在桌面生成一份 juejin-digest.md。
全程沒用鍵盤和鼠標。
這就是 Browser Use——一個開源 Python 庫,讓大模型像人一樣使用瀏覽器。
下面是一次完整運行的終端日誌,可以直觀感受它是怎麼一步步走完任務的:
最終生成的產物長這樣:
這玩意跟以前的"自動化"有什麼本質區別
寫過爬蟲、寫過 Selenium 腳本的人會有疑問:自動化操作瀏覽器不是十幾年前就有了嗎?
差別在 "靠什麼定位元素":
多模態大模型 = 能直接看圖、不只會讀文字的大模型,比如 GPT-4o、Claude Sonnet、Gemini。
前兩種方案的本質是"按規則匹配 DOM",規則一改就廢。Browser Use 的做法是:把當前瀏覽器畫面截圖 + 抽取出頁面上所有可點擊/可輸入的元素列表,一起交給大模型判斷"現在該做什麼、點哪個",然後調用 Playwright 把動作落到頁面上。
跟人用瀏覽器很像——人也不去看 DOM 選擇器,人就是"看到一個按鈕,伸手去點"。
需要潑一盆冷水:Browser Use 對小幅改版很魯棒,但不等於無敵。Cloudflare、阿里雲盾、瑞數這類強反爬照樣會攔。它解決的是"DOM 選擇器維護成本"和"網頁結構複雜沒法用腳本"的問題,不是繞過風控的銀彈。
順便說清楚:跟 Anthropic 的 Computer Use 是什麼關係
很多人把這兩個搞混,簡單區分:
簡單粗暴地選:要操作瀏覽器外的東西(Excel、本地文件、桌面軟件)用 Computer Use;只在網頁裏折騰用 Browser Use。
兩者邊界正在模糊——Browser Use 也在融合"看像素 + 算座標點擊"的 Computer Use 模式,給 Claude 系列模型默認開啓。
三個適合用 Browser Use 的場景
下面三個場景都是它真正擅長的方向。具體效果會隨網絡、模型、網站狀態浮動,沒必要糾結絕對數字,關鍵是看它的能力邊界在哪。
場景一:每天早上自動抓行業資訊做日報
任務描述:定時打開幾個固定信息源(掘金、InfoQ、若干公眾號網頁版、知乎專欄),挑出最新更新,每條做一句話摘要,整理成 markdown 發到郵箱或存到本地。
判斷:完全可用。比 RSS 工具的好處是模型能理解"什麼內容值得放進日報",不是機械堆連結。偶爾會被某個站點的登錄彈窗或權限牆卡住,task 裏多寫一句"遇到彈窗就關掉"能解決大半。
場景二:盯一個商品價格,到位通知
任務描述:盯某電商頁面一個商品的價格,每隔幾小時檢查一次,達到目標價就通過推送服務(Server 醬、Bark、企微機器人)通知。
判斷:能用,但要誠實:這種任務用專門比價工具或一段 Playwright 腳本更省錢也更穩。AI 方案的真正價值是不用為每個新網站單獨寫代碼——同一段 task 描述換個網址就能跑。
一次實際運行的日誌參考:
場景三:自動填一份選項很多的表單
任務描述:內部調研問卷或公開表單,根據一份事先準備好的回答說明,按要求填寫並提交。
判斷:可用但必須人工校驗。表單類任務最怕填錯,建議在 task 裏要求 AI 提交前先生成一份"答案預覽",人掃一眼再放過。"其他(請說明)"這種開放題偶爾會猶豫或填出奇怪答案,對成功率要求高的場景慎用。
上手:從零到第一次跑通
環境準備:
Playwright = 微軟出的瀏覽器自動化底層工具,Browser Use 用它來執行真實的點擊和輸入動作。
最小可跑代碼:
存成 demo.py,運行 python demo.py,瀏覽器會自動彈出來開始操作。
第一次跑通的標誌:終端打印出任務結果,並給出搜索到的第一條標題。
想看瀏覽器實時操作?關掉無頭模式
默認情況下瀏覽器是"可見"的,但如果你裝了某些雲端版本或者改了配置,可能跑起來啥都看不到。強制讓瀏覽器顯示出來:
想讓它"記得登錄態"?複用 Chrome 用戶目錄
每次都要重新登錄是新手最頭疼的問題。解法是讓 Browser Use 複用一個固定的用戶目錄——你手動登錄一次,下次自動帶着 cookie 啓動:
第一次跑會彈出空白瀏覽器,你手動登錄目標網站;之後所有任務都會帶着這套登錄態啓動。注意:這個目錄裏會存放 cookie 和緩存,等同密碼,別提交到 git。
常見報錯
原理:六步循環
整個工作流就是一個不斷循環的過程:
注意第 2 步——Browser Use 不是隻"看圖"。它同時把頁面裏能交互的元素提取出來給模型一份清單,這樣模型可以說"點第 7 號連結"而不是"點座標 (480, 320)"。這是它比純 Computer Use 在網頁場景下更準的原因。
但代價是:每一步都要調一次多模態大模型 + 等模型響應 + 執行動作 + 再截圖。一個 30 步的任務就是 30 次模型調用,這就是它慢和貴的根本原因。
現在的邊界:能幹什麼、不能幹什麼
不吹。這玩意現在還有不少限制,提前講清楚比事後失望好。
做不好的事:
適合的場景:
不適合的場景:
寫在最後
模型在變強,但真正改變工作方式的,往往是圍繞模型的工具和流程。Browser Use 不是又一個新 AI 工具,它代表了一類新的"AI 用工具的方式"——AI 不再只輸出文字,它能直接去用人類用的軟件。這條路才剛剛開始,瀏覽器只是第一個被它接管的入口。
國內中文社區對它的深度內容還很少,大部分人只是聽過名字。早一點親手玩過,就早一點知道這條路能通往哪裏。