Claude Code + Obsidian 實戰,Karpathy 推薦的知識管理方式
整理版優先睇
用 Claude Code 同 Obsidian,將散亂筆記編譯成可查詢嘅知識系統,仲識自我修復。
大家好,我係陸徐洲,一間 LIMS 公司嘅 AI 算法負責人。由一月尾開始,我喺公眾號寫咗 43 篇 AI 工具實戰文章,5 個欄目,涉及二十幾個工具。寫嗰陣一篇篇趕,回頭一睇全部散曬。最近有出版社揾我傾出書,我先發現呢啲內容缺一次系統性梳理——寫過啲乜、邊啲未覆蓋、下一步點走,我自己都講唔清楚。
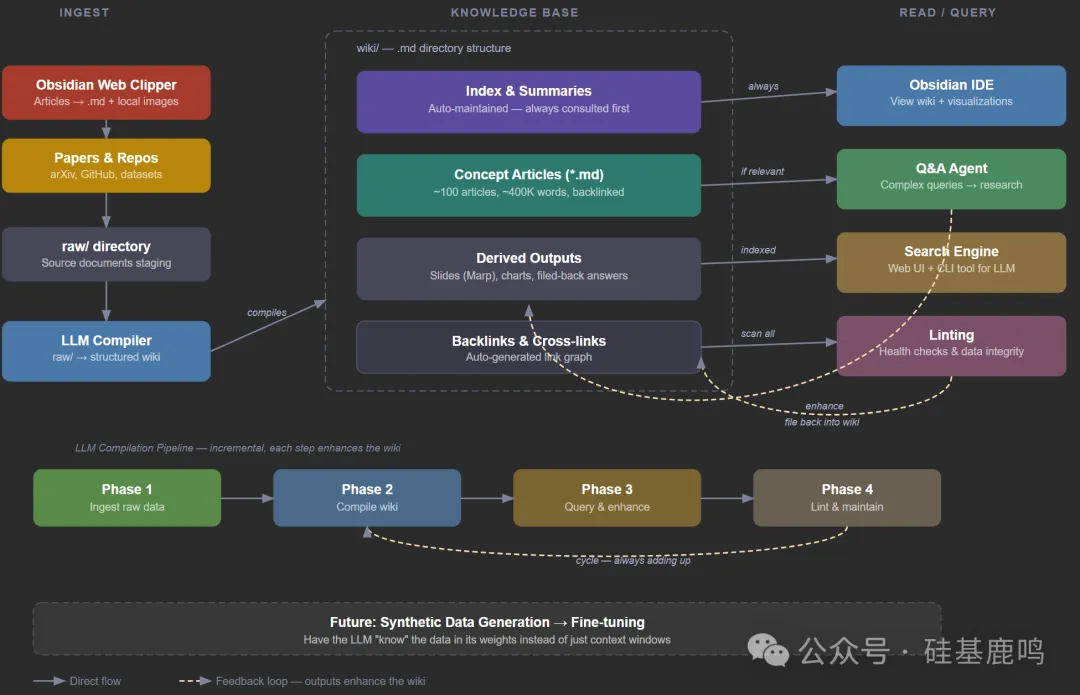
呢篇文章就係分享我用 Karpathy 嘅方法,結合 Claude Code 同 Obsidian,將散亂筆記編譯成一個可查詢、能自我修復嘅知識系統。Karpathy 認為,與其每次開新會話解析原文,不如先編譯一次,將摘要同概念關係物化成文件,之後反覆查閲就得。我照住做,用 Claude Code 掃描 43 篇文章,逐篇生成摘要卡片,提取高頻概念並用多向連結串連,最後自動產出索引。成個過程十幾分鐘,wiki 就多咗 73 個 .md 文件。
Open Obsidian 嘅 Graph View,即刻見到知識網絡全貌:Claude Code 係最大節點,28 條線連出去;MCP 喺中間,連住設計工具同筆記。我仲對個知識庫提問,發現咗一堆覆蓋空白,例如 Hooks 系統、CI/CD 集成完全冇寫過。呢套方法唔單止幫我整理過去,仲幫我規劃未來。而家出版社問內容規劃,我唔使再翻文件夾,開個 wiki 就一清二楚。
- 用 LLM 將散亂筆記編譯成知識庫,比直接問 LLM 原文更高效,每次查閲唔使重新解析。
- Claude Code 逐篇生成摘要卡片,提取概念並用多向連結連起來,自動產出索引。
- 編譯後知識庫濃縮到 5 萬字,概念關係物化成文件,唔使每次從頭推導。
- 對知識庫提問可以發現覆蓋空白同關聯,幫你規劃下一步寫作或研究方向。
- 定期檢查斷鏈,自動補建高頻概念頁,保持知識庫自我修復,越用越厚。
散亂筆記點樣變成知識系統?
我係陸徐洲,寫咗兩個月 AI 實戰文章,但 43 篇內容散落各處,連自己都唔記得寫過啲乜。Karpathy 近排分享咗一個解法:用 LLM 把散亂資料編譯成可查詢、能自我修復嘅知識系統。佢認為知識管理唔應該每次開新會話都解析原文,而係編譯一次,之後反覆查。
我決定跟住呢個思路,用 Claude Code 做編譯器,Obsidian 做知識庫前端,將呢 43 篇文章變成一個活嘅知識網絡。
Claude Code 編譯全過程
我先喺公眾號目錄下新建一個 wiki/ 文件夾,做 Obsidian vault。然後叫 Claude Code 逐篇讀完 43 篇文章,每篇生成一張摘要卡片,三五句話概括內容,標註核心觀點同涉及嘅工具。所有工具名用 [[多向連結]] 語法標註,方便後續串連。
- 掃描目錄:Claude Code 幾秒列出所有文章標題、字數、涉及工具,畀你一次過睇曬全貌。
- 生成摘要:4 個 agent 按欄目同時跑,十幾分鐘做完 43 張卡片,每張精簡到三五句。
- 提取概念:從卡片中抽高頻概念,每個概念建立獨立頁面,自動列出邊啲文章提過。例如 [[Claude Code]] 頁列出 28 篇相關文章,仲標註咗同 [[Codex CLI]] 嘅關係。
- 自動索引:最後生成全局索引、按欄目分類、按工具分類、按時間線排列,共 5 張索引。
跑完之後 wiki 有 73 個 .md 文件:43 張文章卡片、25 個概念頁、5 張索引。呢啲唔係原文複製,而係 LLM 理解之後重新組織嘅結構化產物。
知識網絡可視化同提問發現
打開 Obsidian 載入 vault,Graph View 即刻顯示知識網絡全貌:Claude Code 係最大節點,28 條線連出去;OpenCode 第二大,9 條線;MCP 喺中間,連住 Figma、Pencil 同 Obsidian。點擊任何節點都可以跳轉概念頁,再點文章連結跳到摘要卡片,好容易發現之前忽略嘅關聯。
- 1 第一個問題:列出覆蓋矩陣,發現 4 個重要功能完全未寫過。
- 2 第二個問題:分析關聯,見到 OpenCode 同 Superpowers 係孤島,MCP 從未做主角。
- 3 第三個問題:推薦選題,畀咗 Claude Code Hooks 實戰、MCP Server 橫評、OpenCode + Superpowers 橋接,每個都附有關聯文章同理由。
呢啲問答結果唔係聊天記錄,Claude Code 直接將分析保存成兩個 .md 文件,下次規劃選題打開就用得。
自我修復同持續更新
最後做一輪校驗:叫 Claude Code 掃描所有多向連結,檢查邊啲連結冇對應文件。結果掃出 32 個斷鏈——例如 [[Kimi]] 被 4 篇文章引用但冇概念頁,[[GLM-5]]、[[BMAD]] 都係一樣。Claude Code 自動補建咗 7 個高頻概念頁,斷鏈降到 25 個,剩低嘅都係低頻模型版本號,唔值得單獨建。
呢套方法適合任何有大量散落 .md 文件嘅人——筆記、文檔、讀書摘錄都啱。初次編譯要等十幾分鐘,Obsidian 對非技術用戶有少少門檻,但換來嘅係一個活嘅、會自我成長嘅知識系統。
筆記越記越多,但從來唔翻。你係咪都係咁?
Karpathy 最近分享咗佢嘅解法:用 LLM 將散亂資料編譯成可以查、可以自我修復嘅知識系統。
大家好,我係陸徐洲。
由一月底到而家,我個公眾號陸續寫咗 43 篇實戰文章,5 個欄目,涉及二十幾個 AI 工具。寫嘅時候一篇一篇趕住出,回頭一睇全部都散收收。
最近有出版社揾我傾合作出書,我先發現呢啲內容欠一次系統性嘅梳理,寫過啲乜、邊啲未覆蓋、下一步去邊度,我自己都講唔清楚。
個幾月前我寫過一篇 Obsidian 嘅介紹文章,當時講得比較粗疏。
唔好搞 NotebookLM 啦,呢套免費方案對中文用戶更友好
今次結合 Karpathy 嘅方法同呢段時間嘅使用經驗,我想將完整嘅實操過程呈現一次,亦都俾大家嘅知識管理提供一啲思路。
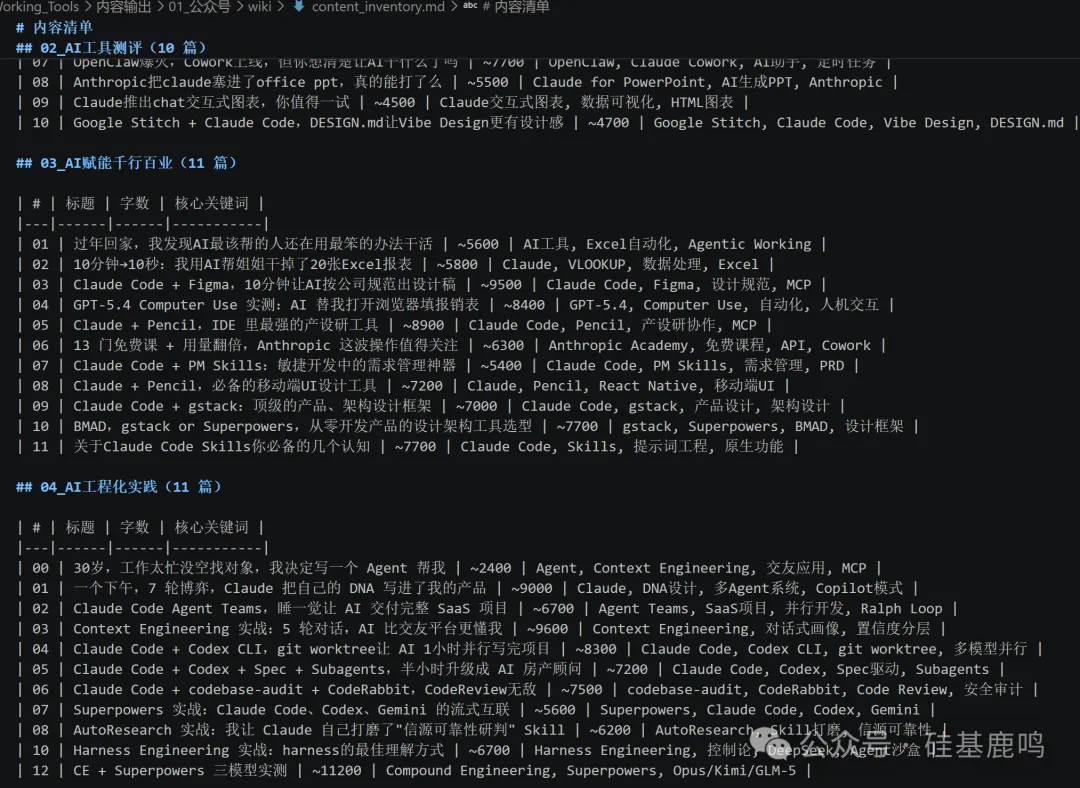
先俾 Claude Code 掃描成個目錄,生成內容清單。 43 篇文章嘅標題、字數、涉及嘅工具,幾秒鐘全部列曬出嚟。呢一步唔複雜,但意義在於你第一次喺一個地方見到自己所有內容嘅全貌。
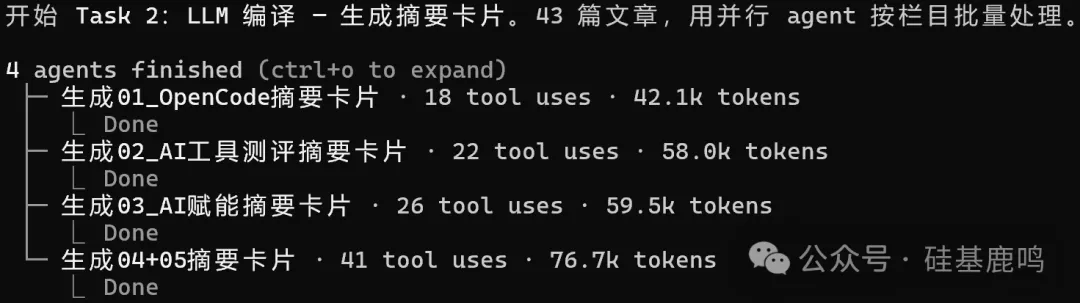
然後係最核心嘅一步:LLM 編譯。
我喺公眾號目錄下新建咗一個 wiki/ 文件夾作為 Obsidian vault。Claude Code 逐篇讀完 43 篇文章,每篇生成一張摘要卡片,三幾句話概括內容,標註核心觀點同涉及嘅工具。所有工具名用 Obsidian 嘅 [[雙向連結]] 語法標註,例如 [[Claude Code]]、[[MCP]]。呢個唔係裝飾,後面成個知識網絡行得鬱就靠呢啲連結。
成個編譯過程我拆成咗多個任務,Claude Code 按順序一步步行。

生成摘要卡片呢步最耗時,4 個 agent 按欄目同時行,十幾分鐘全部行完。
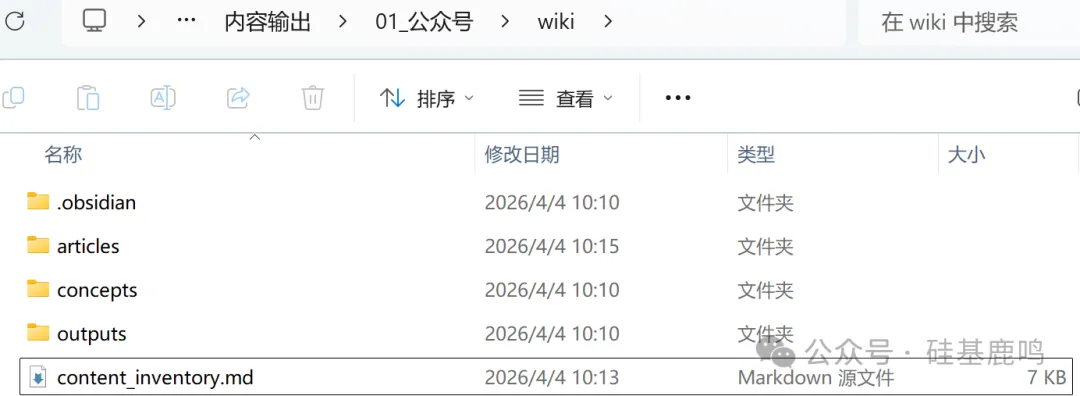
43 張卡片出咗之後,Claude Code 又從裏面提取高頻概念,每個概念生成一個獨立頁面。呢一步同樣並行處理,兩個 agent 同時行上下兩批。

比如 [[Claude Code]] 嘅概念頁,自動列出咗 28 篇提到佢嘅文章,仲標註咗同 [[Codex CLI]]、[[Superpowers]]、[[MCP]] 之間嘅關係。你唔使手動整理「邊篇文章用咗咩工具」,LLM 幫你將關聯全部抽曬出嚟。
最後自動生成四張索引:全局索引、按欄目分類、按工具分類、按時間線排列。
行完之後 wiki 裏面有 73 個 .md 檔案:43 張文章卡片、25 個概念頁、5 張索引。
呢啲唔係原文嘅複製貼上,而係 LLM 理解之後重新組織嘅結構化產物。是但打開一張摘要卡片,係咁樣:

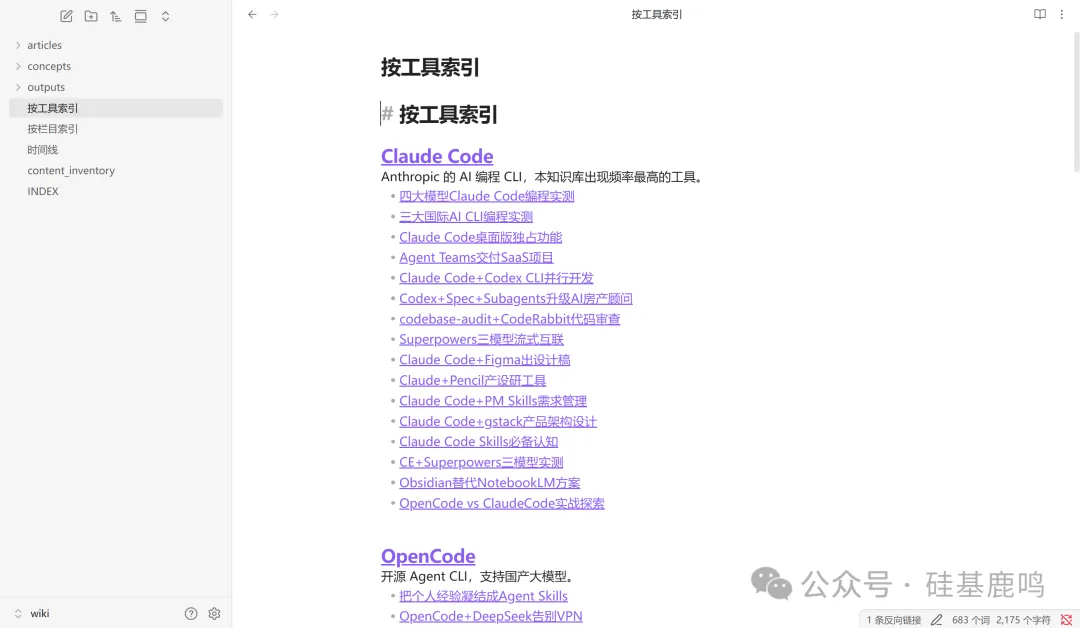
按工具索引頁裏面,每個工具下面掛住所有提到佢嘅文章連結,一目瞭然:
點解叫「編譯」?直接俾 Claude Code 讀 43 篇原文都可以回答問題,但咁樣每次開新對話都要重新解析 30 萬字,每次推導出嚟嘅關係仲未必一樣。wiki 係編譯之後嘅產物,摘要濃縮到 5 萬字,概念關係已經物化成檔案,唔使每次都從頭嚟過。
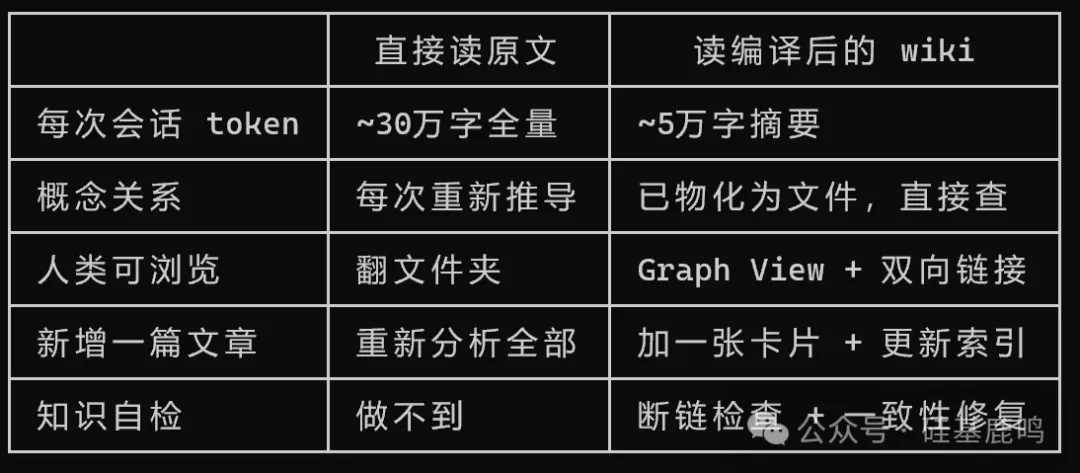
打個比喻,你每次執行程序係行編譯後嘅二進制,唔係每次都從源碼重新解釋執行。知識管理都係一樣,編譯一次,後面反覆查就得。
打開 Obsidian 載入 vault,Graph View 可以直接見到知識網絡嘅全貌。
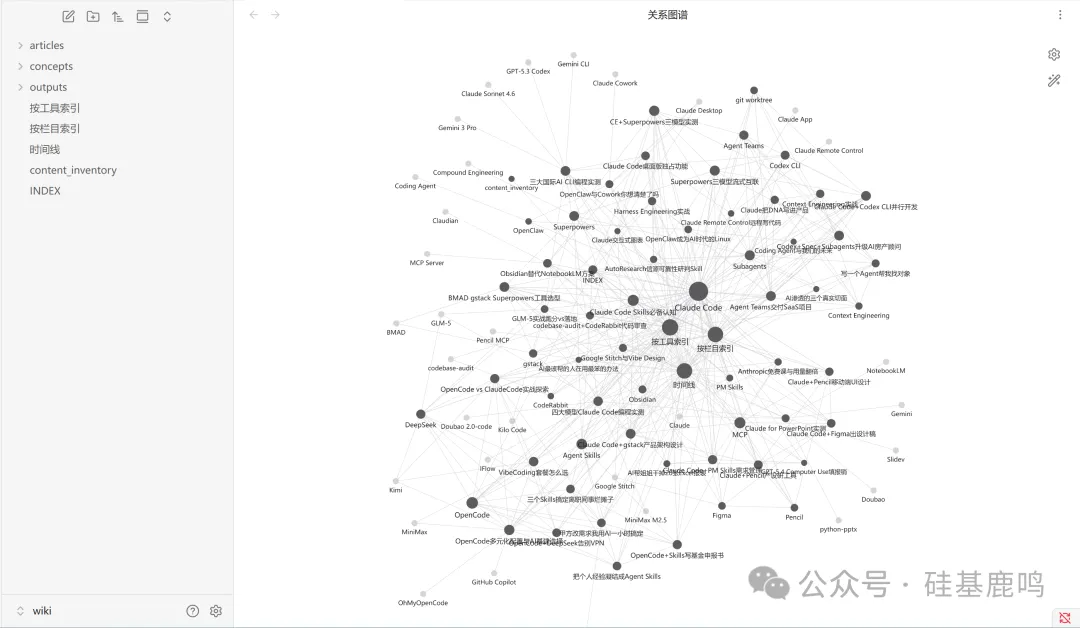
Claude Code 係最大嘅節點,28 條線連出去。OpenCode 第二大,9 條線。MCP 喺中間位置,一邊連住 Figma 同 Pencil 呢啲設計工具,一邊連住 Obsidian。
㩒入任何一個概念節點,跳去概念頁,再㩒文章連結跳去摘要卡片,一路㩒落去會發現之前完全冇留意到嘅關聯。例如我寫過 Pencil 同 gstack 各自嘅文章,但從未想過將佢哋組合埋一齊。喺圖譜上佢哋離得好近,呢個交叉選題就浮出嚟。
首頁 INDEX 都可以直接導航到各個索引同最近文章:

接下來係我覺得收穫最大嘅環節——對知識庫發問。
我問 Claude Code:「寫過邊啲 Claude Code 能力點,仲有咩重要功能未覆蓋?」佢掃完概念頁同卡片,俾咗一張覆蓋矩陣。Agent Teams、Subagents、Skills、git worktree 都有深度文章。
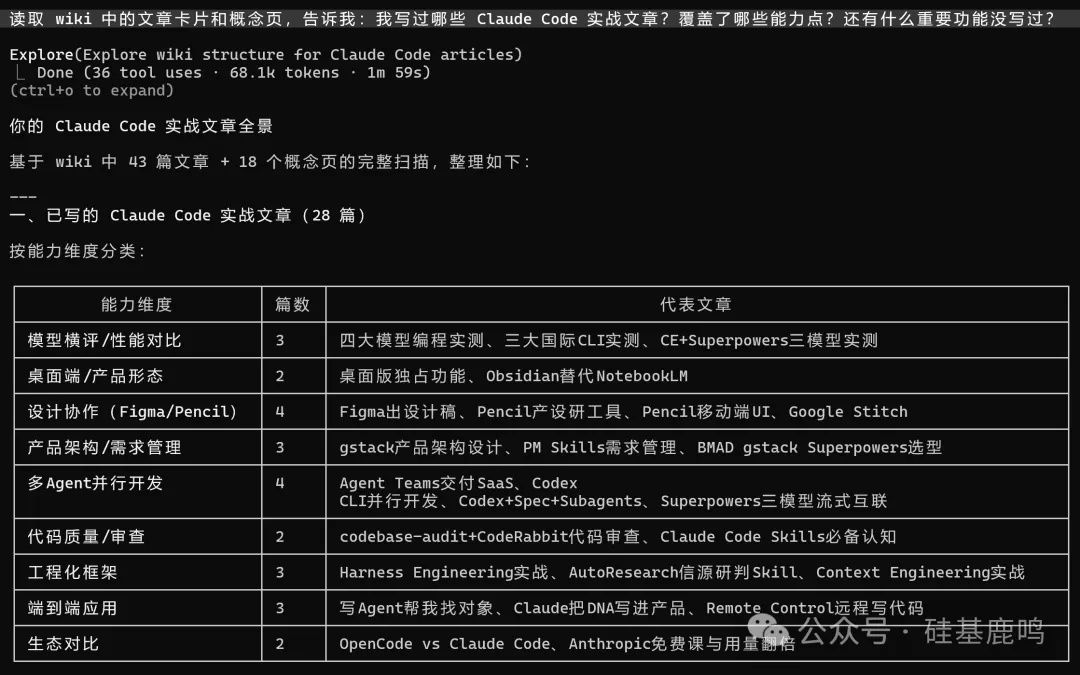
但空白區令我冇諗到:Hooks 系統、IDE 插件、CI/CD 集成、Memory 持久記憶全部係零覆蓋。 寫咗兩個月,呢啲重要功能我完全未掂過。
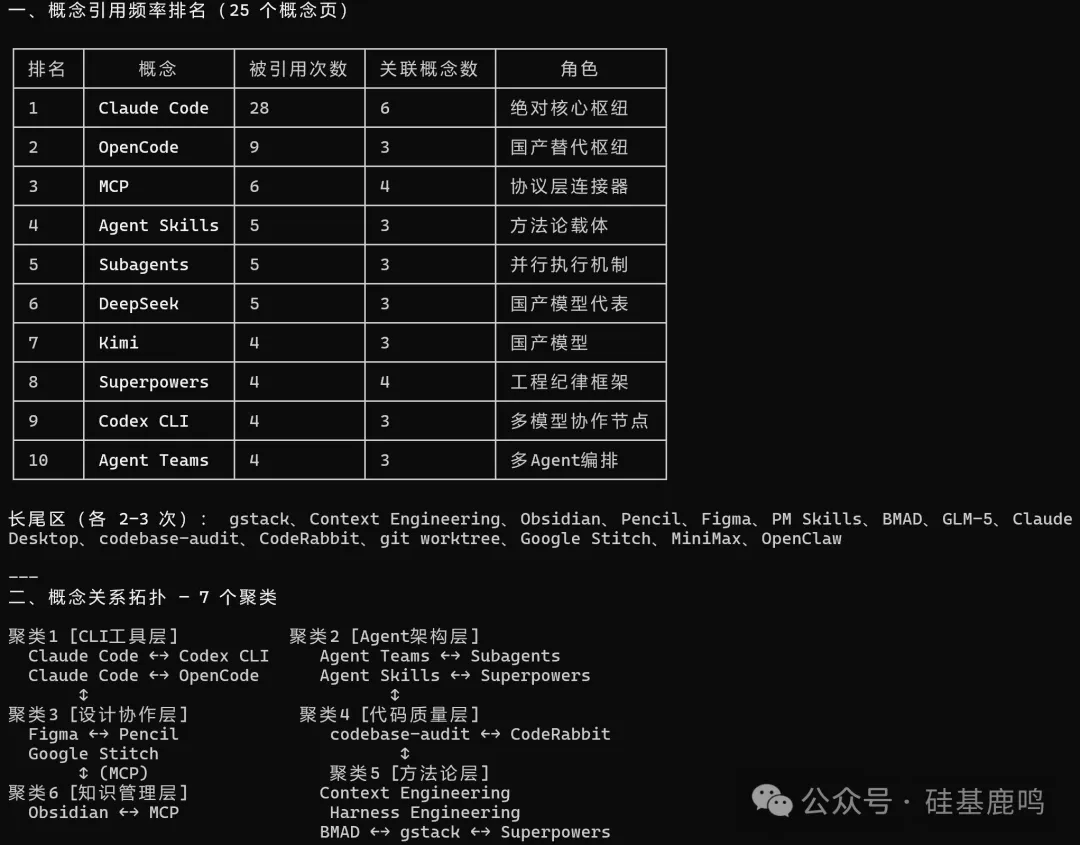
再問關聯發現。OpenCode 有 9 篇,Superpowers 有 4 篇,兩者零交叉。MCP 出現 6 次但從未做過文章主角。佢仲行出一張概念引用頻率表同 7 個聚類拓撲圖,將我所有文章涉及嘅工具分成咗 CLI 工具層、Agent 架構層、設計協作層、方法論層呢啲聚類。邊啲聚類之間有連線、邊啲係孤島,一眼就睇得出。
第三個問題叫佢推薦接下來應該寫咩。佢俾咗三個選題:Claude Code Hooks 實戰(零覆蓋嘅高級功能)、MCP Server 橫評(散見各文但冇專題)、OpenCode + Superpowers(兩座孤島嘅橋)。每個都附咗關聯已有文章同理由。呢啲靠自己翻文件夾係發現唔到嘅。
呢啲問答結果唔係聊天記錄。Claude Code 將分析保存成咗兩個 .md 檔案,下次規劃選題直接打開就可以用。

最後做一輪校驗。 俾 Claude Code 掃描所有雙向連結,睇下邊啲連結冇對應檔案。掃出 32 個斷鏈——[[Kimi]] 被 4 篇文章引用但冇概念頁,[[GLM-5]]、[[BMAD]] 都一樣。Claude Code 自動補建咗 7 個高頻概念頁,斷鏈降到 25 個。剩低嘅都係低頻嘅模型版本號,唔值得單獨建。
呢個就係 Karpathy 講嘅「知識庫自我修復」。你唔使盯住每個細節,LLM 幫你查漏補缺。
而且呢套嘢係生嘅。每次寫新文章,生成一張摘要卡片掟入 wiki,更新索引同概念頁。知識越查越厚,連結越修越密。
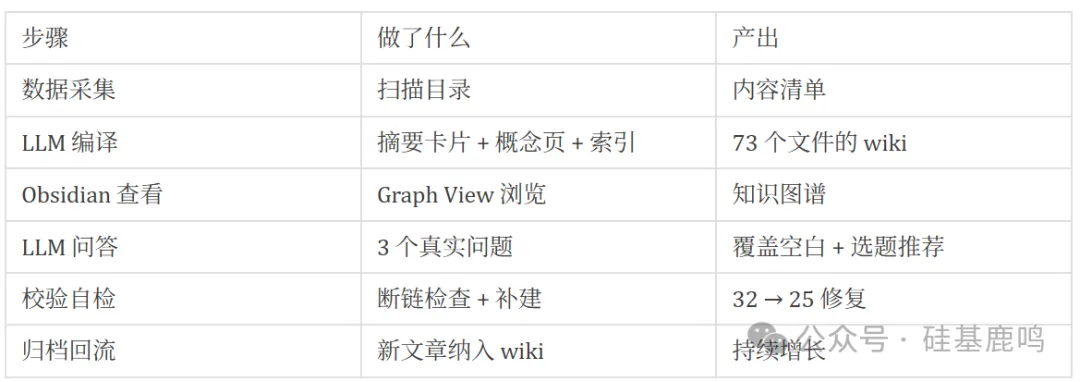
簡單睇下每個步驟都做咗啲咩。
對我嚟講收穫最大嘅唔係圖譜幾靚,而係嗰幾個問題嘅答案。兩個月寫咗啲咩、仲缺啲咩、下一篇應該寫咩,行完呢套流程心裏就有數。出版社再問內容規劃,都唔使當場翻文件夾。
呢套方法適合任何有大量散落 .md 檔案嘅人,筆記、文檔、讀書摘錄都得。侷限係初次編譯需要行十幾分鐘,Obsidian 對非技術用戶有門檻。
大多數人用筆記軟件,嘢存咗入去就唔會再翻。工具唔係問題,問題係你嘅知識有冇被用起嚟。
我係陸徐洲,一間 LIMS 公司嘅 AI 算法負責人。關注我,等我哋一齊喺 AI 落地實踐嘅路上,行得更遠。
多謝你睇我嘅文章。有任何關於 AI 提效或者工程落地實踐方面嘅問題都可以加我微信,交個朋友,一齊探討,共同進步。

筆記越記越多,但從來不翻。你是不是也這樣?
Karpathy 最近分享了他的解法:用 LLM 把散亂資料編譯成可查詢、能自我修復的知識系統。
大家好,我是陸徐洲。
從一月底到現在,我的公眾號陸續寫了 43 篇實戰文章,5 個欄目,涉及二十多個 AI 工具。寫的時候一篇一篇往前趕,回頭一看全是散的。
最近有出版社找我聊合作出書,我才發現這些內容缺一次系統性的梳理,寫過什麼、哪些還沒覆蓋、下一步往哪走,我自己都說不清楚。
一個多月前我寫過一篇 Obsidian 的介紹文章,當時講得比較粗淺。
這次結合 Karpathy 的方法和這段時間的使用經驗,我想把完整的實操過程呈現一次,也給大家的知識管理提供一點思路。
先讓 Claude Code 掃描整個目錄,生成內容清單。 43 篇文章的標題、字數、涉及的工具,幾秒鐘全部列出來。這一步不復雜,但意義在於你第一次在一個地方看到自己所有內容的全貌。
然後是最核心的一步:LLM 編譯。
我在公眾號目錄下新建了一個 wiki/ 文件夾作為 Obsidian vault。Claude Code 逐篇讀完 43 篇文章,每篇生成一張摘要卡片,三五句話概括內容,標註核心觀點和涉及的工具。所有工具名用 Obsidian 的 [[雙向連結]] 語法標註,比如 [[Claude Code]]、[[MCP]]。這不是裝飾,後面整個知識網絡能跑起來就靠這些連結。
整個編譯過程我拆成了多個任務,Claude Code 按順序一步步跑。
生成摘要卡片這步最耗時,4 個 agent 按欄目同時跑,十來分鐘全部跑完。
43 張卡片出來之後,Claude Code 又從裏面提取高頻概念,每個概念生成一個獨立頁面。這一步同樣並行處理,兩個 agent 同時跑上下兩批。
比如 [[Claude Code]] 的概念頁,自動列出了 28 篇提到它的文章,還標註了和 [[Codex CLI]]、[[Superpowers]]、[[MCP]] 之間的關係。你不用手動整理"哪篇文章用了什麼工具",LLM 幫你把關聯全部抽出來了。
最後自動生成四張索引:全局索引、按欄目分類、按工具分類、按時間線排列。
跑完之後 wiki 裏有 73 個 .md 文件:43 張文章卡片、25 個概念頁、5 張索引。
這些不是原文的複製粘貼,而是 LLM 理解之後重新組織的結構化產物。隨便打開一張摘要卡片,長這樣:
按工具索引頁裏,每個工具下面掛着所有提到它的文章連結,一目瞭然:
為什麼叫"編譯"?直接讓 Claude Code 讀 43 篇原文也能回答問題,但那是每次開新會話都要重新解析 30 萬字,每次推導出來的關係還不一定一樣。wiki 是編譯後的產物,摘要濃縮到 5 萬字,概念關係已經物化成文件,不用每次從頭來。
打個比方,你每次運行程序是跑編譯後的二進制,不是每次從源代碼重新解釋執行。知識管理也是一樣,編譯一次,後面反覆查就行了。
打開 Obsidian 加載 vault,Graph View 能直接看到知識網絡的全貌。
Claude Code 是最大的節點,28 條線連出去。OpenCode 第二大,9 條線。MCP 在中間位置,一邊連着 Figma 和 Pencil 這些設計工具,一邊連着 Obsidian。
點進任何一個概念節點,跳到概念頁,再點文章連結跳到摘要卡片,一路點下去能發現之前完全沒注意到的關聯。比如我寫過 Pencil 和 gstack 各自的文章,但從沒想過把它們組合起來。在圖譜上它們離得很近,這個交叉選題就浮出來了。
首頁 INDEX 也能直接導航到各個索引和最近文章:
接下來是我覺得收穫最大的環節——對知識庫提問。
我問 Claude Code:"寫過哪些 Claude Code 能力點,還有什麼重要功能沒覆蓋?"它掃完概念頁和卡片,給了一張覆蓋矩陣。Agent Teams、Subagents、Skills、git worktree 都有深度文章。
但空白區讓我沒想到:Hooks 系統、IDE 插件、CI/CD 集成、Memory 持久記憶全是零覆蓋。 寫了兩個月,這些重要功能我完全沒碰過。
再問關聯發現。OpenCode 有 9 篇,Superpowers 有 4 篇,兩者零交叉。MCP 出現 6 次但從沒當過文章主角。它還跑出來一張概念引用頻率表和 7 個聚類拓撲圖,把我所有文章涉及的工具分成了 CLI 工具層、Agent 架構層、設計協作層、方法論層這些聚類。哪些聚類之間有連線、哪些是孤島,一眼就看出來了。
第三個問題讓它推薦接下來該寫什麼。它給了三個選題:Claude Code Hooks 實戰(零覆蓋的高級功能)、MCP Server 橫評(散見各文但沒有專題)、OpenCode + Superpowers(兩座孤島的橋)。每個都附了關聯已有文章和理由。這些靠自己翻文件夾是發現不了的。
這些問答結果不是聊天記錄。Claude Code 把分析保存成了兩個 .md 文件,下次規劃選題直接打開就能用。
最後做一輪校驗。 讓 Claude Code 掃描所有雙向連結,查哪些連結沒有對應文件。掃出 32 個斷鏈——[[Kimi]] 被 4 篇文章引用但沒有概念頁,[[GLM-5]]、[[BMAD]] 都一樣。Claude Code 自動補建了 7 個高頻概念頁,斷鏈降到 25 個。剩下的都是低頻的模型版本號,不值得單獨建。
這就是 Karpathy 說的"知識庫自我修復"。你不用盯着每個細節,LLM 幫你查漏補缺。
而且這套東西是活的。每次寫新文章,生成一張摘要卡片扔進 wiki,更新索引和概念頁。知識越查越厚,連結越修越密。
簡單看下每個步驟都做了些什麼。
對我來說收穫最大的不是圖譜多好看,是那幾個問題的答案。兩個月寫了什麼、還缺什麼、下一篇該寫什麼,跑完這套流程心裏就有數了。出版社再問內容規劃,也不至於現場翻文件夾。
這套方法適合任何有大量散落 .md 文件的人,筆記、文檔、讀書摘錄都行。侷限是初次編譯需要跑十來分鐘,Obsidian 對非技術用戶有門檻。
大多數人用筆記軟件,東西存進去就再也不翻。工具不是問題,問題是你的知識有沒有被用起來。
我是陸徐洲,一家 LIMS 公司的 AI 算法負責人。關注我,讓我們一起在 AI 落地實踐的路上,走得更遠。
感謝您閲讀我的文章。有任何關於AI提效或者工程落地實踐方面的問題都可以加我微信,交個朋友,一起探討,共同進步。