Claude Code + Obsidian,打造個人一站式內容創作管理引擎
整理版優先睇
用 Claude Code + Obsidian 打造個人內容創作引擎,實現選題、調研、寫作、管理一站式閉環
作者魯工係經營兩個公眾號(機器學習實驗室、AI編程實驗室)嘅內容創作者,寫咗超過430篇原創文章。以前佢寫作流程好原始:瀏覽器開十幾個標籤頁調研、用Markdown編輯器寫初稿、素材散落各處。佢見到Andrej Karpathy提出「知識編譯器」概念,發現自己早喺用Claude Code + Obsidian做類似嘅嘢——將原始素材持續整理成結構化知識庫,而家維護成本接近零。
佢嘅系統係將所有文章放喺Obsidian vault,用Claude Code透過Obsidian Skills插件讀寫vault。兩種工具通過文件系統打通,唔需要額外API。核心結構包括兩個文章目錄、Canvas選題規劃文件、Base數據庫視圖同素材庫。整體結論係呢個組合可以覆蓋內容創作全部環節,而且有明顯嘅複利效應:素材庫越積越厚,canvas越完善,寫新文章企喺之前積累上。
作者分享咗實際幾個月嘅體感:調研時間由1-2小時縮短到10分鐘、選題唔再憑感覺而有全局視圖、文章之間透過wikilinks互相關聯、狀態管理變得好清晰。佢認為呢套系統搭建成本好低(Obsidian免費,Claude Code本身有訂閲),主要投入係時間。如果係技術內容創作者,無論寫公眾號、博客定係Newsletter,都好值得試呢個組合。
- Claude Code + Obsidian 組合可以覆蓋選題、調研、寫作、發佈管理全部環節,形成完整閉環。
- 目錄結構要儘量扁平(最多兩層),並用 Git 做版本控制,防止 Claude Code 改錯文件。
- 用 Obsidian Canvas 做可視化選題矩陣,有助於平衡各主題產出,避免被熱點牽住。
- 素材調研時用 defuddle 抓取網頁,原材料和加工品分開存放,方便日後複用。
- 每篇文章都有複利效應:素材庫越積越厚,寫新文章可以跳過一半調研,全流程時間比初期縮短三分之一。
整體設計與選題規劃:扁平目錄加 Canvas 視圖
作者嘅 Obsidian vault 結構好簡單:兩個文章目錄(AI編程實驗室、機器學習實驗室)、兩個 .base 數據庫視圖、兩個 canvas 選題規劃,再加一個素材庫同日常寫作記錄目錄。Claude Code 透過 Obsidian Skills 插件操作 vault,包括 defuddle(網頁抓取)、obsidian-cli(命令列)、obsidian-markdown(Markdown 語法)、obsidian-bases(數據庫視圖)同 json-canvas(畫布文件)。佢強調兩個架構經驗:目錄結構要扁平,超過兩層嵌套會令 Claude Code 搜尋效率明顯下降;vault 一定要用 Git 做版本控制,萬一 Claude Code 改錯文件都可以回滾。
vault 一定要用 Git 做版本控制,Claude Code 改錯都可回滾
選題規劃方面,每個公眾號一個 canvas 文件,用分組節點將主題歸類。例如 AI編程實驗室嘅 canvas 有 Claude Code 核心組(44篇)、Vibe Coding 生態組(25篇)、科研線組(9篇)等。每個組分「已覆蓋主題」同「待填補選題」,組之間用連線標註關係。寫完新文章後,作者會叫 Claude Code 更新 canvas,將對應選題由待填補移去已覆蓋。呢個全局視圖幫佢平衡各方向產出,唔會畀熱點新聞帶住走。
Canvas 全局視圖令科研線選題佔比由不足10%提升,成為差異化優勢
素材調研與查重引用:defuddle 抓取、原材料加工品分流
寫技術文章最耗時間嘅係調研。作者而家用 defuddle 抓取網頁內容,佢會自動去掉導航欄、廣告等雜項,輸出乾淨 Markdown,比直接 WebFetch 慳 token 之餘仲保留原文內容。抓落嚟嘅素材統一存到 knowledge_base/,文件名按「日期來源_主題」格式命名。下次寫相關主題時,Claude Code 會先搜 vault 有冇現成素材,經常跳過一半調研工作。
defuddle 自動去廣告慳 token,輸出乾淨 Markdown 保留原文
- defuddle 抓取唔到嘅內容(需要登錄、動態加載),改用 Agent Reach 工具鏈:xreach 訪問 X 推文、Exa 做語義搜索、Jina Reader 讀取其他網頁。
- 素材庫嘅原始抓取最好唔好改,作者早期會加批註,後來發現引用同一份素材時分唔清邊啲係原始數據、邊啲係主觀判斷。而家 knowledge_base/ 嘅文件存咗就唔鬱,需要加工就喺 _briefs/ 另記,原材料同加工品分開放。
原材料和加工品分開放,原始素材先可以畀唔同文章反覆乾淨引用
查重方面,每次開始新文章前,Claude Code 會先喺 vault 搜尋同主題嘅已發佈文章。如果搜到,寫作時嘅處理規則係:基礎概念不再展開,一句話帶過加舊文連結。例如呢篇文章提到 Skills,作者就唔會再解釋 Skills 係咩,因為之前文章已經寫得好詳細。舊文嘅微信連結可以從 vault 每篇 .md 文件頂部嘅「原文地址」行直接提取,呢個係批量遷移文章時預先埋好嘅。
查重規則:基礎概念不再展開,一句話帶過加一箇舊文連結
文章管理與正文編排:Base 視圖加個人 Writing Skill
Obsidian 嘅 Base 功能可以將文件夾所有 Markdown 文件當作數據庫查詢展示。作者為兩個頻道各建一個 .base 文件,展示文章標題、發佈日期、作者、狀態、距今天數、預估字數同標籤。按 status 分組,draft 排最前,published 排後面,一眼睇到每篇稿嘅狀態。佢仲設咗篩選條件:按標籤篩選某系列寫咗幾篇、按日期排序睇近30日發文密度。如果發現某個標籤(例如 claude-code)太頻繁出現,就會寫其他方向內容。
Base 視圖按 status 分組,draft 排最前,一眼睇到每篇狀態
常用篩選條件:按標籤篩選系列篇數、按日期排序睇發文密度
正文編排最核心嘅係 louwill-tech-writer Skill,入面固化咗作者寫作風格、文章模板、開篇結尾規則、去AI味檢查清單。呢個 Skill 會將終稿自動存入 vault 對應目錄,添加 frontmatter(標題、日期、作者、頻道、狀態、標籤),確保新文章被 .base 視圖識別。寫作時引用舊文,Skill 會搜 vault 找到舊文標題同微信連結直接插入。不過作者強調,每篇文章最終成文仍有80%以上係人工碼字,AI只負責信息加工同框架編排,佢會全部人工 review 後改掉。
louwill-tech-writer Skill 只負責信息加工與框架編排,AI 寫嘅文字全部人工 review 改掉
實際效果與搭建建議:調研時間縮短三分一,複利效應明顯
作者從去年12月用到而家,中間迭代過幾版。最明顯嘅變化係調研時間由以前1-2小時縮短到10分鐘(如果 vault 有相關素材)。Canvas 全局視圖令選題唔再憑感覺,科研線產出佔比由不足10%提高到有意識補充。文章之間透過 wikilinks 同舊文引用形成相互關聯嘅知識網絡,讀者可以點舊文連結睇詳細介紹。
調研時間由1-2小時縮短到10分鐘,如果有相關素材
搭建成本好低:Obsidian 免費,Claude Code 本身有訂閲,Obsidian Skills 係社區開源。主要投入係時間——文章遷移花咗一個週末,.base 同 .canvas 配置各少於一小時,louwill-tech-writer Skill 開發同迭代花咗啲時間。作者推薦技術內容創作者(公眾號、博客、Newsletter)試呢個組合,強調 Obsidian 管存儲展示,Claude Code 管智能處理同信息編排,兩者透過文件系統打通,簡單粗暴但非常有效。
Claude Code + Obsidian 的結合點就是文件系統,簡單粗暴但非常有效
大家好,我係魯工。
最近Andrej Karpathy出咗條帖,話LLM嘅真正價值唔係一次性問答,而係做「知識編譯器」,將原始材料餵入去,持續維護一個結構化嘅知識庫,知識編譯一次之後保持更新,而唔係每次查詢嗰陣由頭推導。
我見到呢個講法嘅第一反應係:呢個咪就係我一直做緊嘅嘢?我早喺舊年12月已經全面用Claude Code + Obsidian作為我嘅個人內容管理工具。雖然我一直冇喺公眾號寫過Obsidian方法論嘅內容。
不過對於Karpathy嘅一啲觀點,我仍然好認同:人類放棄維護Wiki係因為維護成本增長得快過價值,LLM令到維護成本接近零,呢件事終於可以持續運轉。
我寫公眾號都快10年,舊號【機器學習實驗室】由2017年年初就開始寫,雖然而家冇乜流量同價值,但係都沉澱咗一啲經驗。新號【AI編程實驗室】由舊年10月開始寫,雖然而家已經過咗平台嘅流量扶持期,但係都出過10w+嘅技術爆款文章。
兩個號加埋發咗430幾篇原創文章。早幾年寫文章嘅流程好原始:瀏覽器開十幾個標籤頁做調研,Markdown編輯器或者直接公眾號編輯器裏面寫初稿,然後做簡單排版。素材散落喺唔同文件夾裏面,寫過嘅文章查起嚟都好麻煩,更唔好講系統化管理。
2021年嗰陣我寫過一篇一篇技術原創嘅產出始末,記錄咗當時嘅寫作流程。而家返轉頭睇,簡直係新石器時代嘅內容創作方式。
轉捩點係舊年下半年,我開始將所有文章遷移到Obsidian vault裏面管理,同時用Claude Code做主力寫作輔助工具。呢兩樣嘢單獨用都好勁,但係組合埋之後,我發現佢哋可以覆蓋內容創作嘅全部環節:由選題規劃、素材調研、正文寫作到發佈管理,形成一個完整嘅閉環。
今日呢篇就講下我係點樣將呢套系統搭起嚟,同埋實際行咗幾個月之後嘅真實體感。
0. 整體設計
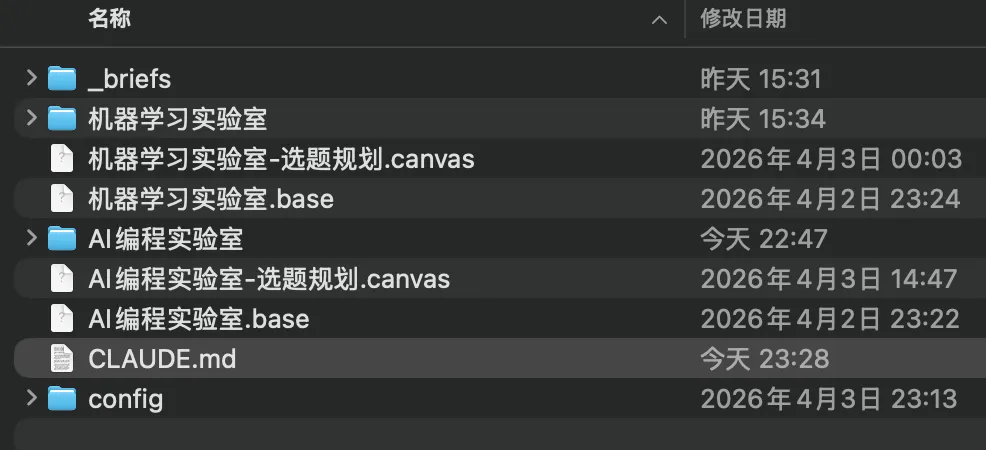
我嘅Obsidian vault就係一個文件夾,路徑喺本地磁碟上。裏面嘅核心結構好簡單:兩個文章目錄(AI編程實驗室/、機器學習實驗室/),兩個.base 數據庫視圖文件,兩個canvas 選題規劃文件,再加_knowledge_base/ 素材庫同 _briefs/等日常寫作需求記錄。
Claude Code透過Obsidian Skills插件集嚟操作呢個vault。目前我裝咗5個Obsidian Skills:defuddle(網頁抓取)、obsidian-cli(命令列操作)、obsidian-markdown(Markdown 語法)、obsidian-bases(數據庫視圖)、json-canvas(畫布文件)。
簡單講就係,Obsidian負責儲存同展示,Claude Code負責讀寫同智能處理。兩者透過文件系統自然打通,唔需要任何額外嘅API對接。
兩個架構經驗:第一,目錄結構盡量扁平。我試過喺_knowledge_base/下按主題分子文件夾,Claude Code喺超過兩層嵌套嗰陣搜索效率明顯下降。而家就一層,靠文件名前綴區分,反而更好用。第二,vault一定要用Git做版本控制,Claude Code間中會改錯文件,有Git隨時可以回滾。
1. 選題規劃:用Canvas做可視化內容矩陣
寫公眾號最怕嘅係選題重複同主題失衡。124篇AI編程實驗室嘅文章,邊啲話題寫過、邊啲未覆蓋、各系列之間係咩關係,淨靠個腦記係唔現實嘅。
我嘅做法係用Obsidian嘅Canvas文件做選題規劃。每個號一個canvas,裏面用分組節點將主題歸類。例如AI編程實驗室嘅canvas裏面,Claude Code核心係一個組(44篇),Vibe Coding生態係一個組(25篇),Vibe Researching科研線係一個組(9篇),Agent與OpenClaw係一個組(14篇)。
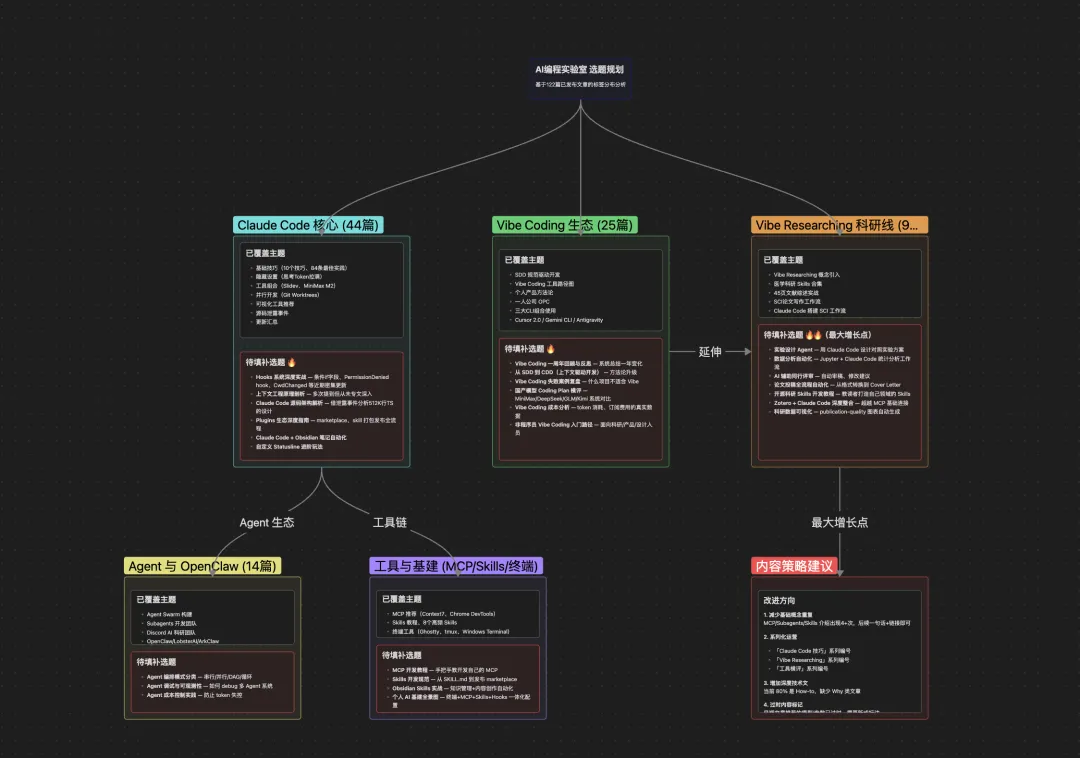
每個組裏面分兩塊:已覆蓋主題同待填補選題。組與組之間用連線標註關係,例如Claude Code核心組到Agent組嘅連線標註咗「Agent生態」,到工具基建組標註咗「工具鏈」。
呢個canvas唔係靜態嘅。每次寫完一篇新文章,我會叫Claude Code幫我更新canvas,將待填補裏面對應嘅選題移到已覆蓋。每隔一兩星期我都會打開 canvas睇下全局,判斷下一步寫咩方向。
實際體感:科研線嘅選題我一直知道要補,但係冇canvas嘅全局視圖,好容易俾熱點新聞帶住走,成日寫Claude Code更新之類嘅。有咗呢個視圖之後,我可以更有意識咁平衡各個方向嘅產出。
2. 素材調研:defuddle + 素材沉澱
寫技術文章最花時間嘅環節其實唔係寫,而係調研。以前我嘅調研素材用完就掉,下次寫相關主題又再重新查。
而家嘅流程係:調研階段用defuddle抓網頁內容。defuddle呢個工具嘅好處係佢會自動去掉網頁上面嘅導航欄、廣告、側邊欄呢啲雜七雜八嘅嘢,淨係留低正文內容,輸出成乾淨嘅Markdown。同直接用WebFetch抓相比,token消耗可以慳唔少,而且可以拎到原文內容。
抓落嚟嘅素材我統一存到vault嘅knowledge_base/目錄。文件名按(日期來源_主題)嘅格式命名。咁樣做嘅好處係,下次再寫相關主題嗰陣,Claude Code會先搜一遍vault裏面有冇現成素材,成日可以跳過一半嘅調研工作。
舉個具體例子。上星期寫Claude Code一星期更新彙總嗰篇文章嗰陣,Anthropic官方changelog、GitHub releases頁面、Fortune嘅報道我都用defuddle抓咗一遍存到素材庫。呢個星期寫另一篇Claude Code短評嗰陣,呢啲素材直接重用,基本冇花額外嘅調研時間。
如果defuddle抓唔到嘅內容(例如需要登入嘅頁面、動態加載嘅內容),我會轉用Agent Reach工具鏈,用xreach訪問X推文,用Exa做語義搜索,用Jina Reader讀取其他網頁。關於Agent Reach嘅具體用法,可以參考:Agent Reach,可能係Claude Code/OpenClaw最好嘅聯網工具。
呢度補充一個踩坑經驗:素材庫裏面嘅原始抓取,最好唔好改。早期我會順手喺素材文件度加批註,後嚟發現寫另一篇文章引用同一份素材嗰陣,分唔清邊啲係原始數據、邊啲係上次嘅主觀判斷。而家_knowledge_base/裏面嘅文件存咗入去就唔鬱,需要加工就喺_briefs/裏面另外記。原材料同加工品分開放,原始素材先可以俾唔同文章重複乾淨引用。
3. 查重與引用:避免內容撞車
我兩個號430幾篇文章,雖然賬號定位唔同,但係主題之間難免有交叉。MCP呢個概念我喺至少4篇文章裏面介紹過,Skills嘅基礎用法都重複寫咗幾次。讀者睇多咗會覺得「又喺度講呢個」,對我自己嚟講都係浪費篇幅。雖然每篇文章都可能觸達到唔同嘅讀者羣體,但係保持內容嘅延續性同關聯性都非常重要。
而家每次開始寫新文章之前,Claude Code會先喺vault裏面做一次查重。搜索邏輯好簡單:按關鍵詞同標籤搜索AI編程實驗室/同機器學習實驗室/兩個目錄,睇下有冇同主題嘅已發佈文章。
如果搜到,寫作嗰陣嘅處理規矩係:基礎概念唔再展開,一句話帶過加一個舊文連結。例如呢篇文章提到Skills,我就唔會再花三段話解釋Skills 係咩,因為之前嗰篇推薦我日常高頻使用嘅8個Skills,產出效率翻一倍已經寫得好詳細。
舊文嘅微信原文連結可以從vault裏面每篇.md文件頂部嘅「原文地址」行直接提取。呢個係之前批量遷移文章嗰陣就整好嘅,而家寫新文章引用舊文嗰陣非常方便。
4. 文章管理:用 Base 做數據庫視圖
Obsidian嘅Base功能(.base文件)可以將一個文件夾裏面所有嘅Markdown文件當作數據庫嚟查詢同展示。我俾兩個頻道各建咗一個base文件。
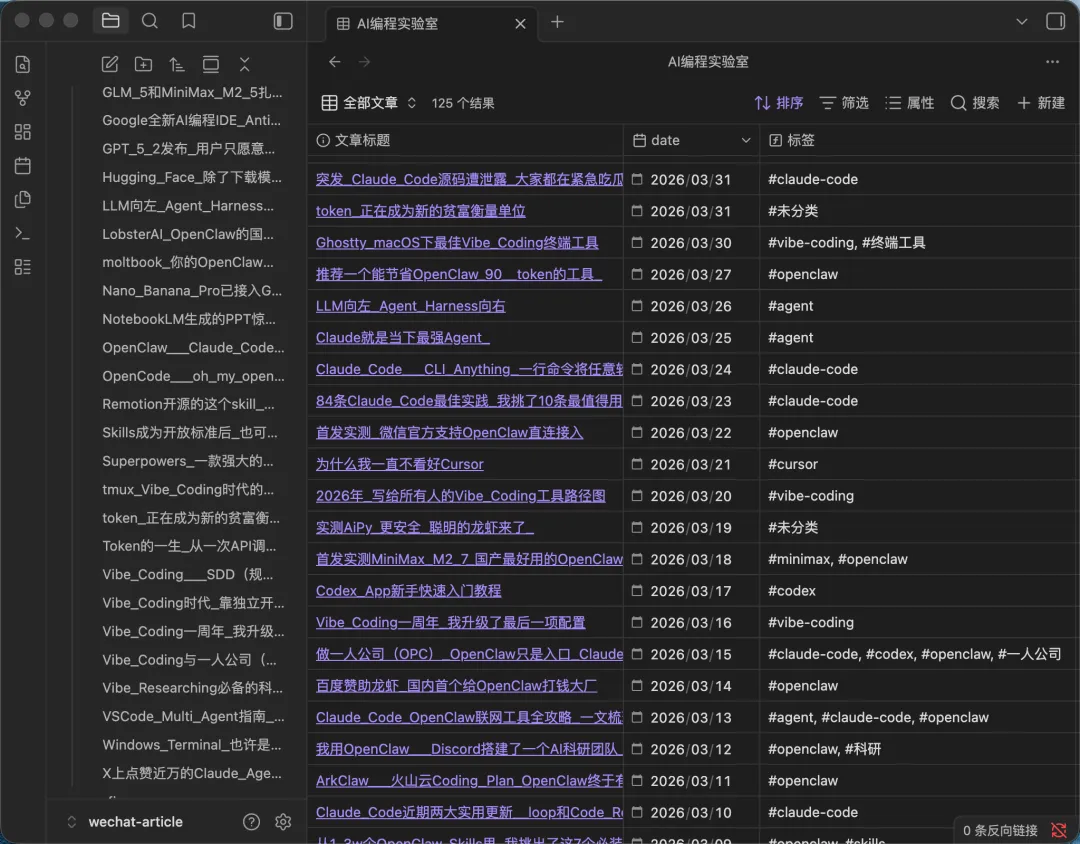
以AI編程實驗室.base為例,佢嘅配置好簡潔:篩選條件係AI編程實驗室目錄下面所有嘅.md文件,展示字段包括文章標題、發佈日期、作者、狀態、距今天數、預估字數同標籤。
喺Obsidian裏面打開呢個.base文件,就可以見到一個類似Notion數據庫嘅表格視圖。我按status字段分組,draft(草稿)排喺最前,published(已發佈)排喺後面。一眼就可以見到每篇稿嘅狀態。
我仲設咗幾個常用嘅篩選條件:按標籤篩選某個系列寫咗幾多篇,按日期排序睇近30日嘅發文密度。如果發現某個標籤(例如claude-code)近期出現得太頻密,可能就應該寫下其他方向嘅內容。
5. 正文編排:louwill-tech-writer Skill
呢個係成個流程最核心嘅環節。我專登開發咗一個louwill-tech-writer嘅個人Skill嚟處理正文嘅內容編排,裏面固化咗我嘅寫作風格、文章模板、開篇結尾規則、去AI味檢查清單等等。
呢個Skill同Obsidian嘅集成體現喺幾個地方:寫完嘅終稿自動存入vault對應目錄,自動加frontmatter(標題、日期、作者、頻道、狀態、標籤),確保新文章可以被.base數據庫視圖識別到。寫作嗰陣如果需要引用舊文,Skill會搜索vault揾到舊文標題同微信連結,直接插入。
當然,每篇文章最終嘅成文,仍然有80%以上嘅文字都係我人手打出來嘅,skill只負責信息加工同框架編排,AI寫出嚟嘅文字,我基本上都會全部人手review之後改過。呢個都係我一向以嚟嘅內容創作習慣。
我之前喺我用Claude Code寫咗一篇45頁嘅文獻綜述,質量可以發一區SCI裏面強調,喺寫作方面,要將AI當作係高質量嘅信息編排與加工器,而唔係生成器。無論係寫論文、寫專利,定係日常寫作,人手古法仍然係無可替代嘅部分。
6. 實際效果
呢套系統我由舊年12月到而家,中間迭代過幾版,講幾個我體感比較明顯嘅變化。
調研時間縮短咗。以前每篇文章調研要花1到2個鐘,而家vault裏面有相關素材嘅話,10分鐘就可以搞掂。
選題唔再靠感覺。Canvas全局視圖令我對兩個頻道嘅內容分佈有咗清晰認知。科研線係我嘅差異化優勢,之前產出佔比唔夠10%,有咗視圖後有意識咁補返。
文章之間有咗關聯。透過wikilinks同舊文引用,形成咗互相關聯嘅知識網絡,讀者可以㩒舊文連結睇詳細介紹。
最令我體感深刻嘅係複利效應。素材庫越積越厚,canvas越來越完善,每次寫新文章都企喺之前嘅積累上面。最近幾篇嘅全流程時間比啱啱搭嗰陣縮短咗三分之一,好似大模型嘅緩存概念,前期投入,後期命中。
狀態管理清晰咗。邊啲草稿、邊啲已發佈,.base視圖裏面一目瞭然。
呢套系統嘅搭建都冇乜成本。Obsidian本身免費,Claude Code嘅訂閲我本來就用緊,Obsidian Skills係社羣開源嘅。主要投入嘅係時間:文章遷移用咗一個週末,.base同.canvas 嘅配置各用咗唔夠一個鐘,louwill-tech-writer Skill嘅開發同迭代用咗一啲時間。
如果你都喺度做技術內容創作,無論係公眾號、博客定係Newsletter,呢套 Claude Code + Obsidian嘅組合都值得試下。Obsidian管儲存同展示,Claude Code管智能處理同信息編排,兩者嘅結合點就係文件系統,簡單粗暴但係非常有效。
如果覺得有用,㩒個讚或者睇下,都方便更多朋友見到。
我係魯工,九年AI算法老兵,AI全棧開發者,深耕AI編程賽道。有興趣嘅朋友都可以加我微信(louwill26_)交個朋友。
大家好,我是魯工。
最近Andrej Karpathy發了條帖子,說LLM的真正價值不是一次性問答,而是充當"知識編譯器",把原始素材喂進去,持續維護一個結構化的知識庫,知識被編譯一次然後保持更新,而不是每次查詢時從頭推導。
我看到這個說法的第一反應是:這不就是我一直在做的事嗎?我早在去年12月份就全面使用Claude Code + Obsidian作為我個人內容管理工具了。雖然我一直沒在公眾號寫過Obsidian方法論的內容。
不過對於Karpathy的一些觀點,我還是非常認同的:人類放棄維護Wiki是因為維護成本增長得比價值快,LLM把維護成本打到接近零了,這件事終於能持續運轉。
我寫公眾號都快10年了,老號【機器學習實驗室】從2017年年初就開始寫,雖然現在沒啥流量和價值了,但卻也沉澱了一些經驗。新號【AI編程實驗室】從去年10月份開始寫,雖然目前已經過了平台的流量扶持期,但也曾出過10w+的技術爆款文章。
兩個號加起來發了430多篇原創文章。早些年寫文章的流程很原始:瀏覽器開十幾個標籤頁做調研,Markdown編輯器或者直接公眾號編輯器裏寫初稿,然後再做簡單排版。素材散落在各種文件夾裏,寫過的文章查起來也費勁,更別提系統化管理了。
2021年那會我寫過一篇一篇技術原創的產出始末,記錄了當時的寫作流程。現在回頭看,簡直是新石器時代的內容創作方式。
轉折點是去年下半年,我開始把所有文章遷移到Obsidian vault裏管理,同時用Claude Code作為主力寫作輔助工具。這兩個東西單獨用都很強,但組合起來之後,我發現它們能覆蓋內容創作的全部環節:從選題規劃、素材調研、正文寫作到發佈管理,形成一個完整的閉環。
今天這篇就聊聊我是怎麼把這套系統搭起來的,以及實際跑了幾個月之後的真實體感。
0. 整體設計
我的Obsidian vault就是一個文件夾,路徑在本地磁盤上。裏面的核心結構很簡單:兩個文章目錄(AI編程實驗室/、機器學習實驗室/),兩個.base 數據庫視圖文件,兩個canvas 選題規劃文件,再加上_knowledge_base/ 素材庫和 _briefs/等日常寫作需求記錄。
Claude Code通過Obsidian Skills插件集來操作這個vault。目前我裝了5個Obsidian Skills:defuddle(網頁抓取)、obsidian-cli(命令行操作)、obsidian-markdown(Markdown 語法)、obsidian-bases(數據庫視圖)、json-canvas(畫布文件)。
簡單來說就是,Obsidian負責存儲和展示,Claude Code負責讀寫和智能處理。兩者通過文件系統天然打通,不需要任何額外的API對接。
兩個架構經驗:第一,目錄結構儘量扁平。我試過在_knowledge_base/下按主題分子文件夾,Claude Code在超過兩層嵌套時搜索效率明顯下降。現在就一層,靠文件名前綴區分,反而更好用。第二,vault一定用Git做版本控制,Claude Code偶爾會改錯文件,有Git隨時能回滾。
1. 選題規劃:用Canvas做可視化內容矩陣
寫公眾號最怕的是選題重複和主題失衡。124篇AI編程實驗室的文章,哪些話題寫過了、哪些還沒覆蓋、各個系列之間是什麼關係,光靠腦子記是不現實的。
我的做法是用Obsidian的Canvas文件做選題規劃。每個號一個canvas,裏面用分組節點把主題歸類。比如AI編程實驗室的canvas裏,Claude Code核心是一個組(44篇),Vibe Coding生態是一個組(25篇),Vibe Researching科研線是一個組(9篇),Agent與OpenClaw是一個組(14篇)。
每個組裏分兩塊:已覆蓋主題和待填補選題。組與組之間用連線標註關係,比如Claude Code核心組到Agent組的連線標註了"Agent生態",到工具基建組標註了"工具鏈"。
這個canvas不是靜態的。每次寫完一篇新文章,我會讓Claude Code幫我更新canvas,把待填補裏對應的選題移到已覆蓋。每隔一兩週我也會打開 canvas看一眼全局,判斷下一步寫什麼方向。
實際體感:科研線的選題我一直知道該補,但沒有canvas的全局視圖,很容易被熱點新聞帶着跑,老寫Claude Code更新之類的。有了這個視圖之後,我可能能更有意識地平衡各個方向的產出。
2. 素材調研:defuddle + 素材沉澱
寫技術文章最耗時間的環節其實不是寫,是調研。以前我的調研素材用完就扔,下次寫相關主題又得重新查。
現在的流程是:調研階段用defuddle抓網頁內容。defuddle這個工具的好處是它會自動去掉網頁上的導航欄、廣告、側邊欄這些雜七雜八的東西,只留下正文內容,輸出成乾淨的Markdown。跟直接用WebFetch抓比,token消耗能省不少,並且能獲取原文內容。
抓下來的素材我統一存到vault的knowledge_base/目錄。文件名按(日期來源_主題)的格式命名。這樣做的好處是,下次再寫相關主題時,Claude Code會先搜一遍vault裏有沒有現成素材,經常能跳過一半的調研工作。
舉個具體的例子。上週寫Claude Code一週更新彙總那篇文章時,Anthropic官方changelog、GitHub releases頁面、Fortune的報道我都用defuddle抓了一遍存到了素材庫。這周寫另一篇Claude Code短評時,這些素材直接複用,基本沒花額外的調研時間。
如果defuddle抓不了的內容(比如需要登錄的頁面、動態加載的內容),我會切換到Agent Reach工具鏈,用xreach訪問X推文,用Exa做語義搜索,用Jina Reader讀取其他網頁。關於Agent Reach 的具體用法,可以參考:Agent Reach,可能是Claude Code/OpenClaw最好的聯網工具。
這裏補一個踩坑經驗:素材庫裏的原始抓取,最好不要改。早期我會順手在素材文件里加批註,後來發現寫另一篇文章引用同一份素材時,分不清哪些是原始數據、哪些是上次的主觀判斷。現在_knowledge_base/裏的文件存進去就不動,需要加工就在_briefs/裏單獨記。原材料和加工品分開放,原始素材才能被不同文章反覆乾淨引用。
3. 查重與引用:避免內容撞車
我兩個號430多篇文章,雖然賬號定位不同,但主題之間免不了有交叉。MCP這個概念我在至少4篇文章裏介紹過,Skills的基礎用法也重複寫了好幾次。讀者看多了會覺得"又在講這個",對我自己來說也是在浪費篇幅。雖然每篇文章都可能觸達到不同的讀者羣體,但保持內容的延續性和關聯性也非常重要。
現在每次開始寫新文章之前,Claude Code會先在vault裏做一遍查重。搜索邏輯很簡單:按關鍵詞和標籤搜索AI編程實驗室/和機器學習實驗室/兩個目錄,看有沒有同主題的已發佈文章。
如果搜到了,寫作時的處理規則是:基礎概念不再展開,一句話帶過加一箇舊文連結。比如這篇文章裏提到Skills,我就不會再花三段話解釋Skills 是什麼了,因為之前那篇推薦我日常高頻使用的8個Skills,產出效率翻一倍已經寫得很詳細。
舊文的微信原文連結可以從vault裏每篇.md文件頂部的"原文地址"行直接提取。這個是之前批量遷移文章時就埋好的,現在寫新文章引用舊文時非常方便。
4. 文章管理:用 Base 做數據庫視圖
Obsidian的Base功能(.base文件)可以把一個文件夾裏的所有Markdown文件當作數據庫來查詢和展示。我給兩個頻道各建了一個base文件。
以AI編程實驗室.base為例,它的配置很簡潔:篩選條件是AI編程實驗室目錄下的所有.md文件,展示字段包括文章標題、發佈日期、作者、狀態、距今天數、預估字數和標籤。
在Obsidian裏打開這個.base文件,就能看到一個類似Notion數據庫的表格視圖。我按status字段分組,draft(草稿)排在最前面,published(已發佈)排在後面。一眼就能看到每篇稿子的狀態。
我還設了幾個常用的篩選條件:按標籤篩選某個系列寫了多少篇,按日期排序看近30天的發文密度。如果發現某個標籤(比如claude-code)近期出現太頻繁了,也許就該寫寫其他方向的內容了。
5. 正文編排:louwill-tech-writer Skill
這是整個流程裏最核心的環節。我專門開發了一個louwill-tech-writer的個人Skill來處理正文的內容編排,裏面固化了我的寫作風格、文章模板、開篇結尾規則、去AI味檢查清單等等。
這個Skill跟Obsidian的集成體現在幾個地方:寫完的終稿自動存入vault對應目錄,自動添加frontmatter(標題、日期、作者、頻道、狀態、標籤),確保新文章能被.base數據庫視圖識別到。寫作時如果需要引用舊文,Skill會搜索vault找到舊文標題和微信連結,直接插入。
當然了,每篇文章最終的成文,仍然有80%以上的文字都是我人工碼字寫出來的,skill只負責信息加工和框架編排,AI寫出來的文字,我基本上都會全部人工review後改掉。這也是我一貫來的內容創作習慣。
我之前在我用Claude Code寫了一篇45頁的文獻綜述,質量可以發一區SCI裏強調,在寫作方面,要把AI當作是高質量是信息編排與加工器,而不是生成器。無論是寫論文、寫專利,還是日常寫作,人工古法仍然是不可替代的部分。
6. 實際效果
這套系統我從去年12月份到現在,中間迭代過幾版,說幾個我體感比較明顯的變化。
調研時間縮短了。以前每篇文章調研要花1到2小時,現在vault裏有相關素材的話,10分鐘就可以搞定。
選題不再憑感覺。Canvas全局視圖讓我對兩個頻道的內容分佈有了清晰認知。科研線是我的差異化優勢,之前產出佔比不到10%,有了視圖後有意識地在補。
文章之間有了關聯。通過wikilinks和舊文引用,形成了相互關聯的知識網絡,讀者可以點舊文連結看詳細介紹。
最讓我體感深刻的是複利效應。素材庫越積越厚,canvas越來越完善,每次寫新文章都站在之前的積累上。最近幾篇的全流程時間比剛搭時縮短了三分之一,像大模型的緩存概念,前期投入,後期命中。
狀態管理清晰了。哪些草稿、哪些已發佈,.base視圖裏一目瞭然。
這套系統的搭建也沒啥成本。Obsidian本身免費,Claude Code的訂閲我本來就在用,Obsidian Skills是社區開源的。主要投入的是時間:文章遷移花了一個週末,.base和.canvas 的配置各花了不到一小時,louwill-tech-writer Skill的開發和迭代花了一些時間。
如果你也在做技術內容創作,不管是公眾號、博客還是Newsletter,這套 Claude Code + Obsidian的組合都值得試試。Obsidian管存儲和展示,Claude Code管智能處理和信息編排,兩者的結合點就是文件系統,簡單粗暴但非常有效。
如果覺得有用,點個贊或者在看,也方便更多朋友看到。
我是魯工,九年AI算法老兵,AI全棧開發者,深耕AI編程賽道。感興趣的朋友也可以加我微信(louwill26_)交個朋友。