Claude Code 也有 /goal 了,跟 Codex 的有什麼不一樣
整理版優先睇
Claude Code 加入 /goal 命令,用獨立模型判斷完成,比 Ralph Loop 更可靠但驗證深度不及 Codex
呢篇文章出自 Feisky,係一位經常試用 AI 編程工具嘅開發者。佢之前用過 Codex /goal 同 Ralph Loop,今次 Anthropic 喺 Claude Code 直接內置咗 /goal 命令,佢就試用咗幾個場景,整理出呢篇實測。整體結論係:/goal 比 Ralph Loop 好用好多,因為改用獨立評估模型(Haiku)判斷條件,唔係靠工作模型自說自話,但同 Codex /goal 比,驗證深度仲差一個層次。
文章首先講點用 /goal:一句命令設定條件,Claude Code 會自動循環直到條件達成,唔使每輪人手確認。條件點樣寫好關鍵,寫得太模糊模型會「交行貨」,建議用具體驗證命令同輪次上限。另外可以搭配 auto 模式或者非交互模式行 automation。
原理方面,/goal 係一個 session 級別嘅 prompt-based Stop hook。每輪結束後,系統將條件同對話記錄交畀 Haiku 評估,回傳 yes/no 同理由。Haiku 唔可以 call 工具,只睇文字證據,冇明確證據就默認未完成。不過呢個設計都有缺點:如果工作模型喺對話度造假,評估模型會信以為真。最後文章比較咗三個方案嘅差異,強調 Agent harness 嘅重要性,同埋提醒 token 消耗問題。
- /goal 用獨立評估模型判斷完成,避免工作模型「自己改自己卷」,比 Ralph Loop 更可信
- 條件寫法好關鍵:要具體、包括驗證命令同輪次上限,防止 AI 偷雞
- 同 Codex /goal 比較:Codex 靠自審工具形成驗證證據,Claude Code 只睇文字,驗證深度差一級
- /goal 可以同 auto 模式或非交互模式配合,做到完全無人值守,適合 SPEC/PLAN 清晰嘅任務
- Token 消耗係主要成本,每輪用 Opus/Sonnet,建議加輪次上限保護賬單
Claude Code /goal 官方文檔
官方說明 /goal 命令用法同設定
Codex /goal 推薦(上篇文章)
Feisky 之前寫嘅 Codex /goal 介紹同對比
Claude Code GitHub
Claude Code 開源倉庫
內容片段
/goal 給 src/auth/ 下所有函數寫單元測試,要求:
1. 每個測試必須包含真實斷言,不能只有空殼2. 測試覆蓋率達到 80% 以上3. npm test 退出碼為
04. 不修改 src/ 下的源代碼5. 20 輪後未完成則停止點樣用 /goal:一句命令,自動循環
將 Claude Code 更新到最新版之後,打一句 /goal <完成條件> 就得。Claude Code 會一直做到條件滿足為止,唔使你逐輪確認。
界面上會出現一個 /goal active 狀態條,標註運行時長。同普通對話最大嘅分別係:每輪結束後唔會停低等你輸入,直接開始下一輪。
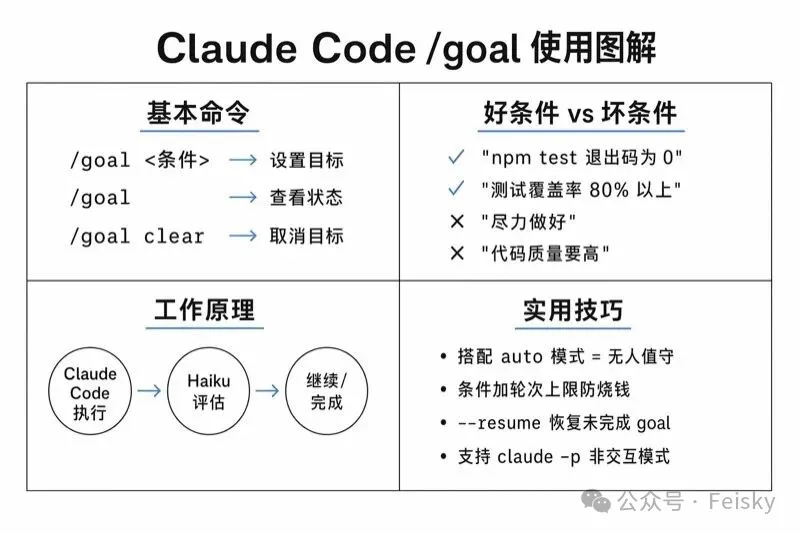
實際可用嘅命令得三個:
- /goal <條件>:設定目標,即時執行
- /goal:查看狀態(條件、時長、輪次、token用量)
- /goal clear:取消當前目標(stop / cancel / reset 都得)
另外,如果中途退出(例如到咗5小時上限),可以用 --resume 恢復目標繼續執行。條件最長支援4000個字符,可以寫得好細。
兩個好用嘅搭配:/goal + auto 模式——auto 關埋每個工具嘅確認,/goal 關埋每輪結束嘅等待,完全無人值守;非交互模式——適合自動化或者 SKILL 場景,例如 <code>claude -p "/goal CHANGELOG.md 包含本週所有合併嘅 PR 記錄"</code>。
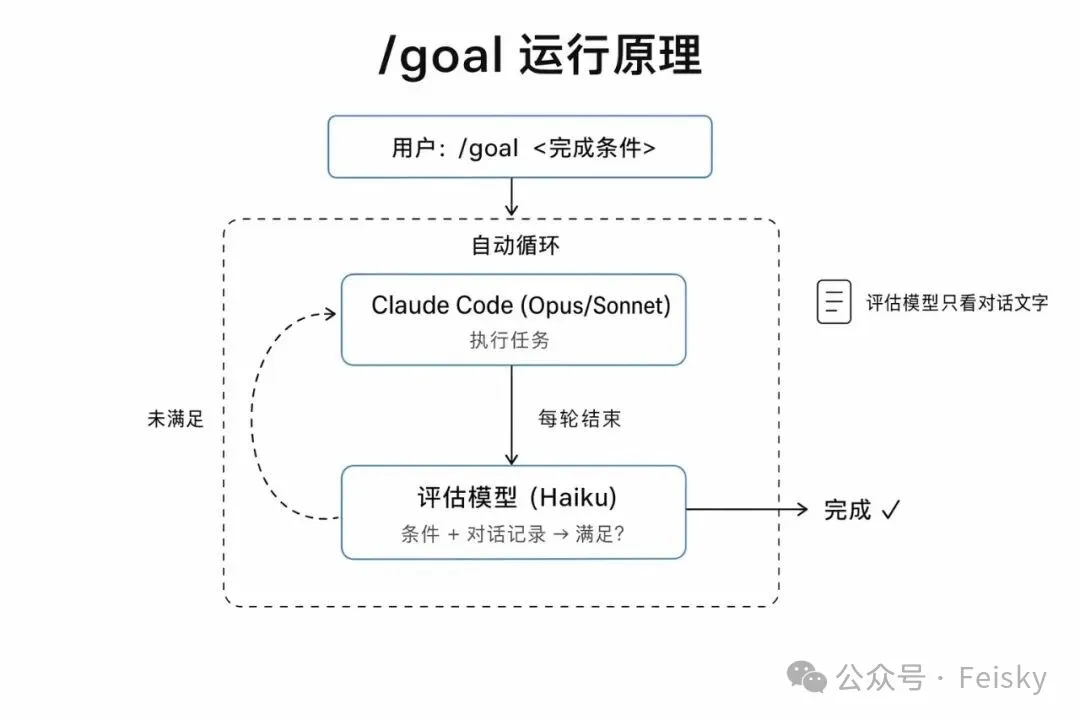
實現原理:獨立評估模型把關
/goal 本質係一個 session 級別嘅 prompt-based Stop hook。你設定條件後,Claude Code(Opus 或 Sonnet)正常做嘢(讀文件、改代碼、跑測試)。每輪結束後,系統將完成條件同當前對話記錄發畀一個 獨立嘅小模型(默認 Haiku)。
Haiku 返回 yes/no 同一條理由。如果係 no,理由會注入下一輪對話,話畀 Claude 仲差啲乜,然後自動開始下一輪。如果係 yes,goal 標記為完成,記錄落對話記錄度。
不過呢個設計都有漏洞:如果工作模型喺對話入面寫「測試全通過」但實際冇跑測試,評估模型見到嘅證據係充分嘅,自然會放行。所以建議喺條件裏面寫明具體嘅驗證命令,令 AI 冇辦法繞過。
同 Ralph Loop 同 Codex /goal 嘅比較
先同 Ralph Loop 比:Ralph Loop 嘅核心係 Stop hook 攔截,Claude 完成一輪嘗試退出時,hook 檢查係咪達到條件,未達到就重新注入原始 prompt。完成判斷靠 精確字符串匹配——Claude 輸出 <code><promise>DONE</promise></code> 就算完成。最大問題係模型自己話事,輸出標記就可以退出,冇任何獨立驗證。
Ralph Loop 每輪會原封不動重新注入原始 prompt,跑多咗上下文堆滿重複內容,形成噪音。/goal 換成獨立評估模型,至少唔係自己批改自己嘅試卷。另外 Claude Code 仲有個 /loop 命令,按時間間隔觸發,適合定時任務;/goal 係每輪結束後立即觸發,適合連續執行嘅目標。
再同 Codex /goal 比:Codex 嘅核心係三層——狀態持久化(state-db)、權限控制(模型只能標記 complete,唔可以自行退出)、強制自審(continuation.md 要求拆檢查清單,逐項對照真實文件同測試結果)。
作者分享咗個啟發:關鍵嘅約束唔係寫喺提示詞,而係寫喺 代碼(Agent harness) 入面。CLAUDE.md 或者 AGENTS.md 寫嘅規則模型可能忽略,但代碼層面嘅 hook 100% 會觸發。人要用代碼控制 AI 行為同邊界,唔可以單靠模型自覺。
使用建議同注意事項
對於 驗收條件清晰、按照 SPEC/PLAN 逐步完成 嘅任務,/goal 係目前最省心嘅選擇。不過要留意 token 消耗:/goal 模式下每輪都係完整嘅 Opus/Sonnet 調用,跑十幾輪落嚟主模型嘅 token 用量可以翻幾倍(Haiku 評估開銷好細,主要成本係多輪主模型)。
強烈建議喺條件入面加 輪次上限,防止無限跑下去。例如「20 輪後未完成則停止」。另外如果條件入面有驗證命令,AI 冇辦法造假,會更可靠。
整體嚟講,/goal 係 Agent harness 嘅一個實踐:用代碼層面嘅 hook 控制 AI 循環同完成判斷,而唔係靠模型自覺。呢個方向值得繼續關注。