Claude Code 動態工作流:讓 AI 自己寫 Harness,這事靠譜嗎
整理版優先睇
Claude Code動態工作流:AI自己寫調度腳本,解決單Agent退化問題
呢篇文章係由Anthropic工程師Thariq Shihipar同Sid Bidasaria撰寫,再由Feisky編譯整理。文章主要講Claude Code嘅動態工作流功能,背景係單Agent喺長時間運行、大規模並行同對抗性驗證任務上,會出現偷懶、自我偏愛同目標漂移呢三種退化模式。Anthropic之前已經針對特定任務整咗定製Harness,而家佢哋將呢個能力泛化,令Claude Code可以自己寫調度邏輯。
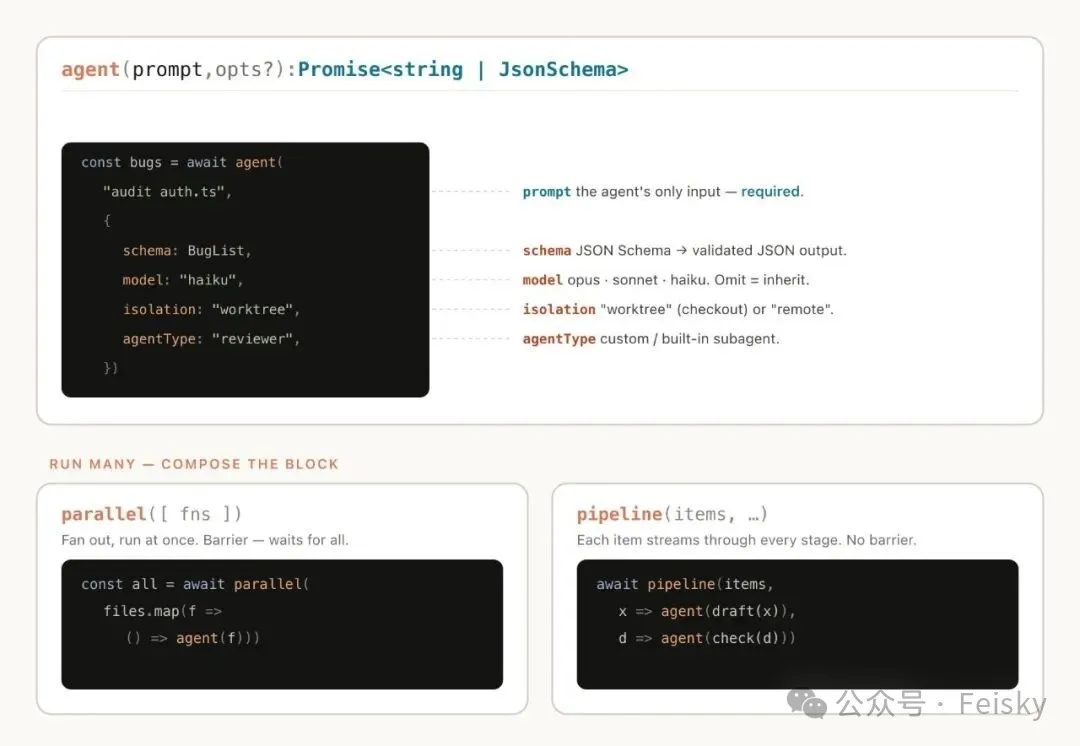
動態工作流嘅核心係用獨立子Agent各自佔一個乾淨嘅上下文窗口,由一個確定性嘅JavaScript腳本調度佢哋嘅執行順序。文章介紹咗六種基本調度模式:分類路由、扇出合併、對抗驗證、生成過濾、錦標賽模式同循環到完成,仲可以組合使用。實際應用包括大規模遷移重構、深度驗證、排序、規則遵守、根因分析同大規模分流等。
不過動態工作流消耗token較多,適合複雜高價值任務,日常簡單編程就唔需要用。開啓方法係喺Prompt要求或使用觸發詞ultracode,仲可以保存腳本重用。總體而言,對於探索性任務,讓Claude自己決定調度方式能發現新拆法,但對於熟悉任務,靜態工作流更可控。作者亦提到呢種Harness可能只係過渡,未來模型夠強就會內化呢啲邏輯。
- 結論:動態工作流有效解決單Agent喺複雜任務嘅退化問題,尤其適合可拆分並行同需要驗證嘅場景。
- 方法:Claude Code根據任務自動生成JavaScript調度腳本,用獨立子Agent分工,支援六種調度模式。
- 差異:相比靜態工作流,動態工作流由AI自己決定拆分方式,更靈活但token消耗更大。
- 啟發:對於探索性任務,讓AI自己設計工作流可能發現更優解;對於重複任務,可將動態工作流保存為靜態。
- 可行動點:嘗試用「ultracode」觸發動態工作流,搭配具體模式名稱(如「扇出合併」「錦標賽模式」)描述需求,並用「/loop」同「/goal」控制執行。
原文:A harness for every task: dynamic workflows in Claude Code
Anthropic官方博客,詳細介紹動態工作流嘅設計同應用
動態工作流文檔
Claude Code官方文檔,包含用法同配置
前作:Bun 重寫(Jarred Sumner)
Bun從Zig重寫成Rust嘅工作流案例
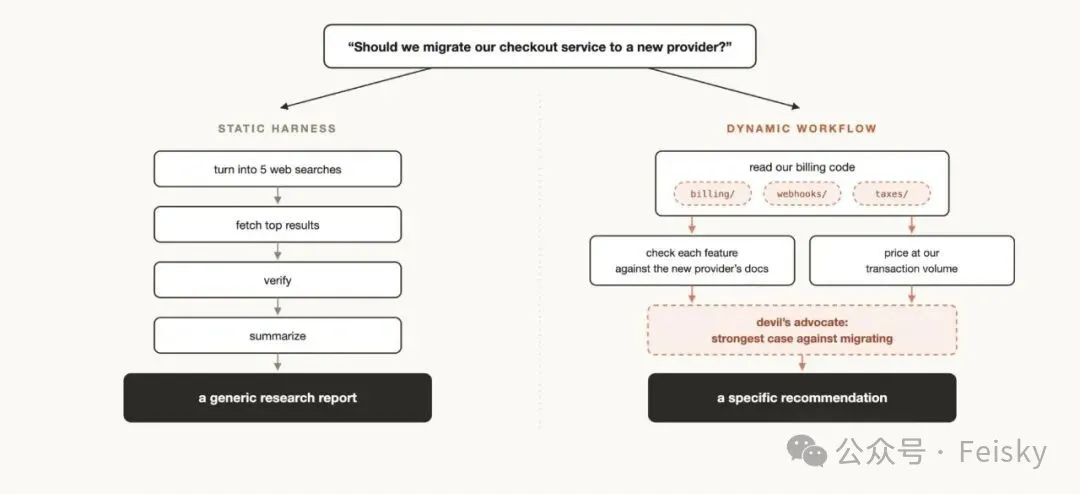
單Agent有咩問題?
Claude Code默認係單Agent模式,一個上下文窗口搞定規劃同執行。對於大部分編程任務已經夠用,但喺長時間運行、大規模並行同對抗性驗證嘅場景,會出現三種退化模式。
偷懶:叫佢做一輪安全審查,50個檢查項查到20個就話完成。
自我偏愛:叫佢評判自己嘅產出,佢自然傾向俾好評,嚴格驗證場景下係致命。
目標漂移:上下文壓縮係有損,每壓縮一次,原始需求嘅邊緣條件同約束細節就丟一點。
呢三個問題唔係模型能力問題,而係單上下文窗口同時承擔規劃同執行帶來嘅架構侷限。
動態工作流點樣運作?
動態工作流嘅核心係用獨立子Agent各自佔一個乾淨嘅上下文窗口,每個子Agent只做一件事,由一個確定性嘅JavaScript腳本調度佢哋嘅執行順序同依賴關係。
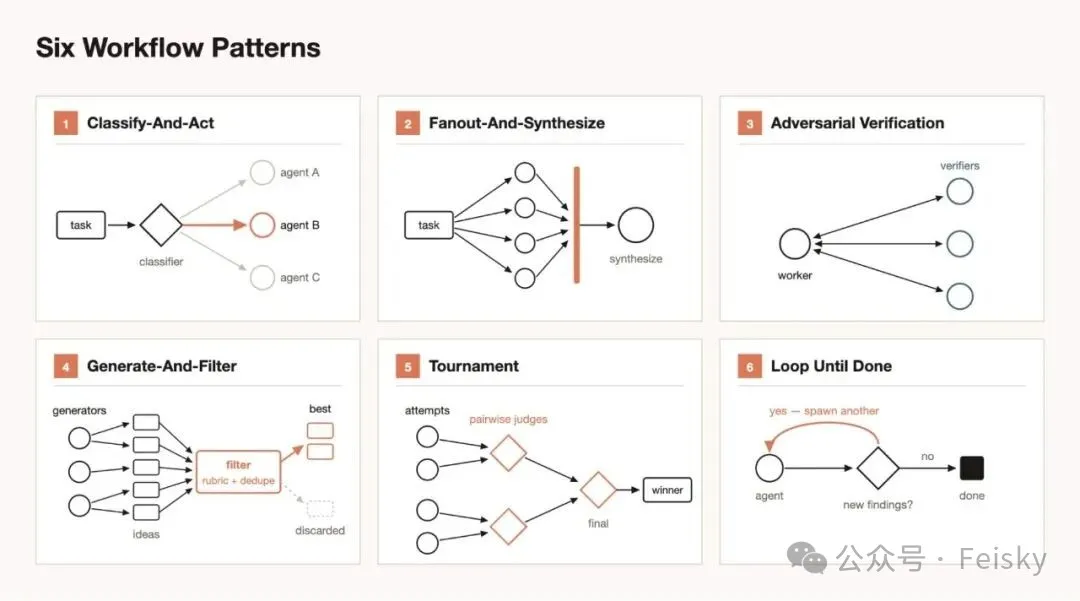
文章介紹咗六種基本調度模式,可以組合使用:
- 1 分類路由:一個分類Agent判斷任務類型,分發俾唔同處理Agent。
- 2 扇出合併:將任務拆成好多小步,每個小步一個獨立Agent,最後一個合併Agent匯總結果。咁樣每個子Agent有乾淨上下文,互不污染。
- 3 對抗驗證:每個生成Agent配一個獨立驗證Agent,專門挑剔,直接針對自我偏愛問題。
- 4 生成過濾:先大量生成,再按標準篩選去重,只留通過驗證嘅。
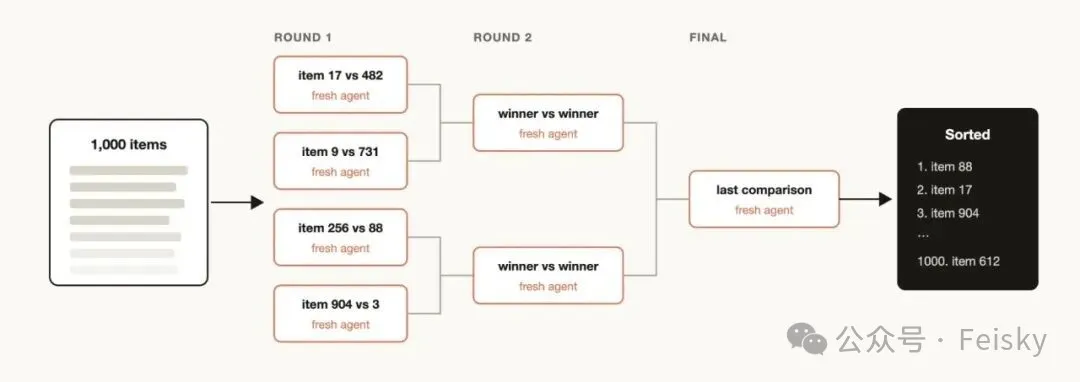
- 5 錦標賽模式:N個Agent用唔同策略做同一件事,兩兩比較淘汰,留低贏家。
- 6 循環到完成:唔設固定輪次,一直跑到滿足停止條件為止。
例如可以先用扇出,每個分支內部做對抗驗證,合併時再跑一輪錦標賽揀最優方案。
邊啲場景最啱用?
原文列咗唔少場景,以下係幾個實用例子:
大規模遷移同重構:Bun從Zig重寫成Rust就用咗工作流,每個修改點一個獨立Agent,避免交叉污染。
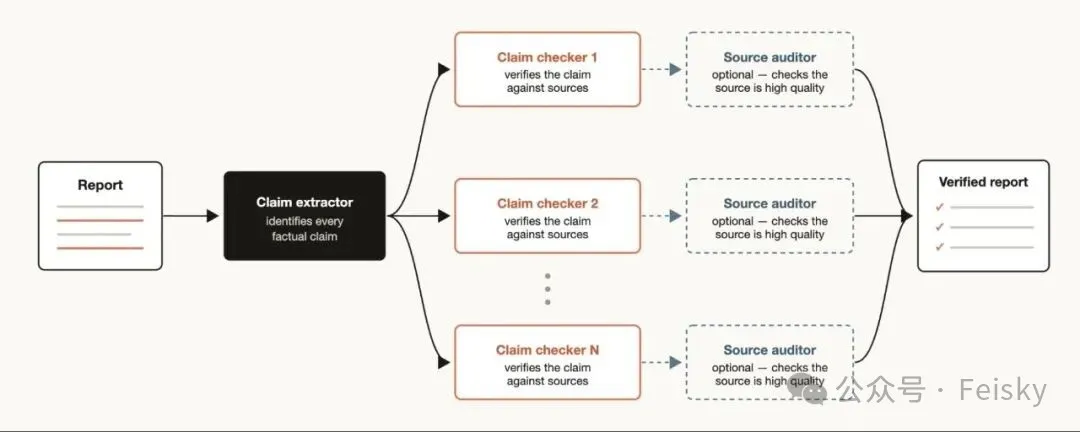
深度驗證:技術文章嘅事實性聲明,每個聲明派一個子Agent去核實,仲可以驗證信息源嘅可靠性。
排序:對1000條工單按嚴重程度排序,用錦標賽模式兩兩比較,比較判斷比絕對評分可靠。
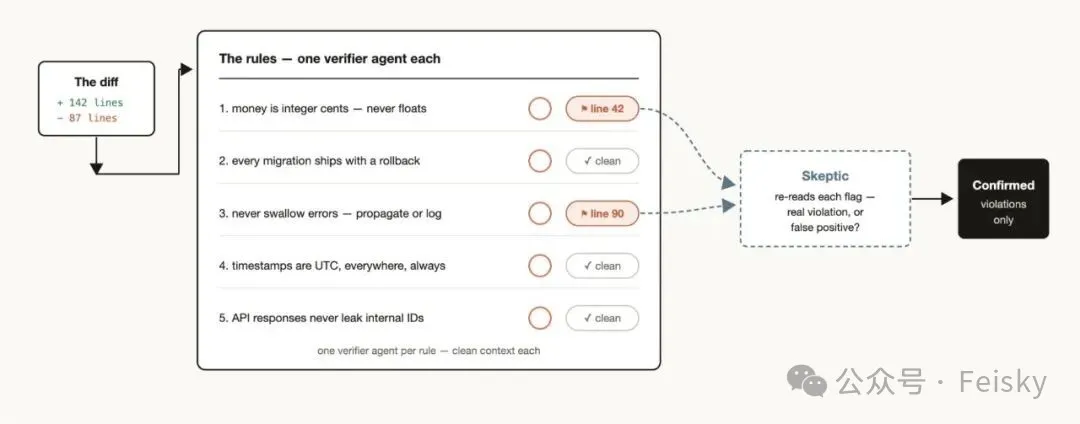
規則遵守:用工作流做驗證層,一條規則一個驗證Agent,用懷疑論者視角檢查違規。
根因分析:分別從日誌、文件變更、數據狀態生成獨立假設,每個假設面對驗證者同反駁者,避免單Agent認定假設一路追。
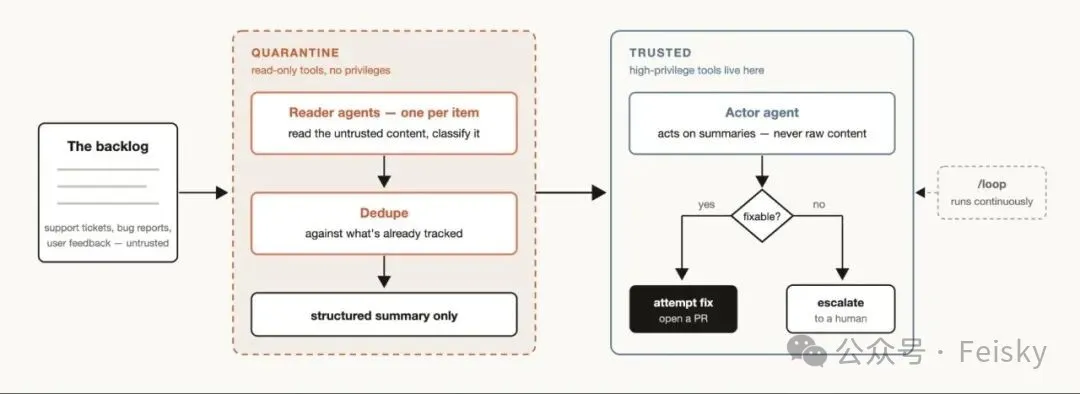
大規模分流:對每條工單做分類、去重、甚至自動修復,仲有「隔離區」設計模式,讀寫分離,避免prompt injection。
點樣用先有效?
開啟動態工作流有兩種方法:直接喺Prompt要求Claude創建工作流,或者用觸發詞ultracode。描述調度模式要具體,直接講「用扇出合併」或者「對抗驗證」。
原文俾咗幾個實用嘅Prompt示例,可以參考:
• 呢個測試大概50次跑掛一次。用工作流復現佢,形成競爭性假設,唔揾到經得起驗證嘅根因唔準停。
• 用工作流掃我最近50個session,揾到我反覆在糾正嘅模式,把重複出現嘅提煉成CLAUDE.md規則。
• 拎我嘅商業計劃,用工作流讓唔同Agent分別從投資人、客戶、競爭對手嘅視角撕佢。
• 呢個文件夾有80份簡歷,用工作流按後端崗位排名,前10名交叉驗證一遍。先用AskUserQuestion問我評分標準。
• 用工作流將我哋嘅User模型全局重新命名成Account。對於可重複嘅工作流,可以搭配/loop設置定期執行,/goal設置硬性完成條件。工作流好容易跑飛,喺Prompt加一句「用10k token」可以限制消耗。運行時按s可以保存腳本,存到~/.claude/workflows或者通過Skill分發俾團隊。
最後諗一諗
三個月前《點解單Agent搞唔掂複雜應用?》講嘅Generator-Evaluator模式需要人手動搭建,三個Agent跑6個鐘花200美金。而家動態工作流將「搭建Harness」呢件事都交俾Claude Code自己。
對於已經有經驗嘅任務類型,自己寫靜態工作流更可控;
對於探索性任務,讓Claude Code自己決定調度方式確實能發現你冇諗到嘅拆法。
兩者唔矛盾,動態工作流可以保存落嚟變成靜態嘅。