Claude Code 在大型代碼庫中是如何工作的:最佳實踐與入門指南【譯自 Anthropic 官方文檔】
整理版優先睇
Claude Code 喺大型代碼庫點樣運作?核心係基礎設施唔係模型
呢篇文章係翻譯自 Anthropic 官方文檔,由 Anthropic Applied AI 團隊總結咗 Claude Code 喺大型代碼庫成功落地嘅有效模式。整體結論係:Claude Code 嘅表現唔單止取決於背後模型,更取決於圍繞模型搭建嘅「基礎設施(harness)」,包括 CLAUDE.md、hooks、skills、plugins、MCP servers 等擴展點。
Claude Code 透過智能體式搜索(agentic search)直接喺開發者本地運行,唔需要預先索引,所以能實時處理最新代碼。但呢種方法需要充分嘅初始上下文,所以要透過 CLAUDE.md 同技能嚟做好上下文工程。基礎設施嘅五個擴展點各司其職:CLAUDE.md 提供每次會話嘅背景,hooks 令設置自我進化,skills 按需加載專業知識,plugins 方便經驗傳播,MCP servers 連接外部工具。另外 LSP 集成同子智能體進一步增強能力。
文章仲提出三個成功部署嘅配置模式:保持 CLAUDE.md 精簡分層、定期更新 CLAUDE.md 以配合模型進化、指定專人負責管理配置同推廣。對於大型組織,尤其係受監管行業,需要有治理機制,例如設定技能審批流程。總括嚟講,願意花時間設置好基礎設施嘅團隊,Claude Code 表現會更好。
- 結論:Claude Code 嘅成功取決於基礎設施(harness)多過模型本身,團隊應重點投資 CLAUDE.md、hooks、skills 等擴展點。
- 方法:使用分層 CLAUDE.md 文件,根目錄定義全局規則,子目錄定義局部規範,並透過子目錄初始化限制上下文範圍。
- 差異:相比傳統基於 RAG 嘅 AI 工具,Claude Code 無需預先索引,直接喺本地最新代碼上運行,避免過時結果,但需要充分初始上下文。
- 啟發:定期(每 3-6 個月)審查配置,尤其喺模型升級後移除過時規則,避免限制新模型能力。
- 可行動點:組織應指定直接負責人(DRI)或團隊管理 Claude Code 配置,建立標準化嘅 CLAUDE.md 層級結構同技能庫,並跨部門協作制定治理流程。
基礎設施(Harness)比模型更重要
好多團隊誤以為 Claude Code 嘅能力完全由背後模型決定,因而淨係盯住 基準測試。但實際上,圍繞模型搭建嘅「生態系統」——我哋叫佢做 基礎設施(harness)——對最終表現嘅決定性作用遠大於模型本身。呢個基礎設施由五個擴展點同兩項額外能力構成。
- 1 CLAUDE.md:每次會話自動讀取嘅上下文文件,根目錄管全局,子目錄管局部規範。一定要保持精簡,只留最通用嘅資訊。
- 2 Hooks:喺關鍵時刻自動運行嘅腳本。最正嘅用法係「停止鈎子」喺會話結束時建議更新 CLAUDE.md,或者「啟動鈎子」動態加載團隊上下文。
- 3 Skills:按需加載嘅專業知識,例如「安全審查技能」淨係喺審查漏洞時喚醒,唔會每次會話都加載,避免浪費上下文空間。
- 4 Plugins:將技能、hooks、MCP 配置打包成可安裝嘅包裹,方便全公司分發好嘅工作流配置。
- 5 MCP 服務器:連接內部工具、數據源同 API 嘅通道,令 Claude 可以存取原本觸碰唔到嘅系統。
除咗五個擴展點,仲有 LSP 集成 提供精確到「符號」級別嘅導航(例如 go to definition 同 find all references),同埋 子智能體(Subagents) 將「探索」同「編輯」分開,由獨立嘅 Claude 實例負責摸清子系統然後回報。
成功部署嘅三個配置模式
點樣為大型代碼庫配置 Claude Code 好取決於代碼庫結構,但有三種模式反覆出現喺成功案例中。
模式二:隨模型進化更新 CLAUDE.md。AI 模型越嚟越聰明,你為舊模型寫嘅規則可能變成絆腳石。例如,之前要求重構必須單文件修改,新模型可能係多文件協作嘅高手。建議每 三到六個月 做一次認真盤點,尤其喺大型模型更新之後。
模式三:指定專人負責管理與推廣。單靠技術配置唔夠,組織層面都要投入。成功嘅團隊通常有 智能體管理員(Agent Manager) 或者至少一個 直接負責人(DRI),負責管理配置、權限策略、插件市場同 CLAUDE.md 規範,仲要將好嘅經驗集中傳播,否則經驗只會留喺少數人腦入面。
對於受監管行業,仲要早啲建立治理機制:設定認可技能清單、強制代碼審查流程、有限初始訪問權限,然後逐步擴大。跨部門聯合工作組(工程、信息安全、合規)可以確保過渡順滑。
而家,Claude Code 已經喺好多複雜嘅生產環境入面大顯身手:無論係幾百萬行代碼嘅單一代碼庫(monorepos),長達幾十年嘅舊系統,跨越幾十個代碼庫嘅分佈式架構,定係有幾千個開發者嘅大組織。同細型、簡單嘅代碼項目相比,呢啲環境充滿挑戰。例如,唔同子目錄下嘅構建命令可能差好遠,或者歷史遺留代碼散落喺各個文件夾,連個統一嘅根目錄都揾唔到。
呢篇文章會帶你瞭解,我哋觀察到嗰啲令 Claude Code 喺大規模場景下成功落地嘅有效模式。喺呢度,「大型代碼庫」涵蓋咗各種複雜嘅部署情況:幾百萬行嘅單一代碼庫、沉澱幾十年嘅遺留系統、分散喺唔同倉庫嘅幾十個微服務(microservices),或者係呢啲情況嘅任意組合。此外,仲包括嗰啲通常唔被認為適合用 AI 輔助編程工具嘅編程語言,例如 C、C++、C#、Java 同 PHP(其實 Claude Code 喺呢啲語言上嘅表現比大多數團隊預期嘅好得多,特別係隨住最近模型嘅升級)。雖然每個大型代碼庫嘅部署都會受到其特定嘅版本控制系統、團隊結構同歷史習慣嘅影響,但呢篇文章總結嘅呢啲模式具有普遍適用性,對於準備引入 Claude Code 嘅團隊嚟講,係一個絕佳嘅起點。
Claude Code 係點樣喺大型代碼庫入面穿梭㗎?
Claude Code 瀏覽代碼庫嘅方式,就好似一位經驗豐富嘅軟件工程師:佢會喺文件系統入面穿梭,睇文件內容,用 grep 命令(註釋:grep 係一種好強大嘅文字搜尋工具,程式設計師成日用嚟喺大量文件入面揾特定嘅詞句)精準定位需要嘅資訊,並順藤摸瓜咁追蹤代碼庫入面嘅各種引用關係。佢直接喺開發者嘅本地電腦上面運行,唔需要你預先構建、維護代碼庫索引,亦都唔需要將代碼上傳到雲端伺服器。
傳統嘅基於 RAG(註釋:RAG,即係 Retrieval-Augmented Generation 檢索增強生成,指 AI 透過檢索外部數據庫嚟揾答案嘅技術)嘅 AI 編程工具係咁樣運作嘅:佢哋會將整個代碼庫轉化為向量(embedding),當用戶提問嘅時候,再檢索出相關嘅代碼片段。但係喺龐大嘅代碼庫面前,呢種系統往往會崩潰。因為向量化嘅處理速度,根本跟唔上活躍開發團隊提交代碼嘅節奏。當開發者向索引提問嘅時候,系統裏面嘅代碼可能仲係幾星期、幾日甚至幾小時前嘅舊版本。檢索出嚟嘅結果可能係一個兩星期前就被團隊改咗名嘅函數,或者引用咗一個喺上個迭代(sprint)入面已經被刪咗嘅模塊,而且系統仲唔會提示你呢啲資訊已經過期咗。
智能體式嘅搜尋(Agentic search)就巧妙避開咗呢啲雷區。當幾千個工程師喺不斷提交新代碼嘅時候,佢唔需要維護向量化嘅數據管道,亦都唔需要集中式嘅索引。每位開發者嘅 Claude 實例都喺最新、最即時嘅代碼庫上面進行工作。
但係,呢種方法都有一定嘅代價:只有當 Claude 掌握咗足夠嘅「初始上下文」,知道應該去邊度揾嘢嘅時候,佢先可以發揮出最佳水平。即係話,代碼庫嘅初始設置越完善,通過 CLAUDE.md 文件同各種技能層層鋪墊上下文工程(Context Engineering),Claude 嘅導航能力就越強。如果你喺一個擁有十億行代碼嘅庫入面,叫佢去揾一個模糊不清嘅代碼模式,咁喺佢開始做嘢之前,你可能已經將佢嘅上下文窗口(context-window)限額用曬。所以,嗰啲願意花時間將代碼庫設置好嘅團隊,往往可以獲得更好嘅效果。
基礎設施(Harness)同模型同樣重要
關於 Claude Code,人哋最常見嘅一個誤區係:佢嘅能力完全由背後嘅模型決定。所以,團隊往往只係盯住模型喺各項基準測試(benchmarks)入面嘅表現,或者佢完成特定測試任務嘅情況。但係喺實際應用入面,圍繞模型搭建嘅「生態系統」——我哋稱之為基礎設施(harness)——對 Claude Code 最終表現嘅決定性作用,其實遠大過模型本身。
呢個基礎設施由五個擴展點構建而成:CLAUDE.md 文件、鈎子(hooks)、技能(skills)、插件(plugins)同 MCP 服務器(MCP servers)。佢哋各司其職。團隊搭建呢啲擴展點嘅順序非常關鍵,因為每一層都係建立喺前一層嘅基石上面。此外,仲有兩項額外嘅能力完善咗整個系統:LSP 集成同子 AI 智能體(subagents)。下面,我哋詳細解釋一下呢啲組件同能力到底可以做啲乜嘢:
CLAUDE.md[2]文件係重中之重。 呢啲係 Claude 喺每次會話開始嗰陣都會自動讀取嘅上下文文件:根目錄下面嘅文件用嚟掌握全局情況,子目錄下面嘅文件就用嚟瞭解局部嘅代碼規範。佢哋為 Claude 提供咗出色完成任務所需嘅代碼庫背景知識。因為無論係咩任務,呢啲文件每次都會被加載,所以一定要令佢哋保持精簡,只保留最通用嘅資訊,避免佢哋變成拖累性能嘅累贅。
鈎子(Hooks)[3]令整個設置具備自我進化嘅能力。 (註釋:鈎子係指喺特定事件發生前後自動執行嘅一段代碼片段)大多數團隊將鈎子視為阻止 Claude 犯錯嘅腳本,但佢哋更重要嘅價值在於持續改進。例如,一個「停止鈎子(stop hook)」可以喺會話結束嗰陣,趁住記憶仲新鮮,反思啱啱發生嘅事並提出更新 CLAUDE.md 嘅建議。一個「啟動鈎子(start hook)」可以動態加載特定團隊嘅上下文,咁樣每個開發者就唔使手動配置,就可以為自己負責嘅模塊獲得正確嘅環境設置。對於好似代碼檢查(linting)同格式化呢種自動化嘅工作,鈎子可以強制執行規則,咁比起淨係靠 Claude 去記住一條指令要靠譜、一致得多。
技能(Skills)[4]令你可以隨時調用所需嘅專業知識,又唔會令每次會話變得臃腫。 喺一個包含幾十種任務類型嘅大型代碼庫入面,並唔係每次任務都需要加載曬所有嘅專業知識。技能透過漸進式呈現(progressive disclosure)[5]解決咗呢個問題:佢哋將嗰啲如果唔拎走就會霸佔上下文空間嘅專業工作流同領域知識獨立出嚟,只有喺任務需要嗰陣先進行加載。舉個例,當 Claude 審查代碼漏洞嘅時候,「安全審查技能」先會被喚醒;而當代碼被修改而且需要更新文檔嘅時候,「文檔處理技能」先會被加載。
技能仲可以被限制喺特定嘅路徑下面,咁樣佢哋只會喺代碼庫嘅相關部分被激活。例如,負責支付服務嘅團隊可以將佢哋嘅「部署技能」綁定到支付相關嘅目錄,咁樣當有人喺呢個大型代碼庫嘅其他地方工作嘅時候,呢個技能就唔會自動加載。
插件(Plugins)[6]令好用嘅經驗得以傳播。 大型代碼庫面對嘅一個挑戰係,「好用嘅配置」往往只喺細圈子入面流傳(tribal knowledge)。插件將各種技能、鈎子同 MCP 配置打包成一個可以安裝嘅獨立包裹。咁樣一來,當一個新入職嘅工程師喺第一日安裝咗呢個插件,佢即刻就可以擁有同嗰啲老手一樣咁強大嘅上下文知識同能力。企業仲可以透過企業內部應用市場(managed marketplaces)[7]將插件嘅更新分發俾整個組織。
舉個真實嘅例子,同我哋合作嘅一間大型零售企業,開發咗一項技能,將 Claude 同佢哋內部嘅分析平台連接起嚟。咁樣,業務分析師唔使切換軟件,就可以直接喺自己嘅工作流入面拉取業務表現數據。喺向全公司推廣之前,佢哋將呢個功能打包成咗插件進行分發。
語言服務器協議(LSP)集成為 Claude 提供咗好似開發者喺集成開發環境(IDE)入面一樣咁強大嘅導航能力。 (註釋:LSP 係一種令編輯器可以理解代碼邏輯嘅協議,實現咗類似代碼自動補全、跳轉到定義等高級功能)大多數針對大型代碼庫嘅 IDE 都運行緊 LSP,支援住「跳轉到定義(go to definition)」同「查找所有引用(find all references)」嘅功能。將呢個能力賦予 Claude,就可以令佢擁有精確到「符號(symbol)」級別嘅準度:佢可以順住一個函數嘅調用揾到佢嘅定義,喺唔同文件入面追蹤引用,甚至可以分清喺唔同語言入面名完全一樣但實際上係唔同嘅函數。如果冇 LSP,Claude 就只能靠死板嘅文字匹配,咁好容易令佢揾錯目標。我哋合作過嘅一間企業軟件公司,喺全面推廣 Claude Code 之前,率先喺全公司範圍內部署咗 LSP 集成,目的就係為咗確保喺海量代碼入面,C 同 C++ 嘅代碼導航依然精準可靠。對於多語言混合嘅代碼庫嚟講,呢個係最具價值嘅投資之一。
MCP 服務器(MCP servers)係連接萬物嘅橋樑。 MCP 服務器係 Claude 連接內部工具、數據源同嗰啲原本冇辦法接觸到嘅 API 嘅通道。最硬核嘅團隊會將結構化搜索封裝成工具,透過 MCP 服務器令 Claude 直接調用。亦有其他團隊透過 MCP 將 Claude 同內部嘅文檔系統、工單系統或者分析平台連接起嚟。
子智能體(Subagents)[8]將「探索」同「編輯」分開。 子智能體係一個獨立嘅 Claude 實例,擁有自己專屬嘅上下文窗口。佢負責接下任務,埋頭苦幹,然後只將最終結果彙報俾「父級」系統。當整個基礎設施搭建完畢之後,一啲團隊會先啟動一個「只讀」嘅子智能體去摸清某個子系統嘅底細,並將發現記錄喺一個文件入面;然後,主智能體再根據呢張完整嘅「地圖」去進行全局嘅代碼編輯。
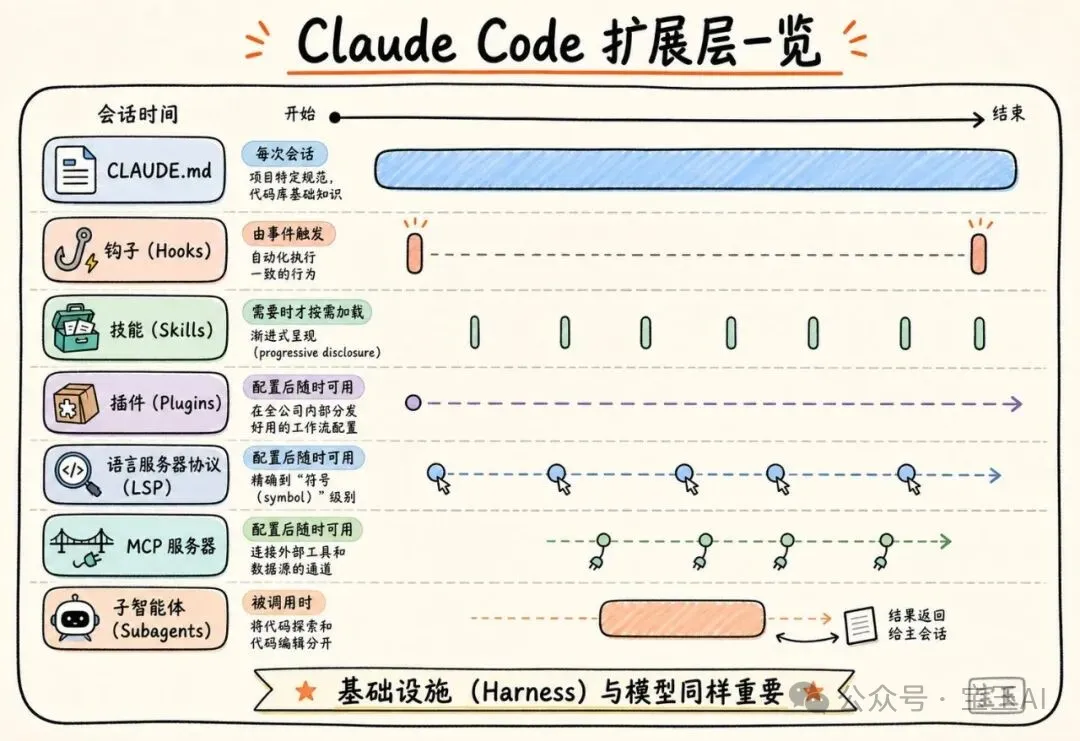
Claude Code 擴展層一覽。
下表總結咗每個組件嘅具體功能、加載時機,同埋我哋觀察到嘅最常見嘅誤區:
*LSP 係透過插件層訪問嘅。子智能體係一種任務委託能力,而唔係一個需要配置嘅擴展點。
成功部署嘅三個配置模式
你應該點樣為一個大型代碼庫配置 Claude Code,好大程度上取決於呢個代碼庫自身嘅結構。不過,喺我哋觀察到嘅眾多成功案例入面,有三種模式反覆出現。
令龐大嘅代碼庫變得容易導航
Claude 喺大型代碼庫入面可以幫到幾大忙,取決於佢可以幾快揾到正確嘅上下文。如果喺每次會話入面塞入太多上下文,性能就會直線下降;但如果上下文太少,Claude 又會好似無頭蒼蠅咁亂撞。最有效嘅部署方式,往往係喺前期投入精力,令代碼庫對 Claude 嚟講變得「清晰易懂」。我哋總結咗以下幾個常見模式:
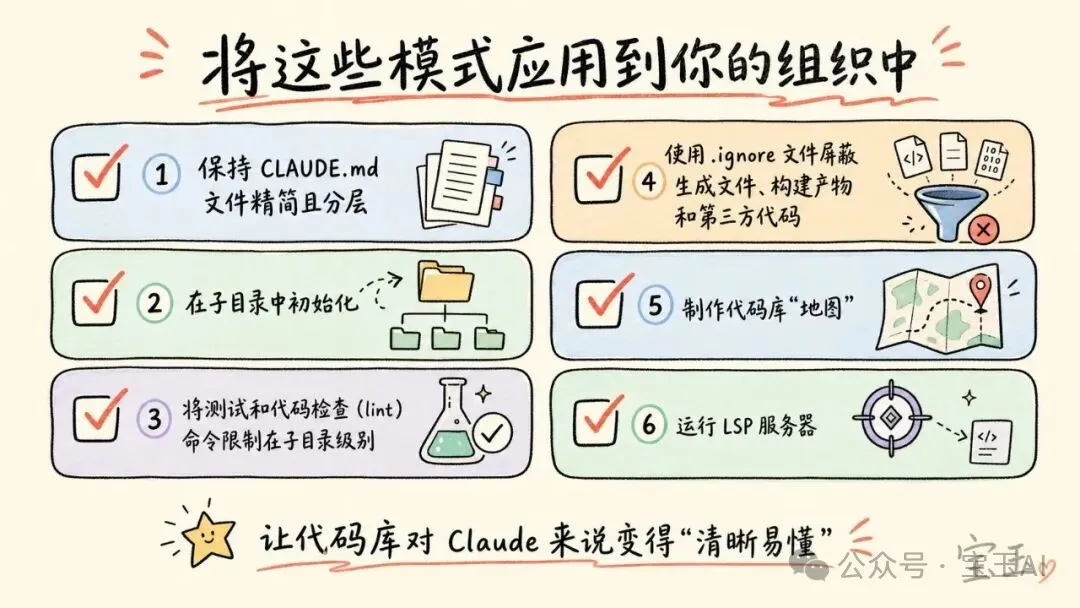
• 保持 CLAUDE.md 文件精簡同分層。 當 Claude 喺代碼庫入面穿梭嗰陣,佢會不斷將呢啲文件內容疊加起嚟:根目錄文件提供全局視角,子目錄文件提供局部規範。所以,根文件入面只應該放最核心嘅指引同絕對唔可以踩嘅坑;除此之外嘅其他內容,對根文件嚟講都係噪音。 • 喺子目錄入面初始化,而唔係喺代碼庫根目錄。 將 Claude 限制喺同當前任務直接相關嘅代碼區域入面,佢嘅表現會係最好嘅。喺單一代碼庫(monorepos)入面,呢個可能聽起嚟有啲違反直覺,因為好多工具都默認需要喺根目錄運行。但係唔使擔心,Claude 會自動沿住目錄樹向上爬,並且讀取沿途發現嘅所有 CLAUDE.md 文件,所以佢絕對唔會丟失根目錄嘅上下文資訊。 • 將測試同代碼檢查(lint)命令限制喺子目錄級別。 試想像嚇,如果 Claude 只係修改咗一個微服務,但係跑曬成個大項目嘅測試用例,呢個唔單止會導致超時,仲會令毫無關聯嘅輸出結果塞滿上下文。所以,子目錄級別嘅 CLAUDE.md 文件應該清楚說明只適用於呢個區域嘅命令。呢種方法喺面向服務(service-oriented)嘅代碼架構入面非常有效,因為每個目錄都有自己嘅測試同構建命令。不過,喺嗰啲交叉依賴極深嘅編譯型語言大型代碼庫入面,想要做到按子目錄限制範圍會比較困難,可能需要針對項目定製構建配置。 • 使用 .ignore文件屏蔽生成文件、構建產物同第三方代碼。 在.claude/settings.json中提交permissions.deny規則,意味住呢啲排除項進入了版本控制。咁樣,團隊入面嘅每個開發者都可以享受到同樣嘅「降噪」效果,唔使自己再去搞配置。喺某啲項目入面,生成嘅代碼本身就係開發工作嘅一部分。冇關係,嗰啲負責代碼生成器嘅開發者可以喺本地設置入面覆蓋項目嘅排除規則,呢個完全唔會影響到團隊嘅其他人。• 當目錄結構唔夠清晰嗰陣,製作代碼庫「地圖」。 有啲組織嘅代碼並冇跟常規嘅目錄結構規規矩矩咁整理。呢個時候,你可以喺代碼庫根目錄下面建立一個輕量級嘅 Markdown 文件,列出每個頂級資料夾同埋一句話說明嗰度裝啲乜嘢。呢個就好似俾咗一份目錄畀 Claude,佢喺打開文件之前可以先行睇嚇。如果一個代碼庫有幾百個頂級資料夾,最好採用分層嘅方法:根文件只描述最頂層嘅結構,子目錄嘅 CLAUDE.md 就提供下一級嘅細節,當 Claude 遊走到相應樹節點嗰陣再按需加載。對於簡單嘅情況,只需要用 @提及(mention)令 Claude 應該參考嘅特定文件或目錄就得。• 運行 LSP 服務器,令 Claude 按照「符號」而唔係「字符串」嚟搜尋。 喺一個龐大嘅代碼庫入面,如果只係用文字去搜尋一個常見嘅函數名,可能會返回成千上萬個結果。Claude 會消耗大量嘅上下文空間,一個一個打開文件去估到底邊個先係真正嘅目標。而 LSP 只會返回指向同一個代碼邏輯符號(symbol)嘅引用,等於係喺 Claude 閲讀之前就將過濾工作做好咗。要實現呢個,你需要為你嘅編程語言安裝一個代碼智能插件(code intelligence plugin)[9] 以及相應嘅語言服務器程式。Claude Code 嘅官方文檔入面有關於可用插件同故障排除嘅詳細介紹。
需要注意嘅係:喺某啲極端場景下,即使係分層嘅 CLAUDE.md 方法都會失效。例如一個代碼庫入面塞咗幾十萬個資料夾同幾百萬個文件,或者係一啲使用非 Git 版本控制嘅舊系統。我哋會喺呢個系列嘅後續文章入面專門探討呢啲難題。
隨住模型越來越聰明,要持續更新 CLAUDE.md 文件
隨住 AI 模型嘅不斷進化,你為當前模型寫嘅指令,去到未來可能會變成絆腳石。例如,之前為咗幫 Claude 繞過某個坑而寫嘅 CLAUDE.md 規則,等新模型發佈之後,可能就會變得多餘,甚至變成束縛。舉個例,假設之前有個規則話俾 Claude 聽:重構代碼嘅時候必須拆分成對單個文件嘅修改。呢個確實可以幫早期嘅老模型穩住陣腳,但如果你換咗更強大嘅新模型,呢條規則反而會阻止佢去執行佢本可以完美勝任嘅跨文件協同修改。
同樣,為咗彌補特定模型缺陷(無論係模型推理能力上嘅,定係 Claude Code 工具本身嘅侷限)而拼湊出嚟嘅技能同鈎子,一旦呢啲缺陷被修復,佢哋就會變成毫無意義嘅負擔。例如,喺一個使用 Perforce(註釋:一種常用於大型遊戲同企業級開發嘅集中式版本控制系統)嘅代碼庫入面,之前寫咗一個鈎子專門攔截文件寫入操作以強制執行 p4 edit。但後來 Claude Code 原生支援咗 Perforce 模式,呢個鈎子就變成咗多餘嘅擺設。
我哋建議團隊每三到六個月就對配置進行一次認真嘅盤點。而且,如果喺大型模型更新發布之後,你覺得代碼助手嘅表現好似停滯不前咁,咁絕對值得再去審查一次配置。
指定專人負責 Claude Code 嘅管理同推廣
淨靠技術配置係冇辦法真正推動團隊廣泛使用嘅。嗰啲成功落地嘅組織,同樣喺組織管理架構上投入咗心血。
嗰啲推廣得最快嘅團隊,喺全面開放權限之前,都專門投入咗人力進行基礎設施建設。哪怕只係一個細團隊,甚至得一個人,只要將工具打磨好,確保當開發者第一次接觸 Claude 嗰陣,佢就已經完美融入咗現有嘅工作流。喺一間公司入面,幾位工程師提前編寫好咗一套插件同 MCP,保證喺發布嘅第一日大家就可以用上。而喺另一間公司,甚至有一個專門管理 AI 編程工具嘅團隊,喺推廣開始前就將基礎設施全部搭好咗。喺呢兩個案例入面,開發者初次體驗到嘅都係滿滿嘅生產力,而唔係挫敗感,普及率自然水漲船高。
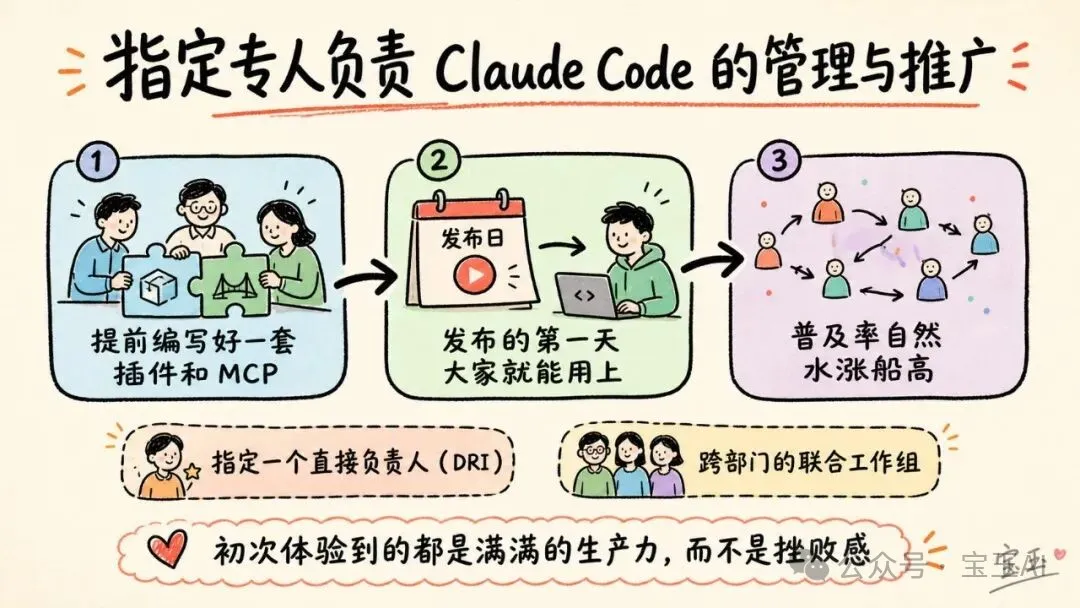
目前,做呢啲工作嘅團隊通常屬於「開發者體驗(Developer Experience)」或「開發者生產力(Developer Productivity)」部門,呢個原本亦係負責新員工入職培訓同開發內部工具嘅部門。此外,一啲組織入面仲湧現咗一個新角色:智能體管理員(Agent Manager)。呢個係一個融合咗產品經理同工程師職能嘅崗位,專門負責管理 Claude Code 嘅生態系統。對於冇專職團隊嘅公司,最起碼要指定一個直接負責人(DRI,Directly Responsible Individual):呢個人擁有管理 Claude Code 配置嘅權限,可以拍板決定各項設置、權限策略、插件市場同 CLAUDE.md 嘅規範,並負責令呢啲內容保持最新狀態。
由下而上自發嘅擁抱確實可以激發熱情,但如果冇人將好用嘅經驗集中起嚟,呢種熱情好容易變成一盤散沙。你需要一個人或一個團隊嚟整理、推廣正確嘅 Claude Code 使用習慣(例如標準化嘅 CLAUDE.md 層級結構,或者精選嘅技能同插件庫)。如果冇人做呢啲事,經驗就會被困喺少數人腦入面,工具嘅普及也就到頭了。
喺大型組織入面,尤其係受到嚴格監管嘅行業,早晚會面對各種治理難題:邊個嚟決定邊啲技能同插件可以上線?點樣防止成千上萬個工程師喺自己嘅電腦上面重複造輪子?點樣確保 AI 生成嘅代碼可以好似人類寫嘅代碼一樣經歷嚴格嘅代碼審查?為咗喺早期就應對呢啲問題,我哋建議從設定一組受認可嘅技能、強制嘅代碼審查流程同最初嘅有限訪問權限開始,隨住信心嘅增強再逐步擴大範圍。
我哋觀察到,推行得最順滑嘅組織,往往喺早期就組建咗跨部門嘅聯合工作組。佢哋將工程、信息安全同合規部門嘅代表聚埋一齊,共同定義需求,並制定出清晰嘅推廣路線圖。
將呢啲模式應用到你嘅組織入面
Claude Code 係圍繞住傳統嘅軟件工程環境設計嘅:喺呢啲環境入面,工程師係代碼庫嘅主力軍,代碼託管使用 Git,代碼亦都跟標準嘅目錄結構。大多數大型代碼庫都符合呢個模式,但如果遇到非傳統嘅架構,例如包含大量二進制資產嘅遊戲引擎、使用非主流版本控制系統嘅環境,或者係令非技術人員都參與代碼貢獻嘅項目,就需要進行額外嘅配置功夫。我哋呢篇指南默認你係用傳統架構,而且文中提到嘅呢啲模式已經喺我哋嘅好多客戶身上得到成功驗證。如果仲存在其他複雜情況,咁就需要根據你哋自己嘅代碼庫、工具鏈同組織架構嚟具體分析。呢個正係 Anthropic 嘅 Applied AI 團隊大顯身手嘅地方,佢哋會直接同工程團隊並肩作戰,將呢啲通用嘅模式轉化為最適合你哋組織嘅定製化方案。
即刻體驗企業版 Claude Code (Claude Code for Enterprise)[10]。
特別感謝 Anthropic Applied AI 團隊嘅 Alon Krifcher、Charmaine Lee、Chris Concannon、Harsh Patel、Henrique Savelli、Jason Schwartz、Jonah Dueck 同 Kirby Kohlmorgen,多謝佢哋分享咗喺大規模環境入面部署 Claude Code 嘅寶貴經驗;同時亦多謝 Zoox 公司嘅 Amit Navindgi 對本文提供嘅寶貴反饋。
引用連結
[1] How Claude Code works in large codebases: Best practices and where to start: https://claude.com/blog/how-claude-code-works-in-large-codebases-best-practices-and-where-to-start[2]CLAUDE.md: https://code.claude.com/docs/en/memory[3]鈎子(Hooks): https://code.claude.com/docs/en/hooks-guide[4]技能(Skills): https://code.claude.com/docs/en/skills[5] 漸進式呈現(progressive disclosure): https://platform.claude.com/docs/en/agents-and-tools/agent-skills/best-practices[6]插件(Plugins): https://code.claude.com/docs/en/plugins[7] 企業內部應用市場(managed marketplaces): https://support.claude.com/en/articles/13837433-manage-claude-cowork-plugins-for-your-organization[8]子智能體(Subagents): https://code.claude.com/docs/en/sub-agents[9] 代碼智能插件(code intelligence plugin): https://code.claude.com/docs/en/discover-plugins#code-intelligence[10]企業版 Claude Code (Claude Code for Enterprise): https://claude.com/product/claude-code/enterprise
如今,Claude Code 已經在諸多複雜的生產環境中大顯身手:無論是數百萬行代碼的單一代碼倉庫(monorepos),長達幾十年的老舊系統,跨越幾十個代碼庫的分佈式架構,還是擁有數千名開發者的龐大組織。與小型、簡單的代碼項目相比,這些環境充滿了挑戰。比如,不同子目錄下的構建命令可能千差萬別,或者歷史遺留代碼散落在各個文件夾中,連個統一的根目錄都找不到。
這篇文章將帶你瞭解,我們觀察到的那些讓 Claude Code 在大規模場景下成功落地的有效模式。在這裏,“大型代碼庫”涵蓋了各種複雜的部署情況:數百萬行的單一代碼庫、沉澱幾十年的遺留系統、分散在不同倉庫裏的幾十個微服務(microservices),或者是這些情況的任意組合。此外,這還包括那些通常不被認為適合用 AI 輔助編程工具的編程語言,比如 C、C++、C#、Java 和 PHP(其實 Claude Code 在這些語言上的表現比大多團隊預期的要好得多,特別是隨着最近模型的升級)。雖然每個大型代碼庫的部署都會受到其特定的版本控制系統、團隊結構和歷史習慣的影響,但本文總結的這些模式具有普遍適用性,對於準備引入 Claude Code 的團隊來說,是一個絕佳的起點。
Claude Code 是如何在大型代碼庫中穿梭的?
Claude Code 瀏覽代碼庫的方式,就像一位經驗豐富的軟件工程師:它會在文件系統中穿梭,閲讀文件內容,使用 grep 命令(註釋:grep 是一種強大的文本搜索工具,程序員常用來在大量文件中查找特定的詞句)精準定位需要的信息,並順藤摸瓜地追蹤代碼庫中的各種引用關係。它直接在開發者的本地電腦上運行,不需要你預先構建、維護代碼庫索引,也不需要把代碼上傳到雲端服務器。
傳統的基於 RAG(註釋:RAG,即 Retrieval-Augmented Generation 檢索增強生成,指 AI 通過檢索外部數據庫來尋找答案的技術)的 AI 編程工具是這樣工作的:它們會把整個代碼庫轉化為向量(embedding),當用戶提問時,再檢索出相關的代碼片段。但是在龐大的代碼庫面前,這種系統往往會崩潰。因為向量化的處理速度,根本跟不上活躍開發團隊提交代碼的節奏。當開發者向索引提問時,系統裏的代碼可能還是幾周、幾天甚至幾小時前的舊版本。檢索出來的結果可能是一個兩週前就被團隊改了名的函數,或者引用了一個在上個迭代(sprint)中已經被刪掉的模塊,而且系統還不會提示你這些信息已經過期了。
智能體式的搜索(Agentic search)則巧妙避開了這些雷區。當數千名工程師在不斷提交新代碼時,它不需要維護向量化的數據管道,也不需要集中式的索引。每位開發者的 Claude 實例都在最新、最實時的代碼庫上進行工作。
但是,這種方法也有一定的代價:只有當 Claude 掌握了足夠的“初始上下文”,知道該去哪裏找東西時,它才能發揮出最佳水平。也就是說,代碼庫的初始設置越完善,通過 CLAUDE.md 文件和各種技能層層鋪墊上下文工程(Context Engineering),Claude 的導航能力就越強。如果你在一個擁有十億行代碼的庫中,讓它去尋找一個模糊不清的代碼模式,那麼在它開始幹活之前,你可能就已經把它的上下文窗口(context-window)限額給耗盡了。所以,那些願意花時間把代碼庫設置好的團隊,往往能獲得更好的效果。
基礎設施(Harness)與模型同樣重要
關於 Claude Code,人們最常見的一個誤區是:它的能力完全由背後的模型決定。因此,團隊往往只盯着模型在各項基準測試(benchmarks)中的表現,或者它完成特定測試任務的情況。但在實際應用中,圍繞模型搭建的“生態系統”——我們稱之為基礎設施(harness)——對 Claude Code 最終表現的決定性作用,其實遠大於模型本身。
這個基礎設施由五個擴展點構建而成:CLAUDE.md 文件、鈎子(hooks)、技能(skills)、插件(plugins)和 MCP 服務器(MCP servers)。它們各司其職。團隊搭建這些擴展點的順序非常關鍵,因為每一層都是建立在前一層的基石之上。此外,還有兩項額外的能力完善了整個系統:LSP 集成和子 AI 智能體(subagents)。下面,我們來詳細解釋一下這些組件和能力到底能做什麼:
CLAUDE.md[2]文件是重中之重。 這些是 Claude 在每次會話開始時都會自動讀取的上下文文件:根目錄下的文件用於掌握全局情況,子目錄下的文件則用於瞭解局部的代碼規範。它們為 Claude 提供了出色完成任務所需的代碼庫背景知識。因為不管是什麼任務,這些文件每次都會被加載,所以一定要讓它們保持精簡,只保留最通用的信息,避免它們變成拖累性能的累贅。
鈎子(Hooks)[3]讓整個設置具備自我進化的能力。 (註釋:鈎子是指在特定事件發生前後自動執行的一段代碼片段)大多數團隊把鈎子看作是阻止 Claude 犯錯的腳本,但它們更重要的價值在於持續改進。比如,一個“停止鈎子(stop hook)”可以在會話結束時,趁着記憶還新鮮,反思剛才發生的事情並提出更新 CLAUDE.md 的建議。一個“啓動鈎子(start hook)”可以動態加載特定團隊的上下文,這樣每個開發者不用手動配置,就能為自己負責的模塊獲得正確的環境設置。對於像代碼檢查(linting)和格式化這種自動化的工作,鈎子可以強制執行規則,這比僅僅依靠 Claude 去記住一條指令要靠譜、一致得多。
技能(Skills)[4]讓你能夠隨時調用所需的專業知識,又不會讓每次會話變得臃腫。 在一個包含幾十種任務類型的大型代碼庫中,並不是每次任務都需要加載所有的專業知識。技能通過漸進式呈現(progressive disclosure)[5]解決了這個問題:它們把那些如果不拿走就會擠佔上下文空間的專業工作流和領域知識獨立出來,只有在任務需要時才進行加載。舉個例子,當 Claude 審查代碼漏洞時,“安全審查技能”才會被喚醒;而當代碼被修改且需要更新文檔時,“文檔處理技能”才會被加載。
技能還可以被限制在特定的路徑下,這樣它們只會在代碼庫的相關部分被激活。比如,負責支付服務的團隊可以將他們的“部署技能”綁定到支付相關的目錄,這樣當有人在這個大型代碼庫的其他地方工作時,這個技能就不會自動加載。
插件(Plugins)[6]讓好用的經驗得以傳播。 大型代碼庫面臨的一個挑戰是,“好用的配置”往往只在小圈子裏流傳(tribal knowledge)。插件把各種技能、鈎子和 MCP 配置打包成一個可以安裝的獨立包裹。這樣一來,當一個新入職的工程師在第一天安裝了這個插件,他立刻就能擁有和那些老手們一樣強大的上下文知識和能力。企業還可以通過企業內部應用市場(managed marketplaces)[7]把插件的更新分發給整個組織。
舉個真實的例子,與我們合作的一家大型零售企業,開發了一項技能,將 Claude 與他們內部的分析平台連接起來。這樣,業務分析師不用切換軟件,就能直接在自己的工作流里拉取業務表現數據。在向全公司推廣之前,他們將這個功能打包成了插件進行分發。
語言服務器協議(LSP)集成為 Claude 提供了像開發者在集成開發環境(IDE)中一樣強大的導航能力。 (註釋:LSP 是一種讓編輯器能理解代碼邏輯的協議,實現了類似代碼自動補全、跳轉到定義等高級功能)大多數針對大型代碼庫的 IDE 都運行着 LSP,支持着“跳轉到定義(go to definition)”和“查找所有引用(find all references)”的功能。把這個能力賦予 Claude,就能讓它擁有精確到“符號(symbol)”級別的準度:它可以順着一個函數的調用找到它的定義,在不同文件中追蹤引用,甚至能分清在不同語言里名字完全一樣但實際上卻是不同的函數。如果沒有 LSP,Claude 就只能靠死板的文本匹配,這很容易讓它找錯目標。我們合作過的一家企業軟件公司,在全面推廣 Claude Code 之前,率先在全公司範圍內部署了 LSP 集成,目的就是為了確保在海量代碼中,C 和 C++ 的代碼導航依然精準可靠。對於多語言混合的代碼庫來說,這是最具價值的投資之一。
MCP 服務器(MCP servers)是連接萬物的橋樑。 MCP 服務器是 Claude 連接內部工具、數據源和那些原本無法觸達的 API 的通道。最硬核的團隊會把結構化搜索封裝成工具,通過 MCP 服務器讓 Claude 直接調用。也有其他團隊通過 MCP 把 Claude 與內部的文檔系統、工單系統或者分析平台連接起來。
子智能體(Subagents)[8]把“探索”和“編輯”分開。 子智能體是一個獨立的 Claude 實例,擁有自己專屬的上下文窗口。它負責接下任務,埋頭苦幹,然後只把最終結果彙報給“父級”系統。當整個基礎設施搭建完畢後,一些團隊會先啓動一個“只讀”的子智能體去摸清某個子系統的底細,並把發現記錄在一個文件中;然後,主智能體再根據這張完整的“地圖”去進行全局的代碼編輯。
Claude Code 擴展層一覽。
下表總結了每個組件的具體功能、加載時機,以及我們觀察到的最常見的誤區:
*LSP 是通過插件層訪問的。子智能體是一種任務委託能力,而不是一個需要配置的擴展點。
成功部署的三個配置模式
你該如何為一個大型代碼庫配置 Claude Code,很大程度上取決於這個代碼庫自身的結構。不過,在我們觀察到的眾多成功案例中,有三種模式反覆出現。
讓龐大的代碼庫變得易於導航
Claude 在大型代碼庫中能幫多大忙,取決於它能多快找到正確的上下文。如果在每次會話中塞入過多的上下文,性能就會直線下降;但如果上下文太少,Claude 又會像無頭蒼蠅一樣亂撞。最有效的部署方式,往往是在前期投入精力,讓代碼庫對 Claude 來說變得“清晰易懂”。我們總結了以下幾個常見模式:
• 保持 CLAUDE.md 文件精簡且分層。 當 Claude 在代碼庫中穿梭時,它會不斷地把這些文件內容疊加起來:根目錄文件提供全局視角,子目錄文件提供局部規範。因此,根文件裏只應該放最核心的指引和絕對不能踩的坑;除此之外的其他內容,對根文件來說都是噪音。 • 在子目錄中初始化,而不是在代碼庫根目錄。 把 Claude 限制在與當前任務直接相關的代碼區域裏,它的表現會是最好的。在單一代碼庫(monorepos)中,這可能聽起來有點反直覺,因為很多工具都默認需要在根目錄運行。但別擔心,Claude 會自動沿着目錄樹往上爬,並且讀取沿途發現的所有 CLAUDE.md 文件,所以它絕不會丟失根目錄的上下文信息。 • 將測試和代碼檢查(lint)命令限制在子目錄級別。 試想一下,如果 Claude 只是修改了一個微服務,卻跑遍了整個大項目的測試用例,這不僅會導致超時,還會讓毫無關聯的輸出結果塞滿上下文。因此,子目錄級別的 CLAUDE.md 文件應該清楚地說明只適用於該區域的命令。這種方法在面向服務(service-oriented)的代碼架構中非常奏效,因為每個目錄都有自己的測試和構建命令。不過,在那些交叉依賴極深的編譯型語言大型代碼庫裏,想要做到按子目錄限制範圍會比較困難,可能需要針對項目定製構建配置。 • 使用 .ignore文件屏蔽生成文件、構建產物和第三方代碼。 在.claude/settings.json中提交permissions.deny規則,意味着這些排除項進入了版本控制。這樣,團隊裏的每個開發者都能享受到同樣的“降噪”效果,不用自己再去折騰配置。在某些項目中,生成的代碼本身就是開發工作的一部分。沒關係,那些負責代碼生成器的開發者可以在本地設置中覆蓋項目的排除規則,這完全不會影響到團隊的其他人。• 當目錄結構不夠清晰時,製作代碼庫“地圖”。 有些組織的代碼並沒有按照常規的目錄結構規規矩矩地整理。這時候,你可以在代碼庫根目錄下建一個輕量級的 Markdown 文件,列出每個頂級文件夾以及一句話說明那裏邊裝的是什麼。這就相當於給 Claude 提供了一份目錄,它在打開文件之前可以先掃一眼。如果一個代碼庫有幾百個頂級文件夾,最好採用分層的方法:根文件只描述最頂層的結構,子目錄的 CLAUDE.md 則提供下一級的細節,當 Claude 遊走到相應樹節點時再按需加載。對於簡單的情況,只需使用 @提及(mention)讓 Claude 應該參考的特定文件或目錄就可以了。• 運行 LSP 服務器,讓 Claude 按照“符號”而不是“字符串”來搜索。 在一個龐大的代碼庫裏,如果只用文本去搜索一個常見的函數名,可能會返回成千上萬個結果。Claude 會耗費大量的上下文空間,一個個打開文件去猜到底哪個才是真正的目標。而 LSP 只會返回指向同一個代碼邏輯符號(symbol)的引用,等於是在 Claude 閲讀之前就把過濾工作做好了。要實現這個,你需要為你的編程語言安裝一個代碼智能插件(code intelligence plugin)[9] 以及相應的語言服務器程序。Claude Code 的官方文檔裏有關於可用插件和故障排除的詳細介紹。
需要注意的是:在某些極端場景下,即便是分層的 CLAUDE.md 方法也會失效。比如一個代碼庫裏塞了幾十萬個文件夾和幾百萬個文件,或者是一些使用非 Git 版本控制的老舊系統。我們會在這個系列的後續文章中專門探討這些難題。
隨着模型越來越聰明,要持續更新 CLAUDE.md 文件
隨着 AI 模型的不斷進化,你為當前模型寫的指令,到了未來可能會變成絆腳石。比如,之前為了幫 Claude 繞過某個坑而寫的 CLAUDE.md 規則,等新模型發佈後,可能就變得多餘,甚至變成了束縛。舉個例子,假設之前有個規則告訴 Claude:重構代碼時必須拆分成對單個文件的修改。這確實能幫早期的老模型穩住陣腳,但如果你換上了更強大的新模型,這條規則反而會阻止它去執行它本可以完美勝任的跨文件協同修改。
同樣,為了彌補特定模型缺陷(不管是模型推理能力上的,還是 Claude Code 工具本身的侷限)而拼湊出來的技能和鈎子,一旦這些缺陷被修復,它們就會變成毫無意義的負擔。比如,在一個使用 Perforce(註釋:一種常用於大型遊戲和企業級開發的集中式版本控制系統)的代碼庫裏,之前寫了一個鈎子專門攔截文件寫入操作以強制執行 p4 edit。但後來 Claude Code 原生支持了 Perforce 模式,這個鈎子就成了多餘的擺設。
我們建議團隊每三到六個月就對配置進行一次認真的盤點。而且,如果在大型模型更新發布後,你感覺代碼助手的表現好像停滯不前了,那絕對值得再去審查一次配置。
指定專人負責 Claude Code 的管理與推廣
單靠技術配置是無法真正推動團隊廣泛使用的。那些成功落地的組織,同樣在組織管理架構上投入了心血。
那些推廣得最快的團隊,在全面開放權限之前,都專門投入了人力進行基礎設施建設。哪怕只是一個小團隊,甚至只有一個人,只要把工具打磨好,確保當開發者第一次接觸 Claude 時,它就已經完美融入了現有的工作流。在一家公司裏,幾位工程師提前編寫好了一套插件和 MCP,保證在發佈的第一天大家就能用上。而在另一家公司,甚至有一個專門管理 AI 編程工具的團隊,在推廣開始前就把基礎設施全部搭好了。在這兩個案例中,開發者初次體驗到的都是滿滿的生產力,而不是挫敗感,普及率自然水漲船高。
目前,做這些工作的團隊通常屬於“開發者體驗(Developer Experience)”或“開發者生產力(Developer Productivity)”部門,這原本也是負責新員工入職培訓和開發內部工具的部門。此外,一些組織裏還湧現出了一個新角色:智能體管理員(Agent Manager)。這是一個融合了產品經理和工程師職能的崗位,專門負責管理 Claude Code 的生態系統。對於沒有專職團隊的公司,最起碼要指定一個直接負責人(DRI,Directly Responsible Individual):這個人擁有管理 Claude Code 配置的權限,能夠拍板決定各項設置、權限策略、插件市場和 CLAUDE.md 的規範,並負責讓這些內容保持最新狀態。
由下而上自發的擁抱確實能激發熱情,但如果沒有人把好用的經驗集中起來,這種熱情很容易變成一盤散沙。你需要一個人或一個團隊來整理、推廣正確的 Claude Code 使用習慣(比如標準化的 CLAUDE.md 層級結構,或是精選的技能和插件庫)。如果沒有人做這些事,經驗就會被困在少數人腦子裏,工具的普及也就到頭了。
在大型組織中,尤其是受到嚴格監管的行業,早晚會面臨各種治理難題:誰來決定哪些技能和插件可以上線?怎麼防止成千上萬個工程師在自己的電腦上重複造輪子?怎麼確保 AI 生成的代碼能像人類寫的代碼一樣經歷嚴格的代碼審查?為了在早期就應對這些問題,我們建議從設定一組受認可的技能、強制的代碼審查流程和最初的有限訪問權限開始,隨着信心的增強再逐步擴大範圍。
我們觀察到,推行最順滑的組織,往往在早期就組建了跨部門的聯合工作組。他們把工程、信息安全和合規部門的代表聚在一起,共同定義需求,並制定出清晰的推廣路線圖。
將這些模式應用到你的組織中
Claude Code 是圍繞着傳統的軟件工程環境設計的:在這些環境裏,工程師是代碼庫的主力軍,代碼託管使用 Git,代碼也遵循標準的目錄結構。大多數大型代碼庫都符合這個模子,但如果遇到非傳統的架構,比如包含大量二進制資產的遊戲引擎、使用非主流版本控制系統的環境,或者是讓非技術人員也參與代碼貢獻的項目,就需要進行額外的配置工作了。我們這篇指南默認你使用的是傳統架構,而且文中提到的這些模式已經在我們的許多客戶身上得到了成功驗證。如果還存在其他的複雜情況,那就需要根據你們自己的代碼庫、工具鏈和組織架構來具體分析了。這正是 Anthropic 的 Applied AI 團隊大顯身手的地方,他們會直接與工程團隊並肩作戰,把這些通用的模式轉化為最適合你們組織的定製化方案。
立刻體驗企業版 Claude Code (Claude Code for Enterprise)[10]。
特別感謝 Anthropic Applied AI 團隊的 Alon Krifcher、Charmaine Lee、Chris Concannon、Harsh Patel、Henrique Savelli、Jason Schwartz、Jonah Dueck 和 Kirby Kohlmorgen,感謝他們分享了在大規模環境中部署 Claude Code 的寶貴經驗;同時也感謝 Zoox 公司的 Amit Navindgi 對本文提供的寶貴反饋。
引用連結
[1] How Claude Code works in large codebases: Best practices and where to start: https://claude.com/blog/how-claude-code-works-in-large-codebases-best-practices-and-where-to-start[2]CLAUDE.md: https://code.claude.com/docs/en/memory[3]鈎子(Hooks): https://code.claude.com/docs/en/hooks-guide[4]技能(Skills): https://code.claude.com/docs/en/skills[5] 漸進式呈現(progressive disclosure): https://platform.claude.com/docs/en/agents-and-tools/agent-skills/best-practices[6]插件(Plugins): https://code.claude.com/docs/en/plugins[7] 企業內部應用市場(managed marketplaces): https://support.claude.com/en/articles/13837433-manage-claude-cowork-plugins-for-your-organization[8]子智能體(Subagents): https://code.claude.com/docs/en/sub-agents[9] 代碼智能插件(code intelligence plugin): https://code.claude.com/docs/en/discover-plugins#code-intelligence[10]企業版 Claude Code (Claude Code for Enterprise): https://claude.com/product/claude-code/enterprise