Claude Code 多 Agent 編排:4 步選對 Workflows 還是 /goal
整理版優先睇
用「流程確定性」決定用 Workflows 定 /goal,而唔係任務大細
呢篇文章係術哥分享嘅 Claude Code 多 Agent 編排實戰指南。術哥本身係 AI 編程同 Agent 生態嘅技術實踐者,佢發現好多開發者唔知幾時用 Dynamic Workflows 定 /goal,所以整理咗官方資料同社區經驗,幫大家分清兩者嘅本質差異。
文章核心結論係:選擇邊種工具唔取決於任務難度,而取決於你對流程嘅確定程度。如果你可以提前畫到流程圖(例如 PR 審查、批量遷移),就用 Workflows;如果你只知最終結果要咩,但中間步驟唔肯定(例如修 lint 錯誤、重構遺留代碼),就用 /goal。兩者仲可以搭配使用,進一步提升效率。
文章仲詳細拆解咗 Workflows 嘅四種調度形態、/goal 嘅雙模型循環機制,同埋社區常用嘅四步判斷法。最後提醒唔好盲目自動化,要先治理後擴大,先喺低風險任務試跑,沉澱模板,先再上大任務。
- Workflows 同 /goal 嘅分界線係流程確定性,而唔係任務難度:能畫流程圖就用 Workflows,只知終點就用 /goal。
- Workflows 用 JavaScript 腳本將編排邏輯從主會話卸載,避免上下文爆炸,支持並行/流水線/Loop/Fan-out 四種調度。
- /goal 用雙模型循環(主模型執行 + Haiku 評估),條件驅動、自動驗收,適合探索性修復或優化任務。
- 判斷時可用四步法:可拆?可驗?可收斂?可複用?按答案流向對應工具,細任務直接對話,唔好複雜化。
- 實際可以組合使用:Workflows 內部用 /goal 循環、/goal 觸發 Workflows、Auto mode 加速執行,但要注意 token 成本同上下文管理。
大任務常見嘅兩大問題同 Claude Code 嘅解法
用 Claude Code 做小任務好爽,但任務一大就會出現兩個問題:上下文越積越長,Claude 開始忘記最初目標;或者喺多個檔案之間來回切換,一旦會話崩潰,進度就歸零。
Claude Code 分別用咗兩套機制嚟解決:Dynamic Workflows 負責編排同上下文卸載,而 /goal 負責目標驅動嘅自主循環。但社區經常有個困惑:呢兩樣嘢到底有咩分別?幾時用邊個?
Dynamic Workflows:將編排邏輯從上下文卸走
Dynamic Workflows 係 Claude Opus 4.8(2026 年 5 月底)推出嘅研究預覽功能。佢嘅核心做法係將以往全部塞喺主會話嘅任務拆解、等待、複核、返工等邏輯,拆出去畀一段 JavaScript 腳本管理。
具體分三層:Claude(主模型)寫 workflow 腳本並解釋最終結果;Workflow runtime 執行腳本、管理階段、保存中間狀態;Subagents 各自讀檔案、執行指令、輸出結構化結果。Claude 唔再需要將 20 個 subagent 嘅中間輸出全部裝入上下文,只要睇聚合結果就得。
- 1 Parallel(批處理屏障):適合全局去重、多路交叉驗證,但要留意慢任務會拖住整個階段。
- 2 Pipeline(流水線):適合檔案級遷移、批量轉換,如果要用全局視圖就要小心漏咗衝突。
- 3 Loop:反覆修復直到無新增錯誤、測試失敗回滾,但要設好終止條件,否則會空轉。
- 4 Fan-out / Fan-in:大範圍搜索後集中彙總,彙總 schema 唔穩定會污染結論。
export default {
metadata: {
name: "最小示例",
description: "演示 Workflow 基本結構"
},
agents: [
/* 至少調用一次 agent */
],
return: finalResult // 必須返回結果
}/goal:條件驅動嘅自主循環
/goal 解決嘅問題係點樣令 Claude 自己不斷執行直至達到你滿意嘅狀態。佢嘅機制係 雙模型循環:你先設定一個目標條件(例如「所有 lint 錯誤已修復,eslint 輸出無錯誤」),主模型執行一輪,然後由 獨立嘅輕量評估模型(預設 Haiku)判定條件是否滿足。
呢個設計嘅關鍵係 執行與評估分離。評估模型淨係睇會話中明確輸出嘅內容,唔可以自己執行命令或讀檔案,確保評價獨立客觀。
- 基本用法:/goal 修復 src 目錄下所有 lint 錯誤,直到 eslint 輸出無錯誤信息
- 非交互式:claude -p "/goal 所有測試通過,npm test 退出碼為 0"
- 幾個硬限制(來自社區交叉驗證):條件長度上限 4000 字符;單個會話只支援一個激活目標;評估模型 token 消耗遠低於主模型
/goal 同其他循環機制嘅分別:/loop 係時間驅動(固定間隔執行),Stop hook 係配置入面定義嘅自動停止條件,Auto mode 只係自動審批工具調用唔啓動新輪次。而 /goal 係條件驅動——上一輪完成後,評估模型判定達標先停。
四步判斷法:可拆→可驗→可收斂→可複用
社區總結咗一套好實用嘅四步法:第一步,可拆嗎?任務能否拆成相對獨立嘅單元?拆唔到就直接對話或用 /goal。第二步,可驗嗎?每一步結果能否被編譯、測試或規則驗證?驗到就用 Workflows,驗唔到就睇 /goal。
第三步,可收斂嗎?需唔需要通過發現、複核、修正逐步逼近答案?需要嘅話,Workflows 嘅 Loop 或 /goal 嘅循環都適合。第四步,值得複用嗎?呢個流程以後會唔會再跑?會就寫 Workflows 腳本存落嚟,唔會就用 /goal 更輕量。
協同策略同落地建議
三種工具唔使三選一,可以靈活搭配:Workflows + 內部 /goal——喺 Workflow 某個階段用 /goal 式循環(例如自動修復直到 lint 同 test 全過);/goal 觸發 Workflows——由 /goal 設定大目標,Claude 自行決定調用 Workflow;Auto mode 處理審批——自動允許工具調用,但唔等於無人值守。
寫好 /goal 條件係關鍵:要 單一可衡量嘅最終狀態、明確嘅驗證方式(最好用命令輸出)、加上關鍵約束條件。Workflow 腳本默認放臨時目錄,生命週期得三日,記得複製到 ~/.claude/workflows/ 持久化。
- 落地三步走:第一步低風險任務試跑(如 /deep-research 或小範圍代碼巡檢);第二步沉澱有效模板(安全審計、release 檢查等);第三步先上大任務(大遷移、大審計)。
- 常見誤區:驗收條件寫得太闊(例如「代碼質量達到生產級別」)、不該自動化時硬上(高風險任務拆小步人工確認)、token 成本失控(Loop 設好終止條件)、以為用 Workflows 就唔使理上下文(大任務要拆多個 workflow)。
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 130 篇,AI 編程最佳實戰「2026」系列第 39 篇
大家好,歡迎嚟到 術哥無界 | ShugeX | 運維有術。
我是術哥,一個專注喺 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫嘅技術實踐者同開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。

用 Claude Code 做細任務,體驗好順滑 - 改個函數、修個 bug、重構一段邏輯,幾分鐘搞掂。但任務一大就出問題:上下文越來越長,Claude 開始唔記得最初嘅目標;或者喺多個檔案之間來回切換,中間狀態全靠聊天記錄維繫,一旦會話崩潰,進度歸零。
呢兩類問題,Claude Code 分別俾咗兩套解法:Dynamic Workflows 解決編排同上下文卸載,**/goal** 解決目標驅動嘅自主循環。但社區入面一個常見嘅困惑係:呢兩樣嘢到底有咩分別?幾時應該用邊個?可唔可以一齊用?
睇完一輪官方資料同社區討論之後,我發現答案其實好簡單 - 分界線唔係任務難唔難,而係流程確唔確定。下面展開講下。
說明:本文基於 Claude Code 官方文檔(Workflows、Goal Mode)同社區討論整理分析而成,部分機制細節同最佳實踐嚟自社區交叉驗證,尚未喺生產環境完成全場景驗證。文入面嘅配置模板同參數建議只供參考,實際效果請以你嘅業務數據同環境測試結果為準。如果有實際使用經驗,歡迎喺評論區分享交流。
1. 先搞清楚:佢哋各自解決咩問題
Workflows:將編排邏輯由聊天上下文度卸出去
Dynamic Workflows(跟 Claude Opus 4.8 喺 2026 年 5 月底推出,而家處於研究預覽階段)解決嘅核心問題係上下文卸載。
之前做複雜任務,所有嘅任務拆分、等待、複核、返工都壓喺主會話上下文入面。典型嘅 ReAct 式循環:Claude 諗 → 做 → 睇 → 再諗 → 再做。上下文越積越多,質量越來越差。
Workflows 嘅做法係將呢個循環由聊天上下文度搬出來,交俾一段 JavaScript 腳本去管:
換句話講,Claude 唔再需要將 20 個 subagent 嘅中間輸出全部塞入上下文。佢只需要寫好腳本,最後睇下匯集結果就夠。
一句講曬:主會話上下文唔會再爆。
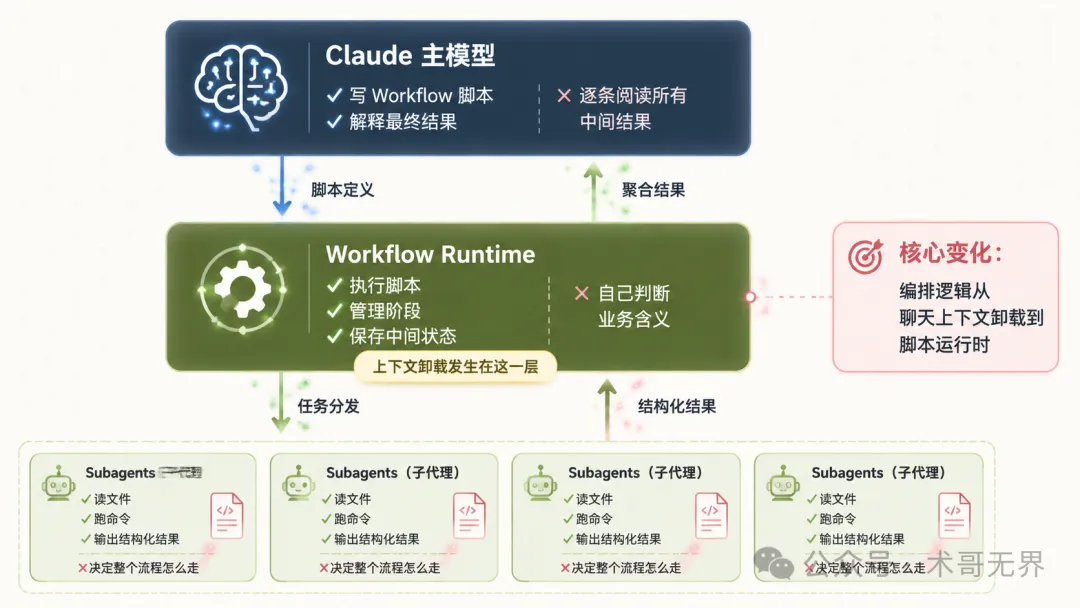
圖 1:Dynamic Workflows 三層架構 — 編排邏輯由聊天上下文卸載到腳本運行時
/goal:條件驅動嘅自主循環
/goal 解決嘅問題有啲唔同 - 點樣令 Claude 自己行落去,行到你滿意為止。
核心機制係雙模型循環:
你設定一個目標條件(例如:所有 lint 錯誤已修復, eslint輸出無錯誤)主模型執行一輪操作 輕量評估模型(默認 Haiku)獨立判定條件係咪滿足 唔滿足 → 主模型根據原因繼續下一輪;滿足 → 循環結束
呢度有一個關鍵嘅設計原則:執行同評估分離。要 Claude 自己判斷做得好唔好係靠唔住嘅,所以專登用一個獨立嘅輕量模型嚟驗收。評估模型只可以睇到會話入面明確輸出嘅內容,唔可以自己執行命令或讀檔案,咁就保證咗評估嘅獨立性。
# 基本用法
/goal 修復 src 目錄下所有 lint 錯誤,直到 eslint 輸出無錯誤信息
# 非交互式
claude -p "/goal 所有測試通過,npm test 退出碼為 0"
幾個硬限制(嚟自社區交叉驗證):
條件長度上限 4000 字符 單個會話只支援一個激活目標 評估模型(Haiku)嘅 token 消耗遠低於主模型
/goal 同 Claude Code 入面其他幾種循環機制都唔一樣。/loop 係時間驅動嘅,按固定間隔執行,適合週期性任務。Stop hook 係配置文件入面定義嘅自動停止條件,支援全會話作用域。Auto mode 只係自動審批工具調用,唔會啟動新嘅輪次。而 /goal 係條件驅動嘅 - 上一輪完成之後,評估模型判定係咪達標,達標先至停。呢四種機制嘅適用場景完全唔同:
/goal | ||
/loop | ||
2. 核心區別:確定性,唔係難度
好多人覺得 Workflows 係俾大任務用嘅,/goal 係俾細任務用嘅。呢個理解唔係好準確。
真正嘅分界線係流程係咪確定。
幾時用 Workflows?
你可以提前畫出流程圖嘅任務。例如:
PR 審查:安全審查 → 性能審查 → 可讀性審查 → 架構審查 → 匯總 批量遷移:讀源檔案 → 轉換格式 → 寫目標檔案 → 執行測試 → 驗證結果 深度研究:並行搜索多個來源 → 交叉驗證 → 合成報告
呢啲任務有個共通點:步驟可以提前諗清楚,每一步做咩大致確定,中間可能有條件分支但唔會太多。
Workflows 提供四種調度形態:
而且 Workflows 嘅腳本唔係靜態 DAG - 佢用嘅係命令式 JavaScript。你可以喺腳本入面寫 while、if,根據上一階段返咗幾多結果臨時決定下一階段開幾個 agent。流程嘅形狀喺運行時生出來。
// 最小化結構示意
{
metadata: {
name: "最小示例",
description: "演示 Workflow 基本結構"
},
agents: [
/* 至少調用一次 agent */
],
return: finalResult // 必須返回結果
}
幾時用 /goal?
你可以講得清楚最終結果係點樣,但講唔清楚中間要經過咩步驟。
典型場景:
自動修復 lint 錯誤:你知道終點係 eslint輸出乾淨,但唔知要改幾多檔案、改幾次重構遺留代碼:你知道終點係所有測試通過,但中間可能需要反覆調整 質量打磨:你知道終點係性能測試達標,但優化路徑唔確定
/goal 嘅價值在於:你只需要描述終點,唔需要規劃路徑。Claude 會自己探索、試錯、修正。
幾時都唔用?
社區經驗入面有一條共識特別重要:
對於細任務,原生 Claude Code 比任何精心設計嘅工作流都好用。
改一兩個檔案嘅事,直接同 Claude 傾偈,比設計 workflow 或寫 goal 條件快好多。唔好將簡單問題複雜化。
3. 多 Agent 編排嘅能力梯度
將視角拉遠啲,Claude Code 嘅多 Agent 編排其實有一個清晰嘅能力梯度:
核心區別:Skills 解決能力問題(幾時調用咩工具),Workflow 解決流程問題(多個 Agent 點樣協作、調度、驗證、匯集)。
有人可能會問:Workflows 同 n8n、Coze 呢類自動化平台有咩分別?
定位完全唔同。n8n 係人預先畫好流程圖俾系統行;Dynamic Workflows 係 Claude 根據當次任務動態生成腳本俾 runtime 行。前者係穩定業務流程嘅產品化,後者係複雜工程任務嘅臨場拆解。同 LangGraph 都唔喺同一層面 - LangGraph 係生產級 agent runtime,Workflows 係開發者喺代碼倉庫入面自己用嘅編排工具。
下面係一個深度研究 Workflow 嘅編排示例,三個階段:並行搜索 → 交叉驗證 → 報告合成。
export default {
metadata: {
name: "deep-research",
description: "多來源深度研究 Workflow"
},
stages: [
{
id: "search",
description: "並行搜索官方文檔、學術論文和社區討論",
parallel: true,
agents: [
{
id: "official-docs",
tools: ["web-search"],
prompt: "搜索並整理與主題相關的官方文檔"
},
{
id: "academic",
tools: ["web-search"],
prompt: "搜索相關學術論文和技術報告"
},
{
id: "community",
tools: ["web-search"],
prompt: "搜索社區討論和實戰經驗"
}
]
},
{
id: "verification",
dependsOn: ["search"],
parallel: false,
agents: [
{
id: "fact-checker",
prompt: "交叉驗證搜索結果,標註可信度"
}
]
},
{
id: "synthesis",
dependsOn: ["verification"],
agents: [
{
id: "report-writer",
prompt: "基於驗證後的素材合成研究報告"
}
]
}
]
};
呢個腳本嘅結構好直觀:搜索階段三個 agent 並行執行,各自負責唔同來源;驗證階段串行執行,做交叉核驗;合成階段產出最終報告。每個階段透過 dependsOn 聲明依賴關係,runtime 自動管理執行順序。
4. 點樣判斷應該用邊個?
社區總結咗一套四步判斷法,我覺得幾實用:
第一步:拆得開嗎?
任務能唔能夠拆成相對獨立嘅單元?拆得到 → 繼續睇;拆唔到 → 直接對話或用 /goal。
第二步:驗得到嗎?
每一步嘅結果能唔能夠俾編譯、測試、規則驗證?驗得到 → 適合 Workflows;驗唔到 → 睇下 /goal 得唔得。
第三步:收斂得到嗎?
需唔需要透過發現、複核、修正逐步逼近答案?需要 → Workflows 嘅 Loop 或 /goal 嘅循環都得。
第四步:值得複用嗎?
呢個流程之後仲會再行嗎?會 → Workflows 寫腳本存落嚟;唔會 → /goal 更加輕量。
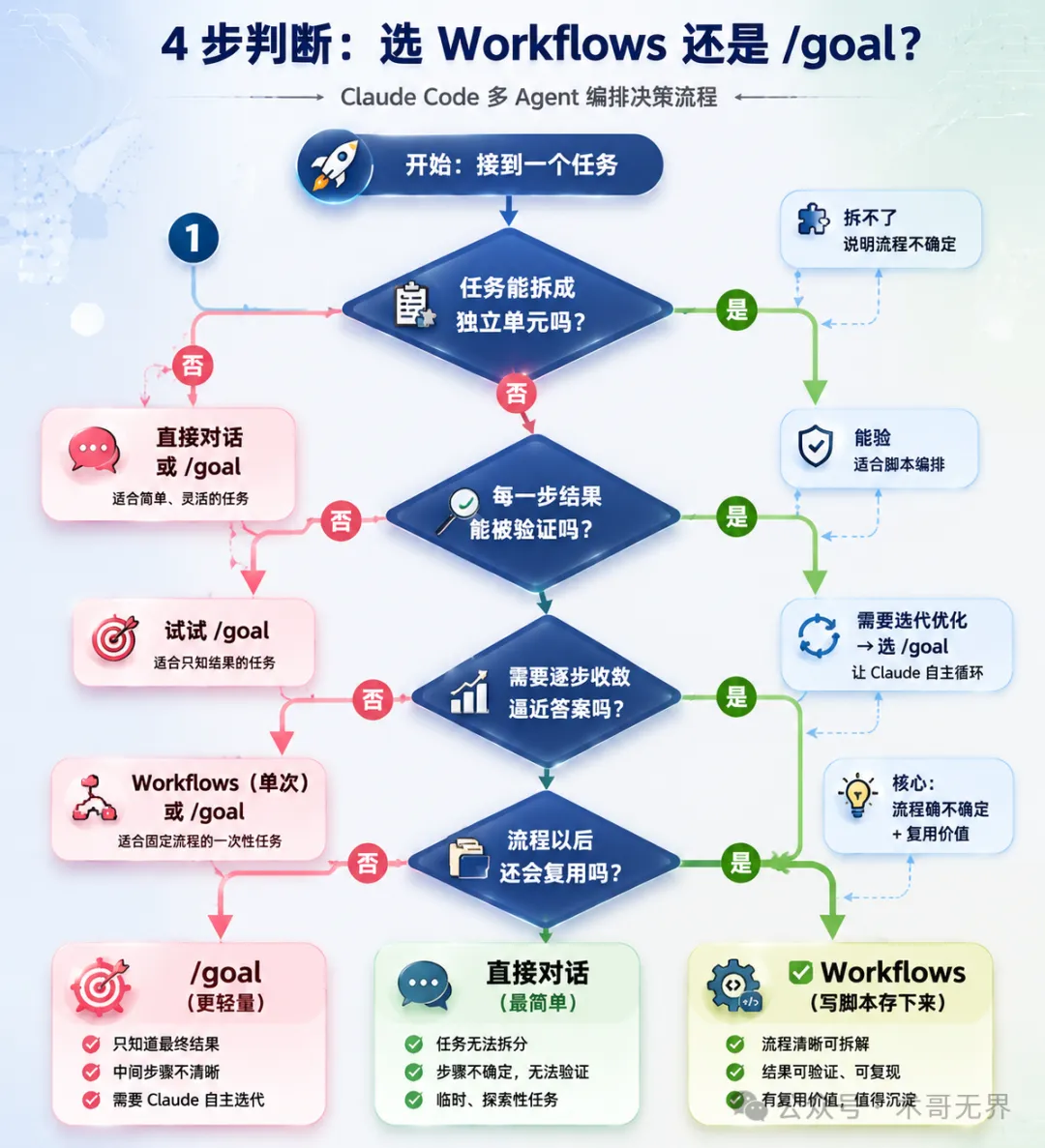
圖 2:四步判斷法 — 拆得開→驗得到→收斂得到→值得複用,三個終點分別對應唔同工具
舉個具體例子。假設你要將 75 萬行代碼由 Zig 遷移到 Rust(Bun 項目據講就係咁做):
流程確定:讀 Zig → 翻譯 → 寫 Rust → 行測試 → 修錯誤 → 再行測試 結果可驗:編譯通過、測試通過 需要收斂:唔可能一次翻譯完就全部啱 值得複用:類似嘅遷移流程之後可能仲要用
呢個就係典型嘅 Workflows 場景。
但如果你嘅任務係將某個模塊嘅性能優化到 benchmark 達標,你唔知具體要改咩、改幾次,咁就更加適合 /goal。
5. 協同策略:三個工具點樣配搭用?
實際項目入面,Workflows、/goal 同 Auto mode 唔使三揀一,完全可以配搭住用。
組合一:Workflows + 內部 /goal
喺 Workflow 嘅某個階段入面用 /goal 式嘅循環邏輯。例如一個代碼巡檢 + 自動修復嘅 Workflow:
階段一(Parallel):多個 subagent 分別掃描安全、性能、可讀性問題 階段二(Loop):自動修復發現嘅問題,直到 lint 同 test 全部通過 ← 呢度就係 /goal式嘅循環階段三(Pipeline):生成修復報告
組合二:/goal 觸發 Workflows
用 /goal 設定一個大目標,等 Claude 自己決定喺執行過程中調用 Workflow。適合嗰啲你清楚要咩結果、但實現路徑可能好複雜嘅場景。
組合三:Auto mode 處理審批
Auto mode 嘅作用係自動審批工具調用(例如允許執行 npm test),佢唔會啟動新嘅輪次,只係令單輪執行更順暢。喺長任務嘅執行過程中開咗 Auto mode,可以減少人工介入嘅頻率。
但要留意:Auto mode 唔等於無人值守。佢只係幫你慳返撳同意呢一步,唔係幫你做判斷。
6. 實戰最佳實踐
寫好 /goal 的條件
這是 /goal 能唔能夠行得好嘅關鍵。社區總結嘅三條原則:
單一可衡量嘅最終狀態:唔好寫「令代碼變好」,要寫 eslint src/ --max-warnings 0輸出無警告明確嘅驗證方式:可以用命令輸出嘅就用命令,例如 npm test退出碼為 0關鍵約束條件:加上限制,例如只修改 test/auth目錄下嘅檔案
條件寫得越具體,評估模型嘅判定就越準確。條件寫得太模糊,要麼提前通過(結果唔滿意),要麼永遠唔通過(空轉燒 token)。
管理好 Workflows 腳本
Workflow 腳本默認存放喺臨時目錄,生命週期得三日。如果呢個流程之後仲要用,記得將佢複製到 ~/.claude/workflows/ 目錄持久化。
腳本都可以納入版本控制。呢一點比純對話式編排強太多 - 你可以 review、diff、回滾,團隊入面嘅其他人都可以直接複用。
六種編排形態速查
除咗前面提到嘅四種調度形態,社區資料仲整理咗更完整嘅六種編排模式:
流水線(Pipeline):順序執行,適合有前後依賴嘅多步驟任務 同步聚合(Parallel Aggregate):並行執行之後匯總,適合多源信息收集 對抗驗證(Adversarial Validation):多個 Agent 互相校驗結果,提高準確性 提前終止(Early Termination):滿足條件就跳過後續階段,節省資源 累積式(Iterative Enhancement):疊代增強,每輪喺上一輪基礎上改進 嵌套式(Nested Workflow):工作流入面再套工作流,適合複雜嘅多層編排
實際使用入面,一個 Workflow 往往唔係只用一種形態,而係多種形態組合。例如先用 Parallel Aggregate 收集信息,再用 Pipeline 逐步處理,最後 Adversarial Validation 交叉驗證。
啟用同版本要求
# 方式一
export ANTHROPIC_WORKFLOW=1
claude
# 方式二
export CLAUDE_CODE_ENABLE_WORKFLOW=true
claude
版本要求:
基礎 Workflow:Claude Code V2.1.47 或以上 Dynamic Workflows 完整功能:V2.1.154 或以上
觸發關鍵詞係 ultra work。
上下文管理嘅心法
唔理用邊種工具,上下文管理都係核心戰場。社區反饋入面幾條成日被提到嘅經驗:
CLAUDE.md 唔好超過 150 行 - 太長反而睇唔到重點 上下文用咗大約 50% 就應該執行 compact - 唔好等到滿咗先壓縮 唔相關嘅工作流分開項目 - 避免上下文污染 完成一個任務就即刻提交代碼 - 唔好積住
呢啲唔完全係 Workflows 或 /goal 嘅專屬建議,但用多 Agent 編排時更加重要 - 信息量大了,上下文更容易崩。
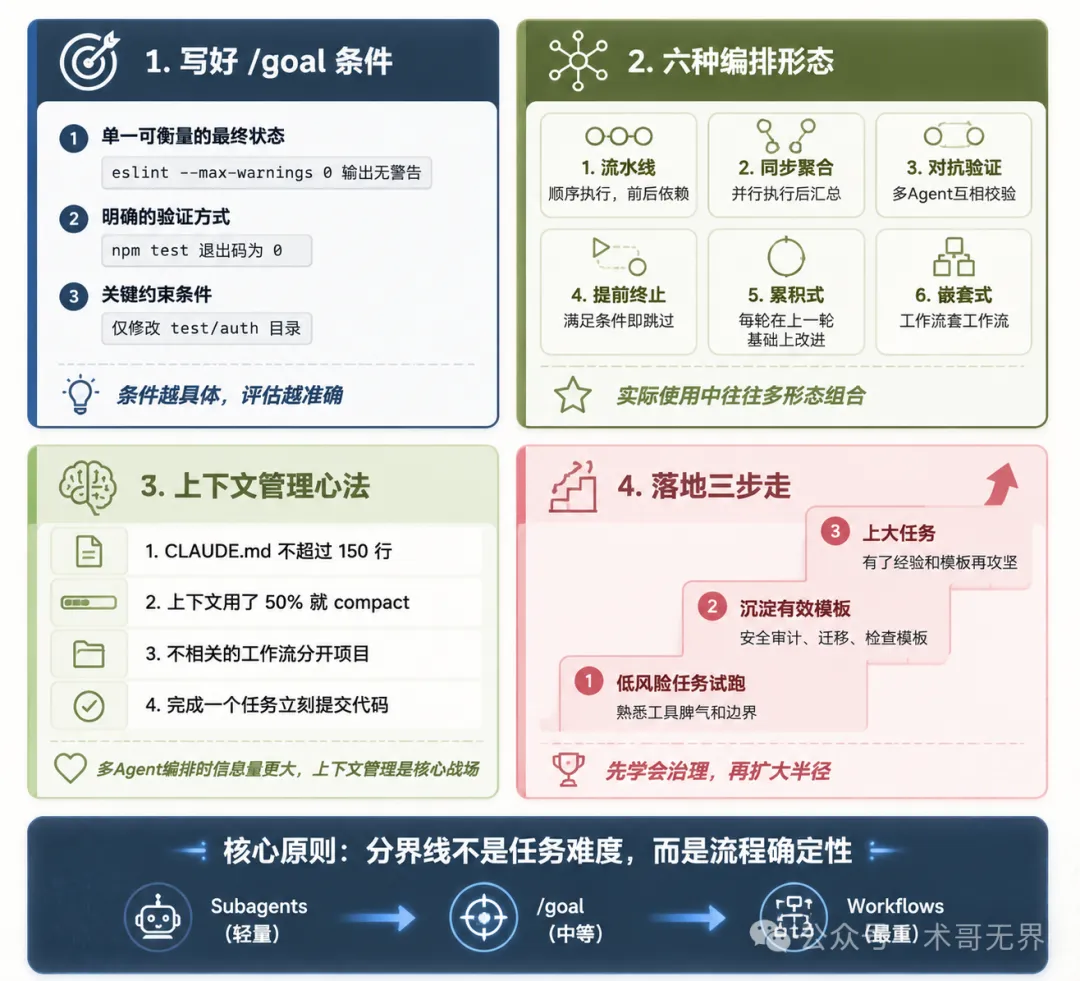
圖 3:多 Agent 編排最佳實踐 — /goal 條件三原則、六種編排形態、上下文管理心法、落地三步走
7. 常見誤區
整理社區討論嘅時候,有幾個坑大家踩得比較集中。
誤區一:驗收條件寫得唔好
這是 /goal 新手常見嘅坑。條件寫得太寬泛,例如「代碼質量達到生產級別」,評估模型根本判斷唔到。結果要麼好早就通過,要麼無限循環。
解法:條件入面一定要有可量化、可驗證嘅終點。命令退出碼、測試覆蓋率數字、lint 輸出內容,呢啲係好嘅驗收標準。「代碼睇落唔錯」就唔係。
誤區二:唔應該自動化時硬上
唔係所有任務都適合 Workflows 或 /goal。支付邏輯、安全策略、權限模型呢類高風險代碼,直接俾 Agent 自動改係好危險。社區亦有人提到,需要成日中途拍板嘅探索任務都唔適合完全自動化。
解法:高風險任務拆成細步,每步人工確認。或者用 Workflows 嘅校驗階段,關鍵節點暫停等人審批。留意,Workflow 運行中唔接受普通人工輸入,所以需要簽核嘅任務應該拆成多個 workflow。
誤區三:token 成本失控
多 Agent 編排嘅 token 消耗會比普通對話明顯高好多。每個 subagent 都係獨立嘅模型調用,16 個並行就係 16 倍嘅消耗。雖然 Haiku 評估模型嘅消耗好低,但主模型嘅消耗係實實在在嘅。
解法:
先喺低風險任務上試行,觀察實際消耗 Loop 類任務一定要設定好終止條件 唔係一定要 16 並行嘅就開少幾個 agent 對於探索性任務,先用普通對話試一輪,確定方向之後先上 Workflow
誤區四:上下文管理唔當
用咗 Workflows 就唔理上下文?唔係。Workflow 解決嘅係編排過程入面嘅上下文卸載,但唔等於你可以無限堆任務。單次運行最多 1000 個 agent,跨會話唔可以恢復 - 退出咗之後唔可以原地續行。
解法:大任務拆成多個 workflow。每個 workflow 聚焦一個明確嘅子目標,行完睇結果再決定下一步。
8. 落地建議:先治理,再擴大
如果你準備喺項目入面開始用 Workflows 同 /goal,社區建議嘅落地路徑係分三步行:
第一步:低風險任務試行
用 /deep-research 做信息收集,或者用 Workflow 做細範圍嘅代碼巡檢。呢啲任務風險低,就算結果唔理想都唔會破壞咩嘢。主要目的係熟習工具嘅脾氣同邊界。
第二步:沉澱有效模板
行咗幾次之後,將確實有效嘅流程沉澱成 Workflow 模板。安全審計模板、release 檢查模板、代碼遷移模板 - 呢啲都係可以喺團隊入面分享嘅。
第三步:上大任務
有咗經驗同模板之後,再將大遷移、大審計呢類任務交俾 Workflow。呢個時候你對工具嘅邊界、token 消耗、常見坑點都有體感,出問題嘅機會細好多。
你喺項目入面用過 Workflows 或 /goal 嗎?體驗如何?歡迎喺評論區講下實際踩過嘅坑。
總結
講到底,Claude Code 嘅多 Agent 編排俾咗開發者三種唔同粒度嘅工具:
Subagents:最輕量,適合臨時派發 /goal:中等,適合我知道終點但唔知道路徑嘅自主循環Workflows:最重,適合流程確定、需要編排同複用嘅大規模任務
揀邊個唔取決於任務大細,而取決於你對流程嘅確定程度。流程確定 → Workflows;終點確定但路徑唔確定 → /goal;都唔確定 → 先用普通對話探索。
唔好急住將所有任務都自動化。先用好基本能力,再逐步引入編排工具。先學識治理,再擴大半徑。
好啦,多謝你睇我嘅文章,如果鍾意可以點讚轉發俾需要嘅朋友,我哋下一期再見!敬請期待!
🚩 2026 年「術哥無界」系列實戰文檔 X 篇原創計劃 第 130 篇,AI 編程最佳實戰「2026」系列第 39 篇
大家好,歡迎來到 術哥無界 | ShugeX | 運維有術。
我是術哥,一名專注於 AI 編程、AI 智能體、Agent Skills、MCP、雲原生、AIOps、Milvus 向量數據庫的技術實踐者與開源佈道者!
Talk is cheap, let's explore。無界探索,有術而行。
用 Claude Code 做小任務,體驗很絲滑 - 改個函數、修個 bug、重構一段邏輯,幾分鐘搞定。但任務一大就出問題:上下文越來越長,Claude 開始忘記最初的目標;或者在多個文件之間來回切換,中間狀態全靠聊天記錄維繫,一旦會話崩潰,進度歸零。
這兩類問題,Claude Code 分別給了兩套解法:Dynamic Workflows 解決編排和上下文卸載,**/goal** 解決目標驅動的自主循環。但社區裏一個常見的困惑是:這倆東西到底有什麼區別?什麼時候該用哪個?能不能一起用?
翻了一圈官方資料和社區討論之後,我發現答案其實很簡單 - 分界線不是任務難不難,而是流程確不確定。下面展開聊聊。
說明:本文基於 Claude Code 官方文檔(Workflows、Goal Mode)和社區討論整理分析而成,部分機制細節和最佳實踐來自社區交叉驗證,尚未在生產環境中完成全場景驗證。文中的配置模板和參數建議僅供參考,實際效果請以你的業務數據和環境測試結果為準。如果有實際使用經驗,歡迎在評論區分享交流。
1. 先搞清楚:它們各自解決什麼問題
Workflows:把編排邏輯從聊天上下文中卸出去
Dynamic Workflows(隨 Claude Opus 4.8 於 2026 年 5 月底推出,目前處於研究預覽階段)解決的核心問題是上下文卸載。
之前做複雜任務,所有的任務拆分、等待、複核、返工都壓在主會話上下文裏。典型的 ReAct 式循環:Claude 想 → 做 → 看 → 再想 → 再做。上下文越積越多,質量越來越差。
Workflows 的做法是把這個循環從聊天上下文裏挪出來,交給一段 JavaScript 腳本去管:
換句話說,Claude 不再需要把 20 個 subagent 的中間輸出全裝進上下文。它只需要寫好腳本,最後看一下聚合結果就夠了。
一句話:主會話上下文不再爆炸。
圖 1:Dynamic Workflows 三層架構 — 編排邏輯從聊天上下文卸載到腳本運行時
/goal:條件驅動的自主循環
/goal 解決的問題不太一樣 - 怎麼讓 Claude 自己跑下去、跑到你滿意為止。
核心機制是雙模型循環:
你設定一個目標條件(比如:所有 lint 錯誤已修復, eslint輸出無錯誤)主模型執行一輪操作 輕量評估模型(默認 Haiku)獨立判定條件是否滿足 不滿足 → 主模型根據原因繼續下一輪;滿足 → 循環結束
這裏面有一個關鍵的設計原則:執行與評估分離。讓 Claude 自己判斷做得夠不夠好是靠不住的,所以專門用一個獨立的輕量模型來驗收。評估模型只能看到會話中明確輸出的內容,不能自己跑命令或讀文件,這就保證了評估的獨立性。
# 基本用法
/goal 修復 src 目錄下所有 lint 錯誤,直到 eslint 輸出無錯誤信息
# 非交互式
claude -p "/goal 所有測試通過,npm test 退出碼為 0"
幾個硬限制(來自社區交叉驗證):
條件長度上限 4000 字符 單個會話只支持一個激活目標 評估模型(Haiku)的 token 消耗遠低於主模型
/goal 和 Claude Code 裏其他幾種循環機制也不一樣。/loop 是時間驅動的,按固定間隔執行,適合週期性任務。Stop hook 是配置文件裏定義的自動停止條件,支持全會話作用域。Auto mode 只是自動審批工具調用,不啓動新的輪次。而 /goal 是條件驅動的 - 上一輪完成後,評估模型判定是否達標,達標了才停。這四種機制的適用場景完全不同:
/goal | ||
/loop | ||
2. 核心區別:確定性,不是難度
很多人覺得 Workflows 是給大任務用的,/goal 是給小任務用的。這個理解不夠準確。
真正的分界線是流程是否確定。
什麼時候用 Workflows?
你能提前畫出流程圖的任務。比如:
PR 審查:安全審查 → 性能審查 → 可讀性審查 → 架構審查 → 彙總 批量遷移:讀源文件 → 轉換格式 → 寫目標文件 → 運行測試 → 驗證結果 深度研究:並行搜索多來源 → 交叉驗證 → 合成報告
這些任務有個共同點:步驟能提前想清楚,每一步做什麼大致確定,中間可能有條件分支但不會太多。
Workflows 提供四種調度形態:
而且 Workflows 的腳本不是靜態 DAG - 它用的是命令式 JavaScript。你可以在腳本里寫 while、if,根據上一階段返回了多少結果臨時決定下一階段開幾個 agent。流程的形狀在運行時長出來。
// 最小化結構示意
{
metadata: {
name: "最小示例",
description: "演示 Workflow 基本結構"
},
agents: [
/* 至少調用一次 agent */
],
return: finalResult // 必須返回結果
}
什麼時候用 /goal?
你能說清楚最終結果長什麼樣,但說不清楚中間要經過哪些步驟。
典型場景:
自動修復 lint 錯誤:你知道終點是 eslint輸出乾淨,但不知道要改多少文件、改幾次重構遺留代碼:你知道終點是所有測試通過,但中間可能需要反覆調整 質量打磨:你知道終點是性能測試達標,但優化路徑不確定
/goal 的價值在於:你只需要描述終點,不需要規劃路徑。Claude 會自己探索、試錯、修正。
什麼時候都不用?
社區經驗裏有一條共識特別重要:
對於小任務,原生 Claude Code 比任何精心設計的工作流都好用。
改一兩個文件的事,直接跟 Claude 對話,比設計 workflow 或寫 goal 條件快得多。別把簡單問題搞複雜了。
3. 多 Agent 編排的能力梯度
把視角拉遠一點,Claude Code 的多 Agent 編排其實有一個清晰的能力梯度:
核心區別:Skills 解決能力問題(什麼時候調用什麼工具),Workflow 解決流程問題(多個 Agent 怎麼協作、調度、驗證、聚合)。
有人可能會問:Workflows 和 n8n、Coze 這類自動化平台有什麼區別?
定位完全不一樣。n8n 是人提前畫好流程圖讓系統跑;Dynamic Workflows 是 Claude 根據當次任務動態生成腳本讓 runtime 跑。前者是穩定業務流程的產品化,後者是複雜工程任務的臨場拆解。和 LangGraph 也不在一個層面 - LangGraph 是生產級 agent runtime,Workflows 是開發者在代碼倉庫裏自己用的編排工具。
下面是一個深度研究 Workflow 的編排示例,三階段:並行搜索 → 交叉驗證 → 報告合成。
export default {
metadata: {
name: "deep-research",
description: "多來源深度研究 Workflow"
},
stages: [
{
id: "search",
description: "並行搜索官方文檔、學術論文和社區討論",
parallel: true,
agents: [
{
id: "official-docs",
tools: ["web-search"],
prompt: "搜索並整理與主題相關的官方文檔"
},
{
id: "academic",
tools: ["web-search"],
prompt: "搜索相關學術論文和技術報告"
},
{
id: "community",
tools: ["web-search"],
prompt: "搜索社區討論和實戰經驗"
}
]
},
{
id: "verification",
dependsOn: ["search"],
parallel: false,
agents: [
{
id: "fact-checker",
prompt: "交叉驗證搜索結果,標註可信度"
}
]
},
{
id: "synthesis",
dependsOn: ["verification"],
agents: [
{
id: "report-writer",
prompt: "基於驗證後的素材合成研究報告"
}
]
}
]
};
這個腳本的結構很直觀:搜索階段三個 agent 並行跑,各自負責不同來源;驗證階段串行執行,做交叉核驗;合成階段產出最終報告。每個階段通過 dependsOn 聲明依賴關係,runtime 自動管理執行順序。
4. 怎麼判斷該用哪個?
社區總結了一套四步判斷法,我覺得挺實用的:
第一步:可拆嗎?
任務能不能拆成相對獨立的單元?能拆 → 往下看;拆不了 → 直接對話或用 /goal。
第二步:可驗嗎?
每一步的結果能不能被編譯、測試、規則驗證?能驗 → 適合 Workflows;不能驗 → 看看 /goal 行不行。
第三步:可收斂嗎?
需不需要通過發現、複核、修正逐步逼近答案?需要 → Workflows 的 Loop 或 /goal 的循環都行。
第四步:值得複用嗎?
這個流程以後還會再跑嗎?會 → Workflows 寫腳本存下來;不會 → /goal 更輕量。
圖 2:四步判斷法 — 可拆→可驗→可收斂→可複用,三個終點分別對應不同工具
舉個具體例子。假設你要把 75 萬行代碼從 Zig 遷移到 Rust(Bun 項目據說就是這麼幹的):
流程確定:讀 Zig → 翻譯 → 寫 Rust → 跑測試 → 修錯誤 → 再跑測試 結果可驗:編譯通過、測試通過 需要收斂:不可能一次翻譯完就全對 值得複用:類似的遷移流程以後可能還要用
這就是典型的 Workflows 場景。
但如果你的任務是把某個模塊的性能優化到 benchmark 達標,你不知道具體要改什麼、改幾次,那就更適合 /goal。
5. 協同策略:三個工具怎麼搭配用?
實際項目中,Workflows、/goal 和 Auto mode 不需要三選一,完全可以搭配着用。
組合一:Workflows + 內部 /goal
在 Workflow 的某個階段裏用 /goal 式的循環邏輯。比如一個代碼巡檢 + 自動修復的 Workflow:
階段一(Parallel):多個 subagent 分別掃描安全、性能、可讀性問題 階段二(Loop):自動修復發現的問題,直到 lint 和 test 全部通過 ← 這裏就是 /goal式的循環階段三(Pipeline):生成修復報告
組合二:/goal 觸發 Workflows
用 /goal 設定一個大目標,讓 Claude 自己決定在執行過程中調用 Workflow。適合那種你清楚要什麼結果、但實現路徑可能很複雜的場景。
組合三:Auto mode 處理審批
Auto mode 的作用是自動審批工具調用(比如允許運行 npm test),它不啓動新的輪次,只是讓單輪執行更流暢。在長任務的執行過程中開啓 Auto mode,可以減少人工介入的頻率。
但要注意:Auto mode 不等於無人值守。它只是幫你省掉點同意這一步,不是幫你做判斷。
6. 實戰最佳實踐
寫好 /goal 的條件
這是 /goal 能不能跑好的關鍵。社區總結的三條原則:
單一可衡量的最終狀態:不要寫讓代碼變好,要寫 eslint src/ --max-warnings 0輸出無警告明確的驗證方式:能用命令輸出的就用命令,比如 npm test退出碼為 0關鍵約束條件:加上限制,比如僅修改 test/auth目錄下的文件
條件寫得越具體,評估模型的判定就越準確。條件寫得太模糊,要麼提前通過(結果不滿意),要麼永遠不通過(空轉燒 token)。
管理好 Workflows 腳本
Workflow 腳本默認存放在臨時目錄,生命週期只有三天。如果這個流程以後還要用,記得把它複製到 ~/.claude/workflows/ 目錄持久化。
腳本也可以納入版本控制。這一點比純對話式編排強太多 - 你可以 review、diff、回滾,團隊裏其他人也能直接複用。
六種編排形態速查
除了前面提到的四種調度形態,社區資料還整理了更完整的六種編排模式:
流水線(Pipeline):順序執行,適合有前後依賴的多步驟任務 同步聚合(Parallel Aggregate):並行執行後彙總,適合多源信息收集 對抗驗證(Adversarial Validation):多個 Agent 互相校驗結果,提高準確性 提前終止(Early Termination):滿足條件就跳過後續階段,節省資源 累積式(Iterative Enhancement):迭代增強,每輪在上一輪基礎上改進 嵌套式(Nested Workflow):工作流套工作流,適合複雜的多層編排
實際使用中,一個 Workflow 往往不是隻用一種形態,而是多個形態組合。比如先 Parallel Aggregate 收集信息,再 Pipeline 逐步處理,最後 Adversarial Validation 交叉驗證。
啓用和版本要求
# 方式一
export ANTHROPIC_WORKFLOW=1
claude
# 方式二
export CLAUDE_CODE_ENABLE_WORKFLOW=true
claude
版本要求:
基礎 Workflow:Claude Code V2.1.47 或以上 Dynamic Workflows 完整功能:V2.1.154 或以上
觸發關鍵詞是 ultra work。
上下文管理的心法
不管用哪種工具,上下文管理都是核心戰場。社區反饋裏幾條被反覆提到的經驗:
CLAUDE.md 不超過 150 行 - 太長反而抓不住重點 上下文用了 50% 左右就該執行 compact - 別等到滿了再壓縮 不相關的工作流分開項目 - 避免上下文污染 完成一個任務就立刻提交代碼 - 別攢着
這些不完全是 Workflows 或 /goal 的專屬建議,但用多 Agent 編排時格外重要 - 信息量大了,上下文更容易崩。
圖 3:多 Agent 編排最佳實踐 — /goal 條件三原則、六種編排形態、上下文管理心法、落地三步走
7. 常見誤區
整理社區討論的時候,有幾個坑大家踩得比較集中。
誤區一:驗收條件寫不好
這是 /goal 新手常見的坑。條件寫得太寬泛,比如代碼質量達到生產級別,評估模型根本沒法判斷。結果要麼早早通過,要麼無限循環。
解法:條件裏一定要有可量化、可驗證的終點。命令退出碼、測試覆蓋率數字、lint 輸出內容,這些是好的驗收標準。代碼看起來不錯不是。
誤區二:不該自動化時硬上
不是所有任務都適合 Workflows 或 /goal。支付邏輯、安全策略、權限模型這類高風險代碼,直接讓 Agent 自動改是很危險的。社區也有人提到,需要頻繁中途拍板的探索任務也不適合完全自動化。
解法:高風險任務拆成小步,每步人工確認。或者用 Workflows 的校驗階段,關鍵節點暫停等人審批。注意,Workflow 運行中不接受普通人工輸入,所以需要籤核的任務應該拆成多個 workflow。
誤區三:token 成本失控
多 Agent 編排的 token 消耗會比普通對話明顯高出不少。每個 subagent 都是獨立的模型調用,16 個併發就是 16 倍的消耗。雖然 Haiku 評估模型的消耗很低,但主模型的消耗是實打實的。
解法:
先在低風險任務上試跑,觀察實際消耗 Loop 類任務一定要設好終止條件 不是非得 16 併發的就少開幾個 agent 對於探索性任務,先用普通對話試一輪,確定方向後再上 Workflow
誤區四:上下文管理不當
用了 Workflows 就不管上下文了?不是。Workflow 解決的是編排過程中的上下文卸載,但不等於你可以無限堆任務。單次運行最多 1000 個 agent,跨會話不可恢復 - 退出後不能原地續跑。
解法:大任務拆成多個 workflow。每個 workflow 聚焦一個明確的子目標,跑完看結果再決定下一步。
8. 落地建議:先治理,再擴大
如果你準備在項目裏開始用 Workflows 和 /goal,社區建議的落地路徑是分三步走:
第一步:低風險任務試跑
用 /deep-research 做信息收集,或者用 Workflow 做小範圍的代碼巡檢。這些任務風險低,即使結果不理想也不會破壞什麼。主要目的是熟悉工具的脾氣和邊界。
第二步:沉澱有效模板
跑了幾次之後,把確實有效的流程沉澱成 Workflow 模板。安全審計模板、release 檢查模板、代碼遷移模板 - 這些都是可以在團隊裏共享的。
第三步:上大任務
有了經驗和模板之後,再把大遷移、大審計這類任務交給 Workflow。這時候你對工具的邊界、token 消耗、常見坑點都有體感了,出問題的概率小很多。
你在項目中用過 Workflows 或 /goal 嗎?體驗如何?歡迎在評論區聊聊實際踩過的坑。
總結
說到底,Claude Code 的多 Agent 編排給了開發者三種不同粒度的工具:
Subagents:最輕量,適合臨時派發 /goal:中等,適合我知道終點但不知道路徑的自主循環Workflows:最重,適合流程確定、需要編排和複用的大規模任務
選哪個不取決於任務大小,而取決於你對流程的確定程度。流程確定 → Workflows;終點確定但路徑不確定 → /goal;都不確定 → 先用普通對話探索。
別急着把所有任務都自動化。先用好基礎能力,再逐步引入編排工具。先學會治理,再擴大半徑。
好啦,謝謝你觀看我的文章,如果喜歡可以點贊轉發給需要的朋友,我們下一期再見!敬請期待!