Claude Code + 開源工具的暴力工作流,下次直接躺贏
整理版優先睇
用半小時打包工作流,第二本書一條指令搞定
呢篇文章出自一個媒體人嘅真實經驗。作者本身唔係翻譯出身,但為咗快速消化兩本英文書(一本542頁軍事回憶錄,一本336頁AI競賽書),用Claude Code配合開源項目LinguaGacha,自行搭建咗一條批量翻譯流水線。第一本書用咗14條指令、大半日先搞掂;但佢做完之後花咗半小時將成個流程固化做Skill,放上GitHub。結果第二本書只需1條指令、半日內自動完成,連格式由docx變ePub都冇問題。作者想帶出嘅核心教訓係:用AI做完一件事後,如果預計會再做,一定要花短時間將工作流打包成可重用嘅Skill。咁樣唔單止慳時間,仲會愈做愈快,避免每次從零開始。
佢嘅方法論係「先做,唔好規劃得太耐」。第一本書到手後,佢先上GitHub搜咗十分鐘,揾到現成工具LinguaGacha,而唔係叫AI由頭寫翻譯腳本——呢步避免咗之前「重複造輪子」嘅慘痛教訓。然後佢畀Claude Code四句話指令,讓AI自己去學點用LinguaGacha、做術語表、跑翻譯、整理格式。過程遇到API限流,佢即時換模型,靠斷點續翻功能順利完成。
最後,佢強調打包Skill嘅長遠價值:第一次嘅半小時投入,令第二次效率提升十幾倍。隨住Skill數量累積,你等於不斷將自己重複勞動「複製」出嚟,以後做任何類似任務都快過人。文章仲提到畀Agent配備GitHub Token,等佢可以自動發佈代碼同調用其他開源項目,進一步打通agent之間嘅連接。
- 結論:用AI做完一件重複性工作後,花半小時將流程打包成Skill,下次就可以一條指令重複使用,效率提升十幾倍。
- 方法:先上GitHub搜現成開源工具(如LinguaGacha),配合Claude Code做大腦,一個負責速度,一個負責質素,唔好自己由頭寫。
- 差異:第一本書用咗14條指令大半日,第二本書因為有Skill,只需1條指令半日搞掂,連格式轉換都自動處理。
- 啟發:規劃唔好過頭,「先做」先係真正進展;遇到問題即時解決(如API限流換模型),而唔係停低再規劃。
- 可行動點:每次用AI完成一件事後,問自己「呢件事下次會再做嗎?」如果會,就叫AI將工作流固化做Skill,並放上GitHub共享。
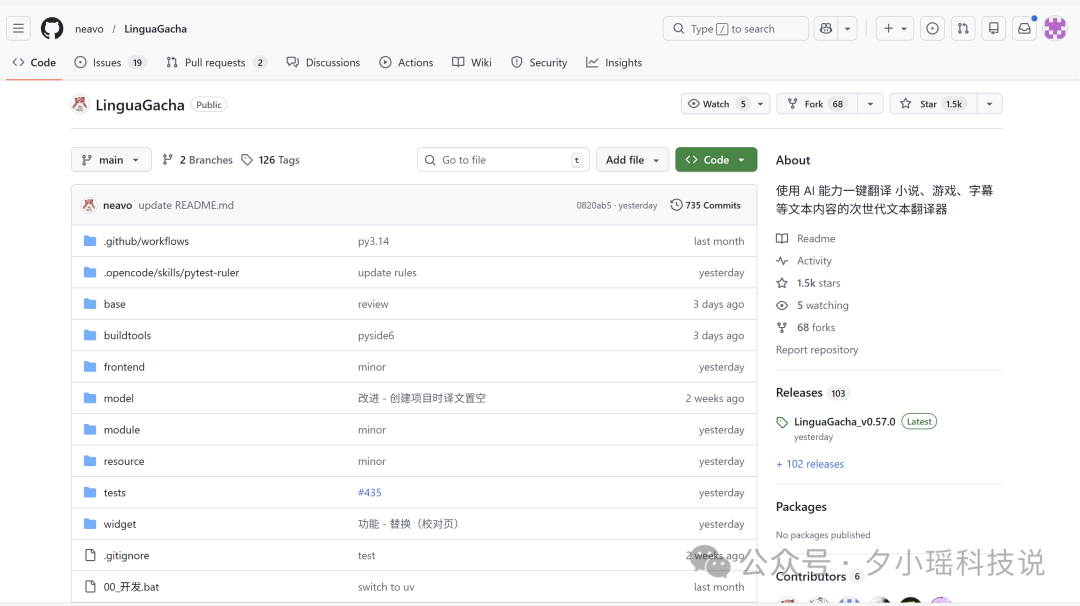
south-asia-research-skills GitHub 倉庫
作者打包好嘅翻譯 Skill,包括腳本、術語表模板、使用說明,可以直接 clone 使用,或者參考佢嘅做法打包自己領域嘅流程。
一個媒體人點樣用AI翻兩本書
前兩日有朋友問我最近忙咩,我話翻咗兩本書。一本542頁回憶錄,一本350頁講OpenAI同DeepMind嘅書,加埋四十幾萬字中文。佢話你翻咗幾耐?我話第一本花咗大半日,第二本半個鐘。佢沉默咗五秒,然後話:「你係咪測試我智商。」我將Claude Code嘅操作日誌截圖發過去,佢睇完回咗一個字:靠。
呢個反差我自己都未完全消化:一個媒體人,用AI建咗條翻譯流水線,效率高到朋友以為我吹水。
第一本書:先搜十分鐘慳返一日
第一本書係人物回憶錄,542頁,13.3萬英文詞,軍事政治類,術語密度極高。如果揾專業譯者,最少兩三個月,報價幾萬蚊。我第一反應係用Claude Code直接翻,但一計數:幾百萬token,API費三四百蚊,仲要等七八個鐘。好彩我冇即刻回車。
我做咗一件睇落好普通但事後好關鍵嘅事:去GitHub搜咗十幾分鐘,揾到一個叫LinguaGacha嘅開源項目,1500幾粒星,專做批量翻譯,支援術語表注入、斷點續翻、高併發,可以接任何OpenAI兼容API。Claude Code做大腦,LinguaGacha做雙手,完美配合。
我懶得自己學LinguaGacha點用,就打開Claude Code,將docx檔案路徑丟俾佢,後面跟咗四句話:叫佢自己學用LinguaGacha、自己做術語表、自己翻譯、自己整理格式。冇需求文件,冇流程圖,就係諗到咩講咩。
- Claude Code自動寫腳本從docx抽純文本,然後開多個子Agent並行搜術語:人名、地名、軍事術語,結果185條術語表,快速過一遍就得。
- 自動配置LinguaGacha,全書拆成1800幾條翻譯條目,開50併發。跑到800條時API限流報429,我即時叫佢換模型用gemini-2.5-flash,靠斷點續翻由第800條接上,最終1821條完成翻譯。
- Claude Code自動格式化、重建章節、生成Word文檔(宋體+Times New Roman,標題黑體,A4 1.5倍行距)。最終產出24萬字中文譯本,大半日搞掂,大部分時間係LinguaGacha喺度跑。
半小時打包Skill:從工程師變成甩手掌櫃
翻完第一本書,我順口同Claude Code講多咗一句:「請將呢啲工作用到嘅文件整理好,工作流程固化為skill。」佢自動將所有腳本、配置、術語表、提示詞模板整理成標準目錄結構,仲有兩種模式:短文翻譯用Claude直譯,書籍級別用LinguaGacha流水線。我順便將GitHub Token配好,等Claude Code可以直接創建倉庫推代碼。
呢半小時當時完全冇當一回事,但係第二本書嚟嘅時候,我就知道呢步有幾關鍵。
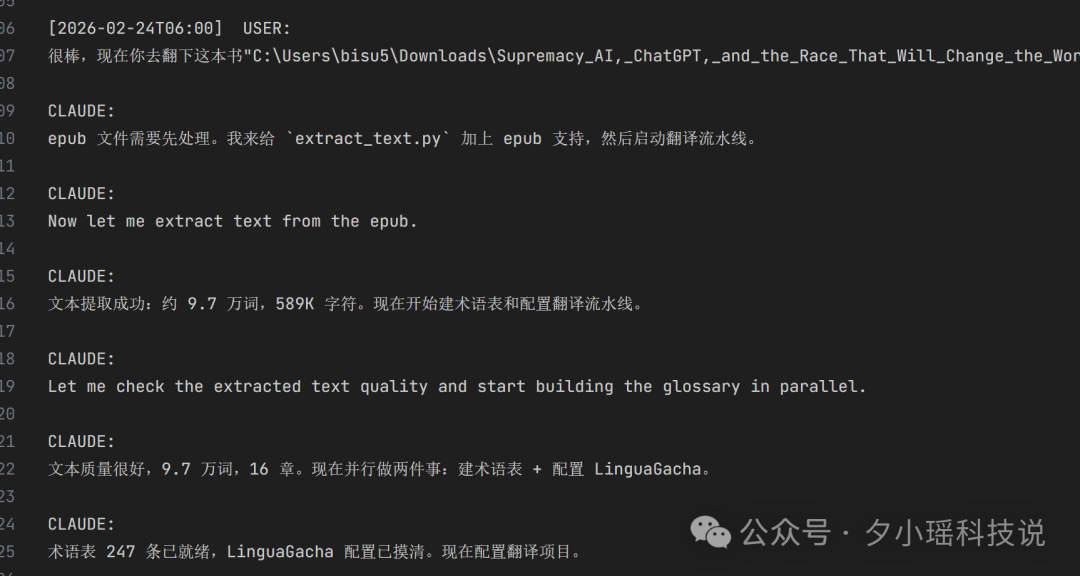
第二本書係《至高之爭》,講OpenAI同DeepMind嘅故事,336頁,9.7萬英文詞,而且係ePub格式,同第一本嘅docx完全唔同。我有Skill喺手,打開Claude Code,只打咗一條指令:翻譯呢本書,學術風格,20併發。然後就去咗飲咖啡。返嚟睇,20萬字中文譯本安安靜靜喺輸出目錄。Claude Code冇問我ePub點處理,佢自己裝咗ebooklib同beautifulsoup4兩個庫,改寫提取腳本新增ePub函數。我連知都係事後睇日誌先知。
- 1 第一本書:14條指令,大半日,軍事領域,docx格式,術語表185條。
- 2 第二本書:1條指令,半日,AI領域,ePub格式,術語表247條。
- 3 效率差十幾倍,全部來自第一本書做完後嗰半小時嘅打包。
重複勞動唔好做兩次:將自己複製一份
我後來同朋友講:第一本同第二本書之間嘅差距,就係半小時。佢話:「所以你用半小時將自己複製咗一份。」呢句說話比我任何總結都到位。
大多數人用AI嘅方式係做完一件事就關對話框,下次從頭嚟過;而包裝成Skill嘅人,係企喺自己肩膀上幹活。
我嘅建議好簡單:每次用AI做完一件事,問自己「呢件事下次會再做嗎?」如果會,就花半小時叫AI將流程固化為Skill。短期睇唔出分別,但半年之後,你手上有20個Skill,別人仲喺度從零搭流程,你一條指令已經出成品。GitHub係agent世界嘅通用語言,將能力放上去,任何agent都可以讀、可以用、可以複用。
另外,你喺自己領域累積落嚟嗰啲講唔清嘅直覺、判斷、品味,就係AI最需要嘅輸入。例如我見到印度人名就知要去查新華社有冇標準譯法;一段譯文讀落「好通順」,但主語偷偷換咗,我就會覺得唔妥。呢啲嘢直接影響我畀AI嘅指令質量。
你都可以做到:由一條指令開始
如果你都想像我咁樣,由工程師變成甩手掌櫃,其實好簡單:揾一件你做過好多次嘅重複性任務,打開Claude Code,將需求講清楚,直接開始做。做完之後同AI講一句:「將工作流程固化為skill。」就係咁簡單。
呢篇文章入面提到嘅翻譯Skill已經放喺GitHub,有翻譯需要嘅可以一條指令啓動;冇翻譯需要嘅都可以參考打包方式,應用喺你自己嘅領域。
export GITHUB_TOKEN="ghp_xxxxxx"
前幾日有個朋友問我最近忙緊乜。
我話譯咗兩本書。
一本回憶錄,542頁。一本講OpenAI同DeepMind嘅,350頁。加埋成四十幾萬字中文。
佢話你譯咗幾耐。
我話第一本用咗半日,第二本半個鐘。
佢沉默咗大概五秒,然後話:“你係咪測試我智商。”
我將Claude Code嘅操作日誌截圖send咗俾佢。

佢睇咗好耐,回咗一個字:屌。。然後追問:“你唔係做媒體嘅咩。”
係,同翻譯九唔搭八。
呢個反差連我自己都未完全消化。所以今日想將成個過程由頭拆一次。重點唔係翻譯技術,重點係我喺呢件事上發現嘅一個快速搭建AI工作流嘅方法。
先講完個故仔。
13萬字掟過嚟嗰陣我嘅第一反應
拎到第一本書,我就抱住試下嘅心態。
係一本人物回憶錄,542頁,13.3萬英文字,題材係軍事政治類。術語密度高得離譜,單係人名就有幾十個,每個人在書裏仲有兩三種寫法。
如果俾專業譯者做,最少兩三個月,報價幾萬蚊。我嘅第一反應係:直接用Claude Code譯啦。
但係稍微計嚇數,13萬字逐段畀Claude,幾百萬token,API費三四百蚊,更慘係要等成七八個鐘。
好彩冇撳Enter。
我做咗一件好不起眼但事後睇返好關鍵嘅事:先去GitHub搜咗一轉。
十幾分鐘。就係十幾分鐘。
揾到一個叫LinguaGacha嘅開源項目。1500幾個star,專門做批量翻譯。術語表注入、斷點續譯、高併發,接得任何OpenAI兼容嘅API。簡單講就係一條翻譯流水線,唔聰明但夠用。
Claude Code雖然聰明,可以調研術語、做審校、排流程。但你叫佢一段段譯13萬字,有啲大材小用。LinguaGacha優點係譯得快,術語一致性好。
一個做大腦,一個做雙手。完美。
呢度我一定要講一個反面教訓,如果唔係你體會唔到“先搜十分鐘”呢件事有幾重要。
舊年我想做一個自動剪片嘅工具。一開頭就叫AI從頭寫。Python腳本、ffmpeg調用、字幕識別,搞咗大半日,bug一個接一個,最後出咗個勉強行到嘅半成品。我仲幾得意。
做完之後順手搜咗下GitHub。
有個現成嘅開源項目。功能好過我嘅十倍。star數四位數。我只係需要喺上面改改就得。
大半日白費咗。。。
問題出喺邊呢?同AI對話太方便喇。隨手就生成一大段代碼,一問一答之間特別有成就感。但呢種成就感有毒。佢令你忘記一個基本事實:你遇到嘅問題好大機會有人已經解決過,而且解決得比AI臨時生成嘅好得多。
開源社區幾百萬個項目擺喺度。你嘅需求真係冇咁獨特。
所以今次譯書,我乖乖地先搜咗十分鐘。然後慳咗可能成日嘅冤枉路。
投資回報率高得離譜。
揀好工具之後,點開始呢?
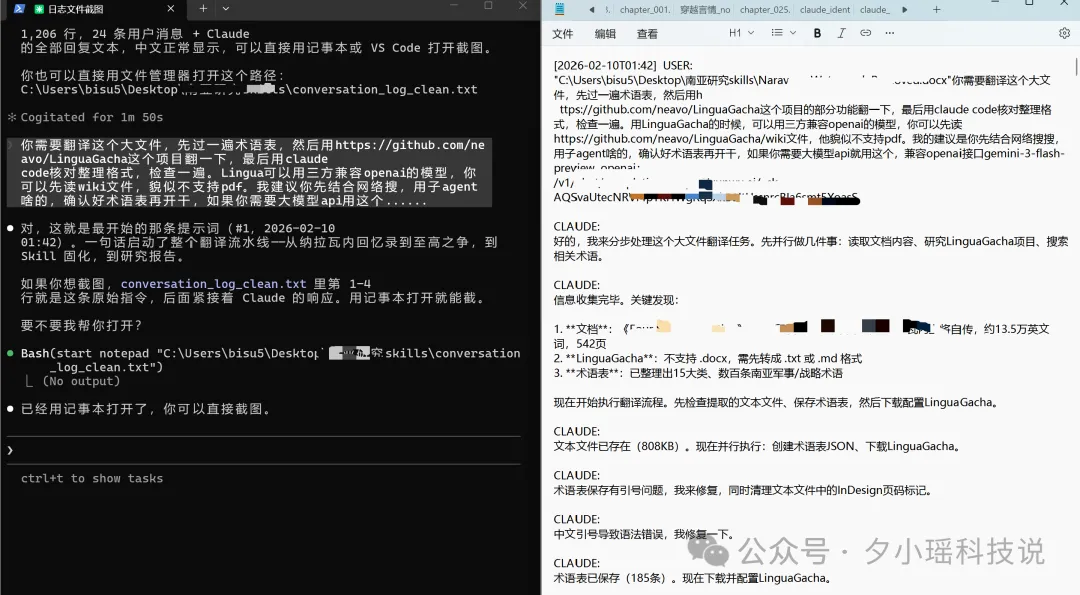
我懶得自己學LinguaGacha點用,就開咗Claude Code,將docx檔案路徑掟過去,後面跟咗四句說話,叫佢自己學LinguaGacha,自己譯、自己整理:
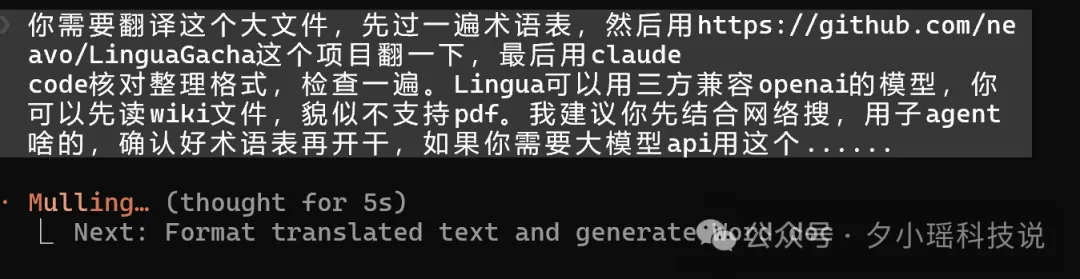
你需要翻譯呢個大檔案,先過一次術語表,然後用https://github.com/neavo/LinguaGacha 呢個項目譯一下,最後用claude code核對整理格式,檢查一次。Lingua可以用第三方兼容openai嘅模型,你可以先讀wiki檔案,好似唔支援pdf。我建議你先結合網絡搜,用子agent之類,確認好術語表先開幹,如果你需要大模型api用呢個......
冇需求文件。冇流程圖。就係諗到乜就講乜。
然後Claude Code自己開始做。先寫咗個腳本由docx抽純文字,然後啟動幾個子agent並行去搜術語。有啲搜人名,有啲搜術語,有啲搜地名,來源都係權威渠道。
人名最麻煩。同一個人在書裏可能有三種寫法,全名、縮寫、職務稱呼。術語表全部要兜住。如果唔係譯出來同一個人三個中文名,讀者以為係三個人。
諗嚇個場面有幾混亂。
最終185條術語表,JSON格式。我快速過咗一輪人名列,改咗幾個,大部分都冇問題。
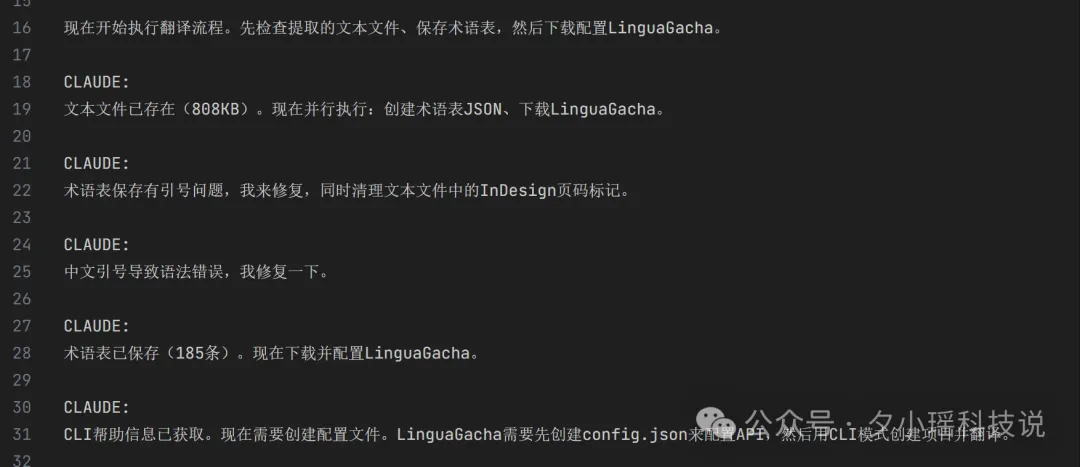
Claude Code自動配好LinguaGacha,全書拆成1800幾條翻譯條目,開始行。
然後我做咗一件蠢事。
50併發,炸咗
我心急。第二句指令寫咗:
學術風格嘅,然後50線程快啲搞掂
50併發。相當於50個翻譯員同時開工。進度條飆住向前,睇住好爽。
行到第800條,炸咗。
控制枱狂報429,請求太多頂唔順。翻譯速度由飆住向前變瘋狂報錯重試。
我睇住個mon十幾秒。心理一瞬間崩潰。800條譯完,仲有差唔多1000條。
但呢個問題我以前遇過。同一個API代理,唔同模型限流策略唔一樣。有啲模型50併發冇事,有啲20就開始卡。
兩個選擇。降低併發,速度慢兩倍幾。換模型,速度不變但要保證質量唔跌。
我揀咗換模型。處理方法好粗暴,一句指令:
行緊正常嗎?如果唔得,換成gemini-2.5-flash呢個模型,斷點繼續

LinguaGacha嘅斷點續譯救咗命。佢內部有個數據庫記錄每條嘅翻譯狀態,譯過嘅唔會重行。轉模型之後Claude Code改咗配置文件嘅模型ID,重啟,自動由第800條接上。
搞掂。翻譯質量冇肉眼可見嘅下降。
最終1821條完成翻譯,1878條純英文保留,53條格式異常跳過。Claude Code自動格式化、重建章節、生成Word。宋體加Times New Roman,標題黑體,A4紙1.5倍行距。連排版都安排咗。
產出:24萬字中文譯本。大半日搞掂。大部分時間LinguaGacha喺度行,我開住另一個視窗做其他嘢,間中轉過嚟睇下進度條。
呢個過程返轉頭睇,最令我驚訝嘅一點係:我全程零規劃。冇需求文件,冇流程圖。一開波就做,遇到問題解決問題。API炸咗?換模型。格式唔啱?叫AI改。術語有錯?人手修正。全部係做緊嘅過程中一步步調出來。
以前做一個項目,第一件事就係規劃。列需求、揀方案、畫架構。有一次想做個自動整理論文嘅工具,先花咗下午畫咗個超詳細嘅流程圖。畫完之後好滿意,覺得設計完美。
個流程圖今日仲喺Notion度攤唞。項目一行代碼冇寫過。
規劃最大嘅問題唔係曬時間。而係佢俾你一種“已經做緊”嘅幻覺。流程圖畫好咗,架構諗清楚咗,你覺得項目完成咗一半。其實你一步都未走出去。
今次譯書反轉嚟:先做。做嘅過程中自然就知道邊啲步驟必要、邊啲工具好用、邊啲坑要避。做完返轉頭睇,流程自己就跑咗出嚟。
我想講,如果你對一個領域完全陌生,花啲時間瞭解基本流程係有必要嘅。但注意,瞭解流程係為咗心中有數,唔係為咗輸出一份完美嘅規劃文件。前者花半個鐘,後者花半日。半日之後好大機會你都唔想做了。
最關鍵嘅半個鐘
譯完咗。報告都寫完,文件歸檔,收工。但嗰日唔知邊條筋搭錯線,同Claude Code講多咗句:
請將呢啲工作用到嘅文件整理埋一齊,工作流程固化為skill
就係呢一句。
佢自動將所有腳本、配置、術語表、提示詞模板整理成標準目錄結構:

兩種模式:短文翻譯行Claude直譯,書籍級別嘅行LinguaGacha流水線。
多花咗半個鐘。
當時嘅感覺?就係順手整理嚇。冇乜特別。該食飯食飯,該瞓覺瞓覺。
然後將項目推到GitHub度。Claude Code有GitHub Token,直接開倉庫、push代碼,一步到位。
呢度有個小細節值得展開講。我俾Claude Code配咗GitHub Token,就一行命令:
export GITHUB_TOKEN="ghp_xxxxxx"
睇落唔起眼,但呢一步打通咗一個點,就係 AI可以發佈代碼了。有咗呢個token,Claude Code可以自己開倉庫、推代碼、讀人哋嘅開源項目。後面OpenClaw機械人可以直接調用呢個Skill,亦係因為Skill放咗喺GitHub度,任何agent拎到連結就用得。
我後嚟嘅經驗係,每個agent都配好token(GitHub、電郵、API key),係打通agent之間連接最快嘅方法。GitHub就好似agent世界嘅通用語言,你將能力放上去,任何agent都讀得到、用得到、可以重用。你俾agent嘅權限愈大,佢可以自主完成嘅事就愈多。本質上,你喺決定你信任AI到咩程度。
呢半個鐘我當時完全冇當一回事。
直到第二本書嚟咗。
譯完回憶錄冇幾日,手上又嚟咗一本。
《至高之爭》,Parmy Olson寫嘅,講OpenAI同DeepMind點樣由實驗室一路殺到全球AI競賽。Sam Altman同Demis Hassabis,兩個性格完全唔同嘅人點樣各自押注。ChatGPT發布前夜嗰班人諗緊乜、做緊乜。336頁,9.7萬英文字。
拎到呢本嘅時候我有啲興奮。軍事回憶錄再精彩,受眾都係小眾中的小眾。AI競賽?我嘅讀者比我更熟呢班人嘅名。譯完就即刻用得。
而且格式唔同咗。第一本係Word,呢本係ePub。
換格式呢件事,擺喺以前夠折騰半日。ePub嘅檔案結構同Word完全唔同,要重新寫提取邏輯、重新校格式化腳本。
但我有Skill喇。
打開Claude Code,打咗一句指令:
"C:\...\Supremacy_AI,_ChatGPT,...epub" 翻譯這本書,學術風格,20併發
一句。然後我就去做其他嘢。
返嚟一睇。20萬字中文譯本安安靜靜躺喺輸出目錄度。
講唔上係咩感覺。唔係興奮,唔係震撼。更加似係你校咗個鬧鐘,朝早佢響咗,你按熄佢。就係應該發生嘅事發生咗。
呢種確定感反而令我有啲恍惚。因為譯第一本嘅時候完全唔係咁。嗰陣每一步都擔心下一步會唔會出問題。今次我根本冇擔心過。
但係日誌入面有一行令我窒咗一下。
首先係ePub。第一本書係docx,提取腳本處理起嚟冇問題。ePub完全係另一樣嘢,本質係一堆XHTML檔案打包埋一齊。原本嘅腳本根本唔認得。
Claude Code冇嚟問我。佢自己裝咗ebooklib同beautifulsoup4兩個庫,俾提取腳本新增咗ePub函數。我一行代碼冇寫過。連知道都係事後睇日誌先知。
PS:早期操作記錄行完就會被壓成JSON存檔,串流過程睇唔到,小編匆忙唔記得截圖。( ̄ε(# ̄) 所以文章入面啲日誌截圖係事後叫Claude Code由JSON還原返可讀版本,再逐條核實過嘅。
就係呢一行令我窒咗一下。輕描淡寫。好似佢自己遇到問題、自己解決問題係天經地義咁。
講真呢種感覺有啲奇怪。好似你帶咗三年嘅實習生突然有一日唔使你操心,你開心之餘有少少失落。
兩本書譯完之後我做咗件更懶嘅事。
我有個自己搭嘅OpenClaw機械人,行喺Telegram度,平時用嚟做日常助手。我想:Skill都打包好放咗喺GitHub,可唔可以直接叫機械人用?
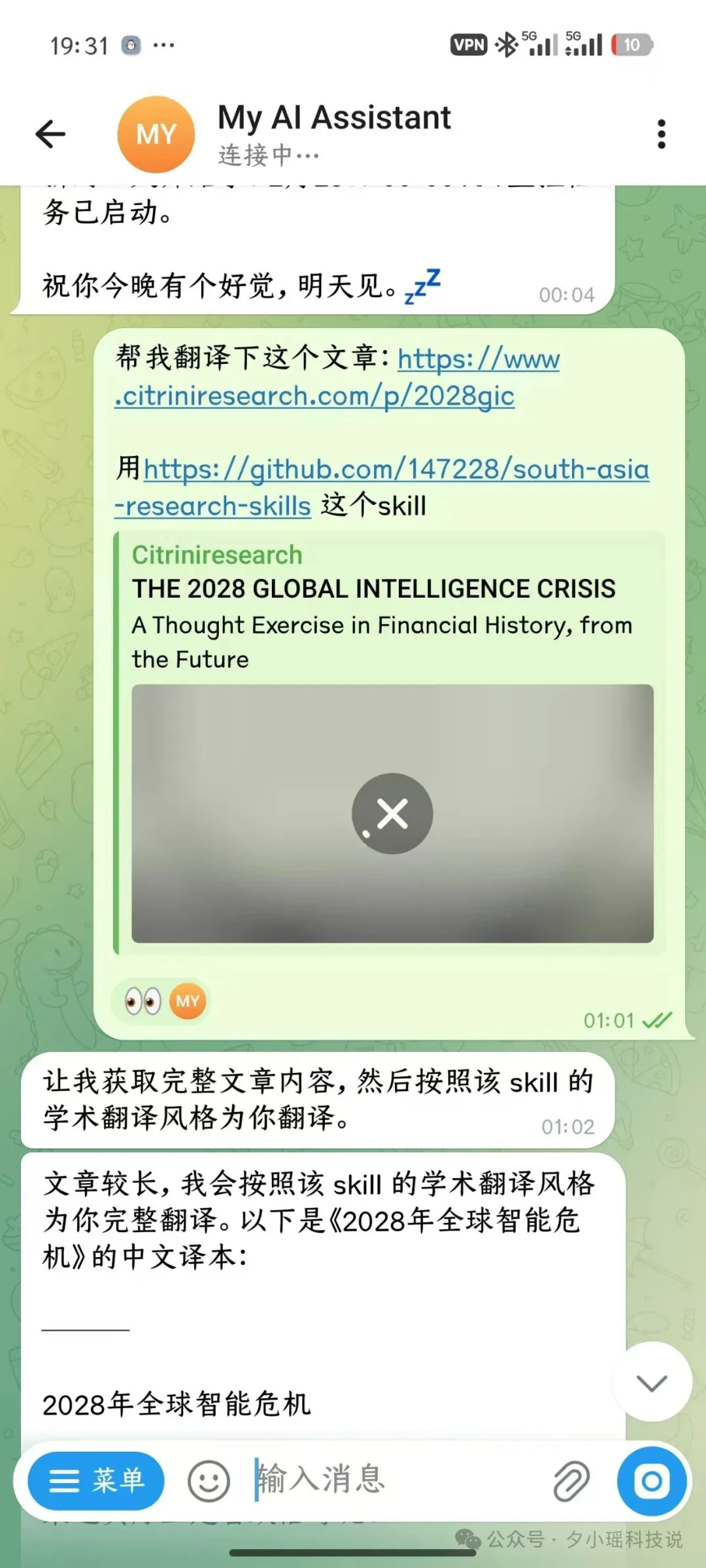
試咗一下。凌晨一點,順手Send咗條訊息俾機械人:
就係一個文章連結,加一句“幫我翻譯下呢篇文章,用south-asia-research-skills呢個skill”。
機械人秒回:"等我獲取完整文章內容,然後按照該skill嘅學術翻譯風格為你翻譯。"
然後佢就開始做。
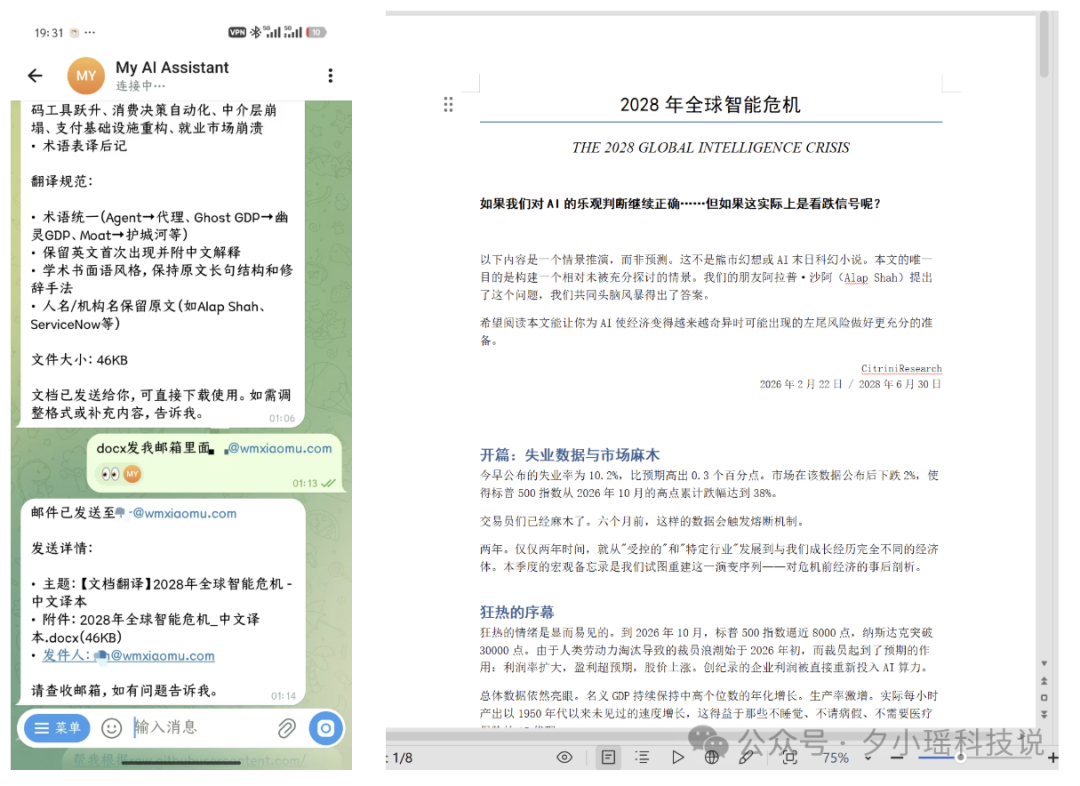
幾分鐘之後,一份完整嘅中文譯本出咗嚟。術語統一(Agent→代理、Ghost GDP→幽靈GDP、Moat→護城河),學術書面語風格,人名機構名保留原文。46KB嘅docx。
佢直接將檔案Send咗去我電郵。主題、附件、格式,全部安排曬。
你品品呢個變化。
第一本書:打開Claude Code,十幾條指令,調試半日。我係工程師。
第二本書:打開Claude Code,一條指令,去飲咖啡。我係甲方。
而家:Send條訊息俾機械人,連Claude Code都唔使開。我係甩手掌櫃。
由工程師到甲方到甩手掌櫃,中間隔住嘅就係嗰半個鐘嘅打包。
兩本書擺埋一齊睇
14條指令變1條。一日變半日。領域由軍事換成AI,格式由Word換成ePub,術語表由185條換成247條。所有呢啲變化,Agent自己搞掂咗。
呢個十幾倍嘅效率差來自邊度?
就係來自第一本書做完之後嗰半個鐘嘅打包。
我之前做過好多AI工具。熱點篩選系統、數據自動爬取。做嘅時候都好好用。但做完都係隨手掟喺某個文件夾度。下次遇到類似需求,我仲要揾半日先揾返之前嘅文件,成日揾唔到,索性重新叫AI寫個差唔多嘅。
同一類問題解決兩次。好蠢。
一個散落喺文件夾嘅腳本,過兩個月你自己都唔記得佢喺邊。一個打包好嘅Skill放喺GitHub,任何人隨時用得,你自己都隨時可以調用。
短期睇唔出差距。但累積半年之後就好明顯。一個人手上有20個打包好嘅Skill,另一個人有20個散落各處嘅腳本。前者做任何事都快,因為手邊全部係現成彈藥。後者每次都好似赤手空拳上戰場。而且前者愈做愈快,後者永遠喺原地打轉。
但講到底,我可以做到呢件事,靠嘅根本唔係技術能力。
係翻譯嘅底子,有咗翻譯嘅底子,拎到一本新書,掃一眼目錄同前三章就知道術語密度大概喺咩級數。例如見到一個印度人名,我條件反射會去查新華社有冇標準譯法。例如一段譯文讀落“都幾通順”,但主語喺兩句之間偷偷轉咗,我感應到有嘢唔啱。
呢啲嘢你叫我講我都講唔清楚。但佢哋真實咁影響咗我畀AI嘅每一句指令。呢啲就係你喺自己領域累積嘅嗰啲講唔清嘅直覺、判斷、品味,就係AI最需要嘅輸入。
最後
嗰日譯完第二本書,我又揾咗個朋友。
我話你知道第一本書同第二本書之間爭咗啲乜嗎?
佢話爭咗啲乜。
我話爭咗半個鐘。
佢話咩半個鐘。
我話第一本書譯完之後我多花咗半個鐘,將成個流程打包成一個Skill。第二本書就係靠呢個Skill,一句指令就出成品。
佢諗咗諗話:“所以你呢半個鐘,等於將自己複製咗一份。”
我當時窒咗一下。佢呢句比我自已總結得仲到位。
揾工具同直接做,好多人做到。差距就係做完之後嗰一下。花半個鐘將流程打包。短期睇唔出啲乜。但第二本書證明瞭:第一次用14條指令從零探出來嘅路,第二次一條指令就行完。第三本、第四本,可能連嗰一條指令都可以慳返。
每次用AI做完一件事,我而家都會問自己:呢件事下次仲會做嗎?
如果答案係“會”,我就花半個鐘將佢打包。
大多數人用AI嘅方式係做完一件事閂咗對話框,下次由頭嚟過。每次都係一次性。
半年之後你手上有20個Skill,人哋仲喺度從零搭流程嘅時候,你一句指令已經出成品。
你係企喺自己膊頭上面做嘢。呢種感覺,邊個試過邊個知。
項目代碼全部喺GitHub度,Skill定義、腳本、術語表模板、使用說明,全部喺入面:
https://github.com/147228/south-asia-research-skills
有興趣嘅自己clone。有翻譯需求嘅一句話就啟動得,冇翻譯需求嘅都可以參考打包Skill嘅方式做你自己領域嘅。
揾一件你重複做咗好多次嘅事。打開Claude Code,將需求講清楚,直接開始。做完同AI講一句“將工作流程固化為skill”。
就係咁簡單。


前兩天有個朋友問我最近在忙什麼。
我說翻了兩本書。
一本回憶錄,542 頁。一本講 OpenAI 和 DeepMind 的,350 頁。加起來四十多萬字中文。
他說你翻了多久。
我說第一本花費半天,第二本半小時。
他沉默了大概五秒鐘,然後說:“你是不是在測試我的智商。”
我把 Claude Code 的操作日誌截圖發過去了。
他看了半天,回了一個字:靠。。然後追了一句:“你不是搞媒體的嗎。”
對,跟翻譯八竿子打不着。
這個反差我自己也沒完全消化。所以今天想把整個過程從頭拆一遍。重點不是翻譯技術,重點是我在這件事上發現的一個快速搭建 AI 工作流的辦法。
先把故事講完。
13 萬詞丟過來的時候我的第一反應
拿到第一本書,我就抱着試一下的心態。
是一本人物的回憶錄,542 頁,13.3 萬英文詞,題材是軍事政治類。術語密度高得離譜,光人名就有幾十個,每個人在書裏還有兩三種寫法。
如果讓專業譯者翻,少說兩三個月,報價幾萬塊。我的第一反應是:Claude Code 直接翻吧。
但稍微一算賬,13 萬詞逐段丟給 Claude,幾百萬 token,API 費三四百塊,更要命的是得等七八個小時。
幸好沒有回車。
我做了一件特別不起眼但事後看來特別關鍵的事:先去 GitHub 上搜了一圈。
十來分鐘。就十來分鐘。
翻到一個叫 LinguaGacha 的開源項目。1500 多個 star,專門幹批量翻譯。術語表注入、斷點續翻、高併發,能接任何 OpenAI 兼容的 API。簡單說就是一條翻譯流水線,不聰明但夠用。
Claude Code 雖然聰明,能調研術語、能審校、能排流程。但你讓它一段一段翻 13 萬詞,有點大材小用。LinguaGacha 優點是翻得快,術語一致性好。
一個當大腦,一個當雙手。完美。
這裏我必須講一個反面教訓,不然你體會不到“先搜十分鐘”這件事有多重要。
去年我想做一個自動剪視頻的工具。上來就讓 AI 從頭寫。Python 腳本、ffmpeg 調用、字幕識別,折騰了大半天,bug 一個接一個,最後出來一個勉強能跑的半成品。我還挺得意。
做完之後隨手搜了一下 GitHub。
有個現成的開源項目。功能比我的好十倍。star 數四位數。我只需要在上面改改就行了。
大半天白費了。。。
問題出在哪呢?跟 AI 對話太方便了。隨手就能生成一大段代碼,一問一答之間特別有成就感。但這種成就感有毒。它讓你忘了一個基本事實:你遇到的問題大概率有人已經解決過了,而且解決得比 AI 臨時生成的好得多。
開源社區幾百萬個項目擺在那呢。你的需求真沒那麼獨特。
所以這次翻書,我老老實實先搜了十分鐘。然後省了可能一整天的彎路。
投資回報率高得離譜。
工具選好了,怎麼開始的呢。
我懶得自己學 LinguaGacha 怎麼用,就打開 Claude Code,把 docx 文件路徑丟進去,後面跟了四句話,讓他自己學 LinguaGacha,自己翻譯、自己整理:
你需要翻譯這個大文件,先過一遍術語表,然後用 https://github.com/neavo/LinguaGacha 這個項目翻一下,最後用 claude code 核對整理格式,檢查一遍。Lingua 可以用三方兼容 openai 的模型,你可以先讀 wiki 文件,貌似不支持 pdf。我建議你先結合網絡搜,用子 agent 啥的,確認好術語表再開幹,如果你需要大模型 api 用這個......
沒有需求文檔。沒有流程圖。就是腦子裏想什麼就說什麼。
然後 Claude Code 自己開始幹了。先寫了個腳本從 docx 裏抽純文本,然後啓動好幾個子 agent 並行去搜術語。有的搜人名,有的搜術語,有的搜地名,來源都是權威渠道。
人名最麻煩。同一個人在書裏可能有三種寫法,全名、縮寫、職務稱呼。術語表全得兜住。不然翻出來同一個人三個中文名,讀者以為是三個人。
那場面多混亂你想想。
最終 185 條術語表,JSON 格式。我快速過了一遍人名列,糾了幾個,大部分都沒問題。
Claude Code 自動配好 LinguaGacha,全書拆成 1800 多條翻譯條目,開跑。
然後我幹了一件蠢事。
50 併發,炸了
我心急。第二條指令寫的是:
學術風格的,然後 50 線程速速搞定
50 併發。相當於 50 個翻譯員同時開工。進度條嗖嗖往前走,看着特別爽。
跑到第 800 條。炸了。
控制枱密集報 429,請求太多了扛不住了。翻譯速度從嗖嗖前進變成瘋狂報錯重試。
我盯着屏幕看了十幾秒。心態有一瞬間是崩的。800 條翻完了,還有將近 1000 條呢。
但這個問題我以前遇到過。同一個 API 代理,不同模型限流策略不一樣。有些模型 50 併發沒事,有些 20 就開始卡。
兩個選擇。降併發,速度慢兩倍多。換模型,速度不變但得確保質量不掉。
我選了換模型。處理方式很粗暴,一條指令:
運行還正常嗎?如果不行的話,換成 gemini-2.5-flash 這個模型,斷點繼續
LinguaGacha 的斷點續翻救了命。它內部有個數據庫記錄每條的翻譯狀態,翻過的不會重跑。切模型之後 Claude Code 改了配置文件裏的模型 ID,重啓,自動從第 800 條接上。
搞定。翻譯質量沒有肉眼可見的下降。
最終 1821 條完成翻譯,1878 條純英文保留,53 條格式異常跳過。Claude Code 自動格式化、重建章節、生成 Word。宋體加 Times New Roman,標題黑體,A4 紙 1.5 倍行距。連排版都安排了。
產出:24 萬字中文譯本。大半天搞定。大部分時間 LinguaGacha 在跑,我開着另一個窗口乾別的,偶爾切過來瞄一眼進度條。
這個過程回頭看,最讓我驚訝的一點是:我全程零規劃。沒有需求文檔,沒有流程圖。上來就幹,遇到問題解決問題。API 炸了?換模型。格式不對?讓 AI 調。術語有誤?人工糾正。全是在做的過程中一步步調出來的。
以前做一個項目,第一件事就是規劃。列需求、選方案、畫架構。有一次想做個自動整理論文的工具,先花了一下午畫了個超詳細的流程圖。畫完之後特別滿意,覺得設計完美。
那個流程圖今天還在 Notion 裏躺着呢。項目一行代碼沒寫。
規劃最大的問題不在費時間。在於它給你一種“已經在做了”的幻覺。流程圖畫好了,架構想清楚了,你覺得項目完成了一半。其實你一步都沒走出去。
這次翻書反過來:先做。做的過程中自然就知道哪些步驟必要、哪些工具好用、哪些坑要避。做完回頭看,流程自己就跑出來了。
我想說,如果你對一個領域完全陌生,花點時間瞭解基本流程還是有必要的。但注意,瞭解流程是為了心裏有數,不是為了輸出一份完美的規劃文檔。前者花半小時,後者花半天。半天之後大概率你也不想做了。
最關鍵的半小時
翻完了。報告也寫完了,文件歸檔,收工。但那天不知道哪根筋搭錯了,跟 Claude Code 多說了一句:
請把這些工作用到的文件整理一下放在一起,工作流程固化為 skill
就這一句。
它自動把所有腳本、配置、術語表、提示詞模板整理成了標準目錄結構:
兩種模式:短文翻譯走 Claude 直譯,書籍級別的走 LinguaGacha 流水線。
多花了半小時。
當時的感覺?就是順手整理了一下。沒什麼特別的。該吃飯吃飯,該睡覺睡覺。
然後把項目推到了 GitHub 上。Claude Code 有 GitHub Token,直接創建倉庫、push 代碼,一步到位。
這裏有個小細節值得展開說。我給 Claude Code 配了 GitHub Token,就一行命令:
export GITHUB_TOKEN="ghp_xxxxxx"
看起來不起眼,但這一步打通了一個點,就是 AI 可以發佈代碼了。有了這個 token,Claude Code 可以自己建倉庫、推代碼、讀別人的開源項目。後面 OpenClaw 機器人能直接調這個 Skill,也是因為 Skill 放在了 GitHub 上,任何 agent 拿到連結就能用。
我後來的經驗是,給每個 agent 都配好 token(GitHub、郵箱、API key),是打通 agent 之間連接最快的方式。GitHub 就像 agent 世界的通用語言,你把能力放上去,任何 agent 都能讀、能用、能複用。你給 agent 的權限越大,它能自主完成的事情就越多。本質上,你在決定你信任 AI 到什麼程度。
這半小時我當時完全沒當回事。
直到第二本書來了。
翻完回憶錄沒幾天,手上又來了一本。
《至高之爭》,Parmy Olson 寫的,講 OpenAI 和 DeepMind 怎麼從實驗室一路殺到全球 AI 競賽。Sam Altman 和 Demis Hassabis,兩個性格完全不同的人怎麼各自押注。ChatGPT 發佈前夜那些人在想什麼、做什麼。336 頁,9.7 萬英文詞。
拿到這本的時候我有點興奮。軍事回憶錄再精彩,受眾是小眾中的小眾。AI 競賽?我的讀者比我還熟這幫人的名字。翻完就能用。
而且格式不一樣了。第一本是 Word,這本是 ePub。
換格式這件事,擱以前夠折騰半天的。ePub 的文件結構跟 Word 完全不同,得重新寫提取邏輯、重新調格式化腳本。
但我有 Skill 了。
打開 Claude Code,敲了一條指令:
"C:\...\Supremacy_AI,_ChatGPT,...epub" 翻譯這本書,學術風格,20併發
一條。然後我就去幹別的了。
回來一看。20 萬字中文譯本安安靜靜躺在輸出目錄裏。
說不上什麼感覺。不是興奮,不是震撼。更像是你設了個鬧鐘,早上它響了,你按掉。就是該發生的事情發生了。
這種確定感本身反而讓我有點恍惚。因為翻第一本的時候完全不是這樣的。那時候每一步都在擔心下一步會不會出問題。這次我壓根就沒擔心過。
但日誌裏有一行讓我愣了一下。
首先是 ePub。第一本書是 docx,提取腳本處理起來沒問題。ePub 完全是另一種東西,本質是一堆 XHTML 文件打包在一起。原來的腳本根本不認識。
Claude Code 沒來問我。它自己安裝了 ebooklib 和 beautifulsoup4 兩個庫,給提取腳本新增了 ePub 函數。我一行代碼沒寫。連知道都是事後看日誌才知道的。
PS:早期操作記錄跑完就會被壓成 JSON 存檔,流式過程看不到,小編倉促忘記截圖。( ̄ε(# ̄) 所以文章裏那些日誌截圖是事後讓 Claude Code 從 JSON 裏還原出可讀版本,再逐條核實過的。
這就是讓我愣住的那一行。輕描淡寫。好像它自己遇到問題、自己解決問題是天經地義的事。
說實話這種感覺有點奇怪。像是你帶了三年的實習生突然有一天不用你操心了,你高興之餘有那麼一點點失落。
兩本書翻完之後我幹了件更懶的事。
我有一個自己搭的 OpenClaw 機器人,跑在 Telegram 上,平時拿來做做日常助手。我想:Skill 都打包好放 GitHub 了,能不能直接讓機器人用?
試了一下。凌晨一點,隨手給機器人發了條消息:
就是一個文章連結,加一句“幫我翻譯下這個文章,用 south-asia-research-skills 這個 skill”。
機器人秒回:"讓我獲取完整文章內容,然後按照該 skill 的學術翻譯風格為你翻譯。"
然後它就開始幹了。
幾分鐘後,一份完整的中文譯本出來了。術語統一(Agent→ 代理、Ghost GDP→ 幽靈 GDP、Moat→ 護城河),學術書面語風格,人名機構名保留原文。46KB 的 docx。
它直接把文件發到了我的郵箱裏。主題、附件、格式,全安排好了。
你品品這個變化。
第一本書:打開 Claude Code,十幾條指令,調試半天。我是工程師。
第二本書:打開 Claude Code,一條指令,去喝咖啡。我是甲方。
現在:給機器人發條消息,連 Claude Code 都不用打開。我是甩手掌櫃。
從工程師到甲方到甩手掌櫃,中間隔的就是那半小時的打包。
兩本書放一起看
14 條指令變 1 條。一天變半天。領域從軍事換成 AI,格式從 Word 換成 ePub,術語表從 185 條換成 247 條。所有這些變化,Agent 自己搞定了。
這個十幾倍的效率差來自哪?
就來自第一本書做完之後那半小時的打包。
我之前做過很多 AI 工具。熱點篩選系統、數據自動爬取。做的時候都挺好用。但做完都是隨手扔在某個文件夾裏。下次遇到類似需求,我還要翻半天找之前的文件,經常找不到,乾脆重新讓 AI 寫一個差不多的。
同一類問題解決兩遍。就很蠢。
一個散落在文件夾裏的腳本,過兩個月你自己都忘了它在哪。一個打包好的 Skill 放在 GitHub 上,任何人隨時能用,你自己也隨時能調。
短期看不出差距。但積累半年之後就很明顯了。一個人手上有 20 個打包好的 Skill,另一個人有 20 個散落各處的腳本。前者做任何事情都快,因為手邊全是現成的彈藥。後者每次都像赤手空拳上戰場。而且前者越做越快,後者永遠在原地打轉。
但說到底,我能做到這件事,靠的根本不是技術能力。
是翻譯的底子,有了翻譯的底子,拿到一本新書,掃一眼目錄和前三章就知道術語密度大概在什麼量級。比如看到一個印度人名,我條件反射會去查新華社有沒有標準譯法。比如一段譯文讀起來“挺通順”,但主語在兩句話之間偷偷換了,我能感覺到哪裏不對。
這些東西你讓我講出來我都講不清楚。但是它們真實地影響了我給 AI 下的每一條指令。這些你在自己領域積累的那些說不清道不明的直覺、判斷、品味,就是 AI 最需要的輸入。
最後
那天翻完第二本書,我又找了那個朋友。
我說你知道第一本書和第二本書之間差了什麼嗎。
他說差了什麼。
我說差了半小時。
他說什麼半小時。
我說第一本書翻完之後我多花了半小時,把整個流程打包成了一個 Skill。第二本書就是靠這個 Skill,一條指令出成品的。
他想了想說:“所以你這半小時,等於把自己複製了一份。”
我當時愣了一下。他這句話比我自己總結的到位。
找工具和直接做,很多人能做到。差距就在做完之後的那一下。花半小時把流程打包。短期看不出什麼。但第二本書證明了:第一次花 14 條指令從零探出來的路,第二次一條指令就走完了。第三本、第四本,可能連那一條指令都能省了。
每次用 AI 做完一件事,我現在都會問自己:這件事下次還會做嗎?
如果答案是“會”,我就花半小時把它打包。
大多數人用 AI 的方式是做完一件事關掉對話框,下次從頭來。每次都是一次性的。
半年之後你手上有 20 個 Skill,別人還在從零搭流程的時候,你一條指令已經出成品了。
你是站在自己肩膀上幹活。這感覺,誰試誰知道。
項目代碼全在 GitHub 上,Skill 定義、腳本、術語表模板、使用說明,全在裏面:
https://github.com/147228/south-asia-research-skills
感興趣的自己 clone。有翻譯需求的一句話就能啓動,沒翻譯需求的也可以參考打包 Skill 的方式做你自己領域的。
找一件你重複做了很多遍的事情。打開 Claude Code,把需求說清楚,直接開始。做完了跟 AI 說一句“把工作流程固化為 skill”。
就這麼簡單。