Claude Code 抓網頁的 5 種方案,我全測了一遍
整理版優先睇
實測比較五種 Claude Code 抓網頁方案,幫你揀最啱用嗰個
呢篇文章係作者親自實測五種用 Claude Code 抓網頁內容嘅方案之後寫嘅對比心得。作者平時成日要用 Claude Code 嚟保存文章、收集數據,發現市面上嘅方案好多,但各自擅長嘅領域唔同,好易揀錯。佢將呢五種方案由最輕量到最重型排咗個順序,逐個測試佢哋嘅強項同弱項,最後總結出一套按場景揀方案嘅實用建議。文章嘅核心結論係:呢五種方案唔係互相取代,而係互補,冇一個「最好」嘅萬能方案,最緊要係按自己嘅需要去揀。
作者分析咗五種方案嘅技術層次、功能特點同適用場景。最輕量嘅係 WebFetch,Claude Code 內置工具,零配置,但唔識執行 JavaScript,連 X 嘅帖子都抓唔到。Playwright MCP 就係真實瀏覽器,可以完整渲染 JS 渲染嘅頁面,仲可以互動。Scrapling 係 Python 爬蟲框架,內置反反爬同自適應解析,適合批量同長期監控。Firecrawl 係雲端 SaaS,幫你搞掂曬所有麻煩嘢,但數據會經過第三方伺服器。Agent-Reach 就係一個編排層,整合咗 11+ 社交平台嘅專用工具,適合跨平台採集。
作者最後根據唔同場景,畀出實用嘅選型建議,仲分享咗佢自己日常用嘅組合:先用 WebFetch 試靜態頁面,唔夠用就上 Playwright,有批量需要再加 Scrapling。總之,按需升級,唔好過度配置。
- 五種方案分屬唔同技術層次,互補唔係替代,揀方案要先搞清楚你需要處理嘅係乜嘢層次嘅問題。
- WebFetch 最輕量但唔支援 JavaScript,連 X 帖子都抓唔到,只適合攞靜態頁面嘅文字內容。
- Playwright MCP 係真實瀏覽器,識得執行 JS 同互動,係處理現代 SPA 應用嘅首選,但唔適合批量爬取。
- Scrapling 內置反反爬同自適應解析,性能係 BeautifulSoup 嘅 400-600 倍,適合批量採集同長期監控。
- 實用組合:先試 WebFetch,唔夠用上 Playwright,有批量需要再加 Scrapling,按需求逐步升級就唔會過度配置。
五種方案,分層解答你嘅抓網頁難題
用 Claude Code 做內容創作,成日都要抓網頁內容。保存一篇好文章、攞推文數據、批量收集競品資訊,都係要由網頁攞數據。但係 Claude Code 生態入面嘅方案至少有 5 種,由內置工具到雲端服務到專業爬蟲框架,功能重疊,第一次接觸真係好難揀。
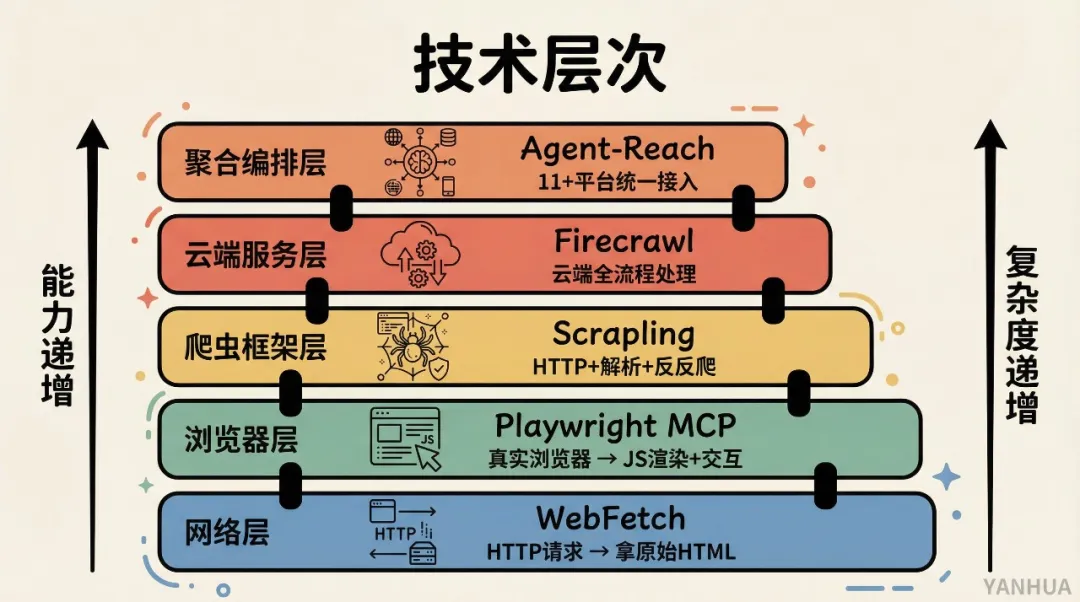
作者將呢 5 種方案由輕到重排咗個次序:WebFetch(網絡層)、Playwright MCP(瀏覽器層)、Scrapling(爬蟲框架層)、Firecrawl(雲端服務層)、Agent-Reach(聚合編排層)。佢哋係唔同技術層次嘅嘢,互補關係,唔係替代關係。
逐個實測:五種方案嘅真功夫
WebFetch 係 Claude Code 內置工具,零配置,對靜態頁面好快。但佢唔執行 JavaScript,現代網頁好多都依賴 JS 渲染,攞到的可能只係個空殼。作者實測抓 X 帖子,直接返「JavaScript is not available」。
Playwright MCP 係微軟嘅瀏覽器自動化框架,通過 MCP 接入 Claude Code。佢會啟動真實 Chromium 瀏覽器,完整渲染 JS,仲可以互動。作者用同一條 X 帖子測試,成功拎到全文、作者、互動數據,未登錄都搞掂。
Scrapling 係 Python 爬蟲框架,提供三種 Fetcher 模式切換,最特別係 自適應解析:網站改版都唔怕,用相似度算法自動揾返對應內容。性能方面,解析速度比 BeautifulSoup 快 400-600 倍。
Firecrawl 係雲端 SaaS,YC 孵化,畀個 URL 就幫你搞掂曬渲染、反爬、清洗,返乾淨 Markdown 或 JSON。最新嘅 /agent 功能可以智能導航複雜網站。但係最大問題係 數據會經過第三方伺服器,私隱要諗清楚。
Agent-Reach 係一個編排層,將 X、YouTube、B 站等 11+ 平台嘅最佳工具整合埋一齊,每個平台用最啱嘅工具。本地運行、免費開源,但係 依賴鏈好長,任何一個底層工具出問題都會影響整體。
橫向對比:關鍵維度話你知點揀
作者將幾個關鍵維度擺埋一齊對比。JS 渲染方面,WebFetch 唔得,Playwright 同 Firecrawl 原生支援,Scrapling 可選。互動能力(點擊、填表、滾動)只有 Playwright 做到。批量爬取就係 Scrapling 同 Firecrawl 嘅主場。
反反爬方面,Scrapling 內置繞過 Cloudflare,Firecrawl 雲端處理。數據私隱方面,只有 Firecrawl 經過雲端,其他都係本地。配置難度由低到高:WebFetch 零配置,Firecrawl 低門檻(API Key),Playwright 同 Agent-Reach 中等,Scrapling 最高。
- 快速睇靜態頁面 → WebFetch,零配置最輕量
- 頁面需要 JS 渲染或登錄 → Playwright MCP,真實瀏覽器
- 需要點擊填表等交互 → Playwright MCP,五個入面唯一做得到
- 批量提取結構化數據 → Scrapling,呢個係佢主場
- 網站有 Cloudflare 防護 → Scrapling StealthyFetcher,專做呢樣嘢
- 長期監控網站變化 → Scrapling,自適應解析加斷點續爬
- 大規模全站爬取 → Firecrawl,雲端處理最省心
- 跨多個社交平台採集 → Agent-Reach,11+ 平台統一入口
實測結果同容易忽略嘅位
作者用自己一條 X 帖子做實測。WebFetch 失敗,Playwright MCP 成功,結論好直接:現代 SPA 應用一定要用瀏覽器級別嘅方案。
幾個容易忽略嘅點:WebFetch 唔等於瀏覽器,適用範圍比你想像窄。Playwright 唔適合批量,開完整 Chromium 一次只做一個頁面,性能浪費。Firecrawl 嘅私隱問題唔可以忽視,敏感數據要揀本地方案。Agent-Reach 本質係編排層,唔自己做抓取,升級依賴可能引發連鎖問題。
最後作者重申:呢五種方案各自擅長唔同層次嘅問題,冇最好嘅方案,只有最合適嘅方案。按需升級,先由最輕量嘅方案開始試起,就唔會浪費時間同資源。
用 Claude Code 做內容創作,有個甩唔開嘅需求:抓網頁內容。
保存一篇好文章、抓取推文數據、批量收集競爭對手資訊,都要從網頁攞資料。但 Claude Code 生態入面用到嘅方法最少有 5 種,從內置工具到雲端服務到專業爬蟲框架,睇落功能重疊,第一次接觸好難揀。
我將呢 5 種方法都實測咗一次,呢篇文章就係對比結果。每種方法擅長啲乜、唔擅長啲乜、咩場景應該用邊個,睇完就清楚曬。
先講一個關鍵前提:佢哋唔喺同一個層次
呢 5 種方法最容易踩嘅陷阱,就係拎嚟直接橫向比較。佢哋其實係唔同技術層次嘅嘢,就好似螺絲批、電鑽同裝修公司,各自解決唔同層面嘅問題。
① WebFetch(網絡層)→ 最輕量嘅 HTTP 請求工具
② Playwright MCP(瀏覽器層)→ 模擬真人操作嘅真實瀏覽器
③ Scrapling(爬蟲框架層)→ 自適應解析嘅 Python 爬蟲框架
④ Firecrawl(雲端服務層)→ 網頁數據提取嘅 SaaS 服務
⑤ Agent-Reach(聚合編排層)→ 11+ 社交平台嘅統一接入層
由上到下,層級遞增,能力遞增,複雜度都遞增。互補關係,唔係替代關係。
下面逐個講。
方法一:WebFetch
WebFetch 係 Claude Code 自帶嘅內置工具,零配置,開箱即用。工作方式好直接:發一個 HTTP 請求,拎到 HTML,轉成 Markdown 返回。
好處真係好輕。唔使裝依賴,唔使配置,對靜態頁面幾秒鐘就有結果。安全性都最高,有內置沙箱,自動 HTTPS 升級,仲帶 15 分鐘緩存。
問題在於佢唔執行 JavaScript。現代網頁大量依賴 JS 渲染內容,WebFetch 拎到嘅可能只係一個空殼。唔支持登錄,唔可以點擊、滾動、填表單,碰到企業級反爬策略都可能被直接攔截。
簡單講,WebFetch 拎到嘅係「伺服器返回嘅原始文檔」,唔係「你喺瀏覽器入面見到嘅頁面」。
適合:快速睇一個博客文章、抓公開嘅 API 文檔、獲取靜態頁面文本。
不適合:X/Twitter、SPA 單頁應用、任何需要登錄嘅頁面。
我實測咗一下,用佢抓 X 帖子,直接返回 "JavaScript is not available",完全拎唔到內容。
方法二:Playwright MCP
Playwright 係微軟維護嘅瀏覽器自動化框架,通過 MCP 協議接入 Claude Code。佢啟動一個真實嘅 Chromium 瀏覽器,完整加載頁面、執行 JS、渲染 DOM。
同 WebFetch 最大嘅分別:Playwright 拎到嘅係你對眼見到嘅嗰個頁面。JS 渲染嘅內容、動態加載嘅數據,全部都有。而且佢可以互動,撳掣、填表單、模擬滾動、截圖,甚至可以在瀏覽器入面行完登錄流程。微軟維護,社羣成熟,文檔豐富,數據都全部喺本地處理。
代價係重。每次操作都啟動完整嘅 Chromium,資源消耗唔細。一次只能操作一個頁面,本質上係測試/自動化工具,唔係為批量爬取設計嘅。如果你只想睇一個靜態博客寫咗啲乜,用 Playwright 確實有啲大材小用。
適合:JS 渲染頁面(SPA、React/Vue 應用)、需要登錄嘅內容、需要互動操作、截圖。
不適合:大規模批量爬取、高頻率抓取。
同樣嘅 X 帖子測試,Playwright 完整拎到咗全文、作者資訊、互動數據(回覆/轉發/點讚/書籤/瀏覽量)、圖片連結。未登錄狀態就能抓取 Article 類型帖子。
方法三:Scrapling
Scrapling 係一個 Python 爬蟲框架,GitHub 20.6K stars,92% 測試覆蓋率。同頭兩個唔同,佢唔只係「發請求拎內容」,而係一套完整嘅爬蟲工程體系。
佢提供三種 Fetcher 模式可以切換:普通 HTTP 請求(Fetcher,類似 WebFetch),反反爬模式(StealthyFetcher,內置繞過 Cloudflare),瀏覽器渲染(DynamicFetcher,類似 Playwright)。
Scrapling 最值得講嘅特性係自適應解析。做過爬蟲嘅都知道,網站一改版,選擇器就失效,要手動更新。Scrapling 用相似度算法自動重新定位元素,DOM 結構變咗都能揾到對應內容。對於長期運行嘅爬蟲任務,呢個能力非常實用。
性能方面,官方數據係解析速度比 BeautifulSoup 快 400-600 倍。v0.4 仲引入咗 Spider 框架,類似 Scrapy API,支持異步並發、斷點續爬、流式處理。
但門檻都唔低:需要 Python 3.10+ 環境,學習曲線比頭兩個陡好多,都唔適合互動場景。如果你只係偶爾抓一個頁面,Scrapling 有啲殺雞用牛刀。佢嘅價值在長期嘅、批量嘅、需要應對反爬嘅數據採集任務。
佢都內置咗 MCP Server,可以直接喺 Claude Code 中調用。
方法四:Firecrawl
Firecrawl 行嘅係完全唔同嘅路線:雲端 SaaS。YC 孵化,$14.5M A 輪,GitHub 69K+ stars,35 萬+開發者喺用。
你俾佢一個 URL,佢喺雲端完成所有骯髒工作(瀏覽器渲染、反爬繞過、內容清洗、結構化提取),直接返回乾淨嘅 Markdown 或結構化 JSON。除咗單頁抓取,仲支持全站爬取、站點地圖發現、搜索+抓取一體化。2026 年 1 月推出嘅 /agent 功能可以智能導航複雜網站,自動搜索同採集數據。
最大嘅好處係省心。唔使裝本地依賴,唔使理版本兼容,有官方 MCP Server,npx -y firecrawl-mcp 一行搞掂。
最大嘅顧慮係私隱。你抓取嘅所有內容都會經過 Firecrawl 嘅伺服器。抓公開資訊(博客、文檔、新聞)問題唔大,但涉及敏感數據嘅話,建議行本地方案。另外係費用,有免費額度,但大量使用需要付費。仲有服務商依賴嘅問題,Firecrawl 死咗你就死咗。
方法五:Agent-Reach
Agent-Reach 同頭四個都唔一樣。佢唔係一個獨立嘅爬蟲引擎,而係一個「腳手架」,將 X/Twitter、YouTube、B 站、小紅書、Reddit、LinkedIn 等 11+ 平台嘅最佳抓取工具整合埋一齊,通過 MCP 協議提供統一入口。
YouTube 用 yt-dlp(148K stars),X 用 xreach CLI(cookie 認證),通用網頁用 Jina Reader。每個平台揀最合適嘅工具嚟做。本地運行,免費開源。
問題是依賴鏈太長。底層掛住 yt-dlp、xreach、Jina Reader、feedparser、gh CLI 呢一堆工具,任何一個出問題都會影響整體。項目相對較新(GitHub 4.2K stars,v1.2.0),穩定性仲喺驗證中,多工具版本兼容嘅維護成本都唔低。
佢嘅價值在「廣度」而唔係「深度」。唔會比 Firecrawl 更擅長抓網頁,都唔會比 Scrapling 更擅長反爬,但如果你需要同時從多個社交平台採集資訊,佢能省唔少事。
橫向對比
將幾個關鍵維度放埋一齊睇:
JS 渲染:WebFetch 唔得,Playwright 同 Firecrawl 原生支持,Scrapling 可選,Agent-Reach 取決於底層工具。
互動能力(點擊、填表、滾動):只有 Playwright 做到,其他四個都唔得。
批量爬取:Scrapling 同 Firecrawl 嘅核心能力,其他三個唔適合。
反反爬:Scrapling 內置,Firecrawl 雲端處理,Playwright 有限支持,WebFetch 同 Agent-Reach 基本冇。
數據私隱:Firecrawl 嘅數據經過雲端,其他四個都係本地處理。
配置難度:WebFetch 零配置,Firecrawl 低門檻(API Key),Playwright 同 Agent-Reach 中等,Scrapling 最高。
費用:只有 Firecrawl 收費(有免費額度),其他都免費。
實測:抓 X 帖子
齋講唔練冇用,我拎一條自己嘅 X 帖子做咗測試。
WebFetch:失敗。返回 "JavaScript is not available"。X 係 SPA 應用,內容全靠 JS 渲染,WebFetch 拎到嘅就係一個空殼。
Playwright MCP:成功。完整拎到全文、作者、發佈時間、互動數據、圖片連結。未登錄狀態就搞掂。

結論好直接:X 呢類現代 SPA 應用,必須用瀏覽器級別嘅方法。需要登錄先睇得嘅內容,可以在 Playwright 中行登錄流程,或者用 Agent-Reach 嘅 xreach(cookie 認證)。
選型建議
唔好糾結「邊個最好」,按場景揀:
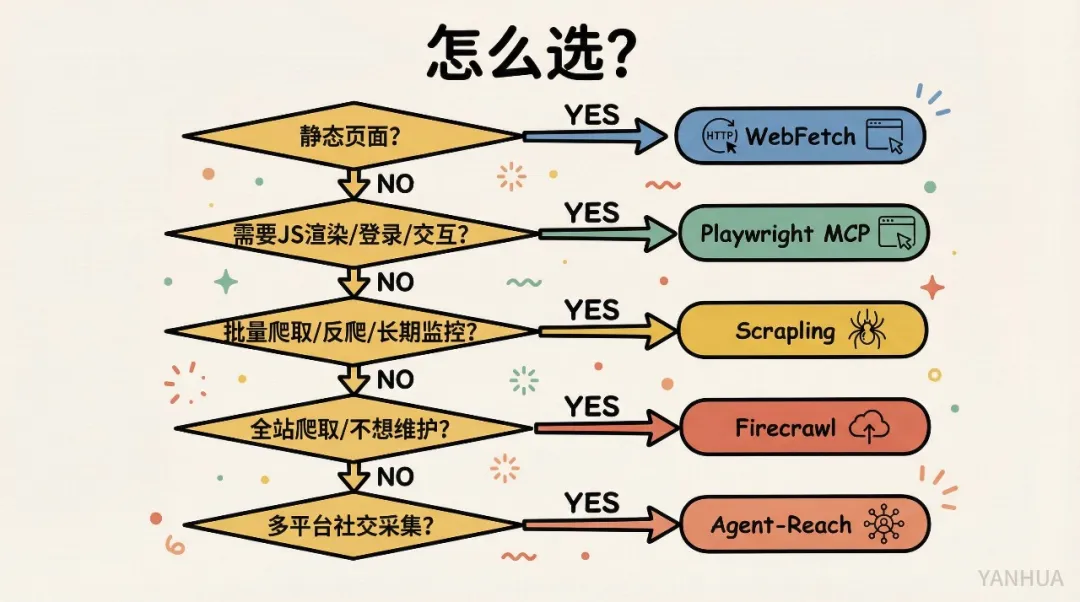
快速睇一個靜態頁面 → WebFetch,零配置最輕量。
頁面需要 JS 渲染或登錄 → Playwright MCP,需要真實瀏覽器。
需要點擊、填表等互動 → Playwright MCP,五個方法入面唯一做到嘅。
批量提取結構化數據 → Scrapling,呢個係佢嘅主場。
網站有 Cloudflare 防護 → Scrapling StealthyFetcher,專門做呢樣嘢嘅。
長期監控網站變化 → Scrapling,自適應解析 + 斷點續爬。
大規模全站爬取 → Firecrawl,雲端處理,省心。
跨多個社交平台採集 → Agent-Reach,11+ 平台統一入口。
在意數據私隱 → Scrapling 或 Agent-Reach,純本地。
唔想維護工具鏈 → Firecrawl,SaaS 零維護。
我用緊嘅組合
實際用落嚟,淨揀一個係唔夠嘅,組合先至好用。
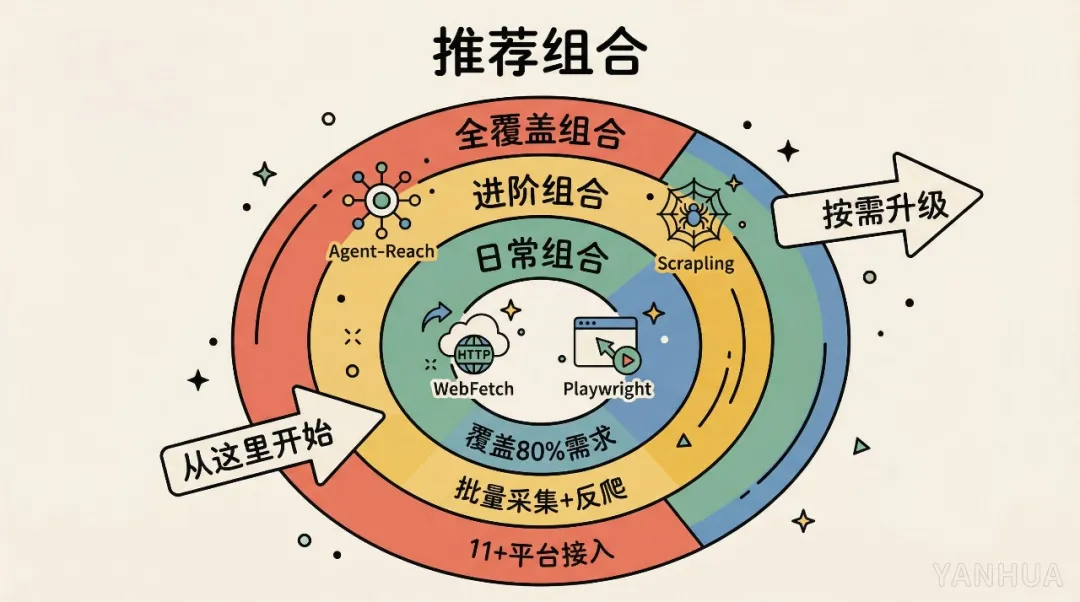
日常組合:WebFetch + Playwright MCP
大部分場景用 WebFetch 先試,靜態頁面直接搞掂。遇到 JS 渲染或需要互動嘅再轉 Playwright。呢兩個覆蓋咗我 80% 嘅日常需求。
進階組合:加上 Scrapling MCP
如果你有批量採集或長期監控嘅需求,Scrapling 嘅批量調度同自適應解析係頭兩個做唔到嘅。三者都本地運行,數據唔外傳。
全覆蓋組合:再加 Agent-Reach
需要同時從 YouTube、B 站、小紅書等多平台採集,Agent-Reach 能省唔少事。但要有心理準備,依賴鏈長,維護成本都高。
幾個容易忽略嘅位
WebFetch 唔等於瀏覽器。 好多人第一次用 WebFetch 會覺得奇怪「點解拎唔到內容」,原因就係佢唔執行 JS。而家大部分網站都有 JS 渲染嘅內容,所以 WebFetch 嘅適用範圍比你想象嘅窄。
Playwright 唔適合批量。 佢啟動嘅係完整嘅 Chromium,一次操作一個頁面。拎佢做批量爬蟲,就好似揸法拉利送外賣,性能浪費嚴重。
Firecrawl 嘅私隱問題唔可以忽視。 所有數據經過第三方伺服器處理。如果你只係抓公開文章,問題唔大。但如果涉及商業敏感資訊或用戶數據,請揀本地方案。
Agent-Reach 本質係編排層。 佢自己唔做抓取,底層全靠第三方工具。升級某個依賴可能引發連鎖問題,心入面要有數。
最後
呢 5 種方法各自擅長唔同層次嘅問題,冇「最好」嘅方法,只有「最合適」嘅方法。
如果你啱啱開始用 Claude Code 做網頁抓取,我嘅建議係:先從 WebFetch 開始,唔夠用就上 Playwright,有批量需求再上 Scrapling。 按需升級,唔好過度配置。
用 Claude Code 做內容創作,有一個綁不開的需求:抓網頁內容。
保存一篇好文章、抓取推文數據、批量採集競品信息,都需要從網頁拿數據。但 Claude Code 生態裏能用的方案至少有 5 種,從內置工具到雲端服務到專業爬蟲框架,看起來功能重疊,第一次接觸很難選。
我把這 5 種方案都實測了一遍,這篇文章就是對比結果。每種方案擅長什麼、不擅長什麼、什麼場景該用哪個,看完就清楚了。
先說一個關鍵前提:它們不在同一個層次
這 5 種方案最容易踩的坑,就是拿來直接橫向比較。它們其實是不同技術層次的東西,就像螺絲刀、電鑽和裝修公司,各自解決不同層面的問題。
① WebFetch(網絡層)→ 最輕量的 HTTP 請求工具
② Playwright MCP(瀏覽器層)→ 模擬真人操作的真實瀏覽器
③ Scrapling(爬蟲框架層)→ 自適應解析的 Python 爬蟲框架
④ Firecrawl(雲端服務層)→ 網頁數據提取的 SaaS 服務
⑤ Agent-Reach(聚合編排層)→ 11+ 社交平台的統一接入層
從上到下,層級遞增,能力遞增,複雜度也遞增。互補關係,不是替代關係。
下面逐個說。
方案一:WebFetch
WebFetch 是 Claude Code 自帶的內置工具,零配置,開箱即用。工作方式很直接:發一個 HTTP 請求,拿到 HTML,轉成 Markdown 返回。
好處是真的輕。不用裝依賴,不用配置,對靜態頁面幾秒鐘就有結果。安全性也最高,有內置沙箱,自動 HTTPS 升級,還帶 15 分鐘緩存。
問題在於它不執行 JavaScript。現代網頁大量依賴 JS 渲染內容,WebFetch 拿到的可能只是一個空殼。不支持登錄,不能點擊、滾動、填表單,碰到企業級反爬策略也可能被直接攔截。
簡單說,WebFetch 拿到的是「服務器返回的原始文檔」,不是「你在瀏覽器裏看到的頁面」。
適合:快速看一個博客文章、抓公開的 API 文檔、獲取靜態頁面文本。
不適合:X/Twitter、SPA 單頁應用、任何需要登錄的頁面。
我實測了一下,用它抓 X 帖子,直接返回 "JavaScript is not available",完全拿不到內容。
方案二:Playwright MCP
Playwright 是微軟維護的瀏覽器自動化框架,通過 MCP 協議接入 Claude Code。它啓動一個真實的 Chromium 瀏覽器,完整加載頁面、執行 JS、渲染 DOM。
和 WebFetch 最大的區別:Playwright 拿到的是你眼睛看到的那個頁面。JS 渲染的內容、動態加載的數據,全都有。而且它能交互,點按鈕、填表單、模擬滾動、截圖,甚至可以在瀏覽器裏走完登錄流程。微軟維護,社區成熟,文檔豐富,數據也全部在本地處理。
代價是重。每次操作都啓動完整的 Chromium,資源消耗不小。一次只能操作一個頁面,本質上是測試/自動化工具,不是為批量爬取設計的。如果你只想看一個靜態博客寫了什麼,上 Playwright 確實有點大材小用。
適合:JS 渲染頁面(SPA、React/Vue 應用)、需要登錄的內容、需要交互操作、截圖。
不適合:大規模批量爬取、高頻率抓取。
同樣的 X 帖子測試,Playwright 完整拿到了全文、作者信息、互動數據(回覆/轉發/點贊/書籤/瀏覽量)、圖片連結。未登錄狀態就能抓取 Article 類型帖子。
方案三:Scrapling
Scrapling 是一個 Python 爬蟲框架,GitHub 20.6K stars,92% 測試覆蓋率。和前兩個不同,它不只是「發請求拿內容」,而是一套完整的爬蟲工程體系。
它提供三種 Fetcher 模式可以切換:普通 HTTP 請求(Fetcher,類似 WebFetch),反反爬模式(StealthyFetcher,內置繞過 Cloudflare),瀏覽器渲染(DynamicFetcher,類似 Playwright)。
Scrapling 最值得說的特性是自適應解析。做過爬蟲的都知道,網站一改版,選擇器就失效,得手動更新。Scrapling 用相似度算法自動重新定位元素,DOM 結構變了也能找到對應內容。對於長期運行的爬蟲任務,這個能力非常實用。
性能方面,官方數據是解析速度比 BeautifulSoup 快 400-600 倍。v0.4 還引入了 Spider 框架,類 Scrapy API,支持異步併發、斷點續爬、流式處理。
但門檻也不低:需要 Python 3.10+ 環境,學習曲線比前兩個陡很多,也不適合交互場景。如果你只是偶爾抓一個頁面,Scrapling 有點殺雞用牛刀。它的價值在長期的、批量的、需要應對反爬的數據採集任務。
它也內置了 MCP Server,可以直接在 Claude Code 中調用。
方案四:Firecrawl
Firecrawl 走的是完全不同的路線:雲端 SaaS。YC 孵化,$14.5M A 輪,GitHub 69K+ stars,35 萬+開發者在用。
你給它一個 URL,它在雲端完成所有髒活(瀏覽器渲染、反爬繞過、內容清洗、結構化提取),直接返回乾淨的 Markdown 或結構化 JSON。除了單頁抓取,還支持全站爬取、站點地圖發現、搜索+抓取一體化。2026 年 1 月推出的 /agent 功能可以智能導航複雜網站,自動搜索和採集數據。
最大的好處是省心。不用裝本地依賴,不用管版本兼容,有官方 MCP Server,npx -y firecrawl-mcp 一行搞定。
最大的顧慮是隱私。你抓取的所有內容都會經過 Firecrawl 的服務器。抓公開信息(博客、文檔、新聞)問題不大,但涉及敏感數據的話,建議走本地方案。另外是費用,有免費額度,但大量使用需要付費。還有服務商依賴的問題,Firecrawl 掛了你就掛了。
方案五:Agent-Reach
Agent-Reach 和前四個都不一樣。它不是一個獨立的爬蟲引擎,而是一個「腳手架」,把 X/Twitter、YouTube、B 站、小紅書、Reddit、LinkedIn 等 11+ 平台的最佳抓取工具整合在一起,通過 MCP 協議提供統一入口。
YouTube 用 yt-dlp(148K stars),X 用 xreach CLI(cookie 認證),通用網頁用 Jina Reader。每個平台挑最合適的工具來做。本地運行,免費開源。
問題是依賴鏈太長。底層掛着 yt-dlp、xreach、Jina Reader、feedparser、gh CLI 這一堆工具,任何一個出問題都會影響整體。項目相對較新(GitHub 4.2K stars,v1.2.0),穩定性還在驗證中,多工具版本兼容的維護成本也不低。
它的價值在「廣度」而不是「深度」。不會比 Firecrawl 更擅長抓網頁,也不會比 Scrapling 更擅長反爬,但如果你需要同時從多個社交平台採集信息,它能省不少事。
橫向對比
把幾個關鍵維度放在一起看:
JS 渲染:WebFetch 不行,Playwright 和 Firecrawl 原生支持,Scrapling 可選,Agent-Reach 取決於底層工具。
交互能力(點擊、填表、滾動):只有 Playwright 能做,其他四個都不行。
批量爬取:Scrapling 和 Firecrawl 的核心能力,其他三個不適合。
反反爬:Scrapling 內置,Firecrawl 雲端處理,Playwright 有限支持,WebFetch 和 Agent-Reach 基本沒有。
數據隱私:Firecrawl 的數據經過雲端,其他四個都是本地處理。
配置難度:WebFetch 零配置,Firecrawl 低門檻(API Key),Playwright 和 Agent-Reach 中等,Scrapling 最高。
費用:只有 Firecrawl 收費(有免費額度),其他都免費。
實測:抓 X 帖子
光說不練沒用,我拿一條自己的 X 帖子做了測試。
WebFetch:失敗。返回 "JavaScript is not available"。X 是 SPA 應用,內容全靠 JS 渲染,WebFetch 拿到的就是一個空殼。
Playwright MCP:成功。完整拿到全文、作者、發佈時間、互動數據、圖片連結。未登錄狀態就能搞定。
結論很直接:X 這類現代 SPA 應用,必須用瀏覽器級別的方案。需要登錄才能看的內容,可以在 Playwright 中走登錄流程,或者用 Agent-Reach 的 xreach(cookie 認證)。
選型建議
別糾結「哪個最好」,按場景選:
快速看一個靜態頁面 → WebFetch,零配置最輕量。
頁面需要 JS 渲染或登錄 → Playwright MCP,需要真實瀏覽器。
需要點擊、填表等交互 → Playwright MCP,五個方案裏唯一能做的。
批量提取結構化數據 → Scrapling,這是它的主場。
網站有 Cloudflare 防護 → Scrapling StealthyFetcher,專門幹這個的。
長期監控網站變化 → Scrapling,自適應解析 + 斷點續爬。
大規模全站爬取 → Firecrawl,雲端處理,省心。
跨多個社交平台採集 → Agent-Reach,11+ 平台統一入口。
在意數據隱私 → Scrapling 或 Agent-Reach,純本地。
不想維護工具鏈 → Firecrawl,SaaS 零維護。
我在用的組合
實際用下來,單選一個是不夠的,組合才好用。
日常組合:WebFetch + Playwright MCP
大部分場景用 WebFetch 先試,靜態頁面直接搞定。遇到 JS 渲染或需要交互的再切 Playwright。這兩個覆蓋了我 80% 的日常需求。
進階組合:加上 Scrapling MCP
如果你有批量採集或長期監控的需求,Scrapling 的批量調度和自適應解析是前兩個做不到的。三者都本地運行,數據不外傳。
全覆蓋組合:再加 Agent-Reach
需要同時從 YouTube、B 站、小紅書等多平台採集,Agent-Reach 能省不少事。但要有心理準備,依賴鏈長,維護成本也高。
幾個容易忽略的點
WebFetch 不等於瀏覽器。 很多人第一次用 WebFetch 會困惑「為什麼拿不到內容」,原因就是它不執行 JS。現在大部分網站都有 JS 渲染的內容,所以 WebFetch 的適用範圍比你想象的窄。
Playwright 不適合批量。 它啓動的是完整的 Chromium,一次操作一個頁面。拿它做批量爬蟲,就像開法拉利送外賣,性能浪費嚴重。
Firecrawl 的隱私問題不能忽視。 所有數據經過第三方服務器處理。如果你只是抓公開文章,問題不大。但如果涉及商業敏感信息或用戶數據,請選本地方案。
Agent-Reach 本質是編排層。 它自己不做抓取,底層全靠第三方工具。升級某個依賴可能引發連鎖問題,心裏要有數。
最後
這 5 種方案各自擅長不同層次的問題,沒有「最好」的方案,只有「最合適」的方案。
如果你剛開始用 Claude Code 做網頁抓取,我的建議是:先從 WebFetch 開始,不夠用了上 Playwright,有批量需求再上 Scrapling。 按需升級,別過度配置。