Claude Code 最佳實踐之一,把你的重複工作打包成一個 Skill
整理版優先睇
學習如何根據自身需求,將重複工作打包成 Claude Code Skill,並以知識體檢實例說明最佳實踐。
呢篇文章係由艾康分享,佢係一位 Obsidian 同 AI 工具嘅活躍用戶,成日研究點樣將 LLM 整合到日常工作流入面。今次佢收到朋友推薦一篇關於 Obsidian 同 LLM 結合嘅文章,入面提到好多 Skill,但佢淨係揀咗一個「知識體檢」嘅 Idea 嚟實踐,因為呢個最貼近佢自己每星期都要手動盤點知識庫嘅重複工作。
作者想解決嘅問題係:點樣唔係盲目複製別人嘅 Skill,而係從自身嘅重複勞動入面長出真正有用嘅工具。佢整體結論係:好嘅 Skill 係慢慢生出來嘅,核心設計一定要由自己判斷,AI 幫手執行就得,唔可以畀 AI 完全決定做唔做同一點樣做。佢用知識體檢 Skill 做例子,示範咗點樣將一個 Idea 變成可執行嘅 Skill,包括點樣調整 AI 方案、善用 Obsidian CLI 嘅 obsidian eval 功能,同埋用 Anthropic 官方嘅 skill-creator 快速搭建骨架。
- 選擇 Skill 嘅標準:一定要從自己每日重複嘅工作入面長出來,解決當下真實問題,唔好照搬別人嘅 SOP。
- 核心設計嘅取捨:AI 生成嘅第一版方案未必適合,例如知識體檢嘅「自動補全」要改做「引導使用者深入思考」,因為加深理解係 AI 代替唔到嘅。
- 工具價值被低估:Obsidian CLI 嘅 obsidian eval 可以喺幾秒內掃描成個 vault,揾出幽靈概念等問題,效率遠超語義搜索或手寫正則。
- 快速搭建方法:用 Anthropic 官方嘅 skill-creator 可以幾分鐘就起到 Skill 骨架,重點係打磨 SKILL.md 嘅 description 同核心邏輯。
- 可行動點:留意自己工作中嘅重複信號(例如每次都要手動檢查格式、彙總資訊),將佢哋打包成 Skill,提升效率。
skill-creator
Anthropic 官方提供嘅用嚟創建 Skill 嘅骨架工具,可以快速生成標準目錄結構同元數據。
揀啱 Skill:從自身重複勞動出發
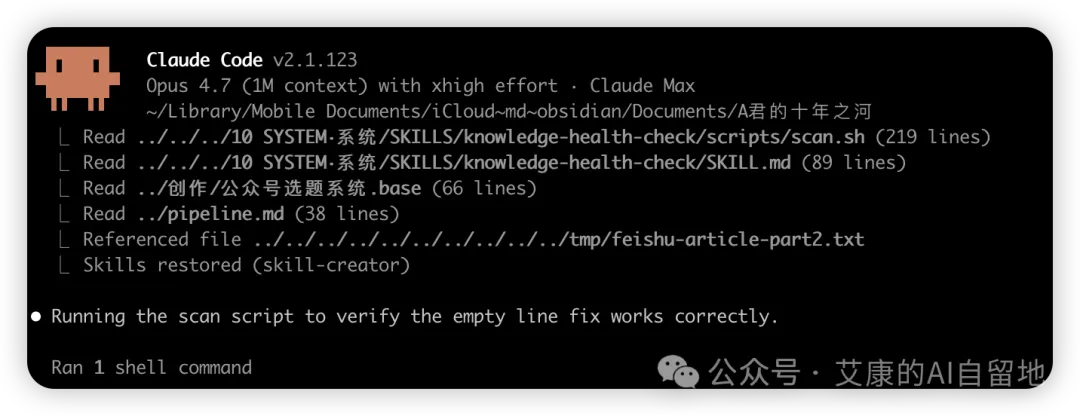
作者朋友分享咗一篇關於 Obsidian 同 LLM 結合嘅文章,入面提到好多 Skill。但作者淨係揀咗一個「知識體檢」嘅 Idea,因為呢個最貼近佢自己每星期都要手動盤點知識庫嘅重複工作。佢發現,以前見到別人嘅酷炫 Skill 就裝,結果多數用唔長,因為解決嘅唔係自己當下嘅問題。
所以今次作者淨係聚焦喺「知識庫健康度檢查」呢個方向上,因為佢每星期確實想盤一次自己嘅知識庫,但以前每次都要手動跑一堆查詢。呢啲重複就係信號。
重複工作就係信號
核心設計:AI 方案要人手調整
作者叫 Claude Code 出方案,佢方案好完整:掃描原子筆記,揾出四類問題——幽靈概念、孤島筆記、過時筆記、支柱失衡。但作者睇完之後,第一反應係「唔得」。問題出喺「自動補」三個字上。
於是作者叫 Claude Code 重新設計:每一類問題都配上一條對話路徑,引導自己思考。例如幽靈概念先問理解再釐清盲區,孤島筆記列出鄰居讓自己決定連定拆,過時筆記讀完問「你而家仲咁諗咩」,支柱平衡只問「呢個係有意識嘅選擇嗎」。
AI 幫你執行,但唔會幫你判斷「值唔值得做」
引導思考比自動補全更有價值
- 1 幽靈概念:先問你對呢個概念嘅理解,再幫你釐清盲區。
- 2 孤島筆記:列出潛在鄰居,由你自己決定要連定要拆。
- 3 過時筆記:讀一次原文,問你「你而家仲咁諗咩」。
- 4 支柱平衡:唔做判斷,只問「呢個係有意識嘅選擇嗎」。
工具價值:Obsidian CLI 同 skill-creator
方案定好之後要落地。作者話 Obsidian CLI 嘅價值被低估咗,尤其係 obsidian eval 功能。以前要揾出所有被雙鏈引用但無實際筆記嘅概念,用語義搜索慢唔準仲燒 token,寫 grep 正則又要處理別名、錨點好煩。但 obsidian eval 可以直接喺 Obsidian 內部跑 JavaScript,幾秒就 scan 完 747 篇筆記。
obsidian eval:直接調用 Obsidian 內部 API
747 篇筆記秒回
至於點樣開始寫一個 Skill,Anthropic 官方有提供 skill-creator,裝好之後講句「幫我根據討論結果創建一個知識體檢 Skill」,佢就自動生成標準目錄結構。剩下就係寫核心邏輯同打磨 SKILL.md 嘅 description。最後用 package_skill.py 打包成 .skill 檔案分享。
knowledge-health-check/
├── SKILL.md # Skill 嘅元信息 + 使用說明
├── scripts/ # 可執行腳本
└── references/ # 參考文檔(可選)幾分鐘就完成骨架,真正花時間係核心設計邏輯
作者強調,skill-creator 只幫到執行層面,真正要諗清楚嘅係「呢個 Skill 到底想解決咩問題」同「點樣引導使用者」。
總結:你嘅重複就係你嘅 Skill
目前呢個知識體檢 Skill 已經塞入作者每星期嘅覆盤流程,每次跑大約一分鐘,就知邊啲筆記需要補充。但作者話重點唔係呢個 Skill 本身,而係你每日重複做嘅嘢入面,一定藏住屬於你自己嘅 Skill。
從重複到 Skill,成本低迴報高
- 識別自己工作中嘅重複動作。
- 從一個最痛嘅點出發,設計核心邏輯。
- 用 skill-creator 快速搭建骨架。
- 反覆迭代,讓 Skill 慢慢生長。
呢篇文有2632字,大概要睇5分鐘。
前幾日,有個朋友掉咗篇文章畀我。
內容講 Obsidian 點樣同 LLM 結合,整一套自己嘅內容工廠。
我大致睇咗嚇,發現入面提到嘅用法,我大部分都瞭解過,亦都實踐過。本來準備熄咗佢。
但有一小段內容,令到我停低咗。
係關於「知識庫自動補全空白」嘅一個Idea 💡。
我覺得唔錯,於是就結合 Claude Code 整咗一個 Skill,叫做 knowledge-health-check知識體檢。
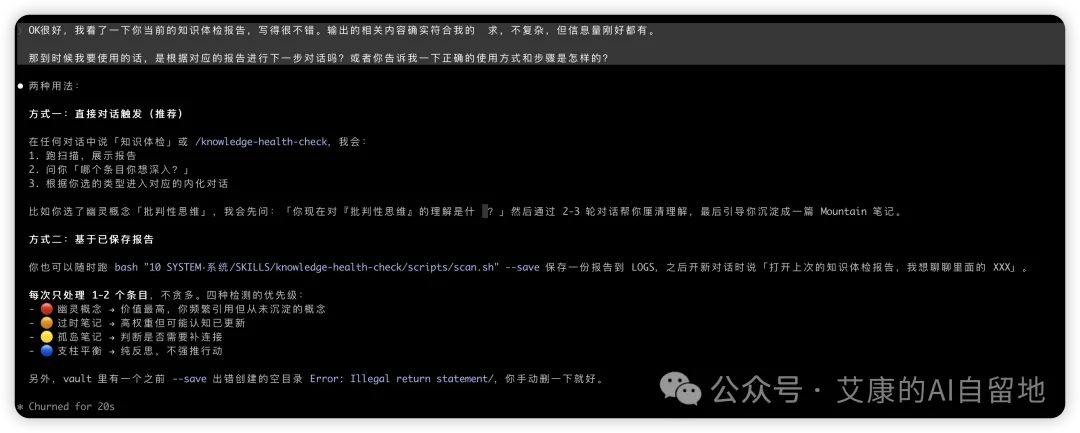
跑出嚟嘅報告,大概係咁樣:
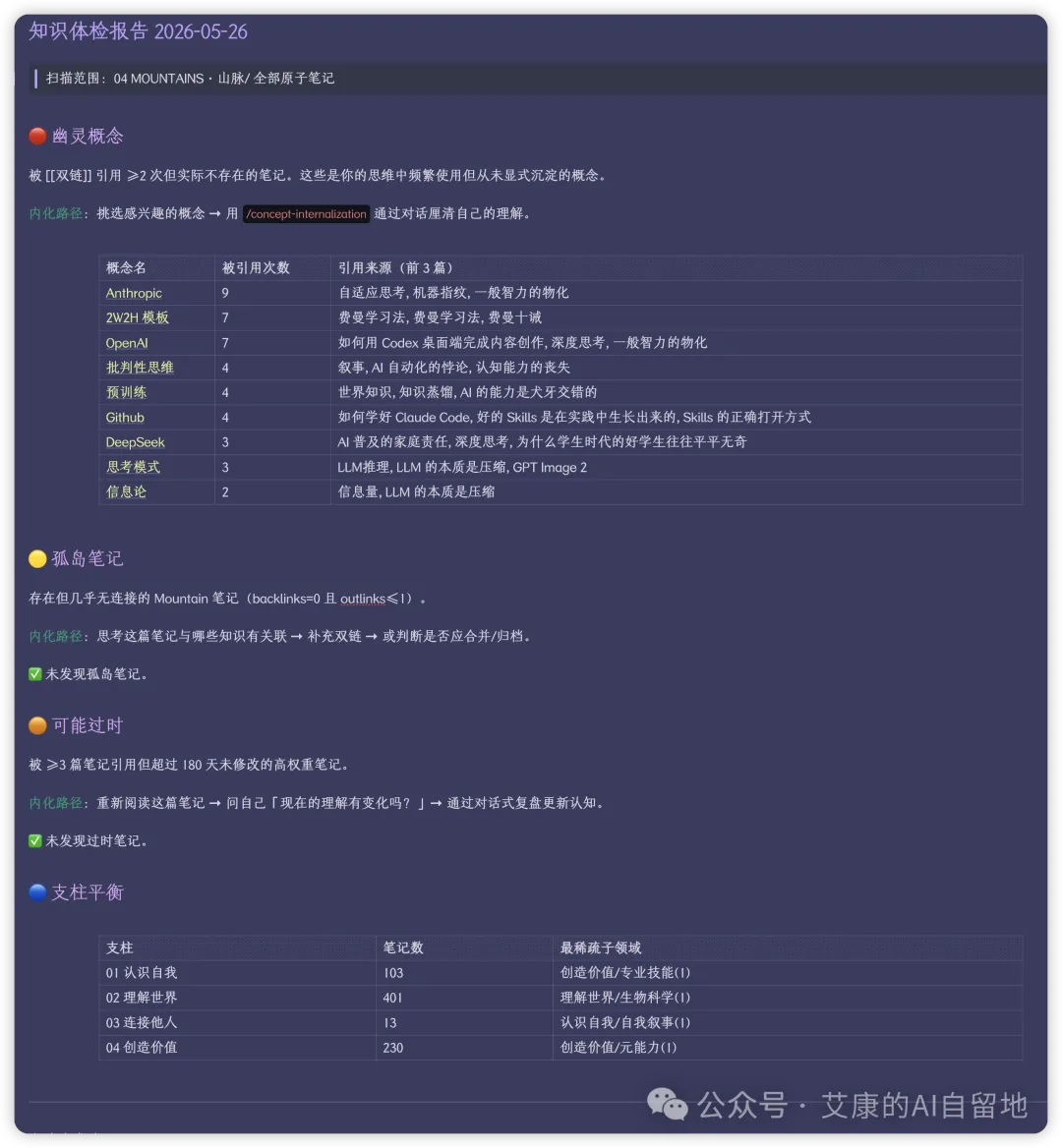
佢掃咗我整個 vault,發現我有 9個成日俾人引用、但從來未沉澱過嘅「幽靈概念」。
比如 Anthropic 俾人引用咗9次,OpenAI 7次,批判性思維 4次。
呢啲都係我口頭上成日用、平時寫筆記一直喺度 [[]] 連結、但從來冇專登寫一篇筆記好好梳理過嘅筆記。
呢篇文章就嚟傾一傾,點樣根據一個 Idea 💡 整好一個 Skill?
(講多句,呢段討論嘅對話過程,我本來想截圖俾大家睇。但 Claude Code 嘅上下文用到一定長度,會自動 compact 壓縮一次。搞到原始細節就揾唔返,所以文章入面少咗啲對應會話嘅截圖)
好嘅 Skill 係喺實踐中生長出嚟
首先喺嗰篇文章入面,其實分享咗好幾個 Skill。
Deep Research 風格嘅知識庫自動補全、Obsidian Bases 做內容生命週期管理、文章入面推薦嘅一大推現成 Skill,仲有幾個零碎嘅玩法。
三個月前嘅我,大概會全部試一次。
而家嘅我,只係揀咗一個:知識體檢。
點解?
因為我之前踩過呢個坑。
每次喺 X 或者 YouTube 見到人哋曬好型嘅 Skill,我都會即刻裝上試下,GitHub 上有 marketplace 嘅,都會去淘。
結果呢?
裝咗一大堆,真正一直穩定喺度用嘅並唔多。
唔係工具唔得,係佢哋解決嘅問題,根本唔係我而家面對緊嘅問題。
因為人哋嘅 SOP 唔係我嘅 SOP。
真正行得通嘅 Skill,一定係喺自己每日重複勞動嘅地方長出嚟。
係嗰啲你每次做一件事,都要花幾分鐘解釋一次上下文嘅地方。係嗰啲你做嚇做嚇,發現自己已經做過類似嘅事,仲要返去摷溝通記錄嘅地方。
好嘅 Skill 係慢慢長出嚟,唔係直接複製人哋,更加唔係一次性整出嚟。
所以今次,我只係揀咗最啱我而家工作流程嘅方向:我每星期真係想整理一次自己嘅知識庫,但每次都要手動行一大堆查詢。
Skill 嘅最佳實踐
揀定方向之後,我叫 Claude Code 出咗一套方案。
佢嘅方案我一睇,幾完整:
掃瞄我嘅原子筆記,揾出四類問題:幽靈概念、孤島筆記、過時筆記、支柱失衡(呢類筆記係知識庫設計特有嘅)。然後針對每一類,自動補全或者修復。
聽落都啱。
但我睇完之後,第一個反應係:不行。
問題出喺「自動補」呢三個字度。
咩意思?
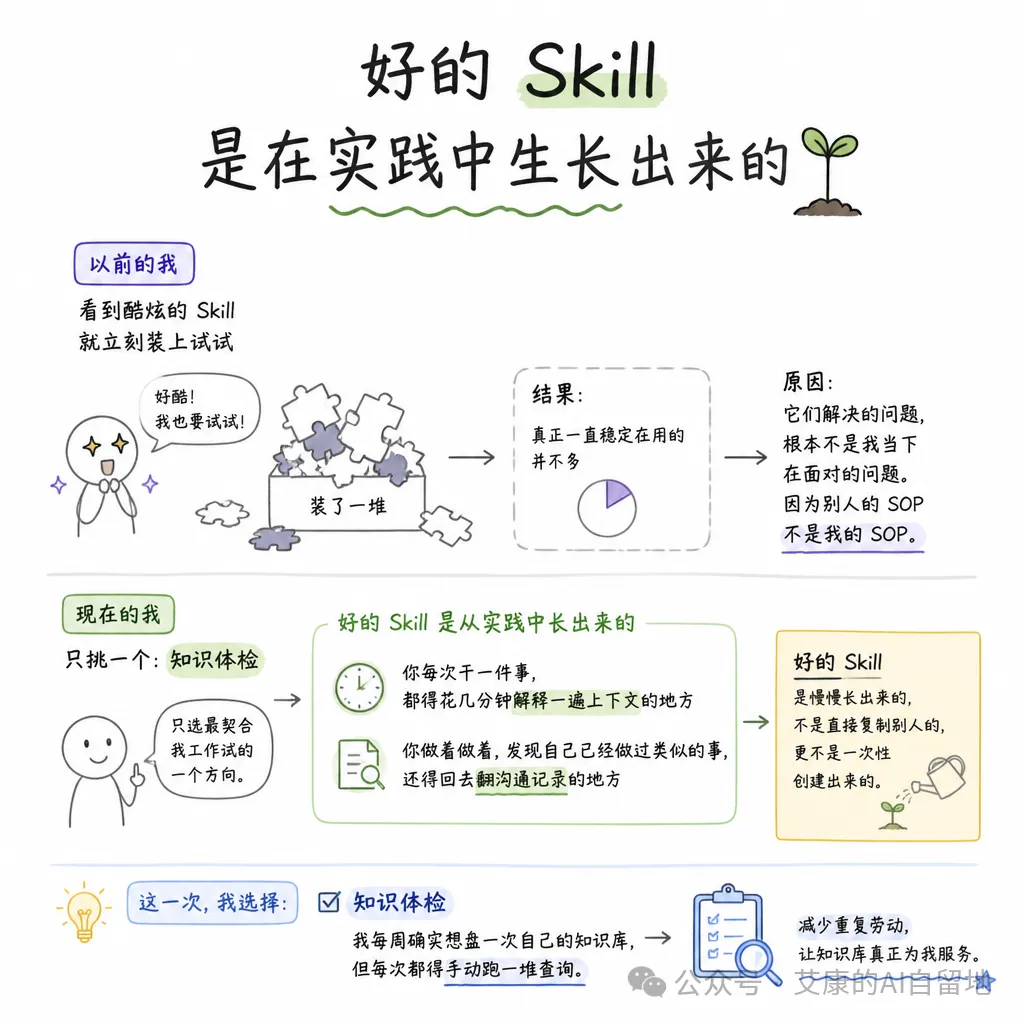
即係「檢測出空白」係一件事,「填補空白」係另一件事,「加深理解」係完全唔同嘅第三件事。
檢測出空白,AI 行個腳本就搞得掂。
填補空白,AI 用語義搜索 + 生成,都搞得七七八八。
但加深理解,呢個係得我自己先做到嘅事。
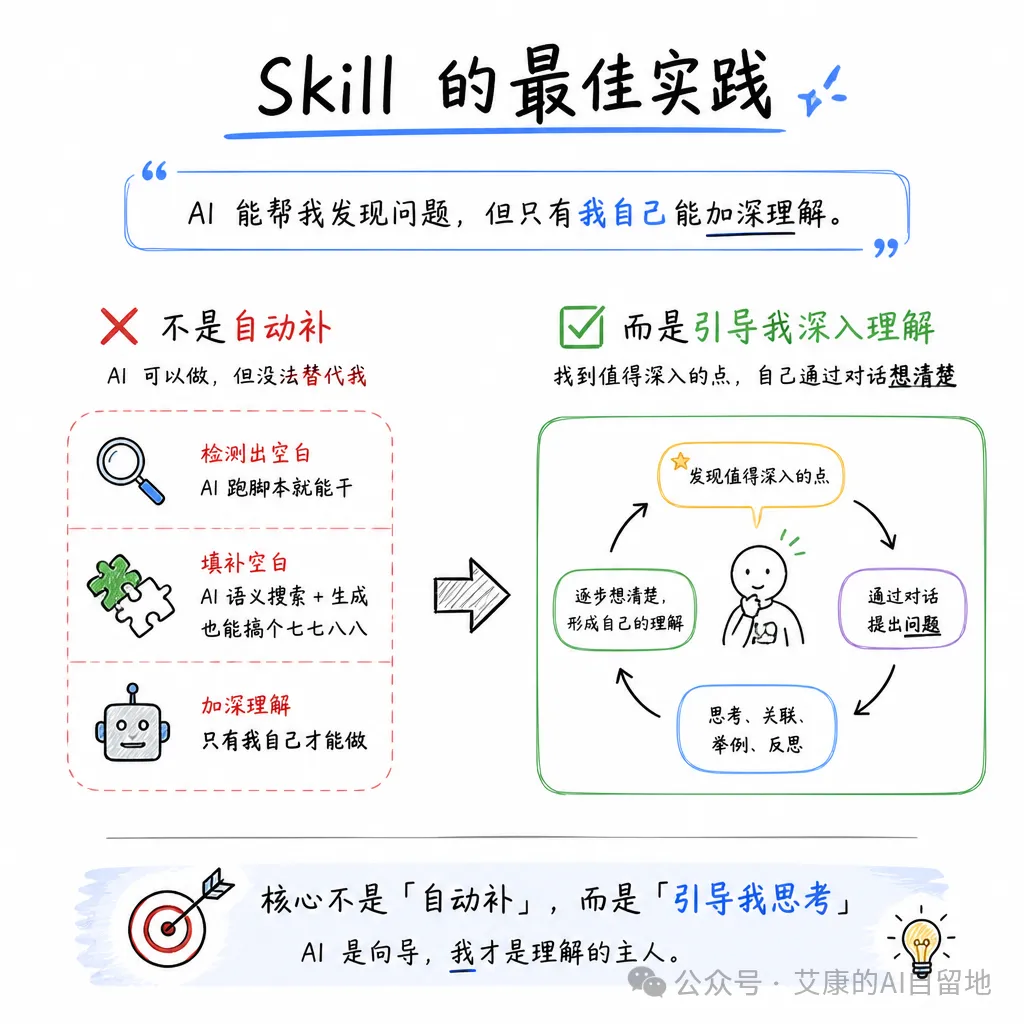
係我喺某個概念面前,停低諗幾分鐘。係我將佢同我之前嘅某段經歷串埋一齊。係我試圖解釋俾人聽嘅時候,發現自己原來根本冇諗清楚。
呢啲過程,AI 係代替唔到我嘅。
所以呢個 Skill 嘅核心,唔可以係「自動補」。
佢應該係:揾到啲值得我深入嘅點,引導我自己透過對話將佢哋一點一點諗清楚。
所以我將呢個判斷掉咗畀 Claude Code,叫佢將方案重新設計一次。
每一類問題,都配上一條對話路徑:
• 幽靈概念:先問我對呢個概念嘅理解,再幫我釐清盲區 • 孤島筆記:先列出潛在鄰居,再俾我自己決定要連定拆 • 過時筆記:讀一次原文,問我「你而家仲係咁諗嗎?」 • 支柱平衡:唔做判斷,只問「呢個係有意識嘅選擇嗎?」
成個 Skill 先算真正有咗靈魂。
寫到呢度,我想講嘅其實係:
AI 俾你嘅第一版方案,並唔一定完全符合你嘅預期。
佢可以幫你完成執行,但佢唔會代你判斷「呢件事到底值唔值得做」、「應該用咩方式做」。
呢部分,永遠都只可以係你自己。
Obsidian CLI 嘅價值俾人低估咗
方案定咗,開始落地。
如果你之前冇乜用過 Obsidian CLI(Obsidian 官方推出嘅命令行工具),可能完全意識唔到佢嘅價值。
假設你都要做呢件事:喺自己嘅 vault 度,揾出「俾雙鏈 [[]] 引用咗 ≥2 次,但實際上根本冇呢篇筆記」嘅所有概念。
你可能會點樣做?
方案一:叫 AI 行語義搜索。
慢、唔準、仲燒 token。一次掃幾百篇筆記要行好幾分鐘,最後仲經常有遺漏。
方案二:寫一段 grep + 正則,去匹配所有嘅 [[xxx]]。
聽落可行。但你會好快發現,連結入面嘅別名([[原連結|顯示別名]])、錨點([[筆記#章節]])、subpath,全部要自己寫規則去處理。
寫到一半,你就放棄咗。
呢兩條路,其實都行唔通。
但係有咗 Obsidian CLI 之後,呢件事變成咗一行命令。
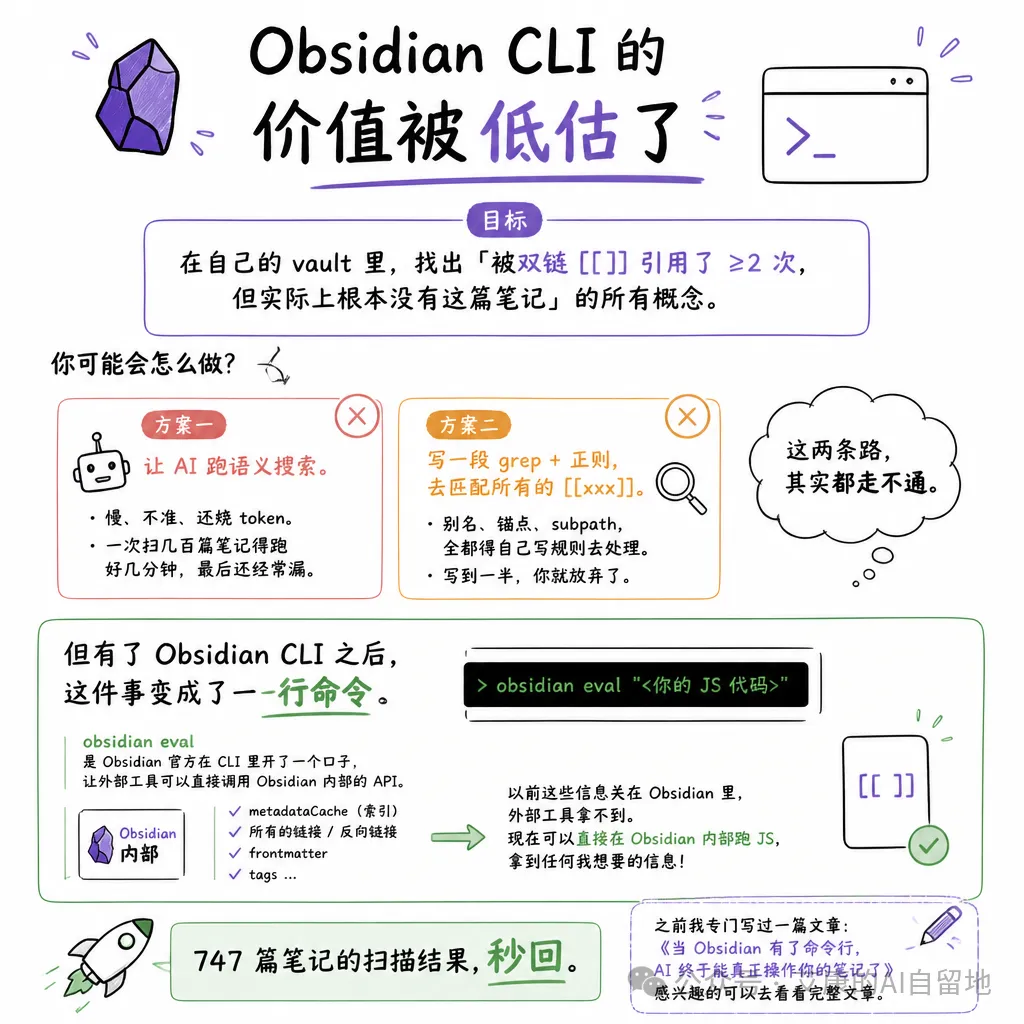
佢入面有一個叫 obsidian eval 嘅功能。
簡單講,就係 Obsidian 官方喺 CLI 度開咗一個口,俾外部工具可以直接調用 Obsidian 內部嘅 API。
即係 Obsidian 自己運行嘅時候,有維護一個 metadataCache(可以理解成 Obsidian 喺內存度俾你整個 vault 做嘅一個索引)。
所有嘅連結、反向連結、frontmatter、tags,佢都知道。
但呢啲資訊以前係鎖喺 Obsidian 入面嘅,外部工具攞唔到。
而家透過 obsidian eval,我可以寫一段 JavaScript,直接喺 Obsidian 內部行,攞到任何我想要嘅資訊。

747篇筆記嘅掃描結果,秒回。
之前我專登寫過一篇文章(當 Obsidian 有了命令行,AI 終於能真正操作你的筆記了),介紹過呢個工具,有興趣嘅可以去睇返完整文章。
點樣動手:用 skill-creator 起一個骨架
講到呢度,可能會有朋友問:知道思路啦,咁具體點樣動手寫一個 Skill?
新手最容易卡喺最初嘅幾個問題度:目錄應該點樣組織?SKILL.md 入面嘅元數據應該點樣寫?觸發詞點樣定?
Anthropic 官方早就諗到呢件事。佢哋專登出咗一個用嚟「創建 Skill」嘅 Skill,叫 skill-creator。

佢嘅作用好簡單:按官方規範,幫你將一個標準嘅 Skill 骨架快速搭起。
安裝都好簡單。
從 Anthropic 官方嘅 skills 倉庫度將 skill-creator 文件夾下載落嚟,放到 ~/.claude/skills/ 目錄就得。
Codex、Gemini CLI 用戶類似,放到對應工具嘅 skills 路徑下就得。
或者直接將 Github 地址發俾你嘅 Agent,叫佢自己安裝。
Github 地址:https://github.com/anthropics/skills/tree/main/skill-creator
裝好之後唔使記任何命令,直接同 Claude Code 講一句:「幫我根據上面嘅討論結果創建一個用嚟檢測知識庫健康度嘅 Skill」。
佢會自動調用 skill-creator,行一個 init_skill.py,生成一份標準嘅目錄結構:
knowledge-health-check/
├── SKILL.md # Skill 的元信息 + 使用說明
├── scripts/ # 可執行腳本
└── references/ # 參考文檔(可選)剩下嘅事,就係將核心邏輯寫入 scripts/,再將 SKILL.md 嘅 description 打磨清楚(呢一步好關鍵,AI之後可唔可以正確觸發呢個 Skill,全睇 description 寫得準唔準)。
最後再行一次官方提供嘅 package_skill.py,可以將成個目錄打包做 .skill 文件,方便分享俾人,亦方便自己跨設備同步。
我做知識體檢呢個 Skill,Skill 本身嘅部分都交俾 skill-creator 喇,幾分鐘就搞掂咗,真正花時間嘅,係前面提到嘅核心設計邏輯嗰部分。
寫喺最後
目前呢個 Skill 而家已經塞咗入我每星期嘅覆盤流程度,行一次大概一分幾鐘,就知道目前知識庫度需要補充嘅具體筆記。
但我想講嘅重點唔係呢個 Skill 本身。
而係你每日喺重複做嘅嗰啲事情度,一定匿埋咗屬於你自己嘅 Skill。
每次寫完文章都要手動檢查格式、調整 frontmatter?每次整理週報都要從五六個地方彙總資訊?每次同 AI 對話都要先花三分鐘交代一次背景?
呢啲重複,就係信號。
所以,如果你都遇過呢啲信號,咁可以去試下。

以上,就係呢篇文全部內容,如果覺得呢篇文章對你有啟發,點讚、畀心、分享三連就係對我最大嘅支持,謝謝~
• 用 Gemini 解鎖 YouTube 新用法,資訊獲取效率提升 10 倍
• 有咗 NotebookLM 之後,仲需要 Obsidian 嗎?
• 我試咗 NotebookLM 學習法之後,徹底拋棄傳統學習方式
• NotebookLM 再次升級,嚟自 Google 嘅年終禮物
• 我用 NotebookLM 解鎖 PPT 嘅 5 種玩法,實現咗 PPT 自由
• 全網都喺度抄 Karpathy 嘅知識庫,但係大多數人只係學到皮毛
本文字數 2632,閲讀大約需 5 分鐘
前幾天,有朋友丟給我一篇文章。
內容是關於 Obsidian 怎麼跟 LLM 結合,搭一套自己的內容工廠。
我大致翻了一下,發現裏面提到的用法,我大部分都瞭解過,也實踐過。本來準備關掉了。
但有一小段內容,讓我停了下來。
是關於「知識庫自動補全空白」的一個Idea 💡。
我覺得不錯,於是結合 Claude Code 做出了一個 Skill,叫做 knowledge-health-check,知識體檢。
跑出來的報告,大概長這樣:
它掃了我整個 vault,發現我有 9 個被頻繁引用、但從未沉澱過的「幽靈概念」。
比如 Anthropic 被引用了 9 次,OpenAI 7 次,批判性思維 4 次。
這些都是我嘴上一直在用、平時寫筆記一直在 [[]] 連結、但從來沒有專門寫一篇筆記好好梳理過的筆記。
這篇文章就來聊一聊,如何根據一個 Idea 💡 創建好一個 Skill?
(多說一句,這一段討論的對話過程,我本來想截圖給大家看的。但 Claude Code 的上下文用到一定長度,會自動 compact 壓縮一次。導致原始細節就找不回來了,所以文章裏面缺少了一些對應會話的截圖)
好的 Skill 是在實踐中生長出來的
首先在那篇文章裏,其實分享了好幾個 Skill。
Deep Research 風格的知識庫自動補全、Obsidian Bases 做內容生命週期管理、文章裏推薦的一堆現成 Skill,還有幾個零碎的玩法。
三個月前的我,大概率會都試一遍。
現在的我,只挑了一個:知識體檢。
為什麼?
因為我之前踩過這個坑。
每次在 X 或者 Youtube 看到別人曬酷炫的 Skill,我都會立刻裝上試一下,GitHub 上有 marketplace 的,也會去淘。
結果呢?
裝了一堆,真正一直穩定在用的並不多。
不是工具不行,是它們解決的問題,根本不是我當下在面對的問題。
因為別人的 SOP 不是我的 SOP。
真正能跑得起來的 Skill,一定是從自己每天重複勞動的地方長出來的。
是那些你每次幹一件事,都得花幾分鐘解釋一遍上下文的地方。是那些你做着做着,發現自己已經做過類似的事,還得回去翻溝通記錄的地方。
好的 Skill 是慢慢長出來的,不是直接複製別人的,更不是一次性創建出來的。
所以這一次,我只挑了那個最契合我當下工作流的方向:我每週確實想盤一次自己的知識庫,但每次都得手動跑一堆查詢。
Skill 的最佳實踐
挑定方向之後,我讓 Claude Code 先出一套方案。
它的方案我一看,挺完整:
掃描我的原子筆記,找出四類問題:幽靈概念、孤島筆記、過時筆記、支柱失衡(這類筆記是知識庫設計所特有的)。然後針對每一類,自動補全或者修復。
聽上去都對。
但我看完之後,第一反應是:不行。
問題出在「自動補」這三個字上。
什麼意思?
也就是「檢測出空白」是一件事,「填補空白」是另一件事,「加深理解」是完全不同的第三件事。
檢測出空白,AI 跑個腳本就能幹。
填補空白,AI 用語義搜索 + 生成,也能搞個七七八八。
但加深理解,這是隻有我自己才能做的事。
是我在某個概念面前,停下來想幾分鐘。是我把它跟我之前的某段經歷串起來。是我在試圖解釋給別人聽的時候,發現自己原來根本沒想清楚。
這些過程,AI 是替不了我的。
所以這個 Skill 的核心,不能是「自動補」。
它應該是:找到那些值得我深入的點,引導我自己通過對話把它們一點一點想清楚。
所以我把這個判斷丟給了 Claude Code,讓它把方案重新設計一遍。
每一類問題,都配上一條對話路徑:
• 幽靈概念:先問我對這個概念的理解,再幫我釐清盲區 • 孤島筆記:先列出潛在鄰居,再讓我自己決定要連還是要拆 • 過時筆記:讀一遍原文,問我「你現在還這麼想嗎」 • 支柱平衡:不做判斷,只問「這是有意的選擇嗎」
整個 Skill 才算真正有了靈魂。
寫到這裏,我想說的其實是:
AI 給你的第一版方案,並不一定就是完全符合你的預期的。
它能幫你完成執行,但它不會替你判斷「這件事到底值不值得做」、「該用什麼方式做」。
這部分,永遠只能是你自己。
Obsidian CLI 的價值被低估了
方案定了,開始落地。
如果你之前沒怎麼用過 Obsidian CLI(Obsidian 官方推出的命令行工具),可能完全意識不到它的價值。
假設你也要做這件事:在自己的 vault 裏,找出「被雙鏈 [[]] 引用了 ≥2 次,但實際上根本沒有這篇筆記」的所有概念。
你可能會怎麼做?
方案一:讓 AI 跑語義搜索。
慢、不準、還燒 token。一次掃幾百篇筆記得跑好幾分鐘,最後還經常漏。
方案二:寫一段 grep + 正則,去匹配所有的 [[xxx]]。
聽上去可行。但你很快會發現,連結裏的別名([[原連結|顯示別名]])、錨點([[筆記#章節]])、subpath,全都得自己寫規則去處理。
寫到一半,你就放棄了。
這兩條路,其實都走不通。
但有了 Obsidian CLI 之後,這件事變成了一行命令。
它裏面有一個叫 obsidian eval 的功能。
簡單說,就是 Obsidian 官方在 CLI 裏開了一個口子,讓外部工具可以直接調用 Obsidian 內部的 API。
也就是 Obsidian 自己運行的時候,有維護了一個 metadataCache(可以理解成 Obsidian 在內存裏給你整個 vault 做的一個索引)。
所有的連結、反向連結、frontmatter、tags,它都知道。
但這些信息以前是關在 Obsidian 裏面的,外部工具拿不到。
現在通過 obsidian eval,我可以寫一段 JavaScript,直接在 Obsidian 內部跑,拿到任何我想要的信息。
747 篇筆記的掃描結果,秒回。
之前我專門寫過一篇文章(當 Obsidian 有了命令行,AI 終於能真正操作你的筆記了),介紹過這個工具,感興趣的可以去看看完整文章。
怎麼動手:用 skill-creator 起一個骨架
講到這裏,可能有朋友會問:知道思路了,那具體怎麼動手寫一個 Skill?
新手最容易卡在最初的幾個問題上:目錄該怎麼組織?SKILL.md 裏的元數據該怎麼寫?觸發詞怎麼定?
Anthropic 官方早就想到了這件事。他們專門出了一個用來「創建 Skill」的 Skill,叫 skill-creator。
它的作用很單純:按官方規範,幫你把一個標準的 Skill 骨架快速搭起來。
安裝也很簡單。
從 Anthropic 官方的 skills 倉庫裏把 skill-creator 文件夾下載下來,放到 ~/.claude/skills/ 目錄就行。
Codex、Gemini CLI 用戶類似,放到對應工具的 skills 路徑下即可。
或者直接把 Github 地址發給你的 Agent,讓它自己安裝。
Github 地址:https://github.com/anthropics/skills/tree/main/skill-creator
裝好之後不用記任何命令,直接跟 Claude Code 說一句:「幫我根據上面的討論結果創建一個用來檢測知識庫健康度的 Skill」。
它會自動調用 skill-creator,跑一個 init_skill.py,生成一份標準的目錄結構:
knowledge-health-check/
├── SKILL.md # Skill 的元信息 + 使用說明
├── scripts/ # 可執行腳本
└── references/ # 參考文檔(可選)剩下的事情,就是把核心邏輯寫進 scripts/,再把 SKILL.md 的 description 打磨清楚(這一步很關鍵,AI 之後能不能正確觸發這個 Skill,全看 description 寫得準不準)。
最後再跑一次官方提供的 package_skill.py,可以把整個目錄打包成 .skill 文件,方便分享給別人,也方便自己跨設備同步。
我做知識體檢這個 Skill,Skill 本身的部分都交給 skill-creator 了,幾分鐘就完成了,真正花時間的,是前面提到的核心設計邏輯那部分。
寫在最後
目前這個 Skill 現在已經塞進我每週的覆盤流程裏了,跑一次大概一分多鐘,就能知道目前知識庫裏需要補充的具體筆記。
但我想說的重點不是這個 Skill 本身。
而是你每天在重複做的那些事情裏,一定藏着屬於你自己的 Skill。
每次寫完文章都要手動檢查格式、調整 frontmatter?每次整理週報都要從五六個地方彙總信息?每次跟 AI 對話都要先花三分鐘交代一遍背景?
這些重複,就是信號。
所以,如果你也遇到過這樣的信號,那可以去試試。
以上,就是本文全部內容,如果覺得這篇文章對你有啓發,點贊、比心、分享三連就是對我最大的支持,謝謝~
• 用 Gemini 解鎖 YouTube 新用法,信息獲取效率提升 10 倍
• 有了 NotebookLM 後,還需要 Obsidian 嗎?
• 我試了 NotebookLM 學習法後,徹底拋棄傳統學習方式
• 我用 NotebookLM 解鎖 PPT 的 5 種玩法,實現了 PPT 自由
• 全網都在抄 Karpathy 的知識庫,但大多數人只學到了皮毛