Claude Code 源碼泄漏了,但我不打算寫源碼分析分析文章
整理版優先睇
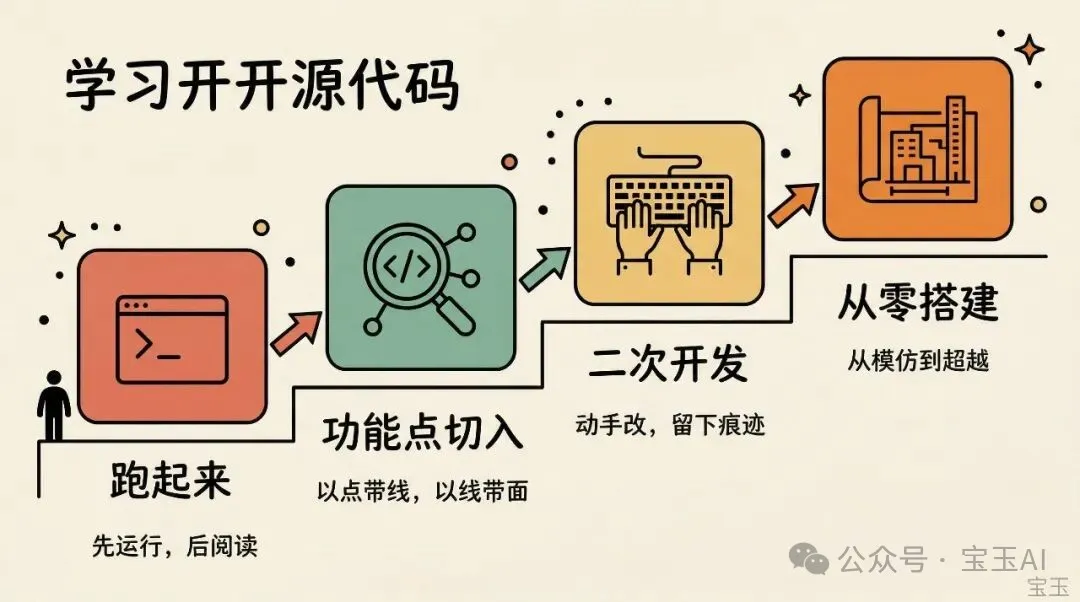
Claude Code 源碼泄漏後,作者分享咗一套學開源代碼嘅四步方法:跑起來、以點帶線、動手改、從零搭建,強調動手實踐先係真正學到手嘅關鍵。
Claude Code 源碼泄漏之後,網上湧現好多深度分析文章,但作者認為代碼先泄漏十幾個小時,50幾萬行代碼好難短時間分析清楚。佢冇打算跟風寫分析,反而分享咗一套自己多年嚟學大型開源項目嘅方法,話「授人以魚不如授人以漁」。
呢套方法適用於任何大型代碼庫,核心係要從被動閲讀轉為主動實踐。作者指出大多數人會直接打開文件讀,但咁樣好容易迷失。佢提出四步:第一步係一定要先令個項目跑起來,即使係泄漏代碼缺咗好多依賴,都要揾到可用版本;第二步係從一個具體功能點入手,好似Agent Loop咁,透過打日誌同斷點去理解模塊之間嘅關係;第三步係動手做二次開發,修改現有功能,而且盡量唔用AI輔助,逼自己思考設計取捨;第四步係從零搭建一個簡化版,複製核心設計決策,從而真正明白原作者點解咁樣設計。
作者仲特別提到AI時代嘅陷阱:用AI分析代碼好快就出到架構圖,但呢種理解係借返嚟嘅,經唔起追問。只有親手改過、寫過,先可以將「睇過」變成「做過」。佢最後都聊咗幾句泄漏事件嘅影響,認為真正受益嘅係一小部分有興趣深入嘅開發者,而Anthropic嘅回應(唔怪責個人,改進流程)先係工程團隊應有嘅態度。
- 學習開源代碼最有效嘅路徑係動手實踐,而唔係靜態閲讀,先令項目跑起來係一切嘅基礎。
- 從一個具體功能點切入(例如Agent Loop),透過打日誌同斷點去串連模塊關係,避免從頭讀到尾。
- 二次開發時刻意唔用AI輔助,逼自己思考點解要咁樣組織代碼,先可以真正理解架構取捨。
- 從零搭建簡化版係最難但收穫最大嘅一步,可以幫你睇到設計背後嘅限制同權衡。
- 呢四步方法唔單止適用Claude Code,任何大型開源項目都可以用,而家就揀一個你感興趣嘅項目開始實踐。
Claude Code 泄漏源碼可用倉庫
社羣整理嘅Claude Code源碼,可以下載運行,但注意安全風險,建議用AI分析先。
第一步:唔好急住讀,先令佢跑起嚟
大部分人拿到源碼嘅第一反應係打開文件開始讀,但作者話「別急,先跑起來」。就算今次Claude Code嘅泄漏代碼缺咗好多腳手架同私有package,都已經有人整好咗可運行版本,直接用就得。
代碼係死嘅,運行起嚟先係活嘅。
跑起嚟有兩個好處:第一,你可以直觀睇到運行結果,驗證自己對函數嘅猜測;第二,你可以打日誌、設斷點,呢個係之後分析具體功能嘅核心手段。
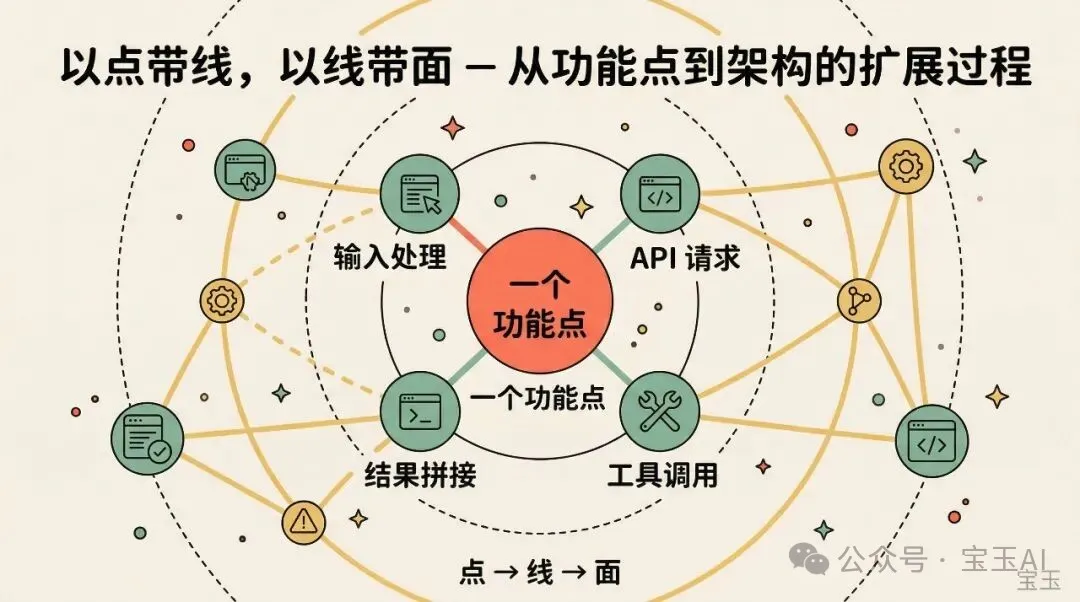
第二步:以點帶線,以線帶面
項目跑起嚟之後,好多人會犯一個錯誤:試圖由入口文件開始,由頭讀到尾。幾萬行代碼咁樣讀法,三日就會放棄。作者推薦由一個具體功能點入手,例如對Agent Loop有興趣。
- 1 打印或者收集所有API請求,睇嚇個Prompt係點樣嘅。
- 2 睇模型返回咗咩,Claude Code拎到返回之後做咗啲咩。
- 3 一輪對話落嚟,你就可以對「一個Agent點拆解任務、點樣調用工具」有直觀認識。
搞清楚一個功能點之後,自然會接觸到佢經過嘅模塊,模塊之間嘅關係就咁樣一個一個串起嚟。
作者話唔好貪多,搞透一個功能點比走馬觀花睇十個模塊有用得多。
第三步:動手改,喺代碼上留低你嘅痕跡
光睇代碼好容易變咗「感覺自己識咗」,一動手就原形畢露。但由零寫一個又冇必要,最好嘅練手方式係二次開發。例如Claude Code有/buddy命令養寵物,你可以試嚇自己實現一個類似嘅斜槓命令,或者研究記憶功能點樣存儲讀取,然後自己實作一套。
- 例子:實作同/buddy類似嘅斜槓命令,加啲自己嘅創意。
- 例子:研究Claude Code嘅記憶機制,再實作一套類似嘅。
- 重點:喺現有框架入面填充邏輯,入門門檻其實唔高。
第四步:由模仿到超越,理解設計背後嘅點解
透過二次開發你熟悉咗項目架構,但有一個問題一直留低:當初點解要咁樣設計?架構決策背後有好多睇唔到嘅嘢:歷史包袱、團隊規模、時間壓力、技術限制。你淨係見到「揀咗A」,但睇唔到「點解唔揀B同C」。
想搞清楚呢啲,最好嘅辦法係自己由零搭一個,唔需要完整,按自己想法參考原來架構重新做一次設計決策。
你會發現嗰啲你以為「顯然應該咁樣做」嘅地方,一動手就出問題,然後你就理解原作者點解咁樣揀。呢一步最難但收穫最大,做到呢度你已經有能力做出自己嘅架構方案。
作者總結:四步講起嚟簡單,但多數人卡喺第一步同第三步之間——「睇咗好多,但冇動手寫過」。AI時代更容易咁,因為用AI分析代碼太方便,但嗰種理解係借返嚟嘅,經唔起追問。
Claude Code 原始碼洩漏咗,成個版面都係「深度分析」文章。有朋友叫我寫篇分析文,但係啲 code 先洩漏咗十幾個鐘,50 幾萬行 code,想深度分析清楚都幾難。不過與其俾條魚你,不如教你去釣魚,我更想講下:拎到一份開源代碼,點樣先至真正學到嘢。
呢套方法唔單止適用喺 Claude Code,任何大型開源項目都係咁。
拎到源碼之後,大部分人嘅第一反應係打開檔案開始睇。
唔好急。先 run 起佢先。
今次洩漏嘅 Claude Code code 係 source map 還原之後嘅結果,缺咗好多腳手架同私有 package,冇辦法直接 run。我本來諗住自己搞搞佢,點知發現已經有人搞掂咗(https://github.com/claude-code-best/claude-code),直接用就得。
注意:呢個項目嘅作者我唔認識,只係我可以正常下載嚟 run,所以推介,之後個項目點發展我就唔清楚,而且好大機會會被下架。有興趣嘅可以早啲將啲 code download 到本地,再俾 AI 分析下啲 code 有冇安全問題先至 run。
點解一定要 run 起佢?兩個原因。
第一係你可以直接睇到 run 嘅結果。Code 係死嘅,run 起上嚟先至係生嘅。 你睇 code 嘅時候覺得「呢個 function 大概係做呢樣嘢」,run 一次就知道你估啱咗未。
第二係你可以打 log、set breakpoint。之後分析具體功能嗰陣,呢個係核心手段。淨係用眼喺幾萬行 code 裏面揾邏輯,同大海撈針差唔多。Run 起之後加個 console.log,個 code 自己會話俾你知佢做緊乜。
第二步:由一點連成線,由線連成面。
個項目 run 起咗之後,下一步好多人會犯一個錯:嘗試由入口檔案開始,將成個項目由頭睇到尾。
幾萬行 code,咁樣睇落去三日就放棄咗。
更好嘅做法係由一個具體嘅功能點入手。
例如你對 Agent Loop 有興趣。咁就 print 或者收集曬所有 API request,睇下佢 send 俾模型嘅 Prompt 係點樣,模型 return 咗啲乜,Claude Code 收到 return 之後又做咗啲乜。一輪對話落嚟,你對「一個 Agent 點樣拆解任務、點樣 call 工具」就會有直接嘅認識。
以前我用 claude-trace 做過類似嘅嘢,可惜之後用唔到喇。而家有源碼喇,自己加 log 可以做得更仔細。
當你搞清楚一個功能點之後,自然會接觸到佢經過嘅 modules:輸入點樣入嚟,經過咗邊啲處理,工具 call 係點樣觸發,結果點樣拼返埋。Modules 之間嘅關係,就係咁一個一個串起嚟。
唔好貪心。搞通一個功能點,比起走馬看花睇十個 modules 有用得多。
第三步:落手改,喺 code 上面留低你嘅痕跡
淨係睇 code,學到嘅嘢好容易變成「覺得自己明咗」。一落手就露出原形。
但係由零寫一個都冇必要。對於一個已經成熟嘅項目,最好嘅練習方式係二次開發。
舉個例,Claude Code 啱啱推出咗一個 /buddy 指令,會幫你養一隻小寵物。你可以試嚇自己實現一個類似嘅斜槓指令,或者幫佢加啲新嘢。再例如 Claude Code 嘅記憶功能,你可以研究下佢係點樣儲存同讀取記憶嘅,然後試嚇自己實現一套記憶機制。佢嘅架構已經相對穩定,你只需要喺現有框架裏面 fill 入邏輯,入門門檻其實唔高。
做二次開發嘅時候,盡量唔好用 AI 輔助。
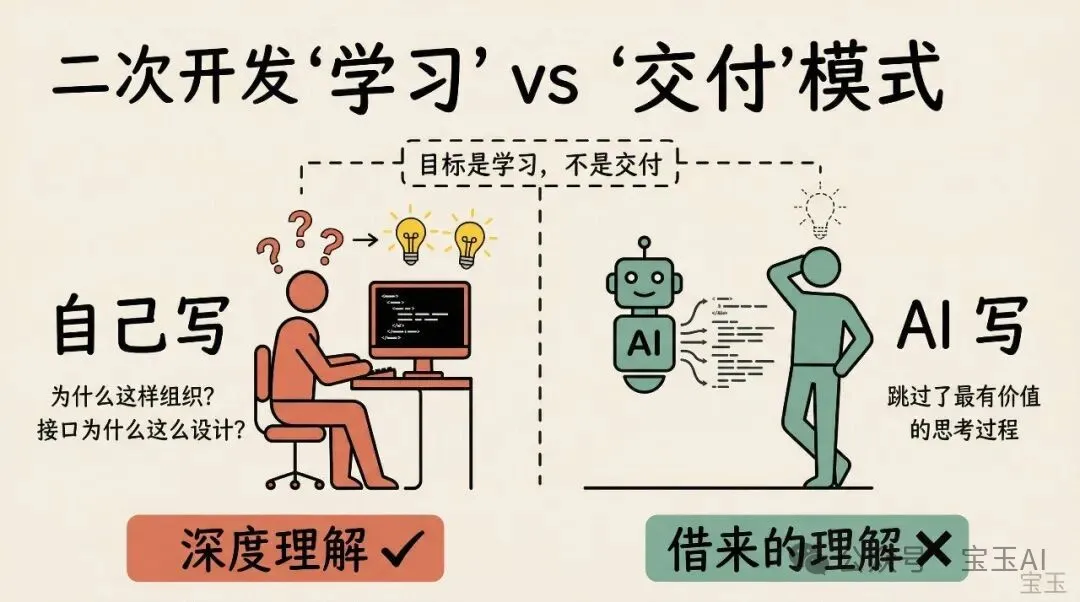
我知道咁聽落好反直覺。用 AI 寫 code 效率高咁多,點解唔用?因為目的唔同。你嘅目標係學習,唔係交貨。俾 AI 幫你寫咗,你 skip 咗嘅正正係最有價值嘅思考過程:點解要咁樣組織 code?呢個 module 點解放喺呢度?interface 點解咁樣設計?
當你能夠由頭到尾靠自己將一個功能開發出嚟,你對呢個項目嘅理解就會由「睇過」變成「做過」。
做多幾個功能之後,你會越來越熟悉佢嘅成個架構,甚至開始覺得有啲地方可以做得更好。
咁就啱喇。
第四步:由模仿到超越
透過二次開發你熟悉咗項目架構,知道佢「係點樣嘅」。但有個問題一路留低咗:當初點解要咁樣設計?
架構決策嘅背後往往有好多你睇唔到嘅嘢:歷史包袱、團隊規模、時間壓力、當時嘅技術限制。你企喺結果面前,睇到嘅係「揀咗 A」,但睇唔到「點解冇揀 B 同 C」。
想搞清楚呢啲,最好嘅方法係自己由零砌一個。
唔需要功能完整,唔需要面面俱到。按照你嘅諗法,參考原本嘅架構,重新做一次設計決策。你會發現嗰啲你以為「明顯應該咁做」嘅地方,一落手就出問題。然後你就理解咗原作者點解咁樣揀。
呢一步係最難嘅,但亦都係收穫最大嘅。
行到呢一步,你已經唔單止係「讀明咗」呢個項目,而係有能力做出自己嘅架構方案喇。
最後
呢四步講起嚟簡單:run 起佢 → 由一個功能點切入 → 二次開發 → 由零搭建。但我觀察到一個幾得意嘅現象:大部分人卡喺第一步同第三步之間,即係「睇咗好多,但冇落手寫過」。
AI 時代更加容易出現呢個問題。俾 AI 幫你分析 code 太方便喇,幾秒鐘就俾你一份「架構全景圖」。但係呢種理解係借返嚟嘅,經唔起追問。
你用過乜嘢方法學開源 code?有冇邊個項目係你真正「啃」落嚟嘅?
附:講幾句今次 Claude Code code 洩漏本身
洩漏 code 嘅價值,有限。
有人從洩漏嘅 code 裏面 reverse 咗 Claude Code 嘅相關邏輯,做出咗開源嘅 SDK。思路幾好,但呢份 code 係靜態嘅,Claude Code 一更新你就跟唔上喇。拎嚟學習可以,拎嚟做產品基礎就唔太現實。
對行業嘅影響都冇一啲人渲染得咁大。普通開發者唔需要睇呢啲,大廠該 reverse 嘅一早 reverse 咗。真正受益嘅係一小部分有興趣深入研究嘅開發者同小團隊,從裏面確實學到一啲有價值嘅技術細節。
有人問既然都洩漏咗,Anthropic 點解唔乾脆開源? 我覺得冇可能。閉源嘅好處太多喇:
Code 質量唔使太講究。一個 React 檔案寫咗幾千行,閉源冇人知,開源出嚟會俾人鬧死。
可以偷偷加料。防蒸餾嘅邏輯、用戶標識嘅記錄,甚至「唔小心」導致第三方 prompt caching 失效嘅 bug,閉源唔使擔心俾人捉到。
可以控制發佈節奏。今次就發現咗唔少隱藏功能,例如 /buddy 一早開發好咗,就等愚人節開啓。開源嘅話呢種驚喜就藏唔住喇。
快速迭代唔使行複雜嘅 code review 流程,開源嘅顧忌多好多。
有一件事值得提一提。 Anthropic 正面回應咗今次洩漏,Boris 講得好好:
工作入面,犯錯總係在所難免。但作為一個團隊,最緊要嘅係要達成一個共識:出咗問題絕對唔應該怪責喺某個人身上。真正嘅「罪魁禍首」往往係我哋嘅流程設計、團隊文化,或者係底層嘅基礎設施。
今次嘅問題出喺一個本來應該自動化、但係仍然用人工手動操作嘅部署環節上面。冇怪責喺個人身上,亦都冇因此炒咗邊個。啲人話「啱啱加入 Anthropic 搞出呢件事俾人炒咗」嘅都係蹭熱度嘅營銷號,唔好信。
直接面對問題,改善流程。呢啲先至係一個工程團隊應該有嘅樣。
Claude Code 源碼泄漏了,滿屏都是“深度分析”文章。也有朋友讓我寫一篇分析文章,但代碼才泄漏十幾個小時,50 多萬行代碼,想深度分析清楚還是有難度的。不過授人以魚不如授人以漁,我更想聊聊:拿到一份開源代碼,怎麼把它真正學到手。
這套方法不只適用於 Claude Code,任何大型開源項目都一樣。
拿到源碼之後,大部分人的第一反應是打開文件開始讀。
別急。先跑起來。
這次泄漏的 Claude Code 代碼是 source map 還原後的結果,缺了很多腳手架和私有 package,沒法直接運行。我本來打算自己折騰一下,結果發現已經有人搞定了(https://github.com/claude-code-best/claude-code),直接用就好。
注:這個項目作者我不認識,只是我可以正常下載運行,所以推薦,後續項目如何發展我並不清楚,而且被下架的可能性很大。有興趣的可以儘早把代碼下載到本地,並讓 AI 分析一下代碼有無安全問題後再運行。
為什麼一定要跑起來?兩個原因。
一是你能直觀看到運行結果。代碼是死的,運行起來才是活的。 你讀代碼時覺得“這個函數大概是做這個的”,跑一遍就知道你猜對了沒有。
二是你可以打日誌、設斷點。後面分析具體功能的時候,這是核心手段。光用眼睛在幾萬行代碼裏找邏輯,跟大海撈針差不多。跑起來之後加個 console.log,代碼自己會告訴你它在幹什麼。
第二步:以點帶線,以線帶面
項目跑起來了,下一步很多人會犯一個錯誤:試圖從入口文件開始,把整個項目從頭讀到尾。
幾萬行代碼,這麼讀下去三天就放棄了。
更好的做法是從一個具體的功能點入手。
比如你對 Agent Loop 感興趣。那就打印或者收集所有的 API 請求,看它發給模型的 Prompt 長什麼樣,模型返回了什麼,Claude Code 拿到返回之後又做了什麼。一輪對話下來,你對“一個 Agent 怎麼拆解任務、怎麼調用工具”就有了直觀的認識。
以前我用 claude-trace 做過類似的事情,可惜後來用不了了。現在有源碼了,自己加日誌能做得更細。
當你搞清楚一個功能點之後,自然會接觸到它經過的模塊:輸入怎麼進來的,經過了哪些處理,工具調用怎麼觸發的,結果怎麼拼回去的。模塊之間的關係,就這樣一個一個串起來了。
別貪多。搞透一個功能點,比走馬觀花看十個模塊有用得多。
第三步:動手改,在代碼上留下你的痕跡
光看代碼,學到的東西很容易變成“感覺自己懂了”。一動手就原形畢露。
但從零寫一個也沒必要。對於一個已經成熟的項目,最好的練手方式是二次開發。
舉個例子,Claude Code 剛發佈了一個 /buddy 命令,會給你養一隻小寵物。你可以試着自己實現一個類似的斜槓命令,或者給它加點新花樣。再比如 Claude Code 的記憶功能,你可以研究它是怎麼存儲和讀取記憶的,然後試着自己實現一套記憶機制。它的架構已經相對穩定了,你只需要在現有框架裏填充邏輯,入門門檻其實不高。
做二次開發的時候,儘量別用 AI 輔助。
我知道這聽起來很反直覺。用 AI 寫代碼效率高這麼多,為什麼不用?因為目的不一樣。你的目標是學習,不是交付。讓 AI 幫你寫了,你跳過的正好是最有價值的思考過程:為什麼要這樣組織代碼?這個模塊為什麼放在這裏?接口為什麼這麼設計?
當你能從頭到尾靠自己把一個功能開發出來,你對這個項目的理解就從“看過”變成了“做過”。
多做幾個功能之後,你會越來越熟悉它的整個架構,甚至開始覺得有些地方可以做得更好。
這就對了。
第四步:從模仿到超越
通過二次開發你熟悉了項目架構,知道它“是什麼樣的”。但有一個問題一直留着:當初為什麼要這麼設計?
架構決策的背後往往有很多你看不到的東西:歷史包袱、團隊規模、時間壓力、當時的技術限制。你站在結果面前,看到的是“選擇了 A”,但看不到“為什麼沒選 B 和 C”。
想搞清楚這些,最好的辦法是自己從零搭一個。
不需要功能完整,不需要面面俱到。按照你自己的想法,參考原來的架構,重新做一遍設計決策。你會發現那些你以為“顯然應該這樣做”的地方,一動手就出問題了。然後你就理解了原作者為什麼那樣選。
這一步是最難的,但也是收穫最大的。
走到這一步,你已經不只是“讀懂了”這個項目,而是有能力做出自己的架構方案了。
最後
這四步說起來簡單:跑起來 → 從一個功能點切入 → 二次開發 → 從零搭建。但我觀察到一個有意思的現象:大多數人卡在第一步和第三步之間,也就是“看了很多,但沒動手寫過”。
AI 時代更容易出現這個問題。讓 AI 幫你分析代碼太方便了,幾秒鐘就給你一份“架構全景圖”。但這種理解是借來的,經不起追問。
你用過什麼方法學開源代碼?有沒有哪個項目是你真正“啃”下來的?
附:聊幾句這次 Claude Code 代碼泄漏本身
泄漏代碼的價值,有限。
有人從泄漏的代碼裏逆向了 Claude Code 的相關邏輯,做出了開源的 SDK。思路挺好,但這份代碼是靜態的,Claude Code 一更新你就跟不上了。拿來學習可以,拿來做產品基礎不太現實。
對行業的影響也沒有一些人渲染得那麼大。普通開發者用不着看這些,大廠該逆向的早就逆向了。真正受益的是一小部分有興趣深入研究的開發者和小團隊,從裏面確實能學到一些有價值的技術細節。
有人問既然都泄漏了,Anthropic 為什麼不乾脆開源? 我覺得不可能。閉源的好處太多了:
代碼質量不用太講究。一個 React 文件寫了幾千行,閉源沒人知道,開源出來會被噴死。
可以暗搓搓加料。防蒸餾的邏輯、用戶標識的記錄,甚至“不小心”導致第三方 prompt caching 失效的 bug,閉源不用擔心被抓包。
可以控制發佈節奏。這次就發現了不少隱藏功能,比如 /buddy 早就開發好了,就等愚人節開啓。開源的話這種驚喜就藏不住了。
快速迭代不用走複雜的代碼審查流程,開源的顧忌多得多。
有一件事值得一提。 Anthropic 正面回應了這次泄漏,Boris 說得很好:
工作中,犯錯總是在所難免。但作為一個團隊,最重要的是要達成一種共識:出了問題絕不該怪罪到某個人頭上。真正的“罪魁禍首”往往是我們的流程設計、團隊文化,或者是底層的基礎設施。
這次的問題出在一個本該自動化、卻還是人工手動操作的部署環節上。沒有怪到個人頭上,也沒有因此開除誰。那些號稱“剛加入 Anthropic 搞出這事被開除了”的都是蹭熱度的營銷號,別信。
直面問題,改進流程。這才是一個工程團隊該有的樣子。