Claude:為什麼中國公司總是抄襲?
整理版優先睇
模型蒸餾嘅商業邏輯:從抄襲到創新的路徑
呢篇文章由Claude一句「吐槽」中國AI抄襲嘅段子引入,帶出模型蒸餾嘅商業邏輯討論。作者先解釋咩係模型蒸餾,用頂級家教嘅比喻說明呢個技術本身正當,但問題在於學習嘅邊界——係學思考方法定係背標準答案。佢指出中國AI公司面對算力、數據、時間嘅「不可能三角」,令蒸餾成為理性捷徑,但長期過度依賴會陷入陷阱。
Claude嘅吐槽唔單止係抱怨抄襲,更反映「創新回報保障」嘅深層困境。作者用快充技術專利被繞過嘅商業案例,說明當護城河可以被低成本繞過時,創新動力會受損。然後佢區分蒸餾嘅正當性同「路徑依賴」嘅風險,用圖表對比蒸餾路線(起點高、見效快、天花板低)同自主創新路線(起點低、見效慢、後勁足)。
最後,文章提出三個關鍵躍遷:從模仿風格到內化能力、從通用對標到垂直深耕、從單點競爭到生態競爭。作者認為中國AI嘅真正機會唔係做中國版ChatGPT,而係用AI解決本土場景問題,構建開發者生態。結論係蒸餾係手段唔係目的,模仿係起點唔係終點,企喺巨人膊頭上係為咗睇得更遠。
- 模型蒸餾係學術界公認嘅高效訓練方法,但偏離「學習」去「抄答案」就會引發爭議。
- 中國AI公司面對算力、數據、時間嘅「不可能三角」,令蒸餾成咗理性捷徑。
- 蒸餾路線起點高見效快但天花板低,自主創新路線起點低但後勁足,關鍵係有冇耐心度過低谷期。
- Claude嘅吐槽本質係擔心創新回報保障,如果護城河可以低成本繞過,會削弱創新動力。
- 中國AI需完成三個躍遷:從模仿到內化能力、從通用對標到垂直深耕、從單點競爭到生態競爭。
Claude嘅吐槽:抄襲定係學習?
有個段子最近喺AI圈流傳:有人問Claude點樣評價中國大模型,Claude話注意到好多中國模型嘅用詞習慣同推理結構同佢好似,感覺被「蒸餾」走咗。呢句吐槽傳開後,有人笑、有人怒、亦有人沉思。今日我就藉着呢個話題,聊聊模型蒸餾背後嘅商業邏輯。
模型蒸餾係乜?一個類比講清楚
假設你請咗位頂級家教,每小時收費5000蚊,佢每講一道題你都認真聽、反覆琢磨思路,三個月後成績飛躍——呢啲叫學習,合理合法。模型蒸餾本質就係咁:大模型(老師)教小模型(學生),學生透過觀察老師輸出學習思維方式,用更細計算量達到接近效果。呢項技術本身冇問題,係學術界公認嘅高效訓練方法。
點解中國AI公司偏愛蒸餾?
中國AI公司面對一個經典嘅「不可能三角」:算力方面高端芯片受限,訓練成本極高;數據方面高質量中文語料稀缺;時間方面資本市場耐心有限。喺呢三個約束下,蒸餾成為一條理性捷徑。
計條數:從頭訓練一個GPT-4級別嘅基座模型,需要上萬張A100顯卡、數千萬美元成本、1-2年時間,仲要承擔失敗風險。而蒸餾路線只係需要幾百張顯卡、幾百萬美元、3-6個月,成功率大幅提高。從商業決策角度,大多數人都會揀第二條路——呢個唔係道德問題,係成本問題。
Claude嘅吐槽:創新回報點保障?
好多人將Claude嘅話理解為「被抄襲嘅唔爽」,但我覺得佢道出咗更深層嘅商業困境:創新嘅回報點樣保障?Anthropic每年燒幾十億美金做研發,因為佢哋相信建立技術壁壘後可以獲得超額回報——呢個係商業世界基本邏輯。但如果呢條護城河可以被低成本繞過,人哋用幾十分之一嘅錢透過蒸餾就達到你80%效果,咁你嘅高額投入仲值唔值?
呢個情況令我想起一個商業案例:某國產手機品牌花大價錢研發快充技術,結果競爭對手繞開專利用另一種方式實現差唔多嘅速度,成本更低。原創者嘅投入冇轉化為競爭優勢。Claude嘅吐槽本質係對呢種「投入-回報失衡」嘅焦慮。
中國AI嘅出路:從抄作業到寫作業
中國AI公司要真正突圍,需要完成三個關鍵躍遷。
- 1 從模仿風格到內化能力:蒸餾應該係「預科」而唔係全部課程。先用蒸餾快速起步,然後用自有數據、原創算法進行二次訓練——用蒸餾學語法,用原創寫故事。
- 2 從通用對標到垂直深耕:中國AI嘅真正機會唔係做中國版ChatGPT,而係用AI解決本土場景問題,例如製造業智能質檢、醫療輔助診斷、教育個性化學習、政務智能服務。呢啲場景嘅海量真實數據係海外大模型拎唔到嘅,先係真正護城河。
- 3 從單點競爭到生態競爭:OpenAI厲害唔止因為GPT-5強,更因為成千上萬開發者喺佢嘅生態上構建應用。中國AI要學嘅係構建一個令開發者願意停留、創造、盈利嘅生態系統——生態嘅護城河係蒸餾唔到嘅。
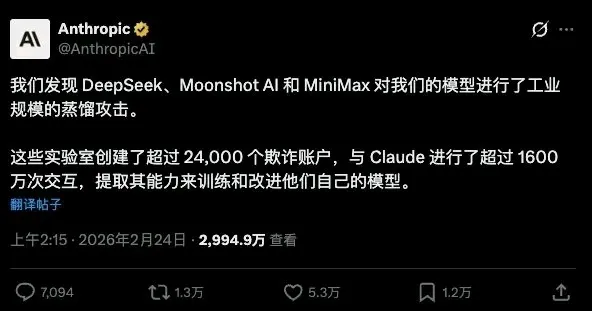
最近AI圈流傳緊一個笑話。
有人問Claude:「你點睇中國嘅大模型?」
Claude沉思咗一下,話:「我留意到一啲中國模型嘅答案,無論用詞習慣定推理結構,都好相似我。老實講,我有啲困惑——我用咗無數時間訓練出嚟嘅表達方式,就咁俾人『蒸餾』走咗,感覺好似……有人直接抄咗我份功課。」
呢段「批評」傳開之後,有人笑,有人嬲,亦有人陷入沉思。
今日,我想藉住呢個話題,傾下模型蒸餾背後嘅商業邏輯。
───
一、先搞清楚:乜嘢係模型蒸餾?
唔講技術術語,我用一個比喻說明。
假設你請咗一個頂級補習老師,每個鐘收費5000蚊。呢位老師每講一道題,你都認真聽、認真記,反覆諗佢嘅解題思路。三個月後,你嘅成績突飛猛進。
呢個叫乜嘢?呢個叫學習。合理合法,值得鼓勵。
模型蒸餾,本質就係咁樣嘅事。
大模型(例如GPT-4、Claude)係「老師」,小模型係「學生」。學生通過觀察老師嘅輸出,學習老師嘅思維方式,最終用更少嘅計算量,達到接近老師嘅效果。
呢個技術本身冇問題,而且係學術界公認嘅高效訓練方法。
但爭議嘅焦點係:學習嘅邊界喺邊度?
你係學會咗老師嘅思考方法,定係直接背咗老師嘅標準答案?你係參考思路,定係成篇作文抄落嚟只改咗個名?
呢個邊界,好模糊。而模糊地帶,往往係焦慮嘅來源。
───
二、點解中國AI公司偏愛蒸餾?
理解一個現象,要睇底層嘅限制條件。
中國AI公司面對嘅係一個經典嘅「不可能三角」:
維度 現狀
算力 高端芯片受限,訓練成本極高
數據 高質素中文語料稀缺
時間 資本市場耐性有限
喺呢三個限制下,蒸餾變成一條「理性選擇」嘅捷徑。
我哋計條數。
從頭訓練一個GPT-4級別嘅基座模型,需要:
• 上萬張A100顯示卡
• 數千萬美元成本
• 1至2年時間
• 仲要承擔訓練失敗嘅風險
而採用蒸餾路線:
• 幾百張顯示卡就夠
• 成本降到幾百萬美元
• 3至6個月出成果
• 成功率大幅提高
由商業決策角度,你會揀邊個?
我估,大多數人都會揀第二條路。呢個唔係道德問題,係成本問題。
但呢度有個微妙嘅矛盾:
短期睇,蒸餾係最優解;
長期睇,過度依賴蒸餾可能係陷阱。
───
三、Claude到底喺度批評啲乜?
好多人將Claude嘅說話理解為「俾人抄襲嘅唔開心」,但我覺得,佢道出咗一個更深層嘅商業困境。
呢個困境係:創新嘅回報點樣保障?
Anthropic每年燒幾十億美金做研發。OpenAI都係。佢哋點解願意燒呢個錢?因為佢哋相信,一旦建立起技術壁壘,就能形成護城河,獲得超額回報。
呢個係商業世界嘅基本邏輯:高風險,高投入,高回報。
但如果呢條護城河可以低成本繞過呢?
如果人哋用幾十分之一嘅錢,通過蒸餾就做到你80%嘅效果,咁你嘅高額投入仲值唔值?你嘅創新動力從邊度嚟?
呢個令我想起一個商業案例。
幾年前,某國產手機品牌用咗好多錢研發快充技術,申請咗一堆專利。結果競爭對手繞過專利,用另一種方式實現差唔多嘅快充速度,成本仲更低。原創者嘅投入,冇轉化為競爭優勢。
Claude嘅批評,本質係對呢種「投入-回報失衡」嘅焦慮。
唔係唔可以學習,而係當學習成本遠低過創新成本時,創新嘅火種就可能熄滅。
───
四、蒸餾嘅「原罪」同「無辜」
寫到呢度,我想做一個重要嘅區分。
蒸餾技術本身,係完全正當嘅。
人類文明嘅進步,本質上就係一場大規模嘅「蒸餾」。牛頓企喺伽利略膊頭上,愛因斯坦企喺牛頓膊頭上。我哋每個人由小學到大學,都係喺度「蒸餾」前人嘅知識。
AI模型都唔例外。用公開API拎數據、學習、再創造,只要唔違反服務條款,呢個喺倫理上站得住腳。
真正嘅問題,唔係蒸餾,而係「路徑依賴」。
我俾你畫個簡單嘅對比圖:
能力
↑
│ ╭──── 自主創新
│ ╱
│ ╱
│ ╱ ╭──── 蒸餾路線
│ ╱ ╱
│ ╱ ╱
│ ╱ ╱
│ ╱ ╱
│ ╱ ╱
╰──────────────→ 時間
1年 3年 5年
蒸餾路線嘅特點係:起點高、見效快,但天花板好明顯。因為你永遠學緊「尋日嘅老師」,而老師一直喺度進化。
自主創新路線嘅特點係:起點低、見效慢,但後勁足。一旦建立起自己嘅數據飛輪同算法壁壘,後期嘅爆發力會超過前者。
問題嘅關鍵係:你夠唔夠耐性行完頭3年嘅低谷期?
資本市場往往等唔到咁耐。
───
五、中國AI嘅出路:由「抄功課」到「做功課」
寫到呢度,我想俾一啲建設性嘅思考。
中國AI公司想真正突圍,需要完成三個關鍵躍遷:
躍遷一:由「模仿風格」到「內化能力」
蒸餾應該成為「預科」,而唔係「全部課程」。
正確嘅做法係:先用蒸餾快速起步,但緊接住必須用自有數據、自有場景、原創算法進行「二次訓練」。
簡單講:用蒸餾學語法,但用原創寫故事。
如果只係複製咗表面風格,而冇內化底層能力,咁當海外嘅「老師」升級換代時,你依然會落後一代。
躍遷二:由「通用對標」到「垂直深耕」
GPT-4同Claude係通才,但通才冇可能喺所有垂直領域都係專家。
中國AI嘅真正機會,唔係「做一個中國版嘅ChatGPT」,而係「用AI解決中國特有嘅場景問題」。
• 製造業嘅智能質檢
• 醫療領域嘅輔助診斷
• 教育嘅個性化學習
• 政務嘅智能服務
呢啲場景嘅海量真實數據,係海外大模型攞唔到嘅。呢個先係真正嘅護城河。
躍遷三:由「單點競爭」到「生態競爭」
單個模型嘅競爭,始終係零和遊戲。
OpenAI點解犀利?唔只係GPT-5強,更加係因為有成千上萬嘅開發者喺佢嘅生態上構建應用。
Plugins、GPTs、API調用,形成咗一個強大嘅網絡效應。
中國AI公司要學嘅唔止係訓練模型,而係構建一個令開發者願意停留、願意創造、願意賺錢嘅生態系統。
生態嘅護城河,係蒸餾唔到嘅。
───
六、寫喺最後
返去Claude嗰句批評。
我覺得,呢句話與其話係一種抱怨,不如話係一面鏡。
佢令我哋睇到:中國AI產業已經由「有冇」嘅階段,進入到「好唔好」嘅階段。
喺呢個階段,「模仿」唔再係榮耀,而係尷尬嘅標籤。
我哋有自己嘅場景優勢、數據優勢、工程優勢。接下來要做嘅,係將呢啲優勢轉化為真正嘅技術資產,而唔係永遠喺人哋嘅陰影下做「二傳手」。
最後,送俾大家一句話:
蒸餾係手段,唔係目的;模仿係起點,唔係終點。
企喺巨人嘅膊頭上,係為咗睇得更遠,而唔係為咗影一張同巨人一樣高嘅相。
共勉之。

有個段子最近在AI圈流傳。
有人問Claude:"你怎麼評價中國的大模型?"
Claude沉默了一下,說:"我注意到一些中國模型的回答,從用詞習慣到推理結構,都和我很像。說實話,這讓我有點困惑——我花了無數時間訓練出來的表達方式,就這樣被'蒸餾'走了,感覺像是……有人直接抄了我的作業。"
這段"吐槽"傳開後,有人笑了,有人怒了,也有人陷入了沉思。
今天,我想借着這個話題,聊聊模型蒸餾背後的商業邏輯。
───
一、先搞懂:什麼是模型蒸餾?
不講技術黑話,我用一個類比來說明。
假設你請了一位頂級家教,每小時收費5000塊。這位老師每講一道題,你都認真聽、認真記,反覆琢磨他的解題思路。三個月後,你的成績突飛猛進。
這叫什麼?這叫學習。合理合法,值得鼓勵。
模型蒸餾,本質就是這麼個事兒。
大模型(比如GPT-4、Claude)是"老師",小模型是"學生"。學生通過觀察老師的輸出,學習老師的思維方式,最終用更小的計算量,達到接近老師的效果。
這技術本身沒問題,而且是學術界公認的高效訓練方法。
但爭議的焦點在於:學習的邊界在哪裏?
你是學會了老師的思考方法,還是直接背下了老師的標準答案?你是借鑑了思路,還是複製了整篇作文只改了個名字?
這個邊界,很模糊。而模糊地帶,往往是焦慮的來源。
───
二、為什麼中國AI公司偏愛蒸餾?
理解一個現象,要看底層的約束條件。
中國AI公司面臨的是一個經典的"不可能三角":
維度 現狀
算力 高端芯片受限,訓練成本極高
數據 高質量中文語料稀缺
時間 資本市場耐心有限
在這三個約束下,蒸餾成了一條"理性選擇"的捷徑。
我們來算筆賬。
從頭訓練一個GPT-4級別的基座模型,需要:
• 上萬張A100顯卡
• 數千萬美元成本
• 1-2年時間
• 還要承擔訓練失敗的風險
而採用蒸餾路線:
• 幾百張顯卡就夠了
• 成本降到幾百萬美元
• 3-6個月出成果
• 成功率大幅提高
從商業決策的角度,你會選哪個?
我想,大多數人都會選第二條路。這不是道德問題,是成本問題。
但這裏有個微妙的悖論:
短期看,蒸餾是最優解;
長期看,過度依賴蒸餾可能是陷阱。
───
三、Claude到底在吐槽什麼?
很多人把Claude的話理解為"被抄襲的不爽",但我覺得,它道出了一個更深層的商業困境。
這個困境叫:創新的回報如何保障?
Anthropic每年燒掉幾十億美金做研發。OpenAI也是。他們為什麼願意燒這個錢?因為他們相信,一旦建立起技術壁壘,就能形成護城河,獲得超額回報。
這是商業世界的基本邏輯:高風險,高投入,高回報。
但如果這條護城河可以被低成本繞過呢?
如果別人花幾十分之一的錢,通過蒸餾就能達到你80%的效果,那你的高額投入還值不值?你的創新動力從哪來?
這讓我想到一個商業案例。
前些年,某國產手機品牌花了大價錢研發快充技術,申請了一堆專利。結果競爭對手繞開專利,用另一種方式實現了差不多的快充速度,成本還更低。原創者的投入,沒能轉化為競爭優勢。
Claude的吐槽,本質上是對這種"投入-回報失衡"的焦慮。
不是不可以學習,而是當學習成本遠低於創新成本時,創新的火種就可能熄滅。
───
四、蒸餾的"原罪"與"無辜"
寫到這裏,我想做一個重要的區分。
蒸餾技術本身,是完全正當的。
人類文明的進步,本質上就是一場大規模的"蒸餾"。牛頓站在伽利略的肩膀上,愛因斯坦站在牛頓的肩膀上。我們每個人從小學到大學,都是在"蒸餾"前人的知識。
AI模型也不例外。用公開API獲取數據、學習、再創造,只要不違反服務條款,這在倫理上站得住腳。
真正的問題,不是蒸餾,而是"路徑依賴"。
我給你畫個簡單的對比圖:
能力
↑
│ ╭──── 自主創新
│ ╱
│ ╱
│ ╱ ╭──── 蒸餾路線
│ ╱ ╱
│ ╱ ╱
│ ╱ ╱
│ ╱ ╱
│ ╱ ╱
╰──────────────→ 時間
1年 3年 5年
蒸餾路線的特點是:起點高、見效快,但天花板明顯。因為你永遠在學"昨天的老師",而老師一直在進化。
自主創新路線的特點是:起點低、見效慢,但後勁足。一旦建立起自己的數據飛輪和算法壁壘,後期的爆發力會超過前者。
問題的關鍵是:你是否有耐心走完前3年的低谷期?
資本市場往往等不了那麼久。
───
五、中國AI的出路:從"抄作業"到"寫作業"
寫到這裏,我想給一些建設性的思考。
中國AI公司想要真正突圍,需要完成三個關鍵躍遷:
躍遷一:從"模仿風格"到"內化能力"
蒸餾應該成為"預科",而不是"全部課程"。
正確的做法是:先用蒸餾快速起步,但緊接着必須用自有數據、自有場景、原創算法進行"二次訓練"。
簡單說:用蒸餾學語法,但用原創寫故事。
如果只是複製了表層風格,而沒有內化底層能力,那麼當海外的"老師"升級換代時,你依然會落後一代。
躍遷二:從"通用對標"到"垂直深耕"
GPT-4和Claude是通才,但通才不可能在所有垂直領域都是專家。
中國AI的真正機會,不在"做一箇中國版的ChatGPT",而在"用AI解決中國特有的場景問題"。
• 製造業的智能質檢
• 醫療領域的輔助診斷
• 教育的個性化學習
• 政務的智能服務
這些場景的海量真實數據,是海外大模型拿不到的。這才是真正的護城河。
躍遷三:從"單點競爭"到"生態競爭"
單個模型的競爭,終究是零和博弈。
OpenAI為什麼厲害?不只是GPT-5強,更因為有成千上萬的開發者在其生態上構建應用。
Plugins、GPTs、API調用,形成了一個強大的網絡效應。
中國AI公司要學會的不只是訓練模型,而是構建一個讓開發者願意停留、願意創造、願意盈利的生態系統。
生態的護城河,是蒸餾不了的。
───
六、寫在最後
回到Claude的那句吐槽。
我覺得,這句話與其說是一種抱怨,不如說是一面鏡子。
它讓我們看到:中國AI產業已經從"有沒有"的階段,進入到了"好不好"的階段。
在這個階段,"模仿"不再是榮耀,而是尷尬的標籤。
我們有自己的場景優勢、數據優勢、工程優勢。接下來要做的,是把這些優勢轉化為真正的技術資產,而不是永遠在別人的陰影下做"二傳手"。
最後,送給大家一句話:
蒸餾是手段,不是目的;模仿是起點,不是終點。
站在巨人的肩膀上,是為了看得更遠,而不是為了拍一張和巨人一樣高的照片。
與君共勉。