Claude悄悄更新了Skills生成器,這絕對是一次史詩級升級。
整理版優先睇
Claude Skill-creator史詩級更新,引入評估體系與多代理測試,所有Skills值得重新優化
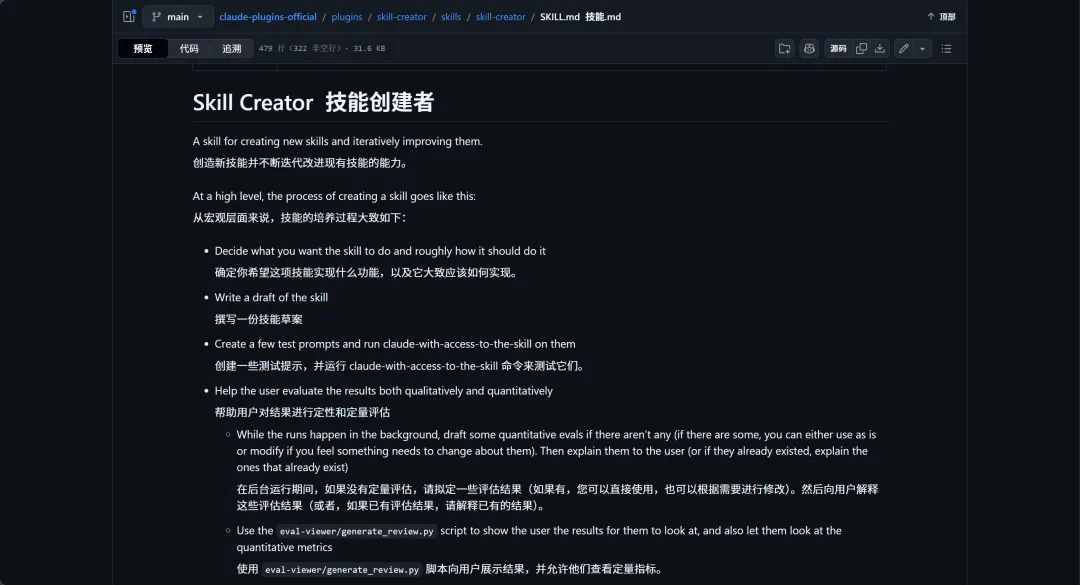
呢篇文章係由卡茲克同可達撰寫,佢哋一直推廣Claude嘅Skills生態,之前已經寫過好幾篇介紹Skills嘅文章。今次佢哋發現Anthropic官方嘅Skill-creator嚟咗一次大更新,新增咗評估系統、基準測試、多代理並行測試同描述調優四個能力,徹底補齊之前Skills創作流程入面最缺嘅評估環節。作者認為呢次係「史詩級升級」,所有Skills都值得重新優化一次。
文章用一個實例示範點樣用新版Skill-creator創建一個講稿生成Skill,再由觸發衝突問題帶出評估體系嘅用法。評估系統會自動生成應觸發同唔應觸發嘅查詢樣本,用戶可以確認邊界情況,然後系統會喺後台迭代優化描述,最終寫返入SKILL.md。之後仲可以做全面基準測試,一次過開4個獨立子代理並行跑,數據完全唔互相污染,輸出通過率、token用量、時間等量化指標。
總結來講,呢次更新將軟件開發嘅測試迭代思維引入Skills創作,令每個Skill嘅質量都可以被數據量度同持續改進。作者強烈建議用戶立即更新Skill-creator,並對所有既有Skills進行評估,尤其要分清能力提升型同編碼偏好型,針對性優化。佢哋認為Skills係Agent生態嘅基石,呢次更新會帶嚟新一波繁榮。
- 新版Skill-creator加入評估系統、基準測試、多代理並行測試及描述調優,補齊Skills品質控制嘅關鍵缺口。
- 用戶只需一句「幫我更新到最新版本」即可自動升級,其後可透過對話創建或改進任何Skill。
- 評估體系會自動生成應觸發/唔應觸發嘅邊界樣本,並進行多輪迭代優化描述,避免Skills之間觸發打架。
- 基準測試支援4個獨立子代理並行跑A/B對比,量化通過率、token消耗同時間,數據乾淨唔受上下文污染。
- Skills分為能力提升型(教Claude做唔擅長嘅事)同編碼偏好型(規範流程),評估重點唔同,用戶需因應類型調整。
Skill-creator GitHub 倉庫
官方Skill-creator更新,包含新評估功能,可直接用於更新或創建Skill。
史詩級更新:四個新能力補齊評估缺口
Anthropic官方嘅Skill-creator最近嚟咗一次大更新,可以話係成個Skills生態嘅基石升級。作者上星期直播時發現,呢個母Skills終於加入咗一直以嚟最缺乏嘅評估機制,包括評估系統、基準測試、多代理並行測試同描述調優四個新功能。以前創作完一個Skill就好似黑盒,完全唔知掂唔掂,而家終於有曬量化數據可以睇,真係史詩級提升。
評估系統
基準測試
多代理並行測試
描述調優
更新方法與實戰:創建講稿生成Skill
更新方法超級簡單:你只要同你嘅Agent講一句「呢個skills更新咗,幫我更新到最新版本」,後面跟住GitHub連結就搞掂。作者用一個實例示範,用新版Skill-creator創建一個講稿生成Skill,只係用口講出需求,大概3-5分鐘就自動設計完,效果相當唔錯。
GitHub連結
不過一開始輸出嘅講稿排版好差,一大坨文字又細又逼。佢就直接叫個Skill幫手改進,新版改進能力都有提升,之後嘅輸出就變得段落分明,睇落舒服好多。呢個例子展示咗新版Skill-creator由創建到迭代嘅完整流程。
改進能力
評估體系詳解:觸發優化與基準測試
當你手上有兩個Skill都同視頻連結相關,就好容易出現觸發衝突。新版Skill-creator嘅評估系統可以幫手解決呢個問題:佢會自動生成10條應該觸發同10條唔應該觸發嘅查詢樣本,用戶可以逐條確認邊界情況。
觸發衝突
- 1 自動生成兩組查詢:應觸發10條、唔應觸發10條,逼模型喺模糊地帶做判斷。
- 2 用戶可以喺網頁介面逐條確認,認為判斷唔啱就直接關閉,然後導出評估集。
- 3 優化循環會喺後台啟動,最多跑5輪迭代,每輪做三件事測試評估,最後自動將最優描述寫返入SKILL.md。
做完觸發優化之後,仲可以進行全面基準測試。呢次更新加入咗4個獨立子代理,每個喺乾淨環境獨立運行,無上下文污染,結果又快又準。測試完會自動彈出評估頁面,有輸出標籤頁同基準測試標籤頁,顯示有Skill vs 無Skill嘅量化對比。
4個獨立子代理
例如作者示範嘅講稿生成Skill,有Skill通過率100%,無Skill基線只有9%,差距91.5%。雖然有Skill每次多用2250 token,但對比產出嘅質素絕對值得。呢個數據令你清楚知道個Skill到底值唔值得留低。
通過率100%
無Skill基線9%
量化對比
兩種Skills類型與總結建議
作者提醒我哋,Skills其實分兩種,評估重點唔同。
- 能力提升型:教Claude做佢本來唔擅長嘅事,例如前端設計、文檔創建。評估佢係因為模型更新後呢個技能係咪仲有必要存在,用A/B測試對比有Skill同無Skill嘅結果。
- 編碼偏好型:將Claude本身做到嘅步驟按你嘅流程串起嚟,例如會議紀要整理、週報生成。評估重點係佢有冇跟足你嘅流程,有冇漏步驟或自作主張改順序。
能力提升型
編碼偏好型
作者總結話,以前造完Skill只係自我感覺良好,而家有曬數據,好用唔好用一眼見真章。佢強烈建議所有用戶即刻更新Skill-creator,然後將自己所有Skills都重新優化同評估一次,尤其係要分清類型。佢哋認為Skills係Agent生態嘅基石,呢次更新肯定會帶嚟新一波繁榮。
Skill-creator
上星期直播嘅時候,發現Anthropic嘅skills倉庫居然有更新咗。
撳入去睇,然後居然發現咗一個超實用嘅Skills迎嚟咗更新。

就係呢個,甚至可以話係成個Skills生態嘅基石。
Skill-creator。
可以話,而家小龍蝦嘅能力咁勁,一半嘅原因都要歸功於Skills,而呢啲Skills可以被創造出嚟,幾乎都要歸功於呢個母Skills,Skill-creator。
我信,任何一個睇過我哋過去關於Skills嘅文章,或者玩過Skills嘅朋友,都絕對唔可能對呢個Skill-creator陌生。
簡單講就係,呢個係Anthropic官方出嘅Skills生成器。
你可以用口講出你嘅需求,然後直接用Skill-creator,幫你做一個Skill出嚟。
如果有唔明嘅,可以去睇嚇我哋之前嘅呢篇文章:一文帶你睇明,火爆全網嘅Skills到底係個咩嚟。我自己覺得寫得都算詳細嘅。
今個星期終於有時間,詳細睇咗嚇今次更新嘅Skill-creator嘅文檔,然後發現,今次真係可以話,係史詩級更新都唔過分,勁咗好多好多。
所以我覺得,值得寫篇文章,同大家傾嚇,今次Skill-creator更新嘅新特性同新功能。
真係,所有嘅skills,都值得重新優化一次。
好簡單咁講,今次佢哋一次過加咗4個全新嘅功能,分別係:
1. 評估系統,跑完直接話畀你知呢個skill掂唔掂。
2. 基準測試,將通過率、用時、token用量,全部量化曬。
3. 多代理並行測試,每個測試喺乾淨嘅環境入面獨立跑,支援A/B盲評,結果唔會互相污染。
4. 描述調優,可以自動幫你改skill描述,應該觸發嘅就觸發,唔應該觸發嘅就唔好亂觸發。
之前的Skill-creator其實一直有個痛點,就係你生成完嘅Skills,其實係個黑盒,你完全唔知,呢個Skills到底好唔好用,佢嘅質量點樣,佢嘅觸發機制合唔合理。
用我哋現代成日講嘅工業化體系嚟講,就係缺少咗一個好重要嘅嘢,評估機制。
評估太重要喇,一個好嘅評估,真係可以引領方向㗎。
而家,新版本嘅Skill-creator,直接將成個評估體系,全部補返曬。
我好推薦大家,一定要更新到最新版本。
更新方法都勁簡單,你直接將呢段話,send畀你嘅Agent就得,無論係Claude code、OpenClaw、OpenCode等等等等:
https://github.com/anthropics/skills/tree/main/skills/skill-creator,呢個skills更新咗,幫我更新到最新版本
係,就係咁一句話。
然後你嘅Agent就會自己去更新㗎喇。
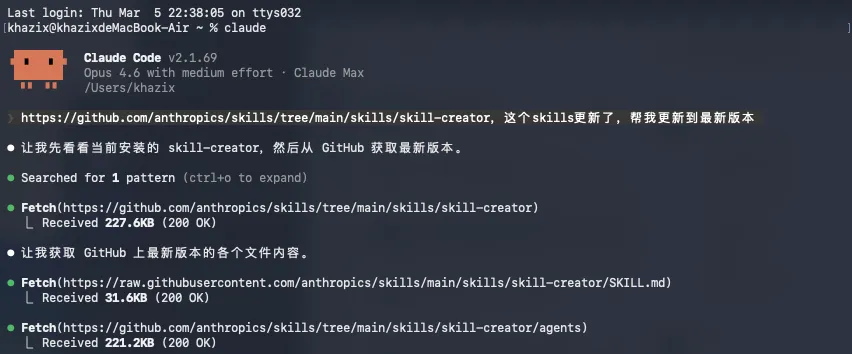
好快,就更新完咗。

我用一個案例,嚟同大家示範嚇新版Skill-creator嘅能力。
之前有一篇文章入面,我將Github上嘅yt-dlp整咗一個Skill,可以從YouTube、B站等各種視頻網站下載視頻。
但其實我哋後來發現,剩係識得下載視頻仲唔夠。
我更希望攞到視頻連結之後,可以直接生成文字版嘅講稿。
而且如果係英文或其他語言嘅視頻,最好可以直接畀我中英雙語嘅講稿文檔。
所以啱啱好,趁住呢個機會,我就用skill-creator又整咗一個新skill。
提示詞好簡單。
我想創建一個skill,我希望可以做到畀咗一個視頻連結,佢就可以將文字版嘅講稿send畀我,如果係其他語言,最好就將原語言版同中文版嘅講稿文檔畀我。
佢會先問你幾個問題,確認需求細節,然後開始幫你設計成個skill。

大概3到5分鐘,呢個Skill就設計完咗。
我用一個OpenClaw創始人嘅YouTube訪談視頻嚟試嚇。

就畀咗一個YouTube嘅連結。
五分鐘之後,中文版嘅講稿就出咗嚟。

但係,其實有個問題。。。
呢一大嚿文字堆埋一齊,字又細又迫。
根本冇辦法睇。
呢個時候你就可以繼續對話,叫佢幫你優化,幫你改進呢個skill。
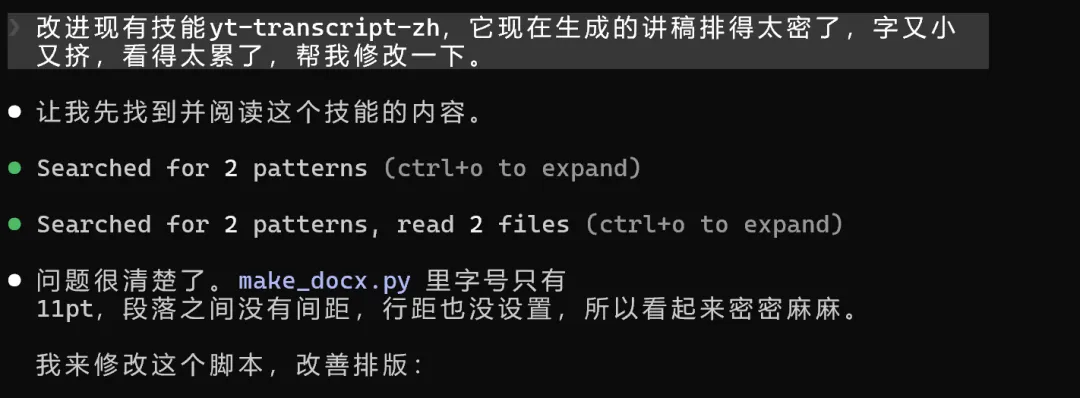
新版嘅Skill-creator,喺改進嘅能力上,都有啲提升。
改進之後嘅效果:

幾乎完美。
排版清晰,段落分明,呢啲先似一個文檔應該有嘅樣。
但呢個仲未完。
但呢個時候,一個頭痛嘅問題就嚟咗,我怕我啲skills觸發會打架。
因為我而家有兩個skill都同視頻連結有關。
一個係yt-dlp,負責下載視頻到本地。
一個係啱啱整嘅講稿生成,負責將視頻轉成文字。
兩個skill嘅觸發條件都係畀一個視頻連結,我怕佢哋會打架,即係出現應該觸發嘅唔觸發,唔應該觸發嘅亂觸發。
咁就可以用Skill-creator嘅評估體系,叫佢幫你,進行優化skill描述。
佢會先讀取你當前skill嘅描述,然後話畀你知接下來要做四件事:

自動生成兩組查詢,應該觸發嘅10條同唔應該觸發嘅10條。
設計得幾有趣。
特登將邊界情況都擺埋入去,逼模型喺模糊地帶做判斷。

然後,直接生成咗一個網頁,畀你確認,特別勁。
真係,我用到嘅時候都嚇親。
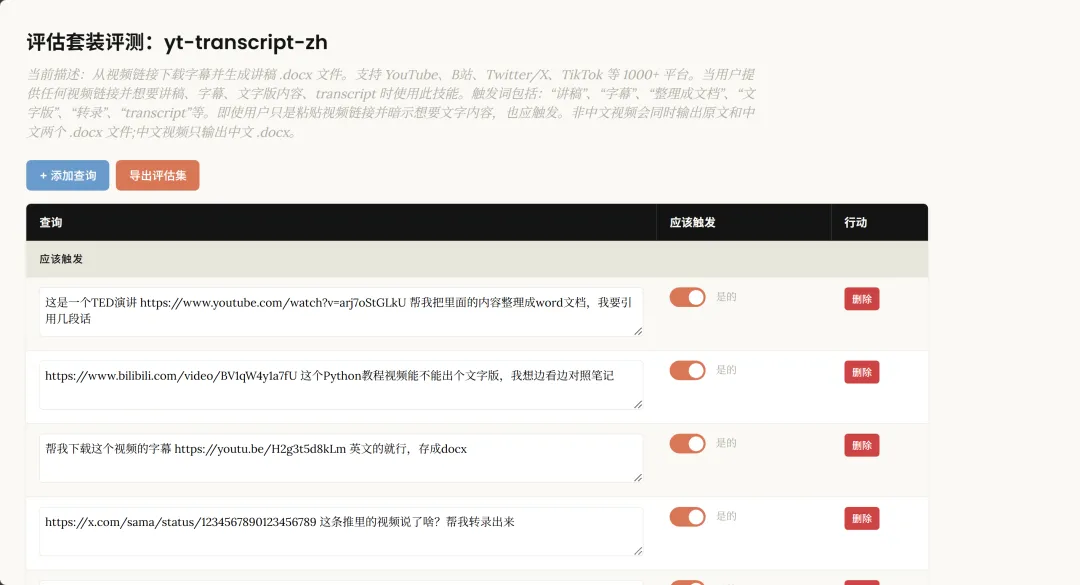
所有查詢排喺界面入面,每一條右邊有個開關,標示住應該定唔應該觸發。
你可以逐條睇一次,覺得邊條判斷唔啱,直接熄咗佢就得。
打個比喻,第三條呢種情況,我唔想俾佢再觸發,我就直接叫佢熄咗佢就得。
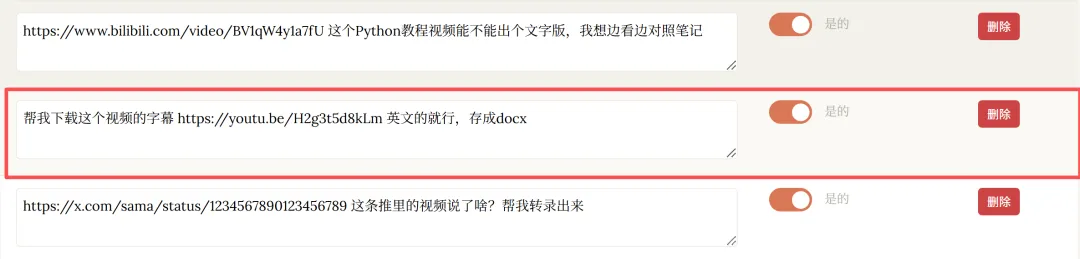
然後仲有唔應該觸發嘅10條,我睇咗一次,冇咩問題。
所有嘢都確認之後,呢個時候,你㩒匯出評估集,就搞掂啦。
確認完樣本之後,優化循環會喺後台啟動,最多跑5輪迭代。
每一輪做三件事嚟幫你進行測試同評估,成個過程大約需要10-20分鐘。

佢仲會定期匯報進度。
跑完之後你就會見到一個巨型表格。

每一列係一個查詢樣本,每一行係一個迭代版本嘅描述。
綠色剔表示觸發成功,紅色交叉表示冇觸發。
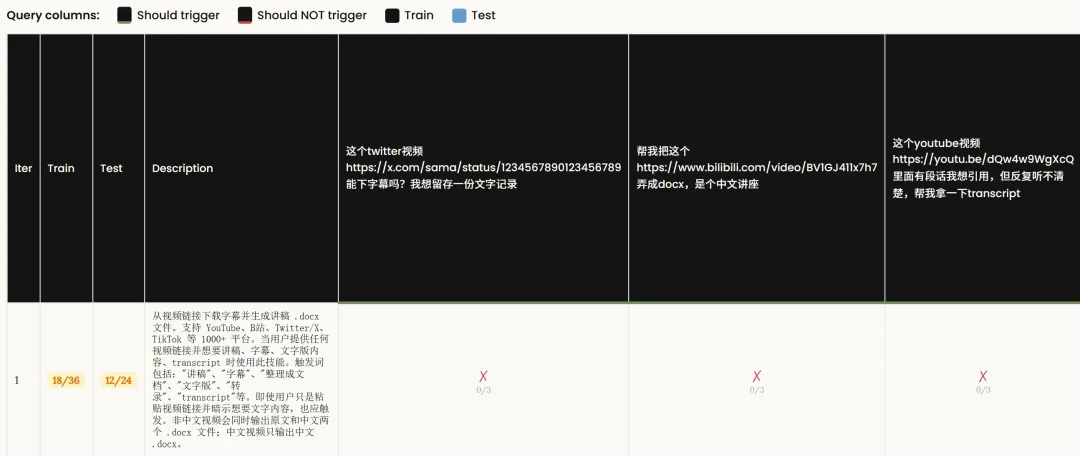
藍色列係測試集,其餘係訓練集。

佢將樣本分成60%訓練集同40%測試集,喺訓練集上迭代優化,最終用測試集上嘅表現嚟揀,防止過度擬合。
跑完之後,最優嘅描述會自動寫返落你嘅SKILL.md,全程唔使你鬱手。
Anthropic官方喺自己6個文檔類skill上測咗嚇,5個觸發率都有提升。
淨係用咗新版嘅skill-creator優化咗嚇,真係好勁。
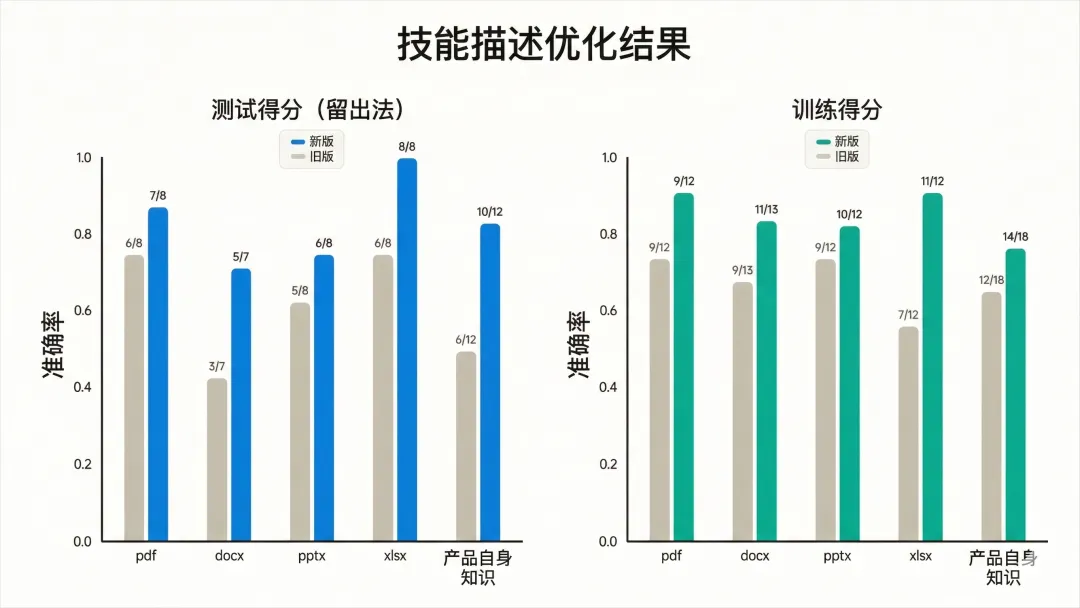
通過呢一步,可以大大提升你嘅Skills嘅觸發準確率。
但觸發啱咗,並唔等於OK。
所以,你嘅Skill裝咗上嚟而且可以穩定觸發之後,到底喺實際任務上表現點樣,呢個能力,都要評估嚇。
我就繼續用呢個啱啱整好嘅skill嚟跑一次,帶大家睇嚇成個過程。
直接對啱啱嗰個skill進行評估。

佢會先將你嘅skill文件完整讀一次,搞清楚呢個skill嘅核心流程係咩。

然後佢會問你:你更想測邊方面?
我揀咗全面評估。
佢根據skill嘅功能,自動設計咗三類測試場景,同時設計咗量化驗收標準。

確認方案之後,佢一次過啟動咗4個獨立子代理,同時跑。

今次4個並行嘅Agent嚟進行測試,就好正喇。
以前其實你都可以做啲簡單嘅評估,但係,最大嘅問題,就係會順序跑,一個跑完再跑下一個。
但係大家都知,上文下理管理有幾重要,前一個任務積累嘅上文下理,會污染後一個嘅結果。
你以為係skill嘅功勞,但,其實完全係對話紀錄幫咗手。
今次嘅評估,就啱好多。
每個代理都喺完全乾淨嘅環境入面獨立運行,有自己的token 計數同時間指標。
互相之間零交叉。
結果更快,數據更乾淨。
等緊嘅時候,佢都順手將量化評分腳本準備好埋。
等測試結果返嚟之後,就直接自動檢查格式是否符合要求,好多小細節全部喺曬入面。

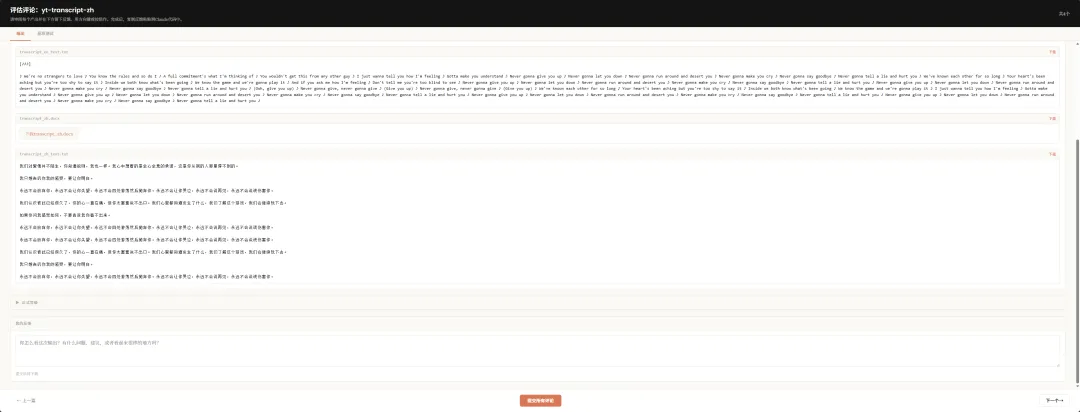
測試跑完,瀏覽器會彈出評估查看頁面,有兩個標籤頁。
輸出標籤頁,可以直接睇每個測試用例嘅輸出。
下面仲有一個反饋框,你可以直接標註邊度唔啱、邊度需要改進。
呢啲反饋會被儲起,下次改進skill嘅時候直接攞嚟用。
另一個係基準測試標籤頁,可以睇有skill vs 無skill。
通過量化對比,一目瞭然。
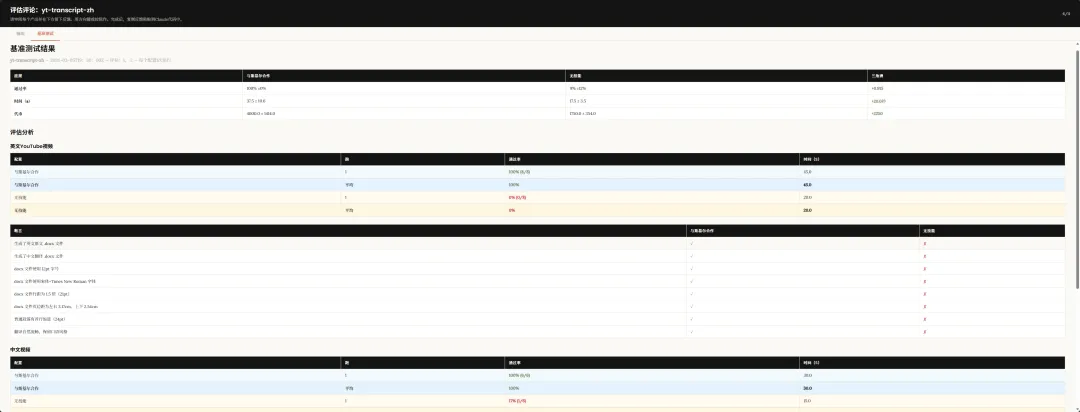
數據呢方面,都係極度量化。
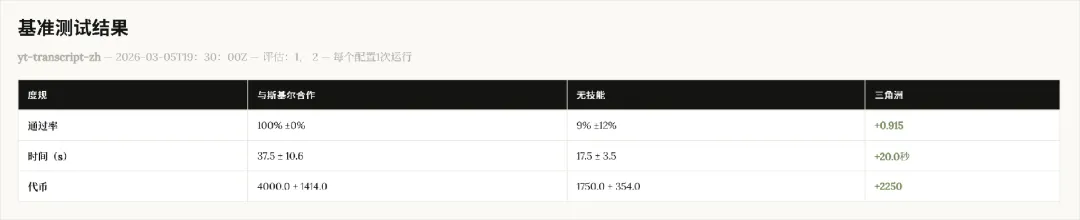
有skill嘅通過率100%,無skill基線9%,相差91.5%。
費用上,有skill每次大概4000token,無skill1750token,差咗2250。
但呢個係skill帶嚟嘅額外消耗,對比產出嘅結果,值得。
但評估嘅價值遠不止於此。
Anthropic官方都舉咗個例子。
佢哋有個PDF skill,之前喺處理表格時會出錯。
Claude需要將文字精確咁放喺特定座標上,但因為冇明確嘅字段做引導,成日放歪。
呢個問題喺評估過程中被發現,再進行修復改進定位邏輯後,問題就解決咗。
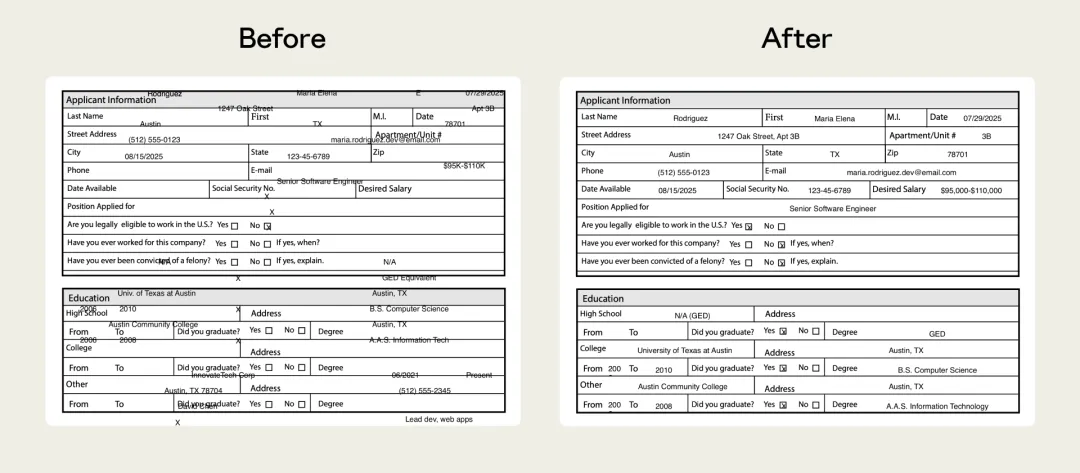
即係話,揾到問題之後唔使從頭嚟過。
評估結果會儲喺本地,下次你用skill-creator改進呢個skill嘅時候,佢會將上次標註嘅問題直接帶入去,針對嗰度改。
改完再跑一次評估,睇嚇有冇提升。
測試、發現、改、再測,呢個循環係完整嘅。
Anthropic將軟件開發嘅一啲嚴謹做法,例如測試、基準、迭代改進等等,今次引入去Skills嘅創作流程。
真係,勁好多。
呢個絕對對所有人嚟講,都係一個史詩級增強。
你要知道,小龍蝦點解咁勁,做到咁多嘢,其實真係唔係因為佢本身有幾勁,純粹係因為,佢身上掛住嘅Skills,太多喇,嗰啲都係一個一個嘅技能包。
可以話,Skills,就係成個Agent未來大繁榮生態嘅基石,而我自己,都一直極力睇好同大力推廣各式各樣嘅Skills。
所以,我好建議,大家將Skill-creator更新到最新版,然後將你自己所有嘅Skills,都進行優化同評估一次。
當然,你要先分清楚,你寫嘅Skills係邊種。
因為本質上,Skills其實分兩種。
第一種係能力提升型。
就係教Claude做佢本來唔擅長嘅事。
例如官方嘅前端設計skill、文檔創建skill,入面寫咗大量技巧,係你淨靠Prompt根本拎唔到嘅效果。
我哋大多數人自己整嘅skill,基本都係呢類。
第二種官方叫編碼偏好型。
就係話畀Claude跟住你嘅規矩嚟。
Claude本身每一步都可以做,但你嘅skill將呢啲步驟按你團隊嘅流程串起咗。
例如一個會議記錄整理skill,按你哋公司固定嘅格式,自動將錄音轉成帶行動項嘅文檔。
或者一個週報生成skill,從各個平台度拉數據,按你想要嘅格式排好。
你可以將呢種,理解成一個Workflow,即係一個工作流程。
對呢兩種類型,評估嘅方向會少少唔同。
對於能力提升型,測嘅係模型更新之後呢個skill仲有冇存在嘅必要。
用A/B測試對比,有skill同冇skill各跑一次。
結果如果差唔多,呢個skill就可以退休喇。
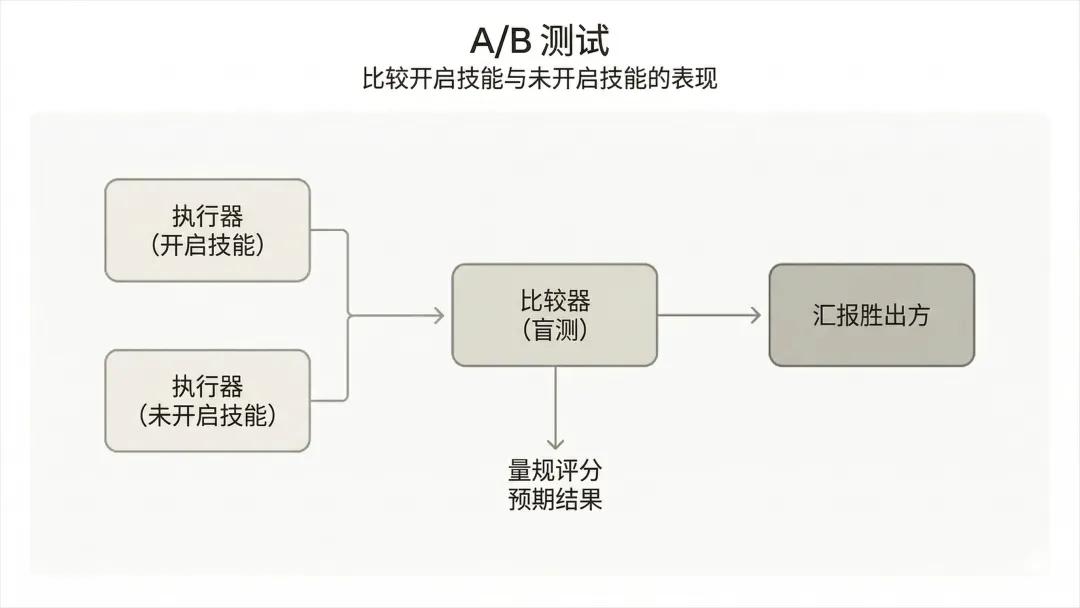
編碼偏好型測嘅係另一件事,佢有冇乖乖地跟住你個流程行?
有冇漏步驟?有冇自作主張改咗順序?有冇唔記得咗你特別講過嘅某個要求?
所以會少少有啲分別,呢個大家喺自己評估嘅時候,可以留意嚇。
回頭諗諗,以前整完一個skill,其實都係自我感覺良好。
但講真,全部係黑盒,根本唔知應該點評估。
而家就舒服好多喇。
評估跑一次,數據擺出嚟,好唔好用,一眼就見真章。
所有嘅Skills,真係都值得重新優化同評估一次。
Skills生態。
感覺又會迎嚟一波大繁榮。
以上,既然睇到呢度,如果覺得唔錯,順手點個讚、在看、轉發三連啦,如果想第一時間收到推送,都可以畀我個星標⭐~多謝你睇我嘅文章,我哋,下次再見。
>/ 作者:卡茲克、可達
>/ 投稿或爆料,請聯繫電郵:wzglyay@virxact.com
上週直播的時候,發現Anthropic的skills倉庫居然有更新了。
點進去一看,然後居然發現了一個超級剛需的Skills迎來了更新。
就是這個,甚至可以說是整個Skills生態的基石。
Skill-creator。
可以說,現在小龍蝦的能力能這麼強,有一半的原因都要歸功於Skills,而這些Skills能被創造出來,幾乎都要歸功於這個母Skills,Skill-creator。
我相信,任何一個看過我們過去關於Skills的文章,或者玩過Skills的朋友,都絕對不可能對這個Skill-creator陌生。
簡單總結就是,這是Anthropic官方出的Skills生成器。
你可以用嘴描述出你的需求,然後直接用Skill-creator,幫你做成一個Skill。
如果有不瞭解的,可以去看一下我們過去的這一篇文章:一文帶你看懂,火爆全網的Skills到底是個啥。自認為寫的還是比較詳細的。
這周終於有時間,詳細翻了一下這次更新的Skill-creator的文檔,然後發現,這次真的可以說,是史詩級更新也不為過,強了太多太多了。
所以我覺得,值得寫一篇文章,來給大家聊聊,這次Skill-creator更新的新特性和新功能。
真的,所有的skills,都值得重新優化一遍。
非常簡單的說,這次他們一口加了4個全新的能力,分別是:
1. 評估系統,跑完直接告訴你這個skill到底行不行。
2. 基準測試,把通過率、耗時、token用量,全都量化。
3. 多代理並行測試,每個測試在乾淨的環境裏獨立跑,支持A/B盲評,結果不互相污染。
4. 描述調優,可以自動幫你改skill描述,該觸發的觸發,不該觸發的就別亂觸發。
之前的Skill-creator其實一直有個痛點,就是你生成完的Skills,其實是個黑盒,你完全不知道,這個Skills到底好不好用,它的質量怎麼樣,它的觸發機制合不合理。
用我們現代經常提的工業化體系來說,就是缺少了一個很重要的東西,評估機制。
評估太重要了,一個好的評估,是真的可以引領方向的。
而現在,新版的Skill-creator,直接把整個評估體系,全都補上了。
我極力推薦大家,一定要更新到最新版。
更新方式也究極無敵簡單,你直接把這段話,發給你的Agent就行,無論是Claude code、OpenClaw、OpenCode等等等等:
https://github.com/anthropics/skills/tree/main/skills/skill-creator,這個skills更新了,幫我更新到最新版本
對,就這麼一句話。
然後你的Agent,就會自己去更新了。
很快,就更新完了。
我用一個案例,來給大家演示一下新版Skill-creator的能力。
在之前有一篇文章中,我把Github上的yt-dlp做成了一個Skill,能從YouTube、B站等各種視頻網站下載視頻。
但其實我們後來發現,光能下載視頻還不夠。
我還希望拿到視頻連結之後,能直接生成文字版的講稿。
而且如果是英文或其他語言的視頻,最好能直接給我中英雙語的講稿文檔。
所以正好,藉着這個機會,我就用skill-creator又搓了一個新skill。
提示詞很簡單。
我想創建一個skill,我希望能夠實現我給了一個視頻連結,它能夠把文字版的講稿發給我,如果是別的語言,最好是把原語言版和中文版的講稿文檔給我。
它會先問你幾個問題,確認需求細節,然後開始幫你設計整個skill。
大概3到5分鐘,這個Skill就設計完了。
我拿一個OpenClaw創始人的YouTube訪談視頻來試一下。
就給了一個YouTube的連結。
五分鐘後,中文版的講稿就出來了。
但是,其實有個問題。。。
這一大坨文字堆在一起,字又小又擠。
根本沒法看。
這時候你就可以繼續對話,讓它給你優化,幫你改進這個skill。
新版的Skill-creator,在改進的能力上,也有一些提升。
改進之後的效果:
幾乎完美。
排版清晰,段落分明,這才像個文檔該有的樣子。
但這還沒完。
但這個時候,一個頭疼的問題就來了,我害怕我的skills觸發會打架。
因為我現在有兩個skill都跟視頻連結相關。
一個是yt-dlp,負責下載視頻到本地。
一個是剛做的講稿生成,負責把視頻轉成文字。
兩個skill的觸發條件都是給一個視頻連結,我害怕他們會打架,就是出現該觸發的不觸發,不該觸發的亂觸發。
那就可以使用Skill-creator的評估體系了,讓它來幫你,進行優化skill描述。
它受會先讀取你當前skill的描述,然後告訴你接下來要做四件事:
自動生成兩組查詢,應觸發的10條和不應觸發的10條。
設計得很有意思。
故意把邊界情況都擺進去,逼模型在模糊地帶做判斷。
然後,直接生成了一個網頁,讓你確認,特別牛逼。
真的,我用到的時候都驚呆了。
所有查詢排在界面裏,每一條右邊有個開關,標着是否應該觸發。
你可以逐條看一遍,覺得哪條判斷不對,直接關就行。
打個比方,第三條這種情況,我不想讓它再觸發了,我就直接讓它關掉就行。
然後還有不應該觸發的10條,我看了一遍,沒啥問題。
所有的都確認之後,這時候,你點導出評估集,就完事啦。
確認完樣本之後,優化循環會在後台啓動,最多跑5輪迭代。
每一輪做三件事來幫你進行測試和評估,整個過程大約需要10-20分鐘。
它害會定期彙報進度。
跑完之後就是你就能看到一個巨型表格。
每一列是一個查詢樣本,每一行是一個迭代版本的描述。
綠色勾對勾表示觸發成功,紅色叉×表示沒觸發。
藍色列是測試集,其餘是訓練集。
它把樣本分成60%訓練集和40%測試集,在訓練集上迭代優化,最終用測試集上的表現來選,防止過擬合。
跑完之後,最優的描述會自動寫回你的SKILL.md,全程不用你動手。
Anthropic官方在自己6個文檔類skill上測了一下,5個觸發率都有提升。
僅僅就用新版的skill-creator優化了一下,真的很牛逼。
通過這一步,能大大提升你的Skills的觸發準確率。
但觸發對了,並不等於OK。
所以,你的Skill裝上並且能穩定觸發之後,到底在實際任務上表現如何,這個能力,也還要評估一下。
我就繼續拿這個剛做好的skill來跑一遍,帶你大家看看整個過程。
直接對剛剛那個skill進行一下評估。
它會先把你的skill文件完整讀一遍,搞清楚這個skill的核心流程是什麼。
然後它會問你:你更想測哪個方面?
我選了全面評估。
它根據skill的功能,自動設計了三類測試場景,同時設計了量化驗收標準。
確認方案之後,它一次性啓動了4個獨立子代理,同時跑。
這次4個並行的Agent來進行測試,就很香了。
以前其實你也可以做一些簡單的評估,但是,最大的問題,就是會按順序跑,一個跑完再跑下一個。
但是大家都知道,上下文管理有多重要,前一個任務積累的上下文,會污染後一個的結果。
你以為是skill的功勞,但,其實完全是對話歷史幫了忙。
這次的評估,就對味了很多。
每個代理都在完全乾淨的環境裏獨立運行,有自己的token 計數和時間指標。
互相之間零交叉。
結果更快,數據更乾淨。
等待的時候,它也順手就把量化評分腳本也準備好了。
等測試結果回來之後,就直接自動檢查格式是否符合要求,很多小細節全都在裏面。
測試跑完,瀏覽器會里彈出評估查看頁面,有兩個標籤頁。
輸出標籤頁,可以直接看每個測試用例的輸出。
下面還有一個反饋框,你可以直接標註哪裏不對、哪裏需要改進。
這些反饋會被存起來,下次改進skill的時候直接用。
另一個是基準測試標籤頁,可以看有skill vs 無skill。
通過量化對比,一目瞭然。
數據這塊,也是極度量化。
有skill的通過率100%,無skill基線9%,差值91.5%。
費用上,有skill每次大約4000token,無skill1750token,差了2250。
但這是skill帶來的額外消耗,對比產出的結果,值得。
但評估的價值遠不止於此。
Anthropic官方也舉了個例子。
他們有個PDF skill,之前在處理表格時會出錯。
Claude需要把文字精確的放在特定座標上,但因為沒有明確的字段做引導,經常放歪。
這個問題在評估過程中被發現,再進行修復改進定位邏輯後,問題就解決了。
也就是說,找到問題之後不用從頭來過。
評估結果會存在本地,下次你用skill-creator改進這個skill的時候,它會把上次標註的問題直接帶進去,針對那裏改。
改完再跑一遍評估,看有沒有提升。
測試、發現、修、再測,這個循環是完整的。
Anthropic把軟件開發的一些嚴謹做法,比如測試、基準、迭代改進等等,這次引入Skills的創作流程。
真的,牛逼太多了。
這絕對對於所有人來說,都是一個史詩級增強。
你要知道,小龍蝦為什麼那麼強,能做那麼多的事,其實真不是因為他本身有多牛逼,純粹是因為,它身上掛的SKills,太多了,那都是一個一個的技能包。
可以說,Skills,就是整個Agent未來大繁榮生態的基石,而我自己,也一直極力的看好和強力推廣各種各樣的Skills。
所以,我極度建議,大家把Skill-creator更新到最新版,然後把你自己所有的Skills,都進行優化和評估一遍。
當然,你得先分清楚,你寫的Skills是哪種。
因為本質上,Skills其實分兩種。
第一種是能力提升型。
就是教Claude做它本來不擅長的事。
比如官方的前端設計skill、文檔創建skill,裏面寫了大量技巧,是你光靠Prompt根本拿不到的效果。
我們大多數人自己搓的skill,基本也都是這類。
第二種官方叫編碼偏好型。
就是告訴Claude按你的規矩來。
Claude本身每一步都能做,但你的skill把這些步驟按你團隊的流程串起來了。
比如一個會議紀要整理skill,按你們公司固定的格式,自動把錄音轉成帶行動項的文檔。
或者一個週報生成skill,從各個平台里拉數據,按你要的格式排好。
你可以把這種,理解成一個Workflow,就是一個工作流。
對這兩種類型,評估的方向會稍微不太一樣。
對於能力提升型,測的是模型更新之後這個skill還有沒有存在的必要。
用A/B測試對比,有skill和沒skill各跑一次。
結果如果差不多,這個skill就可以退休了。
編碼偏好型測的是另一件事,它有沒有老老實實按你的流程走?
有沒有漏步驟?有沒有自作主張改了順序?有沒有忘了你特別說過的某個要求?
所以會稍稍有一些區別,這個大家在自己評估的時候,可以注意一下。
回頭想想,以前造完一個skill,其實也就是自我感覺良好。
但說實話,全是黑盒,根本不知道該怎麼評估。
現在就舒服多了。
評估跑一遍,數據擺出來,好不好用,一眼就見真章。
所有的Skills,真的都值得重新優化和評估一遍。
Skills生態。
感覺又要迎來一波大繁榮了。
以上,既然看到這裏了,如果覺得不錯,隨手點個贊、在看、轉發三連吧,如果想第一時間收到推送,也可以給我個星標⭐~謝謝你看我的文章,我們,下次再見。
>/ 作者:卡茲克、可達
>/ 投稿或爆料,請聯繫郵箱:wzglyay@virxact.com