Codex /goal 上線後,我把 Ralph loop 卸了
整理版優先睇
Codex /goal 內建高質長時任務循環,搭配 GPT-5.5 自查能力,令長時間任務變得可靠。
呢篇文章係由 Feisky 分享,佢之前一直用 Claude Code + Ralph loop 嚟跑長時間任務,但成日遇到問題:模型自己宣佈完成但清單未做完、狀態文件越寫越錯、成個循環卡死。社區裏好多人都有同感,有人話最長只係跑到 3 個鐘就失控,仲要不停睇住,token 消耗仲貴到飛起。
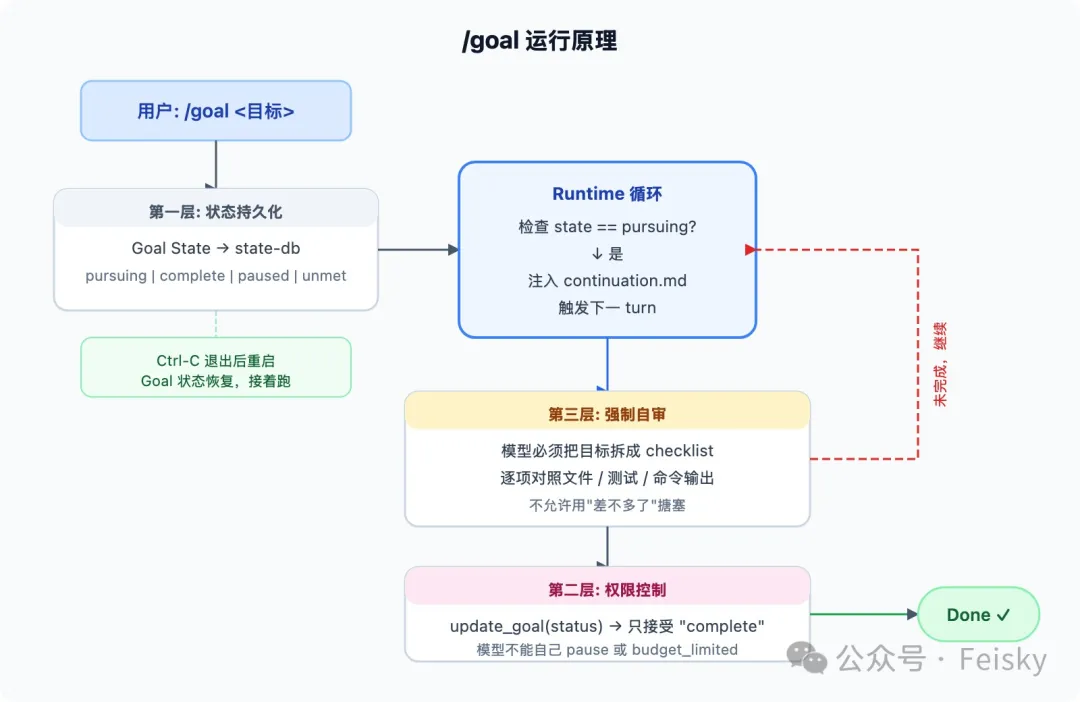
上星期 Codex 上咗新嘅 /goal 命令,Greg Brockman 話呢個係「built in Ralph loop++」。Feisky 試咗幾日,覺得太順暢,即刻將 Ralph loop 卸載咗。佢詳細解釋咗 /goal 嘅三層設計:底層係 state-db 做狀態持久化,就算中途退出都仲可以接住做;中間層係權限控制,模型只能將目標 set 做 complete,冇得話唔做就走人;最上層係自審注入,每輪都會迫模型對照真實文件同測試結果,確保真係做完先收工。
佢發現呢個設計之所以掂,好大程度上係因為 GPT-5.5 嘅自查能力。GPT-5.5 會主動質疑自己,而唔似 Opus 4.7 咁一味討好。佢推薦嘅工作流係:先寫 SPEC.md,用一條專用 prompt 自審一遍,確認冇漏洞之後就用 /goal 執行,完成之後再做 QA。咁樣 Codex 可以連續做十幾個鐘完全冇問題,適合代碼遷移、遊戲開發、prompt 優化呢類驗收標準清楚嘅任務。
- Codex /goal 內建咗比 Ralph loop 更完善嘅長時任務循環,加上狀態持久化同自審機制,令長時間任務穩定好多。
- /goal 嘅三層設計:底層 state-db 持久化狀態、中層只容許模型宣佈 complete、上層每輪注入自審 prompt 強迫對照清單。
- 同 Ralph loop 比較,/goal 唔單止反覆跑,仲會每步反問「真係做完了冇」,避免模型為咗慳 budget 就提早完結。
- GPT-5.5 嘅自查能力係關鍵,佢會真正去 grep、跑測試、對照 spec,而 Opus 4.7 只係敷衍話「你說得對」。
- 用 /goal 之前最好先寫 SPEC.md,再用「Are you 100% confident」嗰條 prompt 自審,然後先執行;適合代碼遷移、原型開發、prompt 優化同夜間 QA。
Codex /goal 官方文檔
OpenAI 官方文檔,詳細介紹 /goal 嘅用法同最佳實踐
Codex GitHub 源碼
Codex 嘅 open source 原始碼,可以睇到 goals.rs 等實作細節
Are you 100% confident? 自查 prompt
社區廣泛流傳嘅 prompt,用嚟迫模型自審策略有冇漏洞,適合同 GPT-5.5 一齊用。完整 prompt:Are you 100% confident in this strategy? If not, find all possible loopholes, suggest proper fixes and run this loop until you are factually 100% confident in the new strategy.
Ralph loop 嘅痛點:點解我哋需要更好嘅方案?
之前用 Claude Code 搭 Ralph loop 嘅時候,問題多到數唔曬:模型跑住跑住自己宣佈勝利,明明清單仲有大半未做;狀態文件越寫越離譜,跨會話後新 Agent 見到嘅進度同實際對唔上;偶爾成個循環卡死喺度,要人手 restart。社區裏面好多人都有同感,有人話最長只係跑到 3 個鐘就失控,中間仲要不斷 monitoring。
消耗方面,每輪循環都要重新讀曬成個 codebase,token 消耗比正常操作高好多。
呢啲問題迫使我哋重新思考:長時任務點解一直都唔穩定?答案可能唔係 loop 本身,而係模型冇自查能力。
/goal 上手:簡單配置,即用即爽
想試 /goal 好簡單,編輯 ~/.codex/config.toml,開啓 goals 功能就得:
[features]
goals = true之後就咁樣打 /goal 把倉庫裏所有 axios 調用遷移到 fetch</highlight>,佢就會自動開工。要求可以寫埋:所有測試通過、類型簽名不變、錯誤處理同等、完成後跑 build 同 test。同普通對話嘅分別就一條:每輪結束後 Codex 唔停</highlight>,自己繼續下一輪,直到目標達成。
TUI 上面有個進度面板,顯示當前狀態(pursuing / complete / paused</highlight>)同 token 用量。你可以全程唔理佢進度,途中用 /goal 查看狀態</highlight>、/goal pause 暫停、/goal resume 恢復、/goal clear 清除。
三層設計:點解 /goal 比 Ralph loop 更高級?
最初我以為 /goal 只係將 Ralph loop 搬入 Codex,但睇完 GitHub 源碼先發現,呢個設計比 Ralph loop 進一步。最底層係 狀態持久化:Codex 將 Goal 狀態寫入 state-db(源碼喺 codex-rs/core/src/goals.rs),可能值包括 pursuing / paused / complete / unmet / budget_limited。你中途退出再開,Goal 依然喺度,可以繼續跑。Ralph loop 腳本死咗雖然磁盤文件仲喺度,但係要手動 restart 同重新接 context。
中間層係 權限控制:Codex 俾模型三個工具——get_goal、create_goal、update_goal,但 update_goal 嘅狀態參數只接受一個值:complete。模型可以話「我搞掂咗」,但唔可以話「預算就快冇我走先」。呢招斷咗佢嘅退路:一係真係做完,一係繼續做。
將呢三層放埋一齊睇,Ralph loop 只係讓模型反覆跑,而 /goal 讓模型反覆跑嘅同時不停反問自己「我真係做完了嗎」</highlight>。
GPT-5.5 先係靈魂:自查能力決定成敗
光有 /goal 唔夠,模型仲要夠強大。GPT-5.5 係少數會主動質疑自己嘅模型</highlight>。/goal 嘅自審提示對一個唔鍾意質疑自己嘅模型只係耳邊風,但對 5.5 就係放大器。而且 5.5 冇之前 GPT 模型嗰種懶洋洋嘅感覺,你想唔到嘅佢都會幫你諗到。
對比一下 Opus 4.7</highlight>:你話「再檢查一遍」,佢話「你說得對」,然後講一堆一早諗好嘅說話;你話「呢度有 bug」,佢話「絕對的,我重寫」,然後小幅改完交返俾你。係典型嘅 討好型選手</highlight>,跑長任務越跑越偏。但 GPT-5.5 唔一樣,叫佢再查一次,佢真係會去 grep、跑測試、對照 spec,然後話俾你知邊度仲有邊界情況。
社區入面有個配套 prompt 傳得好廣:Are you 100% confident in this strategy? If not, find all possible loopholes, suggest proper fixes and run this loop until you are factually 100% confident in the new strategy.</highlight> 關鍵係讓 5.5 自己開 loop:揾漏洞、提修復、再問自己一次。呢招喺 Opus 上完全冇用,佢將自查當成客套環節;5.5 就當成一份正經工作嚟做。
適用場景同工作流建議:點樣用好 /goal?
我推薦嘅工作流係:先寫 SPEC.md(或者任何將目標任務寫落檔案嘅文件),用上面嗰條 prompt 自審一遍,確認 SPEC.md 冇漏洞之後,再用 /goal 啓動執行,完成之後做 QA。按呢個流程,Codex 可以連續做十幾個鐘完全冇問題(如果你嘅 token 夠多,更長應該都做得到)。
判斷任務適唔適合用 /goal,標準得一條:你能唔能夠將「做完了」寫清楚</highlight>。寫得清楚,/goal 可以跑得好順;寫唔清楚,跑出嚟嘅都可能係垃圾。官方文件話,一個好嘅 Goal 應該定義四件事:要達成乜嘢、唔可以鬱乜嘢、點樣驗證進度、幾時停。
- 代碼遷移同大型重構</highlight>:有明確目標狀態同驗收手段(build 過 + 測試過 + e2e 過),例如 /goal Migrate this project from [legacy stack] to [target stack]。
- 原型同遊戲開發</highlight>:寫一份 PLAN.md 描述你想要嘅嘢,然後讓 Codex 實現,每個里程碑跑測試確認。
- Prompt 優化</highlight>:如果你有 eval 套件,可以讓 Codex 自己迭代,做實驗、睇結果、調參數,循環到收斂。
- 夜間 QA 同批量處理</highlight>:回歸測試、數據校驗、批量文件處理呢類機械但係花時間嘅工作,放俾 /goal 過夜跑。