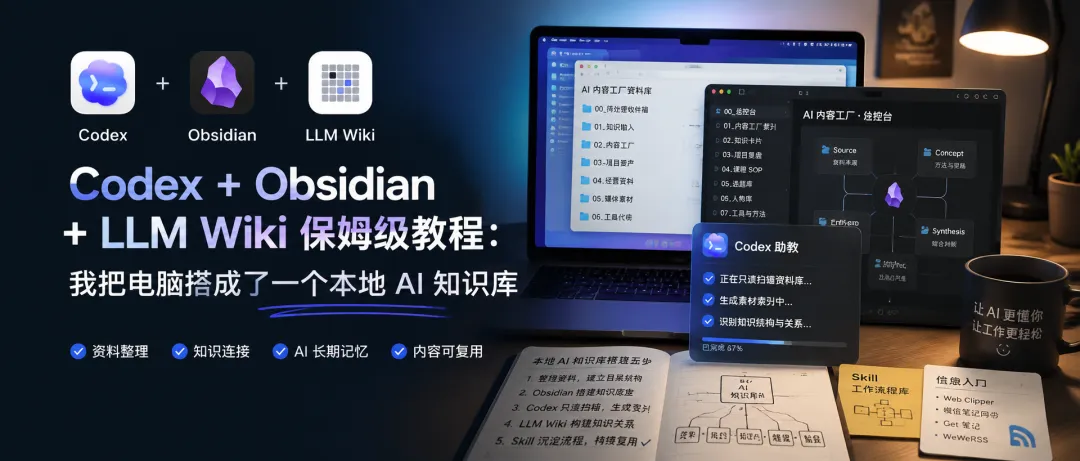
Codex + Obsidian + LLM Wiki 保姆級教程:我把電腦搭成了一個本地 AI 知識庫
整理版優先睇
本地AI知識庫搭建心法:先整理資料,再談工具
小石學長係教Codex本地知識庫課程嘅講師,佢發現同學用AI時成日卡住,因為資料散亂喺電腦唔同地方,AI每次都要重新理解背景。作者決定親身重新整理自己嘅電腦同資料,從中提煉出一套實戰方法。
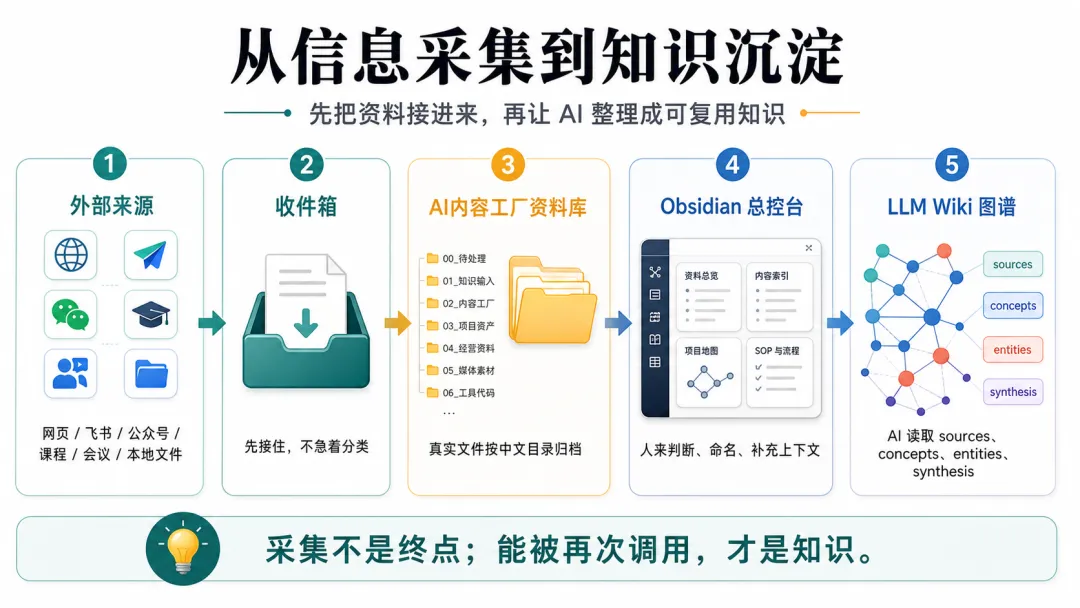
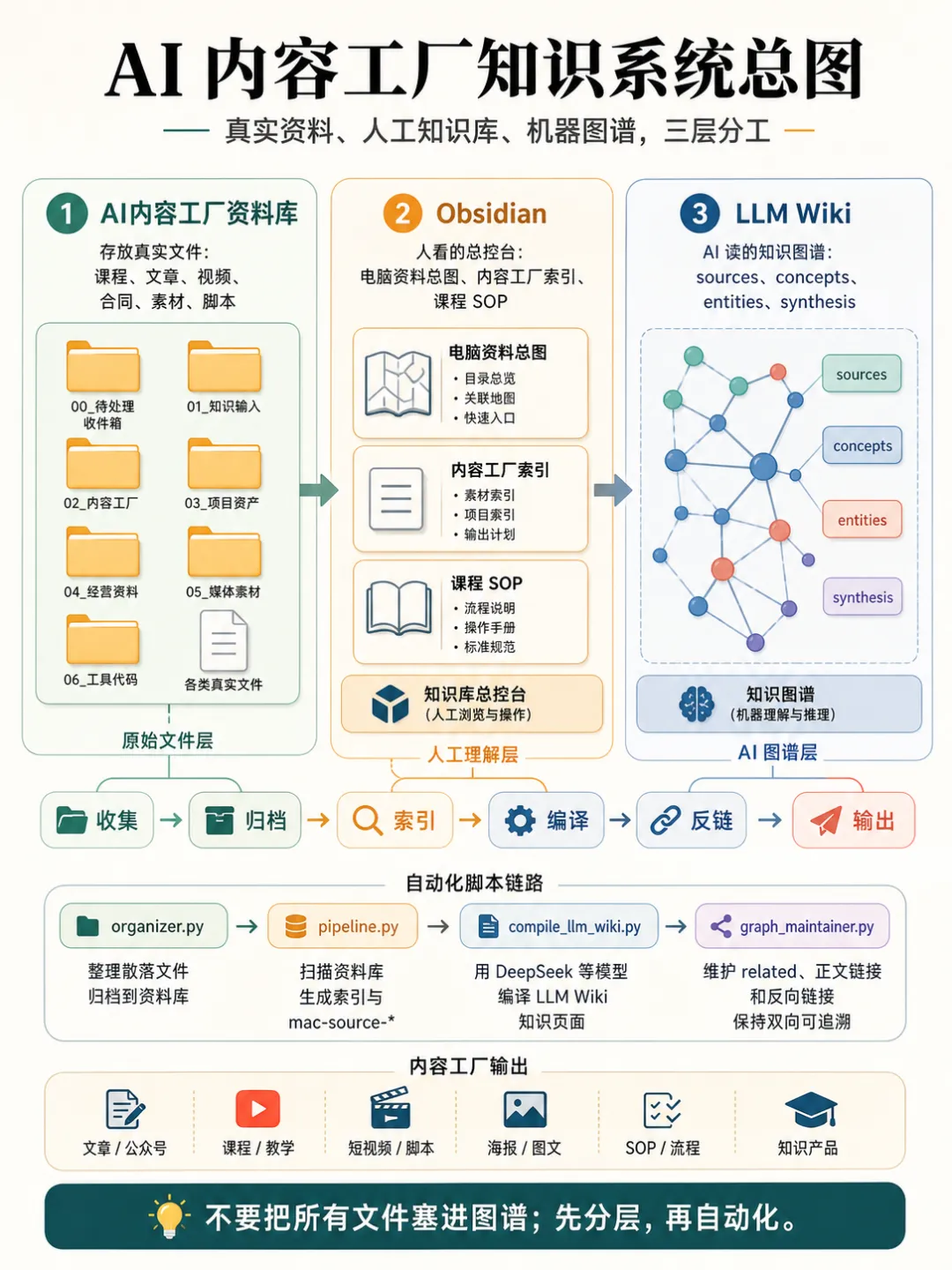
佢認為影響AI效率嘅關鍵唔係提示詞,而係有冇一套人同AI都睇得明嘅工作環境。第一步係「畀資料揾個家」:建立兩個根目錄,一個放原始資料(例如「AI內容工廠資料庫」),一個放知識系統(Obsidian倉庫)。原始資料按類型分目錄,知識系統負責索引、卡片、覆盤等。呢個結構讓AI之後可以真正參與工作。
整體結論係:當你將資料放好、規則寫清楚、索引建好、流程沉澱成Skill,AI就能愈來愈懂你嘅工作,唔使每次從零開始。文章最後提供五個起步步驟,由建立資料庫到沉澱Skill,適合想即時行動嘅讀者。
- 本地AI知識庫核心係建立可複用嘅資料結構,而唔係單靠提示詞。
- 先整理電腦目錄:分開原始資料(如「AI內容工廠資料庫」)同知識系統(Obsidian索引)。
- Obsidian係人用嘅總控台,LLM Wiki係AI用嘅知識地圖,兩者分工明確。
- Codex第一條指令應該係「只讀掃描」,限制權限、明確結果、先出報告。
- 跟住五步走:建立資料庫→建立Obsidian倉庫→Codex只讀掃描→LLM Wiki分結構→沉澱Skill。
先畀資料揾個家,唔好急住裝插件
好多同學一上嚟就問Obsidian裝咩插件、LLM Wiki點配置、Codex要唔要開完全權限。但順序搞錯咗,如果下載目錄、桌面、飛書、微信收藏全部亂七八糟,AI再聰明都只能靠估。
作者建議先做一件好土嘅事:畀資料揾個家。
Terminal
AI內容工廠資料庫/
├── 00_待處理收件箱/
├── 01_知識輸入/
├── 02_內容工廠/
├── 03_項目資產/
├── 04_經營資料/
├── 05_媒體素材/
└── 06_工具代碼/呢個目錄結構唔使照抄,重點係讓人和AI都知道待處理嘅嘢去邊、課程資料去邊、公眾號素材去邊、項目代碼去邊。規則清晰,Codex先有機會真正開工。
Obsidian唔係大倉庫,係你嘅總控台
以前好多人將Obsidian當成文件夾咩都掉入去,結果越搞越亂。作者建議分工拆開:真實文件繼續放「AI內容工廠資料庫」,Obsidian負責做人睇嘅總控台,放電腦資料總圖、內容工廠索引、課程SOP、項目覆盤。
LLM Wiki就似AI用嘅知識地圖,將資料拆成Source、Concept、Entity、Synthesis呢啲結構。
雖然聽起嚟有啲工程化,但解決嘅係好樸素嘅問題:AI以後讀資料時,唔會淨係見到一堆文件名,而係知道呢啲資料之間有咩關係。
Codex第一條指令:只讀掃描,唔好亂鬱文件
Codex係本地員工,可以入工作區讀文件、跑腳本、生成索引。但畀佢嘅指令唔可以太虛,例如「幫我整理嚇資料」就太寬,AI好易偏離。
作者建議新手第一條指令寫得保守啲:只讀掃描,不要修改任何文件。
請只讀掃描呢個內容工廠目錄,不要修改任何文件。
請告訴我:
1. 而家有咩資料,分別係咩主題。
2. 邊啲目錄係空嘅。
3. 邊啲文件命名唔規範。
4. 邊啲資料適合做公眾號、課程、短視頻或項目覆盤。
最後生成一份素材索引.md,保存到02_知識卡片目錄。呢條指令有三個好處:限制權限、明確結果、先畀報告再由人決定下一步。尤其係合同、客戶資料、商業素材,一定要有人把關。
Skill係重複工作嘅崗位手冊,唔好淨係收藏
提示詞似一次性溝通,Skill更似崗位手冊。如果你每週都要做公眾號選題、整理課程文稿、提煉爆款標題,每次都重新同AI解釋會好煩。
將流程寫成Skill之後,AI下次就可以按同一套標準執行。
完整嘅Skill通常唔只有提示詞文件,仲有腳本、參考資料、模板、示例素材。但唔好瘋狂收藏,一定要打開睇嚇個標準啱唔啱你、輸出係咪符合業務、有冇步驟要刪或加模板。
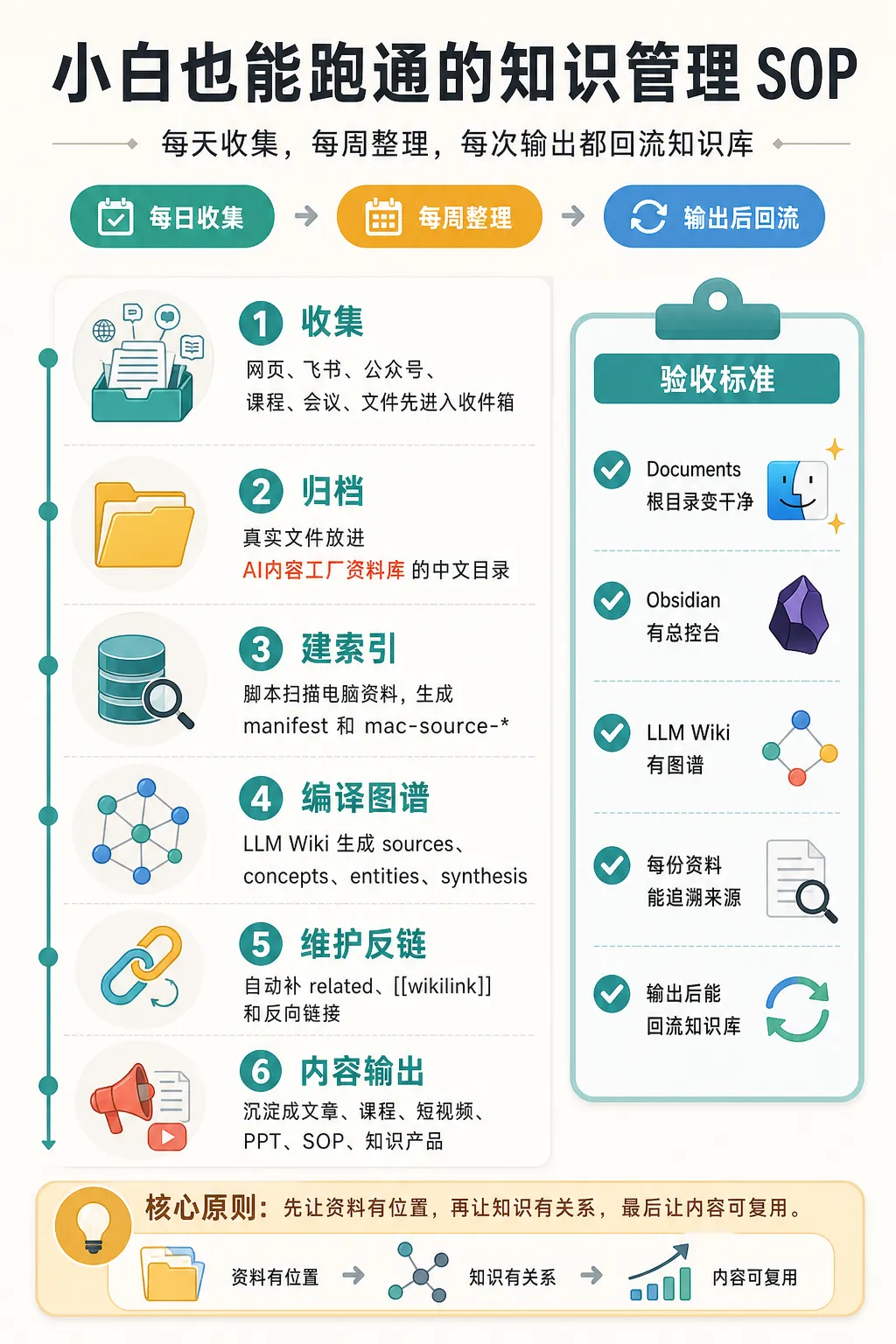
五步起動,由一個文件夾開始
如果你都想搭自己嘅本地AI知識庫,作者建議唔好貪多,跟住呢個順序做:
- 1 建立AI內容工廠資料庫,將真實文件放整齊。
- 2 建立Obsidian倉庫,只放索引、知識卡片、覆盤同總控台。
- 3 用Codex做一次只讀掃描,生成素材索引。
- 4 考慮LLM Wiki,將重要資料分成Source、Concept、Entity、Synthesis。
- 5 將重複流程沉澱成Skill,例如公眾號選題、課程文稿整理、素材索引生成。
呢五步跑完,你就已經比大多數收藏咗一堆資料嘅人向前咗一大步。
因為你嘅資料開始可以被複用,知識開始有關係,輸出開始能迴流。唔使急住整理全世界,先讓AI睇明你電腦嘅一小塊地方,好多長期能力都係由呢度長出嚟。

最近上Codex本地知識庫呢課,我發現一個都幾現實嘅問題。
好多同學已經識用GPT,亦會叫AI寫文、總結資料、整圖、寫劇本,但係一遇到複雜少少嘅任務,就即刻卡住。
卡住嘅地方好具體:資料散曬喺電腦度,文件唔知放咗去邊,飛書文件揾唔到,聊天記錄撈唔返出嚟,AI次次都要重新聽一次背景。
呢個問題我自己都撞過,所以今次準備課程嘅時候,我冇先講一大堆概念,反而先將自己嘅電腦同資料重新整理咗一次。
愈整理愈明顯,真正影響AI效率嘅,好多時唔係某一句提示詞。
更加關鍵嘅係,電腦裏面有冇一套可以俾人和AI都睇得明嘅工作環境。
先唔好急住裝插件,第一步係幫資料揾個竇
好多人一開頭就問,Obsidian插件裝邊啲,LLM Wiki點樣設定,Codex使唔使開曬權限。
呢啲當然要學,但係順序唔好搞錯。
如果下載目錄、桌面、飛書、微信收藏、網盤、項目文件夾全部都亂曬龍,AI再聰明都只能一邊估一邊做嘢。
我而家會提議你先做一件好老土嘅事:幫資料揾個竇。
電腦裏面先保留兩個真實根目錄,一個放原始資料,一個放知識系統。
原始資料可以叫「AI內容工廠資料庫」,裏面放課程資料、公眾號素材、短視頻素材、項目資產、劇本、圖片、影片同音檔。
知識系統就放喺Obsidian度,主要放索引、知識卡、項目覆盤、課程SOP同內容選題。
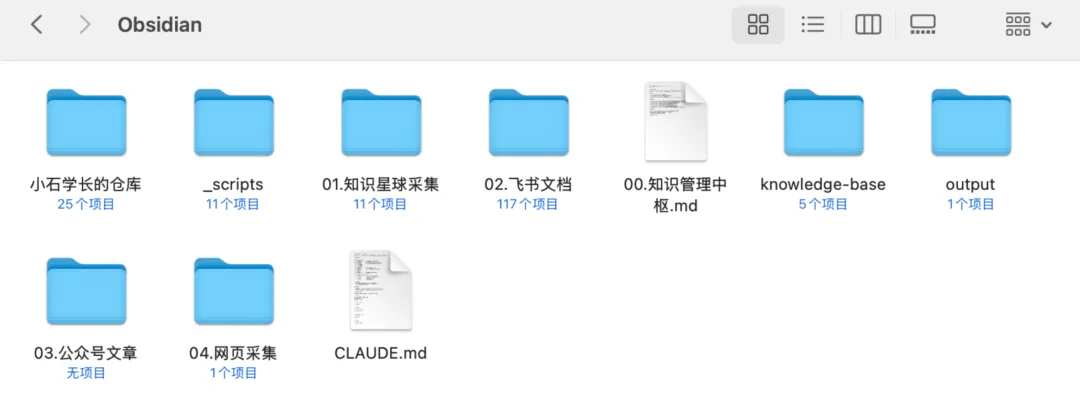
我而家Mac電腦裏面嘅文件目錄係咁:
呢個目錄唔使照抄。
重點係要令到人和AI都知道,未處理嘅嘢去邊,課程資料去邊,公眾號素材去邊,項目代碼去邊。
只要呢個規則清楚,Codex後面先有機會真係入嚟做嘢。
Obsidian唔係大倉庫,佢似人嘅總控制枱
我以前都好易將Obsidian當成一個大文件夾,咩都掉曬入去。
截圖、影片、壓縮檔、課程文件、網頁收藏,全部塞曬入去,睇落好似好勤力,但實際上會越來越亂。
而家我會將分工拆開。
真實文件繼續放喺AI內容工廠資料庫度,Obsidian負責做畀人睇嘅總控制枱,LLM Wiki負責令AI讀得明知識關係。
你可以將Obsidian理解成每日打開嘅操控枱。
呢度有電腦資料總圖、內容工廠索引、課程SOP、項目覆盤。
LLM Wiki就似AI用嘅知識地圖,佢會將資料拆做Source、Concept、Entity、Synthesis呢啲結構。
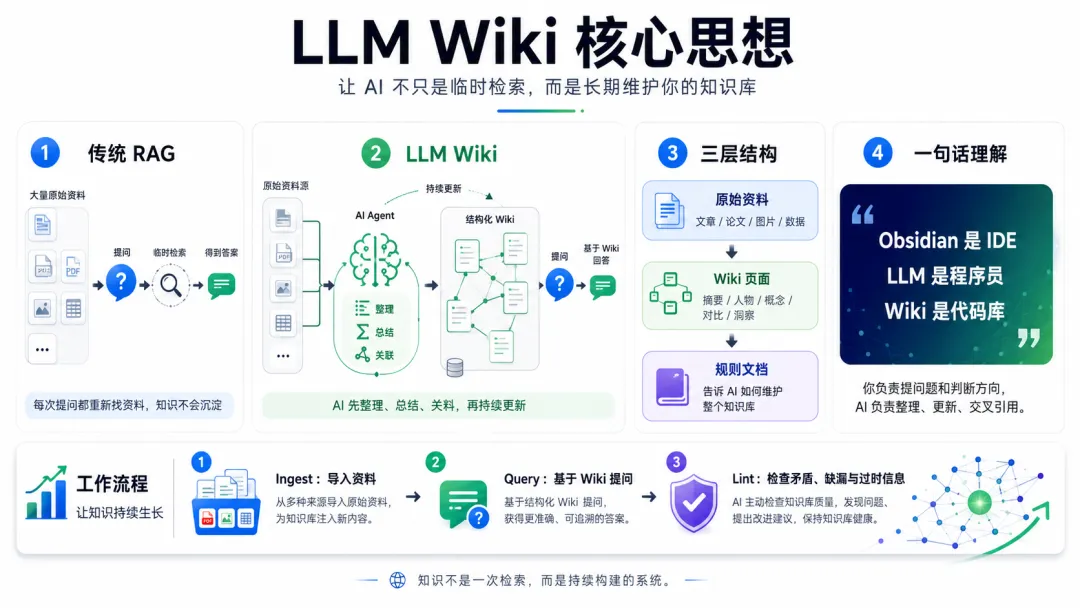
Source係資料來源,例如一篇課程文稿、一份飛書SOP、一條公眾號文章。
Concept係方法,例如素材索引、只讀掃描、知識卡。
Entity係工具同項目,例如Codex、Obsidian、飛書、VVRSS。
Synthesis係綜合判斷,例如AI內容工廠點樣運作、一個項目點樣由資料變成文章。
呢套結構聽落有啲似工程化,但佢解決嘅係一個好樸素嘅問題:AI以後讀資料時,唔止睇到一堆文件名,仲知道呢啲資料之間有咩關係。
Codex入嚟之後,先等佢只讀掃描
Codex喺呢套系統入面,我更願意當佢係本地員工。
佢可以入工作區、讀文件、行script、生成索引、整理文件、將結果寫返去指定位置。
但係俾Codex嘅指令唔可以太虛。
唔好講「幫我整理下資料」,呢句太闊喇。
你自己都冇講清楚整理到咩程度,AI好易走歪。
我建議新手第一條指令就寫得保守啲:
呢條指令好處有三個。
佢限制權限,只讀掃描,唔會亂鬱文件;佢明確結果,要生成素材索引;佢叫AI先畀報告,再俾人決定下一步。
我唔建議大家一開頭就叫AI批量移動文件。
先等佢睇明你部電腦,再慢慢畀權限。
特別係合約、客戶資料、學員作品、商業項目素材,都要有人把關。
Skill適合做重複工作,唔好淨係收藏唔改
呢課入面我成日講Skill,因為佢對普通人真係有用。
提示詞似一次性溝通,Skill似崗位手冊。
例如你每星期都要做公眾號選題、整理課程文稿、提煉爆款標題、寫短視頻劇本、將飛書文件同步去Obsidian。
每次都重新同AI解釋一次,會好煩。
將流程寫成Skill之後,佢下次就可以跟同一套標準執行。
一個完整嘅Skill通常唔止得提示詞文件。
佢仲可以有script、參考資料、模板、示例素材。
呢個結構好似一個小崗位嘅工作包。

所以我都唔建議大家瘋狂收藏Skill。
真正重要嘅工作,最好打開睇一眼。
佢嘅標準啱唔啱你,輸出符唔符合你嘅業務,有冇步驟要刪,有冇模板要加,呢啲都要改。
AI好強,但你嘅工作規則最好都係自己掌握。
資訊入口都要搭,唔係知識庫好快斷糧
本地知識庫只會整理現有資料。
如果你冇穩定嘅資訊來源,後面都好難持續輸出。
呢課入面我講咗幾個入口。
Obsidian Web Clipper適合隨手剪藏網頁;微信筆記同步助手適合將微信見到嘅資料同步去Obsidian;Get筆記適合將課程、直播、會議轉做文字,再交俾AI整理;WeWeRSS適合將公眾號文章變成可以訂閲嘅資訊源。
呢啲工具本身唔神奇,關鍵係佢哋令到資訊可以穩定咁入嚟。
內容工廠最怕嘅情況,係AI好叻寫,但手頭冇原料,或者原料入咗嚟之後又亂曬。
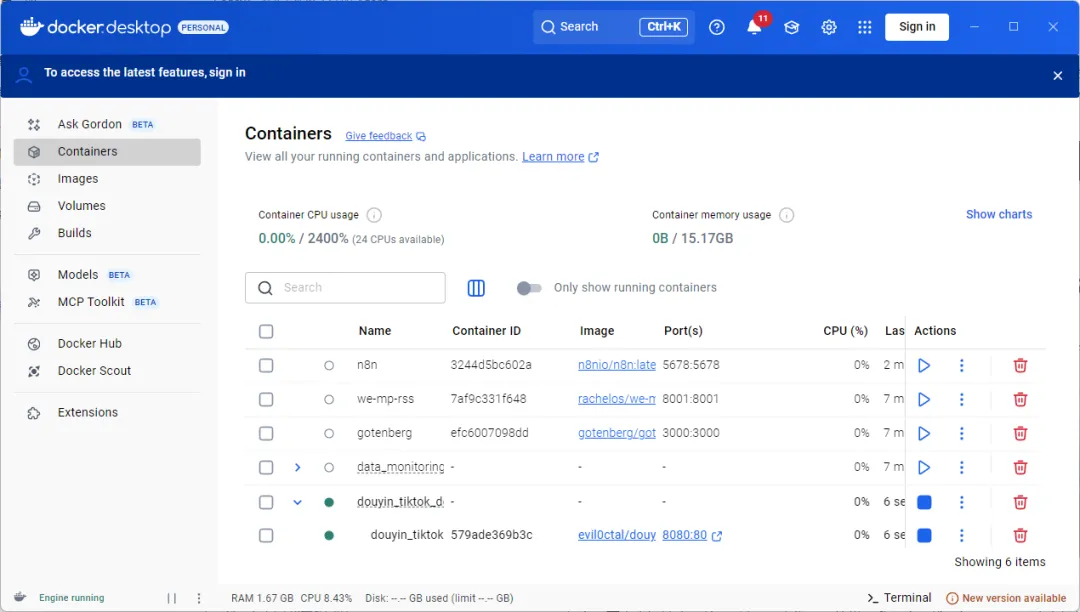
課程最後我仲示範咗用Codex部署WeWeRSS。
對程式設計師嚟講,呢個可能唔難,但對好多普通用戶嚟講,一句話叫Codex拉個項目落嚟、部署好、打開本地頁面、掃碼登入、開始監控公眾號,呢個體驗會好唔同。
你會突然發現,AI唔止係回答你。
佢可以將好多本來要手動搞嘅步驟,變成一個可以執行嘅流程。
如果你今日就想開始,先做呢五步
如果你而家都想搭自己嘅本地AI知識庫,我建議唔好貪多,先跟呢個順序嚟。
呢五步做完,你已經比大多數淨係收藏咗一堆資料嘅人行前咗一大步。
因為你嘅資料開始可以被重用,你嘅知識開始有關係,你嘅輸出開始可以迴流。
結語
最後講少少我真實嘅感受。
Codex、Obsidian、LLM Wiki、Skill、RSS、飛書、script,名多到數唔曬,好多人第一個反應就係想放棄。
但我自己行落嚟,反而覺得佢解決嘅係一個好核心嘅問題:唔好令AI每次都由零開始。
你以前睇過嘅文章、做過嘅項目、踩過嘅坑、講過嘅課、寫過嘅SOP,如果全部都散落喺聊天記錄同文件夾入面,AI下次都係唔識你。
但當你將資料放好、規則寫清楚、索引起好、流程沉澱成Skill,佢就可以一次比一次更加明你嘅工作。
呢個先係我覺得本地AI知識庫真正有價值嘅地方。
佢唔係為咗令電腦睇落高級,而係為咗你每次開AI嘅時候,唔使重新講一次自己係邊個、做過啲咩、跟住要做咩。
如果你都想搭一套,可以由最細嘅一步開始。
今晚就叫Codex只讀掃描一個文件夾,唔好急住整理全世界,先等AI睇明你電腦入面嘅一小塊地方。
好多長期能力,都係由呢一小塊地方生出來嘅。
最近上 Codex 本地知識庫這節課,我發現一個挺現實的問題。
很多同學已經會用 GPT,也會讓 AI 寫文章、總結資料、做圖、生成腳本,但任務稍微複雜一點,馬上就卡住。
卡住的地方很具體:資料散在電腦裏,文件不知道放哪,飛書文檔找不到,聊天記錄翻不出來,AI 每次都要重新聽一遍背景。
這個問題我自己也遇到過,所以這次準備課程時,我沒有先講一堆概念,反而先把自己的電腦和資料重新整理了一遍。
越整理越明顯,真正影響 AI 效率的,往往不是某一句提示詞。
更關鍵的是,電腦裏有沒有一套能讓人和 AI 都看懂的工作環境。
先別急着裝插件,第一步是給資料找個家
很多人一上來就問,Obsidian 插件裝哪些,LLM Wiki 怎麼配置,Codex 要不要開完全權限。
這些當然要學,但順序別搞反。
如果下載目錄、桌面、飛書、微信收藏、網盤、項目文件夾全是亂的,AI 再聰明也只能一邊猜一邊幹活。
我現在更建議先做一件很土的事:給資料找個家。
電腦裏先保留兩個真實根目錄,一個放原始資料,一個放知識系統。
原始資料可以叫“AI內容工廠資料庫”,裏面放課程資料、公眾號素材、短視頻素材、項目資產、腳本、圖片、視頻和音頻。
知識系統放在 Obsidian 裏,主要放索引、知識卡片、項目覆盤、課程 SOP 和內容選題。
我現在 Mac 電腦裏的文件目錄是這樣:
這個目錄不用照抄。
重點是讓人和 AI 都知道,待處理的東西去哪,課程資料去哪,公眾號素材去哪,項目代碼去哪。
只要這個規則清楚,Codex 後面才有機會真正進來幹活。
Obsidian 不是大倉庫,它更像人的總控台
我以前也很容易把 Obsidian 當成一個大文件夾,什麼都往裏面扔。
截圖、視頻、壓縮包、課程文件、網頁收藏,全部塞進去,看起來很勤奮,實際會越來越亂。
現在我會把分工拆開。
真實文件繼續放在 AI 內容工廠資料庫裏,Obsidian 負責做人看的總控台,LLM Wiki 負責讓 AI 讀懂知識關係。
你可以把 Obsidian 理解成每天打開的操作枱。
這裏有電腦資料總圖,有內容工廠索引,有課程 SOP,有項目覆盤。
LLM Wiki 則更像 AI 用的知識地圖,它會把資料拆成 Source、Concept、Entity、Synthesis 這些結構。
Source 是資料來源,比如一篇課程文稿、一份飛書 SOP、一條公眾號文章。
Concept 是方法,比如素材索引、只讀掃描、知識卡片。
Entity 是工具和項目,比如 Codex、Obsidian、飛書、VVRSS。
Synthesis 是綜合判斷,比如 AI 內容工廠怎麼跑起來,一個項目怎麼從資料變成文章。
這套結構聽起來有點像工程化,但它解決的是一個很樸素的問題:AI 以後讀資料時,不只看到一堆文件名,還能知道這些資料之間有什麼關係。
Codex 進來以後,先讓它只讀掃描
Codex 在這套系統裏,我更願意把它當成本地員工。
它可以進入工作區,讀文件,跑腳本,生成索引,整理文檔,把結果寫回指定位置。
但給 Codex 的指令不能太虛。
不要說“幫我整理一下資料”,這句話太寬了。
你自己都沒說清楚整理到什麼程度,AI 很容易跑偏。
我建議新手第一條指令就寫得保守一點:
這條指令好在三個地方。
它限制權限,只讀掃描,不會亂動文件;它明確結果,要生成素材索引;它讓 AI 先給報告,再讓人決定下一步。
我不建議大家一上來就讓 AI 批量移動文件。
先讓它看懂你的電腦,再一點點給權限。
尤其是合同、客戶資料、學員作品、商業項目素材,都要有人把關。
Skill 適合做重複工作,不要只收藏不改
這節課裏我反覆講 Skill,因為它對普通人真的有用。
提示詞更像一次性溝通,Skill 更像崗位手冊。
比如你每週都要做公眾號選題、整理課程文稿、提煉爆款標題、生成短視頻腳本、把飛書文檔同步到 Obsidian。
每次都重新跟 AI 解釋一遍,會很煩。
把流程寫成 Skill 以後,它下次就能按同一套標準執行。
一個完整的 Skill 通常不只有提示詞文件。
它還可以有腳本、參考資料、模板、示例素材。
這個結構很像一個小崗位的工作包。
所以我也不建議大家瘋狂收藏 Skill。
真正重要的工作,最好打開看一眼。
它的標準適不適合你,輸出符不符合你的業務,有沒有需要刪掉的步驟,有沒有可以加進去的模板,這些都要改。
AI 很強,但你的工作規則最好還是自己掌握。
信息入口也要搭,不然知識庫很快斷糧
本地知識庫只會整理已有資料。
如果你沒有穩定的信息來源,後面也很難持續輸出。
這節課裏我講了幾個入口。
Obsidian Web Clipper 適合隨手剪藏網頁;微信筆記同步助手適合把微信裏看到的資料同步到 Obsidian;Get 筆記適合把課程、直播、會議轉成文字,再交給 AI 整理;WeWeRSS 適合把公眾號文章變成可訂閲的信息源。
這些工具本身不神奇,關鍵是它們讓信息能穩定進來。
內容工廠最怕的情況,是 AI 很會寫,但手裏沒有原料,或者原料進來以後又亂掉。
課程最後我還演示了用 Codex 部署 weweRSS。
對程序員來說,這可能不算難,但對很多普通用戶來說,一句話讓 Codex 把項目拉下來、部署起來、打開本地頁面、掃碼登錄、開始監控公眾號,這個體驗會很不一樣。
你會突然意識到,AI 不只是回答你。
它可以把原來很多需要手動折騰的步驟,變成一個能執行的流程。
如果你今天就想開始,先跑這五步
如果你現在也想搭自己的本地 AI 知識庫,我建議別貪多,先按這個順序來。
這五步跑完,你就已經比大多數收藏了一堆資料的人往前走了一大步。
因為你的資料開始能被複用,你的知識開始有關係,你的輸出開始能迴流。
結語
最後說一點我的真實感受。
Codex、Obsidian、LLM Wiki、Skill、RSS、飛書、腳本,名字一多,很多人第一反應就是勸退。
但我自己跑下來,反而覺得它解決的是一個很核心的問題:別讓 AI 每次都從零開始。
你過去看過的文章、做過的項目、踩過的坑、講過的課、寫過的 SOP,如果都散落在聊天記錄和文件夾裏,AI 下次還是不認識你。
但當你把資料放好,把規則寫清楚,把索引建起來,把流程沉澱成 Skill,它就能一次比一次更懂你的工作。
這才是我覺得本地 AI 知識庫真正有價值的地方。
它不是為了讓電腦看起來高級,它是為了讓你每次打開 AI 的時候,不用重新講一遍自己是誰、做過什麼、接下來要幹什麼。
如果你也想搭一套,可以先從最小的一步開始。
今晚就讓 Codex 只讀掃描一個文件夾,別急着整理全世界,先讓 AI 看懂你電腦裏的一小塊地方。
很多長期能力,都是從這一小塊地方長出來的。