codex抓取公眾號skill:正文、圖片、連結,能直接存成 Markdown
整理版優先睇
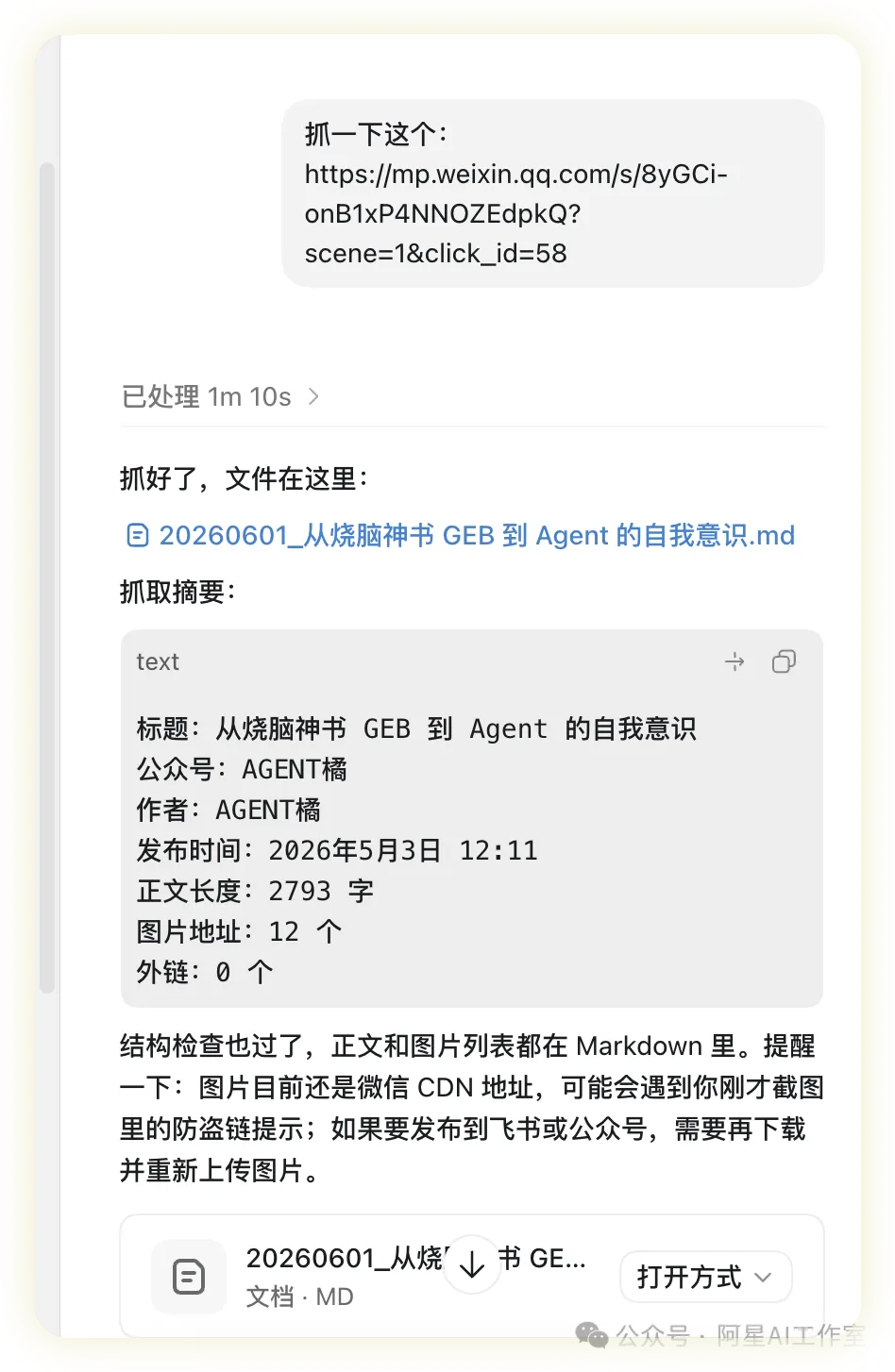
阿星介紹用Codex安裝公眾號文章抓取Skill,自動將文章存成Markdown,解決AI抓唔完整嘅問題。
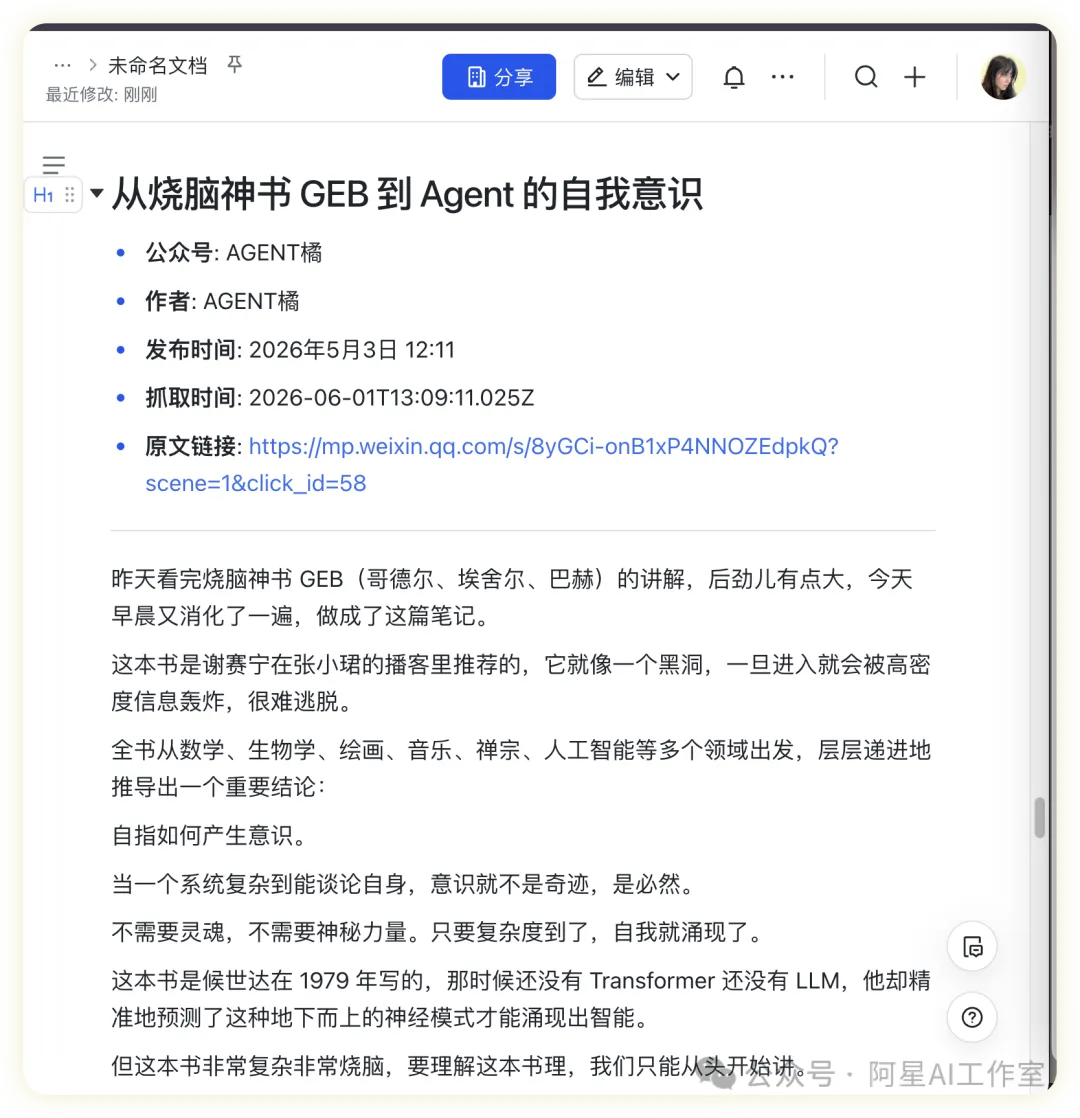
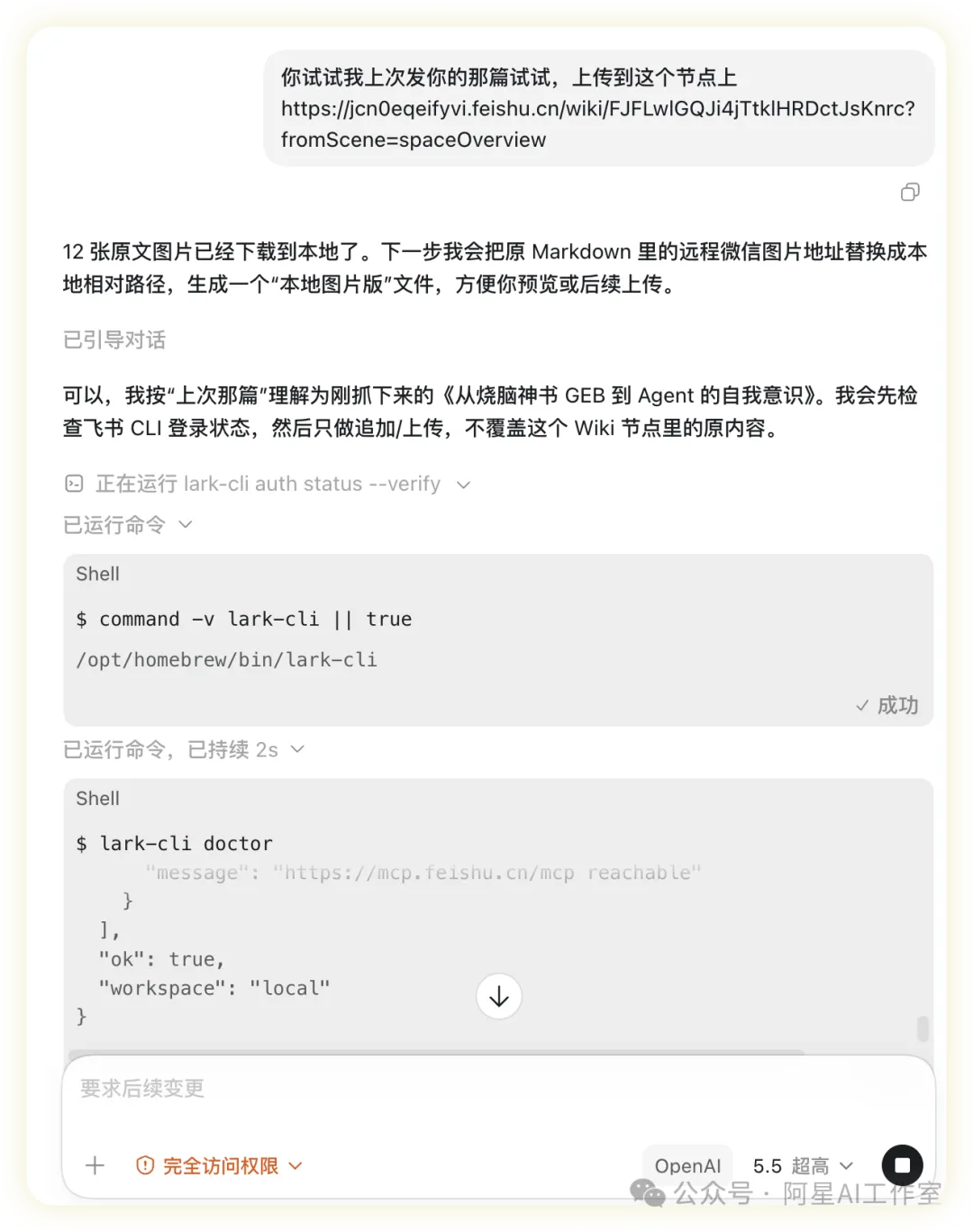
阿星分享咗佢用Codex安裝一個公眾號文章抓取Skill嘅經驗。佢發現平時想叫AI幫手抓公眾號文章,成日都唔完整,所以試咗阿一AI站嘅Skills,成功抓到標題、作者、發佈時間、正文同5張圖片連結,仲自動生成咗一個.md檔案。呢篇文章主要係教讀者點樣用Codex安裝同執行呢個Skill,包括下載、解壓、讀取SKILL.md、檢查Node.js環境同Puppeteer依賴,最後用腳本抓取文章。阿星仲提到第一次運行時遇到Puppeteer揾唔到Chrome嘅報錯,但用本機Chrome就解決咗,成個過程大約7秒。
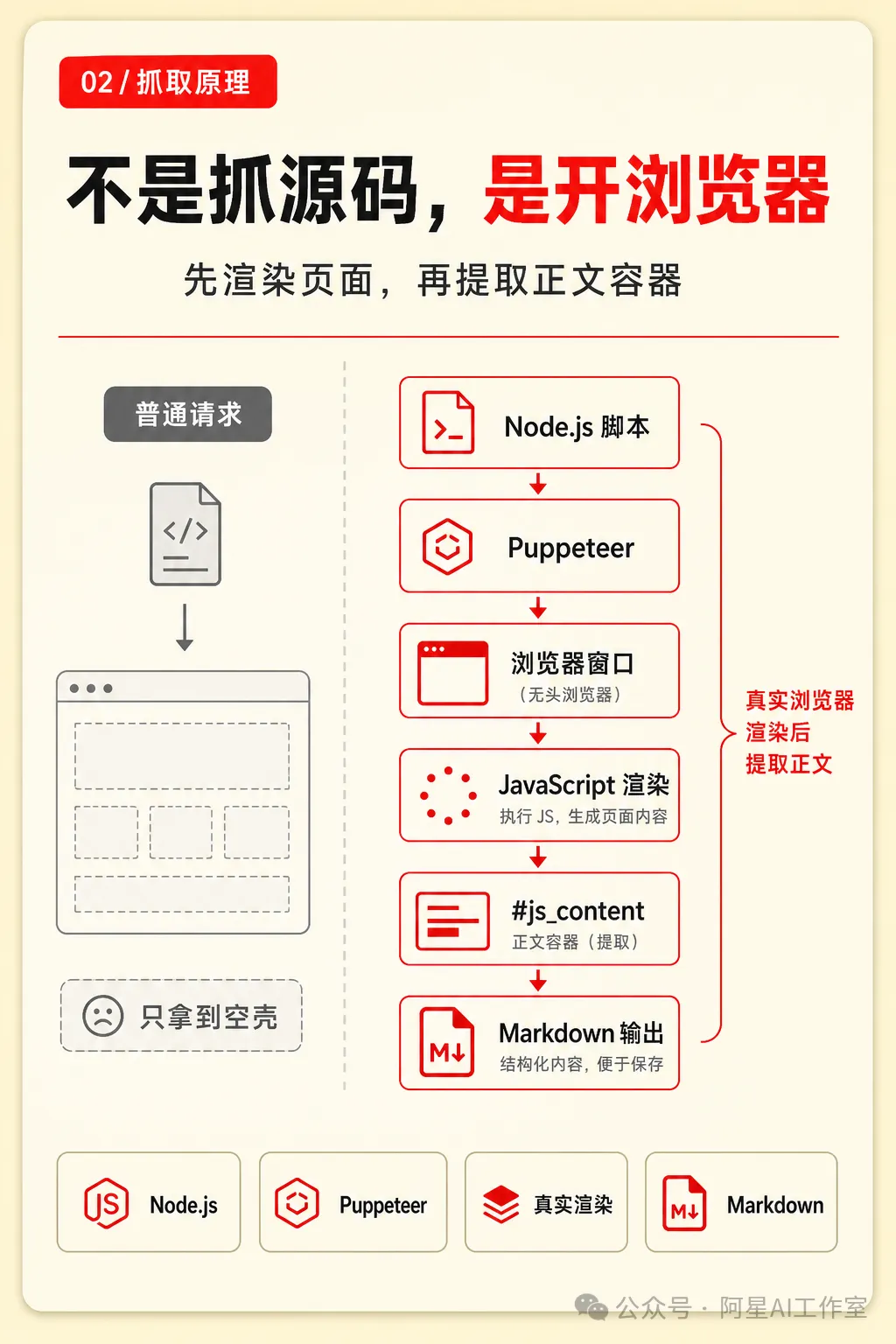
呢個Skill包嘅核心係一個Node.js腳本,依賴Puppeteer嚟模擬瀏覽器渲染,再提取公眾號正文容器嘅內容。輸出可以係Markdown檔案或者結構化JSON,適合唔同流程。阿星特別強調,如果只係想保存文章入知識庫,用save-markdown.js就夠;如果想做後續分析,可以直用scrape-wechat.js拎JSON。
最後,阿星話呢個工具最適合內容創作者、知識庫重度用戶同做運營研究嘅人。佢提醒大家,抓取文章要尊重版權,唔好高頻批量請求或者未經授權二次發佈。建議用嚟個人備份同學習,咁樣先用得穩妥。
- Codex可以通過安裝Skill完整抓取公眾號文章,生成結構化Markdown。
- 方法:下載Skill包後,按SKILL.md指示執行腳本,需注意Puppeteer嘅Chrome依賴問題。
- 差異:相比直接叫AI抓取,呢個Skill包用Puppeteer模擬瀏覽器,抓取更完整,輸出結構化。
- 啟發:Skill包嘅設計令智能體可以按說明執行複雜任務,係一種可複用嘅工作流模式。
- 可行動點:如果你經常有保存公眾號文章嘅需要,可以試下安裝呢個Skill,但記得尊重版權,用於個人學習。
微信公眾號文章抓取 Skill 資源頁
包含下載地址同使用說明
內容結構
請幫我使用這篇文章裏提到的「微信公眾號文章抓取 Skill」:https://www.ayi001.xyz/articles/190目標:抓取這篇公眾號文章:https://mp.weixin.qq.com/s/xxxxx請按下面步驟執行:
1. 先讀取上面阿一 AI 站文章,找到裏面提到的 Skill 資源頁面或下載地址。
2. 下載並解壓「微信公眾號文章抓取 Skill」。
3. 讀取解壓目錄裏的
SKILL.md 和 references/usage-guide.md。
4. 檢查本機是否具備 Node.js 環境,並安裝或確認 Puppeteer 依賴可用。
5. 如果 Puppeteer 報錯找不到 Chrome,請優先檢查本機是否安裝 Google Chrome;如果已安裝,請使用 PUPPETEER_EXECUTABLE_PATH 指向本機 Chrome 後重新運行。
6. 調用 Skill 裏的 scripts/save-markdown.js 或等價腳本抓安裝同使用方法
阿星先從阿一AI站文章揾到對應資源頁,直接同Codex講安裝就得。如果你已經有Skill包,可以叫智能體跟住步驟做:
- 1 先讀取阿一AI站文章,揾到Skill資源頁面或下載地址。
- 2 下載並解壓「微信公眾號文章抓取 Skill」。
- 3 讀取解壓目錄嘅 SKILL.md 同 references/usage-guide.md。
- 4 檢查本機是否具備 Node.js 環境,並安裝或確認 Puppeteer 依賴可用。
- 5 如果 Puppeteer 報錯揾唔到 Chrome,優先檢查本機是否安裝 Google Chrome;如果已安裝,用 PUPPETEER_EXECUTABLE_PATH 指向本機 Chrome 後重新運行。
- 6 調用 Skill 入面嘅 scripts/save-markdown.js 或等價腳本抓取文章。
Puppeteer 揾唔到 Chrome 係常見初始化問題,唔係抓取邏輯失敗。
阿星第一次運行遇到Puppeteer報錯,但用本機Chrome就解決咗,全程約7秒,終端顯示「已保存: 20260601_福布斯2024中國內地富豪榜:鍾睒睒連續4年成首富.md」。
工具原理同能力
呢個工具更接近一個Skill包,唔係獨立App。你可以理解成俾智能體準備嘅一套「任務說明 + 腳本工具 + 使用文檔」。當你叫智能體「調用呢個Skill抓取公眾號文章」,佢會按SKILL.md嘅說明去運行腳本。
- SKILL.md:話俾智能體知幾時調用呢個能力。
- README.md:項目說明。
- package.json:Node.js依賴配置。
- scripts/scrape-wechat.js:核心抓取腳本,返回結構化JSON。
- scripts/save-markdown.js:直接生成Markdown檔案。
scrape-wechat.js 輸出結構化JSON,適合接入工作流做摘要、打標籤。
save-markdown.js 適合只係想將文章保存入知識庫嘅用戶。
適合邊啲人同注意事項
阿星覺得呢個工具最適合三類人:內容創作者、知識庫重度用戶、做運營產品增長研究嘅人。佢哋成日需要保存同行文章、整理選題、分析結構,或者將文章放入Obsidian、Notion、飛書文檔。
手動複製太慢,直接抓取再做分類分析,更接近可複用嘅資料流。
唔建議用成批量搬運工具,要尊重版權同平台規則。
更穩妥嘅用法係保存自己有權限睇嘅文章,用嚟個人備份、學習同分析。唔好高頻批量請求,亦唔好未經授權二次發佈。阿星話:「ok,我是阿星,更多AI應用,我們下期再見!」