DeepSeek 120 倍價差背後,藏着模型緩存的秘密
整理版優先睇
DeepSeek 120倍價差背後,係硬碟級Prompt Cache嘅功勞,開發者只要學識「靜在前,動在後」就可以大幅減低成本。
呢篇文章係由Dragon Code營運者寫嘅技術拆解文,作者想解釋DeepSeek同一個模型點解會有120倍嘅價格差異——緩存命中0.025元,未命中3元。佢由Token講起,再深入KV Cache同Prompt Cache嘅原理,最後用Claude Code團隊嘅6條鐵律同中轉站實際數據,話俾讀者知點樣先可以命中最多緩存。
整體結論係:DeepSeek之所以咁平,唔係模型細,而係佢將Prompt Cache寫落硬碟,壽命由幾分鐘拉到幾日,令到唔同用戶可以共享同一段開頭嘅prefill結果。開發者只要掌握「靜態內容放前面,動態內容放後面」呢個原則,就可以大幅提高命中率,慳返一大筆錢。
文章仲提醒咗三個常見陷阱:首次請求唔會命中、唔同API Key唔共享緩存、同埋中轉站亂改system prompt會令緩存永遠失效。最後,作者強調喺中轉站日誌睇清楚藍色「緩存讀取」同黃色「緩存寫入」字段,先知道自己有冇慳到錢。
- DeepSeek 120倍價差嘅秘密係硬碟級Prompt Cache,唔係模型本身平咗。
- KV Cache係單次請求內嘅草稿紙,加速生成;Prompt Cache係跨請求共享,直接打折。
- 靜態前綴(system prompt、工具定義)一定要放前面,動態內容(時間、用戶ID)放後面。
- Claude Code團隊將緩存命中率當SLA監控,命中率低過門檻要當SEV報。
- 喺中轉站日誌留意藍色「緩存讀取」同黃色「緩存寫入」,首次請求唔會命中,唔同API Key唔共用緩存。
120倍價差嘅起點:Token同緩存
DeepSeek定價表上,同一模型緩存命中0.025元、未命中3元,相差120倍。要搞清楚呢個秘密,先要知Token係乜——AI公司按Token收費,因為模型每處理一個Token就要做一次矩陣運算,而Token就係模型眼中嘅最小單位。
模型眼裏冇字、冇問題、冇句子,只有Token。
OpenAI同Anthropic都話唔同模型Tokenizer切出嚟嘅Token數可以差好多,DeepSeek官方俾嘅粗估值係1個中文字約0.6 Token,但實際以API返回為準。
兩類緩存:KV Cache同Prompt Cache
KV Cache係模型嘅草稿紙,將前面已計好嘅K同V存喺顯存,新字只計自己嗰份,避免重複計算。但佢只喺單次請求內有效,唔影響API收費。
KV Cache省嘅係模型自己嘅算力,唔係你嘅錢。
Prompt Cache就係跨請求共享嘅大黑板,將重複嘅prompt前綴prefill結果存起,下次同一個開頭直接跳過prefill。DeepSeek仲將佢寫落硬碟,壽命由幾分鐘拉到幾日,呢個先係120倍價差嘅真正秘密。
- KV Cache:單次請求內加速decode,所有LLM都有,底層基建。
- Prompt Cache:跨請求共享,直接打折,係商業產品。
- DeepSeek用MLA技術壓縮KV Cache體積,先可以放硬碟做到長壽命。
Claude Code團隊嘅6條緩存鐵律
技術專家Ankit Sinha做過實驗:優化前綴嘅請求平均成本0.0096美元,加咗隨機幹擾字符就升到0.0333美元,企業年費可以差近25萬美元。Anthropic嘅Claude Code團隊將緩存命中率當SLA管,公開咗6條鐵律。
- 1 靜態在前,動態在後:system prompt、工具定義放前面,用戶問題、時間放後面。
- 2 更新信息走message:唔好改system prompt,用<system-reminder>標籤傳遞。
- 3 唔好中途換模型:緩存綁模型,換模型要重新prefill,仲貴。
- 4 唔好中途加減工具:工具列表都係cached prefix一部分,改動會令緩存失效。
- 5 工具多就defer_loading:用Tool Search stub代替完整schema,工具數目保持唔變。
- 6 監控緩存命中率:低過門檻當SEV報,同嘅服務可用性一樣重要。
點樣喺中轉站睇緩存有冇命中
作者營運Dragon Code中轉站(底層係Sub2API),打開使用記錄就會見到四個關鍵字段:綠色輸入token(冇命中)、紅色輸出token、藍色緩存讀取(打折)、黃色緩存寫入(首次創建)。
藍色緩存讀取 token 愈多,賬單愈平。
作者舉咗個實例:一次請求如果全部行原價要0.453美元,cache-friendly之後只係0.1036美元,慳咗4.7倍。
- 首次請求唔會命中,見到黃色緩存寫入係正常。
- 唔同賬號、唔同API Key之間唔共享緩存。
- 中轉站如果偷改system prompt,會令緩存永遠失效,揀中轉站時呢條比價格更重要。
總結:靜在前,動在後,緩存係王道
回到開頭嗰張表:0.025元 vs 3元,120倍價差就係緩存命中同未命中嘅分別。KV Cache係模型自己嘅草稿紙,Prompt Cache係服務商嘅公共草稿紙。
靜態在前,動態在後——呢句係慳錢嘅核心心法。
AI價格戰打到最後,拼嘅係邊個更識得留低已經算過嘅嘢。對開發者嚟講,理解緩存可能比換幾個平模型更有用。

下面呢張 DeepSeek 嘅定價圖,好多人應該都見過。
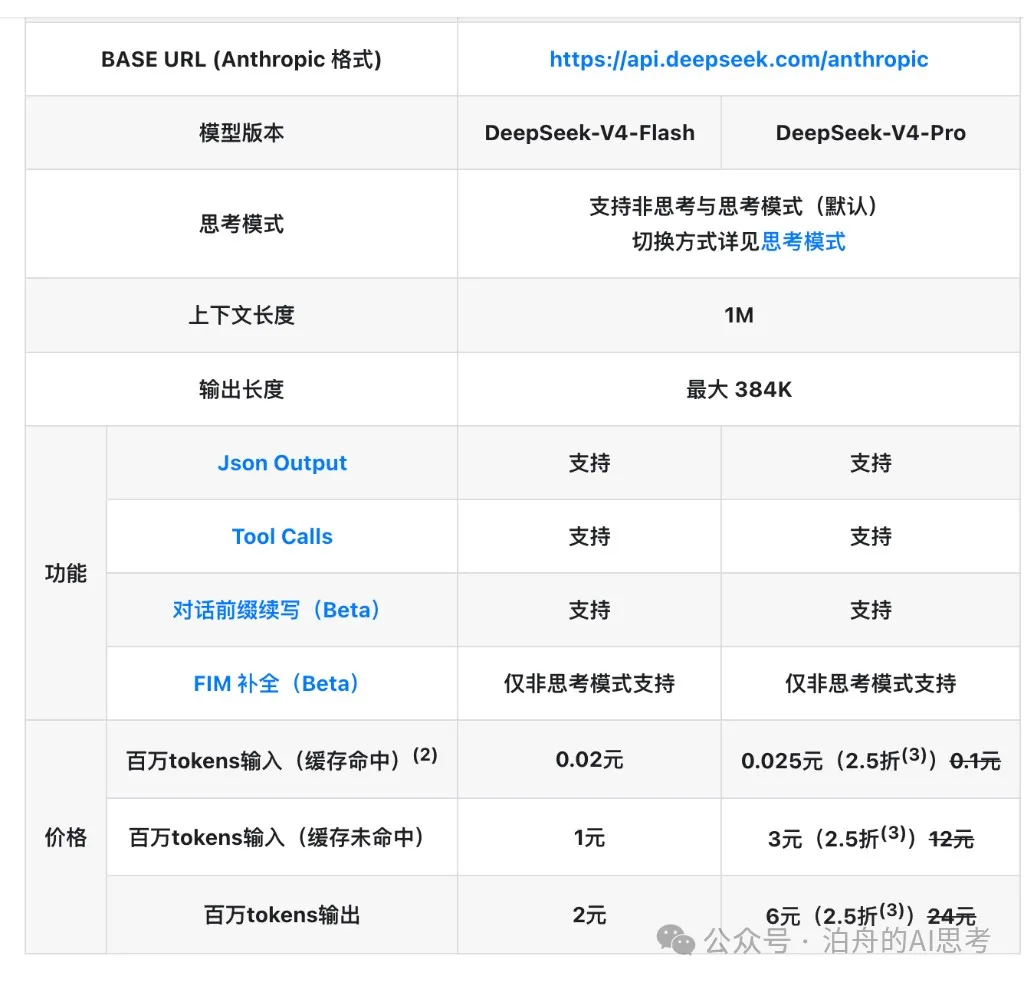
睇下裏便呢兩欄數字:
- • 緩存命中:0.025 元 / 百萬 tokens
- • 緩存未命中:3 元 / 百萬 tokens
同一個模型,同一段輸入,差 120 倍。
咁緩存究竟係乜嘢呢?點解可以令到模型價格差咁多,然後每個模型廠商都喺度強調緩存要點樣做,將緩存命中率當做生命線嚟維護。
呢篇就嚟將呢件事講清楚:乜嘢係緩存,KV Cache 同 Prompt Cache 分別係乜,點樣令到自己嘅請求多啲命中緩存,日常用嘅中轉站裏便呢啲字段又應該點樣睇。
但係傾緩存之前,要先傾一個繞唔開嘅詞:Token。
先傾下 token
所有 AI 公司都按 token 收費,唔係按問題數,亦唔係按字數。原因好簡單:模型眼裏冇字、冇問題、冇句子,只有 token。
token 係模型將人類語言切成嘅最細處理單元。但同一段話切出嚟有幾多 token,唔同模型俾嘅答案會有啲唔同。OpenAI 喺自家 cookbook 裏便清楚講過:唔同模型用唔同嘅 encoding,同一段字符串喺唔同 tokenizer 下切出嚟嘅 token 數可以差好多。
要一個粗略概念,可以睇 DeepSeek 官方俾嘅口徑:1 個中文字元大約 0.6 token,1 個英文字元大約 0.3 token。但 DeepSeek 自己都強調,呢個只係粗略估算,實際數量取決於模型 tokenizer,以 API 返回嘅 usage 為準。
Anthropic 嗰邊冇公開「中文每字幾多 token」呢種固定比例,只俾咗一個 token counting 接口俾你自己去數,文檔裏便都講明返嘅係估算值。
點解按 token 計費?因為模型每處理一個 token 都要做一次矩陣運算,所有顯存、算力、電費,最終都按 token 呢個粒度被消耗。按字數收費唔準,唔同 tokenizer 切出嚟嘅 token 數本來就唔一樣。按問題收費更加離譜,一個「你好」先得 2 個 token,一份幾萬字嘅財報掉入去就係幾萬 token,算力差幾千倍。
所以下面講嘅緩存,講來講去都係同一件事:邊啲 token 係新計嘅,邊啲 token 係從緩存直接拎嘅。前者按原價收,後者按打折價收,兩者中間可以差一兩個數量級。
一. 冇緩存嘅 AI 有幾蠢
先記住一個反直覺嘅事實:模型每爆一個新字,都要將前面所有字重新計一次。
LLM 嘅工作方式叫自迴歸。AI 圈叫呢個做自迴歸,翻譯過嚟就係單字蹦迪——一個字一個字咁爆出嚟,爆下一個字嘅時候一定要見到前面所有嘅字。
如果唔做任何優化,呢件事會變成災難。
你叫模型續寫一篇 1 萬字嘅文章。生成第 10001 個字時,模型要將前面 1 萬個字全部塞入注意力機制重計一次。生成第 10002 個字,又要計一次。生成第 10003 個字,又計一次。
更加可怕嘅係,呢個計算量唔係線性增長。文章長度翻倍,計算量唔係翻倍,係翻 4 倍。10 萬字嘅文章生成下一個字,理論上要做嘅乘法次數,係 1 萬字嘅 100 倍。
呢個就係注意力機制嘅二次方爆炸。字越長,算力消耗呈指數級膨脹。
放到真實模型上有幾嚇人?Llama 3-70B 想撐住 100 萬 token 嘅上下文,淨係中間過程產生嘅臨時數據,就要佔用 330 GB 顯存。一張頂級 H100 都先得 80 GB,根本裝唔落。喺任何冇優化嘅年代,長上下文呢件事喺工程上係冇可能嘅,更加唔好講實時生成。
我之前見到一個比喻特別貼切:一個學生讀小說,每讀到一句新句子,都要由第一頁第一個字開始重新讀一次先至明。讀到第 100 頁時,佢實際已經將第 1 頁讀咗 100 次,將第 50 頁讀咗 50 次。
好明顯冇人會咁樣讀書。工程師們都唔可以俾模型咁樣做,如果唔係 GPU 早就燒穿咗。
所以模型一定要諗辦法記筆記。記低嘅筆記,就係跟住要講嘅緩存。
二. KV Cache:閲讀時嘅草稿紙
最早俾工程師發明出嚟記筆記嘅工具,叫 KV Cache。
要明白 KV Cache 喺度做乜,要先返去模型工作嘅本質:模型就係一個根據前面嘅字預測下一個字嘅機器。
舉個例。你俾佢輸入 今天天氣真,模型讀完呢 5 個字,預測出下一個字好大機會係 好。把 好 駁上去,輸入變成 今天天氣真好,模型再去預測第 7 個字,可能係逗號,亦都可能係 啊。再駁上去,再預測第 8 個字,循環咁做。
問題嚟啦:預測第 7 個字嘅時候,前 6 個字喺注意力層計出嚟嗰堆 K 同 V,同頭先計第 6 個字時係一模一樣。如果每生成一個字都將前面所有字重計一次,就係上節講嘅二次方爆炸。
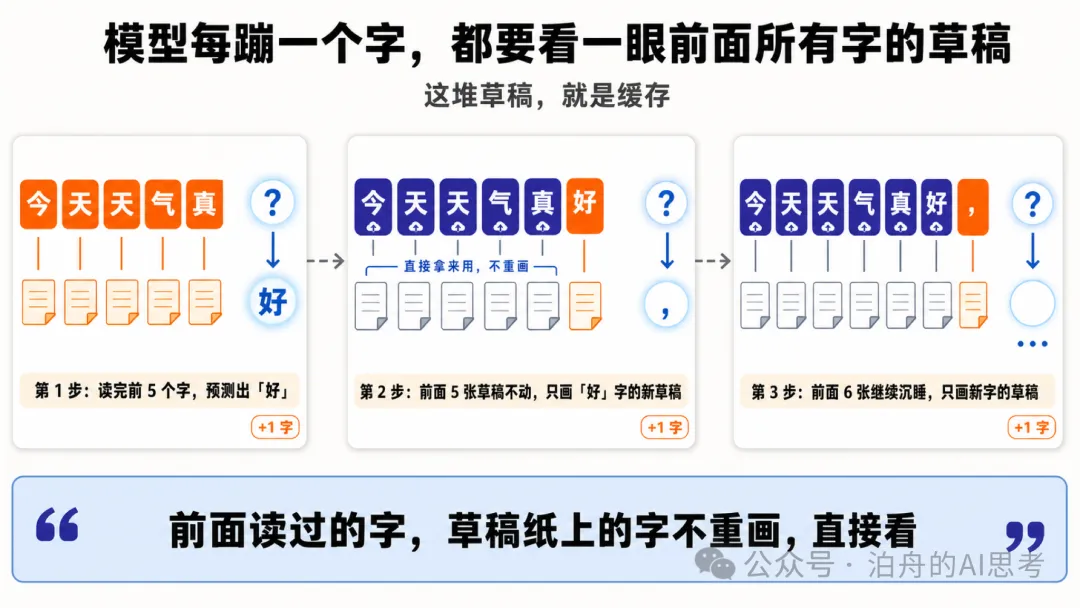
KV Cache 做嘅嘢就係:將前面已經計過嘅 K 同 V 存在顯存入面,下一個字只計自己嗰份,前面嗰啲直接攞嚟用。
K 係 Key,可以理解為目錄索引;V 係 Value,係索引指向嘅具體內容。每個 token 喺每一層注意力入面都會計出呢兩份嘢。
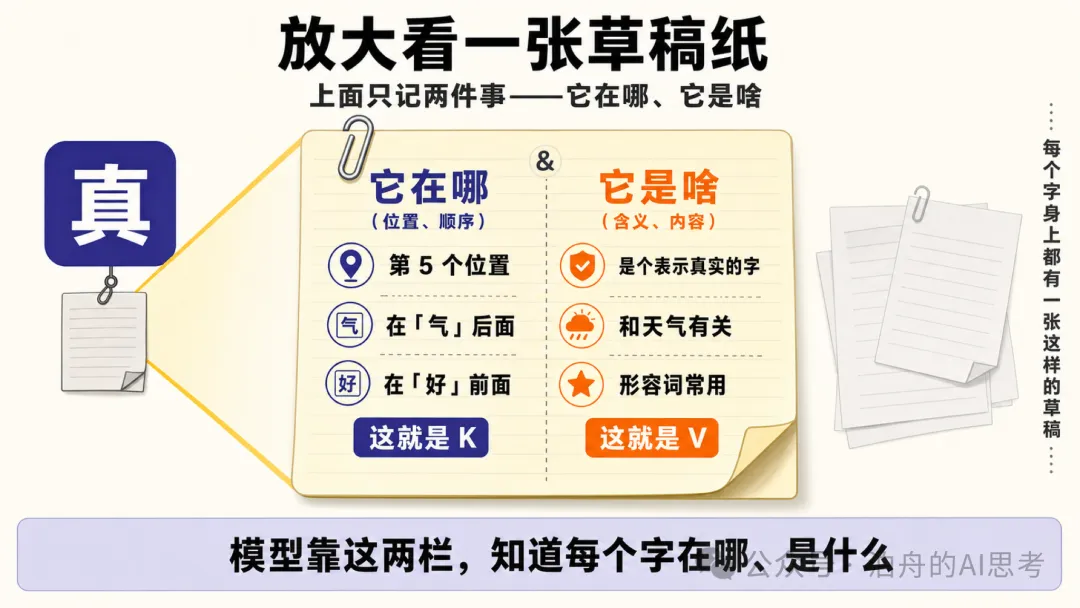
打個更加日常嘅比喻。做閲讀理解時你會喺草稿紙上記低核心人物、關鍵事件、重要數字。讀第二段唔使返轉頭重讀第一段,直接睇草稿紙就可以接返。KV Cache 就係呢張草稿紙。
有咗 KV Cache,嗰個二次方爆炸嘅災難就被壓平咗。模型生成第 10001 個字,只需要計呢一個字自己嘅 K 同 V,再去查前面 1 萬個字嘅草稿紙。算力消耗由指數級降到咗線性。
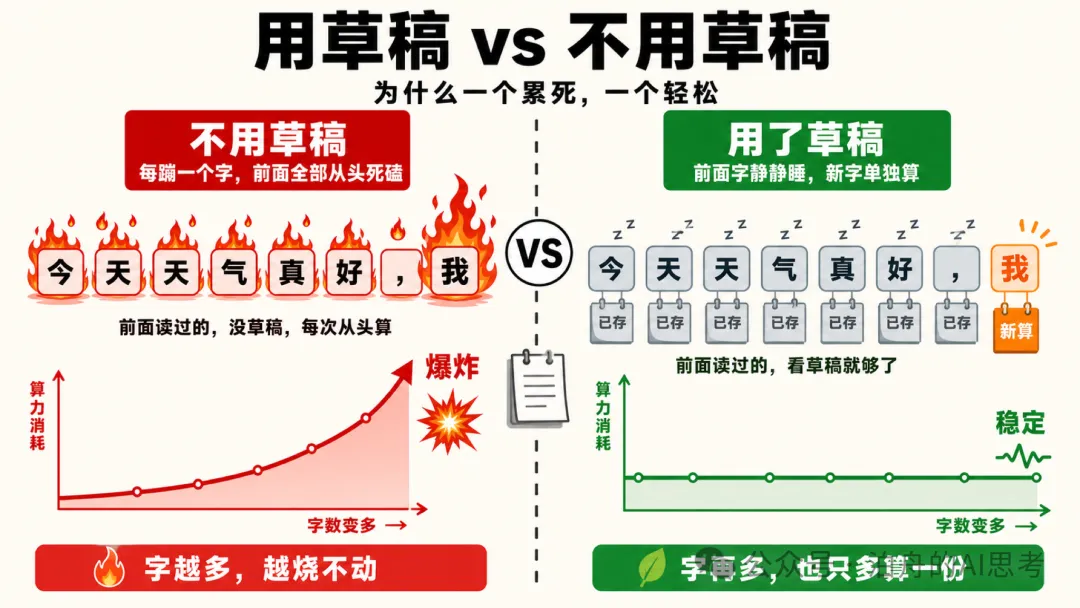
但 KV Cache 有三個關鍵限制,記住呢三條後面先至好理解 Prompt Cache:
- • 只喺一次請求裏便有效。呢次對話生成完,成張草稿紙直接撕咗佢
- • 唔影響 API 計費。你輸入 1 萬 token,模型該收幾多都係收幾多。KV Cache 慳嘅係模型自己嘅算力,唔係你嘅錢
- • 所有 LLM 都有。GPT、Claude、Gemini、DeepSeek、通義、文心,冇 KV Cache 嘅模型今日已經跑唔起
KV Cache 係大廠為咗唔令自己破產一定要做嘅底層基建。機器要能夠跑得鬱,KV Cache 係起點唔係終點。
留返個伏筆:每次嚟一個新請求,草稿紙都要從頭畫過。一萬個用戶問同一個 system prompt 底下嘅問題,就要畫一萬張幾乎一樣嘅草稿紙。咁樣唔浪費咩?
為瞭解決呢件事,工程師們整咗第二樣嘢。
三. Prompt Cache 同 DeepSeek 嘅硬盤緩存
返去嗰個一萬用戶嘅場景。如果大家都用同一個 system prompt,前面 5000 個 token 完全一樣,邊個嚟重計 9999 次都會覺得肉赤。
Prompt Cache 做嘅就係呢件事:跨請求複用,一個用戶計過嘅前綴,下個用戶直接攞。
要講清楚 Prompt Cache 同 KV Cache 嘅分別,要先將模型做嘢嘅過程切成兩半。
模型處理一次請求分兩步。第一步叫 prefill,將你輸入嘅成段 prompt 讀入嚟,計出每個 token 嘅 K 同 V。第二步叫 decode,一個字一個字咁爆答案出嚟。KV Cache 慳嘅係 decode 嗰步嘅算力,Prompt Cache 慳嘅係 prefill 呢步嘅錢。
一個用嚟加速生成,一個用嚟加速讀題。兩者作用階段唔同,作用域都唔同。
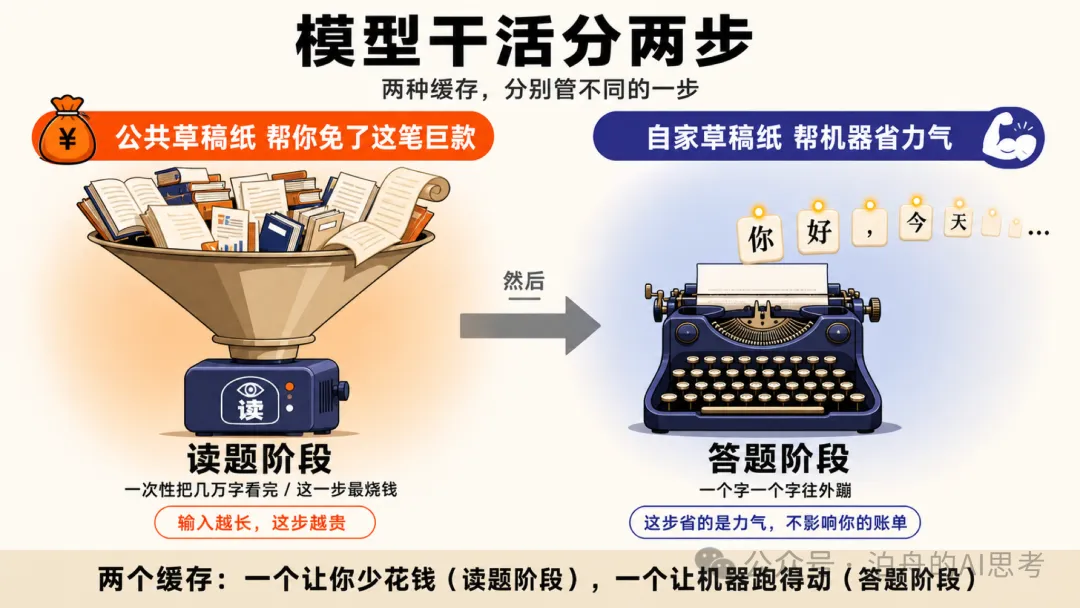
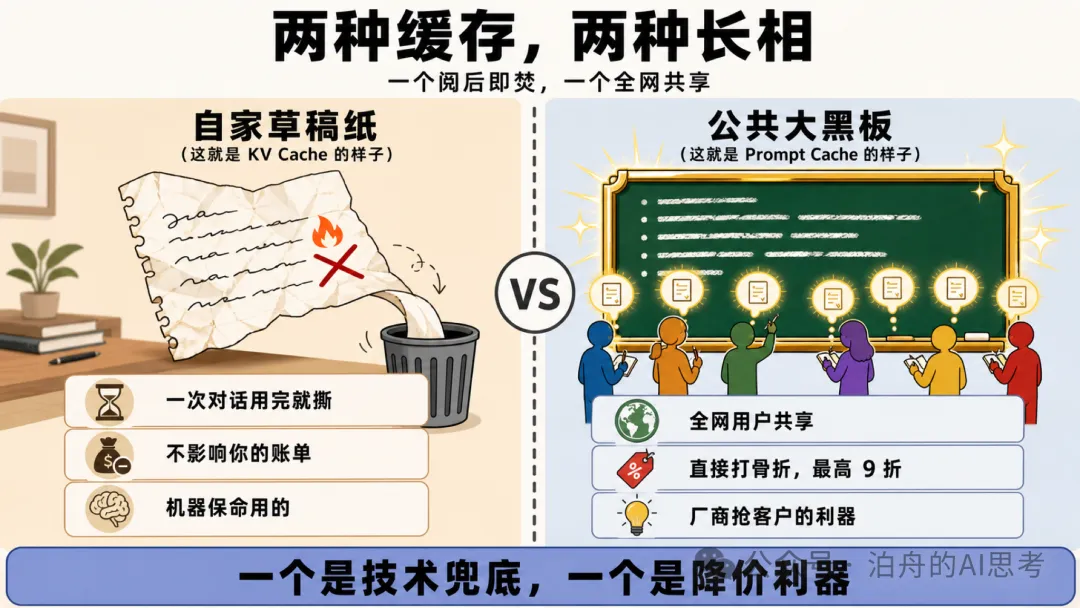
KV Cache 係大廠為咗唔令自己破產一定要做嘅底層基建,Prompt Cache 係大廠為咗搶客主動推出嘅商業產品。一個係技術兜底,一個係降價利器。
DeepSeek 點解可以比別家平咁多
OpenAI 同 Anthropic 嘅 Prompt Cache 都放喺顯存入面。顯存貴又少,留唔住嘢,5 到 10 分鐘就會被擠走。Anthropic 將呢套機制直接寫入咗定價:以 Claude Opus 4 系列為例,原價
DeepSeek 做咗一件別家冇做嘅事:將 Prompt Cache 直接寫到硬盤上,官方叫 Context Caching on Disk。
最容易誤解嘅一點:佢唔係叫模型每生成一個字都去硬盤讀 KV,咁樣真係會拖死。佢存嘅係 prompt 前綴嘅 prefill 結果(計好嘅 K/V 狀態),下次同樣開頭入嚟,prefill 直接跳過,將狀態從硬盤載入顯存,再正常 decode。
慳返嘅係更加貴嗰步:一段幾十萬 token 嘅 prefill 算力,遠比 NVMe 讀一次緩存嘅 I/O 成本貴。前提係緩存體積要夠細,DeepSeek 用自研嘅 MLA(多頭潛在注意力)將 KV Cache 壓到好細,啱啱好可以塞入硬盤陣列。
效果係可用時間直接拉滿:別家顯存入面 5 到 10 分鐘,DeepSeek 硬盤入面幾小時到幾日(官方話係 best effort,唔保證 100% 命中)。你今日發嘅請求,前綴可能命中咗尋日某個陌生人發過嘅同一段話。兩個素未謀面嘅人,因為開頭寫得一樣,第二個人直接享受咗第一個人俾過嘅算力賬單。
呢個先係 120 倍差價嘅真正秘密。唔係模型細,係緩存做到咗硬盤上。DeepSeek 仲將佢整成默認開啓,每次響應直接返回 prompt_cache_hit_tokens 和 prompt_cache_miss_tokens,命中幾多一目瞭然。
四. Claude Code 團隊嘅 6 條 cache 鐵律
知道咗原理,下一個問題係:點樣寫 prompt 先可以令到緩存命中率最高。
先睇一組真實數據。
技術專家 Ankit Sinha 做過一個嚴謹嘅統計實驗。優化前綴嘅請求平均使
將呢個數字推到企業生產線。每日萬級請求嘅規模下,淨係因為開頭加咗一個冇必要嘅時間戳,企業嘅年度 API 賬單由 9.5 萬美元飆到 33.3 萬美元,多燒近 25 萬。一個時間戳嘅代價。
呢個唔係誇張。Anthropic 自己嘅 Claude Code 團隊喺公開復盤入面直接話,佢哋成個工程架構都係圍繞 prompt caching 設計嘅,命中率跌少少都當 SEV 報。下面係佢哋公開嘅 6 條鐵律。
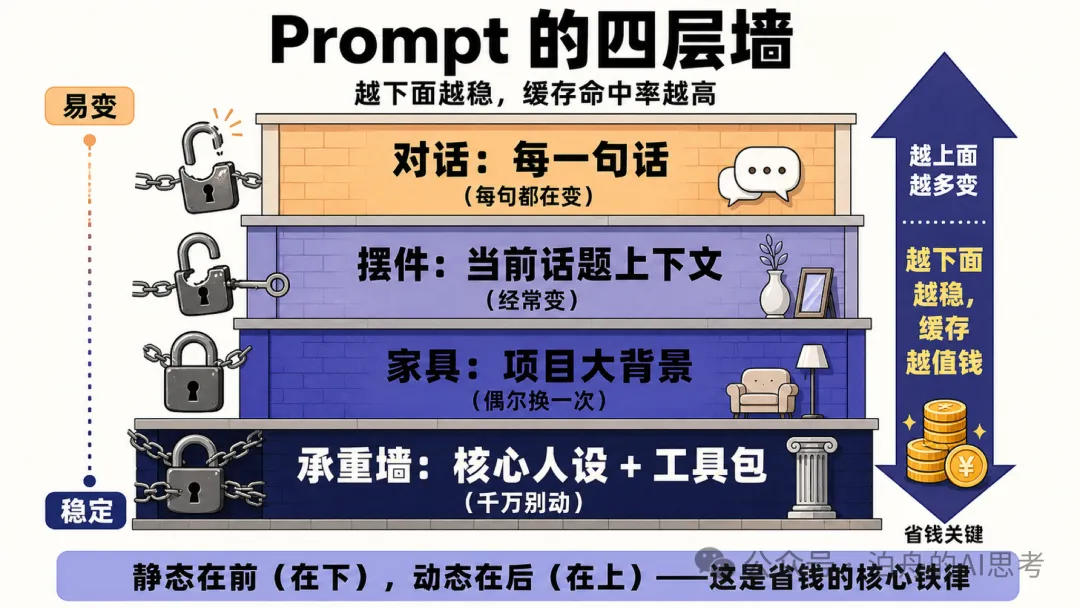
1. 靜態喺前,動態喺後
Claude Code 嘅 prompt 嚴格分 4 層,由前到後依次係:
- • 第 1 層 Static system prompt + Tools(全局共享緩存)
- • 第 2 層 Claude.MD(項目級緩存)
- • 第 3 層 Session context(會話級緩存)
- • 第 4 層 Conversation messages(動態對話)
越靠前嘅越穩定,越靠後嘅越多變。呢個順序保證咗無論邊個會話入嚟,前 3 層都能夠命中緩存。
Claude Code 自己都踩過坑:喺 static system prompt 入面塞過詳細時間戳,結果每分鐘緩存失效一次;工具定義順序非確定性洗牌,每次都換位,緩存當場全廢。
2. 要傳更新資訊?行 message 通道
日期變咗、用戶改咗文件、當前揀咗嘅代碼唔同咗,呢啲更新資訊唔好去改 system prompt。
system prompt 一改,前綴就變,成段緩存全廢。
Claude Code 嘅做法係:喺下一條 user message 或者 tool result 入面加一個 <system-reminder> 標籤,將更新資訊塞入去(例如 而家係星期三 呢種)。新嘅資訊照樣送到模型度,但前綴穩定唔變,緩存繼續命中。
3. 唔好中途轉模型
呢條最反直覺。
假設你同 Opus 傾咗 10 萬 token,問到一個簡單問題,想轉去 Haiku 慳啲錢。直覺上係慳咗,實際上更貴。
因為緩存係綁模型嘅。由 Opus 轉去 Haiku,等於要同 Haiku 重新建一次 10 萬 token 嘅緩存。呢一筆 prefill 計落,比 Opus 將呢個問題答完仲貴。
要轉模型點算?用 subagent。叫 Opus 準備一個 handoff message,將上下文壓縮成幾百 token 交俾 Haiku 處理。Claude Code 自己嘅 Explore agent 就係咁樣用 Haiku。
4. 唔好中途加減工具
工具列表都係 cached prefix 嘅一部分。加一個工具、減一個工具,成段對話嘅緩存即刻失效。
呢條最容易踩嘅場景係 plan 模式。
直覺上,入 plan 模式應該轉去得唯讀嘅工具集(唔可以俾 agent 改文件)。但咁樣一轉就破壞緩存。Claude Code 嘅做法好精妙:將 EnterPlanMode 同 ExitPlanMode 設計成兩個工具本身,所有工具永遠在線,只係透過呢兩個工具觸發狀態切換。
附帶好處:agent 自己都可以喺發現難題時主動叫 EnterPlanMode 入 plan 模式,全程緩存唔中斷。
5. 工具多就 defer_loading,唔好刪
MCP 工具幾十個全部塞入 prompt 入面,每次請求帶嘅 schema 都貴到肉赤。刪走一啲?又破壞緩存。
Claude Code 嘅解法叫 Tool Search。發出嘅工具列表入面,唔重要嘅嗰啲只放一個輕量 stub,只有工具名同 defer_loading: true。模型喺需要時透過一個叫 ToolSearch 嘅工具叫出完整工具,schema 只喺揀中時先加載。
咁樣,cached prefix 永遠穩定,所有 stub 順序固定,工具數量恆定,緩存命中率拉滿。
6. 好似監控 uptime 咁樣監控緩存命中率
Claude Code 對緩存命中率設咗告警閾值。命中率跌到某個數以下,工程師團隊當 SEV 報。
呢個係佢哋公開嘅運維紅線。將緩存命中率當 SLA 嚟管,同將服務可用性當 SLA 嚟管,一樣咁嚴肅。
將呢 6 條歸到一處,講嘅都係同一件事——前綴守住。任何一個字元嘅變化,都會令到後面全部作廢。
五. 點樣喺中轉站睇緩存讀寫
講咗咁多原理同規則,你點樣先知自己寫嘅 prompt 真係命中咗緩存?
淨係睇 API 文檔唔夠。有冇命中,要去日誌度睇。
最直接嘅地方係中轉站嘅使用記錄。我自己營運嘅 Dragon Code,底層係基於 Sub2API 呢套系統。市面上主流嘅中轉站多數都係 Sub2API 或 NewAPI 同源,字段生得差唔多。
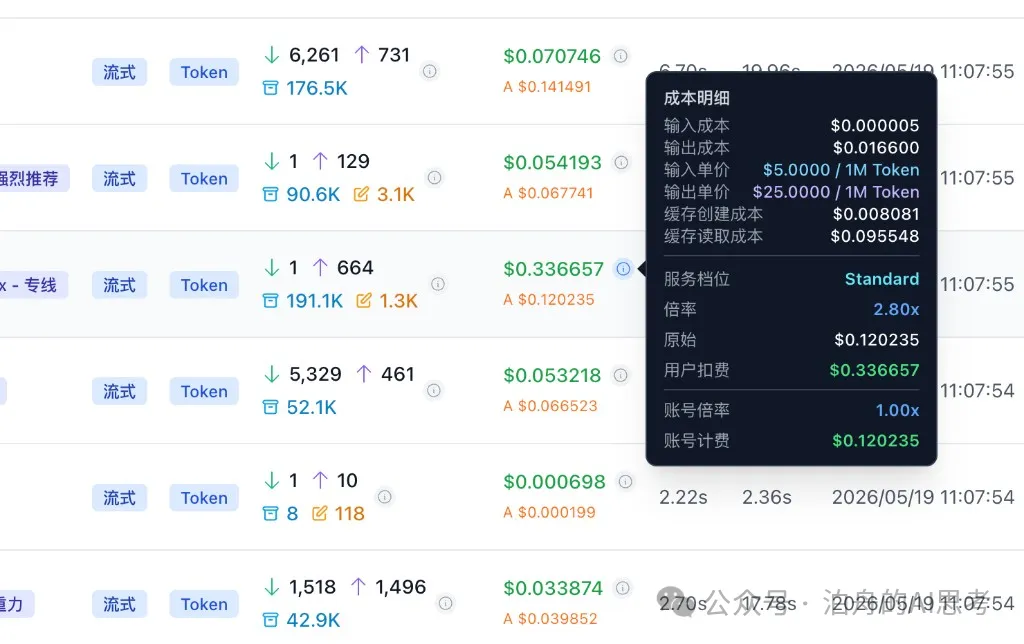
打開一次請求嘅明細,你會見到四個關鍵字段:
- • ↓ 綠色:輸入 token。呢部分係冇命中緩存嘅,按原價計
- • ↑ 紅色:輸出 token
- • 📦 藍色:緩存讀取 token。命中咗緩存,按打折價計
- • ✏️ 黃色:緩存寫入 token。首次創建緩存有少少溢價
舉個真實例子。我前幾日有一次請求係咁樣:
- • 輸入成本 $0.000005(得 1 個 token 行原價)
- • 緩存讀取成本 $0.095548(90.6K token 命中緩存)
- • 緩存創建成本 $0.008081(3.1K token 寫入新緩存)
- • 總計 $0.103634
如果呢次請求全部行原價(93.7K token 按普通輸入價),賬單大概係 $0.453。即係話,寫得 cache-friendly 之後,呢一次請求慳咗 4.7 倍。
NewAPI 體系嘅中轉站都係一樣,輸入日誌入面都可以見到對應嘅緩存讀寫字段。
呢度講下三種最容易踩嘅坑,表面睇命中、其實冇命中:
- 1. 首次請求唔會命中。你嘅 prompt 第一次發出去,正在創建緩存,見到 ✏️ 黃色嗰欄係正常嘅,唔使驚
- 2. 唔同賬號、唔同 API Key 之間唔共享。OpenAI 同 Anthropic 文檔入面都明確寫咗,prompt cache 唔跨組織。兩個團隊就算用一模一樣嘅 system prompt,緩存都係各自計
- 3. 中轉站偷偷改咗 system prompt。一啲中轉站會注入自家嘅安全提示詞,或者喺尾部加用戶 ID。呢種操作會將前綴污染咗,永遠都命中唔到。揀中轉站時呢條比價錢更加重要
將呢三條記低。下次見到自己嘅賬單貴到離譜,先去日誌度睇下係咪緩存冇命中,而唔係懷疑模型加咗價。
寫喺最後
返去開頭嗰張表:0.025 元 vs 3 元。
同樣係 100 萬 token,價格可以差到 120 倍,靠嘅唔係一句神秘咒語,就係緩存命中咗。
下次再有人問你,LLM 嘅緩存究竟係乜,你可以咁樣講:
KV Cache 係模型自己嘅草稿紙,等佢喺同一段生成入面唔使重複計前文。Prompt Cache 係服務商嘅公共草稿紙,等唔同請求可以複用同一段開頭。
真係要記一句話,就記呢句:靜態喺前,動態喺後。
以後寫 system prompt、工具定義、長文檔,盡量放前面,唔好成日變。用戶問題、時間、隨機 ID,盡量放後面。
AI 價格戰打到最後,拼嘅唔只係模型能力,亦係邊個更會將已經計過嘅嘢留低。對開發者嚟講,理解呢一點,可能比轉幾款平價模型更加有用。
下面這張 DeepSeek 的定價圖,很多人應該都見過。
看一眼裏面這兩欄數字:
- • 緩存命中:0.025 元 / 百萬 tokens
- • 緩存未命中:3 元 / 百萬 tokens
同一個模型,同一段輸入,差 120 倍。
那麼緩存究竟是什麼呢?為什麼能夠讓模型價格差這麼多,然後每個模型廠商都在強調緩存要怎麼做,把緩存命中率作為生命線來維護。
這篇就來把這件事講清楚:什麼是緩存,KV Cache 和 Prompt Cache 分別是什麼,怎麼讓自己的請求多命中緩存,日常用的中轉站裏這些字段又該怎麼看。
但聊緩存之前,得先聊一個繞不開的詞:Token。
先聊聊 token
所有 AI 公司都按 token 收費,不是按問題數,也不是按字數。原因很簡單:模型眼裏沒有字、沒有問題、沒有句子,只有 token。
token 是模型把人類語言切成的最小處理單元。但同一段話切出來多少 token,不同模型給的答案不太一樣。OpenAI 在自家 cookbook 裏明確說過:不同模型用不同的 encoding,同一段字符串在不同 tokenizer 下切出來的 token 數能差挺多。
要個粗略概念,可以看 DeepSeek 官方給的口徑:1 箇中文字符大約 0.6 token,1 個英文字符大約 0.3 token。但 DeepSeek 自己也強調,這只是粗估,實際數量取決於模型 tokenizer,以 API 返回的 usage 為準。
Anthropic 那邊沒公開"中文每字多少 token"這種固定比例,只給了一個 token counting 接口讓你自己去數,文檔裏也明說返回的是估算值。
為什麼按 token 計費?因為模型每處理一個 token 都要做一遍矩陣運算,所有顯存、算力、電費,最終都按 token 這個粒度被消耗。按字數收費不準,不同 tokenizer 切出來的 token 數本來就不一樣。按問題收費更離譜,一個"你好"才 2 個 token,一份幾萬字的財報丟進去就是幾萬 token,算力差幾千倍。
所以下面講的緩存,講來講去都是同一件事:哪些 token 是新算的,哪些 token 是從緩存裏直接拿的。前者按原價收,後者按打折價收,兩者中間能差一兩個數量級。
一. 沒有緩存的 AI 有多蠢
先記住一個反直覺的事實:模型每蹦一個新字,都要把前面所有字重新算一遍。
LLM 的工作方式叫自迴歸。AI 圈管這個叫自迴歸,翻譯過來就是單字蹦迪——一個字一個字往外蹦,蹦下一個字的時候必須看見前面所有的字。
如果不做任何優化,這件事會變成災難。
你讓模型續寫一篇 1 萬字的文章。生成第 10001 個字時,模型要把前面 1 萬個字全部塞進注意力機制重算一遍。生成第 10002 個字,再算一遍。生成第 10003 個字,又算一遍。
更可怕的是,這個計算量不是線性增長。文章長度翻倍,計算量不是翻倍,是翻 4 倍。10 萬字的文章生成下一個字,理論上要做的乘法次數,是 1 萬字的 100 倍。
這就是注意力機制的二次方爆炸。字越長,算力消耗呈指數級膨脹。
放到真實模型上有多嚇人?Llama 3-70B 想撐住 100 萬 token 的上下文,光是中間過程產生的臨時數據,就要佔掉 330 GB 顯存。一張頂級 H100 也才 80 GB,根本裝不下。在沒有任何優化的年代,長上下文這件事在工程上是不可能的,更別說實時生成了。
我之前看到一個比喻特別貼切:一個學生讀小說,每讀到一句新句子,都要從第一頁第一個字開始重新讀一遍才能理解。讀到第 100 頁時,他實際已經把第 1 頁讀了 100 遍,把第 50 頁讀了 50 遍。
顯然沒人會這麼讀書。工程師們也不能讓模型這麼幹,不然 GPU 早燒穿了。
所以模型必須想辦法記筆記。記下來的筆記,就是後面要講的緩存。
二. KV Cache:閲讀時的草稿紙
最早被工程師發明出來記筆記的工具,叫 KV Cache。
要明白 KV Cache 在幹什麼,得先回到模型工作的本質:模型就是一個根據前面的字預測下一個字的機器。
舉個例子。你給它輸入 今天天氣真,模型讀完這 5 個字,預測出下一個字大概率是 好。把 好 拼上去,輸入變成 今天天氣真好,模型再去預測第 7 個字,可能是逗號,也可能是 啊。再拼上去,再預測第 8 個字,循環往復。
問題來了:預測第 7 個字的時候,前 6 個字在注意力層算出來的那堆 K 和 V,跟剛才算第 6 個字時是一模一樣的。如果每生成一個字都把前面所有字重算一遍,就是上一節講的二次方爆炸。
KV Cache 乾的事就是:把前面已經算過的 K 和 V 存在顯存裏,下一個字只算自己的那一份,前面那些直接拿來用。
K 是 Key,可以理解為目錄索引;V 是 Value,是索引指向的具體內容。每個 token 在每一層注意力裏都會算出這兩份東西。
打個更日常的比方。做閲讀理解時你會在草稿紙上記下核心人物、關鍵事件、重要數字。讀第二段不用回頭重讀第一段,直接看草稿紙就能續上。KV Cache 就是這張草稿紙。
有了 KV Cache,那個二次方爆炸的災難就被壓平了。模型生成第 10001 個字,只需要算這一個字自己的 K 和 V,再去查前面 1 萬個字的草稿紙。算力消耗從指數級降到了線性。
但 KV Cache 有三個關鍵限制,記住這三條後面才好理解 Prompt Cache:
- • 只在一次請求裏有效。這次對話生成完,整張草稿紙直接撕掉
- • 不影響 API 計費。你輸入 1 萬 token,模型該收多少還是收多少。KV Cache 省的是模型自己的算力,不是你的錢
- • 所有 LLM 都有。GPT、Claude、Gemini、DeepSeek、通義、文心,沒有 KV Cache 的模型今天已經跑不起來了
KV Cache 是大廠為了不讓自己破產必須做的底層基建。機器要能跑得動,KV Cache 是起點不是終點。
留個伏筆:每來一個新請求,草稿紙都要從頭重畫。一萬個用戶問同一個 system prompt 下的問題,就要畫一萬張幾乎一樣的草稿紙。這不浪費嗎?
為了解決這件事,工程師們造了第二樣東西。
三. Prompt Cache 和 DeepSeek 的硬盤緩存
回到那個一萬用戶的場景。如果都用同一個 system prompt,前面 5000 個 token 完全一樣,誰來重算 9999 次都覺得心疼。
Prompt Cache 乾的就是這件事:跨請求複用,一個用戶算過的前綴,下個用戶直接拿。
要講清楚 Prompt Cache 和 KV Cache 的區別,得先把模型幹活的過程切成兩半。
模型處理一次請求分兩步。第一步叫 prefill,把你輸入的整段 prompt 讀進來,算出每個 token 的 K 和 V。第二步叫 decode,一個字一個字往外蹦回答。KV Cache 省的是 decode 那一步的算力,Prompt Cache 省的是 prefill 這一步的錢。
一個用來加速生成,一個用來加速讀題。兩者作用階段不同,作用域也不同。
KV Cache 是大廠為了不讓自己破產必須做的底層基建,Prompt Cache 是大廠為了搶客戶主動推出的商業產品。一個是技術兜底,一個是降價利器。
DeepSeek 為什麼能比別家便宜這麼多
OpenAI 和 Anthropic 的 Prompt Cache 都放在顯存裏。顯存貴又少,留不住東西,5 到 10 分鐘就被擠掉了。Anthropic 把這套機制直接寫進了定價:以 Claude Opus 4 系列為例,原價
DeepSeek 幹了一件別家沒做的事:把 Prompt Cache 直接寫到硬盤上,官方叫 Context Caching on Disk。
最容易誤解的點:它不是讓模型每生成一個字都去硬盤讀 KV,那真會拖死。它存的是 prompt 前綴的 prefill 結果(算好的 K/V 狀態),下次同樣開頭進來,prefill 直接跳過,把狀態從硬盤加載進顯存,再正常 decode。
省下的是更貴的那一步:一段幾十萬 token 的 prefill 算力,遠比 NVMe 讀一次緩存的 I/O 成本貴。前提是緩存體積要夠小,DeepSeek 用自研的 MLA(多頭潛在注意力)把 KV Cache 壓到了極小,剛好能塞進硬盤陣列。
效果是壽命直接拉滿:別家顯存裏 5 到 10 分鐘,DeepSeek 硬盤裏幾小時到幾天(官方說是 best effort,不保證 100% 命中)。你今天發的請求,前綴可能命中了昨天某個陌生人發過的同一段話。兩個素不相識的人,因為開頭寫得一樣,第二個人直接享受了第一個人付過的算力賬單。
這才是 120 倍價差的真正秘密。不是模型小,是緩存做到了硬盤上。DeepSeek 還把它做成默認開啓,每次響應裏直接返回 prompt_cache_hit_tokens 和 prompt_cache_miss_tokens,命中多少一目瞭然。
四. Claude Code 團隊的 6 條 cache 鐵律
知道了原理,下一個問題是:怎麼寫 prompt 才能讓緩存命中率最高。
先看一組真實數據。
技術專家 Ankit Sinha 做過一個嚴謹的統計實驗。優化前綴的請求平均花
把這個數字推到企業生產線。每天萬級請求的規模下,僅僅因為開頭加了一個不必要的時間戳,企業的年度 API 賬單從 9.5 萬美元飆到 33.3 萬美元,多燒近 25 萬。一個時間戳的代價。
這不是誇張。Anthropic 自己的 Claude Code 團隊在公開復盤裏直接說,他們整個工程架構都是圍繞 prompt caching 設計的,命中率掉一點都當 SEV 報。下面是他們公開的 6 條鐵律。
1. 靜態在前,動態在後
Claude Code 的 prompt 嚴格分 4 層,從前到後依次是:
- • 第 1 層 Static system prompt + Tools(全局共享緩存)
- • 第 2 層 Claude.MD(項目級緩存)
- • 第 3 層 Session context(會話級緩存)
- • 第 4 層 Conversation messages(動態對話)
越靠前的越穩定,越靠後的越多變。這個順序保證了不管哪個會話進來,前 3 層都能命中緩存。
Claude Code 自己也踩過坑:在 static system prompt 裏塞過詳細時間戳,結果每分鐘緩存失效一次;工具定義順序非確定性洗牌,每次都換位置,緩存當場全廢。
2. 要傳更新信息?走 message 通道
日期變了、用戶改了文件、當前選中的代碼不一樣了,這些更新信息別去改 system prompt。
system prompt 一改,前綴就變,整段緩存全廢。
Claude Code 的做法是:在下一條 user message 或者 tool result 里加一個 <system-reminder> 標籤,把更新信息塞進去(比如 現在是星期三 這種)。新的信息照樣送達模型,但前綴穩定不變,緩存繼續命中。
3. 不要中途換模型
這條最反直覺。
假設你跟 Opus 聊了 10 萬 token,問到一個簡單問題,想切到 Haiku 省點錢。直覺上是省了,實際更貴。
因為緩存是綁模型的。從 Opus 切到 Haiku,等於要給 Haiku 重新建一遍 10 萬 token 的緩存。這一筆 prefill 算下來,比 Opus 把這個問題答完還貴。
要切模型怎麼辦?用 subagent。讓 Opus 準備一個 handoff message,把上下文壓縮成幾百 token 交給 Haiku 處理。Claude Code 自己的 Explore agent 就是這麼用 Haiku 的。
4. 不要中途加減工具
工具列表也是 cached prefix 的一部分。加一個工具、減一個工具,整段對話的緩存立刻失效。
這條最容易踩的場景是 plan 模式。
直覺上,進 plan 模式應該切到只讀工具集(不能讓 agent 改文件)。但這一切就破壞緩存。Claude Code 的做法很精妙:把 EnterPlanMode 和 ExitPlanMode 設計成兩個工具本身,所有工具永遠在線,只通過這兩個工具觸發狀態切換。
附帶好處:agent 自己也可以在發現難題時主動調 EnterPlanMode 進 plan 模式,全程緩存不中斷。
5. 工具多就 defer_loading,不要刪
MCP 工具幾十個全塞進 prompt 裏,每次請求帶的 schema 都貴到肉疼。刪掉一些?又破壞緩存。
Claude Code 的解法叫 Tool Search。發出去的工具列表裏,不重要的那些只放一個輕量 stub,只有工具名和 defer_loading: true。模型在需要時通過一個叫 ToolSearch 的工具調出完整工具,schema 只在選中時才加載。
這樣,cached prefix 永遠穩定,所有 stub 順序固定,工具數量恆定,緩存命中率拉滿。
6. 像監控 uptime 一樣監控緩存命中率
Claude Code 對緩存命中率設了告警閾值。命中率掉到某個數以下,工程師團隊當 SEV 報。
這是他們公開的運維紅線。把緩存命中率當 SLA 來管,跟把服務可用性當 SLA 來管,一樣嚴肅。
把這 6 條歸到一處,講的都是同一件事——前綴守住。任何一個字符的變化,都會讓後面全部作廢。
五. 怎麼在中轉站看緩存讀寫
講了這麼多原理和規則,你怎麼知道自己寫的 prompt 真的命中了緩存?
光看 API 文檔不夠。命中沒命中,得去日誌裏看。
最直接的地方是中轉站的使用記錄。我自己運營的 Dragon Code,底層是基於 Sub2API 這套系統。市面上主流的中轉站基本都是 Sub2API 或 NewAPI 同源,字段長得都差不多。
打開一次請求的明細,你會看到四個關鍵字段:
- • ↓ 綠色:輸入 token。這部分是沒命中緩存的,按原價算
- • ↑ 紅色:輸出 token
- • 📦 藍色:緩存讀取 token。命中了緩存,按打折價算
- • ✏️ 黃色:緩存寫入 token。首次創建緩存有一點溢價
舉個真實的例子。我前幾天有一次請求長這樣:
- • 輸入成本 $0.000005(只有 1 個 token 走原價)
- • 緩存讀取成本 $0.095548(90.6K token 命中緩存)
- • 緩存創建成本 $0.008081(3.1K token 寫入新緩存)
- • 總計 $0.103634
如果這次請求全部走原價(93.7K token 按普通輸入價),賬單大概是 $0.453。也就是說,寫得 cache-friendly 之後,這一次請求省了 4.7 倍。
NewAPI 體系的中轉站也是一樣,輸入日誌裏都能看到對應的緩存讀寫字段。
這裏說一下三種最容易踩的坑,看上去命中、其實沒命中:
- 1. 首次請求不會命中。你的 prompt 第一次發出去,正在創建緩存,看到 ✏️ 黃色那欄是正常的,不要慌
- 2. 不同賬號、不同 API Key 之間不共享。OpenAI 和 Anthropic 文檔裏都明確寫了,prompt cache 不跨組織。兩個團隊即使用一模一樣的 system prompt,緩存也是各算各的
- 3. 中轉站偷偷改了 system prompt。一些中轉站會注入自家的安全提示詞,或者在尾部追加用戶 ID。這種操作會把前綴污染掉,永遠命不中。挑中轉站時這一條比價格還重要
把這三條記下來。下次看到自己的賬單貴得離譜,先去日誌裏看一眼是不是緩存沒命中,而不是懷疑模型漲價了。
寫在最後
回到開頭那張表:0.025 元 vs 3 元。
同樣是 100 萬 token,價格能差到 120 倍,靠的不是一句神秘咒語,就是緩存命中了。
下次再有人問你,LLM 的緩存到底是什麼,你可以這麼講:
KV Cache 是模型自己的草稿紙,讓它在同一次生成裏別重複算前文。Prompt Cache 是服務商的公共草稿紙,讓多個請求複用同一段開頭。
真要記一句話,就記這個:靜態在前,動態在後。
以後寫 system prompt、工具定義、長文檔,儘量放前面,別天天變。用戶問題、時間、隨機 ID,儘量放後面。
AI 價格戰打到最後,拼的不只是模型能力,也是誰更會把已經算過的東西留下來。對開發者來說,理解這一點,可能比多換幾個便宜模型更有用。