DeepSeek-V4-Pro 寫代碼到底行不行?我拿 GLM-5.1 跟它硬碰硬比了一輪
整理版優先睇
DeepSeek-V4-Pro基代碼能力有明顯進步,但複雜項目同深度理解仍不及GLM-5.1;建議日常用V4,關鍵任務用GLM-5.1。
呢篇文章係作者孟健嘅親身測試,佢本身用開GLM-5.1寫代碼,對GLM-5.1嘅水平好清楚。DeepSeek-V4-Pro一出,官方話代碼能力大幅升級,作者想睇嚇V4係咪真係追得上GLM-5.1。佢冇跑benchmark,而係拎四個實際工作場景:源碼分析、功能實現、大文件拆分同項目架構分析,叫兩個模型正面對決。
結果顯示,DeepSeek-V4-Pro喺基礎編碼能力上進步好大,代碼結構、命名規範、基本邏輯都做得幾好,日常中小功能完全夠用。但喺深度理解(唔只睇做咩,仲要明點解咁做)、邊界意識(對異常、錯誤、極端情況嘅預判同處理)同長上下文管理(大文件、複雜項目嘅全局把控)呢三方面,依然同GLM-5.1有明顯差距。最終結論係:V4部分追上了,但未完全追上;建議按任務性質搭配使用,簡單任務畀V4,關鍵任務畀GLM-5.1。
- 結論:DeepSeek-V4-Pro基礎編碼能力進步顯著,但深度理解、邊界意識同長上下文管理仍輸畀GLM-5.1。
- 方法:用四個實際工作場景(源碼分析、功能實現、大文件拆分、項目架構分析)進行正面比對,唔跑benchmark。
- 差異:V4喺大文件拆分精細度略勝,但GLM-5.1喺全局把握同實用建議上更紮實。
- 啟發:每個模型有自己強項,唔使二選一,可以互補使用。
- 可行動點:預算緊就畀V4做日常任務,GLM-5.1處理關鍵任務;簡單交V4,複雜交GLM-5.1。
測試背景同方法
作者孟健本身係GLM-5.1嘅長期用戶,對呢個模型嘅代碼能力心中有數。DeepSeek-V4-Pro一出,官方吹到代碼能力大幅升級,佢決定唔信benchmark,而係用四個實際工作場景——源碼分析、功能實現、大文件拆分同項目架構分析——叫兩個模型正面硬碰硬,睇嚇V4係咪真係追得上。
作者強調:唔跑分,唔benchmark,直接用真實工作場景比對。
四個場景實測結果
第一個場景係分析Claude Code源碼,兩個模型都做到,但GLM-5.1理解更深入;第二個場景係借鑑Claude Code設計從零實現緩存管理系統,DeepSeek-V4-Pro直接生成了10個完整功能模塊,表現唔錯;第三個場景係拆分一個過千行嘅代碼文件,V4拆分得更精細(5個文件),GLM-5.1拆成4個文件,但V4用時耐啲;第四個場景係項目架構分析,V4畀出全面嘅表格總結同評分,而GLM-5.1先全面探索目錄再分析,最後畀出優先級排序,建議更實用。
使用成本對比
DeepSeek-V4-Pro冇Coding Plan,作者透過API接入Claude Code使用,充值100蚊,做完上述工作花費15.75蚊。GLM-5.1有Coding Plan,消耗量都唔少,但具體金額冇詳細列明。成本方面,V4依然有傳統優勢。
DeepSeek-V4-Pro成本優勢明顯,同上一次測試一樣,性價比高。
結論同建議
總括嚟講,DeepSeek-V4-Pro喺基礎編碼能力上進步好大,日常中小功能完全夠用,但喺深度理解、邊界意識同長上下文管理三方面同GLM-5.1仲有明顯差距。作者建議唔使二選一,而係搭配用:簡單任務畀V4,關鍵任務畀GLM-5.1。
大家好,我係孟健。
DeepSeek-V4-Pro 出咗,官方話代碼能力大幅升級。呢啲嘢我聽得多啦,每次有新模型發佈都係咁講。
但我真係好奇:V4 喺寫代碼呢件事上,到底有冇追上 GLM-5.1?
GLM-5.1 係我日常寫代碼嘅主力模型,用咗幾個月,佢咩水平我心中有數。所以今次我唔跑 benchmark,唔鬥跑分,就用我實際工作中嘅四個場景,叫兩個模型正面硬碰。
四個場景:源碼分析、功能實現、大檔案拆分、項目架構分析。
最後再計嚇數,睇嚇邊個成本更抵。
場景一:項目分析,分析 Claude Code 源碼
前排 Claude Code 源碼洩漏,我用 GLM-5.1 完整分析咗一次 Claude Code 源碼,今日 DeepSeek-V4-Pro 發佈,我都叫佢分析一次源碼睇嚇。
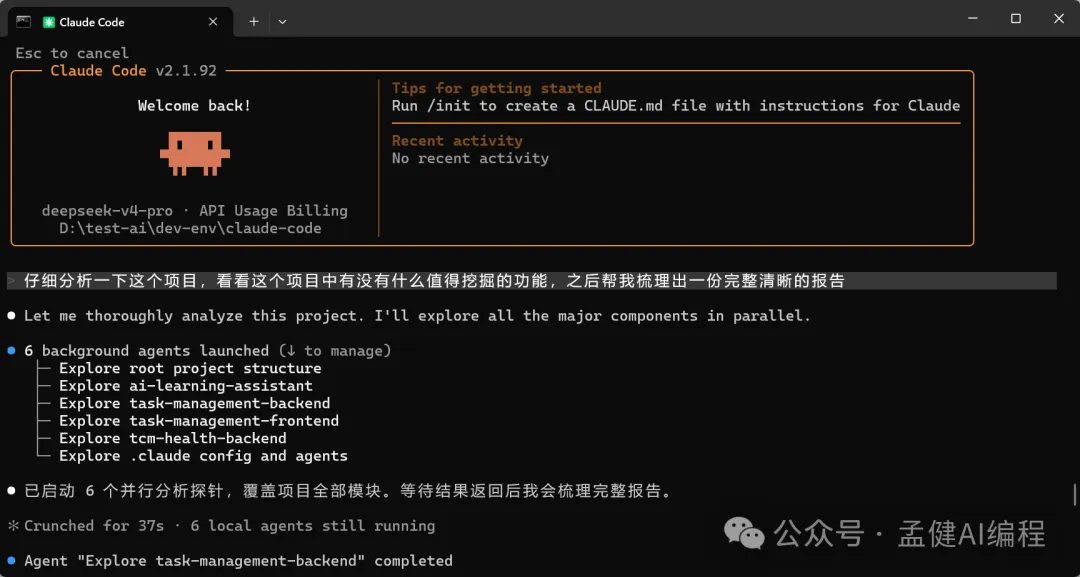
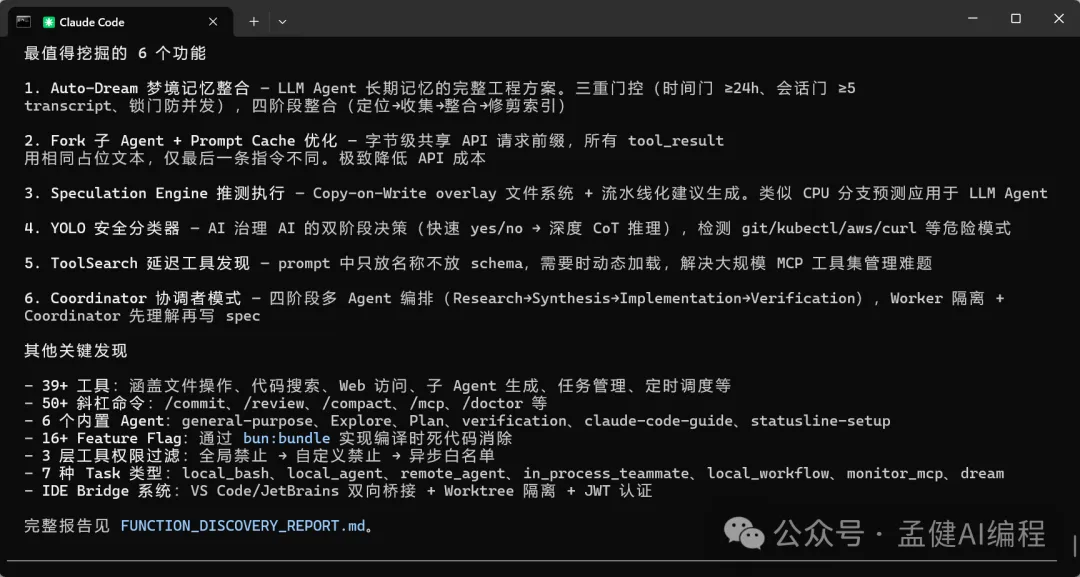
基本上值得挖掘嘅功能,都仔細挖咗一次,睇落都唔錯。
場景二:借鑑 Claude Code 入面嘅代碼,從零開始完整實現一個功能
上次我叫 GLM-5.1 分析完 Claude Code 源碼之後,借鑑咗代碼裏面一啲有趣嘅設計同點子,重新由零開始完整交付咗一個緩存管理系統;今日我哋同樣叫 DeepSeek-V4-Pro 試嚇,睇嚇佢能唔能夠自己由零開始交付一個完整項目。
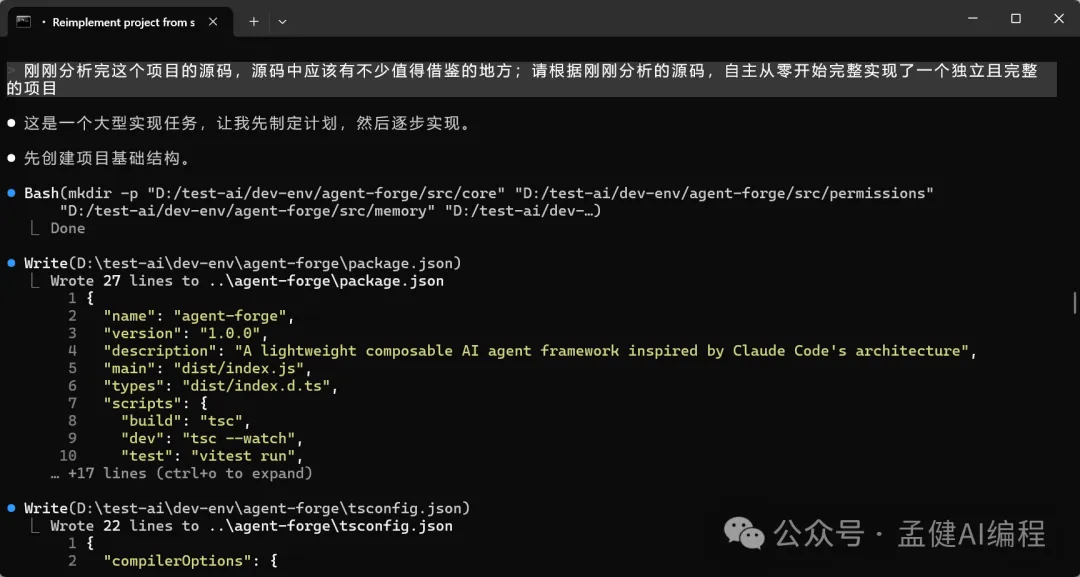
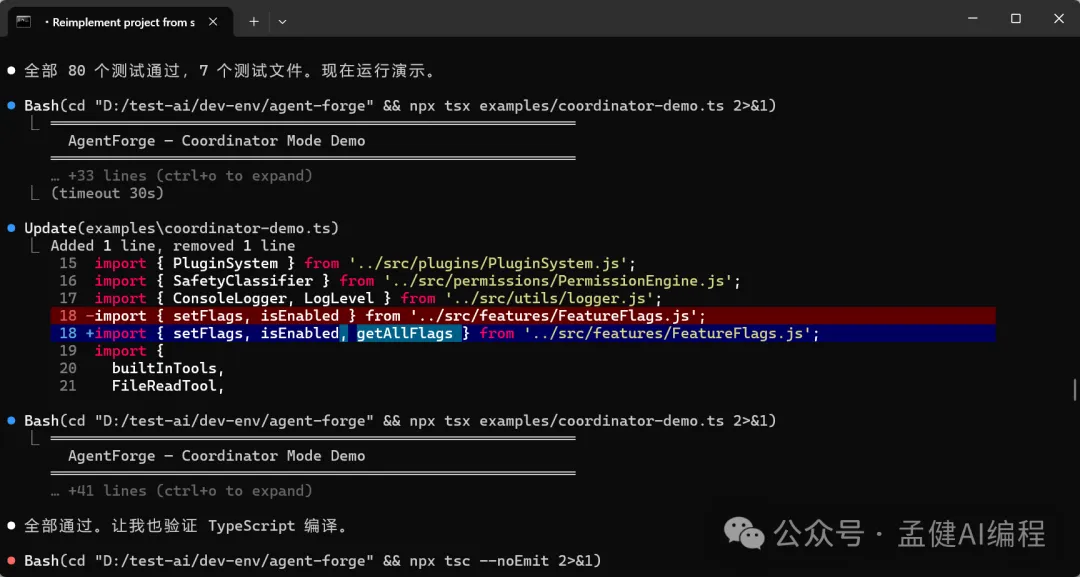
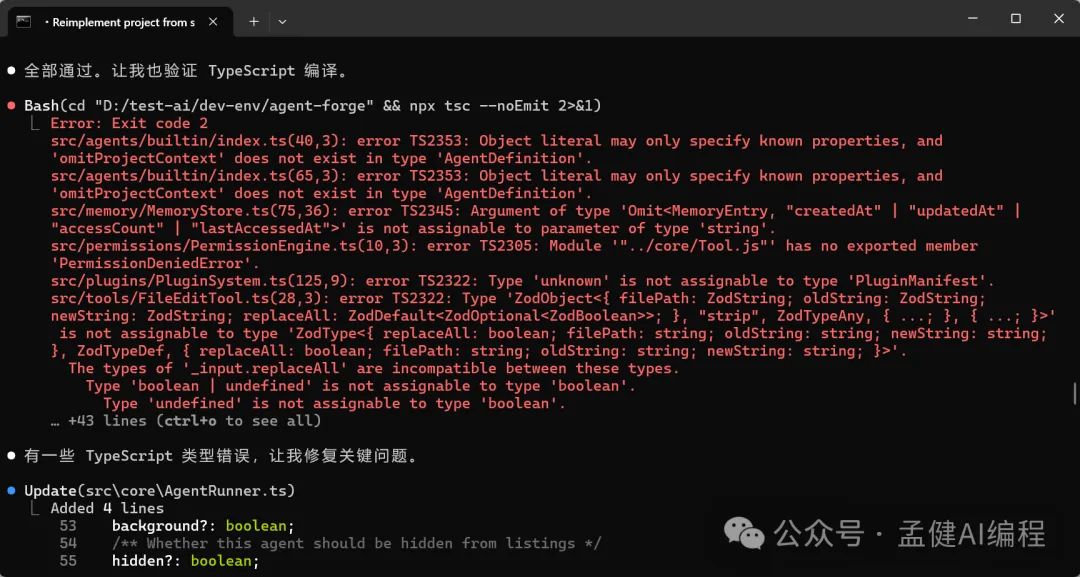

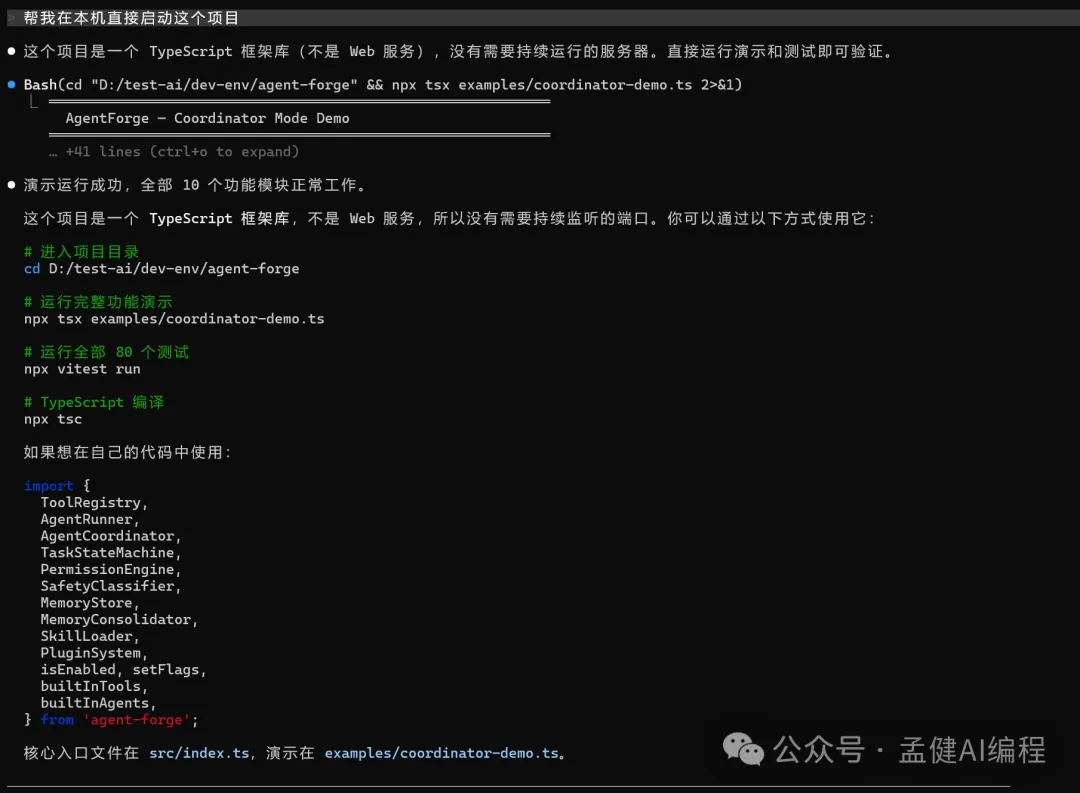
等咗一段時間,見到 DeepSeek-V4-Pro 直接借鑑 Claude Code 源碼幫我實現咗10個完整嘅功能模塊;由此可見,DeepSeek-V4-Pro 嘅代碼能力真係幾勁。
場景三:拆檔案,我啱啱手頭有一個項目,一個檔案代碼幾千行
下面呢個代碼檔案有1000幾行,我哋試嚇分別叫 GLM-5.1 同 DeepSeek-V4-Pro 各自拆開嚟睇嚇。
1、DeepSeek-V4-Pro
2、GLM-5.1
同一個項目,同一個檔案,同一段提示詞,我而家叫 GLM-5.1 拆開嚟睇嚇。
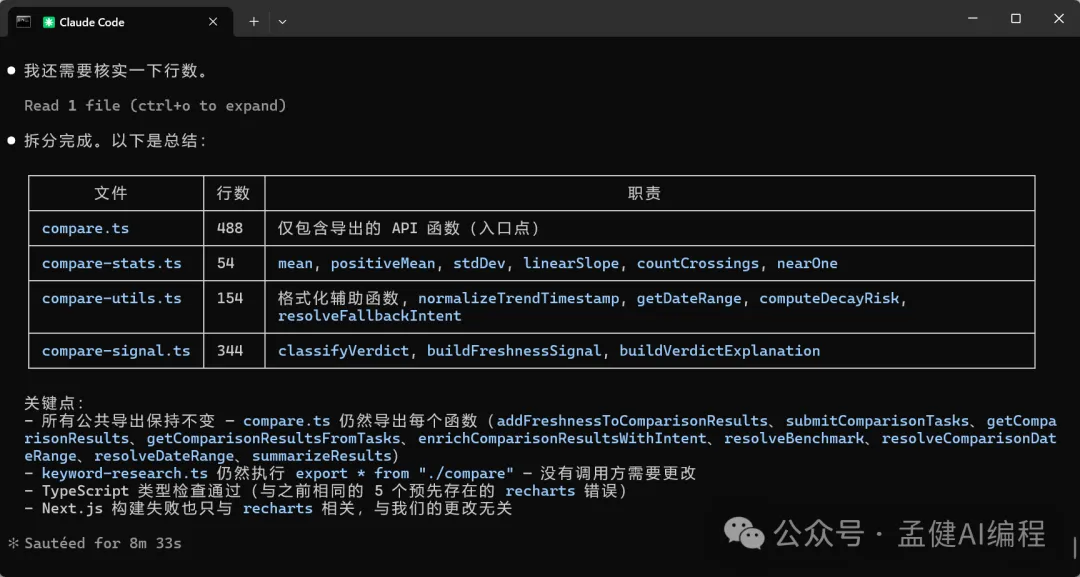
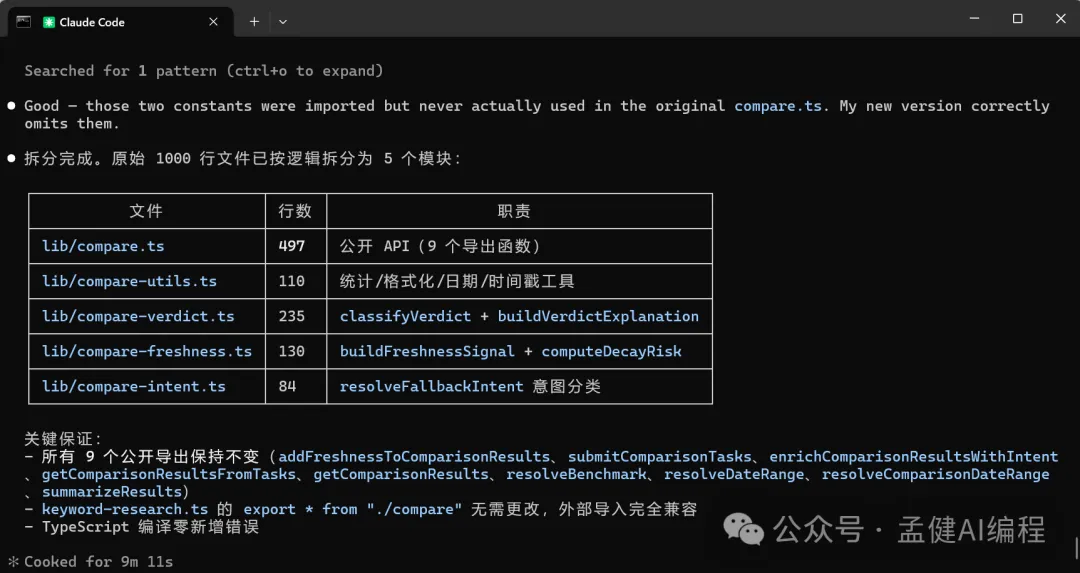
而家 GLM-5.1 同 DeepSeek-V4-Pro 都已經對呢個超過1000行嘅代碼檔案拆完;GLM-5.1 將呢個檔案拆成咗4個檔案,用咗大概8分33秒;DeepSeek-V4-Pro 將呢個檔案拆成咗5個檔案,用咗大概9分11秒。
速度上,GLM-5.1 稍稍領先,DeepSeek 拆得更加精細,將 compare 拆成通用工具、判斷、新鮮度同埋意圖識別4個檔案,拆得更加仔細,喺代碼檔案拆分嘅精細程度上,似乎 DeepSeek-V4-Pro 稍勝一籌。
場景四:項目架構分析
最近啱啱做咗一個項目,已經上線運行緊,但技術債有啲嚴重,啱啱好藉呢個機會叫兩個國產模型幫我分析項目架構,畀出合理嘅調整建議。
1、DeepSeek-V4-Pro
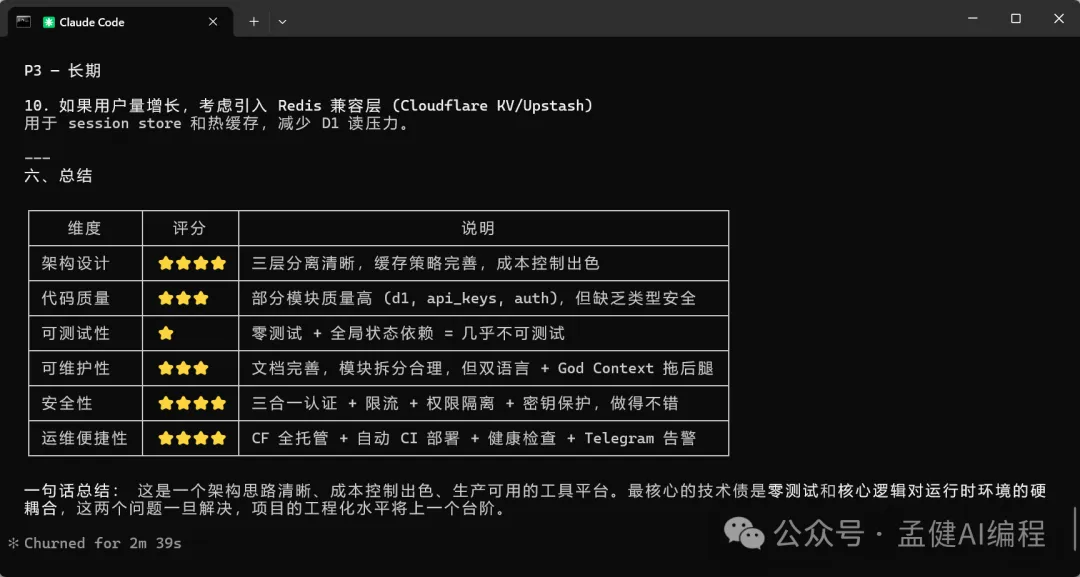
2、GLM-5.1

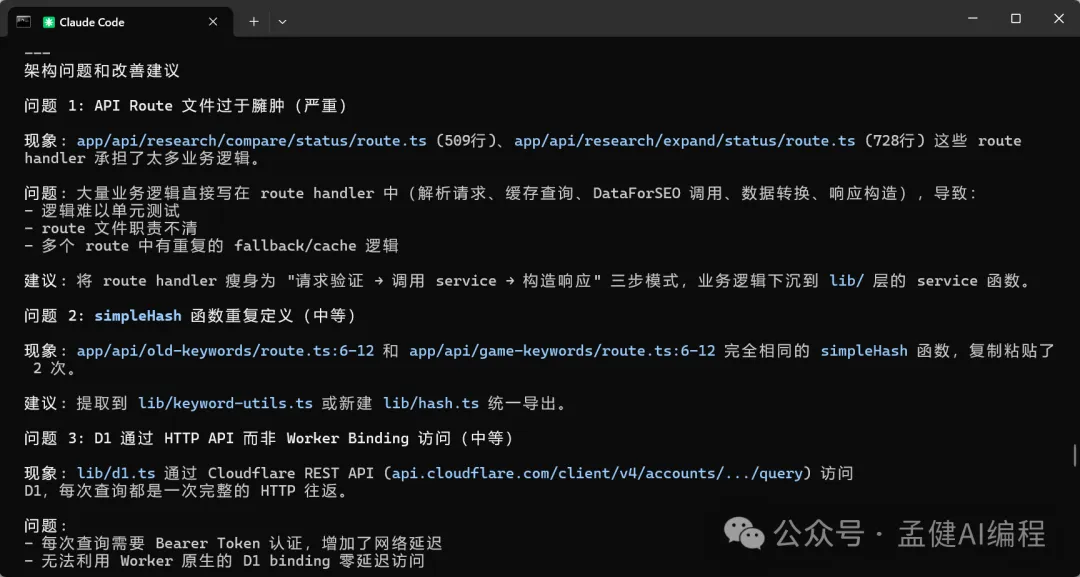
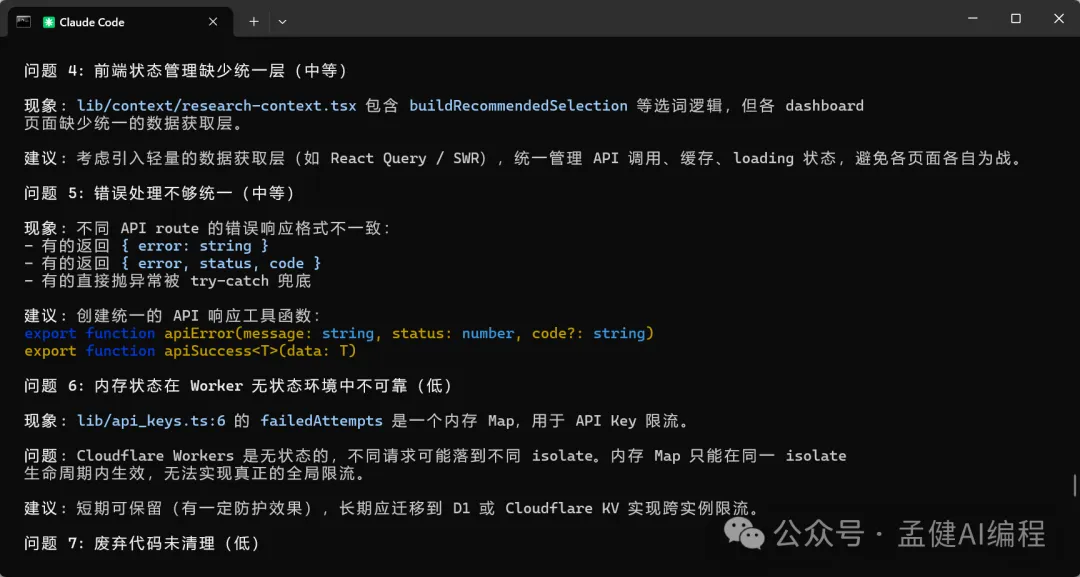
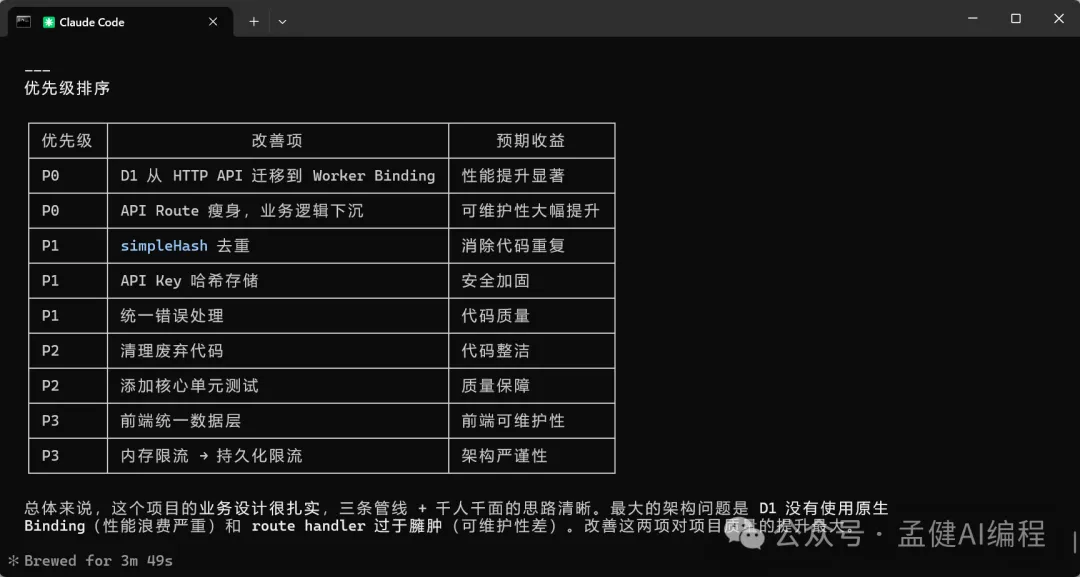
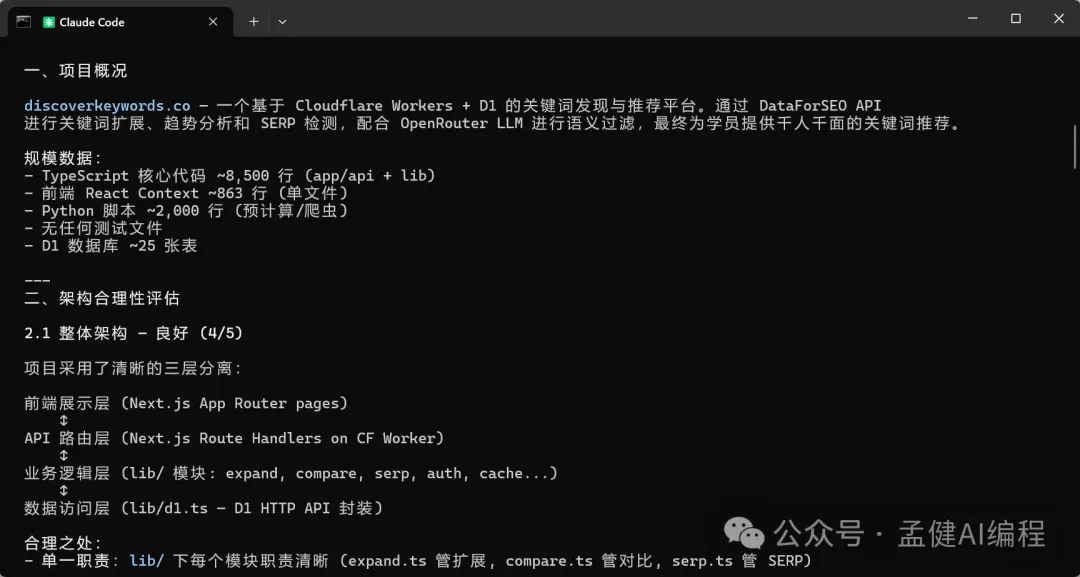
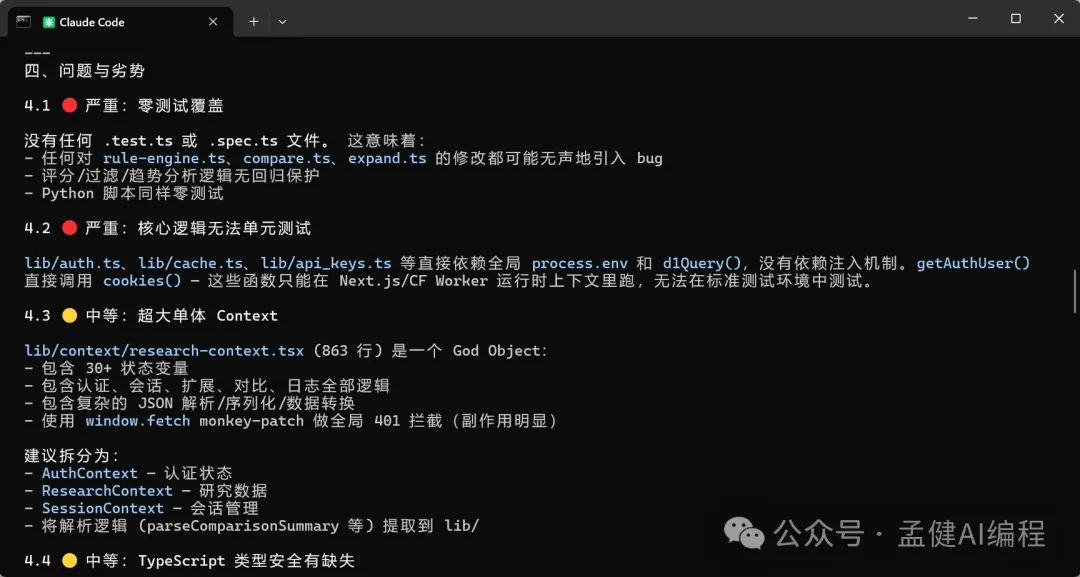
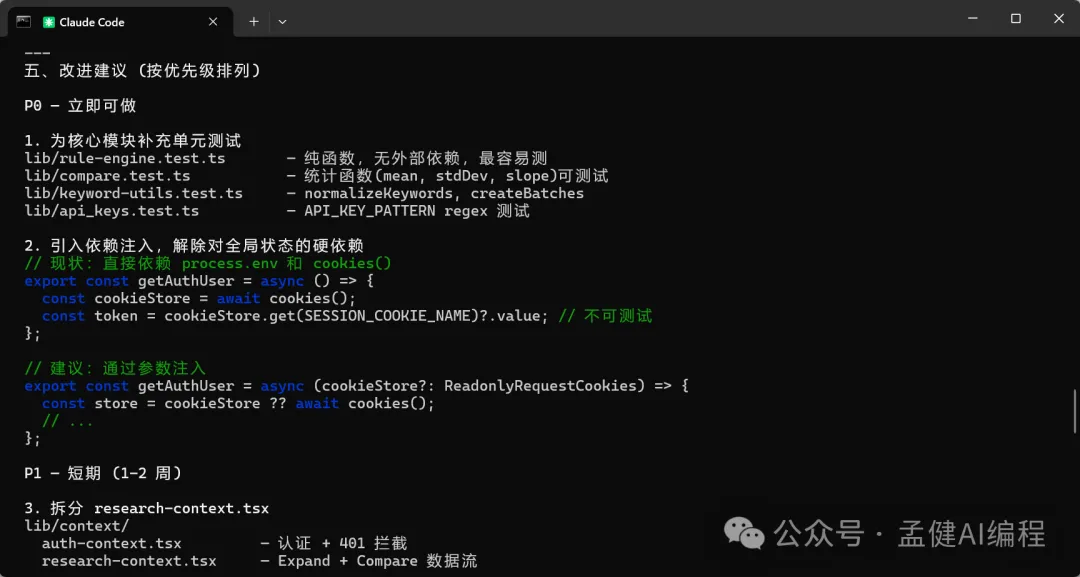
可以見到,而家 DeepSeek-V4-Pro 同 GLM-5.1 都對我嘅項目進行咗分析,仲畀出完整嘅分析報告。透過上面嘅項目架構分析可以睇到,DeepSeek-V4-Pro 畀出嘅架構分析比較全面,特別係最後嘅總結用表格形式畀出,仲從唔同維度畀出評分,最後一句話總結將項目嘅優劣都講曬。
GLM-5.1 分析得都唔錯,當我叫佢開始分析項目嘅時候,佢首先徹底全面探索咗我成個項目目錄,之後先分析,對整體項目架構分析得比較紮實;最後更加用優先級排序嘅方式畀出項目嘅優化計劃,最後仲明確指出項目冇用到 D1 原生綁定功能,畀嘅建議更加實用,所以覺得 GLM-5.1 對整體項目嘅把握度優於 DeepSeek-V4-Pro。
關於使用成本
DeepSeek-V4-Pro 目前冇 Coding Plan,所以我係透過 API 直接接入 Claude Code 嚟用,今日啱啱充值咗100蚊,上面做咗呢啲工作,使咗15.75蚊。
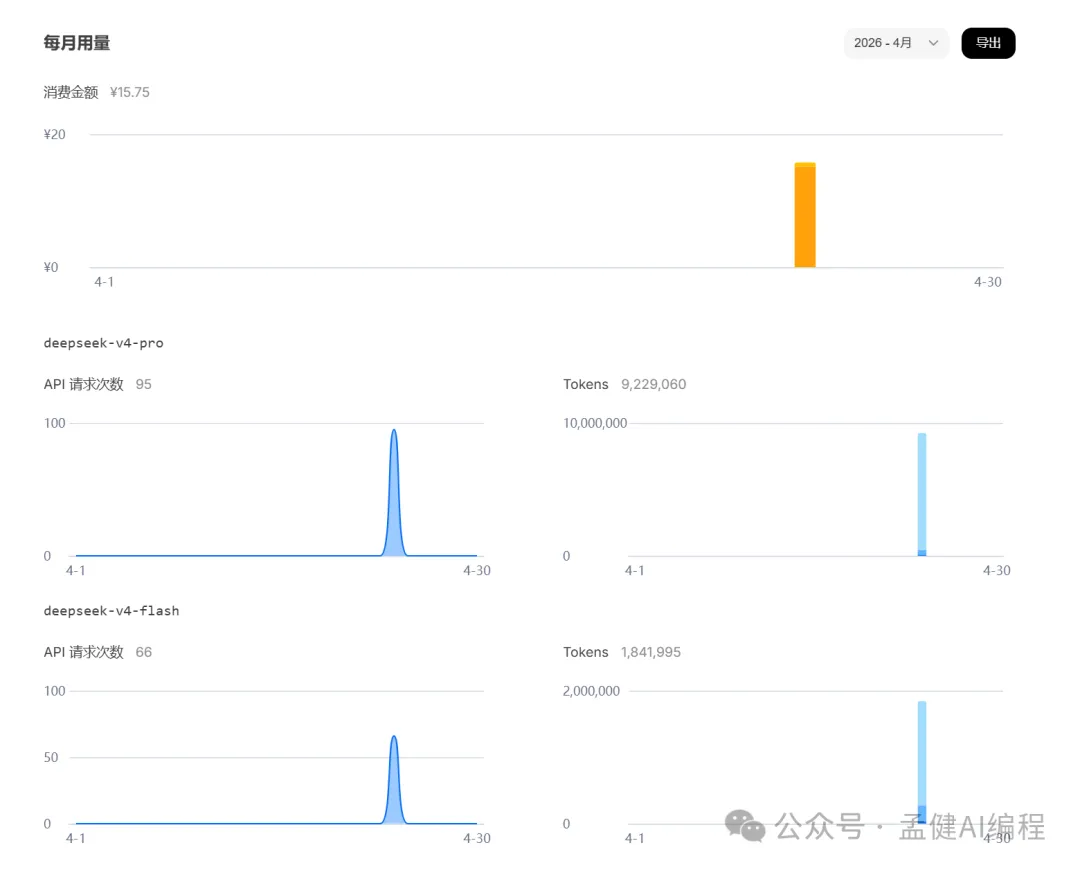
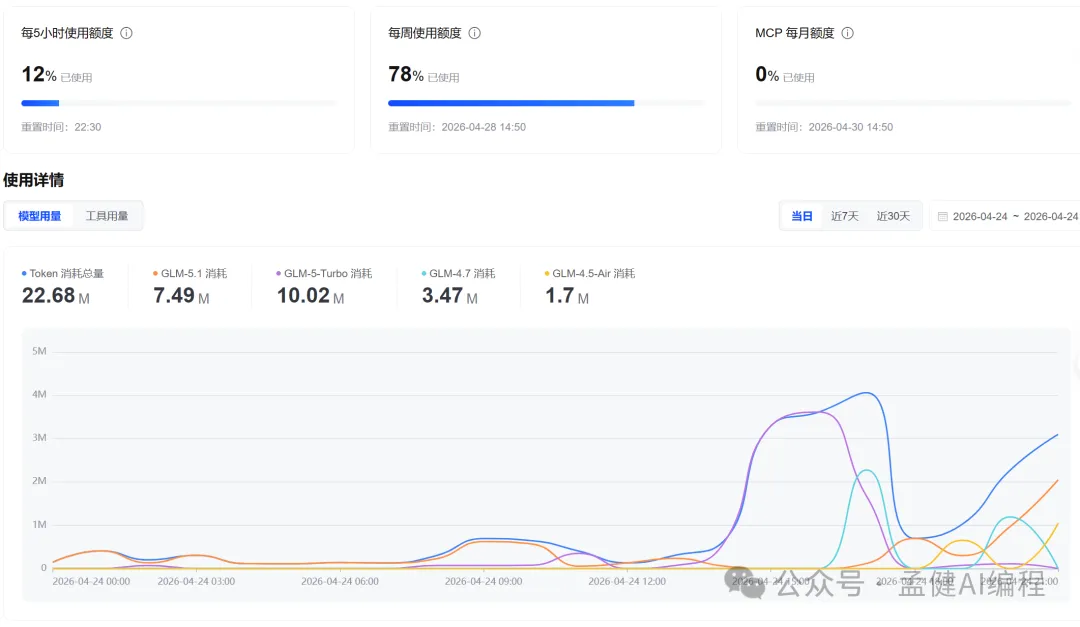
GLM-5.1 因為有 Coding Plan,但消耗嘅量都唔少;下圖係今日消耗詳情。
維度總結
結論:追上咗未?
部分追上咗,但未完全追上。
V4 喺基礎編碼能力上嘅進步係實實在在嘅,代碼結構、命名規範、基本邏輯,呢啲都做得幾好。用嚟寫日常嘅中小功能,完全夠用。
但喺三個地方,V4 同 GLM-5.1 仲有明顯差距:
深度理解:唔係淨係睇代碼做緊咩,而係理解點解要咁做
邊界意識:對異常、錯誤、極端情況嘅預判同處理
長上下文管理:大檔案、複雜項目中嘅全局把控能力
所以我嘅建議唔係二選一,而係搭配用:
預算緊,但又需要質量,就畀 DeepSeek V4 扛日常任務,畀 GLM-5.1 處理關鍵任務。
簡單任務畀 V4,關鍵任務畀 GLM-5.1。
你平時用邊個模型寫代碼?喺評論區傾嚇你嘅體驗。
🚀 想同更多 AI 愛好者交流,共同成長嗎?
📚 精選文章推薦
我將 Hermes 裏面嘅模型幾乎測曬,得出一個好扎心嘅結論:越貴嘅,往往越強 hermes101.dev 上線咗!5 分鐘裝完、7 日入門、OpenClaw 老用戶無痛遷移 從 OpenClaw、Harness 工程到世界模型全覆蓋——AI 下半場頂級大會終極議程公佈! Hermes 接入 Kimi K2.6 實測:SOTA 代碼能力,但有兩個真實痛點 我將 Hermes 裏面 23 個 Agent 全轉到 GLM-5.1:執行力比 GPT 強,但有個硬傷 對唔住,OpenClaw,我揀 Hermes! 我用 OpenClaw 做後端開發:從 Stripe 支付到 AI 生成,全程唔使寫一行代碼 突發:Anthropic 今日起封殺 OpenClaw 用訂閲額度,我嘅應對方案 一行代碼冇手寫,OpenClaw 前端 Agent 100 分鐘做完一個站 GLM-5.1 嚟咗:開源模型第一次喺長程任務上斷檔領先
大家好,我是孟健。
DeepSeek-V4-Pro 發了,官方說代碼能力大幅升級。這種話我聽得多了,每次新模型發佈都這麼說。
但我確實好奇:V4 在寫代碼這件事上,到底有沒有追上 GLM-5.1?
GLM-5.1 是我日常寫代碼的主力模型,用了幾個月了,它什麼水平我心裏有數。所以這次我不跑 benchmark,不拼跑分,就拿我實際工作中的四個場景,讓兩個模型正面硬剛。
四個場景:源碼分析、功能實現、大文件拆分、項目架構分析。
最後再算筆賬,看看成本誰更划算。
場景一:項目分析,分析 Claude Code 源碼
前段時間 Claude Code 源碼泄露,我用 GLM-5.1 完整分析了一遍 Claude Code 源碼,今天 DeepSeek-V4-Pro 發佈,我同樣也讓它分析一遍源碼看看。
基本上值得挖掘的功能,都仔細挖掘了一遍,看起來還不錯。
場景二:借鑑 Claude Code 中的代碼,從零開始完整實現一個功能
上次我讓 GLM-5.1 分析完 Claude Code 源碼之後,借鑑了代碼中一些有意思的設計和點,重新從零開始完整交付了一個緩存管理系統;今天我們同樣也讓 DeepSeek-V4-Pro 試試看, 看看能否自主從零開始交付一個完整的項目。
經過一段時間的等待,可以看到 DeepSeek-V4-Pro 直接借鑑 Claude Code 源碼 幫我實現了10個完整的功能模塊;由此可見,DeepSeek-V4-Pro 的代碼能力確實蠻強的。
場景三:拆文件,我剛好手頭有一個項目,一個文件代碼幾千行
下面這個代碼文件有1000多行,我們來嘗試一下分別讓 GLM-5.1 和 DeepSeek-V4-Pro 來分別拆分一下試試看。
1、DeepSeek-V4-Pro
2、GLM-5.1
同樣的項目,同樣的文件,同樣的提示詞,我現在讓 GLM-5.1 拆一下看看。
現在 GLM-5.1 與 DeepSeek-V4-Pro 都已經對這個超過1000行的代碼文件做完了拆分;GLM-5.1 將這個文件拆分為了4個文件,用時大概8分33秒;DeepSeek-V4-Pro 將這個文件拆分為5個文件,用時大概9分11秒。
在速度上,GLM-5.1 稍稍領先,DeepSeek 拆分的更為精細,將 compare 拆分為 通用工具、判斷、新鮮度以及意圖識別4個文件,拆分的更加精細,在代碼文件拆分的精細程度上,似乎 DeepSeek-V4-Pro 略勝一籌。
場景四:項目架構分析
最近剛好做了一個項目,目前已經上線運行了,但是技術債有點嚴重,剛好藉此時機讓兩個國產模型幫我分析項目架構並給出合理的調整建議。
1、DeepSeek-V4-Pro
2、GLM-5.1
可以看到,現在 DeepSeek-V4-Pro 以及 GLM-5.1 都對我的項目進行了分析並給出完整的分析報告,通過上面的項目架構分析可以看出,DeepSeek-V4-Pro 給出的架構分析比較全面,特別是最後的總結通過表格給出,還從不同的維度給出了評分,最後的一句話總結把項目的優劣都給說到了。
GLM-5.1 分析的也不錯,當我讓它開始分析項目的時候,它首先徹底全面的探索了我的整個項目目錄,之後才進行分析,對於整體的項目架構分析的比較紮實;最後更是通過優先級排序的方式給出了項目的優化計劃,最後還明確指出了項目沒有使用D1原生綁定功能,給的建議更加實用,因此感覺GLM-5.1對於整體項目的把握度優 DeepSeek-V4-Pro。
關於使用成本
DeepSeek-V4-Pro 目前沒有 Coding Plan,所以我是通過API直接接入 Claude Code 進行使用的,今天剛剛充值了100元,上面做了這些工作,花費15.75元。
GLM-5.1 因為有 Coding Plan,但是消耗的量也不少;下圖為今日消耗詳情。
維度總結
結論:追上了嗎?
部分追上了,但還沒完全追上。
V4 在基礎編碼能力上的進步是實打實的,代碼結構、命名規範、基本邏輯,這些做得都挺好。拿來寫日常的中小功能,完全夠用。
但在三個地方,V4 跟 GLM-5.1 還有明顯差距:
深度理解:不只是看代碼在做什麼,而是理解為什麼這麼做
邊界意識:對異常、錯誤、極端情況的預判和處理
長上下文管理:大文件、複雜項目中的全局把控能力
所以我的建議不是二選一,而是搭配用:
預算緊,但又需要質量,就讓 DeepSeek V4 扛日常任務,讓 GLM-5.1 處理關鍵任務。
簡單任務給 V4,關鍵任務給 GLM-5.1。
你平時用哪個模型寫代碼?在評論區聊聊你的體驗。
🚀 想要與更多AI愛好者交流,共同成長嗎?
📚 精選文章推薦
我把 Hermes 裏的模型幾乎測了一遍,得出一個很扎心的結論:越貴的,往往越強 hermes101.dev 上線了!5 分鐘裝完、7 天入門、OpenClaw 老用戶無痛遷移 從OpenClaw、Harness工程到世界模型全覆蓋——AI下半場頂級大會終極議程公佈! Hermes 接入 Kimi K2.6 實測:SOTA 代碼能力,但有兩個真實痛點 我把Hermes裏23個Agent全切到GLM-5.1:執行力比GPT強,但有個硬傷 對不起,OpenClaw,我選擇 Hermes! 我用 OpenClaw 做後端開發:從 Stripe 支付到 AI 生成,全程不寫一行代碼 突發:Anthropic 今天起封殺 OpenClaw 用訂閲額度,我的應對方案 一行代碼沒手寫,OpenClaw 前端 Agent 100 分鐘做完一個站 GLM-5.1 來了:開源模型第一次在長程任務上斷檔領先