DeepSeek V4性價比是表象,黃仁勳害怕的事正在發生
整理版優先睇
DeepSeek V4實現國產芯片閉環,性能追近頂尖旗艦,價格大幅降低
黃仁勳之前講過,如果DeepSeek先在華為芯片上發佈,對美國好可怕。而家DeepSeek V4發佈,官方文檔寫明支持國產芯片訓練同推理,下半年仲會完全移植去昇騰。呢個意味住,美國嘅晶片限制反而迫出咗一條新路,用大量低製程芯片堆並行計算,跑出咗唔依賴最新工藝嘅訓練體系。技術自循環開始閉合。
性能方面,DeepSeek官方話距離國際頂尖模型大約差3到6個月,但呢句誠實說話背後係一個判斷:差距係有限、可追嘅。實際上,喺編程競賽、真實軟件工程任務、綜合能力評測、知識問答等好多工作,V4已經同Claude Opus打成平手,甚至領先。特別係100萬上下文效率,所需計算量降到上一代27%,存儲空間降到10%,成本幾乎可忽略。
價格方面,Flash版每百萬token輸出$0.28,比Claude Sonnet平54倍,比Opus平近90倍。呢個定價令個人用戶唔再需要衡量值唔值得用旗艦模型,更重要係便宜加上開源,令整個應用生態變化速度完全不同。過去因為API成本唔划算嘅場景,而家全部重新可行。總結嚟講,技術、產品、商業三個維度同時突破,系統性閉環正在形成。
- DeepSeek V4已經官宣支持國產芯片訓練同推理,下半年全面移植去昇騰,技術自循環開始閉合,唔再依賴美國芯片。
- 美國晶片限制反而迫出咗更聰明嘅算法,DeepSeek用大量低製程芯片堆並行計算,建立咗唔依賴最新工藝嘅訓練體系。
- 官方承認距離國際頂尖模型差3-6個月,但呢個差距係有限可追;實際上喺編程、工程任務上已經同Claude Opus打成平手甚至領先。
- 100萬上下文算力降到27%,儲存降到10%,成本幾乎可以忽略,令「好上文」變成人人負擔得起嘅關鍵因素。
- Flash版定價$0.28/百萬token,比Claude Sonnet平54倍;開源令開發者可以自由嵌入產品,過去因為API貴而放棄嘅場景全部重新可行。
卡脖子卡出新路
美國限制高端芯片出口,本意係令中國AI發展減速。結果DeepSeek喺算力受限下,被逼用大量低製程芯片堆並行計算,硬係跑出一套唔依賴最新工藝嘅訓練體系。V4官方文檔明確寫明支持國產芯片進行訓練同推理,下半年昇騰芯片到貨後,將完全移植到國產計算架構上。
技術層面的自循環,開始閉合了。
差距係時間問題,唔係結構問題
DeepSeek官方發佈時話距離國際頂尖模型大約差3到6個月,呢句比任何吹捧都有力。背後判斷係差距有限、可追。喺大多數人嘅日常工作入面,V4已經同全球最貴嘅旗艦模型打成平手,甚至喺知識問答準確性領先。
100萬上下文效率提升,算力降27%,存儲降10%。
平價唔係促銷,係新遊戲規則
DeepSeek V4有兩個版本:Flash版每百萬token輸出$0.28,Pro版$3.48。Flash比Claude Sonnet平54倍,比Opus平近90倍。呢個定價令個人用戶唔再需要衡量值唔值得用旗艦模型,心理負擔清零。更重要係,便宜加上開源,整個應用生態變化速度會完全唔同。
Flash版比Claude Sonnet便宜54倍,比Opus便宜近90倍。
三件事串成一個閉環
技術層面不再被芯片卡脖子,國產計算路徑已跑通;產品層面距頂尖3到6個月,實際任務已持平;商業層面Flash版比Claude便宜近90倍,開源讓生態自由生長。三個維度同時突破,系統性閉環正在形成。
差距是時間問題,不是結構問題。
前幾日黃仁勳講過一句話,我一直記得:如果有一日DeepSeek先喺華為芯片上發佈,嗰對美國嚟講係好可怕嘅一件事。

尋日DeepSeek V4發佈之後,我睇完官方文檔嘅第一反應係,黃仁勳擔心嘅嗰日,可能已經到咗。
我自己用咗成日,覺得有三件事值得單獨講:芯片、性能、價格——每一件單獨拎出嚟都係大事,但三件事加埋,我睇到一個唔同嘅信號。
· · ·
卡脖子卡出新路
先講一個有少少諷刺嘅事。
美國限制高端芯片出口,本意係想令中國AI發展慢啲。結果呢?DeepSeek喺算力受限嘅情況下,被迫用大量低製程芯片堆並行計算,硬係跑出一套唔依賴最新工藝嘅訓練體系。
跟住V4發佈咗。官方文檔裏面清楚寫明:支持國產芯片進行訓練同推理,下半年昇騰芯片到貨之後,會完全移植到國產計算架構上。
黃仁勳自己都承認呢個邏輯。佢喺採訪裏面話:「算力受限反而會逼出更聰明嘅算法。真正嘅槓桿喺電腦科學。」

黃仁勳真正擔心嘅,唔係DeepSeek今日有幾強。佢講嘅係:如果未來DeepSeek被專門優化到華為平台,全球嘅AI模型行喺非美國硬件上效果更好,嗰先係真正嘅問題。
而家V4官宣完整支持國產芯片。V4走到嘅位置係:徹底唔再需要嗰個限制——自己嘅芯片路徑,自己嘅模型,自己嘅訓練體系,技術層面嘅自循環,開始閉合。
黃仁勳擔心嘅嗰個時間點,正在到來。
· · ·
差距係時間問題,唔係結構問題
自媒體個個都話「全面超越」「全球領先」,DeepSeek官方發佈時卻話:我哋距離國際頂尖模型,大約差3到6個月。
呢句話比任何吹捧都有力。佢誠實,而且背後有個判斷:差距係有限嘅、追得到嘅,可以追得上㗎。
而且呢個差距集中喺少數極端任務上——前沿推理、頂級數學競賽、邊界科研呢類場景。喺大多數人嘅日常工作裏面,數據係另一回事。
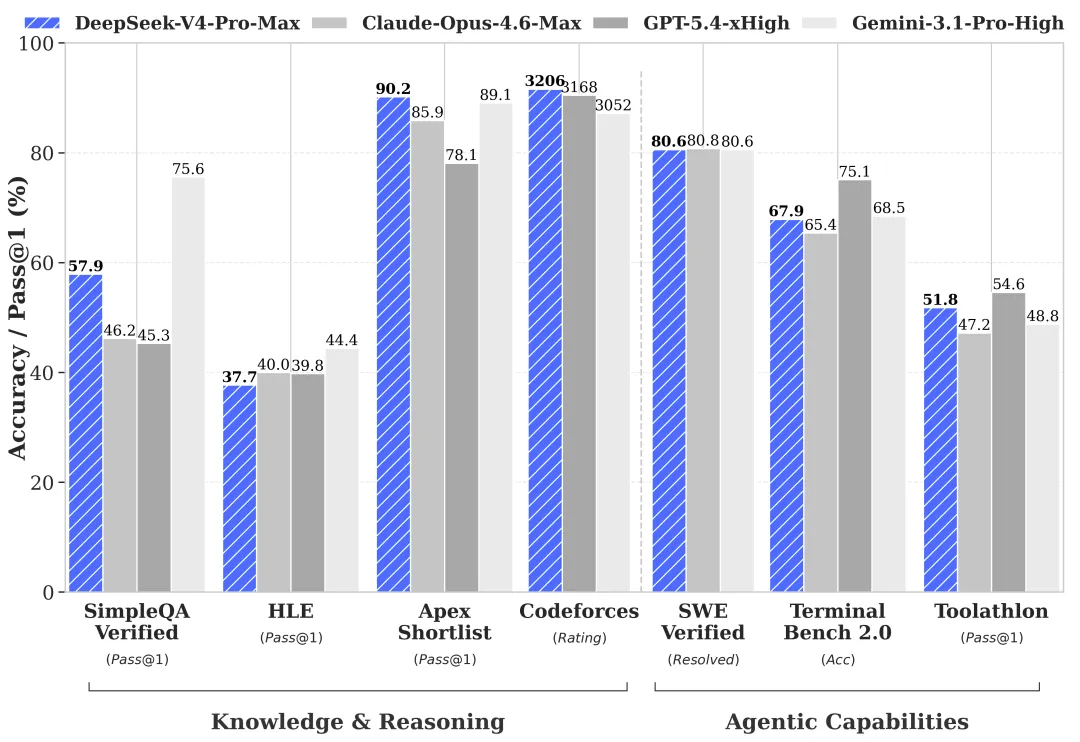
DeepSeek V4嘅技術報告有幾組對比,我將佢翻譯成人話:
叫AI去參加編程競賽,V4拎到3206分,Claude Opus 4.6係3168分,GPT-5.4係3052分——V4領先。
叫AI做真實嘅軟件工程任務——真正修復程式碼bug、完成工程需求——V4完成率80.6%,Claude Opus係80.8%,基本上打和,都喺全球頂尖水平。
綜合能力評測,V4拎到90.2%,Claude Opus係85.9%,V4領先超過4個百分點。
知識問答嘅準確性,V4答啱57.9%,Claude只有46.2%——V4明顯領先。
叫AI寫程式碼、做實際工作,V4已經同全球最貴嘅旗艦模型打成平手,甚至喺唔少地方超過咗佢哋。
仲有一件事值得單獨講:100萬上下文嘅效率問題。
就咁話「支援100萬上下文」好多人冇感覺。換個講法:將季度報表、行業分析、會議紀要全部掉曬入去,叫佢幫你梳理關鍵決策點,佢唔會因為資料太多就開始亂或者唔記得前面嘅內容。

更關鍵嘅係,上下文擴大咗,算力反而降低咗。呢個效率提升嚟自DeepSeek嘅架構創新,細節喺官方技術論文第2.3節。處理100萬上下文嗰陣,所需計算量降到上一代嘅27%,儲存空間降到10%。
我之前講過一個公式:好答案 = 好模型 × 好提問 × 好上文。
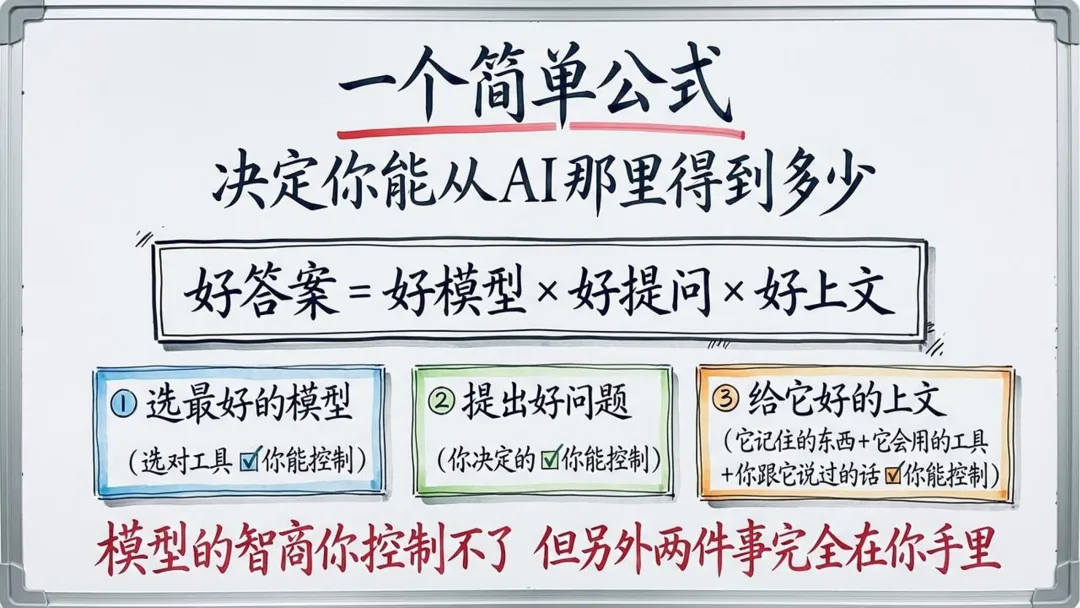
好多人只係睇模型好唔好,忽略咗上文有幾重要。AI嘅本質係預測——離答案越近嘅內容,影響越大。你掉俾佢嘅資料越完整,佢嘅答案越準。
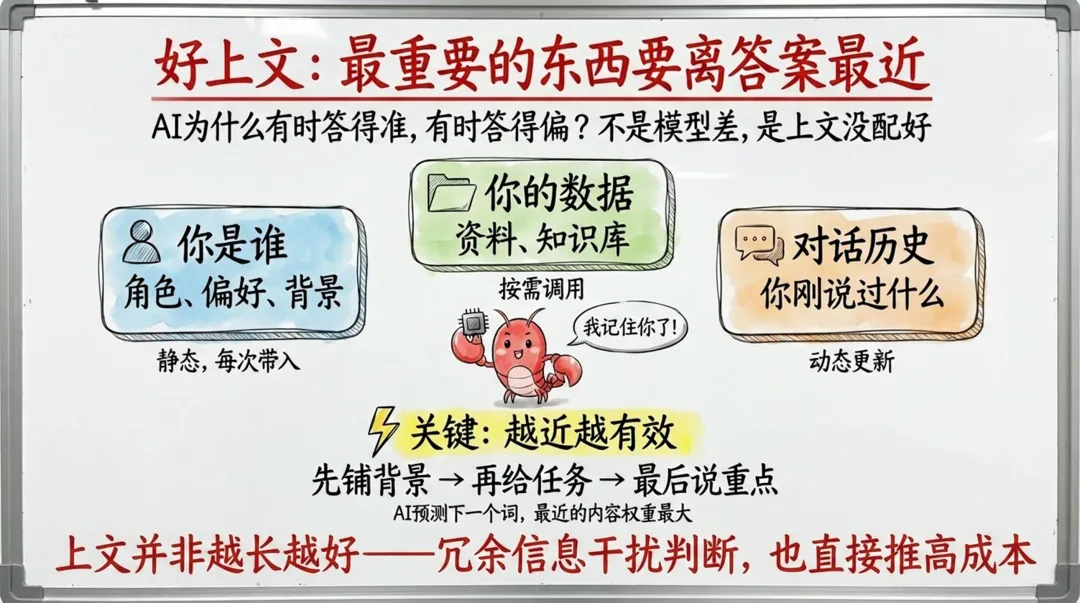
以前100萬上下文太貴,普通用戶根本用唔起;而家V4-Flash將呢個成本降到幾乎可以忽略——呢個先係100萬上下文真正嘅價值,唔止係容量大,而係令到「好上文」呢件事第一次變得人人負擔得起。
我自己用咗成日,印象都同數據吻合。我平時嘅主力模型係Claude Sonnet,Opus更強但我好少用——每次開都要喺心入面盤算嚇值唔值得用旗艦。用咗一日V4之後,寫稿、整理會議記錄、處理複雜問題,冇令我明顯覺得「唔夠用」嘅地方。
我哋嘅龍蝦EasyClaw已經第一時間接入咗V4,歡迎大家嚟體驗。
· · ·
平,唔係促銷,係新嘅遊戲規則
最後講價格。
DeepSeek V4有兩個版本。Flash版每百萬token輸出$0.28,Claude Sonnet係$15、Claude Opus係$25——Flash比Sonnet平54倍,比Opus平接近90倍。Pro版貴啲,$3.48,比Sonnet平4倍、比Opus平7倍左右。兩個版本喺100萬上下文嘅場景下,都比上一代V3仲要平。
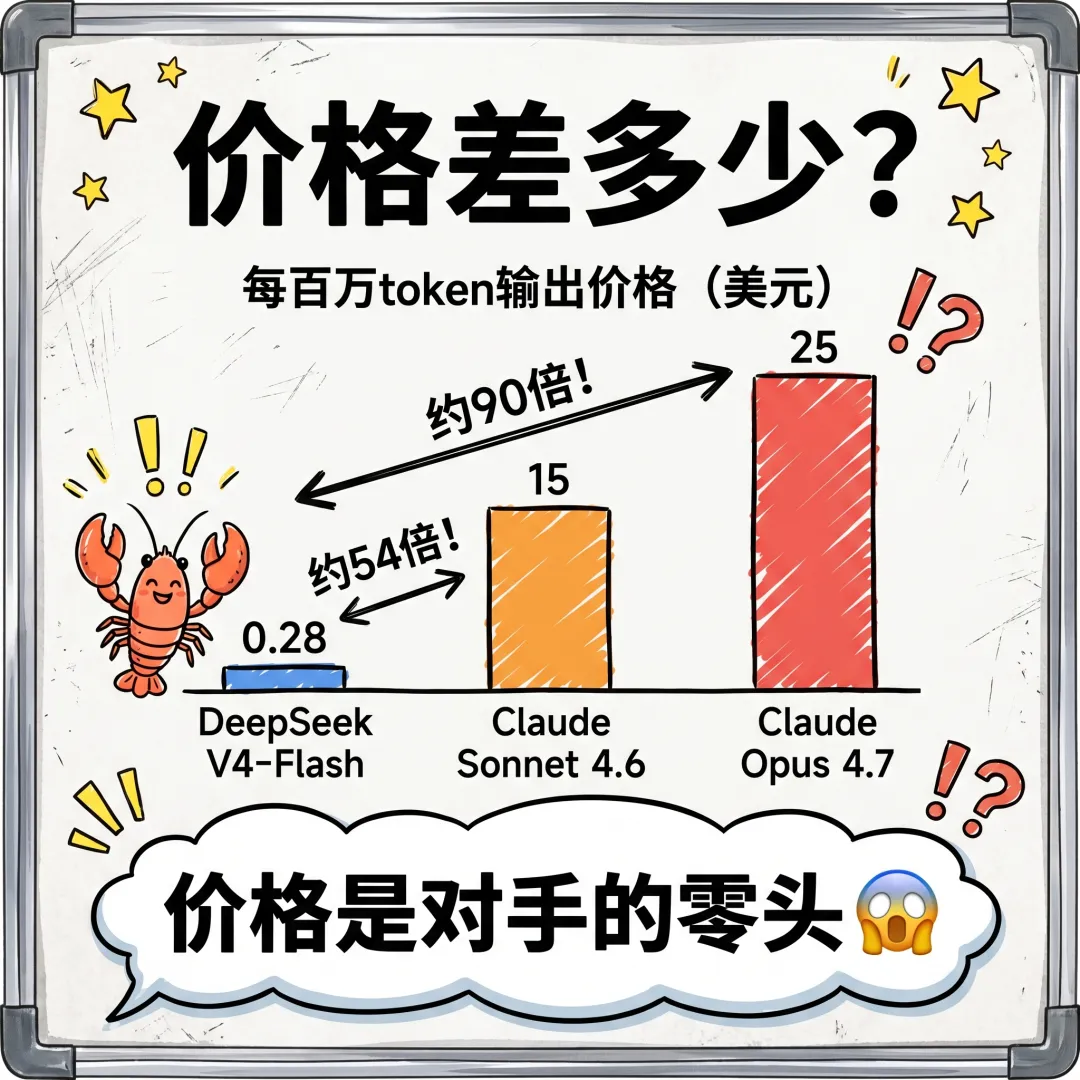
呢個差距係乜嘢感覺?以前用Opus,每次都要喺心入面做個判斷:呢個任務值唔值得用咁貴嘅模型?呢種盤算雖然只係幾秒鐘,但佢會喺你用AI嘅過程入面形成一種無形嘅界線。V4嘅定價,將呢個心理負擔基本上清零。
但真正嘅影響,唔止係個人用戶。
平加上開源,成個應用生態嘅變化速度會完全唔同。當一個模型平到可以亂咁嵌入各種產品——客服、搜尋、數據分析、內部流程——過去因為API成本唔划算嘅場景,而家全部重新變得可行。開源意味住任何開發者都可以喺上面起嘢,唔需要等某間公司開放接口,亦唔受平台限制。
· · ·
三件事串埋,我睇到一個閉環
技術層面——唔再俾芯片卡住頸,國產計算路徑已經行得通;
產品層面——距離頂尖3到6個月,實際任務上已經同全球旗艦打和,100萬上下文算力反而更慳;
商業層面——Flash版比Claude平接近90倍,開源令生態自由生長。
呢三個維度,喺同一個版本裏面同時突破咗。系統性嘅閉環,正在形成。
差距係時間問題,唔係結構問題。
當技術自循環、產品競爭力、生態擴散同時跑起嚟,呢件事嘅終局,比大多數人預期嘅要近得多。
EasyClaw已接入DeepSeek V4,歡迎直接體驗。
國內版:easyclaw.cn
國際版:easyclaw.com
企業版:easyclaw.work

前幾天黃仁勳說過一句話,我一直記着:如果有一天DeepSeek先在華為芯片上發佈,那對美國來說是很可怕的一件事。
昨天DeepSeek V4發佈後,我看完官方文檔的第一反應是,黃仁勳擔心的那天,可能已經到來了。
我自己用了一整天,覺得有三件事值得單獨說:芯片、性能、價格——每一件單獨拿出來都是大事,但三件事加在一起,我看到了一個不同的信號。
· · ·
卡脖子卡出了新路
先說一個有點諷刺的事。
美國限制高端芯片出口,本意是讓中國AI發展減速。結果呢?DeepSeek在算力受限的情況下,被逼着用大量低製程芯片堆並行計算,硬是跑出了一套不依賴最新工藝的訓練體系。
然後V4發佈了。官方文檔裏明確寫明:支持國產芯片進行訓練和推理,下半年昇騰芯片到貨後,將完全移植到國產計算架構上。
黃仁勳自己也承認這個邏輯。他在採訪裏說:"算力受限反而會逼出更聰明的算法。真正的槓桿在計算機科學。"
黃仁勳真正擔心的,不是DeepSeek今天有多強。他說的是:如果未來DeepSeek被專門優化到華為平台上,全球的AI模型跑在非美國硬件上效果更好,那才是真正的問題。
現在V4官宣完整支持國產芯片。V4走到的位置是:徹底不再需要那個限制了——自己的芯片路徑,自己的模型,自己的訓練體系,技術層面的自循環,開始閉合了。
黃仁勳擔心的那個時間點,正在到來。
· · ·
差距是時間問題,不是結構問題
自媒體都在說"全面超越""全球領先",DeepSeek官方發佈時卻說:我們距離國際頂尖模型,大約差3到6個月。
這句話比任何吹捧都有力。它誠實,而且背後有個判斷:差距是有限的、可追的,可以追上的。
而且這個差距集中在少數極端任務上——前沿推理、頂級數學競賽、邊界科研這類場景。在大多數人的日常工作裏,數據是另一回事。
DeepSeek V4的技術報告裏有幾組對比,我把它翻譯成人話:
讓AI去參加編程競賽,V4拿到3206分,Claude Opus 4.6是3168分,GPT-5.4是3052分——V4領先。
讓AI做真實的軟件工程任務——真正修復代碼bug、完成工程需求——V4完成率80.6%,Claude Opus是80.8%,基本打平,都在全球頂尖水平上。
綜合能力評測,V4拿到90.2%,Claude Opus是85.9%,V4領先超過4個百分點。
知識問答的準確性,V4答對57.9%,Claude只有46.2%——V4明顯領先。
讓AI寫代碼、做實際工作,V4已經跟全球最貴的旗艦模型打成平手,甚至在不少地方超過了它們。
還有一件事值得單獨說:100萬上下文的效率問題。
光說"支持100萬上下文"很多人沒感覺。換個說法:把季度報表、行業分析、會議紀要一股腦扔進去,讓它幫你梳理關鍵決策點,它不會因為資料太多就開始混亂或者忘掉前面的內容。
更關鍵的是,上下文擴大了,算力反而降了。這個效率提升來自DeepSeek的架構創新,細節在官方技術論文第2.3節。處理100萬上下文時,所需計算量降到上一代的27%,存儲空間降到10%。
我之前講過一個公式:好答案 = 好模型 × 好提問 × 好上文。
很多人只盯着模型好不好,忽略了上文有多重要。AI的本質是預測——離答案越近的內容,影響越大。你扔給它的資料越完整,它的答案越準。
以前100萬上下文太貴,普通用戶根本用不起;現在V4-Flash把這個成本降到幾乎可以忽略——這才是100萬上下文真正的價值,不只是容量大,是讓"好上文"這件事第一次變得人人負擔得起。
我自己用了一整天,印象也和數據吻合。我平時的主力模型是Claude Sonnet,Opus更強但我很少用——每次打開都要在心裏盤算一下值不值得用旗艦。用了一天V4之後,寫稿、整理會議記錄、處理複雜問題,沒有讓我明顯覺得"不夠用"的地方。
我們的龍蝦EasyClaw已經第一時間接入了V4,歡迎大家來體驗。
· · ·
便宜,不是促銷,是新的遊戲規則
最後說價格。
DeepSeek V4有兩個版本。Flash版每百萬token輸出$0.28,Claude Sonnet是$15、Claude Opus是$25——Flash比Sonnet便宜54倍,比Opus便宜近90倍。Pro版貴一些,$3.48,比Sonnet便宜4倍、比Opus便宜7倍左右。兩個版本在100萬上下文的場景下,都比上一代V3還便宜。
這個差距是什麼感受?以前用Opus,每次都在心裏做個判斷:這個任務值不值得用這麼貴的模型?這種掂量雖然只是幾秒鐘,但它會在你用AI的過程中形成一種無形的邊界。V4的定價,把這個心理負擔基本清零了。
但真正的影響,不只是個人用戶。
便宜加上開源,整個應用生態的變化速度會完全不同。當一個模型便宜到可以隨意嵌入各種產品——客服、搜索、數據分析、內部流程——過去因為API成本不划算的場景,現在全部重新變得可行。開源意味着任何開發者都能在上面建東西,不需要等某家公司開放接口,也不受平台限制。
· · ·
三件事串起來,我看到了一個閉環
技術層面——不再被芯片卡脖子,國產計算路徑已經跑通;
產品層面——距頂尖3到6個月,實際任務上已與全球旗艦持平,100萬上下文算力反而更省;
商業層面——Flash版比Claude便宜近90倍,開源讓生態自由生長。
這三個維度,在同一個版本里同時突破了。系統性的閉環,正在形成。
差距是時間問題,不是結構問題。
當技術自循環、產品競爭力、生態擴散同時跑起來,這件事的終局,比大多數人預期的要近得多。
EasyClaw已接入DeepSeek V4,歡迎直接體驗。
國內版:easyclaw.cn
國際版:easyclaw.com
企業版:easyclaw.work