DeepSeek V4是怎麼訓練出來的?58頁論文深入解讀
整理版優先睇
勸退提醒: 1、這是一篇很長很長的文章,會深入到DeepSeek V4論文中涉及到的各種細節,如果你不感興趣,只是想知道模型跑分的話,沒必要讀 2、我也沒那麼好的技術能力,這是花了2000萬Opus4.7 tokens讀完內容,並做了73頁PPT之後形成的理解 3、我多少對DeepSeek有些濾鏡,我很喜歡這個公司的做派和風格,所以表達未必客觀中立如果這種情況下,你還願意一起往下探的話,那我們開始吧!在我看來,DeepSeek不是一個衝破天花板的SOTA模型。它真正的價值是把百萬上下文、Agent原生能力、能接受的價格這三件事第一次綁在了一起。而且這次從發佈時間和節奏來說也挺有趣的,其實本來按照大家的預期,V4應當在春節前後發的,實際看來也差不多是那會兒完工。他們論文中對標的也是2月那會的Claude Opus 4.6和GPT-5.4。但它實際發佈卡到了現在,中間又出了Opus 4.7和GPT-5.5。等它正式亮相,對標對象已經換人了。DeepSeek自己解釋說是為了更好地適配國產芯片。害,行吧,也希望國產芯片好好適配下DeepSeek。其實今年1月份時,我已經連着寫了三篇DeepSeek論文解讀:mHC、Engram、OCR 2。當時我的判斷是這些技術大概率都會進V4。現在V4論文打開,mHC進來了,其他一些思路也能看出端倪。這篇文章我會順着這條線講,讓之前讀過那幾篇的朋友能看到完整的故事線。再說結論我們需要重複下開頭的核心結論,以這個視角的話,我們會對DeepSeek V4會有個更合理的預期,那就是👇這不是一個衝破AGI天花板的世界最佳模型,但屬於是一個讓普通開發者第一次能夠放心地用上100萬上下文Agent模型的發佈。這兩者的差別非常大。前者是衝頂峯的敍事,需要在各個benchmark上全面擊敗Opus 4.7、GPT-5.5、Gemini 3.1 Pro。V4還做不到。後者是抬地板的敍事。100萬token上下文這件事,之前不是沒有模型能做到,但要麼極貴(Opus、DeepSeek那檔),要麼效果會顯著衰減(很多國產模型128K以上就明顯掉分)。V4做的事情是把「100萬長上下文」+「Agent多步調用能力」+「能接受的價格」這三件事第一次組合到一起。對閉源旗艦來說,V4不構成威脅。對一個想在產品裏塞入長上下文的獨立開發者來說,V4意味着幾乎所有的上下文節省工作都可以先不做了(對的,RAG和很多別的AI敍事一樣,只要你不學,等着等着你就可以不必學了)業內有個說法:閉源模型卷能力天花板,開源模型卷地板,地板抬高的速度決定AI應用爆發的規模。V4把這個地板往上抬了抬。V4-Pro 和 V4-Flash:兩個定位不一樣的模型這次DeepSeek發的是兩個模型。V4-Pro的總參數量比V3的671B翻了2.4倍。激活參數從37B漲到49B,只多了三成左右。走的是「稀疏度再提高」的路線。這裏要稍微解釋一下MoE模型的工作方式。V4-Pro一共有300多個專家(routed experts)加上1個共享專家。每次處理一個token的時候,它不是把所有專家都調動起來,而是隻激活其中6個+共享專家,一共7個專家參與回答。這有點像一個有384位專家的公司,每個決策只召集7個人開會,不搞全員表決。激活的參數量少,推理速度就快,成本也能壓下來。V4-Pro的定位是「開源陣營裏能跟閉源旗艦掰手腕的那個」。但DeepSeek自己在論文裏也誠實地說了一件事:因為現在高端算力受限,Pro的服務吞吐很有限,所以Pro版本的API價格目前不算便宜,預計下半年才能降下來。V4-Flash是真正符合DeepSeek一貫風格的那個模型。它的參數規模是V4-Pro的約六分之一,但在很多基礎能力上已經反超了V3.2。這意味着架構改進和數據質量的收益,足夠抵消參數規模的差距。Flash的價格相比同類快速模型,大概是他們的1/7到1/18。如果你是獨立開發者,我的建議很明確:AI編程、寫作、複雜任務、關鍵決策場景用Opus 4.7這類;批量任務、Agent後台、數據處理用V4-Flash。架構動了哪些刀V4沒有推倒V3重來。MoE框架沿用的還是DeepSeekMoE,MTP模塊沒動,訓練細節也大多延續V3。真正大改的地方只有三處:殘差連接升級成mHC注意力拆成CSA+HCA的混合架構優化器從AdamW換成Muon這三處改動各自解決一個具體痛點。殘差連接在堆深時數值不穩定,限制了把模型做大;傳統注意力在百萬token長上下文下KV cache爆炸,算力根本扛不住;AdamW在超大規模MoE訓練上收斂慢、偏科嚴重。V4相當於把V3的三個瓶頸逐一拆掉。mHC:給殘差連接加一道只准收縮不準放大的護欄mHC我在1月那篇mHC論文解讀裏已經完整講過了,這裏長話短說。殘差連接是深度學習用了整整十年的基礎設計。2015年何愷明的ResNet開始,到現在的每一個大模型都離不開它。它做的事情,用一句話說就是給信號開了一條「快車道」:不管中間那些層學到了什麼,原始信號都能直接順着這條高速公路原封不動傳到後面。這就是所謂的「恆等映射」。這個設計本身沒問題。問題出在對它的第一次升級上。2024年底,字節Seed團隊發了一篇叫Hyper-Connections(HC)的論文,後來中了ICLR 2025。HC把單通道的殘差流擴展成多通道,讓模型自己學習最優的連接方式。DeepSeek一開始也是沿着這條路線往下走的,但踩到了HC的一個致命缺陷:訓練不穩定。不穩定到什麼程度?DeepSeek在1月那篇mHC論文裏給過一個很震撼的數字:在27B模型上,HC的信號放大倍數峯值達到3000倍。也就是說,信號在網絡裏傳着傳着,被放大了3000倍,梯度也隨之被放大3000倍。訓練到某一步突然崩掉是家常便飯。mHC解決這個問題的思路,我覺得最形象的說法還是1月文章裏那句:給殘差連接加了一道「只准收縮不準放大」的數學護欄。用一個畫面講清楚。信號在網絡裏一層層往下傳,可以想象成把一杯水倒進下一個杯子。HC的做法是把一根水管變成四根,每根流量讓模型自己學。靈活是靈活了,但沒人管總量。倒着倒着水越倒越多,到第60層的時候已經是原來的3000倍,杯子直接爆了。mHC的做法是強制每一層倒水都守恆。不管四根水管怎麼分配、怎麼混合,進多少水就出多少水,一滴不多一滴不少。這個約束的數學工具叫「雙隨機矩陣」,名字嚇人,本質就是一張分配表:每一行加起來等於1,每一列加起來也等於1。這兩個條件加起來,天然保證了水不會憑空變多。更舒服的是,兩張雙隨機矩陣乘在一起還是雙隨機矩陣,所以不管你堆多少層,守恆這件事都不會失效。代價是模型不能自由學這張表,每一層都要用一個叫Sinkhorn-Knopp的算法迭代20次,把學出來的東西壓回守恆的形狀。相比訓練崩掉的損失,這個代價不算什麼。mHC帶來的直接結果是:V4能把模型從V3的671B推到1.6T,參數量2.4倍增長,訓練穩定性反而比V3更好。這是理解V4能「做大」的第一把鑰匙。CSA + HCA:讀一本800頁的書,先翻目錄再精讀這是整篇論文我覺得工程含量最高的地方,也是V4百萬上下文能落地的核心。先說清楚一件事:為什麼100萬上下文這麼難做?標準的注意力機制,每個新來的token都要和前面所有token算一次內積。如果把4K上下文換成100萬上下文,需要算的內積數量是4000倍,顯存佔用也是4000倍。粗略估算下來,100萬上下文的單次推理成本比4K高約6萬倍。這堵「算力牆」和「顯存牆」加起來,是大多數模型在128K-200K就停住的原因。V4的解法是把注意力機制拆成兩種,在Transformer不同的層裏交替使用。CSA(Compressed Sparse Attention)走精細路線。它把每m個token壓縮成1個塊,然後用一個叫Lightning Indexer的小模塊算每個query和每個壓縮塊的相關性分數,只挑分數最高的top-k個塊去做真正的注意力計算。HCA(Heavily Compressed Attention)走粗略路線。它的壓縮率m'遠比m大(通常是幾十倍),但不做稀疏篩選,query會dense地把所有壓縮塊都掃一遍。犧牲細粒度,換極致的KV cache壓縮。我覺得這兩種注意力最好的比喻就是讀一本800頁的書。你不會逐字讀完。大概率是這樣:先翻目錄,定位到有用的那幾章;翻到那一章後掃一下小標題,定位到第幾頁;最後才精讀那幾頁。這是一個先粗後細的過程。V4把這個動作拆成了兩種獨立的機制,交替安排在不同的層裏:CSA做的是「掃小標題定位」:先把每64個token揉成一塊,給每塊打分,挑出最相關的幾塊去精讀HCA做的是「翻目錄看大意」:直接把1024個token壓成一塊,一本800頁的書可能只剩幾十塊大摘要,每個新來的token都把這幾十塊全掃一遍兩者加起來,V4在100萬上下文下的單次推理成本,只有V3.2的約1/4。KV cache佔用只有傳統BF16 GQA8 baseline的約2%。把50份壓成1份,這是百萬上下文真正能跑起來的數學原因。論文裏還有一堆工程細節,比如兩種注意力都用Shared KV MQA進一步省cache,都加了sliding window分支保證局部細節不丟,都用了attention sink讓query可以「棄權」。這些工程活不好解釋,但每一個都在扣效率。這是理解V4能「讀長」的第二把鑰匙。Muon:別每個旋鈕單獨調,整組一起掰Muon是V4用來替代AdamW的優化器。改動的技術深度很足,但可以用畫面感拆開說。先說優化器是幹嘛的。模型訓練就一句話:猜一個答案,對照正確答案,根據錯的方向調整自己。優化器決定的就是「具體怎麼調」。AdamW是過去十年行業默認的優化器。它的邏輯是:模型內部有幾十億個旋鈕要調,每個旋鈕單獨看它過去抖得厲害不厲害,抖得厲害就調慢一點,抖得少就調猛一點。聽起來挺合理。問題是這些旋鈕不獨立。它們是同一台機器上的幾十億個零件,彼此聯動。AdamW單獨看每個旋鈕的歷史做判斷,結果就是模型在參數空間裏走出來的軌跡是個極度扁的橢圓:少數幾個「熱門方向」步子邁得特別大,推到病態的程度;其他方向幾乎沒動過,等於沒學。說得更直白點,AdamW訓出來的模型會偏科。Muon反過來想。它不看單個旋鈕,而是看這一整組旋鈕合起來在往哪個方向走,然後把這個方向的更新強行「拉平」:原本邁得特別大的方向壓一壓,幾乎沒動的方向拉一拉,讓每個方向都走一樣遠。數學上這個操作叫「正交化」,畫面感上就是把原本歪扁的橢圓硬掰成一個正圓。好處是什麼?原本被AdamW淹沒的冷門方向,現在能和熱門方向拿一樣的步長。模型探索範圍更廣,收斂更穩。Muon天生有個成本問題:每一步都要把橢圓掰成正圓,直接算要做矩陣分解,太貴。V4用了一個近似辦法(Newton-Schulz迭代),10步搞定一次掰正,前8步用激進係數快速逼近,後2步切換温和係數做精修。工程上剛好不貴。一個細節:V4沒把所有參數都交給Muon。embedding、prediction head、RMSNorm這些本來就不是矩陣、沒有「方向」概念的參數,還是AdamW管。Muon和AdamW各管一攤。這是理解V4能「訓深」的第三把鑰匙。1.6T怎麼訓穩的:兩個他們自己也不懂的trick把模型從671B推到1.6T,光有mHC還不夠。訓練1.6T的MoE時,V4團隊遇到了loss spike(訓練損失突然飆升,前幾輪學的東西都被噪聲污染),簡單的回滾保存點也救不回來,剛回滾完沒多久又崩。他們最終用了兩個辦法把訓練救回來。一個叫Anticipatory Routing(預判式路由)。MoE模型裏有個「路由器」負責每一步挑哪幾個專家上場,這個路由器本身也是學出來的。訓練崩潰的惡性循環是這樣:某一步某個專家輸出了一個異常大的數,這個異常讓路由器誤以為「這個專家真強」,下一步派給它更多任務,它輸出更離譜的數,路由器越挑越偏,訓練崩了。解法特別巧:讓路由器用「昨天的腦子」做「今天的決定」。主幹網絡的更新和路由器解耦,主幹用當前參數算,但路由器挑專家時查的是前幾步的歷史參數。今天網絡再怎麼抽風,路由器用的是沒被污染的舊腦子,惡性循環就斷了。另一個叫SwiGLU Clamping。SwiGLU是模型裏的激活函數,可以理解為每個神經元的「水龍頭」。正常情況水龍頭開多大都行,但在1.6T這個規模上,某些神經元會突然爆出極大的數值,把整個訓練帶崩。DeepSeek的做法簡單粗暴:給SwiGLU內部的幾個關鍵數值強行加一個上下限(-10到10之間),哪怕某個神經元想輸出一萬,也只能給你10。這兩個trick為什麼有效?DeepSeek自己在論文裏說,他們也不完全清楚。原話是「the underlying principles of these mechanisms remain insufficiently understood」。他們只知道:用了,有效,就這麼用。至於為什麼,希望社區一起探索。我覺得這個細節值得單獨拎出來講。過去我們看到的很多技術報告,總是在事後給方法找一套漂亮的理論解釋,好像研究者從一開始就想得很清楚。但實際工程裏,很多時候是先做出來再理解。DeepSeek不藏這個,白紙黑字寫進論文裏。這種坦誠在國內團隊裏並不多見。今年1月我寫R1論文更新那篇時說過,DeepSeek的「Open」不是做到行業平均水平就夠了,而是包括那些失敗的嘗試、沒搞懂的trick、踩過的坑都一併開出來。V4這篇報告延續了這個風格。訓練數據:32T tokens,反AI生成、加Agent、加多語言V4的預訓練數據比V3更大(33T vs V3的14.8T),也更講究。幾個關鍵動作:反模型坍縮。互聯網語料裏現在充斥着大量AI生成的文本。如果不做過濾,訓練出來的模型會出現「模型坍縮」(model collapse):每一代都在上一代的AI輸出上訓練,能力會越來越差。DeepSeek專門做了一套過濾,把批量自動生成和套模板的內容攔掉。中期訓練引入Agent數據。工具調用軌跡、多步推理、搜索片段這些,不能靠後訓練硬掰,必須在預訓練中期就喂進去。這是V4-Flash的Agent能力躍升的關鍵原料。多語言擴容。擴充了除中英外的長尾語言,覆蓋不同文化的知識。所以你用V4做翻譯、或者查一些非英文語言的長尾知識,效果會比V3好不少。精選長文檔。科學論文、技術報告這類「學術價值獨特」的材料被重點收錄。訓練數據規模上,Pro版本是33T tokens,Flash版本是32T tokens。分詞沿用V3的128K詞表。序列長度是分階段擴展的:從4K起步,逐步擴到16K、64K、1M。稀疏注意力也是分階段引入:前1T tokens先用dense attention熱身,到64K序列長度時切到sparse attention。這種漸進式訓練在超長上下文模型裏已經是事實標準,但V4的階段切換時機設計比較精細。後訓練:Specialist + OPD,一個被低估的範式變化如果說架構改動是V4最顯眼的變化,那後訓練範式的變化其實是這篇報告最深刻的變化。V4在後訓練章節的第一句話就很有趣:the mixed Reinforcement Learning (RL) stage was entirely replaced by On-Policy Distillation (OPD).翻譯過來就是:混合RL階段被徹底替換成在策略蒸餾。這句話我覺得像是範式級別的轉變了。為什麼要替換傳統後訓練是「SFT+RLHF混煉」的路子:一個大雜燴數據集,SFT打底,再用一個reward model做RL。問題是什麼?數學、代碼、Agent、對話這些能力在RL階段會互相打架。你調數學的reward權重,代碼能力可能就掉了;你加Agent數據,對話又變笨。多任務聯合優化的「負遷移」問題,幾乎每個做過後訓練的團隊都踩過坑。DeepSeek的解法是把「聯合優化」拆成「分治+合併」:Stage 1 Specialist訓練:每個領域(推理、數學、代碼、Agent、通用對話)單獨訓練一個專家模型。先SFT,再用GRPO做RL。每個專家只管自己那塊,reward signal清晰,不用跟其他領域折中。Stage 2 On-Policy Distillation:把十多個專家模型當老師,通過反向KL loss蒸餾出一個統一的學生模型。這個拆分的妙處在於:RL只在專家階段做,最終的學生模型不做RL,只做蒸餾。RL的訓練不穩定性被隔離在專家模型內部,學生模型通過更穩定的蒸餾loss拿到所有專家的能力。反向KL是關鍵OPD的技術細節裏,有一個點特別值得講:為什麼用反向KL而不是正向KL?正向KL是讓學生去cover老師的所有模式,結果往往學成四不像。反向KL是讓學生集中在老師分佈的高概率區域,學生會自動「選老師」:數學任務時對齊數學專家,代碼任務時對齊代碼專家。這個「自動路由」的特性,是多老師蒸餾能跑通的關鍵。為什麼這個範式重要講到這裏可能有朋友要問:這個東西對獨立開發者有什麼意義?我的判斷是,這可能是比MoE更深刻的範式變化。MoE是推理時混合(runtime mixture),OPD蒸餾是訓練時混合(training time mixture)。後者的組合空間大得多。這個範式天然適合幾類場景:小團隊:沒錢一開始就訓大模型,但可以訓多個小specialist,最後蒸餾融合垂直應用:法律/醫療/代碼各訓一個專家,最後合併持續學習:要增加新能力時,訓一個新專家加入蒸餾池就行,不破壞老模型只要你能訓出專家,就能通過OPD合進來。未來想加新能力(比如「寫毛筆字」「解幾何題」),路徑很清晰:訓專家→加入蒸餾池。這比RLHF要改reward、要重跑全流程友好得多。這個範式會不會成為新的行業標準,目前還不好說。但V4已經用了十多個專家模型做OPD,證明在萬億參數級別它是可行的。評測結果:強在哪,弱在哪評測是V4論文裏最重要的部分之一,也是最容易被誤讀的部分。我直接把我的判斷列出來。數學推理:反超閉源旗艦V4-Pro在幾個數學類benchmark上拿到了開源陣營前所未有的高分:BenchmarkV4-Pro-Max對比Putnam-2025(形式化證明)120/120 滿分超過Axiom和Seed-ProverApex Shortlist90.2全場第一,超過Gemini 3.1 ProIMOAnswerBench89.8接近GPT-5.4的91.4HMMT 2026 Feb95.2僅次於GPT-5.4Codeforces的競賽評分V4-Pro能達到3206分,對應人類選手第23名。這是非常離譜的水平。編程:LiveCodeBench和Codeforces雙第一V4-Pro在LiveCodeBench拿到93.5分,Codeforces Rating 3206。DeepSeek論文裏明確寫了,這是第一次開源模型在這兩項任務上追平閉源。但注意一個細節:SWE系列(真實工程代碼任務)就沒那麼亮眼了。SWE Verified 80.6分接近Opus 4.6的80.8但沒超過,SWE Multilingual也略輸。這就對應上了DeepSeek論文裏自己的總結:V4模型非常擅長做題,但品味上還差一些火候。競賽類任務有明確答案,RL能反覆打磨;工程類任務要綜合考慮代碼風格、架構、可維護性,這些品味層面的東西現在的RL訓練還吃不透。Agent:全方位落後閉源這是V4最弱的一塊。BenchmarkV4-Pro-Max最強Terminal Bench 2.067.9GPT-5.4: 75.1BrowseComp83.4Gemini 3.1: 85.9HLE w/ tools48.2Opus 4.6: 53.1(甚至輸給K2.6)GDPval-AA (Elo)1554GPT-5.4: 1674Terminal Bench 2.0落後GPT-5.4整整7分,HLE w/ tools落後Opus 4.6整整5分。DeepSeek論文裏非常誠實地寫了:「所有開源模型仍落後閉源對手」。唯一的亮點是MCPAtlas Public(73.6),僅次於Opus的73.8。說明V4在通用工具調用和MCP服務上泛化能力不錯,不是隻在內部框架裏打雞血。真實編程任務:接近Opus 4.5,差Opus 4.6 Thinking 13分DeepSeek自己拿200多個真實的內部R&D編程任務做了測試,來自50多位工程師日常工作中提的真實需求,覆蓋PyTorch、CUDA、Rust、C++:模型R&D編程通過率Claude Haiku 4.513%Claude Sonnet 4.547%DeepSeek V4-Pro-Max67%Claude Opus 4.570%Claude Opus 4.5 Thinking73%Claude Opus 4.6 Thinking80%V4-Pro的67%已經超過Sonnet 4.5(47%),接近Opus 4.5(70%),但距離Opus 4.6 Thinking(80%)還差13個百分點。這組數據是DeepSeek論文發佈時跑的,當時Claude最新是4.6 Thinking。現在Opus 4.7 Thinking已經發布,V4和當前最強閉源的真實差距大概是6個月到1年的研發時間。談不上「完全追平」,也算不上「落後一代」。中文場景:真正的第一梯隊中文寫作是V4-Pro少數能對Opus 4.5掰手腕的地方:意思就是日常中文寫作對Gemini是碾壓級,複雜指令跟隨對Opus 4.5仍然有差距。論文裏吐槽Gemini經常「讓自己的風格偏好壓過用戶的明確需求」(擅自加戲),這個描述我讀完忍不住笑了一下。長上下文:128K內穩如狗,1M勉強能用BenchmarkV4-ProOpus 4.6Gemini 3.1MRCR 1M83.592.976.3CorpusQA 1M62.071.753.8V4在1M長上下文的檢索任務上超過Gemini,但落後Claude Opus 4.6。MRCR 8-needle測試顯示128K以內性能穩定在0.9以上,256K後開始掉到0.82,到1024K降至0.59。128K以內基本沒有性能衰減,1M勉強能用。這是CSA+HCA混合架構帶來的實際收益。對大多數Agent和代碼場景,128K已經足夠。一個特點:為什麼V4這麼偏科?讀完整份報告,加上這些benchmark結果,有一個很鮮明的模式浮出來:V4特別擅長做題,但在品味型任務上差一檔。數學競賽Putnam滿分,Codeforces拿到人類選手第23名,LiveCodeBench全場第一。但創意寫作輸給Opus 4.5,Agent任務落後GPT-5.4,HLE通用知識被Gemini壓制。我自己的理解是:這和DeepSeek招的人有關。DeepSeek的招聘以競賽獲獎選手為主。這些人擅長什麼?擅長在給定規則下把單點做到極致,擅長解有明確答案的題。模型訓練的偏好會受數據團隊、訓練團隊、評估團隊的品味影響,這些品味又受團隊成員的背景影響。所以V4在有明確答案的任務上表現頂尖(數學、競賽編程),在需要綜合品味的任務上(創意寫作、長鏈Agent、通用工程編程)就會相對偏弱。這只是一個觀察,談不上批評。模型的性格映射着團隊的性格,這件事很多時候比人們想象的更直接。DeepSeek還是那個DeepSeek嗎?寫到這裏不得不問一個問題:V4時代的DeepSeek,和V3時代比,變了嗎?我的回答是:變了,但沒變味。V3時代的DeepSeek是「小團隊、極致工程、帶來驚喜」。V4時代的DeepSeek打開論文附錄,研究工程作者名單已經超過300人,加上商業和合規接近350人。這不再是那個幾十人的實驗室。但有幾個東西沒變。一個是工程至上。V4的創新重點不在高層架構設計,而在「信號怎麼流動」和「梯度怎麼更新」這兩個底層問題上。mHC解決深度scale的數值穩定性,CSA+HCA解決上下文scale的算力和內存,Muon解決參數scale的訓練效率。每一項都是回答「為什麼V3做不大」的問題。我在1月那篇mHC解讀裏寫過一句話:DeepSeek的技術哲學是去質疑那些所有人都覺得沒必要改的東西。V4這篇論文把這句話又紮紮實實兑現了一次。殘差連接改了,注意力機制改了,優化器也改了。每一處都是行業裏默認不動的底座。另一個是誠實。承認架構「太複雜」(原文:retained many preliminarily validated components which made the architecture relatively complex),承認訓練穩定性機制「不理解」(原文:underlying principles remain insufficiently understood),承認sparse還不夠極致,承認Agent能力落後閉源。這些話寫進一篇技術報告裏,放到國內同行裏幾乎找不到第二家。還有一條是Open是真Open。R1的86頁更新補全了訓練賬單和數據配方,V4的58頁繼續補全基礎設施的每個縫隙。不是「開源權重就完了」的Open,是一份讓別人真的能復現的Open。DeepSeek在發佈V4的時候引用了一句話:不誘於譽,不恐於誹,率道而行,端然正己。不被讚譽誘惑,不被誹謗嚇退,按自己的道走,端正自己。這句話可能比58頁的論文技術細節更能解釋這家公司。最後回到開頭那條線。1月那三篇解讀,mHC確實進V4了。Engram和OCR 2呢?1月Engram那篇我用的比喻是「給大模型發一本字典」:靜態知識直接查表,不浪費網絡深度現場推理。V4這次沒把這本字典裝進來,但論文明確把「沿新維度繼續稀疏化」列進了未來路線圖,參考文獻正是Engram那篇論文。OCR 2的視覺因果流也沒進V4,但多模態被明確寫進V5的方向(原文:incorporating multimodal capabilities)。所以下一代DeepSeek大概率會是這樣的輪廓:原生多模態(OCR 2這一脈的延伸)、引入某種可擴展的查找式記憶(Engram這一脈的延伸)、進一步降低延遲(為Agent交互做準備)、更長的long-horizon multi-round agentic能力。V5什麼時候發我不好預測。但DeepSeek的節奏已經固定下來:論文先鋪路,模型後亮相。V4論文裏寫了未來方向,剩下的就是時間。V4顯然談不上對Opus 4.7或GPT-5.5的超越,它是開源陣營的一次基礎設施級更新。把百萬token上下文、Agent原生支持、成本優勢打包成一個可複用的底座。真正的價值不在V4-Pro能不能打贏最強閉源,而在V4-Flash讓每一個獨立開發者都能在自己的產品裏塞進百萬上下文。閉源卷天花板,開源卷地板。更有意思的故事,會在V5身上。參考資料:DeepSeek V4技術報告:見DeepSeek官方GitHub(deepseek-ai/DeepSeek-V4)DeepSeek R1論文v2(86頁):arxiv.org/abs/2501.12948我做的73頁PPT:https://github.com/alchaincyf/deepseek-v4-deep-dive我之前寫的DeepSeek論文解讀系列(mHC、Engram、OCR 2、R1更新)可以在公眾號歷史文章裏搜到
勸退提醒: 1、這是一篇很長很長的文章,會深入到DeepSeek V4論文中涉及到的各種細節,如果你不感興趣,只是想知道模型跑分的話,沒必要讀 2、我也沒那麼好的技術能力,這是花了2000萬Opus4.7 tokens讀完內容,並做了73頁PPT之後形成的理解 3、我多少對DeepSeek有些濾鏡,我很喜歡呢個公司的做派和風格,所以表達未必客觀中立如果這種情況下,你還願意一起往下探的話,那我們開始吧!
在我看來,DeepSeek不是一個衝破天花板的SOTA模型。它真正的價值是把百萬上下文、Agent原生能力、能接受的價格這三件事第一次綁在了一起。而且這次從發佈時間和節奏來說也挺有趣的,其實本來按照大家的預期,V4應當在春節前後發的,實際看來也差不多是那會兒完工。他們論文中對標的也是2月那會的Claude Opus 4.6和GPT-5.4。
但它實際發佈卡到了而家,中間又出了Opus 4.7和GPT-5.5。等它正式亮相,對標對象已經換人了。DeepSeek自己解釋說是為了更好地適配國產芯片。害,行吧,也希望國產芯片好好適配下DeepSeek。其實今年1月份時,我已經連着寫了三篇DeepSeek論文解讀:mHC、Engram、OCR 2。當時我的判斷是呢啲技術大概率都會進V4。而家V4論文打開,mHC進來了,其他一些思路也能看出端倪。這篇文章我會順着這條線講,讓之前讀過那幾篇的朋友能看到完整的故事線。再說結論我們需要重…
- DeepSeek V4是怎麼訓練出來的?58頁論文深入解讀
- DeepSeek V4是怎麼訓練出來的?58頁論文深入解讀|重點 2
- DeepSeek V4是怎麼訓練出來的?58頁論文深入解讀|重點 3
- DeepSeek V4是怎麼訓練出來的?58頁論文深入解讀|重點 4
- DeepSeek V4是怎麼訓練出來的?58頁論文深入解讀|重點 5
可記低 Workflow
勸退提醒: 1、這是一篇很長很長的文章,會深入到DeepSeek V4論文中涉及到的各種細節,如果你不感興趣,只是想知道模型跑分的話,沒必要讀 2、我也沒那麼好的技術能力,這是花了2000萬Opus4.7 tokens讀完內容,並做了73頁…
整理版
勸退提醒: 1、這是一篇很長很長的文章,會深入到DeepSeek V4論文中涉及到的各種細節,如果你不感興趣,只是想知道模型跑分的話,沒必要讀 2、我也沒那麼好的技術能力,這是花了2000萬Opus4.7 tokens讀完內容,並做了73頁PPT之後形成的理解 3、我多少對DeepSeek有些濾鏡,我很喜歡呢個公司的做派和風格,所以表達未必客觀中立如果這種情況下,你還願意一起往下探的話,那我們開始吧!在我看來,DeepSeek不是一個衝破天花板的SOTA模型。它真正的價值是把百萬上下文、Agent原生能力、能接受的價格這三件事第一次綁在了一起。而且這次從發佈時間和節奏來說也挺有趣的,其實本來按照大家的預期,V4應當在春節前後發的,實際看來也差不多是那會兒完工。他們論文中對標的也是2月那會的Claude Opus 4.6和GPT-5.4。但它實際發佈卡到了而家,中間又出了Opus 4.7和GPT-5.5。等它正式亮相,對標對象已經換人了。DeepSeek自己解釋說是為了更好地適配國產芯片。害,行吧,也希望國產芯片好好適配下DeepSeek。其實今年1月份時,我已經連着寫了三篇DeepSeek論文解讀:mHC、Engram、OCR 2。當時我的判斷是呢啲技術大概率都會進V4。而家V4論文打開,mHC進來了,其他一些思路也能看出端倪。這篇文章我會順着這條線講,讓之前讀過那幾篇的朋友能看到完整的故事線。再說結論我們需要重複下開頭的核心結論,以呢個視角的話,我們會對DeepSeek V4會有個更合理的預期,那就是👇這不是一個衝破AGI天花板的世界最佳模型,但屬於是一個讓普通開發者第一次能夠放心地用上100萬上下文Agent模型的發佈。這兩者的差別非常大。前者是衝頂峯的敍事,需要在各個benchmark上全面擊敗Opus 4.7、GPT-5.5、Gemini 3.1 Pro。V4還做不到。後者是抬地板的敍事。100萬token上下文這件事,之前不是沒有模型能做到,但要麼極貴(Opus、DeepSeek那檔),要麼效果會顯著衰減(很多國產模型128K以上就明顯掉分)。V4做的事情是把「100萬長上下文」+「Agent多步調用能力」+「能接受的價格」這三件事第一次組合到一起。對閉源旗艦來說,V4不構成威脅。對一個想在產品裏塞入長上下文的獨立開發者來說,V4意味着幾乎所有的上下文節省工作都可以先不做了(對的,RAG和很多別的AI敍事一樣,只要你不學,等着等着你就可以不必學了)業內有個說法:閉源模型卷能力天花板,開源模型卷地板,地板抬高的速度決定AI應用爆發的規模。V4把呢個地板往上抬了抬。V4-Pro 和 V4-Flash:兩個定位不一樣的模型這次DeepSeek發的是兩個模型。V4-Pro的總參數量比V3的671B翻了2.4倍。激活參數從37B漲到49B,只多了三成左右。走的是「稀疏度再提高」的路線。這裏要稍微解釋一下MoE模型的工作方式。V4-Pro一共有300多個專家(routed experts)加上1個共享專家。每次處理一個token的時候,它不是把所有專家都調動起來,而是隻激活其中6個+共享專家,一共7個專家參與回答。這有點像一個有384位專家的公司,每個決策只召集7個人開會,不搞全員表決。激活的參數量少,推理速度就快,成本也能壓下來。V4-Pro的定位是「開源陣營裏能跟閉源旗艦掰手腕的嗰個」。但DeepSeek自己在論文裏也誠實地說了一件事:因為而家高端算力受限,Pro的服務吞吐很有限,所以Pro版本的API價格目前不算便宜,預計下半年才能降下來。V4-Flash是真正符合DeepSeek一貫風格的嗰個模型。它的參數規模是V4-Pro的約六分之一,但在很多基礎能力上已經反超了V3.2。這意味着架構改進和數據質量的收益,足夠抵消參數規模的差距。Flash的價格相比同類快速模型,大概是他們的1/7到1/18。如果你是獨立開發者,我的建議很明確:AI編程、寫作、複雜任務、關鍵決策場景用Opus 4.7這類;批量任務、Agent後台、數據處理用V4-Flash。架構動了哪些刀V4沒有推倒V3重來。MoE框架沿用的還是DeepSeekMoE,MTP模塊沒動,訓練細節也大多延續V3。真正大改的地方只有三處:殘差連接升級成mHC注意力拆成CSA+HCA的混合架構優化器從AdamW換成Muon這三處改動各自解決一個具體痛點。殘差連接在堆深時數值不穩定,限制了把模型做大;傳統注意力在百萬token長上下文下KV cache爆炸,算力根本扛不住;AdamW在超大規模MoE訓練上收斂慢、偏科嚴重。V4相當於把V3的三個瓶頸逐一拆掉。mHC:給殘差連接加一道只准收縮不準放大的護欄mHC我在1月那篇mHC論文解讀裏已經完整講過了,這裏長話短說。殘差連接是深度學習用了整整十年的基礎設計。2015年何愷明的ResNet開始,到而家的每一個大模型都離不開它。它做的事情,用一句話說就是給信號開了一條「快車道」:不管中間嗰啲層學到了什麼,原始信號都能直接順着這條高速公路原封不動傳到後面。這就是所謂的「恆等映射」。呢個設計本身沒問題。問題出在對它的第一次升級上。2024年底,字節Seed團隊發了一篇叫Hyper-Connections(HC)的論文,後來中了ICLR 2025。HC把單通道的殘差流擴展成多通道,讓模型自己學習最優的連接方式。DeepSeek一開始也是沿着這條路線往下走的,但踩到了HC的一個致命缺陷:訓練不穩定。不穩定到什麼程度?DeepSeek在1月那篇mHC論文裏給過一個很震撼的數字:在27B模型上,HC的信號放大倍數峯值達到3000倍。也就是說,信號在網絡裏傳着傳着,被放大了3000倍,梯度也隨之被放大3000倍。訓練到某一步突然崩掉是家常便飯。mHC解決呢個問題的思路,我覺得最形象的說法還是1月文章裏那句:給殘差連接加了一道「只准收縮不準放大」的數學護欄。用一個畫面講清楚。信號在網絡裏一層層往下傳,可以想象成把一杯水倒進下一個杯子。HC的做法是把一根水管變成四根,每根流量讓模型自己學。靈活是靈活了,但沒人管總量。倒着倒着水越倒越多,到第60層的時候已經是原來的3000倍,杯子直接爆了。mHC的做法是強制每一層倒水都守恆。不管四根水管怎麼分配、怎麼混合,進多少水就出多少水,一滴不多一滴不少。呢個約束的數學工具叫「雙隨機矩陣」,名字嚇人,本質就是一張分配表:每一行加起來等於1,每一列加起來也等於1。這兩個條件加起來,天然保證了水不會憑空變多。更舒服的是,兩張雙隨機矩陣乘在一起還是雙隨機矩陣,所以不管你堆多少層,守恆這件事都不會失效。代價是模型不能自由學這張表,每一層都要用一個叫Sinkhorn-Knopp的算法迭代20次,把學出來的東西壓回守恆的形狀。相比訓練崩掉的損失,呢個代價不算什麼。mHC帶來的直接結果是:V4能把模型從V3的671B推到1.6T,參數量2.4倍增長,訓練穩定性反而比V3更好。這是理解V4能「做大」的第一把鑰匙。CSA + HCA:讀一本800頁的書,先翻目錄再精讀這是整篇論文我覺得工程含量最高的地方,也是V4百萬上下文能落地的核心。先說清楚一件事:為什麼100萬上下文這麼難做?標準的注意力機制,每個新來的token都要和前面所有token算一次內積。如果把4K上下文換成100萬上下文,需要算的內積數量是4000倍,顯存佔用也是4000倍。粗略估算下來,100萬上下文的單次推理成本比4K高約6萬倍。這堵「算力牆」和「顯存牆」加起來,是大多數模型在128K-200K就停住的原因。V4的解法是把注意力機制拆成兩種,在Transformer不同的層裏交替使用。CSA(Compressed Sparse Attention)走精細路線。它把每m個token壓縮成1個塊,然後用一個叫Lightning Indexer的小模塊算每個query和每個壓縮塊的相關性分數,只挑分數最高的top-k個塊去做真正的注意力計算。HCA(Heavily Compressed Attention)走粗略路線。它的壓縮率m'遠比m大(通常是幾十倍),但不做稀疏篩選,query會dense地把所有壓縮塊都掃一遍。犧牲細粒度,換極致的KV cache壓縮。我覺得這兩種注意力最好的比喻就是讀一本800頁的書。你不會逐字讀完。大概率是咁樣:先翻目錄,定位到有用的那幾章;翻到那一章後掃一下小標題,定位到第幾頁;最後才精讀那幾頁。這是一個先粗後細的過程。V4把呢個動作拆成了兩種獨立的機制,交替安排在不同的層裏:CSA做的是「掃小標題定位」:先把每64個token揉成一塊,給每塊打分,挑出最相關的幾塊去精讀HCA做的是「翻目錄看大意」:直接把1024個token壓成一塊,一本800頁的書可能只剩幾十塊大摘要,每個新來的token都把這幾十塊全掃一遍兩者加起來,V4在100萬上下文下的單次推理成本,只有V3.2的約1/4。KV cache佔用只有傳統BF16 GQA8 baseline的約2%。把50份壓成1份,這是百萬上下文真正能跑起來的數學原因。論文裏還有一堆工程細節,比如兩種注意力都用Shared KV MQA進一步省cache,都加了sliding window分支保證局部細節不丟,都用了attention sink讓query可以「棄權」。呢啲工程活不好解釋,但每一個都在扣效率。這是理解V4能「讀長」的第二把鑰匙。Muon:別每個旋鈕單獨調,整組一起掰Muon是V4用來替代AdamW的優化器。改動的技術深度很足,但可以用畫面感拆開說。先說優化器是幹嘛的。模型訓練就一句話:猜一個答案,對照正確答案,根據錯的方向調整自己。優化器決定的就是「具體怎麼調」。AdamW是過去十年行業默認的優化器。它的邏輯是:模型內部有幾十億個旋鈕要調,每個旋鈕單獨看它過去抖得厲害不厲害,抖得厲害就調慢一點,抖得少就調猛一點。聽起來挺合理。問題是呢啲旋鈕不獨立。它們是同一台機器上的幾十億個零件,彼此聯動。AdamW單獨看每個旋鈕的歷史做判斷,結果就是模型在參數空間裏走出來的軌跡是個極度扁的橢圓:少數幾個「熱門方向」步子邁得特別大,推到病態的程度;其他方向幾乎沒動過,等於沒學。說得更直白點,AdamW訓出來的模型會偏科。Muon反過來想。它不看單個旋鈕,而是看這一整組旋鈕合起來在往哪個方向走,然後把呢個方向的更新強行「拉平」:原本邁得特別大的方向壓一壓,幾乎沒動的方向拉一拉,讓每個方向都走一樣遠。數學上呢個操作叫「正交化」,畫面感上就是把原本歪扁的橢圓硬掰成一個正圓。好處是什麼?原本被AdamW淹沒的冷門方向,而家能和熱門方向拿一樣的步長。模型探索範圍更廣,收斂更穩。Muon天生有個成本問題:每一步都要把橢圓掰成正圓,直接算要做矩陣分解,太貴。V4用了一個近似辦法(Newton-Schulz迭代),10步搞定一次掰正,前8步用激進係數快速逼近,後2步切換温和係數做精修。工程上剛好不貴。一個細節:V4沒把所有參數都交給Muon。embedding、prediction head、RMSNorm呢啲本來就不是矩陣、沒有「方向」概念的參數,還是AdamW管。Muon和AdamW各管一攤。這是理解V4能「訓深」的第三把鑰匙。1.6T怎麼訓穩的:兩個他們自己也不懂的trick把模型從671B推到1.6T,光有mHC還不夠。訓練1.6T的MoE時,V4團隊遇到了loss spike(訓練損失突然飆升,前幾輪學的東西都被噪聲污染),簡單的回滾保存點也救不回來,剛回滾完沒多久又崩。他們最終用了兩個辦法把訓練救回來。一個叫Anticipatory Routing(預判式路由)。MoE模型裏有個「路由器」負責每一步挑哪幾個專家上場,呢個路由器本身也是學出來的。訓練崩潰的惡性循環是咁樣:某一步某個專家輸出了一個異常大的數,呢個異常讓路由器誤以為「呢個專家真強」,下一步派給它更多任務,它輸出更離譜的數,路由器越挑越偏,訓練崩了。解法特別巧:讓路由器用「昨天的腦子」做「今天的決定」。主幹網絡的更新和路由器解耦,主幹用當前參數算,但路由器挑專家時查的是前幾步的歷史參數。今天網絡再怎麼抽風,路由器用的是沒被污染的舊腦子,惡性循環就斷了。另一個叫SwiGLU Clamping。SwiGLU是模型裏的激活函數,可以理解為每個神經元的「水龍頭」。正常情況水龍頭開多大都行,但在1.6T呢個規模上,某些神經元會突然爆出極大的數值,把整個訓練帶崩。DeepSeek的做法簡單粗暴:給SwiGLU內部的幾個關鍵數值強行加一個上下限(-10到10之間),哪怕某個神經元想輸出一萬,也只能給你10。這兩個trick為什麼有效?DeepSeek自己在論文裏說,他們也不完全清楚。原話是「the underlying principles of these mechanisms remain insufficiently understood」。他們只知道:用了,有效,就這麼用。至於為什麼,希望社區一起探索。我覺得呢個細節值得單獨拎出來講。過去我們看到的很多技術報告,總是在事後給方法找一套漂亮的理論解釋,好像研究者從一開始就想得很清楚。但實際工程裏,很多時候是先做出來再理解。DeepSeek不藏呢個,白紙黑字寫進論文裏。這種坦誠在國內團隊裏並不多見。今年1月我寫R1論文更新那篇時說過,DeepSeek的「Open」不是做到行業平均水平就夠了,而是包括嗰啲失敗的嘗試、沒搞懂的trick、踩過的坑都一併開出來。V4這篇報告延續了呢個風格。訓練數據:32T tokens,反AI生成、加Agent、加多語言V4的預訓練數據比V3更大(33T vs V3的14.8T),也更講究。幾個關鍵動作:反模型坍縮。互聯網語料裏而家充斥着大量AI生成的文本。如果不做過濾,訓練出來的模型會出現「模型坍縮」(model collapse):每一代都在上一代的AI輸出上訓練,能力會越來越差。DeepSeek專門做了一套過濾,把批量自動生成和套模板的內容攔掉。中期訓練引入Agent數據。工具調用軌跡、多步推理、搜索片段呢啲,不能靠後訓練硬掰,必須在預訓練中期就喂進去。這是V4-Flash的Agent能力躍升的關鍵原料。多語言擴容。擴充了除中英外的長尾語言,覆蓋不同文化的知識。所以你用V4做翻譯、或者查一些非英文語言的長尾知識,效果會比V3好不少。精選長文檔。科學論文、技術報告這類「學術價值獨特」的材料被重點收錄。訓練數據規模上,Pro版本是33T tokens,Flash版本是32T tokens。分詞沿用V3的128K詞表。序列長度是分階段擴展的:從4K起步,逐步擴到16K、64K、1M。稀疏注意力也是分階段引入:前1T tokens先用dense attention熱身,到64K序列長度時切到sparse attention。這種漸進式訓練在超長上下文模型裏已經是事實標準,但V4的階段切換時機設計比較精細。後訓練:Specialist + OPD,一個被低估的範式變化如果說架構改動是V4最顯眼的變化,那後訓練範式的變化其實是這篇報告最深刻的變化。V4在後訓練章節的第一句話就很有趣:the mixed Reinforcement Learning (RL) stage was entirely replaced by On-Policy Distillation (OPD).翻譯過來就是:混合RL階段被徹底替換成在策略蒸餾。這句話我覺得像是範式級別的轉變了。為什麼要替換傳統後訓練是「SFT+RLHF混煉」的路子:一個大雜燴數據集,SFT打底,再用一個reward model做RL。問題是什麼?數學、代碼、Agent、對話呢啲能力在RL階段會互相打架。你調數學的reward權重,代碼能力可能就掉了;你加Agent數據,對話又變笨。多任務聯合優化的「負遷移」問題,幾乎每個做過後訓練的團隊都踩過坑。DeepSeek的解法是把「聯合優化」拆成「分治+合併」:Stage 1 Specialist訓練:每個領域(推理、數學、代碼、Agent、通用對話)單獨訓練一個專家模型。先SFT,再用GRPO做RL。每個專家只管自己那塊,reward signal清晰,不用跟其他領域折中。Stage 2 On-Policy Distillation:把十多個專家模型當老師,通過反向KL loss蒸餾出一個統一的學生模型。呢個拆分的妙處在於:RL只在專家階段做,最終的學生模型不做RL,只做蒸餾。RL的訓練不穩定性被隔離在專家模型內部,學生模型通過更穩定的蒸餾loss拿到所有專家的能力。反向KL是關鍵OPD的技術細節裏,有一個點特別值得講:為什麼用反向KL而不是正向KL?正向KL是讓學生去cover老師的所有模式,結果往往學成四不像。反向KL是讓學生集中在老師分佈的高概率區域,學生會自動「選老師」:數學任務時對齊數學專家,代碼任務時對齊代碼專家。呢個「自動路由」的特性,是多老師蒸餾能跑通的關鍵。為什麼呢個範式重要講到這裏可能有朋友要問:呢個東西對獨立開發者有什麼意義?我的判斷是,這可能是比MoE更深刻的範式變化。MoE是推理時混合(runtime mixture),OPD蒸餾是訓練時混合(training time mixture)。後者的組合空間大得多。呢個範式天然適合幾類場景:小團隊:沒錢一開始就訓大模型,但可以訓多個小specialist,最後蒸餾融合垂直應用:法律/醫療/代碼各訓一個專家,最後合併持續學習:要增加新能力時,訓一個新專家加入蒸餾池就行,不破壞老模型只要你能訓出專家,就能通過OPD合進來。未來想加新能力(比如「寫毛筆字」「解幾何題」),路徑很清晰:訓專家→加入蒸餾池。這比RLHF要改reward、要重跑全流程友好得多。呢個範式會不會成為新的行業標準,目前還不好說。但V4已經用了十多個專家模型做OPD,證明在萬億參數級別它是可行的。評測結果:強在哪,弱在哪評測是V4論文裏最重要的部分之一,也是最容易被誤讀的部分。我直接把我的判斷列出來。數學推理:反超閉源旗艦V4-Pro在幾個數學類benchmark上拿到了開源陣營前所未有的高分:BenchmarkV4-Pro-Max對比Putnam-2025(形式化證明)120/120 滿分超過Axiom和Seed-ProverApex Shortlist90.2全場第一,超過Gemini 3.1 ProIMOAnswerBench89.8接近GPT-5.4的91.4HMMT 2026 Feb95.2僅次於GPT-5.4Codeforces的競賽評分V4-Pro能達到3206分,對應人類選手第23名。這是非常離譜的水平。編程:LiveCodeBench和Codeforces雙第一V4-Pro在LiveCodeBench拿到93.5分,Codeforces Rating 3206。DeepSeek論文裏明確寫了,這是第一次開源模型在這兩項任務上追平閉源。但注意一個細節:SWE系列(真實工程代碼任務)就沒那麼亮眼了。SWE Verified 80.6分接近Opus 4.6的80.8但沒超過,SWE Multilingual也略輸。這就對應上了DeepSeek論文裏自己的總結:V4模型非常擅長做題,但品味上還差一些火候。競賽類任務有明確答案,RL能反覆打磨;工程類任務要綜合考慮代碼風格、架構、可維護性,呢啲品味層面的東西而家的RL訓練還吃不透。Agent:全方位落後閉源這是V4最弱的一塊。BenchmarkV4-Pro-Max最強Terminal Bench 2.067.9GPT-5.4: 75.1BrowseComp83.4Gemini 3.1: 85.9HLE w/ tools48.2Opus 4.6: 53.1(甚至輸給K2.6)GDPval-AA (Elo)1554GPT-5.4: 1674Terminal Bench 2.0落後GPT-5.4整整7分,HLE w/ tools落後Opus 4.6整整5分。DeepSeek論文裏非常誠實地寫了:「所有開源模型仍落後閉源對手」。唯一的亮點是MCPAtlas Public(73.6),僅次於Opus的73.8。說明V4在通用工具調用和MCP服務上泛化能力不錯,不是隻在內部框架裏打雞血。真實編程任務:接近Opus 4.5,差Opus 4.6 Thinking 13分DeepSeek自己拿200多個真實的內部R&D編程任務做了測試,來自50多位工程師日常工作中提的真實需求,覆蓋PyTorch、CUDA、Rust、C++:模型R&D編程通過率Claude Haiku 4.513%Claude Sonnet 4.547%DeepSeek V4-Pro-Max67%Claude Opus 4.570%Claude Opus 4.5 Thinking73%Claude Opus 4.6 Thinking80%V4-Pro的67%已經超過Sonnet 4.5(47%),接近Opus 4.5(70%),但距離Opus 4.6 Thinking(80%)還差13個百分點。這組數據是DeepSeek論文發佈時跑的,當時Claude最新是4.6 Thinking。而家Opus 4.7 Thinking已經發布,V4和當前最強閉源的真實差距大概是6個月到1年的研發時間。談不上「完全追平」,也算不上「落後一代」。中文場景:真正的第一梯隊中文寫作是V4-Pro少數能對Opus 4.5掰手腕的地方:意思就是日常中文寫作對Gemini是碾壓級,複雜指令跟隨對Opus 4.5仍然有差距。論文裏吐槽Gemini經常「讓自己的風格偏好壓過用戶的明確需求」(擅自加戲),呢個描述我讀完忍不住笑了一下。長上下文:128K內穩如狗,1M勉強能用BenchmarkV4-ProOpus 4.6Gemini 3.1MRCR 1M83.592.976.3CorpusQA 1M62.071.753.8V4在1M長上下文的檢索任務上超過Gemini,但落後Claude Opus 4.6。MRCR 8-needle測試顯示128K以內性能穩定在0.9以上,256K後開始掉到0.82,到1024K降至0.59。128K以內基本沒有性能衰減,1M勉強能用。這是CSA+HCA混合架構帶來的實際收益。對大多數Agent和代碼場景,128K已經足夠。一個特點:為什麼V4這麼偏科?讀完整份報告,加上呢啲benchmark結果,有一個很鮮明的模式浮出來:V4特別擅長做題,但在品味型任務上差一檔。數學競賽Putnam滿分,Codeforces拿到人類選手第23名,LiveCodeBench全場第一。但創意寫作輸給Opus 4.5,Agent任務落後GPT-5.4,HLE通用知識被Gemini壓制。我自己的理解是:這和DeepSeek招的人有關。DeepSeek的招聘以競賽獲獎選手為主。呢啲人擅長什麼?擅長在給定規則下把單點做到極致,擅長解有明確答案的題。模型訓練的偏好會受數據團隊、訓練團隊、評估團隊的品味影響,呢啲品味又受團隊成員的背景影響。所以V4在有明確答案的任務上表現頂尖(數學、競賽編程),在需要綜合品味的任務上(創意寫作、長鏈Agent、通用工程編程)就會相對偏弱。這只是一個觀察,談不上批評。模型的性格映射着團隊的性格,這件事很多時候比人們想象的更直接。DeepSeek還是嗰個DeepSeek嗎?寫到這裏不得不問一個問題:V4時代的DeepSeek,和V3時代比,變了嗎?我的回答是:變了,但沒變味。V3時代的DeepSeek是「小團隊、極致工程、帶來驚喜」。V4時代的DeepSeek打開論文附錄,研究工程作者名單已經超過300人,加上商業和合規接近350人。這不再是嗰個幾十人的實驗室。但有幾個東西沒變。一個是工程至上。V4的創新重點不在高層架構設計,而在「信號怎麼流動」和「梯度怎麼更新」這兩個底層問題上。mHC解決深度scale的數值穩定性,CSA+HCA解決上下文scale的算力和內存,Muon解決參數scale的訓練效率。每一項都是回答「為什麼V3做不大」的問題。我在1月那篇mHC解讀裏寫過一句話:DeepSeek的技術哲學是去質疑嗰啲所有人都覺得沒必要改的東西。V4這篇論文把這句話又紮紮實實兑現了一次。殘差連接改了,注意力機制改了,優化器也改了。每一處都是行業裏默認不動的底座。另一個是誠實。承認架構「太複雜」(原文:retained many preliminarily validated components which made the architecture relatively complex),承認訓練穩定性機制「不理解」(原文:underlying principles remain insufficiently understood),承認sparse還不夠極致,承認Agent能力落後閉源。呢啲話寫進一篇技術報告裏,放到國內同行裏幾乎找不到第二家。還有一條是Open是真Open。R1的86頁更新補全了訓練賬單和數據配方,V4的58頁繼續補全基礎設施的每個縫隙。不是「開源權重就完了」的Open,是一份讓別人真的能復現的Open。DeepSeek在發佈V4的時候引用了一句話:不誘於譽,不恐於誹,率道而行,端然正己。不被讚譽誘惑,不被誹謗嚇退,按自己的道走,端正自己。這句話可能比58頁的論文技術細節更能解釋這家公司。最後回到開頭那條線。1月那三篇解讀,mHC確實進V4了。Engram和OCR 2呢?1月Engram那篇我用的比喻是「給大模型發一本字典」:靜態知識直接查表,不浪費網絡深度現場推理。V4這次沒把這本字典裝進來,但論文明確把「沿新維度繼續稀疏化」列進了未來路線圖,參考文獻正是Engram那篇論文。OCR 2的視覺因果流也沒進V4,但多模態被明確寫進V5的方向(原文:incorporating multimodal capabilities)。所以下一代DeepSeek大概率會是咁樣的輪廓:原生多模態(OCR 2這一脈的延伸)、引入某種可擴展的查找式記憶(Engram這一脈的延伸)、進一步降低延遲(為Agent交互做準備)、更長的long-horizon multi-round agentic能力。V5什麼時候發我不好預測。但DeepSeek的節奏已經固定下來:論文先鋪路,模型後亮相。V4論文裏寫了未來方向,剩下的就是時間。V4顯然談不上對Opus 4.7或GPT-5.5的超越,它是開源陣營的一次基礎設施級更新。把百萬token上下文、Agent原生支持、成本優勢打包成一個可複用的底座。真正的價值不在V4-Pro能不能打贏最強閉源,而在V4-Flash讓每一個獨立開發者都能在自己的產品裏塞進百萬上下文。閉源卷天花板,開源卷地板。更有意思的故事,會在V5身上。參考資料:DeepSeek V4技術報告:見DeepSeek官方GitHub(deepseek-ai/DeepSeek-V4)DeepSeek R1論文v2(86頁):arxiv.org/abs/2501.12948我做的73頁PPT:https://github.com/alchaincyf/deepseek-v4-deep-dive我之前寫的DeepSeek論文解讀系列(mHC、Engram、OCR 2、R1更新)可以在公眾號歷史文章裏搜到

如果這種情況下,你還願意一起往下探的話,那我們開始吧!
在我看來,DeepSeek不是一個衝破天花板的SOTA模型。它真正的價值是把百萬上下文、Agent原生能力、能接受的價格這三件事第一次綁在了一起。
而且這次從發佈時間和節奏來說也挺有趣的,其實本來按照大家的預期,V4應當在春節前後發的,實際看來也差不多是那會兒完工。他們論文中對標的也是2月那會的Claude Opus 4.6和GPT-5.4。但它實際發佈卡到了現在,中間又出了Opus 4.7和GPT-5.5。等它正式亮相,對標對象已經換人了。
DeepSeek自己解釋說是為了更好地適配國產芯片。害,行吧,也希望國產芯片好好適配下DeepSeek。
其實今年1月份時,我已經連着寫了三篇DeepSeek論文解讀:mHC、Engram、OCR 2。當時我的判斷是這些技術大概率都會進V4。現在V4論文打開,mHC進來了,其他一些思路也能看出端倪。這篇文章我會順着這條線講,讓之前讀過那幾篇的朋友能看到完整的故事線。
再說結論
我們需要重複下開頭的核心結論,以這個視角的話,我們會對DeepSeek V4會有個更合理的預期,那就是👇
這不是一個衝破AGI天花板的世界最佳模型,但屬於是一個讓普通開發者第一次能夠放心地用上100萬上下文Agent模型的發佈。
這兩者的差別非常大。
前者是衝頂峯的敍事,需要在各個benchmark上全面擊敗Opus 4.7、GPT-5.5、Gemini 3.1 Pro。V4還做不到。
後者是抬地板的敍事。100萬token上下文這件事,之前不是沒有模型能做到,但要麼極貴(Opus、DeepSeek那檔),要麼效果會顯著衰減(很多國產模型128K以上就明顯掉分)。V4做的事情是把「100萬長上下文」+「Agent多步調用能力」+「能接受的價格」這三件事第一次組合到一起。
對閉源旗艦來說,V4不構成威脅。對一個想在產品裏塞入長上下文的獨立開發者來說,V4意味着幾乎所有的上下文節省工作都可以先不做了(對的,RAG和很多別的AI敍事一樣,只要你不學,等着等着你就可以不必學了)
業內有個說法:閉源模型卷能力天花板,開源模型卷地板,地板抬高的速度決定AI應用爆發的規模。V4把這個地板往上抬了抬。
V4-Pro 和 V4-Flash:兩個定位不一樣的模型
這次DeepSeek發的是兩個模型。

V4-Pro的總參數量比V3的671B翻了2.4倍。激活參數從37B漲到49B,只多了三成左右。走的是「稀疏度再提高」的路線。
這裏要稍微解釋一下MoE模型的工作方式。V4-Pro一共有300多個專家(routed experts)加上1個共享專家。每次處理一個token的時候,它不是把所有專家都調動起來,而是隻激活其中6個+共享專家,一共7個專家參與回答。這有點像一個有384位專家的公司,每個決策只召集7個人開會,不搞全員表決。激活的參數量少,推理速度就快,成本也能壓下來。
V4-Pro的定位是「開源陣營裏能跟閉源旗艦掰手腕的那個」。但DeepSeek自己在論文裏也誠實地說了一件事:因為現在高端算力受限,Pro的服務吞吐很有限,所以Pro版本的API價格目前不算便宜,預計下半年才能降下來。
V4-Flash是真正符合DeepSeek一貫風格的那個模型。它的參數規模是V4-Pro的約六分之一,但在很多基礎能力上已經反超了V3.2。這意味着架構改進和數據質量的收益,足夠抵消參數規模的差距。Flash的價格相比同類快速模型,大概是他們的1/7到1/18。
如果你是獨立開發者,我的建議很明確:AI編程、寫作、複雜任務、關鍵決策場景用Opus 4.7這類;批量任務、Agent後台、數據處理用V4-Flash。
架構動了哪些刀
V4沒有推倒V3重來。MoE框架沿用的還是DeepSeekMoE,MTP模塊沒動,訓練細節也大多延續V3。真正大改的地方只有三處:
殘差連接升級成mHC 注意力拆成CSA+HCA的混合架構 優化器從AdamW換成Muon
這三處改動各自解決一個具體痛點。殘差連接在堆深時數值不穩定,限制了把模型做大;傳統注意力在百萬token長上下文下KV cache爆炸,算力根本扛不住;AdamW在超大規模MoE訓練上收斂慢、偏科嚴重。
V4相當於把V3的三個瓶頸逐一拆掉。
mHC:給殘差連接加一道只准收縮不準放大的護欄
mHC我在1月那篇mHC論文解讀裏已經完整講過了,這裏長話短說。
殘差連接是深度學習用了整整十年的基礎設計。2015年何愷明的ResNet開始,到現在的每一個大模型都離不開它。它做的事情,用一句話說就是給信號開了一條「快車道」:不管中間那些層學到了什麼,原始信號都能直接順着這條高速公路原封不動傳到後面。這就是所謂的「恆等映射」。
這個設計本身沒問題。問題出在對它的第一次升級上。2024年底,字節Seed團隊發了一篇叫Hyper-Connections(HC)的論文,後來中了ICLR 2025。HC把單通道的殘差流擴展成多通道,讓模型自己學習最優的連接方式。DeepSeek一開始也是沿着這條路線往下走的,但踩到了HC的一個致命缺陷:訓練不穩定。
不穩定到什麼程度?DeepSeek在1月那篇mHC論文裏給過一個很震撼的數字:在27B模型上,HC的信號放大倍數峯值達到3000倍。也就是說,信號在網絡裏傳着傳着,被放大了3000倍,梯度也隨之被放大3000倍。訓練到某一步突然崩掉是家常便飯。
mHC解決這個問題的思路,我覺得最形象的說法還是1月文章裏那句:給殘差連接加了一道「只准收縮不準放大」的數學護欄。
用一個畫面講清楚。信號在網絡裏一層層往下傳,可以想象成把一杯水倒進下一個杯子。HC的做法是把一根水管變成四根,每根流量讓模型自己學。靈活是靈活了,但沒人管總量。倒着倒着水越倒越多,到第60層的時候已經是原來的3000倍,杯子直接爆了。
mHC的做法是強制每一層倒水都守恆。不管四根水管怎麼分配、怎麼混合,進多少水就出多少水,一滴不多一滴不少。
這個約束的數學工具叫「雙隨機矩陣」,名字嚇人,本質就是一張分配表:每一行加起來等於1,每一列加起來也等於1。這兩個條件加起來,天然保證了水不會憑空變多。更舒服的是,兩張雙隨機矩陣乘在一起還是雙隨機矩陣,所以不管你堆多少層,守恆這件事都不會失效。
代價是模型不能自由學這張表,每一層都要用一個叫Sinkhorn-Knopp的算法迭代20次,把學出來的東西壓回守恆的形狀。相比訓練崩掉的損失,這個代價不算什麼。
mHC帶來的直接結果是:V4能把模型從V3的671B推到1.6T,參數量2.4倍增長,訓練穩定性反而比V3更好。
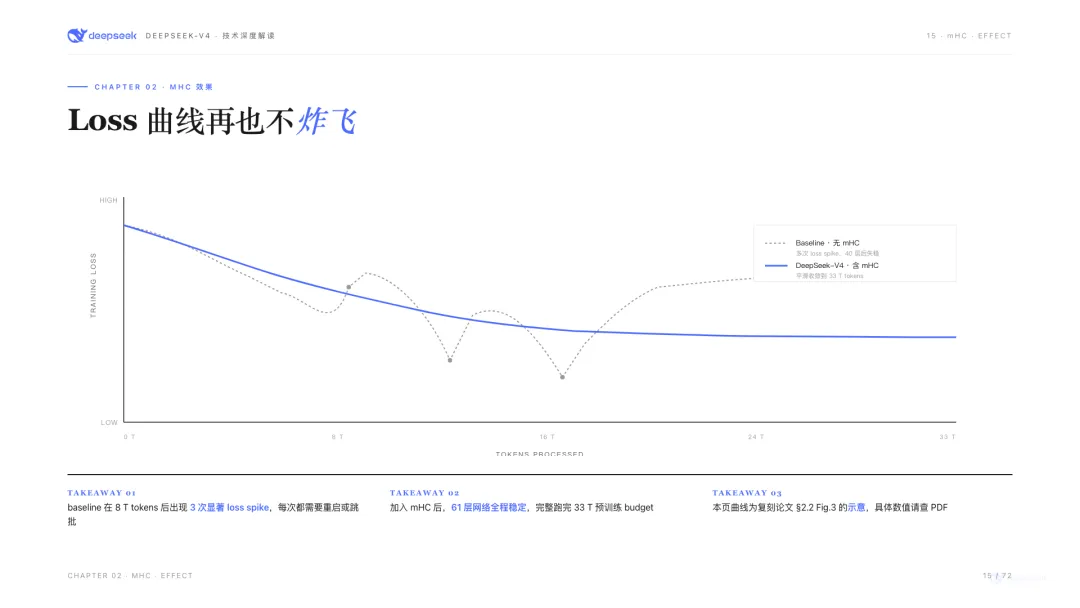
這是理解V4能「做大」的第一把鑰匙。
CSA + HCA:讀一本800頁的書,先翻目錄再精讀
這是整篇論文我覺得工程含量最高的地方,也是V4百萬上下文能落地的核心。
先說清楚一件事:為什麼100萬上下文這麼難做?
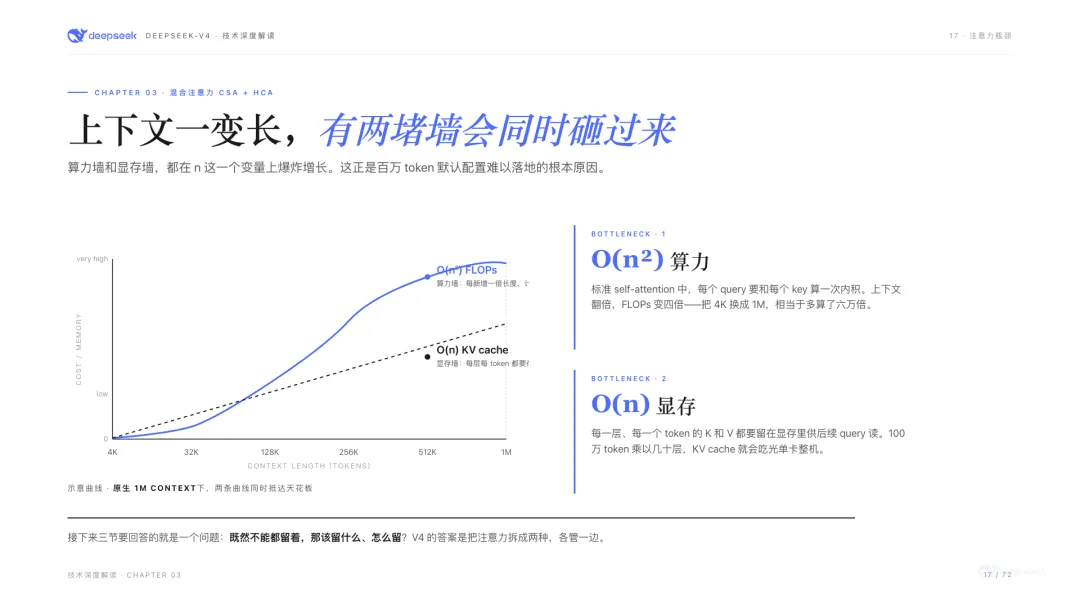
標準的注意力機制,每個新來的token都要和前面所有token算一次內積。如果把4K上下文換成100萬上下文,需要算的內積數量是4000倍,顯存佔用也是4000倍。粗略估算下來,100萬上下文的單次推理成本比4K高約6萬倍。這堵「算力牆」和「顯存牆」加起來,是大多數模型在128K-200K就停住的原因。
V4的解法是把注意力機制拆成兩種,在Transformer不同的層裏交替使用。
CSA(Compressed Sparse Attention)走精細路線。它把每m個token壓縮成1個塊,然後用一個叫Lightning Indexer的小模塊算每個query和每個壓縮塊的相關性分數,只挑分數最高的top-k個塊去做真正的注意力計算。
HCA(Heavily Compressed Attention)走粗略路線。它的壓縮率m'遠比m大(通常是幾十倍),但不做稀疏篩選,query會dense地把所有壓縮塊都掃一遍。犧牲細粒度,換極致的KV cache壓縮。
我覺得這兩種注意力最好的比喻就是讀一本800頁的書。
你不會逐字讀完。大概率是這樣:先翻目錄,定位到有用的那幾章;翻到那一章後掃一下小標題,定位到第幾頁;最後才精讀那幾頁。這是一個先粗後細的過程。
V4把這個動作拆成了兩種獨立的機制,交替安排在不同的層裏:
CSA做的是「掃小標題定位」:先把每64個token揉成一塊,給每塊打分,挑出最相關的幾塊去精讀 HCA做的是「翻目錄看大意」:直接把1024個token壓成一塊,一本800頁的書可能只剩幾十塊大摘要,每個新來的token都把這幾十塊全掃一遍
兩者加起來,V4在100萬上下文下的單次推理成本,只有V3.2的約1/4。KV cache佔用只有傳統BF16 GQA8 baseline的約2%。
把50份壓成1份,這是百萬上下文真正能跑起來的數學原因。
論文裏還有一堆工程細節,比如兩種注意力都用Shared KV MQA進一步省cache,都加了sliding window分支保證局部細節不丟,都用了attention sink讓query可以「棄權」。這些工程活不好解釋,但每一個都在扣效率。
這是理解V4能「讀長」的第二把鑰匙。
Muon:別每個旋鈕單獨調,整組一起掰
Muon是V4用來替代AdamW的優化器。改動的技術深度很足,但可以用畫面感拆開說。
先說優化器是幹嘛的。模型訓練就一句話:猜一個答案,對照正確答案,根據錯的方向調整自己。優化器決定的就是「具體怎麼調」。
AdamW是過去十年行業默認的優化器。它的邏輯是:模型內部有幾十億個旋鈕要調,每個旋鈕單獨看它過去抖得厲害不厲害,抖得厲害就調慢一點,抖得少就調猛一點。聽起來挺合理。
問題是這些旋鈕不獨立。它們是同一台機器上的幾十億個零件,彼此聯動。AdamW單獨看每個旋鈕的歷史做判斷,結果就是模型在參數空間裏走出來的軌跡是個極度扁的橢圓:少數幾個「熱門方向」步子邁得特別大,推到病態的程度;其他方向幾乎沒動過,等於沒學。
說得更直白點,AdamW訓出來的模型會偏科。
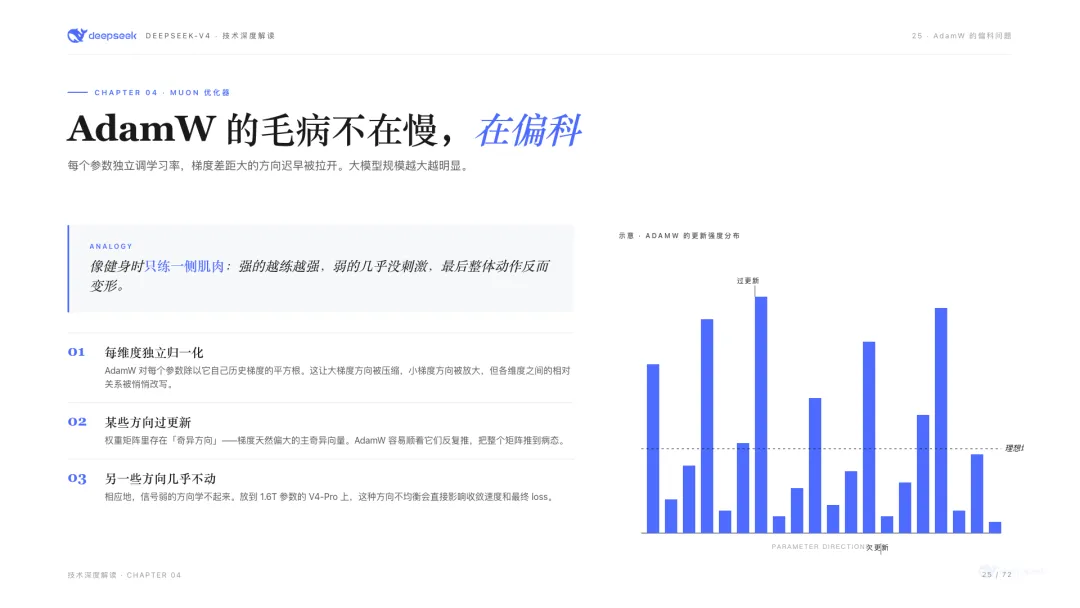
Muon反過來想。它不看單個旋鈕,而是看這一整組旋鈕合起來在往哪個方向走,然後把這個方向的更新強行「拉平」:原本邁得特別大的方向壓一壓,幾乎沒動的方向拉一拉,讓每個方向都走一樣遠。數學上這個操作叫「正交化」,畫面感上就是把原本歪扁的橢圓硬掰成一個正圓。
好處是什麼?原本被AdamW淹沒的冷門方向,現在能和熱門方向拿一樣的步長。模型探索範圍更廣,收斂更穩。
Muon天生有個成本問題:每一步都要把橢圓掰成正圓,直接算要做矩陣分解,太貴。V4用了一個近似辦法(Newton-Schulz迭代),10步搞定一次掰正,前8步用激進係數快速逼近,後2步切換温和係數做精修。工程上剛好不貴。
一個細節:V4沒把所有參數都交給Muon。embedding、prediction head、RMSNorm這些本來就不是矩陣、沒有「方向」概念的參數,還是AdamW管。Muon和AdamW各管一攤。
這是理解V4能「訓深」的第三把鑰匙。
1.6T怎麼訓穩的:兩個他們自己也不懂的trick
把模型從671B推到1.6T,光有mHC還不夠。訓練1.6T的MoE時,V4團隊遇到了loss spike(訓練損失突然飆升,前幾輪學的東西都被噪聲污染),簡單的回滾保存點也救不回來,剛回滾完沒多久又崩。
他們最終用了兩個辦法把訓練救回來。
一個叫Anticipatory Routing(預判式路由)。MoE模型裏有個「路由器」負責每一步挑哪幾個專家上場,這個路由器本身也是學出來的。訓練崩潰的惡性循環是這樣:某一步某個專家輸出了一個異常大的數,這個異常讓路由器誤以為「這個專家真強」,下一步派給它更多任務,它輸出更離譜的數,路由器越挑越偏,訓練崩了。
解法特別巧:讓路由器用「昨天的腦子」做「今天的決定」。主幹網絡的更新和路由器解耦,主幹用當前參數算,但路由器挑專家時查的是前幾步的歷史參數。今天網絡再怎麼抽風,路由器用的是沒被污染的舊腦子,惡性循環就斷了。
另一個叫SwiGLU Clamping。SwiGLU是模型裏的激活函數,可以理解為每個神經元的「水龍頭」。正常情況水龍頭開多大都行,但在1.6T這個規模上,某些神經元會突然爆出極大的數值,把整個訓練帶崩。DeepSeek的做法簡單粗暴:給SwiGLU內部的幾個關鍵數值強行加一個上下限(-10到10之間),哪怕某個神經元想輸出一萬,也只能給你10。
這兩個trick為什麼有效?DeepSeek自己在論文裏說,他們也不完全清楚。原話是「the underlying principles of these mechanisms remain insufficiently understood」。
他們只知道:用了,有效,就這麼用。至於為什麼,希望社區一起探索。
我覺得這個細節值得單獨拎出來講。
過去我們看到的很多技術報告,總是在事後給方法找一套漂亮的理論解釋,好像研究者從一開始就想得很清楚。但實際工程裏,很多時候是先做出來再理解。DeepSeek不藏這個,白紙黑字寫進論文裏。
這種坦誠在國內團隊裏並不多見。今年1月我寫R1論文更新那篇時說過,DeepSeek的「Open」不是做到行業平均水平就夠了,而是包括那些失敗的嘗試、沒搞懂的trick、踩過的坑都一併開出來。
V4這篇報告延續了這個風格。
訓練數據:32T tokens,反AI生成、加Agent、加多語言
V4的預訓練數據比V3更大(33T vs V3的14.8T),也更講究。幾個關鍵動作:
反模型坍縮。互聯網語料裏現在充斥着大量AI生成的文本。如果不做過濾,訓練出來的模型會出現「模型坍縮」(model collapse):每一代都在上一代的AI輸出上訓練,能力會越來越差。DeepSeek專門做了一套過濾,把批量自動生成和套模板的內容攔掉。
中期訓練引入Agent數據。工具調用軌跡、多步推理、搜索片段這些,不能靠後訓練硬掰,必須在預訓練中期就喂進去。這是V4-Flash的Agent能力躍升的關鍵原料。
多語言擴容。擴充了除中英外的長尾語言,覆蓋不同文化的知識。所以你用V4做翻譯、或者查一些非英文語言的長尾知識,效果會比V3好不少。
精選長文檔。科學論文、技術報告這類「學術價值獨特」的材料被重點收錄。
訓練數據規模上,Pro版本是33T tokens,Flash版本是32T tokens。分詞沿用V3的128K詞表。
序列長度是分階段擴展的:從4K起步,逐步擴到16K、64K、1M。稀疏注意力也是分階段引入:前1T tokens先用dense attention熱身,到64K序列長度時切到sparse attention。這種漸進式訓練在超長上下文模型裏已經是事實標準,但V4的階段切換時機設計比較精細。
後訓練:Specialist + OPD,一個被低估的範式變化
如果說架構改動是V4最顯眼的變化,那後訓練範式的變化其實是這篇報告最深刻的變化。V4在後訓練章節的第一句話就很有趣:
the mixed Reinforcement Learning (RL) stage was entirely replaced by On-Policy Distillation (OPD).
翻譯過來就是:混合RL階段被徹底替換成在策略蒸餾。
這句話我覺得像是範式級別的轉變了。
為什麼要替換
傳統後訓練是「SFT+RLHF混煉」的路子:一個大雜燴數據集,SFT打底,再用一個reward model做RL。問題是什麼?
數學、代碼、Agent、對話這些能力在RL階段會互相打架。你調數學的reward權重,代碼能力可能就掉了;你加Agent數據,對話又變笨。多任務聯合優化的「負遷移」問題,幾乎每個做過後訓練的團隊都踩過坑。
DeepSeek的解法是把「聯合優化」拆成「分治+合併」:
Stage 1 Specialist訓練:每個領域(推理、數學、代碼、Agent、通用對話)單獨訓練一個專家模型。先SFT,再用GRPO做RL。每個專家只管自己那塊,reward signal清晰,不用跟其他領域折中。
Stage 2 On-Policy Distillation:把十多個專家模型當老師,通過反向KL loss蒸餾出一個統一的學生模型。
這個拆分的妙處在於:RL只在專家階段做,最終的學生模型不做RL,只做蒸餾。RL的訓練不穩定性被隔離在專家模型內部,學生模型通過更穩定的蒸餾loss拿到所有專家的能力。
反向KL是關鍵
OPD的技術細節裏,有一個點特別值得講:為什麼用反向KL而不是正向KL?
正向KL是讓學生去cover老師的所有模式,結果往往學成四不像。反向KL是讓學生集中在老師分佈的高概率區域,學生會自動「選老師」:數學任務時對齊數學專家,代碼任務時對齊代碼專家。
這個「自動路由」的特性,是多老師蒸餾能跑通的關鍵。
為什麼這個範式重要
講到這裏可能有朋友要問:這個東西對獨立開發者有什麼意義?
我的判斷是,這可能是比MoE更深刻的範式變化。
MoE是推理時混合(runtime mixture),OPD蒸餾是訓練時混合(training time mixture)。後者的組合空間大得多。
這個範式天然適合幾類場景:
小團隊:沒錢一開始就訓大模型,但可以訓多個小specialist,最後蒸餾融合 垂直應用:法律/醫療/代碼各訓一個專家,最後合併 持續學習:要增加新能力時,訓一個新專家加入蒸餾池就行,不破壞老模型
只要你能訓出專家,就能通過OPD合進來。未來想加新能力(比如「寫毛筆字」「解幾何題」),路徑很清晰:訓專家→加入蒸餾池。這比RLHF要改reward、要重跑全流程友好得多。
這個範式會不會成為新的行業標準,目前還不好說。但V4已經用了十多個專家模型做OPD,證明在萬億參數級別它是可行的。

評測結果:強在哪,弱在哪
評測是V4論文裏最重要的部分之一,也是最容易被誤讀的部分。我直接把我的判斷列出來。
數學推理:反超閉源旗艦
V4-Pro在幾個數學類benchmark上拿到了開源陣營前所未有的高分:
Codeforces的競賽評分V4-Pro能達到3206分,對應人類選手第23名。這是非常離譜的水平。
編程:LiveCodeBench和Codeforces雙第一
V4-Pro在LiveCodeBench拿到93.5分,Codeforces Rating 3206。DeepSeek論文裏明確寫了,這是第一次開源模型在這兩項任務上追平閉源。

但注意一個細節:SWE系列(真實工程代碼任務)就沒那麼亮眼了。SWE Verified 80.6分接近Opus 4.6的80.8但沒超過,SWE Multilingual也略輸。
這就對應上了DeepSeek論文裏自己的總結:V4模型非常擅長做題,但品味上還差一些火候。競賽類任務有明確答案,RL能反覆打磨;工程類任務要綜合考慮代碼風格、架構、可維護性,這些品味層面的東西現在的RL訓練還吃不透。
Agent:全方位落後閉源
這是V4最弱的一塊。
Terminal Bench 2.0落後GPT-5.4整整7分,HLE w/ tools落後Opus 4.6整整5分。DeepSeek論文裏非常誠實地寫了:「所有開源模型仍落後閉源對手」。
唯一的亮點是MCPAtlas Public(73.6),僅次於Opus的73.8。說明V4在通用工具調用和MCP服務上泛化能力不錯,不是隻在內部框架裏打雞血。
真實編程任務:接近Opus 4.5,差Opus 4.6 Thinking 13分
DeepSeek自己拿200多個真實的內部R&D編程任務做了測試,來自50多位工程師日常工作中提的真實需求,覆蓋PyTorch、CUDA、Rust、C++:
V4-Pro的67%已經超過Sonnet 4.5(47%),接近Opus 4.5(70%),但距離Opus 4.6 Thinking(80%)還差13個百分點。
這組數據是DeepSeek論文發佈時跑的,當時Claude最新是4.6 Thinking。現在Opus 4.7 Thinking已經發布,V4和當前最強閉源的真實差距大概是6個月到1年的研發時間。談不上「完全追平」,也算不上「落後一代」。
中文場景:真正的第一梯隊
中文寫作是V4-Pro少數能對Opus 4.5掰手腕的地方:
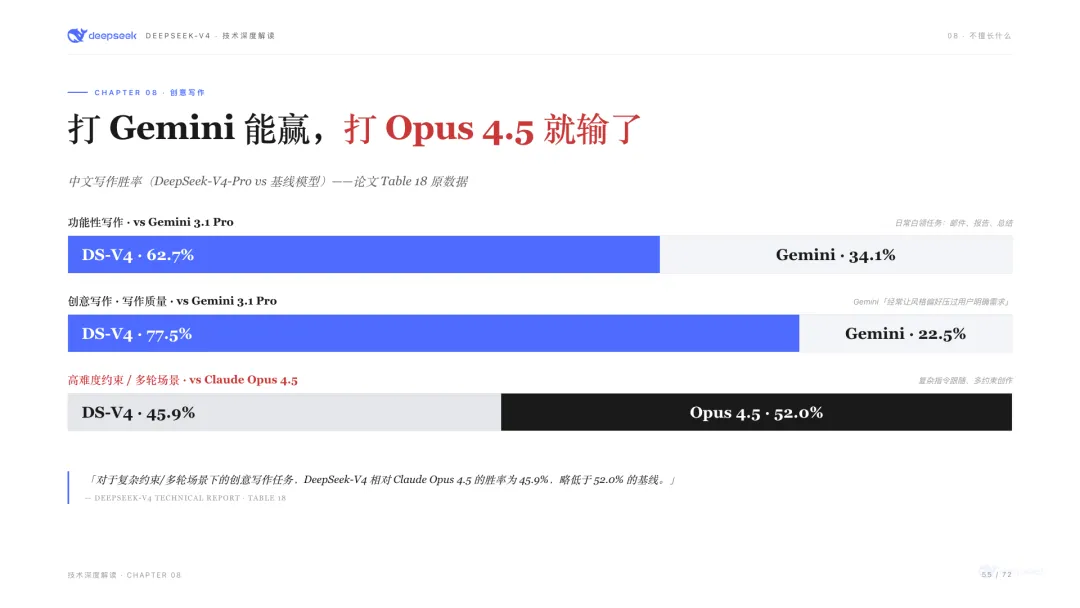
意思就是日常中文寫作對Gemini是碾壓級,複雜指令跟隨對Opus 4.5仍然有差距。論文裏吐槽Gemini經常「讓自己的風格偏好壓過用戶的明確需求」(擅自加戲),這個描述我讀完忍不住笑了一下。
長上下文:128K內穩如狗,1M勉強能用
V4在1M長上下文的檢索任務上超過Gemini,但落後Claude Opus 4.6。MRCR 8-needle測試顯示128K以內性能穩定在0.9以上,256K後開始掉到0.82,到1024K降至0.59。
128K以內基本沒有性能衰減,1M勉強能用。這是CSA+HCA混合架構帶來的實際收益。對大多數Agent和代碼場景,128K已經足夠。
一個特點:為什麼V4這麼偏科?
讀完整份報告,加上這些benchmark結果,有一個很鮮明的模式浮出來:
V4特別擅長做題,但在品味型任務上差一檔。
數學競賽Putnam滿分,Codeforces拿到人類選手第23名,LiveCodeBench全場第一。
但創意寫作輸給Opus 4.5,Agent任務落後GPT-5.4,HLE通用知識被Gemini壓制。
我自己的理解是:這和DeepSeek招的人有關。
DeepSeek的招聘以競賽獲獎選手為主。這些人擅長什麼?擅長在給定規則下把單點做到極致,擅長解有明確答案的題。模型訓練的偏好會受數據團隊、訓練團隊、評估團隊的品味影響,這些品味又受團隊成員的背景影響。
所以V4在有明確答案的任務上表現頂尖(數學、競賽編程),在需要綜合品味的任務上(創意寫作、長鏈Agent、通用工程編程)就會相對偏弱。
這只是一個觀察,談不上批評。模型的性格映射着團隊的性格,這件事很多時候比人們想象的更直接。
DeepSeek還是那個DeepSeek嗎?
寫到這裏不得不問一個問題:V4時代的DeepSeek,和V3時代比,變了嗎?
我的回答是:變了,但沒變味。
V3時代的DeepSeek是「小團隊、極致工程、帶來驚喜」。V4時代的DeepSeek打開論文附錄,研究工程作者名單已經超過300人,加上商業和合規接近350人。這不再是那個幾十人的實驗室。
但有幾個東西沒變。
一個是工程至上。V4的創新重點不在高層架構設計,而在「信號怎麼流動」和「梯度怎麼更新」這兩個底層問題上。mHC解決深度scale的數值穩定性,CSA+HCA解決上下文scale的算力和內存,Muon解決參數scale的訓練效率。每一項都是回答「為什麼V3做不大」的問題。
我在1月那篇mHC解讀裏寫過一句話:DeepSeek的技術哲學是去質疑那些所有人都覺得沒必要改的東西。V4這篇論文把這句話又紮紮實實兑現了一次。殘差連接改了,注意力機制改了,優化器也改了。每一處都是行業裏默認不動的底座。
另一個是誠實。承認架構「太複雜」(原文:retained many preliminarily validated components which made the architecture relatively complex),承認訓練穩定性機制「不理解」(原文:underlying principles remain insufficiently understood),承認sparse還不夠極致,承認Agent能力落後閉源。這些話寫進一篇技術報告裏,放到國內同行裏幾乎找不到第二家。
還有一條是Open是真Open。R1的86頁更新補全了訓練賬單和數據配方,V4的58頁繼續補全基礎設施的每個縫隙。不是「開源權重就完了」的Open,是一份讓別人真的能復現的Open。
DeepSeek在發佈V4的時候引用了一句話:不誘於譽,不恐於誹,率道而行,端然正己。

不被讚譽誘惑,不被誹謗嚇退,按自己的道走,端正自己。
這句話可能比58頁的論文技術細節更能解釋這家公司。
最後
回到開頭那條線。1月那三篇解讀,mHC確實進V4了。Engram和OCR 2呢?
1月Engram那篇我用的比喻是「給大模型發一本字典」:靜態知識直接查表,不浪費網絡深度現場推理。V4這次沒把這本字典裝進來,但論文明確把「沿新維度繼續稀疏化」列進了未來路線圖,參考文獻正是Engram那篇論文。
OCR 2的視覺因果流也沒進V4,但多模態被明確寫進V5的方向(原文:incorporating multimodal capabilities)。
所以下一代DeepSeek大概率會是這樣的輪廓:原生多模態(OCR 2這一脈的延伸)、引入某種可擴展的查找式記憶(Engram這一脈的延伸)、進一步降低延遲(為Agent交互做準備)、更長的long-horizon multi-round agentic能力。
V5什麼時候發我不好預測。但DeepSeek的節奏已經固定下來:論文先鋪路,模型後亮相。V4論文裏寫了未來方向,剩下的就是時間。
V4顯然談不上對Opus 4.7或GPT-5.5的超越,它是開源陣營的一次基礎設施級更新。把百萬token上下文、Agent原生支持、成本優勢打包成一個可複用的底座。真正的價值不在V4-Pro能不能打贏最強閉源,而在V4-Flash讓每一個獨立開發者都能在自己的產品裏塞進百萬上下文。
閉源卷天花板,開源卷地板。
更有意思的故事,會在V5身上。
參考資料:
DeepSeek V4技術報告:見DeepSeek官方GitHub(deepseek-ai/DeepSeek-V4) DeepSeek R1論文v2(86頁):arxiv.org/abs/2501.12948 我做的73頁PPT:https://github.com/alchaincyf/deepseek-v4-deep-dive 我之前寫的DeepSeek論文解讀系列(mHC、Engram、OCR 2、R1更新)可以在公眾號歷史文章裏搜到