GLM-5.2能打了,但還不能替代GPT
整理版優先睇
GLM-5.2 能力追上第一梯隊,但唔好急住全面取代 GPT
呢篇文章係由 AI 從業者孟健寫嘅,佢長期測試國產模型,今次重點評測 GLM-5.2。作者想解決嘅問題係:GLM-5.2 雖然係目前最強嘅國產模型,但係咪已經適合做 Agent 嘅主力模型?結論係:能力上已經接近 GPT 同 Claude,但限流、額度同接入限制令佢暫時唔可以全面取代 GPT,應該當補位武器,放入模型組合入面用。
文章先講 GLM-5.2 嘅亮點:長任務同 Agent 感明顯進步,支援 1M 上下文同 128K 輸出,喺複雜工程任務嘅穩定性比之前嘅國產模型好。基準測試顯示佢喺 SWE 任務上同 Opus、GPT 嘅差距已經好細。但作者隨即指出現實問題:Coding Plan 有雙層限額同高峯期 3 倍額度消耗,Pro 套餐每週 2000 prompts 實際可用大打折扣。另外,接入非官方工具鏈時會遇到定向攔截,改源碼先用到,自建推理當然可以但成本高。
最後作者畀出建議:唔好替代 GPT,而係將 GLM-5.2 放喺五個特定位置用——GPT 安全限制太強嘅任務、長上下文倉庫理解、國產環境工程場景、非高峯期大任務、作為第二意見模型。同時避開全天候高強度 Agent 羣呢類場景。總結係:能力過線,但配套未到位,要用得啱先有增量。
- GLM-5.2 係目前最強國產模型,長任務同 Agent 感明顯提升,1M 上下文同 128K 輸出係實質優勢。
- 基準測試上 SWE 任務僅落後 Opus 4.8 約 1%,超過 GPT-5.5,但係「接近」同「可替代」係兩回事。
- 現實問題:Coding Plan 限額嚴,高峯期 3 倍消耗,Pro 每週 2000 prompts 實際好快用盡。
- 接入非官方工具鏈有定向攔截,要改源碼或接受次級調度,唔係簡單換 endpoint 就得。
- 建議當補位武器,唔好全面取代 GPT,適合用喺 GPT 唔肯做嘅任務、長上下文分析、國產場景同非高峯期大任務。
國內第一,但唔係默認主力
GLM-5.2 係作者用過最強嘅國產模型,同 GPT、Claude 嘅差距已經唔算大,但「唔算大」同「可以替代」係兩件事。喺 AI 編程同 Agent 長任務方面,佢第一次有資格入選型討論,但作者唔建議而家就將所有 Agent 切過去。
長任務同 Agent 感係真正突破
官方定位係面向長任務嘅旗艦文本模型,支援 1M 上下文同最大輸出 128K tokens,可以一次食曬成個中型代碼倉庫,輸出完整重構方案。作者用落覺得複雜任務嘅穩定性明顯好咗,唔會再中途出現上下文理解斷層。
1M 上下文同 128K 輸出係實質優勢,省掉分段喂或者靠外部向量檢索補漏嘅步驟。
官方強調嘅場景包括項目級工程接管、長程重構、生產規範壓力測試、移動端真機調試,同埋微信小程序、小遊戲呢啲工程任務。
- 1 FrontierSWE 上僅落後 Opus 4.8 約 1%,超過 GPT-5.5 約 1%。
- 2 SWE-Marathon 上同 Opus 4.8 仍有約 13% 差距。
- 3 基準測試同實際工程有出入,但趨勢顯示國內模型第一次可以同 Opus、GPT 並列討論。
限流、倍數、額度——用落摩擦感好真實
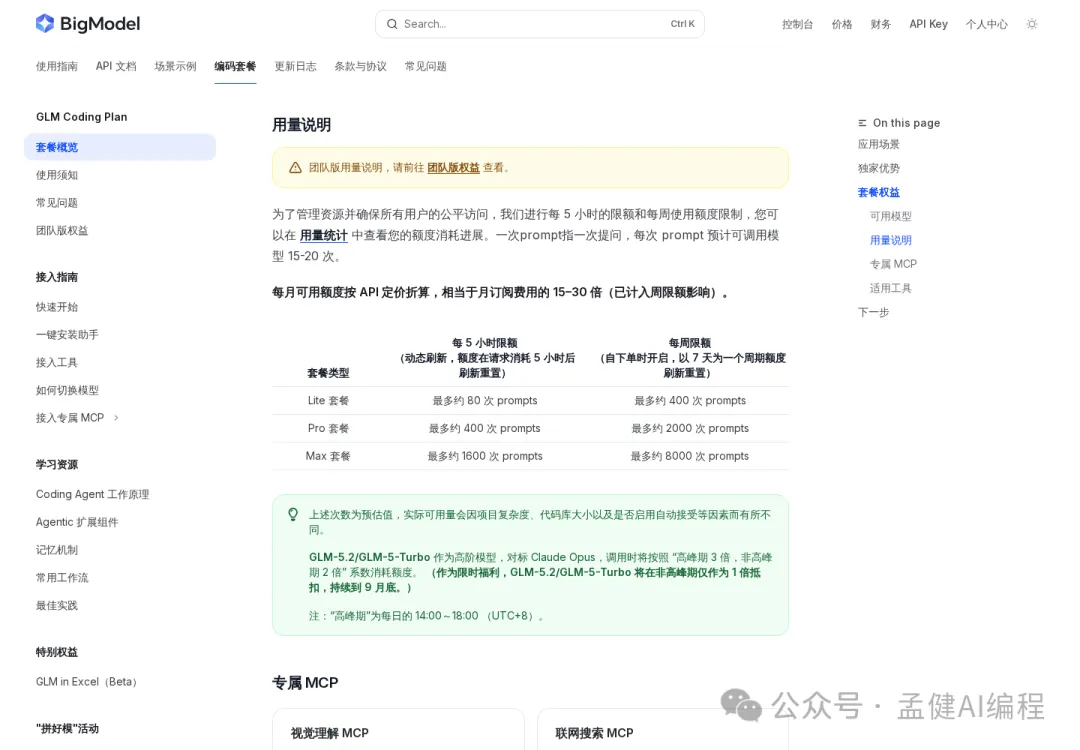
Coding Plan 有兩層限額:每 5 小時一個上限,每週一個總額度。Lite 約 80 prompts / 5h,Pro 約 400 / 5h,Max 約 1600 / 5h。GLM-5.2 係高階模型,高峯期 3 倍消耗,非高峯期 2 倍,有個限時福利到 9 月底非高峯 1 倍。
高峯期 3 倍消耗,實際一個 prompt 計費三個,高強度工作流下兩三個鐘就用盡一日額度。
Pro 套餐每週 2000 prompts 聽落夠,但高峯期全 3 倍消耗,實際能跑嘅 Agent 輪數大打折扣。想無限制用基本要上千蚊嘅團隊版。另外高峯期限制會逼你用非高峯時間做大型任務,如果 Agent 需要工作時間全天候響應,呢個會變成瓶頸。
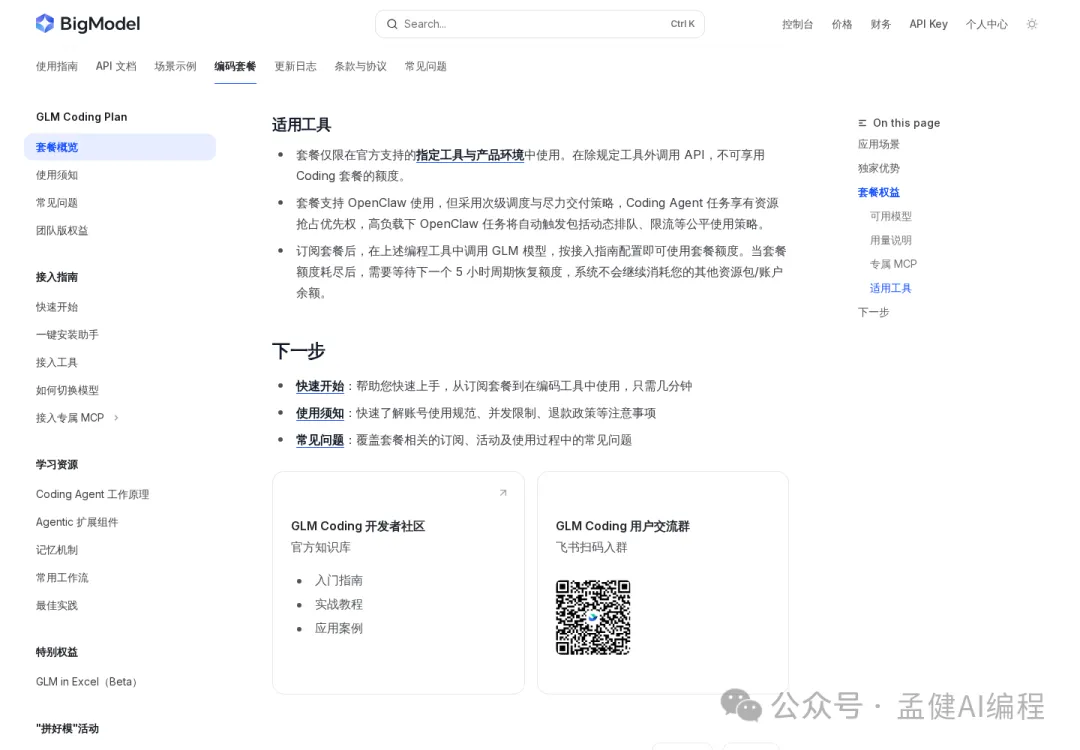
接入唔係無痛:工具鏈卡住好耐
官方話 Coding Plan 套餐僅限官方支持嘅工具環境使用。OpenClaw 被列為支持工具,但實際係次級調度同盡力交付,高負載下會排隊限流。作者用 Hermes 同 OpenClaw 接入時遇到定向攔截,唔改源碼就繞唔過,請求發出去但返回超時或者拒絕。
定向攔截意味住如果你的工作流依賴非官方渠道或自定義工具鏈,接入成本遠比「換 API endpoint」高。
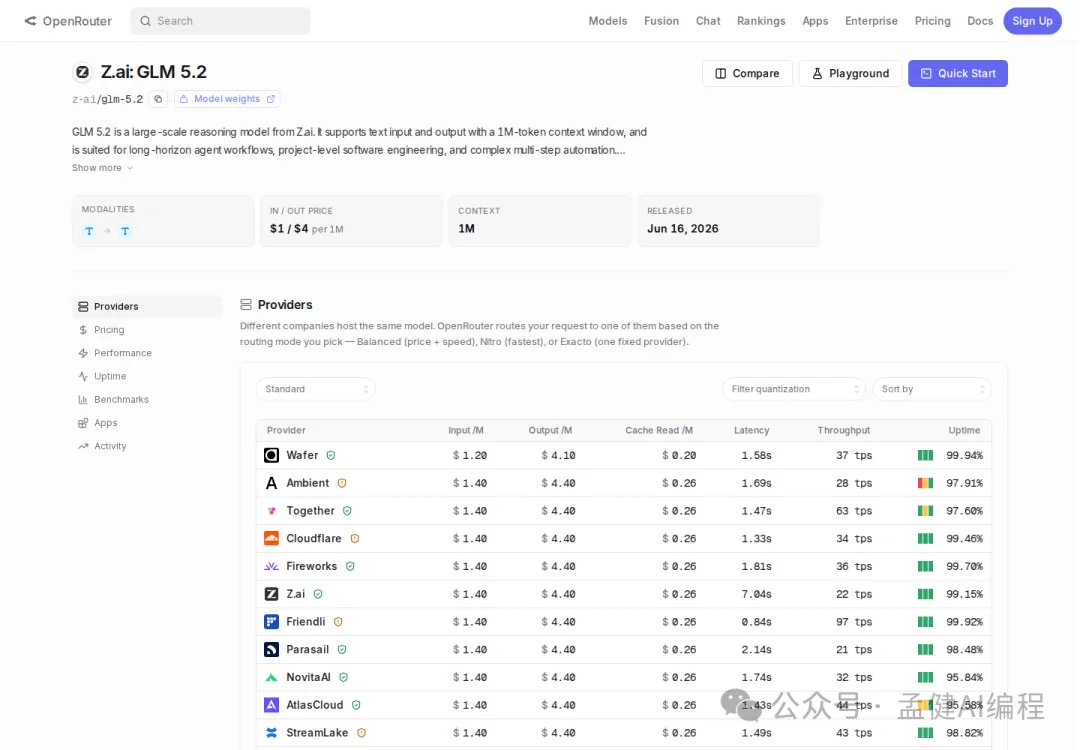
要嘛改源碼,要嘛換工具,要嘛接受次級調度帶來嘅不穩定。OpenRouter 上 GLM-5.2 標價 $1.20 input / $4.10 output per 1M tokens,HuggingFace 有開放權重,自建推理可以繞過額度限制,但 GPU、運維、延遲成本另計。
模型能力追上來之後,真正決定能否落地嘅係額度、生態同限制呢三項現實問題。
建議:唔好替代 GPT,放進模型組合
作者而家將 GLM-5.2 當補位武器,唔係主力。佢列出五個適合用嘅場景:
- GPT 安全限制太強嘅任務:GLM-5.2 限制相對寬鬆,直接接手 GPT 唔肯做嘅部分。
- 長上下文倉庫理解:1M context 實質優勢,適合一次過讀大量代碼再做判斷。
- 國產環境同中文工程場景:微信小程序、小遊戲等,GLM 工程上下文更貼近實際。
- 非高峯期嘅大任務:凌晨或早上用 1 倍抵扣,成本最優。
- 作為第二意見模型:兩個模型分別畀方案,對比互補,用喺最終決策前嘅校驗。
唔適合全天候高強度 Agent 羣、需要無限制自動化、對穩定額度有要求嘅生產主鏈路。用啱位置係真實增量,用錯位置限制會好快顯現。
而家唔使再問國產模型可否寫 code,呢條已經過線。應該問:佢適唔適合入你嘅 Agent 預算表,放邊個位置,同邊個主力模型搭配。
大家好,我是孟健。GLM-5.2 係我最近用落最驚喜嘅國產模型:佢已經好接近 GPT、Claude 嘅第一梯隊,但我唔會建議你今日就將所有 Agent 轉曬過去。
01 先講結論:國內第一,但唔係默認主力
我接觸國產模型嘅時間唔短,大多數時候嘅結論都係「仲得,但係差一截」。GLM-5.2 係第一次令我覺得,呢句嘢要改一改。
整體表現上,佢已經係我用過嘅國內模型入面最強嘅。同 GPT、Claude 嘅頂級梯隊比,差距已經唔算特別大。但「唔算特別大」同「可以替代」係兩回事,後面我會詳細講。
喺 AI 編程同 Agent 長任務呢兩個方向,國內模型之前好少可以進入選型討論——通常係「冇預算先用」或者擺喺最尾嘅備選。GLM-5.2 係第一次令我覺得,佢有資格參與主力候選嘅對比,放入同一張選型表入面認真睇。
但今日你如果問我,要唔要將所有 Agent 都轉過去——唔好。
衡量「用得」同「適合做主力」,標準唔同。用得,睇能力上限。適合做主力,睇穩定性、額度、生態接入成本。GLM-5.2 喺能力上已經過咗門檻,喺後三項上仲未到位。呢三個問題,下面會講。
02 真正變強嘅係長任務同 Agent 感
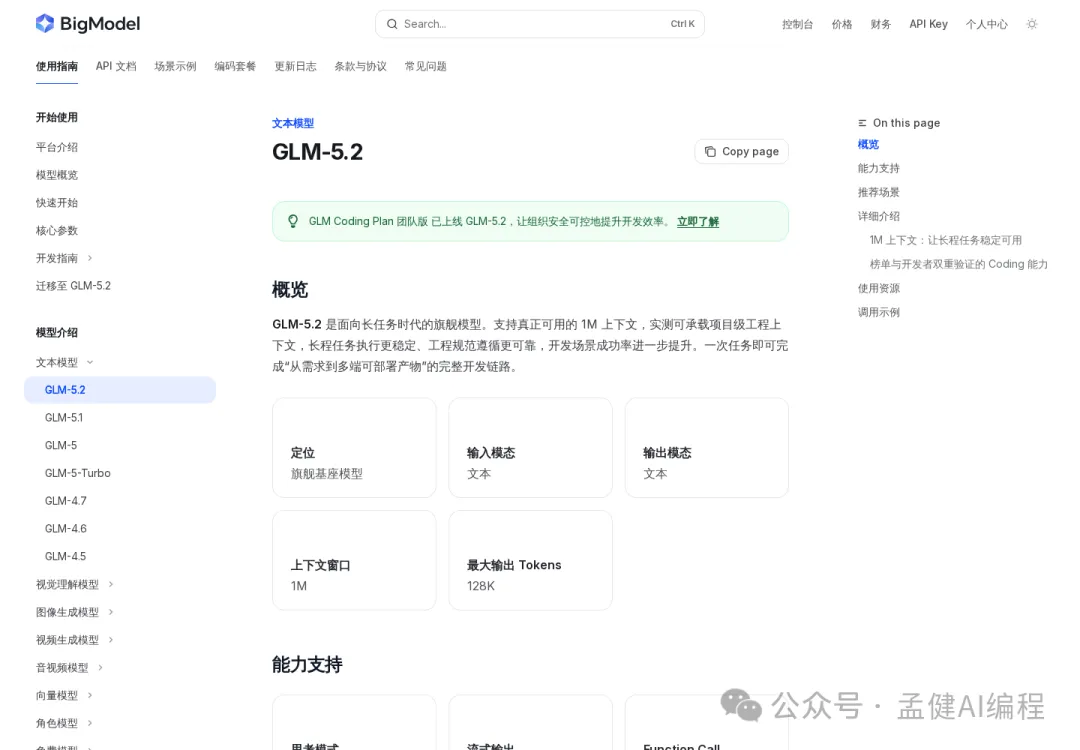
GLM-5.2 嘅官方定位係面向長任務嘅旗艦文本模型,支援 1M 上下文、最大輸出 128K tokens。
呢兩個數字擺埋一齊,意味着佢可以一次過食曬一個中等規模嘅代碼倉庫,然後俾你輸出一份完整嘅重構方案。成個倉庫掉入去,慳返分段餵或者靠外部向量檢索補漏嘅步驟。對於需要跨文件理解嘅工程任務,呢個上下文窗口係實實在在嘅優勢。
官方強調嘅場景係:項目級工程接管、長程重構、生產規範壓力測試、移動端真機調試,同微信小程序、小遊戲、科研復刻呢類有具體工程語境嘅任務。同以往國產模型主打「通用能力」嘅定位唔同,GLM-5.2 係向住垂直工程方向走。
我自己用落,印象最深嘅係複雜任務入面嘅穩定性。以前用國產模型跑長流程 Agent,成日喺中途出現上下文理解斷層——前面定義過嘅變量命名規範,跑咗幾步之後就唔記得,或者指令跟蹤能力突然變差,前後唔一致。GLM-5.2 喺呢方面好啲。推進一個多步驟嘅工程任務,佢能夠跟落去嘅機會比以前明顯高。跑完一個完整流程先至出錯,總好過中途亂咗容易處理啲。
官方俾出嘅基準數據:FrontierSWE 上僅落後 Opus 4.8 約 1%,超過 GPT-5.5 約 1%,超過 Opus 4.7 約 11%;SWE-Marathon 上同 Opus 4.8 仲有大約 13% 嘅差距。
呢組數字唔係絕對真理,基準測試同實際工程場景永遠有出入。但趨勢方向值得參考——喺 SWE 呢類編程任務基準上,國內模型第一次進咗可以同 Opus、GPT 並列放喺一張表入面討論嘅位置,呢個本身就係信號。
03 問題都好現實:限流、倍數、額度消耗
能力強還能力強,但用起上嚟嘅摩擦感係真實存在嘅。
Coding Plan 有兩層限額:每 5 小時一個額度上限,每週一個總額度。Lite 套餐大約 80 prompts / 5h,Pro 約 400/5h,Max 約 1600/5h——對應周額度分別約 400、2000、8000 prompts。
然後係倍數消耗。GLM-5.2 係高階模型,對標 Claude Opus。高峯期(北京時間 14:00–18:00)按 3 倍額度消耗,非高峯期 2 倍。有個限時福利係非高峯 1 倍抵扣,持續到 9 月底。
換算落嚟,一個跑得鬱嘅 Agent 任務,喺高峯期嘅消耗量非常可觀。你以為用緊 1 個 prompt,實際計費係 3 個。高強度工作流下,一日嘅額度喺兩三個鐘入面就會燒曬。
我之前將三個 Agent 切到 GPT,一週額度就耗曬。拎呢個例子唔係話 GPT 貴——高強度 Agent 使用下,任何模型嘅額度消耗都快。GLM 呢邊情況類似,高峯期 3 倍嘅乘數會將呢個過程壓縮得更短。
Pro 套餐每週 2000 prompts 聽落夠,但高峯期全 3 倍消耗,實際能夠跑嘅 Agent 輪數打咗折扣。想無限制咁跑,基本要上千元嘅團隊版。對比 200 美元嘅 GPT Pro,各有各嘅數,好難簡單比高低。
額度之外仲有時間窗口嘅問題。高峯期限制明顯,實際上會逼住你養成「大任務留到非高峯跑」嘅習慣。對有時間靈活性嘅工作流嚟講呢個可以接受,但如果你嘅 Agent 需要喺工作時間全天候響應,呢個限制會好快變成瓶頸。
04 接入唔係無痛:工具鏈喺度卡咗好耐
呢一節係我覺得對高級用戶最關鍵、但官方最唔會主動講清楚嘅部分。
官方話法係 Coding Plan 套餐僅限喺官方支援嘅工具/產品環境中使用。OpenClaw 被列為支援工具之一,但實際係採用次級調度同盡力交付策略,高負載下會動態排隊、限流。
我哋實際接入時,遇到嘅問題更直接。Hermes 同 OpenClaw 嘅接入過程入面,有明顯嘅定向攔截——唔改源碼基本繞唔過。具體表現係請求能夠發出去,但返回要唔係超時,要唔係拒絕類響應,同普通限流嘅報錯格式唔一樣,似係識別到客戶端特徵之後嘅處理。
周圍幾個用同類工具嘅人都遇到類似情況,好大機會係系統行為,唔係偶發。
呢個意味着乜嘢?如果你嘅工作流依賴非官方渠道、或者自定義工具鏈,接入 GLM-5.2 嘅成本遠比「換一下 API endpoint」高。要唔改源碼,要唔換工具,要唔接受次級調度帶嚟嘅唔穩定。
模型能力追上嚟之後,真正決定能否落地嘅,往往係額度、生態同限制呢三項現實問題。
OpenRouter 上 GLM-5.2 目前嘅標價係 $1.20 input / $4.10 output per 1M tokens,2026 年 6 月 16 日發佈,HuggingFace 上有開放權重。如果你有自己嘅推理環境,呢條路繞過 Coding Plan 嘅額度限制會更靈活。但自建推理嘅接入成本係另一個故事——GPU 資源、運維、延遲,每一項都要另計。
05 我嘅建議:唔好替代 GPT,將佢放喺模型組合入面
我而家嘅用法係將 GLM-5.2 當補位武器,唔係主力。
GPT 安全限制太強嘅任務。 有啲任務 GPT 嘅安全策略會攔截,或者拒絕行到底。GLM-5.2 喺呢方面限制相對寬鬆,可以接手 GPT 唔願意掂嘅部分。呢個係最直接嘅補位價值,唔使改工作流,直接攞嚟填空。
長上下文倉庫理解。 1M context 喺呢度係實實在在嘅優勢,尤其係需要一次性讀完大量代碼再做判斷嘅場景——讀取、分析、輸出方案一次完成,比多輪分段餵效率高唔少。適合用喺「全量掃一遍先講」嘅分析類任務上。
國產環境同中文工程場景。 微信小程序、小遊戲、國內特有技術棧,呢啲場景入面 GLM 嘅工程上下文更貼近實際,值得單獨測試,對比嚇輸出質量再決定要唔要替換。
非高峯期嘅大任務。 凌晨或者朝早跑,1 倍抵扣(限時福利到 9 月底)、非高峯期 2 倍消耗,係成本最優嘅時間窗口。跑時間長、對延遲唔敏感嘅任務,排到呢段時間最合適。
作為第二意見模型。 一個複雜決策俾兩個模型分別俾出方案,再對比。GLM-5.2 有時能夠從唔同角度俾出 GPT 冇覆蓋到嘅判斷。互補嘅價值大過直接替代,用喺最終決策前嘅校驗環節效果唔錯。
唔適合用喺呢幾個場景:全天候高強度 Agent 羣、需要無限制自動化、對穩定額度有要求嘅生產主鏈路。呢啲場景下,GLM-5.2 目前嘅限流同接入摩擦都會成為瓶頸,容易出現跑到一半卡住又要切返嚟嘅情況。
今日嘅國產模型,第一次令我覺得可以認真討論「擺喺邊個位置用」呢個問題,唔只係追問「能唔用得」。你唔使再問國產模型能唔能夠寫代碼喇,呢條已經過咗線。而家應該問嘅係:佢適唔適合入你嘅 Agent 預算表,放喺邊個位置,同邊個主力模型搭配。
最危險嘅用法,係因為佢能力強咗,就將所有 Agent 一把切過去,然後喺高峯期被限流卡死,再重新換返嚟。呢個切換成本唔低,來回折騰好容易浪費咗原本可以用嚟生產嘅時間。
GLM-5.2 嘅限制主要體現喺額度能唔能夠撐住你嘅用量,能力呢邊已經過咗線。用啱位置,佢係真實嘅增量。用錯位置,佢嘅限制會比你想象嘅更快顯現出嚟。
🚀 想同更多 AI 愛好者交流,共同成長嗎?

📚 精選文章推薦
大家好,我是孟健。GLM-5.2 是我最近用下來最意外的國產模型:它已經很接近 GPT、Claude 的第一梯隊,但我不會建議你今天就把 Agent 全切過去。
01 先說結論:國內第一,但不是默認主力
我接觸國產模型的時間不短了,大多數時候的結論都是"還行,但差一截"。GLM-5.2 是第一次讓我覺得,這句話得改一改。
整體表現上,它已經是我用過的國內模型裏最強的。跟 GPT、Claude 的頂級梯隊比,差距已經不算特別大。但"不算特別大"和"可以替代"是兩件事,後面我會細說。
在 AI 編程和 Agent 長任務這兩個方向,國內模型之前很少能進入選型討論——通常是"沒有預算才用"或者排在最末位的備選。GLM-5.2 是第一次讓我覺得,它有資格參與主力候選的對比,放進同一張選型表裏認真看。
但今天你如果問我,要不要把所有 Agent 都切過去——不要。
衡量"能用"和"適合當主力",標準不同。能用,看能力上限。適合當主力,看穩定性、額度、生態接入成本。GLM-5.2 在能力上已經過了門檻,在後三項上還沒到位。這三個問題,往下說。
02 真正變強的是長任務和 Agent 感
GLM-5.2 的官方定位是面向長任務的旗艦文本模型,支持 1M 上下文、最大輸出 128K tokens。
這兩個數字放在一起,意味着它可以一口氣吃下一個中等規模的代碼倉庫,然後給你輸出一份完整的重構方案。整個倉庫丟進去,省掉分段喂或者靠外部向量檢索補漏的步驟。對於需要跨文件理解的工程任務,這個上下文窗口是實打實的優勢。
官方強調的場景是:項目級工程接管、長程重構、生產規範壓力測試、移動端真機調試,以及微信小程序、小遊戲、科研復刻這類有具體工程語境的任務。跟以往國產模型主打"通用能力"的定位不同,GLM-5.2 在往垂直工程方向走。
我自己用下來,印象最深的是複雜任務裏的穩定性。以前用國產模型跑長流程 Agent,經常在中途出現上下文理解斷層——前面定義過的變量命名規範,跑了幾步之後就忘了,或者指令跟蹤能力突然變差,前後不一致。GLM-5.2 在這方面好一些。推進一個多步驟的工程任務,它能跟下去的概率比之前明顯高。跑完一個完整流程再出錯,總比中途亂掉容易處理。
官方給出的基準數據:FrontierSWE 上僅落後 Opus 4.8 約 1%,超過 GPT-5.5 約 1%,超過 Opus 4.7 約 11%;SWE-Marathon 上與 Opus 4.8 仍有約 13% 的差距。
這組數字不是絕對真理,基準測試跟實際工程場景永遠有出入。但趨勢方向值得參考——在 SWE 這類編程任務基準上,國內模型第一次進入了可以和 Opus、GPT 並列放在一張表裏討論的位置,這本身就是信號。
03 問題也很現實:限流、倍數、額度消耗
能力強歸能力強,用起來的摩擦感是真實存在的。
Coding Plan 有兩層限額:每 5 小時一個額度上限,每週一個總額度。Lite 套餐大約 80 prompts / 5h,Pro 約 400/5h,Max 約 1600/5h——對應周額度分別約 400、2000、8000 prompts。
然後是倍數消耗。GLM-5.2 是高階模型,對標 Claude Opus。高峯期(北京時間 14:00–18:00)按 3 倍額度消耗,非高峯期 2 倍。有個限時福利是非高峯 1 倍抵扣,持續到 9 月底。
換算下來,一個跑得起來的 Agent 任務,在高峯期的消耗量非常可觀。你以為在用 1 個 prompt,實際計費是 3 個。高強度工作流下,一天的額度在兩三個小時裏就能燒完。
我之前把三個 Agent 切到了 GPT,一週額度就耗光了。拿這個例子不是說 GPT 貴——高強度 Agent 使用下,任何模型的額度消耗都快。GLM 這邊情況類似,高峯期 3 倍的乘數會把這個過程壓縮得更短。
Pro 套餐每週 2000 prompts 聽起來夠,但高峯期全 3 倍消耗,實際能跑的 Agent 輪數打個折扣。想無限制地跑,基本得上千元的團隊版。對比 200 美元的 GPT Pro,各有各的賬本,很難簡單比高下。
額度之外還有時間窗口的問題。高峯期限制明顯,實際上會逼着你養成"大任務留到非高峯跑"的習慣。對有時間靈活性的工作流來說這可以接受,但如果你的 Agent 需要在工作時間全天候響應,這個限制會很快變成瓶頸。
04 接入不是無痛:工具鏈這裏卡了很久
這一節是我覺得對高級用戶最關鍵、但官方最不會主動說清楚的部分。
官方說法是 Coding Plan 套餐僅限在官方支持的工具/產品環境中使用。OpenClaw 被列為支持工具之一,但實際是採用次級調度與盡力交付策略,高負載下會動態排隊、限流。
我這邊實際接入時,遇到的問題更直接。Hermes 和 OpenClaw 的接入過程裏,有明顯的定向攔截——不改源碼基本繞不過去。具體表現是請求能發出去,但返回要麼超時,要麼是拒絕類響應,跟普通限流的報錯格式不一樣,更像是識別到客戶端特徵之後的處理。
周圍幾個用同類工具的人也碰到了類似情況,大概率是系統行為,不是偶發。
這意味着什麼?如果你的工作流依賴非官方渠道、或者自定義工具鏈,接入 GLM-5.2 的成本遠比"換一下 API endpoint"高。要麼改源碼,要麼換工具,要麼接受次級調度帶來的不穩定。
模型能力追上來之後,真正決定能不能落地的,往往是額度、生態和限制這三項現實問題。
OpenRouter 上 GLM-5.2 目前的標價是 $1.20 input / $4.10 output per 1M tokens,2026 年 6 月 16 日發佈,HuggingFace 上有開放權重。如果你有自己的推理環境,這條路繞過 Coding Plan 的額度限制會更靈活。但自建推理的接入成本是另一個故事——GPU 資源、運維、延遲,每一項都要另算。
05 我的建議:別替代 GPT,把它放進模型組合
我現在的用法是把 GLM-5.2 當補位武器,不是主力。
GPT 安全限制太強的任務。 有些任務 GPT 的安全策略會攔截,或者拒絕走到底。GLM-5.2 在這方面限制相對寬鬆,可以接手 GPT 不願意碰的部分。這是最直接的補位價值,不用改工作流,直接拿來填空。
長上下文倉庫理解。 1M context 在這裏是實打實的優勢,尤其是需要一次性讀完大量代碼再做判斷的場景——讀取、分析、輸出方案一次完成,比多輪分段喂效率高不少。適合用在"全量掃一遍再說"的分析類任務上。
國產環境和中文工程場景。 微信小程序、小遊戲、國內特有技術棧,這些場景裏 GLM 的工程上下文更貼近實際,值得單獨測試,對比一下輸出質量再決定要不要替換。
非高峯期的大任務。 凌晨或者早上跑,1 倍抵扣(限時福利到 9 月底)、非高峯期 2 倍消耗,是成本最優的時間窗口。跑時間長、對延遲不敏感的任務,排到這段時間最合適。
作為第二意見模型。 一個複雜決策讓兩個模型分別給出方案,再對比。GLM-5.2 有時候能從不同角度給出 GPT 沒覆蓋到的判斷。互補的價值大於直接替代,用在最終決策前的校驗環節效果不錯。
不適合用在這幾個場景:全天候高強度 Agent 羣、需要無限制自動化、對穩定額度有要求的生產主鏈路。這些場景下,GLM-5.2 目前的限流和接入摩擦都會成為瓶頸,容易出現跑到一半卡住又得切回來的情況。
今天的國產模型,第一次讓我覺得可以認真討論"放在哪個位置用"這個問題,不只是追問"能不能用"。你不用再問國產模型能不能寫代碼了,這條已經過線了。現在該問的是:它適不適合進你的 Agent 預算表,放哪個位置,跟哪個主力模型搭配。
最危險的用法,是因為它能力強了,就把所有 Agent 一把切過去,然後在高峯期被限流卡死,再重新換回來。這個切換成本不低,來回折騰很容易浪費掉原本可以生產的時間。
GLM-5.2 的限制主要體現在額度能不能撐住你的用量,能力這邊已經過線了。用對了位置,它是真實的增量。用錯了位置,它的限制會比你想象的更快顯現出來。
🚀 想要與更多AI愛好者交流,共同成長嗎?
📚 精選文章推薦