Google剛剛總結5種Agent設計模式:讓AI連續工作7天不崩
整理版優先睇
Google提出五種設計模式,確保AI Agent能連續運行多日而不崩潰
呢篇文章係翻譯自Google嘅一篇長文,由開發者@addyosmani同@Saboo_Shubham撰寫,講嘅係點樣設計一個可以連續運行幾日甚至一週而唔出問題嘅AI Agent。作者指出,好多開發者花咗好多時間優化Prompt同工具調用,但當Agent需要連續工作五日嗰陣,問題就全部浮現:現有嘅Agent架構天生無狀態,每次交互都要重建上下文,令到長期任務好易失敗。
Google喺Cloud Next 26上宣佈,Agent Runtime而家支援狀態持久化長達七日,並提出五個面向生產環境嘅設計模式,目的係解決長駐Agent嘅穩定性問題。呢啲模式包括存檔續跑、人工介入、分層記憶、後台解耦同Agent集羣調度,每一個都針對特定嘅痛點。
整體結論係:要令Agent穩定運行幾日,必須從架構層面考慮狀態持久化,並按任務複雜度組合呢啲模式。判斷自己需唔需要長駐Agent嘅核心問題係:你嘅Agent完成一次完整任務要幾耐?如果係幾分鐘,可能唔需要;如果係幾小時到幾日,呢五個模式就係起點。
- 長駐Agent需要狀態持久化,Google Agent Runtime支援7日,解決無狀態架構導致嘅上下文丟失問題。
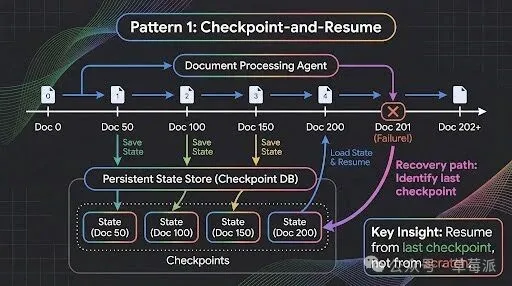
- Checkpoint-and-Resume模式:定期存檔進度(例如每50條記錄),容許局部失敗,平衡可靠性同性能。
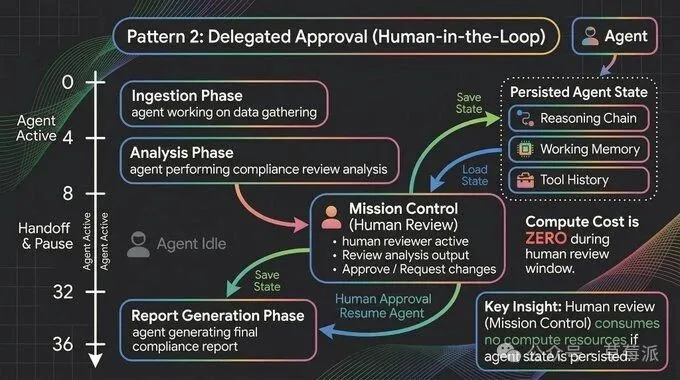
- Human-in-the-Loop模式:Agent喺需要審批時原地暫停,保留完整狀態(推理鏈、工作記憶等),人批完後冷啟動幾乎無延遲。
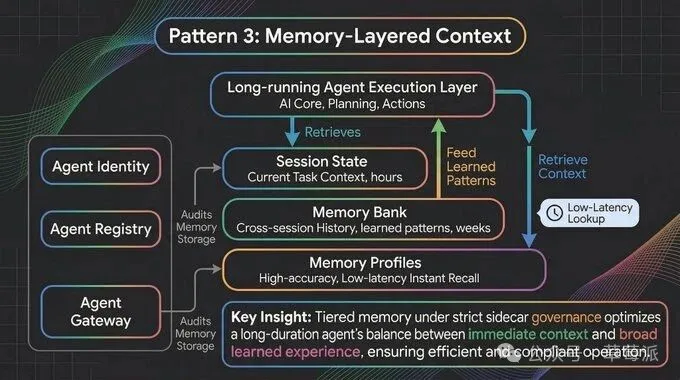
- Memory-Layered Context模式:用身份、註冊表、網關治理記憶,防止記憶漂移同數據互串,兼顧審計同安全。
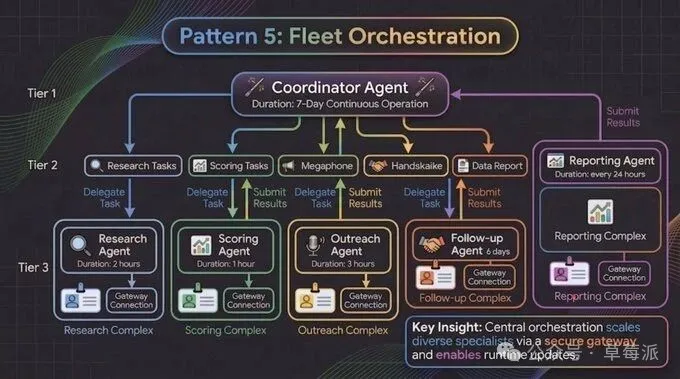
- Fleet Orchestration模式:協調者Agent分發任務畀多個專家Agent,每個獨立部署同迭代,一個出事唔會拖冧成個集羣。
模式一:Checkpoint-and-Resume——存檔續跑
多日任務最常見嘅死法係上下文丟失。Agent跑咗四個鐘、處理咗200份文檔,第201份出錯,冇存檔機制就要由頭嚟過。長駐Agent要將自己當成一個長期運行嘅服務進程,定期存檔進度、容許局部失敗、保證操作可重複執行。
模式二:Human-in-the-Loop——人工介入
好多框架話自己支援「人工介入」,但實質係將狀態序列化成JSON、發Webhook,然後等人去睇。問題係JSON會丟失隱性推理上下文,通知好易俾人忽略,人返嚟後Agent要重新反序列化、重建上下文,仲要確保環境冇變。
模式三:Memory-Layered Context——分層記憶
一個要活七日嘅Agent,淨係靠會話狀態唔夠。佢需要記住幾日前嘅用戶偏好、跨會話積累嘅判斷,同組織背景知識。但好多開發者上線先發現記憶會漂移:Agent嘅行為受到佢積累嘅「經驗」影響,如果佢喺非典型交互入面學到某個捷徑,可能會周圍用。多個Agent共享記憶池仲有數據互串風險。
模式四:Ambient Processing——後台解耦
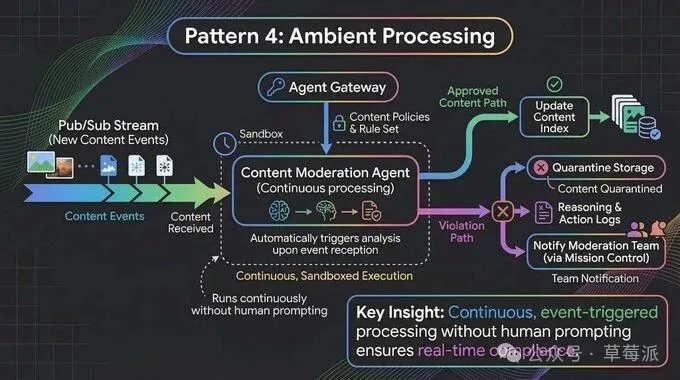
唔係所有長駐Agent都需要同人對話。有啲係純後台:監聽事件、處理數據流、自主行動。例如內容審核Agent可以持續消費用戶生成內容嘅消息隊列,維護自己對趨勢嘅判斷,只喺必要時上報升級。佢運行幾日,冇人叫佢,佢都喺度跑。
模式五:Fleet Orchestration——Agent集羣調度
真實生產環境好少得一個Agent孤軍奮戰。常見結構係一個協調者Agent將任務分發畀多個專家Agent,每個獨立運行、各有生命週期。以銷售拓客為例,可以拆成情報收集、潛客評分、觸達執行三個專家Agent,各自獨立互不幹擾。
琴日,Google 出咗一篇關於 Agent Runtime 嘅長文,畀出咗5個面向生產環境嘅 Agent 設計模式,目的得一個: 點樣令一個 Agent,連續行幾日甚至一個禮拜,都唔會出事。
原文:《5 Agent Design patterns for Long-running AI Agents》
作者:@addyosmani and @Saboo_Shubham
下面係整理咗呢篇文章嘅譯文,如果你正在做 Agent 或者諗住落地,呢篇值得慢慢睇。
開發者花咗幾個禮拜打磨Prompt、優化工具調用、壓低響應延遲——但當你嘅Agent要連續做五日嘢時,呢啲努力全部白費。
真正有價值嘅自動化任務從來唔係喺一次對話入面完成。處理幾千份保險理賠、執行長達一個禮拜嘅銷售觸達序列、喺多個系統之間完成財務對賬——呢啲任務嘅時間單位係日,唔係秒。
一旦你真係去搭呢種長駐Agent,就會撞到一個根本問題:現有嘅Agent架構天生係無狀態嘅。每次互動都要從數據庫重建上下文,上一輪推理過程中啲隱性判斷、置信度嘅起伏、中間形成嘅軟性結論——全部冇晒。
Google喺Cloud Next 26上宣佈,Agent Runtime而家支援狀態持久化長達7日嘅長駐Agent。下面係喺呢個架構上真正用得着嘅五個設計模式。
模式一:Checkpoint-and-Resume----存檔與續跑
多日任務最常見嘅死法:上下文丟失。
Agent行咗四個鐘、處理咗200份文檔,第201份出錯。冇存檔機制,就要由頭再嚟。
長駐Agent嘅做法係將自己當成一個長期運行嘅服務進程,而唔係一次性請求處理器——就好似數據管道處理百萬條記錄咁:定期存檔進度、允許局部失敗、保證操作可重複執行。
存檔粒度嘅選擇好關鍵。每處理一條就存檔,開銷太大;只喺最後存檔,風險太高。每50條存一次,係喺可靠性和性能之間取得平衡——具體數字取決於每個處理單元嘅代價。
模式二:Human-in-the-Loop----人工介入
每個框架都話自己支援「人工介入」。
但實際落地時,大多數實現係咁:將狀態序列化成JSON,Send一個Webhook,然後祈禱有人去睇佢。問題接踵而來:JSON序列化會冇咗隱性推理上下文;通知淹沒喺幾十條警報入面冇人理;人幾個鐘後先返嚟,Agent仲要重新反序列化、重建上下文,再祈禱呢段時間入面乜都冇變。
長駐Agent嘅處理方式唔同:當Agent去到一個需要審批嘅節點,佢就原地暫停——完整嘅執行狀態保留喺嗰度,推理鏈、工作記憶、工具調用記錄、待執行嘅動作,一樣唔少。暫停期間零計算消耗,等人批完咗,冷啟動幾乎冇延遲。
呢8到32個鐘嘅等待時間,對Agent嚟講係「休眠」,對人嚟講係「正常審批流程」。兩邊嘅節奏終於對得上了。
模式三:Memory-Layered Context----分層記憶
一個要生存7日嘅Agent,剩係靠會話狀態遠遠唔夠。佢需要記住幾日前嘅用戶偏好、跨會話積累嘅判斷,以及任何單次對話都裝唔落嘅組織背景知識。
但大多數開發者直到上線先意識到一個問題:記憶會漂移。Agent嘅行為唔只由代碼同Prompt決定,亦被佢積累嘅「經驗」塑造。如果佢從幾次非典型互動入面學到某個捷徑係可以行嘅,佢可能會開始周圍行呢個捷徑。多個Agent共享記憶池,仲會帶嚟數據互相干擾嘅風險。
解決方案係好似治理微服務咁治理Agent嘅記憶:
Agent身份(Identity):相當於IAM,決定呢個Agent可以訪問邊啲記憶庫同工具
Agent註冊表(Registry):相當於服務發現,追蹤所有活躍Agent嘅版本同執行狀態
Agent閘道(Gateway):相當於API閘道,攔截唔合規嘅記憶寫入——例如Agent嘗試將用戶嘅個人敏感資訊寫入長期記憶,直接喺呢一層擋住
由第一日就將審計機制建入記憶層。要問嘅唔止係我嘅Agent喺度做乜,仲有佢喺度記住乜,呢啲記憶又點樣改變佢嘅行為。
模式四:Ambient Processing----背景解耦
唔係所有長駐Agent都需要同人對話。有啲係純背景嘅:監聽事件、處理數據流、喺冇任何人觸發嘅情況下自主行動。
一個內容審核Agent可以咁樣運作:持續消費用戶生成內容嘅訊息隊列,維護自己對趨勢同模式嘅判斷,只喺必要時上報升級。佢運行幾日,冇人叫佢,佢都喺度行緊。
呢度有一個關鍵嘅架構決策:唔好將內容策略硬編碼入Agent。將策略定義喺Agent閘道入面,等Agent喺運行時執行佢。策略變咗,只更新閘道,所有背景Agent自動適用新規則——而唔係每次改策略都要重新部署一次所有Agent。
對於長時間冇人監管嘅背景Agent嚟講,呢種解耦至關重要。
模式五:Fleet Orchestration----Agent集羣排程
真實生產環境入面,你好少得一個Agent喺度孤軍作戰。更常見嘅結構係:一個協調者Agent將任務分發畀多個專家Agent,每個專家獨立運行、各有自己嘅生命週期。
以銷售拓客流程為例,可以拆成:情報收集Agent、潛在客戶評分Agent、觸達執行Agent——各自獨立,互不干擾。協調者維護全局狀態,負責銜接各專家之間嘅交接。
每個專家Agent有自己嘅身份(限制佢只可以訪問自己應該用嘅工具同記憶),有自己嘅權限邊界(評分Agent睇唔到只有觸達Agent先需要嘅數據),有自己喺註冊表入面嘅記錄(方便追蹤版本同狀態)。
獨立部署嘅好處係可以獨立疊代:評分邏輯需要優化,就只更新評分Agent,觀察效果,確認穩定咗先推廣。一個Agent出問題,唔會拖冧成個集羣。
點樣揀?
呢五個模式可以自由組合。一個合規審查系統可能同時用到:存檔續跑(處理文檔)、人工介入審核、分層記憶(跨會話知識積累)、集羣排程(多專家協作)。
判斷自己係咪需要長駐Agent嘅核心問題得一個:你嘅Agent完成一次完整任務,需要幾耐?
如果係幾分鐘,可能唔需要。如果係幾粒鐘到幾日,呢五個模式就係你應該從邊度開始諗嘅起點。
多謝你睇到呢度,如果覺得鍾意,按個關注,唔迷路~
昨天,Google 發佈了一篇關於 Agent Runtime 的長文,給出了5個面向生產環境的 Agent 設計模式,目的只有一個: 如何讓一個 Agent,連續運行幾天甚至一週,還不出問題。
原文:《5 Agent Design patterns for Long-running AI Agents》
作者:@addyosmani and @Saboo_Shubham
下面是整理的這篇文章的譯文,如果你正在做 Agent 或考慮落地,這一篇值得細看。
開發者們花了幾周時間打磨Prompt、優化工具調用、壓低響應延遲——但當你的Agent需要連續工作五天時,這些努力統統白費。
真正有價值的自動化任務從來不在一次對話裏完成。處理幾千份保險理賠、執行長達一週的銷售觸達序列、在多個系統之間完成財務對賬——這些任務的時間單位是天,不是秒。
一旦你真的去搭這種長駐Agent,就會撞上一個根本性的問題:現有的Agent架構天生是無狀態的。每次交互都要從數據庫重建上下文,上一輪推理過程中那些隱性判斷、置信度的起伏、中間形成的軟性結論——全部丟失。
Google在Cloud Next 26上宣佈,Agent Runtime現在支持狀態持久化長達七天的長駐Agent。下面是在這個架構上真正能用的五個設計模式。
模式一:Checkpoint-and-Resume----存檔與續跑
多日任務最常見的死法:上下文丟失。
Agent跑了四個小時、處理了200份文檔,第201份出錯了。沒有存檔機制,就只能從頭再來。
長駐Agent的做法是把自己當成一個長期運行的服務進程,而不是一個一次性的請求處理器——就像數據管道處理百萬條記錄那樣:定期存檔進度、允許局部失敗、保證操作可重複執行。
存檔粒度的選擇很關鍵。每處理一條就存檔,開銷太大;只在最後存檔,風險太高。每50條存一次,是在可靠性和性能之間取得平衡——具體數字取決於每個處理單元的代價。
模式二:Human-in-the-Loop----人工介入
每個框架都說自己支持"人工介入"。
但實際落地時,大多數實現是這樣的:把狀態序列化成JSON,發一個Webhook,然後祈禱有人去看它。問題接踵而來:JSON序列化會丟失隱性推理上下文;通知淹沒在幾十條告警裏沒人理;人幾小時後才回來,Agent還得重新反序列化、重建上下文,再祈禱這段時間裏什麼都沒變。
長駐Agent的處理方式不同:當Agent到達一個需要審批的節點,它就原地暫停——完整的執行狀態保留在那裏,推理鏈、工作記憶、工具調用記錄、待執行的動作,一樣不丟。暫停期間零計算消耗,等人批完了,冷啓動幾乎沒有延遲。
這8到32小時的等待時間,對Agent來說是"休眠",對人來說是"正常審批流程"。兩邊的節奏終於對上了。
模式三:Memory-Layered Context----分層記憶
一個要活七天的Agent,光靠會話狀態遠遠不夠。它需要記住幾天前的用戶偏好、跨會話積累的判斷,以及任何單次對話都裝不下的組織背景知識。
但大多數開發者直到上線才意識到一個問題:記憶會漂移。Agent的行為不只由代碼和Prompt決定,也被它積累的"經驗"塑造。如果它從幾次非典型交互裏學到了某個捷徑是可以走的,它可能會開始到處走這個捷徑。多個Agent共享記憶池,還會帶來數據互串的風險。
解決方案是像治理微服務一樣治理Agent的記憶:
Agent身份(Identity):相當於IAM,決定這個Agent能訪問哪些記憶庫和工具
Agent註冊表(Registry):相當於服務發現,追蹤所有活躍Agent的版本和執行狀態
Agent網關(Gateway):相當於API網關,攔截不合規的記憶寫入——比如Agent試圖把用戶的個人敏感信息寫進長期記憶,直接在這一層擋住
從第一天就把審計機制建進記憶層。要問的不只是我的Agent在做什麼,還有它在記住什麼,這些記憶又在怎樣改變它的行為。
模式四:Ambient Processing----後台解耦
不是所有長駐Agent都需要跟人對話。有些是純後台的:監聽事件、處理數據流、在沒有任何人觸發的情況下自主行動。
一個內容審核Agent可以這樣工作:持續消費用戶生成內容的消息隊列,維護自己對趨勢和模式的判斷,只在必要時上報升級。它運行幾天,沒人叫它,它也在跑。
這裏有一個關鍵的架構決策:不要把內容策略硬編碼進Agent。把策略定義在Agent網關裏,讓Agent在運行時執行它。策略變了,只更新網關,所有後台Agent自動適用新規則——而不是每次改策略都要重新部署一遍所有Agent。
對於長時間無人監管的後台Agent來說,這種解耦至關重要。
模式五:Fleet Orchestration----Agent集羣調度
真實生產環境裏,你很少只有一個Agent在孤軍奮戰。更常見的結構是:一個協調者Agent把任務分發給多個專家Agent,每個專家獨立運行、各有自己的生命週期。
以銷售拓客流程為例,可以拆成:情報收集Agent、潛客評分Agent、觸達執行Agent——各自獨立,互不干擾。協調者維護全局狀態,負責銜接各專家之間的交接。
每個專家Agent有自己的身份(限制它只能訪問自己該用的工具和記憶),有自己的權限邊界(評分Agent看不到只有觸達Agent才需要的數據),有自己在註冊表裏的記錄(方便追蹤版本和狀態)。
獨立部署的好處是可以獨立迭代:評分邏輯需要優化,就只更新評分Agent,觀察效果,確認穩定了再推廣。一個Agent出問題,不會拖垮整個集羣。
怎麼選?
這五個模式可以自由組合。一個合規審查系統可能同時用到:存檔續跑(處理文檔)、(人工介入)審核、分層記憶(跨會話知識積累)、集羣調度(多專家協作)。
判斷自己是否需要長駐Agent的核心問題只有一個:你的Agent完成一次完整任務,需要多長時間?
如果是幾分鐘,可能不需要。如果是幾小時到幾天,這五個模式就是你應該從哪裏開始想的起點。
謝謝你看到這裏,如果覺得喜歡,點個關注,不迷路~