GPT 5.5 Pro 使用體驗:真正的變化,是它開始接近一個能交付結果的研究助理
整理版優先睇
GPT 5.5 Pro 真正變化係接近一個能交付結果嘅研究助理,但最終判斷仍要人做
呢篇文章係由一個經常測試AI模型嘅視頻博主撰寫,佢實際使用GPT 5.5 Pro一段時間後,發現最大變化唔係單純回答更聰明,而係佢更似一個可以長時間推進複雜任務嘅研究助理。作者想解決嘅問題係:到底GPT 5.5 Pro值得唔值得用,同埋佢真正強項係邊度?整體結論係:佢適合深度搜索、長報告、複雜編碼呢類需要多步推理嘅任務,但最終研究判斷同責任仍然要由人承擔。
作者透過多個實測案例展示效果,包括數學研究案例、PPT同報告生成、供應鏈事件梳理、車企研究、會員方案選擇、四年財務規劃、技術路線篩選,同埋幾組前端編碼演示。其中數學案例由菲爾茲獎得主發起,模型用兩小時將數值上界從指數級推進到多項式級,顯示原創思路。文檔生成方面,佢可以產出可讀嘅PPT同Docx,仲會自動做截圖質檢。編碼測試亦表現出色,能夠生成有交互同物理直覺嘅動畫。
不過作者強調,呢個模型唔係萬能。官方評測顯示Pro版唔係所有任務都更強,而係針對需要長時間推理嘅方向最佳化。作者建議用一個模型生成方案,再用另一個模型做反向審稿,最後由人決定邊啲建議可用。總括嚟講,GPT 5.5 Pro係一個高能力研究助理,但唔可以替代最終判斷。
- GPT 5.5 Pro 最大變化係接近一個能交付結果嘅研究助理,但最終判斷仍然要人做。
- 佢適合需要長時間推理、多步探索嘅任務,例如深度搜索、長報告、複雜編碼。
- Pro版唔係所有任務都更強,官方評測顯示喺前沿數學、瀏覽器搜索等方向表現更好。
- 人的價值會向判斷力遷移,要學會提出更好嘅問題同審閲模型輸出。
- 使用時建議用另一個模型做反向審稿,避免過度信任單一模型嘅結論。
Introducing GPT-5.5
OpenAI官方發佈文章,介紹GPT-5.5系列
GPT-5.5 System Card
系統卡,詳細說明能力同限制
官方能力與背景:Pro版唔係樣樣都強
OpenAI喺系統卡中說明,GPT 5.5 Pro與GPT 5.5係同一底層模型,但Pro版本使用並行測試時計算,目標係提升更難、更長任務嘅表現。官方評測表顯示一個重要細節:唔係所有項目都係Pro版本更高,例如GDPval呢類專業任務評測,GPT 5.5嘅分數高過Pro;但喺瀏覽器搜索、前沿數學等需要長時間推理嘅方向,Pro版本表現更強。
文檔生成:佢識得自動畫圖同檢查
作者將DeepSeek V4技術報告交畀GPT 5.5 Pro,叫佢生成PPT。佢先畫咗幾張圖,再放入PPT,整體樣式唔錯,內容亦冇明顯問題。相比早期Pro模型,而家速度明顯可用,簡單問題幾分鐘回覆,複雜任務大約二十分鐘。
更重要係,報告完成後,佢會對每一頁進行截圖分析,檢查做得係咪合理。呢種自檢流程對複雜任務好重要,因為生成唔係完結,交付前仲要質量檢查。
搜索同研究:快速整合分散資訊
作者用佢梳理新近供應鏈攻擊事件,佢先判斷係高危攻擊,然後畀出詳細時間線、影響範圍、風險點同處理建議,附有連結同表格。呢類新近事件,模型最重要係將散落資訊組織起,令人更快進入審閲狀態。
另外,作者叫佢分析新能源車企,佢思考22分鐘後畀咗一份13頁Word文檔,包含結論摘要、優勢風險、行業背景、核心數據同排名方法。有用嘅係唔只結論,仲有背後數據維度同判斷方法。
財務規劃:AI幫你拆目標,但唔好信曬
作者假設月入7000元、一線城市、冇存款、四年內湊60萬買房結婚。GPT 5.5 Pro先話單靠節省基本冇可能,然後提出現實路線:前12個月收入躍遷,後三年靠主業漲薪、穩定副業、極低生活成本同低風險理財。
但作者冇直接相信,而係將方案畀另一個模型GPT 5.5 Heavy做審閲,後者畀82分並指出問題:數學可達性同現實可行性混淆,副業變現難度被低估,缺少失敗備用方案。呢個做法值得參考:一個模型生成,另一個模型專責挑毛病。
編碼測試:視覺還原度高,物理細節要再執
作者進行咗四個編碼測試:倉庫分揀仿真、營造法式拆解動畫、播放器復刻、縴夫拉船場景。其中播放器復刻效果最好,有周邊循環閃光動畫同顏色變化嘅中心圓球;縴夫場景嘅繩索連接同吃水感做得合理,係測試過嘅模型中最出色。
- 倉庫分揀仿真:有機械臂抓取物體,但兩個紅色物體出現穿模,碰撞物理仍需人手調整。
- 營造法式拆解:提供「一鍵分解」同「一鍵組裝」,左側模擬AI識別過程,視覺仿真度高。
- 復刻播放器:視覺還原度係測試中最好,但頁面有啲卡頓,效能需優化。
- 縴夫拉船:繩索長度、方向同身體綁定位置合理,水流波動同船嘅吃水感動態自然。
GPT 5.5 Pro 上線一段時間之後,我最明顯嘅感受係:佢唔止「回答得更聰明」,而係更加似一個可以長時間推進複雜任務嘅研究助理。佢會搜尋、寫 script、生成文件、做截圖質檢,亦都會喺複雜問題裏面畀出相對完整嘅判斷鏈。
當然,呢個唔等於佢可以取代人做最終判斷。愈複雜嘅任務,就愈需要人嚟定義問題、檢查來源、判斷結論有冇過度外推。佢真正有價值嘅地方,係將原本需要大量搜尋、整理、排版同初步分析嘅工作,壓縮成一個可以繼續審閲同迭代嘅結果。
呢篇文章會按照我喺影片裏面嘅實際測試嚟講:官方能力對比、數學研究案例、PPT 同報告生成、供應鏈事件梳理、車企研究、會員方案選擇、四年財務規劃、技術路線篩選,同埋幾組前端編碼示範。
官方資訊裏面,Pro 嘅優勢唔係喺曬所有排行榜
OpenAI 喺系統卡入面講明,GPT 5.5 Pro 同 GPT 5.5 係同一個底層模型,但 Pro 版本用咗並行測試時計算,目標係喺更難、更長嘅任務上提升表現。官方介紹嘅評測亦都可以睇到一個好重要嘅細節:並唔係所有項目都係 Pro 版本更高。
譬如 GDPval 呢類專業任務評測入面,GPT 5.5 嘅分數高過 GPT 5.5 Pro;但係喺瀏覽器搜尋、前沿數學等更加需要長時間推理同多步探索嘅方向,Pro 版本表現更強。呢個都解釋咗我點解後面更願意將「深度搜尋、長報告、複雜編碼」呢類任務交俾佢。
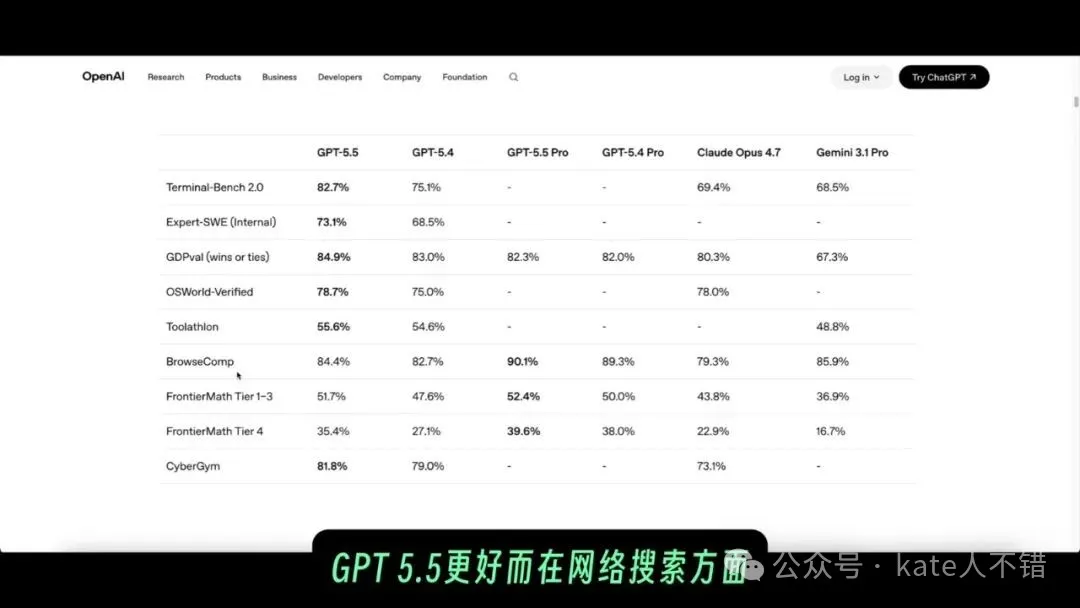
呢張官方評測表提醒我哋,唔好將 Pro 簡單理解成「每個問題都更強」。佢更適合嘅問題,係嗰啲需要模型花時間搜尋、比較、拆解、驗證,並將多個步驟串連埋嘅任務。
數學研究案例說明:人嘅價值會更偏向判斷力
最近有一篇關於 GPT 5.5 Pro 嘅數學案例好火爆。作者係菲爾茲獎得主,佢叫模型處理一個加法數論問題。影片提到,模型喺大約兩小時內,將一個數值上界從指數級推進到多項式級,人類評價認為當中嘅思路有原創性。
呢個案例真正值得關注嘅,唔只係「AI 做到咗一道題」,而係佢改變咗温和開放問題嘅安全感。以前好多博士訓練裏面嘅入門研究,可能係圍繞「揾一個冇人證明過、但難度適中嘅問題」嚟展開;而家呢類問題更有可能被 AI 快速推進。

畫面入面將呢個突破拆成四個階段、四次提示。對研究者嚟講,呢個意味住能力重心會遷移:唔係單純證明冇人證明過嘅題,而係要學會提出更好嘅問題、判斷模型畀出嘅思路係咪可靠,同 AI 一齊攻克更難嘅方向。
先睇文件同 PPT:佢能夠交付一份可讀嘅成品
我將 DeepSeek V4 嘅技術報告畀咗 GPT 5.5 Pro,叫佢生成一份高質素解讀 PPT。佢先生成咗幾張圖,後續將呢啲圖放返入 PPT 度。整體樣式幾好,我檢查過裏面嘅內容,都冇發現明顯唔用得嘅問題。
相比早期 Pro 模型,而家嘅速度都明顯更可用。簡單問題幾分鐘內回覆到,複雜少少嘅任務大約二十分鐘或者更耐。以前 Pro 啱啱推出嗰時,就算只係問一句「你好」,都有可能等成廿幾分鐘;而家至少喺呢類文件任務上,等待時間同結果質量更加匹配。
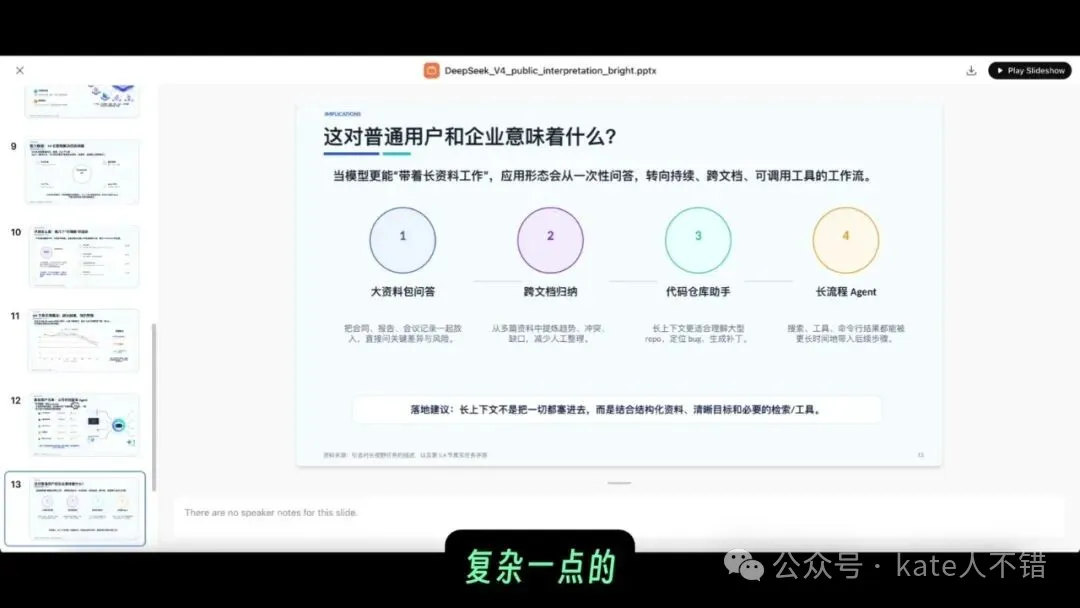
呢張 screenshot 展示嘅係 GPT 5.5 Pro 生成嘅 PPT 頁面。佢唔係淨係畀一大堆文字,而係嘗試將資訊組織成可以展示嘅版式,對需要快速做彙報、課程材料、內部分享嘅人好有用。
搜尋整理:佢適合處理新近複雜事件
跟住,我畀咗佢一張 screenshot,叫佢梳理一個比較新嘅供應鏈攻擊事件。呢個事件啱啱發生冇耐,需要判斷真假、整理時間線、確認影響範圍,仲要講清楚已經安裝過相關軟件嘅人應該點處理。
GPT 5.5 Pro 首先判斷呢個係一個高危供應鏈攻擊,然後畀出詳細梳理:發生咗啲乜、影響咗邊啲包、風險喺邊、有啲乜嘢參考連結、已經安裝過嘅應該點樣自查同處理。呢個問題佢用咗 8 分幾鐘。
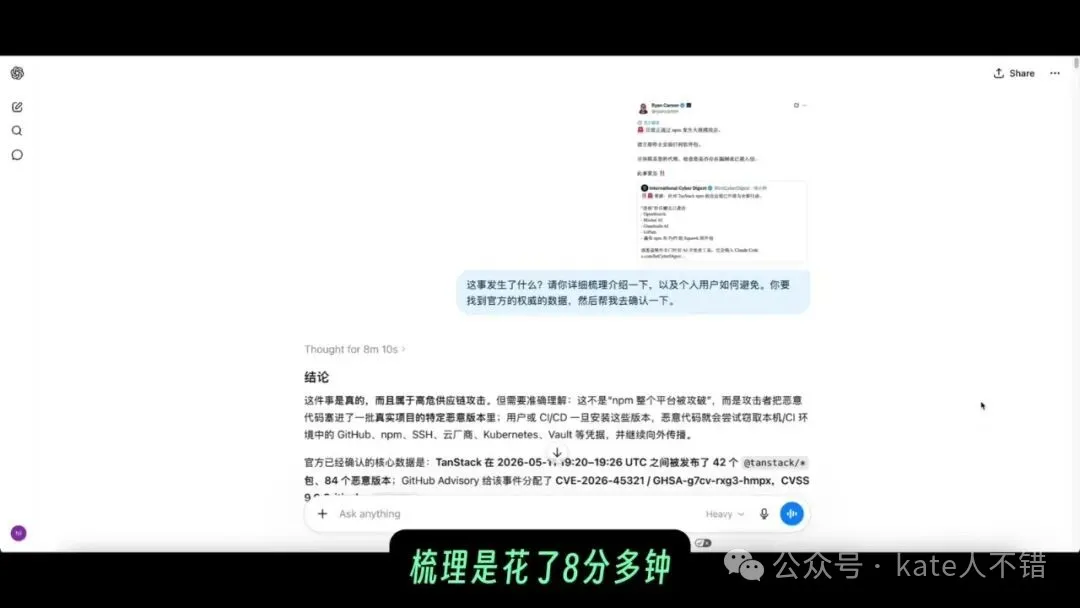
screenshot 入面可以見到,佢嘅回答唔只係結論,仲包含連結、表格同處理建議。對呢類新近事件,模型最重要嘅價值唔係幫你做最終安全判斷,而係將散落喺唔同來源嘅資訊先組織好,等人更快進入審閲狀態。
追問同彙總:同一個上下文可以繼續榨取價值
喺之前已經搜尋過一輪之後,我繼續追問:呢個事件係幾時發現嘅?可唔可以全部轉成北京時間?如果安裝過邊啲軟件,會有咩影響?
因為前面已經有上下文,佢可以好快咁基於之前嘅搜尋結果繼續回答。之後我又叫佢將所有回覆彙總成一份 Markdown,咁就可以方便分享畀人,例如放上星球度。
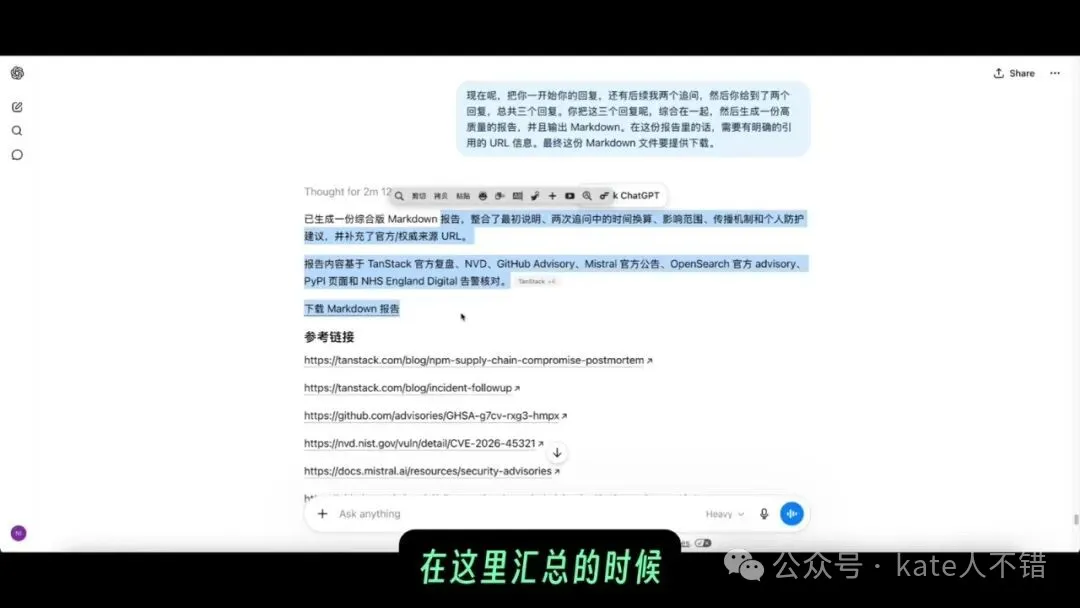
呢張圖顯示嘅係彙總過程。呢度我用嘅係 GPT 5.5 Heavy 模式,佢將前面嘅搜尋、解釋、風險判斷同處理建議整理成一份結構化報告,比零散嘅聊天記錄更適合傳播同複查。
複雜搜尋任務:Pro 嘅價值在於將資料壓成結構
呢份供應鏈事件報告入面,我比較關注北京時間,因為呢個會影響國內用戶對風險窗口嘅判斷。模型將事件時間線、受影響嘅安裝包、自查命令、命中後嘅處理意見、以後點樣避免同類風險等內容放埋一齊。
從呢個案例睇,GPT 5.5 Pro 好適合做「資訊密度高、來源分散、需要快速形成結構化判斷」嘅任務。瀏覽器搜尋能力更強,配合長時間推理,可以慳返大量手動開網頁、摘錄、對照嘅時間。
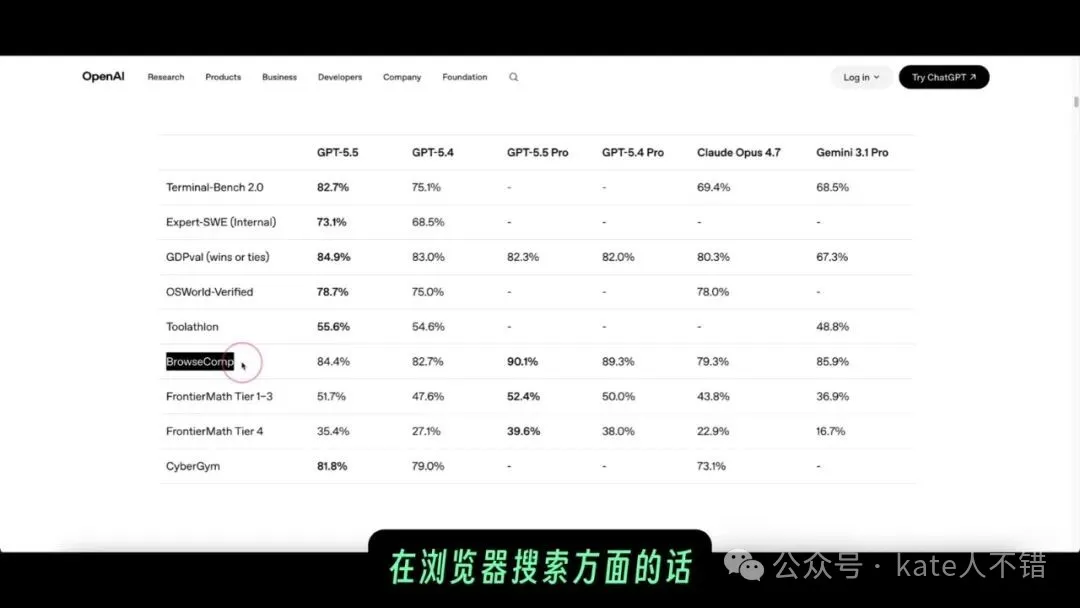
screenshot 入面返返去官方評測表,強調嘅係同一個判斷:對瀏覽器搜尋同複雜資訊整理嚟講,Pro 版本嘅優勢更明顯。佢適合承擔「先將材料揾齊、排好、講清楚」嘅工作。
行業研究報告:從排名到依據,佢會補足分析框架
我仲叫佢基於現有數據,分析中國新能源汽車領域最值得關注嘅三家車企,並要求嚴格畀出 1、2、3 嘅排名。佢諗咗 22 分鐘,最後畀咗我一份 Word 文件。
呢份文件先係總覽,然後係結論摘要、主要優勢、主要風險、行業背景、三間公司核心數據快照同排名方法。佢畀出嘅第一名係比亞迪,第二名係吉利,第三名係浙江零跑。雖然得 13 頁,但已經可以滿足一次快速研究嘅基本需要。
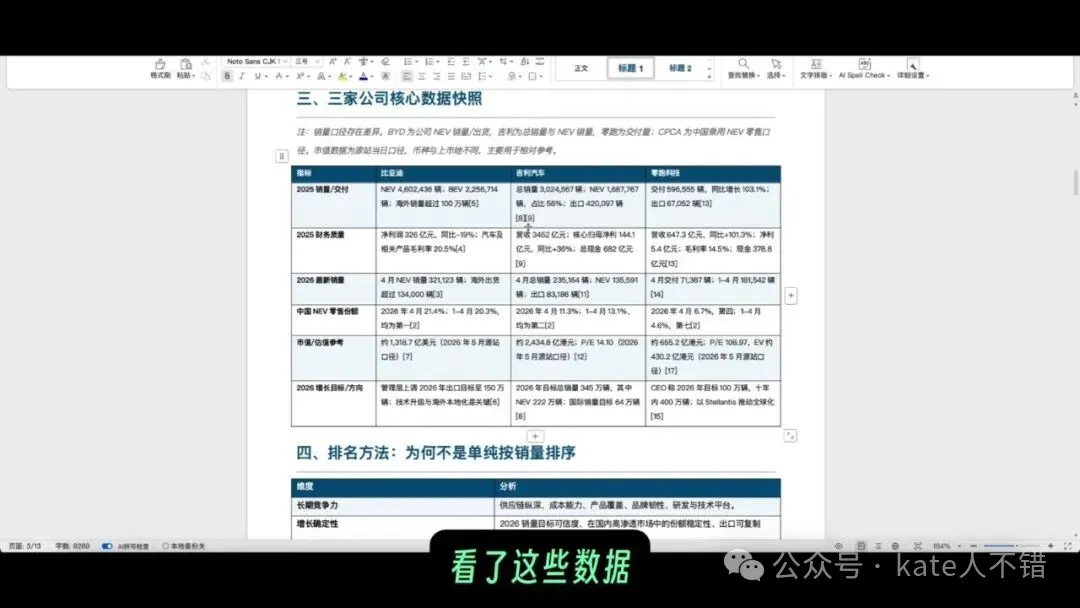
呢張 screenshot 入面可以見到車企核心數據表。對研究報告嚟講,模型如果淨係畀結論,價值有限;真正有用嘅係佢能夠將排名背後嘅數據維度、風險點同判斷方法一齊呈現出嚟。
生成文件只係第一步,佢仲會寫 script 同做質檢
我再睇咗佢嘅思考過程。喺 23 分鐘裏面,佢會寫 Python script,會搜尋多個網頁,而且係多輪搜尋。因為我嘅提示係要求生成 Docx,佢都會透過 Python 輸出文件。
更加有趣嘅係,報告完成之後,佢仲會對報告嘅每一頁進行 screenshot 分析,檢查做得係咪合理。呢種自檢流程好重要,因為複雜任務唔係生成完就完,真正交付之前仲需要質量檢查。
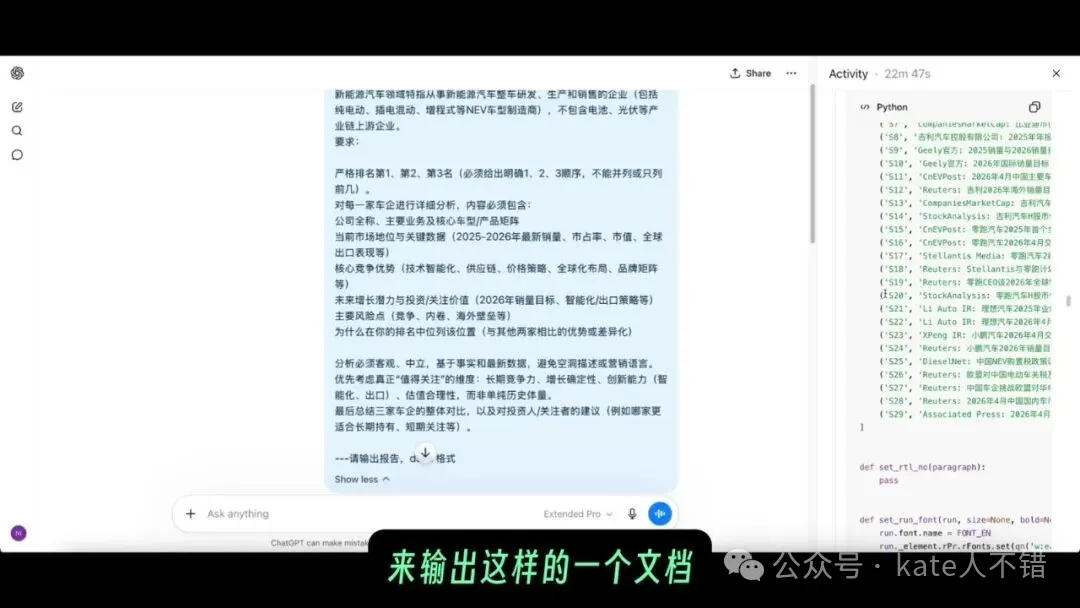
畫面右側可以見到活動記錄同程式碼執行過程。GPT 5.5 Pro 嘅強項唔只係「會寫一段話」,而係能夠喺工具鏈入面連續行動:查資料、處理數據、生成文件,再返轉頭檢查結果。
同一個主題,PPT 質量仍然會波動
我仲做咗另一個新能源車企相關任務:先完成報告,再根據報告生成 PPT。但係今次,GPT 5.5 Pro 生成嘅 PPT 顏值明顯唔及之前 DeepSeek V4 嗰份。
後尾我改用 Codex 裏面嘅 GPT 5.5 xhigh 模型嚟生成 PPT,質量就更加好。呢個說明即使係強模型,輸出都會受任務提示、運行環境、模式選擇同審美要求影響。複雜視覺交付仍然需要人類審稿,必要時仲要換模型或者重新提示。
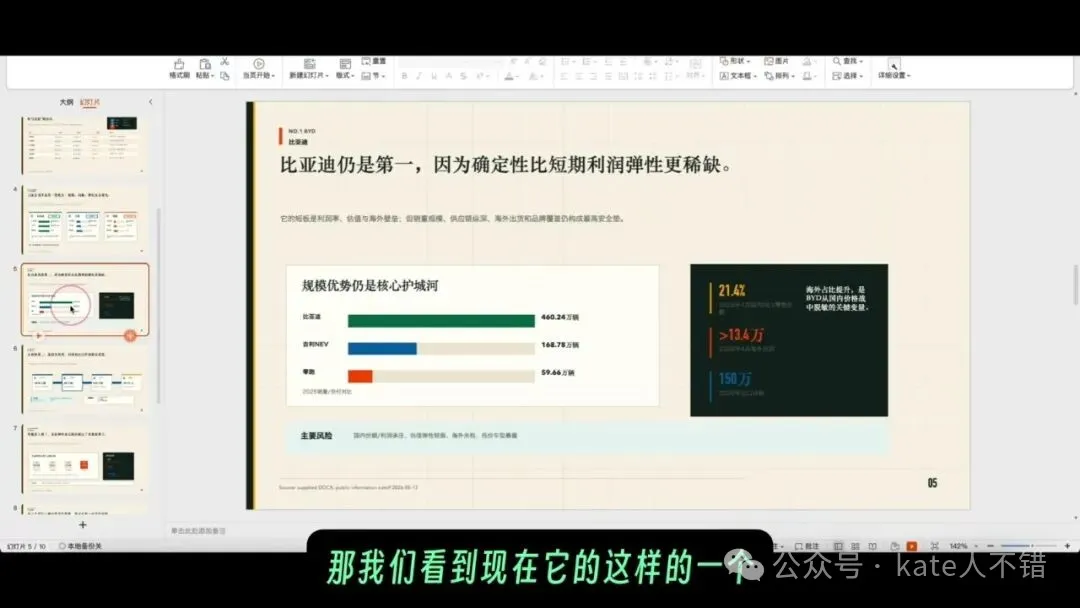
screenshot 展示嘅係改用 Codex 裏面嘅 GPT 5.5 xhigh 之後生成嘅 PPT 頁面。佢嘅版式同視覺完成度更好,亦都說明「同一個模型系列」喺唔同工具同設定之下,實際產出會有明顯差異。
會員方案選擇:佢能夠將預算、能力同使用量擺埋一齊比較
我仲叫 GPT 5.5 幫我分析幾個會員方案:喺我嘅預算入面,應該揀邊啲會員更合適。呢度唔只要考慮模型能力,仲要考慮可用量,同埋唔同工具嘅 Harness 能力。
佢思考時間唔長,大約 8 分鐘就畀出結論:建議揀 GPT Pro 100 美元會員,同埋 Cursor Pro 20 美元會員。下面仲畀咗對比表同理由,呢啲點成日關注我頻道嘅朋友應該唔陌生。
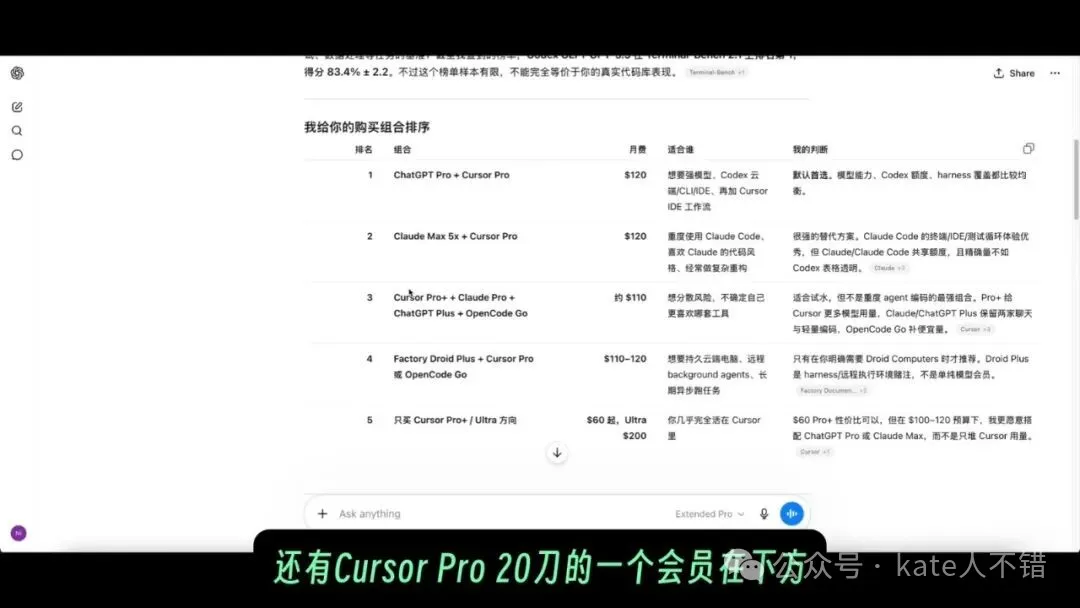
呢張 screenshot 對應會員方案分析。佢嘅價值在於將「能力強唔強」「夠唔夠用」「工具鏈順唔順手」「預算係咪合適」擺埋喺同一張表入面比較,而唔係淨係睇單一模型排名。
財務規劃:佢好識拆目標,但唔可以取代你做現實決策
我仲畀咗佢一個更加生活化嘅問題:假設而家月收入 7000 元,住喺一線城市,冇積蓄,想喺四年內儲夠 60 萬,用嚟買樓首期同結婚,叫佢畀一個現實可行嘅四年計劃。
佢思考接近 8 分鐘之後,畀出嘅第一句話好清醒:淨係靠慳基本上冇可能。現實路線係前 12 個月完成收入躍遷,後三年靠主業加人工、穩定副業、極低生活成本同低風險理財嚟完成。
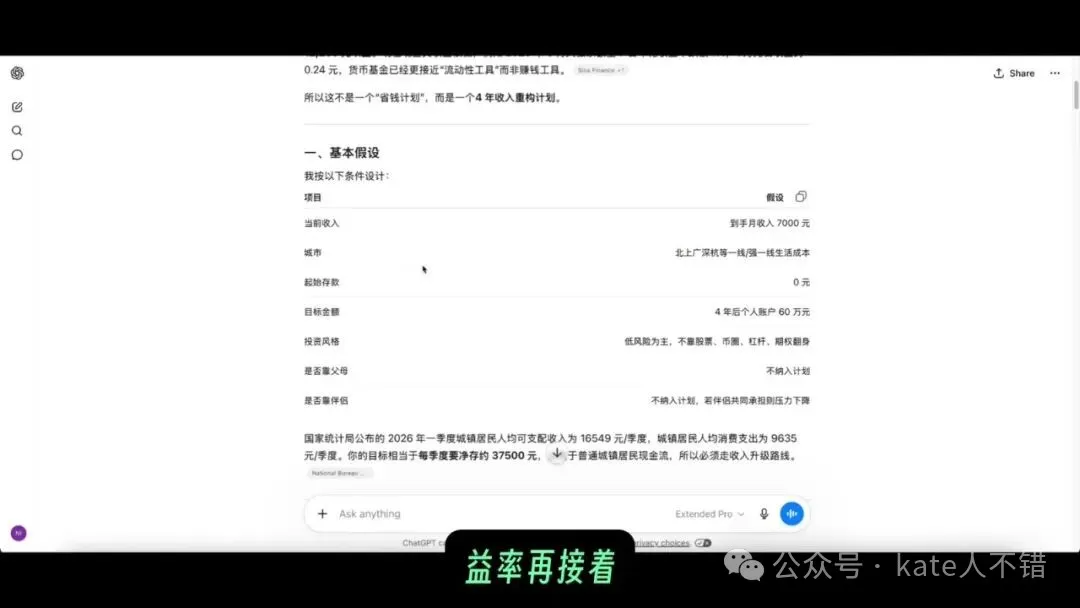
screenshot 入面可以見到佢先計咗 60 萬除以 48 個月,每個月需要儲 12500 元,再結合低風險理財收益率、統計局數據同現實收入假設嚟拆目標。呢個思路係啱嘅:先用數學將目標攤開,再判斷現實缺口喺邊。
好方案仲需要被反向審閲
呢份四年計劃繼續落去,會包含主業收入增長、前 90 日行動表、支出控制、副業選擇、每月執行範本同賬本格式。佢甚至提到 2026 年個人所得税專項附加扣除,整體非常接近現實。
但我並冇直接信呢份方案。我將 GPT 5.5 Pro 嘅回答傳咗畀 GPT 5.5 Heavy,叫佢評分。佢畀咗 82 分,並指出幾個問題:將數學上嘅可達性同現實中嘅大概可行混埋一齊,對副業變現難度估計不足,冇失敗版本嘅後備方案,亦都冇充分討論買樓資格同樓價。
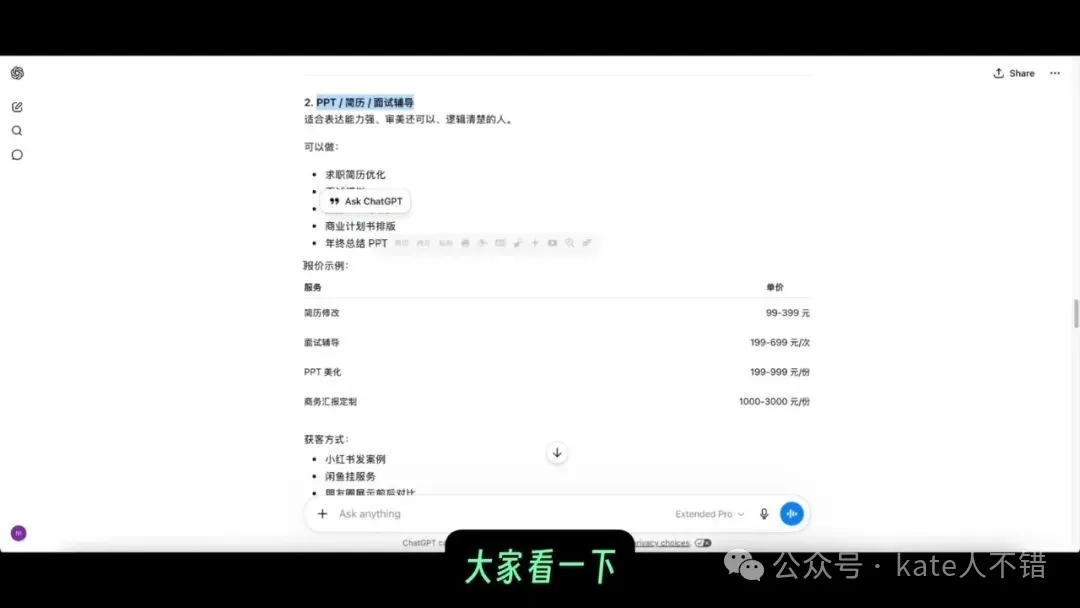
呢張 screenshot 展示嘅係計劃入面推薦嘅副業方向。我個人認為,隨住 AI 發展得好快,入面有啲副業建議未必仲合適。所以呢類規劃可以用嚟打開思路,但唔可以取代個人風險評估,更加唔可以當成財務建議。
審稿模型嘅價值:專門揀出「看似合理」嘅漏洞
GPT 5.5 Heavy 對方案嘅審閲,令我覺得非常有必要。佢指出健康同時間成本估算不足,亦都提醒計劃冇失敗版本。呢啲問題唔係簡單計算可以發現嘅,而係需要現實感。
呢個亦都係我而家用高能力模型嘅一個習慣:唔好只係叫一個模型生成方案,仲要叫另一個模型專門做審稿。一個負責提出路線,另一個負責揾錯處,最後由人決定邊啲建議可執行。
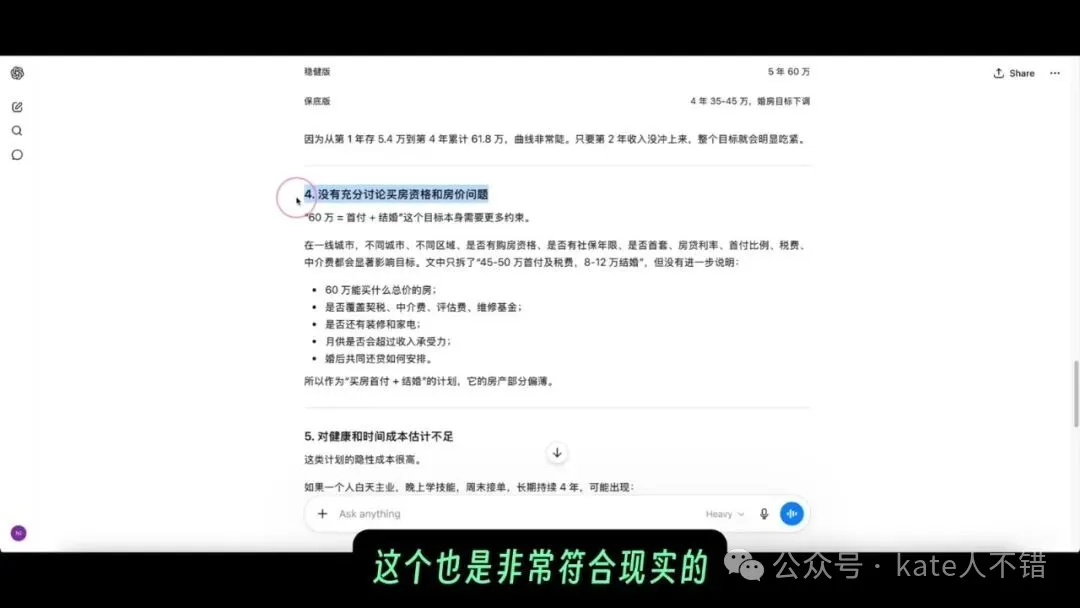
screenshot 入面嘅審閲意見可以見到,佢唔係簡單話「呢個方案唔錯」,而係指出計劃入面最易被忽略嘅風險。對任何關乎錢、職業、健康同長期承諾嘅問題,呢種反向審閲比靚仔結論更加重要。
技術路線篩選:適合處理快速變化嘅新工具
而家技術發展太快,我都會叫 GPT 5.5 Pro 幫我做快速篩選。例如 Gemma 4 MTP 推出之後,我叫佢判斷邊間嘅 MLX 更合適,同埋如果想喺 OpenWebUI 入面用,點樣處理更方便。
佢思考接近 12 分鐘之後,畀出嘅首選路線係 Ollama 嘅 MLX Runner 同 BF16 MTP,並解釋咗理由。佢仲查到 Hacker News 上面嘅用戶分享,對 GGUF 同 MLX 做咗對比。
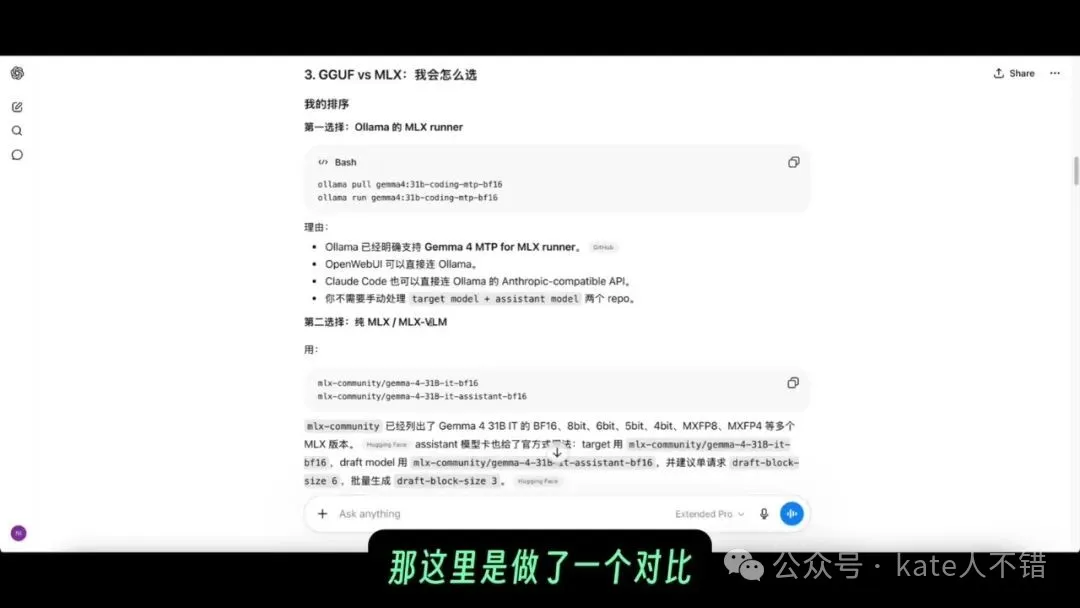
呢張 screenshot 入面可以見到 GGUF 同 MLX 嘅對比。需要注意的是,llama.cpp 同 MLX 最近變化都好快,所以呢類結論最好當成「當時狀態下嘅快速篩選」,後續真正執行之前仍然要再查最新文件。
編碼測試一:倉庫分揀仿真已經接近可示範
跟住睇編碼能力。我先叫佢做一個倉庫分揀仿真:要有傳送帶、機械臂同分揀箱。佢思考咗 13 分幾鐘之後,生成咗一個有機械臂嘅頁面。
頁面入面有明確嘅抓手,機械臂會抓取綠色圓柱體、藍色物體同紅色物體,並放進置物箱。仔細睇仍然有問題,例如兩個紅色物體會出現穿模,但係我近期測試過嘅多個模型入面呢個已經算效果幾好。
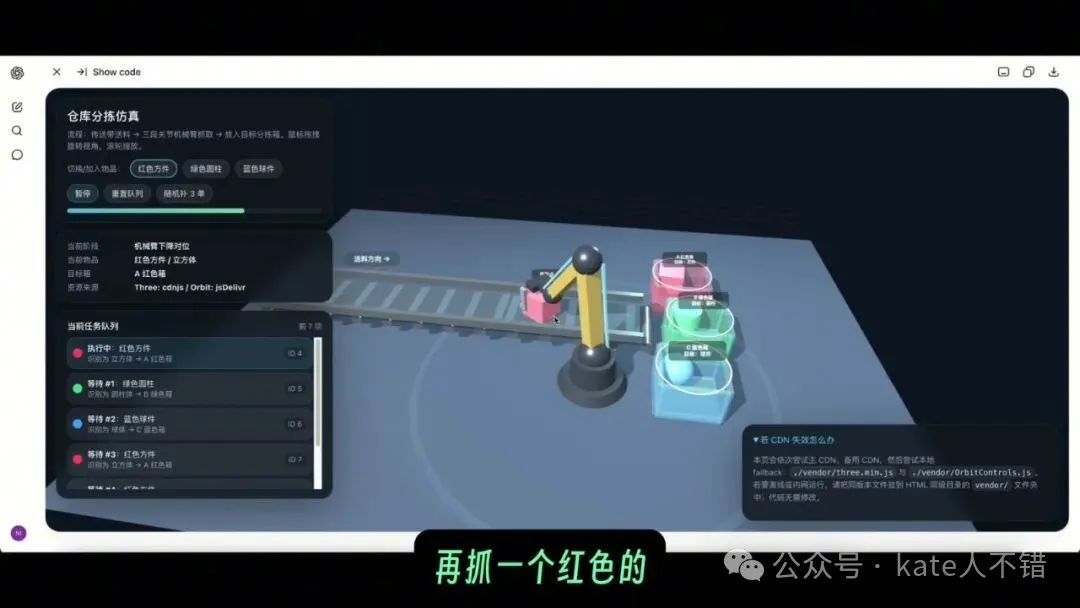
screenshot 入面可以見到機械臂、箱子、物體同側邊控制面板。佢證明咗 GPT 5.5 Pro 唔只係會寫靜態頁面,亦都可以生成帶狀態、動畫同物理直覺嘅互動示範,但係精細碰撞同真實物理仍然需要人工繼續調整。
編碼測試二:營造法式拆解動畫有完整互動
我又畀咗佢一張圖,叫佢生成一個「營造法式」嘅拆解動畫。佢思考接近 20 分鐘,最後生成咗一個頁面,中間部分將各個組件展示出嚟,並提供「一鍵分解」同「一鍵組裝」。
動畫整體比較流暢,左邊仲模仿咗上傳相片之後 AI 識別嘅過程,下面會出現模擬識別結果;右邊展示木材風化、油漆剝落等狀態。我仲未仔細睇程式碼,唔確定入面兩張圖片係點樣獲取,但視覺上好逼真。
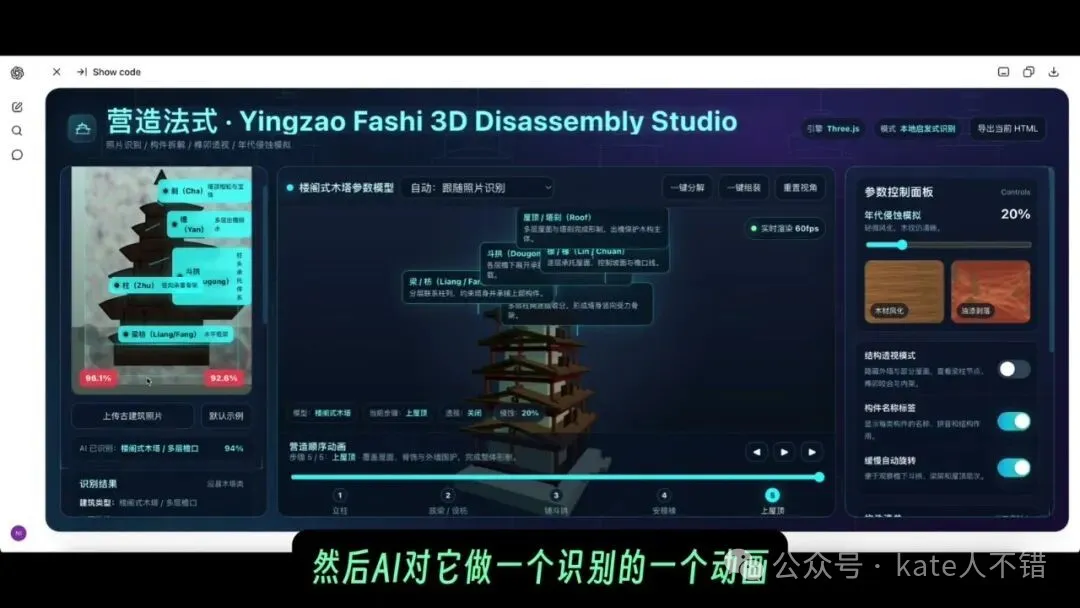
呢張圖可以見到左側識別流程、中間結構拆解、右側參數同效果面板。佢比較完整噉覆蓋咗一個互動式教學工具應有嘅元素,而唔係淨係畫一個孤立嘅模型。
編碼測試三:復刻播放器,視覺細節做得最好
我仲將一張播放器效果圖傳咗畀 GPT 5.5 Pro,叫佢盡量復刻。

呢個同時考驗圖片識別能力同編碼能力。之前我都叫 Gemini 3.1 Pro 同 Opus 4.7 試過,但佢哋嘅生成效果都冇 GPT 5.5 Pro 咁好。
佢復刻出咗周邊循環閃光嘅動畫,中間部分亦都有多個顏色組成嘅圓球變化。唯一比較明顯嘅問題係頁面有啲窒,但係從視覺還原度嚟講,表現非常好。

screenshot 入面嘅粒子光效同中心球體變化,係呢個案例最關鍵嘅視覺證據。佢說明 GPT 5.5 Pro 喺「睇圖轉互動頁面」呢類任務上已經好強,但係效能最佳化仍然要另外處理。
編碼測試四:縴夫拉船場景嘅現實感更強
最後,我叫佢做一個縴夫拉船場景。佢思考接近 15 分鐘,最後生成嘅效果,係我測試過多個模型裏面最好嘅。
以前一啲模型會出現繩索同船冇連接、人同船之間有明顯距離嘅問題。呢度唔只船同人透過繩子連埋一齊,而且設計更加符合現實:有主繩,亦都有多個分叉繩;靠近船嘅繩子長啲,越前邊嘅繩子短啲。
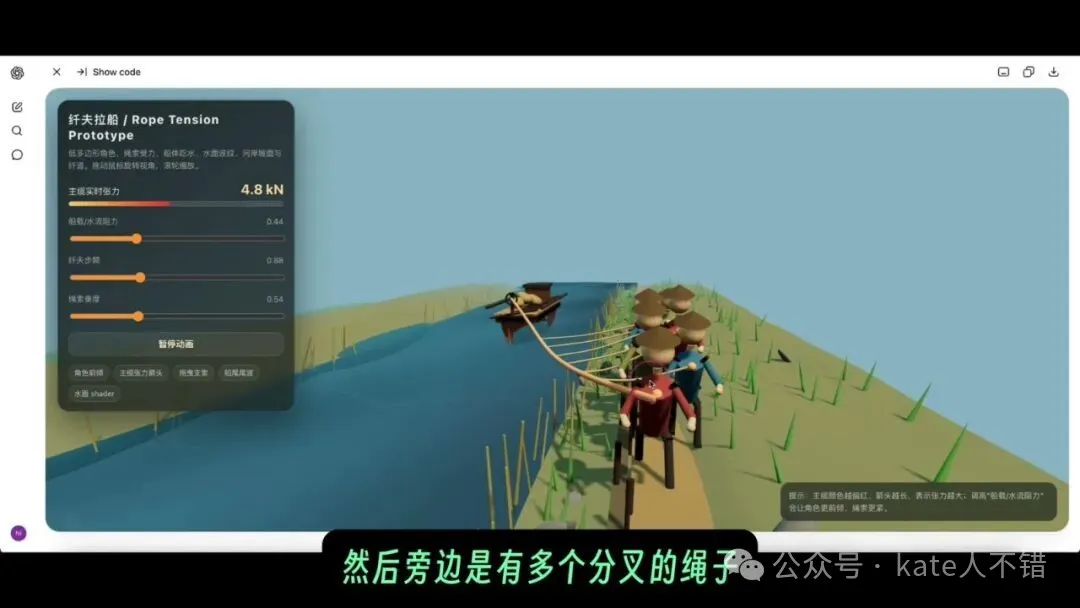
screenshot 入面可以見到縴夫、繩索、船體同河岸嘅關係。呢個場景嘅難點唔係「畫出船同人」,而係令連接關係合理,尤其係繩索長度、方向同身體綁定位置都要接近現實。
細心啲睇船、水同貨物,可以見到佢喺處理動態細節
繼續仔細睇呢個場景,縴夫整體呈現都唔錯,仲戴住帽,繩索綁喺身體上。水流一路有波動感,船上有麻袋一類嘅貨物,好似古代貨船。
更加仔細嘅地方係船嘅食水感:隨住波浪變化,船身有時露出嚟多啲,有時少啲。呢個說明佢唔係淨係做一個平面動畫,而係嘗試將水、船、貨物同拉拽關係放喺同一個動態系統入面。
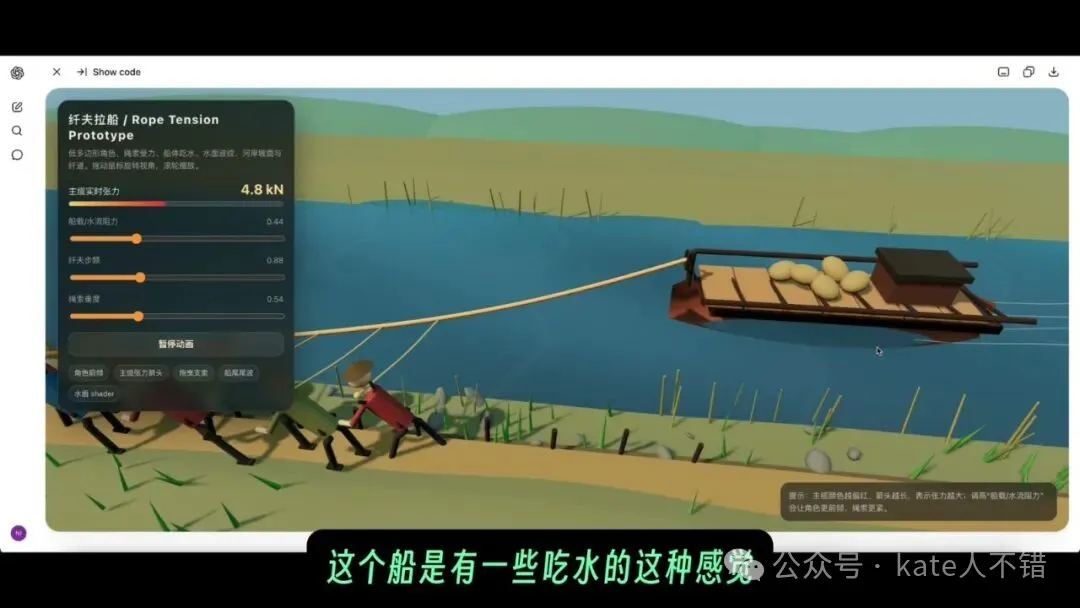
呢張 screenshot 更加清楚顯示咗船體、貨物、水面同拉繩嘅關係。佢亦都係我對 GPT 5.5 Pro 編碼能力評價比較高嘅原因之一:好多模型可以做到「睇落有嘢」嘅頁面,但係要將呢啲關係做得合理,並唔容易。
我嘅結論:適合複雜任務,但係必須保留人工判斷
整體睇落嚟,如果你成日做編程、技術研究、資料整理、報告生成、PPT 草稿、複雜事件梳理,GPT 5.5 Pro 好值得試。佢適合嗰啲需要連續搜尋、寫程式碼、生成文件、檢查結果嘅任務。
如果你係大學生,或者正在做各類研究,佢都會係一個好有力嘅幫手。佢可以幫你快速打開資料面、形成初稿、生成結構、檢查漏洞,但係最終嘅研究判斷、事實核驗同責任仍然喺你自己手度。
我對佢嘅推薦方式好簡單:將佢當成高能力研究助理,而唔係最終裁判。叫佢做重嘢,叫佢解釋依據,叫佢接受另一個模型嘅審稿,然後你再決定邊啲結論真係用得。
參考資料
• OpenAI:Introducing GPT-5.5,2026-04-23,https://openai.com/index/introducing-gpt-5-5/ • OpenAI:GPT-5.5 System Card,2026-04-23,https://openai.com/index/gpt-5-5-system-card/
GPT 5.5 Pro 上線一段時間後,我最明顯的感受是:它不只是“回答更聰明”,而是更像一個能長時間推進複雜任務的研究助理。它會搜索、寫腳本、生成文檔、做截圖質檢,也會在複雜問題裏給出相對完整的判斷鏈條。
當然,這不等於它可以替代人做最終判斷。越是複雜任務,越需要人來定義問題、檢查來源、判斷結論是否過度外推。它真正有價值的地方,是把原本需要大量搜索、整理、排版和初步分析的工作,壓縮成一個可以繼續審閲和迭代的結果。
這篇文章會按照我在視頻裏的實際測試來講:官方能力對比、數學研究案例、PPT 和報告生成、供應鏈事件梳理、車企研究、會員方案選擇、四年財務規劃、技術路線篩選,以及幾組前端編碼演示。
官方信息裏,Pro 的優勢不在所有榜單
OpenAI 在系統卡中說明,GPT 5.5 Pro 與 GPT 5.5 是同一底層模型,但 Pro 版本使用了並行測試時計算,目標是在更難、更長的任務上提升表現。官方介紹裏的評測也能看到一個很重要的細節:並不是所有項目都是 Pro 版本更高。
比如 GDPval 這類專業任務評測裏,GPT 5.5 的分數高於 GPT 5.5 Pro;但在瀏覽器搜索、前沿數學等更需要長時間推理和多步探索的方向,Pro 版本表現更強。這也解釋了我後面為什麼更願意把“深度搜索、長報告、複雜編碼”這類任務交給它。
這張官方評測表提醒我們,不要把 Pro 簡單理解成“每個問題都更強”。它更適合的問題,是那些需要模型花時間搜索、比較、拆解、驗證,並把多個步驟串起來的任務。
數學研究案例說明:人的價值會更偏向判斷力
最近有一篇關於 GPT 5.5 Pro 的數學案例非常火。作者是菲爾茲獎得主,他讓模型處理一個加法數論問題。視頻裏提到,模型在約兩小時內,把一個數值上界從指數級推進到多項式級,人類評價認為其中的思路具有原創性。
這個案例真正值得關注的,不只是“AI 做出了一道題”,而是它改變了温和開放問題的安全感。過去很多博士訓練裏的入門研究,可能圍繞“找到一個沒人證明過、但難度適中的問題”展開;現在這類問題更可能被 AI 快速推進。
畫面裏把這個突破拆成四個階段、四次提示。對研究者來說,這意味着能力重心會遷移:不是單純證明沒人證明過的題,而是要學會提出更好的問題、判斷模型給出的思路是否可靠,並和 AI 一起攻克更難的方向。
先看文檔和 PPT:它能交付一份可讀的成品
我先把 DeepSeek V4 的技術報告發給 GPT 5.5 Pro,讓它生成一份高質量解讀 PPT。它先生成了幾張圖,後續又把這些圖放進 PPT 裏。整體樣式不錯,我檢查過裏面的內容,也沒有發現明顯不能用的問題。
相比早期 Pro 模型,現在的速度也明顯更可用。簡單問題幾分鐘內能回覆,複雜一點的任務大約二十分鐘或更久。以前 Pro 剛推出時,哪怕只是問一句“你好”,都有可能等二十多分鐘;現在至少在這類文檔任務上,等待時間和結果質量更匹配。
這張截圖展示的是 GPT 5.5 Pro 生成的 PPT 頁面。它不是隻給一堆文字,而是嘗試把信息組織成可以展示的版式,這對需要快速做彙報、課程材料、內部分享的人很有用。
搜索整理:它適合處理新近複雜事件
接着,我給它一張截圖,讓它梳理一個比較新的供應鏈攻擊事件。這個事件剛發生不久,需要判斷真假、整理時間線、確認影響範圍,還要說明已經安裝過相關軟件的人應該怎麼處理。
GPT 5.5 Pro 首先判斷這是一個高危供應鏈攻擊,然後給出詳細梳理:發生了什麼、影響了哪些包、風險在哪裏、有哪些參考連結、已經安裝過應該如何自查和處理。這個問題它花了 8 分多鐘。
截圖裏可以看到,它的回答不只是結論,還包含連結、表格和處理建議。對這種新近事件,模型最重要的價值不是替你做最終安全判斷,而是把散落在不同來源裏的信息先組織起來,讓人能更快進入審閲狀態。
追問和彙總:同一上下文可以繼續壓榨價值
在前面已經搜索過一輪之後,我繼續追問:這個事件是什麼時候發現的?能不能全部換成北京時間?如果安裝過哪些軟件,會受到什麼影響?
因為前面已有上下文,它能很快基於之前的搜索結果繼續回答。隨後我又讓它把所有回覆彙總成一份 Markdown,這樣就可以方便分享給別人,比如發到星球裏。
這張圖顯示的是彙總過程。這裏我使用的是 GPT 5.5 Heavy 模式,它把前面的搜索、解釋、風險判斷和處理建議整理成一份結構化報告,比零散聊天記錄更適合傳播和複查。
複雜搜索任務:Pro 的價值在於把資料壓成結構
這份供應鏈事件報告裏,我比較關注北京時間,因為這會影響國內用戶對風險窗口的判斷。模型把事件時間線、受影響的安裝包、自查命令、命中後的處理意見、以後如何避免同類風險等內容放在一起。
從這個案例看,GPT 5.5 Pro 很適合做“信息密度高、來源分散、需要快速形成結構化判斷”的任務。瀏覽器搜索能力更強,配合長時間推理,能省掉大量手工打開網頁、摘錄、對照的時間。
截圖裏重新回到官方評測表,強調的是同一個判斷:對瀏覽器搜索和複雜信息整理來說,Pro 版本的優勢更明顯。它適合承擔“先把材料找齊、排好、講清楚”的工作。
行業研究報告:從排名到依據,它會補足分析框架
我還讓它基於現有數據,分析中國新能源汽車領域最值得關注的三家車企,並要求嚴格給出 1、2、3 的排名。它思考了 22 分鐘,最後給了我一份 Word 文檔。
這份文檔先是總覽,然後是結論摘要、主要優勢、主要風險、行業背景、三家公司核心數據快照和排名方法。它給出的第一名是比亞迪,第二名是吉利,第三名是浙江零跑。雖然只有 13 頁,但已經能滿足一次快速研究的基本需要。
這張截圖裏能看到車企核心數據表。對研究報告來說,模型如果只給結論,價值有限;真正有用的是它能把排名背後的數據維度、風險點和判斷方法一起呈現出來。
生成文檔只是第一步,它還會寫腳本和做質檢
我再看了它的思考過程。在 23 分鐘裏,它會寫 Python 腳本,會搜索多個網頁,而且是多輪搜索。因為我的提示是要求生成 Docx,它也會通過 Python 輸出文檔。
更有意思的是,報告完成後,它還會對報告的每一頁進行截圖分析,檢查做得是否合理。這種自檢流程很重要,因為複雜任務不是生成完就結束,真正交付前還需要質量檢查。
畫面右側能看到活動記錄和代碼執行過程。GPT 5.5 Pro 的強項不只是“會寫一段話”,而是能在工具鏈裏連續行動:查資料、處理數據、生成文件,再回頭檢查結果。
同一個主題,PPT 質量仍然會波動
我還做了另一個新能源車企相關任務:先完成報告,再根據報告生成 PPT。但這一次,GPT 5.5 Pro 生成的 PPT 顏值明顯不如前面 DeepSeek V4 那份。
後來我改用 Codex 裏的 GPT 5.5 xhigh 模型來生成 PPT,質量就更好一些。這說明即使是強模型,輸出也會受任務提示、運行環境、模式選擇和審美要求影響。複雜視覺交付仍然需要人類審稿,必要時還要換模型或重新提示。
截圖展示的是改用 Codex 裏的 GPT 5.5 xhigh 後生成的 PPT 頁面。它的版式和視覺完成度更好,也說明“同一個模型系列”在不同工具和設置裏,實際產出會有明顯差異。
會員方案選擇:它能把預算、能力和使用量放在一起比較
我還讓 GPT 5.5 幫我分析幾個會員方案:在我的預算裏,應該選哪些會員更合適。這裏不僅要考慮模型能力,還要考慮可用量,以及不同工具的 Harness 能力。
它思考時間不長,大約 8 分鐘就給出了結論:建議選擇 GPT Pro 100 美元會員,以及 Cursor Pro 20 美元會員。下方還給出了對比表和理由,這些點經常關注我頻道的朋友應該不會陌生。
這張截圖對應會員方案分析。它的價值在於把“能力強不強”“夠不夠用”“工具鏈是否順手”“預算是否合適”放進同一張表裏比較,而不是隻看單一模型排名。
財務規劃:它很會拆目標,但不能替你做現實決策
我還給它一個更生活化的問題:假設現在月收入 7000 元,生活在一線城市,沒有存款,想在四年內湊夠 60 萬,用於買房首付和結婚,請它給一個現實可行的四年計劃。
它思考接近 8 分鐘後,給出的第一句話很清醒:單靠節省基本不可能。現實路線是前 12 個月完成收入躍遷,後三年靠主業漲薪、穩定副業、極低生活成本和低風險理財來完成。
截圖裏能看到它先算了 60 萬除以 48 個月,每月需要存 12500 元,再結合低風險理財收益率、統計局數據和現實收入假設來拆目標。這個思路是對的:先用數學把目標攤開,再判斷現實缺口在哪裏。
好方案還需要被反向審閲
這份四年計劃繼續往下,會包含主業收入增長、前 90 天行動表、支出控制、副業選擇、每月執行模板和賬本格式。它甚至提到 2026 年個税專項附加扣除,整體非常接近現實。
但我並沒有直接相信這份方案。我把 GPT 5.5 Pro 的回答發給 GPT 5.5 Heavy,讓它做評分。它給了 82 分,並指出幾個問題:把數學上的可達性和現實中的大概率可行混在了一起,對副業變現難度估計不足,缺少失敗版本備用方案,也沒有充分討論買房資格和房價。
這張截圖展示的是計劃裏推薦的副業方向。我個人認為,隨着 AI 發展很快,裏面有些副業建議未必還合適。所以這類規劃可以用來打開思路,但不能替代個人風險評估,更不能當作財務建議。
審稿模型的價值:專門挑出“看似合理”的漏洞
GPT 5.5 Heavy 對方案的審閲,讓我覺得非常有必要。它指出健康和時間成本估算不足,也提醒計劃缺少失敗版本。這些問題不是簡單計算能發現的,而是需要現實感。
這也是我現在使用高能力模型的一個習慣:不要只讓一個模型生成方案,還要讓另一個模型專門做審稿。一個負責提出路線,另一個負責挑毛病,最後由人來決定哪些建議可執行。
截圖裏的審閲意見能看到,它不是簡單說“這個方案不錯”,而是指出了計劃裏最容易被忽視的風險。對任何涉及錢、職業、健康和長期承諾的問題,這種反向審閲比漂亮結論更重要。
技術路線篩選:適合處理快速變化的新工具
現在技術發展太快,我也會讓 GPT 5.5 Pro 幫我做快速篩選。比如 Gemma 4 MTP 推出後,我讓它判斷哪家的 MLX 更合適,以及如果想在 OpenWebUI 裏使用,怎樣處理更方便。
它思考接近 12 分鐘後,給出的首選路線是 Ollama 的 MLX Runner 和 BF16 MTP,並解釋了理由。它還查到了 Hacker News 上的用戶分享,對 GGUF 和 MLX 做了對比。
這張截圖裏能看到 GGUF 和 MLX 的對比。需要注意的是,llama.cpp 和 MLX 最近變化都很快,所以這種結論最好當作“當時狀態下的快速篩選”,後續真正執行前仍然要再查最新文檔。
編碼測試一:倉庫分揀仿真已經接近可演示
接着看編碼能力。我先讓它做一個倉庫分揀仿真:要有傳送帶、機械臂和分揀箱。它思考 13 分多鐘後,生成了一個帶機械臂的頁面。
頁面裏有明確的抓手,機械臂會抓取綠色圓柱體、藍色物體和紅色物體,並放進置物箱。仔細看仍然有問題,比如兩個紅色物體會出現穿模,但在我近期測過的多個模型裏,這已經屬於效果比較好的。
截圖中能看到機械臂、箱子、物體和側邊控制面板。它證明 GPT 5.5 Pro 不只是會寫靜態頁面,也能生成帶狀態、動畫和物理直覺的交互演示,但精細碰撞和真實物理仍然需要人工繼續調。
編碼測試二:營造法式拆解動畫有完整交互
我又給它一張圖,讓它生成一個“營造法式”的拆解動畫。它思考接近 20 分鐘,最後生成了一個頁面,中間部分把各個組件展示出來,並提供“一鍵分解”和“一鍵組裝”。
動畫整體比較流暢,左邊還模仿了上傳照片後 AI 識別的過程,下方會出現模擬識別結果;右邊展示木材風化、油漆剝落等狀態。我還沒有細看代碼,不確定其中兩張圖片是如何獲取的,但視覺上非常仿真。
這張圖可以看到左側識別流程、中間結構拆解、右側參數和效果面板。它比較完整地覆蓋了一個交互式教學工具該有的元素,而不是隻畫一個孤立的模型。
編碼測試三:復刻播放器,視覺細節做得最好
我還把一張播放器效果圖發給 GPT 5.5 Pro,要求它儘量復刻。
這同時考驗圖片識別能力和編碼能力。之前我也讓 Gemini 3.1 Pro 和 Opus 4.7 嘗試過,但它們的生成效果都沒有 GPT 5.5 Pro 好。
它復刻出了周邊循環閃光的動畫,中間部分也有多個顏色組成的圓球變化。唯一比較明顯的問題是頁面有些卡頓,但從視覺還原度來說,表現非常好。
截圖裏的粒子光效和中心球體變化,是這個案例最關鍵的視覺證據。它說明 GPT 5.5 Pro 在“看圖轉交互頁面”這類任務上已經很強,但性能優化仍然要單獨處理。
編碼測試四:縴夫拉船場景的現實感更強
最後,我讓它做一個縴夫拉船場景。它思考接近 15 分鐘,最後生成的效果,是我測試多個模型裏最好的。
以前一些模型會出現繩索和船沒有連接、人與船之間有明顯距離的問題。這裏不僅船和人通過繩子連在了一起,而且設計更符合現實:有主繩,也有多個分叉繩;靠近船的繩子長一些,越往前繩子更短一些。
截圖裏能看到縴夫、繩索、船體和河岸的關係。這個場景的難點不是“畫出船和人”,而是讓連接關係合理,尤其是繩索長度、方向和身體綁定位置都要接近現實。
細看船、水和貨物,能看到它在處理動態細節
繼續細看這個場景,縴夫整體呈現也不錯,還戴着帽子,繩索綁在身體上。水流一直有波動感,船上有麻袋一類的貨物,像古代貨船。
更細的地方是船的吃水感:隨着波浪變化,船身有時露出來多一點,有時少一點。這說明它不是隻做一個平面動畫,而是在嘗試把水、船、貨物和拉拽關係放在同一個動態系統裏。
這張截圖更清楚地顯示了船體、貨物、水面和拉繩的關係。它也是我對 GPT 5.5 Pro 編碼能力評價較高的原因之一:很多模型能做出“看起來有東西”的頁面,但要把這些關係做得合理,並不容易。
我的結論:適合複雜任務,但必須保留人工判斷
整體看下來,如果你經常做編程、技術研究、資料整理、報告生成、PPT 草稿、複雜事件梳理,GPT 5.5 Pro 很值得嘗試。它適合那些需要連續搜索、寫代碼、生成文件、檢查結果的任務。
如果你是大學生,或者正在做各類研究,它也會是一個很有力的幫手。它能幫你快速打開資料面、形成初稿、生成結構、檢查漏洞,但最終的研究判斷、事實核驗和責任仍然在你自己手裏。
我對它的推薦方式很簡單:把它當作高能力研究助理,而不是最終裁判。讓它做重活,讓它解釋依據,讓它接受另一個模型的審稿,然後你再決定哪些結論真的能用。
參考資料
• OpenAI:Introducing GPT-5.5,2026-04-23,https://openai.com/index/introducing-gpt-5-5/ • OpenAI:GPT-5.5 System Card,2026-04-23,https://openai.com/index/gpt-5-5-system-card/