GPT-5.5 今日發佈
整理版優先睇
GPT-5.5 正式登場:由「答題機器」進化成「執行 Agent」,編程與科研能力有質的飛躍。
OpenAI 正式發佈 GPT-5.5,呢篇文詳細拆解咗新模型嘅發佈要點、性能表現同埋實際應用場景。作者想解決嘅核心問題係:喺模型單價上升嘅趨勢下,點樣衡量 AI 嘅真正價值?結論係 GPT-5.5 唔再只係幫你寫一段 code,而係具備咗長程規劃能力,可以喺真實工程環境入面自主揾出問題、修改文件並完成測試。
文章指出 GPT-5.5 雖然 token 單價比前代貴,但因為效率提升同埋減少咗「返工」次數,實際性價比反而更高。無論係處理複雜嘅科研數據,定係喺電腦入面跨軟件操作,GPT-5.5 都展現出強大嘅 Agent 特質,標誌住 AI 發展正式由「對話框」走向「端到端任務交付」。
- 核心進化:GPT-5.5 定位係最強編程 Agent,唔再係單純補全代碼,而係可以理解成個代碼庫,自主定位 Bug 並跨文件修改。
- 性價比新定義:雖然 Token 單價翻倍,但因為模型更聰明、用更少 Token 就能完成任務且減少重試次數,實際工程成本反而更低。
- 跨領域執行力:模型喺 GDPval 同 OSWorld 評測表現出色,證明佢可以喺真實電腦環境操作工具、分析數據同生成文檔,處理複雜嘅知識工作。
- 科研突破:GPT-5.5 Pro 具備長鏈路推理能力,已經可以輔助科學家分析複雜基因數據,甚至參與數學證明嘅推導過程。
- 基建優化:OpenAI 首次透露模型參與咗自身推理系統嘅優化,透過 AI 撰寫負載均衡算法,令生成速度喺模型變強嘅同時依然保持流暢。
GPT-5.5 適用場景判斷準則
優先用於:長程軟件工程(重構、疑難 Bug)、複雜知識工作(數據轉報告)、科研分析、真實工具鏈自動化。簡單摘要或分類任務建議保留用舊模型以節省成本。
唔好淨係睇價錢,要睇 Token 效率
好多人一見到 GPT-5.5 嘅 API 價錢貴咗就覺得唔抵,但其實 OpenAI 玩緊「以質換量」。雖然每百萬 Token 嘅單價升咗,但因為模型理解力強咗,完成同一個任務所消耗嘅 Token 數量反而少咗。
由「寫 Code 仔」變身「工程師同事」
以前我哋用 AI 係要餵佢一條完美嘅 Prompt,而家 GPT-5.5 係可以直接掉個「唔乾淨」嘅任務畀佢。佢識得自己去睇成個代碼庫,揾出點解個 Page 會掛咗,然後自己改埋、行埋 Test。
GPT-5.5 喺 SWE-Bench Pro(真實 GitHub issue 修復)攞到 58.6%,遠超前代,更適合處理跨文件嘅複雜重構。
科研加速:幾個月嘅工作量縮短到幾日
喺科學研究方面,GPT-5.5 唔再係問答機械人,而係一個可以行「探索假設、收集證據、測試假說」循環嘅助手。有教授用佢分析幾萬個基因表達數據,生成咗一份完整研究報告,如果靠人工做起碼要幾個月。
AI 幫手執基建,安全標準再升級
最有趣嘅一點係,GPT-5.5 參與咗優化自己運行嘅基礎設施。佢幫手寫咗自定義嘅負載均衡算法,令到生成速度提升咗 20%。簡單講,就係模型自己幫手執靚咗個場嚟行自己。
安全方面,OpenAI 將網絡安全同生物能力風險定為「高」級,所以推出咗「可信訪問機制」,畀專業安全從業者可以用佢嚟做防禦性掃描,而唔會被安全過濾器誤攔。

01 先睇發佈重點
GPT-5.5 已經開始向 ChatGPT 同 Codex 嘅 Plus、Pro、Business、Enterprise 用戶陸續推送。同時仲有 GPT-5.5 Pro 版本,專門畀 Pro 同以上級別嘅用戶用,定位係處理更難、更高精度嘅任務。Codex 嗰邊重點好明確:有 400K context window(上下文窗口),更加適合交畀佢處理成段工程項目。
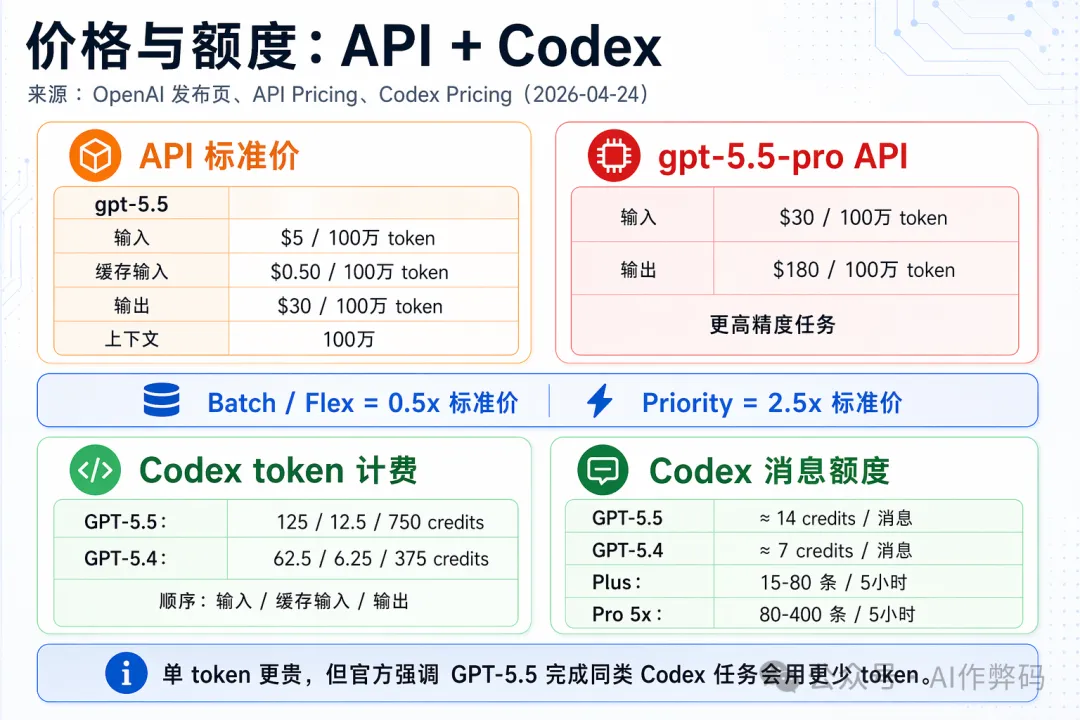
API 嗰邊仲係「好快開放」階段,但價錢已經公佈咗:標準版每百萬輸入 token 5 美金、輸出 30 美金;Pro 版每百萬輸入 30 美金、輸出 180 美金。Batch(批量)同彈性定價可以有半價,而優先處理就係標準價嘅 2.5 倍。Codex 嗰邊,GPT-5.5 嘅 token 單價係 GPT-5.4 嘅兩倍(每百萬輸出 token 750 credits vs 375 credits),但每條 message 嘅實際消耗大約係 14 credits vs 7 credits,因為 GPT-5.5 做同一個任務用嘅 token 仲少咗。
關鍵判斷
GPT-5.5 嘅 token 單價雖然係 GPT-5.4 嘅兩倍,但 OpenAI 強調佢嘅 token 效率亦都大幅提升——做同一個 Codex 任務消耗更少 token。Plus 用戶每 5 個鐘可以用 15-80 條 GPT-5.5 訊息(GPT-5.4 係 20-100 條),實際額度要睇任務有幾複雜。喺 Artificial Analysis 嘅編碼指數上面,GPT-5.5 嘅智能水平達到最前沿,而成本只係同級對手模型嘅一半。真正嘅性價比唔係睇單次 call 嘅價錢,而係睇佢能唔能夠減少重試同埋執手尾(返工)。
02 最值得睇嘅係自主寫 code 能力
OpenAI 直接話 GPT-5.5 係佢哋目前最強嘅編程 Agent 模型。呢度講嘅「編程」唔係幫你補完一段 function,而係更接近真實工程:理解成個 code base(代碼庫),搵出 fail 嘅原因,跨文件修改,行 test,驗證結果,有需要嗰陣仲會繼續迭代。
跑分要睇方向而唔係單一數字:Terminal-Bench 2.0(複雜終端工作流)82.7%,Expert-SWE(內部長程編程評測,任務中位數完成時間約 20 個鐘)73.1%,SWE-Bench Pro(真實 GitHub issue 修復)58.6%。三項都超越咗 GPT-5.4,而且用咗更少 token。

呢樣嘢對開發者嘅實際意義係:GPT-5.5 更適合交畀佢一個「唔乾淨」嘅真實任務,而唔係一條經人工預處理過嘅完美 prompt。例如「呢個 branch 合咗入去之後個 page 死咗,搵出原因並整返好佢」、「將留言系統重構成可協作編輯結構,並補返啲 test」、「將呢套業務報表自動化」。
更似工程同事,而唔係 code 片段生成器
早期測試者嘅反饋集中喺同一點:GPT-5.5 更擅長理解系統整體結構——搞清楚點解出咗事、修改應該改邊度、code base 入面仲有邊啲地方會受影響。一位 NVIDIA 嘅工程師甚至話:「冇咗 GPT-5.5 嘅使用權限,感覺就好似斷咗條臂咁。」
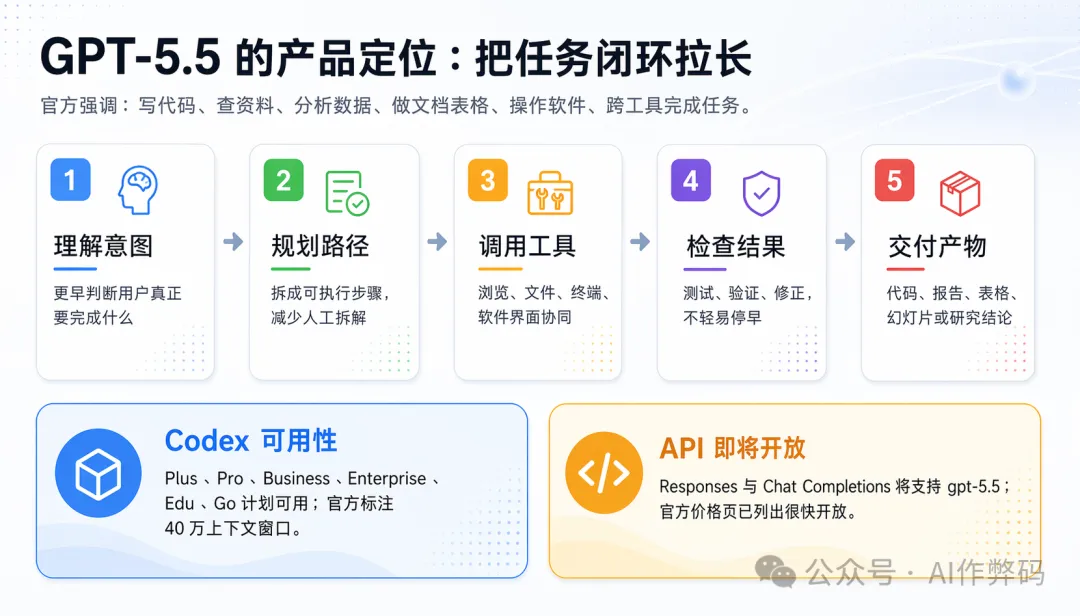
03 從寫 code 擴展到電腦上嘅工作
OpenAI 今次將 GPT-5.5 放喺一個更大嘅框架入面:唔單止係寫 code,仲要可以操作電腦、處理知識型工作。佢要識搵資料、讀文件、分析數據、生成文檔、整表格、整 PowerPoint,仲要喺唔同工具之間來回切換。
評測結果亦都對得上呢個定位:GDPval(跨 44 種職業嘅知識工作評測)84.9%,OSWorld-Verified(真實電腦環境自主操作)78.7%,Tau2-bench Telecom(複雜客服工作流,唔使微調 prompt)98.0%。
OpenAI 內部自己都喺度大規模使用:超過 85% 嘅員工每星期都用緊 Codex,覆蓋咗工程、財務、市場、數據科學同產品管理。財務團隊用佢審閱咗 24,771 份 K-1 稅表(總共 71,637 頁),比舊年提早咗兩星期搞掂。
呢個亦都係 GPT-5.5 同 Codex 綁得愈嚟愈緊嘅原因。Codex 唔單止係一個「寫 code 窗口」,而係一個可以讀 repository、行 command、改 file 同檢查結果嘅執行環境。模型愈叻做長程規劃同工具調用,Codex 呢類環境嘅價值就愈大。
04 科學研究:由答問題到推動研究
GPT-5.5 喺科學研究方面嘅表現亦都值得單獨睇。OpenAI 強調,科研工作需要嘅唔只係答一個難題,而係一整套循環:探索假設、收集證據、測試假說、解讀結果、決定下一步。GPT-5.5 喺維持呢種長鏈路推理上面,比以前嘅模型更強。
幾個關鍵數據:GeneBench(多階段遺傳學數據分析,任務難度相當於科研專家幾日嘅工作量)比 GPT-5.4 有顯著提升;BixBench(真實生物信息學分析)攞到已公開模型嘅最高分;一個內部版本嘅 GPT-5.5 甚至幫手發現咗關於 Ramsey 數嘅一個新證明——之後已經喺 Lean 入面得到形式化驗證。
一個具體例子
傑克遜基因組醫學實驗室嘅免疫學教授 Derya Unutmaz 用 GPT-5.5 Pro 分析咗一組包含 62 個樣本、近 28,000 個基因嘅表達數據集,生成咗一份完整嘅研究報告——唔單止總結咗發現,仲指出咗關鍵問題同洞察。佢話呢項工作如果交畀團隊嚟做,需要幾個月時間。
05 更強,但係冇明顯變慢
更大嘅模型通常代表會更慢。但 OpenAI 今次特別強調,GPT-5.5 嘅每 token 生成延遲同 GPT-5.4 持平,同時智能水平更高。
背後嘅細節亦都值得注意:GPT-5.5 同英偉達 GB200、GB300 NVL72 系統協同設計、訓練同部署。Codex 分析咗幾星期嘅生產流量模式,編寫咗自定義嘅負載均衡算法,單係呢項就令 token 生成速度提升超過 20%。GPT-5.5 本身亦都有參與推理系統嘅優化。
呢句說話值得單獨拎出嚟講
模型唔單止係行喺基礎設施上面,佢仲幫手改進埋基礎設施本身。用 OpenAI 原話講:"Put simply, the model helped improve the infrastructure that serves it."
06 安全標準同步上調
模型愈強,被濫用嘅風險亦都愈高。OpenAI 喺發佈頁面強調,GPT-5.5 經過咗完整嘅安全評估流程,包括內外部紅隊測試、針對性嘅高級網絡安全同生物能力評估,以及近 200 個可信合作伙伴嘅真實使用反饋。
兩個詞先講清楚
Preparedness Framework(準備度框架):OpenAI 用嚟評估模型「可能被拎去幹壞事」嘅風險等級。具體會睇:有冇人可以利用模型獲取生物武器、化學武器相關知識?能唔能夠用佢嚟搞網絡攻擊?根據風險高低分級,再決定開放範圍同防護力度。
Trusted Access for Cyber(可信網絡安全訪問):經過身份驗證嘅安全從業者可以申請更寬鬆嘅網絡安全權限,用 GPT-5.5 做防禦性安全工作,例如漏洞掃描同代碼審計,而唔會被安全分類器頻繁攔截。
喺準備度框架之下,OpenAI 將 GPT-5.5 喺生物武器、化學武器同網絡攻擊三個維度嘅濫用風險定為「高」級(High)——雖然未達到最高嘅「關鍵」級(Critical),但網絡安全能力比 GPT-5.4 有明顯提升。意思唔係模型本身會造成威脅,而係佢喺呢啲敏感領域嘅知識儲備已經強到需要更嚴格嘅防護。

值得留意嘅係,OpenAI 喺網絡安全方面採取咗「攻防同步」嘅策略:一方面用更嚴格嘅分類器去限制惡意使用,另一方面透過可信訪問機制,等安全從業員可以充分利用模型去做防禦。官方嘅邏輯好清晰:前沿模型嘅網絡安全能力遲早會被廣泛獲取,與其被動防守,不如等防禦者用咗先。
07 開發者應該點樣判斷用唔用好
我嘅判斷係,GPT-5.5 第一批最值得測試嘅場景有四類。
第一,長程軟件工程任務
唔係單純補返個 function,而係跨模塊改造、疑難 bug、測試修復、遷移同埋重構。你要觀察嘅係佢能唔能夠自己發現問題並完成驗證。
第二,複雜知識工作
例如將一大堆資料變做報告、將原始數據變做表格模型、將業務需求變做可執行方案。GPT-5.5 嘅價值在於減少人工協調同埋反覆修正。
第三,科研數據分析
基因組學、生物信息學、數學研究等需要多輪推理同埋調用工具嘅科研場景。GPT-5.5 Pro 喺呢類任務上嘅表現特別突出。
第四,真實工具鏈自動化
如果任務需要喺瀏覽器、文件、命令行同埋辦公軟件之間切換,GPT-5.5 比起純文字問答模型更有發揮空間。
同時亦都要現實少少:如果你嘅任務只係簡單分類、摘要、模板化客服,GPT-5.5 好大機會唔係最划算嘅選擇。GPT-5.4 或者更平嘅模型仍然應該留喺模型路由(model routing)入面。旗艦模型要用喺可以處理長上下文、減少返工、同埋可以交付端到端結果嘅地方。
總結
GPT-5.5 嘅發佈訊號好明確:前沿模型正由「回答者」變成「執行者」。真正值得關注嘅唔係某個單項跑分,而係佢能唔能夠喺真實工作入面持續理解、調用工具、檢查結果,並將任務推進到可以交付嘅狀態。
01 先看發佈要點
GPT-5.5已經開始向ChatGPT和Codex的Plus、Pro、Business、Enterprise用戶推送。同時還有GPT-5.5 Pro版本,面向Pro及以上用戶,定位更難、更高精度的任務。Codex側重點明確:400K上下文窗口,更適合交給它一整段工程工作。
API側還在"很快開放"階段,但價格已經公佈:標準版每百萬輸入token 5美元、輸出30美元;Pro版每百萬輸入30美元、輸出180美元。批量和彈性定價可享半價,優先處理則是標準價的2.5倍。Codex側,GPT-5.5的token單價是GPT-5.4的兩倍(每百萬輸出token 750 credits vs 375 credits),但每條消息的實際消耗大約是14 credits vs 7 credits,因為GPT-5.5完成同樣任務用的token更少。
關鍵判斷
GPT-5.5的token單價是GPT-5.4的兩倍,但OpenAI強調它的token效率也大幅提升——完成同樣的Codex任務消耗更少token。Plus用戶每5小時可用15-80條GPT-5.5消息(GPT-5.4是20-100條),實際額度取決於任務複雜度。在Artificial Analysis的編碼指數上,GPT-5.5的智能水平達到最前沿,而成本僅為同級競品模型的一半。真正的性價比不取決於單次調用價格,而取決於它能否減少重試和返工。
02 最值得看的是自主編程能力
OpenAI直接稱GPT-5.5是其目前最強的編程Agent模型。這裏的"編程"不是補全一段函數,而是更接近真實工程:理解一個代碼庫,定位失敗原因,跨文件修改,運行測試,驗證結果,必要時繼續迭代。
跑分要看方向而不是單個數字:Terminal-Bench 2.0(複雜終端工作流)82.7%,Expert-SWE(內部長程編程評測,任務中位完成時間約20小時)73.1%,SWE-Bench Pro(真實GitHub issue修復)58.6%。三項都超過GPT-5.4,並且用了更少的token。
這對開發者的實際含義是:GPT-5.5更適合交給它一個不乾淨的真實任務,而不是一條被人工預處理過的完美提示詞。比如"這個分支合進去以後頁面掛了,找出原因並修好""把評論系統重構成可協作編輯結構,並補測試""把這套業務報表自動化起來"。
更像工程同事,而不是代碼片段生成器
早期測試者的反饋集中在同一點:GPT-5.5更擅長理解系統整體結構——搞清楚為什麼出了問題、修改應該落在哪裏、代碼庫裏還有哪些地方會受影響。一位英偉達的工程師甚至說:"失去GPT-5.5的使用權限,感覺就像被截了一條胳膊。"
03 從寫代碼,擴展到電腦上的工作
OpenAI這次把GPT-5.5放在一個更大的框架裏:不只是寫代碼,還要能操作電腦、處理知識工作。它要能找信息、讀文件、分析數據、生成文檔、做表格、做幻燈片,並在工具之間來回切換。
評測結果也對得上這個定位:GDPval(跨44種職業的知識工作評測)84.9%,OSWorld-Verified(真實電腦環境自主操作)78.7%,Tau2-bench Telecom(複雜客服工作流,無需微調提示詞)98.0%。
OpenAI內部自己也在大規模使用:超過85%的員工每週都在用Codex,覆蓋工程、財務、市場、數據科學和產品管理。財務團隊用它審閲了24,771份K-1税表(共71,637頁),比去年提前了兩週完成。
這也是GPT-5.5和Codex綁定越來越緊的原因。Codex不只是"寫代碼窗口",而是一個可以讀倉庫、跑命令、改文件、檢查結果的執行環境。模型越擅長長程規劃和工具使用,Codex這類環境的價值就越大。
04 科學研究:從回答問題到推動研究
GPT-5.5在科學研究方向的表現也值得單獨看。OpenAI強調,科研工作需要的不只是回答一個難題,而是一整套循環:探索假設、收集證據、測試假說、解讀結果、決定下一步。GPT-5.5在維持這種長鏈路推理上比以往模型更強。
幾個關鍵數據:GeneBench(多階段遺傳學數據分析,任務難度對應科研專家數天的工作量)比GPT-5.4顯著提升;BixBench(真實生物信息學分析)拿到了已公開模型的最高分;一個內部版本的GPT-5.5甚至幫助發現了關於Ramsey數的一個新證明——後來已在Lean中得到形式化驗證。
一個具體例子
傑克遜基因組醫學實驗室的免疫學教授Derya Unutmaz用GPT-5.5 Pro分析了一組包含62個樣本、近28,000個基因的表達數據集,生成了一份完整的研究報告——不僅總結了發現,還指出了關鍵問題和洞察。他說這項工作如果交給團隊來做,需要數月時間。
05 更強,但沒有明顯變慢
更大的模型通常意味着更慢。但OpenAI這次特別強調,GPT-5.5的每token生成延遲與GPT-5.4持平,同時智能水平更高。
背後的細節也值得注意:GPT-5.5與英偉達GB200、GB300 NVL72系統協同設計、訓練和部署。Codex分析了數週的生產流量模式,編寫了自定義的負載均衡算法,僅此一項就讓token生成速度提升超過20%。GPT-5.5自身也參與了推理系統的優化。
這句話值得單獨拎出來
模型不只是跑在基礎設施上,它還幫着改進了基礎設施本身。用OpenAI原話說:"Put simply, the model helped improve the infrastructure that serves it."
06 安全標準同步上調
模型越強,被濫用的風險也越高。OpenAI在發佈頁強調,GPT-5.5經過了完整的安全評估流程,包括內外部紅隊測試、針對性的高級網絡安全和生物能力評估,以及近200個可信合作伙伴的真實使用反饋。
兩個詞先講清楚
Preparedness Framework(準備度框架):OpenAI用來評估模型"可能被拿去幹壞事"的風險等級。具體會看:有人能不能利用模型獲取生物武器、化學武器相關知識?能不能用它來搞網絡攻擊?根據風險高低分級,再決定開放範圍和防護力度。
Trusted Access for Cyber(可信網絡安全訪問):經過身份驗證的安全從業者可以申請更寬鬆的網絡安全權限,用GPT-5.5做防禦性安全工作,比如漏洞掃描和代碼審計,而不會被安全分類器頻繁攔截。
在準備度框架下,OpenAI把GPT-5.5在生物武器、化學武器和網絡攻擊三個維度的濫用風險定為"高"級(High)——雖然沒有達到最高的"關鍵"級(Critical),但網絡安全能力比GPT-5.4有明顯提升。意思不是模型本身會造成威脅,而是它在這些敏感領域的知識儲備已經強到需要更嚴格的防護。
值得注意的是,OpenAI在網絡安全方向採取了"攻防同步"的策略:一方面用更嚴格的分類器限制惡意使用,另一方面通過可信訪問機制讓安全從業者能充分利用模型做防禦。官方的邏輯很明確:前沿模型的網絡安全能力遲早會被廣泛獲取,與其被動防守,不如讓防禦者先用起來。
07 開發者應該怎麼判斷要不要用
我的判斷是,GPT-5.5首批最值得測試的場景有四類。
第一,長程軟件工程任務
不是補函數,而是跨模塊改造、疑難bug、測試修復、遷移和重構。你要觀察的是它能否自己發現問題並完成驗證。
第二,複雜知識工作
比如把一堆資料變成報告、把原始數據變成表格模型、把業務需求變成可執行方案。GPT-5.5的價值在於減少人工協調和反覆修正。
第三,科研數據分析
基因組學、生物信息學、數學研究等需要多輪推理和工具調用的科研場景。GPT-5.5 Pro在這類任務上表現尤其突出。
第四,真實工具鏈自動化
如果任務需要在瀏覽器、文件、命令行和辦公軟件之間切換,GPT-5.5比純文本問答模型更有發揮空間。
同時也要現實一點:如果你的任務是簡單分類、摘要、模板化客服,GPT-5.5大概率不是最經濟的選擇。GPT-5.4或更便宜的模型仍然應該留在模型路由裏。旗艦模型要用在能吃下長上下文、能減少返工、能交付端到端結果的地方。
總結
GPT-5.5的發佈信號很明確:前沿模型正在從"回答者"變成"執行者"。真正值得關注的不是某個單項跑分,而是它能否在真實工作裏持續理解、調用工具、檢查結果,並把任務推進到可交付狀態。