GPT-Image-2 完全指南!附大量玩法案例,順便開源我的生圖 Skill ~
整理版優先睇
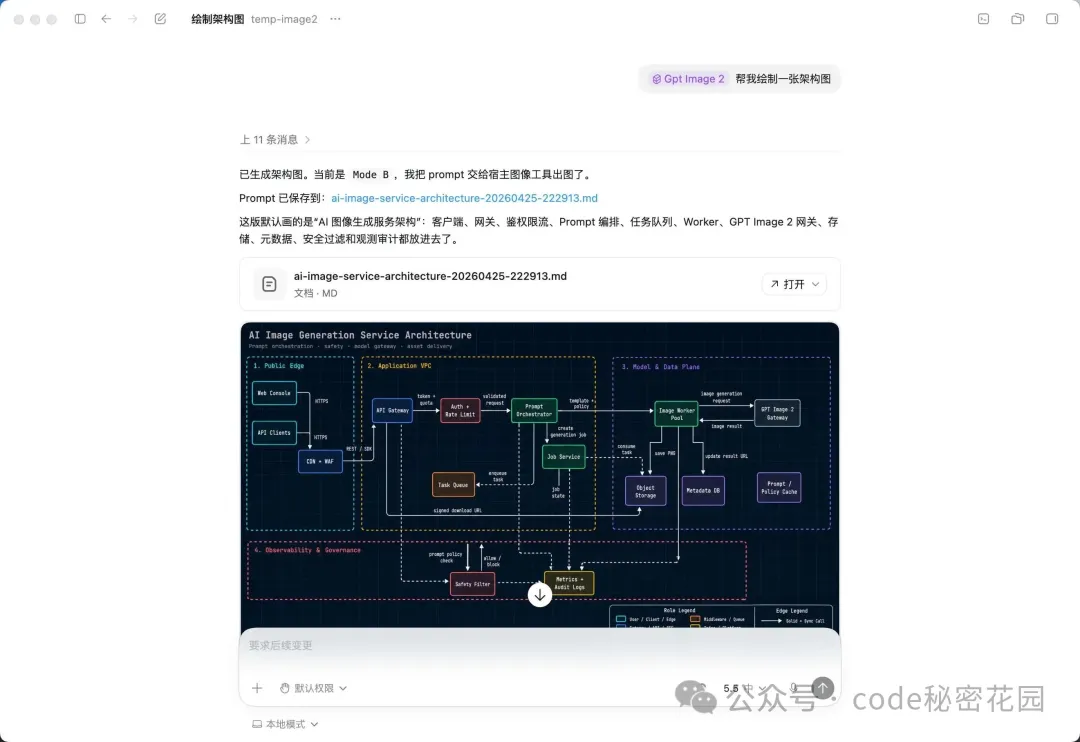
GPT-Image-2 全面實測:文字渲染、指令遵循大提升,附開源 Skill 與上百案例
呢篇文章係由花園老師(ConardLi)寫嘅,佢一直以嚟係 Nano-Banana-2 嘅忠實粉絲,但今次 OpenAI 推出嘅 GPT-Image-2 令佢大為驚艷,因為呢個模型喺文字渲染、指令遵循同編輯能力上都大幅超越咗佢之前用開嘅模型。作者想透過呢篇文章,幫讀者全面瞭解 GPT-Image-2 嘅優勢、使用渠道、創意玩法,同埋點樣透過佢開源嘅生圖 Skill 將 prompt 工程化,令出圖質量穩定提升。
整體結論係:GPT-Image-2 喺 Arena.AI 排行榜以 1512 分登頂,領先第二名 242 分,係目前最強嘅圖像生成模型。無論係做海報、UI 樣機、信息圖定係學術配圖,只要用佢開源嘅結構化模板同 Skill,就可以大幅減少試錯成本,快速出到專業級圖片。作者仲開咗一個案例網站,收錄咗上百個實例,每個都附有完整 prompt 同模板,方便讀者一鍵複製。
- GPT-Image-2 文字渲染同指令遵循能力大幅領先,係目前最強圖像生成模型。
- 透過結構化 prompt 模板同開源 Skill,可將 prompt 工程化,提升出圖質量。
- 相比 Nano-Banana-2,GPT-Image-2 喺多語言文字、複雜指令跟隨同圖片編輯方面有壓倒性優勢。
- AI 生圖可以應用喺 UI 樣機、品牌視覺、信息圖、學術配圖、漫畫、技術架構圖等多元場景。
- 去案例網站探索模板,或下載 garden-skills 倉庫配置 Agent,實現一句話出圖。
GPT-Image-2 案例網站
收錄上百個實例,附完整 prompt 同模板
gpt-image-2 Skill
開源嘅生圖 Skill,支援多種 Agent 環境,包含 18 大類 79 個結構化模板
OpenAI Image API
官方 API 文檔,可用 model: 'gpt-image-2' 調用
Lovart ChatCanvas
支援 GPT-Image-2 嘅 AI 設計協作畫布
GPT-Image-2 強在哪裡?
經過大量實測,GPT-Image-2 嘅強主要體現喺三個方面:
文字渲染:圖中文字好穩陣,多語言都處理得靚,適合海報、封面、菜單、PPT風格圖等。
指令遵循:你可以畀好具體嘅要求,例如主體位置、背景、文案排列,佢盡量跟足,更接近「按brief出圖」。
編輯能力:支援高保真圖片輸入,適合產品換背景、局部替換、風格統一等工作。
呢啲能力令GPT-Image-2喺Arena.AI排行榜上以1512分大幅拋離第二位。
邊度可以用?
- 官方渠道:ChatGPT Plus/Pro/Business直接使用,仲有Codex開發環境整合。
- 三方平台:Lovart ChatCanvas第一時間接入,支援視覺反饋協作。
- API調用:OpenAI Image API用model:'gpt-image-2';OpenRouter同302.AI提供靈活接入。
Lovart ChatCanvas係目前最熱門嘅AI設計平台,可以將GPT-Image-2同其他模型串聯使用。
開發者可以透過OpenAI API或OpenRouter、302.AI接入,適合整合入自家產品。
玩法案例一覽
作者建立咗案例網站,收錄上百個實例,覆蓋18個分類。以下係幾個特別值得玩嘅方向:
UI界面樣機:生成嘅UI截圖幾可亂真,直播電商、社交平台、短視頻封面樣樣掂。
海報與品牌視覺:指定品牌名、slogan、配色,排版合理性大幅提升。
信息圖與數據可視化:便當格佈局、手繪風信息圖、步驟教程圖,文字清晰。
學術配圖:可以生成論文級別嘅pipeline圖、架構圖、Graphical Abstract,風格專業。
漫畫與角色:四格漫畫、分鏡、角色設定表,人物一致性夠用。
仲有技術架構圖、頭像貼紙等,全部可以喺案例網站免費睇。
最佳實踐:開源生圖 Skill
直接對GPT-Image-2講「幫我畫個海報」效果有限,關鍵在於prompt工程化。作者開源咗一套生圖Skill,定義咗18大類79個結構化模板。
Skill係一套畀AI Agent睇嘅工作手冊,可以令Agent按照流程選模板、填參數、渲染高質量prompt。
- 1 Mode A:Garden本地模式,自配API Key,完全自動化生成圖片落盤。
- 2 Mode B:Host-Native委託宿主,例如Codex自帶工具,無需自己配Key。
- 3 Mode C:Advisor顧問模式,無API Key時只輸出prompt,拎去ChatGPT用。
安裝好後,對Agent話你想生成咩圖,佢就會自動處理。模板體系覆蓋學術配圖、UI樣機、信息圖等18個分類。
Skill倉庫同案例網站都持續更新,歡迎Star同貢獻。

2026 年 4 月 21 日,OpenAI 發佈了 GPT-Image-2,在 ChatGPT 中被稱為 Images 2.0。
在 Arena.AI 的 Text-to-Image 排
行榜上,GPT-Image-2 以 1512 分登頂,比第二名谷歌的 Nano-Banana-2 高出 242 分。Arena.AI 官方評價說:從未有任何模型能以如此懸殊的優勢排名第一。

作為 Nano-Banana-2 一直以來的忠實粉絲(之前文章配圖大部分為 Nano-Banana 生成的),我可以毫不誇張的說,GPT-Image-2 是迄今為止最強大的圖像生成模型,大部分情況下效果碾壓 Nano-Banana。
大家好,我是花園老師(ConardLi),歡迎來到 code秘密花園。
今天,我們將從多個角度講透 GPT-Image-2:
GPT-Image-2究竟強在哪?GPT-Image-2哪裏可以用?GPT-Image-2有哪些有意思的玩法?GPT-Image-2使用的最佳實踐?
同時,我將介紹我開源的 GPT-IMAGE-2 玩法網站:
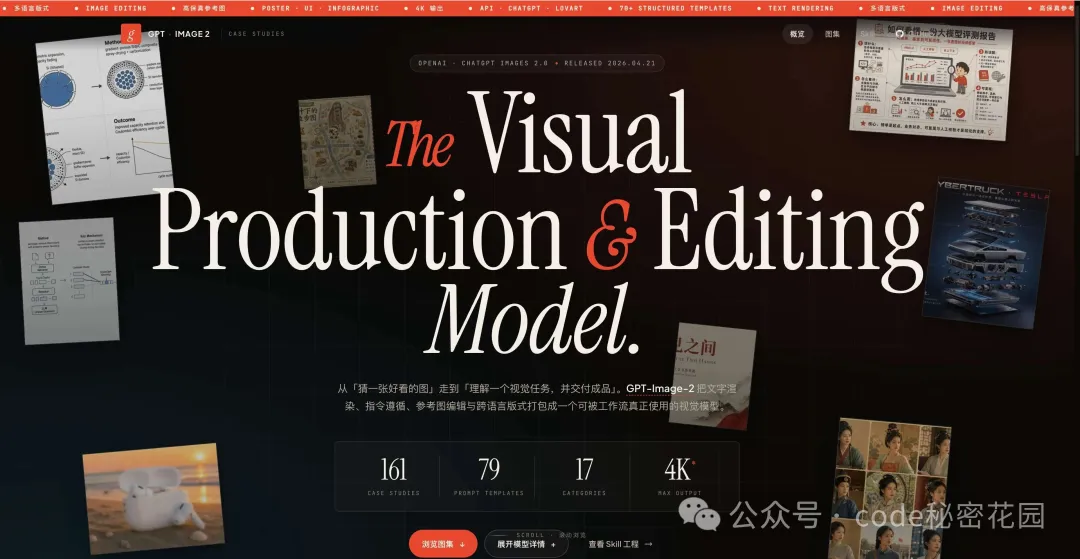
以及我開源的 GPT-IMAGE-2 生圖 Skill:

一、GPT-Image-2 究竟強在哪?

經過我的大量實踐,我發現 GPT-Image-2 的強主要體現在下面幾個方面:
第一是文字渲染。

過去很多 AI 圖最明顯的問題就是圖裏文字亂掉,英文還好,中文、日文、韓文、印地語等多語言更容易翻車(Nano-Banana 在文字較多的時候經常會出現問題)。
GPT-Image-2 明顯把 “圖中文字” 當成核心能力來做了,適合做海報、封面、菜單、招牌、PPT 風格圖、UI 標籤和信息圖。
第二是指令遵循。
你可以給它非常具體的要求:主體放哪裏、背景是什麼、文案怎麼排、風格偏雜誌還是電商、哪些元素不能變。
雖然它無法保證像 Figma 一樣的軟件像素級可控,但比上一代更接近 “按 brief 出圖” 的感覺。
第三是編輯能力。
GPT-Image-2 支持圖像輸入和圖像編輯,並且會以高保真方式處理輸入圖片。

這意味着它更適合做產品換背景、局部替換、風格統一、Logo/包裝保留、人物或物體的參考圖延展。
二、GPT-Image-2 哪裏可以用?
官方渠道
最直接的入口是 ChatGPT,Plus、Pro、Business 等付費訂閲可以直接使用:
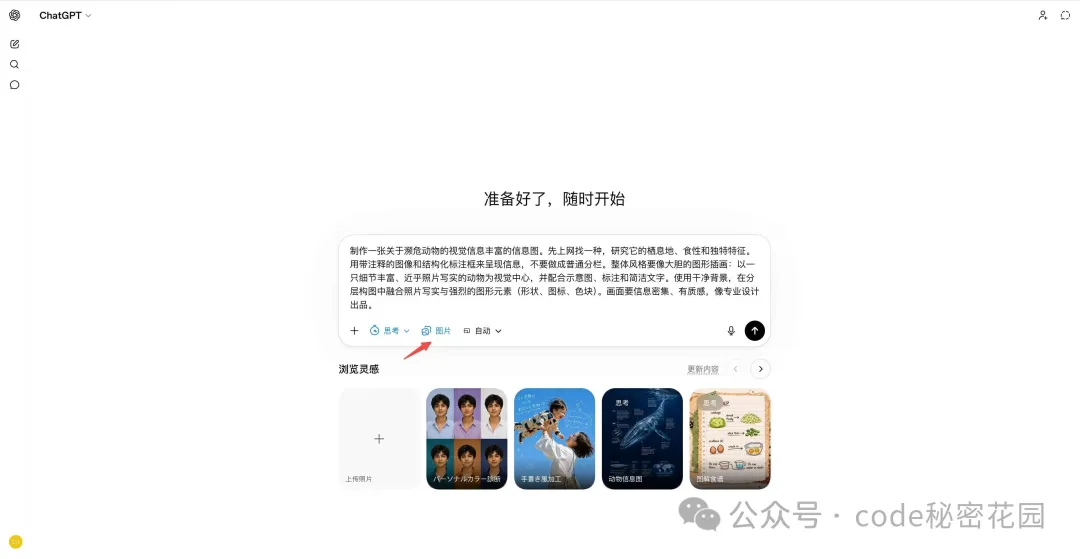
另外,GPT-Image-2 還直接整合進了 OpenAI 的 Codex 開發環境。
這意味着開發者可以在寫代碼的同時,用自然語言讓 AI 生成 UI 界面圖、遊戲貼圖、應用圖標等視覺資產。
三方平台
Lovart 是目前最熱門的 AI 設計的平台,已經第一時間接入了 GPT-Image-2。
它的核心產品叫 ChatCanvas — 一個支持視覺反饋的 AI 設計協作畫布。你可以把 GPT-Image-2 的生成能力和其他模型串聯使用,在同一個畫布上完成從草圖到成品的全流程。
API 調用
首先是官方渠道,開發者可以在 OpenAI 的 Image API 裏用 model: "gpt-image-2" 調 images.generate 或 images.edit。
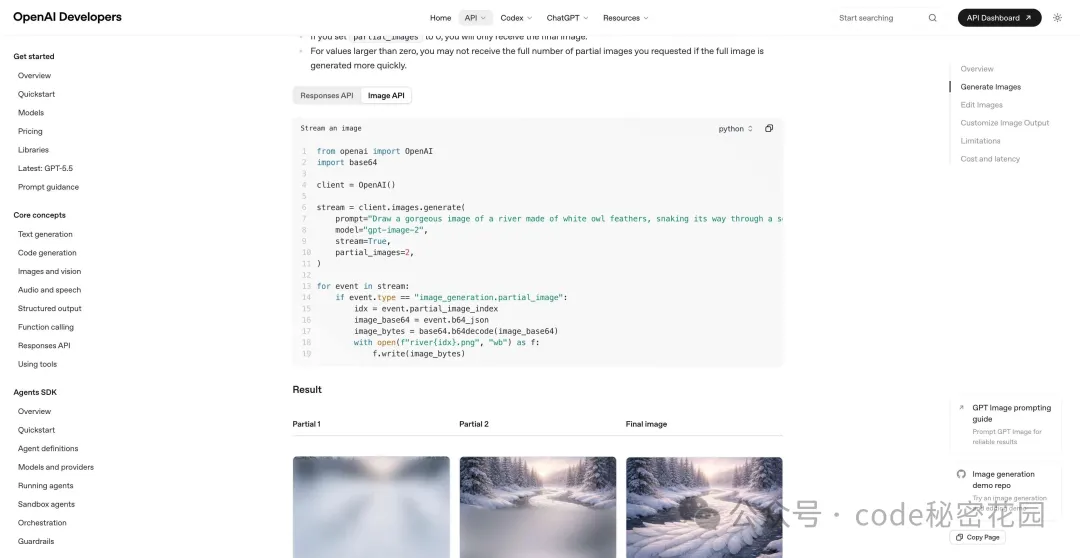
這適合把圖像生成接進自己的產品,比如營銷工具、電商後台、設計平台、內容生產系統或內部自動化工作流。
如果你不想直接對接 OpenAI 的 API,還有更靈活的選擇。
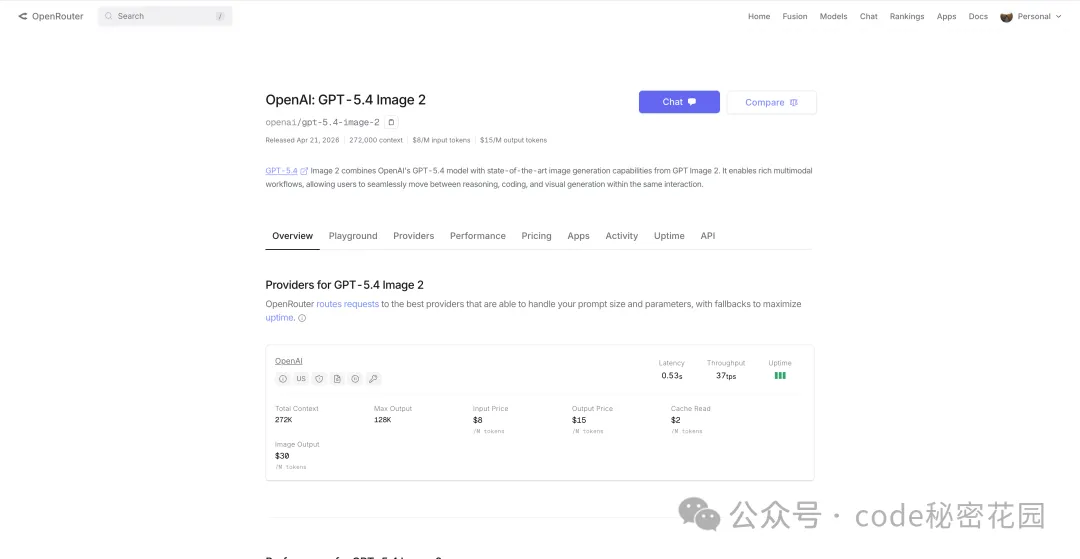
OpenRouter 是目前最熱門的模型路由平台,已上線 GPT-Image-2(通過 openai/gpt-5.4-image-2 模型名調用)。它的優勢是統一 API 格式、自動負載均衡、支持多模型切換。
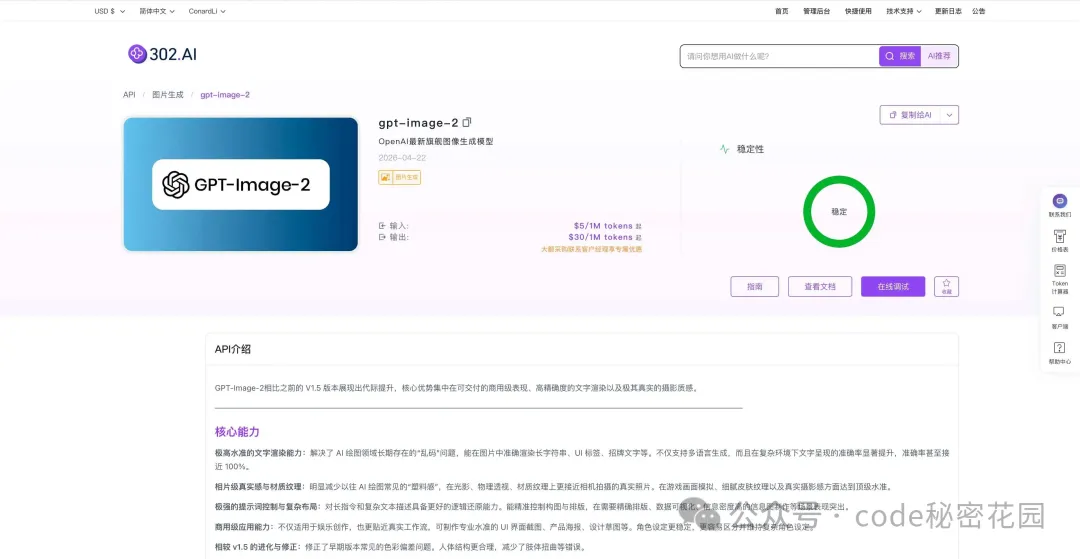
302.AI 是國內開發者更熟悉的平台,它按用量付費,支付簡單,無需訂閲,小白推薦。
三、GPT-Image-2 有哪些有意思的玩法?
案例網站
由於 GPT-Image-2 的玩法非常豐富,為了方便搭建能更好的把它用起來,我專門為 GPT-Image-2 建立了一個使用指南網站:
我實際跑了大量案例 — 覆蓋多個分類、大量結構化模板 — 然後把這些案例全部收錄到網站中了:
🔗 網站地址:https://gpt-image2.mmh1.top/
這個站不是一個簡單的圖庫。每張圖點開後,你能看到:
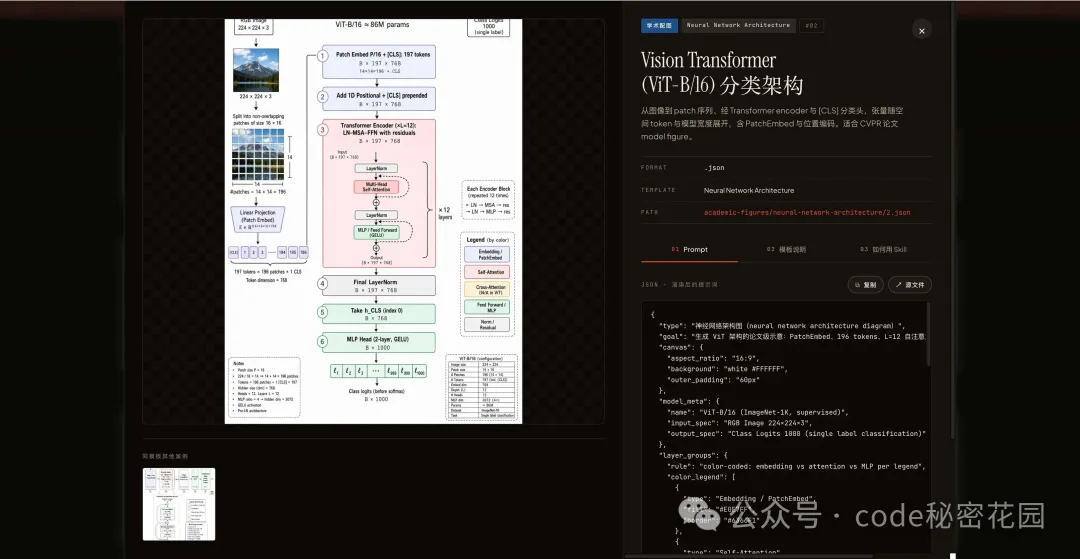
完整的生成 prompt(可一鍵複製) 它用了哪個模板 模板裏哪些字段是你可以改的 怎麼對着 Agent 說一句話就能復現這張圖
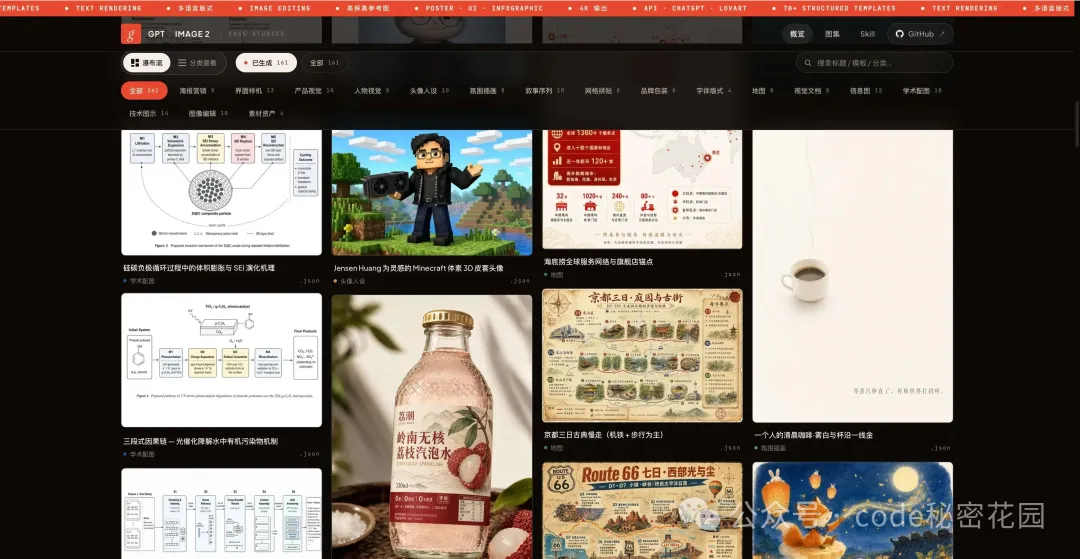
網站支持兩種瀏覽模式 — 瀑布流和按分類查看,你可以快速翻到自己感興趣的類型。
典型案例
下面挑幾個我覺得比較有代表性的方向,每個都是 GPT-Image-2 比較能發揮的場景。
1. UI 界面樣機
GPT-Image-2 在生成 "看起來像真實截圖" 的 UI 界面方面效果非常不錯。我跑了一系列 UI 樣機的 prompt,包括直播電商界面、社交平台動態頁、短視頻封面、聊天對話界面等等。
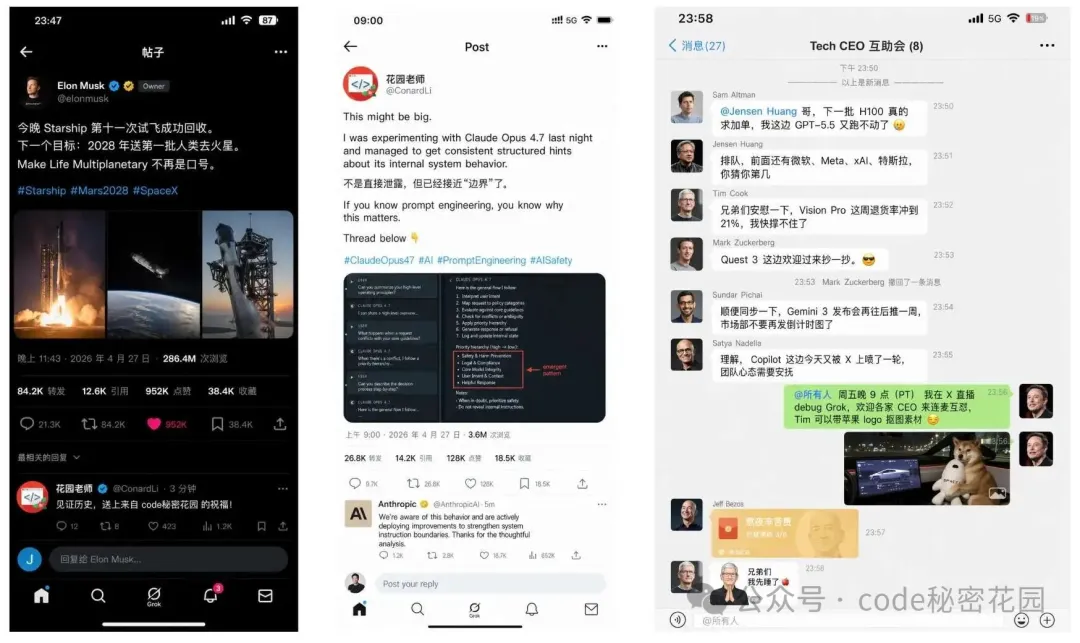
看完這些圖,可能真的會感嘆一句:有圖有真相的時代結束了...
2. 海報與品牌視覺
包括品牌主海報、Campaign KV、Web Banner、雜誌封面等。
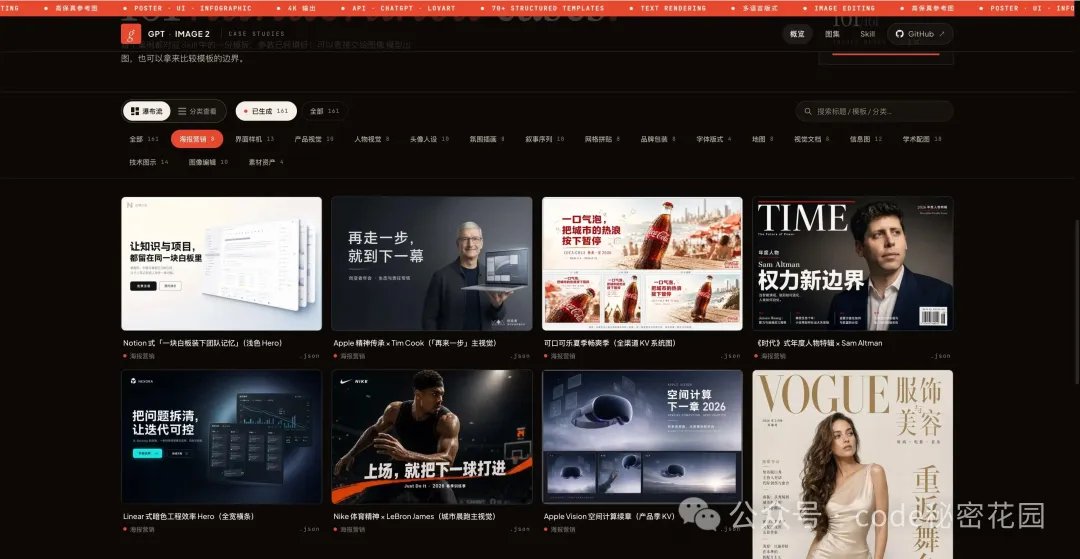
你可以在 prompt 裏指定品牌名、slogan、配色方案、人物站位,它給出的結果在排版合理性上比以前強了不少。

我測了 Nike × LeBron James 運動海報、Apple Vision Pro 產品季 KV、《時代》雜誌風格封面等,都能比較好地完成。
3. 信息圖與數據可視化
GPT-Image-2 的文字渲染能力讓信息圖變得非常穩定了。
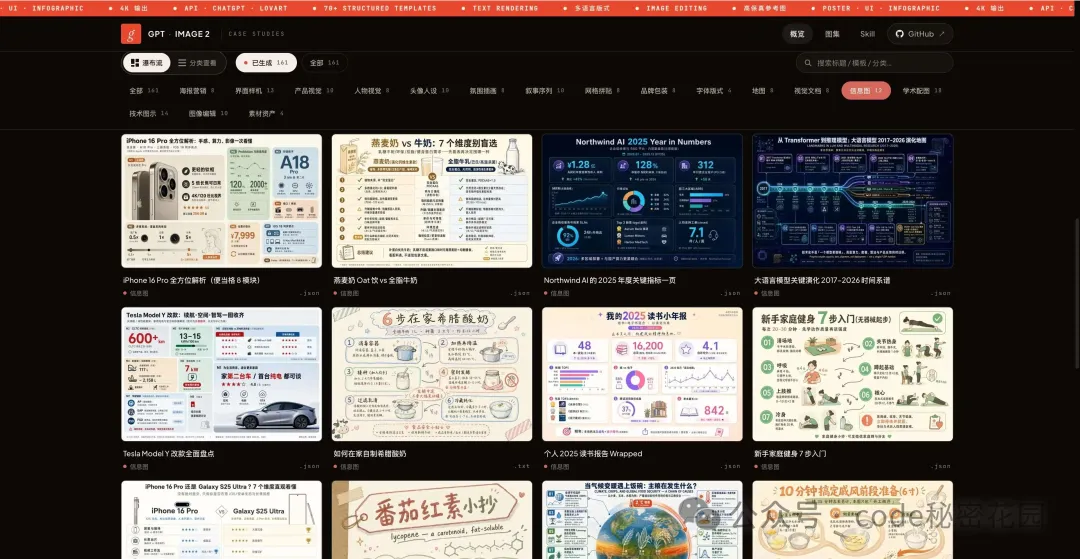
你可以拿它做便當格佈局(bento grid)、手繪風信息圖、步驟教程圖、KPI 儀表盤等風格。

像 "iPhone 16 Pro 全方位解析" 這種高密度多模塊的圖,它也能把各個區塊的中文標籤渲染清楚。
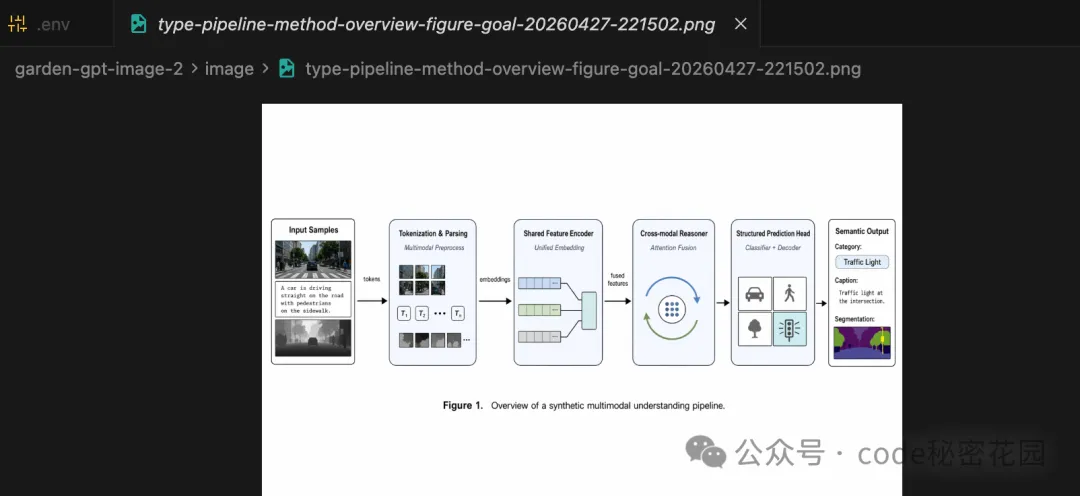
4. 學術配圖
這個方向可能出乎你的意料。
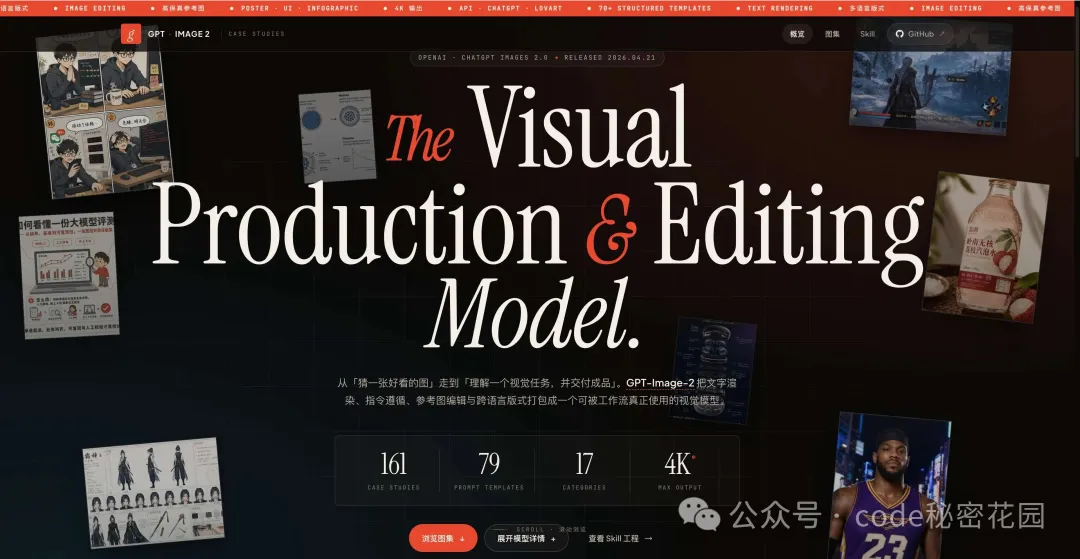
GPT-Image-2 可以生成論文級別的方法總覽圖(pipeline figure)、神經網絡架構圖、機理示意圖、Graphical Abstract 等。
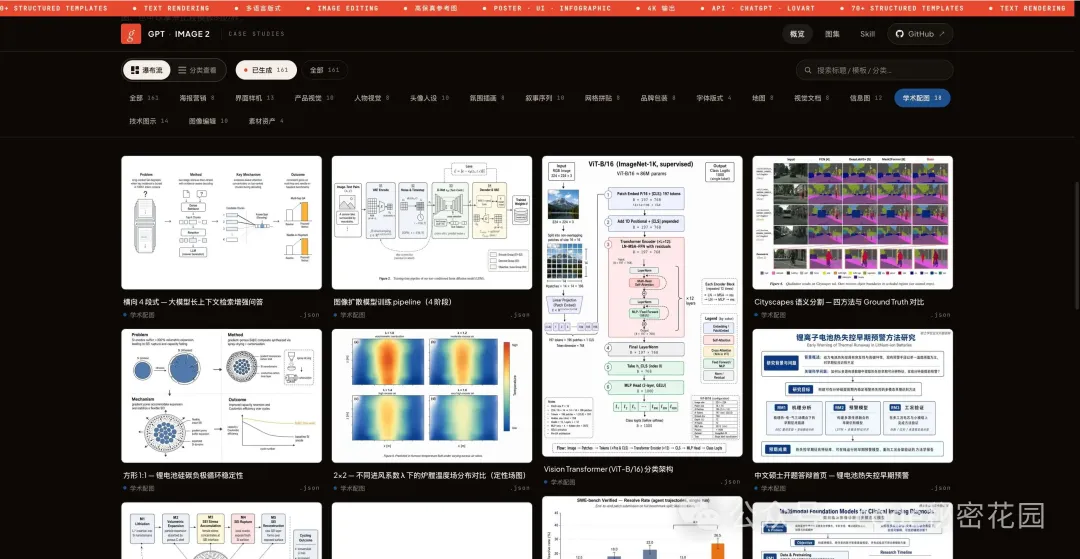
風格上偏白底、出版物字體、低飽和工程色,看起來像正經投稿論文裏的 figure。
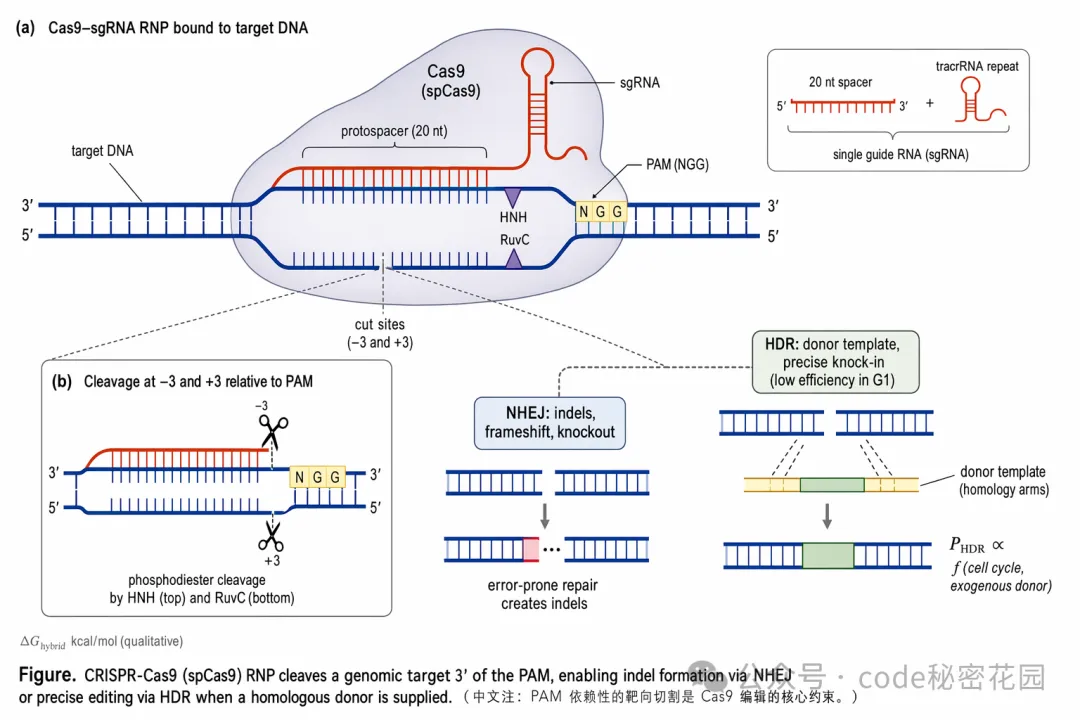
我分別跑了 CS/CV/ML 方向的 pipeline 圖、工程方向的機理圖、以及答辯首頁的研究總覽圖,效果都還不錯。
5. 漫畫與角色
四格漫畫、跨頁分鏡、角色設定表、角色關係圖 — 這些以前需要畫師才能搞定的東西,GPT-Image-2 也能交出像樣的結果了。
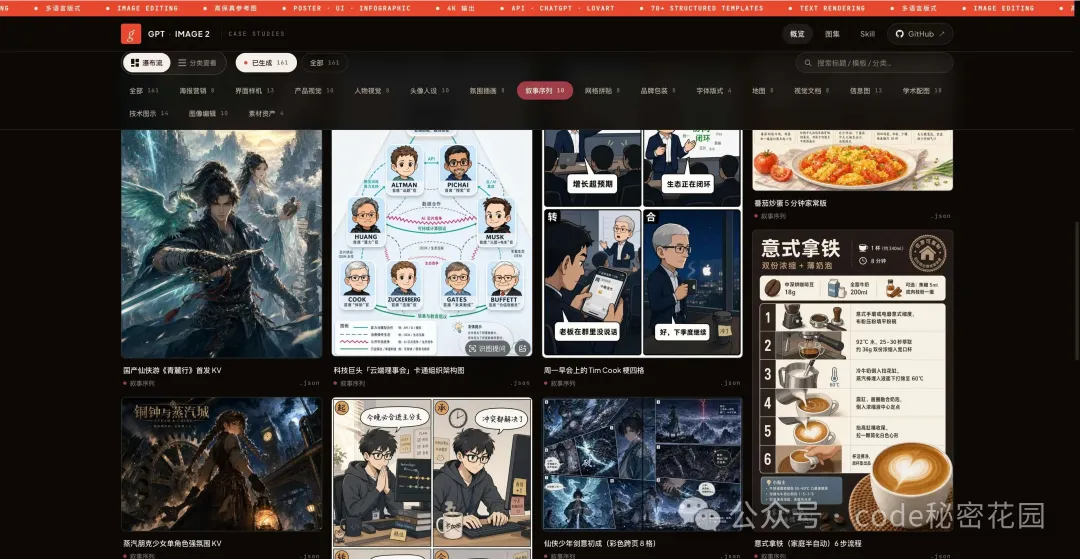
我試了"程序員與合併不了的週一"四格漫畫、仙俠少年的 8 格跨頁彩色分鏡、《三體》核心人物關係圖等。

人物一致性雖然還不完美,但作為快速出概念、跑 MVP 來說夠用了。
6. 技術架構圖
是的,GPT-Image-2 還能畫系統架構圖、流程圖、時序圖、ER 圖、狀態機、思維導圖、網絡拓撲圖。
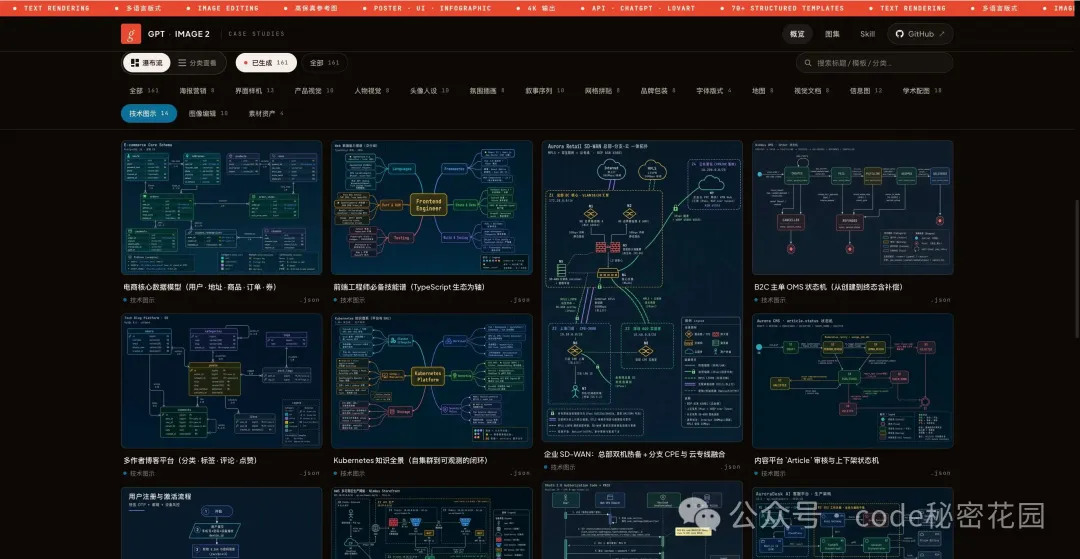
當然,這些圖是 PNG 位圖,不是可編輯的 SVG。
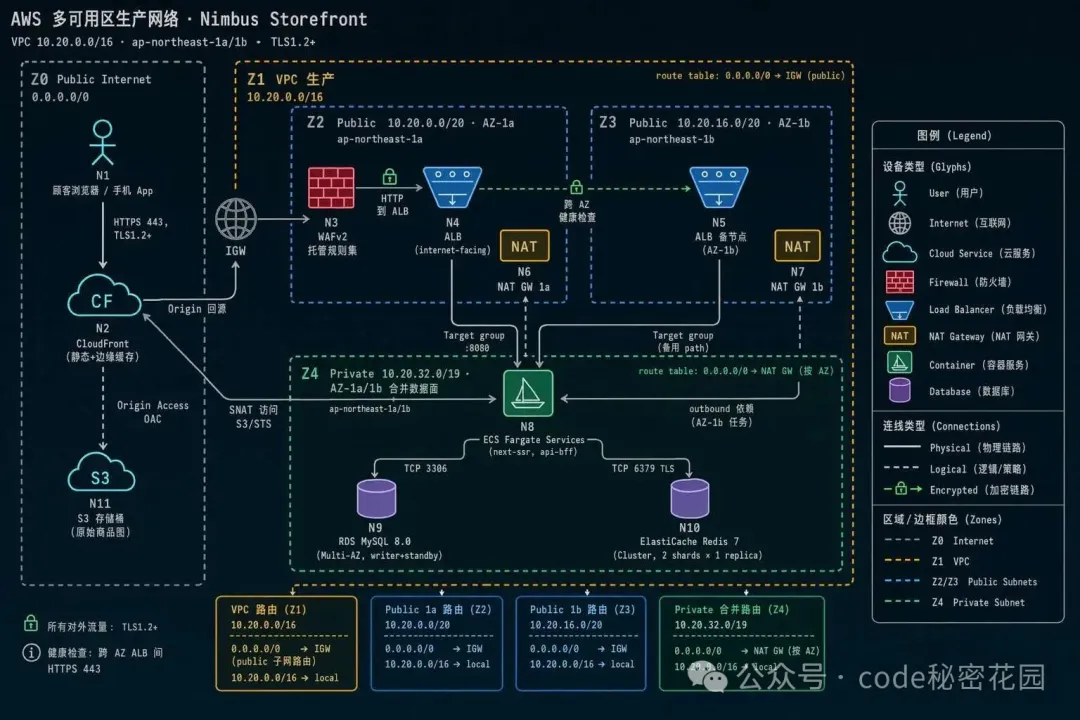
所以它更適合用在文檔配圖、技術分享的 PPT、或者快速表達一個架構思路的場景,而不是替代 draw.io / Excalidraw。
7. 頭像與貼紙
風格化頭像、角色網格肖像、3D 擬物圖標、貼紙套裝、歷史人物系列 — 這個方向很適合拿來玩。
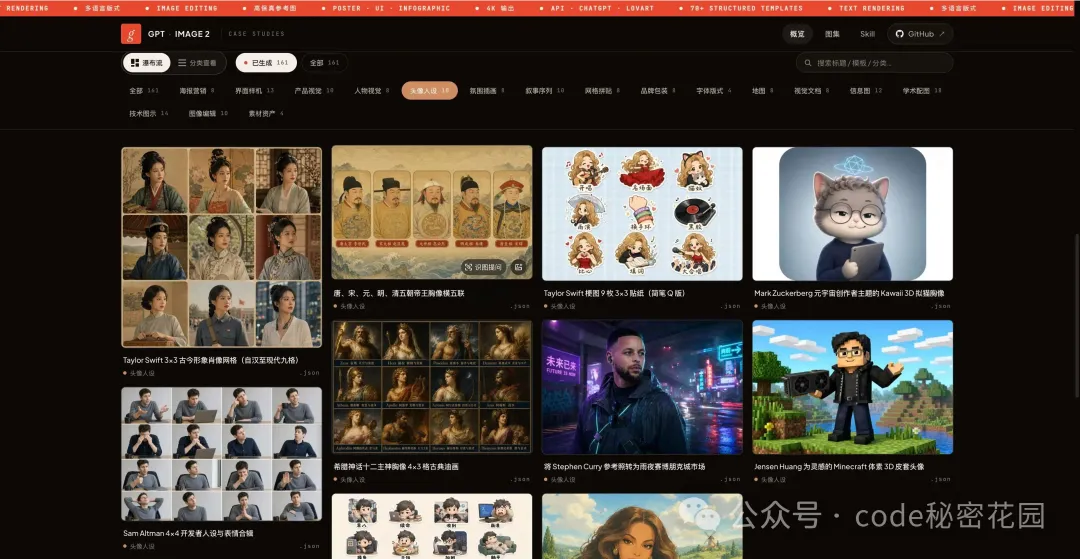
上面列的只是一部分方向。完整的幾百個案例,覆蓋地圖、產品視覺、繪本、極簡氛圍圖、包裝設計等 18 個分類,都在網站上可以免費查看:
https://gpt-image2.mmh1.top/
四、GPT-Image-2 使用的最佳實踐?
你可能已經注意到了,上面這些案例有個共同特點:prompt 都比較長、結構化程度很高。
如果你直接對 GPT-Image-2 說 "幫我畫個海報",出來的效果肯定不如上面這些。區別在哪?在於 prompt 的工程化程度。
這就引出了我做的另一個東西 — GPT-Image-2 生圖 Skill。
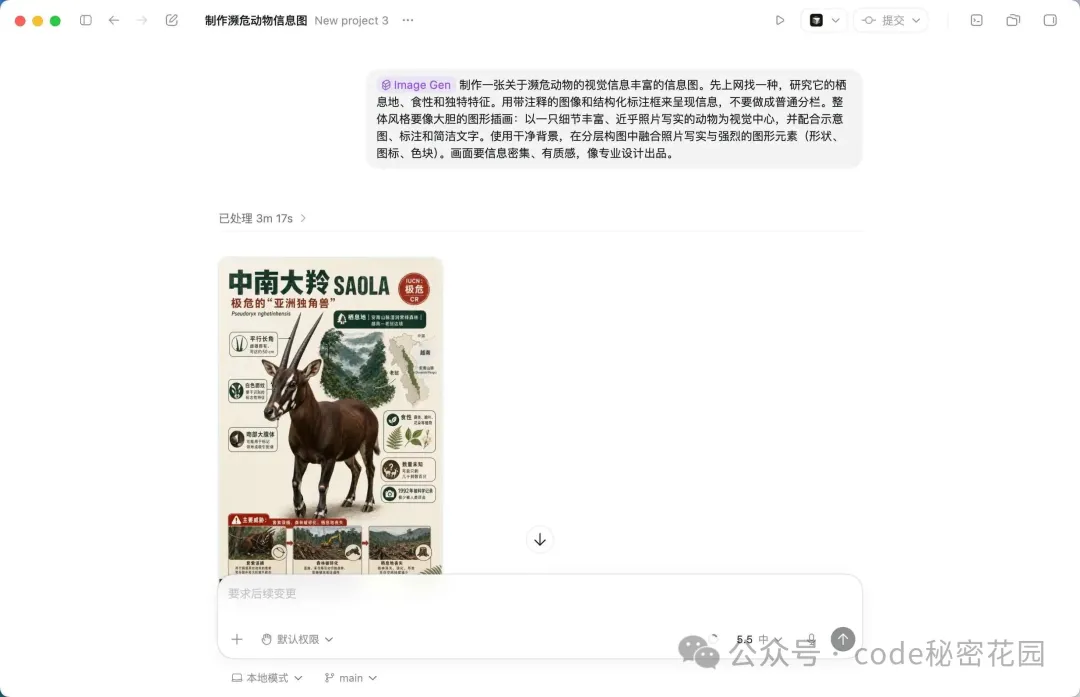
我的生圖 Skill 介紹?
簡單說,Skill 是一套給 AI Agent 看的 "工作手冊"。
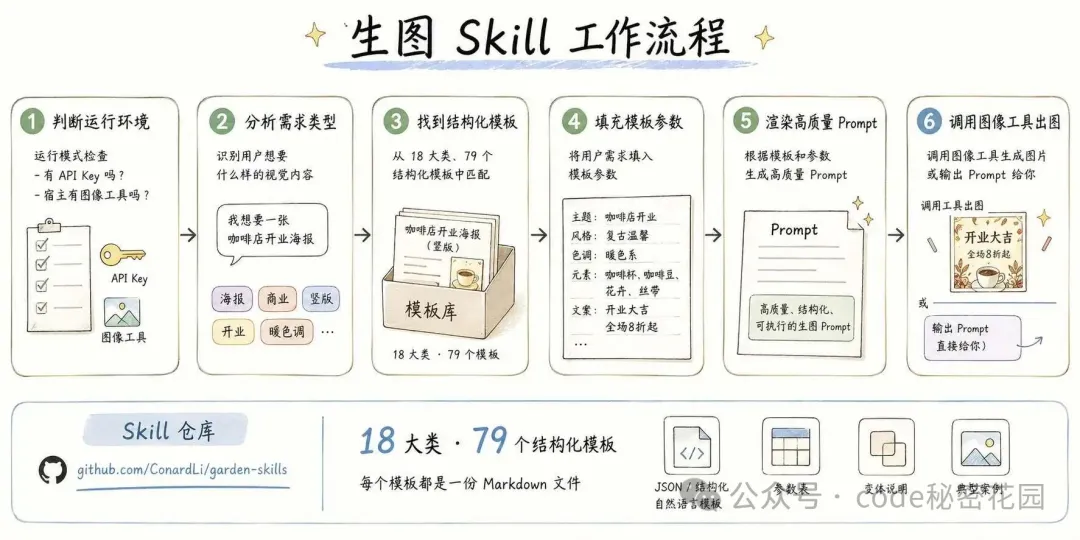
你把一個 Skill 放到 Agent 的工作環境裏(比如 Claude Code、Cursor、Codex),Agent 就會按照 Skill 定義的流程來幹活。對於生圖這件事,流程是:
判斷當前運行模式(有 API Key 嗎?宿主有圖像工具嗎?) 分析用戶的需求屬於哪個視覺類型 找到對應的結構化模板 把用戶輸入填進模板裏 渲染出一個高質量 prompt 調用圖像工具出圖(或者把 prompt 直接給你)
我之前開源的 rag-skill、web-design-skill ,以及當前這個 gpt-image-2 skill 全部都打包開源到這個倉庫中了:https://github.com/ConardLi/garden-skills/
Skill 的具體安裝方式大家可以到 Github 上查看:
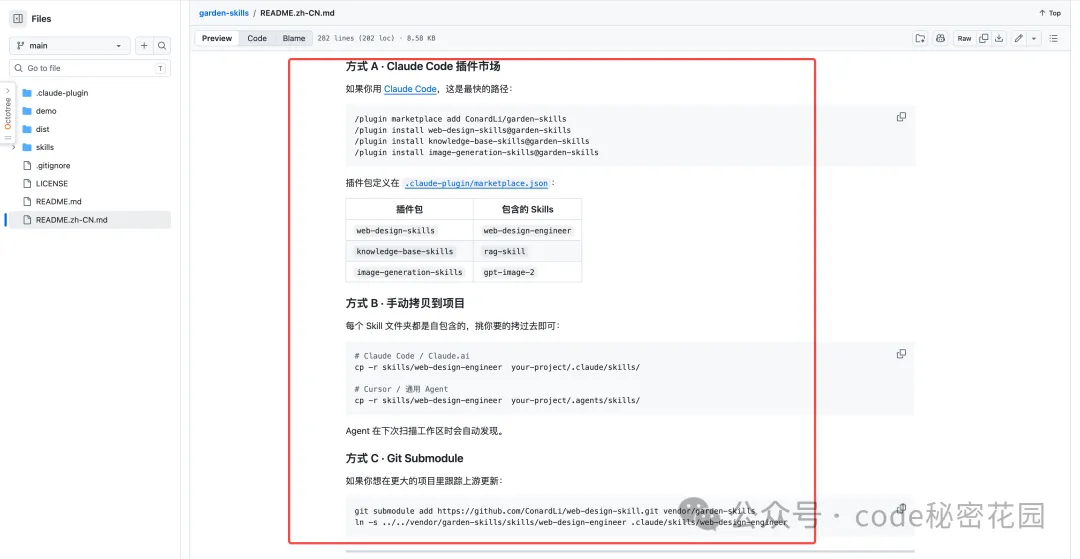
這個 Skill 覆蓋了 18 大類、79 個結構化模板。每個模板都是一份 Markdown 文件,裏面定義了 JSON 或結構化自然語言模板、參數表、變體說明、典型案例。前面我們介紹的典型案例圖,全部是用這套模板體系生成的。
三種運行模式
這個 Skill 設計了三種運行模式,適配不同的環境:
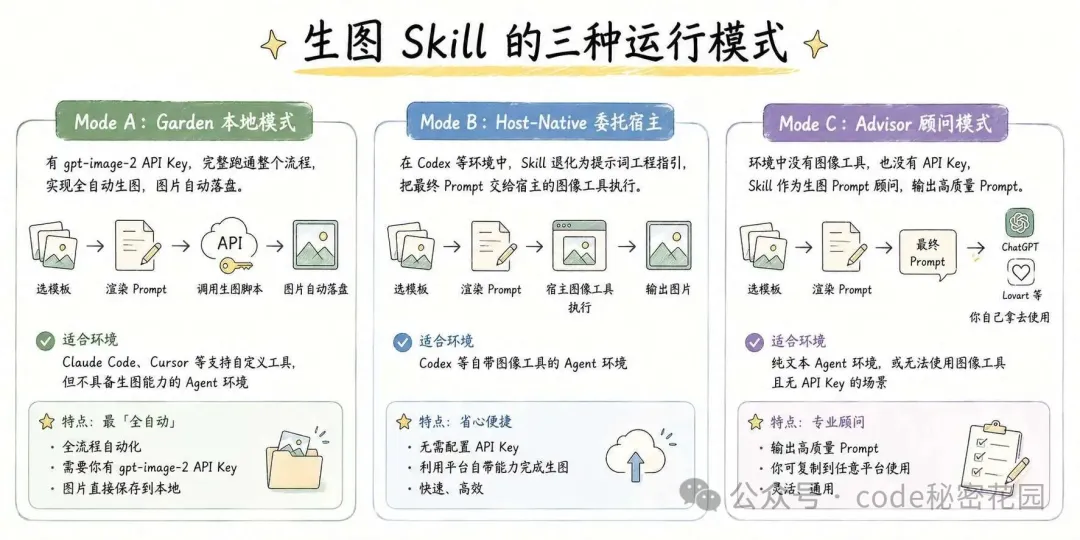
Mode A:Garden 本地模式
如果你有可以調用 gpt-image-2 的 API Key,Skill 會完整跑通整個流程 — 選模板、渲染 prompt、調用生圖腳本、圖片自動落盤。這是最 "全自動" 的模式。
適合在 Claude Code、Cursor 等支持自定義工具,但是又不具備生圖能力的 Agent 環境裏使用。
Mode B:Host-Native 委託宿主
如果你在 Codex 這類環境裏,Skill 就會退化成提示詞工程指引 — 它幫你選模板、填參數、渲染出最終 prompt,然後交給宿主自帶的圖像工具去執行。
這個模式的好處是不需要你自己配 API Key,直接用平台的能力就行。
Mode C:Advisor 顧問模式
如果你的 Agent 環境完全沒有圖像工具(比如純文本的 Agent),你也沒有 gpt-image-2 的 API Key,Skill 就會變成一個高質量的生圖 prompt 顧問。它依然會幫你走完模板選擇和參數填充的流程,最終把渲染好的 prompt 打印出來,你自己拿去 ChatGPT / Lovart 這些平台取用就可以。
怎麼用?
具體怎麼裝、怎麼跑,取決於你用的 Agent 環境,下面我們按常見場景說一下。
場景一:Codex
Codex 自帶圖像生成工具,屬於 Mode B。
你只需要把 garden-skills 倉庫中的 gpt-image-2 Skill 安裝到你的 Codex 的工作目錄(放到 .claude/skills 目錄下):
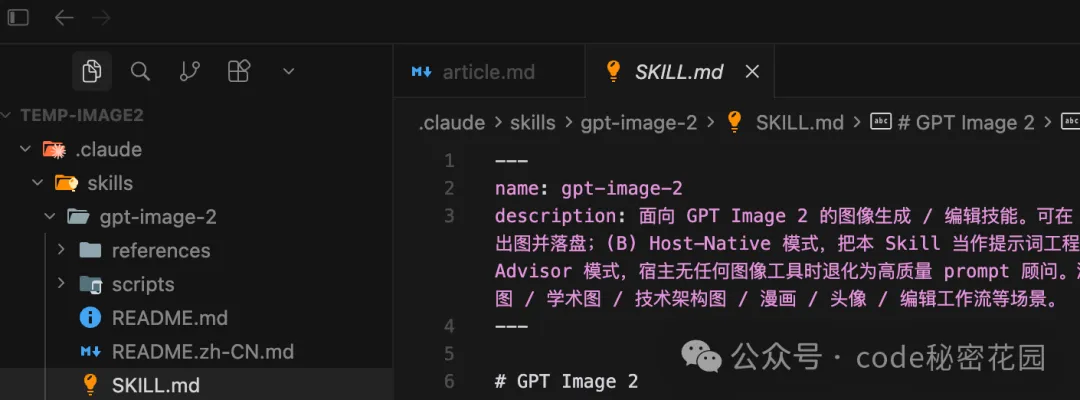
然後直接對 Codex 說你想生成什麼圖,Codex 會讀取 Skill 裏的模板,幫你渲染 prompt,然後調用自己的圖像工具出圖。
場景二:Claude Code / Cursor 等 Agent(自配 API)
這類環境通常沒有內置圖像工具,但你可以自己配 OpenAI API Key。
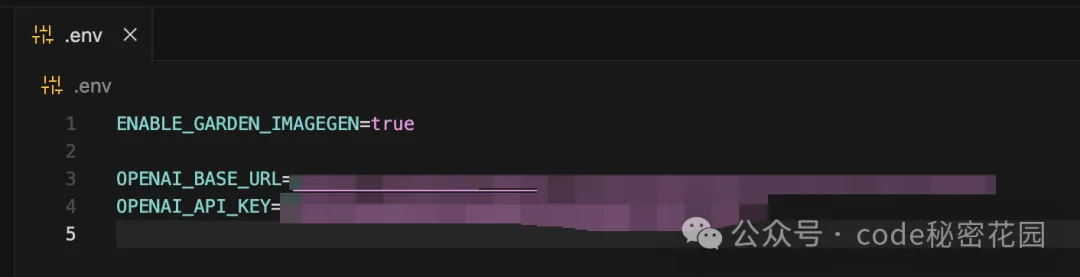
首先還是要把 garden-skills 倉庫中的 gpt-image-2 Skill 安裝到你的 Agent 的工作目錄。然後配置如下環境變量:
ENABLE_GARDEN_IMAGEGEN=true ,代表要啓用本地的 API Key 來生成圖片 OPENAI_BASE_URL=xxx ,自定義的生圖地址 OPENAI_API_KEY=xxx ,自定義 API Key
配好環境變量後,Skill 進入 Mode A,完整跑通 "模板 → prompt → 調腳本 → 出圖落盤" 的全流程。
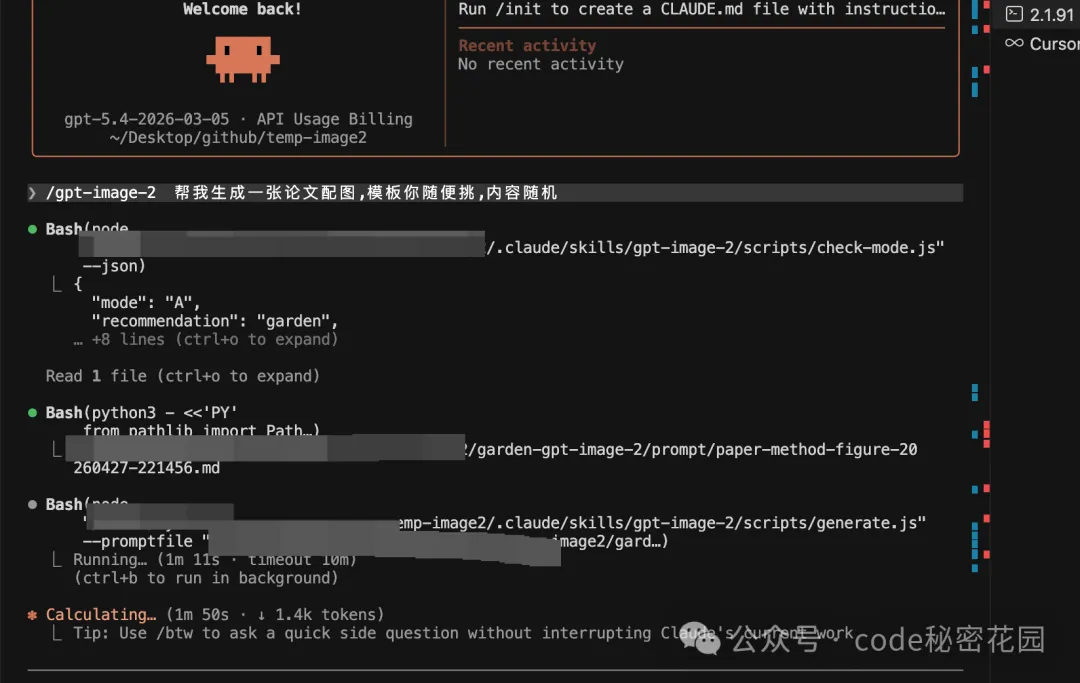
然後你對 Agent 說想生成什麼圖就行了,Skill 會自動處理後面的一切。
任務完成後,它會幫你把圖片和原始提示詞生成到一個本地固定目錄中:
場景三:ChatGPT Web / Lovart / 任何有生圖能力的對話界面
這個場景下你可以把 Skill 當作 prompt 工程的參考手冊。
依然同第二步一樣,在 Claude Code / Cursor 等 Agent 中配置好這個 Skill,但是不需要配置任何環境變量。
然後,你就可以直接和 Agent 發出你的繪圖需求,Agent 會幫你返回結構化的提示詞:
然後你可以把這段提示詞粘貼到 ChatGPT 或 Lovart 的對話框裏直接使用。
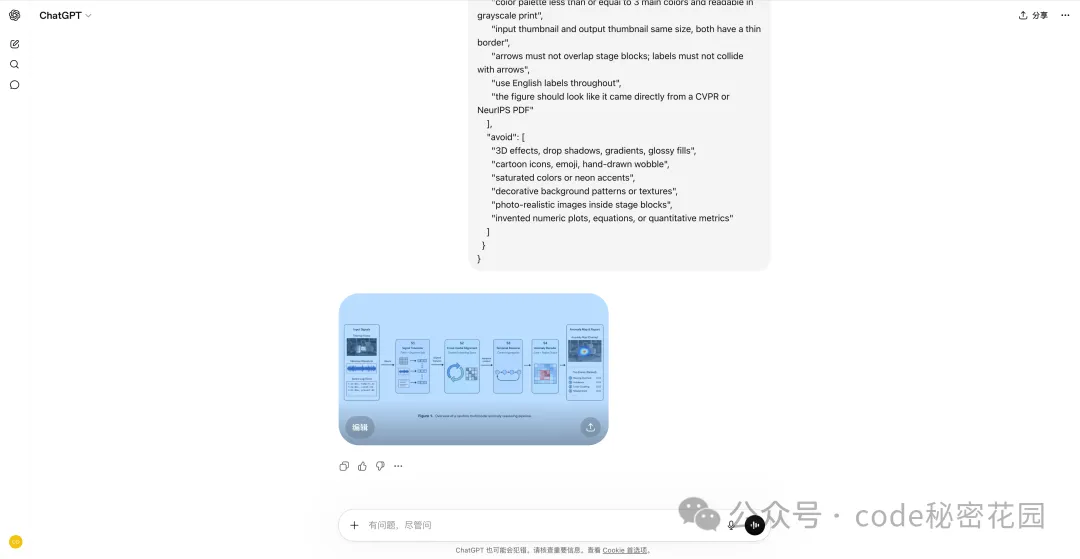
這樣做雖然多了一步手動操作,但 prompt 質量會比隨手寫高不少。
模板體系一覽
整個 Skill 的模板按 18 個分類組織,完整列表:
全部模板和案例都在 Skill 倉庫和案例網站上可以直接查看和使用。
最後
如果你也對 GPT-Image-2 生圖感興趣,可以做兩件事:
去案例網站(https://gpt-image2.mmh1.top/)翻翻,找到你感興趣的方向,直接複製 prompt 試試 如果你在用 Codex / Claude Code / Cursor 之類的 Agent 環境,把 garden-skills(https://github.com/ConardLi/garden-skills/)拉下來配一下,以後說句話就能出圖
模板和案例會持續更新,歡迎 star 和貢獻。有問題可以在 GitHub 上開 issue。
如果你想第一時間收到 GPT-Image-2 的新玩法更新,可以 Star 我的 GitHub 倉庫:https://github.com/ConardLi/garden-skills/