GPT Image 2 海報終於 100% 可編輯
整理版優先睇
Canva Magic Layers 補返 AI 設計最後一公里:GPT Image 2 海報終於可以改字改位
呢篇文章介紹 Canva 新功能 Magic Layers,佢可以將 GPT Image 2、Midjourney、Flux 呢啲 AI 生成嘅平面海報自動拆成幾十個獨立圖層——文字、人物、背景、光效全部變成可編輯元件。以前 AI 海報係『焊死嘅像素圖』,改一個字就要重新生成,成個 layout 又唔同咗;而家 Magic Layers 做到語義級圖層分離,文字變 textbox、圖標變獨立 element,成張圖變返普通 Canva 工程,可以直接改字體、調色、加動效。作者認為呢個工具真正補上咗 AI 設計工作流嘅『微調』環節,令 prompt 工程師加一個 Canva 帳號就能完成過去要兩個人先做到嘅嘢。
文章仲詳細講咗 5 步完整流程:登錄 Canva、喺 Quick actions 開 Magic Layers、上傳 AI 海報、等幾秒自動拆解、之後就任意編輯。作者同時點出 Magic Layers 唔係萬能——複雜插畫拆解精度有限、字體識別偶爾失誤、圖層上限 30-50,最適合社交媒體海報、活動 banner 呢類簡單構圖,唔太適合攝影相、多人物插畫或者 UI 設計稿。
整體結論係:AI 生圖喺 2024-2025 解決咗『畫唔畫得出』,而家 2026 呢波喺解決『畫完之後改唔改得鬱』。Magic Layers 技術上唔算好新,但佢將摳圖、OCR、分層呢啲老功能打包成設計師友善嘅入口,直接駁喺 AI 生圖工…
- 舊問題:AI 海報係焊死嘅像素圖,改任何一個字都要重新生成,成個 layout 會走樣。
- 新解法:Canva Magic Layers 自動將靜態圖反向工程還原成可編輯工程文件,文字、圖標、背景全部獨立。
- 完整流程 5 步:登錄 Canva → Quick actions 開 Magic Layers → 上傳海報 → 等 5-10 秒拆解 → 好似普通 Canva 工程咁編輯。
- 閉環價值:ChatGPT 寫 prompt → GPT Image 2 出圖 → Magic Layers 微調 → Canva 多平台導出,一條龍一人搞掂。
- 侷限:複雜插畫拆解精度有限,最適合社交媒體海報、活動 banner,唔適合攝影相或 UI 設計稿。
舊問題:AI 海報係『焊死嘅像素圖』
以前用 GPT Image 2、Midjourney、Flux 呢啲 AI 生成海報,效果雖然靚,但係想改一個字、換個元素、調整佈局,就只能認命改 prompt 重新生成。重生一次,成個版式又變咗,AI 唔會記住『上次嗰個 layout』。呢個問題喺實際工作入面大到咩程度呢——商業海報、社交媒體首圖、活動 banner,所有『上線前再微調一下』嘅場景,AI 生圖都接唔住最後 10% 嘅修改。
焊死嘅像素圖
以前繞過去嘅辦法只有兩個:轉 Photoshop,分層摳圖手動改(耗時、精度差);或者用 prompt 反覆 reroll,最後接受一張『差不多』嘅(妥協)。兩個都唔優雅。
新解法:Magic Layers 做咗啲咩
Magic Layers 本質上做嘅係一件事:反向工程一張靜態圖,還原成 Canva 原生嘅可編輯工程文件。唔係簡單嘅摳圖,唔係 OCR 識別文字再貼上去——而係語義級嘅圖層分離。
- 文字 → 可編輯 textbox(識別字體、字號、對齊方式)
- Logo / icon → 獨立 element
- 背景紋理、裝飾圖形 → 各自圖層
- 陰影、光斑 → 單獨可調
換字體、調色、加動效、一鍵導出多平台尺寸,全部即時搞掂。
完整流程(5 步)
- 1 登錄 Canva,點左側 '+ Create',進入 Templates 頁。
- 2 喺 Quick actions 揾 Magic Layers(帶 New 標籤)。
- 3 上傳 AI 生成嘅海報(目前只支援圖片格式,PDF / SVG 暫唔支援)。
- 4 等 5-10 秒,Magic Layers 自動分析成張圖,拆成獨立圖層。
- 5 進入編輯器,每一個文本、圖形都可以單獨點選、移動、改字、換色。
成個過程唔使 30 秒,就可以開始編輯。
閉環價值:AI 設計嘅最後一公里
成條工作流拉直咗睇,總共四個環節:創意/草圖(用 ChatGPT 寫 prompt)→ 出圖(用 GPT Image 2 生成視覺成品)→ 微調/編輯(靠 Canva Magic Layers 改字、換色、調位)→ 多平台導出(用 Canva 原生功能搞掂橫豎屏同社交尺寸)。以前嘅『微調』環節係斷嘅,AI 出嘅圖就係終點;而家變成中間產物,下游駁 Canva,成個工作流第一次跑通。
會寫 prompt 嘅人 + 一個 Canva 帳號 = 過去需要『提示詞工程師 + 平面設計師』兩個人先做到嘅事
對個人內容創作者嚟講,呢個係好大嘅 empowerment。
侷限與適用場景
實測 Magic Layers 唔係萬能,有啲場景效果冇咁好:
- 複雜插畫(多人物、密集元素)拆解精度有限,部分元素會被合併
- 字體識別偶爾失誤,需要手動重新揀字體
- 拆解後嘅圖層數量約 30-50 上限,超過會被合併
- 最適合:社交媒體海報(小紅書、X、公眾號封面)、活動 banner、產品發佈圖、簡單插畫類內容圖
- 唔太適合:攝影類成片(拆解意義不大)、多人物複雜插畫、UI 設計稿(建議用 Figma)
寫在最後
AI 生圖喺 2024-2025 解決咗『畫唔畫得出』,2026 呢一波喺解決『畫完之後改唔改得鬱』。Magic Layers 技術上唔算多新——摳圖、OCR、分層都係老嘢——但佢真正嘅價值係將呢啲能力打包成設計師友善嘅入口,兼且直接駁喺 AI 生圖工具嘅下游。下次再有人話『AI 出嘅圖改唔鬱』,叫佢試下呢個。
以前用 GPT Image 2、Midjourney、Flux 呢啲 AI 生成一張好型嘅海報,效果真係驚豔,但係如果想改一個字、換個元素、調整佈局——就唯有投降,改 prompt 再生成過。 一重生,成個版式又變曬。AI 唔會記住「上次嗰個 layout」。 而家,Canva 嘅 Magic Layers徹底改咗遊戲規則:一張平面 AI 圖像,會自動拆成幾十個獨立圖層——文字、人物、背景、光效、簽名——全部可以單獨揀中、移動、刪除、替換、改字體。 就好似喺 Photoshop 度操作矢量圖咁簡單。 GPT Image 2 出圖 + Canva Magic Layers 編輯——AI 設計嘅最後一公里終於補返。 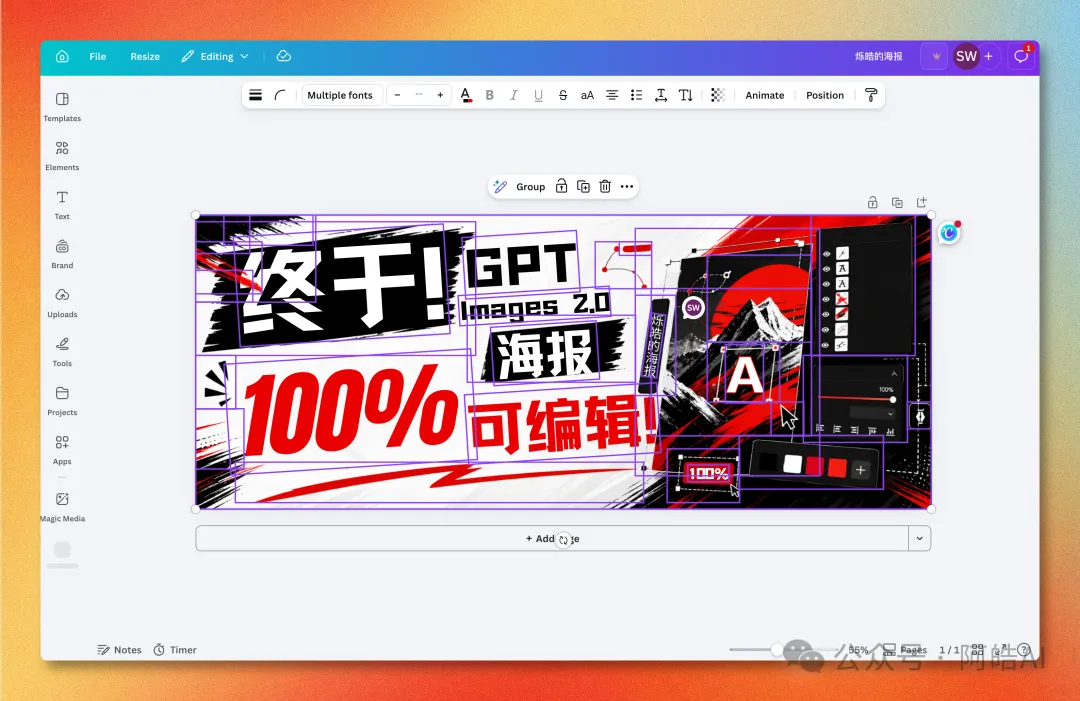 舊問題:AI 海報係「焊死嘅像素圖」任何一張 GPT Image 2、Midjourney、Flux 出嘅海報,本質上都係像素圖。字號、顏色、位置全部「焊死」喺像素入面——改一個字 = 重新生成成張圖。 實際工作入面呢個問題大到咩程度——商業海報、社交媒體頭圖、活動 banner,所有「上線前再微調一下」嘅場景,AI 生圖都搞唔掂最後 10% 嘅修改。 以前繞過去嘅方法得兩個:
兩個都唔優雅。 新解法:Magic Layers 做咗啲咩Magic Layers 本質上做嘅係一件事:反向工程一張靜態圖,將佢還原成 Canva 原生嘅可編輯工程檔案。 唔係簡單嘅摳圖,唔係 OCR 識別文字再貼上去——係語義級嘅圖層分離:
拆完之後,成張圖就係一個普通嘅 Canva 工程,所有 Canva 原有嘅編輯能力都可以直接用——換字體、調色、加動效、一鍵導出多平台尺寸。 完整流程(5 步)Step 1:登入 Canva,撳左邊嘅「+ Create」打開 canva.com,登入之後會停喺 Templates 頁。左邊欄第一個掣 + Create(新增)就係入口。 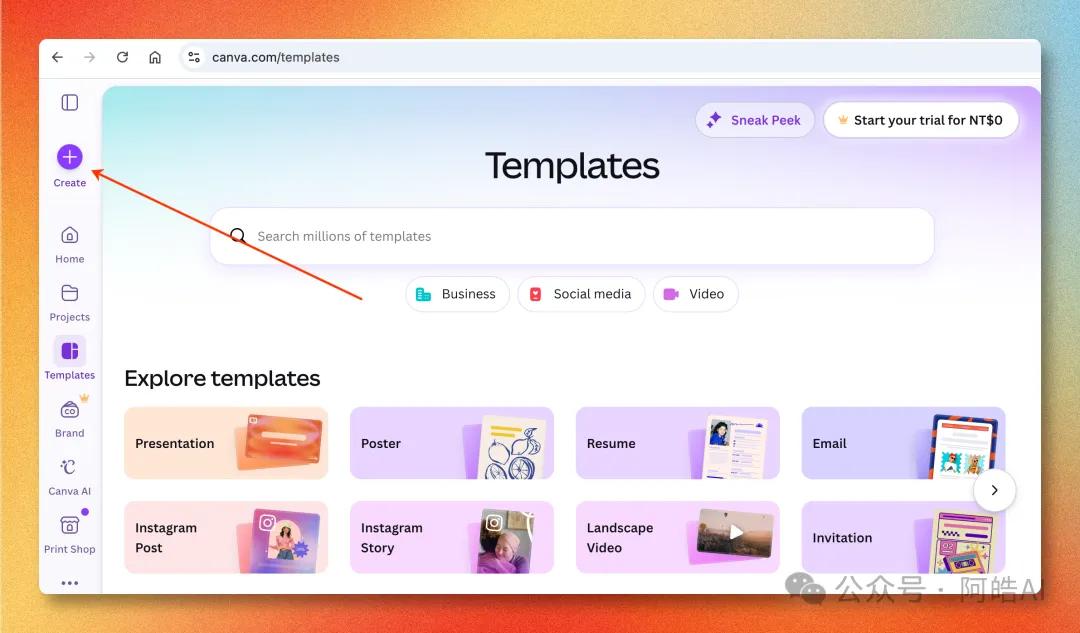 Step 2:喺 Quick actions 嗰度揾 Magic Layers撳完 Create 之後會入去「Create a design」面板,左邊揀 For you → Quick actions,第一個就係帶 New 標籤嘅 Magic Layers。 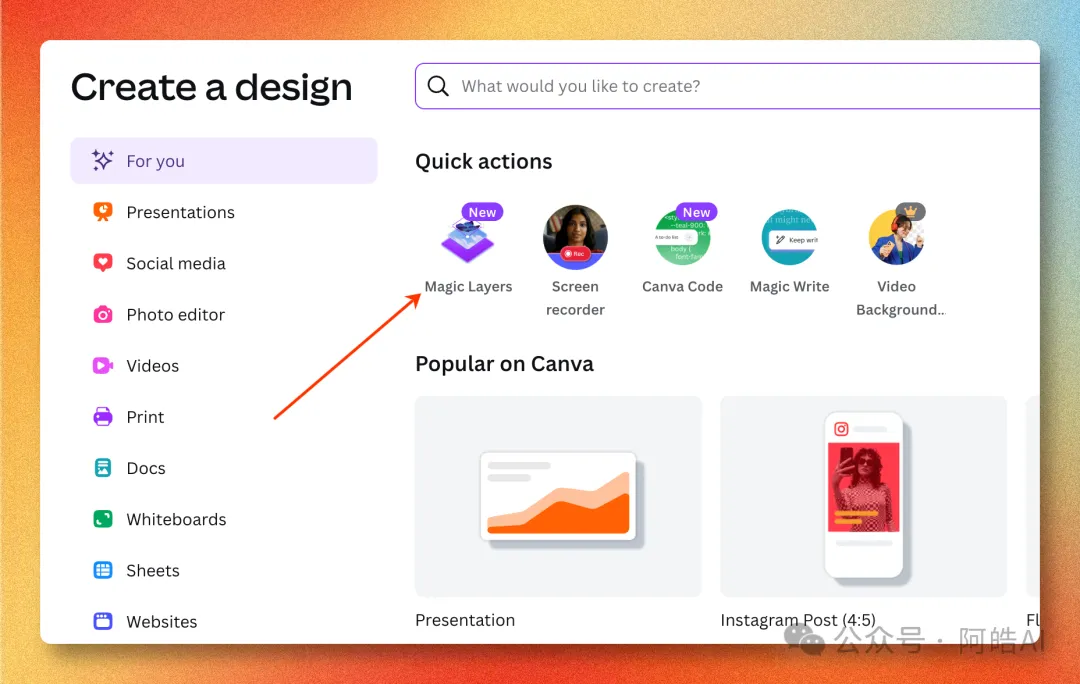 Step 3:上傳 AI 生成嘅海報撳 Magic Layers →「Select your media」,將 GPT Image 2 出嘅海報拖入去。 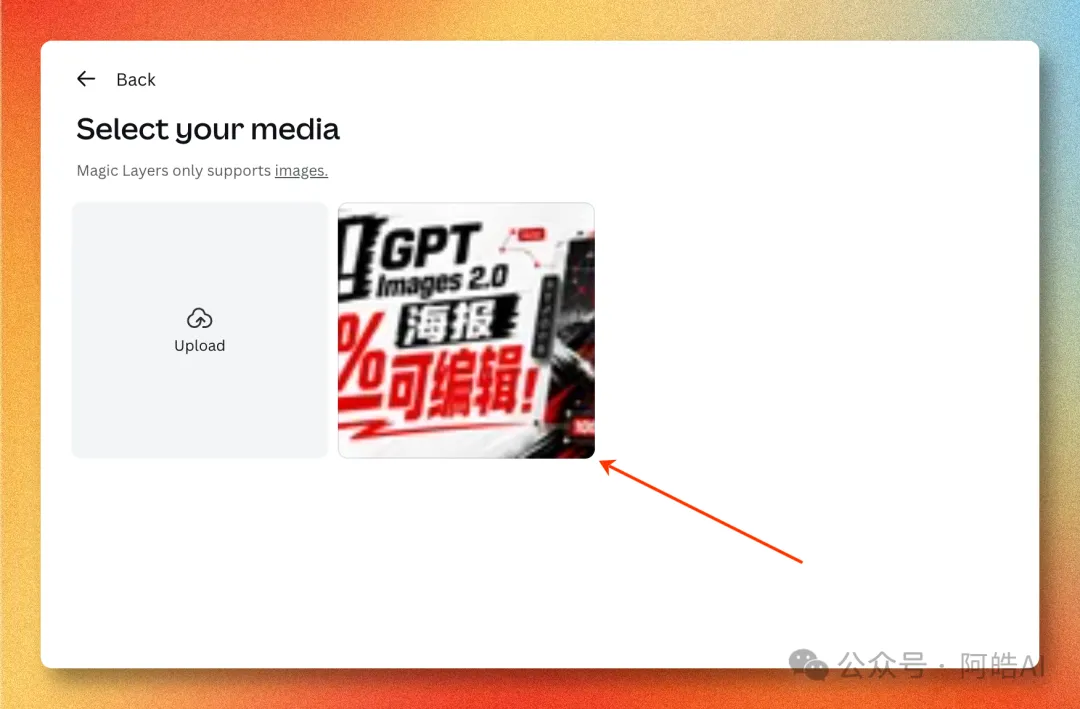 目前淨係支援圖片格式,PDF / SVG 暫時唔支援。 Step 4:等幾秒,自動拆解完成上傳之後大約 5-10 秒,Magic Layers 會分析成張圖嘅元素,將每一塊拆成獨立圖層。 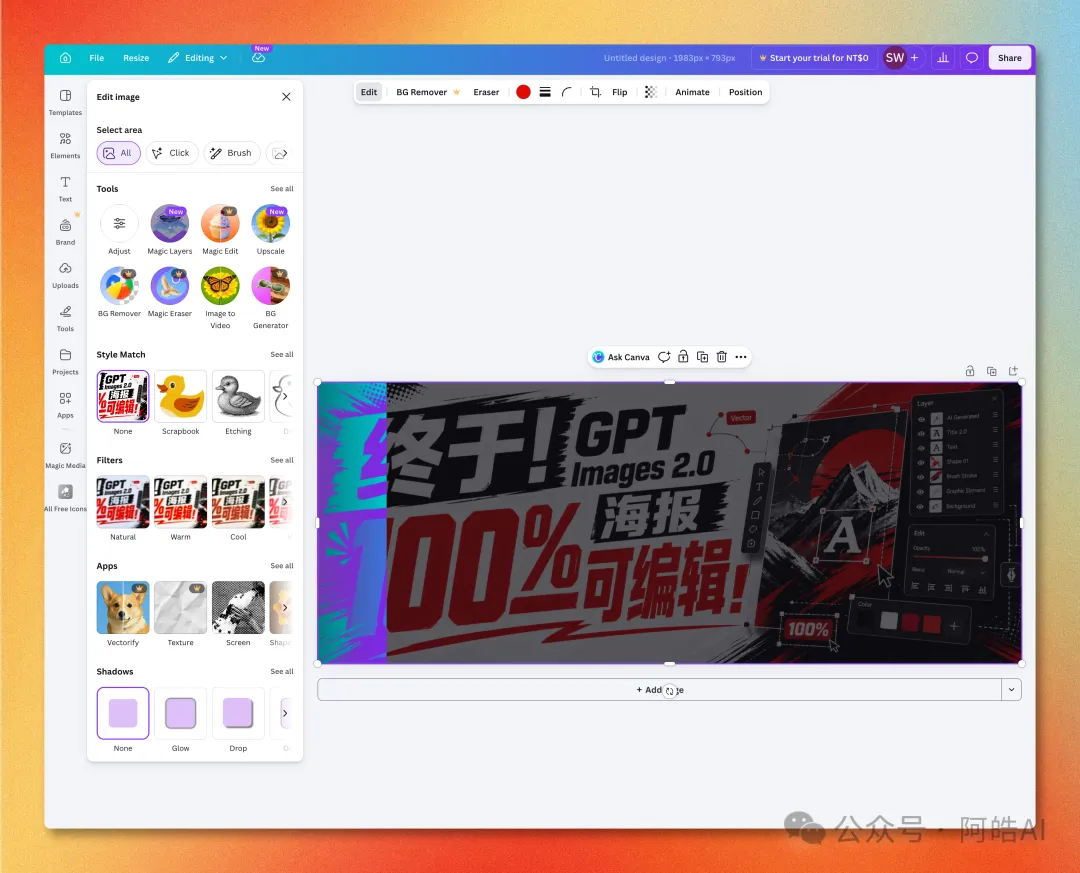 左邊 Edit image 面板可以見到所有可調項目——Adjust、Magic Edit、Magic Eraser、BG Remover、3D Generation 全部直接掛喺拆完嘅圖上面。 Step 5:好似普通 Canva 工程咁編輯入咗編輯器之後,每一個文本、每一個圖形都可以單獨㩒、移動、改字、換色。 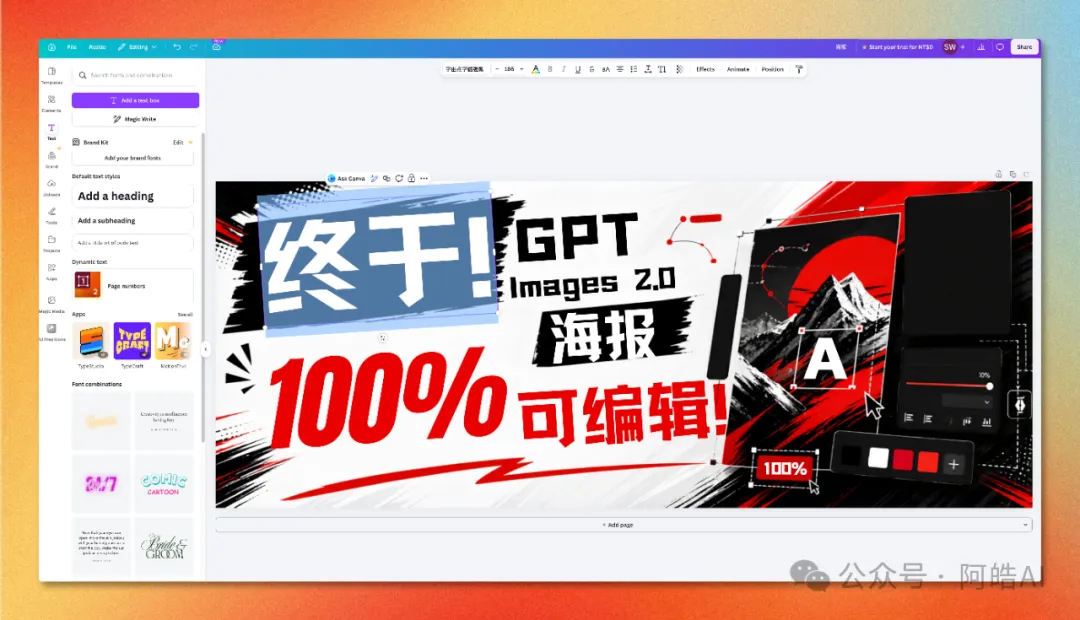 閉環價值:AI 設計嘅最後一公里將成套流程攤開嚟睇,一共有四個環節:創意/草圖用 ChatGPT 寫 prompt 描述想要咩,出圖用 GPT Image 2 生成視覺成品,微調/編輯靠 Canva Magic Layers 改字、換色、調位,多平台導出用 Canva 原生功能搞掂橫直屏同社交媒體尺寸。 呢條鏈路喺以前嘅「微調」環節係斷嘅,AI 出嘅圖就係終點。而家佢變成中間產物,下游接 Canva,整套工作流第一次跑得通。 對個人內容創作者嚟講意味住啲咩——識寫 prompt 嘅人 + 一個 Canva 賬號,就可以做到以前需要「提示詞工程師 + 平面設計師」兩個人先做到嘅嘢。 侷限同適用場景實測出嚟 Magic Layers 唔係萬能:
最適合嘅場景:
唔太適合:
寫喺最後AI 生圖喺 2024-2025 解決咗「畫唔畫得出嚟」,2026 呢一波喺解決「畫完之後鬱唔鬱得"。 Magic Layers 喺技術上唔算好新——摳圖、OCR、分層全部都係舊嘢——佢真正嘅價值係將呢啲能力打包成對設計師友好嘅入口,而且直接接喺 AI 生圖工具嘅下游。 下次再有人話「AI 出嘅圖改唔鬱」,叫佢試下呢個。 |
以前用 GPT Image 2、Midjourney、Flux 這些 AI 生成一張酷炫海報,效果驚豔,但想改一個字、換個元素、調整佈局——就只能認命,改 prompt 重新生成。 重生一次,整個版式又變了。AI 不會記住"上次那個 layout"。 現在,Canva 的 Magic Layers徹底改了遊戲規則:一張平面 AI 圖像,被自動拆成數十個獨立圖層——文字、人物、背景、光效、簽名——全部可以單獨選中、移動、刪除、替換、改字體。 就像在 Photoshop 裏操作矢量圖一樣簡單。 GPT Image 2 出圖 + Canva Magic Layers 編輯——AI 設計的最後一公里被補上了。 舊問題:AI 海報是"焊死的像素圖"任何一張 GPT Image 2、Midjourney、Flux 出的海報,本質都是像素圖。字號、顏色、位置全都"焊死"在像素裏——改一個字 = 重新生成整張圖。 實際工作裏這個問題大到什麼程度——商業海報、社交媒體首圖、活動 banner,所有"上線前再微調一下"的場景,AI 生圖都接不住最後 10% 的修改。 繞過去的辦法以前只有兩個:
兩個都不優雅。 新解法:Magic Layers 做了什麼Magic Layers 本質上做的是一件事:反向工程一張靜態圖,把它還原成 Canva 原生的可編輯工程文件。 不是簡單的摳圖,不是 OCR 識別文字再貼上去——是語義級的圖層分離:
拆完之後,整張圖就是一個普通的 Canva 工程,所有 Canva 原有的編輯能力都能直接用——換字體、調色、加動效、一鍵導出多平台尺寸。 完整流程(5 步)Step 1:登錄 Canva,點左側 "+ Create"打開 canva.com,登錄後會停在 Templates 頁。左側欄第一個按鈕 + Create(添加)就是入口。 Step 2:在 Quick actions 裏找到 Magic Layers點完 Create 後會進入 "Create a design" 面板,左側選 For you → Quick actions,第一個就是帶 New 標籤的 Magic Layers。 Step 3:上傳 AI 生成的海報點 Magic Layers → "Select your media",把 GPT Image 2 出的海報拖進去。 目前只支持圖片格式,PDF / SVG 暫不支持。 Step 4:等待幾秒,自動拆解完成上傳後大約 5-10 秒,Magic Layers 會分析整張圖的元素,把每一塊拆成獨立圖層。 左側 Edit image 面板可以看到所有可調項——Adjust、Magic Edit、Magic Eraser、BG Remover、3D Generation 全都直接掛在拆完的圖上。 Step 5:像普通 Canva 工程一樣編輯進入編輯器之後,每一個文本、每一個圖形都能單獨點選、移動、改字、換色。 閉環價值:AI 設計的最後一公里把整套流程拉直了看,一共四個環節:創意/草圖用 ChatGPT 寫 prompt 描述要什麼,出圖用 GPT Image 2 生成視覺成品,微調/編輯靠 Canva Magic Layers 改字、換色、調位,多平台導出用 Canva 原生功能搞定橫豎屏和社交尺寸。 這條鏈路在過去的"微調"環節是斷的,AI 出的圖就是終點。現在它變成中間產物,下游接 Canva,整套工作流第一次跑通。 對個人內容創作者意味着什麼——會寫 prompt 的人 + 一個 Canva 賬號,能完成過去需要"提示詞工程師 + 平面設計師"兩個人才能幹完的事。 侷限與適用場景實測下來 Magic Layers 不是萬能:
最適合的場景:
不太適合:
寫在最後AI 生圖在 2024-2025 解決了"能不能畫出來",2026 這一波在解決"畫完之後能不能動"。 Magic Layers 在技術上不算多新——摳圖、OCR、分層都是老活——它真正的價值是把這些能力打包成對設計師友好的入口,並且直接接在 AI 生圖工具的下游。 下次再有人說"AI 出的圖改不動",讓 ta 試試這個。 |