/grill-me 是如何改變我的工作流,讓編碼精準得像手術刀
整理版優先睇
用三個skill鏈條,將AI編碼從亂撞變精準——先對齊再動手,先文檔後執行,跨session無縫續接
呢篇文章係一個開發者嘅親身經驗,佢用Claude Code做大型架構重構時,發現舊工作流好多問題:Agent懶得睇code就亂問、Plan模式燒token出唔到有用方案、上下文爆咗之後Agent開始失憶,改完嘅code同原定方案差天共地。佢好頭痕,直到喺GitHub見到一個75.9k Stars嘅Skills倉庫,作者係Matt Pocock,TypeScript社區嘅老手。Matt嘅思路同市面上嘅方案好唔同——佢唔係要塞一個完整流程俾你,而係俾一啲細粒、可組合嘅skill,你可以揀嚟用、改嚟用、拼埋一齊用。
呢位開發者揀咗三個核心skill:/grill-with-docs、/to-prd、/handoff,組成一條新工作鏈。先用/grill-with-docs配合佢自己嘅記憶體系,等Agent基於真實code精準提問,唔再靠估;然後用/to-prd生一份超精確嘅PRD,唔係產品經理嗰種長篇大論,而係聚焦喺改咩、點改、點解咁改,連函數名同文件都寫明;最後用/handoff將成個session壓縮成交付文檔,下一個session可以直接讀取,唔使重頭再講。
呢套方法令佢嘅編碼變得「手術刀式精準」——Agent讀完文檔後直接定位到行號,快速改好,無曬無謂嘅探索同token浪費。作者總結:AI編碼嘅最大瓶頸唔係模型能力,而係對齊成本。你唔主動填平呢個溝通鴻溝,Agent就會靠估,然後燒token、爆上下文。呢三個skil…
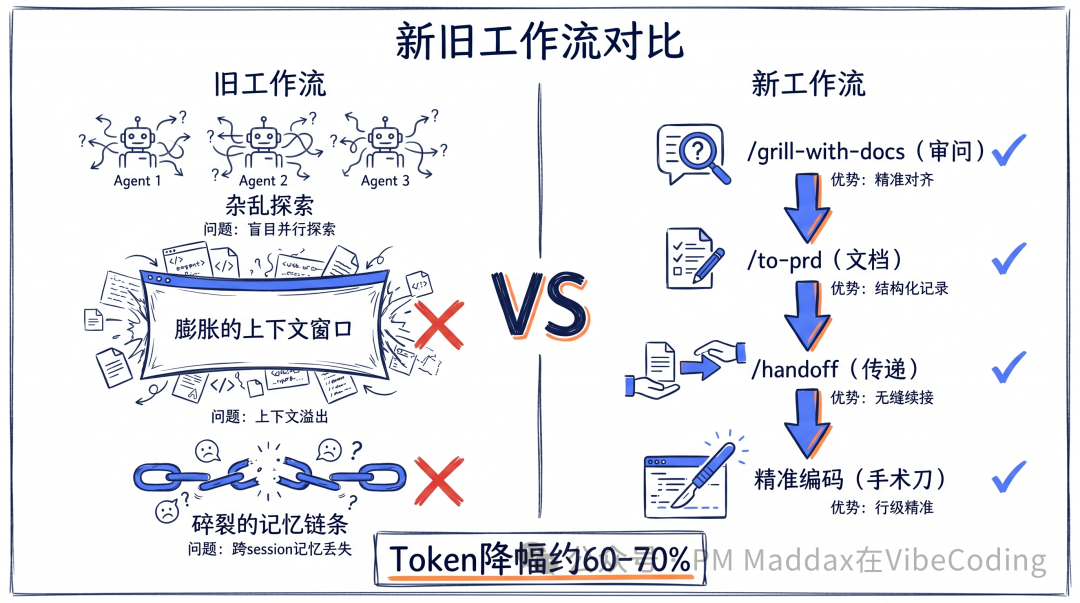
- 舊流程嘅三大死穴:Agent懶得睇code就亂問、Plan模式燒百萬token但方案流於表面、上下文爆咗後Agent失憶,改出矛盾code。
- 新流程以「先對齊再動手」為核心:用/grill-with-docs逼Agent睇完code先問問題,每個決策點都基於真實code追問,確保需求清晰。
- 用/to-prd生成精確到函數名嘅PRD文檔,唔係空話;每條User Story都寫明改邊個文件同點解咁改。
- 跨session續接靠/handoff,自動壓縮當前對話成精簡交付文檔,新session直接讀取執行順序同驗證標準,唔使口述重講。
- 效能提升明顯:中等需求token消耗由50-80萬降至15-25萬,降幅60-70%;但更重要係產出質量——每一步都係充分理解後嘅決策,唔係亂撞。
mattpocock/skills
Matt Pocock開源嘅Claude Code技能集,包含grill-with-docs、to-prd、handoff等細粒skill,可按需組合使用。
舊工作流三大死穴:Agent亂問、Plan燒錢、上下文炸
作者之前嘅流程係:先用蘇格拉底式審問澄清需求,跟住入/plan模式細化方案,最後用Superpower嘅subagent-driven-development進入編碼。表面睇好結構,實際跑起嚟全部係坑。
- Agent偷懶猜想:佢叫Agent用蘇格拉底方式審問,點知Agent唔睇code就直接開始問,問題建立喺錯誤假設上,等於話「我冇睇你code庫,但我覺得係咁㗎啩?」。
- Plan模式變Token焚化爐:/plan模式會啟動並行Explore agent,一個subagent就幾十上百k token,幾個同時跑就百萬級消耗。Linux Do有人做過審計,662次bash調用中Agent用cat/grep/find替代原生工具,累計浪費約56.1萬token。
- 編碼前上下文已炸:盲目探索塞滿無關文件,等到真係寫code時Agent開始失憶——忘記前邊討論,改出矛盾方案。焗住新開窗口重新口述曬所有決策,等於開完兩小時需求會,同事一出門口就唔記得曬。
轉折:三粒skill重塑協作方式
作者發現Matt Pocock嘅Skills倉庫(75.9k stars),入面有三個skill徹底改變佢同AI嘅協作方式:/grill-with-docs、/to-prd、/handoff。Matt嘅核心insight係:「Claude Code tends to spit out a plan really early when in plan mode, creating a document before we've truly understood each other.」——先傾清楚,再動手。
審問完結後,Agent會羅列所有決策點,作者逐條確認。呢一步係分水嶺——確認完就進入文檔化,唔再回頭。跟住用/to-prd生成PRD文檔,唔係產品經理嗰種長篇大論,而係聚焦喺「改咩、點改、點解咁改」,精確到函數名同文件。例如「點解保留create_all做兜底」、「點解用batch_alter_table」、「點解異常處理要移到特定位置」——全部有上下文、有理由、有取捨。
前後對比:從亂撞到手術刀式精準
作者整理咗新舊流程嘅關鍵差異,令人清楚見到改善幅度:
- 1 需求澄清:舊流程Agent猜想式提問;新流程用/grill-with-docs加記憶預熱,基於代碼精準審問。
- 2 方案文檔:舊流程出泛泛計劃;新流程用/to-prd精確到函數名同文件。
- 3 規劃:舊流程並行Explore盲目探索;新流程基於已有上下文精準查閲。
- 4 跨session:舊流程手動口述背景;新流程用/handoff自動壓縮交付文檔。
- 5 編碼執行:舊流程上下文膨脹頻頻偏移;新流程手術刀式精準到行級改動。
- 6 Token消耗:舊流程一箇中等需求約50-80萬token;新流程約15-25萬,降幅60-70%。
不過作者強調,token慳咗係小事,關鍵係產出質量——每一步都係基於充分理解嘅決策,唔係靠估。
寫在最後:對齊成本先係瓶頸
作者想講嘅唔係skill使用教程,而係一個更深層嘅道理:AI編碼嘅最大瓶頸唔係模型能力,而係對齊成本。你瞭解項目、踩過嘅坑、技術債嘅歷史;Agent一無所知。你唔主動填平呢個鴻溝,Agent只能靠估,然後token燒咗、改返轉頭、再燒token、最後上下文爆掉。
- 可行動點:安裝skill倉庫(npx skills@latest add mattpocock/skills),執行/setup-matt-pocock-skills。
- 啟發:下次用AI Agent前,花10分鐘對齊需求,好過之後燒幾十萬token去糾正。
由盲目探索到行級精準,我用咗三個 skill 重塑咗同 Agent 嘅協作方式。
唔耐之前,我嘅一個個人項目需要做整體架構重構,解決積累咗好耐嘅技術債。
我先用並行嘅架構審查 agent 對項目做咗全面掃描。結果出嚟,果然係個大工程——後端數據庫遷移硬編碼喺 lifespan 裏面、核心服務文件職責模糊、前端巨型組件難以維護、異常類型混用、併發模型有資源洩漏風險。
好明顯,一個 session 搞唔掂。
咁點拆?拆完之後點樣跨 session 精準傳遞信息?呢件事令我非常頭痕。
我試過喺一個 session 裏面讓 agent 不斷/compact壓縮上下文,硬撐到底。但到咗後期,偏移量大得離譜——agent 唔記得咗前面嘅決策,開始「自由發揮」,改出嚟嘅代碼同原定方案南轅北轍。一個 633 行嘅核心文件,佢改嚇改嚇就偏到咗唔相關嘅模塊上。
1個鐘之後,我閂咗終端,心裏面剩返一句話:呢個工作流程有問題。
有冇啲咩辦法,可以令呢種大任務唔會偏移?
後來我揾到咗。答案係 Matt Pocock 嘅一條 skill 鏈。
● ● ●
舊工作流程嘅三大問題
我嘅舊流程:蘇格拉底式審問澄清需求 →/plan模式細化方案 → Superpower 嘅 subagent-driven-development 進入編碼。結構睇落冇問題,跑起上嚟全部都係坑。
第一,Agent 偷懶猜想。
我讓 agent 用蘇格拉底方式審問我、澄清需求。理想中佢應該先睇代碼再提問。實際呢?佢直接開始問。問出嚟嘅問題好似幾咁回事,但係建立喺錯誤嘅假設上。等於佢喺度講:「我冇睇你個代碼庫,但我覺得應該係咁掛?」(我發現 superpower 嘅brainstorm 都好懶)
唔啱。你睇咗先啦。
第二,Plan 模式變成 token 焚燒爐。
進/plan模式,Claude Code 成日啓動並行嘅 Explore agent。一個 subagent 幾十上百 k token,幾個同時跑就係百萬級消耗。LINUX DO 上有人做咗 token 審計——662 次 bash 調用裏面 agent 用 cat/grep/find 替代原生工具,累計浪費約 56.1 萬 token。我自己都有過類似體驗:agent 讀咗一堆同需求毫無關係嘅文件,輸出嘅計劃卻泛泛而談。
錢使咗,有用嘅冇幾個。
第三,上下文喺編碼前就爆咗。
盲目探索嘅後果:無關文件塞滿上下文窗口。等到真係要寫代碼嘅時候,agent 開始「失憶」——唔記得咗之前嘅討論,改出同前一輪決策矛盾嘅方案。只能新開窗口,將之前所有決策重新口述一次。
呢個就好似你同同事開咗兩個鐘需求評審會,佢出咗會議室門就忘記得一乾二淨,你要重新講一次。邊個工程師頂得順?
● ● ●
轉折:75.9k Stars 嘅 Skills 倉庫
某日深夜睇 GitHub Trending,見到咗mattpocock/skills,75.9k stars。
Matt Pocock——TypeScript 社區資深貢獻者,total-typescript作者。佢將自己喺.claude目錄裏面日常使用嘅 skill 全部開源咗。
佢嘅思路同市面上 GSD、BMAD、Spec-Kit 呢啲方案好唔一樣。嗰啲方案試圖「擁有你嘅流程」,替你規定每一步點樣做。Matt 唔做呢啲嘢。佢嘅 skills細、可組合、可定製——揀嚟用,魔改都得,組合嚟用都得。
裏面有三個 skill 徹底改變咗我同 AI 嘅協作方式:/grill-with-docs、/to-prd、/handoff。
Matt 講過一段話,確實係咁:
"Claude Code tends to spit out a plan really early when in plan mode, creating a document before we've truly understood each other."
直接講:plan 模式下 agent 急住出方案,你兩個仲未傾清楚。傾清楚先,先再動手。
● ● ●
第一步:先對齊再動手
新工作流程由/grill-with-docs開始。
呢個 skill 淨係做一件事:讓 agent 好似資深工程師咁審問你,逐個決策點追問,直到需求完全清晰。
但有個前提——agent 要先了解現狀,先至問到好問題。我嘅做法係配合Serena記憶體系,我上篇文章所講嘅項目記憶管理方法。每次新 session,agent 先讀核心記憶:項目概覽、技術棧、目錄結構、代碼約定。預熱 session。有咗呢層背景,/grill-with-docs嘅審問變得極之精準。
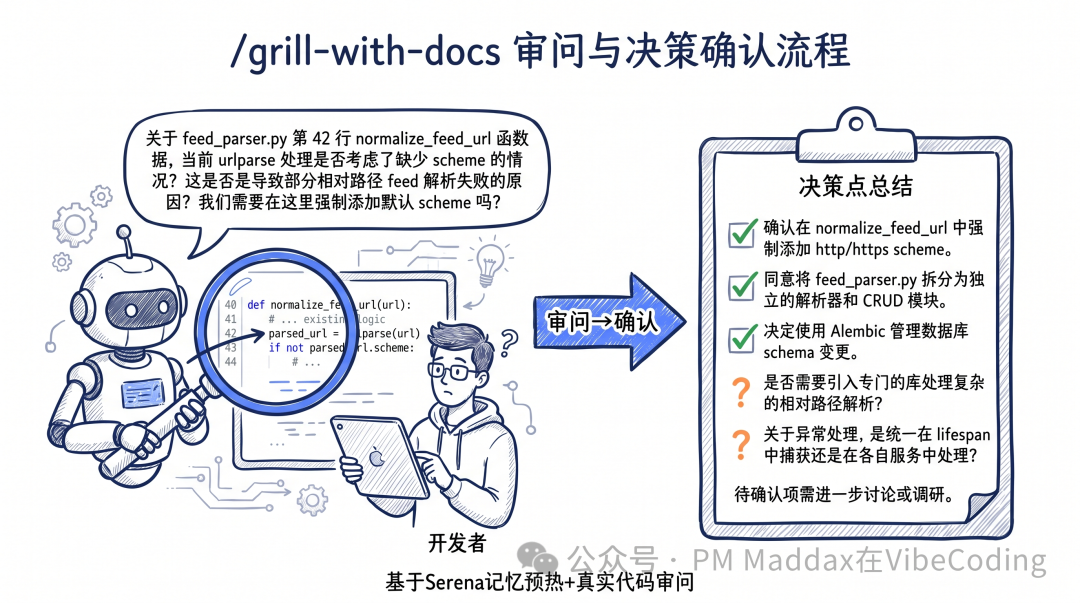
拎我嗰次架構重構做例子。agent 嘅第一個問題唔係「你想做乜」——呢個係舊流程嘅典型開場。而係:
「feed_parser.py 目前 633 行,裏面混合咗 URL 標準化、RSS 解析、全文提取、Feed CRUD 四塊職責。你今次係想全部拆開,定係先處理最痛嘅部分?」
佢會精準咁先睇相關嘅代碼。問嘅係真問題。
Matt Pocock 自己提到,複雜功能嘅 grill session 可以持續半個鐘,agent 連續問30-50 個問題。我嘅經驗係,一般需求大約 15-20 個問題,約 10 分鐘。每一輪都有效——因為 agent 基於真實代碼同記憶嚟問,唔係亂猜。
審問結束,agent 會將所有決策點做一次總結羅列。你逐條確認。呢一步係分水嶺——確認完咗就進入文檔化,唔會再回頭。(注:/grill-with-docs 係 /grill-me 嘅工程版)
● ● ●
第二步:PRD 精確到函數名
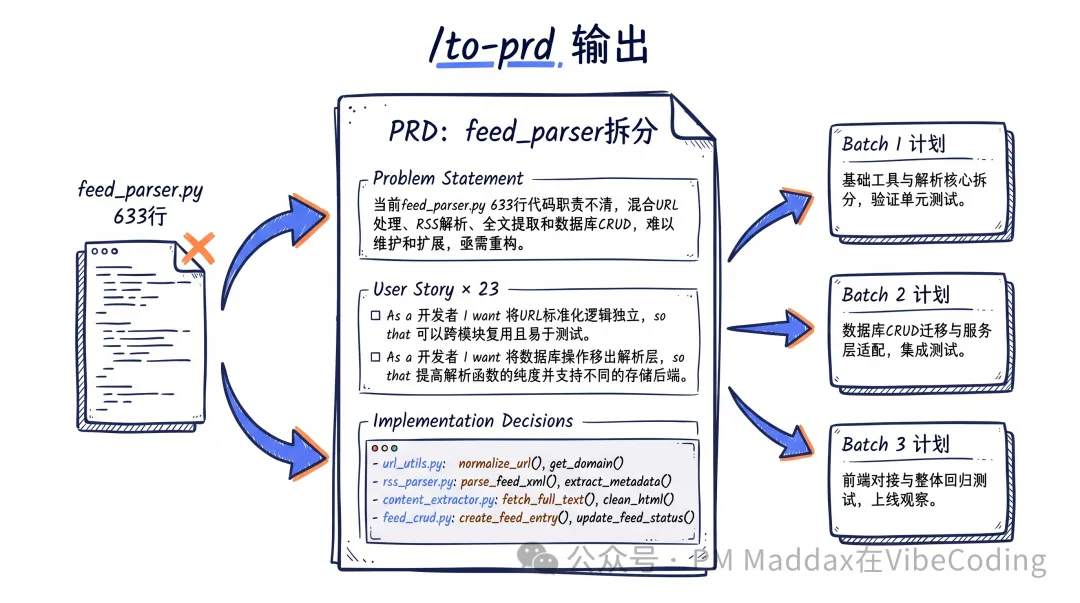
確認完決策點,用/to-prd生成 PRD 文檔。
注意,呢份 PRD不是產品經理寫嗰種長篇大論——冇交互設計稿、冇用戶畫像、冇商業價值分析。佢聚焦喺一個問題上:改乜嘢,點樣改,點解要咁改。
睇我嘅真實 PRD 裏面嘅 Implementation Decisions 片段:

睇到未?唔係「優化數據庫遷移」呢種空話。每一行都係同 agent 討論後敲定嘅具體決策——點解保留 create_all 做兜底、點解用 batch_alter_table、點解異常處理要移到特定位置。呢啲決策有上下文、有理由、有取捨。
23 條 User Story 都係同樣精度。每條都係「As a 開發者, I want [具體變更], so that [具體原因]」嘅格式,精確到函數名同文件。
這就是/grill-with-docs嘅下游效應——因為審問階段 agent 已經睇過代碼、問過細節,PRD 自然精準。唔係憑空想像嘅方案,係從真實代碼裏面長出嚟嘅。
PRD 出嚟之後進入 plan 模式細化。但因為前面已經充分對齊,plan 模式裏面 agent 淨係精準查閲相關文件,唔會啓動冇意義嘅並行探索。我嗰次重構拆咗三個 Batch,每個 Batch 嘅計劃都精確到改邊幾行、驗證標準係乜。
● ● ●
第三步:/handoff —— 跨 session 嘅上下文續命
大需求最頭痕嘅環節嚟咗:上下文窗口快用滿咗。
舊做法係手動新開窗口,口頭將前面嘅背景複述一次。嘥時間、低效率、信息必然會流失。
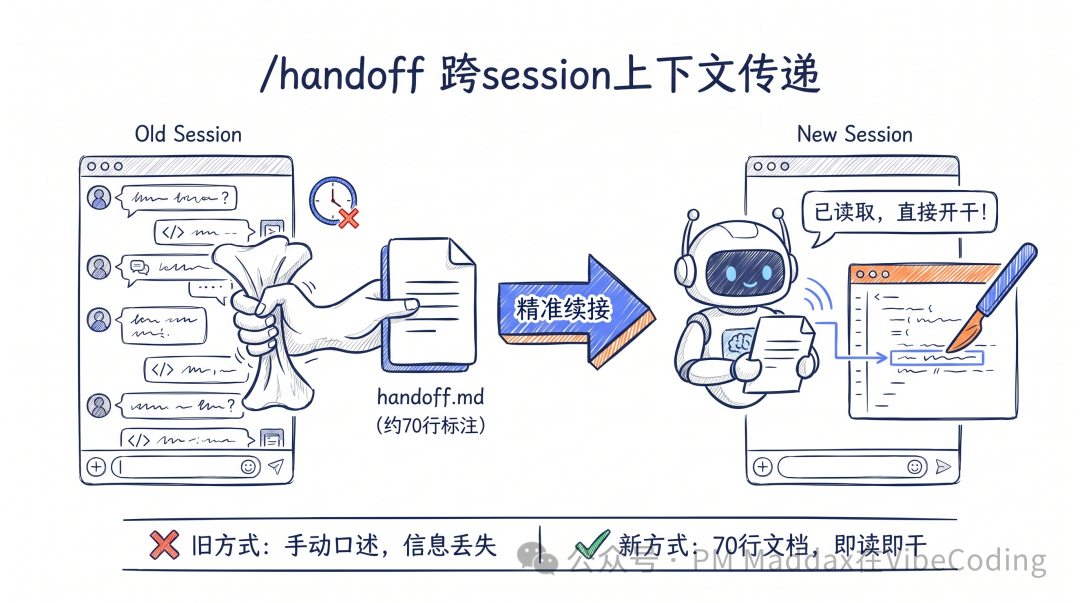
/handoff解決咗呢個問題。佢將當前對話壓縮成一份精簡嘅交付文檔,畀下一個 session 直接消費。
最關鍵嘅係執行順序同依賴關係。我嘅真實 handoff 裏面係咁寫嘅:

冇一個多餘嘅形容詞。執行順序、依賴關係、每個 Batch 改乜、點樣驗證——全部喺裏面。新嘅 session 讀到呢份文檔,知道先做乜後做乜、邊啲可以並行、驗證標準係乜。
新嘅 session 讀到呢份 handoff,唔使我多講一句話,直接開工。
所以先叫「手術刀式編碼」——agent 讀完文檔後精準定位到文件、函數、行號,快速改完。冇冇意義嘅文件遍歷,冇百萬 token 嘅探索浪費。
● ● ●
前後對比
Token 消耗粗略估算:舊流程一個中等需求約 50-80 萬 token,新流程約 15-25 萬。降幅大概 60-70%。
但 token 慳咗都係小事。關鍵產出質量唔同——每一步都係基於充分理解嘅決策,唔係拍腦袋嘅猜測。
● ● ●
寫喺最後
呢篇文章唔係 skill 使用教程。教程好多社區已經寫得好詳細喇。
我想講嘅係一個更深層嘅嘢:AI 編碼嘅最大瓶頸唔係模型能力,係對齊成本。
你瞭解項目、踩過嘅坑、技術債嘅歷史。agent 一無所知。你唔主動填平呢個鴻溝,agent 只能靠估。估錯咗,token 燒咗。改返嚟,更多 token 燒咗。反反覆覆,上下文爆曬。
Matt Pocock 嘅 insight 好簡單:唔好讓 agent 急住動手,先強制對齊,再執行。/grill-with-docs解決對齊,/to-prd解決記錄,/handoff解決續接。三個 skill,一條鏈,將溝通鴻溝一步步填平。
補充一句:呢條 skill 鏈唔只適用於寫程式。喺工作中使用任何 AI agent 工具嘅決策場景下,或者對齊上下文時,都可以用呢套方法。
如果你正在用 Claude Code 或其他 AI Agent 工具,試嚇:
npx skills@latest add mattpocock/skills裝完跑/setup-matt-pocock-skills,下次有需求時用/grill-with-docs開場。
你可能會發現——精準嘅 AI 編碼,靠嘅唔係更強嘅模型,而係更好嘅工作流程。
從盲目探索到行級精準,我用了三個 skill 重塑了和 Agent 的協作方式。
不久前,我的一個個人項目需要做整體架構重構,解決積累已久的技術債。
我先用並行的架構審查 agent 對項目做了全面掃描。結果出來,果然是個大活——後端數據庫遷移硬編碼在 lifespan 裏、核心服務文件職責模糊、前端巨型組件難以維護、異常類型混用、併發模型有資源泄露風險。
很明顯,一個 session 搞不定。
那怎麼拆?拆完之後怎麼跨 session 精準傳遞信息?這事讓我非常頭大。
我試過在一個 session 裏讓 agent 不斷/compact壓縮上下文,硬扛到底。但到了後期,偏移量大得離譜——agent 忘了前面的決策,開始"自由發揮",改出來的代碼跟原定方案南轅北轍。一個 633 行的核心文件,它改着改着就偏到了不相關的模塊上。
1個小時後,我關掉終端,心裏只剩一句話:這工作流有問題。
有沒有什麼辦法,能讓這種大任務不偏移?
後來我找到了。答案是 Matt Pocock 的一條 skill 鏈。
● ● ●
舊工作流的三大問題
我的舊流程:蘇格拉底式審問澄清需求 →/plan模式細化方案 → Superpower的subagent-driven-development 進入編碼。結構看着沒問題,跑起來全是坑。
第一,Agent 偷懶猜想。
我讓 agent 用蘇格拉底方式審問我、澄清需求。理想中它應該先看代碼再提問。實際呢?它直接開始問。問出來的問題挺像那麼回事,但建立在錯誤的假設上。等於它在說:"我沒看你的代碼庫,但我覺得應該是這樣的吧?" (我發現superpower的brainstorm也很懶)
不對。你先看啊。
第二,Plan 模式變成 token 焚燒爐。
進/plan模式,Claude Code 動不動啓動並行的 Explore agent。一個 subagent 幾十上百 k token,幾個同時跑就是百萬級消耗。LINUX DO 上有人做了 token 審計——662 次 bash 調用裏 agent 用 cat/grep/find 替代原生工具,累計浪費約 56.1 萬 token。我自己也有過類似體驗:agent 讀了一堆跟需求毫無關係的文件,輸出的計劃卻泛泛而談。
錢花了,有用的沒幾個。
第三,上下文在編碼前就炸了。
盲目探索的後果:無關文件塞滿上下文窗口。等到真要寫代碼的時候,agent 開始"失憶"——忘了之前的討論,改出跟前一輪決策矛盾的方案。只能新開窗口,把之前所有決策重新口述一遍。
這就像你跟同事開了兩小時需求評審會,他出了會議室門就忘乾淨,你得重講一遍。哪個工程師受得了?
● ● ●
轉折:75.9k Stars 的 Skills 倉庫
某天深夜刷 GitHub Trending,看到了mattpocock/skills,75.9k stars。
Matt Pocock——TypeScript 社區資深貢獻者,total-typescript作者。他把自己在.claude目錄裏日常使用的 skill 全部開源了。
他的思路跟市面上 GSD、BMAD、Spec-Kit 這些方案很不一樣。那些方案試圖"擁有你的流程",替你規定每一步怎麼做。Matt 不幹這事。他的 skills小、可組合、可定製——挑着用,魔改也行,組合着來也行。
裏面有三個 skill 徹底改變了我跟 AI 的協作方式:/grill-with-docs、/to-prd、/handoff。
Matt 說過一段話,確實如此:
"Claude Code tends to spit out a plan really early when in plan mode, creating a document before we've truly understood each other."
直白翻譯:plan 模式下 agent 急着出方案,你倆還沒談明白呢。先聊清楚,再動手。
● ● ●
第一步:先對齊再動手
新工作流從/grill-with-docs開始。
這個 skill 就做一件事:讓 agent 像資深工程師一樣審問你,逐個決策點追問,直到需求完全清晰。
但有個前提——agent 得先了解現狀,才能問出好問題。我的做法是配合Serena記憶體系,我上篇文章所寫的項目記憶管理方法。每次新 session,agent 先讀核心記憶:項目概覽、技術棧、目錄結構、代碼約定。預熱session。有了這層背景,/grill-with-docs的審問變得極其精準。
拿我那次架構重構舉例。agent 的第一個問題不是"你想做什麼"——這是舊流程的典型開場。而是:
"feed_parser.py 目前 633 行,裏面混合了 URL 標準化、RSS 解析、全文提取、Feed CRUD 四塊職責。你這次是想全部拆開,還是先處理最痛的部分?"
它會精準的先看相關的代碼。問的是真問題。
Matt Pocock 自己提到,複雜功能的 grill session 能持續半小時,agent 連續問30-50 個問題。我的經驗是,一般需求在 15-20 個問題,約 10 分鐘。每一輪都有效——因為 agent 基於真實代碼和記憶在問,不是瞎猜。
審問結束,agent 會把所有決策點做一次總結羅列。你逐條確認。這一步是分水嶺——確認完了就進入文檔化,不再回頭。(注:/grill-with-docs是/grill-me的工程版)
● ● ●
第二步:PRD 精確到函數名
確認完決策點,用/to-prd生成 PRD 文檔。
注意,這份 PRD不是產品經理寫的那種長篇大論——沒有交互設計稿、沒有用戶畫像、沒有商業價值分析。它聚焦在一個問題上:改什麼,怎麼改,為什麼這麼改。
看我的真實 PRD 裏的 Implementation Decisions 片段:
看到了嗎?不是"優化數據庫遷移"這種空話。每一行都是跟 agent 討論後敲定的具體決策——為什麼保留 create_all 做兜底、為什麼用 batch_alter_table、為什麼異常處理要移到特定位置。這些決策有上下文、有理由、有取捨。
23 條 User Story 也是同樣精度。每條都是 "As a 開發者, I want [具體變更], so that [具體原因]" 的格式,精確到函數名和文件。
這就是/grill-with-docs的下游效應——因為審問階段 agent 已經看過代碼、問過細節,PRD 自然精準。不是憑空想象的方案,是從真實代碼里長出來的。
PRD 出來後進入 plan 模式細化。但因為前面已充分對齊,plan 模式裏 agent 只精準查閲相關文件,不啓動無意義的並行探索。我那次重構拆了三個 Batch,每個 Batch 的計劃都精確到改哪幾行、驗證標準是什麼。
● ● ●
第三步:/handoff —— 跨 session 的上下文續命
大需求最頭疼的環節來了:上下文窗口快用滿了。
舊做法是手動新開窗口,口頭把前面的背景複述一遍。耗時、低效、信息必然丟失。
/handoff解決了這個問題。它把當前對話壓縮成一份精簡的交付文檔,給下一個 session 直接消費。
最關鍵的是執行順序和依賴關係。我的真實 handoff 裏這樣寫的:
沒有一個多餘的形容詞。執行順序、依賴關係、每個 Batch 改什麼、怎麼驗證——全在裏面。新的 session 讀到這份文檔,知道先幹什麼後幹什麼、哪些能並行、驗證標準是什麼。
新的 session 讀到這份 handoff,不用我多說一句話,直接開幹。
所以才叫"手術刀式編碼"——agent 讀完文檔後精準定位到文件、函數、行號,快速改完。沒有無意義的文件遍歷,沒有百萬 token 的探索浪費。
● ● ●
前後對比
Token 消耗粗估:舊流程一箇中等需求約 50-80 萬 token,新流程約 15-25 萬。降幅大概 60-70%。
但 token 省了還是小事。關鍵產出質量不一樣——每一步都是基於充分理解的決策,不是拍腦袋的猜測。
● ● ●
寫在最後
這篇文章不是 skill 使用教程。教程很多社區已經寫得很詳細了。
我想聊的是一個更底層的事:AI 編碼的最大瓶頸不是模型能力,是對齊成本。
你瞭解項目、踩過的坑、技術債的歷史。agent 一無所知。你不主動填平這個鴻溝,agent 只能靠猜。猜錯了,token 燒了。改回來,更多 token 燒了。反反覆覆,上下文爆掉。
Matt Pocock 的 insight 很簡單:不要讓 agent 急着動手,先強制對齊,再執行。/grill-with-docs解決對齊,/to-prd解決記錄,/handoff解決續接。三個 skill,一條鏈,把溝通鴻溝一步步填平。
補一句:這條 skill 鏈不只適用於寫代碼。在工作中使用任何 AI agent 工具的決策場景下 ,或者對齊上下文時,都可以用這套方法。
如果你正在用 Claude Code 或其他 AI Agent工具,試試:
npx skills@latest add mattpocock/skills裝完跑/setup-matt-pocock-skills,下次有需求時用/grill-with-docs開場。
你可能會發現——精準的 AI 編碼,靠的不是更強的模型,而是更好的工作流。