Harness Engineering又他媽是啥?
整理版優先睇
Harness Engineering 係控制 AI agent 嘅系統框架,比 Prompt 同 Context 更關鍵,係目前 AI 開發嘅真正瓶頸。
呢篇文章出自一位本身寫作同開發都用 AI 嘅作者,佢原本對「Harness Engineering」呢個新名詞好質疑,因為 AI 圈成日亂造詞。但佢讀完 OpenAI、Anthropic 同 Martin Fowler 嘅分析之後,發現呢個詞其實就係描述佢過去半年一直做緊嘅嘢:圍繞 AI agent 搭建嘅成個系統,包括規則、檢查、工具同流程。
作者解釋咗三層關係:Prompt Engineering 係你對 AI 講嘅話(指令),Context Engineering 係畀 AI 睇嘅背景資訊(地圖),而 Harness Engineering 係成個「馬具」——即係限制、引導、反饋同質量檢查嘅系統。佢引用咗幾個硬數據:LangChain 改咗 harness 之後成績由 52.8% 升到 66.5%;OpenAI Codex 團隊用 harness 五個月寫咗 100 萬行代碼;Anthropic 用三 agent 架構(規劃者、生成者、評估者)大幅提升效果。
結論係:模型已經唔係瓶頸,瓶頸係你點樣設計 harness。呢個概念唔係新發明,係將散亂嘅實踐統一起嚟,令成個行業可以溝通。作者仲分享咗自己嘅 CLAUDE.md、hooks 同 skills 系統,最後提出開始 harness 嘅三條實用原則。
- Harness Engineering 係管理 AI agent 嘅關鍵,模型已經唔係瓶頸,瓶頸係圍繞模型嘅系統設計。
- 建立 harness 要包括上下文工程(畀地圖唔畀說明書)、架構約束(硬規則)、垃圾回收(專職檢查 AI 輸出)。
- Harness 同 Prompt/Context 嘅分別在於 Harness 管理成個運轉系統,包括約束、反饋同質量檢查。
- Harness 要根據實際錯誤逐步生長,好似 Mitchell Hashimoto 嘅配置文件逐次追加規則,係一個活系統。
- 開始時畀地圖唔畀說明書,每次犯錯加一條規則,用第二個 AI 檢查第一個 AI 嘅輸出。
Harness Engineering 係乜?
作者起初對呢個新詞好反感,覺得 AI 圈造詞太快。但讀完 OpenAI 同 Anthropic 原文之後,發現呢個詞講嘅就係佢做咗半年嘅嘢:控制 AI agent 嘅成個系統。
作者用咗一個比喻:Prompt Engineering 係你對馬講「向左轉」,Context Engineering 係地圖同路標,而 Harness Engineering 係繮繩、馬鞍同圍欄,令成個系統安全有效運作。
實際案例:同一個模型,換 harness 成績天差地別
LangChain 嘅 coding agent 喺 Terminal Bench 2.0 上面,成績由 52.8% 升到 66.5%,排名由 Top 30 跳到 Top 5。重點係:模型完全冇換,只改咗系統提示詞、工具配置同中間件鈎子。
OpenAI Codex 團隊用 harness 搞出一個 100 萬行代碼嘅 beta 產品,零行人工手寫,大約 1500 個 PR,每個工程師每日 3.5 個 PR,速度係傳統方式嘅 10 倍。不過作者提醒:速度快咗唔代表產出好咗,六個月後維護呢 100 萬行代碼可能好大鑊。
Anthropic 就用咗另一種架構:三 agent——規劃者、生成者、評估者。靈感來自生成對抗網絡,評估者專職挑刺,效果遠比生成者自己檢查自己好。
作者自己嘅 harness 點樣生出來
作者去年 8 月用 Claude Code 搭咗寫作工作流,之後唔使點寫,主要係做選擇同批評。但令呢套系統好用嘅,唔係模型本身,而係圍住佢搭嘅 CLAUDE.md、hooks、skills 同 知識庫。
- CLAUDE.md 變成一個路由器,判斷當前任務屬於邊個工作區,指向對應規則。
- Hooks 係喺 agent 執行關鍵操作前後注入腳本,例如編輯文件前自動跑 linting,生成代碼後自動做類型檢查。
- Skills 係獨立嘅能力包,平時唔佔 context,需要時先叫,例如一個管小紅書配圖,一個管飛書同步。
點樣開始建立你嘅 harness
- 1 畀地圖唔畀說明書:CLAUDE.md 應該似地圖,講項目結構、文件關係、關鍵約束,唔好將每步寫死。
- 2 每次犯錯加一條規則:由空文件開始,agent 犯一個錯就加一條,三個月後個文件就係你嘅 harness。
- 3 用第二個 AI 檢查第一個:Anthropic 嘅 Evaluator 思路,開新對話貼結果叫佢「揾曬所有問題」。
作者最後帶出 Martin Fowler 嘅憂慮:如果太早將人類由「in the loop」移到「on the loop」,將來可能冇人識得設計好嘅 harness。作者自己冇寫過代碼,但靠上千小時同 AI 互動累積咗判斷力。佢話:無論係寫代碼嘅經驗定係同 AI 較勁嘅經驗,足夠多嘅經驗本身就係設計 harness 嘅前提,冇捷徑。
AI圈造新詞的速度,快趕上模型迭代了。過去一年光「XX Engineering」就冒出來四五個。
但我去讀了OpenAI和Anthropic的原文之後,反應變了。不是「哇好新」,是:等等,這不就是我過去半年一直在乾的事嗎?
我寫CLAUDE.md,告訴AI我是誰、什麼規則必須遵守。配hooks,在agent關鍵節點注入檢查。建知識庫,給AI準備決策需要的上下文。調skills,定義AI能用什麼工具、有什麼權限。
做了半年,從來沒覺得這些事需要一個統一的名字。
然後OpenAI發了篇博文說這叫Harness Engineering。Mitchell Hashimoto發了篇博文也說這叫Harness Engineering。Anthropic發了兩篇工程文章,Martin Fowler寫了長文分析,大家都這麼叫。
行,那就叫Harness Engineering。
Harness這個詞,英文原意是馬具、繮繩。不是馬本身,是套在馬身上讓它能拉車、能被引導的那整套東西。沒有它,馬就是一匹亂跑的野馬,力氣再大也白搭。
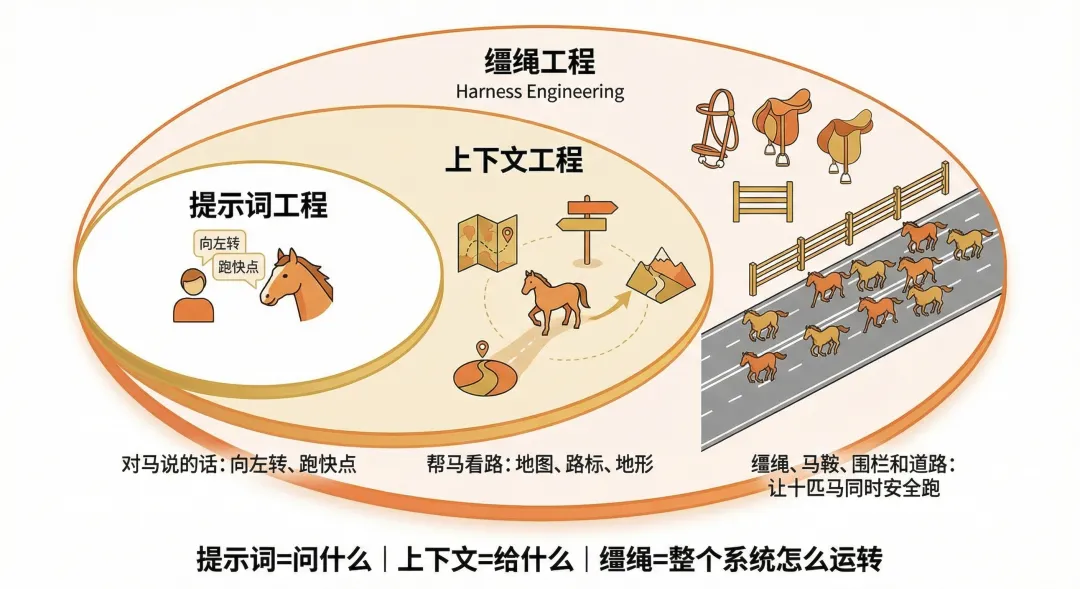
三層關係很好懂:Prompt Engineering是你對馬說的話,向左轉、跑快點。Context Engineering是幫馬看路的一切,地圖、路標、地形。Harness Engineering是繮繩、馬鞍、圍欄和道路本身,讓十匹馬同時安全跑起來的系統。
Prompt管你問什麼,Context管你給模型看什麼,Harness管整個東西怎麼運轉。Context是Harness的一部分,Harness還多管了約束、反饋和質量檢查。
懂了這個,再看最近幾個月的事,很多碎片就拼上了。
先說最硬的一個數據。LangChain的coding agent在Terminal Bench 2.0上,成績從52.8%漲到了66.5%,排名從Top 30跳到Top 5。重點是:模型完全沒換。他們只改了三樣東西:系統提示詞、工具配置、中間件鈎子。
同一個模型,換了套繮繩,成績天差地別。
模型可能已經不是瓶頸了。瓶頸是你給它搭了個什麼樣的環境。
然後是OpenAI自己的實驗。Codex團隊3個工程師,後來擴到7個,5個月,用Codex搞出了一個100萬行代碼的beta產品。零行人工手寫。約1500個PR合併,每個工程師每天3.5個PR,估算速度是傳統方式的10倍。

這些數字很炸。但有個問題沒人聊:這100萬行代碼的質量怎麼樣?
速度快了10倍,不代表產出好了10倍。每人每天3.5個PR,誰在做代碼審查?六個月後需要改需求的時候,這100萬行好改嗎?AI寫的代碼和人寫的代碼有個關鍵區別:人寫代碼時會無意識地留下結構線索,方便將來的自己理解。AI不會。它只解決眼前的任務,不考慮六個月後維護這段代碼的人會不會罵娘。
所以harness不只是讓AI寫得快,還得讓AI寫得能維護。OpenAI的實驗證明了速度,但長期成本還是個問號。
回到他們怎麼做到的。Martin Fowler把harness拆成了三塊。
第一塊:上下文工程。給模型一張地圖,不是一本1000頁的說明書。維護一個持續更新的代碼庫知識庫,加上agent能實時看到的系統狀態。上下文是稀缺資源,塞太多反而擠佔幹活的空間。
第二塊:架構約束。不光靠AI自己檢查,還有代碼檢查器和結構測試在旁邊盯着。硬規則,不遵守就編譯不過。
第三塊:垃圾回收。專門有個agent週期性運行,不寫代碼不做功能,就幹一件事:找文檔裏的矛盾和架構違規。一個專職找茬的AI。
Anthropic走了另一條路。他們搞了個三agent架構:規劃者負責把簡單指令擴展成詳細的產品規格,生成者按迭代一次做一個功能,評估者跑端到端測試。
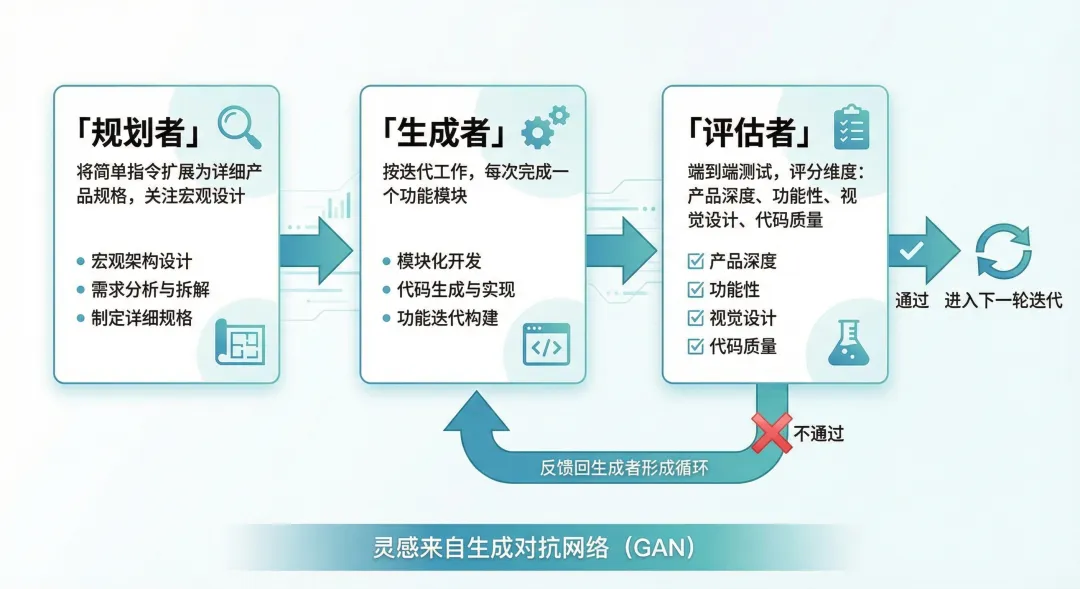
靈感來自生成對抗網絡。訓練一個專門的評估者讓它一直挑刺,比讓生成者自己檢查自己管用得多。誰都不擅長批評自己,AI也一樣。
他們還發現Claude Sonnet 4.5有「上下文焦慮」。不是人焦慮,是模型焦慮。上下文太多,表現反而變差。壓縮不夠,必須定期清空重來。
所以harness不是越大越好。這可能是最反直覺的部分。
到這裏你可能想:這不就是給老東西起了個新名字嗎?
說實話,還真有點。
航天工程師60年前就在做類似的事。NASA讓飛船自動執行任務,圍繞自動化系統設計的約束、反饋循環、冗餘檢查、異常處理,和今天說的harness沒有本質區別。工業控制領域也一樣,PLC編程裏的安全聯鎖機制就是一種harness。
AI圈不是發明了harness engineering,是終於意識到自己需要學幾十年前就有的工程紀律。
但命名還是有價值的。當一羣人各自在做類似的事,沒有共同的詞來說,經驗就傳不開。這個詞出來之後,突然大家都能聊到一起了。就像Vibe Coding,你可以笑它,但它確實讓一種做法變成了可以討論的東西。
Harness Engineering也一樣。價值不在於發明了什麼,在於讓一羣人意識到:自己工作的重心變了。
我自己去年8月搭了Claude Code自動化寫作工作流。從那以後寫文章輕鬆太多,平時做做選擇,噴一噴不滿意的地方就好了。但讓這套系統好用的,不是模型有多強,是我圍繞它搭的那一圈東西。
CLAUDE.md從一個簡單的規則文件,變成了一個路由器。它就幹一件事:判斷當前任務屬於哪個工作區,然後指向對應的規則。寫公眾號時不會被iOS開發的規則干擾。
Hooks是另一層。在agent執行關鍵操作前後注入腳本。編輯文件之前自動跑linting,生成代碼之後自動做類型檢查。這不是prompt裏寫的「請注意代碼規範」,是物理上攔住它,不合格就不讓過。建議和約束,完全兩回事。
Skills解決了模塊化的問題。每個skill是獨立的能力包:一個管小紅書配圖,一個管飛書同步。平時不佔context,需要時才調。
路由器、hooks、skills、知識庫,加在一起就是一個harness。沒人告訴我這叫什麼,它自己長出來的。
這個生長方式,和Mitchell Hashimoto說的一樣。
他是HashiCorp聯合創始人,Terraform創造者,今年2月寫了「My AI Adoption Journey」,首次給這個實踐命名。方法極其樸素:每次agent犯錯,就工程化一個方案,讓它再也犯不了同樣的錯。他拿自己的終端模擬器Ghostty舉例,配置文件裏每一行都對應着agent過去犯過的一次錯。文件是活的,一直在長。
我的CLAUDE.md也是這麼長出來的。被AI搞煩了就加一條,規則太多了就砍一輪。活的系統。
如果你想開始,三條就夠。
給地圖不給說明書。CLAUDE.md應該像地圖:項目結構、文件關係、關鍵約束。不要把每步都寫死。AI需要方向感,不需要僵化步驟。
每次犯錯加一條規則。空文件開始,agent犯一個錯就加一條。三個月後那個文件就是你的harness。高度定製,因為全是你場景裏真實出過的問題。
讓AI查AI。Anthropic的Evaluator思路。別讓AI自己查自己。最簡單的做法:寫完後開一個新對話,把結果貼進去:「找出所有問題」。你會驚訝第二個AI能發現多少第一個漏掉的。
最後聊一個我想了很久的問題。
Martin Fowler在文章裏說:如果太早把人類從「in the loop」移到「on the loop」,將來可能沒人真正懂得怎麼回事,也就沒人能設計好的harness。
這句話值得多讀兩遍。
現在設計harness的人,都是寫過很多年代碼的老手。Mitchell Hashimoto能給Ghostty寫好harness,因為他理解終端模擬器的每個細節。OpenAI那3個工程師能駕馭100萬行代碼,因為他們知道什麼架構是好的、什麼會在三個月後爆炸。
但下一代呢?新手程序員從第一天起就不寫代碼,只寫CLAUDE.md,他能設計出好的harness嗎?
Martin Fowler把這叫「經驗工程」。怎麼在AI寫所有代碼的時代培養新人。
我自己是個有意思的樣本。
我從來沒手寫過代碼,所有產品都是AI寫的。小貓補光燈上了AppStore付費榜Top 1,累計用戶超百萬。我的harness從零開始,在和AI互動中一點一點長出來,沒有任何編程經驗可以遷移。
但我得對自己誠實。
我能設計harness,不是因為我天生懂系統設計。是因為我在和AI協作的上千小時裏,觀察到了它的行為模式。它什麼時候偷懶,什麼時候幻覺,什麼時候需要硬約束而不是温柔提醒。這些判斷力不來自寫代碼的經驗,但來自另一種經驗:和AI反覆較勁的經驗。
問題是,這種經驗能教嗎?我自己說不清楚。
我知道CLAUDE.md該怎麼寫,但讓我教別人為什麼這麼寫,我會卡住。很多決定是直覺做的,直覺來自踩坑,踩坑來自大量重複,大量重複來自時間。這和老程序員說「你寫幾萬行代碼自然就懂了」其實是一回事。
所以問題可能不是「寫代碼的經驗」能不能被替代。而是:不管你積累的是什麼經驗,足夠多的經驗本身就是設計harness的前提。沒有捷徑,換了個賽道而已。
也許Martin Fowler擔心的不是「沒人寫代碼了」,而是「沒人願意花夠多時間踩夠多坑了」。
這個我也不確定。留給你想。