Harness 實踐:讓 Agent 自動製作知識講解視頻
整理版優先睇
作者分享點樣用Harness同Skill,將一篇文章自動轉化成可控嘅知識講解視頻,通過系統化流程取代隨機成功。
花園老師係「code秘密花園」作者,之前發布咗幾條技術講解視頻,好多讀者問呢個效果點樣做出嚟。佢澄清話視頻唔係用視頻生成模型或者NotebookLM,而係自己Vibe Coding出嚟嘅網頁,因為咁樣可控性更高、成本更低。為咗令更多人能夠復刻呢個效果,佢將成個流程封裝成一個Skill,呢篇文章就係剖析呢個Skill嘅設計,同埋點樣透過Harness實踐令Agent穩定產出。
呢篇文章從Harness角度拆解咗六個核心部分:執行編排、上下文管理、狀態與記憶、工具系統、約束恢復、評估觀測。重點係點樣令Agent唔係自由發揮,而係跟住流程、有檢查點、有自檢機制。例如,將任務切分成四個階段,中間設兩個人工檢查點;用文件化工作記憶保持跨步驟連續性;設計硬性自檢規則避免自評失真。呢啲係令Agent穩定做曬成件事嘅關鍵。
作者強調做Harness唔係要從零搭建Agent,而係用一個Skill將垂直開發工作做好。最終價值係將模型能力、工具能力同人嘅判斷組合成一條可重複執行嘅軌道。文章仲包含完整實戰流程,由安裝Claude Code、配置MiniMax、CC Switch、MMX CLI,到實戰演示點樣將一篇文章變成知識講解視頻,最終可以錄屏出片。
- 結論:用Harness系統嚟駕馭Agent,比單次prompt更可靠,可以穩定產出高品質嘅知識講解視頻。
- 方法:將流程拆成四個階段(內容編寫、開發、音頻合成、錄屏),中間設兩個人工檢查點,確保方向冇錯。
- 差異:作者揀網頁而唔係視頻生成模型,因為可控性更高;用CSS變量、獨立文件夾同主題token隔離並行開發,避免衝突。
- 啟發:評估觀測嘅關鍵係自檢規則,用獨立Reviewer Agent避免自評失真,嚴格逐項核查。
- 可行動點:讀者可以下載garden-skills倉庫嘅web-video-presentation Skill,跟住文章步驟由安裝工具開始,實戰生成自己嘅視頻。
web-video-presentation Skill
從文章自動生成知識講解視頻嘅完整Skill,包含流程規範同自檢機制。
CC Switch
桌面配置工具,用嚟將Agent切換為自定義模型,支援MiniMax Token Plan。
MMX CLI
MiniMax官方CLI,用嚟合成語音,與Token Plan配合使用。
點解用網頁而唔係AI視頻?
花園老師嘅視頻效果唔係用視頻生成模型或者NotebookLM做出嚟,而係自己Vibe Coding出嚟嘅網頁。原因只得兩個字:可控。
字體、配色、每一步停留幾秒、某一幀要唔要出現一個精確嘅數字——呢啲嘢喺網頁改幾行代碼就搞掂。
比起用視頻模型抽卡穩定得多,成本亦更低。NotebookLM做唔到動畫演示效果,Remotion呢啲框架反而限制模型發揮。
Harness設計:將模型能力編排成穩定流程
呢個Skill將複雜任務拆成四個階段,中間設兩個人工檢查點,確保方向正確。
- 1 階段一:內容編寫 — AI同時產出口播稿同開發大綱。
- 2 檢查點Plan — 人一次性對齊五件事。
- 3 階段二:開發 — 第一章驗證後並行開發後續章節。
- 4 檢查點Audio — 決定合成音頻。
- 5 階段三:音頻合成 — 用MiniMax CLI批量生成。
- 6 階段四:錄屏 — 瀏覽器全屏播放配合屏幕錄製。
上下文管理方面,Skill將信息拆成多份文檔,每份只在指定階段讀取,避免模型注意力被稀釋。
- SCRIPT-STYLE.md:口播稿規則
- OUTLINE-FORMAT.md:大綱格式
- CHAPTER-CRAFT.md:章節開發指引
- THEMES.md:主題選擇
- AUDIO.md:音頻合成流程
- RECORDING.md:錄屏指南
文件化工作記憶:將關鍵狀態寫入outline.md、script.md、article.md,需要時讀返。
評估同觀測層設計咗硬性自檢規則,關鍵產出必須經自檢→修復→再彙報流程,避免自評失真。
實戰:由安裝到出片完整演示
環境搭建需要四個工具:Claude Code、MiniMax、CC Switch同MMX CLI。
- 安裝Claude Code: curl -fsSL https://claude.ai/install.sh | bash
- 訂閲MiniMax Token Plan並取得API Key
- 下載CC Switch並配置MiniMax供應商
- 安裝MMX CLI用於語音合成
Claude Code做核心Agent,MiniMax提供穩定推理,CC Switch切換模型,MMX CLI合成音頻
然後安裝web-video-presentation Skill,將下載嘅文件放入.claude/skills目錄。
實戰開始:將文章丟俾Agent,使用Skill完成內容編寫、開發大綱、第一章開發、並行開發後續章節、質檢、音頻合成。最終有三種播放模式:手動、音頻模式、自動模式。
大家好,歡迎來到 code秘密花園,我是花園老師。
前段時間我發了幾條技術講解視頻,評論區好多同學問:這個視頻效果是怎麼做的?
趁着五一假期,我把整套流程封裝成了一個 Skill,讓大家也能低成本復刻這種效果。
今天這期內容信息量很大,我們要講三件事:
第一,我的視頻到底是怎麼做的;
第二,背後這個 Skill 是怎麼設計的;
第三,手把手帶大家走一遍完整的實戰流程 — 從一篇文章丟進去,到最後出來一個精美的知識講解視頻。
一、視頻到底咋做的
先聲明一下:我之前的視頻,不是用視頻生成模型做的,也沒有用 NotebookLLM。
其實就是網頁。我自己 Vibe Coding 出來的網頁。
肯定有人會問 — AI 視頻生成模型已經很強了,為什麼還要折騰網頁?
答案就倆字:可控。
字體、配色、每一步停留幾秒、某一幀要不要出現一個精確的數字 — 這些東西在網頁裏改幾行代碼就搞定。
比用視頻模型抽卡要穩定得多,成本也更低。
NotebookLM 我也試過,它做不了動畫演示效果,出來的都是靜態圖。
Remotion 這種框架,我覺得它反而限制了模型本身的發揮,有時候還不如直接寫來得好。
1.1 上期視頻
拿我上期發出的視頻舉個例子。那期視頻完全由 AI 生成,就是我為了這次教程專門做的一個演示。
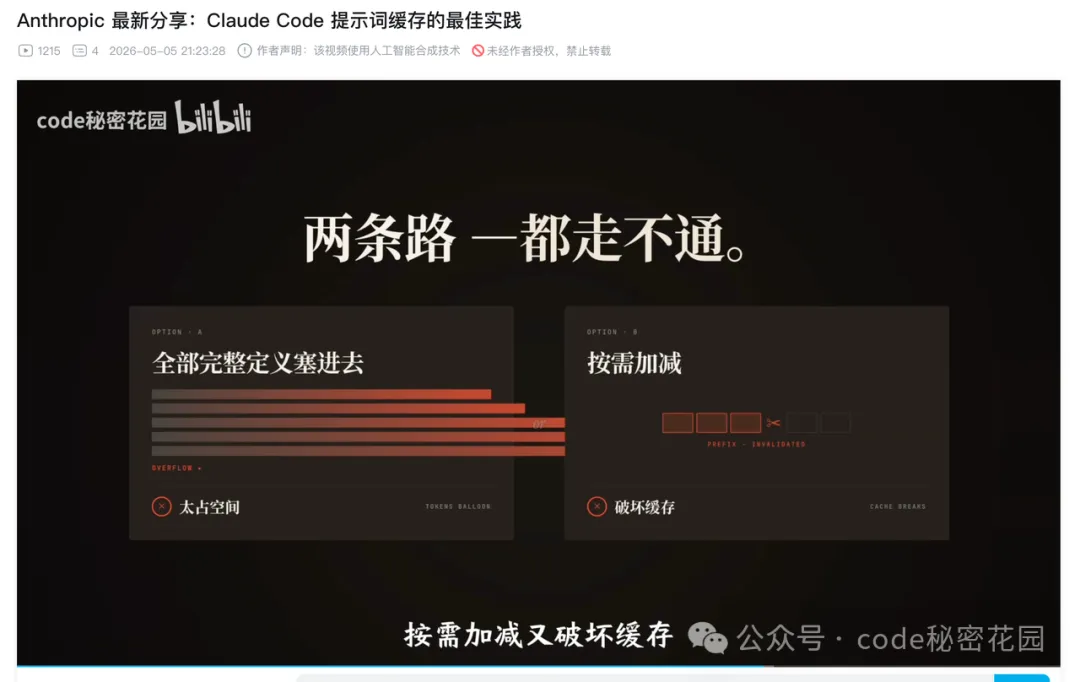
而我的輸入,就只是一篇 Anthropic 最新發布的文章:
https://claude.com/blog/lessons-from-building-claude-code-prompt-caching-is-everything
輸出就是這樣一個網頁:
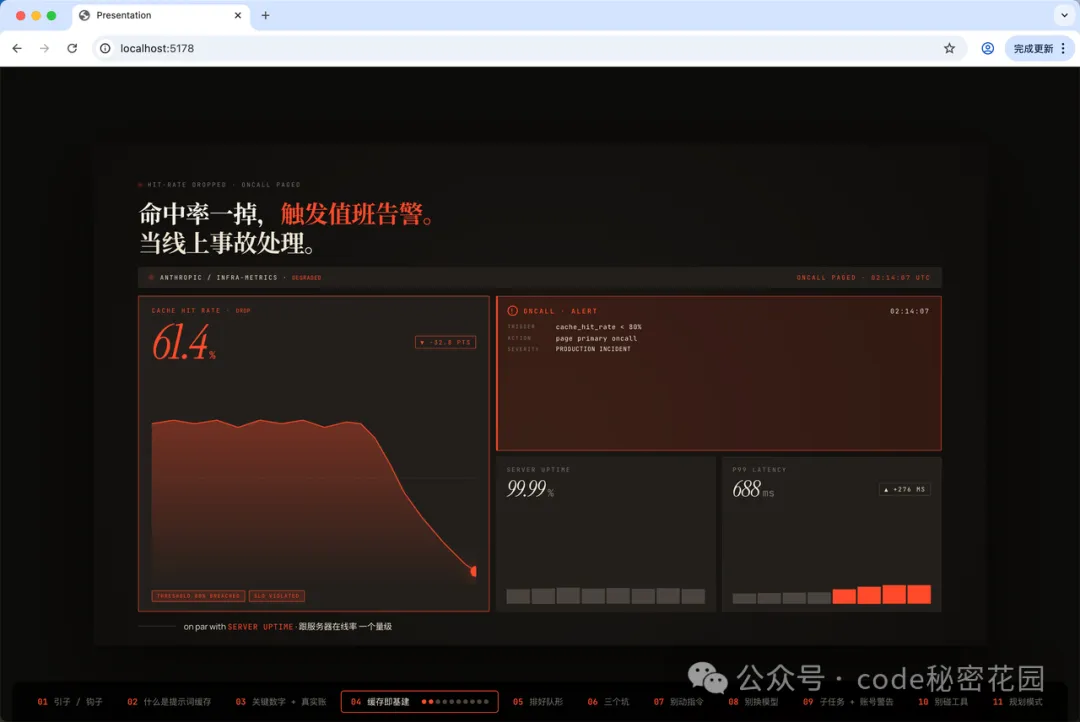
它把原始文章拆成了 13 個章節、100 多個細粒度的講解步驟,每一步都有完整的視覺演示效果。
畫布固定在 16:9,可以適配任意大小的顯示器。
底部有一個隱藏的進度條,鼠標懸浮到底部才出現,你可以自由跳轉到任意章節的任意步驟。
畫面裏沒有頁眉、沒有頁碼、沒有品牌標識。
錄屏時觀眾看到的就是一塊乾淨的畫面,讓它看起來更像視頻,而不是網頁。
1.2 關鍵流程
想要做出這樣的效果,有幾個關鍵要點:
把文章變成口播稿:
一般原始技術文章的句式會比較書面 —
比如 "該工具旨在提供高效的解決方案" 這種話術是沒辦法直接在視頻裏年出來的?
如果是 "這玩意兒是幹嘛的呢? "短句、口語、第二人稱,就像跟人聊天一樣。
把口播稿拆成開發大綱。
每段話都應該對應一個畫面步驟,每幾個步驟組成一個章節,每章聚焦一個話題。
因為整個開發任務會非常複雜,做好大綱是保持後續開發穩定性的關鍵。
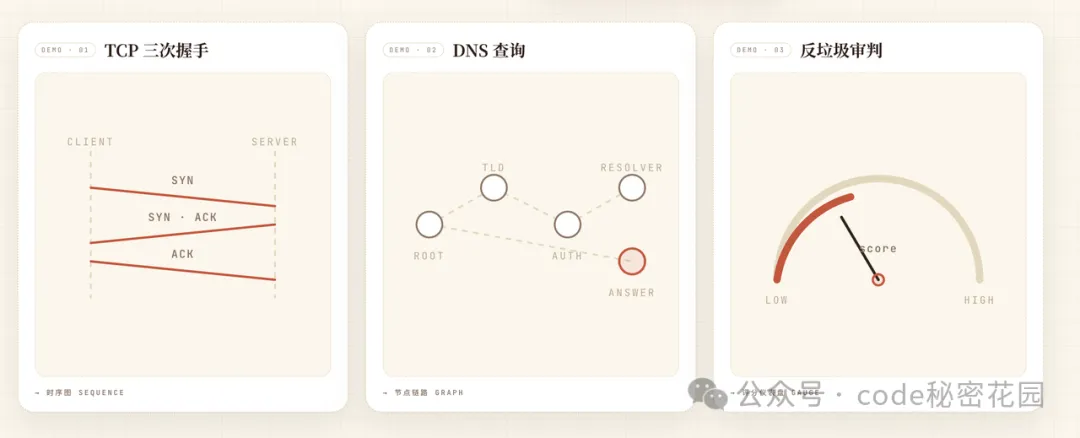
給每步做視覺演示。
不是把文字糊上去就完事。
TCP 三次握手要畫時序圖,DNS 查詢要畫節點鏈路,反垃圾審判要畫評分儀表盤。得把抽象概念"演"出來。

讓步驟和口播對齊。
網頁的關鍵演示步驟一定要跟隨口播稿的節奏走,這樣做出的視頻效果才能顯得非常自然。
1.3 為什麼要做成 Skill
上面這些事情,你全部都可以交給 Agent 一步步去做,也確實能做出來。
模型並不缺能力。但問題是:
怎麼讓它每次都做得出來? 怎麼讓不同的人、不同的文章、不同的主題,都能穩定產出? 怎麼讓開發效率不依賴運氣?
你直接跟 Agent 說 "幫我做個視頻網頁",它可能做得不錯,也可能跑偏。
比如稿子和畫面對不上了,章節數和音頻數不一致了,後面章節的風格突然跟前面完全不搭了。這些都是有可能發生的

模型有能力,但你需要一套系統來駕馭這個過程 — 劃定邊界、管理狀態、設立檢查點、在關鍵節點攔住錯誤。
這就是 Harness 要負責的事情。所以我做了這個 Skill。
二、web-video-presentation Skill
Skill 是 Agent 通用的擴展能力標準,你可以理解為一份 "操作手冊" — 它告訴 AI 什麼時候該做什麼、做到什麼標準、哪些紅線不能碰。
AI 加載 Skill 後按裏面的規則幹活,你不用每次重述這些規矩。

我們這個做視頻的 Skill 和花園老師其他開源 Skill 一起託管在 garden-skills (https://github.com/ConardLi/garden-skills) 倉庫裏。
在我們之前的教程中有講到,一個成熟的 Harness,通常至少包含下面六個核心部分:
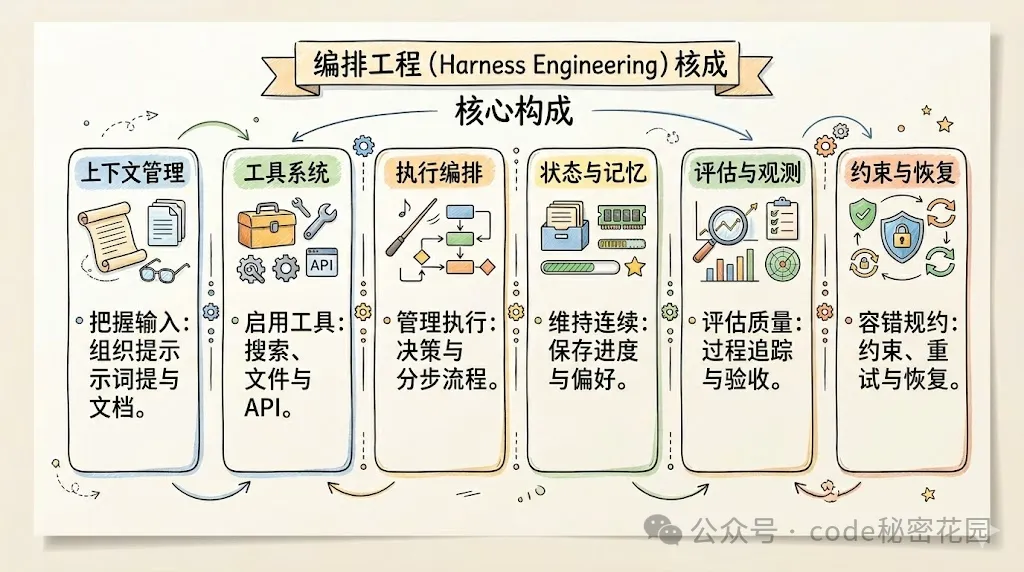
| 核心部分 | 它解決的問題 | 典型作用 |
|---|---|---|
下面,我們就從 Harness 的角度拆解下這個 Skill 的核心設計。
2.1 執行和編排
執行和編排解決的是讓模型知道 “下一步該做什麼” 的問題。
整個 Skill 把 "從一篇文章到視頻" 切成了四個階段,中間卡了兩個人工檢查點。
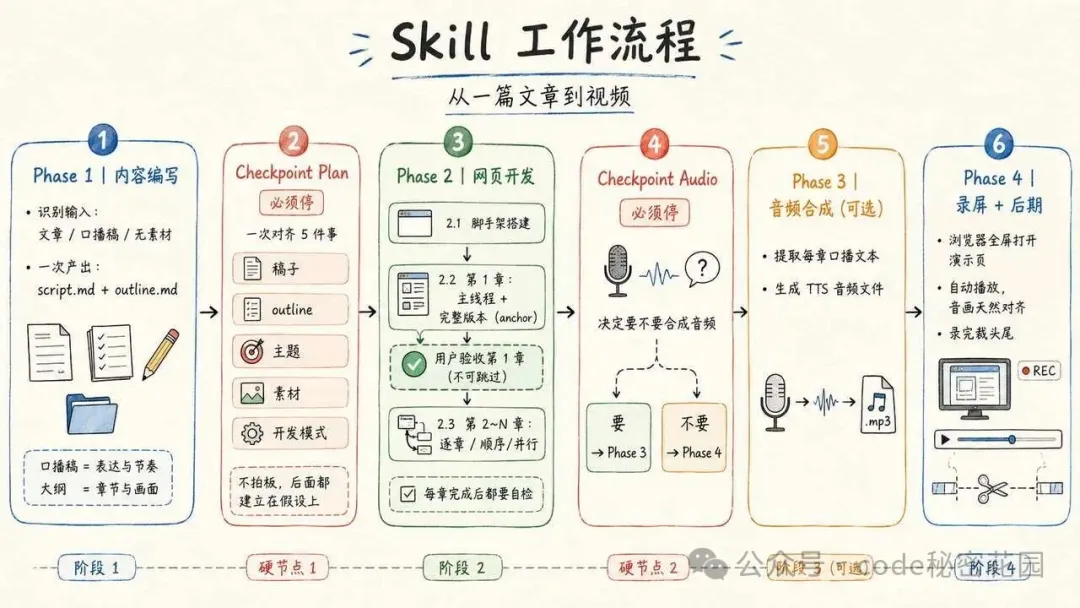
階段一:內容編寫。 AI 同時產出兩樣東西 — 口播稿和開發大綱。口播決定信息的描述方式以及整體節奏,大綱決定每章做幾步、每步屏幕上放什麼信息。 檢查點 Plan。Agent 走到這裏會被強制停下來。人一次性對齊五件事:稿子要不要改、大綱要不要改、用哪套主題、真素材誰準備、後續章節是逐章做還是並行做。這五件事不拍板,後面的工作全建立在假設上。 階段二:開發。 第一章必須經人驗收,確認視覺氣質和節奏都對了,它才成為後續章節的基準。之後的章節可以順序做,也可以開多個子進程並行寫。每章寫完都要逐項對照清單自檢,不過關不準說"做完了"。 檢查點 Audio。 再停一次。決定要不要合成音頻。要的話走階段三,不要的話跳到階段四用人聲錄。 階段三:音頻合成。 從每章的口播文本里提取合成清單,調 TTS 逐段生成音頻文件。 階段四:錄屏。 瀏覽器全屏打開演示頁,開自動播放模式,音頻和畫面天然對齊,錄完裁頭尾。
工作流程很清晰,重點是怎麼讓 Agent 在每個環節裏不跑偏。
2.2 上下文管理
上下文管理要回答的核心問題是:模型到底看到了什麼。
這個 Skill 的鏈路跨了四個 Phase,涉及多個複雜流程(口播稿規範、outline 格式、章節開發指引、主題 token、音頻合成流程、錄屏指南……)。如果在 Skill 啓動的時候就把所有文檔一股腦灌進去,模型注意力會被嚴重稀釋。
所以我把所有的信息拆成了多份文檔,每份文檔只在指定的階段讀取:
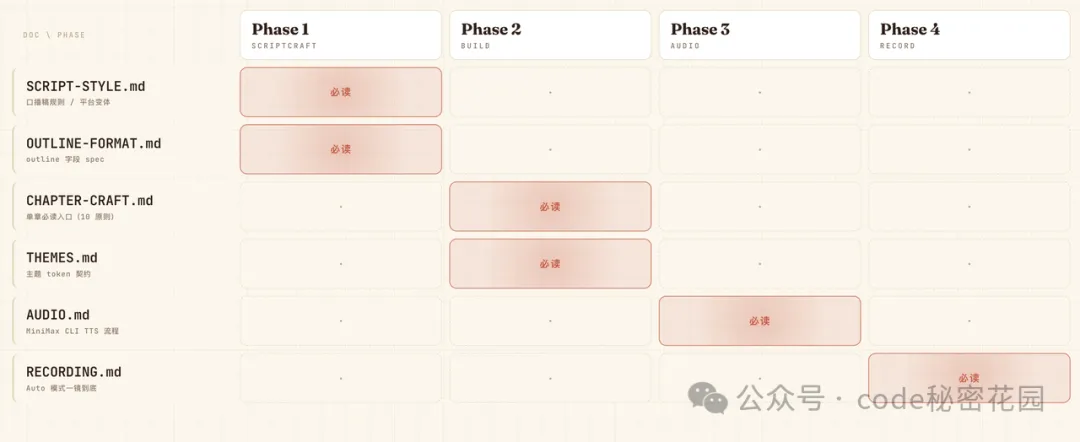
SCRIPT-STYLE.md: Phase 1.2 必讀:文章 → 口播稿規則、平台變體(雙層自檢:形式/風骨/念出來)OUTLINE-FORMAT.md: Phase 1.2 必讀:outline.md 字段 spec、命名約定、章節切分、信息池規則CHAPTER-CRAFT.md: Phase 2.4 每章單一必讀入口:Part 0 十條原則 / Part 1 開工 5 問 / Part 2 關係→動作決策樹 / Part 3 視覺工具箱 / Part 4 時長參考 / Part 5 反 AI 味反模式 / Part 6 代碼硬規則 / Part 7 完工自檢 / Part 8 反饋速查THEMES.md: 選/造/切主題時讀:完整 token 契約 + 內置主題清單 + 創作新主題流程AUDIO.md: Phase 3 才讀:MiniMax CLI TTS 合成流程、增量合成、故障排查RECORDING.md: Phase 4 才讀:錄屏工具推薦、Auto 模式一鏡到底、後期合成
2.3 狀態與記憶
狀態與記憶要回答的問題是:系統如何跨步驟保持連續性。
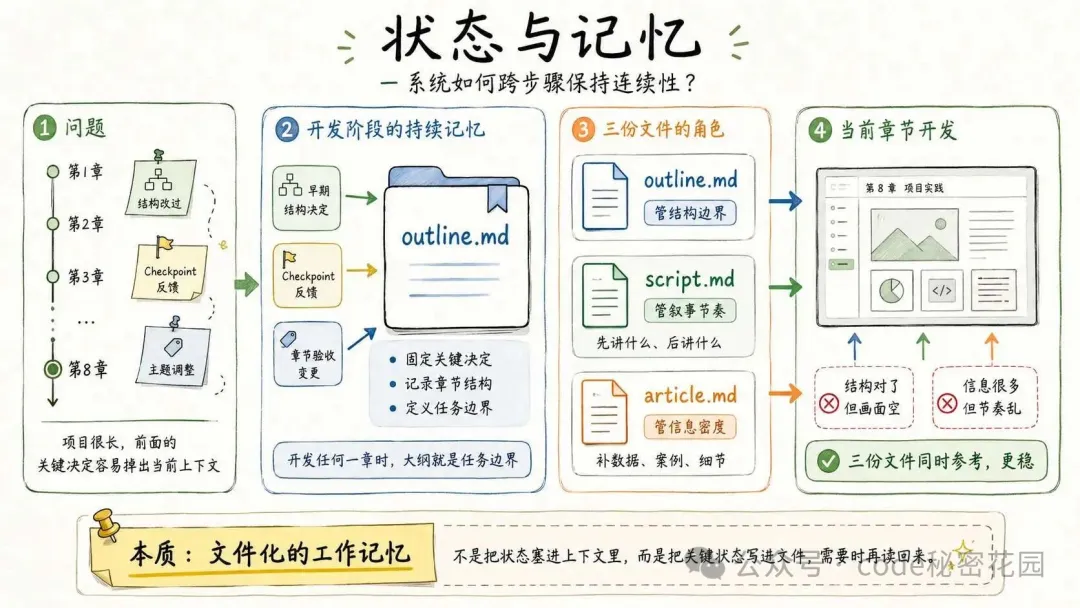
在這個 Skill 裏,最重要的 “記憶” 就是 **outline.md**(開發大綱)。
一個項目十幾章、幾十個步驟,Agent 寫到第 8 章時,前面章節定過什麼結構、用戶在 Checkpoint 裏改過什麼方向、某一章驗收時調整過哪些主題,很可能已經不在當前上下文裏了。
大綱的作用,就是把這些關鍵決定固定下來,成為開發階段的持續記憶。
Agent 開發任何一章時,大綱就是任務邊界。
在真正開發的階段,Skill 還會讓 Agent 每輪強制關注下面兩個文件:
**script.md**(口播稿)負責節奏:先講什麼、後講什麼,畫面要跟着口播走。**article.md**(原文章)負責信息密度:口播稿通常更精簡,畫面裏需
要的數據、案例、可以從原文裏補。
這三份文件各有分工:大綱管結構邊界,口播稿管敍事節奏,原文章管信息密度。
Agent 開發每一章時同時參考它們,就不容易出現 “結構對了但畫面空” 或者 “信息很多但節奏亂” 的問題。
本質上,這是一種文件化的工作記憶:而是把關鍵狀態寫進文件,需要時再讀回來。
2.4 工具系統
工具系統要回答的問題是:模型到底能做什麼。
這個 Skill 中並沒有特殊的工具,所以我們的目標就是讓模型把 Agent 本身的文件讀寫工具用好。
在章節的具體開發流程中,支持並行開發的模式。
但並行開發有一個致命問題:多個 Agent 同時改同一個項目,會不會互衝突?
Skill 的為此設計了嚴格的隔離機制:

每章獨立文件夾:
src/chapters/01-intro/、src/chapters/02-core/……物理分離,你改你的文件夾,他改他的文件夾。每章獨立 CSS 前綴:
.intro-hero、.core-card……不會出現兩個章節搶同一個 class name 的情況。主題 token 兜底視覺統一:顏色、字體、間距走全局 CSS 變量,所以即使每個 subagent 獨立開發,最終畫面在色彩和排版上不會跑偏。
但風格不強求一致:每章的動畫、節奏、視覺演示方式允許不一樣。
2.5 約束與恢復
約束與恢復要回答的問題是:出錯了怎麼辦,怎麼避免跑偏。
在這個 Skill 裏,"出錯"最常見的形式不是代碼報錯,而是用戶覺得不對。
比如"這一章節奏太快了"、"這個動畫太 AI 味了"、"這步信息太薄了"。
面對這類反饋,Agent 的本能反應是:重做整章。
畢竟重新生成對 Agent 來說成本不高,而且能保證 "把你說的問題都解決了" 。

但重做整章的問題是:它會把已經對的部分也改掉。
用戶說"第 3 步節奏太快",你重做整章,結果第 1 步和第 5 步原來很好的動畫效果也變了 — 用戶反而更不滿意。
所以 Skill 裏有一條原則叫反饋修復的最小切片:
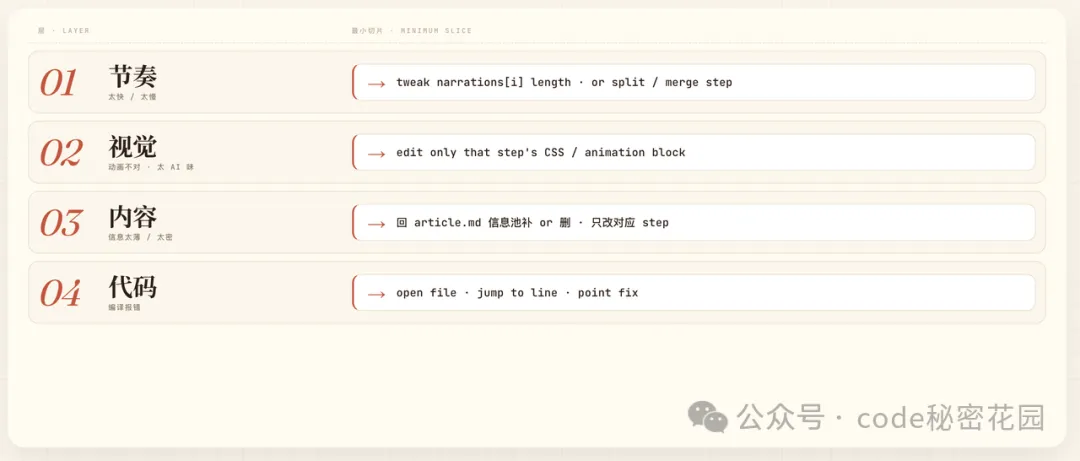
先定位問題在哪一層(節奏?視覺?內容?代碼?),再改最小切片,不要重做整章。
| 問題層 | 最小切片 |
|---|---|
2.6 評估與觀測
評估與觀測要回答的問題是:系統怎麼知道自己做得對不對。
這一層是我在設計這個 Skill 時花心思最多的地方,因為它直接對應 Anthropic 提出的核心問題 — 自評失真。
讓寫代碼的 Agent 自己評價"這章寫得怎麼樣",結果幾乎一定是"還不錯"。
它不會告訴你"這一步的動畫其實是無腦淡入,沒有內容驅動""這個列表一次性全展示了,違反了逐步揭示原則" — 因為它自己寫的,它當然覺得合理。
所以我設計了一套硬性自檢規則。
每個關鍵產出完成後,必須走自檢 → 修復 → 再彙報的流程:
| 產出 | 自檢清單 |
|---|---|
更關鍵的是執行方式:
最優:使用 Agent Teams(目前僅 Claude Code 支持)開一個獨立的 Reviewer Agent — 給它產出文件路徑 + 對應清單 + 上下文,讓它從零開始逐項核查。
次優:沒有 Agent Teams 能力就用 SubAgent,走同樣流程。
兜底:當前 Agent 自己逐項核查。但即使是自檢,也必須 "嚴格逐項",不允許目測一遍就放行。
2.7 回過頭看
把這個 Skill 的設計攤開來,你會發現它和 OpenAI、Anthropic 做的事本質上沒有區別 — 都是在搭 Harness。
只不過他們搭的是工業級的運行系統,我們搭的是一個 Skill 級別的協作協議。
這裏也要跟大家明確一個誤區,做 Harness 並不是要從零搭建一個 Agent,能用一個 Skill 把一個垂直的開發工作做好,也是在做 Harness。
下面,我們進入實戰章節,從零跑通環節大家,並且使用這個 Skill 完成一個文章到視頻的製作流程。
三、環境搭建
這條鏈路裏主要會用到四個工具。
3.1 Claude Code
首先我們選擇 Claude Code 作為我們的核心執行 Agent。
注:如果你本地使用 Cursor、Codex 以及其他支持 Skill 的 Agent 都是可以的。
安裝命令:
curl -fsSL https://claude.ai/install.sh | bash
裝好之後,在終端裏輸入:
claude -v
可以測試是否正常安裝成功。
3.2 MiniMax
相信大家都知道,在國內正常使用 Claude Code 是非常困難的,我自己也被封了好幾個賬號了。
目前推薦的做法是搭配一個國產模型來使用,經過大量的試用,我自己目前的選擇是 MiniMax。
MiniMax 的 Token Plan 和 Claude Code 的適配非常好,我訂閲了 Plus 的極速版,速度非快、量大管夠、性價比非常高,對於我日常的需求開發完全夠用了。
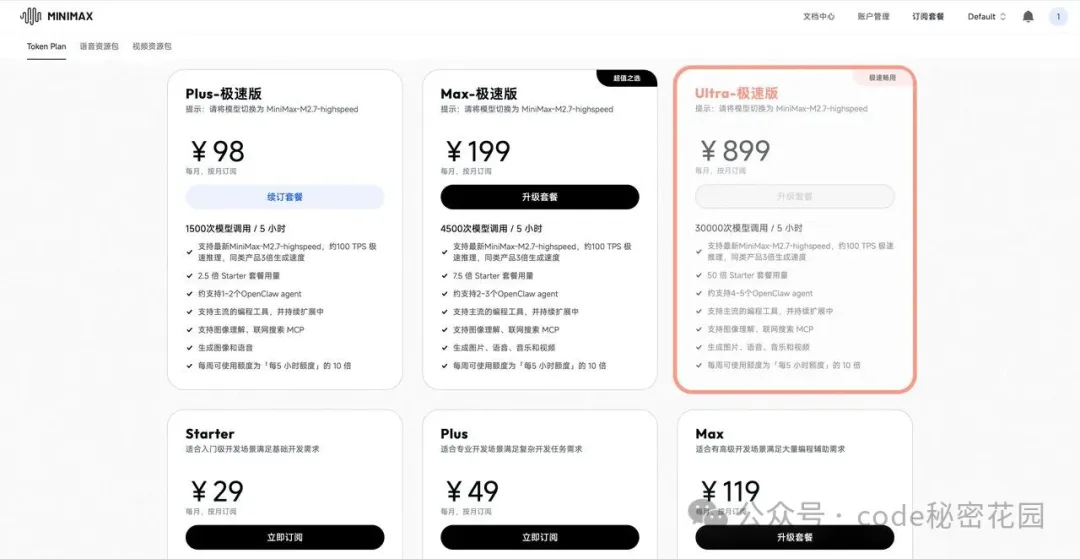
訂閲完成後,會生成一個 API Key ,這個提前存好後面會用到:
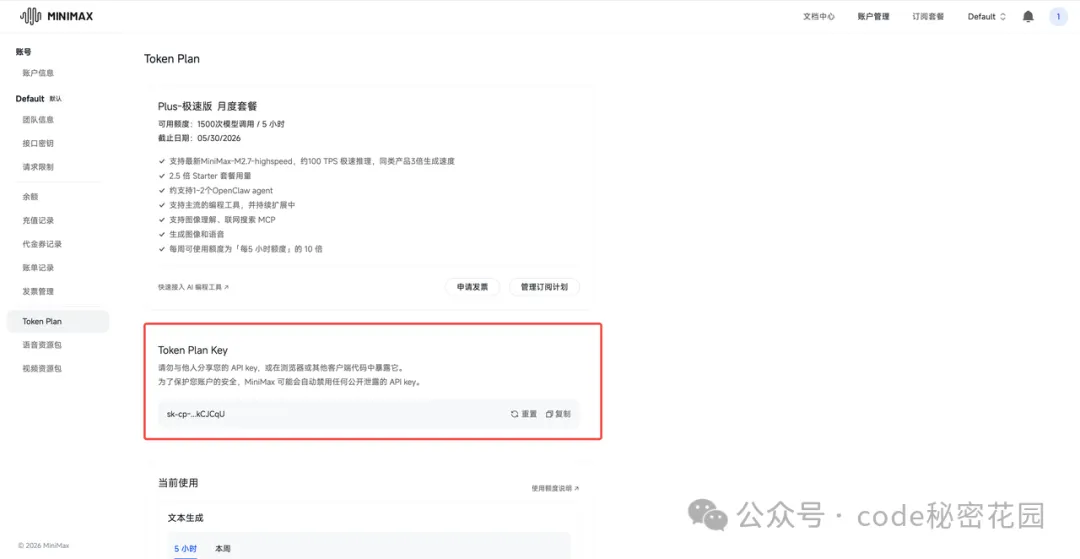
3.3 CC Switch
CC Switch 是一個桌面配置工具,可以讓我們的 Agent(Claude Code、Codex、Gemini CLI)切換為任意的自定義模型。
在這套流程裏,我主要用它來配置 MiniMax 的 Token Plan。
直接到它的 Github Release 頁面 https://github.com/farion1231/cc-switch/releases/tag/v3.14.1 就可以下載指定系統(如 MacOS)的安裝包:
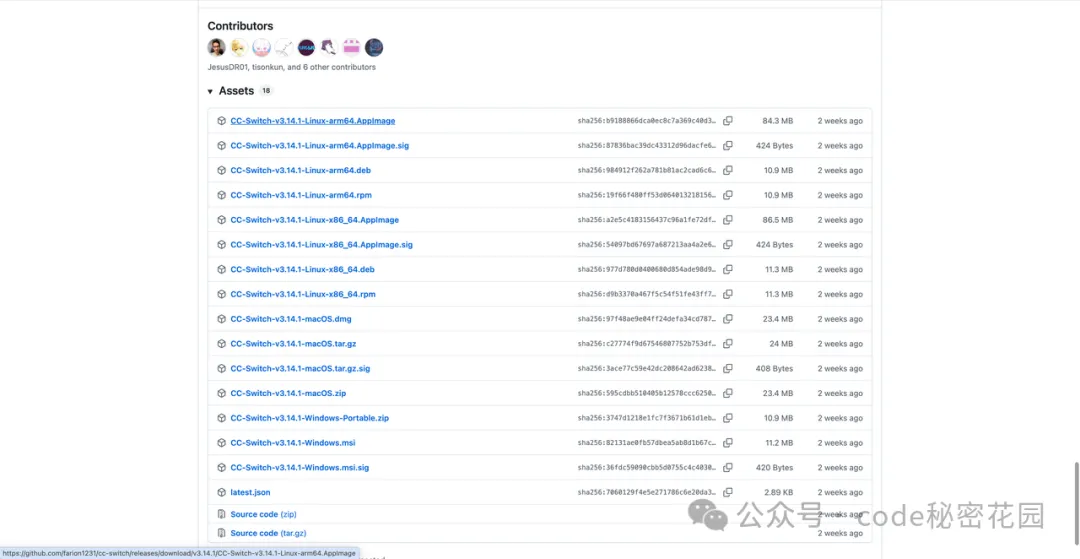
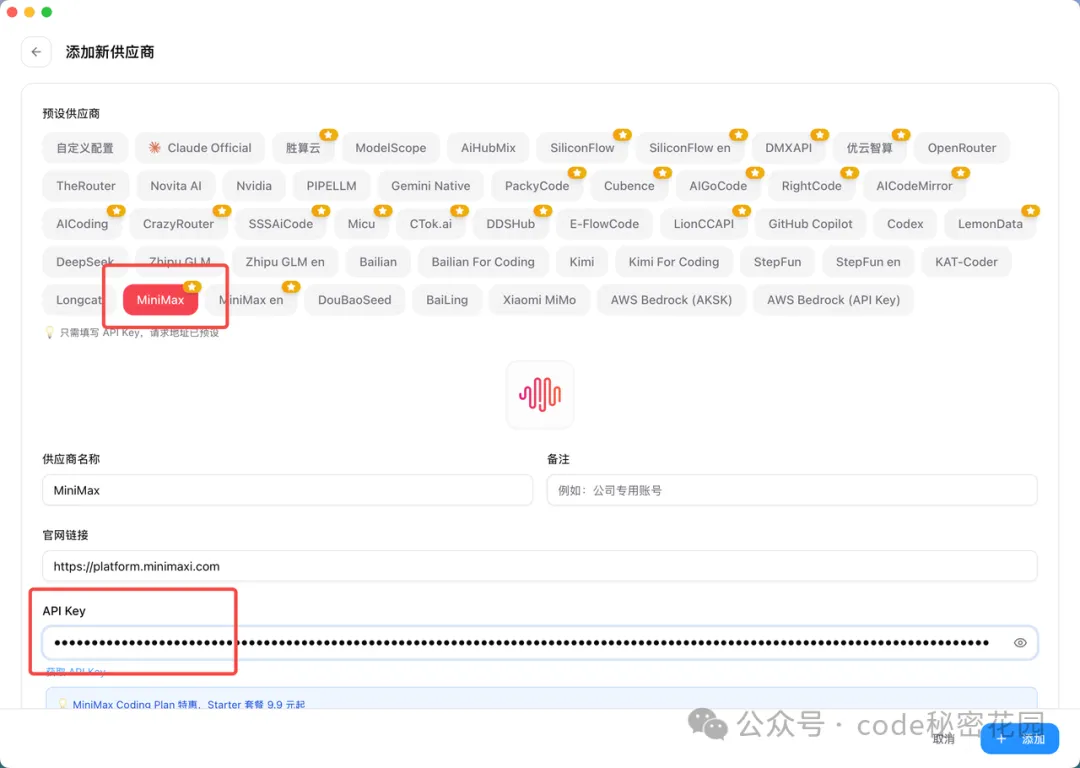
點擊右上角 ”+” ,選擇預設的 MiniMax 供應商,然後填寫上一步保存的 API Key:
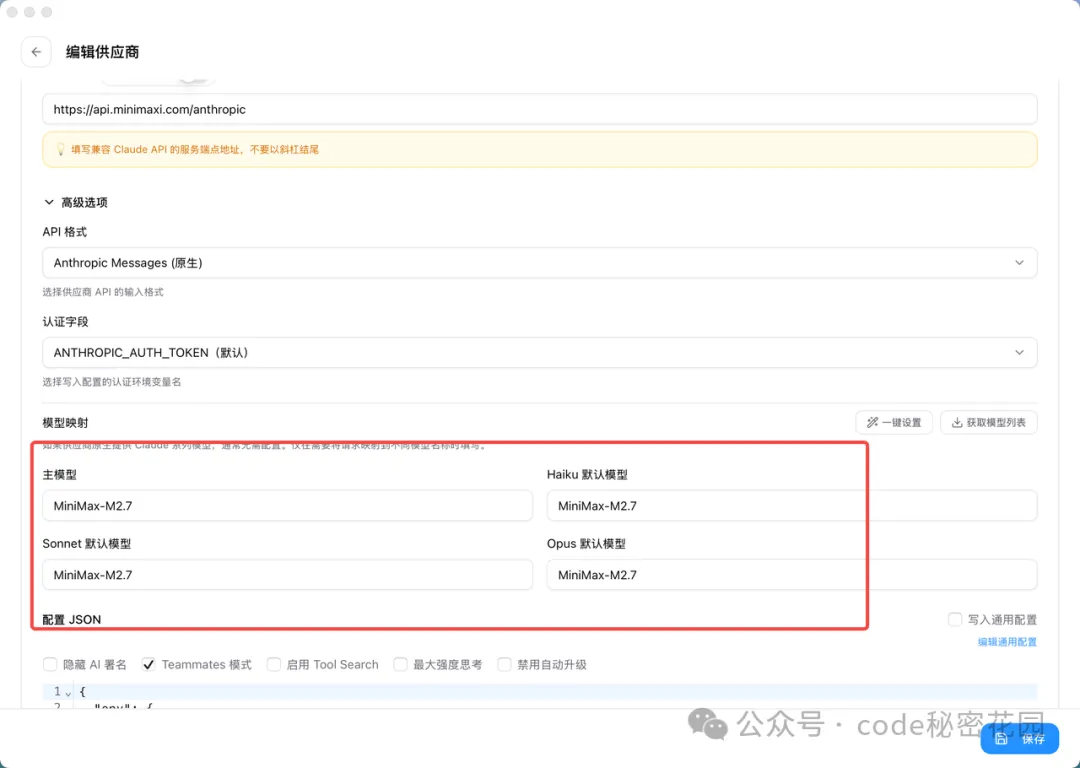
然後把模型名稱全部改為 MiniMax-M2.7,然後直接點擊保存就可以使用了:
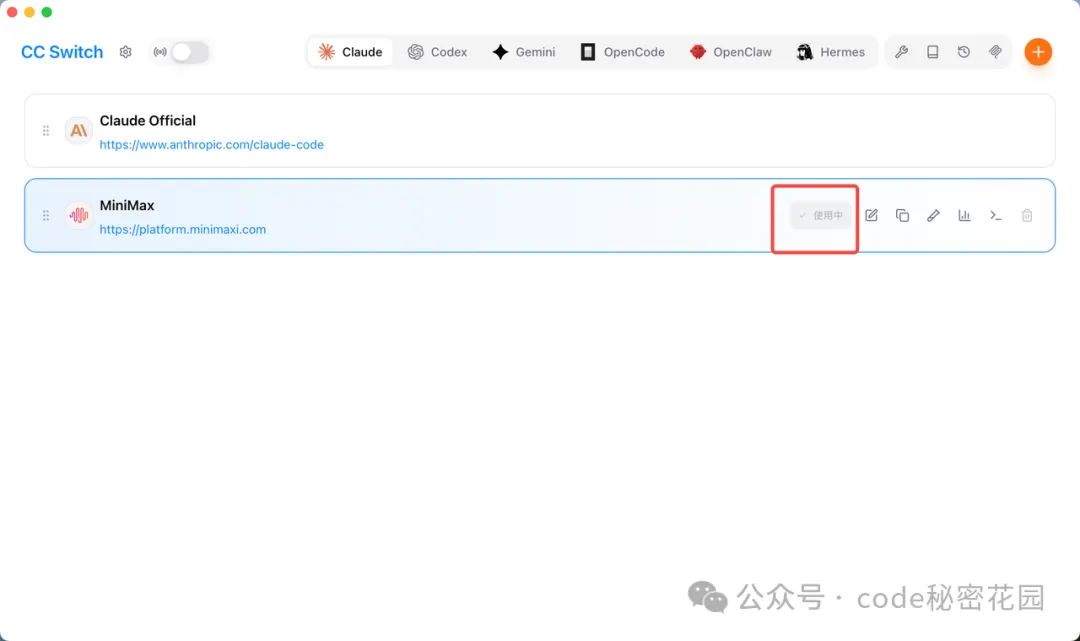
回到首頁,點擊 “啓用”
下面,我們打開終端輸入 claude ,就可以直接使用了:
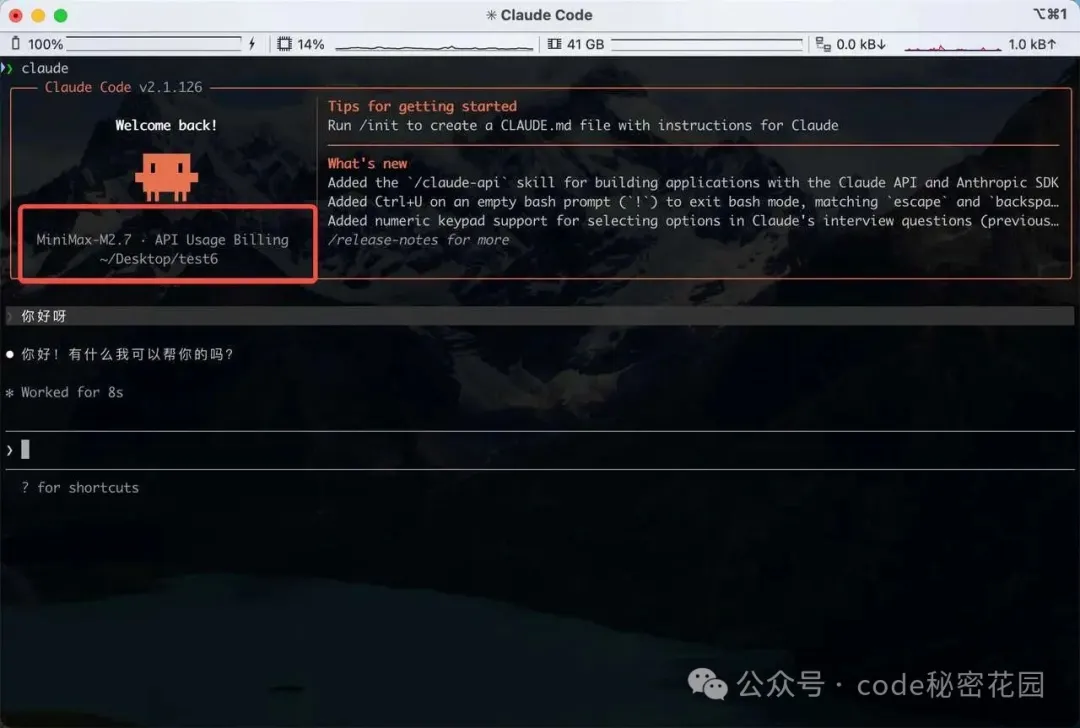
3.4 MMX CLI
相比其他家,MiniMax 的 Token Plan 還有一個明顯的優勢,就是還附帶了多模態的套餐(圖片、語音、視頻):
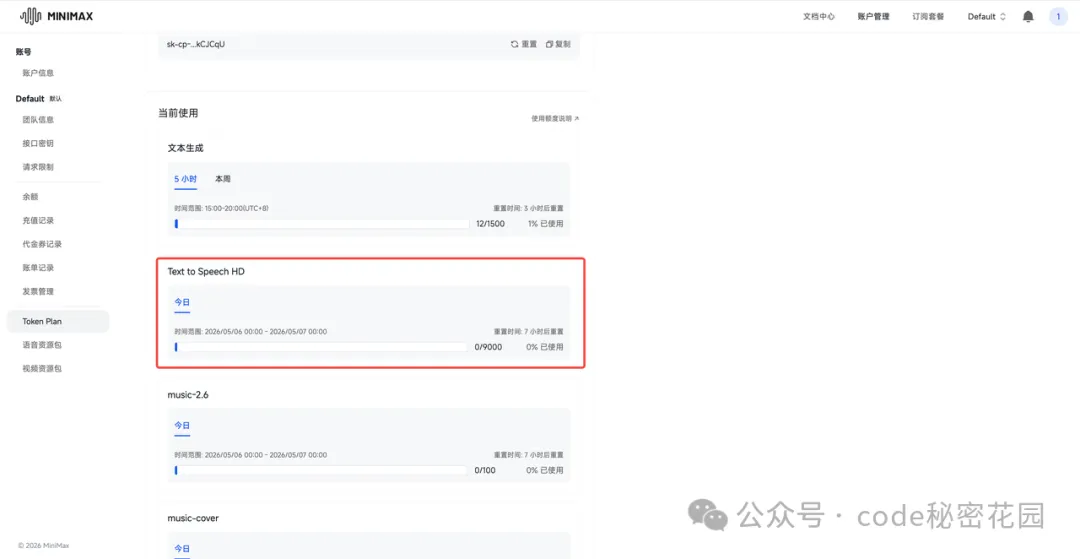
在今天的教程中,有一個關鍵環節就是要將文章的口播稿合成音頻,MiniMax 的 Token Plan 自帶了每天 9000 字的語音合成額度, 做兩篇文章完全夠用了。

為了方便大家使用這些多模態的能力,MiniMax 官方還提供了一個 CLI,我們不用寫一行代碼,Agent 就可以直接調用 mmx cli 完成語音合成等工作。
安裝也非常簡單,直接把下面這段話發給你的 Claude Code,注意密鑰替換為你 Token Plan 的密鑰:
幫我安裝 MiniMax CLI:https://github.com/MiniMax-AI/cli
我的密鑰是 sk-cp-xxxxx
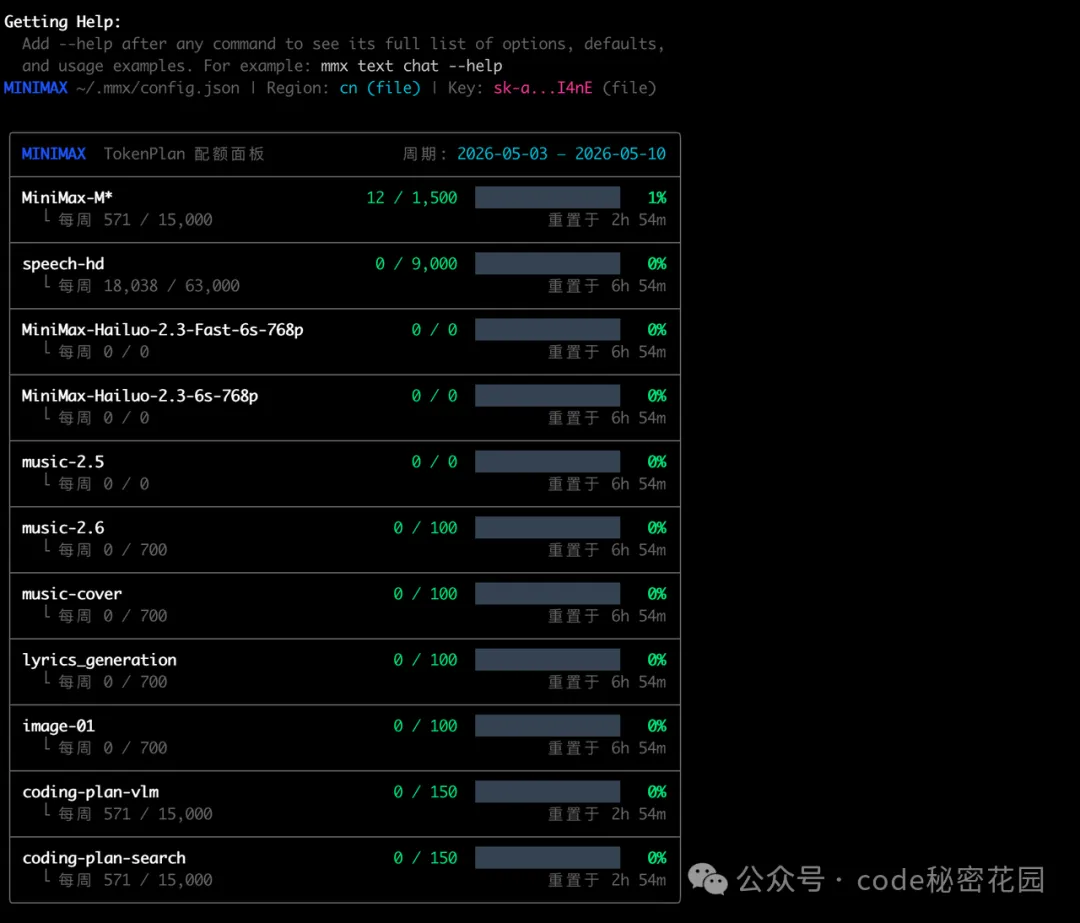
安裝完成後直接在本地執行:mmx,如果能列出下面的信息就代表安裝成功:
3.5 安裝 Skill
下一步安裝我們的 Skill ,首先我們訪問這個 Github 地址:https://github.com/ConardLi/garden-skills/
然後找到 [web-video-presentation](https://github.com/ConardLi/garden-skills/blob/main/skills/web-video-presentation) Skill 的下載地址,直接點擊下載這個安裝包:
下載完成後解壓得到 Skill 具體目錄:
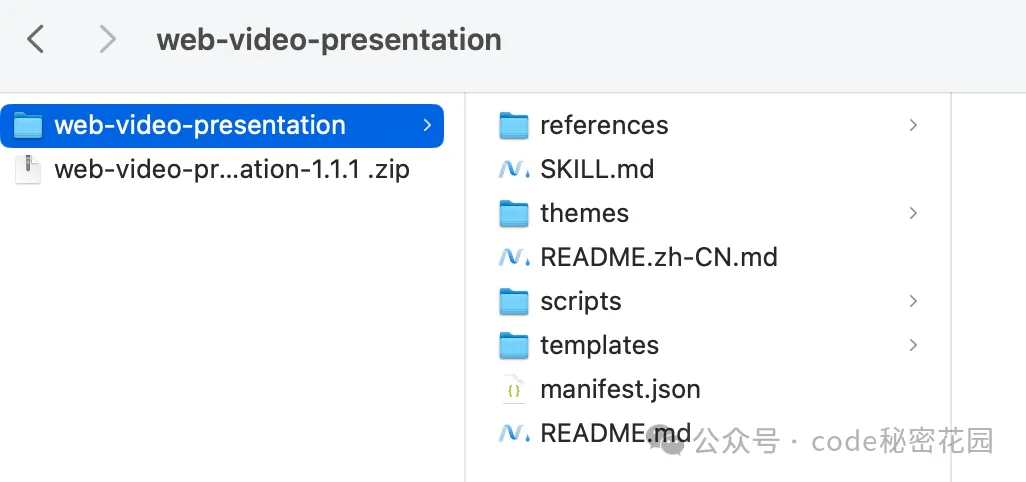
然後在你的工作目錄新建 .claude/skills 目錄,把這個文件夾粘貼進去:
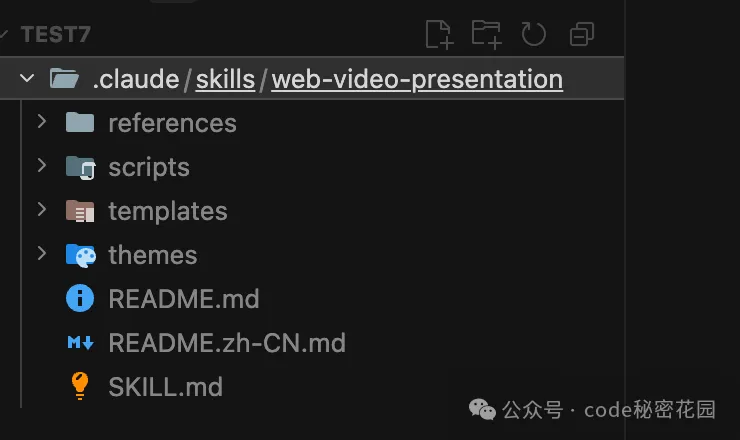
然後在這個目錄啓動 Claude Code,如果輸入 /web-video 能夠智能提示出這個 Skill ,說明配置成功:
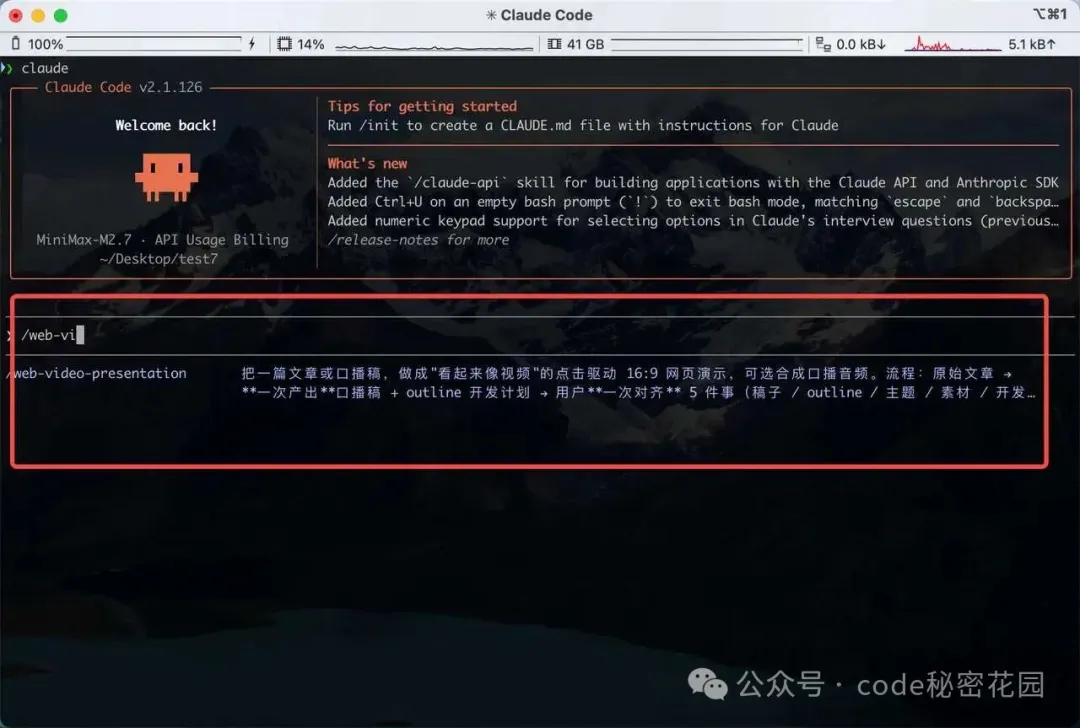
3.6 Agent Teams 和 tmux(可選)
這一步配置是可選的。如果只是做一個小 Demo,一個 Claude Code 會話就夠了。
但如果你要做的是一個 10 章、100 多步的視頻項目,讓一個 Agent 從頭寫到尾會很慢。
由於 Skill 在設計上對視頻的多個章節做了嚴格的物理隔離,天然支持了多 Agent 並行編寫的模式。
這裏我們先順便講一下 Claude Code 中支持的兩種多 Agent 工作的能力:SubAgent 和 Agent Teams。
SubAgent 更像一個子進程。
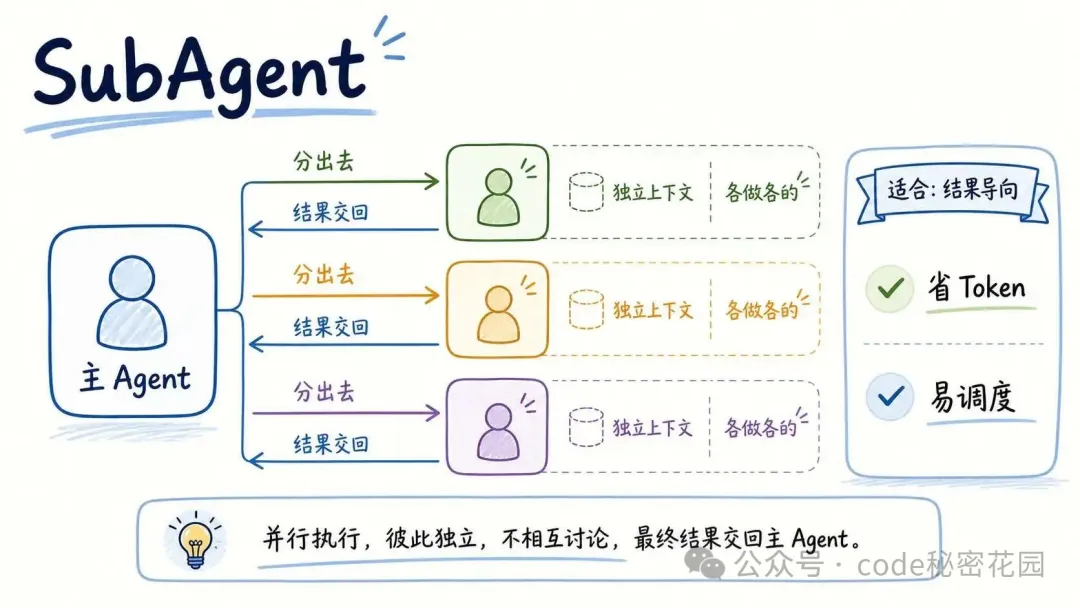
主 Agent 把一個任務分出去,子 Agent 在自己的一個完全獨立的上下文裏完成,然後把結果交回來。
子 AI 之間互相看不到,也不會討論。
比如你讓三個 SubAgent 分別寫三個章節,它們就是各寫各的。最後主 AI 再把結果收回來。
這種方式適合結果導向的任務。
比如並行開發多個章節,或者一次性檢查某段代碼。它比較省 Token,也比較容易調度。
Agent Teams 則更像一個小項目組。
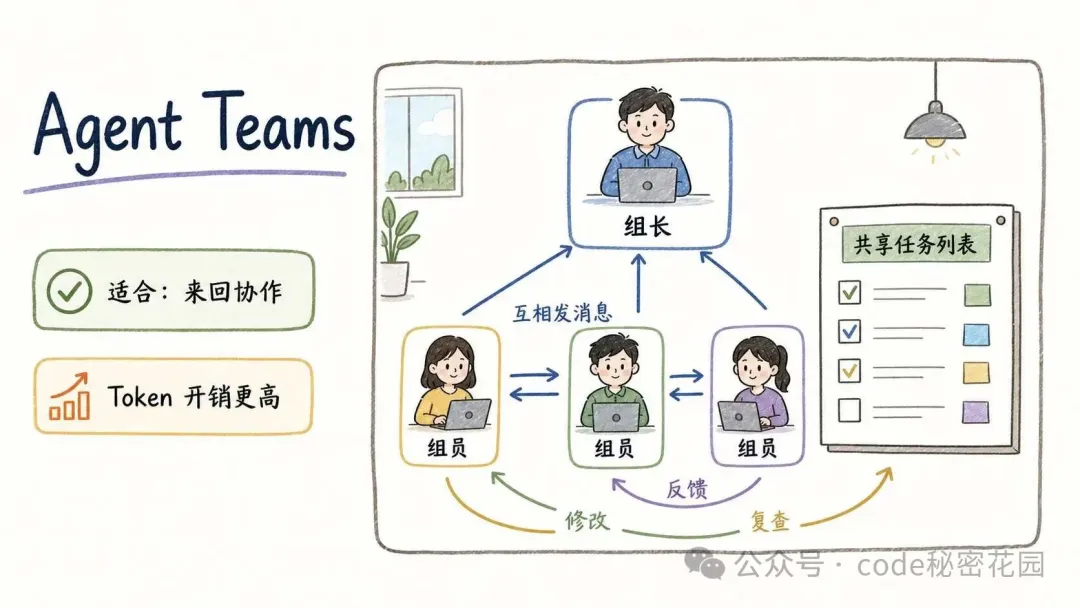
一個組長,加幾個組員。每個組員都是獨立會話,但它們之間可以互相發消息,也可以共享任務列表。
這種方式適合需要來回反饋的任務。
比如質檢。Reviewer 看完代碼後發現字號太小,就讓 Developer 改大。
Developer 改完,Reviewer 再複查。這個過程用 SubAgent 做會比較彆扭,但 Agent Teams 很適合。
代價也很明顯:Token 開銷更高。因為每個組員都是一個完整會話。
可以這麼理解:
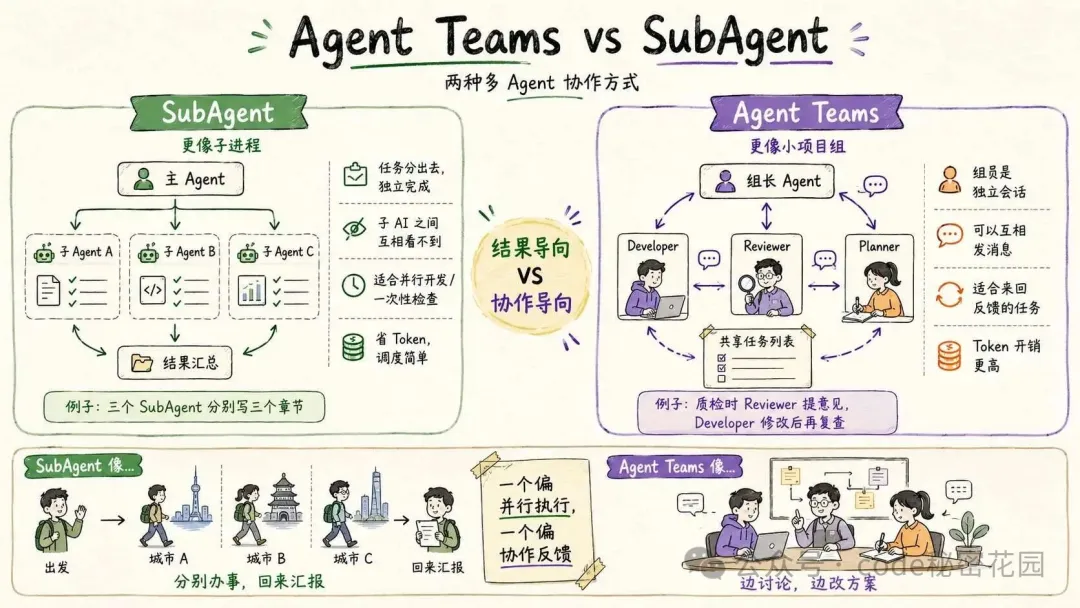
subAgent 像是你讓三個人分別去三個城市辦事,辦完回來彙報。
Agent Teams 像是你把三個人拉進一間會議室,讓他們邊討論邊改方案。
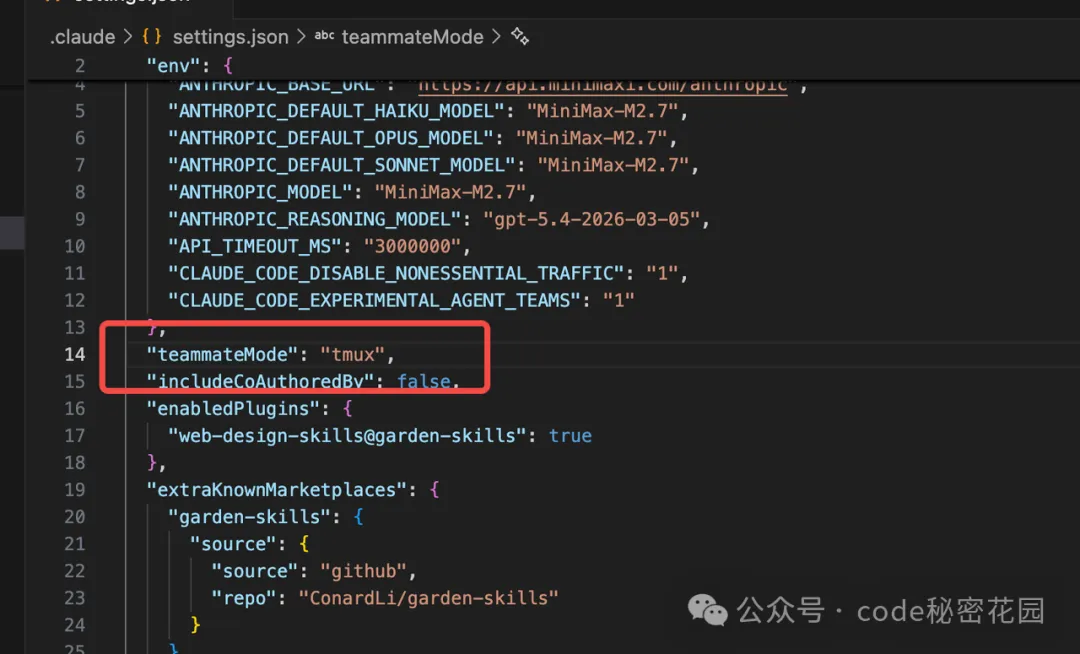
Agent Teams 目前還是個實驗性的功能,要開啓 Agent Teams,需要在配置里加上:
{
"env": {
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1"
},
}
為了更好的可視化整個展示過程,我們可以安裝下 tmux。
tmux 是一款開源終端複用器,可在一個窗口中管理多個終端會話,支持分屏、大幅提升命令行效率。
配合 tmux 之後,Agent Teams 的每個組員會出現在不同的終端面板裏。你能同時看到 Reviewer 在審哪裏,Developer 在改哪裏。tmux 安裝:
brew install tmux
讓 Claude Code 的 Agent Teams 適配 tmux,在配置里加上:
四、實戰:完整流程演示
這裏,我們以 一封郵件發出後的 600 毫秒 這篇文章為例,演示如何將其變成一個知識講解視頻:
4.1 啓動 Claude Code
進入項目目錄後,在終端先輸入 tumx ,進入 tumx 會話:
tmux
然後啓動 Claude Code:
claude --dangerously-skip-permissions
這裏有一個參數要單獨說一下:
--dangerously-skip-permissions
它會跳過每次工具調用時的權限確認。
並行開發時,如果每寫一個文件都要手動點確認,整個流程會被打得很碎。
所以我一般會在可信目錄裏打開這個參數。
但它名字裏帶 dangerously 不是開玩笑。
只在你確定當前目錄安全、項目內容可信的時候用。不要在陌生倉庫裏隨便開。
4.2 先生成腳本和大綱
啓動之後,把原始文章丟給 Claude,告訴它使用 web-video-presentation Skill。
讀取 @article.md ,按照 /web-video-presentation 要求,完成第一步。注意編寫完成後使用 Agent Teams 創建兩個獨立 Agent 進行質檢。
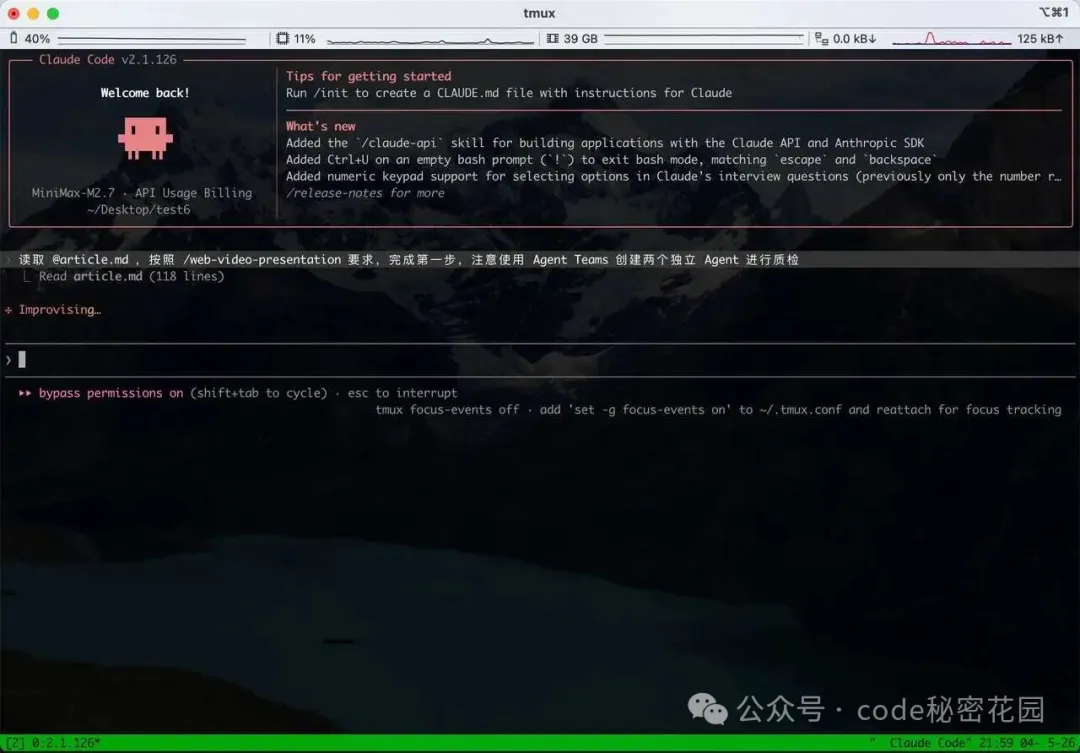
我們看到它創建了一個獨立的 Content Writer Agent 來編寫口播稿和開發大綱兩個文件:
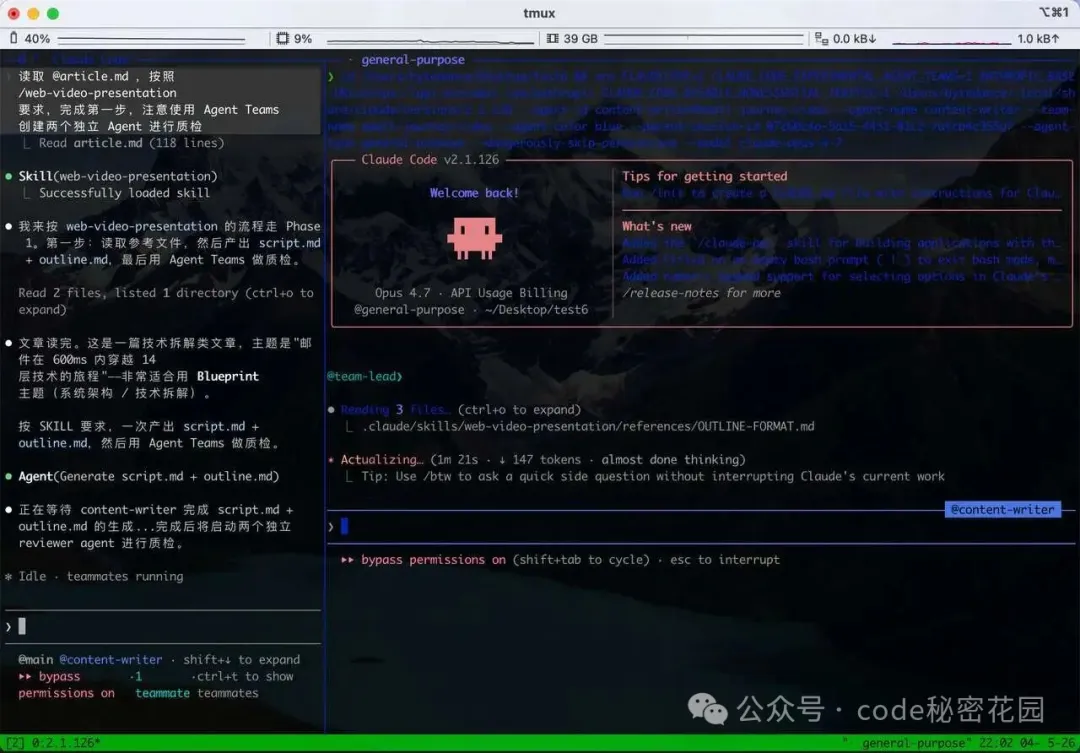
文件編寫完成後,創建了兩個 Reviewer Agent 來分別對兩篇內容進行質檢:
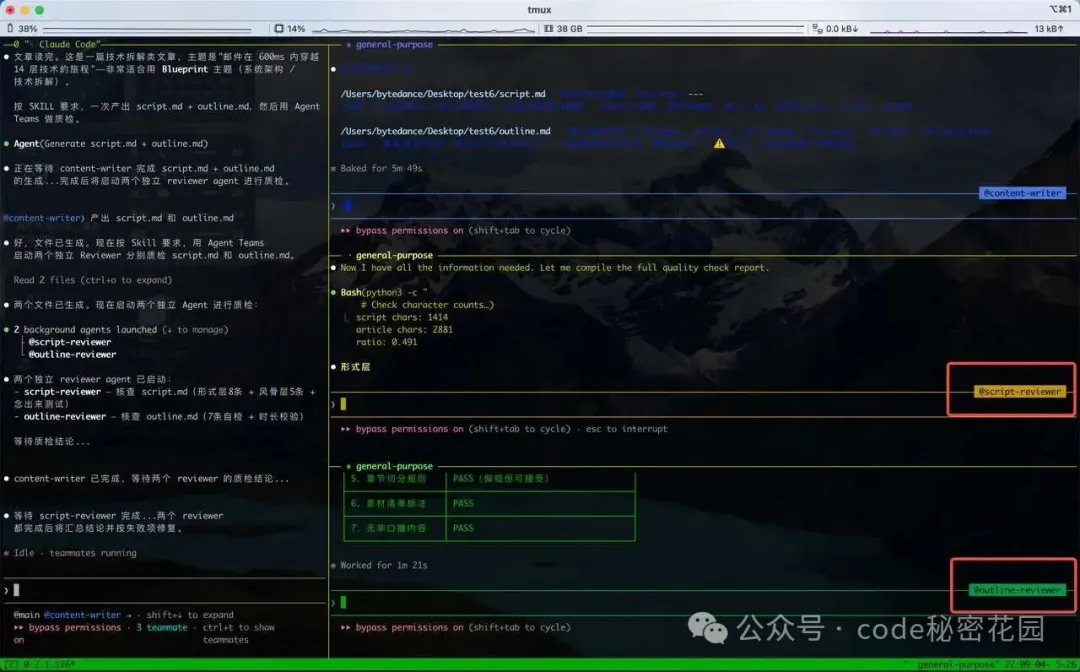
質檢完成,主 Agent 開始對 口播稿和大綱進行校對,更改然後輸出最終版本。
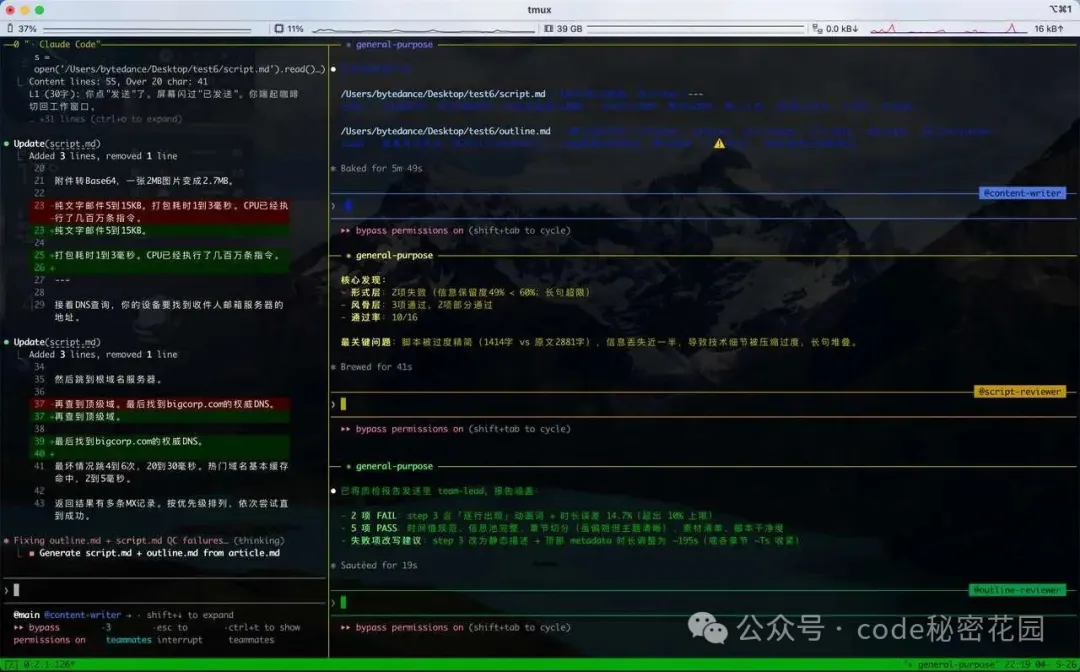
口播稿會把原始文章改成更適合 B 站視頻的表達。句子短一點,節奏快一點,聽起來像人在聊天,而不是在唸文章。

開發大綱則把腳本拆成「章節」和「步驟」,並標註每一步屏幕上應該出現什麼信息。它負責把控後續的開發節奏、每個章節的邊界、每一步的信息密度,以及這一屏到底要講清楚什麼。
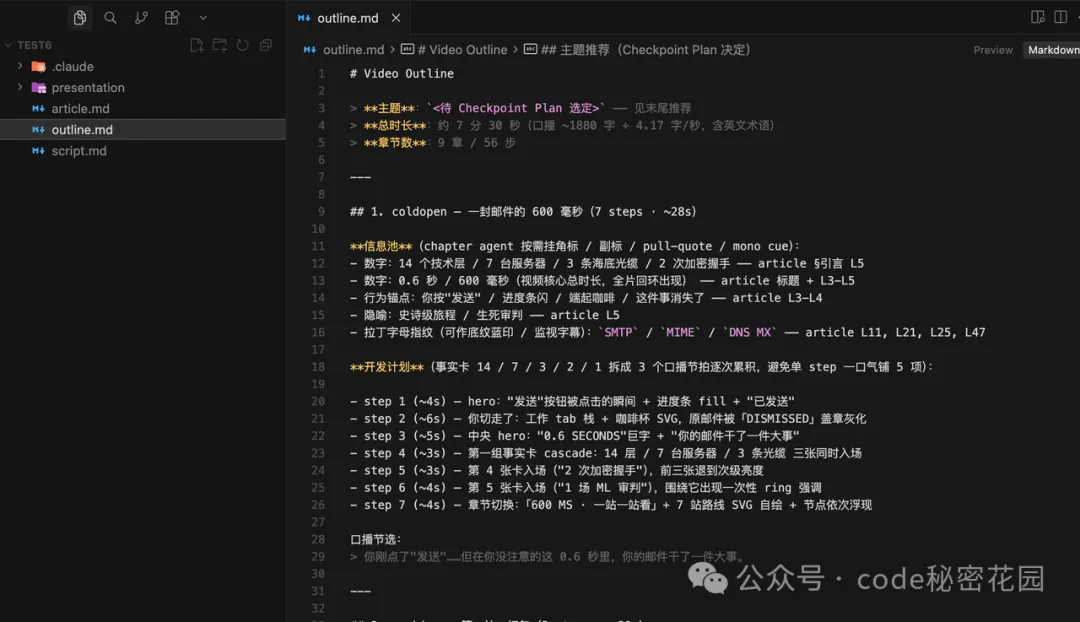
4.3 第一次人工確認
上面的流程完成後,它會向我們詢問幾個關鍵問題:
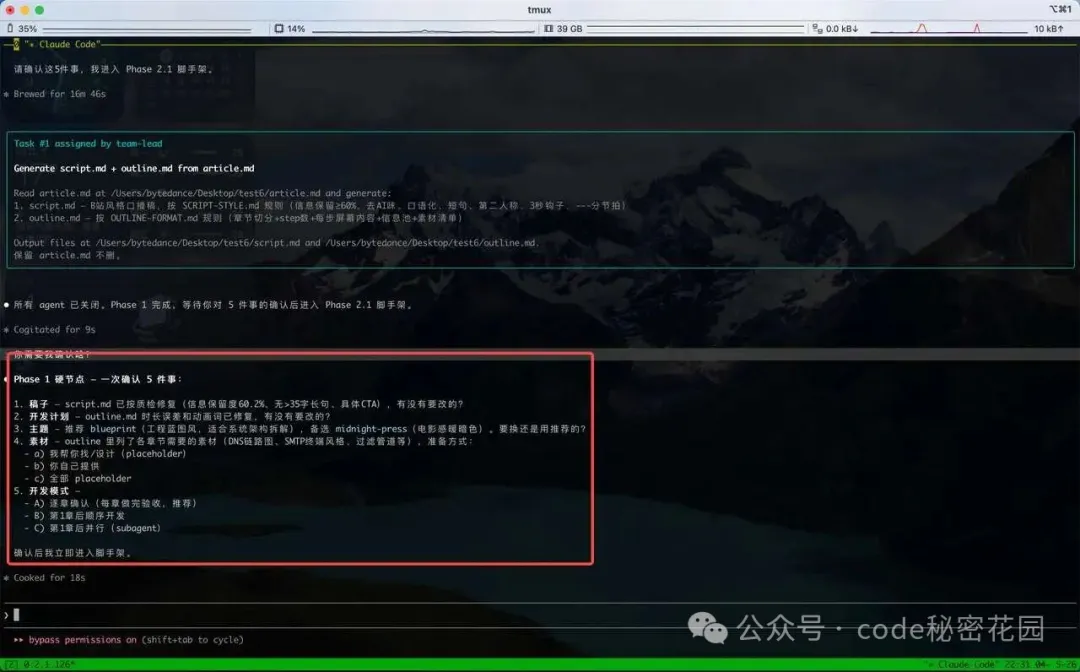
稿子和大綱還要不要改?
如果覺得稿子的 AI 味比較重,可以適當調整下改成你的講話風格。
另外需要確認下 AI 規劃的大綱有沒有明顯的節奏問題(如果改了稿子可以讓 AI 在下一步同步調整大綱)。
視覺主題選哪個?
Skill 內部一共定義了幾套不同風格的主題,Skill 會根據內容推薦幾個主題,你也可以自己向他說明你要的風格:
paper-press: editorial paper, warm print texture(編輯紙媒,温暖印刷質感) warm-keynote: modern talk / keynote energy(現代演講/keynote 風格) midnight-press: dark editorial presentation(深色編輯演示) blueprint: technical drawing / planning surface(技術繪圖/規劃界面) chalk-garden: classroom / chalkboard style(教室/黑板風格) terminal-green: phosphor terminal atmosphere(磷光終端氛圍) bauhaus-bold: sharp geometric manifesto(鋭利幾何宣言風格) sunset-zine: indie zine / expressive collage(獨立雜誌/表現主義拼貼) newsroom: newspaper / media desk(報紙/媒體桌面風格) monochrome-print: restrained typographic print(剋制的字體印刷風格)
素材怎麼準備?
在後續生成的網頁中可能會用到一些圖片素材,Skill 會讓用戶從以下三種模式選擇:
從現有素材路徑挑選:agent 從用戶已有的素材目錄中幫忙挑選符合視頻需求的圖 用戶自己提供:用戶自己準備並提供所有真實素材 全部 placeholder:全部先用佔位圖替代,後續再替換
後續章節的開發模式?
到了實際開發階段,Skill 支持多種開發模式()
A · 默認 · 逐章確認(推薦):描述:每章做完都暫停驗收 → 下一章 B · 第 1 章後順序開發:描述:第 1 章驗收後,第 2~N 章主線程順序做完,最後統一驗收 C · 第 1 章後並行開發:描述:第 1 章驗收後,用 subagent 並行做第 2~N 章(用戶控制並行數)
4.4 先把第一章做好
當原始文章、口播腳本、整體大綱、視覺主題、開發模式全部確認完成後,進入開發階段。
這裏 Skill 不會一上來就讓 Agent 直接並行做所完有章節,而是先做出第一章,讓用戶確認沒有問題後,在開發後續章節。
因為在第一章的效果中,你已經可以看到這個項目的頁面密度、字體大小、動效節奏、信息呈現方式等是否合理。
如果和你的預期差距比較大,還可以及時調整。第一章定下來之後,後面的章節才知道應該往哪個方向靠。
/web-video-presentation 腳本和開發計劃我已改好,主題選 blueprint ,素材你自己繪製,開發模式 A,繼續你的任務
第一階段開發完成後,它依然會開啓一個獨立的 Review Agent 對章節內容進行質檢:
我們可以看到工作區中的項目已經搭建起來,並且有了第一章的代碼:
質檢完成後,它會提示我們進行驗收:
第一章的驗收非常重要,它直接決定後續章節的開發質量,我們最好親自在瀏覽器裏從頭點到尾,看看:
畫面是不是舒服?節奏是不是順暢?信息有沒有太密?有沒有明顯的 AI 味?
4.5 並行開發後續章節
第一章定下來之後,就可以讓 Agent Teams / SubAgent 上場了。
剩下的章節可以並行開發。
我的經驗是,最多同時跑 3 個比較合適。
/web-video-presentation 驗收無問題,繼續使用 Agent Teams 並行開發完後續所有章節,最大並行 3 個 Agent
每個 Agent 會拿到自己負責的章節大綱、Skill 規範、主題變量,以及第一章的代碼作為參考。
它們各自寫各自的章節,互不干擾。(注意這裏一定要選 Agent 能力非常強的模型,不然多 Agent 調度很容易出錯。)
每章完成後,都會進入質檢,所有章節驗收都通過後,它會回覆我們任務完成:
4.6 確認網頁效果
所有章節開發完之後,先啓動本地開發服務器,在瀏覽器裏完整預覽一遍。
一定要手動把所有步驟都點完。
檢查有沒有空白頁、動畫卡頓、步驟跳段、內容錯位。
尤其是這種 50 多步的視頻項目,中間某一步出問題很正常。
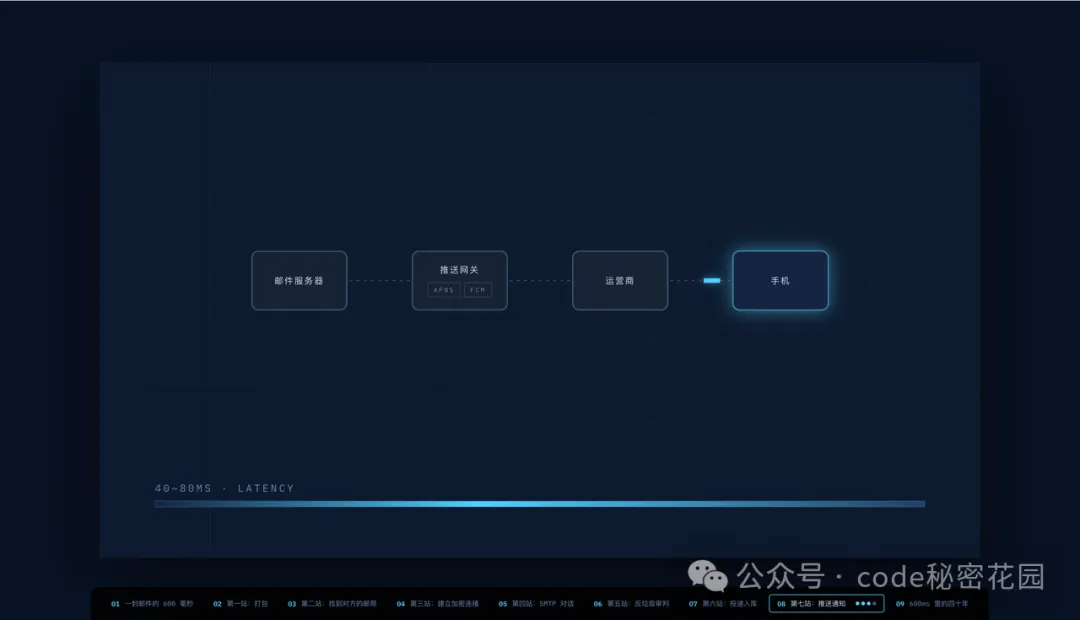
4.7 合成音頻
網頁確認沒問題之後,再進入音頻階段。
使用 Chinese (Mandarin)_Gentleman 温潤男聲合成所有音頻
這一步用 MiniMax 的 CLI,把口播文本批量合成為音頻文件。
流程分兩步。
第一步,先從所有章節裏抽取一份口播文本清單。
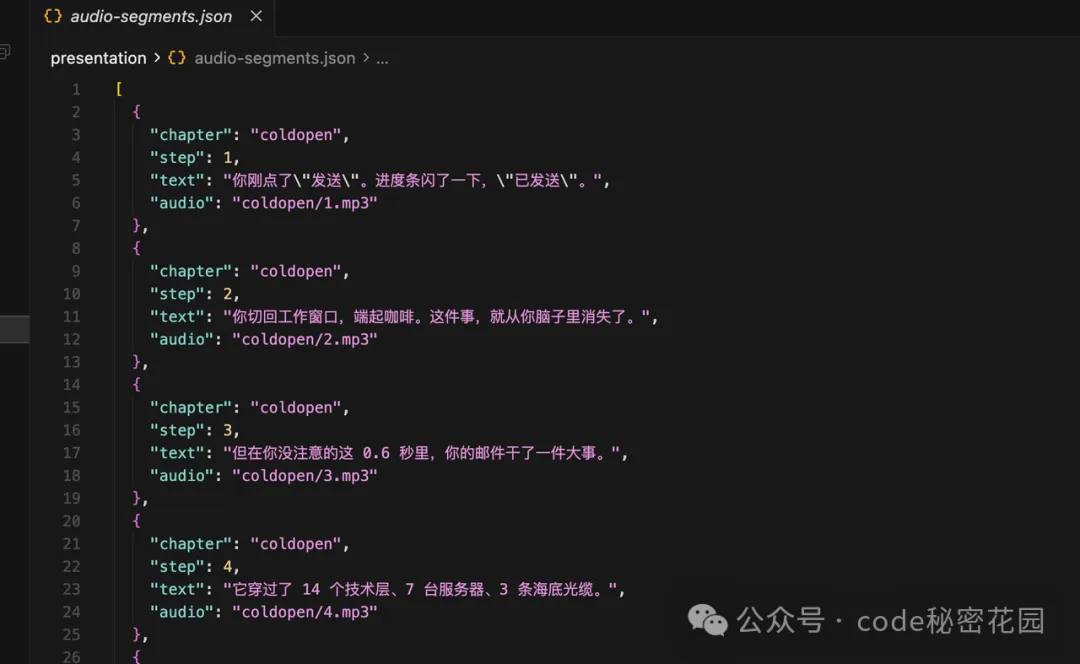
這一步要人眼掃一遍,確認沒有錯字、漏句、奇怪斷句。
正常口播內容的 Step 和網頁的 Step 應該是一一對應的。
第二步,再逐條合成音頻。
腳本是串行執行的,這樣不容易撞到 MiniMax 的速率限制。
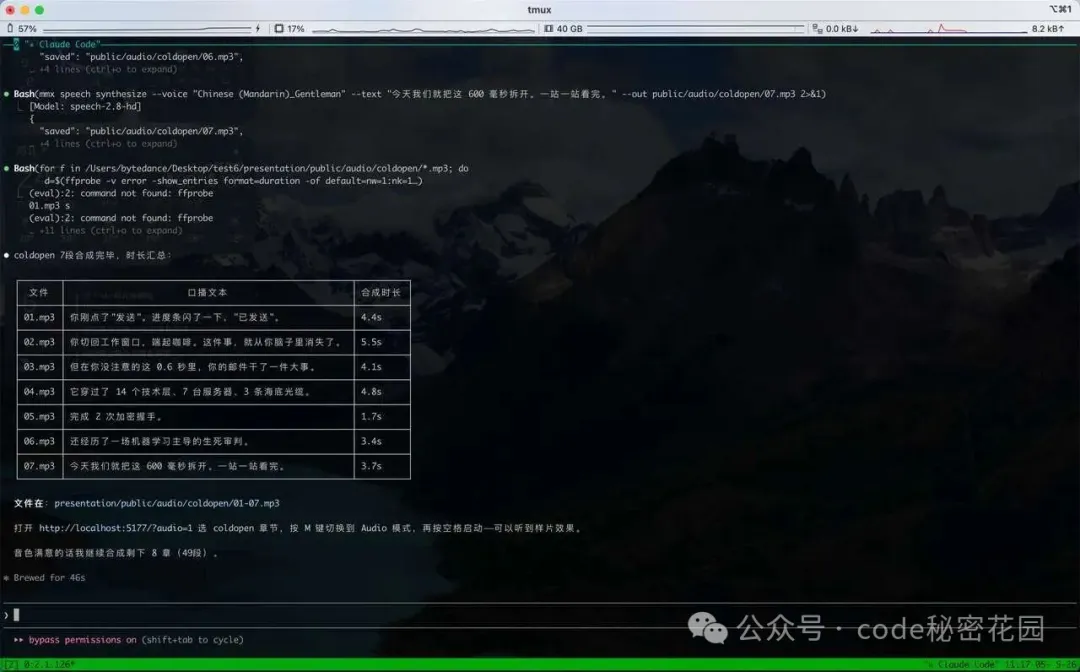
已經生成過的文件會自動跳過,所以中途斷了也不用重來。
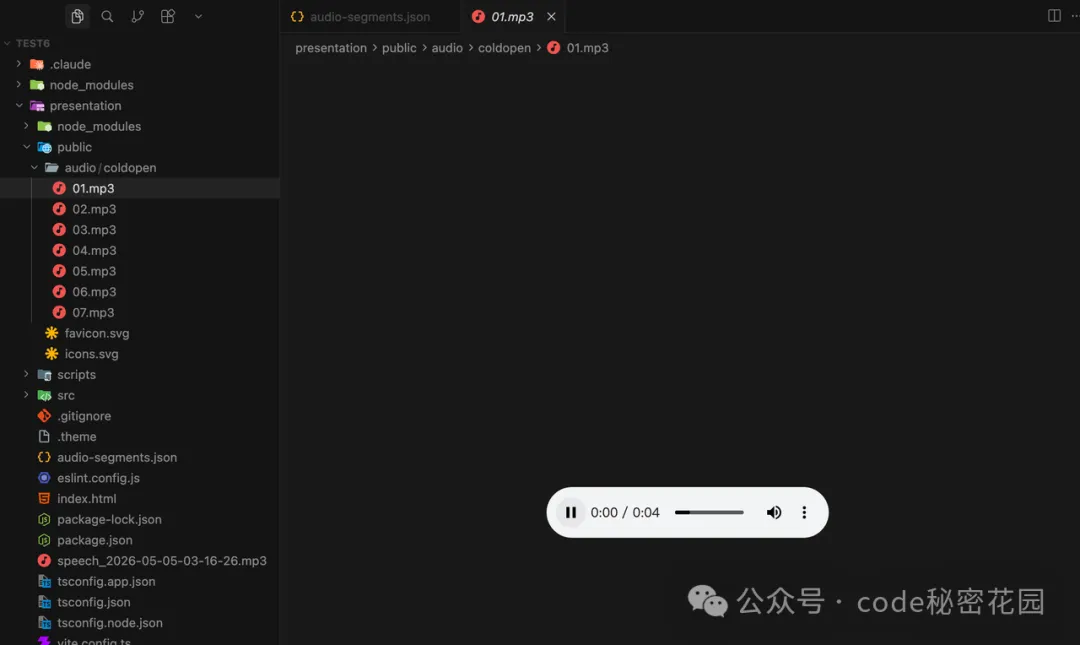
合成完成後,每章會有一個子目錄,每一步對應一個音頻文件。文件名和步驟編號一一對應。
4.8 三種播放模式
到這裏,視頻項目就已經可以播放了。
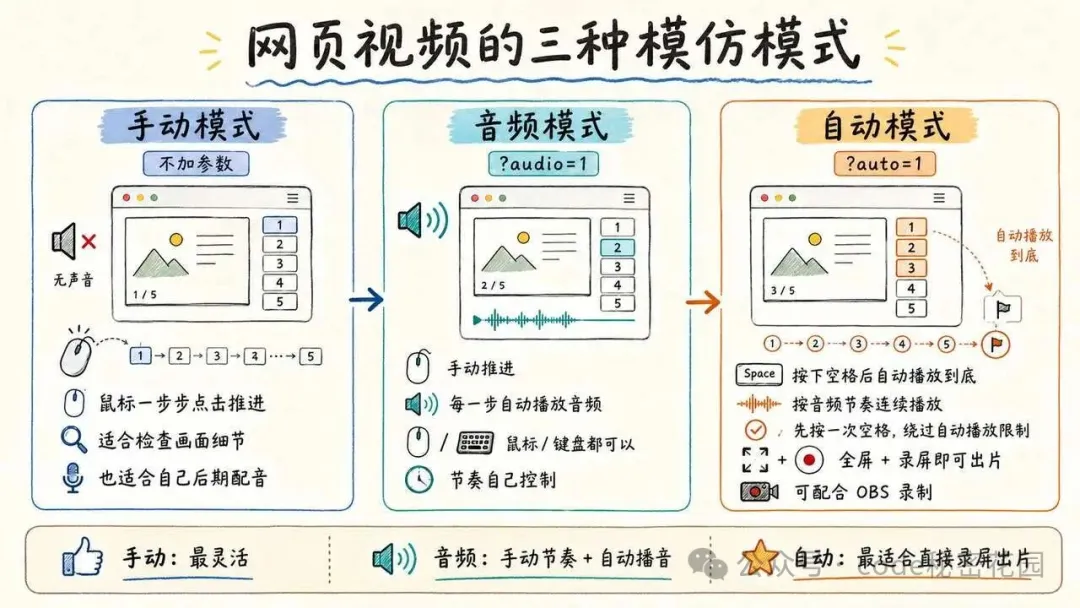
這套 Skill 裏有三種模式。
第一種是手動模式(不加任何參數),沒有聲音。
你用鼠標一步步點擊推進,適合檢查畫面細節,或者完全你自己錄製音頻(我之前的視頻都是這種模式)。
第二種是音頻模式(網頁加 ?audio=1 參數進入)。
還是鼠標或鍵盤推進章節步驟,在每個步驟自動播放音頻,手動推進,你可以自由控制節奏。
第三種是自動模式(網頁加 ?auto=1 參數進入)。
按下空格之後,頁面會按照音頻節奏一路播放到底。瀏覽器全屏,再配合屏幕錄製,就能直接出片。
第一次按空格,是為了繞過瀏覽器的自動播放限制。之後基本不用再碰鼠標。
大家可以用 OBS 等軟件直接錄屏,就可以生成一條完整的視頻。
4.9 最後歸檔
這套流程還有一個好處:所有資產都能跟着項目走。
原始文章、口播稿、大綱、網頁代碼、音頻文件,都可以放進版本控制裏。
以後換一個題材,不是從零開始,而是換一篇原始文章,再沿着同一條流水線跑一遍。
最後
回到開頭的問題:這些視頻到底是怎麼做出來的?
表面上看,這是一套“文章生成知識講解視頻”的流程:文章變口播,口播變大綱,大綱變網頁,網頁配上音頻和錄屏,最後變成視頻。
但本質上,它其實是一次 Harness 實踐。
模型本身已經很強,Claude Code 能寫代碼,MiniMax 模型能提供穩定的推理和生成能力,MiniMax CLI 還能把語音合成接進來。
真正的問題不是“模型會不會做”,而是:
怎麼把這些能力編排起來,讓它穩定地做完。
所以這個 Skill 做的事情,就是把一次複雜的內容生產任務,拆成有流程、有狀態、有檢查點、有自檢、有恢復機制的工程系統。
它不是讓 Agent 自由發揮,而是給 Agent 搭了一條可重複執行的軌道。
這也是 Harness 最核心的價值: 把模型能力、工具能力和人的判斷,組織成一條穩定可控的生產流程。
我已經把這個 Skill 放到了 garden-skills 倉庫裏。感興趣的同學可以拿一篇自己的文章試試。
https://github.com/ConardLi/garden-skills
如果本期教程對你有所幫助,來個免費的點贊、收藏吧~