Harness|02 Prompt的天花板——為什麼我們不得不往前走
整理版優先睇
Prompt engineering 有用但有硬邊界,需要向上走進 harness 層
呢篇文章出自一位LLM應用開發者,佢親身經歷過將複雜業務邏輯全部塞入一個八九百行嘅prompt,結果維護困難、模型升級就崩潰。佢通過自身教訓,總結出prompt層嘅幾條硬邊界,並引用Anthropic官方最佳實踐同12-Factor Agents框架,解釋點解純粹嘅prompt engineering搞唔掂複雜應用。
作者指出,prompt engineering嘅技巧(清晰指令、XML結構、few-shot、CoT)確實有效,但只適用於一次性、短上下文嘅任務。一旦任務需要多步流程、工具調用、狀態管理同人機協作,prompt層就出現根本限制,包括無狀態、上下文上限、不能自糾錯、工具選擇困難、無法做HITL同版本脆弱性。
整體結論係:prompt只係「模型工位嘅指令書」,真正需要嘅係喺佢外面加一層管理層,即係context engineering同harness。呢層負責組裝上下文、編排工具、持久化狀態、處理錯誤同接入人類判斷。作者呼籲開發者唔好再將流程控制同易變知識塞入prompt,而應該向上行,將prompt放到一個對嘅位置。
- Prompt engineering 技巧有用,但只能處理一次性、短上下文任務,複雜應用會遇到硬邊界。
- 作者嘅鐵律:唔好將流程控制(條件分支、循環)同易變知識(業務規則、參數)塞入prompt,應外部化。
- Prompt 嘅六大硬邊界:無狀態、上下文上限、不能自糾錯、工具太多幹擾、無法做到HITL、模型升級易漂移。
- 12-Factor Agents 建議開發者必須擁有prompt層嘅所有權(Own your prompts),確保可觀測同版本管理。
- 可行動點:記錄每次調用完整prompt日誌(system+tools+user+messages+results),作為除錯第一步。
Prompt engineering 嘅真功夫同侷限
Anthropic官方嘅prompt engineering best practices有幾條核心方法,作者親身試過好有效。
清晰指令
XML結構化
Few-shot
Chain of Thought
呢啲技巧確實有效,但只解決一次性、單輪問題。
我嘅踩坑經歷:八九百行 prompt 嘅恐怖 story
作者分享一個企業LLM應用案例,業務邏輯包括意圖識別、查內部知識庫、調微服務API、按角色權限過濾結果。佢將所有邏輯塞入一個
八九百行嘅prompt
,結果每次改動前後邏輯衝突,新人要通讀先敢鬱,模型一升級成個prompt行為
漂移
,要重新調試。
Prompt 嘅六條硬邊界
作者歸納prompt層嘅根本限制,共有六條硬邊界:
- 1 無狀態:每次調用之間唔共享任何嘢
- 2 上下文上限:Claude Sonnet 4.5係200K但實際唔夠用
- 3 不能自糾錯:模型輸出錯嘢唔會知
- 4 工具太多會蒙圈:Vercel案例砍80%工具成功率反升
- 5 無法做HITL:關鍵步驟無辦法等人確認
- 6 改不動就廢:模型升級易漂移
無狀態、上下文上限、不能自糾錯、工具太多、無法HITL、改不動就廢
呢啲邊界令prompt層無辦法承擔複雜應用嘅所有職責。
12-Factor Agents 教路:Own your prompts
humanlayer組織提出嘅
12-Factor Agents
,其中Factor 2「Own your prompts」特別重要。好多agent框架會封裝system prompt,令開發者唔知模型實際見到乜、點解咁答、點樣debug。
作者話:任何agent項目嘅第一條要求,就係將每次調用嘅完整prompt
打日誌打出來
(system + tools + user messages + history + tool results)。95%嘅奇怪行為都可以喺日誌揾到原因。冇呢層觀察能力,prompt就係黑盒,無辦法工程化。
向上走:Context Engineering 係新出路
當prompt層撐唔住,業內有兩條路:一條係繼續優化prompt本身,有效但有限;另一條係向上走,承認prompt只係「模型工位嘅指令書」,然後喺外面蓋一層管理層——
上下文組裝、工具編排、狀態持久化、錯誤回滾、人類介入
。
context engineering 同 harness
就係呢一層。下一篇會講Anthropic點定義——「找到最小高信號token集合」,同埋System Prompt、Tools、Examples、Message History四個組件分別點管。
上篇收尾我話,要知一個抽象層唔夠用,先會明點解要向上行。呢篇就專講prompt呢一層嘅天花板喺邊。

—— 先將prompt嘅功夫擺出嚟
講清楚邊界之前,要承認prompt engineering呢門功夫係存在嘅。Anthropic官方嘅Claude 4 prompt engineering best practices裏面嗰幾條核心方法,我自己用落都好有用。
清晰指令唔好畀模型估,你要佢做乜、唔好做乜、最後輸出咩格式,一行一行寫清楚。我早期最易犯嘅毛病就係想畀模型留啲「發揮空間」,結果佢發揮到周圍都係。
XML結構化Claude對XML標籤嘅理解遠好過純markdown,將任務、上下文、示例、約束分別用<task>、<context>、<example>、<constraint>包起,模型捉重點嘅能力即刻上一個台階。呢招簡單,效果出奇地好。
Few-shot畀兩三個高質量嘅輸入輸出例子,好過你寫一千字嘅描述。但呢度有個陷阱——例子如果揀得唔典型,模型就會學到錯誤嘅pattern,寧願唔畀都唔好亂畀。
Chain of Thought畀模型諗先再答,加一句「先在<thinking>裏面推理,再喺<answer>裏面畀結果」。Claude 4之後嘅擴展思考更加將呢件事做到咗一等公民,開thinking之後準確率經常可以上一截。
呢啲招數都唔係花拳繡腿,係真係打得嘅。但你要意識到——佢哋解決嘅全部係「一次性、單輪、短上下文」問題一旦任務變長、變複雜、需要工具、需要狀態,呢一層就開始吃力。
—— 我自己踩過嘅坑
我以前做一個企業內部嘅LLM應用,業務邏輯都幾複雜,一個請求裏面要做意圖識別、要查內部知識庫、要調幾個微服務API、仲要將結果按角色權限過濾一次。當時harness呢個詞仲未流行,我就一條筋——將所有邏輯塞入prompt裏面。
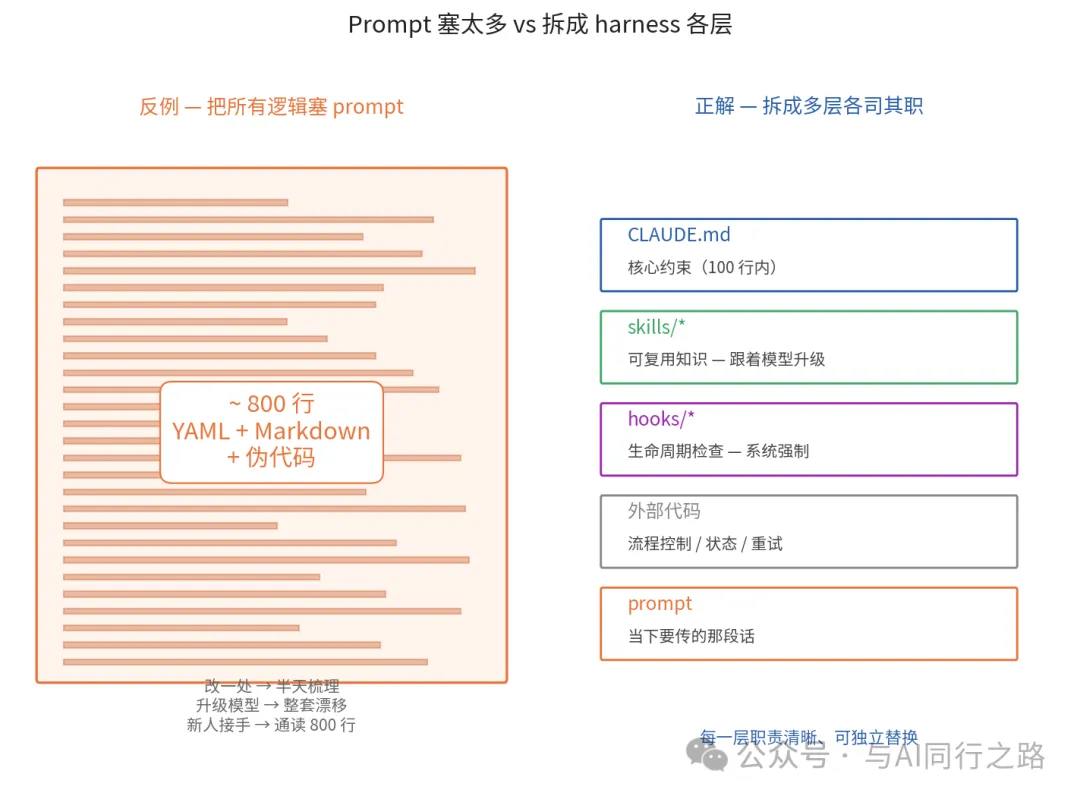
嗰個prompt最後寫咗大概八九百行,YAML配住Markdown再溝啲偽代碼。每改一處,前後邏輯就有衝突,要花半日梳理。新人接手要先將嗰八九百行由頭到尾睇一次先敢改一行。最難頂嘅係,模型版本一升級,整套prompt行為漂移,你又要用重新調一次。

嗰段經歷畀我留低兩條鐵律。第一,prompt裏面唔好塞「流程控制」條件分支、循環、狀態機、錯誤重試,呢啲應該喺外面嘅代碼裏面寫,唔應該畀模型自己喺腦裏面行。第二,prompt裏面唔好塞「易變知識」業務規則、組織架構、產品參數呢啲會變嘅嘢,一係放外部檢索,一係放配置文件,唔可以硬編碼入prompt。
後來我先知道,呢兩條鐵律嘅本質——prompt係有狀態邊界嘅佢係一次性傳畀模型嘅文本塊,冇持久化、冇可觀測、冇回滾、冇版本管理(你可以用git管,但運行時佢就係一個字符串)。將太多嘢塞入呢一層,等於將太多職責畀咗一個無狀態嘅純函數,註定唔可以維護。
—— prompt嘅幾個硬邊界
我將prompt層嘅邊界歸納成幾條,你自己對照嚇睇下係咪踩過。
無狀態每次調用之間唔共享任何嘢,除非你自己手動將歷史塞返入去。呢個意味住任何「長期記憶」都要喺prompt之外做。
上下文有上限Claude Sonnet 4.5係200K,Opus再大啲,睇落好似好多,但真係用起嚟就發覺唔夠。一個中等複雜嘅agent session,幾十次工具調用之後,上下文就開始緊張。下一篇我會講「context rot」——窗口大唔等於真係用得滿,裏面仲有衰減問題。
唔可以自己糾錯模型畀你輸出錯嘅嘢,佢唔知自己錯咗。你要靠外面嘅代碼做驗證、做重試、做fallback。呢套嘢放喺prompt裏面寫唔出嚟——因為佢本質上係控制流唔係描述。
工具調一兩個仲可以,多咗就矇查查呢度有個反直覺嘅事實——工具唔係越多越好。Vercel嗰個將工具數削80%反而成功率升到100%嘅案例,背後機制就係「too many tools, low signal」。模型喺工具描述裏面來回掃描揀選,注意力被稀釋,最後揀得亂七八糟。呢個問題prompt層根本解決唔到,只能靠外面做工具嘅動態裁剪同分組。
冇辦法做HITL需要人確認嘅關鍵步驟——例如執行rm -rf、例如發送郵件、例如付款——你唔可以喺prompt裏面寫「請等用戶確認」。呢啲係harness層先做得嘅事,prompt層根本唔知「用戶」喺邊。
改唔鬱就廢一個長prompt調好咗,模型一升級,行為就開始漂移。你之前用嘅trick喺新模型上可能冇效果甚至反效果。呢種脆弱性係結構性嘅——你將太多嘢耦合喺一段文本入面,任何一處變化都會影響全局。
—— 12-Factor Agents嘅嗰條建議
humanlayer嗰個組織整咗一套12-Factor Agents,將構建agent嘅工程原則歸納成12條,圈內都幾多人引用。其中Factor 2「Own your prompts特別值得拎出嚟講——意思係話,prompt層嘅所有權唔可以丟畀框架。
好多agent框架會幫你封裝system prompt,將佢藏喺框架內部,你只能夠從外面塞用戶消息。結果就係你根本唔知模型實際睇到咗啲乜、點解會咁回答、點樣除錯。Anthropic自家做產品都係咁做嘅——CLAUDE.md係user content,同動態生成嘅system prompt一齊組裝成完整上下文。你睇得到、改得到、可以版本管理,呢個係底線。
我而家做任何agent項目,第一條要求就係——將每一次調用模型時嘅完整prompt(system + tools + user messages + history + tool results)打日誌打出嚟。出問題先睇呢個日誌,95%嘅「奇怪行為」都可以喺呢度揾到原因。冇呢層觀察能力,prompt就係黑盒,黑盒就冇辦法工程化。
—— 咁往邊度走
prompt層撐唔住嘅時候,業內有兩條路。
一條係往裏面走,去優化prompt本身——更強嘅指令工程、更巧嘅XML結構、更聰明嘅few-shot選擇、更深嘅CoT。呢條路有人喺度行,有效但有限。
另一條係向上行,承認prompt係「模型工位嘅指令書」呢一層,然後喺佢外面加一層管理呢個工位嘅嘢——上下文點樣組裝、工具點樣編排、狀態點樣持久化、錯誤點樣回滾、人點樣介入。呢一層就係context engineering同harness。
下一篇我哋就行上去,睇嚇Anthropic將context engineering呢件事點樣定義——點解一句話總結叫「找到最小高信號token集合」,同埋System Prompt、Tools、Examples、Message History呢四個組件分別應該點樣管。
prompt寫得幾好,都唔及將佢放喺一個啱嘅位置。
上一篇收尾我說,得知道一個抽象層不夠用了,才會理解為什麼要往上走。這篇就專門講prompt這一層的天花板在哪。
—— 先把prompt的功夫擺出來
講清楚邊界之前,得先承認prompt engineering這門功夫是有的。Anthropic官方的Claude 4 prompt engineering best practices裏那幾條核心方法,我自己用下來都很管用。
清晰指令。別讓模型猜,你要它幹什麼、不要幹什麼、最後輸出什麼格式,一行一行寫明白。我早期最容易犯的毛病就是想給模型留點"發揮空間",結果它發揮得滿地都是。
XML結構化。Claude對XML標籤的理解遠好於純markdown,把任務、上下文、示例、約束分別用<task>、<context>、<example>、<constraint>包起來,模型抓重點的能力立馬上一個台階。這一招簡單,效果出奇地好。
Few-shot。給兩三個高質量的輸入輸出例子,比你寫一千字的描述都管用。但這裏有個坑——例子如果選得不典型,模型就會學到錯誤的pattern,寧可不給也別瞎給。
Chain of Thought。讓模型先想再答,加一句"先在<thinking>裏推理,再在<answer>裏給結果"。Claude 4之後的擴展思考更是把這件事做成了一等公民,開thinking之後準確率經常能上一截。
這些招數都不是花拳繡腿,是真能打的。但你要意識到——它們解決的全是"一次性、單輪、短上下文"問題。一旦任務變長、變複雜、需要工具、需要狀態,這一層就開始吃力。
—— 我自己踩過的坑
我以前做一個企業內部的LLM應用,業務邏輯挺複雜,一個請求裏要做意圖識別、要查內部知識庫、要調幾個微服務API、還要把結果按角色權限過濾一遍。當時harness這個詞還沒流行,我就一根筋——把所有邏輯塞進prompt裏。
那個prompt最後寫了大概八九百行,YAML配着Markdown再混一點偽代碼。每改一處,前後邏輯就有衝突,要花半天梳理。新人接手要先把那八九百行通讀一遍才敢動一行。最難受的是,模型版本一升級,整套prompt行為漂移,你又得重新調一遍。
那段經歷給我留下兩條鐵律。第一,prompt裏不要塞"流程控制"。條件分支、循環、狀態機、錯誤重試,這些應該在外面的代碼裏寫,不應該讓模型自己在腦子裏跑。第二,prompt裏不要塞"易變知識"。業務規則、組織架構、產品參數這些會變的東西,要麼放外部檢索,要麼放配置文件,不能硬編碼進prompt。
後來我才知道,這兩條鐵律的本質——prompt是有狀態邊界的。它是一次性傳給模型的文本塊,沒有持久化、沒有可觀測、沒有回滾、沒有版本管理(你可以git管,但運行時它就是一個字符串)。把太多東西塞進這一層,等於把太多職責給了一個無狀態的純函數,註定不可維護。
—— prompt的幾個硬邊界
我把prompt層的邊界歸納成幾條,你自己對照看看是不是踩過。
無狀態。每次調用之間不共享任何東西,除非你自己手動把歷史塞回去。這意味着任何"長期記憶"都得在prompt之外做。
上下文有上限。Claude Sonnet 4.5是200K,Opus更大一點,看着挺多,真用起來發現不夠。一箇中等複雜的agent session,幾十次工具調用之後,上下文就開始緊張。下一篇我會講"context rot"——窗口大不等於真的能用滿,裏面還有衰減問題。
不能自己糾錯。模型給你輸出錯的東西,它不知道自己錯了。你要靠外面的代碼做驗證、做重試、做fallback。這套東西放在prompt裏寫不出來——因為它本質上是控制流,不是描述。
工具調一兩個還行,多了就蒙圈。這裏有個反直覺的事實——工具不是越多越好。Vercel那個把工具數砍80%反而成功率漲到100%的案例,背後機制就是"too many tools, low signal"。模型在工具描述裏來回掃描挑選,注意力被稀釋,最後挑得亂七八糟。這個問題prompt層根本解決不了,只能靠外面做工具的動態裁剪和分組。
沒法做HITL。需要人確認的關鍵步驟——比如執行rm -rf、比如發送郵件、比如付款——你不能在prompt裏寫"請等用戶確認"。這是harness層才能乾的事,prompt層根本不知道"用戶"在哪。
改不動就廢。一個長prompt調好了,模型一升級,行為就開始漂移。你之前用的trick在新模型上可能沒效果甚至反效果。這種脆弱性是結構性的——你把太多東西耦合在一段文本里,任何一處變化都會影響全局。
—— 12-Factor Agents的那條建議
humanlayer那個組織搞了一套12-Factor Agents,把構建agent的工程原則歸納成12條,圈內挺多人引。其中Factor 2"Own your prompts"特別值得拎出來講——意思是說,prompt層的所有權不能丟給框架。
很多agent框架會替你封裝system prompt,把它藏在框架內部,你只能從外面塞用戶消息。結果就是你根本不知道模型實際看到了什麼、為什麼這麼回答、怎麼調試。Anthropic自家做產品也是這麼幹的——CLAUDE.md是user content,跟動態生成的system prompt一起組裝成完整上下文。你能看見、能改、能版本管理,這是底線。
我現在做任何agent項目,第一條要求就是——把每一次調用模型時的完整prompt(system + tools + user messages + history + tool results)打日誌打出來。出問題先看這個日誌,95%的"奇怪行為"都能從這兒找到原因。沒有這層觀察能力,prompt就是黑盒,黑盒就沒法工程化。
—— 那往哪裏走
prompt層撐不住的時候,業內有兩條路。
一條是往裏走,去優化prompt本身——更強的指令工程、更巧的XML結構、更聰明的few-shot選擇、更深的CoT。這條路有人在走,有效但有限。
另一條是往上走,承認prompt是"模型工位的指令書"這一層,然後在它外面蓋一層管理這個工位的東西——上下文怎麼組裝、工具怎麼編排、狀態怎麼持久化、錯誤怎麼回滾、人怎麼介入。這一層就是context engineering和harness。
下一篇我們就走上去,看看Anthropic把context engineering這件事怎麼定義的——為什麼一句話總結叫"找到最小高信號token集合",以及System Prompt、Tools、Examples、Message History這四個組件分別該怎麼管。
prompt寫得再好,不如把它放在一個對的位置上。