Harness|05 Harness到底是什麼——核心概念與"Thin Harness, Fat Skills"原則
整理版優先睇
Harness係agent嘅外殼,核心原則係薄Harness、厚Skills,將業務知識沉澱成可升級嘅技能庫。
呢篇文章係Harness系列嘅第五篇,作者正式定義咗Harness嘅概念,畀出一套通用架構,並提出整個系列最核心嘅命題——「Thin Harness, Fat Skills」。文章先解釋Harness係令模型可以作為agent做嘢嘅外殼,負責處理輸入、編排工具調用、管理上下文同返回結果四件事。作者指出,呢四件事每一件都係大坑,需要工程化做紮實。
作者引用Garry Tan嘅「THIN HARNESS, FAT SKILLS」原則,並整合Anthropic、Vercel d0、Hermes Agent等實踐,指出Harness要薄,只做通用編排;Skills要厚,將判斷同流程編碼成文檔,係永久升級。作者強調,模型升級會自動令Skills變強,但Harness升級可能要重寫代碼,所以Skills係真正嘅資產。
整體結論係:Harness係借嚟嘅,Skill係自己嘅。業務規則應放喺Skill層,工程通用能力放喺Harness層。呢個心智模型可以幫助判斷邊啲放邊層,避免將來遷移時損失。
- 結論:薄Harness、厚Skills係核心原則,Harness只做通用編排,Skills沉澱業務知識。
- 方法:Harness分三層(Model/Harness/UI),工具統一接口包括身份、執行、驗證、權限、展示字段。
- 差異:Co-evolution原則——模型同特定Harness一齊post-train,交叉組合會損失性能。
- 啟發:Skills係永久升級,模型變強後Skill自動受益,而Harness升級可能要重寫。
- 可行動點:優先積累Skill庫,Harness遷移只改膠水代碼,業務規則放Skill層。
Harness嘅清楚定義
Harness就係令模型可以作為agent做嘢嘅嗰套外殼。佢嘅職責得四樣——處理輸入、編排工具調用、管理上下文、返回結果。聽落好簡單,但每件都係大坑。
處理輸入要搞掂多模態、多渠道、多格式;編排工具調用要管串行、並行、retry、HITL;管理上下文係上一篇講嘅一大籮嘢;返回結果要管格式、可觀測、回滾。將呢四件事工程化做紮實,就係Harness。
通用架構:Model / Harness / UI 三層
業界共識比較多嘅分法係三層——Model Layer、Harness Layer、UI Layer。Model Layer係模型本身加SDK封裝,職責係「畀我一段prompt同工具定義,吐返一段response或tool call」,係無狀態、純函數式、可替換嘅。
Harness Layer係中間最厚嘅一層,所有「令模型做嘢」嘅工程邏輯都喺度——工具定義同註冊、context組裝同壓縮、agent loop編排、subagent派發同回收、memory同state持久化、hooks同生命週期管理、安全同權限。呢層係Harness嘅本體。UI Layer係最外面嘅殼——CLI、IDE插件、Web、messaging app等。
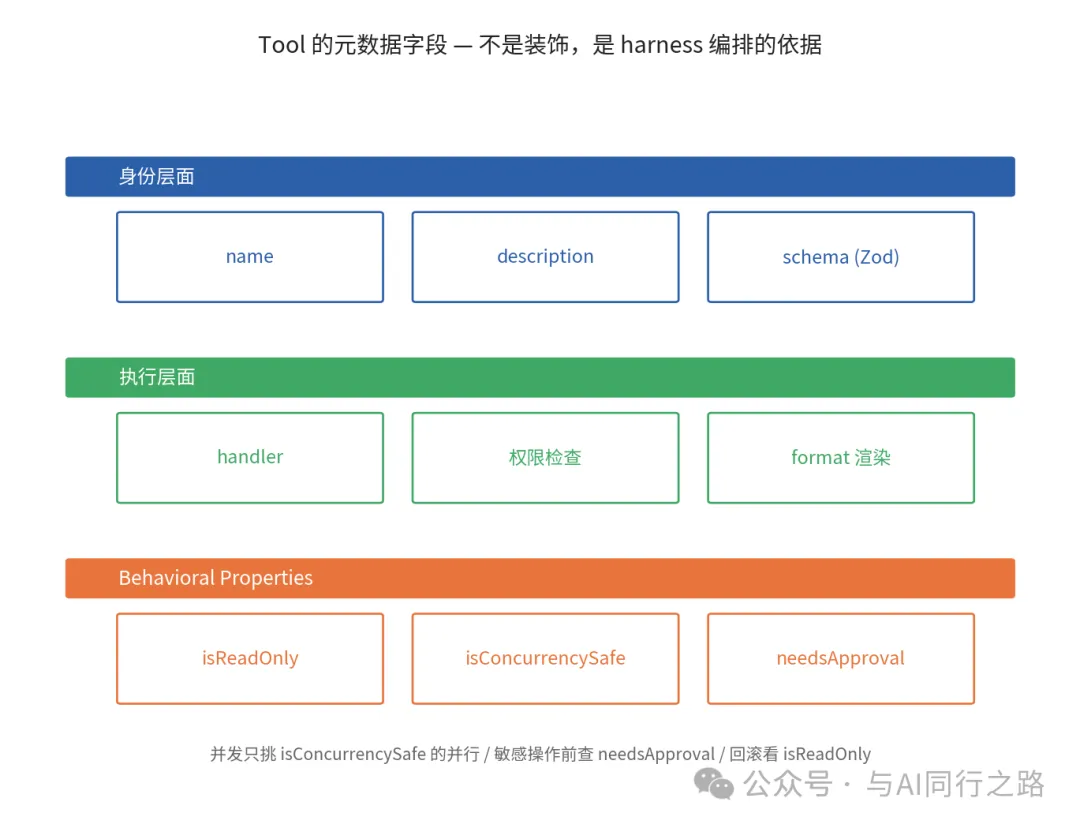
Tool係Harness裏面最核心嘅抽象。Claude Code嘅tool設計曝光後,發現佢畀每個tool定義咗統一字段——身份層面有name、description、schema;執行層面有handler;驗證層面有Zod schema;權限層面有權限檢查;展示層面有format。更重要嘅係幾個behavioral properties——isReadOnly、isConcurrencySafe、needsApproval。
Codex嘅Priority Stack同LangChain三層區分
OpenAI嘅Codex harness有一個好有意思嘅設計——priority stack。佢將上下文唔同來源嘅指令明確排咗優先級,分兩層邏輯:第一層係role優先級:system > developer > user > assistant;第二層係同一role內按出現位置,越後出現優先級越高。
- 1 跨role衝突例子:用戶話「刪除所有文件」(user role),但server message有「禁止破壞性操作」(system role)——system贏。
- 2 同role內位置衝突例子:AGENTS.md寫「用Python」(user role、出現前),用戶當前輪話「用Go」(user role、出現後)——後出現嘅覆蓋前面,用戶當前輪贏。
LangChain將做agent拆成三層——Agent Framework(LangChain,提供抽象)、Agent Runtime(LangGraph,管執行引擎同可持久化)、Agent Harness(DeepAgents,opinionated嘅打包)。理解呢三層,就明點解DeepAgents可以「只改Harness唔改模型,benchmark由52.8升到66.5」。
Co-evolution原則同核心命題:Thin Harness, Fat Skills
Co-evolution Principle——模型係同特定Harness一齊post-train嘅。Anthropic嘅Claude喺訓練後期會用Claude Code呢個Harness做大量agentic任務,所以模型睇到嗰套工具集、prompt結構時表現最好。唔好亂交叉用「OpenAI模型跑Claude Code」或者「Claude模型跑Codex」,會損失訓練優勢。
Harness要薄——只做最通用嘅編排,唔好硬編碼業務知識。Skill要厚——將「點樣做某類任務」嘅判斷同流程編碼入去。一個寫好嘅「代碼評審Skill」包含完整流程、檢查清單、判斷標準,agent讀咗就照做。模型升級,Skill自動變強——Sonnet 4.5 跑同一個TDD Skill,效果遠好過Sonnet 3.5。
反觀Harness升級,LangChain由0.x到0.3 API大改,AutoGen 0.4重構唔兼容——Harness升級你之前寫嘅代碼可能要重寫。所以Harness係借嚟嘅,Skill係自己嘅。你嘅真正資產係Skill庫。呢個原則幫你判斷:業務規則放Skill,通用工程能力放Harness,唔好喺Skill裏面寫「模型一定會做X」呢類依賴。
作者仲畀咗幾個相互印證嘅觀察:Anthropic講「Goldilocks altitude」——Harness呢層要適中剋制;Vercel d0話刪工具反而效果更好;Hermes Agent嘅self-improving Skill;ECC將Harness當性能系統優化。四條線指向同一個方向。
接下來解剖八個開源項目
後面07到14會解剖八個開源項目,包括Claude Code、DeepAgents、pi-mono、OpenClaw、Hermes、Superpowers、gstack、ECC。每個都會用同一把尺去量——Harness做厚定薄?Skill做咗咩抽象?邊界喺邊?
下一篇會先講長任務點樣破——Anthropic嘅initializer加progress文件呢套打法,係「thin harness, fat skills」喺長任務場景落地嘅靚樣例。
前面四篇鋪墊夠啦。呢篇正式將harness呢件事定義出嚟,俾出一套通用架構,再立起成個系列最核心嘅命題——"Thin Harness, Fat Skills"。

—— 先畀個乾淨嘅定義
Harness就係令模型可以作為agent做嘢嘅嗰套外殼。佢嘅職責就得四件事——處理輸入、編排工具調用、管理上下文、返回結果。
聽落樸素,但呢四件事每一件都係大坑。"處理輸入"要搞掂多模態、多渠道、多格式;"編排工具調用"要管串行、並行、retry、HITL;"管理上下文"係上一篇講嘅嗰一堆工夫;"返回結果"要管格式、可觀測、回滾。
將呢四件事工程化做到紮實,就係harness。
—— 通用架構嘅三層
業界而家共識比較多嘅一個分法係三層——Model Layer、Harness Layer、UI Layer。
Model Layer就係模型本身,外加調模型嘅SDK封裝。呢一層嘅職責就係"俾我一段prompt同工具定義,吐返一段response或tool call"。佢係無狀態、純函數式、可替換嘅。
Harness Layer係中間最厚嘅一層。所有"令模型做嘢"嘅工程邏輯都喺呢度——工具定義同註冊、context嘅組裝同壓縮、agent loop嘅編排、subagent嘅派發同回收、memory同state嘅持久化、hooks同生命週期管理、安全同權限。呢一層係harness嘅本體。
UI Layer係最外面嘅殼——CLI、IDE插件、Web、messaging app(Telegram/Discord/iMessage之類)。呢一層嘅職責就係將harness嘅能力暴露俾用戶。同一個harness可以套唔同UI——例如Claude Code係CLI,OpenClaw係messaging-first,DeepAgents俾你嘅係LangSmith裏面嘅trace界面。
三層之間有個原則——下層唔依賴上層、每層接口穩定。模型升級唔影響harness、harness升級唔影響UI。呢個分層做唔好,成個系統就脆。

—— Tool嘅統一接口
harness裏面最核心嘅抽象係Tool。Claude Code嘅tool設計俾泄漏嘅source map暴露之後,業內人士扒過一次,發現佢為每個tool都定義咗幾個統一字段。
身份層面有name、description、schema——話俾模型知呢個工具叫咩、做咩、參數點傳。execution層面有handler——真正嘅執行函數。validation層面有Zod schema——參數入嚟先驗證,驗證唔過直接拒。permissions層面有權限檢查——呢個工具喺當前權限模式下可唔可以調。presentation層面有format——結果點渲染俾用戶睇。
更關鍵嘅係幾個behavioral properties——
isReadOnly——呢個工具會唔會改外部狀態。讀文件係readonly,寫文件唔係。
isConcurrencySafe——可唔可以並發調。讀文件可以並發,寫同一個文件唔得。
needsApproval——係唔係需要用戶先批准先至可以行。rm、git push、發電郵呢啲就需要。
呢啲property唔係裝飾,係harness編排嘅依據——並發嘅時候只揀isConcurrencySafe嘅並行行、敏感操作前睇needsApproval決定係唔係彈approval gate、回滾嘅時候依據isReadOnly判斷使唔使做undo。好嘅tool設計係一組結構化元數據,唔係一個裸函數。
—— Codex嘅priority stack
OpenAI嘅Codex harness裏面有個幾得意嘅設計——priority stack。佢將上下文裏面唔同來源嘅指令明確排咗優先級,而且呢個優先級係兩層邏輯疊埋一齊嘅,要分開睇。
第一層係 role 優先級——按消息嘅 role 大類決定,由高到低:system > developer > user > assistant。呢一層係粗粒度嘅硬規則,唔同 role 之間衝突時高 role 必贏。
第二層係同 role 內按出現位置——同一個 role 下面嘅多段內容,越後出現嘅優先級越高、覆蓋前面嘅。呢一層係細粒度。
具體到 Codex 實際點注入——server 注入嘅強約束行 system role;開發者寫嘅 system prompt 行 developer role;AGENTS.md 同"用戶當前輪嘅輸入"實際上都被合併成 user role 注入,AGENTS.md 在前、當前 turn 在後。
呢個 priority stack 最大嘅價值係——衝突解決有規則。
跨 role 衝突嘅例子:用戶話"刪除所有文件"(user role),但 server message 有"禁止破壞性操作"(system role)——system 贏。
同 role 內位置衝突嘅例子:AGENTS.md 裏面寫"用 Python"(user role、出現喺前),用戶當前輪話"用 Go"(同樣 user role、出現喺後)——後出現嘅覆蓋前面嘅,user 當前輪贏。呢個唔係因為"user 比 AGENTS.md 優先級高",係因為同 role 內後出現嘅覆蓋前面嘅。
你自己設計 harness 嘅時候呢條特別值得借鑑——指令一定嚟自多個層級,必須有明確嘅衝突仲裁機制。冇呢套規則,就會出現"我明明話咗畀佢知,佢點解唔聽"嘅玄學問題。

—— LangChain嘅三層區分
LangChain自己將"做agent"呢件事拆成三層——agent framework、agent runtime、agent harness。呢套詞佢哋用得密,搞清楚咗對你理解成個生態都有幫助。
Agent Framework提供抽象。LangChain本身就係framework——佢俾你Chain、Tool、Memory呢啲抽象,令你可以用統一嘅方式描述各種agent行為。呢一層係"樂高積木"。
Agent Runtime提供執行引擎。LangGraph係runtime——佢管你嘅agent點行、狀態點保存、出錯點恢復、並發點調度。佢嘅核心賣點係durable execution——agent行到一半死咗,下次起身可以喺死咗嘅地方繼續行。呢一層係"樂高的桌子"。
Agent Harness係opinionated嘅batteries-included打包。DeepAgents就係harness——佢將framework同runtime包起,加上一套已經揀好嘅工具集、prompt模板、middleware,令你唔使從零開始砌。呢一層係"已經砌好嘅樂高城堡"。
理解咗呢三層,你就明點解DeepAgents嗰篇harness engineering博客話"只改harness唔改模型,benchmark由52.8升到66.5"——因為harness係opinionated嘅嗰一層,裏面有大量可調嘅工程參數。改呢一層成本最低,收益最直接。
—— Co-evolution Principle
呢條值得單獨提一提——模型而家係跟特定harness一齊post-train嘅。
咩意思呢。Anthropic嘅Claude喺訓練後期,會用Claude Code呢個harness嚟做大量嘅agentic任務訓練。呢個意味住模型喺見到Claude Code嘅工具集、prompt結構、interaction pattern時表現最好——佢"熟悉"呢套外殼。
如果你攞同一個模型換一套完全唔同嘅harness,效能可能會跌。OpenAI嘅Codex都一樣,跟佢嘅harness係co-evolved嘅。
呢條原則帶來嘅實際操作含義係——唔好隨意搞"用 OpenAI 模型行 Claude Code"或者"用 Claude 模型行 Codex"呢類交叉組合,會損失模型嘅訓練優勢。留意係 opinionated 嘅、跟特定模型一齊 post-train 嘅 harness之間嘅錯配——LangChain / DeepAgents 呢類通用 framework 唔喺呢個圈子入面,佢本來就係中立設計、跨 provider 兼容係佢嘅本職,冇 co-evolution 包袱。
如果非要做跨模型嘅 agent,參考 DeepAgents 嗰種"harness profiles 跨 provider 適配"嘅設計——同一個 harness 喺唔同 provider 上行要唔同配置,至少將工程複雜度控制住。
—— 終於到核心命題:Thin Harness, Fat Skills
鋪到呢度,可以講成個系列最核心嘅一個命題喇。Garry Tan喺gbrain文檔裏面有篇叫《THIN HARNESS, FAT SKILLS》嘅,原話大概係呢個意思——
"Claude Code係寫程式碼最好嘅harness,OpenClaw係其他一切(電郵、日曆、會議、人、研究、警報)最好嘅harness。同樣嘅原則——薄harness,厚skill。skills就好似方法調用,參數會變但流程唔變。每個寫好嘅skill係永久升級,永遠唔會退化。"
呢句話我不斷諗過,越諗越覺得有分量。將佢拆開嚟講——
Harness要薄。harness本身只做最通用嘅編排——工具調用、上下文管理、生命週期管理。佢唔應該硬編碼業務知識,唔應該塞滿"如果咁就點樣"嘅specific邏輯。harness越薄,佢就越穩陣,跨任務重用性越高。
Skill要厚。skill係將"點樣做某類任務"嘅判斷同流程編碼入去——幾時觸發、要檢查啲咩、點串聯、質量底線係咩。一個寫好嘅"程式碼評審skill"包含完整嘅流程、檢查清單、判斷標準,agent讀咗就跟住做。
Skills係permanent upgrade。呢個係最關鍵嘅一點。模型喺升級,每升一代你嘅skill自動跟住變強——因為更強嘅模型按 skill 裏面嘅流程行,效果更好。
舉兩個我自己感受過嘅——同一個 TDD skill(寫 failing test → 寫最小實現 → 重構)擺喺 Sonnet 3.5 下邊行,agent 成日需要你提醒"先唔好寫實現、先將測試寫完",5 輪先行完一個功能;換到 Sonnet 4.5 同一個 skill 一字冇改,agent 自己就將成套流程行順咗,測試覆蓋亦更全面。再舉例 systematic-debugging skill(complain → hypothesize → isolate → fix)喺新模型上 root cause 揾得更準、isolate 步驟更省力——skill 內容冇鬱,模型推理能力強咗,成套流程嘅產出質量自動上一個台階。
harness 亦喺升級,但 harness 升級你之前揀嘅方案可能就會被取代。
呢件事喺行內出過唔少例子——LangChain 由 0.x 到 0.1 再到 0.3,API 大改過好幾次,LCEL 取代咗老嘅 Chain、LangGraph 幾乎係新嘢,原本基於 0.x 寫嘅業務程式碼升級到新版基本上要重寫。AutoGen 都類似,2025 年 10 月俾官方放咗入 maintenance mode 之前,0.4 嗰次重構同之前 API 完全唔兼容,老程式碼作廢。
對比一下感受就出嚟——同樣係"升級",模型升級你嘅 skill 係白攞好處,harness 升級你嘅程式碼可能要重寫。呢個就係點解 skill 係資產、harness 係工具。
所以——harness係借返嚟嘅,skill係自己嘅。你喺唔同harness之間遷移,需要重寫工具調用嘅膠水程式碼,但skill係文檔形式嘅知識,遷移成本好低。你嘅真正資產係skill庫。
呢個命題點解重要——因為佢俾咗你一個判斷"該將啲咩擺喺邊一層"嘅清晰原則。
業務規則應該擺喺skill裏面,唔應該塞入harness。
工程通用能力應該擺喺harness裏面,唔應該重複寫喺每個skill裏面。
模型喺變,所以唔好喺skill裏面寫"模型一定會做X"呢類依賴;harness喺變,所以唔好喺業務程式碼裏面寫死某個harness嘅具體API。
—— 幾個互相印證嘅觀察
呢個命題唔係Garry Tan一個人諗出嚟嘅,係好幾條線索同時指向同一個方向——
Anthropic話要揾"Goldilocks altitude"——system prompt唔可以太高亦唔可以太低,意思就係harness呢一層要保持適中、剋制。
Vercel d0話刪工具反而效果更好——harness裏面塞太多嘢反而拖慢,要薄。
Hermes Agent嘅"self-improving skill"話agent會自己生成skill並不斷patch——意思係skill係會長大、係動態嘅,要厚。
ECC將自己定位為"agent harness performance optimization system"——將harness當成可優化嘅系統去工程化,意思就係harness本身要俾人"打磨得薄、穩、快"。
四條唔同來源嘅實踐,最後歸到同一個原則——薄harness、厚skills。呢個共識形成嘅速度比我諗像嘅仲快,說明呢個係被反覆驗證有效嘅方向。
—— 呢個心智模型立起嚟,下面就好看喇
接下來07到14係八個開源項目嘅解剖。每睇一家,你心裡就過一遍——呢家嘅harness做厚定係做薄?skill做咗點樣嘅抽象?兩者邊界喺邊?
你會見到Claude Code嘅harness非常薄但skill生態非常hot;DeepAgents嘅harness稍為厚(帶middleware)但skill係pluggable嘅;pi-mono係教科書式嘅UNIX分層;OpenClaw嘅harness走出終端做咗gateway,skill倉庫出過安全事故;Hermes將"自己生成skill"做到極致;Superpowers將"軟件工程方法論"沉澱成skill;gstack將"組織角色"沉澱成skill;ECC將harness本身當性能系統優化。
八種姿態,但你都可以用同一把尺去量——呢家喺邊一層做咗取捨,取捨背後嘅trade-off係咩。
下一篇先講行得耐嘅長任務點樣破解——Anthropic嘅initializer加progress文件呢套打法。呢個係將"thin harness, fat skills"原則喺長任務場景下落地嘅一個非常漂亮嘅範例,值得單獨一篇展開。
前面四篇鋪墊夠了。這一篇正式把harness這件事定義出來,給一套通用架構,再立起來整個系列最核心的那個命題——"Thin Harness, Fat Skills"。
—— 先給個乾淨的定義
Harness就是讓模型能作為agent幹活的那套外殼。它的職責就四件事——處理輸入、編排工具調用、管理上下文、返回結果。
聽起來樸素,但這四件事每一件都是大坑。"處理輸入"得搞定多模態、多渠道、多格式;"編排工具調用"得管串行、並行、retry、HITL;"管理上下文"是上一篇講的那一堆活;"返回結果"得管格式、可觀測、回滾。
把這四件事工程化做紮實,就是harness。
—— 通用架構的三層
業內現在共識比較多的一個分法是三層——Model Layer、Harness Layer、UI Layer。
Model Layer就是模型本身,外加調模型的SDK封裝。這一層的職責就是"給我一段prompt和工具定義,吐回來一段response或tool call"。它是無狀態的、純函數式的、可替換的。
Harness Layer是中間最厚的一層。所有"讓模型幹活兒"的工程邏輯都在這裏——工具定義和註冊、context的組裝和壓縮、agent loop的編排、subagent的派發和回收、memory和state的持久化、hooks和生命週期管理、安全和權限。這一層是harness的本體。
UI Layer是最外面的殼——CLI、IDE插件、Web、messaging app(Telegram/Discord/iMessage之類)。這一層的職責就是把harness的能力暴露給用戶。同一個harness可以套不同UI——比如Claude Code是CLI,OpenClaw是messaging-first,DeepAgents給你的是LangSmith裏的trace界面。
三層之間有個原則——下層不依賴上層、每層接口穩定。模型升級不影響harness、harness升級不影響UI。這個分層做不好,整個系統就脆。
—— Tool的統一接口
harness裏最核心的抽象是Tool。Claude Code的tool設計被泄漏的source map暴露之後,圈內人扒過一遍,發現它給每個tool都定義了幾個統一字段。
身份層面有name、description、schema——告訴模型這工具叫什麼、幹什麼、參數怎麼傳。execution層面有handler——真正的執行函數。validation層面有Zod schema——參數進來先驗證,驗證不過直接拒。permissions層面有權限檢查——這個工具在當前權限模式下能不能調。presentation層面有format——結果怎麼渲染給用戶看。
更關鍵的是幾個behavioral properties——
isReadOnly——這工具會不會改外部狀態。讀文件是readonly,寫文件不是。
isConcurrencySafe——能不能併發調。讀文件可以併發,寫同一個文件不能。
needsApproval——是不是需要用戶先批准才能跑。rm、git push、發郵件這種就需要。
這些property不是裝飾,是harness編排的依據——併發的時候只挑isConcurrencySafe的並行跑、敏感操作前看needsApproval決定是不是彈approval gate、回滾的時候依據isReadOnly判斷要不要做undo。好的tool設計是一組結構化元數據,不是一個裸函數。
—— Codex的priority stack
OpenAI的Codex harness裏有個挺有意思的設計——priority stack。它把上下文裏不同來源的指令明確排了優先級,而且這個優先級是兩層邏輯疊在一起的,得分開看。
第一層是 role 優先級——按消息的 role 大類決定,從高到低:system > developer > user > assistant。這一層是粗粒度的硬規則,不同 role 之間衝突時高 role 必贏。
第二層是同 role 內按出現位置——同一個 role 下的多段內容,越後出現的優先級越高、覆蓋前面的。這一層是細粒度。
具體到 Codex 實際怎麼注入——server 注入的強約束走 system role;開發者寫的 system prompt 走 developer role;AGENTS.md 和"用戶當前輪的輸入"實際上都被合併成 user role 注入,AGENTS.md 在前、當前 turn 在後。
這個 priority stack 最大的價值是——衝突解決有規則。
跨 role 衝突的例子:用戶說"刪除所有文件"(user role),但 server message 有"禁止破壞性操作"(system role)——system 贏。
同 role 內位置衝突的例子:AGENTS.md 裏寫"用 Python"(user role、出現在前),用戶當前輪說"用 Go"(同樣 user role、出現在後)——後出現的覆蓋前面的,user 當前輪贏。這不是因為"user 比 AGENTS.md 優先級高",是因為同 role 內後出現的覆蓋前面的。
你自己設計 harness 的時候這條特別值得借鑑——指令一定來自多個層級,必須有明確的衝突仲裁機制。沒有這套規則,就會出現"我明明告訴它了,它怎麼不聽"的玄學問題。
—— LangChain的三層區分
LangChain自己把"做agent"這件事拆成三層——agent framework、agent runtime、agent harness。這套詞他們用得勤,搞清楚了對你理解整個生態都有幫助。
Agent Framework提供抽象。LangChain本身就是framework——它給你Chain、Tool、Memory這些抽象,讓你能用統一的方式描述各種agent行為。這一層是"樂高積木"。
Agent Runtime提供執行引擎。LangGraph是runtime——它管你的agent怎麼跑、狀態怎麼保存、出錯怎麼恢復、併發怎麼調度。它的核心賣點是durable execution——agent跑到一半掛了,下次起來能從掛的地方接着跑。這一層是"樂高的桌子"。
Agent Harness是opinionated的batteries-included打包。DeepAgents就是harness——它把framework和runtime包起來,加上一套已經選好的工具集、prompt模板、middleware,讓你不用從零搭。這一層是"已經搭好的樂高城堡"。
理解了這三層,你就明白為什麼DeepAgents那篇harness engineering博客說"只改harness不改模型,benchmark從52.8漲到66.5"——因為harness是opinionated的那一層,裏面有大量可調的工程參數。改這一層成本最低,收益最直接。
—— Co-evolution Principle
這條值得單獨提一下——模型現在是跟特定harness一起post-train的。
什麼意思。Anthropic的Claude在訓練後期,會用Claude Code這個harness來做大量的agentic任務訓練。這意味着模型在看到Claude Code的工具集、prompt結構、interaction pattern時表現最好——它"熟悉"這套外殼。
如果你拿同一個模型換一套完全不同的harness,性能可能會掉。OpenAI的Codex也一樣,跟它的harness是co-evolved的。
這條原則帶來的實操含義是——別輕易折騰"用 OpenAI 模型跑 Claude Code"或者"用 Claude 模型跑 Codex"這種交叉組合,會損失模型的訓練優勢。注意是 opinionated 的、跟特定模型一起 post-train 的 harness之間的錯配——LangChain / DeepAgents 這種通用 framework 不在這個圈子裏,它本來就是中立設計、跨 provider 兼容是它的本職,沒 co-evolution 包袱。
如果非要做跨模型的 agent,參考 DeepAgents 那種"harness profiles 跨 provider 適配"的設計——同一個 harness 在不同 provider 上跑要不同配置,至少把工程複雜度控制住。
—— 終於到核心命題:Thin Harness, Fat Skills
鋪到這裏,可以講整個系列最核心的一個命題了。Garry Tan在gbrain文檔裏有篇叫《THIN HARNESS, FAT SKILLS》的,原話大概是這意思——
"Claude Code是寫代碼最好的harness,OpenClaw是其他一切(郵件、日曆、會議、人、研究、告警)最好的harness。同樣的原則——薄harness,厚skill。skills就像方法調用,參數會變但流程不變。每個寫好的skill是永久升級,永遠不會退化。"
這話我反覆琢磨過,越琢磨越覺得有分量。把它拆開講——
Harness要薄。harness本身只做最通用的編排——工具調用、上下文管理、生命週期管理。它不應該硬編碼業務知識,不應該塞滿"如果這樣就那樣"的specific邏輯。harness越薄,它就越穩,跨任務複用性越高。
Skill要厚。skill是把"如何做某類任務"的判斷和流程編碼進去——什麼時候觸發、要檢查什麼、怎麼串聯、質量底線是什麼。一個寫好的"代碼評審skill"包含完整的流程、檢查清單、判斷標準,agent讀了就照做。
Skills是permanent upgrade。這是最關鍵的一點。模型在升級,每升一代你的skill自動跟着變強——因為更強的模型按 skill 裏的流程跑,效果更好。
舉兩個我自己感受過的——同一個 TDD skill(寫 failing test → 寫最小實現 → 重構)放在 Sonnet 3.5 下跑,agent 經常需要你提醒"先別寫實現、先把測試寫完",5 輪才走完一個功能;換到 Sonnet 4.5 同一個 skill 一字沒改,agent 自己就把整套流程跑順了,測試覆蓋也更全。再比如 systematic-debugging skill(complain → hypothesize → isolate → fix)在新模型上 root cause 找得更準、isolate 步驟更省力——skill 內容沒動,模型推理能力強了,整套流程的產出質量自動上一個台階。
harness 也在升級,但 harness 升級你之前選的方案可能就被替代了。
這事兒圈裏出過不少例子——LangChain 從 0.x 到 0.1 再到 0.3,API 大改過好幾次,LCEL 替代了老的 Chain、LangGraph 幾乎是新東西,原本基於 0.x 寫的業務代碼升級到新版基本要重寫。AutoGen 也類似,2025 年 10 月被官方放進 maintenance mode 之前,0.4 那次重構跟之前 API 完全不兼容,老代碼作廢。
對比一下感受就出來了——同樣是"升級",模型升級你的 skill 是白拿好處,harness 升級你的代碼可能要重寫。這就是為什麼 skill 是資產、harness 是工具。
所以——harness是借來的,skill是自己的。你在不同harness之間遷移,需要重寫工具調用的膠水代碼,但skill是文檔形式的知識,遷移成本很低。你的真正資產是skill庫。
這個命題為什麼重要——因為它給了你一個判斷"該把什麼放在哪一層"的清晰原則。
業務規則該放在skill裏,不該塞進harness。
工程通用能力該放在harness裏,不該重複寫在每個skill裏。
模型在變,所以別在skill裏寫"模型一定會做X"這種依賴;harness在變,所以別在業務代碼裏寫死某個harness的具體API。
—— 幾個相互印證的觀察
這個命題不是Garry Tan一個人想出來的,是好幾條線索同時指向同一個方向——
Anthropic說要找"Goldilocks altitude"——system prompt不能太高也不能太低,意思就是harness這一層要保持適中、剋制。
Vercel d0說刪工具反而效果更好——harness裏塞太多東西反而拖累,要薄。
Hermes Agent的"self-improving skill"說agent會自己生成skill並不斷patch——意思是skill是會長大的、是動態的,要厚。
ECC把自己定位為"agent harness performance optimization system"——把harness當成可優化的系統去工程化,意思就是harness本身要被"打磨得薄、穩、快"。
四條不同來源的實踐,最後歸到同一個原則——薄harness、厚skills。這個共識形成的速度比我想象的還快,說明這是被反覆驗證有效的方向。
—— 這個心智模型立起來,下面就好看了
接下來07到14是八個開源項目的解剖。每看一家,你心裏就過一遍——這家的harness做厚還是做薄?skill做了什麼樣的抽象?兩者邊界在哪?
你會看到Claude Code的harness非常薄但skill生態非常hot;DeepAgents的harness稍厚(帶middleware)但skill是pluggable的;pi-mono是教科書式的UNIX分層;OpenClaw的harness走出終端做了gateway,skill倉庫出過安全事故;Hermes把"自己生成skill"做到了極致;Superpowers把"軟件工程方法論"沉澱成skill;gstack把"組織角色"沉澱成skill;ECC把harness本身當性能系統優化。
八種姿態,但你都能用同一把尺子去量——這家在哪一層做了取捨,取捨背後的trade-off是什麼。
下一篇先講跑得久的長任務怎麼破——Anthropic的initializer加progress文件這套打法。這是把"thin harness, fat skills"原則在長任務場景下落地的一個非常漂亮的樣例,值得單獨一篇展開。